NVIDIA® Jetson デバイスでの Roboflow Inference の使用開始
このwikiガイドでは、NVIDIA Jetson デバイス上で動作する Roboflow inference サーバーを使用して AI モデルを簡単にデプロイする方法を説明します。ここでは Roboflow Universe を使用して既に訓練されたモデルを選択し、そのモデルを Jetson デバイスにデプロイして、ライブウェブカムストリームで推論を実行します!
Roboflow Inference は、コンピュータビジョンモデルを使用およびデプロイする最も簡単な方法で、推論実行に使用される HTTP Roboflow API を提供します。Roboflow inference は以下をサポートしています:
- オブジェクト検出
- 画像セグメンテーション
- 画像分類
そして CLIP や SAM などの基盤モデル。
前提条件
- Ubuntu ホスト PC(ネイティブまたは VMware Workstation Player を使用した VM)
- reComputer Jetson またはその他の NVIDIA Jetson デバイス
このwikiは reComputer J4012 と NVIDIA Jetson Orin NX 16GB モジュールを搭載した reComputer Industrial J4012 でテストおよび検証されています
Jetson に JetPack をフラッシュ
次に、Jetson デバイスに JetPack システムがフラッシュされていることを確認する必要があります。NVIDIA SDK Manager またはコマンドラインを使用して JetPack をデバイスにフラッシュできます。
Seeed Jetson 搭載デバイスのフラッシュガイドについては、以下のリンクを参照してください:
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 キャリアボード
- A205 キャリアボード
- A206 キャリアボード
- A603 キャリアボード
