ReSpeaker Mic Array v3.0

ReSpeaker Mic Array v3.0 es la siguiente evolución de los arrays de micrófonos USB de Seeed Studio, siguiendo al ReSpeaker Mic Array v2.0. Mientras que el v2.0 fue construido sobre el chipset XVF-3000 de XMOS y diseñado como una actualización importante del v1.0, el v3.0 se enfoca en refinar la calidad de audio y el rendimiento de algoritmos, incluso con un menor número de micrófonos físicos.
Comparado con el array de 4 micrófonos del v2.0, el v3.0 también usa 4 micrófonos pero integra algoritmos mejorados de procesamiento de audio incorporados, ofreciendo una captura de voz de campo lejano más clara y mejor manejo de ruido que su predecesor. El v3.0 reemplaza el códec WM8960 del v2.0 con un códec TLV320AIC3104, contribuyendo a una captura de sonido de mayor fidelidad.
Mientras que el v2.0 a menudo se emparejaba con el ReSpeaker Core o se usaba como placa de desarrollo, el v3.0 es más un dispositivo USB plug-and-play—similar al v2.0 en el soporte de USB Audio Class 1.0 para compatibilidad completa con Windows, macOS y Linux—pero ajustado para rendimiento de interfaz de voz listo para usar sin requerir hardware adicional.
En términos de características, ambos soportan captura de voz de campo lejano y algoritmos de mejora de voz como AEC (Cancelación de Eco Acústico), VAD (Detección de Actividad de Voz), DOA (Dirección de Llegada), Beamforming y Supresión de Ruido, pero las optimizaciones de algoritmos del v3.0 entregan audio más limpio en entornos ruidosos del mundo real.
