reComputerでローカルLLMテキスト画像生成を実行する方法
はじめに
テキスト画像生成モデルは、テキストの説明から画像を生成する人工知能(AI)モデルの一種です。これらのモデルは、シーンを説明する文章や段落などのテキスト入力を受け取り、その説明に基づいて画像を生成します。
これらのモデルは、テキストの説明と対応する画像のペアを含む大規模なデータセットで訓練され、テキスト情報と視覚情報の関係を理解することを学習します。
テキスト画像生成モデルは近年大きな進歩を遂げていますが、テキストの説明に正確に一致する高品質で多様な画像を生成することは、AI研究における挑戦的なタスクであり続けています。
概要
このチュートリアルでは、ローカルLLMテキスト画像生成をデプロイして実行するいくつかの方法を探索します:
- 仮想環境の作成(TensorFlowとPyTorchの両方)
- 1.1. Keras Stable Diffusionを使った例の作成
- 1.2. Hugging Faceで利用可能なモデルの一つを使った例の作成
- 1.3. KerasとHugging Faceの両方でAPIを呼び出して画像を生成するために使用する小さなPython APIの作成
- Nvidiaコンテナの使用
トラブルシューティング
始める前に、より多くのメモリを利用可能にするために実行できるいくつかの手順があります。
-
デスクトップGUIを無効にする。JetsonをSSH経由で使用できます。約800MBのメモリを節約できます。
-
ZRAMを無効にしてSwapを使用する。
これらのヒントはNvidia Jetson AI Labで見つけることができ、実装方法も記載されています。
要件
このチュートリアルでは、Nvidia Jetson Orin NX 16GBが必要です。

そして、TensorFlowとPyTorchがインストールされていることを確認する必要がありますが、ここではその手順を説明します。
ステップ1 - 仮想環境の作成
KerasはTensorFlowまたはPyTorchをバックエンドとして使用できます。Hugging Faceは主にPyTorchを使用します。
TensorFlowとPyTorchをインストールしましょう。
Jetson Orin NX用のTensorFlowとPyTorchのインストール方法については、Nvidia Websiteに記載されています。
TensorFlowとPyTorchはグローバルまたは仮想環境にインストールできます。仮想環境を使用します。
仮想環境を使用することで、プロジェクトやパッケージのバージョンが混在するリスクを回避できます。
これが最良の方法ですが、Nvidiaサイトではグローバル方法を推奨しています。
TensorFlow
仮想環境を作成します(kerasの例で使用するためkerasStableEnvironmentという名前を使用しています。他の名前を使用したい場合は変更してください。)
sudo apt install python3.8-venv
python -m venv kerasStableEnvironment
作成後、仮想環境をアクティベートします
source kerasStableEnvironment/bin/activate
アクティブになると、プロンプトの前にその名前が表示されます

仮想環境に入る
cd kerasStableEnvironment
PIPをアップグレードし、いくつかの依存関係をインストールする
pip install -U pip
pip install -U numpy grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast h5py astor termcolor protobuf keras-applications keras-preprocessing wrapt google-pasta setuptools testresources
Jetpack 5.1.1用のTensorFlowをインストールする
使用しているJetPackのバージョンを確認するには、以下のコマンドを実行します:
dpkg -l | grep -i jetpack
結果にはjetpackのバージョンが表示されるはずです:

pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v511 tensorflow==2.12.0+nv23.05
他のJetPackバージョンをお持ちの場合は、正しいURLについてNvidia Websiteを確認してください。
それでは、TensorFlowのインストールを確認しましょう
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
これは以下の行を返すはずです:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
PyTorch
いくつかの依存関係をインストールしましょう
sudo apt install libopenblas-dev
次に、JetPack 5.1.1用のPyTorchをインストールします
pip install --no-cache https://developer.download.nvidia.com/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
インストールとCUDAが利用可能かどうかを確認するには
python -c "import torch; print(torch.cuda.is_available())"
Trueを返すはずです
TensorFlowとPyTorchの両方がインストールされたので、Kerasをインストールして画像を作成しましょう
1.1 Keras
PyTorchとTensorflowをインストールした後、テキストプロンプトから画像を作成する準備が整いました。 仮想環境上にいることを確認してください。
KerasCVには、Stability.aiのテキストから画像への変換モデルであるStable Diffusionの実装(他の複数の実装と共に)があります。
KerasCV実装を使用することで、XLAコンパイルや混合精度サポートなどのパフォーマンス上の利点を活用できます。
kerasと依存関係をインストールします。インストール済みのTensorFlow(またはPyTorch)バージョンと互換性があるため、これらのバージョンを使用します。
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
お好みのエディタを開いて、以下の例を入力してください
vi generate_image.py
import keras_cv
import keras
from PIL import Image
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
prompt = "a cute magical flying dog, fantasy art, golden color, high quality, highly detailed, elegant, sharp focus, concept art, character concepts, digital painting, mystery, adventure"
image = model.text_to_image (prompt,
num_steps = 25, #image quality
batch_size = 1 # how many images to generate at once
)
Image.fromarray(image[0]).save("keras_generate_image.png")
スクリプトの実行中、以下のような統計情報が表示されます
しばらくすると、以下のような結果が得られます

