SenseCraft AI con reSpeaker
Introducción
SenseCraft AI es la plataforma de IA sin código/bajo código de Seeed Studio que simplifica el despliegue de modelos de inteligencia artificial preentrenados en dispositivos de borde como el reSpeaker. Esta guía se centra en configurar el reSpeaker para la detección de palabra de activación usando el disparador personalizado "Lumio", lo que permite el control activado por voz para tus proyectos sin escribir código complejo. Con SenseCraft AI, puedes probar, previsualizar e integrar rápidamente eventos de palabra de activación en tus flujos de trabajo de hardware. La plataforma también te permite crear y cargar tus propios modelos personalizados para detectar eventos de sonido específicos y palabras de activación personalizadas, dándote total flexibilidad para adaptar las interacciones por voz a las necesidades únicas de tu aplicación.
| reSpeaker Lite | reSpeaker XVF3800 | |
|---|---|---|
 | OR |  |
Desplegar modelo existente
Paso 1: Actualizar el firmware del dispositivo
Antes de desplegar el modelo de palabra de activación, asegúrate de que tu reSpeaker XVF3800 esté ejecutando la versión de firmware correcta.
El archivo de firmware requerido es:
respeaker_xvf3800_i2s_master_dfu_firmware_v1.0.7_48k_test5.bin
Sigue el procedimiento estándar de DFU (Actualización de Firmware del Dispositivo) de tu dispositivo para flashear este archivo en el reSpeaker XVF3800.
Si estás usando un reSpeaker Lite, asegúrate de que esté ejecutando la versión de firmware correcta.
El archivo de firmware requerido es:
respeaker_lite_i2s_dfu_firmware_v1.0.9.bin
Sigue el procedimiento estándar de DFU (Actualización de Firmware del Dispositivo) de tu dispositivo para flashear este archivo en el reSpeaker Lite.
Paso 2: Navegar a la plataforma SenseCraft AI
Abre tu navegador web y ve a:
Paso 3: Acceder a la sección de entrenamiento
Desde el menú de navegación principal:
- Haz clic en Products
- Selecciona SenseCraft AI
- Elige Training AI Models
Paso 4: Abrir tu espacio de trabajo
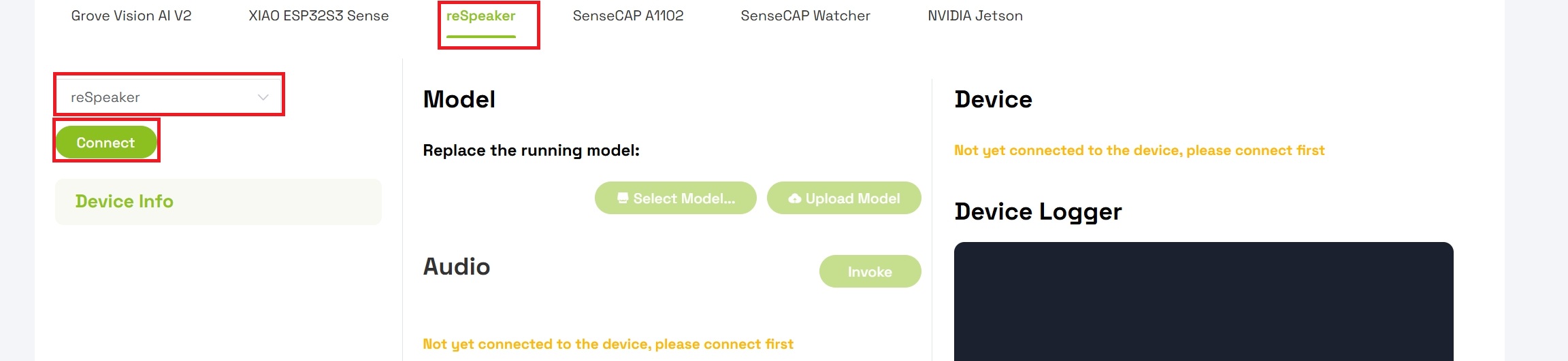
- Navega a tu Workspace