El sistema LED permanece en 12 LEDs RGB programables en ambas versiones, pero el v3.0 está modelado según el diseño más nuevo del USB 4 Mic Array, haciéndolo más pequeño y simple que el factor de forma orientado a desarrolladores del v2.0, mientras aún retiene características clave de interfaz de voz profesional.

![]()
Versión
| Versión del Producto | Cambios | Fecha de Lanzamiento |
|---|---|---|
| ReSpeaker Mic Array v1.0 | Inicial | 15 Ago, 2016 |
| ReSpeaker Mic Array v2.0 | XVSM-2000 está EOL, cambio de MCU a XVF-3000 y reducción de micrófonos de 7 a 4. | 25 Ene, 2018 |
| ReSpeaker Mic Array v3.0 | Códec cambiado a TLV320AIC3104 | 19 Ene, 2021 |
Características
- Captura de voz de campo lejano
- Soporte para USB Audio Class 1.0 (UAC 1.0)
- Array de cuatro micrófonos
- 12 indicadores LED RGB programables
- Algoritmos y características de voz
- Detección de Actividad de Voz
- Dirección de Llegada
- Formación de Haz
- Supresión de Ruido
- Des-reverberación
- Cancelación de Eco Acústico
Especificaciones
- XVF-3000 de XMOS
- 4 micrófonos digitales de alto rendimiento
- Soporta Captura de Voz de Campo Lejano
- Algoritmo de voz en chip
- 12 indicadores LED RGB programables
- Micrófonos: ST MP34DT01TR-M
- Sensibilidad: -26 dBFS (Omnidireccional)
- Punto de sobrecarga acústica: 120 dBSPL
- SNR: 61 dB
- Fuente de Alimentación: 5V DC desde Micro USB o header de expansión
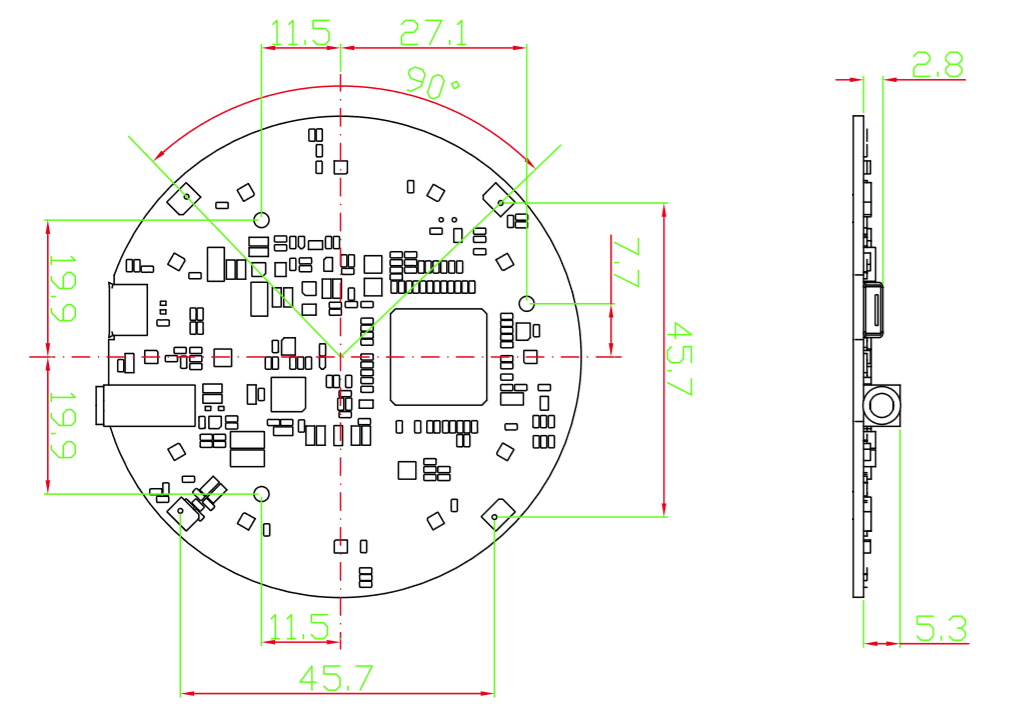
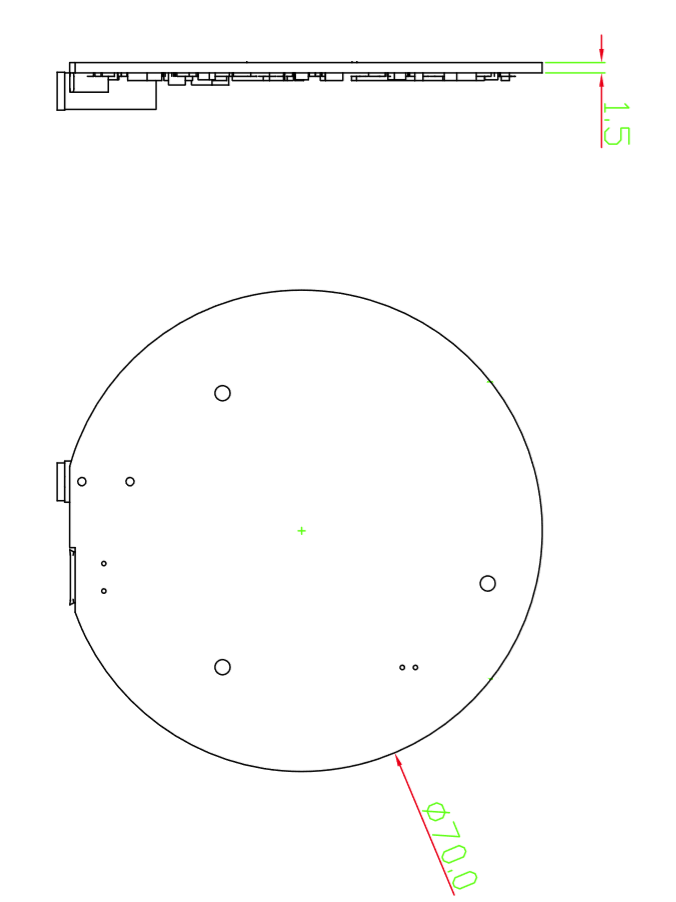
- Dimensiones: 70mm (Diámetro)
