Nodo de Procesamiento de Datos IoT en Tiempo Real Impulsado por Apache Kafka
Nuestro nodo de procesamiento de vanguardia, Kafka-ESP32, combina el poder de Apache Kafka y los microcontroladores ESP32C6 para ofrecer una solución eficiente para manejar flujos de datos IoT. Al usar el XIAO ESP32C6 con el sensor ambiental DHT20, los datos se recopilan y se envían sin problemas a Apache Kafka a través del ESP32C6. Las capacidades de mensajería de alto rendimiento y baja latencia de Kafka permiten el procesamiento y análisis de datos en tiempo real, mientras que su arquitectura distribuida permite una escalabilidad sin esfuerzo. Kafka-ESP32 te permite desarrollar aplicaciones e integraciones personalizadas, revolucionando la forma en que gestionas y utilizas tus activos IoT en el panorama actual impulsado por datos.
Materiales Requeridos
Este ejemplo introducirá el uso del XIAO ESP32C6 con el sensor de temperatura y humedad Grove DHT20 para completar la tarea de SageMaker de AWS IoT Core. A continuación se muestran todos los dispositivos de hardware necesarios para completar esta rutina.
| XIAO ESP32C6 | DHT20 | Placa de Extensión |
|---|---|---|
 |  |  |
Instalación de Docker
¿Por qué usar Docker? Porque Docker puede simular el entorno de múltiples computadoras en una sola máquina y desplegar aplicaciones con gran facilidad. Por lo tanto, en este proyecto, usaremos Docker para configurar el entorno y mejorar la eficiencia.
Paso 1. Descargar Docker
Según tu computadora, descarga diferentes tipos de instalador. Haz clic aquí para ir.
Si tu computadora es Windows, por favor no instales docker hasta que termines el Paso 2.
Paso 2. Instalar WSL(Subsistema de Windows para Linux)
Este paso es para Windows. Puedes omitir este paso si tu computadora es Mac o Linux.
- Ejecuta el siguiente código como administrador.
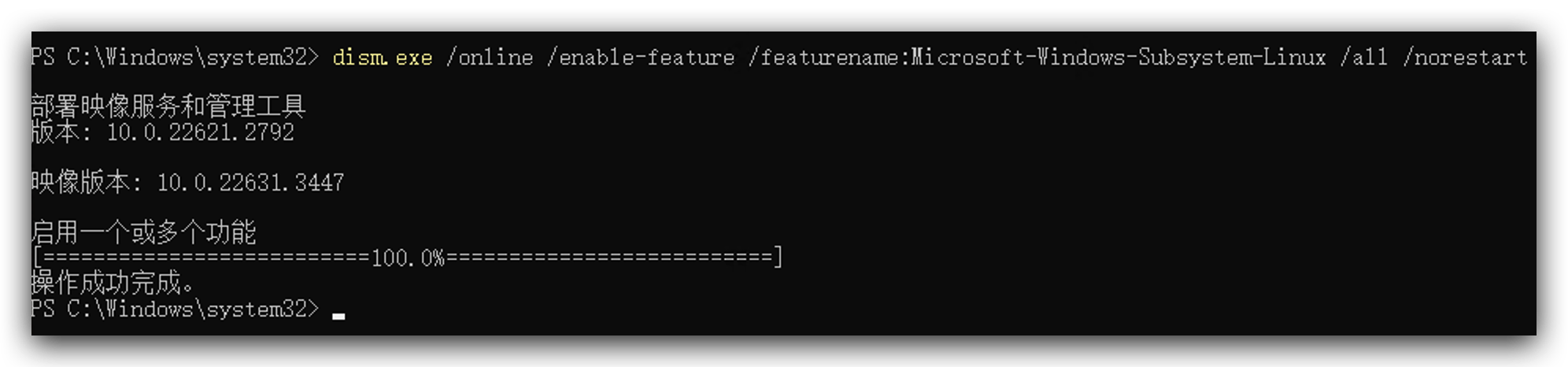
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
-
Descarga esta herramienta desde aquí y haz doble clic para instalarla.
-
Ve a tu Microsoft Store para buscar y descargar la versión de linux que te guste, aquí instalé Ubuntu.
- Después de instalar Linux, necesitas abrirlo y establecer tu nombre de usuario y contraseña, y luego necesitas esperar un minuto para que se inicialice.
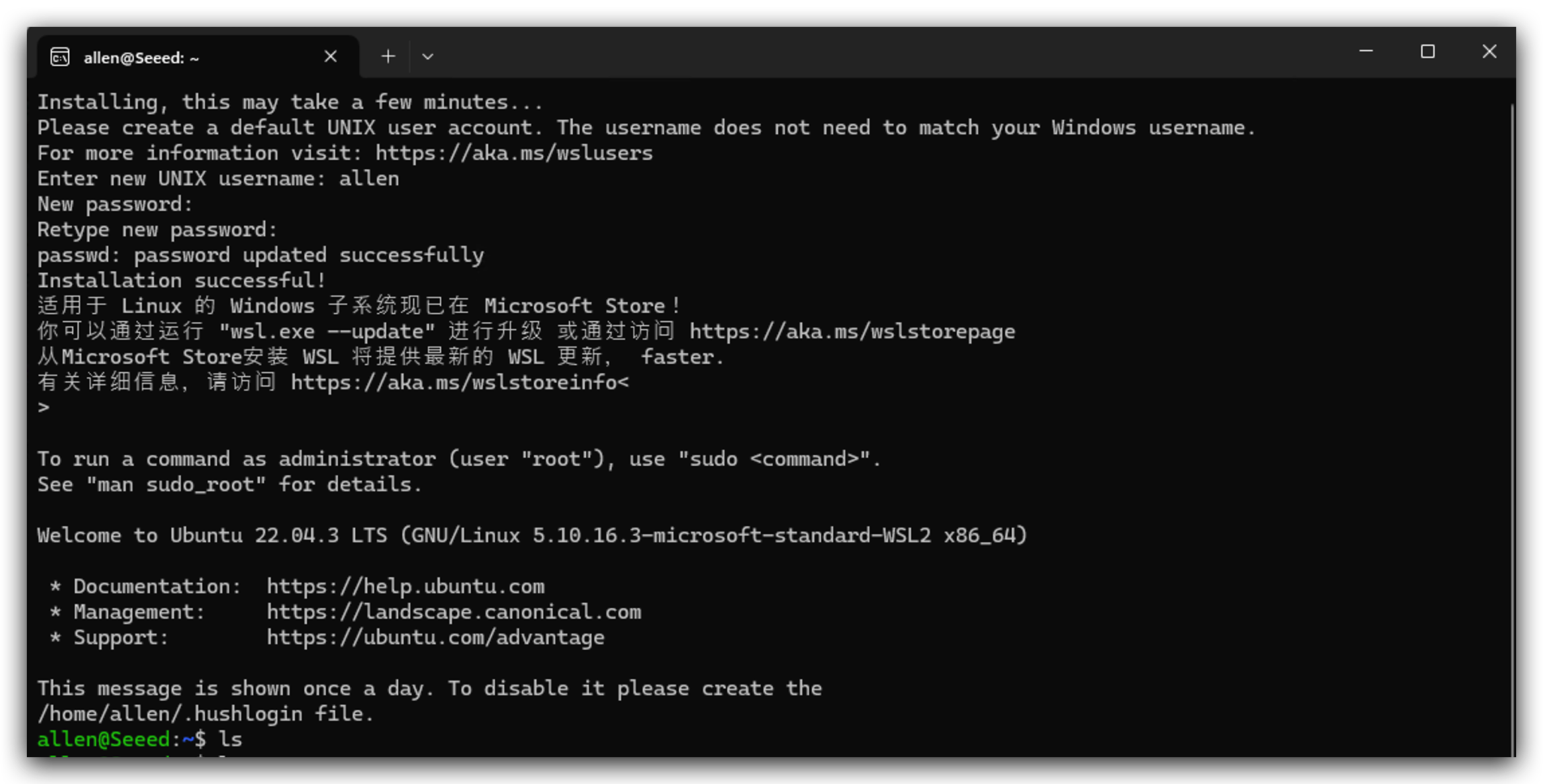
- Ejecuta las siguientes instrucciones para usar WSL.
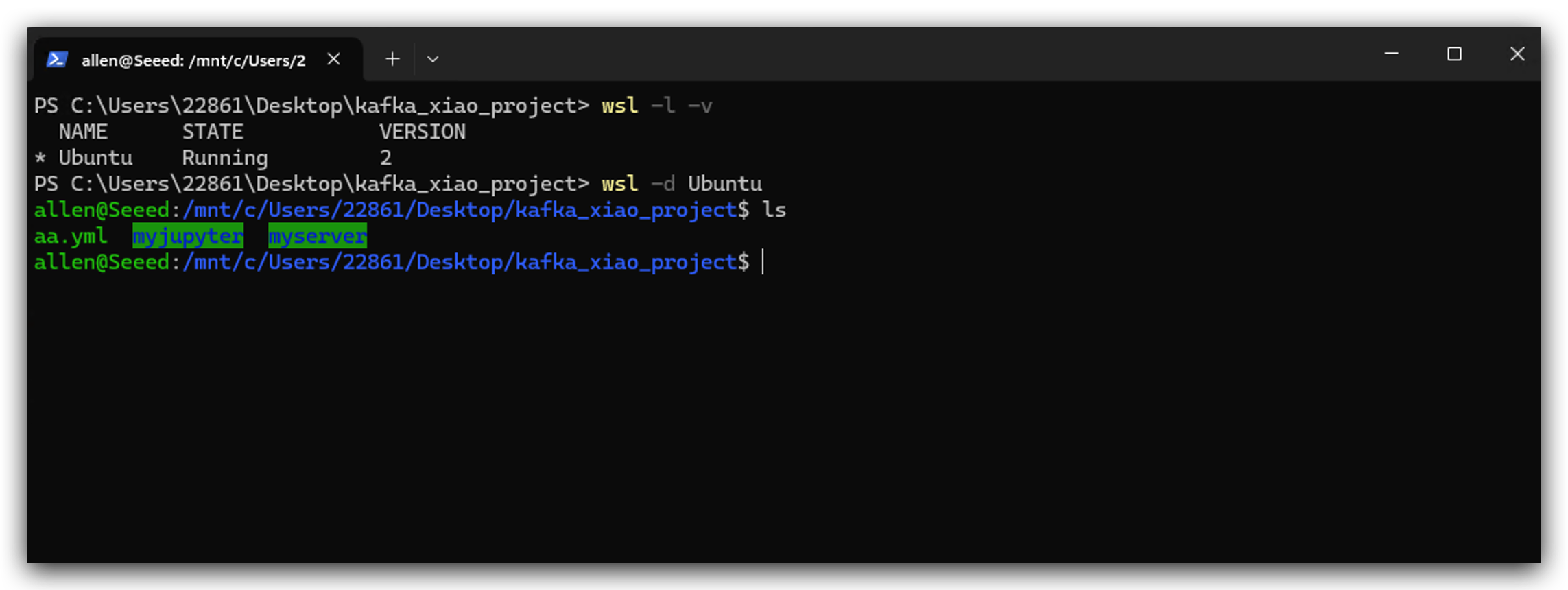
- Después de instalar WSL, ahora puedes hacer doble clic en tu instalador de docker para instalarlo. Cuando veas la siguiente imagen significa que funciona.
