Raspberry Pi 向け reSpeaker 4-Mic Array

ReSpeaker 4-Mic Array for Raspberry Pi は、AI と音声アプリケーション向けに設計された Raspberry Pi 用の 4 マイク拡張ボードです。これにより、Amazon Alexa Voice Service や Google Assistant などを統合した、より強力で柔軟な音声プロダクトを構築できます。
ReSpeaker 2-Mics Pi HAT とは異なり、このボードは AC108 をベースに開発されています。AC108 は高集積の 4 チャンネル ADC で、I2S/TDM 出力変換により高精細な音声キャプチャを実現し、3 メートルの半径内の音を拾うことができます。さらに、この 4-Mics バージョンには 12 個の APA102 プログラマブル LED を備えた LED リングが搭載されています。4 つのマイクと LED リングにより、Raspberry Pi は VAD(Voice Activity Detection)、DOA(Direction of Arrival)の推定、KWS(Keyword Search)を行い、Amazon Echo や Google Home のように LED リングで方向を表示することができます。
特徴
- Raspberry Pi 互換(Raspberry Pi Zero および Zero W、Raspberry PiB+、Raspberry Pi 2B、Raspberry Pi 3B、Raspberry Pi 3B+、Raspberry Pi3 A+、Raspberry Pi 4B をサポート)
- 4 つのマイク
- 半径 3 メートルの音声キャプチャ
- 2 つの Grove インターフェース
- 12 個の APA102 ユーザー LED
- ソフトウェアアルゴリズム:VAD(Voice Activity Detection)、DOA(Direction of Arrival)、KWS(Keyword Search)
注意:ReSpeaker 4-Mic Array for Raspberry Pi にはオーディオ出力インターフェースはありません。音声キャプチャ専用です。オーディオ出力には Raspberry Pi 上の headphone jack を使用できます。
応用アイデア
- 音声インタラクションアプリケーション
- AI アシスタント
ハードウェア概要

- MIC:4 つのアナログマイク
- LED:12 個の APA102 プログラマブル RGB LED、SPI インターフェースに接続
- Raspberry Pi 40 ピンヘッダ:Raspberry Pi Zero および Zero W、Raspberry PiB+、Raspberry Pi 2B、Raspberry Pi 3B、Raspberry Pi 3B+、Raspberry Pi3 A+、Raspberry Pi 4 と互換
- AC108:I2S/TDM 出力変換を備えた高集積 4 チャンネル ADC
- I2C:Grove I2C ポート、I2C-1 に接続
- GPIO12:Grove デジタルポート、GPIO12 & GPIO13 に接続
注意:APA102 RGB LED を使用する場合は、最初に GPIO5 を HIGH に設定して LED の VCC を有効にしてください。
はじめに
ReSpeaker 4-Mic Array を Raspberry Pi に接続する
ReSpeaker 4-Mic Array を Raspberry Pi に取り付ける際は、ReSpeaker 4-Mic Array for Raspberry Pi を重ねるときにピンが正しく揃っていることを確認してください。
注意:ReSpeaker 4-Mic Array のホットプラグは許可されていません。reSpeaker を破損する可能性があります。


ドライバをインストールする
お使いの Pi で the latest Raspberry Pi OS を実行していることを確認してください。(2021.06.30 時点で更新)
- ステップ 1. Seeed voice card のソースコードを取得し、インストールして再起動します。
sudo apt-get update
git clone https://github.com/HinTak/seeed-voicecard.git
cd seeed-voicecard
sudo ./install.sh
sudo reboot now
- ステップ 2. 次に Raspberry Pi 上でオーディオ出力を選択します:
sudo raspi-config
# Select 1 System options
# Select S2 Audio
# Select your preferred Audio output device
# Select Finish
- ステップ 3. サウンドカード名が次のようになっていることを確認します:
pi@raspberrypi:~ $ arecord -L
null
Discard all samples (playback) or generate zero samples (capture)
jack
JACK Audio Connection Kit
pulse
PulseAudio Sound Server
default
playback
ac108
sysdefault:CARD=seeed4micvoicec
seeed-4mic-voicecard,
Default Audio Device
