Jetson Mate 入門ガイド

Jetson Mate は最大 4台のNvidia Jetson Nano/NX SoM を搭載できるキャリアボードです。オンボードの 5ポートギガビットスイッチにより、4台のSoM間での相互通信 が可能です。3台の周辺SoMはそれぞれ個別に電源のオン・オフが可能です。Jetson Nano SoM用の65W 2ポートPD充電器、またはJetson NX SoM用の90W 2ポートPD充電器と1本のイーサネットケーブルがあれば、開発者は簡単に独自のJetsonクラスターを構築できます。
特徴
- 構築と設定が簡単
- パワフルでコンパクト
- 専用ケースとファンが付属
仕様
| 仕様 | -- |
|---|---|
| 電源 | 65w PD |
| 寸法 | 110mm x 110mm |
| オンボードスイッチ | Microchip KSZ9896CTXC |
ハードウェア概要
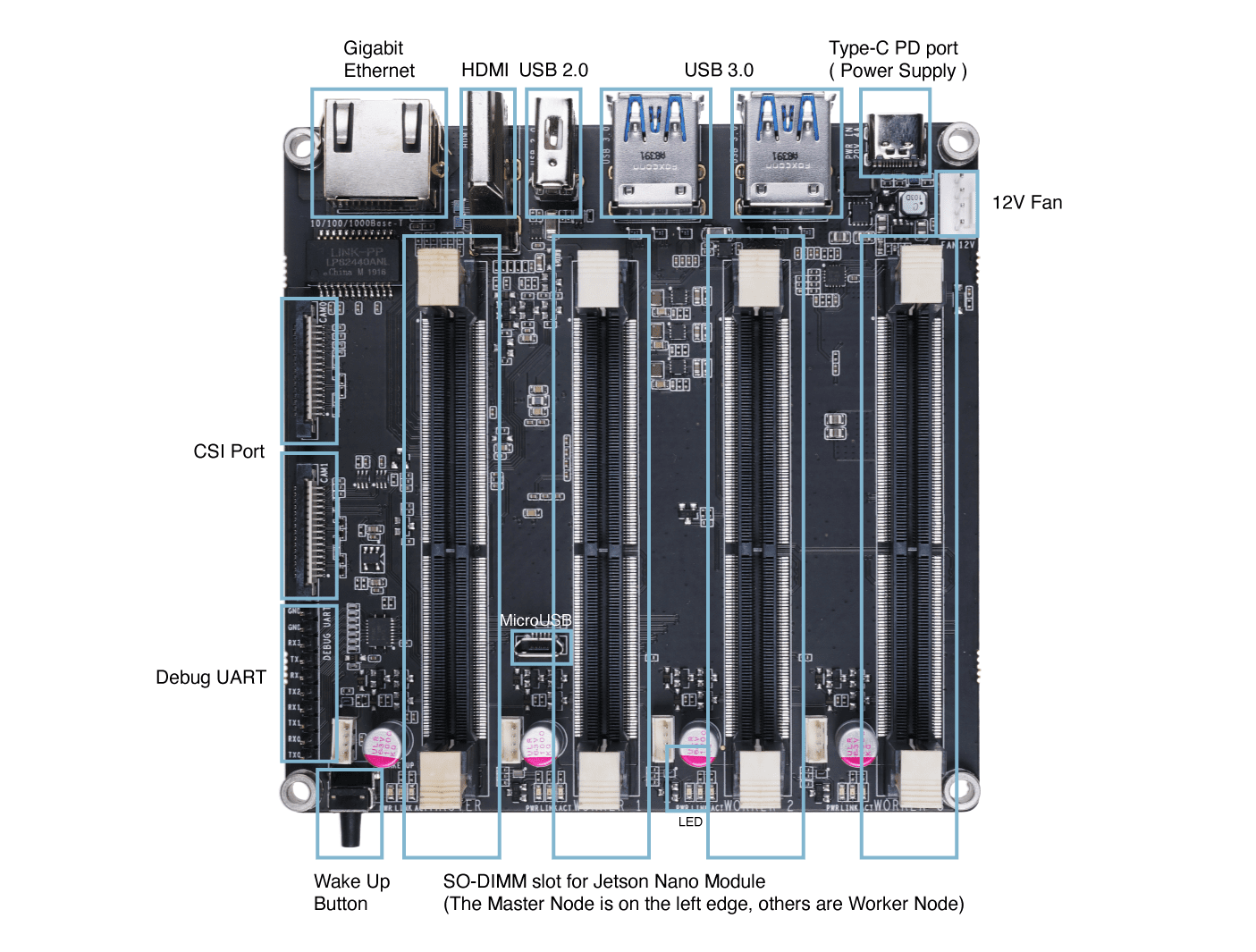