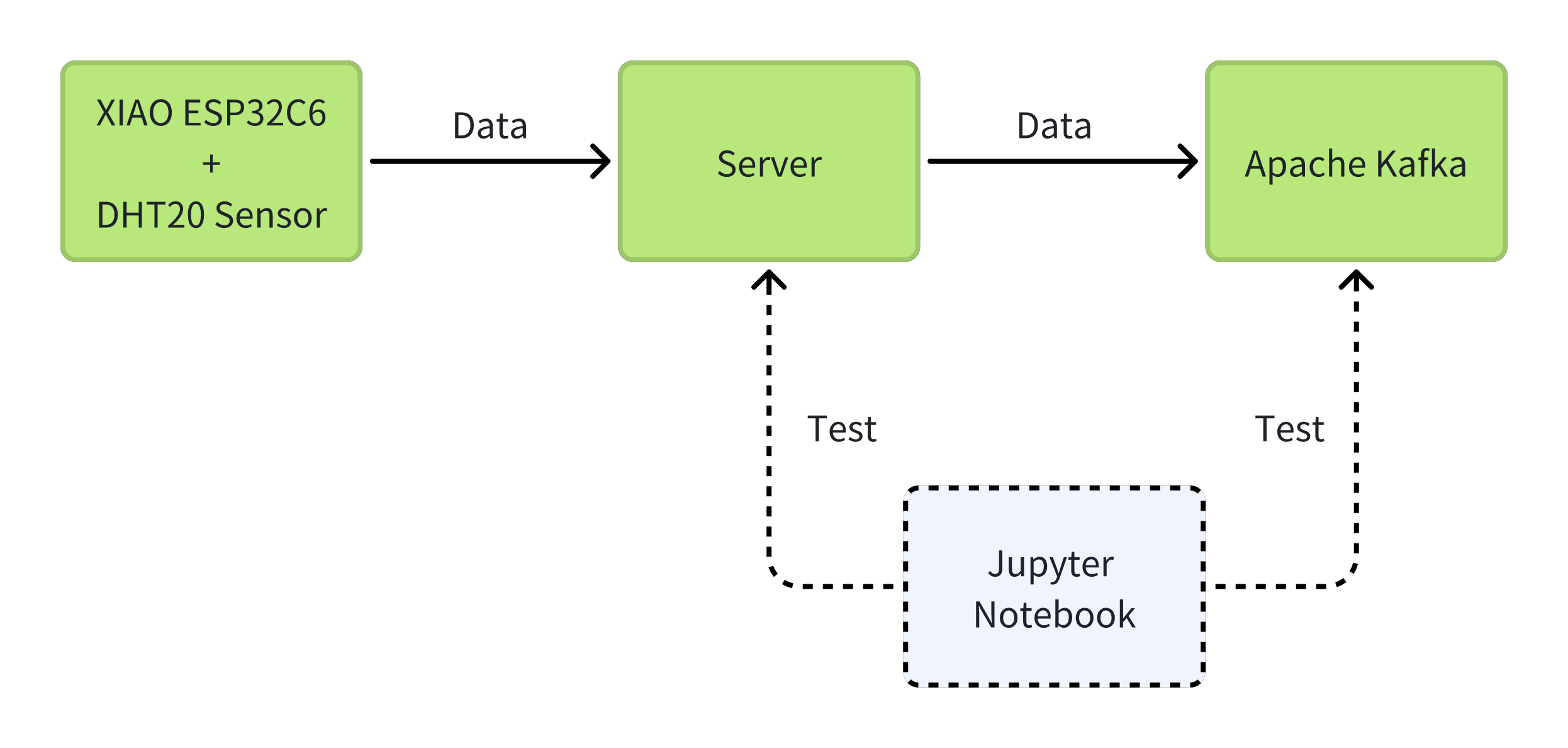
Desplegar Servicios
Antes de comenzar, quiero presentar la función de cada servicio en este proyecto.
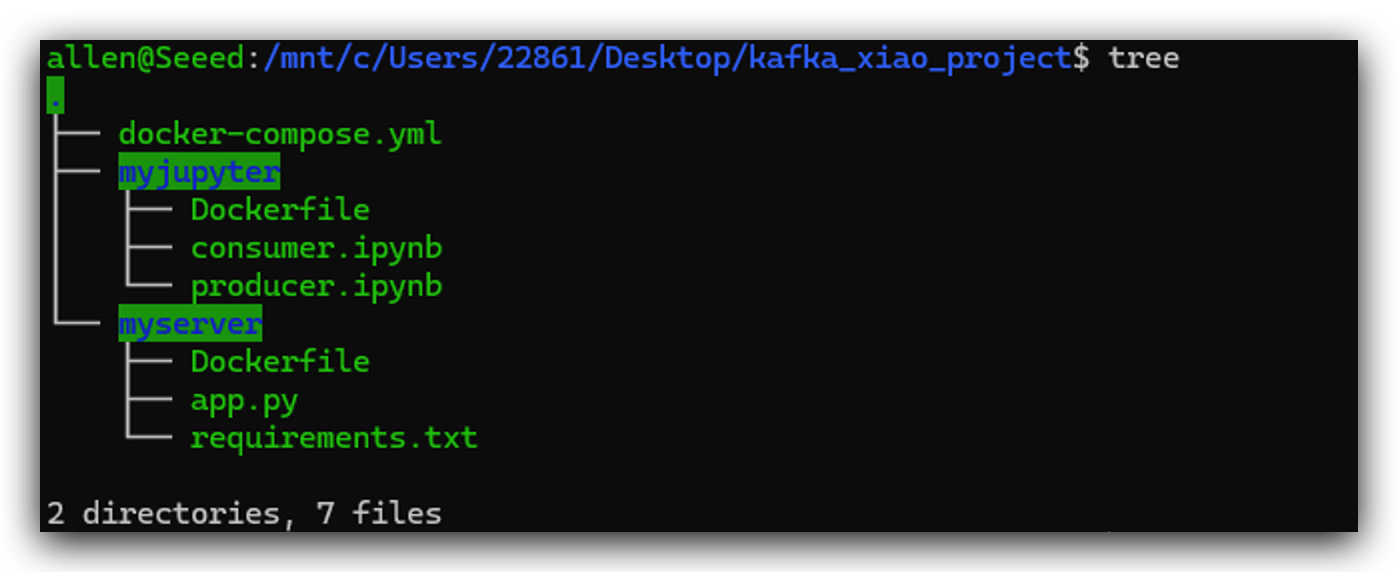
Aquí está la estructura de directorios de este proyecto para tu referencia. Crearé esos archivos uno por uno en los siguientes pasos. La posición de cada archivo es muy importante. Te recomiendo encarecidamente que te refieras a esta estructura de directorios. Crea un directorio kafka_xiao_project e incluye esos archivos.
Paso 3. Desplegar un Servidor Python
Debido a la falta de rendimiento del dispositivo MCU, no puede ser usado directamente como cliente para kafka. Así que necesitas construir un servidor para hacer tránsito de datos. Este paso es para construir un servidor simple con python. El XIAO ESP32C6 es principalmente para recopilar datos del entorno desde DHT20 y enviarlos al servidor.
- Primero necesitamos crear el archivo app.py, que es lo que hace el servidor.
from flask import Flask
from kafka import KafkaProducer, KafkaConsumer
app = Flask(__name__)
@app.route('/favicon.ico')
def favicon():
return '', 204
@app.route('/<temperature>/<humidity>')
def send_data(temperature, humidity):
producer = KafkaProducer(bootstrap_servers='kafka:9092')
data = f'Temperature: {temperature}, Humidity: {humidity}'
producer.send('my_topic', data.encode('utf-8'))
return f'Temperature: {temperature}, Humidity: {humidity}'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
- Crear requirements.txt, que es la biblioteca de dependencias.
flask
kafka-python
- Crear Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
- Después de crear esos 3 archivos, entonces podemos construir una imagen de docker ejecutando el siguiente código.
docker build -t pyserver .
