Cómo ejecutar VLM con interacción de voz en reComputer Jetson
Introducción
Esta guía proporciona una explicación detallada sobre cómo ejecutar un Modelo de Lenguaje Visual (VLM) multimodal con interacción de voz en un dispositivo reComputer Nvidia Jetson. El modelo aprovecha las poderosas capacidades computacionales de la plataforma oficial Nvidia Jetson, combinado con el modelo de voz a texto de código abierto SenseVoice de Alibaba y el modelo de texto a voz (TTS) de coqui-ai, para realizar tareas multimodales complejas. Siguiendo esta guía, podrás instalar y operar exitosamente este sistema, habilitándolo con capacidades de reconocimiento visual e interacción de voz, ofreciendo así soluciones más inteligentes para tus proyectos.
Introducción a VLM (Modelo de Lenguaje Visual)
El Modelo de Lenguaje Visual (VLM) es un modelo multimodal optimizado para la plataforma Nvidia Jetson. Combina procesamiento visual y de lenguaje para manejar tareas complejas, como reconocimiento de objetos y generación de lenguaje descriptivo. VLM es aplicable en campos como conducción autónoma, vigilancia inteligente y hogares inteligentes, ofreciendo soluciones inteligentes e intuitivas.

Introducción a SenseVoice
SenseVoice es un modelo de código abierto enfocado en reconocimiento de voz multilingüe de alta precisión, reconocimiento de emociones del habla y detección de eventos de audio. Entrenado con más de 400,000 horas de datos, soporta más de 50 idiomas y supera al modelo Whisper. El modelo SenseVoice-Small ofrece latencia ultra baja, procesando 10 segundos de audio en solo 70ms. También proporciona ajuste fino conveniente y soporta despliegue en múltiples lenguajes, incluyendo Python, C++, HTML, Java y C#.
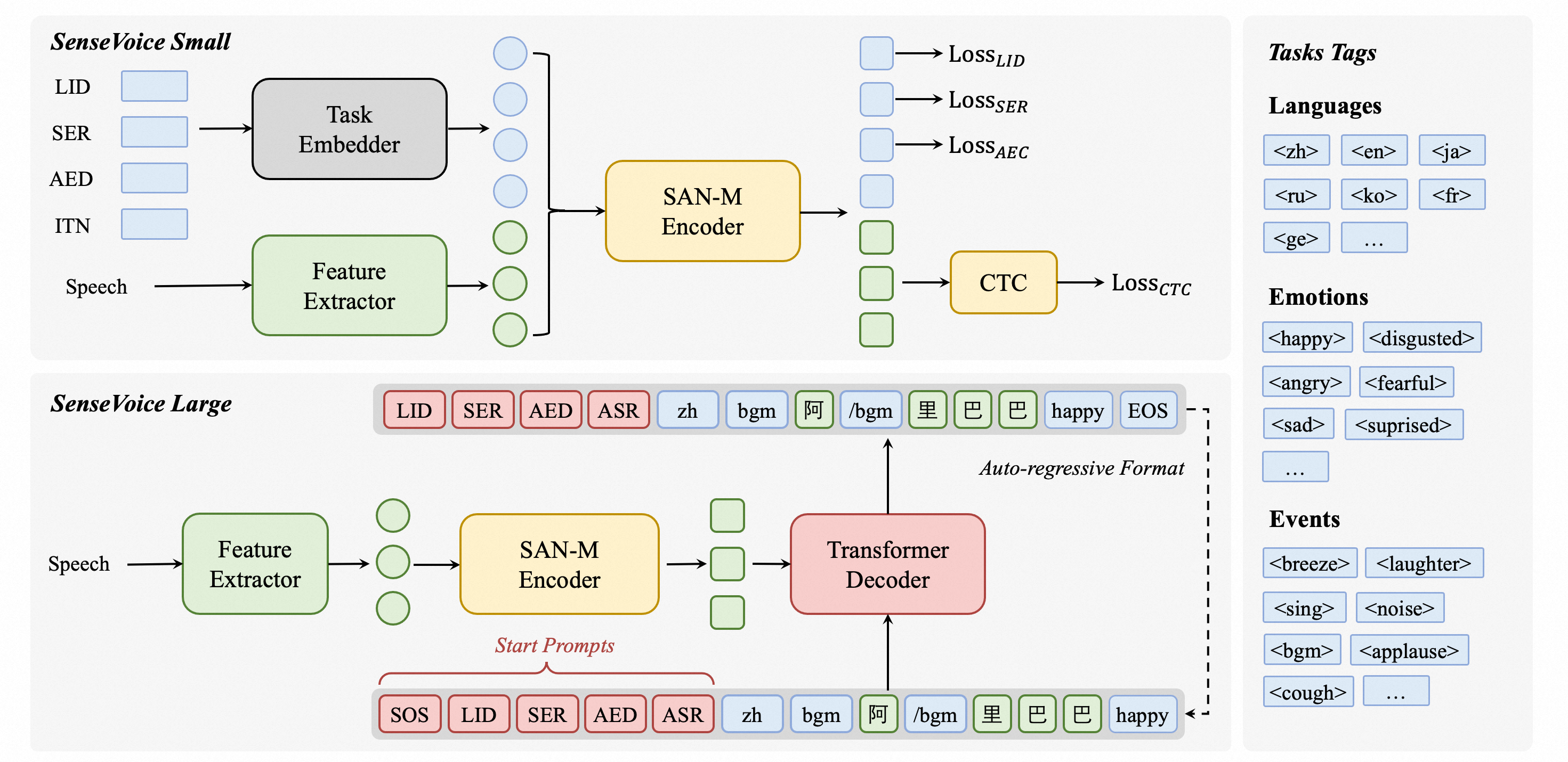
Introducción a TTS (Texto a Voz)
El modelo TTS es un modelo de aprendizaje profundo de alto rendimiento para tareas de texto a voz. Incluye varios modelos como Tacotron2 y vocoders como MelGAN y WaveRNN. El modelo TTS soporta TTS multi-hablante, entrenamiento eficiente y ofrece herramientas para curación de conjuntos de datos y pruebas de modelos. Su base de código modular permite la implementación fácil de nuevas características.