dmix:CARD=seeed4micvoicec,DEV=0
seeed-4mic-voicecard,
Direct sample mixing device
dsnoop:CARD=seeed4micvoicec,DEV=0
seeed-4mic-voicecard,
Direct sample snooping device
hw:CARD=seeed4micvoicec,DEV=0
seeed-4mic-voicecard,
Direct hardware device without any conversions
plughw:CARD=seeed4micvoicec,DEV=0
seeed-4mic-voicecard,
Hardware device with all software conversions
usbstream:CARD=seeed4micvoicec
seeed-4mic-voicecard
USB Stream Output
usbstream:CARD=ALSA
bcm2835 ALSA
USB Stream Output
alsa の設定を変更したい場合は、sudo alsactl --file=ac108_asound.state store を使用して保存できます。そして再度その設定を使用する必要があるときは、sudo cp ~/seeed-voicecard/ac108_asound.state /var/lib/alsa/asound.state にコピーします。
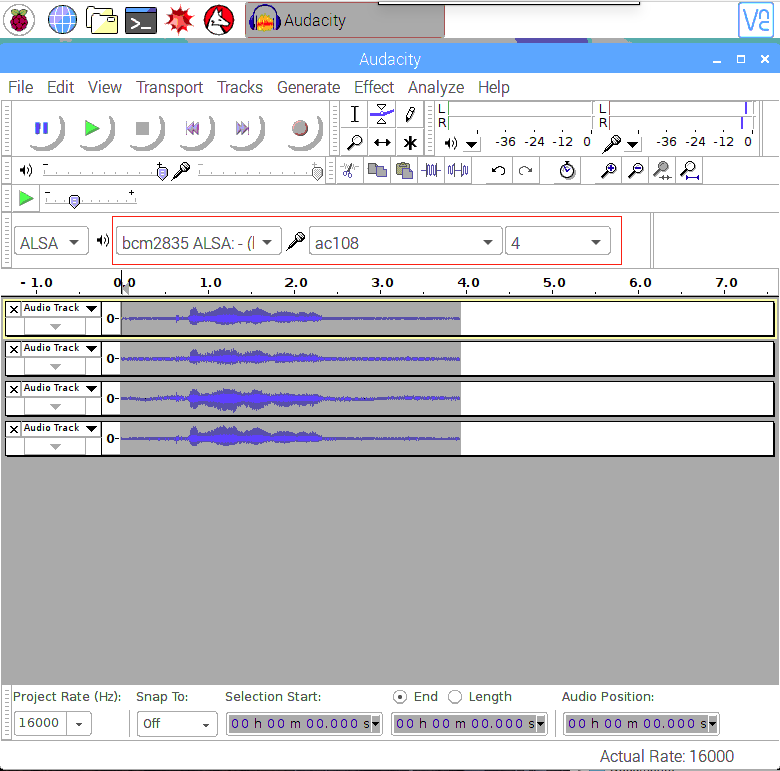
- ステップ 4. Audacity を開き、入力として AC108 & 4 channels、出力として bcm2835 alsa: - (hw:0:0) を選択してテストします:
sudo apt update
sudo apt install audacity
audacity // run audacity
- あるいは、Lite Raspbian Pi OS イメージを使用していて GUI がない場合は、
arecordで録音しaplayで再生できます:
sudo apt-get install sox //for audio conversion
arecord -Dac108 -f S32_LE -r 16000 -c 4 hello.wav // only support 4 channels
sox hello.wav -c 2 stereo.wav // convert to stereo
aplay stereo.wav // make sure default device
// Audio will come out via audio jack of Raspberry Pi
使用概要
以下のサンプルを実行するには、4mics_hat repository リポジトリを Raspberry Pi にクローンします。
git clone https://github.com/respeaker/4mics_hat.git
以下のサンプルで言及されているすべての Python スクリプトは、このリポジトリ内にあります。必要な依存関係をインストールするには、mic_hat リポジトリフォルダから次を実行します。
sudo apt-get install portaudio19-dev libatlas-base-dev
pip3 install -r requirements.txt
APA102 LED
オンボードの各 APA102 LED には追加のドライバチップがあります。ドライバチップは入力ラインを介して希望の色を受信し、新しいコマンドが受信されるまでその色を保持します。

- ステップ 1. SPI を有効化します:
sudo raspi-config
- "Interfacing Options" を選択
- "SPI" を選択
- Enable SPI を選択
- 最後にツールを終了します
- ステップ 2. その後、サンプルコードを実行すると、Alexa Assistant のように LED が点滅するのが確認できます。
python3 interfaces/pixels.py
Python で音声を録音する
Python で音声を録音するために PyAudio python library を使用します。
まず、次のスクリプトを実行して 2 Mic pi hat のデバイスインデックス番号を取得します:
python3 recording_examples/get_device_index.py
以下のようにデバイス ID が表示されます。
Input Device id 2 - seeed-4mic-voicecard: - (hw:1,0)
音声を録音するには、recording_examples/record.py ファイルを nano などのテキストエディタで開き、RESPEAKER_INDEX = 2 をお使いのシステム上の ReSpeaker のインデックス番号に変更します。その後、Python スクリプト record.py を実行して録音を行います:
python3 recording_examples/record.py
- ステップ 6. 4 チャンネルからチャンネル 0 のデータを抽出したい場合は、
record_one_channel.pyの内容を確認してください。他のチャンネル X の場合は、[0::4] を [X::4] に変更してください。
python3 recording_examples/record_one_channel.py