- Verifica que el espacio de trabajo esté configurado con reSpeaker como tipo de dispositivo activo
- Selecciona reSpeaker de la lista de dispositivos
- Haz clic en el botón Connect para establecer una conexión con tu dispositivo
Paso 5: Reemplazar el modelo en ejecución
Una vez conectado, reemplazarás el modelo existente en el dispositivo:
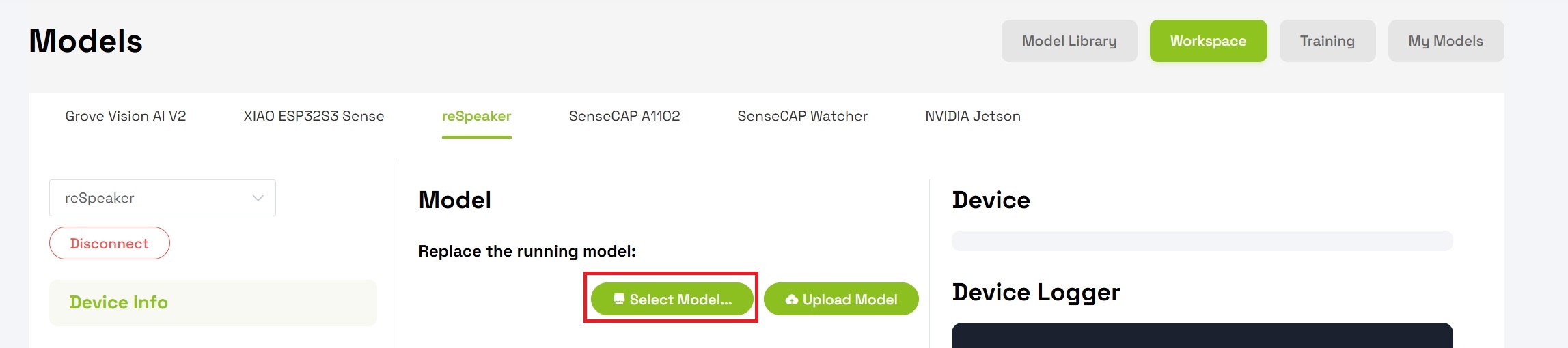
- Localiza la sección Model bajo "Replace the device running model"
- Haz clic en Select Model
- Elige Keyword Spotting- Lumos Keyword recognition de las opciones disponibles
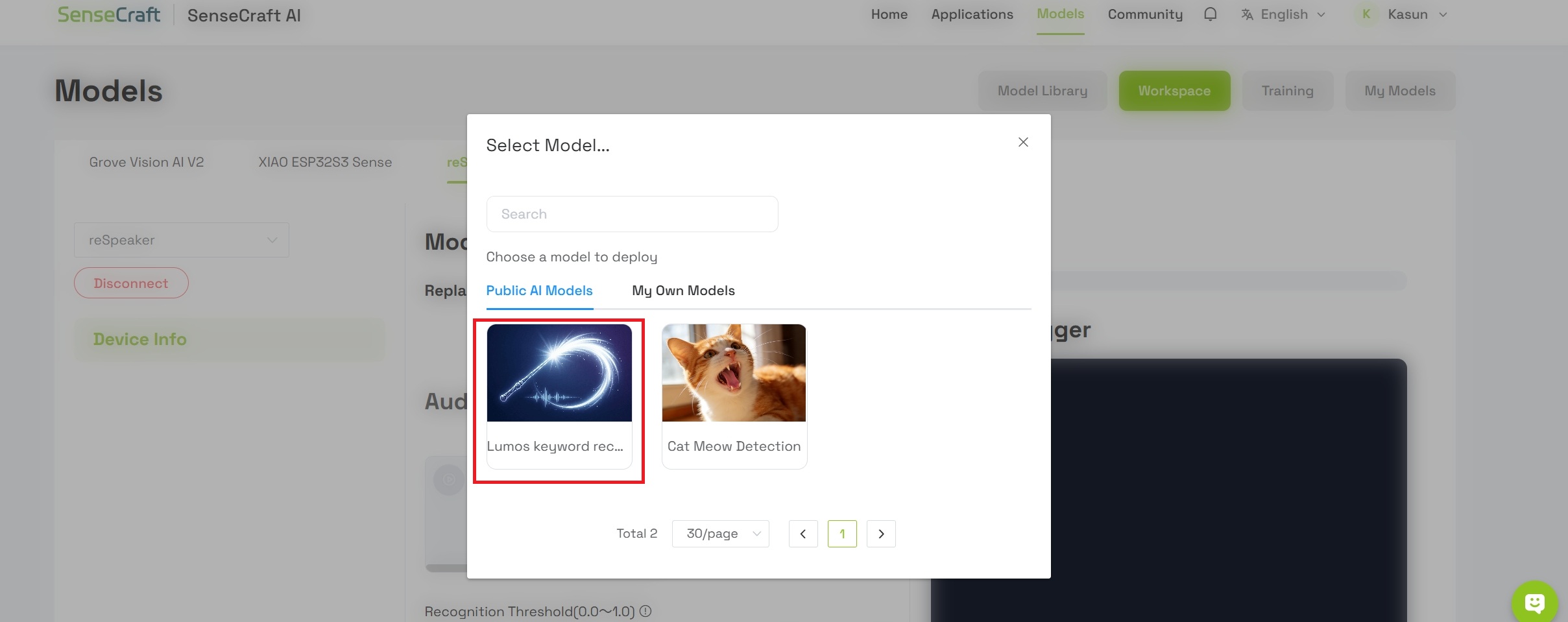
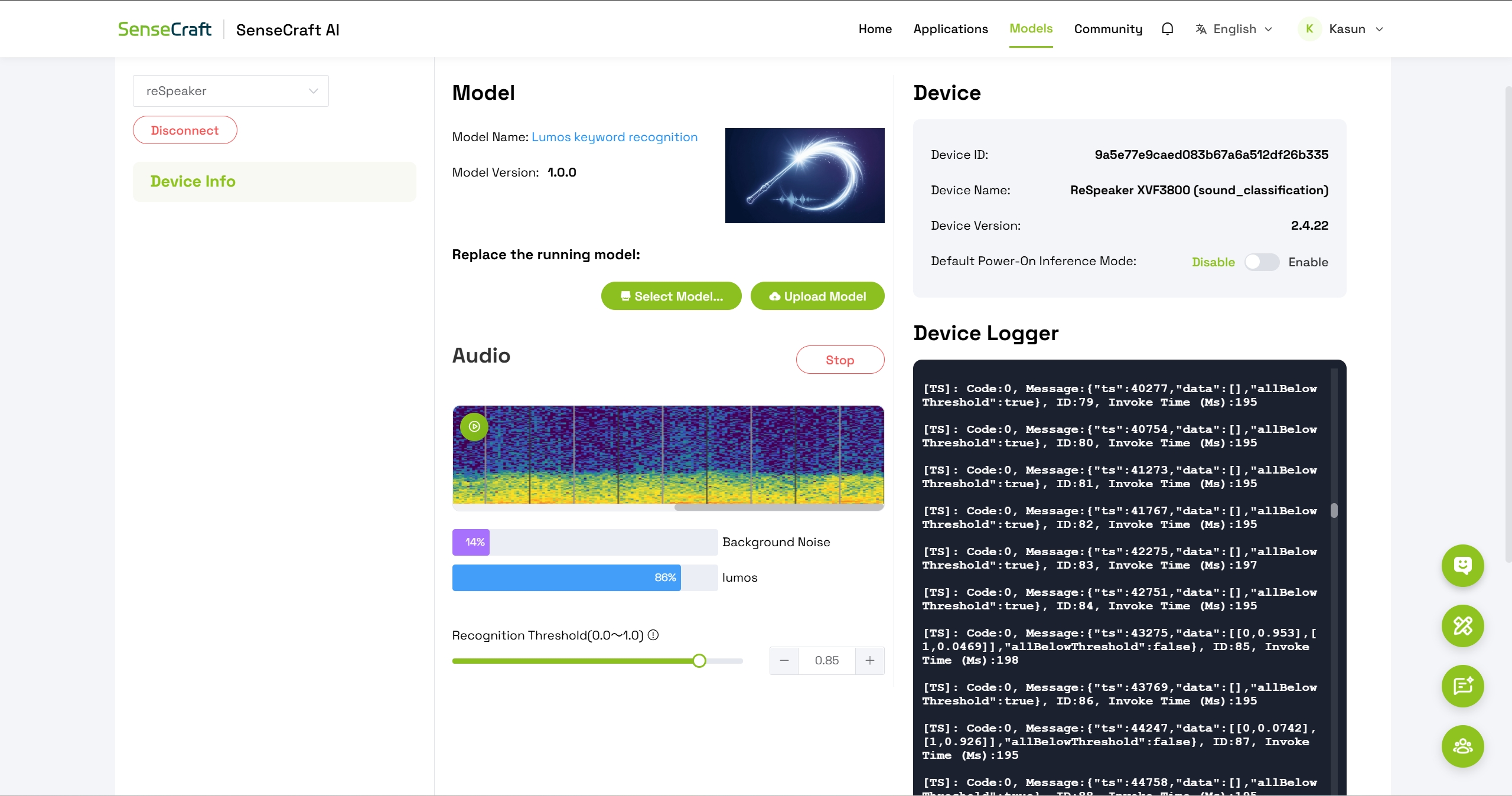
El modelo que estás desplegando se llama Lumos. Es un modelo ligero de reconocimiento de voz diseñado para proporcionar capacidades de interacción por voz eficientes y de baja latencia para dispositivos de borde. Al analizar características espectrales de audio, el modelo puede detectar con precisión la palabra de activación específica "Lumos" incluso en medio de un ruido de fondo ambiental complejo.