ステップ 1.2 - Hugging Face
Hugging Face は機械学習のGithubのようなものです。開発者がMLモデルを構築、デプロイ、共有、トレーニングできるプラットフォームです。
Hugging Face は、MLモデルのダウンロードとトレーニングのプロセスを簡素化するTransformers Pythonライブラリでも知られています。
利用可能なモデルのいくつかを使用してみましょう。 Hugging Face にアクセスして、モデルを表示することを選択します。
左側には、表示したいモデルのタイプを選択できるフィルターがあります。
利用可能なモデルはたくさんありますが、text-to-imageモデルに焦点を当てます。
仮想環境
上記で行ったように仮想環境を作成し、パッケージのバージョンを混乱させたり、不要なパッケージをインストールしたりすることなく、Hugging Face を使用できるようにします。
python -m venv huggingfaceTesting
source huggingfaceTesting/bin/activate
仮想環境を作成した後、その環境に入りましょう。 上記の手順を使用してPyTorchをインストールしてください。
cd huggingfaceTesting
モデル
Hugging Face には多くのtext-to-image モデルがあります。理論的には Jetson で動作するはずですが、実際には動作しません。
stable-diffusion-v1-5
Runaway の stable-diffusion-v1-5 をテストします。
モデルカードには、モデルを使用するために必要なすべての情報が記載されています。

Hugging Face の diffusers ライブラリを使用します。 仮想環境内で(アクティベートした状態で)依存関係をインストールします。
pip install diffusers transformers accelerate
必要な依存関係がすべてインストールされたので、モデルを試してみましょう。 お気に入りのエディタを使用して、以下のコード(モデルカードページでも利用可能)をコピーしてください:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a master jedi cat in star wars holding a lightsaber, wearing a jedi cloak hood, dramatic, cinematic lighting"
image = pipe(prompt).images[0]
image.save("cat_jedi.png")
モデルを試してみましょう。
python stableDiffusion.py
覚えておいてください: これは多くのスペースを必要とします。モデルのチェックポイントがダウンロードされています。これは一度だけ実行されます。

しばらくすると、結果は以下のようになります

SDXL-Turbo
試すことができる別のモデルがあります。Stability AI の SDXL Turbo です。 以下のコードをコピーしてください
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "full body, cat dressed as a Viking, with weapon in his paws, battle coloring, glow hyper-detail, hyper-realism, cinematic"
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
image.save("sdxl-turbo.png")
この記事は、Daria Windによって書かれたMediumの記事から引用されたプロンプトです
これは本当に高速で画像を生成します。スクリプトの実行から終了まで約30秒かかります。 結果は以下の通りです