録音したサンプルを再生するには、例えば aplay システムユーティリティを使用できます。
aplay -f cd -Dhw:0 output.wav #for Stereo sound
aplay -D plughw:0,0 output_one_channel.wav #for Mono sound from one channel
リアルタイム音源定位とトラッキング
ODAS は Open embeddeD Audition System の略です。これは、音源の定位、トラッキング、分離、およびポストフィルタリングを実行するためのライブラリです。
- ステップ 1. ODAS を取得してビルドします。
呼び出す実行ファイルは bin ディレクトリ内に生成されます。
sudo apt-get install libfftw3-dev libconfig-dev libasound2-dev libgconf-2-4
sudo apt-get install cmake
cd ~/Desktop
git clone https://github.com/introlab/odas.git
mkdir odas/build
cd odas/build
cmake ..
make
- ステップ 2. ODAS Studio を取得して実行します。
nodejs v12.22 と npm 6.14 をインストールします。
sudo apt update
sudo apt -y install curl dirmngr apt-transport-https lsb-release ca-certificates
curl -sL https://deb.nodesource.com/setup_12.x | sudo -E bash -
関連するコンパイルツールがインストールされていることを確認します。
sudo apt -y install gcc g++ make
sudo apt -y install nodejs
npm で odas_web の依存関係をインストールします。
cd ~/Desktop
git clone https://github.com/introlab/odas_web
cd odas_web
npm install
再ビルドを行わずに関連する依存モジュールをインストールすることが目的なので、再ビルド中のエラーは無視できます。その後 npm start を実行します。
npm start
または、古い election-rebuild モジュールをビルドするために Python を 2.7 にダウングレードすることもできます。(このステップを行う必要はありません)
sudo apt remove python3 -y
sudo apt install python2 -y
- ステップ 3. odascore は ~/Desktop/odas/build/bin/odaslive にあり、設定ファイルは ~/Desktop/odas/config/odaslive/respeaker_4_mic_array.cfg にあります。
サウンドカードの設定を、私たちのデバイスを指定するように変更する必要があります
arecord -l #type this commond make sure u have arecord installed
次のような出力が表示されます
pi@raspberrypi:~/Desktop/odas/config/odaslive $ arecord -l
**** List of CAPTURE Hardware Devices ****
card 3: seeed4micvoicec [seeed-4mic-voicecard], device 0: bcm2835-i2s-ac10x-codec0 ac10x-codec0-0 [bcm2835-i2s-ac10x-codec0 ac10x-codec0-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
cfg 設定ファイルの 18 行目で、サウンドカードの指定を変更します
vim ~/Desktop/odas/config/odaslive/respeaker_4_mic_array.cfg
# Then type :18
# Then press Enter
# Then press i
# Change card = YOUR CARD ; # We found in "arecord -l"
# For mine is
# card = 3 ;
# Then type :wq # To save the configuration file
次に odas の Web インターフェースを開きます。Local System Monitor インターフェースではシステム監視データを確認でき、ODAS Control インターフェースでは制御カーネルと読み込む設定ファイルを選択できます。
odas Web GUI を起動するには
cd ~/Desktop/odas_web
npm start
ODAS Core の下の空白部分をクリックしてファイルブラウザを開き、"~/Desktop/odas/build/bin/odaslive" 内の Core Path を選択します
ODAS Config の下の空白部分をクリックしてファイルブラウザを開き、"~/Desktop/odas/config/odaslive/respeaker_4_mic_array.cfg" 内の Config Path を選択します
正しく設定されると、次のように表示されます

