Reconocimiento de voz TinyML con Edge Impulse con reSpeaker XVF3800
Descripción general
Desbloquea el control manos libres con detección de comandos de voz en tiempo real usando un sistema de Keyword Spotting (KWS) impulsado por TinyML. Al combinar la matriz de micrófonos de alto rendimiento ReSpeaker XVF3800 con la eficiente XIAO ESP32S3 y la plataforma Edge Impulse, llevamos el reconocimiento de voz a dispositivos compactos y de bajo consumo. Entrena, despliega y escucha: ¡tu dispositivo siempre estará listo para tu próximo comando!
Hardware necesario

Recopilación de datos
Instalación del firmware USB para ReSpeaker XVF3800 con XIAO ESP32S3
Para comenzar la recopilación de datos de audio, asegúrate de que tu ReSpeaker esté flasheado con el firmware USB, lo que le permite funcionar como un micrófono USB.
Configurar el entorno de Python
Luego necesitas crear un entorno de python en tu portátil u ordenador para recopilar los datos de voz. Aquí vamos a crear el respeaker-env
python -m venv respeaker-env
source respeaker-env/bin/activate
Instalar las bibliotecas necesarias:
pip install sounddevice scipy numpy
Encontrar el ID de dispositivo de ReSpeaker
Para grabar desde la entrada de micrófono correcta, necesitamos identificar el índice de dispositivo del micrófono ReSpeaker.
import sounddevice as sd
devices = sd.query_devices()
for i, device in enumerate(devices):
print(f"Device {i}: {device['name']} (input channels: {device['max_input_channels']})")
Busca el nombre de dispositivo que corresponda a ReSpeaker (a menudo llamado algo como ReSpeaker XVF3800 USB 4-Mic Array) y anota el número de índice (por ejemplo, Device 2).
Grabar muestras de audio
El siguiente script te permitirá grabar muestras de audio etiquetadas, organizadas por persona y comando/palabra clave.
import os
import sounddevice as sd
from scipy.io.wavfile import write
# === Settings ===
SAMPLERATE = 16000
CHANNELS = 1 # Mono input
DURATION = 10 # seconds
DEVICE_INDEX = 2 # Replace with correct device index
def record_audio(filename, samplerate=SAMPLERATE, channels=CHANNELS, duration=DURATION, device=DEVICE_INDEX):
print(f"Recording '{filename}' for {duration} seconds...")
recording = sd.rec(int(duration * samplerate),
samplerate=samplerate,
channels=channels,
dtype='int32',
device=device)
sd.wait()
write(filename, samplerate, recording)
print(f"Saved: {filename}")
def get_next_filename(directory, label):
existing = [f for f in os.listdir(directory) if f.startswith(label) and f.endswith('.wav')]
index = len(existing) + 1
return os.path.join(directory, f"{label}.{index}.wav")
def collect_samples():
while True:
sample_name = input("Enter sample name (e.g., PersonA): ").strip()
if not sample_name:
print("Sample name cannot be empty.")
continue
sample_dir = os.path.join(os.getcwd(), sample_name)
os.makedirs(sample_dir, exist_ok=True)
print(f"Directory created: {sample_dir}")
while True:
label = input("Enter sound/voice to record (e.g., yes, no): ").strip()
if not label:
print("Label cannot be empty.")
continue
while True:
filename = get_next_filename(sample_dir, label)
record_audio(filename)
cont = input("Record another sample for this label? (yes/no): ").strip().lower()
if cont != 'yes':
break
next_label = input("Do you want to record a different label? (yes/no): ").strip().lower()
if next_label != 'yes':
break
next_sample = input("Do you want to create a new sample? (yes/no): ").strip().lower()
if next_sample != 'yes':
print("Audio collection completed.")
break
if __name__ == "__main__":
collect_samples()
Ejemplo de estructura de carpetas
/PersonA
├── red.1.wav
├── red.2.wav
├── blue.1.wav
└── blue.2.wav
/PersonB
├── red.1.wav
└── green.1.wav
La carpeta de cada persona contiene archivos .wav etiquetados que posteriormente se cargarán en Edge Impulse para el entrenamiento del modelo.
Carga y preparación de datos de audio en Edge Impulse
Después de recopilar muestras de audio en bruto usando el ReSpeaker XVF3800 y organizarlas por etiqueta, el siguiente paso es cargarlas y procesarlas en Edge Impulse Studio para entrenar tu modelo de Keyword Spotting.
Crear un nuevo proyecto en Edge Impulse
-
Ve a Edge Impulse y accede (o regístrate si eres nuevo).
-
Haz clic en "Create new project".
-
Proporciona un nombre para tu proyecto (por ejemplo, "Voice Command KWS")
Cargar muestras de audio existentes
Para cargar los datos recopilados:
- 1.Navega a la pestaña Data Acquisition.
- 2.Haz clic en "Upload existing data" (arriba a la derecha).
