Desplegando Modelos desde Conjuntos de Datos a XIAO ESP32S3
Bienvenido a este tutorial integral donde nos embarcaremos en un viaje para convertir tu conjunto de datos en un modelo completamente funcional para despliegue en el XIAO ESP32S3. En esta guía, navegaremos a través de los pasos iniciales de etiquetado de nuestro conjunto de datos con las herramientas intuitivas de Roboflow, progresando al entrenamiento del modelo dentro del entorno colaborativo de Google Colab.
Luego procederemos al despliegue de nuestro modelo entrenado usando el SenseCraft Model Assistant, un proceso que cierra la brecha entre el entrenamiento y la aplicación en el mundo real. Al final de este tutorial, no solo tendrás un modelo personalizado ejecutándose en XIAO ESP32S3, sino que también estarás equipado con el conocimiento para interpretar y utilizar los resultados de las predicciones de tu modelo.
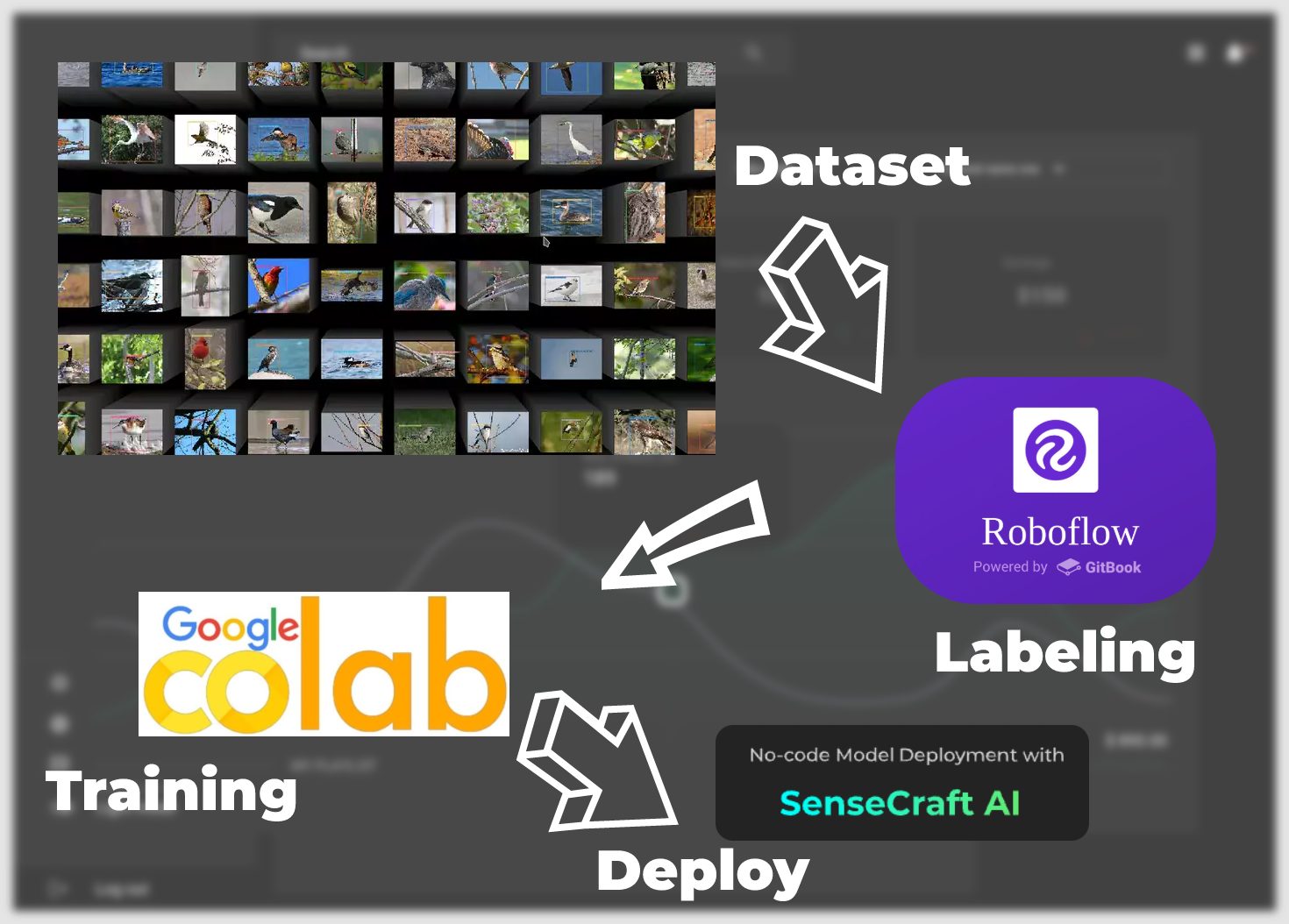
Desde el conjunto de datos hasta el despliegue del modelo, tendremos los siguientes pasos principales.
-
Conjuntos de Datos Etiquetados —— Este capítulo se enfoca en cómo obtener conjuntos de datos que puedan ser entrenados en modelos. Hay dos formas principales de hacer esto. La primera es usar los conjuntos de datos etiquetados proporcionados por la comunidad de Roboflow, y la otra es usar tus propias imágenes específicas del escenario como conjuntos de datos, pero necesitas realizar manualmente el etiquetado tú mismo.
-
Modelo Exportado del Entrenamiento del Conjunto de Datos —— Este capítulo se enfoca en cómo entrenar para obtener un modelo que pueda ser desplegado en XIAO ESP32S3 basado en el conjunto de datos obtenido en el primer paso, utilizando la plataforma Google Colab.
-
Subir modelos vía SenseCraft Model Assistant —— Esta sección describe cómo usar el archivo de modelo exportado para subir el modelo a XIAO ESP32S3 usando el SenseCraft Model Assistant.
-
Protocolos comunes y aplicaciones del modelo —— Finalmente, introduciremos el formato unificado de comunicación de datos de SenseCraft AI para que puedas utilizar el máximo potencial de tus dispositivos y modelos para crear aplicaciones que se ajusten a tus escenarios.
Así que sumerjámonos y comencemos el emocionante proceso de dar vida a tus datos.
Materiales Requeridos
Antes de comenzar, es posible que necesites preparar el siguiente equipo.
| Seeed Studio XIAO ESP32S3 | Seeed Studio XIAO ESP32S3 Sense |
|---|---|
 |  |
Tanto las versiones XIAO ESP32S3 como Sense pueden utilizarse como contenido para este tutorial, pero dado que la versión estándar del producto no permite el uso de la placa de expansión de cámara, recomendaríamos que uses la versión Sense.
Conjuntos de Datos Etiquetados
En el contenido de esta sección, permitimos a los usuarios elegir libremente los conjuntos de datos que tengan. Esto incluye fotos de la comunidad o propias de la escena. Este tutorial introducirá los dos escenarios dominantes. El primero es usar conjuntos de datos etiquetados ya preparados proporcionados por la comunidad de Roboflow. El otro es usar imágenes de alta resolución que hayas tomado y etiquetado el conjunto de datos. Por favor, lee los diferentes tutoriales a continuación según tus necesidades.
Paso 1: Crear una cuenta gratuita de Roboflow
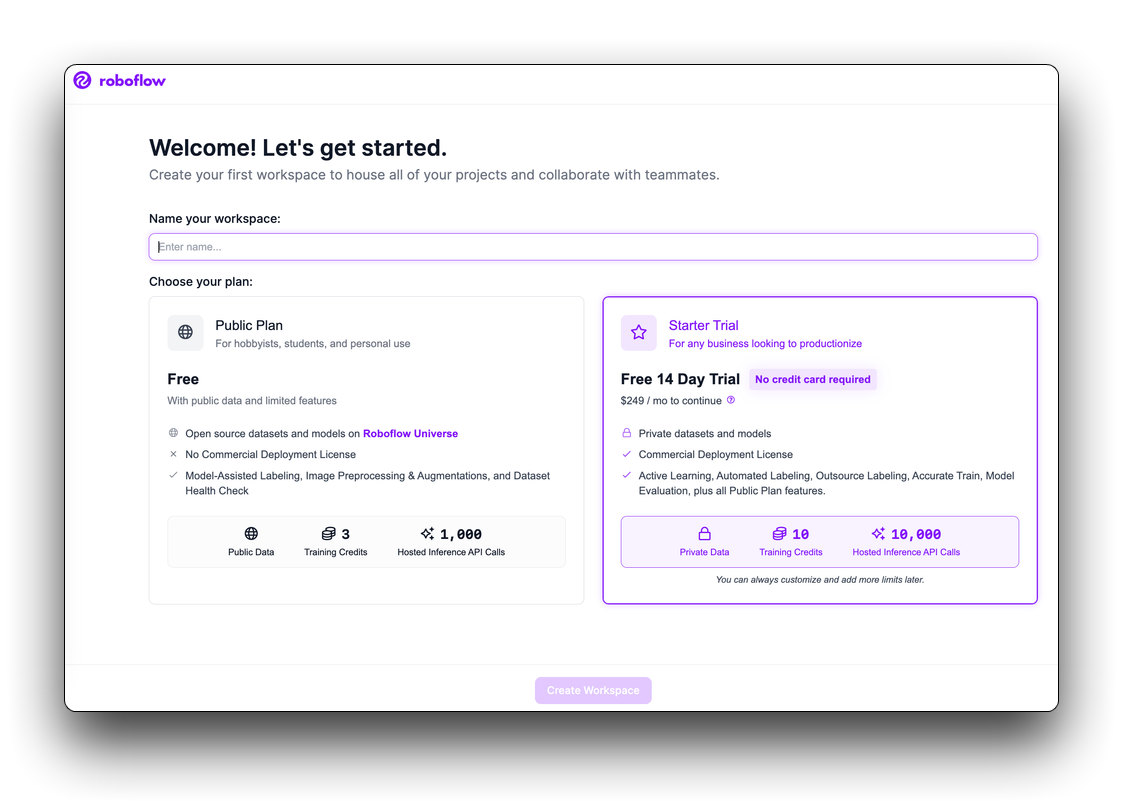
Roboflow proporciona todo lo que necesitas para etiquetar, entrenar y desplegar soluciones de visión por computadora. Para comenzar, crea una cuenta gratuita de Roboflow.
Después de revisar y aceptar los términos de servicio, se te pedirá que elijas entre uno de dos planes: el Plan Público y el Plan Inicial.
Luego, se te pedirá que invites colaboradores a tu espacio de trabajo. Estos colaboradores pueden ayudarte a anotar imágenes o gestionar los proyectos de visión en tu espacio de trabajo. Una vez que hayas invitado personas a tu espacio de trabajo (si quieres hacerlo), podrás crear un proyecto.
Elige cómo obtener tu conjunto de datos
- Descargar conjuntos de datos etiquetados usando Roboflow
- Usar tus propias imágenes como conjunto de datos
Elegir un conjunto de datos adecuado de Roboflow para uso directo implica determinar el conjunto de datos que mejor se ajuste a los requisitos de tu proyecto, considerando aspectos como el tamaño del conjunto de datos, calidad, relevancia y licencia.
Paso 2. Explorar Roboflow Universe
Roboflow Universe es una plataforma donde puedes encontrar varios conjuntos de datos. Visita el sitio web de Roboflow Universe y explora los conjuntos de datos disponibles.
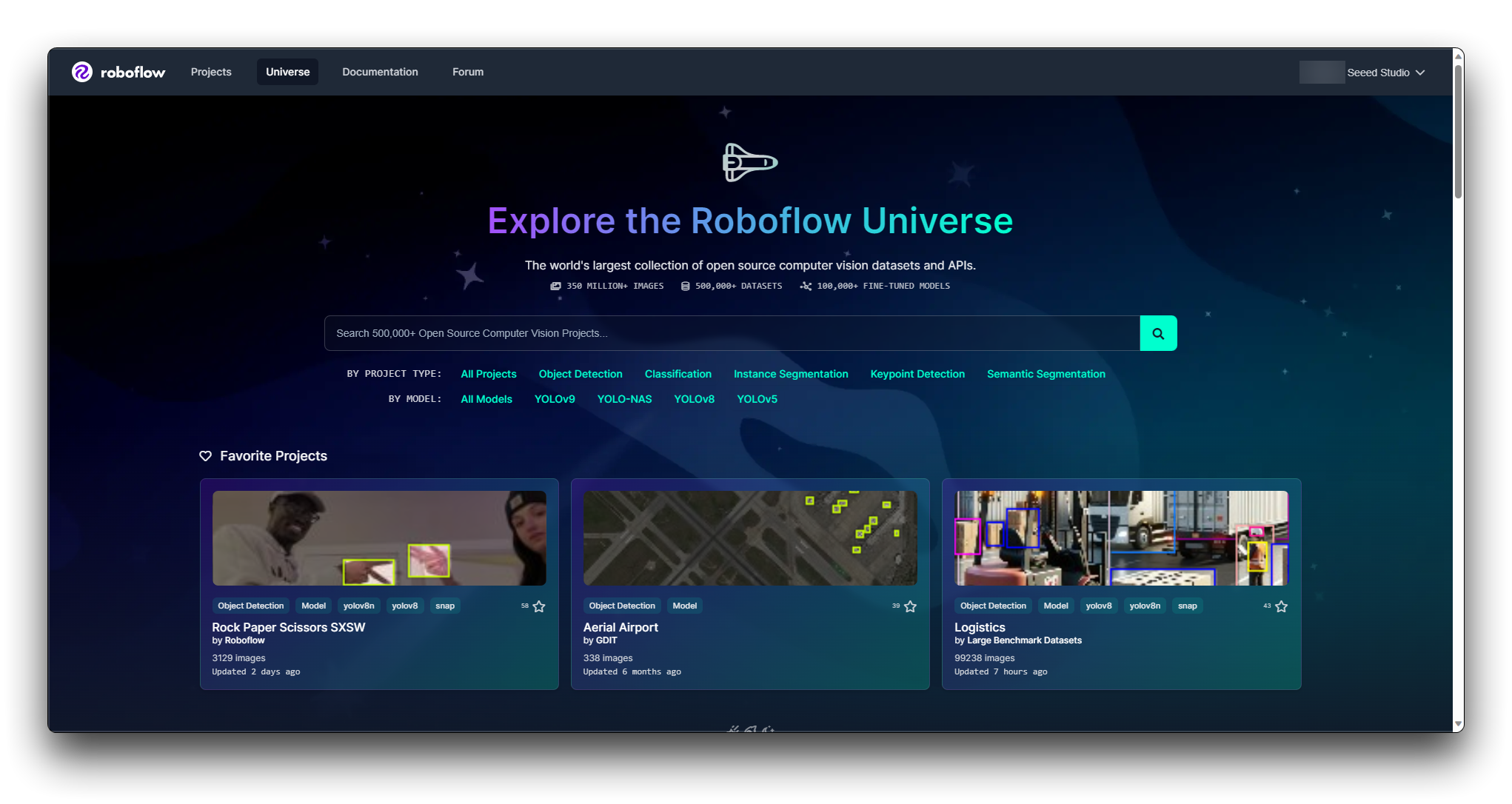
Roboflow proporciona filtros y una función de búsqueda para ayudarte a encontrar conjuntos de datos. Puedes filtrar conjuntos de datos por dominio, número de clases, tipos de anotación y más. Utiliza estos filtros para reducir los conjuntos de datos que se ajusten a tus criterios.
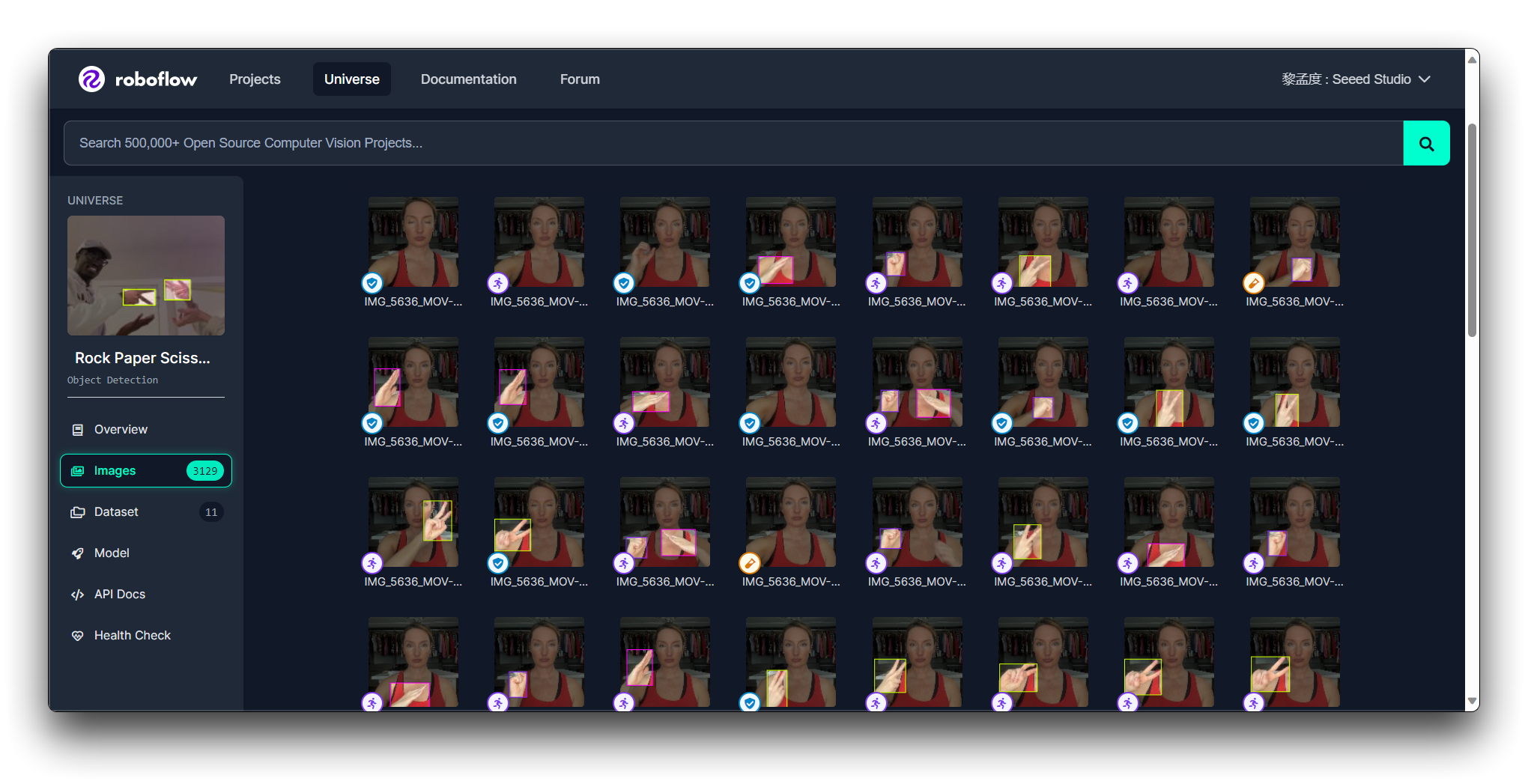
Paso 3. Evaluar Conjuntos de Datos Individuales
Una vez que tengas una lista corta, evalúa cada conjunto de datos individualmente. Busca:
Calidad de Anotación: Verifica si las anotaciones son precisas y consistentes.
Tamaño del Conjunto de Datos: Asegúrate de que el conjunto de datos sea lo suficientemente grande para que tu modelo aprenda efectivamente pero no demasiado grande para manejar.
Balance de Clases: El conjunto de datos debería idealmente tener un número equilibrado de ejemplos para cada clase.
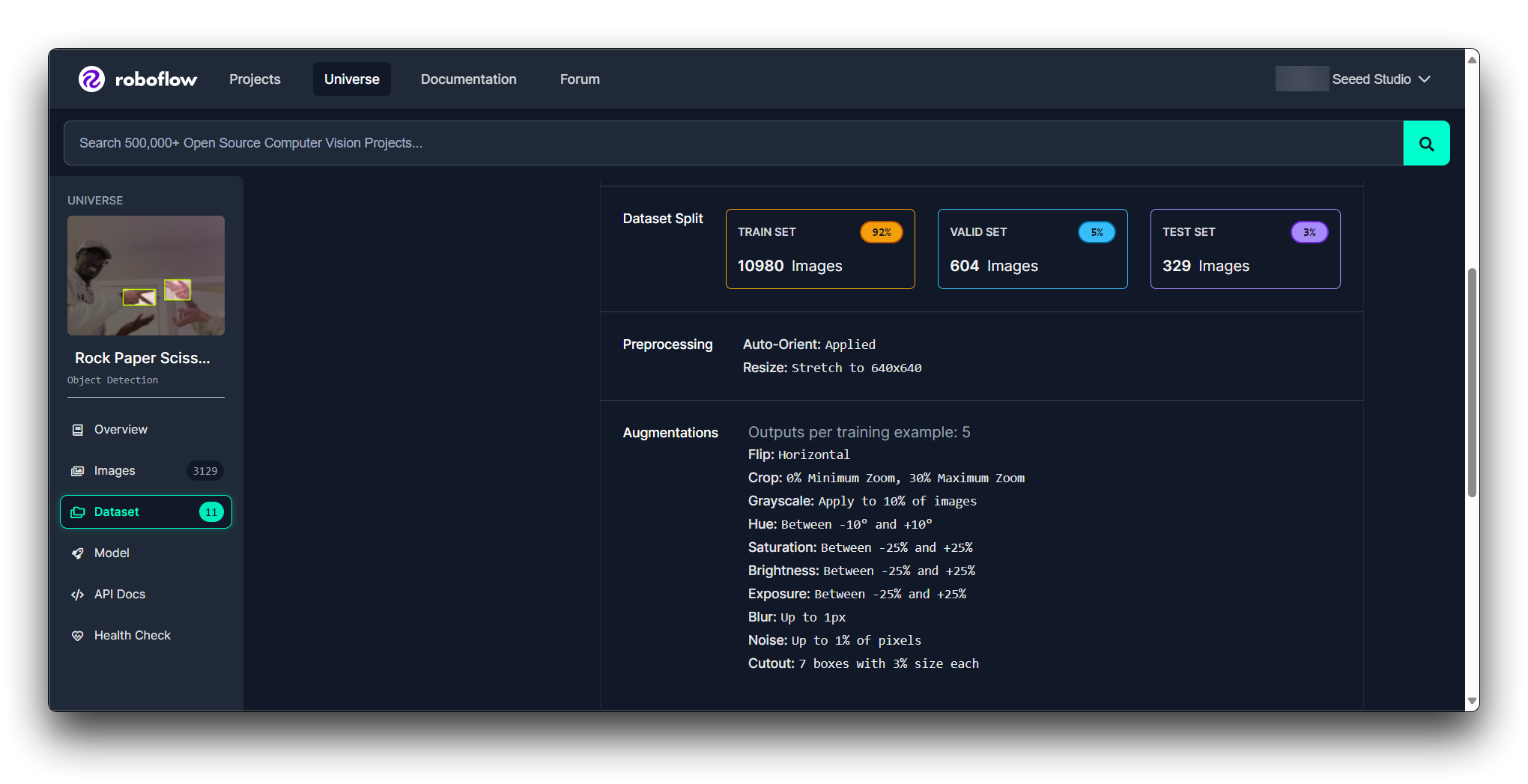
Licencia: Revisa la licencia del conjunto de datos para asegurarte de que puedas usarlo según lo previsto.
Documentación: Revisa cualquier documentación o metadatos que vengan con el conjunto de datos para entender mejor su contenido y cualquier paso de preprocesamiento que ya se haya aplicado.