Prerrequisitos
- Dispositivo reComputer Jetson AGX Orin 64G o reComputer Jetson J4012 16G con más de 16GB de memoria.
- Micrófono altavoz USB sin necesidad de controladores
- Una cámara IP que pueda generar una dirección de flujo RTSP. También hemos incluido instrucciones sobre cómo usar la herramienta NVIDIA Nvstreamer para convertir videos locales en flujos RTSP.
Ya hemos probado la viabilidad de este wiki en reComputer Orin NX 16GB y AGX Orin 64GB Developer Kit.

Instalación
Inicializar el entorno del sistema
-
Después de instalar el sistema inicial con JP6, necesitas verificar la instalación de
CUDAy otras librerías. Puedes verificarlas e instalarlas ejecutandosudo apt-get install nvidia-jetpack. -
Instala
python3-pip,jtopydocker-ce. -
Instala las dependencias necesarias ejecutando los siguientes comandos:
sudo apt-get install libportaudio2 libportaudiocpp0 portaudio19-dev
sudo pip3 install pyaudio playsound subprocess wave keyboard
sudo pip3 --upgrade setuptools
sudo pip3 install sudachipy==0.5.2 -
Verifica que la entrada y salida de audio, así como el micrófono altavoz USB, estén funcionando correctamente y que la conexión de red sea estable.
Instalar VLM
La funcionalidad principal de este proyecto es el modelo de lenguaje visual (VLM). Hemos proporcionado una guía sobre cómo usar el VLM en el reComputer Nvidia Jetson. Por favor, consulta este enlace para instrucciones de instalación y uso. Asegúrate de entender completamente cómo realizar inferencia usando descripciones de texto en el VLM antes de proceder con los siguientes pasos.
Instalar Pytorch Torchaudio
Hemos proporcionado un curso de Nvidia Jetson AI para principiantes, que incluye instrucciones sobre cómo instalar PyTorch, Torchaudio y Torchvision. Por favor, descarga e instala estos paquetes según tu entorno del sistema.