- 3.Selecciona y carga la carpeta que contiene tus archivos .wav
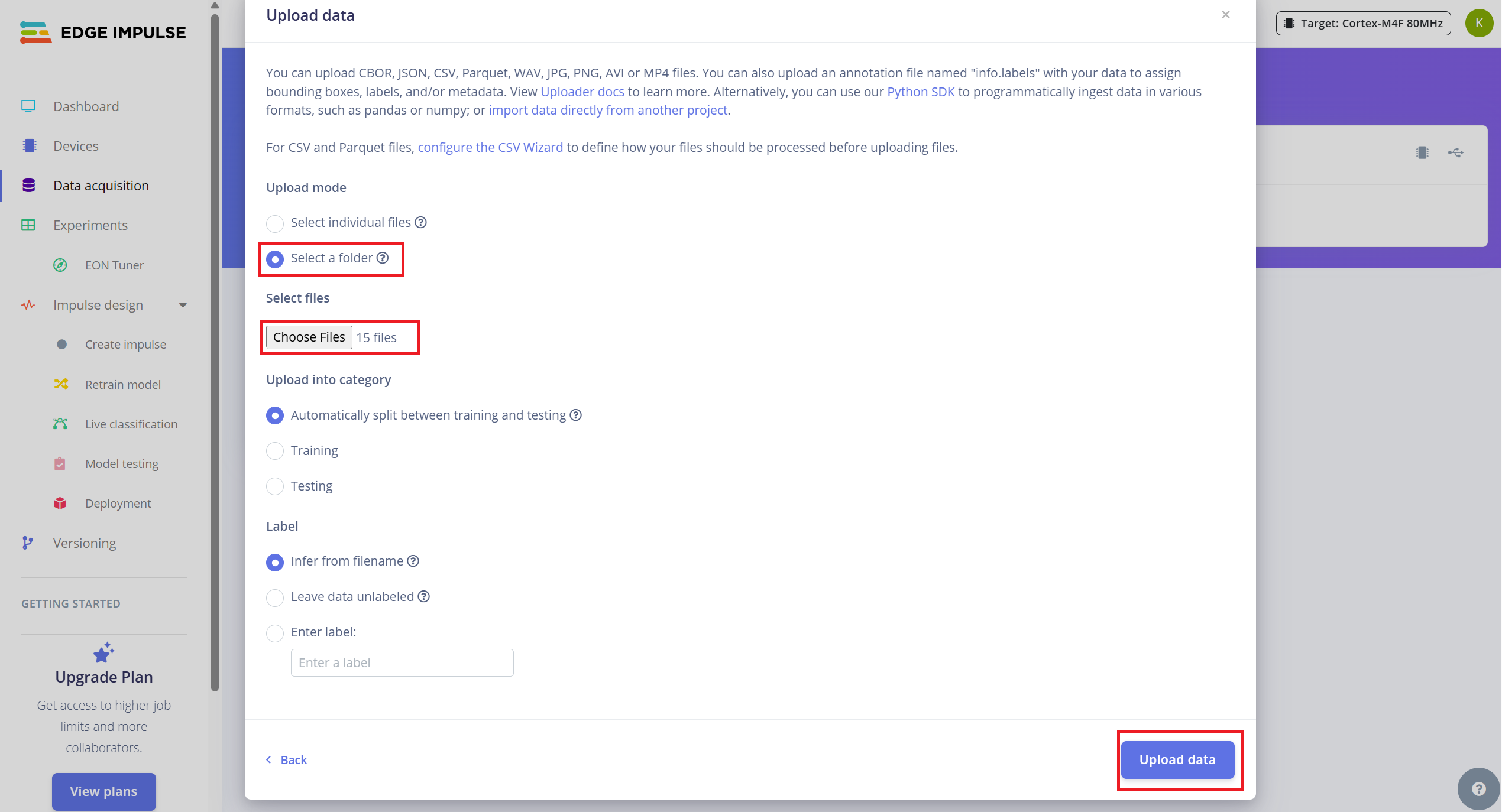
- 4.Activa la opción para dividir automáticamente los datos en entrenamiento y prueba (Edge Impulse recomienda una división de ~80/20).
Dividir audio de 10 segundos en muestras de 1 segundo
Edge Impulse funciona mejor con clips de audio de 1 segundo para Keyword Spotting. Dado que las muestras originales se grabaron en segmentos de 10 segundos, tendrás que dividir cada una en múltiples muestras de 1 segundo.
Sigue estos pasos:
- 1.Después de cargar, ve a la página Data Acquisition.
- 2.Busca una muestra (por ejemplo, yes.1.wav) y haz clic en los tres puntos (…) junto a la muestra.
- 3.Selecciona "Split sample" en el menú.