- Conector de salida de audio jack de 3.5mm
- Consumo de energía: 5V, 180mA con led encendido y 170mA con led apagado
- Frecuencia de Muestreo Máxima: 16Khz
Descripción General del Hardware

-
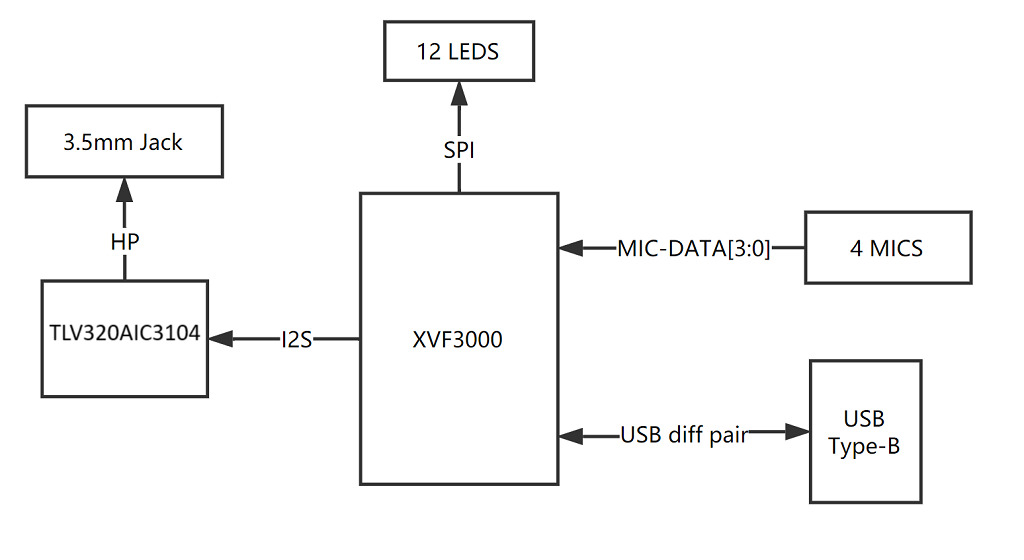
① XMOS XVF-3000: Integra algoritmos DSP avanzados que incluyen Cancelación de Eco Acústico (AEC), formación de haz, des-reverberación, supresión de ruido y control de ganancia.
-
② Micrófono Digital: El MP34DT01-M es un micrófono digital MEMS ultra-compacto, de bajo consumo, omnidireccional, construido con un elemento de detección capacitivo y una interfaz IC.
-
③ LED RGB: LED RGB de tres colores.
-
④ Puerto USB: Proporciona la alimentación y controla el array de micrófonos.
-
⑤ Jack de auriculares de 3.5mm: Salida de audio, podemos conectar altavoces activos o auriculares a este puerto.
-
⑥ TLV320AIC3104: El TLV320AIC3104 es un códec estéreo de bajo consumo que cuenta con controladores de altavoces Clase D para proporcionar 1 W por canal en cargas de 8 W.
Diagrama del Sistema
Mapa de Pines

Dimensiones
Aplicaciones
- Captura de Voz USB
- Altavoz Inteligente
- Sistemas de Asistente de Voz Inteligente
- Grabadoras de Voz
- Sistema de Conferencias de Voz
- Equipo de Comunicación para Reuniones
- Robot de Interacción por Voz
- Asistente de Voz para Automóvil
- Otros Escenarios de Interfaz de Voz
Primeros Pasos
ReSpeaker Mic Array v3.0 es compatible con sistemas Windows, Mac, Linux y Android. Los siguientes scripts están probados en Python2.7.
