SenseCAP A1101に独自のAIモデルを訓練・デプロイする
概要
このwikiでは、特定のアプリケーション向けに独自のAIモデルを訓練し、それをSenseCAP A1101 - LoRaWAN Vision AIセンサーに簡単にデプロイする方法を説明します。さあ、始めましょう!
現在のデバイスファームウェアはEIと互換性があります。2023年3月30日以降にデバイスを購入した場合は、このwikiに従うために、デバイスをデフォルトファームウェアに戻す必要があります。
ハードウェア紹介
このwikiでは主にSenseCAP A1101 - LoRaWAN Vision AIセンサーを使用します。まず、このハードウェアに慣れ親しみましょう。
SenseCAP A1101 - LoRaWAN Vision AIセンサーは、TinyML AI技術とLoRaWAN長距離伝送を組み合わせて、屋外使用向けの低消費電力・高性能AIデバイスソリューションを実現します。このセンサーは、Google TensorFlow Liteフレームワークと複数のTinyML AIプラットフォームをサポートするHimaxの高性能・低消費電力AIビジョンソリューションを特徴としています。異なるモデルで異なるAI機能を実装できます。例えば、害虫検出、人数カウント、物体認識などです。ユーザーはSeeedが提供するモデルを採用したり、AI訓練ツールを通じて独自のモデルを生成したり、Seeedのパートナーモデルプロバイダーからデプロイ可能な商用モデルを調達したりできます。

ソフトウェア紹介
このwikiでは以下のソフトウェア技術を使用します
- Roboflow - アノテーション用
- YOLOv5 - 訓練用
- TensorFlow Lite - 推論用

Roboflowとは?
Roboflowはオンラインベースのアノテーションツールです。このツールを使用すると、すべての画像を簡単にアノテーションし、これらの画像にさらなる処理を追加し、ラベル付きデータセットをYOLOV5 PyTorch、Pascal VOCなどの異なる形式でエクスポートできます!Roboflowには、ユーザーがすぐに利用できるパブリックデータセットもあります。
YOLOv5とは?
YOLOは「You Only Look Once」の略語です。これは、画像内のさまざまなオブジェクトをリアルタイムで検出・認識するアルゴリズムです。Ultralytics YOLOv5は、PyTorchフレームワークに基づくYOLOのバージョンです。
TensorFlow Liteとは?
TensorFlow Liteは、TensorFlowで事前訓練されたモデルを、速度やストレージに最適化できる特別な形式に変換する、オープンソースで製品対応の、クロスプラットフォーム深層学習フレームワークです。この特別な形式のモデルは、AndroidやiOSを使用するモバイルや、Raspberry PiやマイクロコントローラーなどのLinuxベースの組み込みデバイスなどのエッジデバイスにデプロイして、エッジで推論を行うことができます。
Wiki構造
このwikiは3つの主要なセクションに分かれています
最初のセクションは、最少のステップで独自のAIモデルを構築する最も速い方法です。2番目のセクションは、独自のAIモデルを構築するのに時間と労力がかかりますが、知識として確実に価値があります。AIモデルのデプロイに関する3番目のセクションは、最初または2番目のセクションの後に実行できます。
このwikiに従う方法は2つあります:
ただし、最初に1番目の方法に従い、その後2番目の方法に移ることをお勧めします。
1. 公開データセットで独自のAIモデルを訓練する
物体検出プロジェクトの最初のステップは、訓練用のデータを取得することです。公開されているデータセットをダウンロードするか、独自のデータセットを作成することができます!