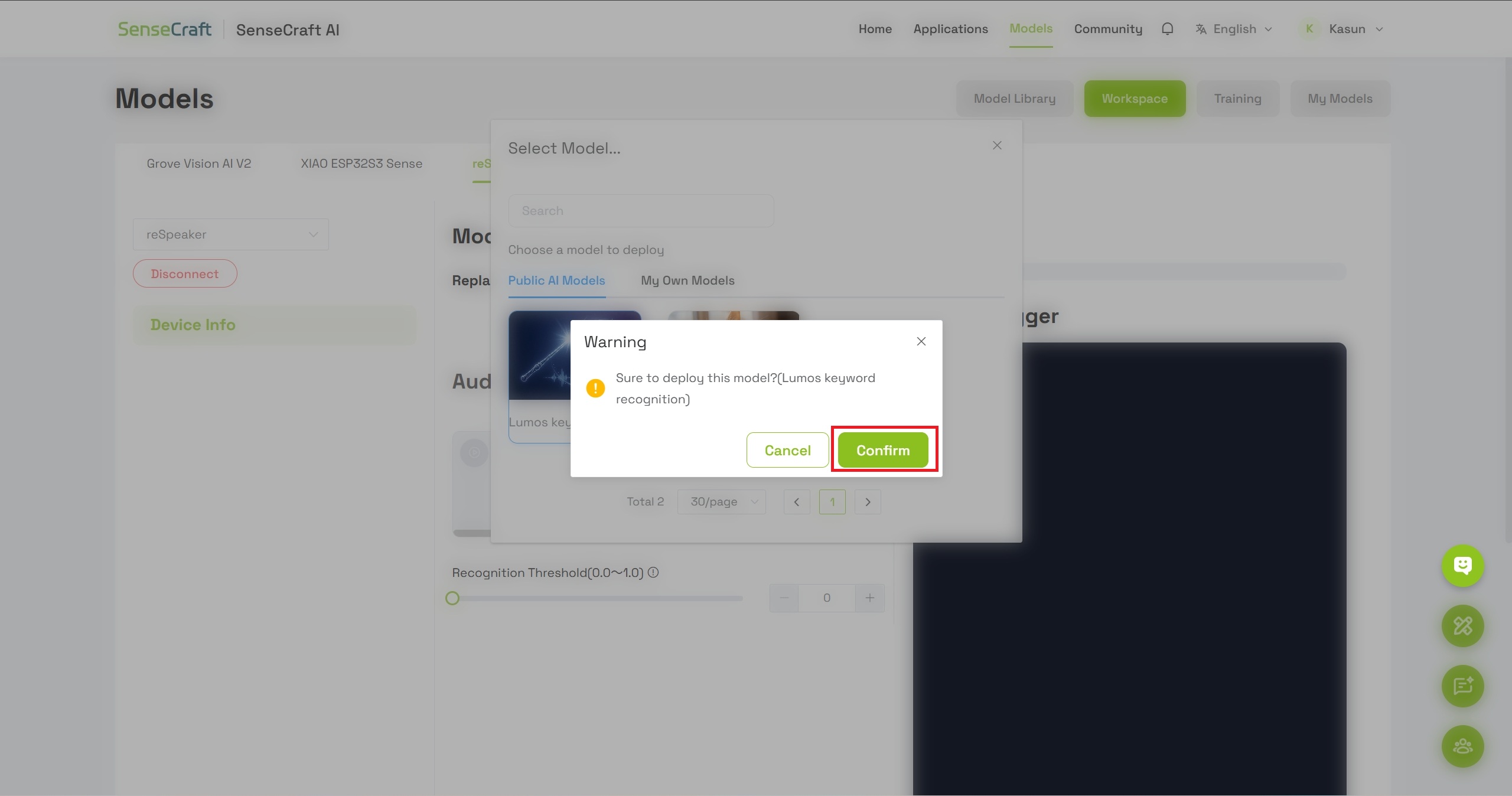
Paso 6: Confirmar el despliegue del modelo
- Aparecerá un cuadro de diálogo con los detalles del modelo
- Haz clic en Confirm para proceder a flashear el modelo en tu dispositivo
- Espera un momento mientras el modelo se flashea en el reSpeaker
Paso 8: Probar la detección de palabra de activación
Después de un despliegue exitoso, verás:
- Visualización del espectro de audio: muestra la entrada de sonido en tiempo real
- Dos clases de detección:
- Ruido de fondo
- Lumos
Para probar la palabra de activación:
- Pronuncia claramente la palabra "Lumos" hacia el micrófono del reSpeaker
- Observa cómo aumenta el nivel de confianza para la clase Lumos
- Ajusta el parámetro de umbral según sea necesario para afinar la sensibilidad de detección
Entrenar y desplegar tu propio clasificador de audio
Paso 1: Abrir la pestaña de entrenamiento
- Navega a https://sensecraft.seeed.cc/
- Desde el menú principal, ve a Products → SenseCraft AI → Training AI Models