- A607 キャリアボード
- Jetson Xavier AGX H01 キット
- Jetson AGX Orin 32GB H01 キット
- reComputer Industrial
- reServer Industrial
このwikiで検証したバージョンであるため、JetPack バージョン 5.1.1 をフラッシュするようにしてください
Roboflow Universe の 50,000 以上のモデルを活用する
Roboflow は、誰もが最速でコンピュータビジョンの展開を開始できるよう、50,000 以上のすぐに使える AI モデルを提供しています。これらのモデルはすべて Roboflow Universe で探索できます。Roboflow Universe では 200,000 以上のデータセットも提供されており、これらのデータセットを使用して Roboflow クラウドサーバーでモデルを訓練したり、独自のデータセットを持参して Roboflow オンライン画像アノテーションツールを使用して訓練を開始したりできます。
-
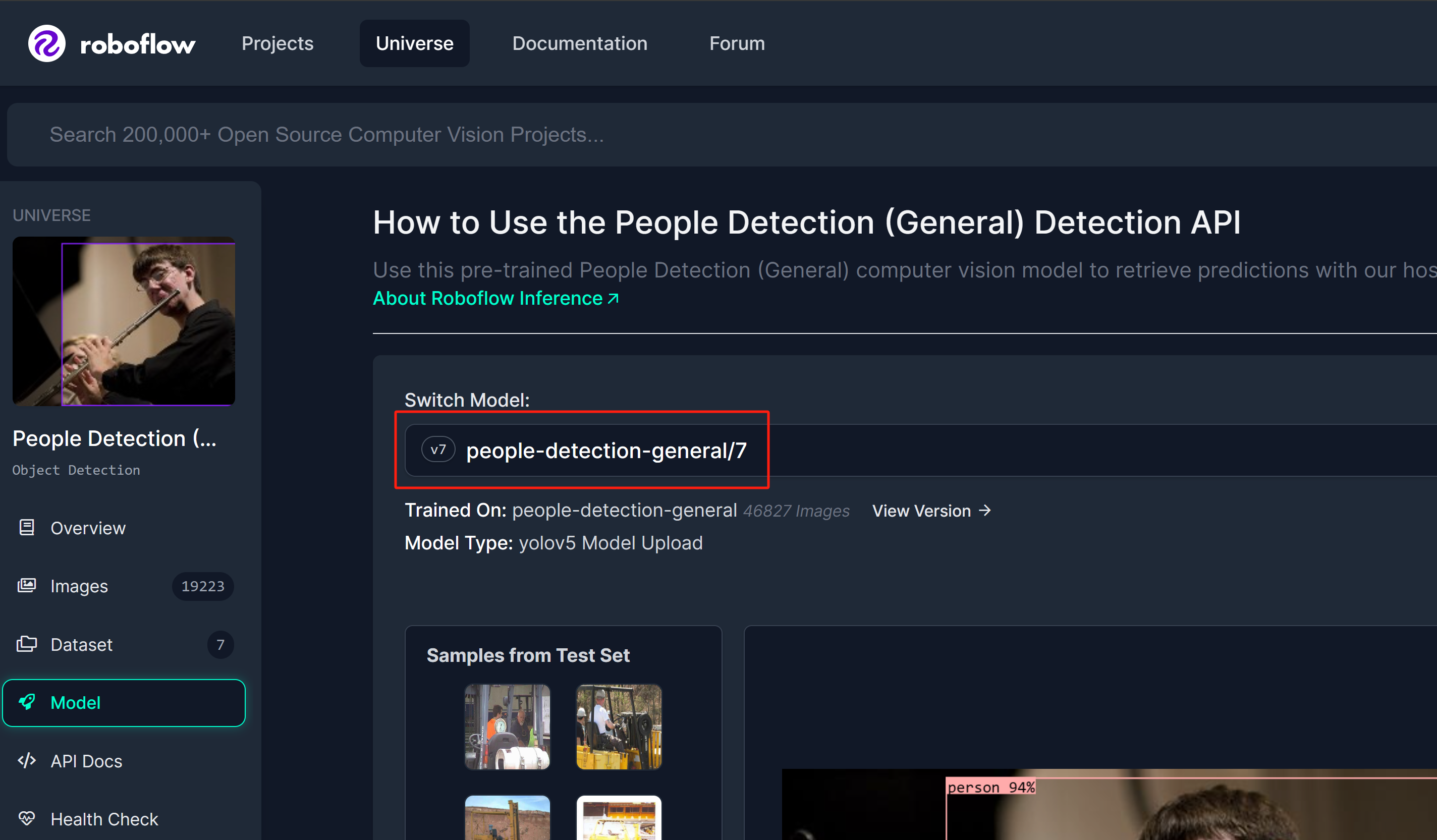
ステップ 1: 参考として Roboflow Universe の人物検出モデルを使用します
-
ステップ 2: ここでモデル名は「model_name/version」の形式に従います。この場合は people-detection-general/7 です。推論を開始する際に、このウィキの後半でこのモデル名を使用します。
Roboflow API キーの取得
Roboflow 推論サーバーが動作するために、Roboflow API キーを取得する必要があります。
-
ステップ 1: 認証情報を入力して新しい Roboflow アカウントにサインアップします
-
ステップ 2: アカウントにサインインし、
Projects > Workspaces > <your_workspace_name> > Roboflow APIに移動し、「Private API Key」セクションの横にある Copy をクリックします