アニメやサイバーパンク専用にトレーニングされたモデルなど、他のモデルも試すことができます。
動作しないモデルもあります。これは、メモリ、利用可能なCPU、さらにはスワップメモリなど、いくつかの要因によるものです。
ステップ1.3 - 小さなAPIの作成
それでは、プロンプトを受け取って画像を生成し、呼び出し元に返すためのFlaskを使った小さなAPIを作成しましょう。
Jetsonが動作していて、APIを呼び出すことで画像を生成できるようにしたいと想像してください - あなた専用のLLM画像生成テキストです。
これを行うプロジェクトは既に存在します(後で見るものなど)が、自分で作ることに勝るものはありません。
新しい仮想環境を作成しましょう
python -m venv imageAPIGenerator
環境をアクティベートして入る
source imageAPIGenerator/bin/activate
cd imageAPIGenerator
これにはFlaskを使用します。FlaskはPythonで書かれたWebアプリケーションフレームワークです。私たちの目的には十分小さなフレームワークです。
Flaskをインストールしてください。
pip install Flask
インストール後、必要な他のすべての依存関係をインストールしましょう。デモンストレーション目的で、依存関係が最も少ないKerasを使用します。
TensorFlowをインストールします。上記の手順に従ってください。 次に、Kerasをインストールします。
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
それでは、アプリケーションの作成を始めましょう。
vi app.py
Flaskが何であるか、何をするものかを知らない方のために、小さな例を試してみましょう。
from flask import Flask
app = Flask (__name__)
@app.route("/generate_image")
def generate_image_api():
return "<h2>Hello World !</h2>"
if __name__ == "__main__":
app.run(host='',port=8080)
実行するには、Pythonスクリプトを実行してください:
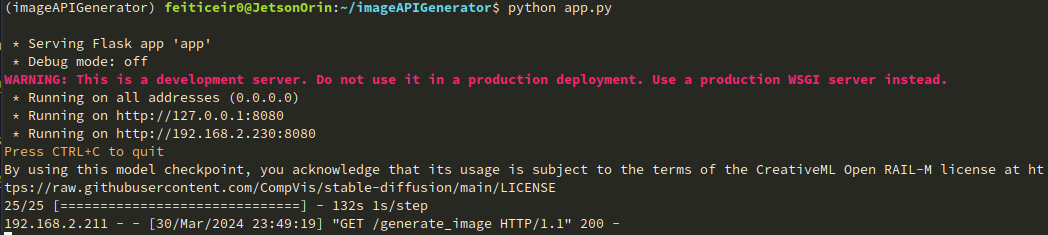
python app.py
以下のように表示されるはずです:

次に、ブラウザを開いて、8080ポートでJetsonデバイスにアクセスしてみてください。


ここで行ったのは、Flaskクラスをインポートすることでした
import Flask
次に、Flaskクラスのインスタンスを作成しました
app = Flask(__name__)
次に、どのURLが関数をトリガーするかをFlaskに伝えるためのルートデコレータを作成します
@app.route("/generate_image")
URLでgenerate_imageを使用すると、私たちの関数がトリガーされます
def generate_image_api():
return "<h2>Hello World !</h2>"
curlを使用してAPIにアクセスすることもできます
curl http://192.168.2.230:8080/generate_image

APIの作成方法がわかったので、実際に作成してみましょう。
vi app.py
そしてコードを貼り付けます
from flask import Flask, request, send_file
import random, string
import keras_cv
import keras
from PIL import Image
#define APP
app = Flask (__name__)
#option for keras
keras.mixed_precision.set_global_policy("mixed_float16")
# generate custom filename
def generate_random_string(size):
"""Generate a random string of specified size."""
return ''.join(random.choices(string.ascii_letters + string.digits, k=size))
"""
This is the function that will generate the image
and save it using a random created filename
"""
def generate_image(prompt):
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
image = model.text_to_image (prompt,
num_steps = 25,
batch_size = 1
)
# image filename
filename = generate_random_string(10) + ".png"
Image.fromarray(image[0]).save(filename)
return filename # return filename to send it to client
#define routes
# Use this to get the prompt. we're going to receive it using GET
@app.route("/generate_image", methods=["GET"])
def generate_image_api():
# get the prompt
prompt = request.args.get("prompt")
if not prompt:
# let's define a default prompt
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image_name = generate_image(prompt)
return send_file(image_name, mimetype='image/png')
if __name__ == "__main__":
app.run(host='0.0.0.0',port=8080)
記憶してください: これはインターネット対応のコードではありません。セキュリティ対策は一切ありません。
実行してみましょう。
ブラウザで URL http://jetsonIP:8080/generate_image を入力して待ちます。
プロンプトを指定しない場合、設定したデフォルトのプロンプトが使用されます。
CLI では、画像が生成されている様子を確認できます