- Haz clic en la pestaña Training para acceder a la interfaz de clasificación de audio

Paso 2: Conectar tu dispositivo reSpeaker
Bajo Audio Classification / Detection:
- Verifica que reSpeaker Microphone esté seleccionado como dispositivo de entrada
- Haz clic en el botón Connect para establecer una conexión
- Espera a que la plataforma confirme la conexión exitosa

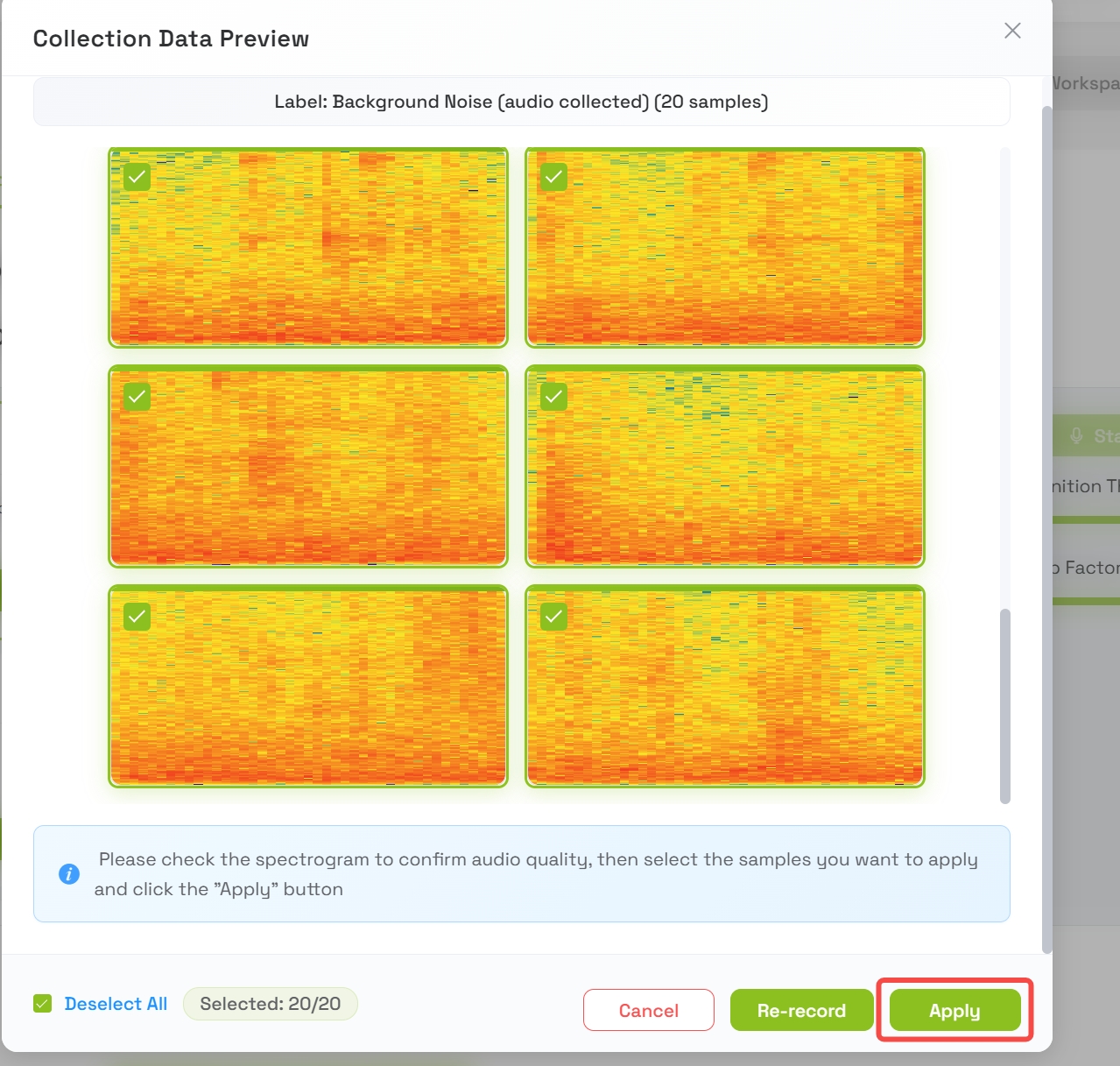
Paso 3: Recopilar datos de ruido de fondo
Antes de entrenar sonidos personalizados, debes establecer una línea base para el ruido ambiental normal.
- Pulsa Collect Training Data for Background Noise

- La plataforma grabará automáticamente durante aproximadamente 20 segundos
- La grabación se dividirá en muestras de 1 segundo
- Una vez completado, aparecerá una vista previa de las muestras de datos de fondo
- Revisa las muestras y pulsa Apply cuando estés satisfecho
Paso 4: Crear una clase de sonido personalizada
Ahora añadirás una nueva clase para el sonido específico que quieres que el modelo detecte.