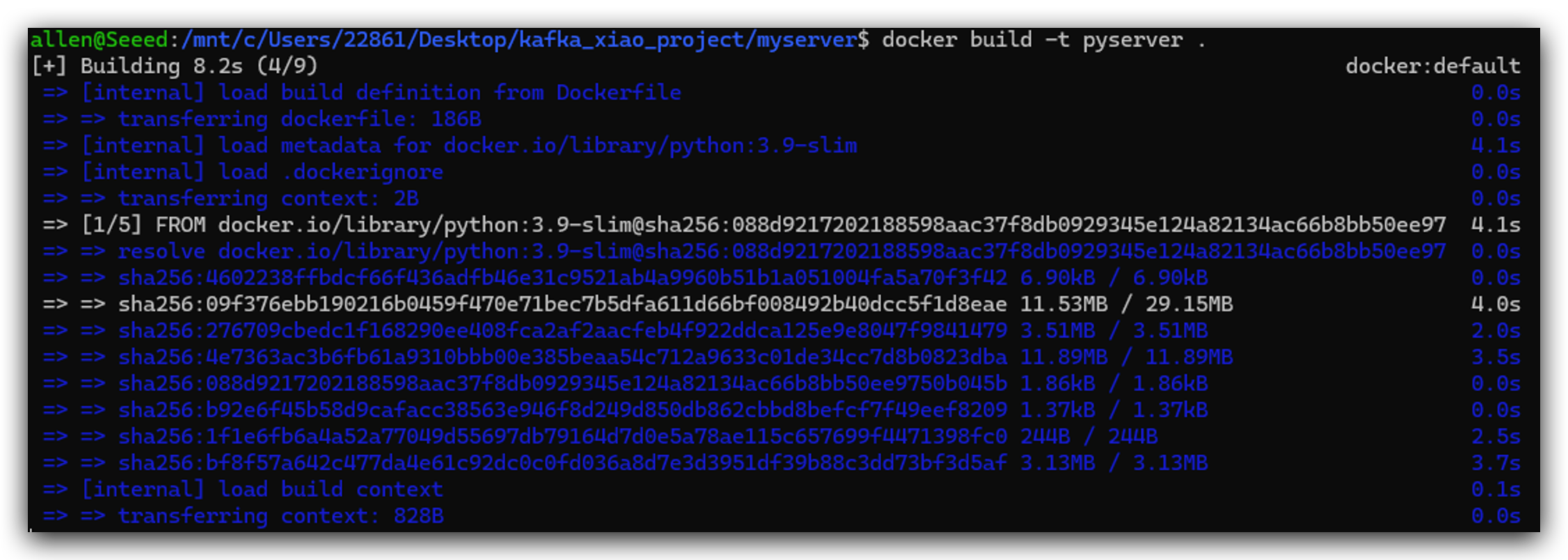
Paso 4. Desplegar Jupyter Notebook
Jupyter Notebook se utiliza principalmente para depuración, y es una herramienta muy buena de usar. Además, podemos usar python para operar Kafka.
- Crear Dockerfile primero.
FROM python:3.9
RUN pip install jupyter
WORKDIR /notebook
EXPOSE 8888
CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]
- Construir la imagen docker de jupyter.
docker build -t jupyter .
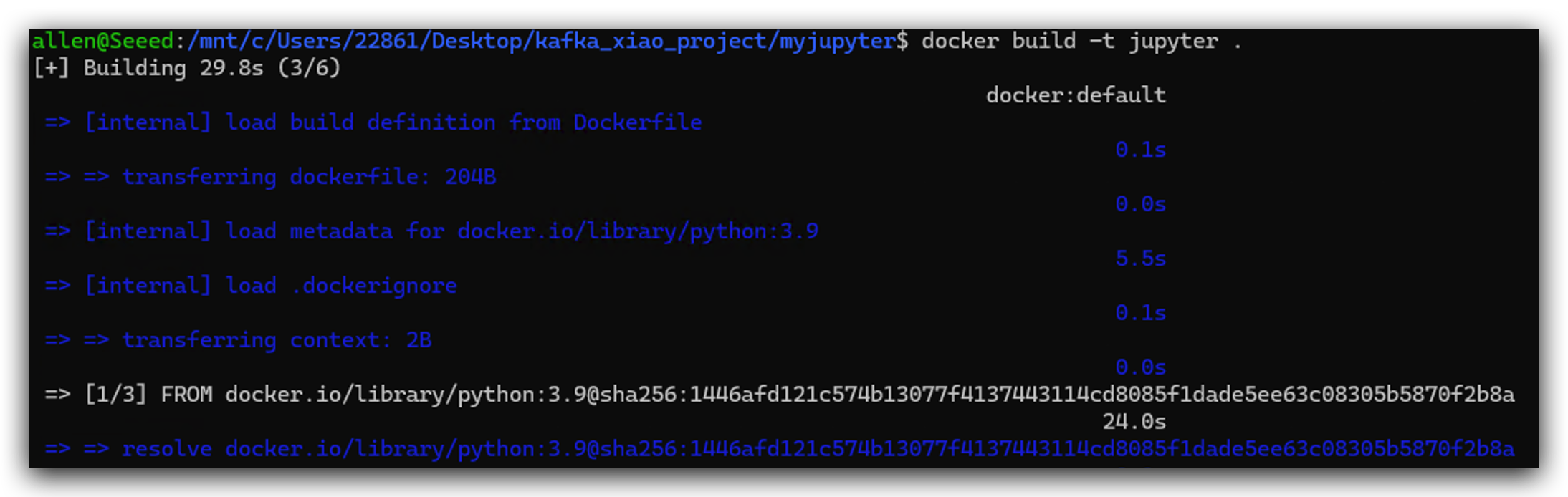
Paso 5. Lanzar el Clúster de Docker
Podemos usar docker-compose.yml para construir el clúster de docker. Cada servicio en docker-compose representa una computadora independiente y usamos kafka-net para conectarlos entre sí.
- Así que primero necesitamos crear docker-compose.yml.
services:
zookeeper:
container_name: zookeeper
hostname: zookeeper
image: docker.io/bitnami/zookeeper
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- kafka-net
kafka:
container_name: kafka
hostname: kafka
image: docker.io/bitnami/kafka
ports:
- "9092:9092"
- "9093:9093"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_BROKER_ID=0
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
depends_on:
- zookeeper
networks:
- kafka-net
jupyter:
image: jupyter:latest
depends_on:
- kafka
volumes:
- ./myjupyter:/notebook
ports:
- "8888:8888"
environment:
- JUPYTER_ENABLE_LAB=yes
networks:
- kafka-net
pyserver:
image: pyserver:latest
depends_on:
- kafka
volumes:
- ./myserver/app.py:/app/app.py
ports:
- "5001:5001"
networks:
- kafka-net
networks:
kafka-net:
driver: bridge
- Y luego lanzamos este clúster de docker ejecutando el siguiente comando.
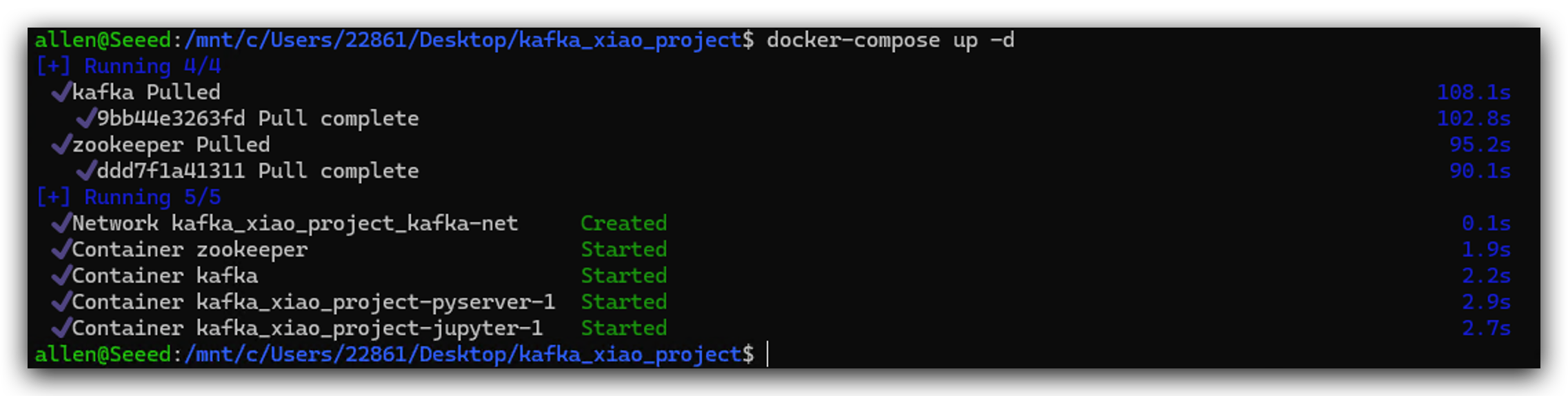
docker-compose up -d
Es posible que el puerto esté ocupado, puedes cambiar el puerto de 5001 a 5002 etc, o cerrar la aplicación que ocupa el puerto.
- En las siguientes operaciones vamos a probar si funciona bien. Primero abrimos el software docker desktop y hacemos clic en pyserver.
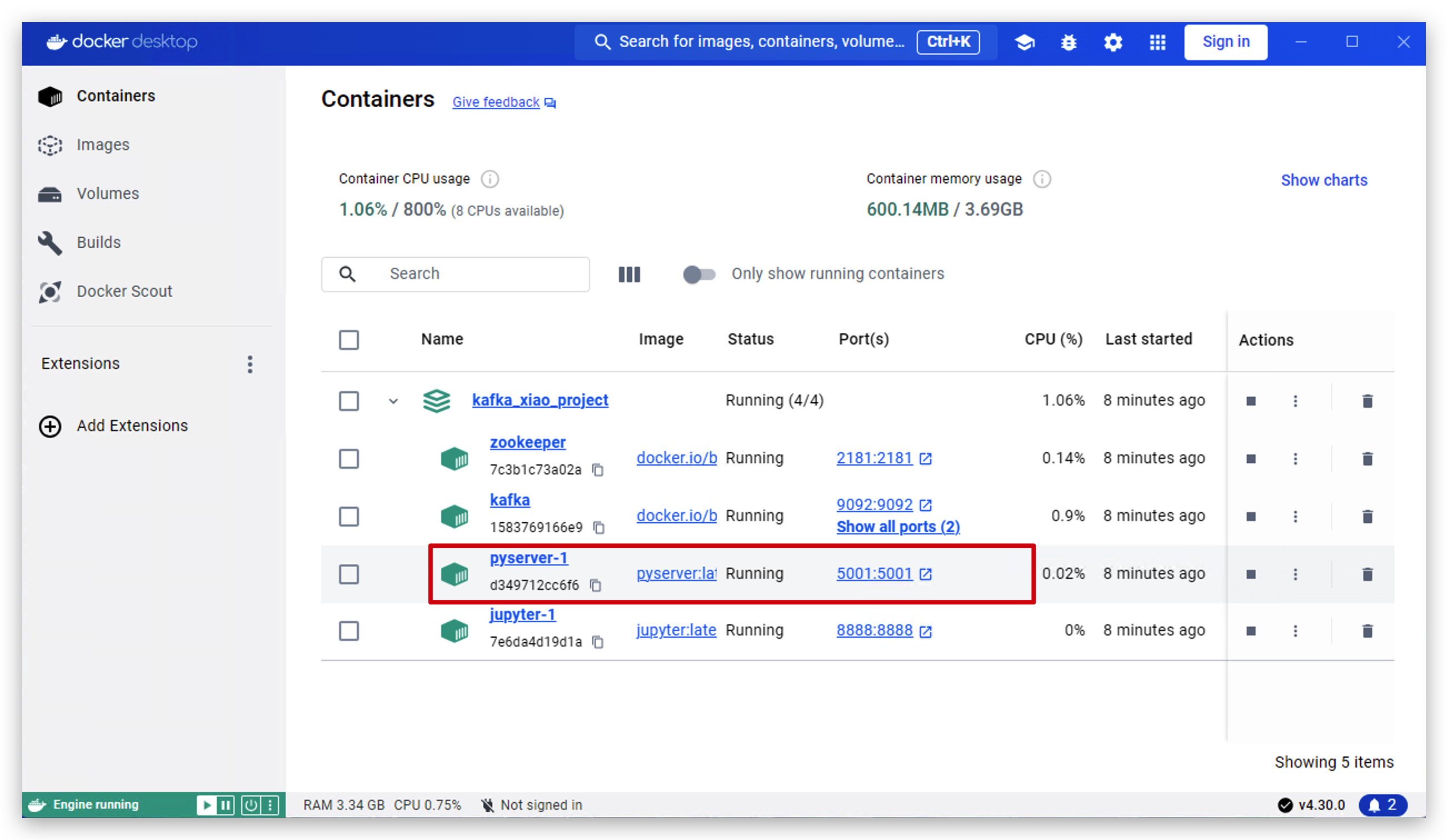
- Ahora el servidor está ejecutándose en
http://127.0.0.1:5001. Haz clic en este enlace para abrirlo.