Para Android, lo probamos con emteria.OS(Android 7.1) en Raspberry. Conectamos el mic array v3.0 al puerto USB de raspberry pi y seleccionamos el ReSpeaker mic array v3.0 como dispositivo de audio. Aquí está la pantalla de grabación de audio.

Aquí está la pantalla de reproducción de audio. Conectamos el altavoz al jack de audio de 3.5mm del ReSpeaker mic array v3.0 y escuchamos lo que grabamos.

Actualizar Firmware
Hay 2 firmwares. Uno incluye datos de 1 canal, mientras que el otro incluye datos de 6 canales (firmware de fábrica). Aquí está la tabla con las diferencias.
| Firmware | Canales | Nota |
|---|---|---|
| 1_channel_firmware.bin | 1 | Audio procesado para ASR |
| 6_channels_firmware.bin | 6 | Canal 0: audio procesado para ASR Canal 1: datos en bruto mic1 Canal 2: datos en bruto mic2 Canal 3: datos en bruto mic3 Canal 4: datos en bruto mic4 Canal 5: reproducción combinada |
Para Linux: El array de micrófonos soporta USB DFU. Desarrollamos un script de python dfu.py para actualizar el firmware a través de USB.
sudo apt-get update
sudo pip install pyusb click
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
sudo python dfu.py --download MicArrayV3_firmware/6_channels_dfu_4.0.0_firmware.bin # The 6 channels version
# if you want to use 1 channel,then the command should be like:
sudo python dfu.py --download MicArrayV3_firmware/1_channel_dfu_4.0.0_firmware.bin
Para Windows/Mac: No sugerimos usar Windows/Mac y máquina virtual Linux para actualizar el firmware.
Demostración Lista para Usar
Aquí está el ejemplo de Cancelación de Eco Acústico con firmware de 6 canales.
- Paso 1. Conecta el cable USB a la PC y el conector de audio al altavoz.

- Paso 2. Selecciona el arreglo de micrófonos v3.0 como dispositivo de salida en el lado de la PC.
- Paso 3. Inicia audacity para grabar.
- Paso 4. Reproduce música en el lado de la PC primero y luego hablamos.
- Paso 5. Veremos la pantalla de audacity como se muestra a continuación, Por favor haz clic en Solo para escuchar el audio de cada canal.

Audio del Canal0 (procesado por algoritmos):
Audio del Canal1 (datos en bruto del Mic1):
Audio del Canal5 (datos de reproducción):
Aquí está el video sobre DOA y AEC.
Instalar Controlador DFU y Control de LED
- Windows: La grabación y reproducción de audio funciona bien por defecto. El controlador Libusb-win32 solo es requerido para controlar LEDs y parámetros DSP en Windows. Usamos una herramienta práctica - Zadig para instalar el controlador libusb-win32 para tanto
SEEED DFUcomoSEEED Control(ReSpeaker Mic Array tiene 2 dispositivos en el Administrador de Dispositivos de Windows).

Por favor asegúrate de que libusb-win32 esté seleccionado, no WinUSB o libusbK.
- MAC: No se requiere controlador.
- Linux: No se requiere controlador.
Ajuste
Para Linux/Mac/Windows: Podemos configurar algunos parámetros de los algoritmos integrados.
- Obtén la lista completa de parámetros, para más información, por favor consulta las FAQ.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
python tuning.py -p
- Ejemplo#1, podemos desactivar el Control Automático de Ganancia (AGC):
python tuning.py AGCONOFF 0
- Ejemplo#2, Podemos verificar el ángulo DOA.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
Controlar los LEDs
Podemos controlar los LEDs del ReSpeaker Mic Array V2 a través de USB. El dispositivo USB tiene una Interfaz de Clase Específica del Proveedor que puede usarse para enviar datos a través de Transferencia de Control USB. Nos referimos a la librería de python pyusb y desarrollamos la librería de python usb_pixel_ring.
