Detección de Palabras Clave con TensorFlow Lite
Introducción
Este proyecto demuestra cómo usar TensorFlow Lite para detección de palabras clave en el ReSpeaker 2-Mics Pi HAT v2. La detección de palabras clave permite la detección en tiempo real de palabras predefinidas desde entrada de audio, habilitando aplicaciones como dispositivos controlados por voz y sistemas interactivos. Te guiaremos a través de los pasos para entrenar un modelo de TensorFlow Lite, desplegarlo en el ReSpeaker HAT y ejecutar reconocimiento de voz localmente.
Requisitos de Hardware y Software
- Hardware: Raspberry Pi con ReSpeaker 2-Mics Pi HAT v2
- Software: TensorFlow Lite, Google Colab, Python y librerías de soporte
Aplicaciones
La detección de palabras clave puede aplicarse en:
- Dispositivos de hogar inteligente
- Robots controlados por voz
- Quioscos interactivos
¿Qué es TensorFlow Lite?
TensorFlow Lite es una versión ligera de TensorFlow diseñada para dispositivos móviles y embebidos. Permite inferencia de aprendizaje automático con baja latencia y tamaños de binario pequeños, haciéndolo ideal para ejecutar modelos en dispositivos de borde como Raspberry Pi.
Entrenar y Obtener el Modelo de TensorFlow Lite
Conjunto de Datos
Usaremos un subconjunto del conjunto de datos Speech Commands para entrenamiento. El conjunto de datos contiene archivos de audio WAV de personas diciendo diferentes palabras, recopilado por Google y liberado bajo una licencia CC BY. El conjunto de datos puede descargarse desde aquí. Para más información sobre conjuntos de datos, consulta esta guía.
¿Por Qué Usar Google Colab?
Google Colab es una plataforma basada en la nube para ejecutar notebooks de Jupyter. Proporciona acceso gratuito a recursos GPU, haciéndolo una excelente opción para entrenar modelos de aprendizaje automático sin requerir poder de cómputo local.
Pasos
Ahora usaremos un Notebook de Google Colab para realizar el entrenamiento de datos y generar un modelo de TensorFlow Lite en formato .tflite.
-
Paso 1. Abre este Notebook de Python
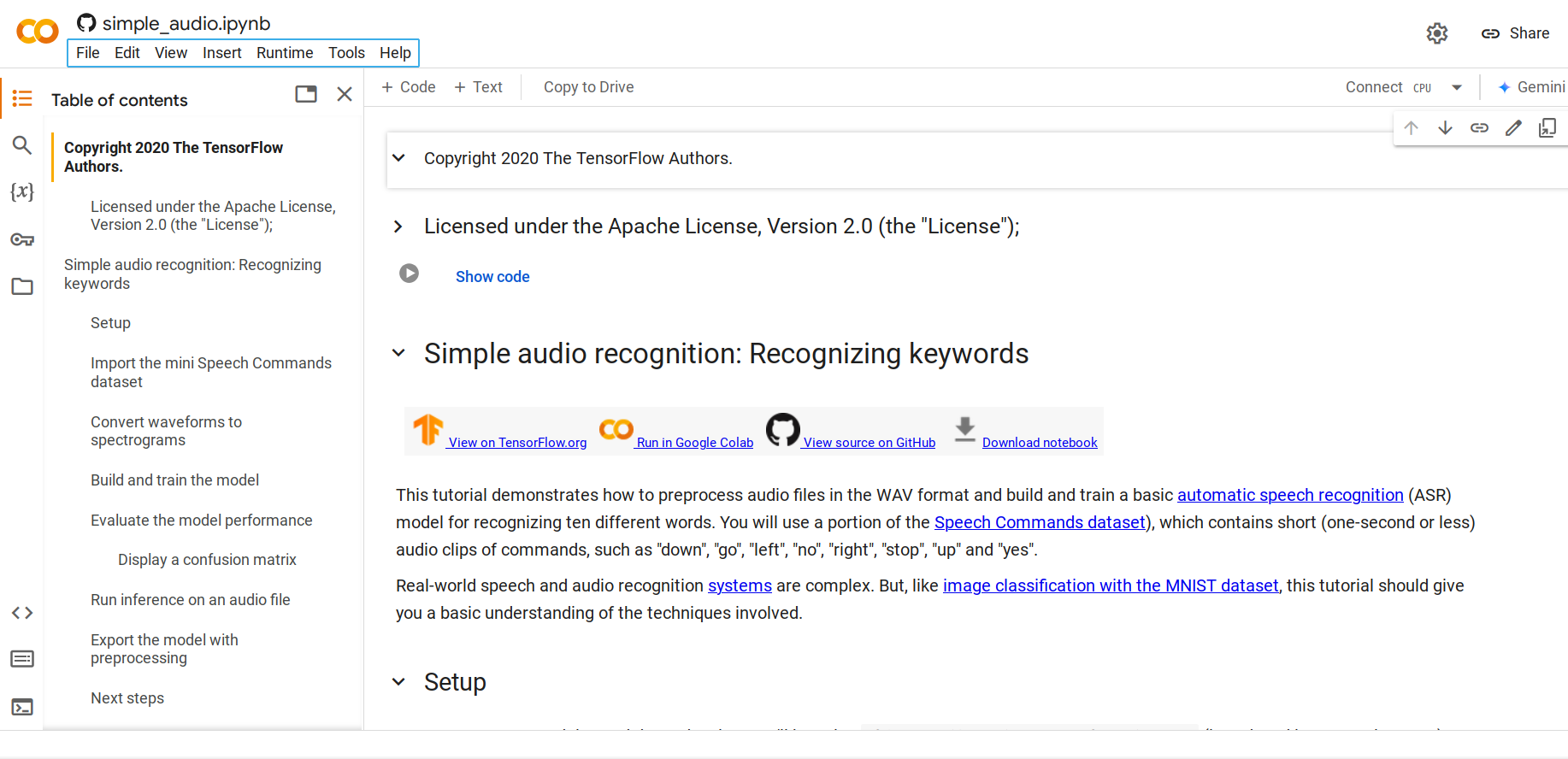
Por defecto, cargará el conjunto de datos mini Speech Commands que es una versión más pequeña del conjunto de datos Speech Commands. El conjunto de datos original consiste