はじめに
!!!Note このガイドでは、ホストPCにUbuntu 18.04 LTSがインストールされています。現在、NVIDIA SDK Managerを使用したOSフラッシュはUbuntu 20.04ではサポートされていません。そのため、Ubuntu 18.04または16.04を使用してください。また、仮想マシン上でUbuntuを実行している場合は、テスト済みのVMware Workstation Playerの使用を推奨します。Oracle VM VirtualBoxはOSフラッシュに失敗するため、使用は推奨されません。
必要なハードウェア
- Jetson Mate
- Jetson Nano/ NXモジュール
- Micro - USBケーブル
- USB Type-Cケーブル付き65Wまたは90W充電アダプター
- Ubuntu 18.04または16.04がインストールされたホストPC
ハードウェアセットアップ
- ステップ 1. Jetson Nano/ NXモジュールをMaster Nodeに挿入します

- ステップ 2. Jetson MateからPCにmicro-USBケーブルを接続します

- ステップ 3. リカバリーモードのためにBOOTとGNDピンの間にジャンパーを接続します

-
ステップ 4. Jetson Mateを電源アダプターに接続し、WAKEボタンを押してJetson Mateの電源を入れます
-
ステップ 5. Jetson Mateの電源が入った後、ジャンパーを取り外します
-
ステップ 6. ホストPCでターミナルウィンドウを開き、以下を実行します
lsusb

出力に 0955:7f21 NVidia Corp. が含まれている場合、Jetson Mate はリカバリモードに入っています
ソフトウェアセットアップ
Developer Kit の micro-SD カードを搭載したモジュールを使用している場合は、Jetson Nano 用のこちらのガイド、Jetson Nano 2GB 用のこちらのガイド、Jetson Xavier NX 用のこちらのガイドに従ってシステムをインストールおよび設定することをお勧めします
eMMC ストレージを搭載したモジュールを使用している場合は、NVIDIA の公式 SDK Manager を使用し、以下の手順に従ってください
- ステップ 1. こちらをクリックして NVIDIA SDK Manager をダウンロードします
注意: ホスト PC の OS に応じて関連するバージョンを選択してください。このガイドで使用するホスト PC は Ubuntu 18.04 を実行しているため、ここでは Ubuntu を選択します

-
ステップ 2. NVIDIA Developer Program Membership のアカウントを作成するか、ログインします
-
ステップ 3. NVIDIA SDK Manager をインストールします
注意: ダウンロードしたファイルをダブルクリックしてインストールします
- ステップ 4. NVIDIA SDK Manager を開くと、接続された Jetson Nano/ NX モジュールが自動的に検出されることがわかります

-
ステップ 5. 接続されたモジュールを選択します
-
ステップ 6. 設定ウィンドウで、Host Machine のチェックを外します。

注意: ここでは DeepStream SDK もチェックが外されています。しかし、これもインストールする予定がある場合は、チェックを入れることができます。ただし、eMMC モジュールの 16GB では、この SDK をインストールするのに十分ではありません。
-
ステップ 7. CONTINUE TO STEP 02 をクリックします
-
ステップ 8. 必要なコンポーネントを確認し、I accept the terms and conditions of the license agreements にチェックを入れます

注意: Jetson OS のみをインストールしたい場合は、Jetson SDK Components のチェックを外すことができます
-
ステップ 9. CONTINUE TO STEP 03 をクリックします
-
ステップ 10. 以下のエラーメッセージがポップアップしたら、Create をクリックします

- ステップ 11. ダウンロードとフラッシュを開始します

- ステップ 12. OS のダウンロードとフラッシュが完了すると、以下の出力が表示されます

-
ステップ 13. Jetson Mate の電源を切ります
-
ステップ 14. ホスト PC でターミナルウィンドウを開き、シリアルターミナルアプリケーションである minicom をインストールします
sudo apt update
sudo apt install minicom
注意: このアプリケーションを使用して、ホストPCとJetson Mate間のシリアル接続を確立します
- ステップ 15. Jetson MateをmicroUSBケーブルでPCに接続したまま電源を入れ、以下を入力して接続されたシリアルポートを識別します
dmesg | grep tty

注意: ここでのポート名は ttyACM0 です
- ステップ 16. minicomを使用してJetson Mateに接続します
sudo minicom -b 9600 -D /dev/ttyACM0
注意: -b はボーレートで、-D はデバイスです
- ステップ 17. Jetson OS の初期設定を実行します