Instalar Speech_vlm (Basado en SenseVoice)
-
Clonar paquetes Speech_vlm:
cd ~/
git clone https://github.com/ZhuYaoHui1998/speech_vlm.git -
Instalar entorno Speech_vlm:
cd ~/speech_vlm
sudo pip3 install -r requement.txt
Instalar TTS (Basado en Coqui-ai)
cd ~/speech_vlm/TTS
sudo pip3 install .[all]
Uso
La estructura del repositorio speech_vlm es la siguiente:
speech_vlm/
├── /TTS # Coqui-ai TTS program
├── config # VLM config
├── README.md #Project Introduction
├── requirements.txt #SenseVoice required environment libraries
├── compose.yaml #VLM Docker Compose startup file
├── delete_id.sh #Delete camera ID script
├── example_1.wav #Audio feedback sound tone template (replaceable)
├── model.py #SenseVoice main program
├── set_alerts.sh #Set up camera alerts
├── set_describe.sh #Text input to have the VLM describe the current scene
├── set_streamer_id.sh #Add RTSP camera to VLM
├── view_rtsp.py # View RTSP stream by opencv
└── vlm_voice.py # multimodal main program
-
Iniciar el VLM
cd ~/speech_vlm
sudo docker compose up -d
-
Añadir flujo RTSP al VLM
Ver el contenido de set_streamer_id.sh bajo el repositorio speech_vlm:
#!/bin/bash
curl --location 'http://0.0.0.0:5010/api/v1/live-stream' \
--header 'Content-Type: application/json' \
--data '{"liveStreamUrl": "RTSP stream address"}'
Reemplaza 0.0.0.0 con la dirección IP del dispositivo Jetson y reemplaza RTSP stream address con la dirección del flujo RTSP de la cámara.
Por ejemplo:
#!/bin/bash
curl --location 'http://192.168.49.227:5010/api/v1/live-stream' \
--header 'Content-Type: application/json' \
--data '{"liveStreamUrl": "rtsp://admin:[email protected]:554//Streaming/Channels/1"}'
Si no tienes una cámara RTSP, hemos proporcionado instrucciones sobre cómo usar NVStreamer para transmitir videos locales como RTSP y añadirlos al VLM.
Ejecuta set_streamer_id.sh
cd ~/speech_vlm
sudo chmod +x ./set_streamer_id.sh
./set_streamer_id.sh
Obtendremos un ID de cámara, este ID es muy importante y necesita ser registrado, así:

- Ejecutar vlm_voice.py
Necesitas reemplazar 0.0.0.0 en las siguientes dos líneas de código Python:
API_URL = 'http://0.0.0.0:5010/api/v1/chat/completions' # API endpoint
REQUEST_ID = "" # Request ID
con la dirección IP de Jetson y completa el ID de cámara devuelto del Paso 2 en lugar de REQUEST_ID.
vlm_voice.py
import pyaudio
import wave
import keyboard
import subprocess
import json
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
import time
import torch
from TTS.api import TTS
import os
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Init TTS
api = TTS("tts_models/en/ljspeech/glow-tts").to(device)
# Configuration parameters
FORMAT = pyaudio.paInt16 # 16-bit resolution
CHANNELS = 1 # Mono channel
CHUNK = 1024 # Number of samples per chunk
OUTPUT_FILENAME = "output.wav" # Output file name
API_URL = 'http://192.168.49.227:5010/api/v1/chat/completions' # API endpoint
REQUEST_ID = "1388b691-3b9f-4bda-9d70-0ff0696f80f4" # Request ID
# Initialize PyAudio
audio = pyaudio.PyAudio()
# Prepare the list to store recording data
frames = []
# Initialize Micphone Rate
print("Available audio input devices:")
for i in range(audio.get_device_count()):
info = audio.get_device_info_by_index(i)
print(f"Device {i}: {info['name']} - {info['maxInputChannels']} channels")
device_index = int(input("Please select the device index for your USB microphone: "))
device_info = audio.get_device_info_by_index(device_index)
supported_sample_rates = [8000, 16000, 32000, 44100, 48000]
supported_rate=0
for rate in supported_sample_rates:
try:
if audio.is_format_supported(rate,
input_device=device_index,
input_channels=1,
input_format=pyaudio.paInt16):
supported_rate=rate
print(f"{rate} Hz is supported.")
except ValueError:
print(f"{rate} Hz is not supported.")