しかし、物体検出を始める最も速くて簡単な方法は何でしょうか?それは...公開データセットを使用することで、自分でデータを収集してアノテーションを付ける時間を大幅に節約できます。これらの公開データセットはすでにアノテーションが付いているため、AIビジョンアプリケーションに集中する時間を増やすことができます。
ハードウェアの準備
- SenseCAP A1101 - LoRaWAN Vision AI Sensor
- USB Type-Cケーブル
- インターネットアクセス可能なWindows/ Linux/ Mac
ソフトウェアの準備
- 追加のソフトウェアを準備する必要はありません
公開されているアノテーション付きデータセットの使用
COCOデータセット、Pascal VOCデータセットなど、多数の公開データセットをダウンロードできます。Roboflow Universeは推奨プラットフォームで、幅広いデータセットを提供しており、コンピュータビジョンモデルの構築に利用できる90,000以上のデータセットと6600万以上の画像があります。また、Googleでオープンソースデータセットを検索して、利用可能な様々なデータセットから選択することもできます。
-
ステップ1. このURLにアクセスして、Roboflow Universeで公開されているApple Detectionデータセットにアクセスします
-
ステップ2. Create AccountをクリックしてRoboflowアカウントを作成します
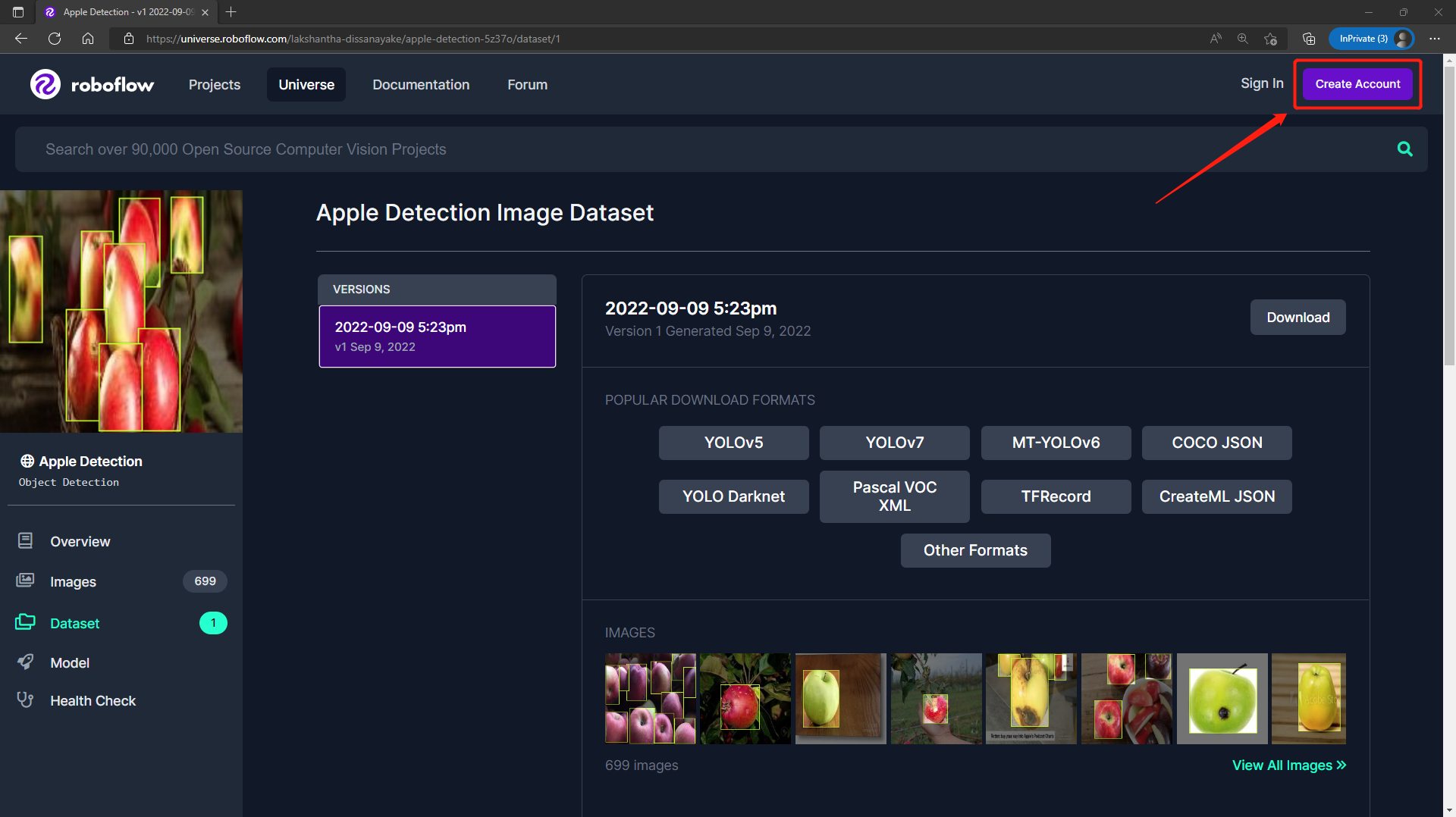
- ステップ3. Downloadをクリックし、FormatとしてYOLO v5 PyTorchを選択し、show download codeをクリックしてContinueをクリックします
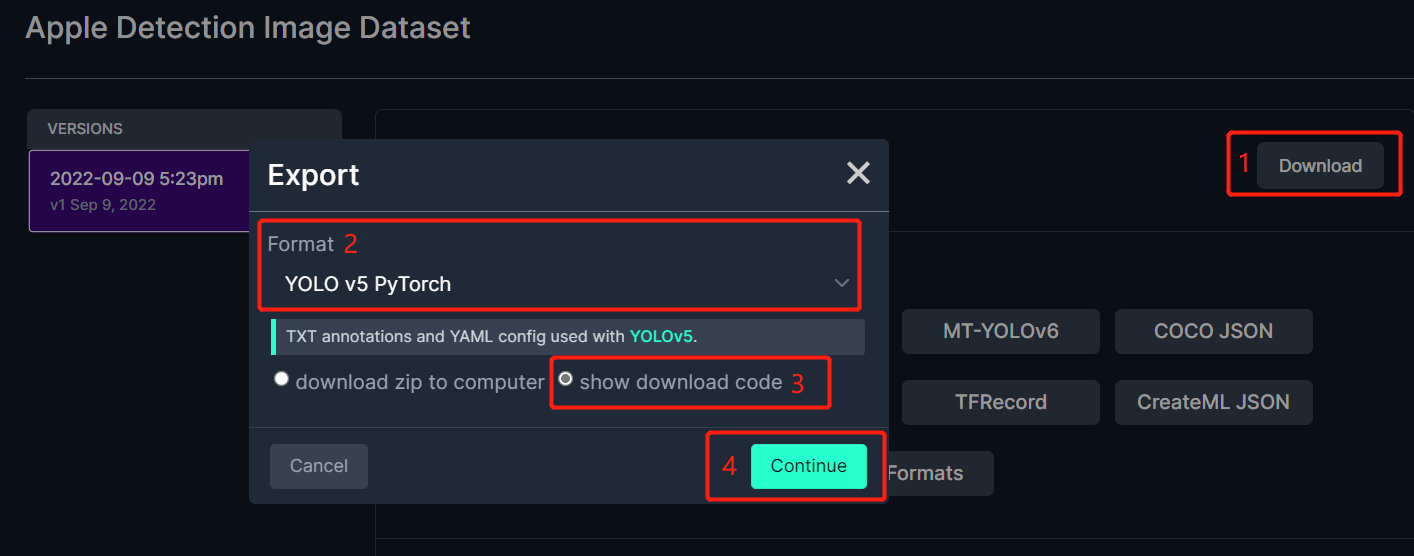
これにより、後でGoogle Colab訓練内で使用するコードスニペットが生成されます。このウィンドウをバックグラウンドで開いたままにしておいてください。
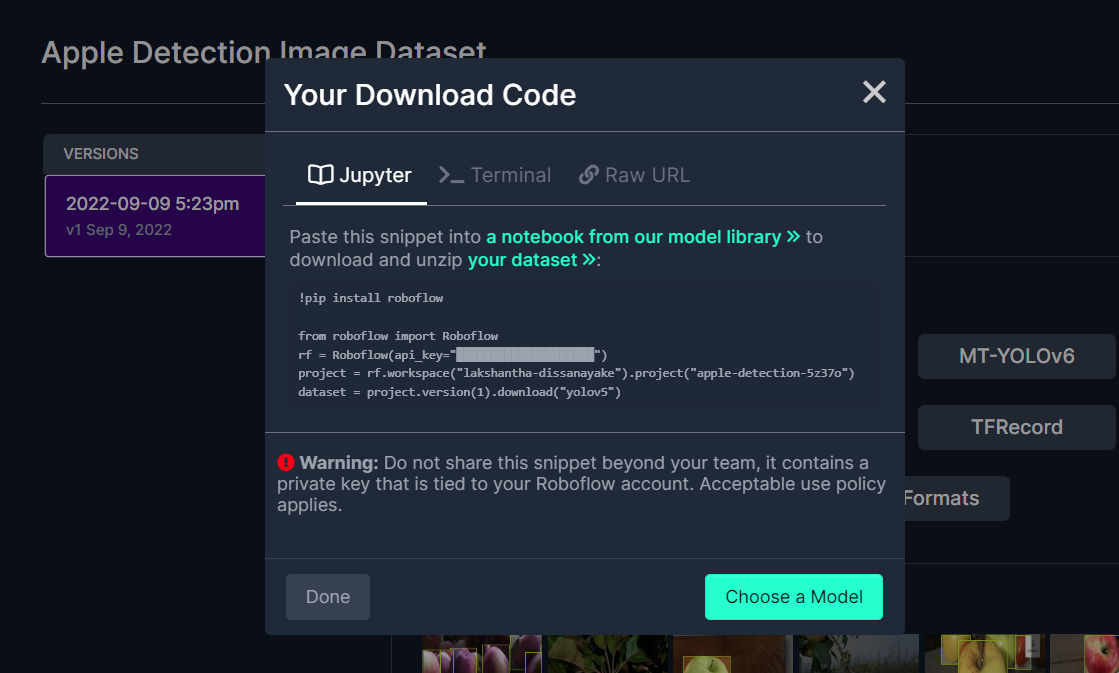
Google ColabでYOLOv5を使用した訓練
公開データセットを選択した後、データセットを訓練する必要があります。ここでは、Google Colaboratory環境を使用してクラウドで訓練を実行します。さらに、Colab内でRoboflow apiを使用してデータセットを簡単にダウンロードします。