4.1 Nombra tu clase
- Haz clic en Add New Class
- Introduce el nombre de la clase: Grassbreaking
- Pulsa Create o confirma la nueva clase
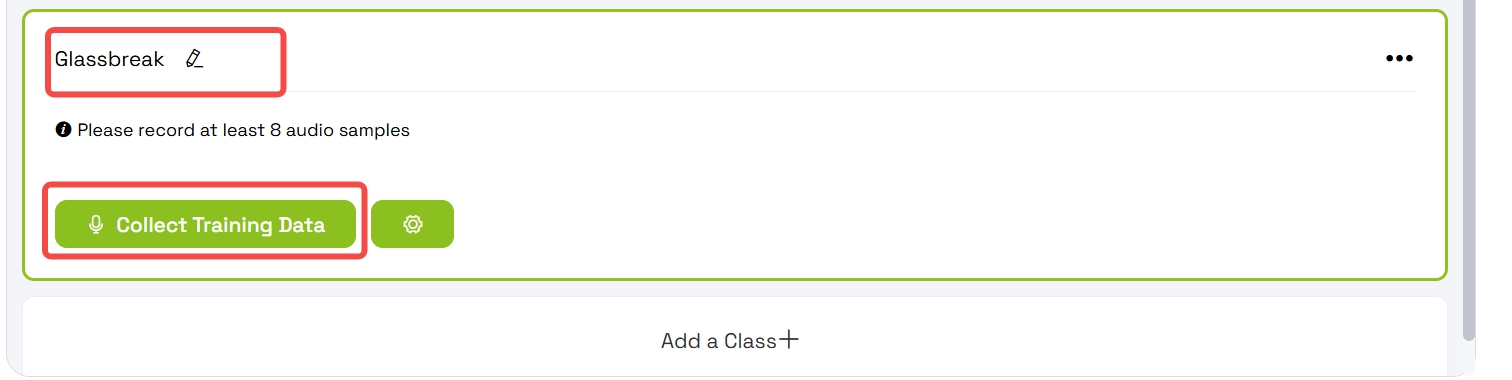
4.2 Recopilar datos de entrenamiento para la clase personalizada
- Selecciona la clase Grassbreaking
- Pulsa Collect Training Data
- La plataforma grabará durante aproximadamente 2 segundos
- La grabación se dividirá en muestras de 1 segundo
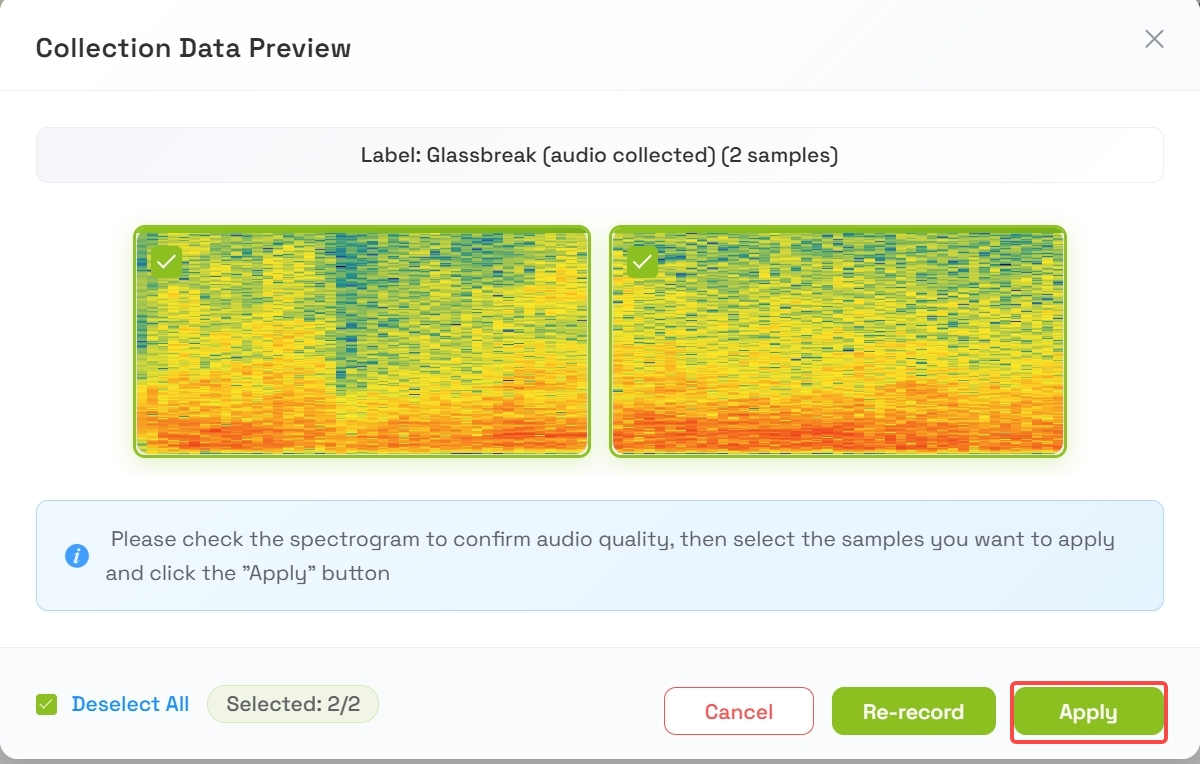
4.3 Revisar y aplicar las muestras
- Después de la recopilación, aparecerá una vista previa de las 2 muestras
- Escucha o revisa las muestras
- Pulsa Apply cuando estés satisfecho con la calidad
4.4 Repetir para más muestras
Para lograr una detección fiable, repite el proceso de recopilación de datos hasta que hayas recopilado al menos 8 muestras para la clase Grassbreaking.