Puedes conocer la condición del modelo a través de Roboflow Health Check.
Paso 4. Descargar la Muestra
Si encuentras el conjunto de datos de tu elección, entonces tienes la opción de descargarlo y usarlo. Roboflow usualmente te permite descargar una muestra del conjunto de datos. Prueba la muestra para ver si se integra bien con tu flujo de trabajo y si es adecuada para tu modelo.
Para continuar con los pasos subsiguientes, recomendamos que exportes el conjunto de datos en el formato mostrado a continuación.
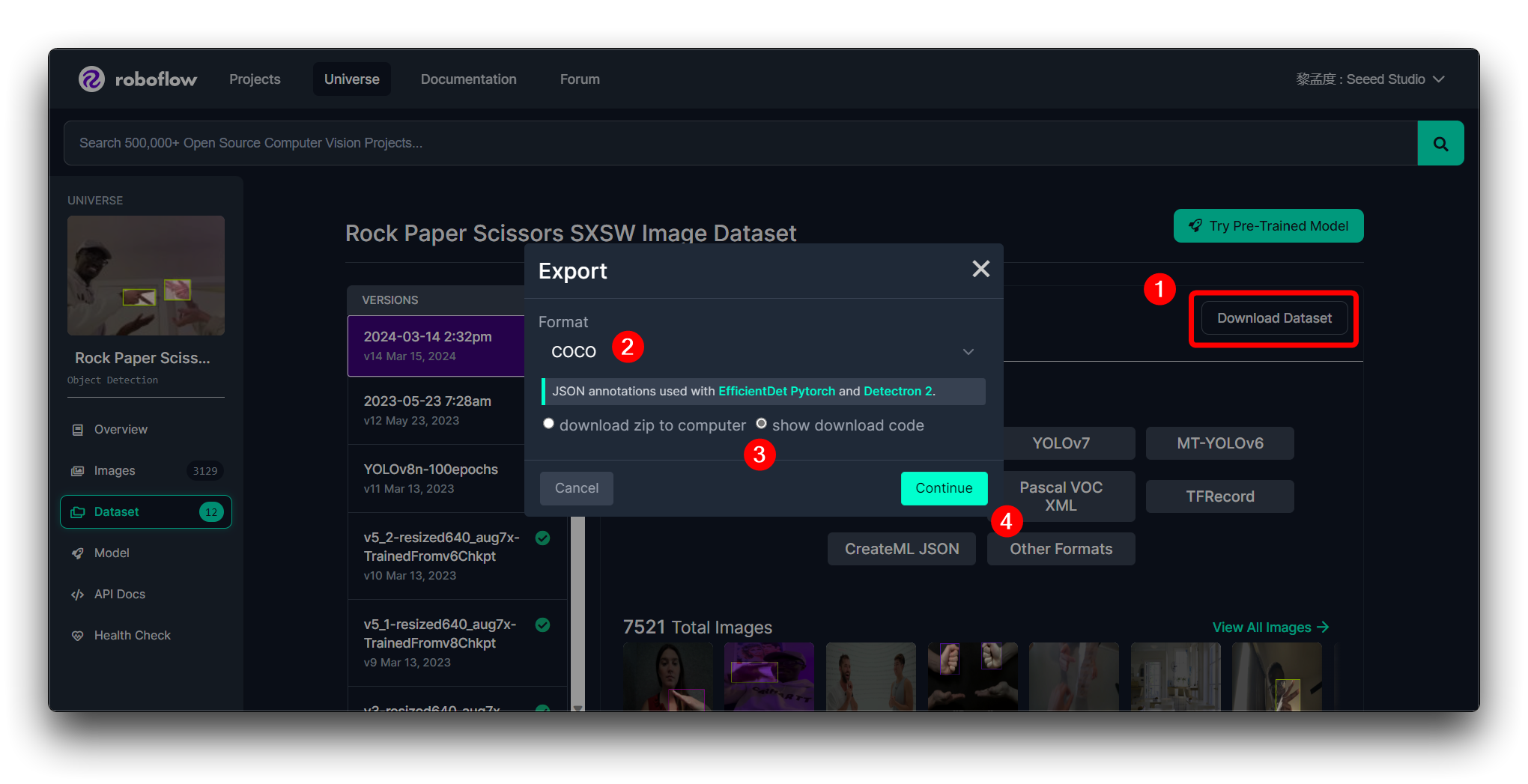
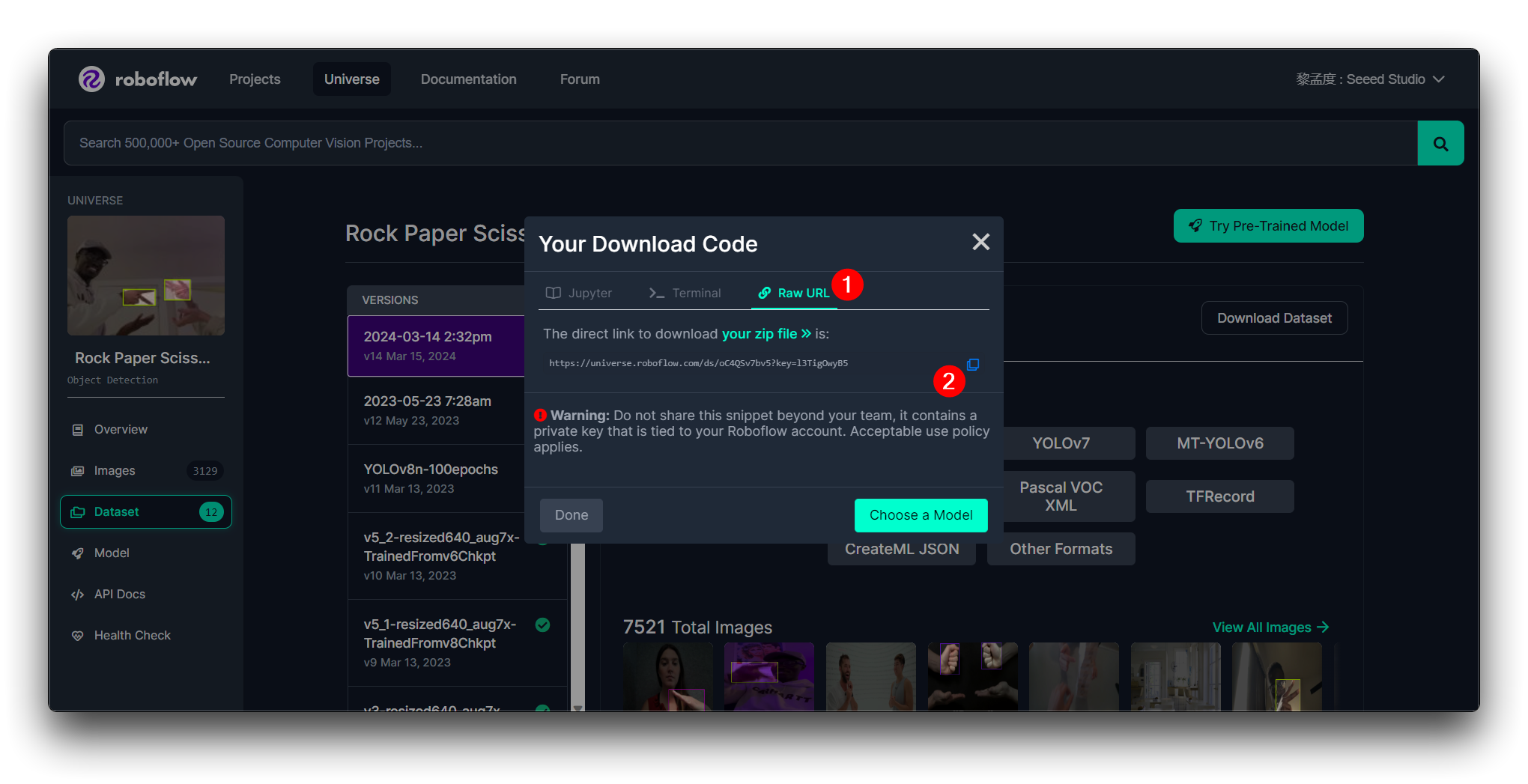
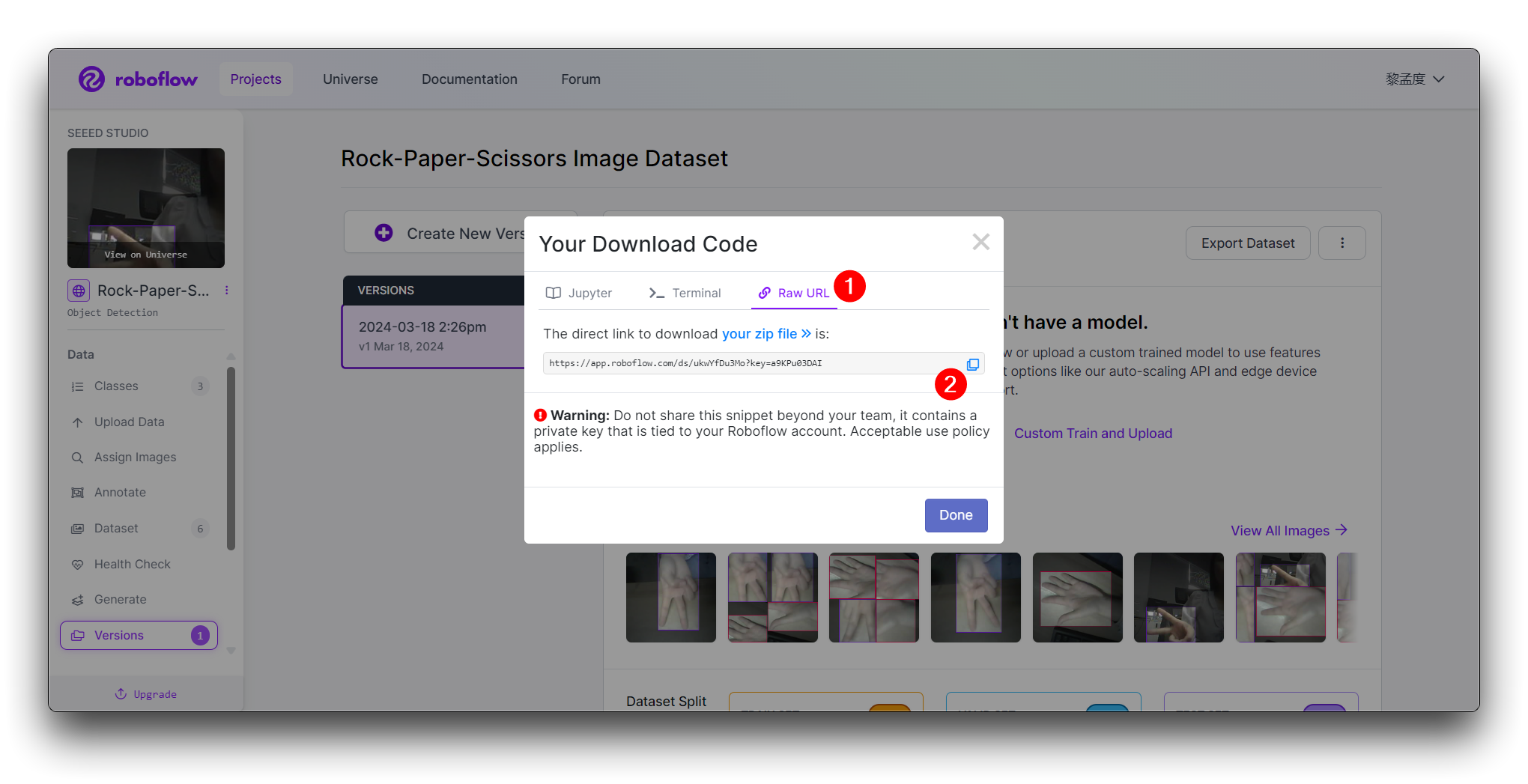
Entonces obtendrás la URL Raw para este modelo, mantenla segura, usaremos ese enlace en el paso de entrenamiento del modelo un poco más tarde.
Si estás usando Roboflow por primera vez y no tienes absolutamente ningún juicio sobre la selección de conjuntos de datos, el paso de entrenar un modelo con un conjunto de datos para realizar una prueba inicial para ver el rendimiento puede ser esencial. Esto puede ayudarte a evaluar si el conjunto de datos cumplirá con tus requisitos.
Si el conjunto de datos cumple con tus requisitos y funciona bien en las pruebas iniciales, entonces es probable que sea adecuado para tu proyecto. De lo contrario, puede que necesites continuar tu búsqueda o considerar expandir el conjunto de datos con más imágenes.
Aquí, usaré la imagen de gesto piedra-papel-tijeras como demostración para guiarte a través de las tareas de carga de imágenes, etiquetado y exportación de un conjunto de datos en Roboflow.
Recomendamos encarecidamente que uses XIAO ESP32S3 para tomar fotos de tu conjunto de datos, lo cual es mejor para XIAO ESP32S3. Un programa de muestra para que XIAO ESP32S3 Sense tome fotos se puede encontrar en el enlace Wiki a continuación.
Paso 2. Crear un Nuevo Proyecto y Subir imágenes
Una vez que hayas iniciado sesión en Roboflow, haz clic en Create Project.
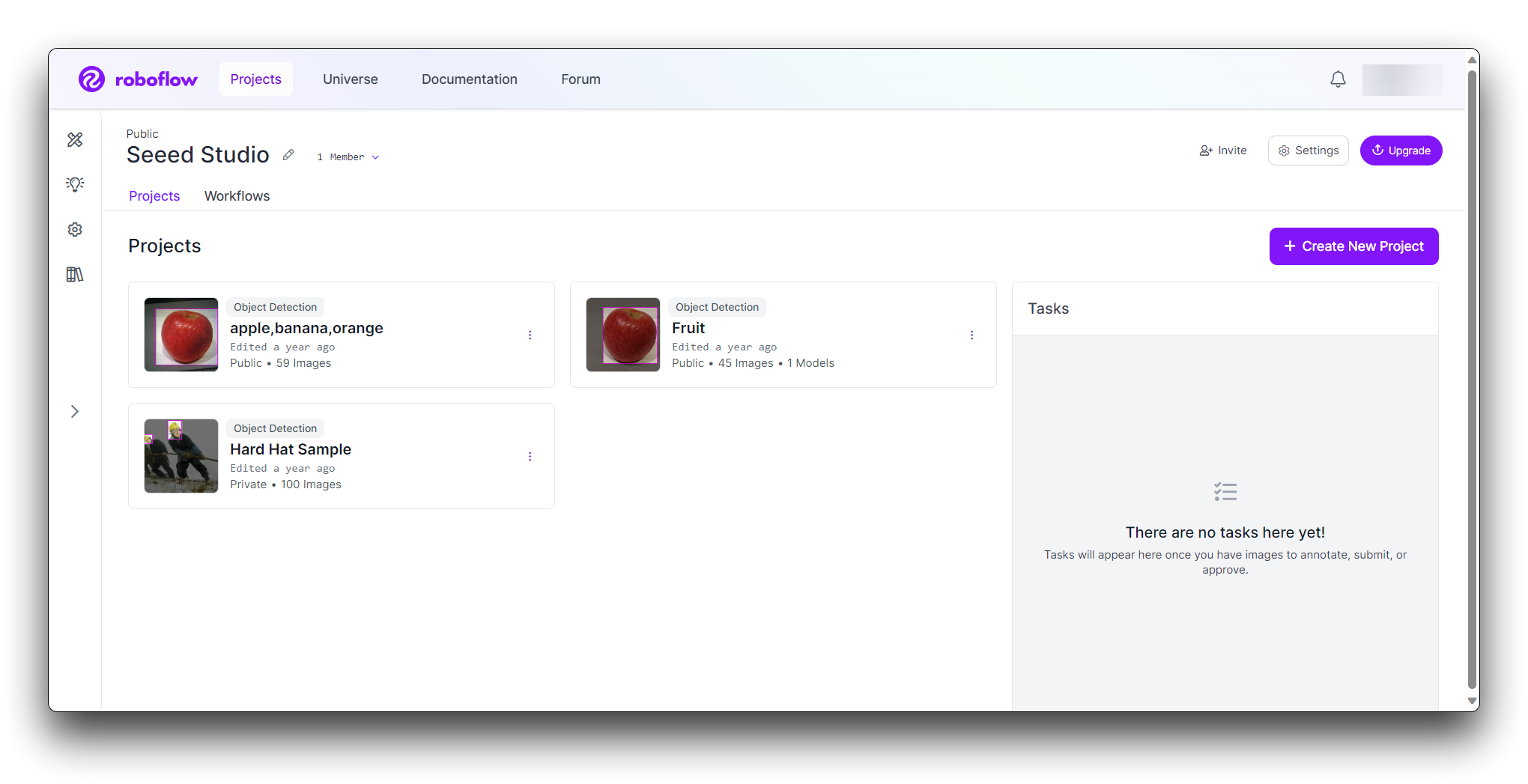
Nombra tu proyecto (por ejemplo, "Piedra-Papel-Tijeras"). Define tu proyecto como Object Detection. Establece las Output Labels como Categorical (ya que Piedra, Papel y Tijeras son categorías distintas).
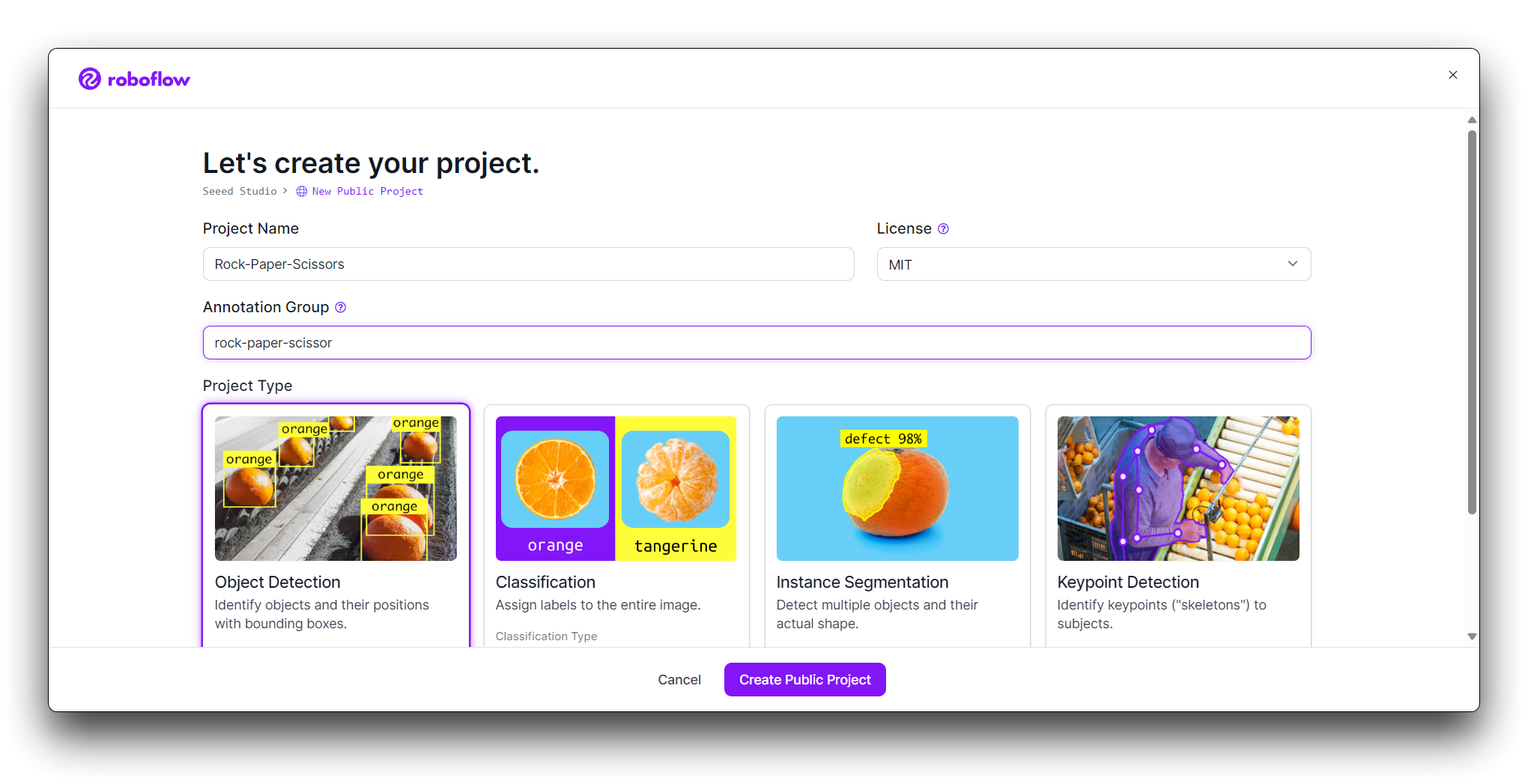
Ahora es momento de subir tus imágenes de gestos de mano.
Recopila imágenes de los gestos de piedra, papel y tijeras. Asegúrate de tener una variedad de fondos y condiciones de iluminación. En la página de tu proyecto, haz clic en "Add Images".