ここをクリックして、すでに準備されたGoogle Colabワークスペースを開き、ワークスペースで説明されているステップを実行し、コードセルを1つずつ実行してください。
注意: Google Colabのステップ4の下のコードセルでは、上記で説明したようにRoboflowからコードスニペットを直接コピーできます
以下の内容を説明します:
- 訓練環境のセットアップ
- データセットのダウンロード
- 訓練の実行
- 訓練されたモデルのダウンロード
699枚の画像を含むりんご検出データセットの場合、16GBのGPUメモリを持つNVIDIA Tesla T4 GPU上で動作するGoogle Colabで訓練プロセスを完了するのに約7分かかりました。
上記のColabプロジェクトに従った場合、デバイスに4つのモデルを一度にロードできることがわかります。ただし、一度に1つのモデルのみをロードできることに注意してください。これはユーザーが指定でき、このwikiで後ほど説明します。
デプロイと推論
訓練されたAIモデルをSenseCAP A1101にデプロイして推論を実行する方法を説明するセクション3に直接ジャンプしたい場合は、ここをクリックしてください。
2. 独自のデータセットで独自のAIモデルを訓練する
パブリックデータセットに検出したいオブジェクトが含まれていない特定の物体検出プロジェクトを構築したい場合は、独自のデータセットを構築することをお勧めします。独自のデータセット用にデータを記録する際は、オブジェクトのすべての角度(360度)をカバーし、オブジェクトを異なる環境、異なる照明、異なる天候条件に配置することを確認する必要があります。独自のデータセットを記録した後、データセット内の画像にアノテーションを付ける必要もあります。これらすべてのステップは、このセクションで説明されます。
携帯電話のカメラを使用するなど、データを収集する方法は異なりますが、データを収集する最良の方法は、SenseCAP A1101に内蔵されたカメラを使用することです。これは、SenseCAP A1101で推論を実行する際に、色、画質、その他の詳細が類似しているため、全体的な検出がより正確になるためです。
ハードウェアの準備
- SenseCAP A1101 - LoRaWAN Vision AI Sensor
- USB Type-Cケーブル
- インターネットアクセス可能なWindows/ Linux/ Mac