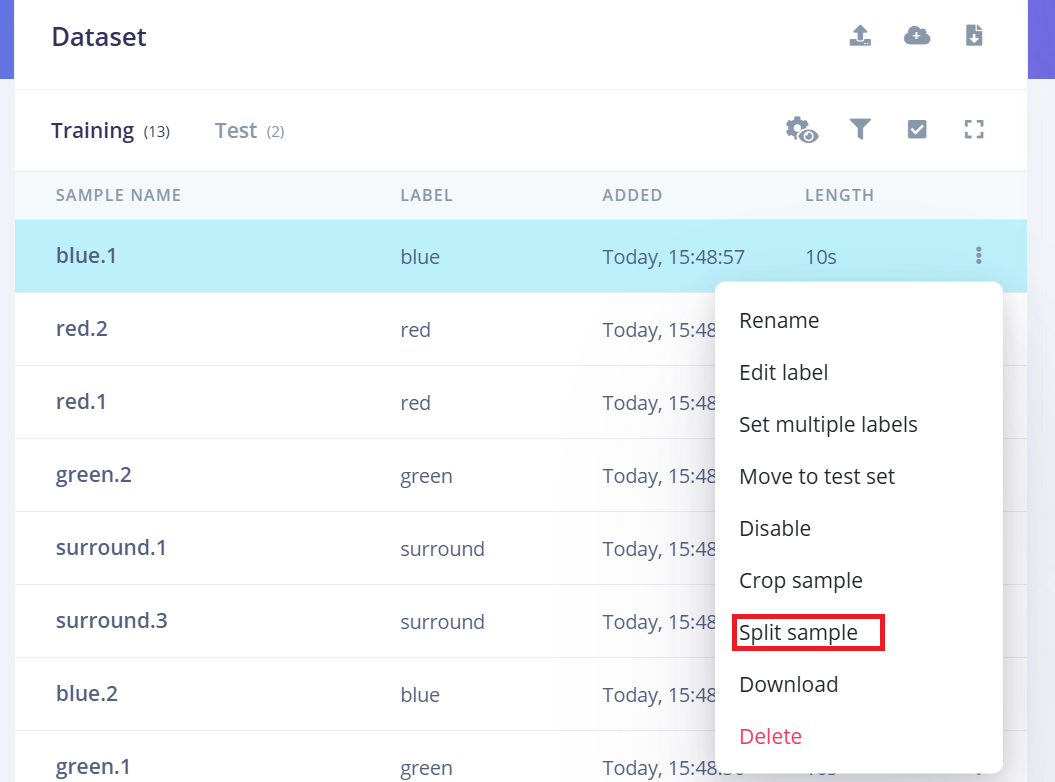
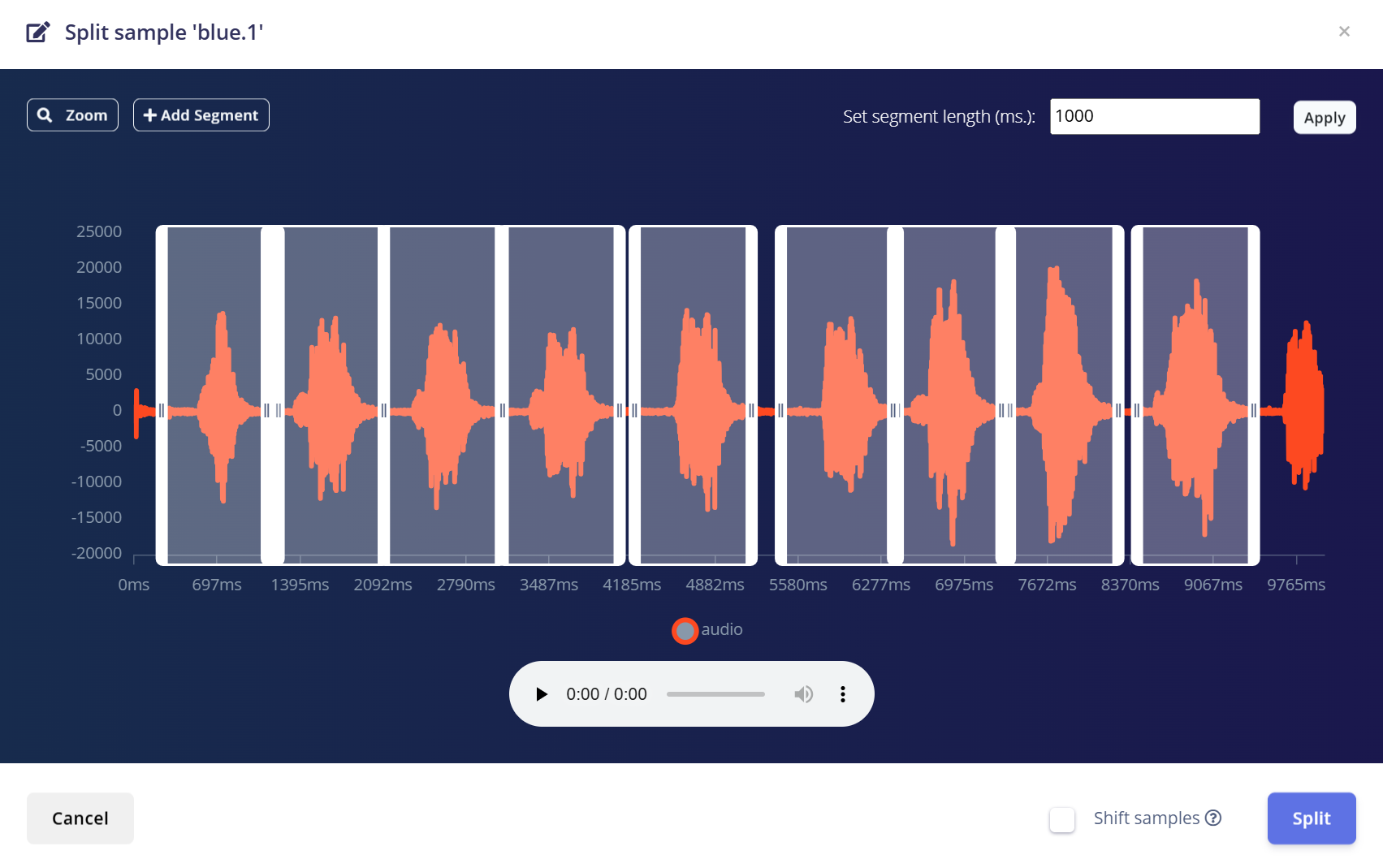
- 4.Utiliza la herramienta para dividir la forma de onda en segmentos de 1 segundo.