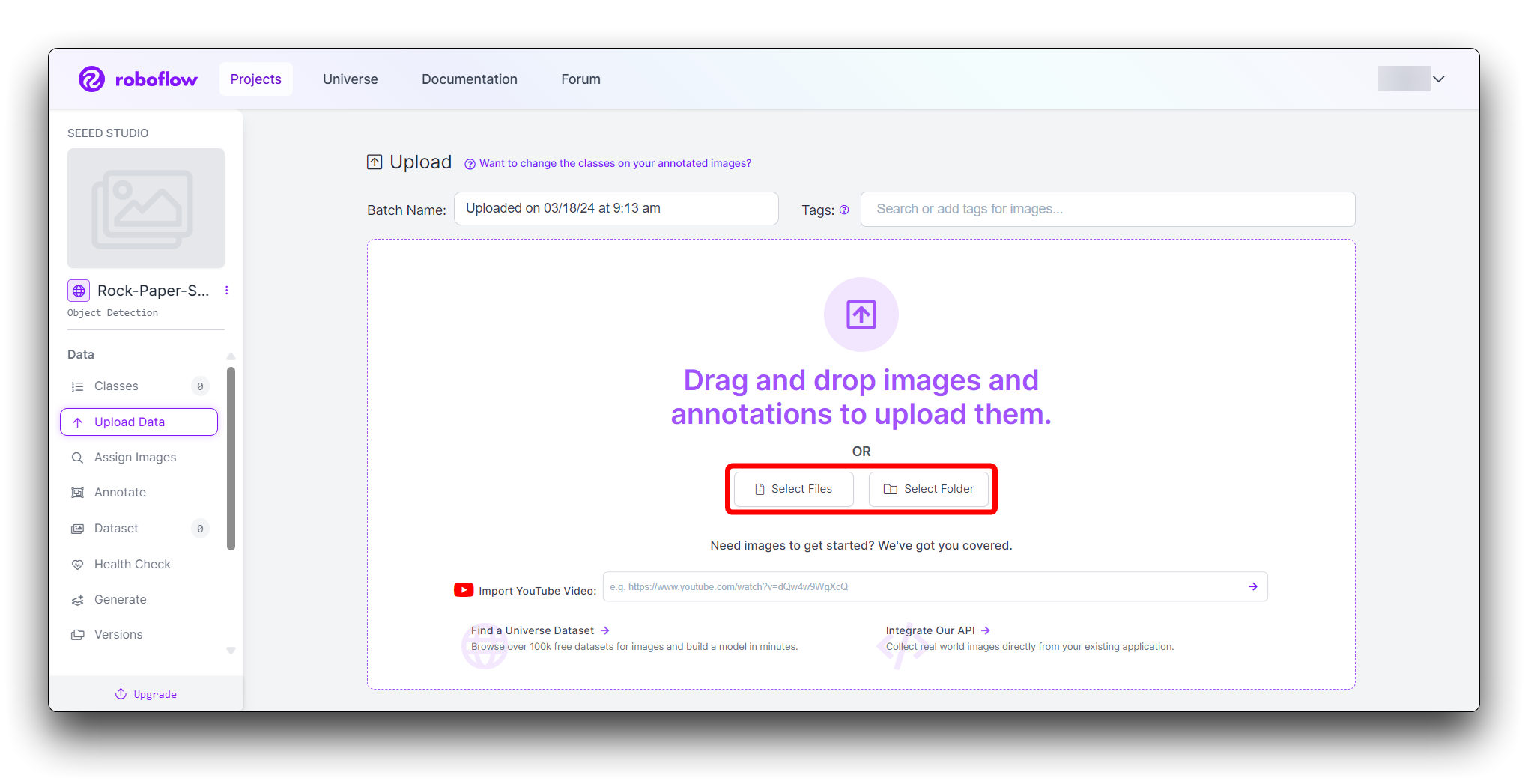
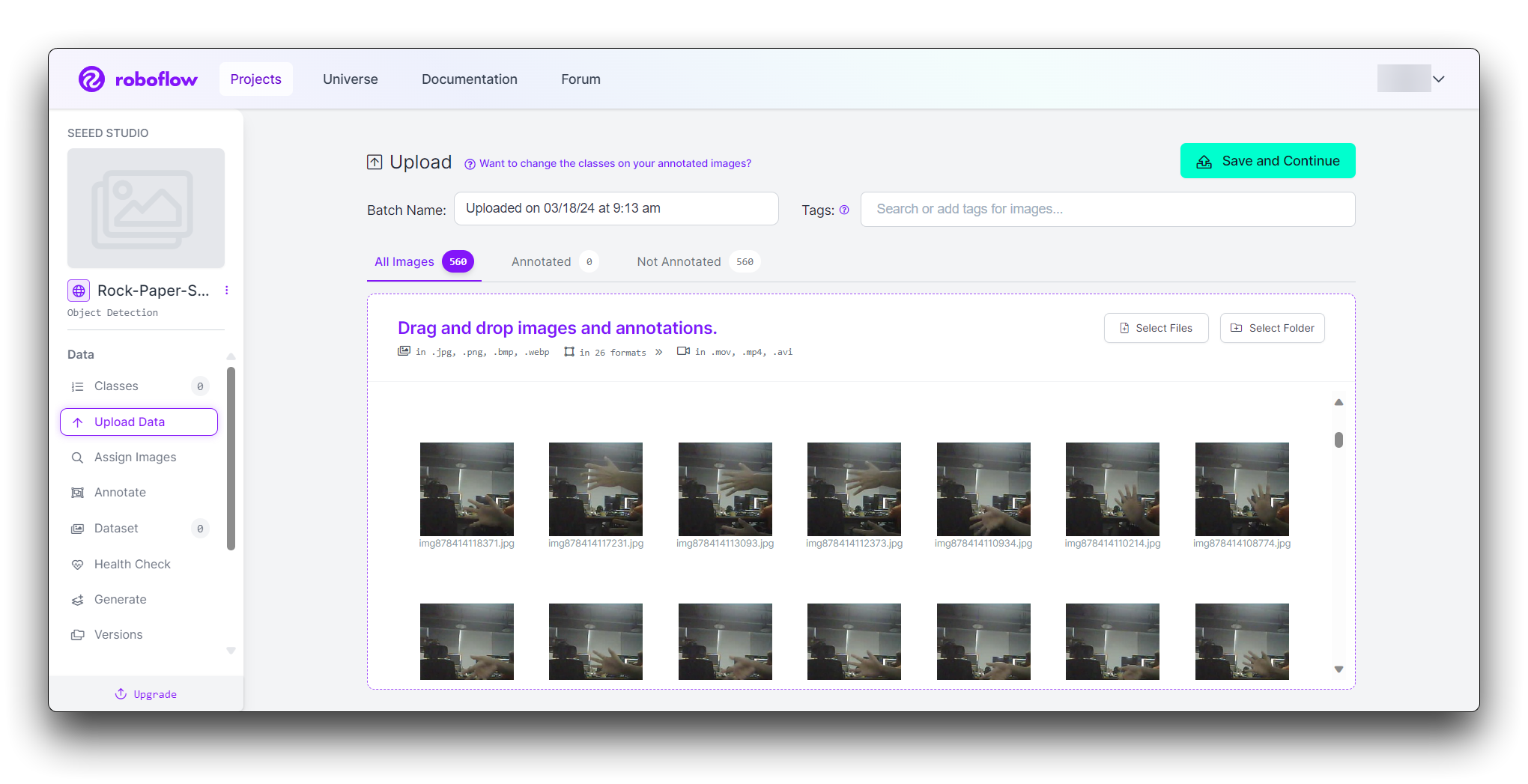
Puedes arrastrar y soltar tus imágenes o seleccionarlas desde tu computadora. Sube al menos 100 imágenes de cada gesto para un conjunto de datos robusto.
¿Cómo se determina el tamaño del conjunto de datos?
Generalmente depende de una variedad de factores: modelo de tarea, complejidad de la tarea, pureza de los datos, y así sucesivamente. Por ejemplo, el modelo de detección del cuerpo humano involucra un gran número de personas, un amplio rango, la tarea es más compleja, por lo que se necesita recopilar más datos. Otro ejemplo es el modelo de detección de gestos, que solo necesita detectar los tres tipos de "piedra", "tijeras" y "papel", y requiere menos categorías, por lo que el conjunto de datos recopilado es de aproximadamente 500.
Paso 3: Anotar Imágenes
Después de subir, necesitarás anotar las imágenes etiquetando los gestos de mano.
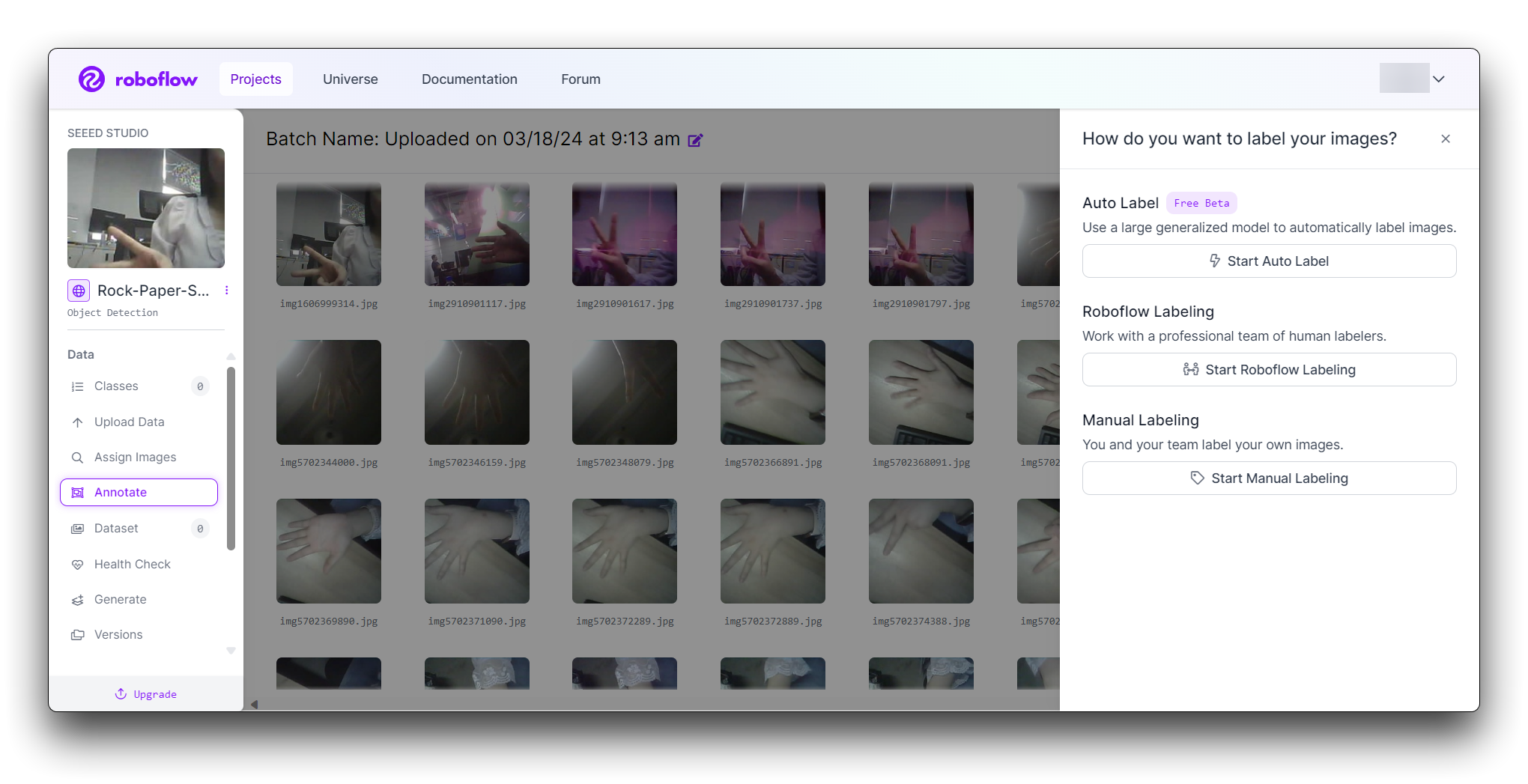
Roboflow ofrece tres formas diferentes de etiquetar imágenes: Auto Label, Roboflow Labeling y Manual Labeling.
- Auto Label: Usa un modelo generalizado grande para etiquetar automáticamente las imágenes.
- Roboflow Labeling: Trabaja con un equipo profesional de etiquetadores humanos. Sin volúmenes mínimos. Sin compromisos por adelantado. Las anotaciones de Bounding Box comienzan en $0.04 y las anotaciones de Polígono comienzan en $0.08.
- Manual Labeling: Tú y tu equipo etiquetan sus propias imágenes.
Lo siguiente describe el método más comúnmente usado de etiquetado manual.
Haz clic en el botón "Manual Labeling". Roboflow cargará la interfaz de anotación.
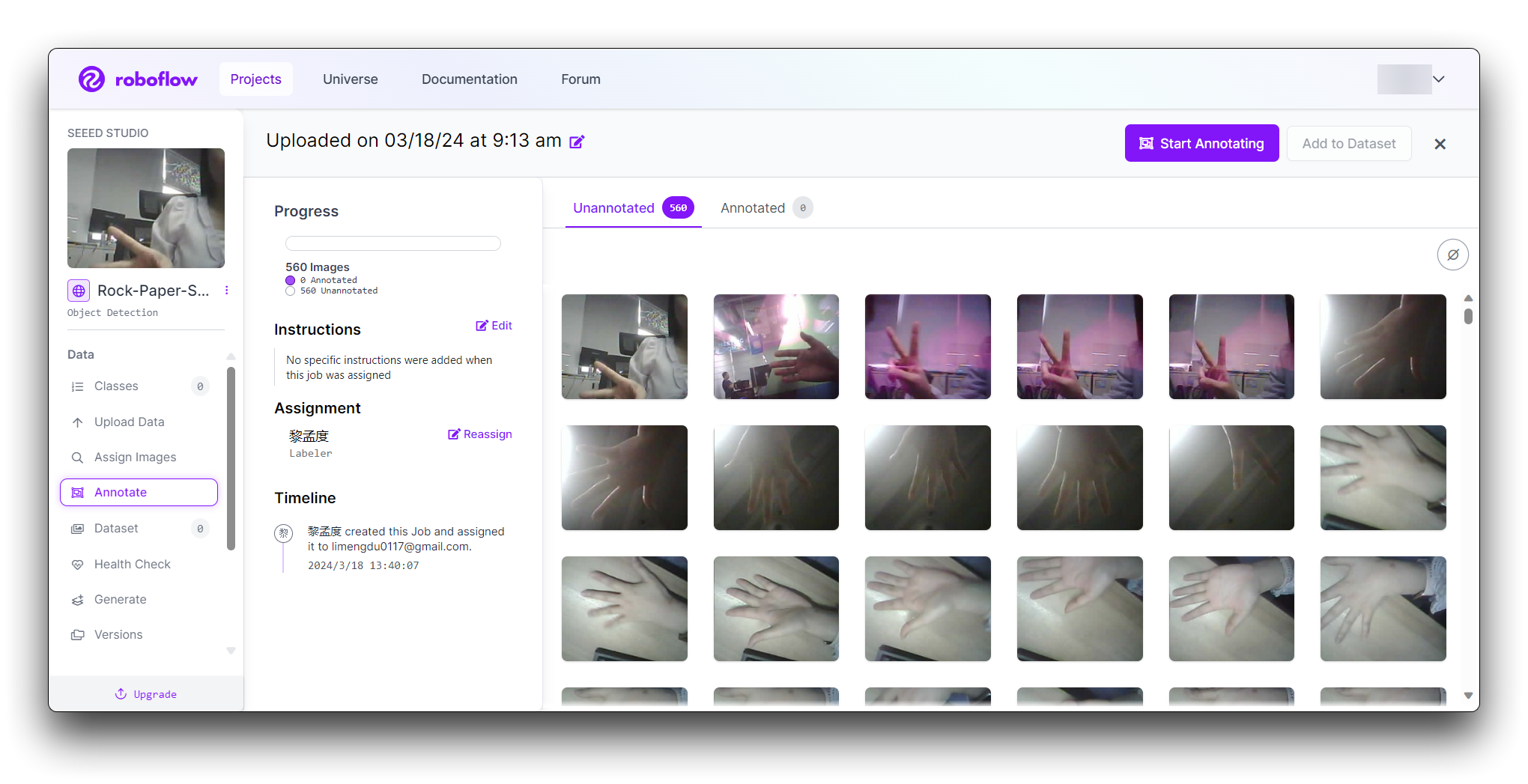
Selecciona el botón "Start Annotating". Dibuja cajas delimitadoras alrededor del gesto de mano en cada imagen.
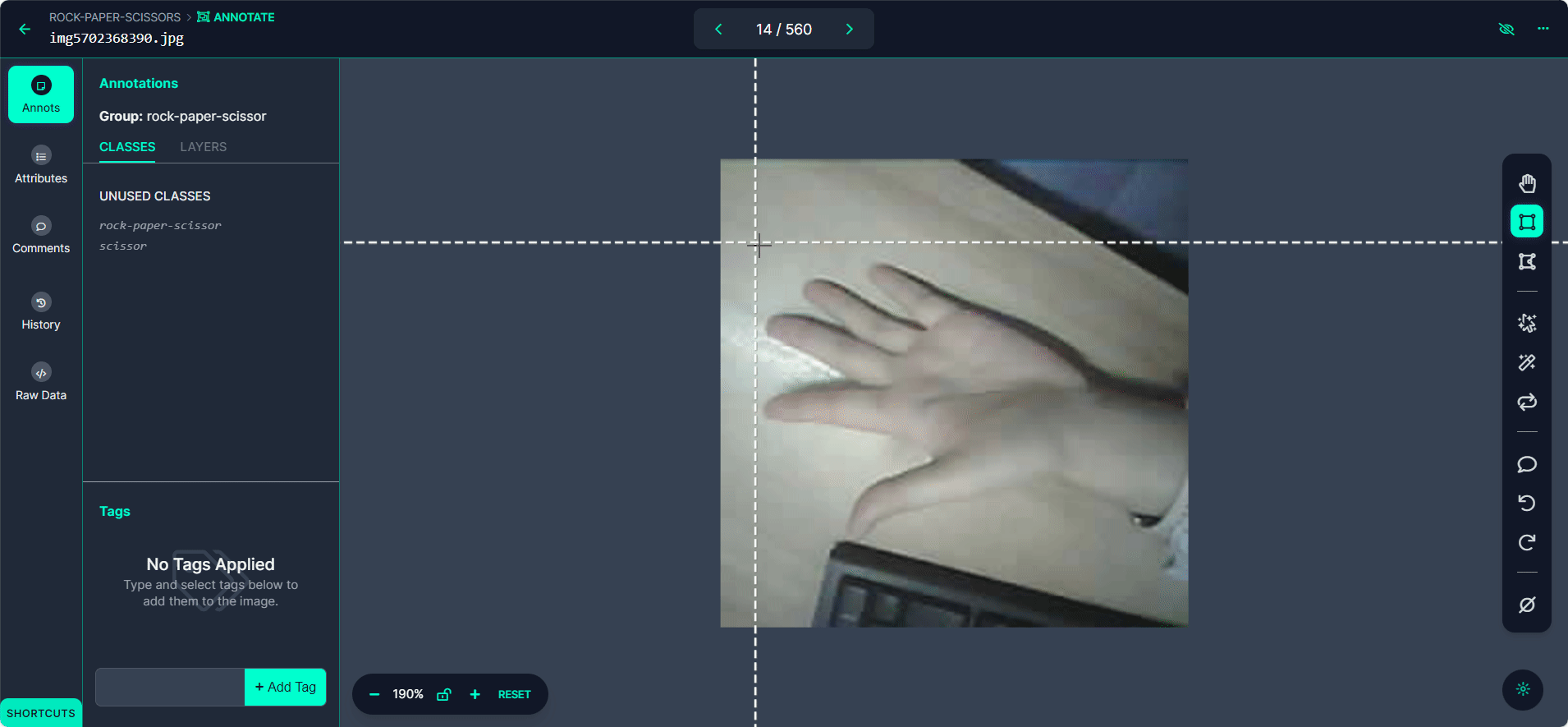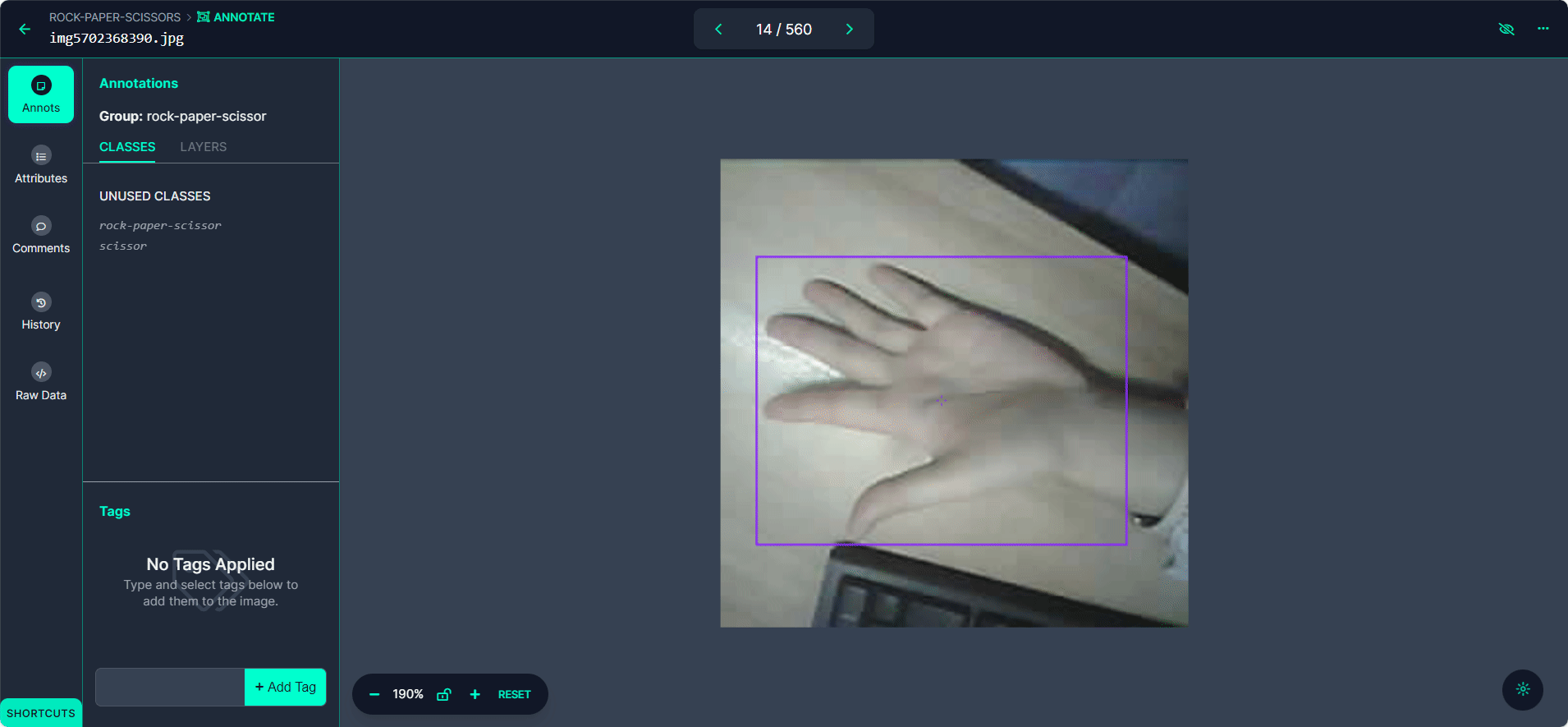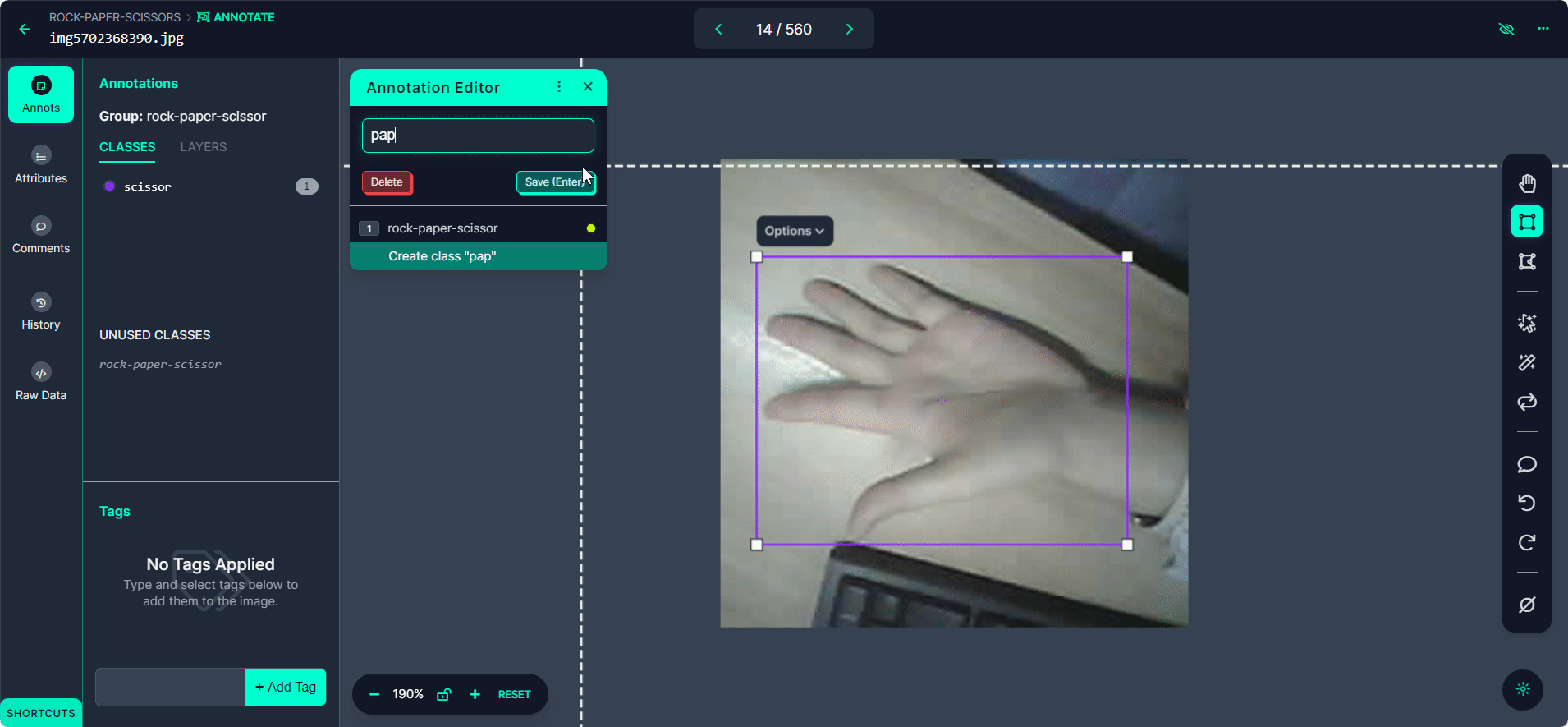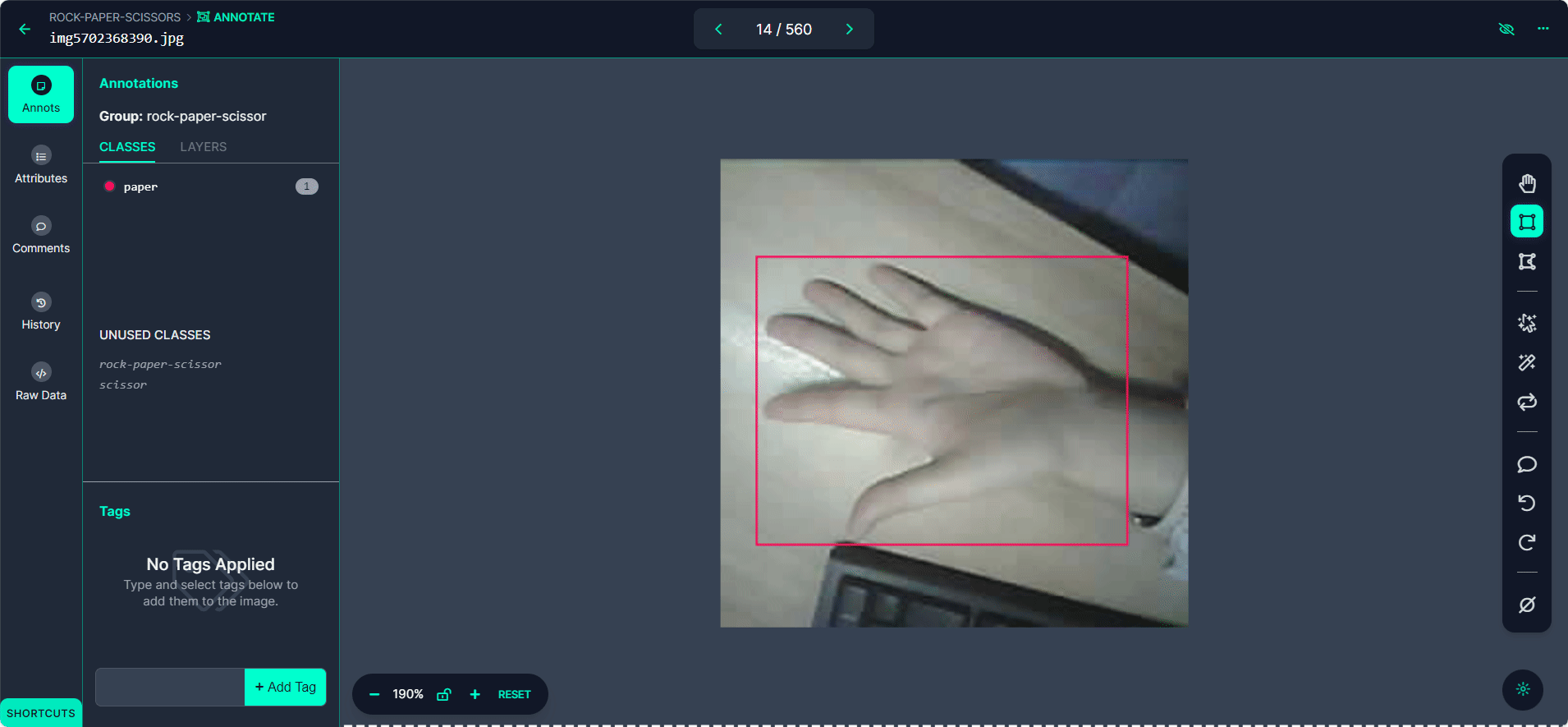
Etiqueta cada caja delimitadora como "Rock", "Paper", o "Scissors".