ソフトウェアの準備
それでは、ソフトウェアをセットアップしましょう。Windows、Linux、Intel Macのソフトウェアセットアップは同じですが、M1/M2 Macでは異なります。
Windows、Linux、Intel Mac
-
ステップ 1. コンピューターにPythonがすでにインストールされていることを確認してください。インストールされていない場合は、このページにアクセスして、最新バージョンのPythonをダウンロードしてインストールしてください
-
ステップ 2. 以下の依存関係をインストールしてください
pip3 install libusb1
M1/ M2 Mac
- ステップ1. Homebrewをインストールする
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- ステップ 2. conda をインストールする
brew install conda
- ステップ 3. libusb をダウンロード
wget https://conda.anaconda.org/conda-forge/osx-arm64/libusb-1.0.26-h1c322ee_100.tar.bz2
- ステップ 4. libusb をインストールする
conda install libusb-1.0.26-h1c322ee_100.tar.bz2
データセットの収集
- ステップ1. USB Type-Cケーブルを使用してSenseCAP A1101をPCに接続します

- ステップ2. ブートボタンをダブルクリックしてブートモードに入ります

この後、ファイルエクスプローラーにSENSECAPとして新しいストレージドライブが表示されます
- ステップ3. この.uf2ファイルをSENSECAPドライブにドラッグアンドドロップします
uf2ファイルのドライブへのコピーが完了すると、ドライブが消えます。これは、uf2がモジュールに正常にアップロードされたことを意味します。
-
ステップ4. このPythonスクリプトをコピーして、PC上に新しく作成したcapture_images_script.pyという名前のファイルに貼り付けます
-
ステップ5. Pythonスクリプトを実行して画像のキャプチャを開始します
python3 capture_images_script.py
デフォルトでは、300msごとに画像をキャプチャします。これを変更したい場合は、次の形式でスクリプトを実行できます