- ステップ 18. 設定が完了したら、SDK Manager ウィンドウに戻り、Jetson Mate に設定したユーザー名とパスワードを入力してInstallをクリックします

注意: 初期設定で設定したユーザー名とパスワードを使用してください
これで SDK コンポーネントのダウンロードとインストールが開始されます

SDK マネージャーが必要なコンポーネントを正常にダウンロードしてインストールすると、以下の出力が表示されます

- ステップ 19. 残りのすべての Jetson Nano/ NX モジュールをフラッシュします
注意: すべてのモジュールは、マスターノードにインストールされている場合にのみフラッシュできます。したがって、マスターノード上でモジュールを一つずつフラッシュして設定する必要があります。
クラスターの起動
- ステップ 1. ルーターから Jetson Mate にイーサネットケーブルを接続します
注意: PC と Jetson Mate が同じルーターに接続されていることを確認してください
- ステップ 2. 前述の通りminicomを使用して Jetson Mate に入り、micro-USB をホスト PC に接続した状態で、以下を入力して Jetson Mate に接続されているモジュールの IP アドレスを取得します
ifconfig
- ステップ3. ホストPCのターミナルで以下を入力してSSH接続を確立します
注意: user を Jetson Nano/ NX のユーザー名に、192.xxx.xx.xx を Jetson Nano/ NX の IP アドレスに置き換えてください
注意: IP アドレスをホスト名に置き換えることでノードに接続することもできます
Jetson Mate で Kubernetes クラスターを構築する
Kubernetes は、最初からクラウドネイティブとして設計されたエンタープライズグレードのコンテナオーケストレーションシステムです。事実上のクラウドコンテナプラットフォームに成長し、コンテナネイティブ仮想化やサーバーレスコンピューティングなどの新しい技術を取り入れながら拡張を続けています。
Kubernetes は、エッジでのマイクロスケールから大規模スケールまで、パブリッククラウドとプライベートクラウドの両方の環境でコンテナなどを管理します。「自宅でのプライベートクラウド」プロジェクトに最適な選択肢であり、堅牢なコンテナオーケストレーションと、需要が高くクラウドに完全に統合されており、その名前が「クラウドコンピューティング」と実質的に同義語となっている技術について学ぶ機会の両方を提供します。
このチュートリアルでは、1つのマスターと3つのワーカーを使用します。以下の手順では、ソフトウェアが master で実行されるか、worker で実行されるか、または worker and master で実行されるかを太字で示します。
Docker の設定
worker and master では、docker ランタイムがデフォルトで "nvidia" を使用するように設定する必要があります。
ファイル /etc/docker/daemon.json を変更します
{
"default-runtime" : "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
Dockerデーモンを再起動します:
sudo systemctl daemon-reload && sudo systemctl restart docker
Docker のデフォルトランタイムを NVIDIA として検証する:
sudo docker info | grep -i runtime
サンプル出力は以下の通りです:
Runtimes: nvidia runc
Default Runtime: nvidia
Kubernetesのインストール
workerとmaster、kubelet、kubeadm、kubectlをインストールします:
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the Kubernetes repo
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt update && sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
スワップを無効にします。再起動するたびにこれをオフにする必要があります。
sudo swapoff -a
deviceQueryをコンパイルします。これは以下の手順で使用します。
cd /usr/local/cuda/samples/1_Utilities/deviceQuery && sudo make
cd
Kubernetesの設定
master、クラスターを初期化します:
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
出力には、クラスターにポッドネットワークをデプロイするためのコマンドと、クラスターに参加するためのコマンドが表示されます。すべてが成功した場合、出力の最後に以下のような内容が表示されるはずです:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
出力された指示に従って、以下のコマンドを実行します:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
コントロールプレーンノードにpod-networkアドオンをインストールします。pod-networkアドオンとしてcalicoを使用します:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
中国にいる場合は、代わりに以下を実行してください:
kubectl apply -f https://gitee.com/wj204811/wj204811/raw/master/kube-flannel.yml
すべてのポッドが起動して実行されていることを確認してください:
kubectl get pods --all-namespaces
サンプル出力は以下の通りです:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-arm64-gz28t 1/1 Running 0 2m8s
kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s
kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s
kube-system etcd-#yourhost 1/1 Running 0 8m25s
kube-system kube-apiserver-#yourhost 1/1 Running 0 8m7s