Consejos para buenas muestras:
- Varía la intensidad del sonido de rotura de hierba
- Recopila muestras desde posiciones o ángulos ligeramente diferentes
- Asegúrate de que el sonido sea claramente audible por encima del ruido de fondo
Paso 5: Entrenar el modelo
Una vez que hayas recopilado suficientes datos, es momento de entrenar el modelo.
5.1 Navegar al paso de entrenamiento
Ve a Step 2: Training en la interfaz.
5.2 Confirmar la selección del dispositivo
Verifica que reSpeaker esté seleccionado como el dispositivo de destino para el entrenamiento.
5.3 Iniciar el entrenamiento
- Pulsa el botón Train
- Espera unos minutos a que se complete el proceso de entrenamiento
- No cierres el navegador ni desconectes el dispositivo durante el entrenamiento

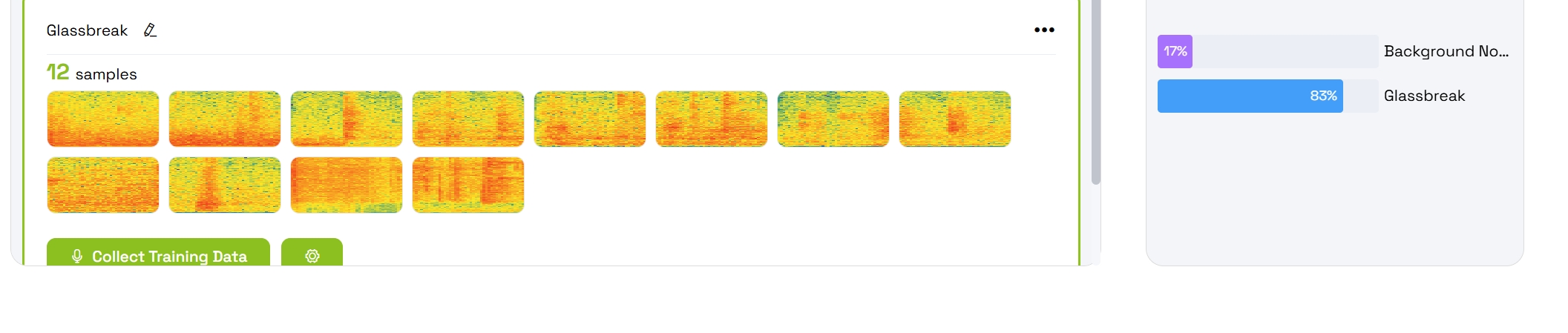
5.4 Revisar los resultados del entrenamiento
Una vez finalizado el entrenamiento, tus clases entrenadas aparecerán con:
- Barras de probabilidad animadas que muestran los niveles de confianza
- Predicciones en tiempo real basadas en la entrada de audio en vivo
Paso 6: Implementar el modelo en reSpeaker
6.1 Ir al paso de implementación
Ve a Step 3: Deploy en la interfaz.
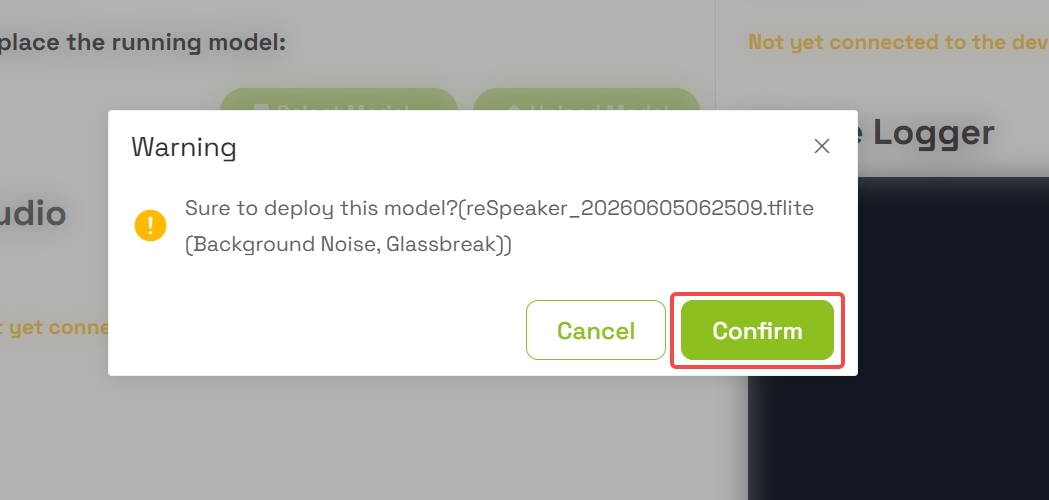
6.2 Implementar el modelo
- Haz clic en el botón Deploy para enviar el modelo a tu dispositivo

- Aparecerá un cuadro de diálogo de confirmación
- Confirma la implementación para enviar el modelo TFLM (TensorFlow Lite Micro) al XIAO ESP32-S3 del reSpeaker
6.3 Esperar a que finalice
El proceso de implementación puede tardar un momento. Espera el mensaje de confirmación que indique que la implementación se ha realizado correctamente.