- a.Puedes arrastrar para ajustar los segmentos o añadir/eliminarlos según sea necesario.
- 5.Haz clic en Save and Split.
Repite este proceso para cada muestra de 10 segundos en todas las clases, tanto de entrenamiento como de prueba.
Esto garantiza que tu conjunto de datos esté correctamente formateado y optimizado para entrenar un modelo de alta precisión.
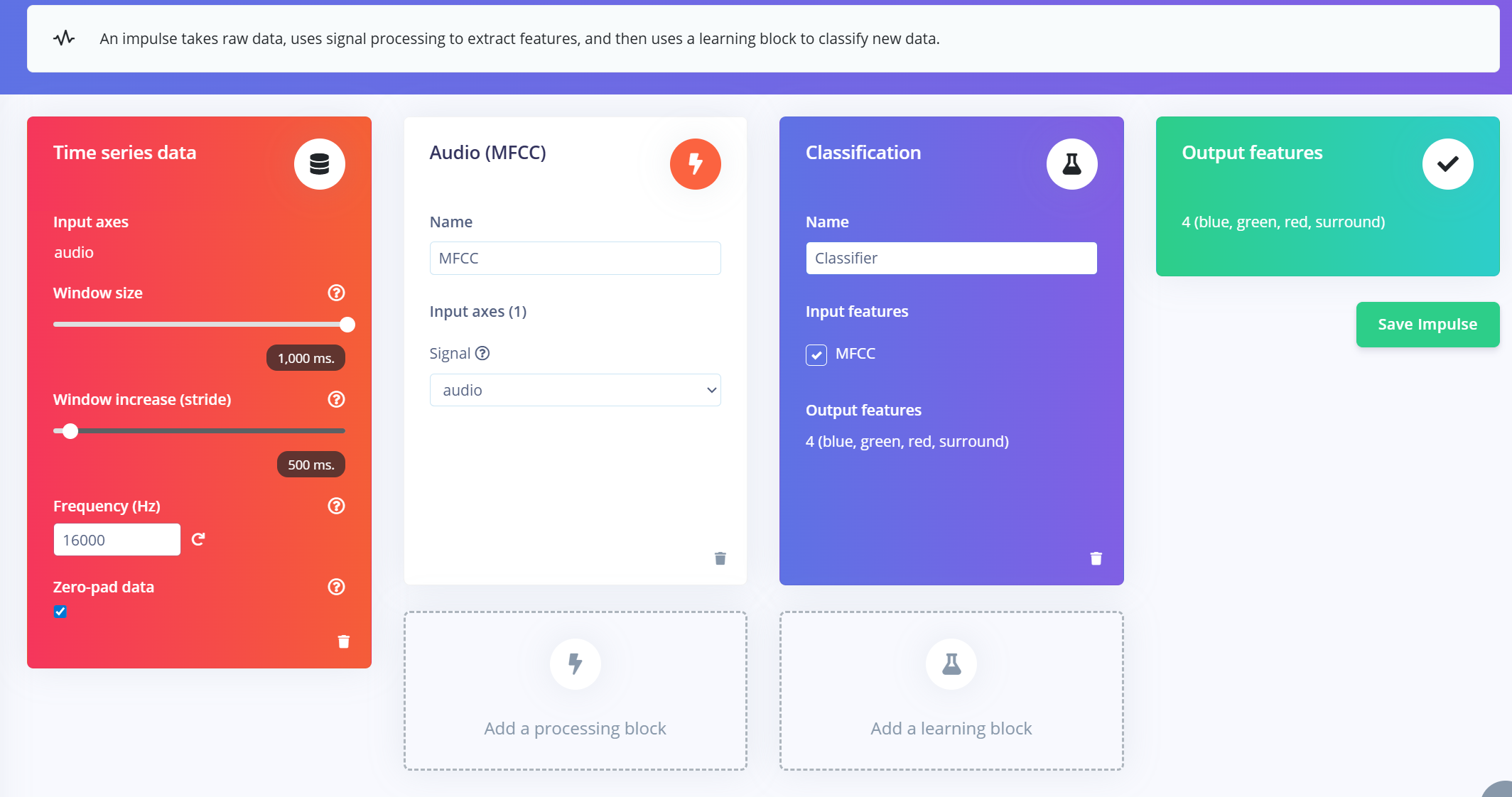
Creación del Impulse (preprocesamiento / definición del modelo)
Un impulse en Edge Impulse define la canalización de extremo a extremo que transforma los datos en bruto en un modelo de aprendizaje automático entrenado. Incluye procesamiento de señal, extracción de características y un bloque de aprendizaje para la clasificación.