kube-system kube-controller-manager-#yourhost 1/1 Running 0 8m3s
kube-system kube-proxy-6sh42 1/1 Running 0 9m7s
kube-system kube-scheduler-#yourhost 1/1 Running 0 8m26s
worker、コンピュートノードをクラスターに参加させます。今度はコンピュートノードをクラスターに追加する時です。コンピュートノードの参加は、Control Planeノードを初期化するために実行したkube initコマンドの最後に提供されたkubeadm joinコマンドを実行するだけです。クラスターに参加させたい他のJetson nanoについて、ホストにログインして、次のコマンドを実行します:
the cluster - your tokens and ca-cert-hash will vary
$ sudo kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
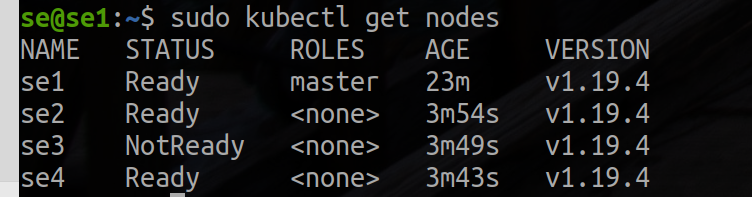
master、各ノードでjoinプロセスが完了すると、kubectl get nodesの出力で新しいノードを確認できるはずです:
kubectl get nodes
こちらがサンプル出力です:
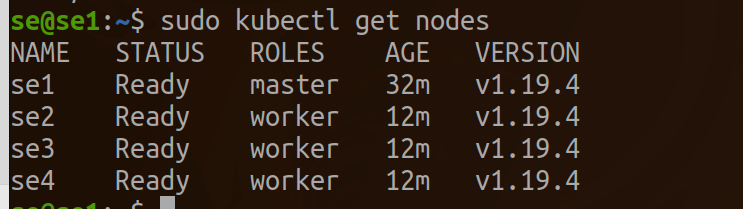
ワーカーのノードとしてタグ付けします。
kubectl label node se2 node-role.kubernetes.io/worker=worker
kubectl label node se3 node-role.kubernetes.io/worker=worker
kubectl label node se4 node-role.kubernetes.io/worker=worker
EGX 2.0インストールの成功を検証する
worker と master、EGXスタックが期待通りに動作することを検証するには、以下の手順に従ってpod yamlファイルを作成してください。get podsコマンドでpodのステータスがcompletedと表示されれば、インストールは成功しています。また、出力にResult=PASSと表示されることを確認することで、cuda-samples.yamlファイルの正常な実行を検証することもできます。 pod yamlファイルを作成し、以下の内容を追加して、samples.yamlとして保存してください:
nano cuda-samples.yaml
以下の内容を追加し、cuda-samples.yamlとして保存してください:
apiVersion: v1
kind: Pod
metadata:
name: nvidia-l4t-base
spec:
restartPolicy: OnFailure
containers:
- name: nvidia-l4t-base
image: "nvcr.io/nvidia/l4t-base:r32.4.2"
args:
- /usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
サンプルGPUポッドを作成します:
sudo kubectl apply -f cuda-samples.yaml
サンプルポッドが作成されたかどうかを確認します:
kubectl get pods
サンプルポッドログを検証して CUDA ライブラリをサポートする:
kubectl logs nvidia-l4t-base
以下はサンプル出力です:
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Xavier"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 7.2
Total amount of global memory: 7764 MBytes (8140709888 bytes)
( 6) Multiprocessors, ( 64) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 1109 MHz (1.11 GHz)
Memory Clock rate: 1109 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: Yes
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
Kubernetes上でJupyterを設定する
workerとmaster、以下の内容を追加してjupyter.yamlとして保存します:
nano jupyter.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: cluster-deployment
spec:
selector:
matchLabels:
app: cluster
replicas: 3 # tells deployment to run 3 pods matching the template
template:
metadata:
labels:
app: cluster
spec:
containers:
- name: nginx
image: helmuthva/jetson-nano-jupyter:latest
ports:
- containerPort: 8888
jupyter GPU ポッドを作成する:
kubectl apply -f jupyter.yml
jupyter ポッドが作成され、実行されているかどうかを確認します:
kubectl get pod
外部ロードバランサーを作成する
kubectl expose deployment cluster-deployment --port=8888 --type=LoadBalancer

ここで、jupyterクラスターがポート31262で外部アクセスを持っていることがわかります。そのため、http://se1.local:31262を使用してjupyterにアクセスします。
以下のコードを使用して利用可能なGPUの数を確認できます。ワーカーは3つしかなく、利用可能なGPUの数は3つです。
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
get_available_gpus()
よし、さあショーの始まりだ。
リソース
- [PDF] Jetson Mate 回路図
- [PDF] Jetson Mate PCB トップ
- [PDF] Jetson Mate PCB ボトム
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを用意しています。