El comando de control de LED se envía mediante usb.core.Device.ctrl_transfer() de pyusb, sus parámetros son los siguientes:
ctrl_transfer(usb.util.CTRL_OUT | usb.util.CTRL_TYPE_VENDOR | usb.util.CTRL_RECIPIENT_DEVICE, 0, command, 0x1C, data, TIMEOUT)
Aquí están las APIs de usb_pixel_ring.
| Comando | Datos | API | Nota |
|---|---|---|---|
| 0 | [0] | pixel_ring.trace() | modo trace, los LEDs cambian dependiendo de VAD* y DOA* |
| 1 | [red, green, blue, 0] | pixel_ring.mono() | modo mono, establece todos los LEDs RGB a un solo color, por ejemplo Rojo(0xFF0000), Verde(0x00FF00), Azul(0x0000FF) |
| 2 | [0] | pixel_ring.listen() | modo listen, similar al modo trace, pero no apaga los LEDs |
| 3 | [0] | pixel_ring.speak() | modo wait |
| 4 | [0] | pixel_ring.think() | modo speak |
| 5 | [0] | pixel_ring.spin() | modo spin |
| 6 | [r, g, b, 0] * 12 | pixel_ring.custimize() | modo personalizado, establece cada LED a su propio color |
| 0x20 | [brightness] | pixel_ring.set_brightness() | establecer brillo, rango: 0x00~0x1F |
| 0x21 | [r1, g1, b1, 0, r2, g2, b2, 0] | pixel_ring.set_color_palette() | establecer paleta de colores, por ejemplo, pixel_ring.set_color_palette(0xff0000, 0x00ff00) junto con pixel_ring.think() |
| 0x22 | [vad_led] | pixel_ring.set_vad_led() | establecer LED central: 0 - apagado, 1 - encendido, otro - depende de VAD |
| 0x23 | [volume] | pixel_ring.set_volume() | mostrar volumen, rango: 0 ~ 12 |
| 0x24 | [pattern] | pixel_ring.change_pattern() | establecer patrón, 0 - patrón Google Home, otros - patrón Echo |
Para Linux: Aquí está el ejemplo para controlar los leds. Por favor sigue los comandos a continuación para ejecutar la demo.
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring
sudo python setup.py install
sudo python examples/usb_mic_array.py
Aquí está el código del usb_mic_array.py.
import time
from pixel_ring import pixel_ring
if __name__ == '__main__':
pixel_ring.change_pattern('echo')
while True:
try:
pixel_ring.wakeup()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.speak()
time.sleep(6)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
time.sleep(1)
Para Windows/Mac: Aquí está el ejemplo para controlar los LEDs.
- Paso 1. Descargar pixel_ring.
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring/pixel_ring
- Paso 2. Crea un led_control.py con el código de abajo y ejecuta 'python led_control.py'
from usb_pixel_ring_v2 import PixelRing
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
print dev
if dev:
pixel_ring = PixelRing(dev)
while True:
try:
pixel_ring.wakeup(180)
time.sleep(3)
pixel_ring.listen()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.set_volume(8)
time.sleep(3)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
Si ves "None" impreso en pantalla, por favor reinstala el controlador libusb-win32.
DOA (Dirección de Llegada)
Para Windows/Mac/Linux: Aquí está el ejemplo para ver el DOA. El LED Verde es el indicador de la dirección de la voz. Para el ángulo, por favor consulta la descripción general del hardware.
- Paso 1. Descarga el usb_4_mic_array.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- Paso 2. Crea un DOA.py con el código de abajo bajo la carpeta usb_4_mic_array y ejecuta 'python DOA.py'
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.direction
while True:
try:
print Mic_tuning.direction
time.sleep(1)
except KeyboardInterrupt:
break
- Step 3. We will see the DOA as below.
pi@raspberrypi:~/usb_4_mic_array $ sudo python doa.py
184
183
175
105
104
104
103
VAD (Detección de Actividad de Voz)
Para Windows/Mac/Linux: Aquí está el ejemplo para ver el VAD. El LED rojo es el indicador del VAD.