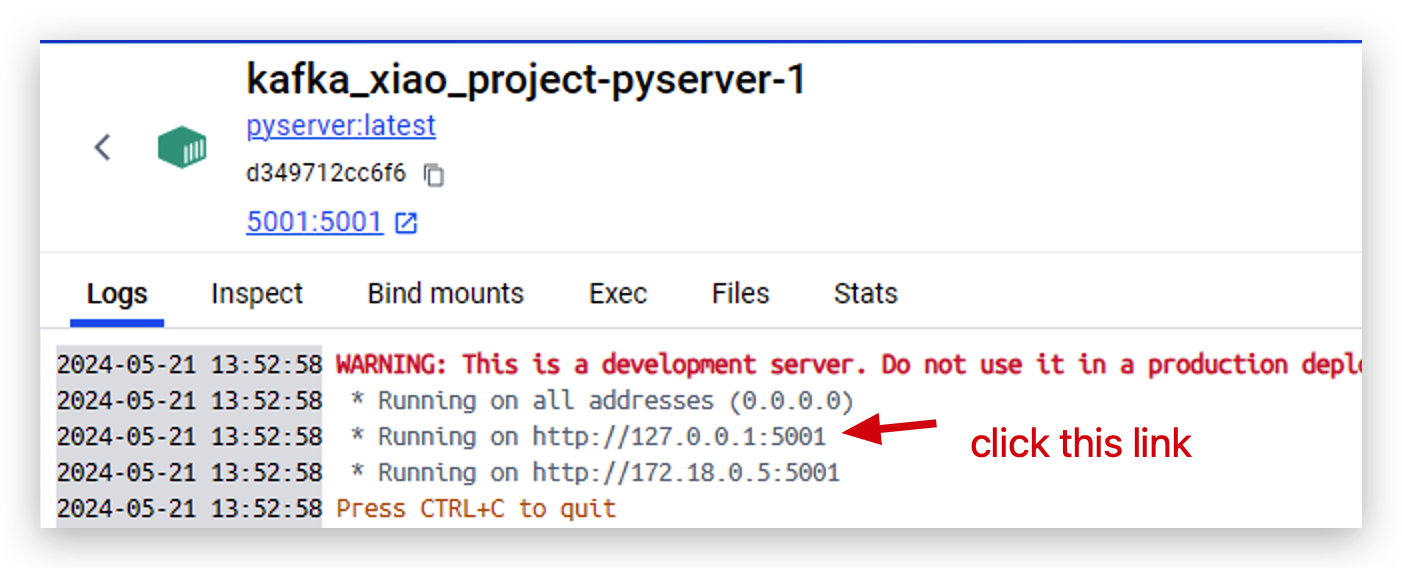
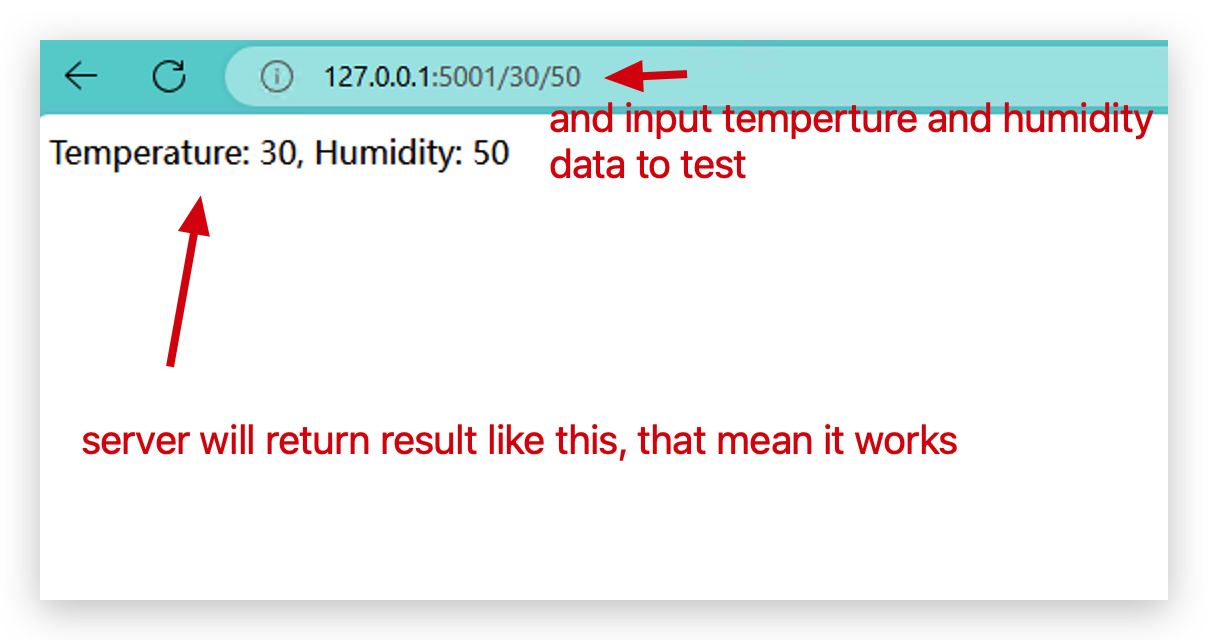
- Y luego ingresa dos parámetros con este formato para probar si el clúster de docker está funcionando bien.
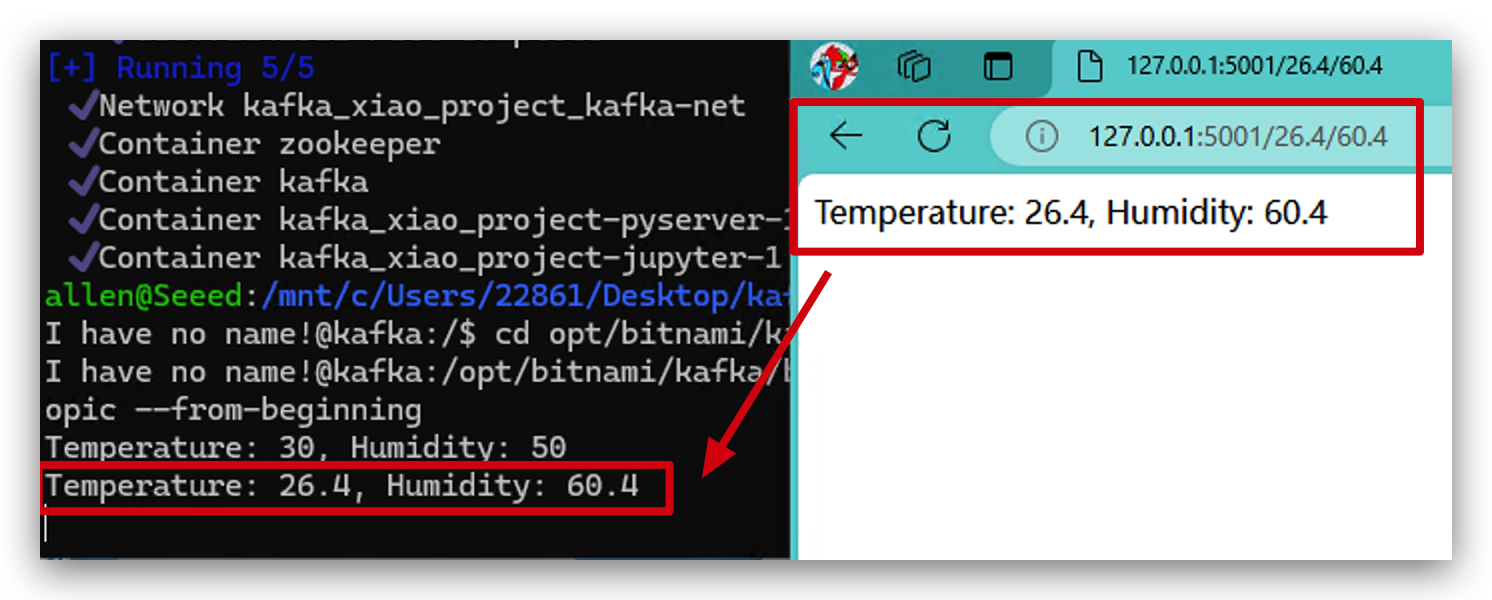
- Vamos dentro de Kafka para ver si los datos fueron enviados a Kafka.
docker exec -it kafka bash
cd opt/bitnami/kafka/bin/
kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic my_topic --from-beginning

- Podemos intentar nuevamente con diferentes parámetros y puedes ver que los datos se enviaron a Kafka inmediatamente. Ahora, ¡Felicitaciones! Tu clúster docker está funcionando perfectamente.