Crear el Impulse
- 1.Navega a la pestaña "Impulse Design" en tu proyecto de Edge Impulse.
- 2.Haz clic en “Create Impulse”.
- 3.Configura la ventana de entrada:
- a.Window size: 1000 ms (1 segundo)
- b.Window increase: 500 ms (ventanas solapadas para aumentar los datos)
- c.Enable "Zero-pad data": Esto garantiza que los segmentos más cortos (por ejemplo, 800 ms) se rellenen con ceros, especialmente útil cuando se aplica recorte de ruido durante la división de muestras.
Añadir el extractor de características MFCC
Después de crear la ventana del impulse:
- 1.Haz clic en “Add a processing block” y selecciona MFCC (Mel Frequency Cepstral Coefficients).
- a.MFCC es un método ampliamente utilizado para convertir señales de audio en características 2D que representan patrones de frecuencia de la voz.
- b.Estas características son perfectas para modelos de reconocimiento basados en voz.
- 2.Configura los parámetros de MFCC (los valores predeterminados funcionan bien en la mayoría de los casos):
- a.Output shape: 13 x 49 x 1
- b.Esto convierte tu clip de audio en una “imagen” para la clasificación.
Añadir un bloque de aprendizaje
- 1.Haz clic en “Add a learning block” y elige “Classification (Keras)”.
- 2.Esto crea una Red Neuronal Convolucional (CNN) personalizada que realizará clasificación de imágenes sobre las características MFCC.
- 3.Ahora puedes continuar a la pestaña NN Classifier para personalizar y entrenar tu modelo.
Preprocesamiento (MFCC)
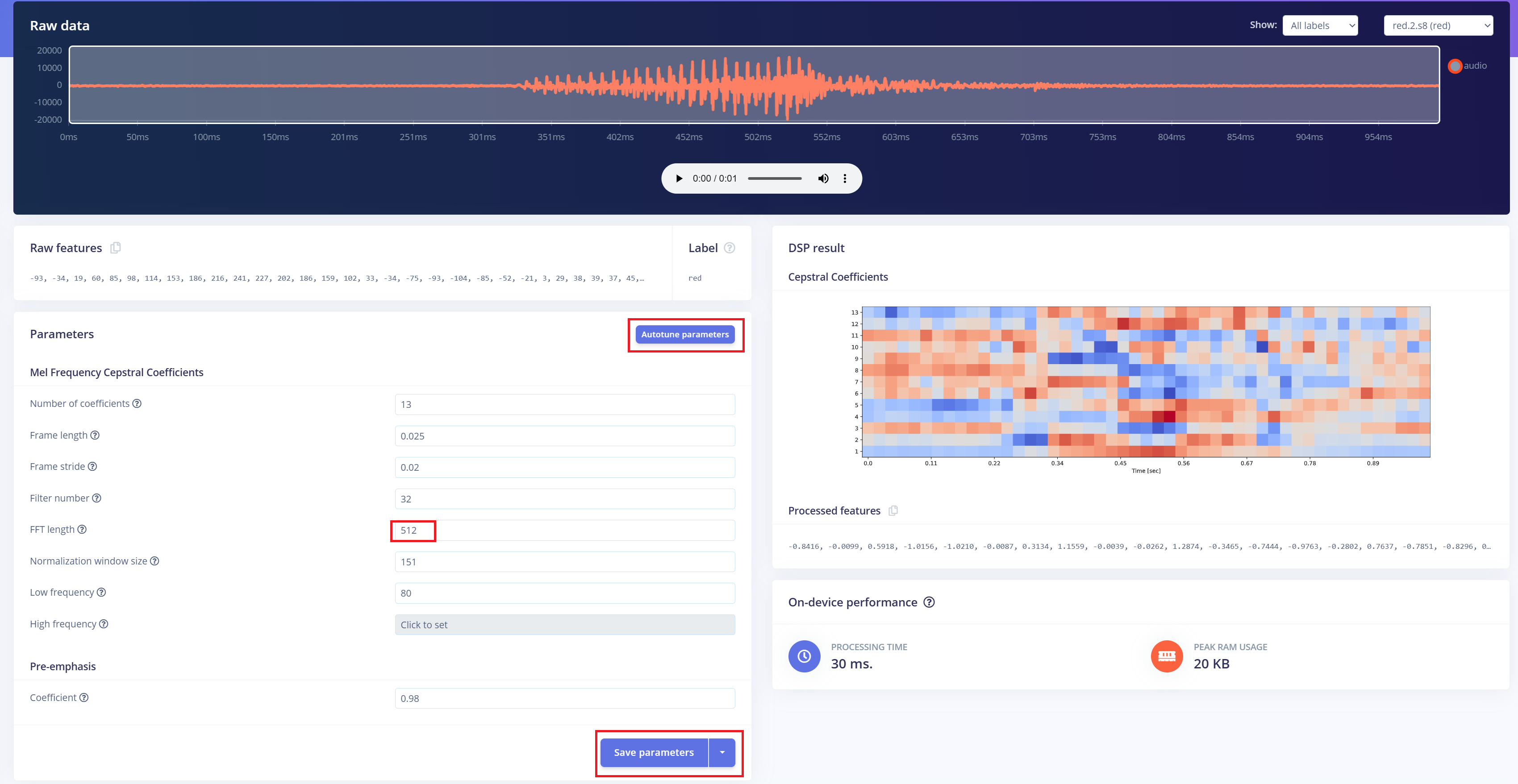
El siguiente paso es generar imágenes de espectrogramas a partir del audio grabado, que se utilizarán para el entrenamiento del modelo. Podemos usar los parámetros DSP predeterminados o, como en nuestro caso, aprovechar la función DSP Autotune para optimizarlos automáticamente y obtener un mejor rendimiento.