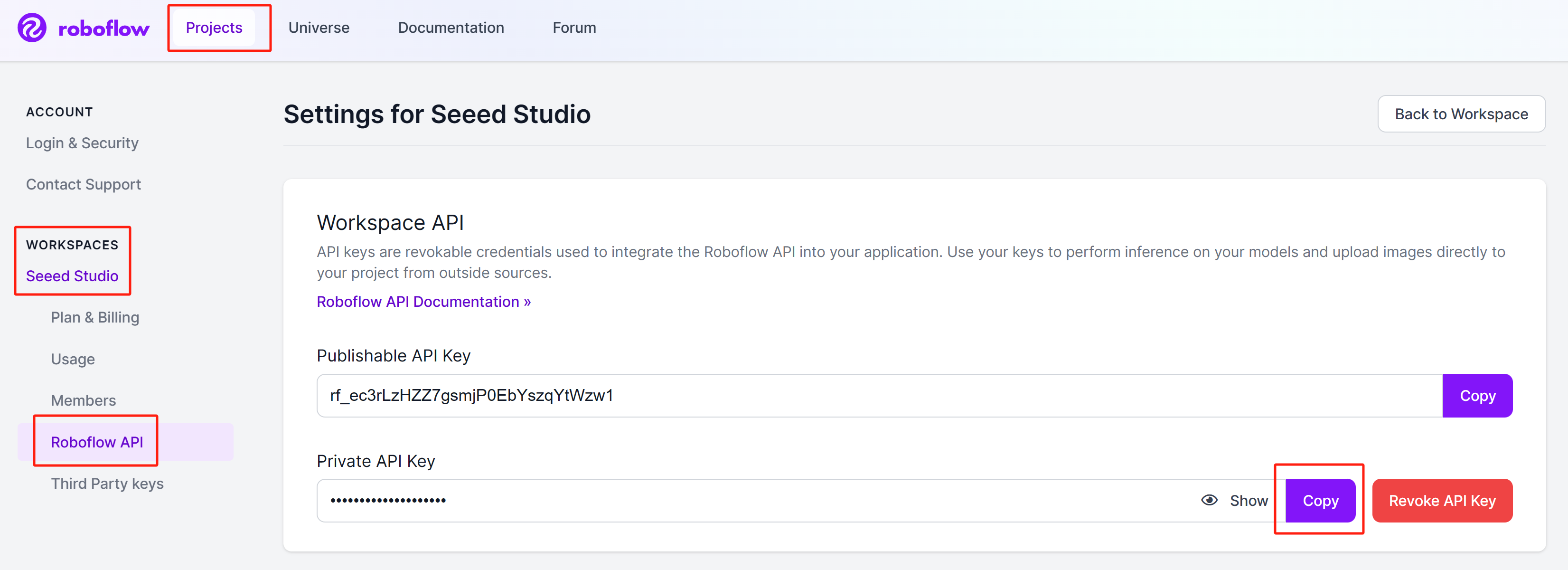
このプライベートキーは後で必要になるため、保管しておいてください。
Roboflow 推論サーバーの実行
NVIDIA Jetson で Roboflow 推論を開始するには、3 つの異なる方法があります。
- pip パッケージを使用 - pip パッケージを使用することが開始する最速の方法ですが、JetPack と共に SDK コンポーネント(CUDA、cuDNN、TensorRT)をインストールする必要があります。
- Docker hub を使用 - Docker hub を使用すると、約 19GB の Docker イメージを最初にプルするため少し時間がかかります。ただし、Docker イメージにはすでにそれらが含まれているため、SDK コンポーネントをインストールする必要はありません。
- ローカル Docker ビルドを使用 - ローカル Docker ビルドを使用することは、Docker hub 方法の拡張で、希望するアプリケーションに応じて Docker イメージのソースコードを変更できます(INT8 で TensorRT 精度を有効にするなど)。
Roboflow 推論サーバーの実行に進む前に、推論する AI モデルと Roboflow API キーを取得する必要があります。まずそれらについて説明します。
- pip Package
- Docker Hub
- Local Docker Build
pip パッケージを使用
- ステップ 1: Jetson デバイスに Jetson L4T のみをフラッシュした場合は、最初に SDK コンポーネントをインストールする必要があります
sudo apt update
sudo apt install nvidia-jetpack -y
- ステップ 2: ターミナルで以下のコマンドを実行して、Roboflow inference server pip パッケージをインストールします
sudo apt update
sudo apt install python3-pip -y