en más de 105,000 archivos de audio en formato de archivo de audio WAV (Waveform) de personas diciendo 35 palabras diferentes. Estos datos fueron recopilados por Google y liberados bajo una licencia CC BY.
-
Paso 2. Conéctate a un nuevo runtime seleccionando Changing runtime type -> CPU -> Save, luego haz clic en Connect.
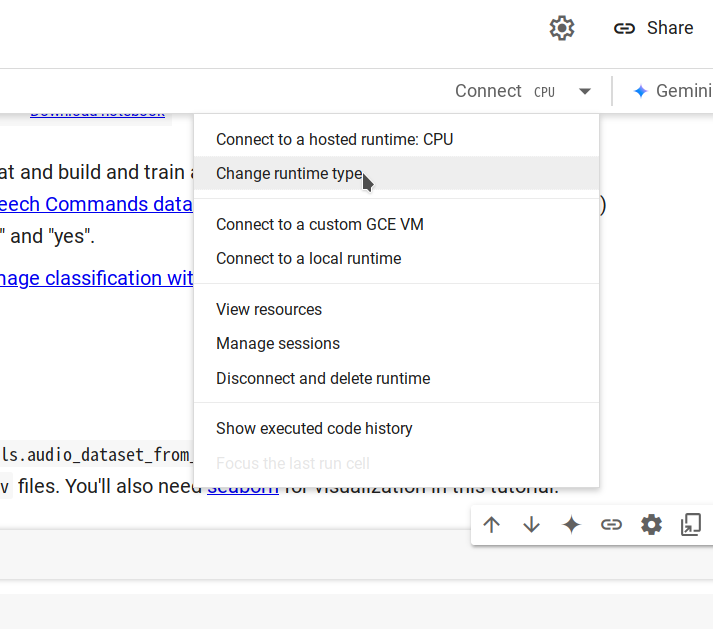
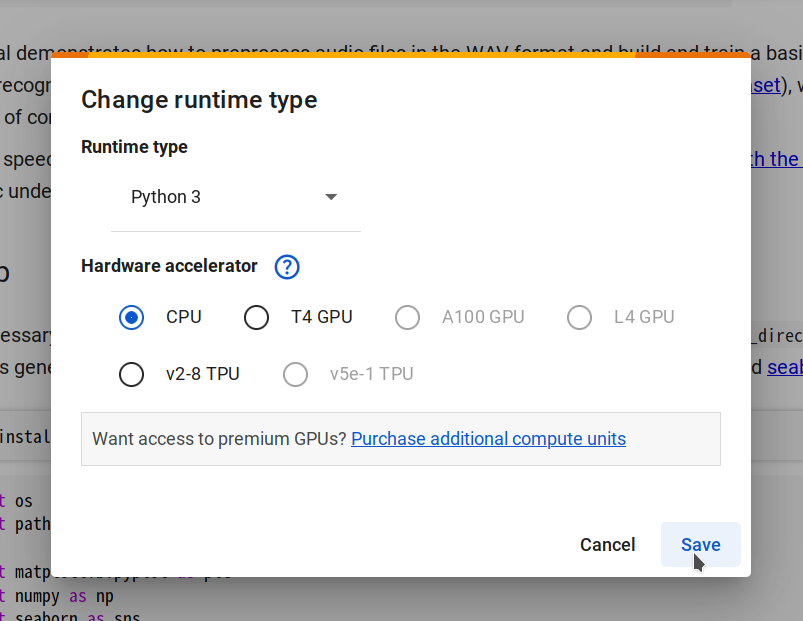
-
Paso 3. Navega a
Runtime > Run allpara ejecutar todas las celdas de código. Este proceso tomará aproximadamente 10 minutos en completarse.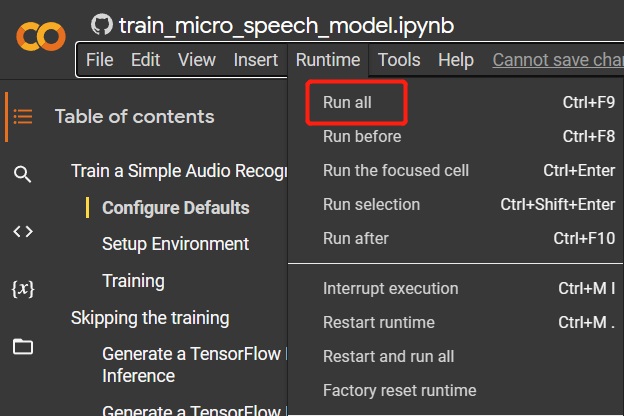
-
Paso 4. Una vez que todas las celdas de código sean ejecutadas, agrega una nueva celda y ejecuta el siguiente código para generar el archivo del modelo
.tflite.converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
-
Paso 5. Haz clic derecho en el archivo
model.tflitegenerado y selecciona Download para guardar el archivo en tu computadora.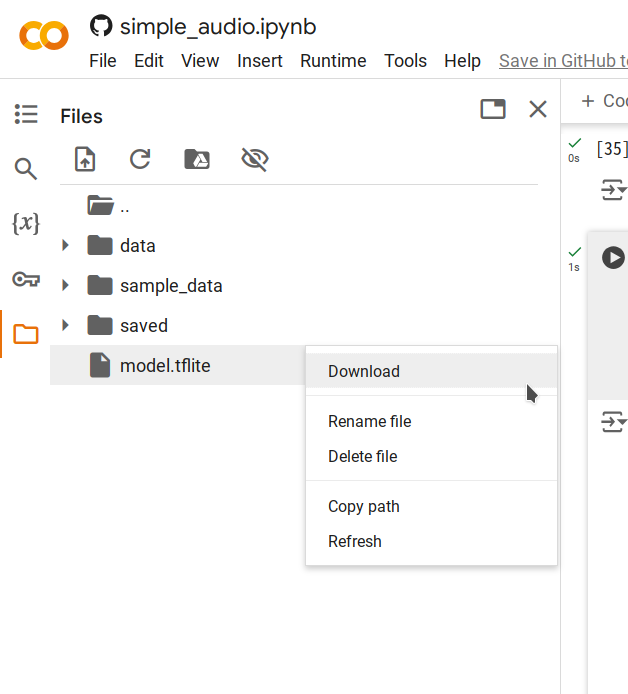
Inferencia Local
Ejecutando el Script de Inferencia
El script inference.py realiza los siguientes pasos:
- Carga el modelo TensorFlow Lite entrenado.