# Initialize the model
model = "./SenseVoiceSmall"
model = AutoModel(
model=model,
vad_model="./speech_fsmn_vad_zh-cn-16k-common-pytorch",
vad_kwargs={"max_single_segment_time": 30000},
trust_remote_code=True,
disable_log=True
)
def extract_content(json_response):
try:
# 解析JSON字符串
data = json.loads(json_response)
# 提取content部分
content = data["choices"][0]["message"]["content"]
print(f"{content}")
return content
except KeyError as e:
print(f"Key error: {e}")
except json.JSONDecodeError as e:
print(f"JSON decode error: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
def start_recording():
global frames
frames = []
try:
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=supported_rate, input=True,
frames_per_buffer=CHUNK, input_device_index=device_index)
print("Recording started... Press '2' to stop recording.")
while True:
if keyboard.is_pressed('2'):
print("Recording stopped.")
break
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
except Exception as e:
print(f"An error occurred during recording: {e}")
def save_recording():
try:
waveFile = wave.open(OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(supported_rate)
waveFile.writeframes(b''.join(frames))
waveFile.close()
print(f"Recording saved as {OUTPUT_FILENAME}")
except Exception as e:
print(f"An error occurred while saving the recording: {e}")
def send_alert(text):
# Construct the JSON payload
payload = {
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant."
},
{
"role": "user",
"content": [
{
"type": "stream",
"stream": {
"stream_id": REQUEST_ID
}
},
{
"type": "text",
"text": text
}
]
}
],
"min_tokens": 1,
"max_tokens": 128
}
# Convert the payload to a JSON string
json_payload = json.dumps(payload)
# Execute the curl command using subprocess
curl_command = [
'curl', '--location', API_URL,
'--header', 'Content-Type: application/json',
'--data', json_payload
]
try:
result = subprocess.run(curl_command, check=True, capture_output=True, text=True)
##Get words
content_result=extract_content(result.stdout)
# TTS
api.tts_to_file(
str(content_result),
speaker_wav="./example_1.wav",
file_path="speech.wav"
)
# Convert audio rate
subprocess.run(['ffmpeg', '-i', 'speech.wav', '-ar',str(supported_rate), 'speech1.wav','-y'])
# Play audio
wf = wave.open('./speech1.wav', 'rb')
stream = audio.open(format=pyaudio.paInt16,
channels=1,
rate=supported_rate,
output=True,
output_device_index=device_index)
data = wf.readframes(1024)
while data:
stream.write(data)
data = wf.readframes(1024)
# Play audio
os.remove('speech.wav')
os.remove('speech1.wav')
stream.stop_stream()
stream.close()
wf.close() # Close the wave file as well
#print(f"Alert sent successfully: {result.stdout}")
except subprocess.CalledProcessError as e:
print(f"An error occurred while sending the alert: {e.stderr}")
finally:
# Even if an error occurs, try to close the stream
if stream.is_active():
stream.stop_stream()
os.remove('speech.wav')
os.remove('speech1.wav')
stream.close()
print("Welcome to the Recording and Speech-to-Text System!")
print("Press '1' to start recording, '2' to stop recording.")
while True:
if keyboard.is_pressed('1'):
print("Preparing to start recording...")
start_recording()
save_recording()
print("Processing the recording file, please wait...")
try:
res = model.generate(
input=f"./{OUTPUT_FILENAME}",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(f"Speech-to-Text Result:\n{text}")
# Send the transcription result as an alert
send_alert(text)
except Exception as e:
print(f"An error occurred while processing the recording: {e}")
time.sleep(0.1) # Reduce CPU usage
Ejecutar Python:
cd ~/speech_vlm
sudo python3 vlm_voice.py
Después de que el programa se inicie, escaneará todos los dispositivos de entrada y salida de audio. Necesitarás seleccionar manualmente el ID de índice del dispositivo de audio deseado. El programa está a punto de comenzar a funcionar, luego presiona 1 para grabar y 2 para enviar.