Usa el botón ">" para moverte a través de tu conjunto de datos, repitiendo el proceso de anotación para cada imagen.
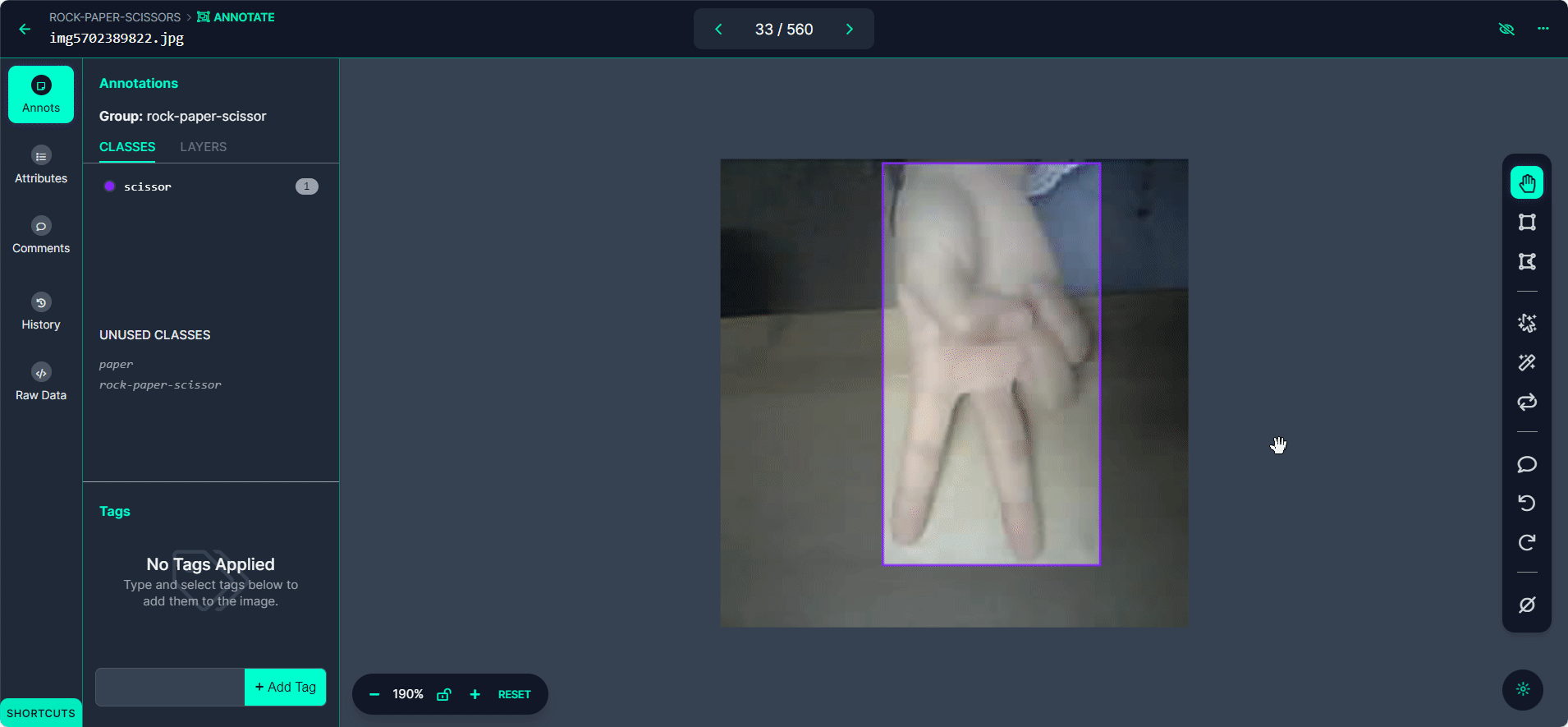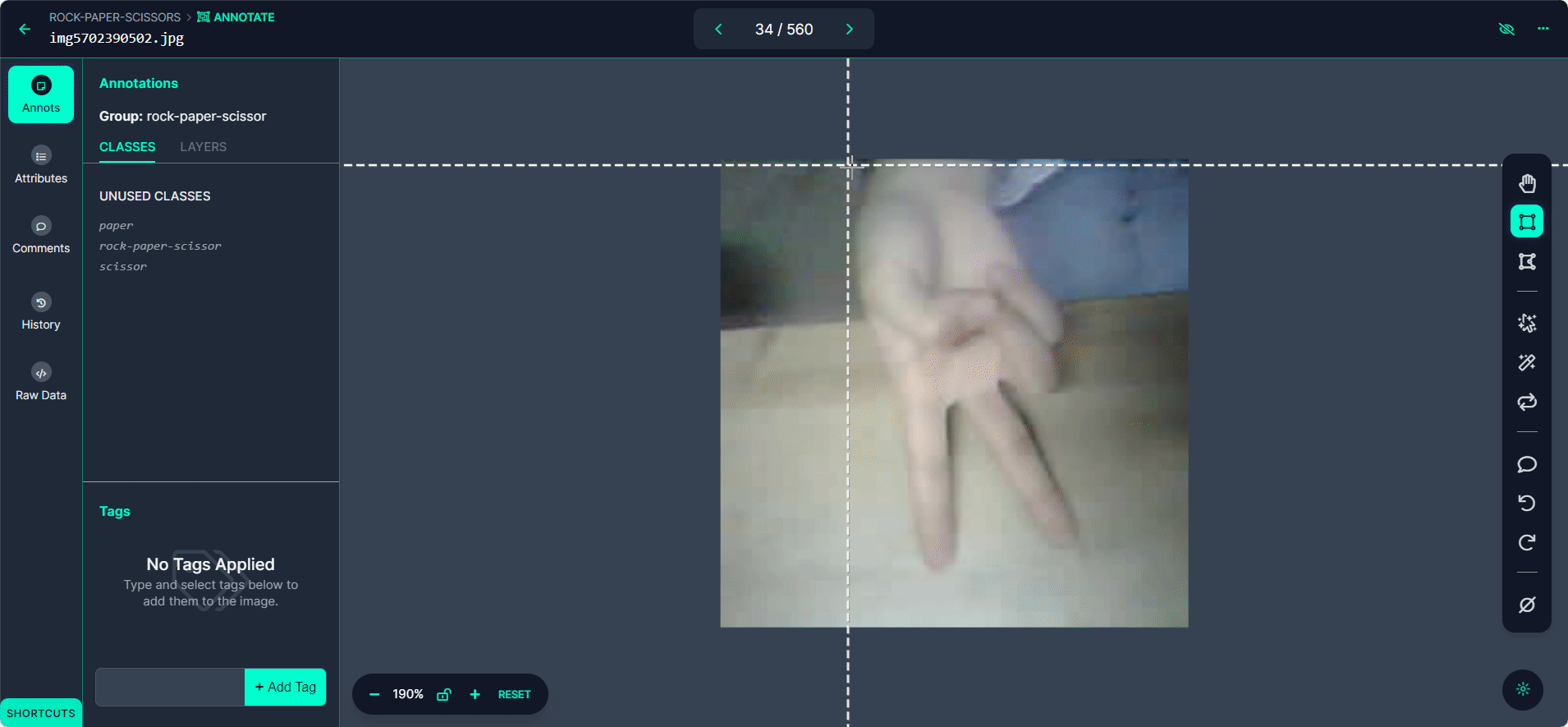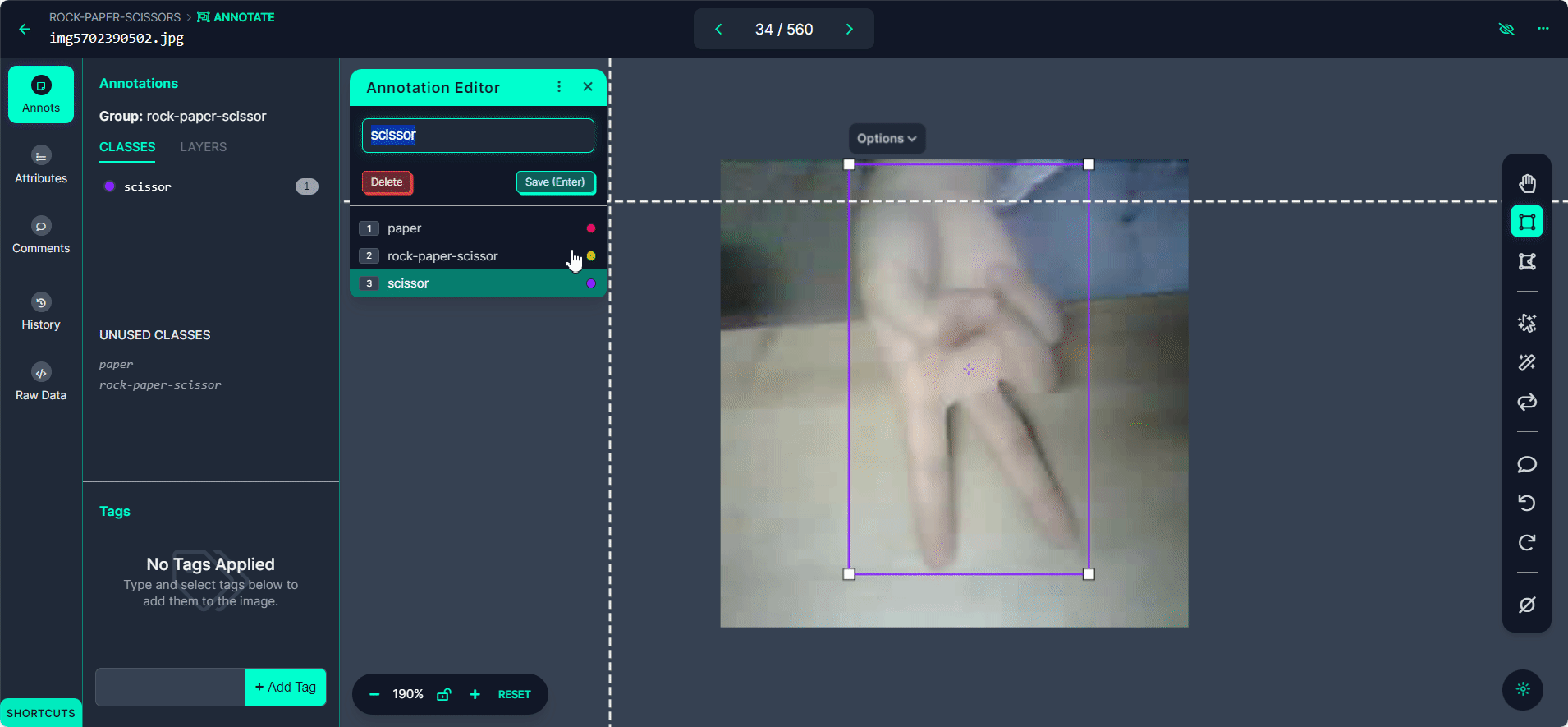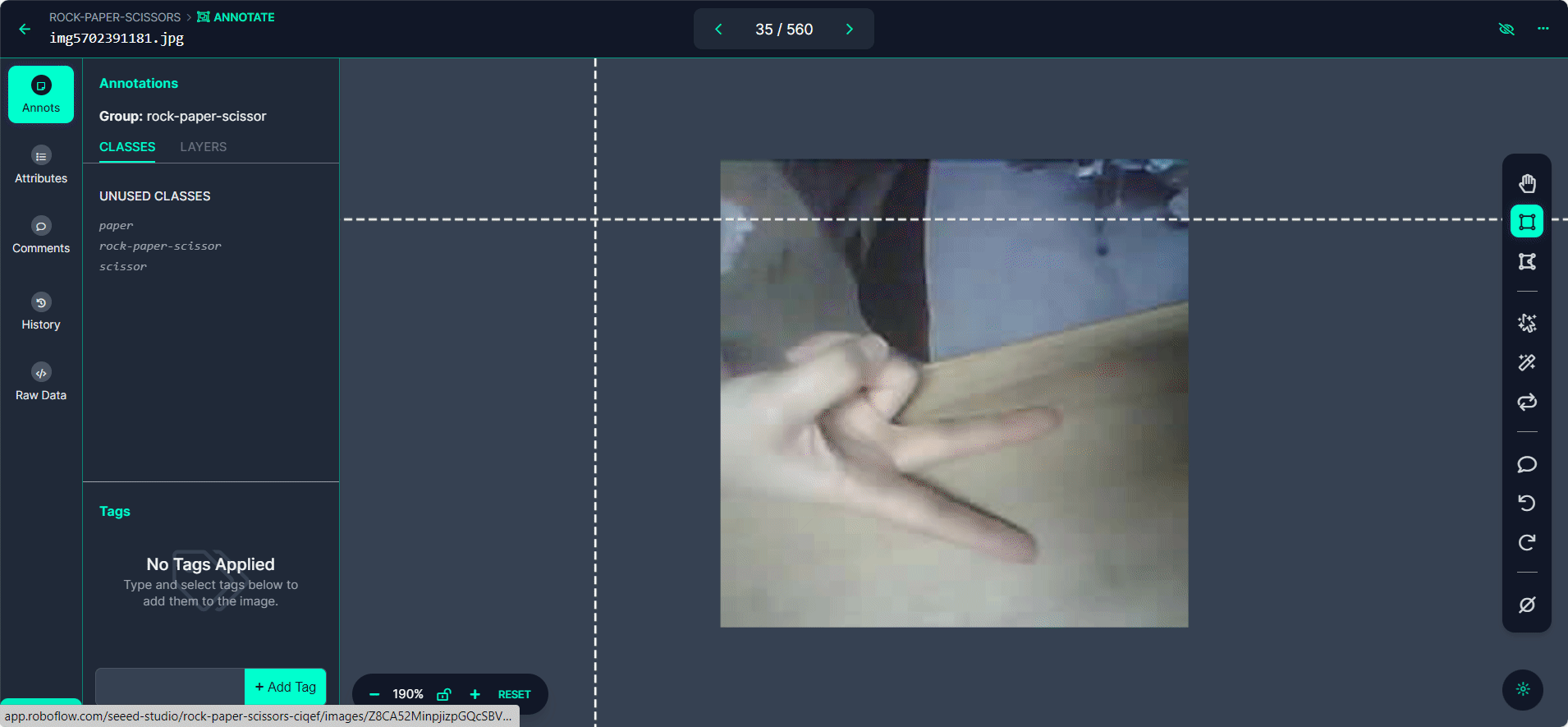
Paso 4: Revisar y Editar Anotaciones
Es esencial asegurar que las anotaciones sean precisas.
Revisa cada imagen para asegurarte de que las cajas delimitadoras estén correctamente dibujadas y etiquetadas. Si encuentras algún error, selecciona la anotación para ajustar la caja delimitadora o cambiar la etiqueta.
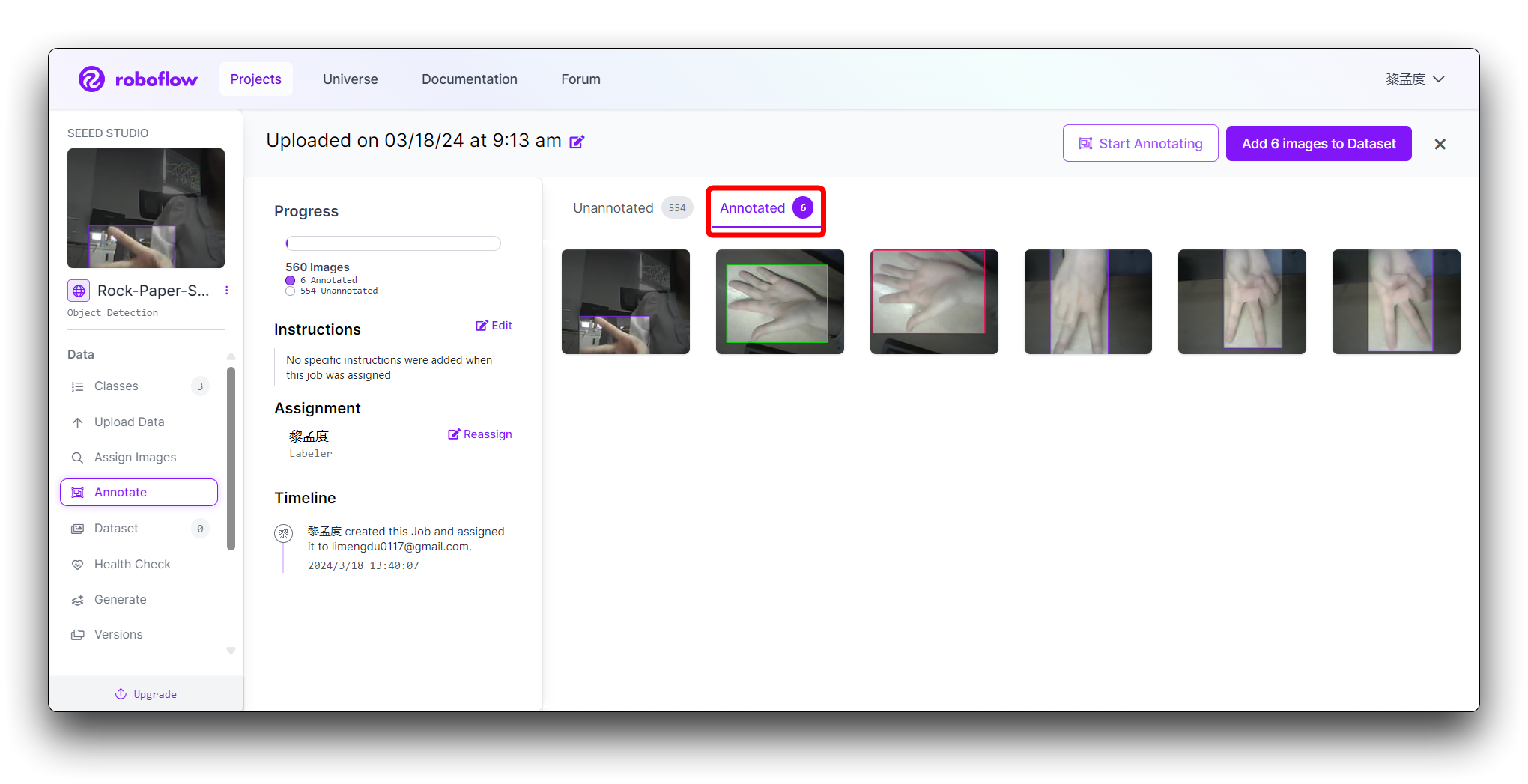
El etiquetado incorrecto afecta el rendimiento general del entrenamiento y puede descartarse si algunos conjuntos de datos no cumplen con los requisitos de etiquetado. Aquí hay algunas demostraciones de etiquetado deficiente.