- Procesa el audio de entrada en un espectrograma adecuado para la inferencia.
- Ejecuta la inferencia y produce la palabra clave detectada junto con las puntuaciones de confianza para cada etiqueta.
Pasos para Ejecutar
-
Sube el archivo de modelo
model.tflitea tu Pi, en este ejemplo, lo ponemos en~/speech_recognition/model.tflite. -
Guarda el siguiente script como
~/speech_recognition/inference.py:import numpy as np
from scipy import signal
from tflite_runtime.interpreter import Interpreter
import soundfile as sf
MODEL_PATH = 'model.tflite'
LABELS = ['no', 'yes', 'down', 'go', 'left', 'up', 'right', 'stop']
def get_spectrogram(waveform, expected_time_steps=124, expected_freq_bins=129):
_, _, Zxx = signal.stft(
waveform,
fs=16000,
nperseg=255,
noverlap=124,
nfft=256
)
spectrogram = np.abs(Zxx)
if spectrogram.shape[0] != expected_freq_bins:
spectrogram = np.pad(spectrogram, ((
0, expected_freq_bins - spectrogram.shape[0]), (0, 0)), mode='constant')
if spectrogram.shape[1] != expected_time_steps:
spectrogram = np.pad(spectrogram, ((
0, 0), (0, expected_time_steps - spectrogram.shape[1])), mode='constant')
if spectrogram.shape != (expected_freq_bins, expected_time_steps):
raise ValueError(
f"Invalid spectrogram shape. Got {spectrogram.shape}, expected ({expected_freq_bins}, {expected_time_steps})."
)
spectrogram = np.transpose(spectrogram)
return spectrogram
def preprocess_audio(file_path):
waveform, sample_rate = sf.read(file_path)
if sample_rate != 16000:
raise ValueError("Expected sample rate is 16 kHz")
if len(waveform.shape) > 1:
waveform = waveform[:, 0]
spectrogram = get_spectrogram(waveform)
spectrogram = spectrogram[..., np.newaxis]
spectrogram = spectrogram[np.newaxis, ...]
return spectrogram
def run_inference(file_path):
spectrogram = preprocess_audio(file_path)
interpreter = Interpreter(MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_shape = input_details[0]['shape']
if spectrogram.shape != tuple(input_shape):
raise ValueError(
f"Expected input shape {input_shape}, got {spectrogram.shape}"
)
interpreter.set_tensor(
input_details[0]['index'], spectrogram.astype(np.float32))
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])[0]
prediction = np.argmax(output_data)
confidence = np.exp(output_data) / \
np.sum(np.exp(output_data))
print(f"command: {LABELS[prediction].upper()}")
for label, conf in zip(LABELS, confidence):
print(f"{label}: {conf:.2%}")
if __name__ == "__main__":
audio_file_path = 'test_audio.wav'
run_inference(audio_file_path) -
Graba un sonido usando el siguiente comando, las palabras clave disponibles son:
no,yes,down,go,left,up,right,stop.$ arecord -D "plughw:2,0" -f S16_LE -r 16000 -d 1 -t wav ~/speech_recognition/test_audio.wav -
Ejecuta el script:
$ python3 inference.py
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
command: YES
no: 8.74%
yes: 21.10%
down: 5.85%
go: 14.57%
left: 11.02%
up: 8.25%
right: 10.53%
stop: 19.94%
Interpretando los Resultados
El script produce el comando detectado (por ejemplo, YES) y las puntuaciones de confianza para todas las etiquetas. Esto proporciona información sobre las predicciones del modelo y te permite evaluar su rendimiento.
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.