Picovoice によるエッジでの音声認識の有効化

Picovoice は、企業がプライベート音声 AI により迅速にイノベーションを起こし差別化できるようにします。音声認識と Natural-language understanding (NLU) technologies を用いて、ブランドや製品を中心とした統合 AI 戦略を構築できます。
Seeed は Picovoice と提携し、開発者向けに ReSpeaker 4 Mic を使用したエッジでの音声認識ソリューションを提供しています。
Picovoice は、自分たちの条件で音声プロダクトを構築するためのエンドツーエンドプラットフォームです。Alexa や Google に似た音声体験を作成できます。しかし、処理は 100% デバイス上で完結します。Picovoice には次のような利点があります:
- プライバシー保護:すべてオフラインで処理されます。本質的に HIPAA および GDPR に準拠しています。
- 高信頼性:常時接続を必要とせずに動作します。
- ゼロレイテンシ:エッジファーストのアーキテクチャにより、予測不能なネットワーク遅延を排除します。
- 高精度:ノイズや残響に強く、クラウドベースの代替手段を大きく上回る性能を発揮します。
- クロスプラットフォーム:一度設計すればどこにでも展開可能です。使い慣れた言語やフレームワークで開発できます。
ReSpeaker 4-Mic Array と Picovoice の入門
ステップ 1. 以下に進む前に、上記の ReSpeaker 4-Mic Array と Raspberry Pi のステップバイステップチュートリアルに従ってください。
注意: Raspberry Pi 上の ReSpeaker 4-Mic Array で Audacity と APA102 LED が正しく動作していることを確認してください。
ステップ 2. ターミナルを開き、次のコマンドを入力して pyaudio ドライバをインストールします。
pip3 install pyaudio
注意: Raspberry Pi に pip3 がインストールされていることを確認してください
ステップ 3. ターミナルで次のコマンドを入力して、ReSpeaker 4-Mic Array 用の Picovoice デモをインストールします。
pip3 install pvrespeakerdemo
デモの使い方
このデモは、Raspberry Pi 上の ReSpeaker 4-Mic Array と Picovoice テクノロジーを利用して LED を制御します。このデモはウェイクワード "Picovoice" によってトリガーされ、その後 LED のオン/オフや色変更などのアクションを受け付けるようになります。
インストールが完了したら、ターミナルで次のコマンドを入力してデモを実行します:
picovoice_respeaker_demo
音声コマンド
このデモで使用できる音声コマンドは次のとおりです:
- Picovoice
デモの出力は次のようになります:
wake word
- Turn on the lights
ライトが点灯し、ターミナルには次のメッセージが表示されるはずです:
{
is_understood : 'true',
intent : 'turnLights',
slots : {
'state' : 'on',
}
}
コマンドの一覧はターミナルに表示されます:
context:
expressions:
turnLights:
- "[switch, turn] $state:state (all) (the) [light, lights]"
- "[switch, turn] (all) (the) [light, lights] $state:state"
changeColor:
- "[change, set, switch] (all) (the) (light, lights) (color) (to) $color:color"
slots:
state:
- "off"
- "on"
color:
- "blue"
- "green"
- "orange"
- "pink"
- "purple"
- "red"
- "white"
- "yellow"
また、次のコマンドを試して色を変更することもできます:
- Picovoice, set the lights to orange
ライトを消すには次のように言います:
- Picovoice, turn off all lights
デモ動画
デモのソースコード
このデモは Picovoice SDK を用いて構築されています。デモのソースコードは GitHub 上の Picovoice Respeaker Demo で入手できます
異なるウェイクワード
Picovoice SDK には、Apache 2.0 ライセンスの無料サンプルウェイクワードが含まれており、主要な音声アシスタント(例: "Hey Google"、"Alexa")や、"Computer"、"Jarvis" のような楽しいものも含まれています。
カスタム音声コマンド
照明コマンドは、Picovoice の Speech-to-Intent コンテキスト によって定義されています。Picovoice Console を使用して、許可される文法を入力することでコンテキストを設計・学習させることができます。編集しながらマイクボタンを使ってブラウザ上で変更をテストできます。Picovoice Console にアクセスしてアカウントを登録してください。Rhino Speech-to-Intent editor を使用してコンテキストを作成し、その後 Raspberry Pi 向けに学習させます。