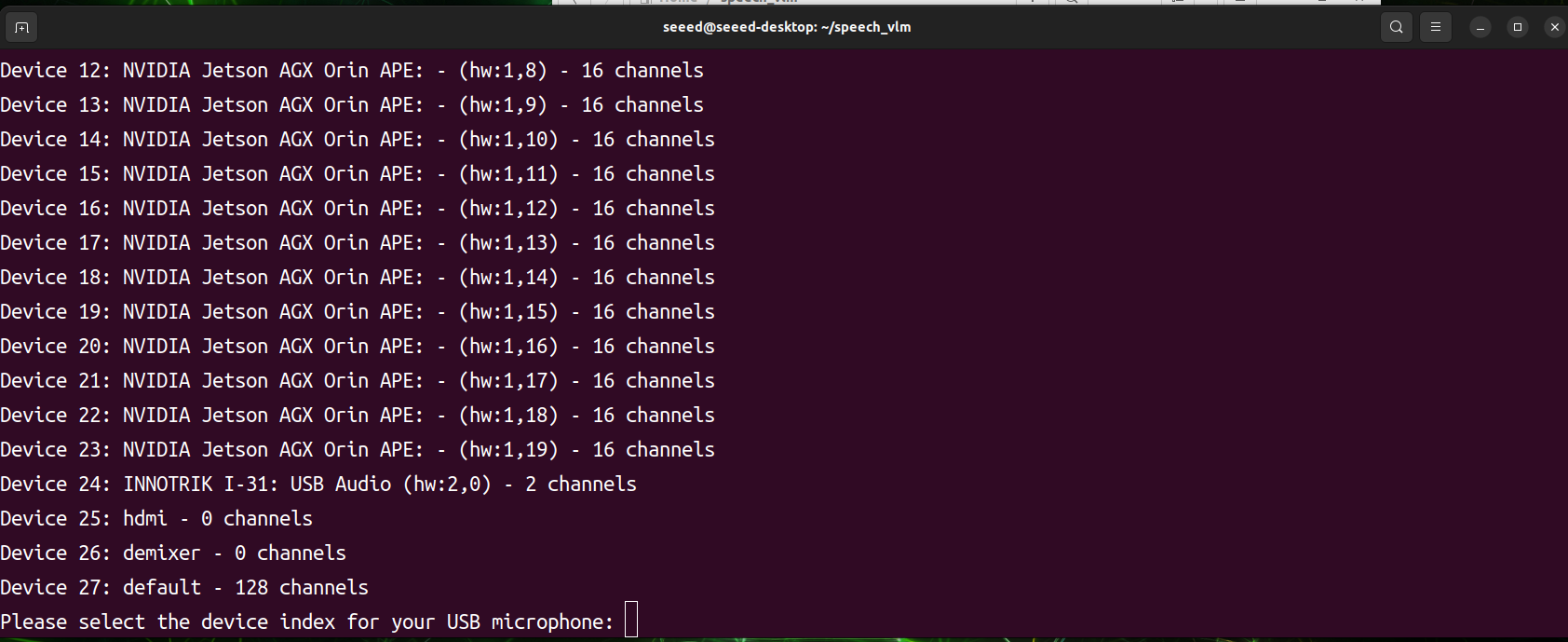
- Ver resultado
Hemos preparado un script view_rtsp.py para ver los resultados de salida. Necesitas reemplazar la parte IP de rtsp_url = "rtsp://0.0.0.0:5011/out" con la dirección IP de tu dispositivo Jetson.