しばらくすると、ブラウザで画像を確認できます
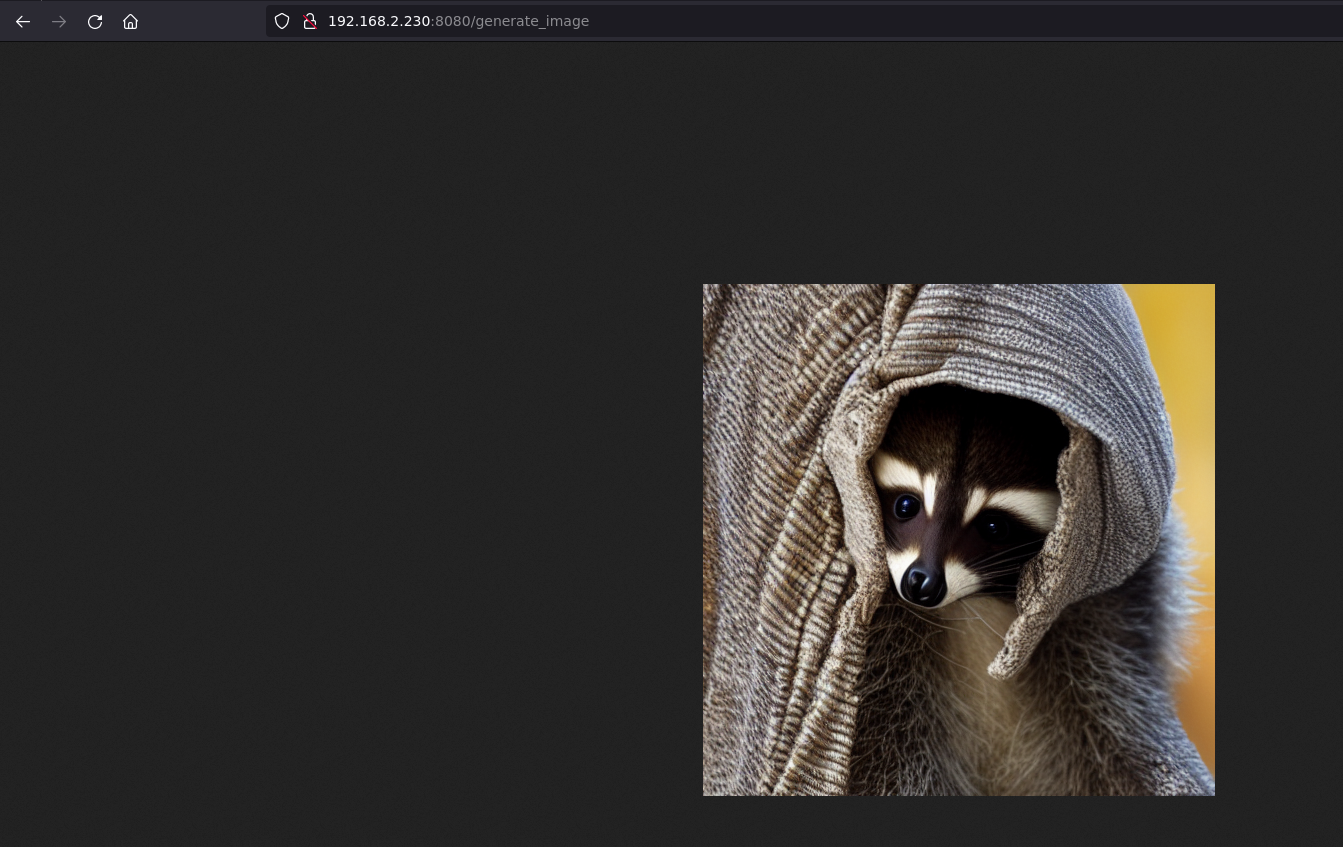
画像が送信されたことも確認できます
curl を使用して画像を取得し、保存することもできます。
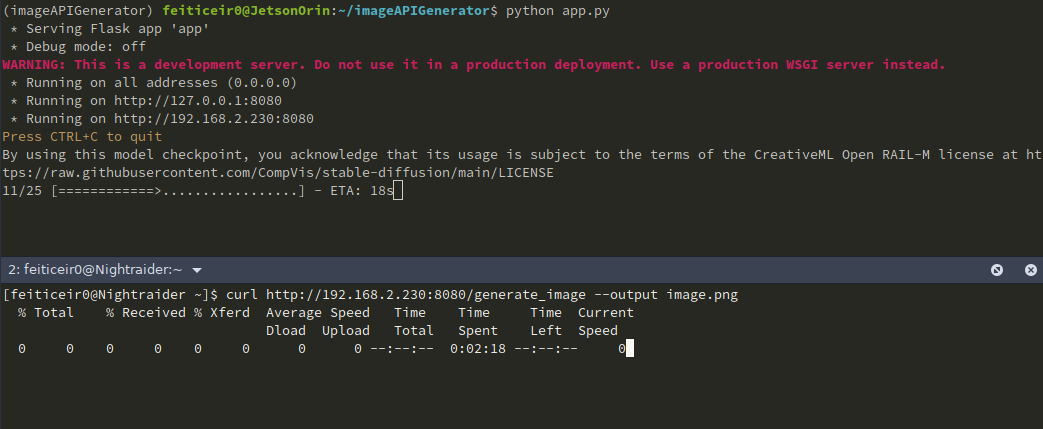
プロンプトを指定したい場合(そうすべきです)、URL は次のようになります http://jetsonIP:8080/generate_image?prompt=<your_prompt>
この例を拡張して、ユーザー入力用のテキストボックスや美しい背景などを含む、より良いページを構築することができます。しかし、これは別のプロジェクトの話です。
ステップ 2 - Nvidia LLM
Stable Diffusion v1.5
Jetson Containers プロジェクトを使用して、AUTOMATIC1111 を使用した stable-diffusion-webui を実行できます。 Jetson Containers プロジェクトは、NVIDIA の従業員である Dusty Franklin によって運営されています。
NVIDIA には NVIDIA Jetson Generative AI Lab プロジェクトがあり、機械学習に関する多くのチュートリアルが提供されています。
このために Stable Diffusion チュートリアル を使用します。
GitHub リポジトリをクローンし、リポジトリに入って依存関係をインストールしましょう
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers/
sudo apt update; sudo apt install -y python3-pip
pip3 install -r requirements.txt
必要なものがすべて揃ったので、stable-diffusion-webui autotag でコンテナを実行しましょう
./run.sh $(./autotag stable-diffusion-webui)
コンテナの実行が開始されます。
しばらくすると、互換性のあるコンテナがあり、続行するかどうかを尋ねるメッセージが表示されます。
Found compatible container dustynv/stable-diffusion-webui:r35.3.1 (2024-02-02, 7.3GB) - would you like to pull it? [Y/n]
コンテナのダウンロードが開始されます。
完了後、モデルをダウンロードしてポート7860でサーバーを実行します。
私の場合、最初はうまく動作しませんでした。何度リフレッシュボタンを押しても、選択できるチェックポイントが表示されませんでした。