複数ウェイクワードの例
Picovoice の機能を示すために、Raspberry Pi と ReSpeaker 4-Mic Array を使用した複数ウェイクワードの例も用意しました。異なるウェイクワードに、特定のタスクを実行させることができます。
このパッケージには、Porcupine を使用して ReSpeaker 4-mic マイクアレイの LED を制御するコマンドラインデモが含まれています。
Porcupine
Porcupine は、高精度かつ軽量なウェイクワードエンジンです。常時待ち受けの音声対応アプリケーションを構築できます。Porcupine は次の特徴を持ちます。
- 実環境で学習されたディープニューラルネットワークを使用しています。
- コンパクトで計算効率に優れています。IoT に最適です。
- クロスプラットフォームです。Raspberry Pi、BeagleBone、Android、iOS、Linux (x86_64)、macOS (x86_64)、Windows (x86_64)、および Web ブラウザをサポートします。さらに、エンタープライズ顧客は ARM Cortex-M SDK にアクセスできます。
- スケーラブルです。ランタイムのフットプリントを増やすことなく、複数の常時待ち受け音声コマンドを検出できます。
- セルフサービスです。開発者は Picovoice Console を使用してカスタムウェイクワードモデルを学習させることができます。
複数ウェイクワード入門
ターミナルで次のコマンドを実行して、デモ用ドライバをインストールします:
pip3 install ppnrespeakerdemo
複数ウェイクワードの使い方
ドライバをインストールした後、ターミナルで次を実行します:
porcupine_respeaker_demo
デモが初期化され、ターミナルに [Listening] と表示されるまで待ちます。その後、次のように言います:
Picovoice
デモの出力は次のようになります:
detected 'Picovoice'
ライトは green に設定されます。次のように言います:
Alexa
ライトは yellow に設定されます。次のように言います:
Terminator
ライトを消します。
ウェイクワードと色の対応
このデモでサポートされているウェイクワードに対応する色は次のとおりです:
AlexaBumblebeeComputerHey GoogleHey SiriJarvisPicovoicePorcupineTerminator
複数ウェイクワード例のソースコード
この例の完全なソースコードはこちらを参照してください: Porcupine Respeaker Demo
Picovoice テクニカルサポート
Picovoice の使用中に技術的な問題が発生した場合は、ディスカッションのために Picovoice を参照してください。
FAQ
Q1: kws_doa.py を実行して snow boy と話しかけても反応がありません
A2: audacity を実行して、4 チャンネルが正常であることを確認してください。データのないチャンネルが 1 つでもあると、snow boy と話しかけても反応がありません。
Q2: "sudo pip install pyaudio" を実行すると #include "portaudio.h" エラーが出ます。
A3: 次のコマンドを実行して問題を解決してください。
sudo apt-get install portaudio19-dev
Q3: journalctl に ...WARNING: memory leak will occur if overlay removed... というメッセージが表示されます
A4: ドライバが最初にロードされるとき(ブート後)に、一度だけ発生するごく小さなメモリリークがあります。ただし、これはブートごと、あるいはロードごとの問題であり、一般的なユーザーはブートごとに一度だけドライバをロードすればよいので、ブートごとに数バイト分のメモリを見失っても問題にはなりません。したがって、これは実際のところユーザーに実害を及ぼす可能性は低い小さな問題であり、ブートごとのメモリ損失に関する不安をあおるメッセージが表示されること以外には影響はありません。
リソース
- [PDF] ReSpeaker 4-Mic Array for Raspberry Pi(PDF)
- [DXF] ReSpeaker 4-Mic Array for Raspberry Pi v1.0
- [3D] ReSpeaker 4-Mic Array for Raspberry Pi v1.0 3D Model
- [AC108] AC108 DataSheet
- [Driver] Seeed-Voice Driver
- [Algorithms] Algorithms includes DOA, VAD, NS
- [Voice Engine] Voice Engine project, provides building blocks to create voice enabled objects
- [Algorithms] AEC
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。私たちは、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じてお選びいただける、複数のコミュニケーションチャネルをご用意しています。