Creación de un modelo de aprendizaje automático
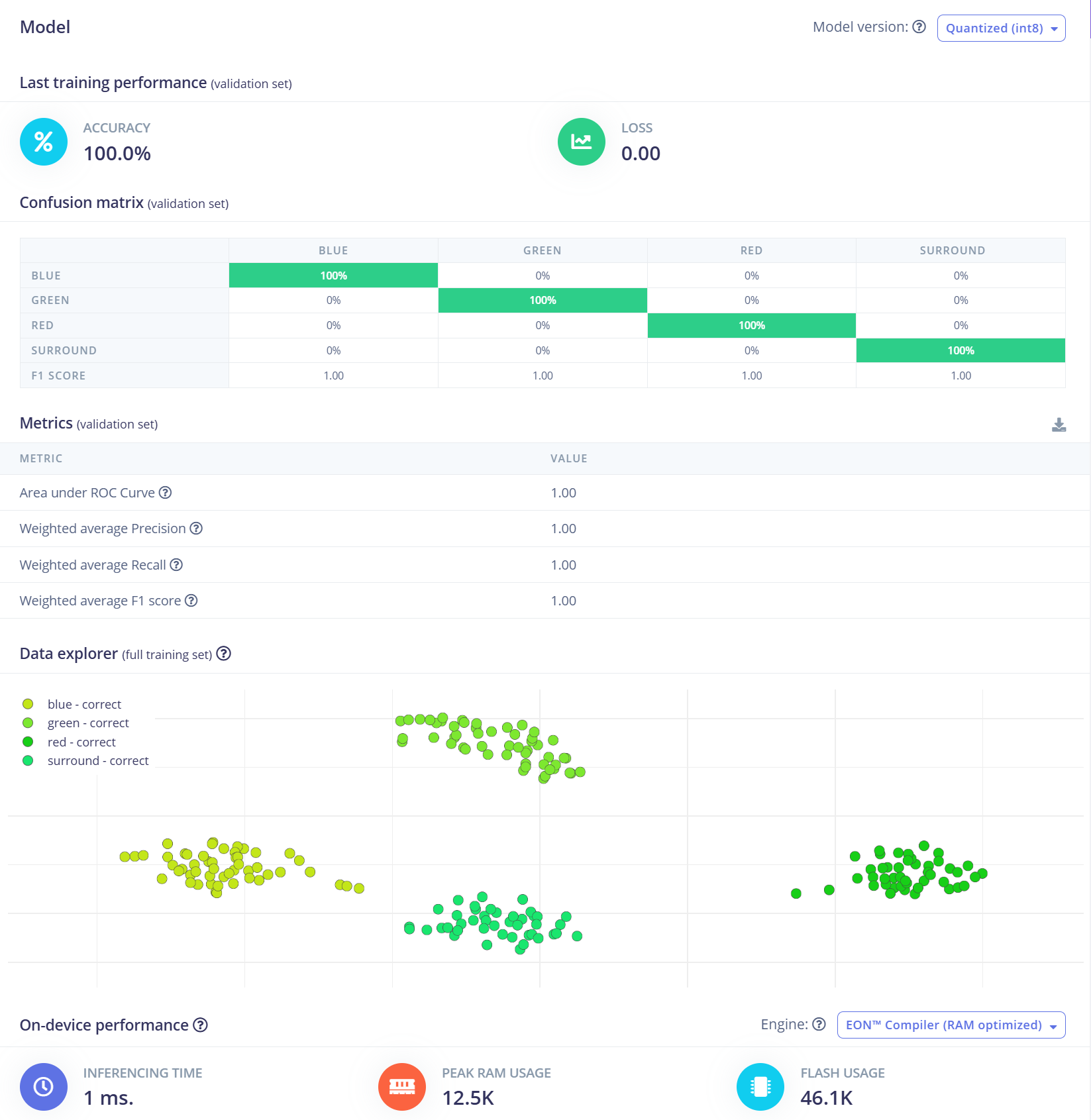
Para este proyecto, utilizaremos un modelo de Red Neuronal Convolucional (CNN). La arquitectura consta de dos capas Conv1D + MaxPooling con 8 y 16 filtros respectivamente, seguidas de una capa Dropout de 0.25. Después de aplanar, la capa densa final incluye cuatro neuronas, una para cada clase. Entrenaremos el modelo usando una tasa de aprendizaje de 0.005 durante 100 épocas. Para mejorar la capacidad de generalización y la robustez, se aplicarán técnicas de aumento de datos como ruido de fondo. Los resultados iniciales son prometedores.