Paso 5: Generar y Exportar el Conjunto de Datos
Una vez que todas las imágenes estén anotadas. En Annotate haz clic en el botón Add x images to Dataset en la esquina superior derecha.
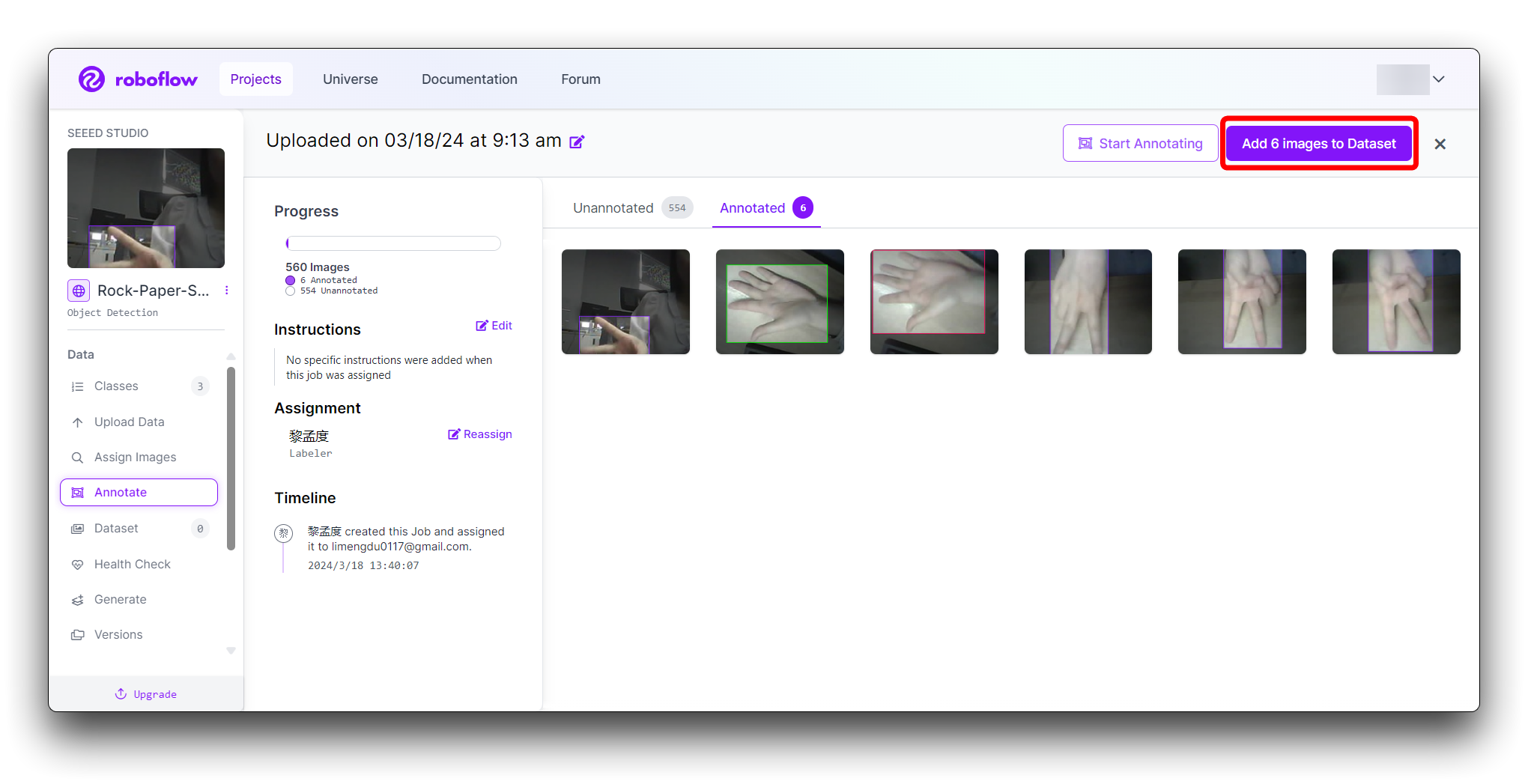
Luego haz clic en el botón Add Images en la parte inferior de la nueva ventana emergente.
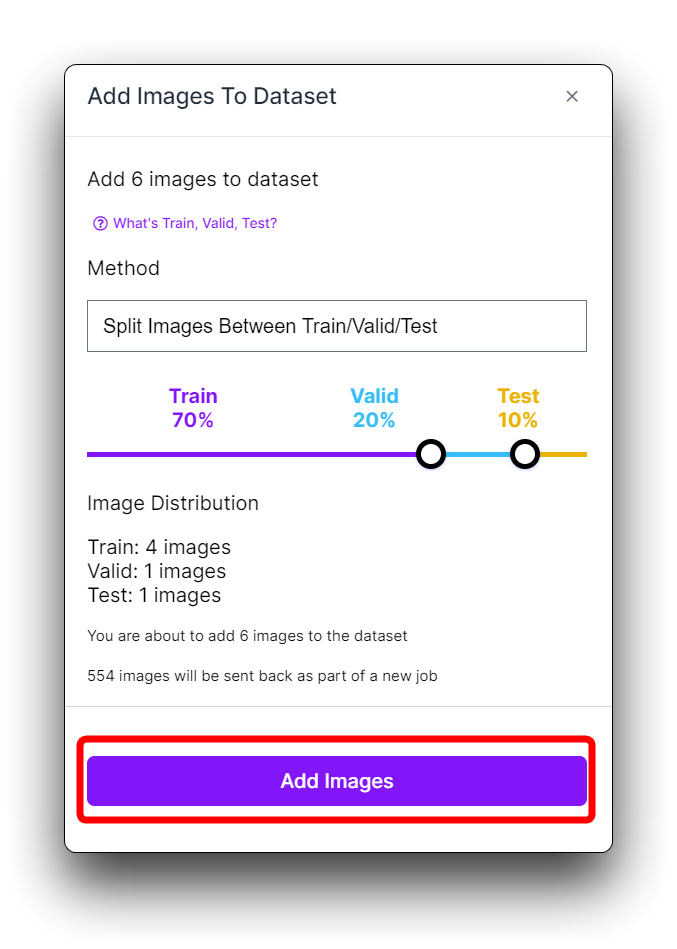
Haz clic en Generate en la barra de herramientas izquierda y haz clic en Continue en el tercer paso Preprocessing.
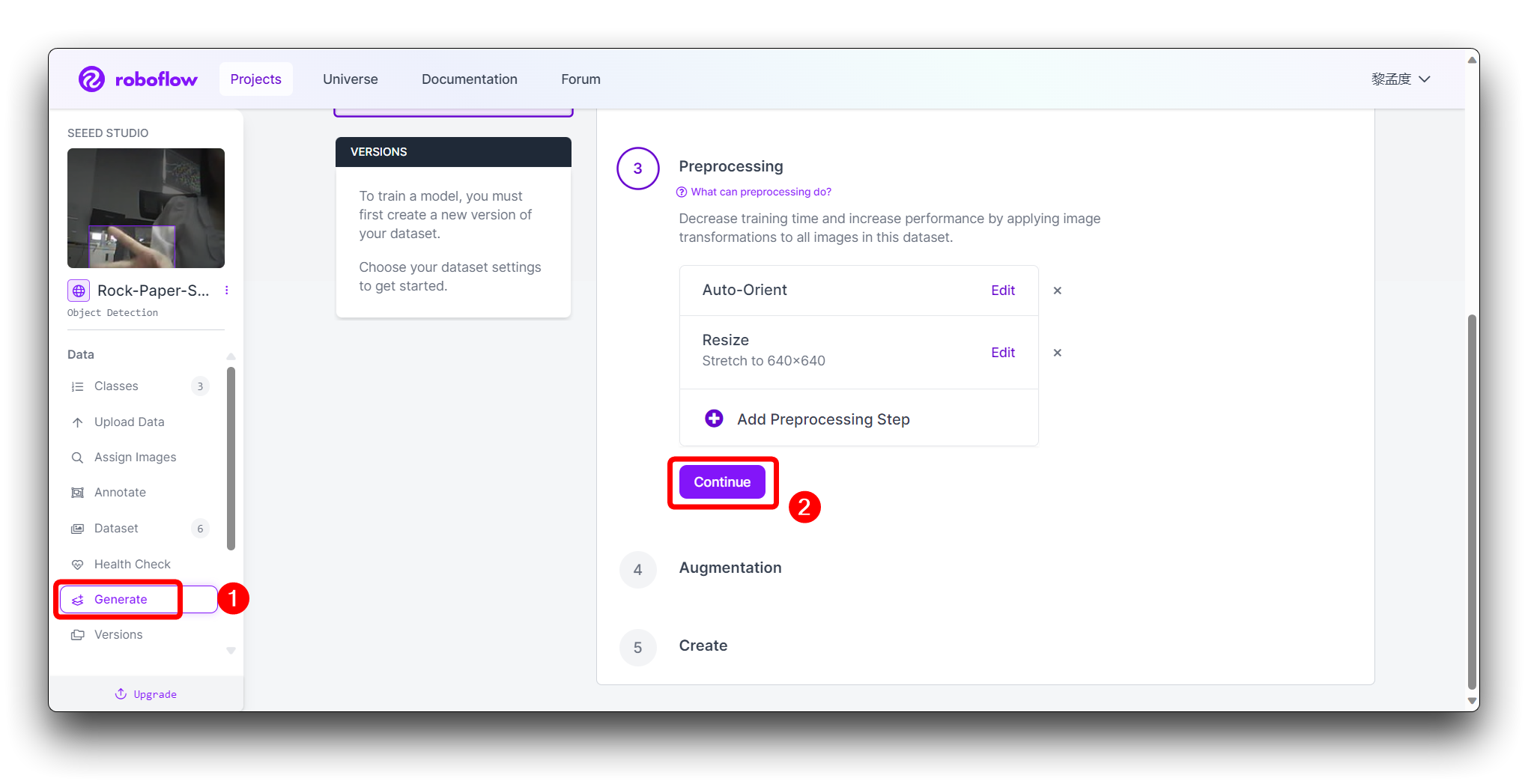
En la Augmentation en el paso 4, selecciona Mosaic, que aumenta la generalización.
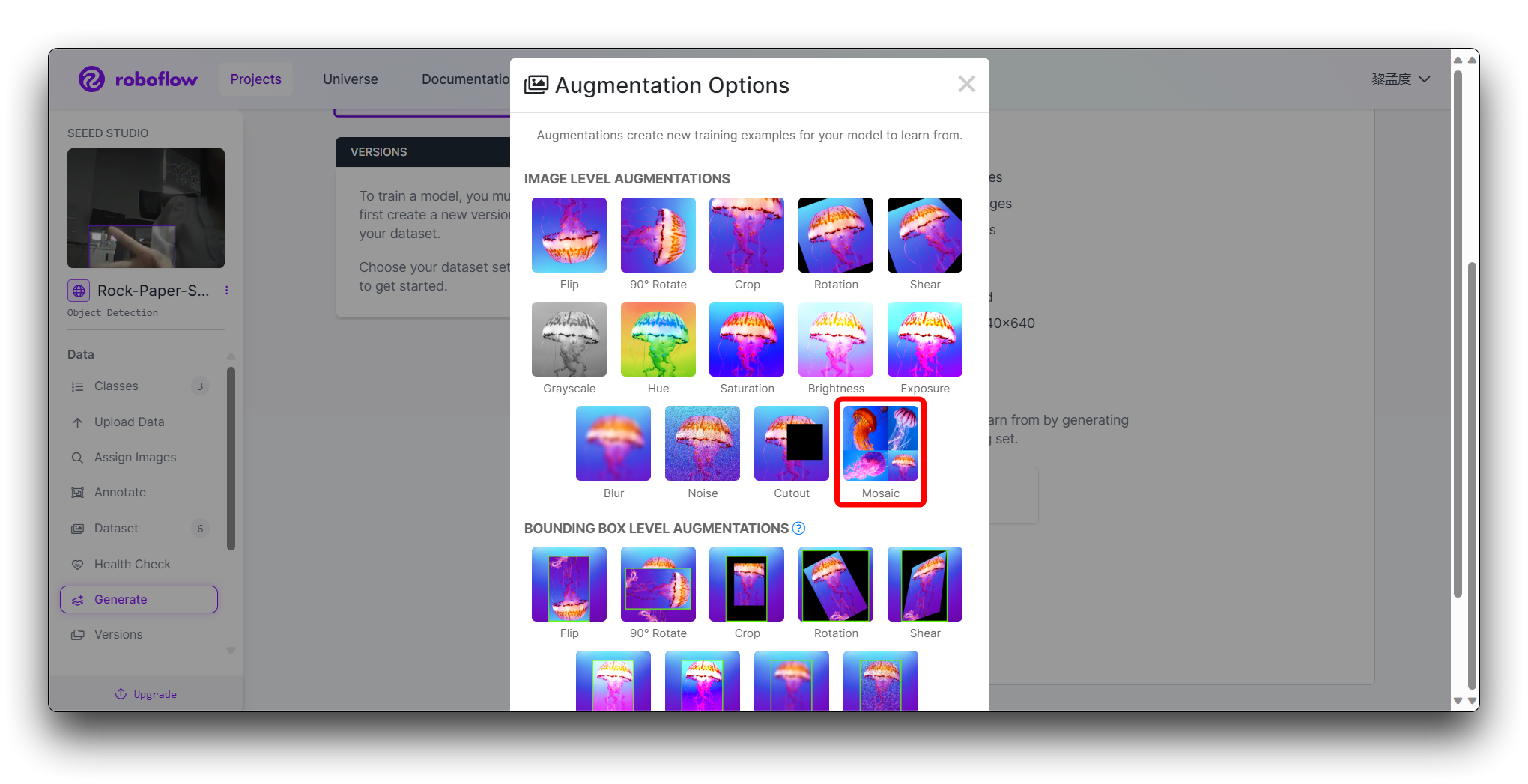
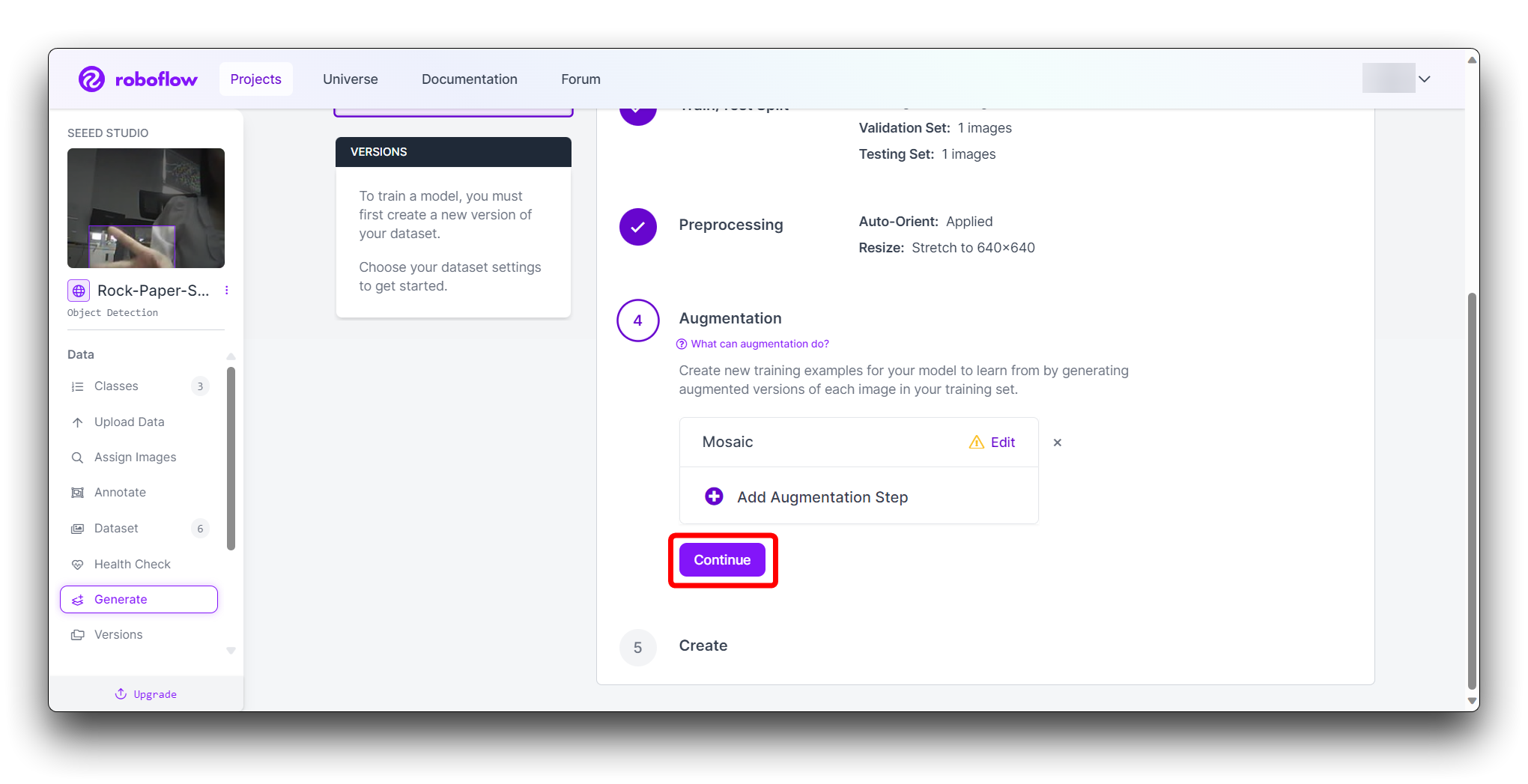
En el paso final Create, por favor calcula el número de imágenes razonablemente según el boost de Roboflow; en general, mientras más imágenes tengas, más tiempo toma entrenar el modelo. Sin embargo, tener más imágenes no necesariamente hará que el modelo sea más preciso, principalmente depende de si el conjunto de datos es lo suficientemente bueno o no.
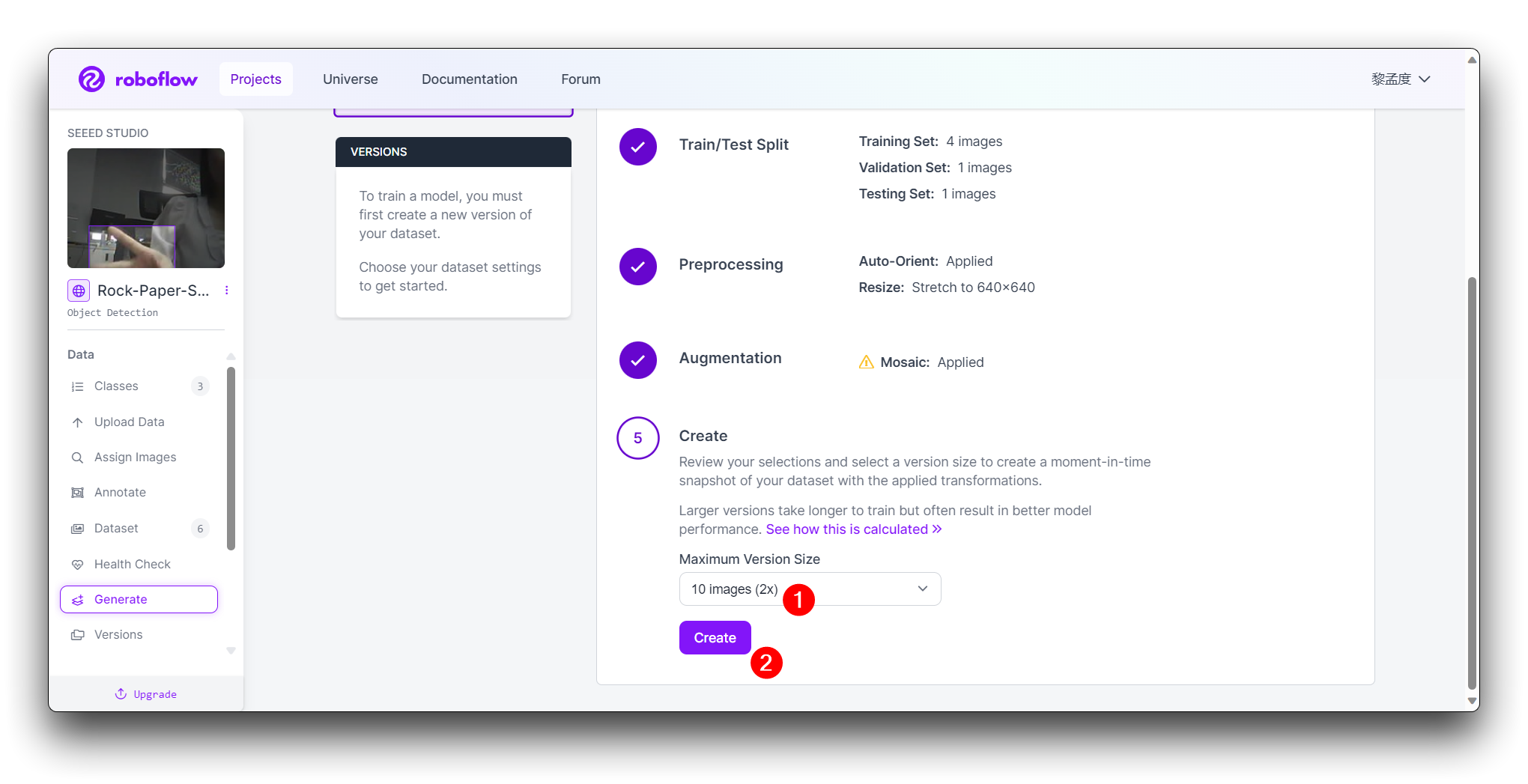
Haz clic en Create para crear una versión de tu conjunto de datos. Roboflow procesará las imágenes y anotaciones, creando un conjunto de datos versionado. Después de que se genere el conjunto de datos, haz clic en Export Dataset. Elige el formato COCO que coincida con los requisitos del modelo que vas a entrenar.
