reComputerでYOLOv8をトレーニングしてデプロイする方法
はじめに
ますます複雑で動的な課題に直面する中、人工知能の応用は問題解決のための新しい道筋を提供し、グローバル社会の持続可能な発展と人々の生活の質の向上に大きく貢献しています。通常、人工知能アルゴリズムをデプロイする前に、AIモデルの設計とトレーニングは高性能コンピューティングサーバー上で行われます。モデルトレーニングが完了すると、エッジ推論のためにエッジコンピューティングデバイスにエクスポートされます。実際には、これらすべてのプロセスはエッジコンピューティングデバイス上で直接実行できます。具体的には、データセットの準備、ニューラルネットワークのトレーニング、ニューラルネットワークの検証、モデルのデプロイなどのタスクをエッジデバイス上で実行できます。これにより、データセキュリティが確保されるだけでなく、追加デバイスの購入に関連するコストも節約できます。

この文書では、 reComputer J4012 上で交通シーン用の物体検出モデルをトレーニングしてデプロイします。 この文書では、 YOLOv8 物体検出アルゴリズムを例として使用し、全プロセスの詳細な概要を提供します。以下で説明するすべての操作はJetsonエッジコンピューティングデバイス上で行われ、Jetsonデバイスには JetPack 5.0 以上のオペレーティングシステムがインストールされていることを確認してください。
データセット
機械学習のプロセスは、与えられたデータ内のパターンを見つけ、そのパターンを捉える関数を使用することです。したがって、データセットの品質はモデルの性能に直接影響します。一般的に言えば、トレーニングデータの品質と量が良いほど、トレーニングされるモデルも良くなります。したがって、データセットの準備は非常に重要です。
トレーニングデータセットを収集する方法は様々あります。ここでは、2つの方法を紹介します:1. 事前にアノテーションされたオープンソースの公開データセットをダウンロードする。2. トレーニングデータを収集してアノテーションする。最後に、すべてのデータを統合して、後続のトレーニング段階に備えます。
公開データセットのダウンロード
公開データセットは、機械学習と人工知能研究で広く使用される共有標準化データリソースです。これらは研究者にアルゴリズムの性能を評価するための標準ベンチマークを提供し、この分野でのイノベーションとコラボレーションを促進します。これらのデータセットは、AIコミュニティをより開放的で革新的で持続可能な方向に導きます。
Roboflow、 Kaggle など、データセットを無料でダウンロードできるプラットフォームは多数あります。ここでは、Kaggleから交通シーンに関連するアノテーション付きデータセット、 Traffic Detection Project をダウンロードします。
抽出後のファイル構造は以下の通りです:
archive
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.jpg
│ │ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.txt
│ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.jpg
│ │ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.txt
│ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.txt
│ ├── ...
└── valid
├── images
│ ├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.jpg
│ ├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.jpg
│ ├── ...
└── labels
├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.txt
├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.txt
├──...