python3 capture_images_script.py --interval <time_in_ms>
例えば、1秒ごとに画像をキャプチャするには
python3 capture_images_script.py --interval 1000
上記のスクリプトを実行した後、SenseCAP A1101は内蔵カメラから継続的に画像をキャプチャし、save_imgという名前のフォルダ内にすべての画像を保存します。
また、録画中にプレビューウィンドウが開きます。
十分な画像をキャプチャした後、ターミナルウィンドウをクリックし、以下のキーの組み合わせを押してキャプチャプロセスを停止します。
- Windows: Ctrl + Break
- Linux: Ctrl + Shift + \
- Mac: CMD + Shift + \
画像収集後のデバイスファームウェアの変更
データセット用の画像の録画が完了した後、SenseCAP A1101内のファームウェアを元に戻す必要があります。これにより、再び物体検出モデルを読み込んで検出を行うことができます。手順を説明します。
-
ステップ1. 前述の通り、SenseCAP A1101をブートモードに入れます
-
ステップ2. お使いのデバイスに応じて、この.uf2ファイルをSENSECAPドライブにドラッグアンドドロップします
uf2ファイルのドライブへのコピーが完了すると、ドライブが消えます。これは、uf2がモジュールに正常にアップロードされたことを意味します。
Roboflowを使用したデータセットのアノテーション
独自のデータセットを使用する場合、データセット内のすべての画像にアノテーションを付ける必要があります。アノテーションとは、検出したい各オブジェクトの周りに長方形のボックスを描き、ラベルを割り当てることです。Roboflowを使用してこれを行う方法を説明します。
Roboflowは、オンラインベースのアノテーションツールです。ここでは、録画したビデオ映像を直接Roboflowにインポートでき、一連の画像としてエクスポートされます。このツールは、データセットを「トレーニング、検証、テスト」に分散するのに役立つため、非常に便利です。また、このツールでは、ラベル付け後にこれらの画像にさらなる処理を追加することができます。さらに、ラベル付けされたデータセットをYOLOV5 PyTorch形式に簡単にエクスポートできます。これはまさに私たちが必要とするものです!