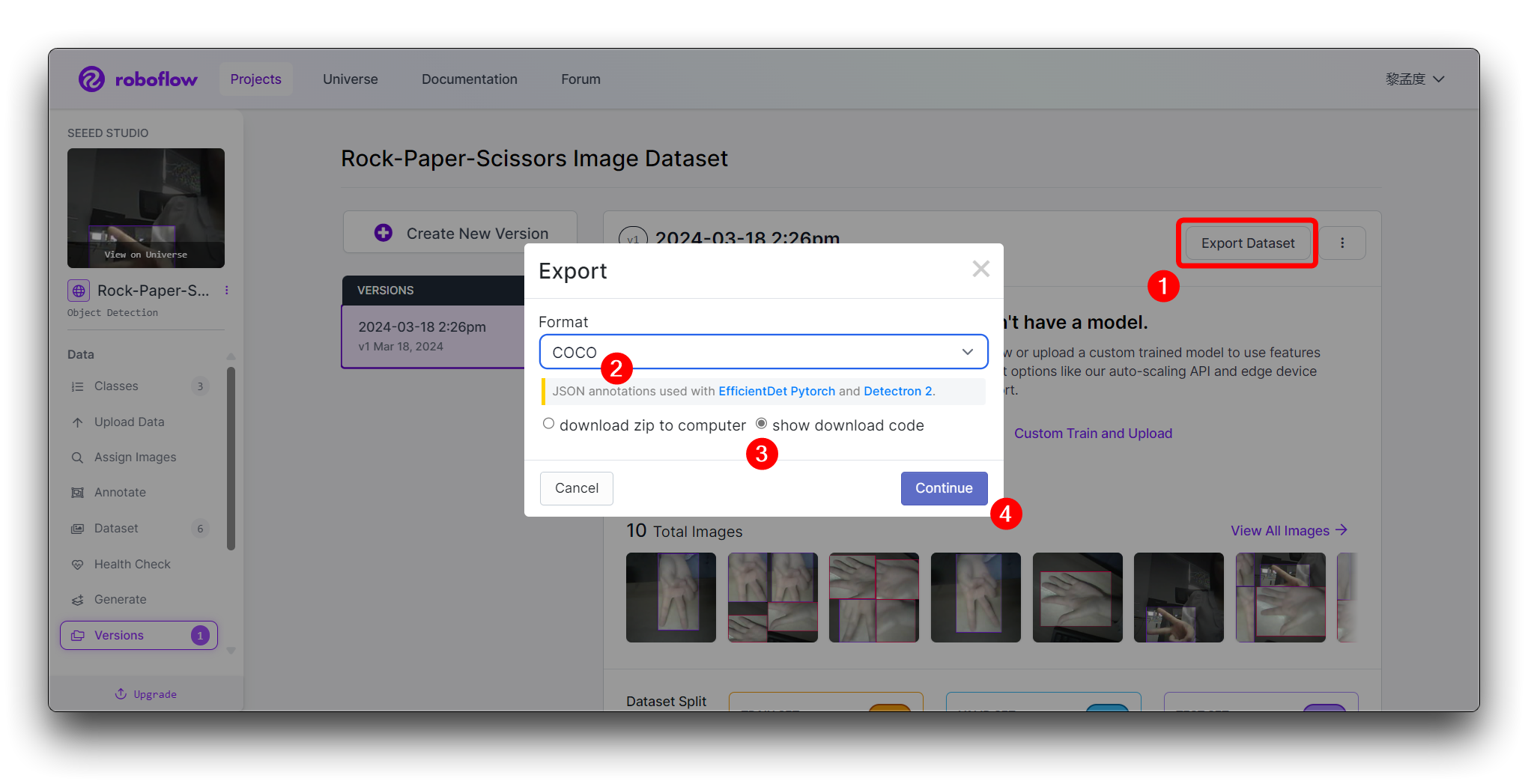
Haz clic en Continue y luego obtendrás la URL Raw para este modelo. Guárdala, usaremos el enlace en el paso de entrenamiento del modelo un poco más tarde.
¡Felicidades! Has usado exitosamente Roboflow para subir, anotar y exportar un conjunto de datos para un modelo de detección de gestos de mano de Piedra-Papel-Tijeras. Con tu conjunto de datos listo, puedes proceder a entrenar un modelo de aprendizaje automático usando plataformas como Google Colab.
Recuerda mantener tu conjunto de datos diverso y bien anotado para mejorar la precisión de tu modelo futuro. ¡Buena suerte con el entrenamiento de tu modelo, y diviértete clasificando gestos de mano con el poder de la IA!
Entrenamiento del Modelo Exportado del Conjunto de Datos
Paso 1. Acceder al Notebook de Colab
Puedes encontrar diferentes tipos de archivos de código de modelos de Google Colab en el Wiki del Asistente de Modelos de SenseCraft. Si no sabes qué código deberías elegir, puedes elegir cualquiera de ellos, dependiendo de la clase de tu modelo (detección de objetos o clasificación de imágenes).
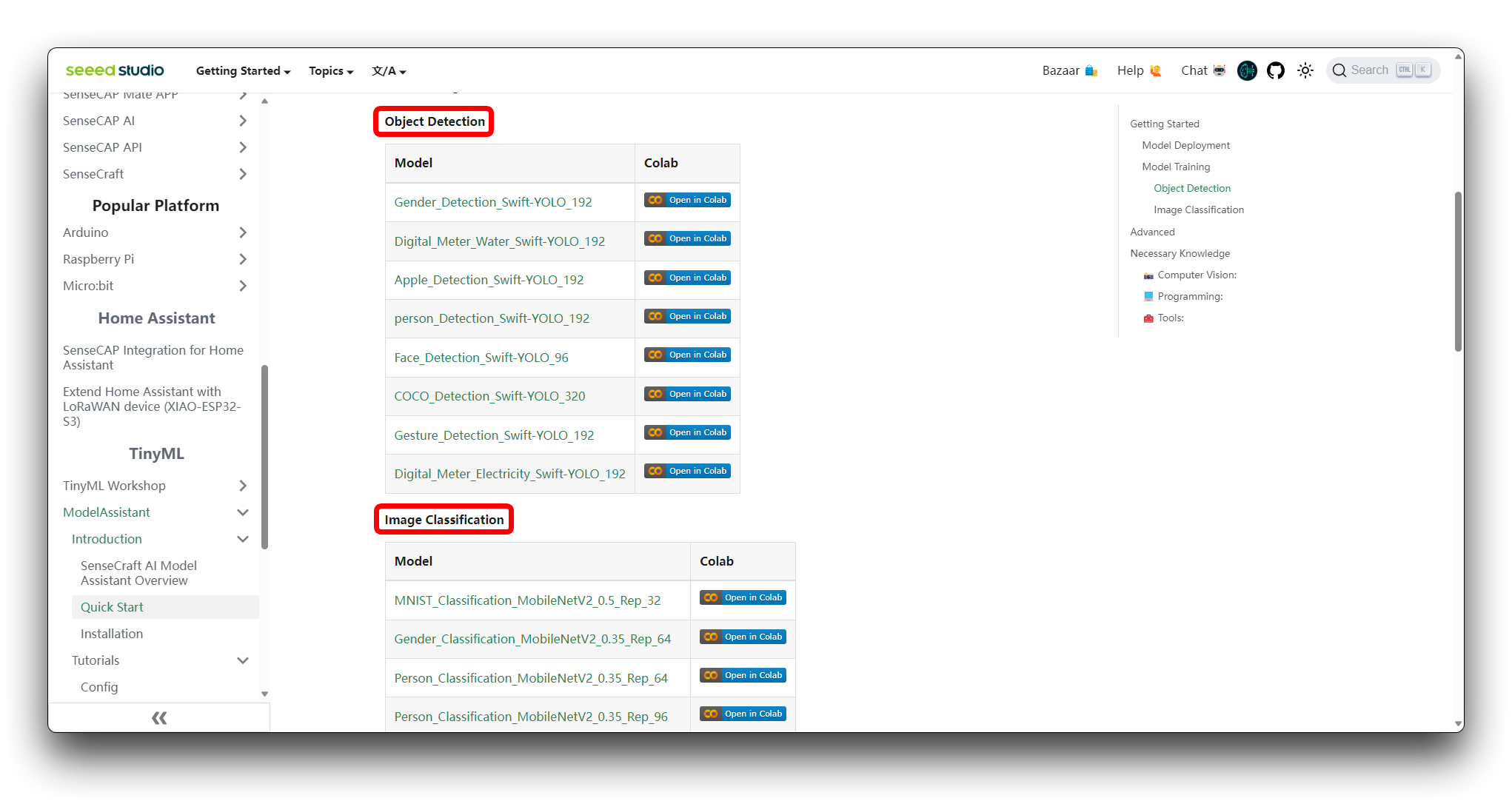
Si aún no has iniciado sesión en tu cuenta de Google, por favor inicia sesión para acceder a todas las funcionalidades de Google Colab.
Haz clic en "Connect" para asignar recursos para tu sesión de Colab.

Paso 2. Agregar tu Conjunto de Datos de Roboflow
Antes de ejecutar oficialmente el bloque de código paso a paso, necesitamos modificar el contenido del código para que el código pueda usar el conjunto de datos que preparamos. Tenemos que proporcionar una URL para descargar el conjunto de datos directamente al sistema de archivos de Colab.
Por favor encuentra la sección Download the dataset en el código. Verás el siguiente programa de ejemplo.
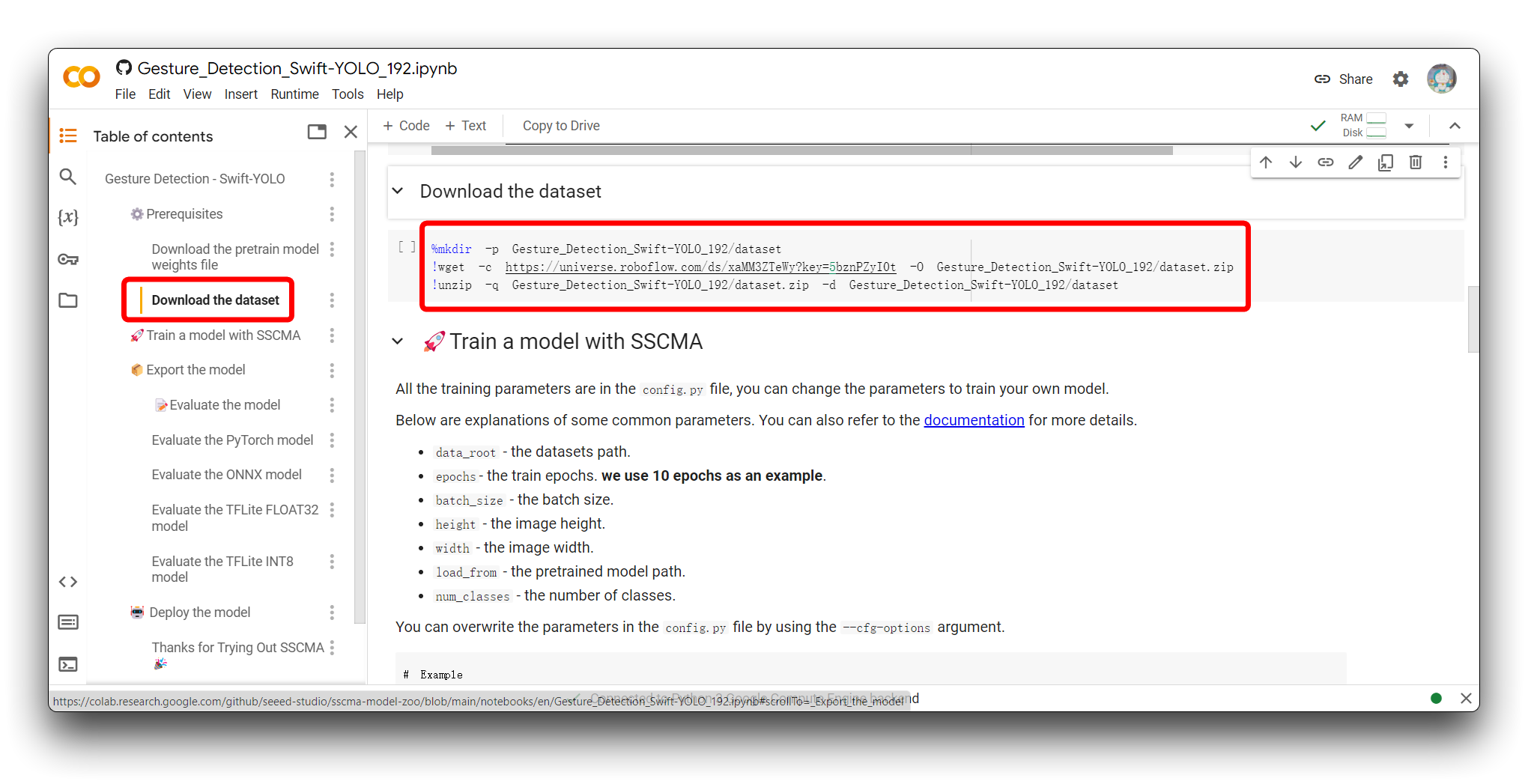
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset
Este fragmento de código se utiliza para crear un directorio, descargar un conjunto de datos desde Roboflow y descomprimirlo en el directorio recién creado dentro de un entorno de Google Colab. Aquí tienes un desglose de lo que hace cada línea:
-
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset:- Esta línea crea un nuevo directorio llamado
Gesture_Detection_Swift-YOLO_192y un subdirectorio llamadodataset. La bandera-pasegura que el comando no devuelva un error si el directorio ya existe y crea cualquier directorio padre necesario.
- Esta línea crea un nuevo directorio llamado
-
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip:- Esta línea utiliza
wget, una utilidad de línea de comandos, para descargar el conjunto de datos desde la URL de Roboflow proporcionada. La bandera-cpermite que la descarga se reanude si se interrumpe. La bandera-Oespecifica la ubicación de salida y el nombre de archivo para el archivo descargado, en este caso,Gesture_Detection_Swift-YOLO_192/dataset.zip.
- Esta línea utiliza
-
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset:- Esta línea utiliza el comando
unzippara extraer el contenido del archivodataset.zipen el directoriodatasetque se creó anteriormente. La bandera-qejecuta el comandounzipen modo silencioso, suprimiendo la mayoría de los mensajes de salida.
- Esta línea utiliza el comando
Para personalizar este código para tu propio enlace de modelo desde Roboflow:
-
Reemplaza
Gesture_Detection_Swift-YOLO_192con el nombre de directorio deseado donde quieras almacenar tu conjunto de datos. -
Reemplaza la URL del conjunto de datos de Roboflow (
https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t) con el enlace a tu conjunto de datos exportado (Es la URL Raw que obtuvimos en el último paso en Conjuntos de Datos Etiquetados). Asegúrate de incluir el parámetro key si es requerido para el acceso. -
Ajusta el nombre de archivo de salida en el comando
wgetsi es necesario (-O tu_directorio/tu_nombre_archivo.zip). -
Asegúrate de que el directorio de salida en el comando
unzipcoincida con el directorio que creaste y el nombre de archivo coincida con el que estableciste en el comandowget.
Si cambias el nombre de un directorio de carpeta Gesture_Detection_Swift-YOLO_192, ten en cuenta que necesitarás hacer cambios a otros nombres de directorio en el código que se usaron antes del cambio, ¡de lo contrario puede ocurrir un error!
Paso 3. Ajuste de parámetros del modelo
El siguiente paso es ajustar los parámetros de entrada del modelo. Por favor ve a la sección Entrenar un modelo con SSCMA y verás el siguiente fragmento de código.
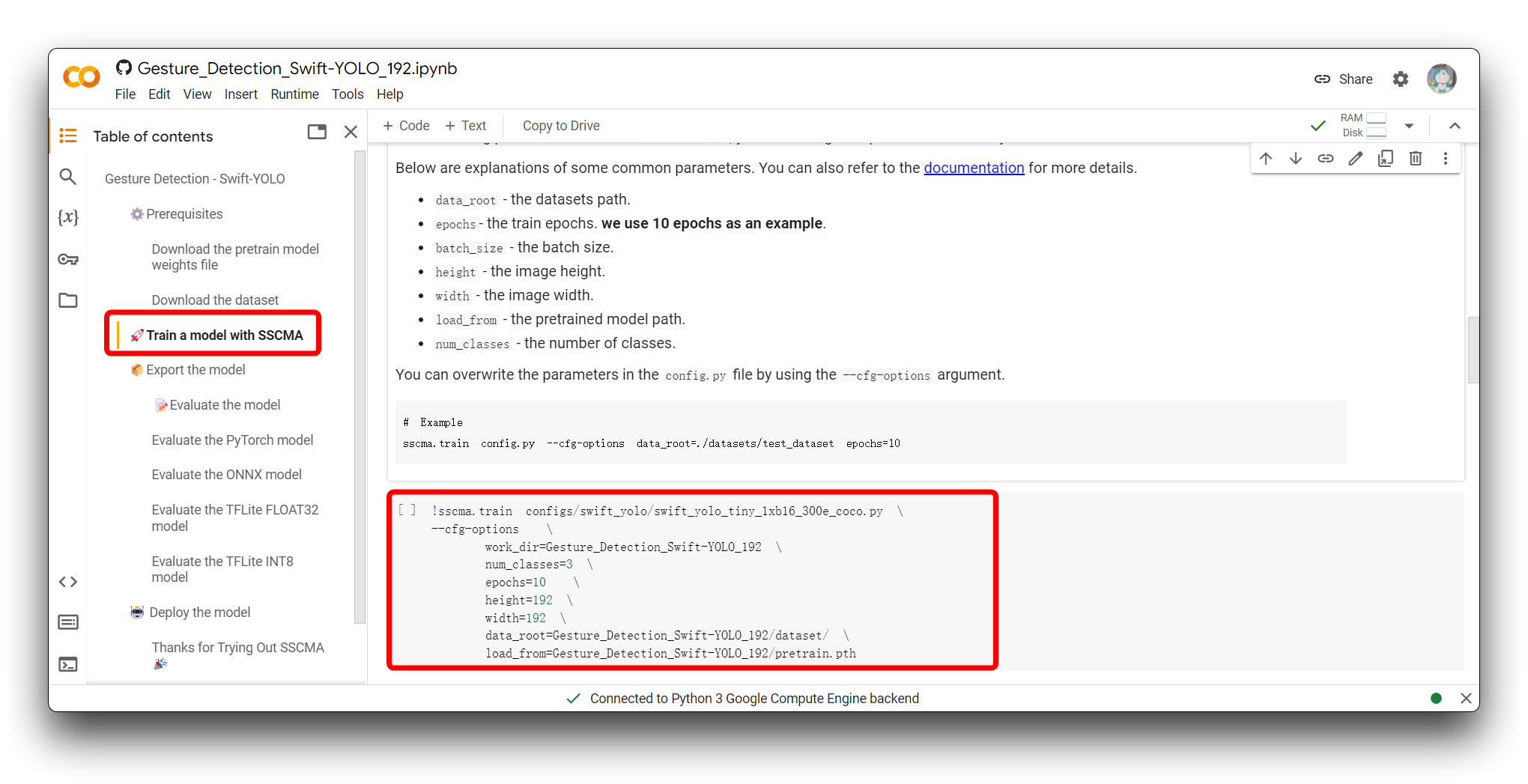
!sscma.train configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \
--cfg-options \
work_dir=Gesture_Detection_Swift-YOLO_192 \
num_classes=3 \
epochs=10 \
height=192 \
width=192 \
data_root=Gesture_Detection_Swift-YOLO_192/dataset/ \
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pth
Este comando se utiliza para iniciar el proceso de entrenamiento de un modelo de aprendizaje automático, específicamente un modelo YOLO (You Only Look Once), usando el framework SSCMA (Seeed Studio SenseCraft Model Assistant). El comando incluye varias opciones para configurar el proceso de entrenamiento. Esto es lo que hace cada parte:
-
!sscma.traines el comando para iniciar el entrenamiento dentro del framework SSCMA. -
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pyespecifica el archivo de configuración para el entrenamiento, que incluye configuraciones como la arquitectura del modelo, el cronograma de entrenamiento, las estrategias de aumento de datos, etc. -
--cfg-optionste permite sobrescribir las configuraciones predeterminadas especificadas en el archivo.pycon las que proporciones en la línea de comandos. -
work_dir=Gesture_Detection_Swift-YOLO_192establece el directorio donde se almacenarán las salidas del entrenamiento, como los registros y los puntos de control del modelo guardado. -
num_classes=3especifica el número de clases que el modelo debe ser entrenado para reconocer. Depende del número de etiquetas que tengas, por ejemplo piedra, papel, tijeras deberían ser tres etiquetas. -
epochs=10establece el número de ciclos de entrenamiento (épocas) a ejecutar. Los valores recomendados están entre 50 y 100. -
height=192ywidth=192establecen la altura y el ancho de las imágenes de entrada que el modelo espera.
Realmente no recomendamos que cambies el tamaño de imagen en el código de Colab, ya que este valor es un tamaño de conjunto de datos más apropiado que hemos verificado que es una combinación de tamaño, precisión y velocidad de inferencia. Si estás usando un conjunto de datos que no es de este tamaño, y puedes querer considerar cambiar el tamaño de imagen para asegurar la precisión, entonces por favor no excedas 240x240.
-
data_root=Gesture_Detection_Swift-YOLO_192/dataset/define la ruta al directorio donde se encuentran los datos de entrenamiento. -
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pthproporciona la ruta a un archivo de punto de control de modelo preentrenado desde el cual el entrenamiento debe reanudarse o usar como punto de partida para el aprendizaje por transferencia.
Para personalizar este comando para tu propio entrenamiento, deberías:
-
Reemplazar
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pycon la ruta a tu propio archivo de configuración si tienes uno personalizado. -
Cambiar
work_diral directorio donde quieres que se guarden las salidas de tu entrenamiento. -
Actualizar
num_classespara que coincida con el número de clases en tu propio conjunto de datos. Depende del número de etiquetas que tengas, por ejemplo piedra, papel, tijeras deberían ser tres etiquetas. -
Ajustar
epochsal número deseado de épocas de entrenamiento para tu modelo. Los valores recomendados están entre 50 y 100. -
Establecer
heightywidthpara que coincidan con las dimensiones de las imágenes de entrada para tu modelo. -
Cambiar
data_rootpara que apunte al directorio raíz de tu conjunto de datos. -
Si tienes un archivo de modelo preentrenado diferente, actualiza la ruta
load_fromen consecuencia.
Paso 4. Ejecutar el código de Google Colab
La forma de ejecutar el bloque de código es hacer clic en el botón de reproducción en la esquina superior izquierda del bloque de código.
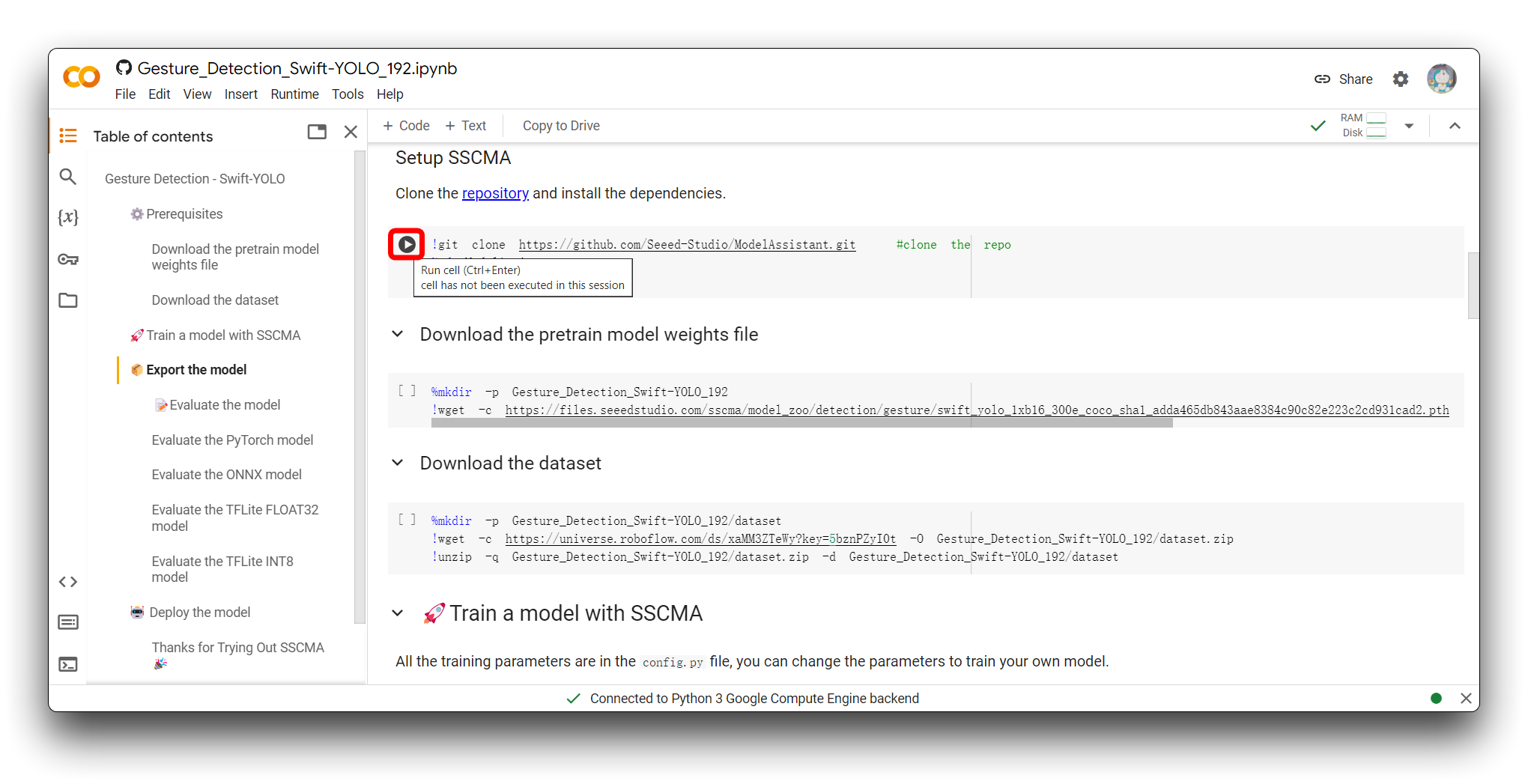
El bloque de código se ejecutará después de que hagas clic en el botón, y si todo va bien, verás la señal de que la ejecución del bloque de código está completa - aparece un símbolo de marca de verificación a la izquierda del bloque. Como se muestra en la figura es el efecto después de que se complete la ejecución del primer bloque de código.