各画像には、その画像の完全な注釈情報を含む対応するテキストファイルがあります。data.jsonファイルには訓練、テスト、検証セットの場所が記録されており、パスを変更する必要があります:
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']
データの収集とアノテーション
公開データセットがユーザーの要件を満たせない場合、特定のニーズに合わせたカスタムデータセットの収集と作成を検討する必要があります。これは、関連データの収集、アノテーション、整理によって実現できます。 デモンストレーションのため、 YouTube から3つの画像をキャプチャして保存し、 Label Studio を使用して画像にアノテーションを付けてみます。
ステップ1. 生データを収集する:

ステップ2. アノテーションツールをインストールして実行する:
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latest
ステップ 3. 新しいプロジェクトを作成し、プロンプトに従ってアノテーションを完了します: Label Studio リファレンスドキュメント
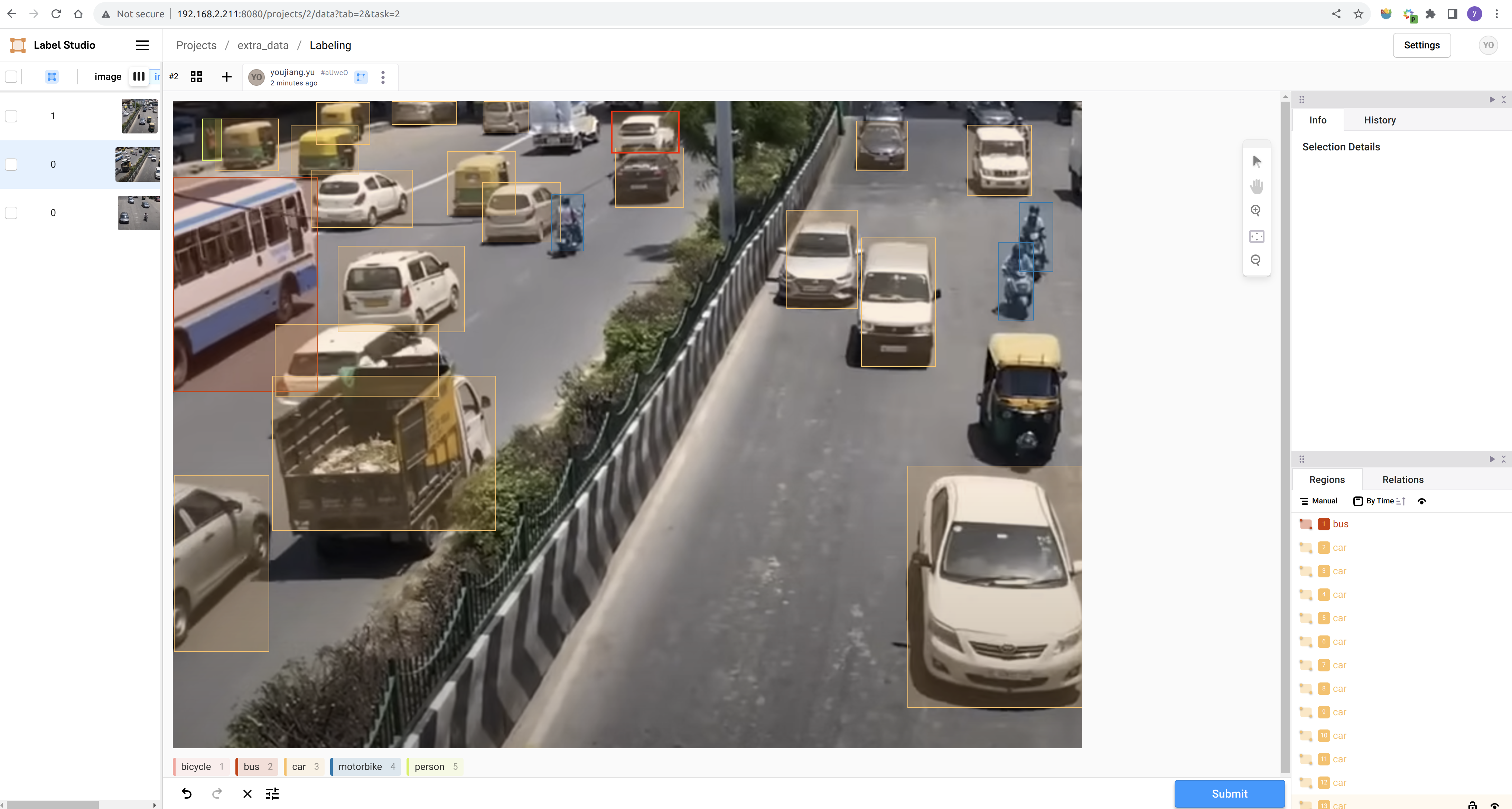
アノテーションが完了したら、データセットをYOLO形式でエクスポートし、アノテーション済みデータをダウンロードしたデータと一緒に整理できます。最も簡単なアプローチは、すべての画像をパブリックデータセットのtrain/imagesフォルダにコピーし、生成されたアノテーションテキストファイルをパブリックデータセットのtrain/labelsフォルダにコピーすることです。
この時点で、2つの異なる方法でトレーニングデータを取得し、それらを統合しました。より高品質なトレーニングデータが必要な場合は、データクリーニング、クラスバランシングなど、考慮すべき追加のステップが多数あります。私たちのタスクは比較的シンプルなので、今回はこれらのステップをスキップし、上記で取得したデータを使用してトレーニングを進めます。
モデル
このセクションでは、reComputer上でYOLOv8のソースコードをダウンロードし、ランタイム環境を設定します。
ステップ 1. 以下のコマンドを使用してソースコードをダウンロードします:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
ステップ2. requirements.txtを開いて関連する内容を修正します:
# Use the `vi` command to open the file
vi requirements.txt
# Press `a` to enter edit mode, and modify the following content:
torch>=1.7.0 --> # torch>=1.7.0
torchvision>=0.8.1 --> # torchvision>=0.8.1
# Press `ESC` to exit edit mode, and finally input `:wq` to save and exit the file.
ステップ 3. YOLOに必要な依存関係をダウンロードし、YOLOv8をインストールするために、以下のコマンドを実行してください:
pip3 install -e .
cd ..
ステップ 4. Jetson版のPyTorchをインストールします:
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.cn/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
ステップ5. 対応するtorchvisionをインストールします:
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.16.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
cd ..
ステップ 6. 次のコマンドを使用して、YOLOが正常にインストールされたことを確認してください:
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'
訓練
モデル訓練とは、モデルの重みを更新するプロセスです。モデルを訓練することで、機械学習アルゴリズムはデータからパターンや関係性を学習し、新しいデータに対する予測や判断を可能にします。
ステップ 1. 訓練用のPythonスクリプトを作成します:
vi train.py
a を押して編集モードに入り、以下の内容を修正してください:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)
ESCを押して編集モードを終了し、最後に:wqを入力してファイルを保存して終了します。
YOLO.train()メソッドには多くの設定パラメータがあります。詳細については
ドキュメント
を参照してください。さらに、特定の要件に基づいてトレーニングを開始するために、より合理化されたCLIアプローチを使用することもできます。
ステップ2. 以下のコマンドでトレーニングを開始します:
python3 train.py
その後、長い待機プロセスが始まります。待機中にリモート接続ウィンドウを閉じる可能性を考慮して、このチュートリアルでは Tmux ターミナルマルチプレクサを使用します。そのため、プロセス中に私が見るインターフェースは次のようになります:
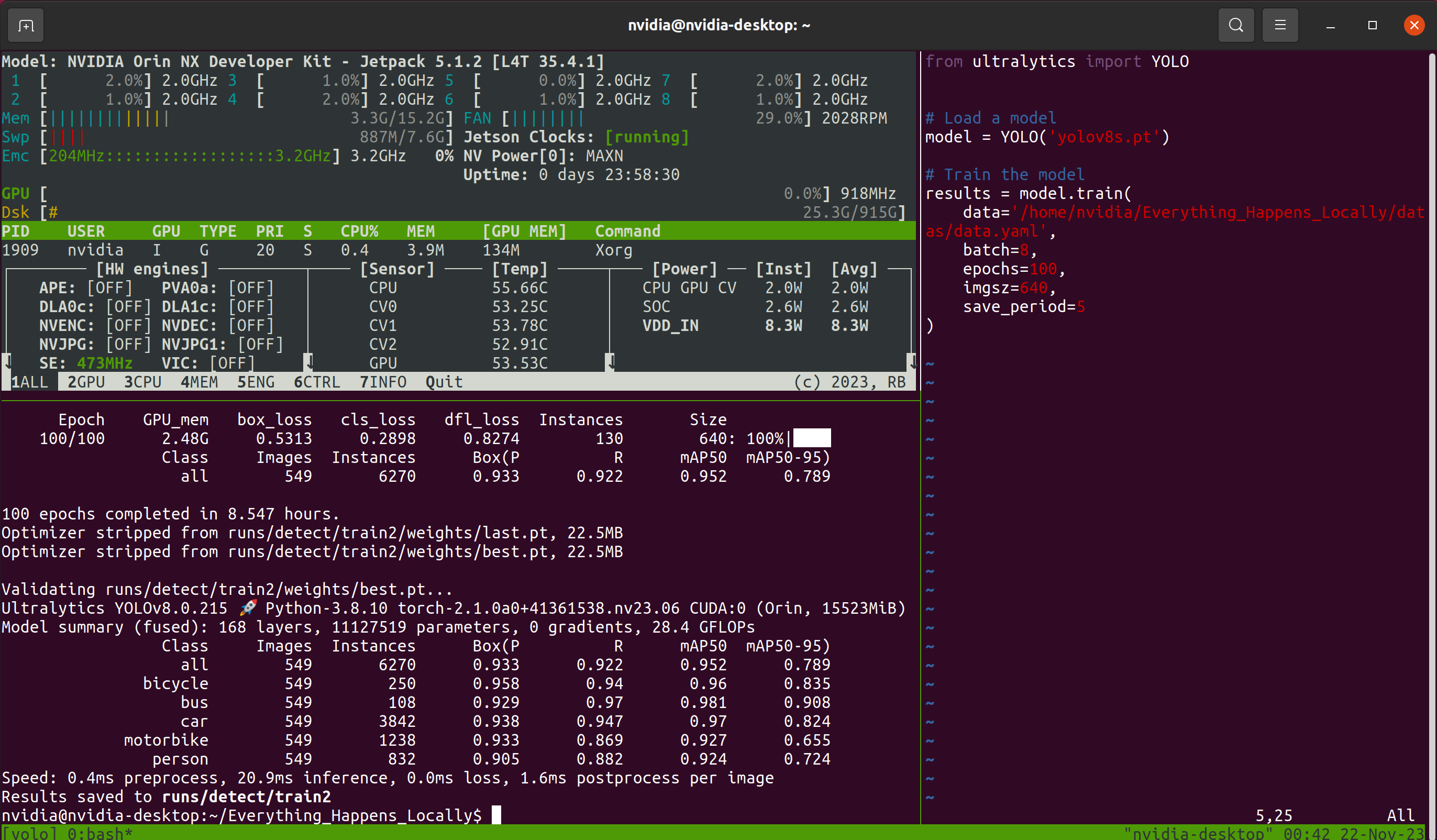
Tmuxはオプションです;モデルが正常にトレーニングされている限り問題ありません。トレーニングプログラムが終了した後、指定されたフォルダでトレーニングプロセス中に保存されたモデル重みファイルを見つけることができます:

検証
検証プロセスでは、データの一部を使用してモデルの信頼性を検証します。このプロセスは、モデルが実世界のアプリケーションで正確かつ堅牢にタスクを実行できることを保証するのに役立ちます。トレーニングプロセス中に出力される情報を詳しく調べると、トレーニング全体を通して多くの検証が散在していることに気づくでしょう。このセクションでは、各評価指標の意味を分析するのではなく、予測結果を調べることでモデルの使用可能性を分析します。
ステップ1. トレーニング済みモデルを使用して特定の画像で推論を実行します:
yolo detect predict \
model='./runs/detect/train2/weights/best.pt' \
source='./datas/test/images/ant_sales-2615_png_jpg.rf.0ceaf2af2a89d4080000f35af44d1b03.jpg' \
save=True show=False
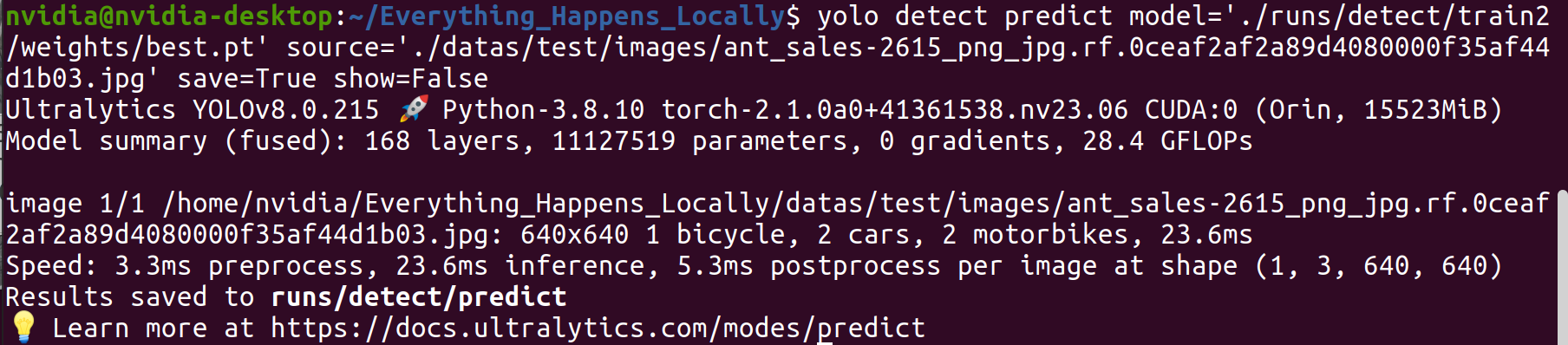
ステップ 2. 推論結果を確認します。
検出結果から、訓練されたモデルが期待される検出性能を達成していることが観察できます。

デプロイメント
デプロイメントは、訓練された機械学習またはディープラーニングモデルを実世界のシナリオに適用するプロセスです。上記で紹介した内容はモデルの実現可能性を検証しましたが、モデルの推論効率は考慮されていませんでした。デプロイメント段階では、検出精度と効率のバランスを見つける必要があります。TensorRT 推論エンジンを使用してモデルの推論速度を向上させることができます。
ステップ 1. 軽量モデルと元のモデルの対比を視覚的に実演するため、viツールを使用して新しい inference.py ファイルを作成し、動画ファイル推論を実装します。8行目と9行目を変更することで推論モデルと入力動画を置き換えることができます。この文書での入力は私が携帯電話で撮影した動画です。
from ultralytics import YOLO
import os
import cv2
import time
import datetime
model = YOLO("/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt")
cap = cv2.VideoCapture('./sample_video.mp4')
save_dir = os.path.join('runs/inference_test', datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