pip install inference-gpu
- ステップ 3: 以下を実行し、事前に取得したRoboflowプライベートAPIキーに置き換えてください
export ROBOFLOW_API_KEY=your_key_here
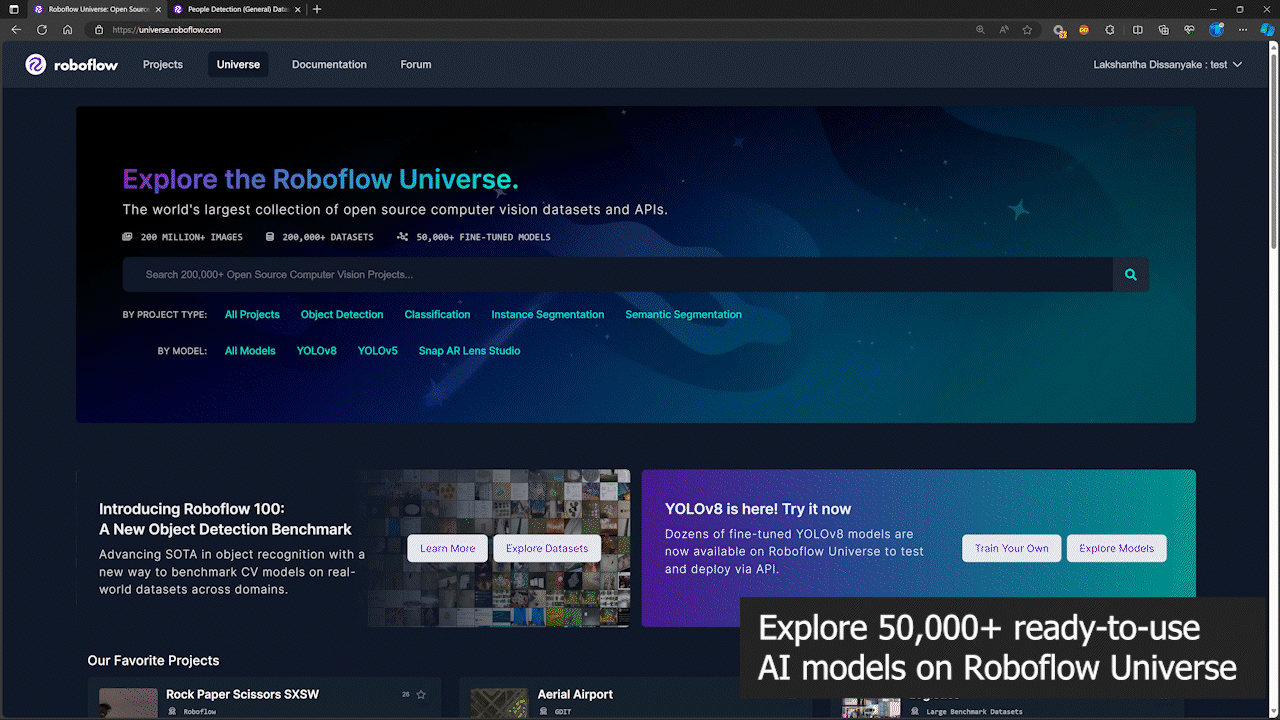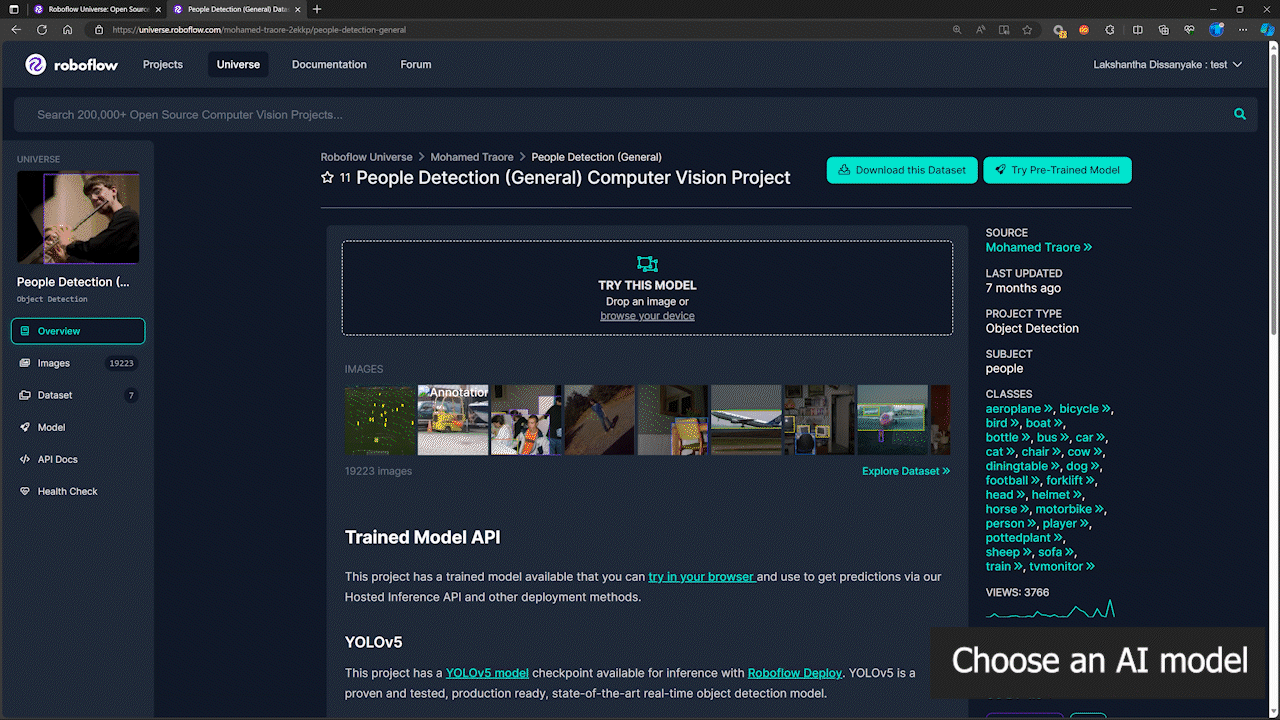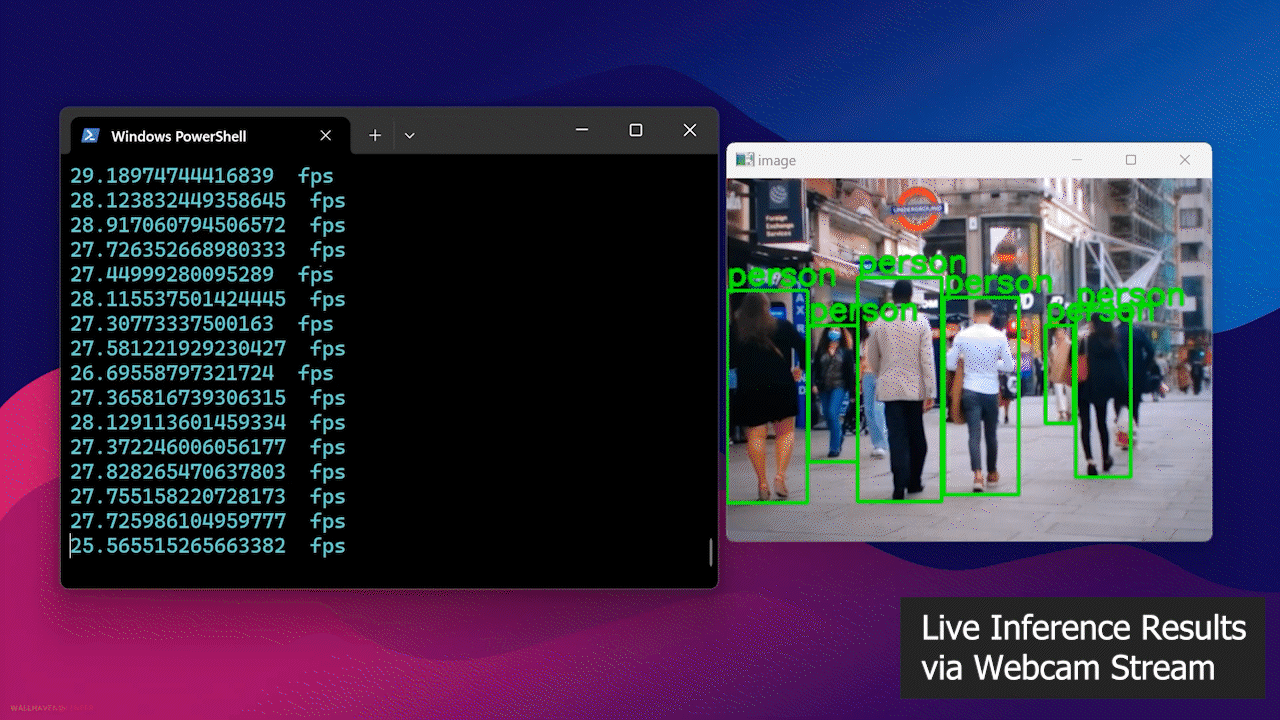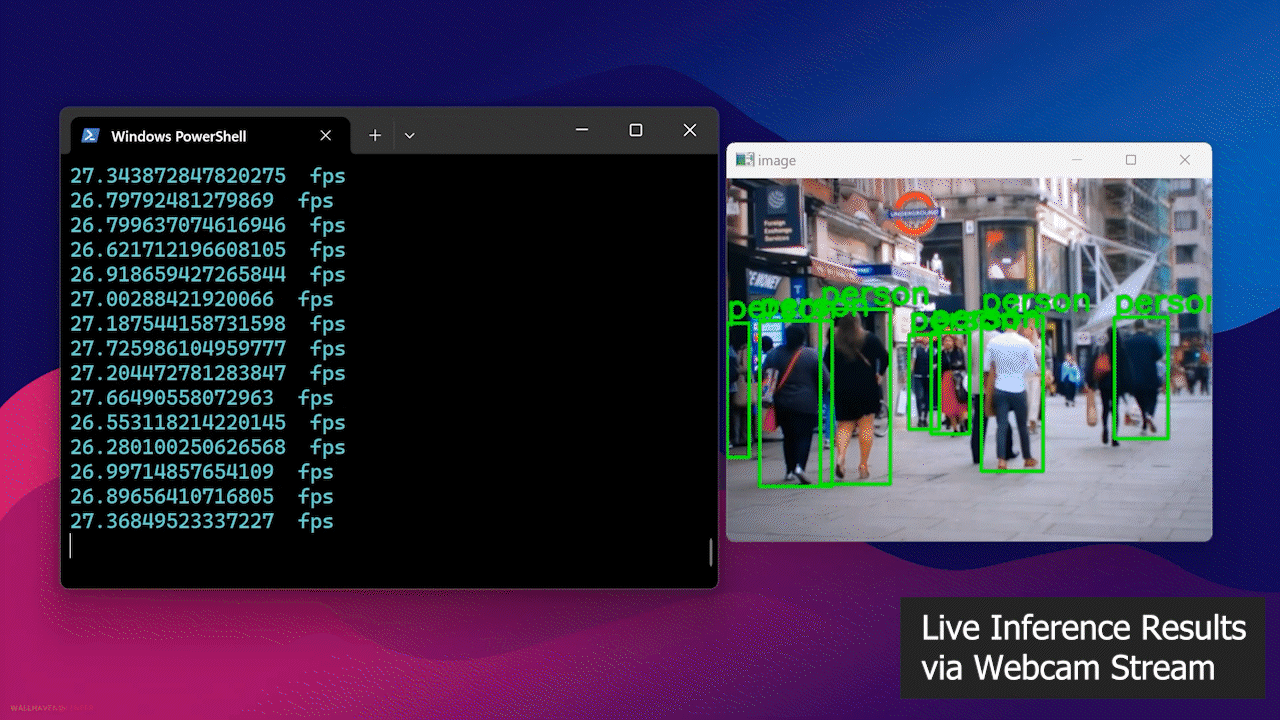
- ステップ 4: Jetsonデバイスにウェブカメラを接続し、以下のPythonスクリプトを実行して、ウェブカメラストリーム上でオープンソースの人物検出モデルを実行します
webcam.py
import cv2
import inference
import supervision as sv
annotator = sv.BoxAnnotator()
inference.Stream(
source="webcam",
model=" people-detection-general/7",
output_channel_order="BGR",
use_main_thread=True,
on_prediction=lambda predictions, image: (
print(predictions),
cv2.imshow(
"Prediction",
annotator.annotate(
scene=image,
detections=sv.Detections.from_roboflow(predictions)
)
),
cv2.waitKey(1)
)
)
最終的に、以下のような結果が表示されます
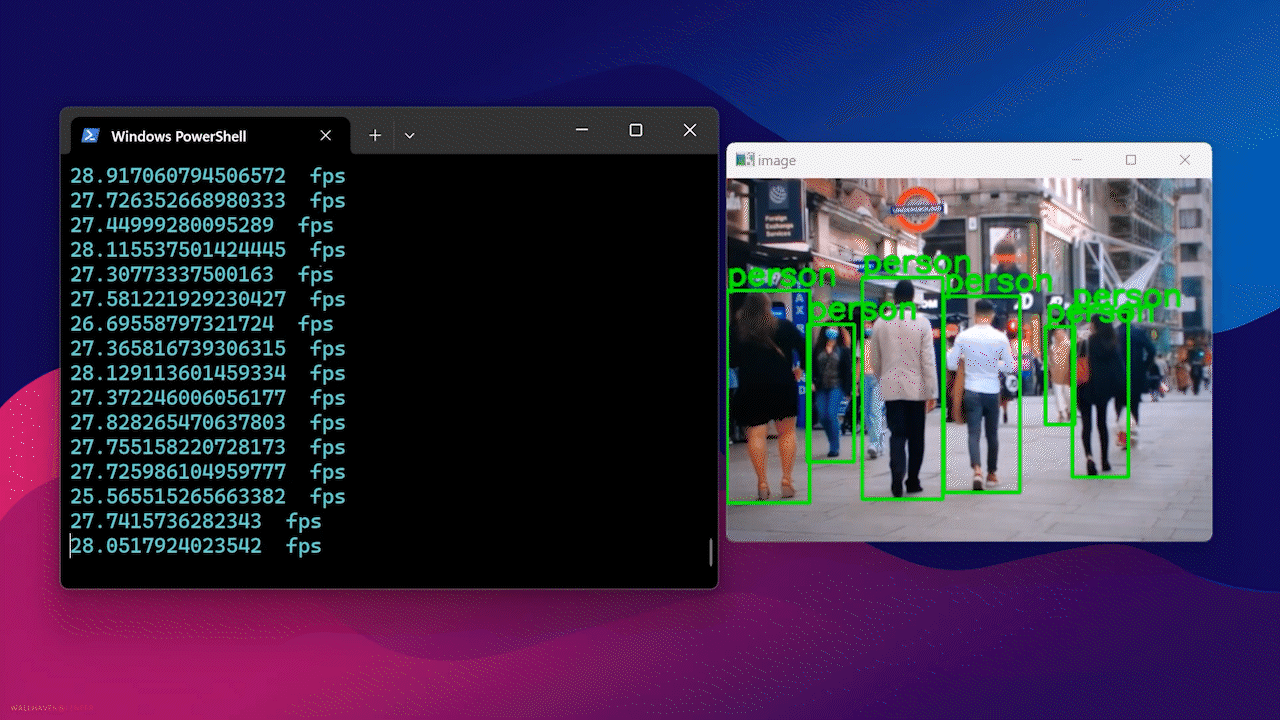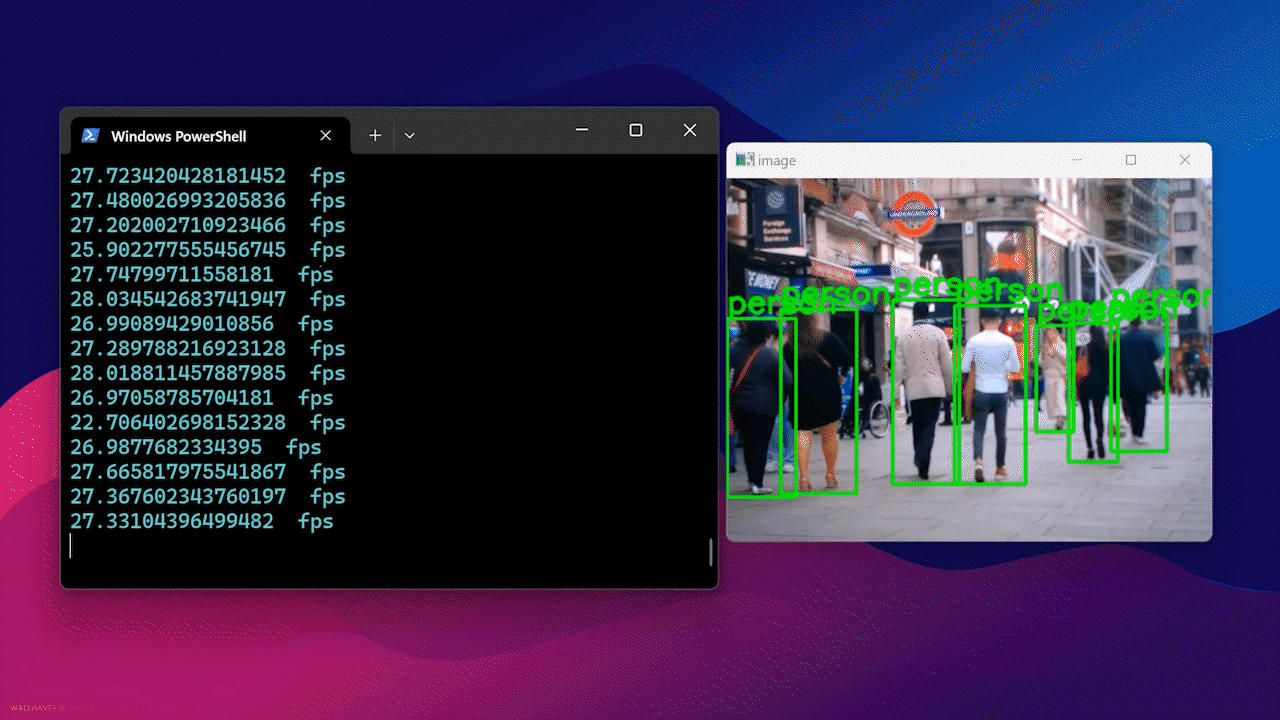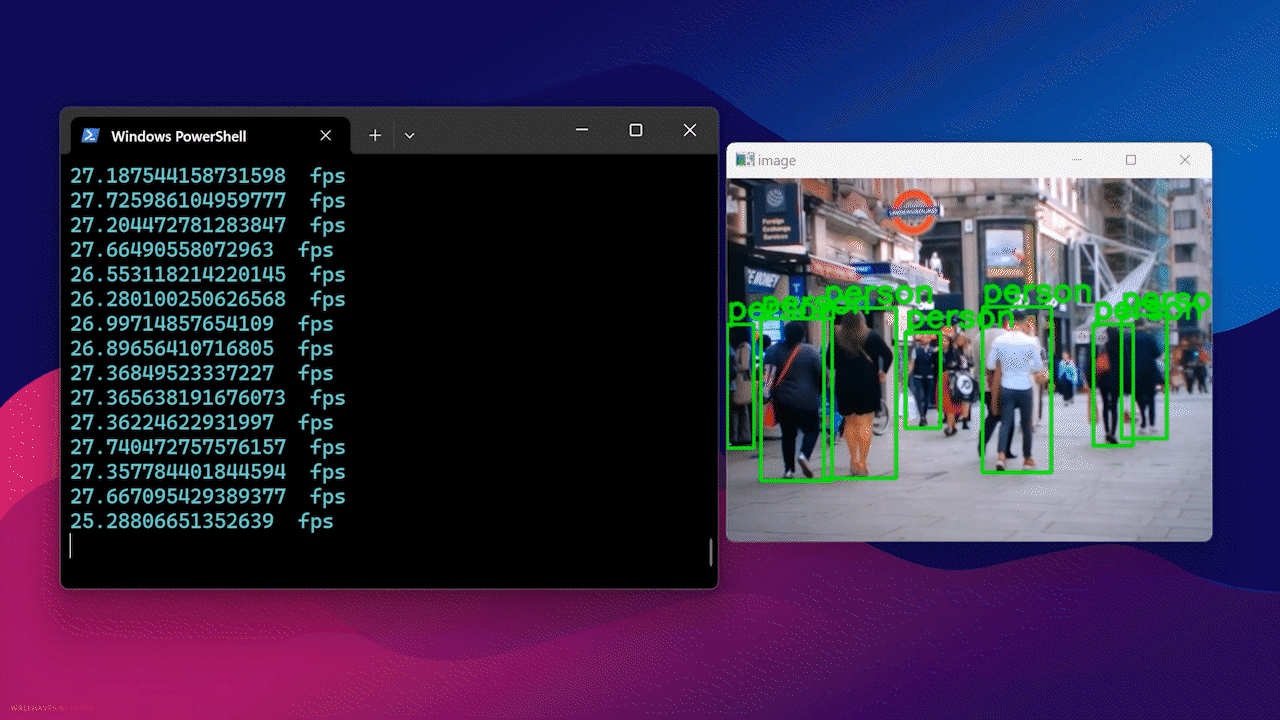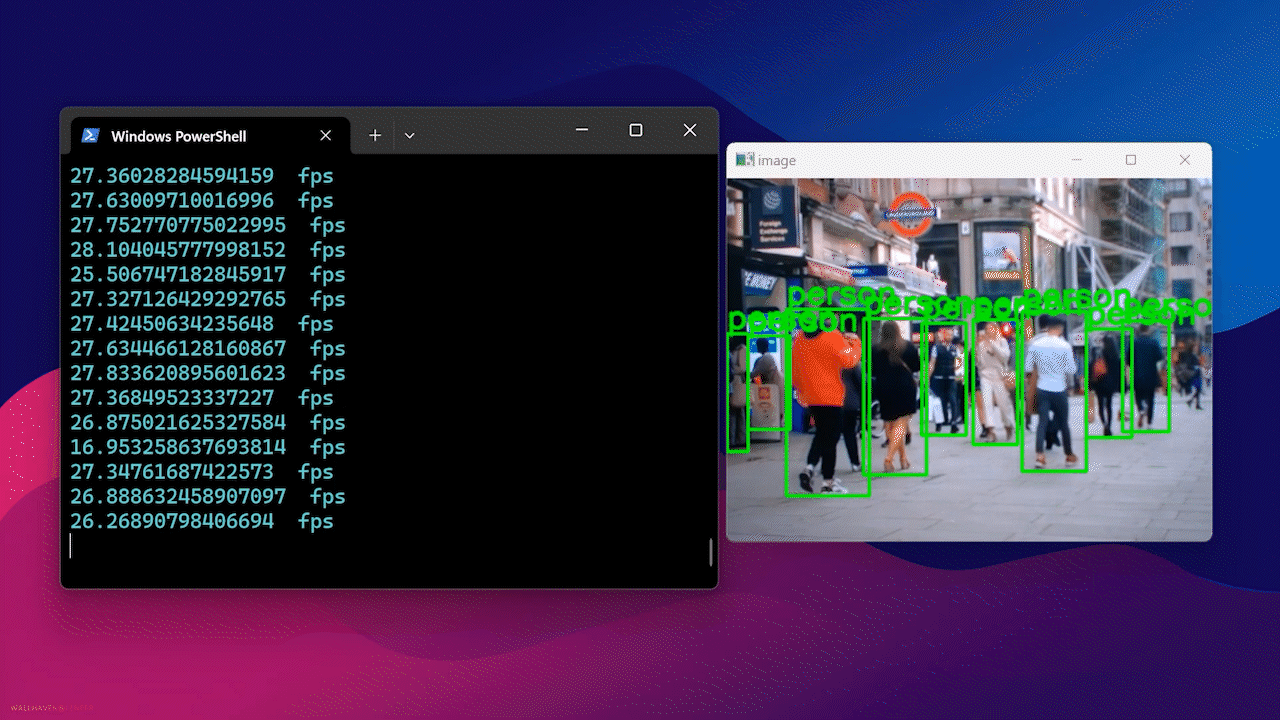