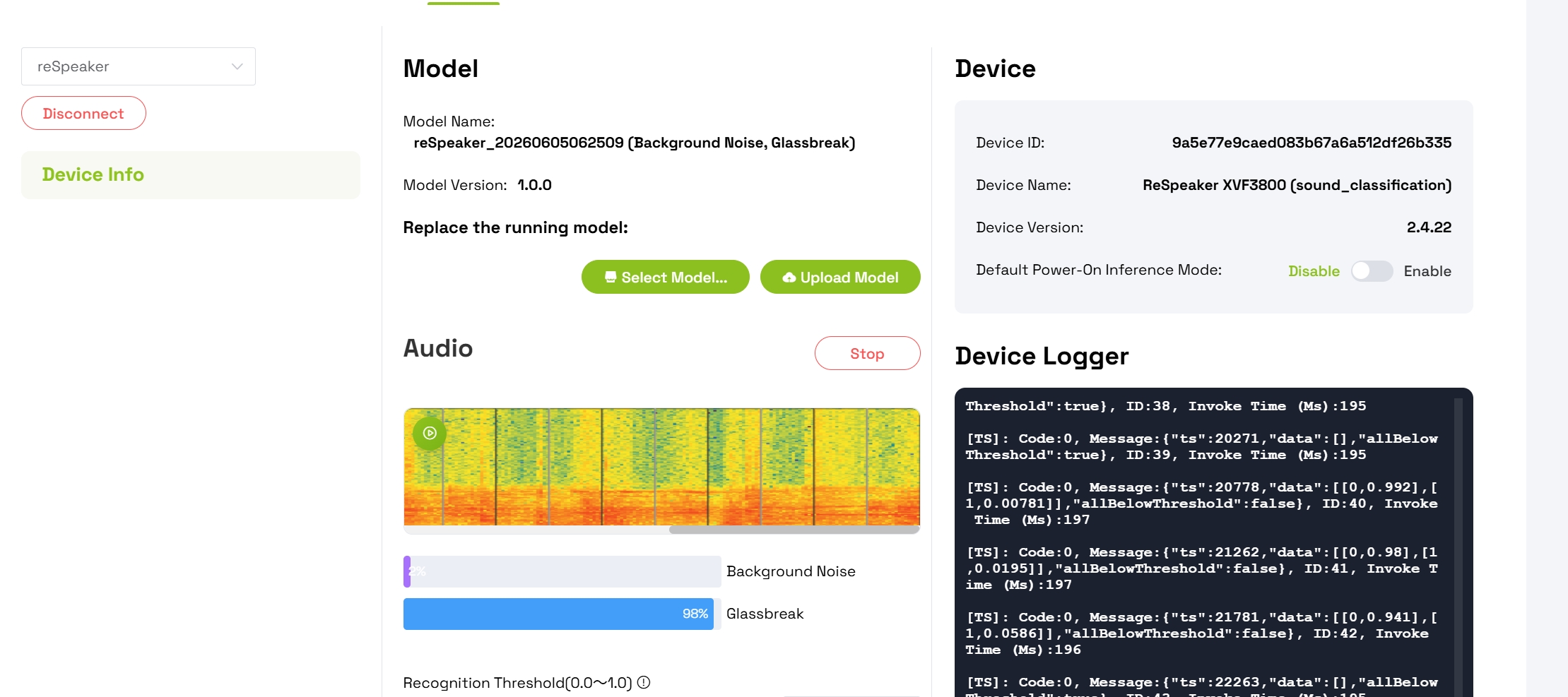
Paso 7: Supervisar la detección en tiempo real
Después de una implementación exitosa:
- La interfaz mostrará barras de confianza animadas para cada clase detectada
- Habla o produce el sonido de rotura de hierba para probar la detección
- Observa cómo aumenta el nivel de confianza para la clase Grassbreaking
- Observa cómo disminuye la confianza de Background Noise cuando se detecta el sonido personalizado
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.