- Paso 1. Descarga el usb_4_mic_array.
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- Paso 2. Crea un VAD.py con el código de abajo bajo la carpeta usb_4_mic_array y ejecuta 'python VAD.py'
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
#print dev
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.is_voice()
while True:
try:
print Mic_tuning.is_voice()
time.sleep(1)
except KeyboardInterrupt:
break
- Step 3. We will see the DOA as below.
pi@raspberrypi:~/usb_4_mic_array $ sudo python VAD.py
0
0
0
1
0
1
0
Para el umbral de VAD, también podemos usar GAMMAVAD_SR para configurarlo. Consulte Tuning para más detalles.
Extraer Voz
Usamos la librería de Python PyAudio para extraer voz a través de USB.
Para Linux: Podemos usar los siguientes comandos para grabar o reproducir la voz.
arecord -D plughw:1,0 -f cd test.wav # record, please use the arecord -l to check the card and hardware first
aplay -D plughw:1,0 -f cd test.wav # play, please use the aplay -l to check the card and hardware first
arecord -D plughw:1,0 -f cd |aplay -D plughw:1,0 -f cd # record and play at the same time
También podemos usar un script de Python para extraer la voz.
- Paso 1, Necesitamos ejecutar el siguiente script para obtener el número de índice del dispositivo del Mic Array:
sudo pip install pyaudio
cd ~
nano get_index.py
- Paso 2, copia el código a continuación y pégalo en get_index.py.
Si estás usando Python 3, este archivo es adecuado para usar get_index.py
import pyaudio
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
numdevices = info.get('deviceCount')
for i in range(0, numdevices):
if (p.get_device_info_by_host_api_device_index(0, i).get('maxInputChannels')) > 0:
print "Input Device id ", i, " - ", p.get_device_info_by_host_api_device_index(0, i).get('name')
-
Paso 3, presiona
Ctrl+Xpara salir y presiona Y para guardar. -
Paso 4, ejecuta 'sudo python get_index.py' y veremos el ID del dispositivo como se muestra a continuación.
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0): USB Audio (hw:1,0)
- Paso 5, cambia
RESPEAKER_INDEX = 2al número de índice. Ejecuta el script de python record.py para grabar un discurso.
import pyaudio
import wave
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 2 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(RESPEAKER_CHANNELS)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
- Paso 6. Si deseas extraer datos del canal 0 de 6 canales, sigue el código a continuación. Para otro canal X, cambia [0::6] a [X::6].
import pyaudio
import wave
import numpy as np
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 3 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 3
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
# extract channel 0 data from 6 channels, if you want to extract channel 1, please change to [1::6]
a = np.fromstring(data,dtype=np.int16)[0::6]
frames.append(a.tostring())
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
Para Windows:
- Paso 1. Ejecutamos el siguiente comando para instalar pyaudio.
pip install pyaudio
- Paso 2. Usa get_index.py para obtener el índice del dispositivo.
C:\Users\XXX\Desktop>python get_index.py
Input Device id 0 - Microsoft Sound Mapper - Input
Input Device id 1 - ReSpeaker 4 Mic Array (UAC1.0)
Input Device id 2 - Internal Microphone (Conexant I)
- Paso 3. Modifica el índice del dispositivo y los canales de record.py y luego extrae la voz.
C:\Users\XXX\Desktop>python record.py
* recording
* done recording
Si vemos "Error: %1 is not a valid Win32 application.", por favor instala la versión Win32 de Python.
Para MAC:
- Paso 1. Ejecutamos el siguiente comando para instalar pyaudio.
pip install pyaudio
- Paso 2. Usa get_index.py para obtener el índice del dispositivo.