Docker Hubの使用
この方法を使用するには、デバイスにJetson L4Tをフラッシュするだけで十分です。これはクライアント・サーバーアーキテクチャを使用し、RoboflowインファレンスサーバーがJetson上の特定のネットワークポートで実行され、同じネットワーク上の任意のPCからこのインファレンスサーバーにアクセスしたり、Jetson自体をサーバーとクライアントの両方として使用したりできます。
サーバーセットアップ - Jetson
以下を実行して、RoboflowインファレンスサーバーDockerコンテナをダウンロードして実行します
sudo docker run --network=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1
以下の出力が表示されれば、推論サーバーが正常に開始されています

クライアントセットアップ - Jetson/ PC
- ステップ 1: 必要なパッケージをインストールする
sudo apt update
sudo apt install python3-pip -y
git clone https://github.com/roboflow/roboflow-api-snippets
cd Python/webcam
pip install -r requirements.txt
-
ステップ 2: 同じディレクトリに roboflow_config.json ファイルを作成し、Roboflow API キー、モデル名を含めます。この GitHub リポジトリに含まれているサンプル roboflow_config.sample.json ファイルを参照できます
-
ステップ 3: 同じデバイスの別のターミナルウィンドウで、または Jetson と同じネットワーク上の別の PC で、以下の Python スクリプトを実行して、ウェブカメラストリームでオープンソースの人物検出モデルを実行します
python infer-simple.py