調べてみると、ストレージ容量が100%使用されていることがわかりました。
feiticeir0@JetsonOrin:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p1 79G 79G 0 100% /
none 7,4G 0 7,4G 0% /dev
tmpfs 7,6G 0 7,6G 0% /dev/shm
tmpfs 1,6G 19M 1,5G 2% /run
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,6G 0 7,6G 0% /sys/fs/cgroup
/dev/loop0 162M 162M 0 100% /snap/chromium/2797
/dev/loop2 128K 128K 0 100% /snap/bare/5
/dev/loop1 70M 70M 0 100% /snap/core22/1125
/dev/loop3 65M 65M 0 100% /snap/cups/1025
/dev/loop4 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop6 162M 162M 0 100% /snap/chromium/2807
/dev/loop5 483M 483M 0 100% /snap/gnome-42-2204/174
/dev/loop7 35M 35M 0 100% /snap/snapd/21185
tmpfs 1,6G 4,0K 1,6G 1% /run/user/1000
他のモデルをテストしていたところ、それらがすべての容量を占有してしまいました。 もしこの問題が発生した場合は、ホームディレクトリに移動し、隠しキャッシュディレクトリ内のhuggingfaceディレクトリを削除してください。
cd ~/.cache
rm -rf huggingface
今度は利用可能な容量があるはずです。または、より多くの容量を持つ新しいドライブを入手してください。:)
今、モデルがダウンロードされています。