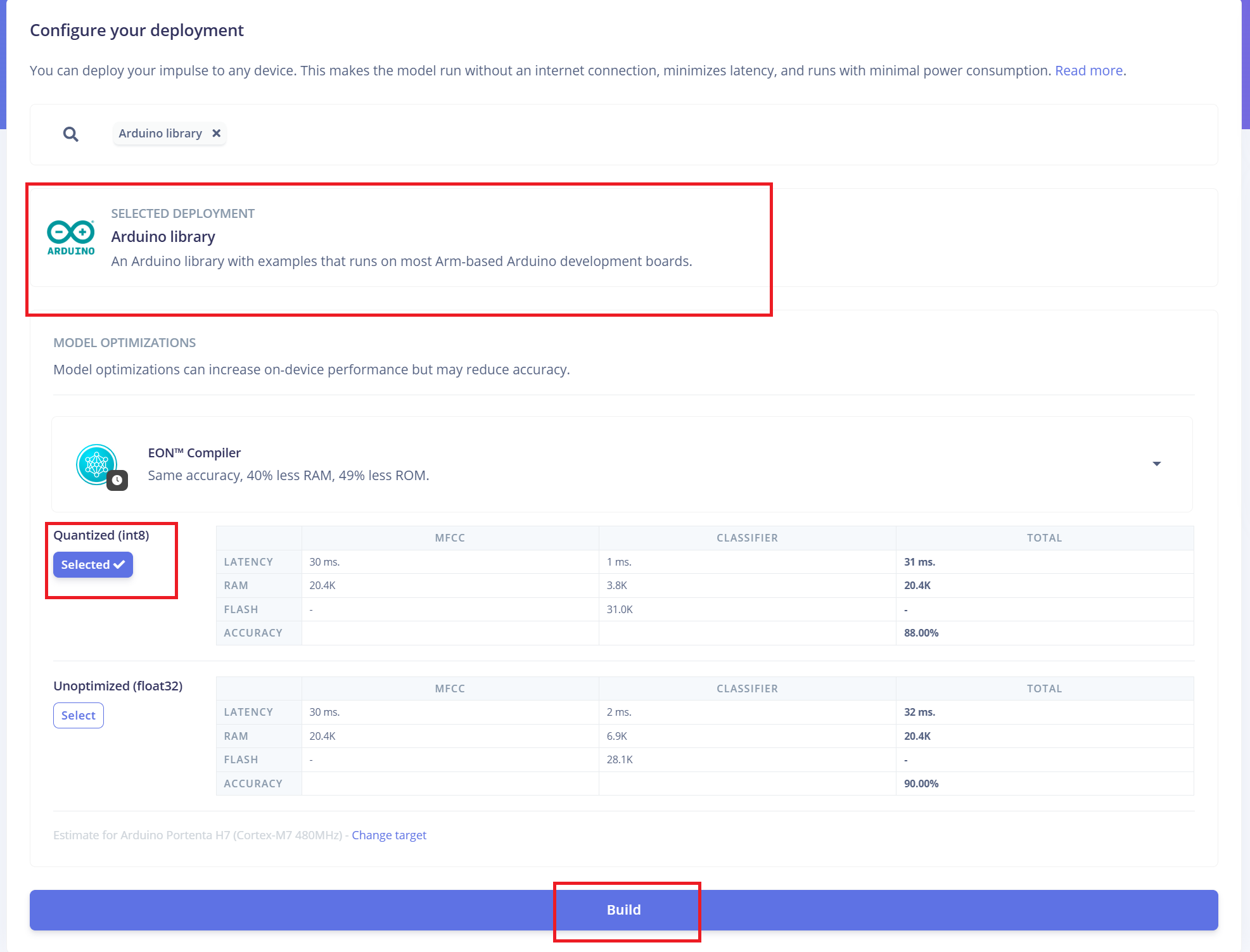
Despliegue en ReSpeaker XVF3800 con XIAO ESP32 S3
Edge Impulse agrupará automáticamente todas las bibliotecas necesarias, las funciones de preprocesamiento y el modelo entrenado en un paquete descargable. Para continuar:
- 1.Selecciona "Arduino Library" como opción de despliegue.