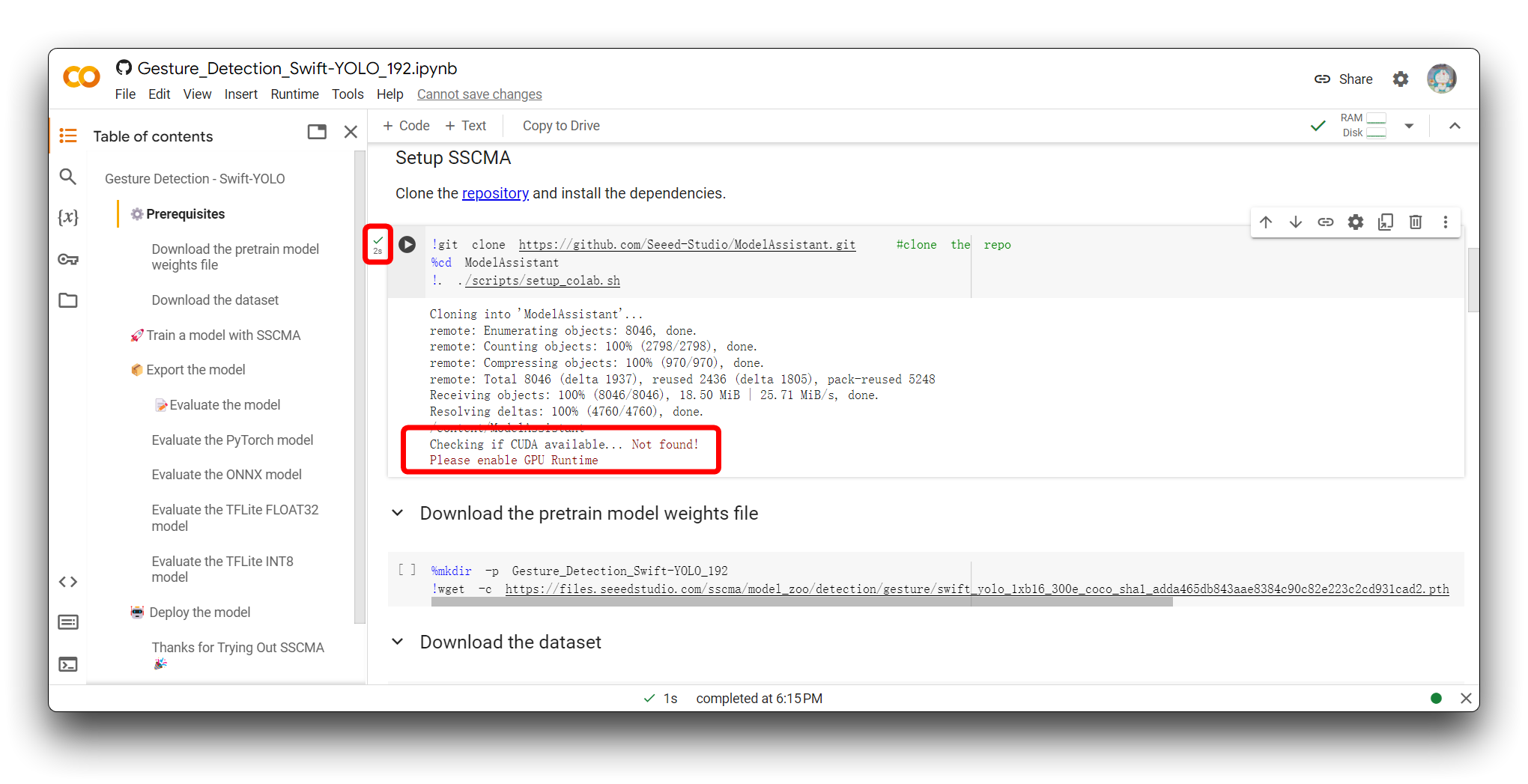
Si encuentras el mismo mensaje de error que el mío en la imagen de arriba, por favor verifica que estés usando una GPU T4, por favor no uses CPU para este proyecto.
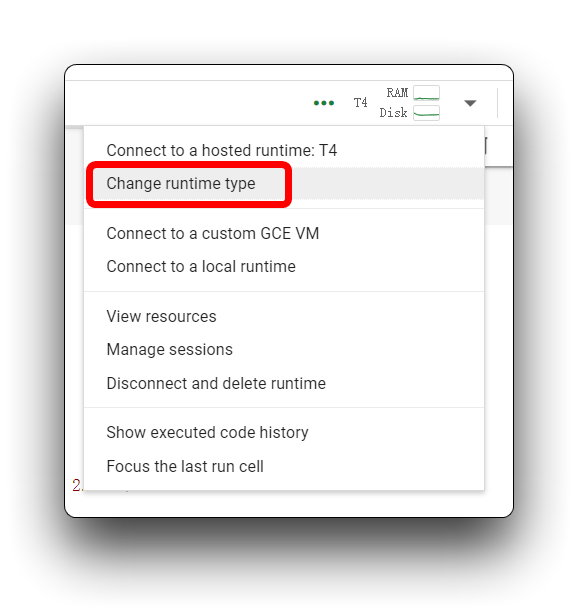
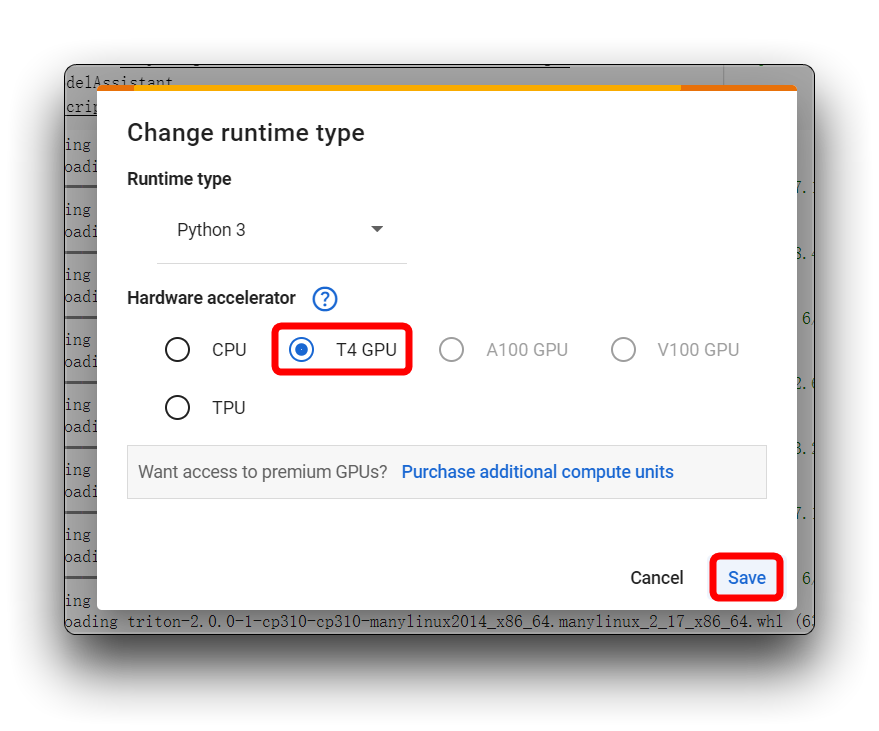
Luego, vuelve a ejecutar el bloque de código. Para el primer bloque de código, si todo va bien, verás el resultado mostrado a continuación.
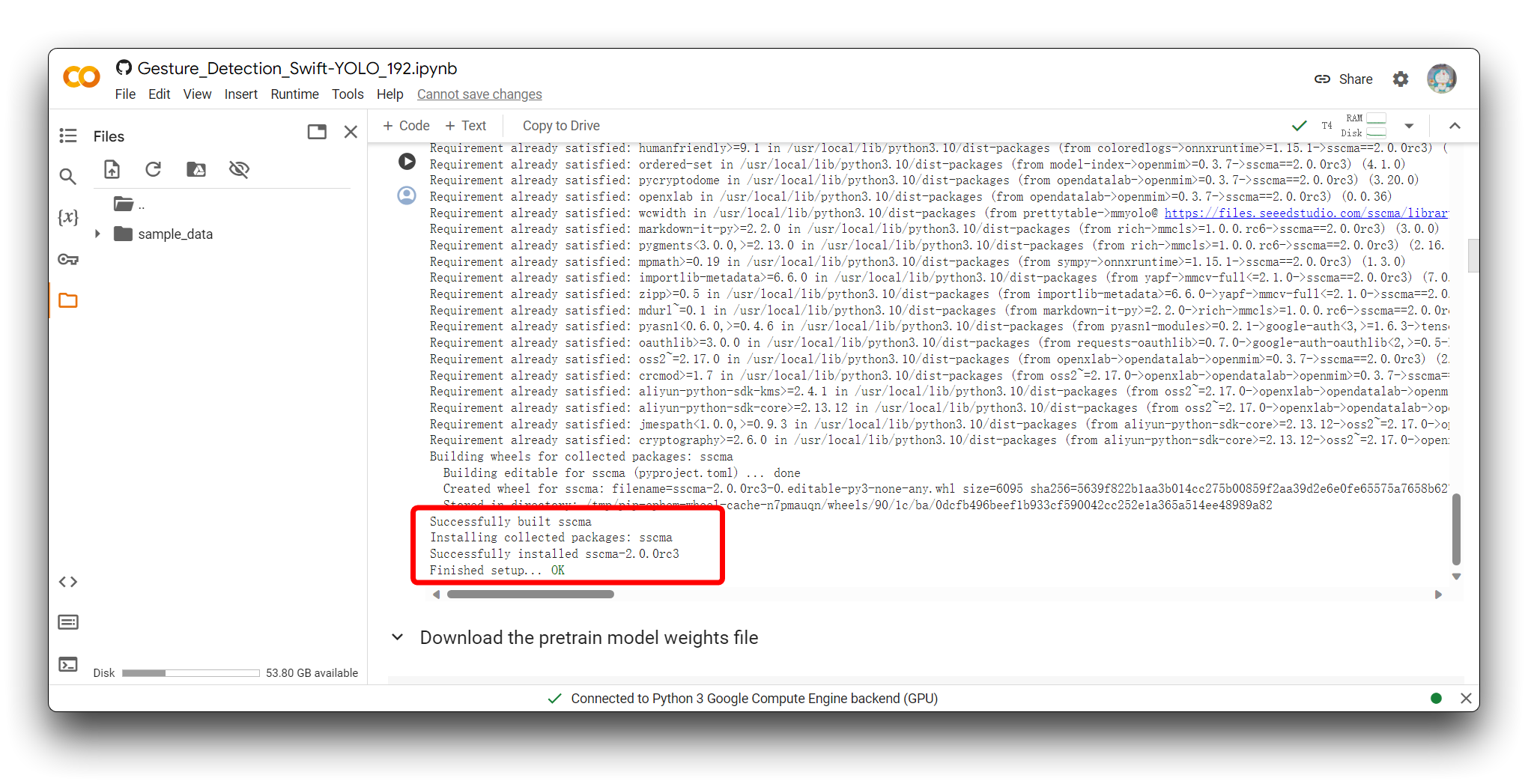
A continuación, ejecuta todos los bloques de código desde Download the pretrain model weights file hasta Export the model. Y por favor asegúrate de que cada bloque de código esté libre de errores.
Las advertencias que aparecen en el código pueden ser ignoradas.
Paso 5. Evaluar el modelo
Cuando llegues a la sección Evaluate the model, tienes la opción de ejecutar el bloque de código Evaluate the TFLite INT8 model.
Evaluar el modelo TFLite INT8 implica probar las predicciones del modelo cuantizado contra un conjunto de datos de prueba separado para medir su precisión y métricas de rendimiento, evaluar el impacto de la cuantización en la precisión del modelo, y perfilar su velocidad de inferencia y uso de recursos para asegurar que cumple con las restricciones de despliegue para dispositivos de borde.
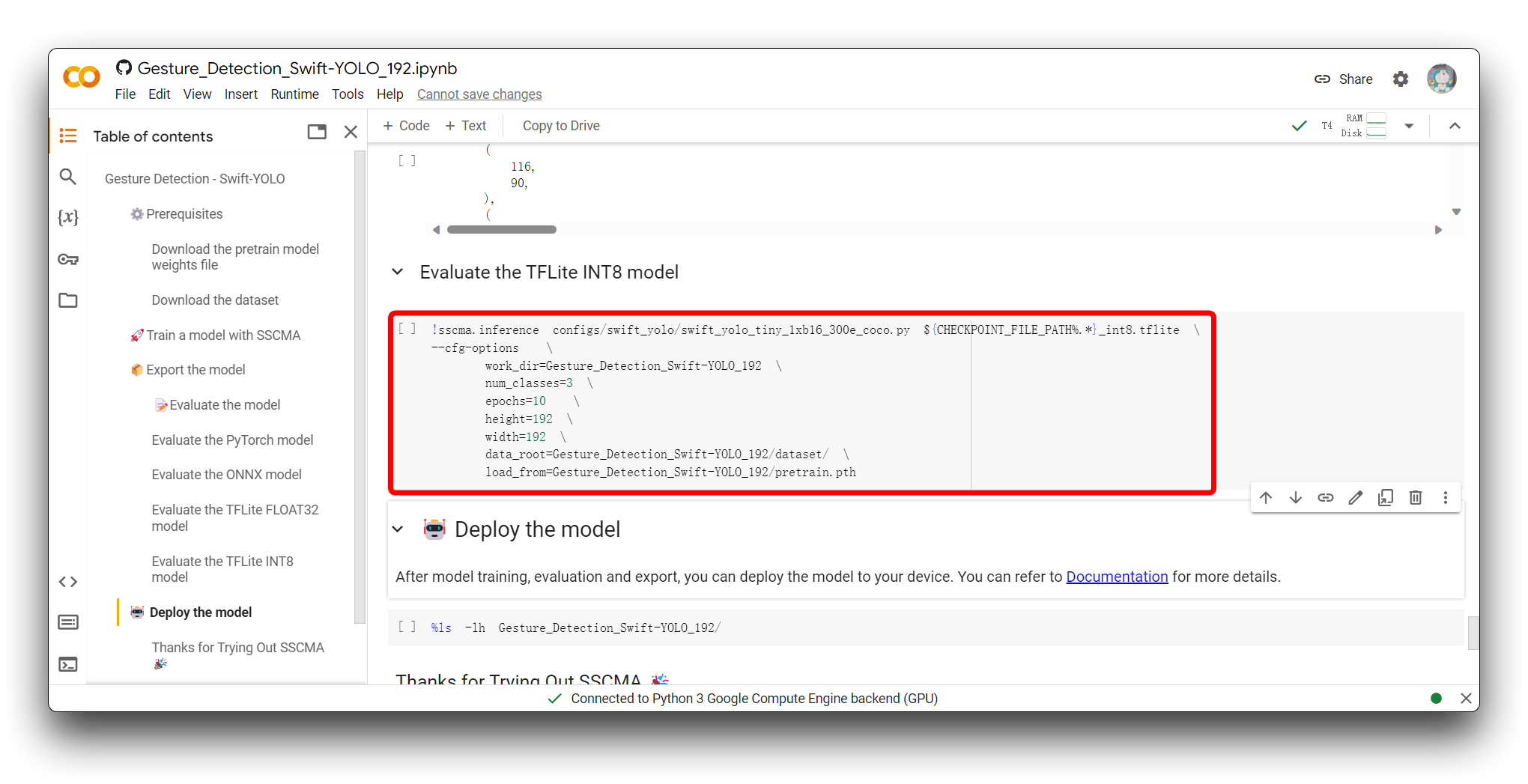
El siguiente fragmento es la parte válida del resultado después de que ejecuté este bloque de código.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.450
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.929
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.474
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.536
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.537
03/19 01:38:43 - mmengine - INFO - bbox_mAP_copypaste: 0.450 0.929 0.361 -1.000 0.474 0.456
{'coco/bbox_mAP': 0.45, 'coco/bbox_mAP_50': 0.929, 'coco/bbox_mAP_75': 0.361, 'coco/bbox_mAP_s': -1.0, 'coco/bbox_mAP_m': 0.474, 'coco/bbox_mAP_l': 0.456}
FPS: 128.350449 fram/s
Los resultados de evaluación incluyen una serie de métricas de Precisión Promedio (AP) y Recuperación Promedio (AR), calculadas para diferentes umbrales de Intersección sobre Unión (IoU) y tamaños de objetos, que se utilizan comúnmente para evaluar el rendimiento de modelos de detección de objetos.
-
AP@[IoU=0.50:0.95 | area=all | maxDets=100] = 0.450
- Esta puntuación es la precisión promedio del modelo a través de un rango de umbrales IoU desde 0.50 hasta 0.95, incrementado en 0.05. Un AP de 0.450 indica que tu modelo tiene una precisión moderada a través de este rango. Esta es una métrica clave comúnmente utilizada para el conjunto de datos COCO.
-
AP@[IoU=0.50 | area=all | maxDets=100] = 0.929
- Con un umbral IoU de 0.50, el modelo logra una alta precisión promedio de 0.929, sugiriendo que detecta objetos muy precisamente bajo un criterio de coincidencia más permisivo.
-
AP@[IoU=0.75 | area=all | maxDets=100] = 0.361
- Con un umbral IoU más estricto de 0.75, la precisión promedio del modelo baja a 0.361, indicando una disminución en el rendimiento bajo criterios de coincidencia más estrictos.
-
AP@[IoU=0.50:0.95 | area=small/medium/large | maxDets=100]
- Las puntuaciones AP varían para objetos de diferentes tamaños. Sin embargo, el AP para objetos pequeños es -1.000, lo que podría indicar una falta de datos de evaluación para objetos pequeños o un rendimiento pobre del modelo en la detección de objetos pequeños. Las puntuaciones AP para objetos medianos y grandes son 0.474 y 0.456, respectivamente, sugiriendo que el modelo detecta objetos medianos y grandes relativamente mejor.
-
AR@[IoU=0.50:0.95 | area=all | maxDets=1/10/100]
- Las tasas de recuperación promedio para diferentes valores de
maxDetsson bastante consistentes, variando desde 0.515 hasta 0.529, indicando que el modelo recupera confiablemente la mayoría de las instancias verdaderas positivas.
- Las tasas de recuperación promedio para diferentes valores de
-
FPS: 128.350449 fram/s
- El modelo procesa imágenes a una velocidad muy rápida de aproximadamente 128.35 cuadros por segundo durante la inferencia, indicando potencial para aplicaciones en tiempo real o casi en tiempo real.
En general, el modelo se desempeña excelentemente con un IoU de 0.50 y moderadamente con un IoU de 0.75. Se desempeña mejor en la detección de objetos medianos y grandes pero puede tener problemas detectando objetos pequeños. Adicionalmente, el modelo infiere a alta velocidad, haciéndolo adecuado para escenarios que requieren procesamiento rápido. Si detectar objetos pequeños es crítico en una aplicación, podríamos necesitar optimizar más el modelo o recopilar más datos de objetos pequeños para mejorar el rendimiento.
Paso 6. Descargar el archivo del modelo exportado
Después de la sección Export the model, obtendrás los archivos del modelo en varios formatos, que se almacenarán en la carpeta ModelAssistant por defecto. En este tutorial, el directorio almacenado es Gesture_Detection_Swift_YOLO_192.
A veces Google Colab no actualiza automáticamente el contenido de una carpeta. En este caso puede que necesites actualizar el directorio de archivos haciendo clic en el ícono de actualización en la esquina superior izquierda.
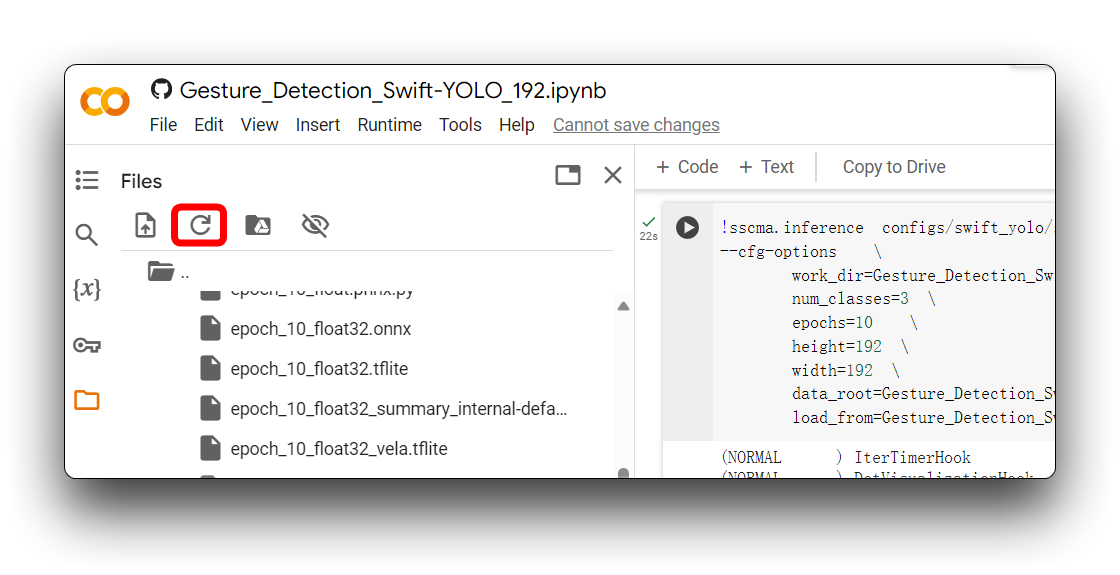
En el directorio anterior, los archivos del modelo .tflite están disponibles para XIAO ESP32S3 y Grove Vision AI V2. Para XIAO ESP32S3 Sense, asegúrate de seleccionar el archivo del modelo que usa el formato xxx_int8.tflite. Ningún otro formato puede ser usado por XIAO ESP32S3 Sense.