Paso 7. Probar Kafka con Python
Este paso trata principalmente sobre cómo usar Python para manipular Kafka. También puedes omitir este paso. No tiene impacto en las operaciones generales del proyecto.
- Abre docker desktop y haz clic en jupyter.
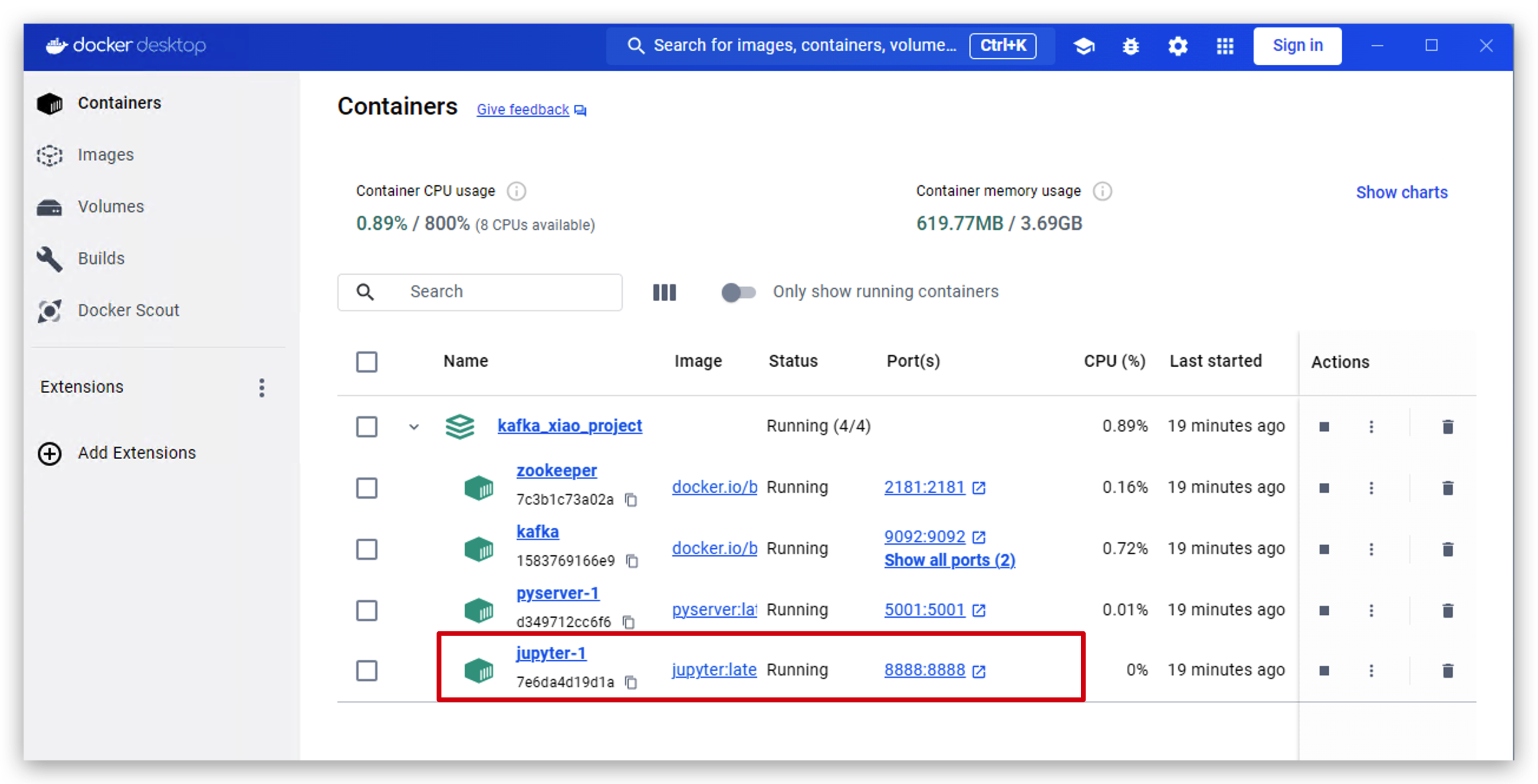
- haz clic en este enlace para acceder a jupyter.
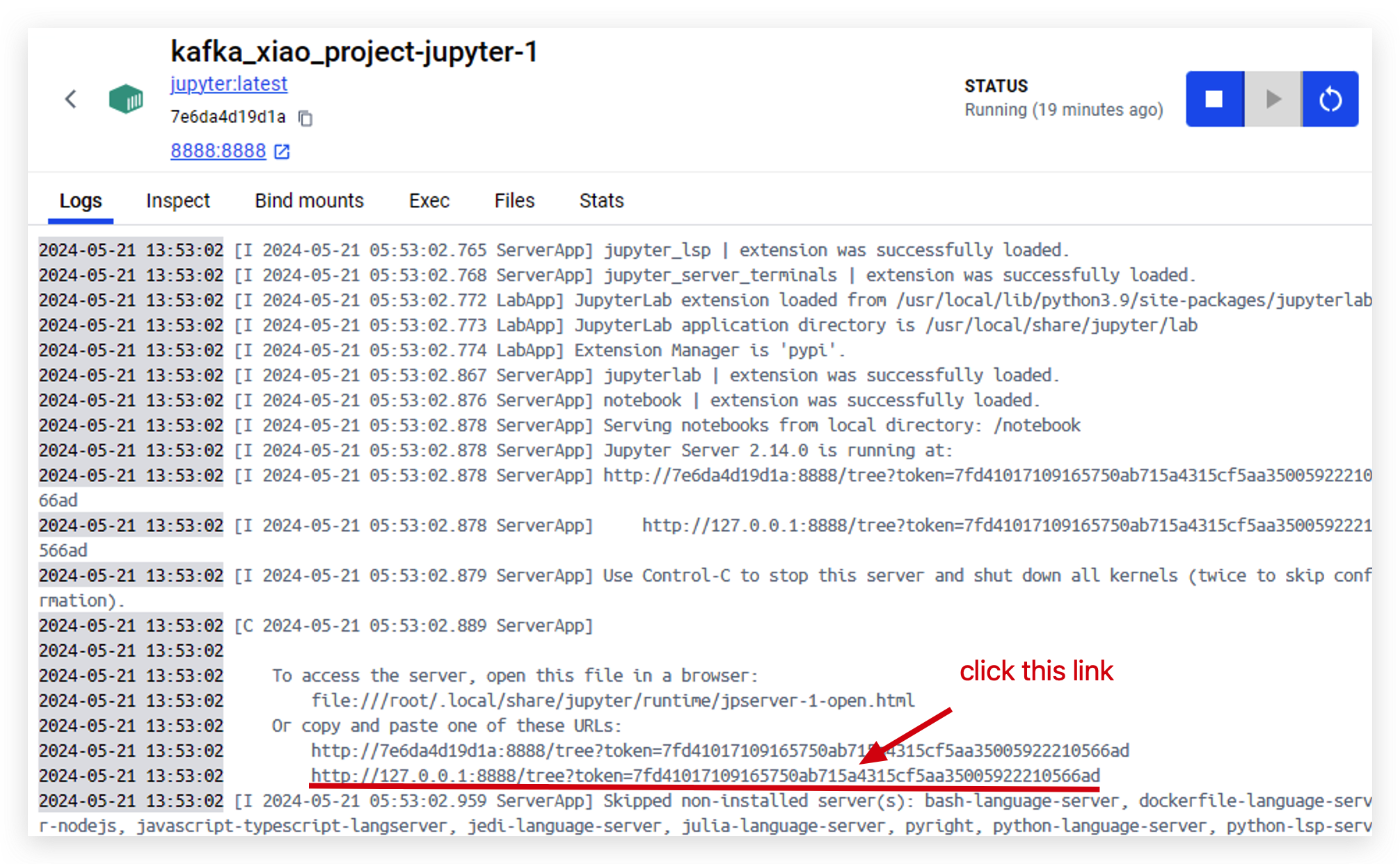
- cuando accedas a jupyter exitosamente, verás esta página.
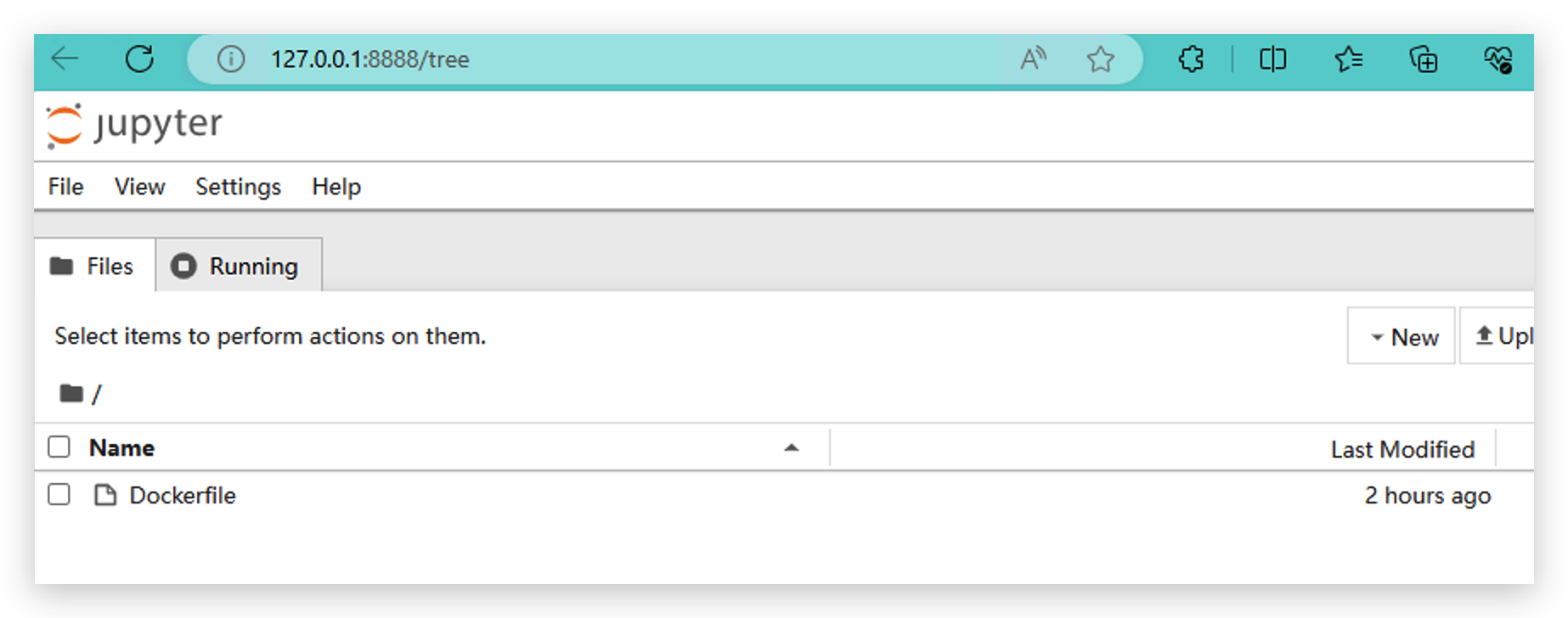
- Haz clic con el botón derecho del ratón y crea New Notebook, usando Python3(ipykernel).