MacBook-Air:Desktop XXX$ python get_index.py
Input Device id 0 - Built-in Microphone
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0)
- Paso 3. Modifica el índice del dispositivo y los canales de record.py y luego extrae la voz.
MacBook-Air:Desktop XXX$ python record.py
2018-03-24 14:53:02.400 Python[2360:16629] 14:53:02.399 WARNING: 140: This application, or a library it uses, is using the deprecated Carbon Component Manager for hosting Audio Units. Support for this will be removed in a future release. Also, this makes the host incompatible with version 3 audio units. Please transition to the API's in AudioComponent.h.
* recording
* done recording
Preguntas Frecuentes
P1: Parámetros de algoritmos integrados
pi@raspberrypi:~/usb_4_mic_array $ python tuning.py -p
name type max min r/w info
-------------------------------
AECFREEZEONOFF int 1 0 rw Adaptive Echo Canceler updates inhibit.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
AECNORM float 16 0.25 rw Limit on norm of AEC filter coefficients
AECPATHCHANGE int 1 0 ro AEC Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
AECSILENCELEVEL float 1 1e-09 rw Threshold for signal detection in AEC [-inf .. 0] dBov (Default: -80dBov = 10log10(1x10-8))
AECSILENCEMODE int 1 0 ro AEC far-end silence detection status.
0 = false (signal detected)
1 = true (silence detected)
AGCDESIREDLEVEL float 0.99 1e-08 rw Target power level of the output signal.
[−inf .. 0] dBov (default: −23dBov = 10log10(0.005))
AGCGAIN float 1000 1 rw Current AGC gain factor.
[0 .. 60] dB (default: 0.0dB = 20log10(1.0))
AGCMAXGAIN float 1000 1 rw Maximum AGC gain factor.
[0 .. 60] dB (default 30dB = 20log10(31.6))
AGCONOFF int 1 0 rw Automatic Gain Control.
0 = OFF
1 = ON
AGCTIME float 1 0.1 rw Ramps-up / down time-constant in seconds.
CNIONOFF int 1 0 rw Comfort Noise Insertion.
0 = OFF
1 = ON
DOAANGLE int 359 0 ro DOA angle. Current value. Orientation depends on build configuration.
ECHOONOFF int 1 0 rw Echo suppression.
0 = OFF
1 = ON
FREEZEONOFF int 1 0 rw Adaptive beamformer updates.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
FSBPATHCHANGE int 1 0 ro FSB Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
FSBUPDATED int 1 0 ro FSB Update Decision.
0 = false (FSB was not updated)
1 = true (FSB was updated)
GAMMAVAD_SR float 1000 0 rw Set the threshold for voice activity detection.
[−inf .. 60] dB (default: 3.5dB 20log10(1.5))
GAMMA_E float 3 0 rw Over-subtraction factor of echo (direct and early components). min .. max attenuation
GAMMA_ENL float 5 0 rw Over-subtraction factor of non-linear echo. min .. max attenuation
GAMMA_ETAIL float 3 0 rw Over-subtraction factor of echo (tail components). min .. max attenuation
GAMMA_NN float 3 0 rw Over-subtraction factor of non- stationary noise. min .. max attenuation
GAMMA_NN_SR float 3 0 rw Over-subtraction factor of non-stationary noise for ASR.
[0.0 .. 3.0] (default: 1.1)
GAMMA_NS float 3 0 rw Over-subtraction factor of stationary noise. min .. max attenuation
GAMMA_NS_SR float 3 0 rw Over-subtraction factor of stationary noise for ASR.
[0.0 .. 3.0] (default: 1.0)
HPFONOFF int 3 0 rw High-pass Filter on microphone signals.