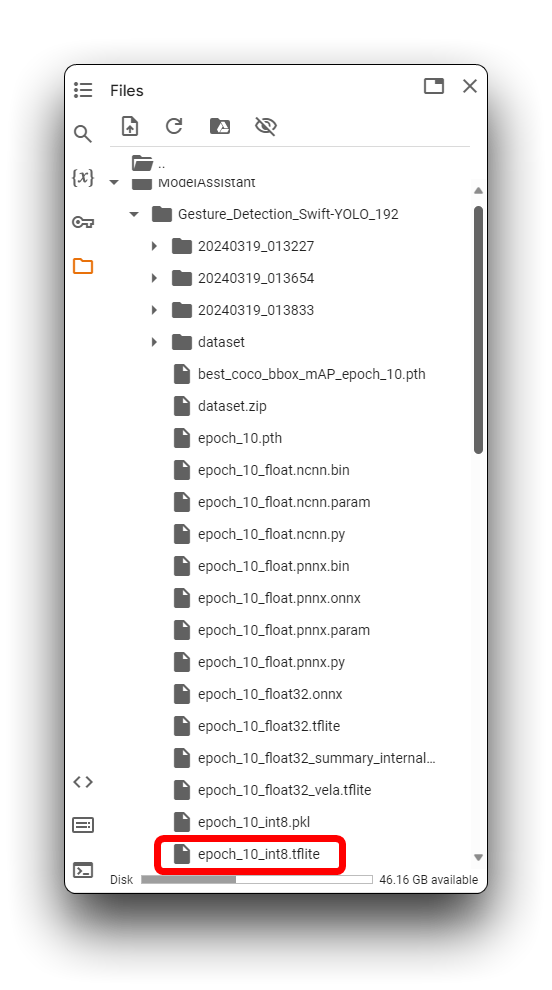
Una vez que hayas encontrado los archivos del modelo, por favor descárgalos localmente a tu computadora tan pronto como sea posible, ¡Google Colab puede vaciar tu directorio de almacenamiento si permaneces inactivo por mucho tiempo!
Así que con los pasos realizados aquí, hemos exportado exitosamente archivos de modelo que pueden ser soportados por XIAO ESP32S3, a continuación vamos a desplegar el modelo al dispositivo.
Subir modelos a través de SenseCraft Model Assistant
Paso 7. Subir modelo personalizado a XIAO ESP32S3
A continuación, llegamos a la página de Model Assistant.
Por favor conecta el dispositivo después de seleccionar XIAO ESP32S3 y luego selecciona Upload Custom AI Model en la parte inferior de la página.
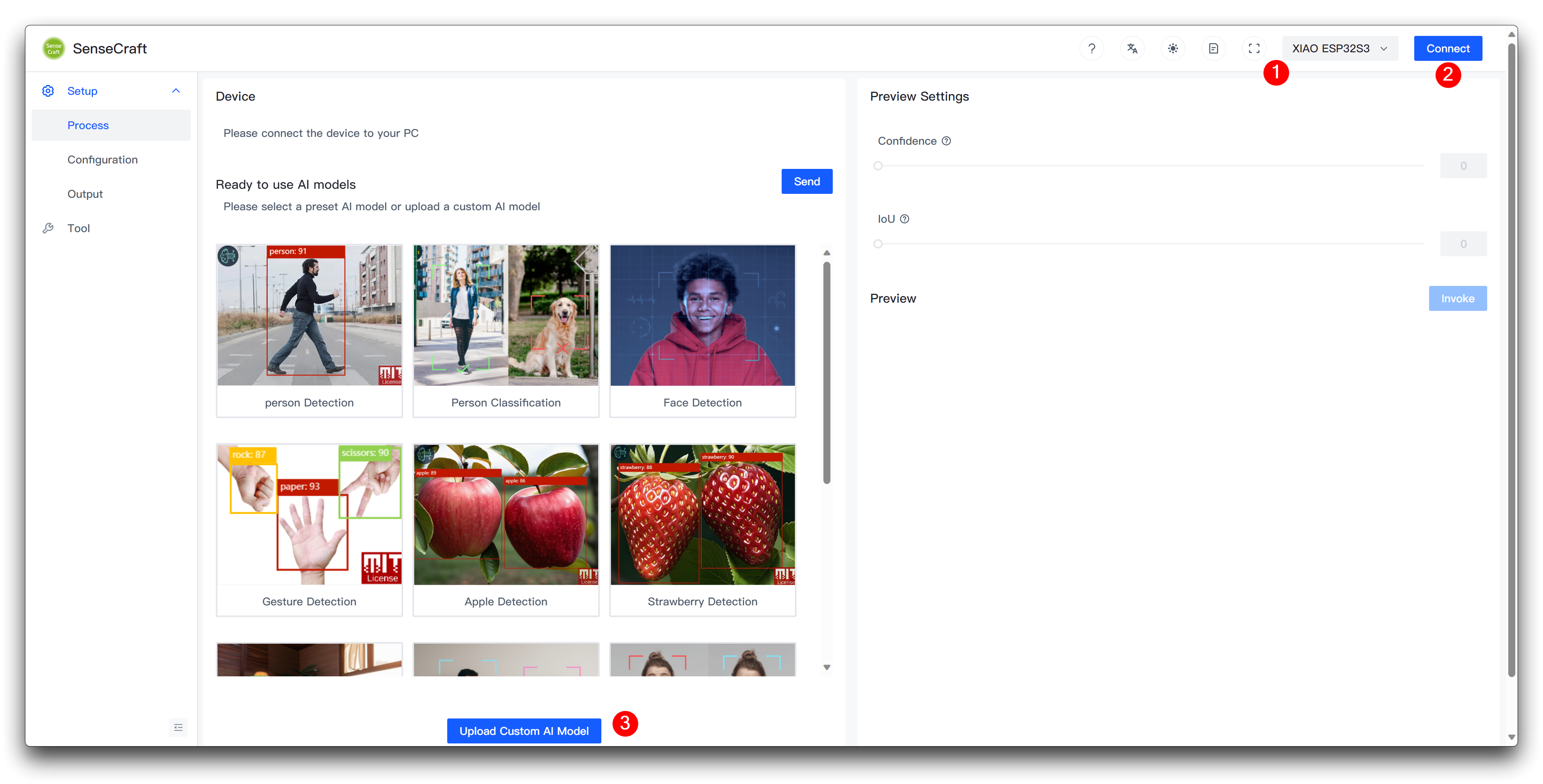
Entonces necesitarás preparar el nombre del modelo, el archivo del modelo y las etiquetas. Quiero destacar aquí cómo se determina este elemento del ID de etiqueta.
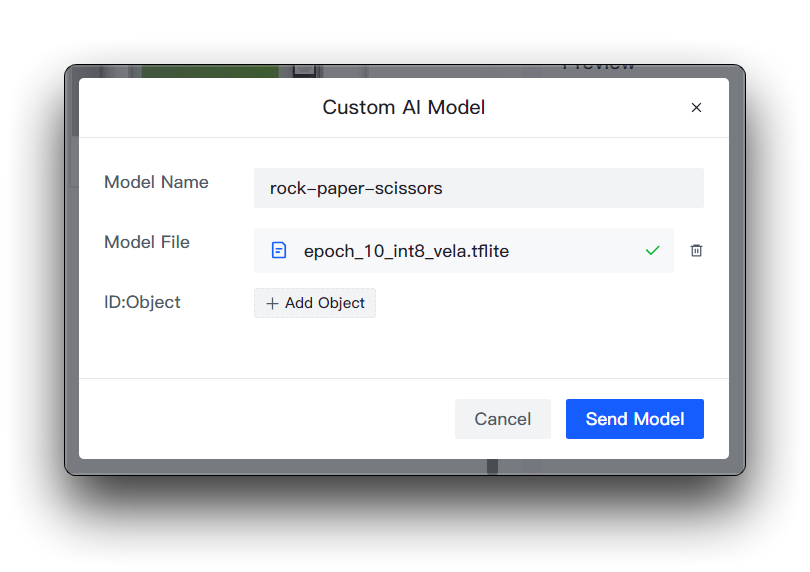
Si estás descargando el conjunto de datos de Roboflow directamente
Si descargaste el conjunto de datos de Roboflow directamente, entonces puedes ver las diferentes categorías y su orden en la página de Health Check. Solo sigue el orden ingresado aquí.
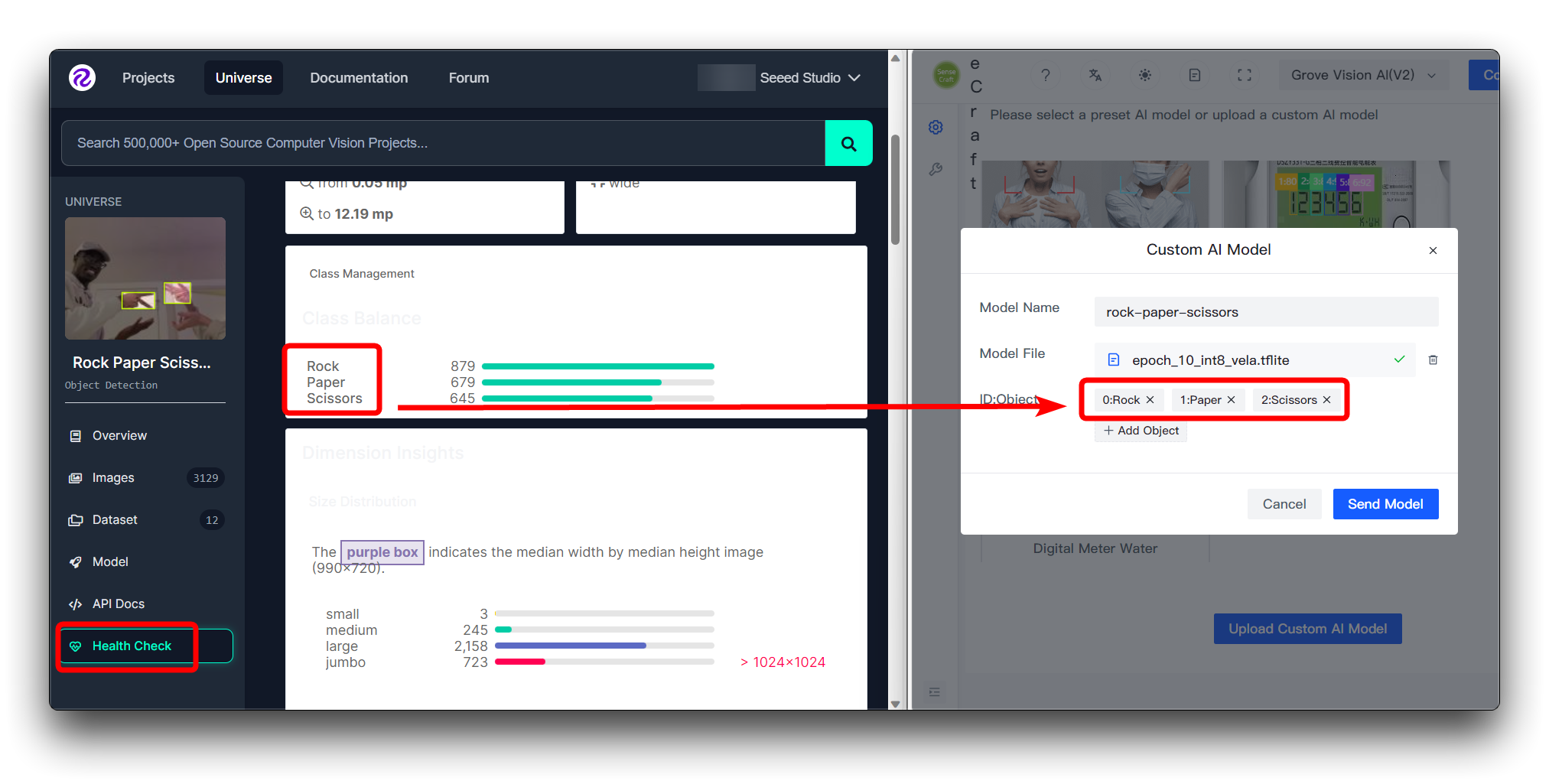
No necesitas llenar los números en ID:Object, solo llena el nombre de la categoría directamente, los números y dos puntos delante de las categorías en la imagen se añaden automáticamente.
Si estás usando un conjunto de datos personalizado
Si estás usando un conjunto de datos personalizado, entonces puedes ver las diferentes categorías y su orden en la página de Health Check. Solo sigue el orden ingresado aquí.
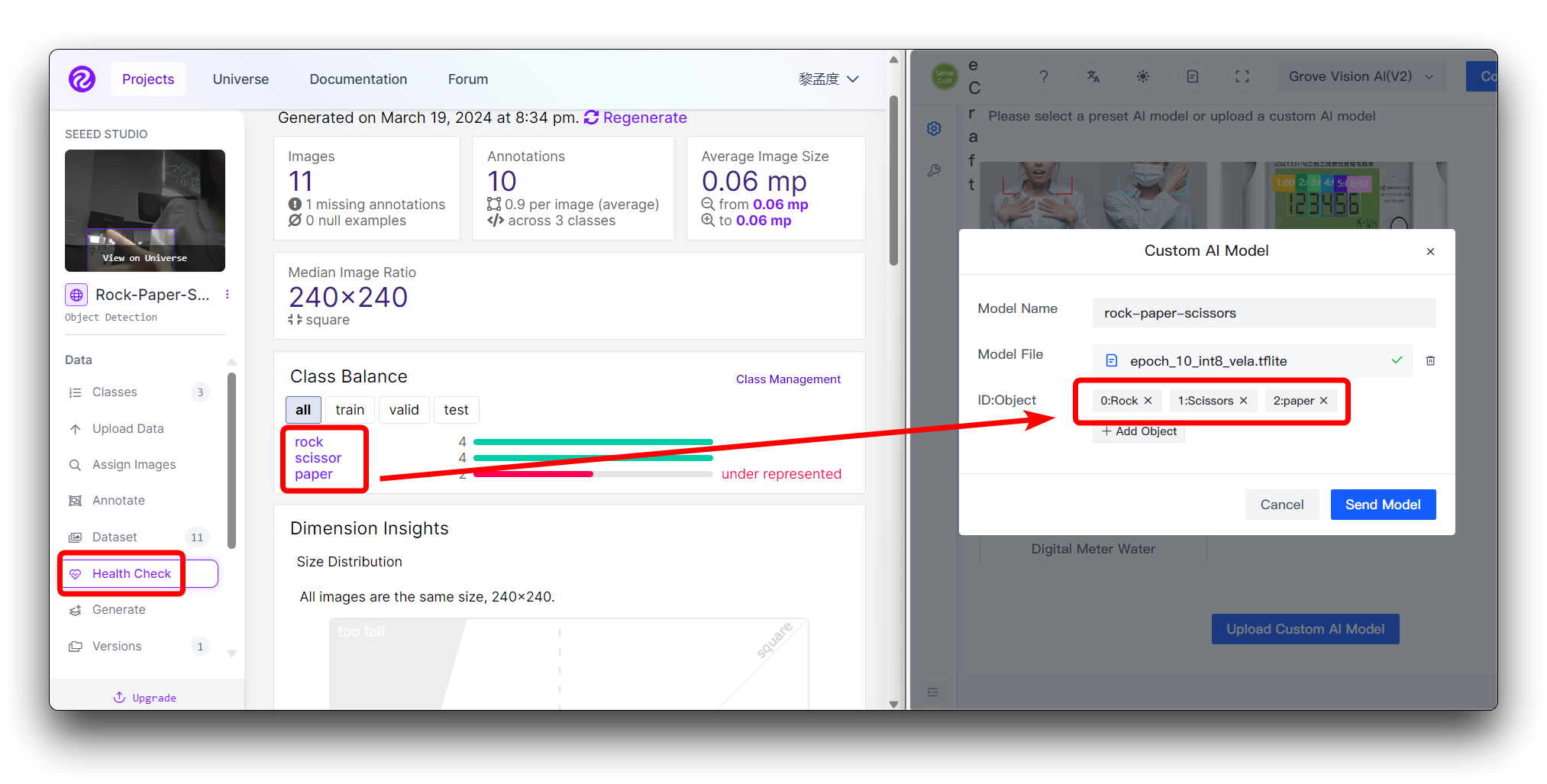
No necesitas llenar los números en ID:Object, solo llena el nombre de la categoría directamente, los números y dos puntos delante de las categorías en la imagen se añaden automáticamente.
Luego haz clic en Send Model en la esquina inferior derecha. Esto puede tomar alrededor de 3 a 5 minutos aproximadamente. Si todo va bien, entonces puedes ver los resultados de tu modelo en las ventanas de Model Name y Preview arriba.
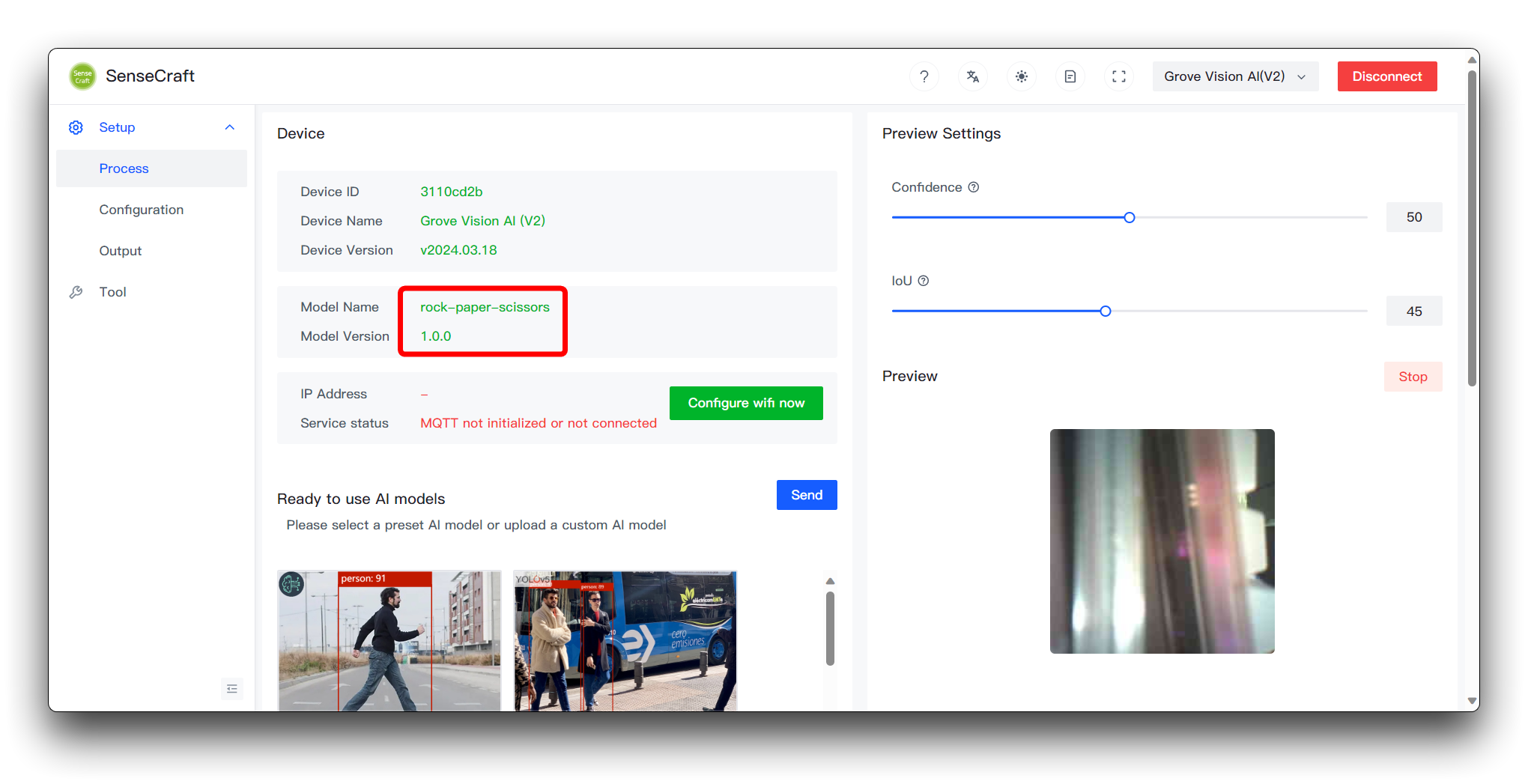
Habiendo llegado hasta aquí, felicitaciones, has sido capaz de entrenar y desplegar exitosamente un modelo propio.
Protocolos comunes y aplicaciones del modelo
Durante el proceso de subir un modelo personalizado, además de los archivos del modelo que podemos visualizar siendo subidos, también está el firmware del dispositivo que necesita ser transferido al dispositivo. En el firmware del dispositivo, hay un conjunto de protocolos de comunicación establecidos que especifican el formato de salida de los resultados del modelo, y lo que el usuario puede hacer con los modelos.
Debido a problemas de espacio, no expandiremos los detalles específicos de estos protocolos en este wiki, detallaremos esta sección a través de documentación en Github. Si estás interesado en un desarrollo más profundo, por favor ve aquí.
Solución de problemas
1. ¿Qué pasa si sigo los pasos y obtengo resultados del modelo menos que satisfactorios?
Si la precisión de reconocimiento de tu modelo no es satisfactoria, podrías diagnosticar y mejorarlo considerando los siguientes aspectos:
-
Calidad y Cantidad de Datos
- Problema: El conjunto de datos podría ser demasiado pequeño o carecer de diversidad, o podría haber inexactitudes en las anotaciones.
- Solución: Aumenta el tamaño y la diversidad de los datos de entrenamiento, y realiza limpieza de datos para corregir cualquier error de anotación.
-
Proceso de Entrenamiento
- Problema: El tiempo de entrenamiento podría ser insuficiente, o la tasa de aprendizaje podría estar configurada incorrectamente, impidiendo que el modelo aprenda efectivamente.
- Solución: Aumenta el número de épocas de entrenamiento, ajusta la tasa de aprendizaje y otros hiperparámetros, e implementa parada temprana para evitar el sobreajuste.
-
Desequilibrio de Clases
- Problema: Algunas clases tienen significativamente más muestras que otras, llevando a un sesgo del modelo hacia la clase mayoritaria.
- Solución: Usa pesos de clase, sobremuestrea las clases minoritarias, o submuestrea las clases mayoritarias para equilibrar los datos.
Al analizar exhaustivamente e implementar mejoras dirigidas, puedes mejorar progresivamente la precisión de tu modelo. Recuerda usar un conjunto de validación para probar el rendimiento del modelo después de cada modificación para asegurar la efectividad de tus mejoras.
2. ¿Por qué veo el mensaje Invoke failed en el despliegue de SenseCraft después de seguir los pasos en la Wiki?
Si encuentras un Invoke failed, entonces has entrenado un modelo que no cumple con los requisitos para usar con el dispositivo. Por favor enfócate en las siguientes áreas.
- Por favor verifica si has modificado el tamaño de imagen de Colab. El tamaño de compresión predeterminado es 192x192, Grove Vision AI V2 requiere que el tamaño de imagen sea comprimido como cuadrado, por favor no uses tamaño no cuadrado para compresión. Tampoco uses tamaño demasiado grande (no se recomienda más de 240x240).
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para proporcionarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.