- Instala la librería kafka-python ejecutando
pip install kafka-python.
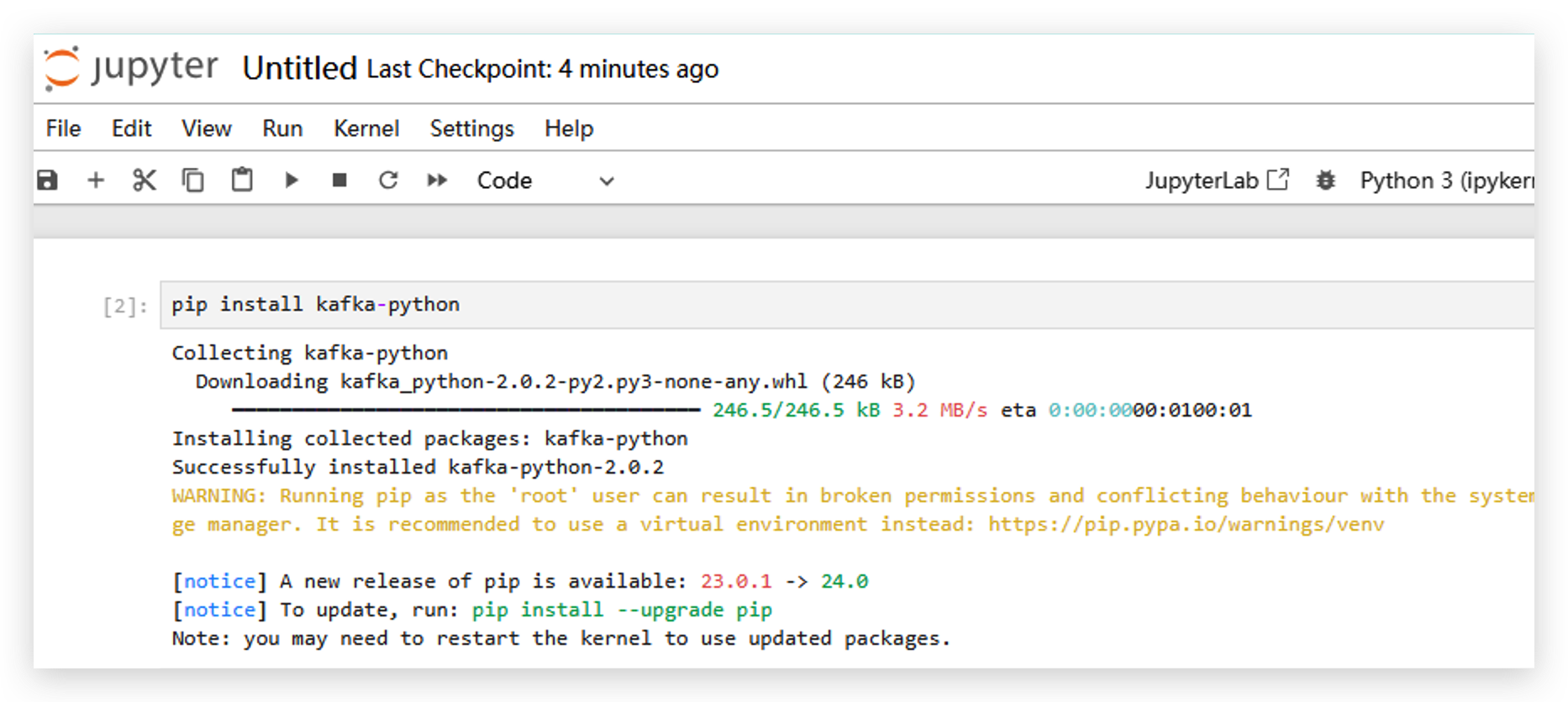
- Después de instalar esa librería, necesitamos reiniciar jupyter.
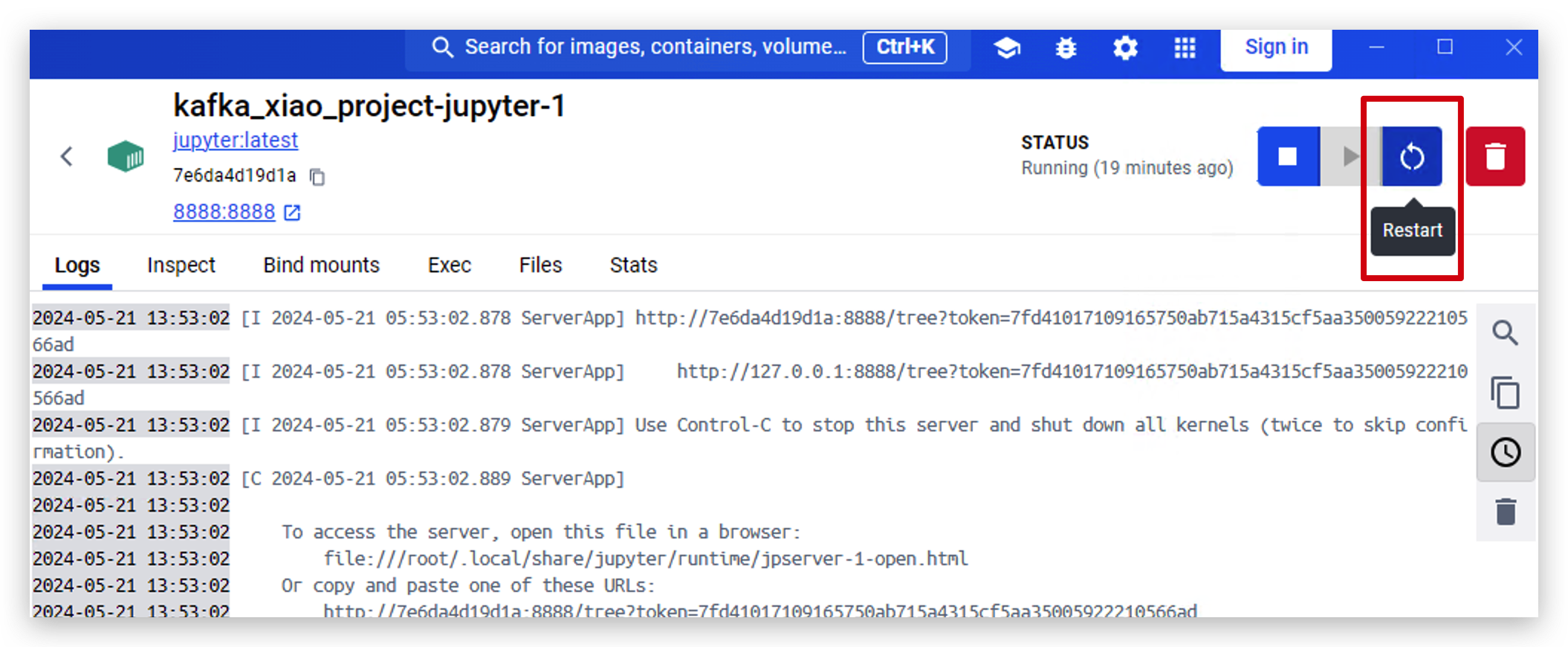
- Ahora ejecuta el siguiente código para enviar algunos datos a Kafka con Python.