このwikiでは、リンゴを含む画像のデータセットを使用して、後でリンゴを検出し、カウントも行えるようにします。
-
ステップ1. こちらをクリックしてRoboflowアカウントにサインアップします
-
ステップ2. Create New Projectをクリックしてプロジェクトを開始します
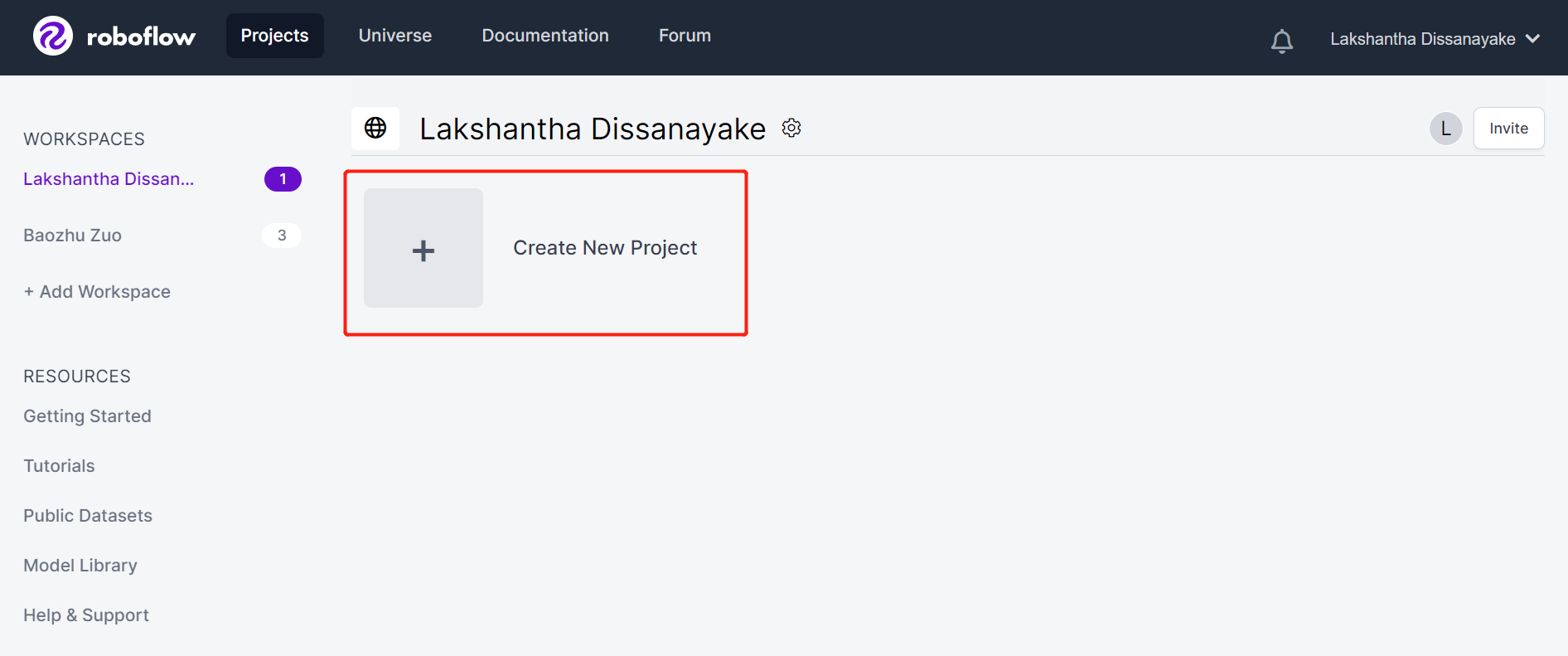
- ステップ3. Project Nameを入力し、**License (CC BY 4.0)とProject type (Object Detection (Bounding Box))**をデフォルトのままにします。