そしてチェックポイントがあります
ブラウザを開いて、JetsonのIPアドレスとポートにアクセスし、AUTOMATIC1111のStable Diffusion webguiを実行します
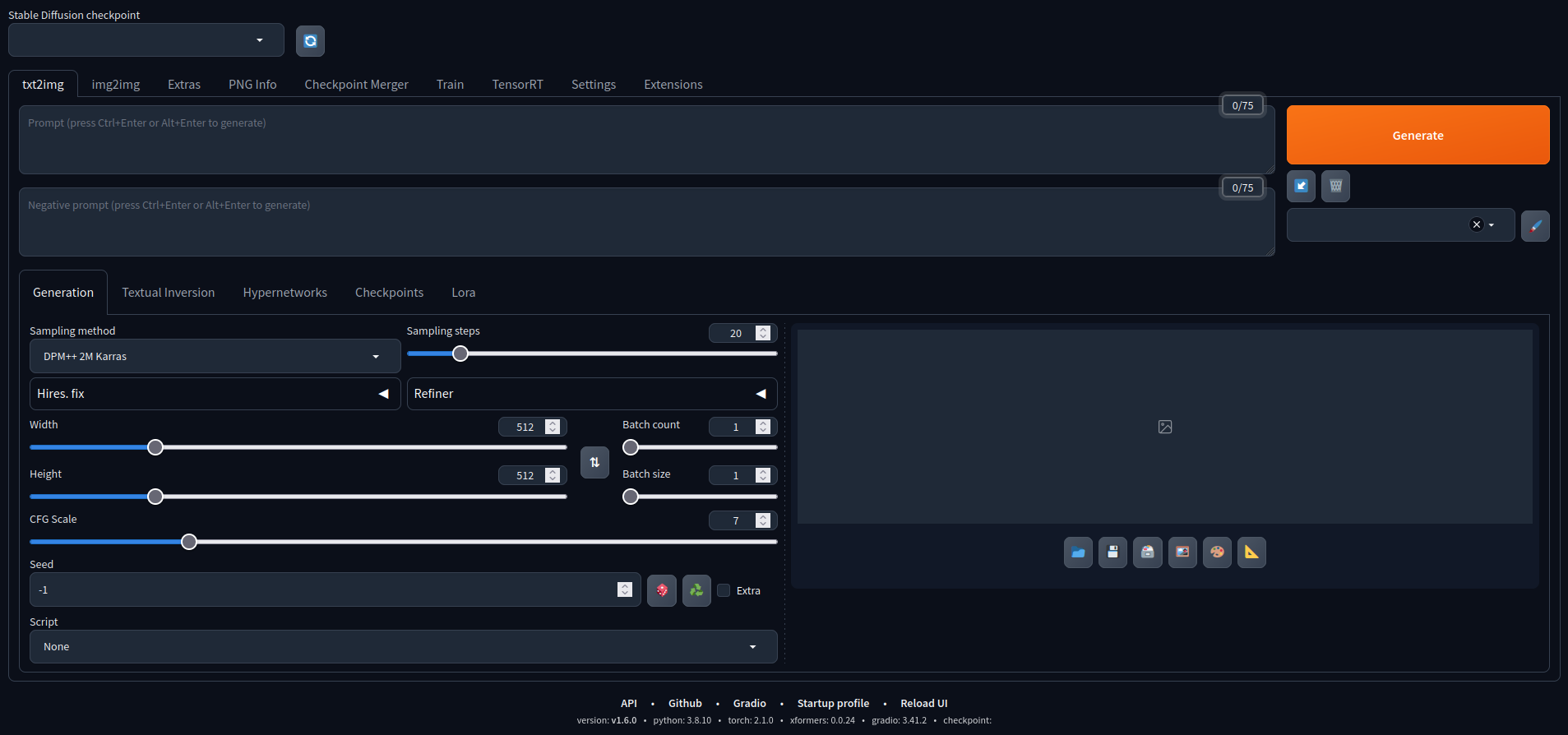
これで遊ぶことができます。 デフォルトモデルで作成された画像をいくつか紹介します。
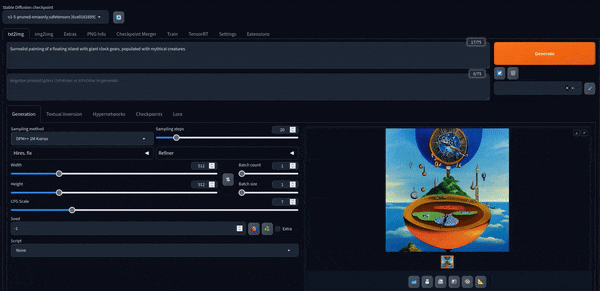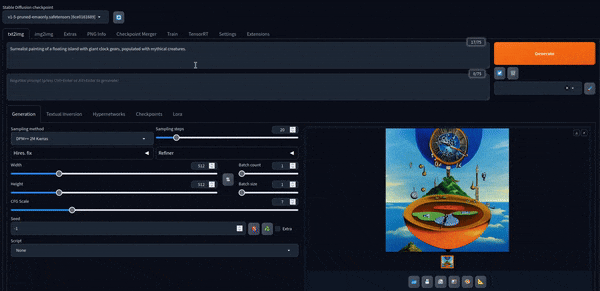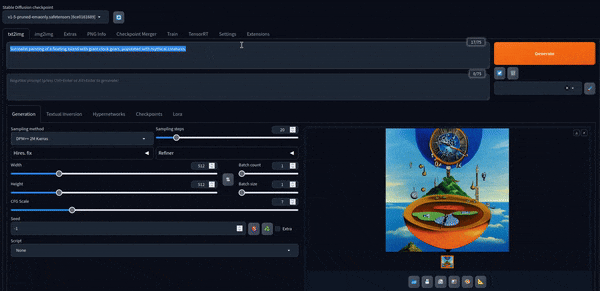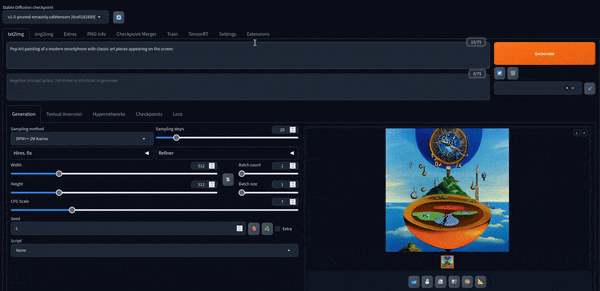
Stable Diffusion XL
AUTOMATIC1111は他のモデルもサポートしています。Stable Diffusion XLを試してみましょう。これは66億のパラメータを持っています。
別のモデルを追加し、ダウンロードを簡単にするために、いくつかの変数を定義し、権限を変更してモデルをダウンロードしましょう。 これはNVIDIAのチュートリアルからの例です。
CONTAINERS_DIR=<where_jetson-containers_is_located>
MODEL_DIR=$CONTAINERS_DIR/data/models/stable-diffusion/models/Stable-diffusion/
sudo chown -R $USER $MODEL_DIR
次に、モデルをダウンロードします
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
モデルがダウンロードされたら、コンテナが実行中の場合はチェックポイントのドロップダウンを更新するか、コンテナを再度起動しましょう。
これで2つのモデルが追加で利用できるようになりました。
これは以下のプロンプトでXLモデルを使用して生成された例です:
A Portrait, fashionable model wearing futuristic clothing, in a cyberpunk roof-top environment, with a neon-lit city background, backlit by vibrant city glow, fashion photography