from kafka import KafkaProducer, KafkaConsumer
#initialize producer
producer = KafkaProducer(bootstrap_servers='localhost:9093')
#send message
producer.send('my_topic', b'Hello, Kafka2')
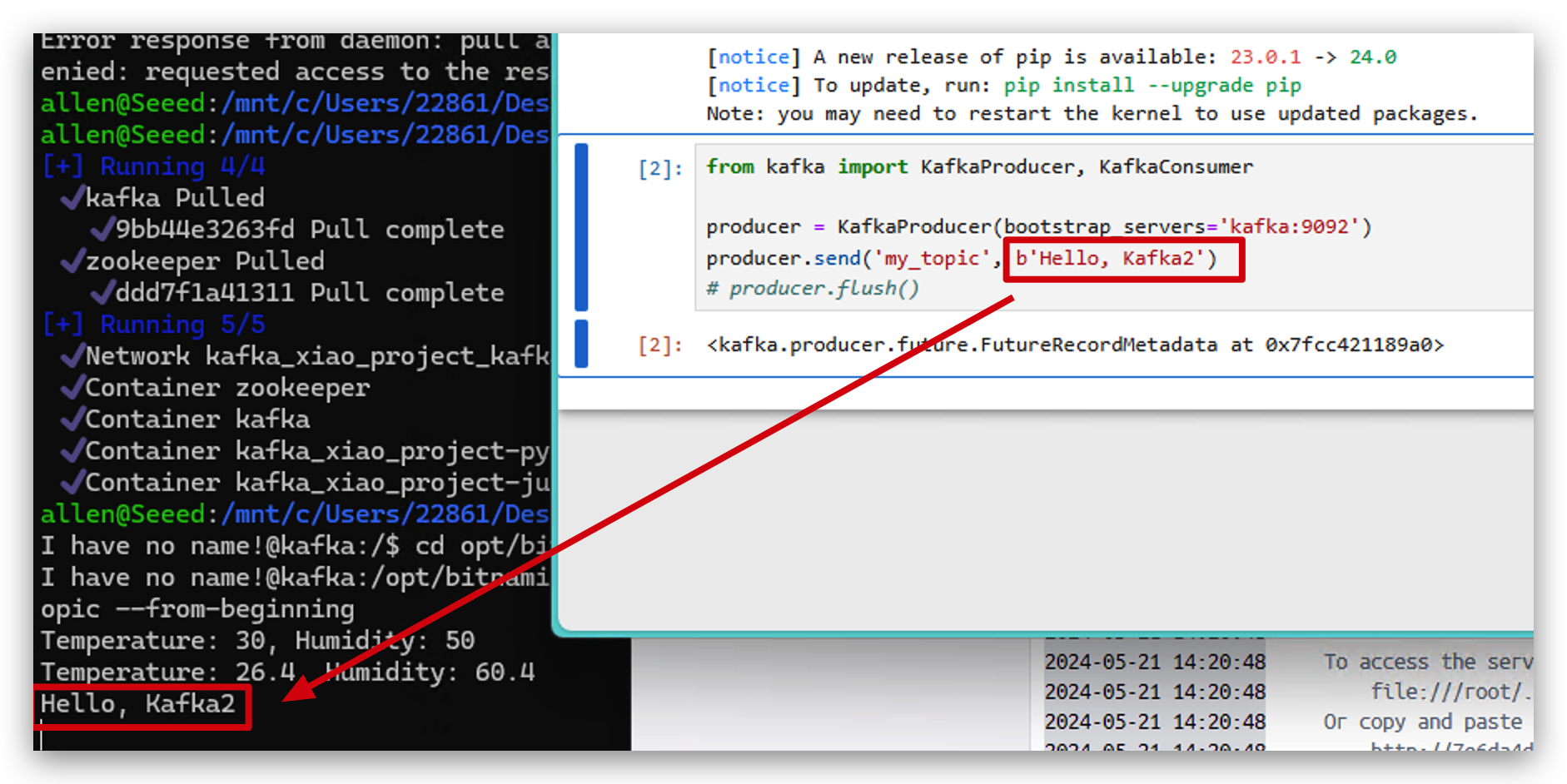
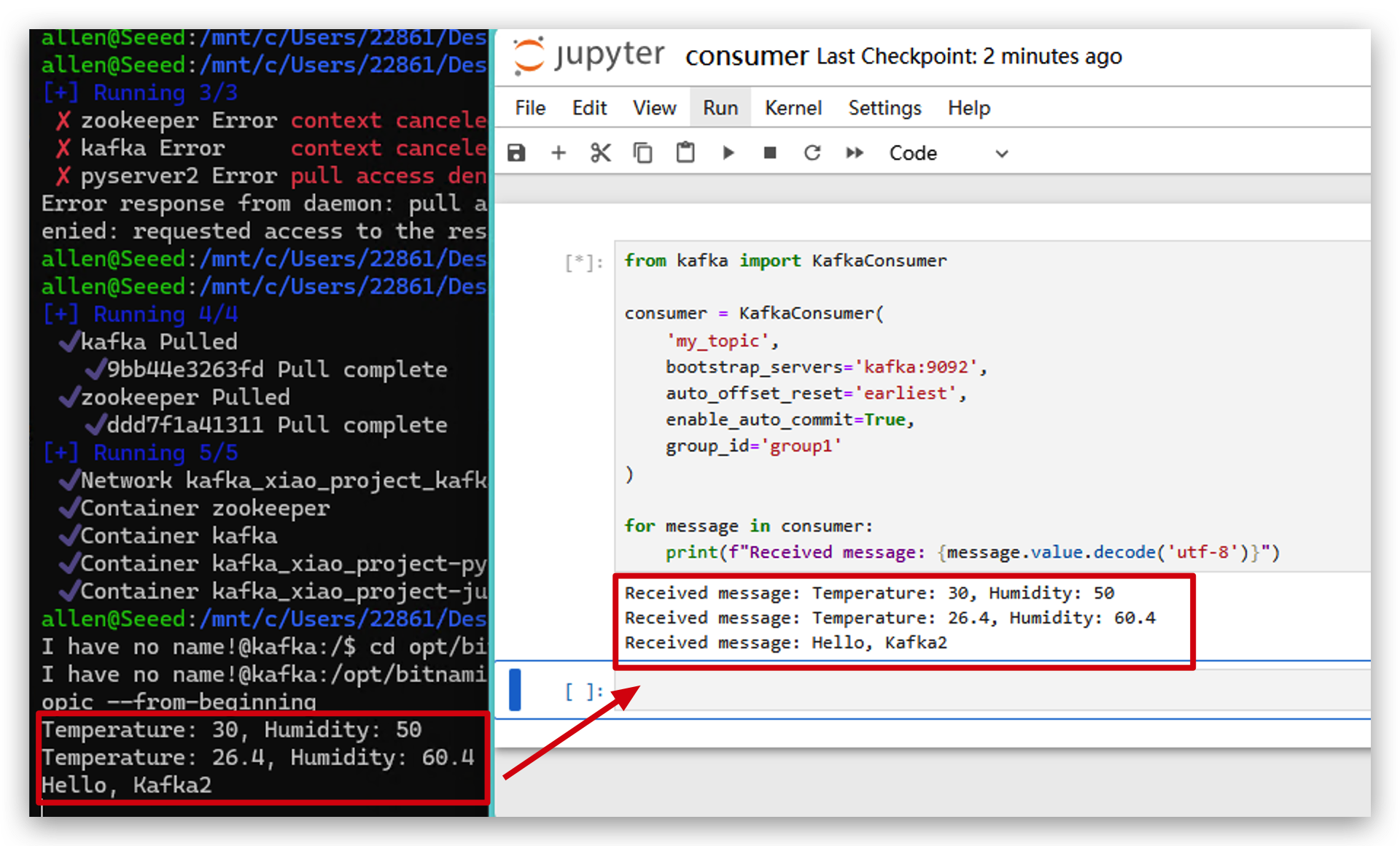
- También puedes verificar esos datos en kafka.
from kafka import KafkaConsumer
# initialize consumer
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers='localhost:9093',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='group1'
)
# receive data and print
for message in consumer:
print(f"Received message: {message.value.decode('utf-8')}")
XIAO ESP32C6 y Apache Kafka
Kafka es una plataforma de streaming distribuida que permite el procesamiento en tiempo real de flujos de datos a escala. Permite la mensajería de publicación-suscripción de datos entre sistemas, proporcionando tolerancia a fallos, persistencia y alto rendimiento. Kafka es ampliamente utilizado para construir pipelines de datos en tiempo real y aplicaciones de streaming en varios dominios.
Ahora, vamos a usar XIAO ESP32C6 y el sensor de temperatura y humedad DHT20 para recopilar datos y enviarlos a Kafka en tiempo real.
Paso 8. Recopilar Datos y Enviar a Apache Kafka
- Copia el siguiente código a tu Arduino IDE.
#include <WiFi.h>
#include <HTTPClient.h>
//Change to your wifi name and password here.
const char* ssid = "Maker_2.4G";
const char* password = "15935700";
//Change to your computer IP address and server port here.
const char* serverUrl = "http://192.168.1.175:5001";
void setup() {
Serial.begin(115200);
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) {
delay(1000);
Serial.println("Connecting to WiFi...");
}
Serial.println("Connected to WiFi");
}
void loop() {
if (WiFi.status() == WL_CONNECTED) {
HTTPClient http;
//Create access link
String url = serverUrl;
url += "/";
url += "30.532"; // tempertature
url += "/";
url += "60.342"; // humidity
http.begin(url);
int httpResponseCode = http.GET();
//Get http response and print
if (httpResponseCode == 200) {
String response = http.getString();
Serial.println("Server response:");
Serial.println(response);
} else {
Serial.print("HTTP error code: ");
Serial.println(httpResponseCode);
}
http.end();
} else {
Serial.println("WiFi disconnected");
}
delay(5000); // access server in every 5s.