What will your model predict?列の下で、アノテーショングループ名を入力します。例えば、私たちの場合はapplesを選択します。この名前は、データセットのすべてのクラスを強調する必要があります。最後に、Create Public Projectをクリックします。
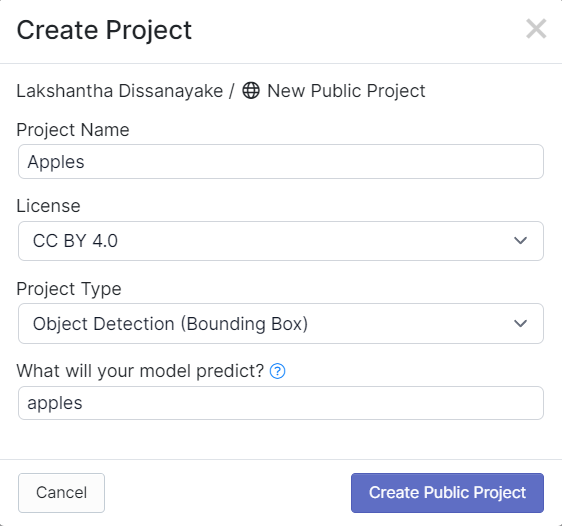
- ステップ4. SenseCAP A1101を使用してキャプチャした画像をドラッグアンドドロップします