ローカル Docker ビルドの使用
サーバーセットアップ - Jetson
この方法を使用するには、デバイスにJetson L4Tをフラッシュするだけで十分です。これはクライアント・サーバーアーキテクチャを使用し、Roboflow推論サーバーがJetson上の特定のネットワークポートで実行され、同じネットワーク上の任意のPCを使用してこの推論サーバーにアクセスしたり、Jetson自体をサーバーとクライアントの両方として使用したりできます。
- ステップ 1: Roboflow推論サーバーリポジトリをクローンする
git clone https://github.com/roboflow/inference
- ステップ 2: "inference"ディレクトリに入り、独自のDockerイメージのコンパイルを開始する
cd inference
sudo docker build \
-f docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1 \
-t roboflow/roboflow-inference-server-jetson-5.1.1:seeed1 .
ここで "-t" の後のテキストは、構築しているコンテナの名前です。任意の名前を付けることができます。
- ステップ 3: 以下のコマンドを実行して、コンパイルした Docker イメージがリストされているかどうかを確認します
sudo docker ps

- ステップ 4: 先ほど構築した Docker イメージを基に Docker コンテナを開始する
docker run --privileged --net=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1:seeed1
以下の出力が表示されれば、推論サーバーが正常に開始されています

クライアント設定 - Jetson/ PC
以下のPythonスクリプトを実行して、Webカメラストリーム上でオープンソースの人物検出モデルを実行します webcam.py
import cv2