- 2.En la parte inferior, elige el formato "Quantized (Int8)".
- 3.Haz clic en "Build" para generar la biblioteca.
Una vez que se complete la descarga:
- 4.Abre el Arduino IDE, ve al menú Sketch.
- 5.Selecciona "Include Library" > "Add .ZIP Library..."
- 6.Elige el archivo .zip descargado desde Edge Impulse para añadirlo a tu proyecto de Arduino.
Cambiar el firmware al modo I2S
Antes de subir el código de Arduino, debes cambiar el firmware del ReSpeaker XVF3800 al modo I2S para habilitar la comunicación mediante el protocolo I2C. Firmware Installation Guide
Integración del código de Arduino
El código de Arduino proporcionado por Edge Impulse requerirá algunas modificaciones para garantizar la compatibilidad con el hardware ReSpeaker XVF3800 y XIAO ESP32S3: actualiza las definiciones de pines GPIO, la frecuencia de muestreo I2S y otros parámetros específicos de hardware según tu configuración.
#define EIDSP_QUANTIZE_FILTERBANK 0
#include <Kasun9603-project-1_inferencing.h> // Change with your one
#include "driver/i2s.h"
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
// ==== AUDIO CONFIG ====
#define I2S_PORT I2S_NUM_0
#define I2S_WS 7 // L/R clock
#define I2S_SD 43 // Serial Data In
#define I2S_SCK 8 // Bit Clock
#define SAMPLE_RATE 16000
#define I2S_SAMPLE_BITS 32
#define SAMPLE_BUFFER_SIZE 2048
// ==== INFERENCE STATE ====
typedef struct {
int16_t *buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static int32_t i2s_samples[SAMPLE_BUFFER_SIZE];
static bool record_status = true;
static bool debug_nn = false;
// ==== FUNCTION DECLARATIONS ====
static bool microphone_inference_start(uint32_t n_samples);
static bool microphone_inference_record(void);
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr);
static void audio_inference_callback(uint32_t n_bytes);
static void capture_samples(void *arg);
static int i2s_init();
static void i2s_deinit();
void setup() {
Serial.begin(115200);
while (!Serial);
ei_printf("XVF3800 Keyword Spotting Inference Start\n");
ei_printf("Model info:\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / (SAMPLE_RATE / 1000));
ei_printf("\tInterval: %.2f ms\n", EI_CLASSIFIER_INTERVAL_MS);
if (!microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT)) {
ei_printf("ERR: Audio buffer allocation failed.\n");
return;
}
ei_printf("Listening...\n");
}
void loop() {
if (!microphone_inference_record()) {
ei_printf("ERR: Failed to record audio.\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
ei_printf("Predictions:\n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" Anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
// ==== INFERENCE AND AUDIO HANDLING ====
static void audio_inference_callback(uint32_t n_bytes) {
for (uint32_t i = 0; i < n_bytes / sizeof(int32_t); i++) {
int16_t val = i2s_samples[i] >> 16; // Convert from 32-bit signed to 16-bit
inference.buffer[inference.buf_count++] = val;
if (inference.buf_count >= inference.n_samples) {
inference.buf_ready = 1;
inference.buf_count = 0;
}
}
}
static void capture_samples(void *arg) {
size_t bytes_read;
while (record_status) {
i2s_read(I2S_PORT, (char *)i2s_samples, SAMPLE_BUFFER_SIZE * sizeof(int32_t), &bytes_read, portMAX_DELAY);
if (bytes_read > 0) {
audio_inference_callback(bytes_read);
} else {
ei_printf("ERR: I2S read failed\n");
}
}
vTaskDelete(NULL);
}
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if (!inference.buffer) return false;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
if (i2s_init() != 0) {
ei_printf("ERR: I2S init failed\n");
return false;
}
xTaskCreate(capture_samples, "CaptureSamples", 4096, NULL, 1, NULL);
return true;
}
static bool microphone_inference_record(void) {
while (!inference.buf_ready) {
delay(10);
}
inference.buf_ready = 0;
return true;
}
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
static int i2s_init() {
i2s_config_t i2s_config = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = (i2s_bits_per_sample_t)I2S_SAMPLE_BITS,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 512,
.use_apll = false,
.tx_desc_auto_clear = false,
.fixed_mclk = 0
};
i2s_pin_config_t pin_config = {
.bck_io_num = I2S_SCK,
.ws_io_num = I2S_WS,
.data_out_num = -1,
.data_in_num = I2S_SD
};
esp_err_t err;
err = i2s_driver_install(I2S_PORT, &i2s_config, 0, NULL);
if (err != ESP_OK) return err;
err = i2s_set_pin(I2S_PORT, &pin_config);
if (err != ESP_OK) return err;
err = i2s_zero_dma_buffer(I2S_PORT);
return err;
}
static void i2s_deinit() {
i2s_driver_uninstall(I2S_PORT);
}
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.