viwe_rtsp.py
import cv2
rtsp_url = "rtsp://192.168.49.227:5011/out"
cap = cv2.VideoCapture(rtsp_url)
if not cap.isOpened():
print("Cannot open RTSP stream")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("Failed to retrieve frame")
break
height, width = frame.shape[:2]
frame_resized = cv2.resize(frame, (int(width // 1.1), int(height // 1.1)))
cv2.imshow('RTSP Stream', frame_resized)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
sudo pip3 install opencv-python
cd ~/speech_vlm
sudo python3 view_rtsp.py
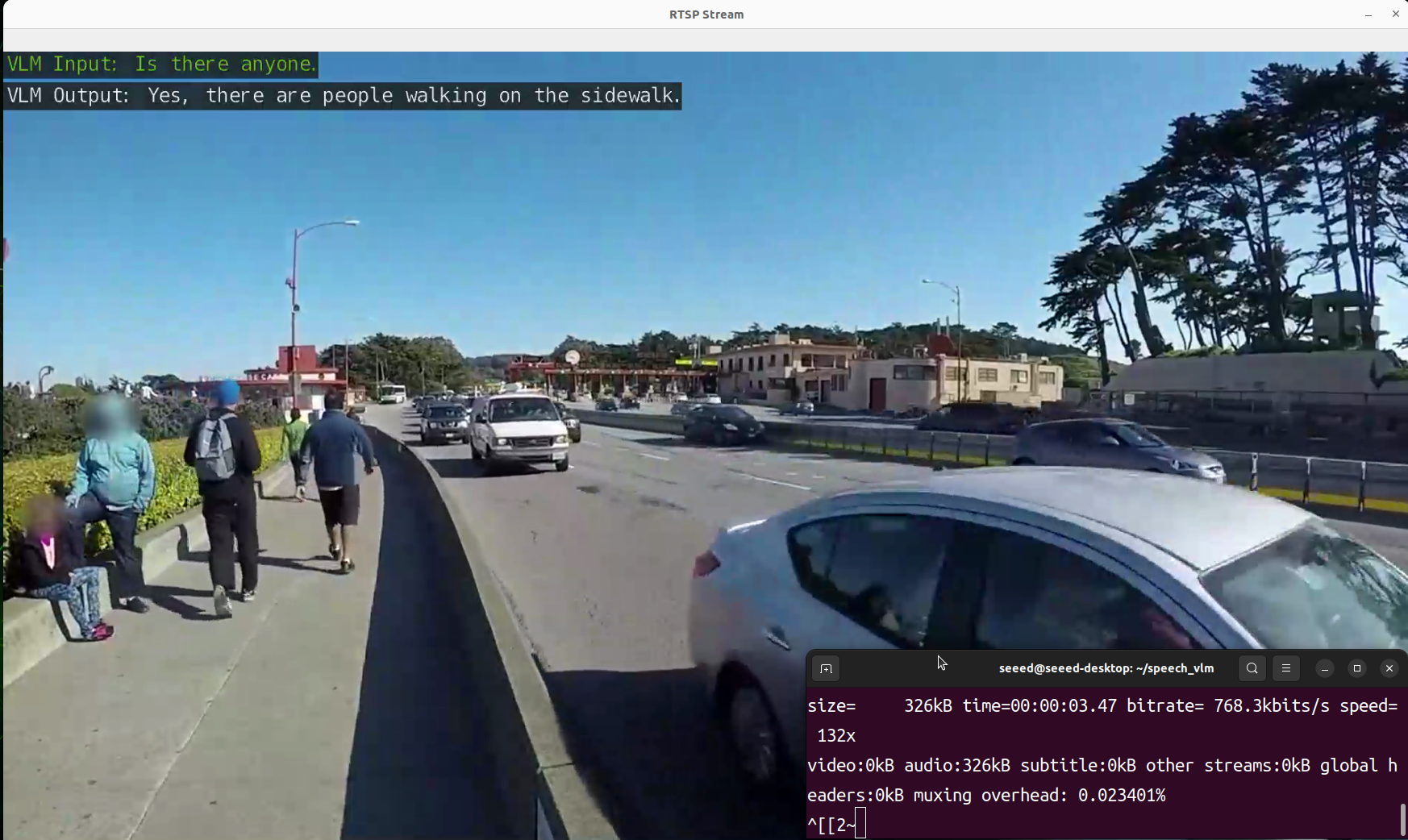
Demostración
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.