import base64
import requests
import time
upload_url = ("http://<ip_address_of_jetson>:9001/"
"people-detection-general/7"
"?api_key=xxxxxxxx"
"&stroke=5")
video = cv2.VideoCapture(0)
while True:
start = time.time()
ret, img = video.read()
if ret:
# Resize (while maintaining the aspect ratio) to improve speed and save bandwidth
height, width, channels = img.shape
scale = 416 / max(height, width)
img = cv2.resize(img, (round(scale * width), round(scale * height)))
# Encode image to base64 string
retval, buffer = cv2.imencode('.jpg', img)
img_str = base64.b64encode(buffer)
# Get prediction from Roboflow Infer API
resp = requests.post(upload_url, data=img_str, headers={
"Content-Type": "application/x-www-form-urlencoded"
}, stream=True)
resp = resp.json()
for bbox in resp["predictions"]:
img = cv2.rectangle(
img,
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2))),
(int(bbox['x']+(bbox['width']/2)), int(bbox['y']+(bbox['height']/2))),
(0, 255, 0),
2)
cv2.putText(
img, f"{bbox['class']}",
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2)-5)),
0, 0.9,
(0, 255, 0), thickness=2, lineType=cv2.LINE_AA
)
cv2.imshow('image', img)
print((1/(time.time()-start)), " fps")
if cv2.waitKey(1) == ord('q'):
break
video.release()
cv2.destroyAllWindows()
注意:スクリプト内の upload_url に含める必要がある要素は以下の通りです:
- roboflow inference サーバーのIPアドレス
- 実行したいモデル
- roboflow api key
モデルはroboflow universeで選択できます
TensorRTの有効化
デフォルトでは、Roboflow inference サーバーはCUDAランタイムを使用しています。しかし、推論速度を向上させるためにTensorRTランタイムに変更したい場合は、"inference/docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1"ファイル内に以下を追加してDockerイメージをビルドできます
ENV ONNXRUNTIME_EXECUTION_PROVIDERS=TensorrtExecutionProvider
さらに詳しく
Roboflowは非常に詳細で包括的なドキュメントを提供しています。そのため、こちらで確認することを強くお勧めします。
技術サポートと製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。さまざまな好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。