}
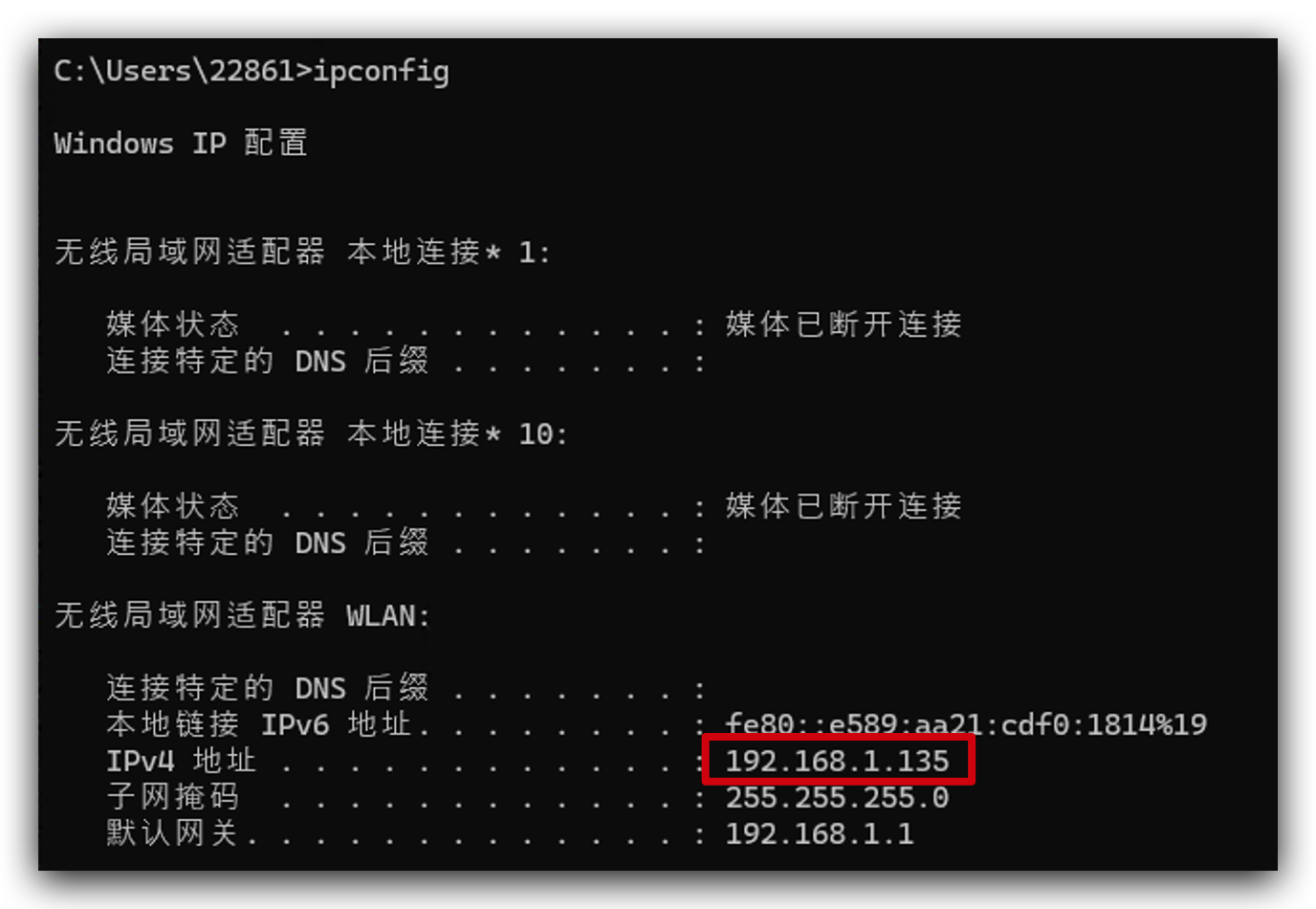
Si no sabes cuál es la dirección IP de tu computadora. Puedes ejecutar ipconfig(Windows) o ifconfig | grep net(Mac o Linux) para verificarla.
- Usa un cable Type-C para conectar tu computadora al C6 y usa un cable Grove para conectar el puerto I2C de la placa de extensión XIAO al sensor DHT20.

- Elige tu placa de desarrollo.
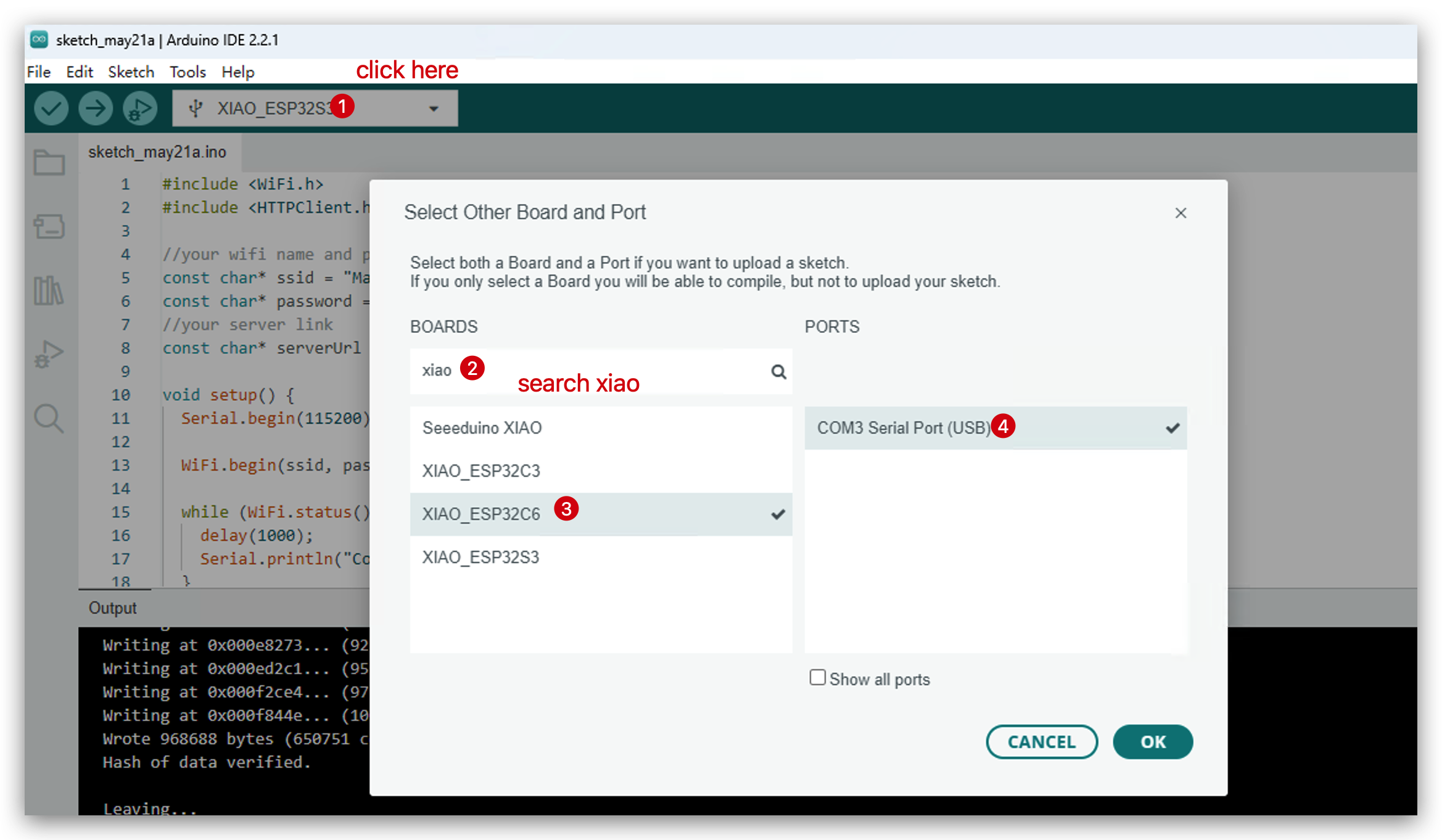
- Sube el código y abre el monitor serie.
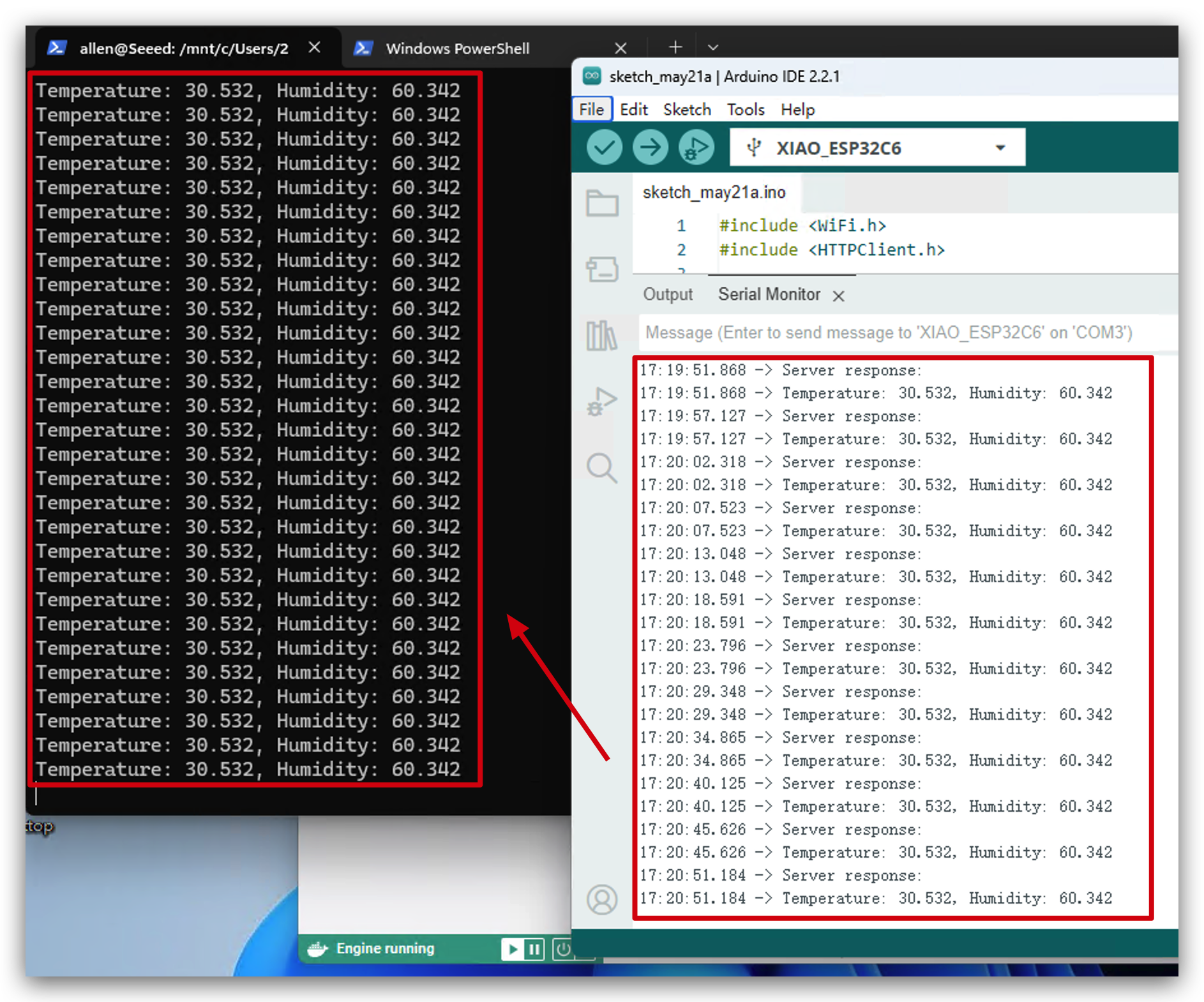
- Abre tu Windows PowerShell que está ejecutando kafka. Ahora verás que los datos del entorno se están enviando a Kafka. ¡Felicitaciones! ¡Has ejecutado este proyecto exitosamente!
Recursos
- [Enlace] Introducción a Apache Kafka
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.