0 = OFF
1 = ON - 70 Hz cut-off
2 = ON - 125 Hz cut-off
3 = ON - 180 Hz cut-off
MIN_NN float 1 0 rw Gain-floor for non-stationary noise suppression.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NN_SR float 1 0 rw Gain-floor for non-stationary noise suppression for ASR.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NS float 1 0 rw Gain-floor for stationary noise suppression.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
MIN_NS_SR float 1 0 rw Gain-floor for stationary noise suppression for ASR.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
NLAEC_MODE int 2 0 rw Non-Linear AEC training mode.
0 = OFF
1 = ON - phase 1
2 = ON - phase 2
NLATTENONOFF int 1 0 rw Non-Linear echo attenuation.
0 = OFF
1 = ON
NONSTATNOISEONOFF int 1 0 rw Non-stationary noise suppression.
0 = OFF
1 = ON
NONSTATNOISEONOFF_SR int 1 0 rw Non-stationary noise suppression for ASR.
0 = OFF
1 = ON
RT60 float 0.9 0.25 ro Current RT60 estimate in seconds
RT60ONOFF int 1 0 rw RT60 Estimation for AES. 0 = OFF 1 = ON
SPEECHDETECTED int 1 0 ro Speech detection status.
0 = false (no speech detected)
1 = true (speech detected)
STATNOISEONOFF int 1 0 rw Stationary noise suppression.
0 = OFF
1 = ON
STATNOISEONOFF_SR int 1 0 rw Stationary noise suppression for ASR.
0 = OFF
1 = ON
TRANSIENTONOFF int 1 0 rw Transient echo suppression.
0 = OFF
1 = ON
VOICEACTIVITY int 1 0 ro VAD voice activity status.
0 = false (no voice activity)
1 = true (voice activity)
P2: ImportError: No module named usb.core
R2: Ejecuta sudo pip install pyusb para instalar pyusb.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
Traceback (most recent call last):
File "tuning.py", line 5, in <module>
import usb.core
ImportError: No module named usb.core
pi@raspberrypi:~/usb_4_mic_array $ sudo pip install pyusb
Collecting pyusb
Downloading pyusb-1.0.2.tar.gz (54kB)
100% |████████████████████████████████| 61kB 101kB/s
Building wheels for collected packages: pyusb
Running setup.py bdist_wheel for pyusb ... done
Stored in directory: /root/.cache/pip/wheels/8b/7f/fe/baf08bc0dac02ba17f3c9120f5dd1cf74aec4c54463bc85cf9
Successfully built pyusb
Installing collected packages: pyusb
Successfully installed pyusb-1.0.2
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
P3: ¿Tienes el ejemplo para la aplicación alexa de Raspberry?
R3: Sí, podemos conectar el arreglo de micrófonos v3.0 al puerto USB de raspberry y seguir la Guía de Inicio Rápido de Raspberry Pi con Script para hacer la interacción de voz con alexa.
P4: ¿Tienes el ejemplo para el arreglo de micrófonos v3.0 con sistema ROS?
R4: Sí, gracias a Yuki por compartir el paquete para integrar ReSpeaker Mic Array v2 con ROS (Robot Operating System) Middleware.
P5: ¿Cómo habilitar el puerto de audio de 3.5mm para recibir la señal así como el puerto USB?
R5: Por favor descarga el nuevo firmware y graba el XMOS siguiendo Cómo actualizar firmware.
Recursos
- [PDF] Esquemático ReSpeaker MicArray v3.0
- [PDF] Resumen del Producto ReSpeaker MicArray v3.0
- [PDF] Modelo 3D ReSpeaker MicArray v3.0
- [SKP] Modelo 3D ReSpeaker MicArray v3.0
- [STP] Modelo 3D ReSpeaker MicArray v3.0
- [PDF] Resumen del Producto XVF3000
- [PDF] Hoja de Datos XVF3000
- [Github] ReSpeaker Mic Array v2 con ROS (Robot Operating System) Middleware
Soporte Técnico y Discusión del Producto
¡Gracias por elegir nuestros productos! Estamos aquí para proporcionarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.