output = cv2.VideoWriter(os.path.join(save_dir, 'result.mp4'), fourcc, fps, size)
while cap.isOpened():
success, frame = cap.read()
if success:
start_time = time.time()
results = model(frame)
annotated_frame = results[0].plot()
total_time = time.time() - start_time
fps = 1/total_time
cv2.rectangle(annotated_frame, (20, 20), (200, 60), (55, 104, 0), -1)
cv2.putText(annotated_frame, f'FPS: {round(fps, 2)}', (30, 50), 0, 0.9, (255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
print(f'FPS: {fps}')
cv2.imshow("YOLOv8 Inference", annotated_frame)
output.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
output.release()
ステップ2. 以下のコマンドを実行し、モデル量子化前の推論速度を記録します:
python3 inference.py

結果は、量子化前のモデルの推論速度が21.9 FPSであることを示しています
ステップ3. 量子化されたモデルを生成します:
pip3 install onnx
yolo export model=/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt format=engine half=True device=0
プログラムが完了すると(約10-20分)、入力モデルと同じディレクトリに.engineファイルが生成されます。このファイルが量子化されたモデルです。

ステップ4. 量子化されたモデルを使用して推論速度をテストします。
ここで、ステップ1で作成したスクリプトの8行目の内容を修正する必要があります。
model = YOLO(<path to .pt>) --> model = YOLO(<path to .engine>)
その後、推論コマンドを再実行します:
python3 inference.py

推論効率の観点から、量子化されたモデルは推論速度において大幅な改善を示しています。
まとめ
この記事では、データ収集とモデル訓練から展開まで、様々な側面をカバーする包括的なガイドを読者に提供しています。重要なことは、すべてのプロセスがreComputerで実行されるため、ユーザーが追加のGPUを必要としないことです。
技術サポートと製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。