試してみてください。一部のオプションが選択されている場合、動作しない可能性があることを覚えておいてください。
他のモデルの追加
さらに多くのモデルを追加することもできます。Hugging Face以外にも、Civitaiはより多くのモデルから選択できる別のハブです。CivitaiにはNSFWモデルもあるため、注意してください。
使用したいモデルを選択し、チェックポイントをダウンロードしてmodelsディレクトリに配置してください。
/home/<user>/<jetson-containers-location>/data/models/stable-diffusion/models/Stable-diffusion/
DreamShaper XLという名前のモデルをダウンロードして試してみます。
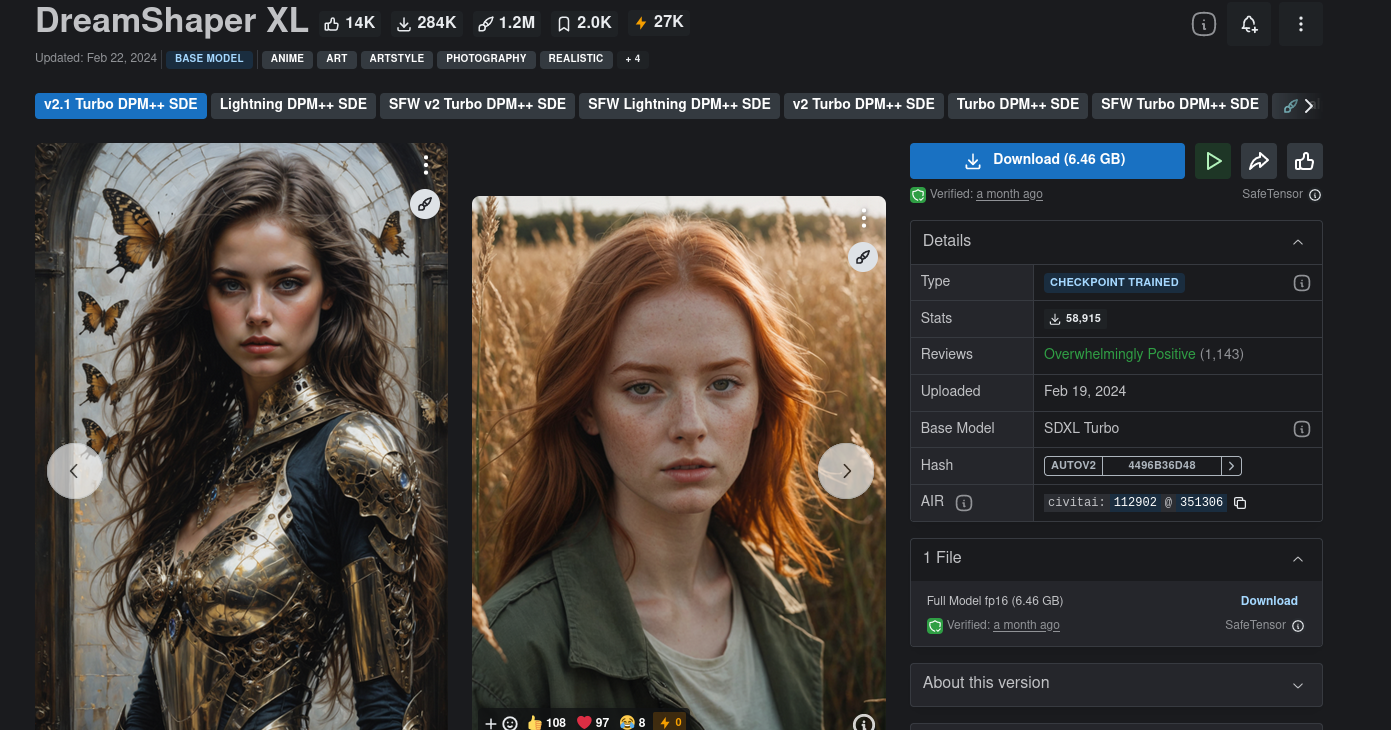
一部のモデルは動作しない可能性があることを覚えておいてください。
設定を調整し、モデルカードを読んで、どの設定が最適に動作するか(もし動作するなら)を知る必要があります。
例えば、このモデルカードでは、サンプリングステップは4-8、サンプリング方法はDPM++ SDE Karrasなどにすべきだと記載されています...
モデルチェックポイントをダウンロードして、上記のディレクトリに追加してください。
リフレッシュ後、モデルが選択可能な状態になっているはずです。 選択時に、AUTOMATIC1111がモデルを最適化します。
強制終了されたりエラーが表示される場合は、より多くの容量を確保してください。私にも同じことが起こりましたが、容量を増やした後、すべてが正常に動作しました。
以下のプロンプトを使用して
holding a staff, orbstaff
<lora:orbstaff:0.60>, ,(by Gabriel Isak and Adam Elsheimer:1.20), (by Jon Whitcomb and Bayard Wu and Malcolm Liepke0.80),8k , professional fashion shot
この画像から、 ネガティブプロンプトなしで、以下の結果を得ました

これらの設定で:
Stable Diffusion XLモデルを使用したサイバーパンクガールの上記のプロンプトを覚えていますか?
こちらが新しい画像です。同じプロンプトで、DreamShaper XLを使用して上記と同じ設定で生成されました

ご覧のように、調整するパラメータを知っていれば、素晴らしい画像を作成できます。:)
大きな画像の方がより良い結果を生み出す傾向があることを学びました。
Nvidia Jetson NX 16GBを使用して画像を生成する方法と、オンデマンドで画像を生成するサーバーとして使用する方法を学んでいただけたことを願っています。
✨ コントリビュータープロジェクト
- このプロジェクトはSeeed Studio コントリビュータープロジェクトによってサポートされています。
- Brunoの努力に感謝し、あなたの作品は展示されます。
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。