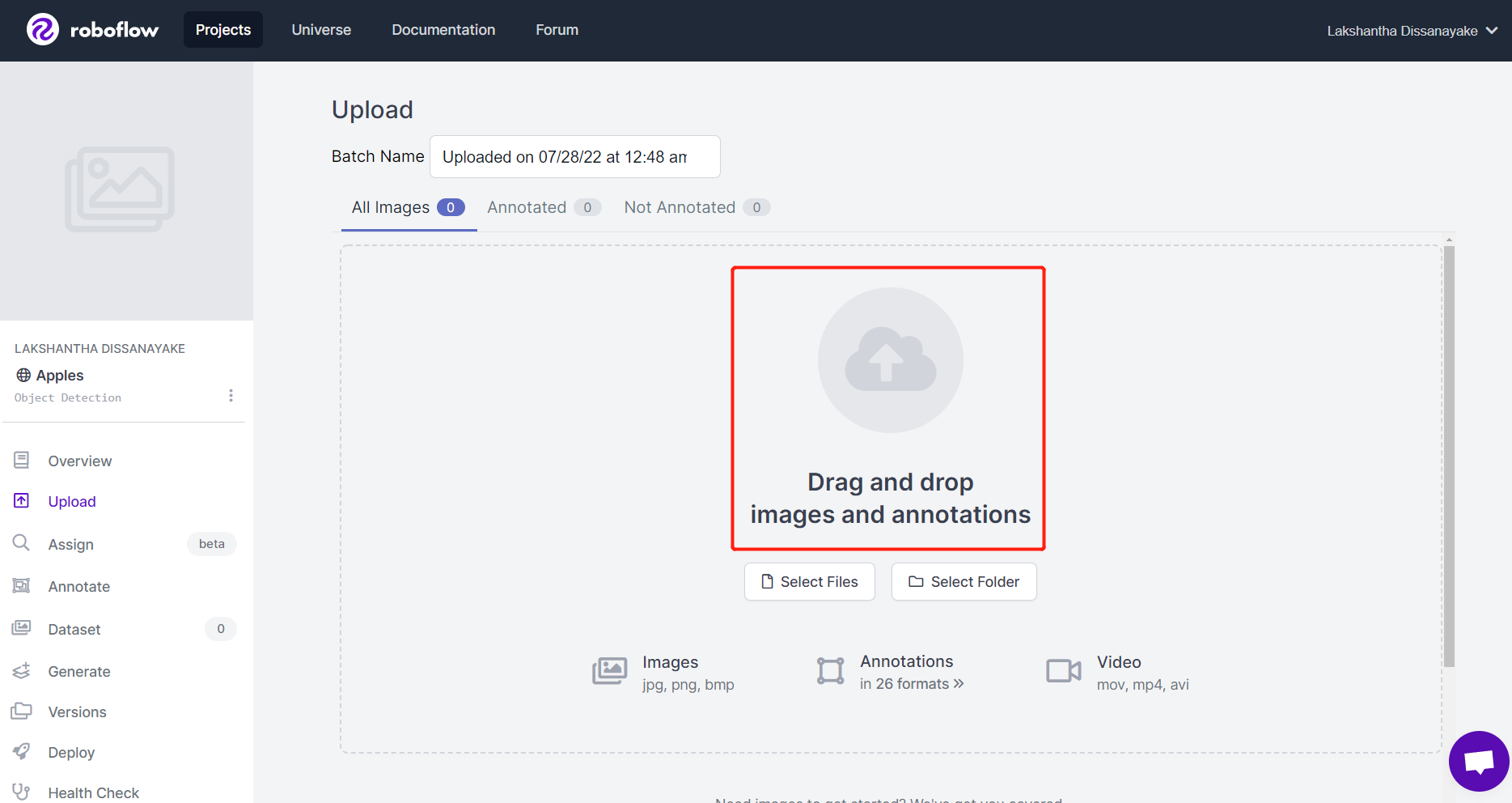
- ステップ5. 画像が処理された後、Finish Uploadingをクリックします。画像がアップロードされるまで辛抱強く待ちます。
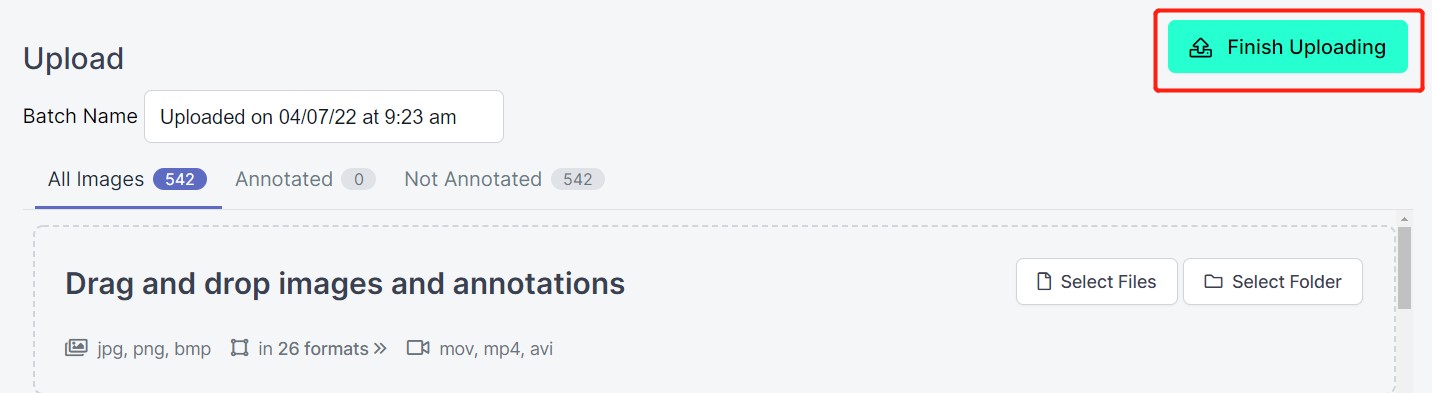
- ステップ6. 画像がアップロードされた後、Assign Imagesをクリックします
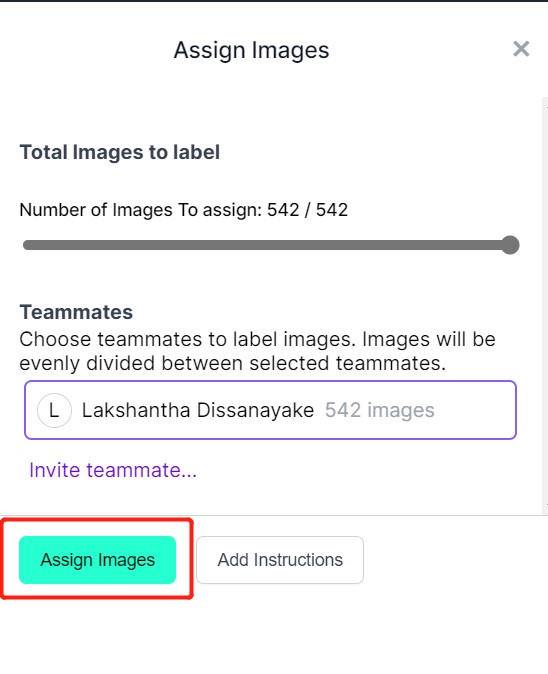
- ステップ7. 画像を選択し、リンゴの周りに長方形のボックスを描き、ラベルをappleとして選択し、ENTERを押します
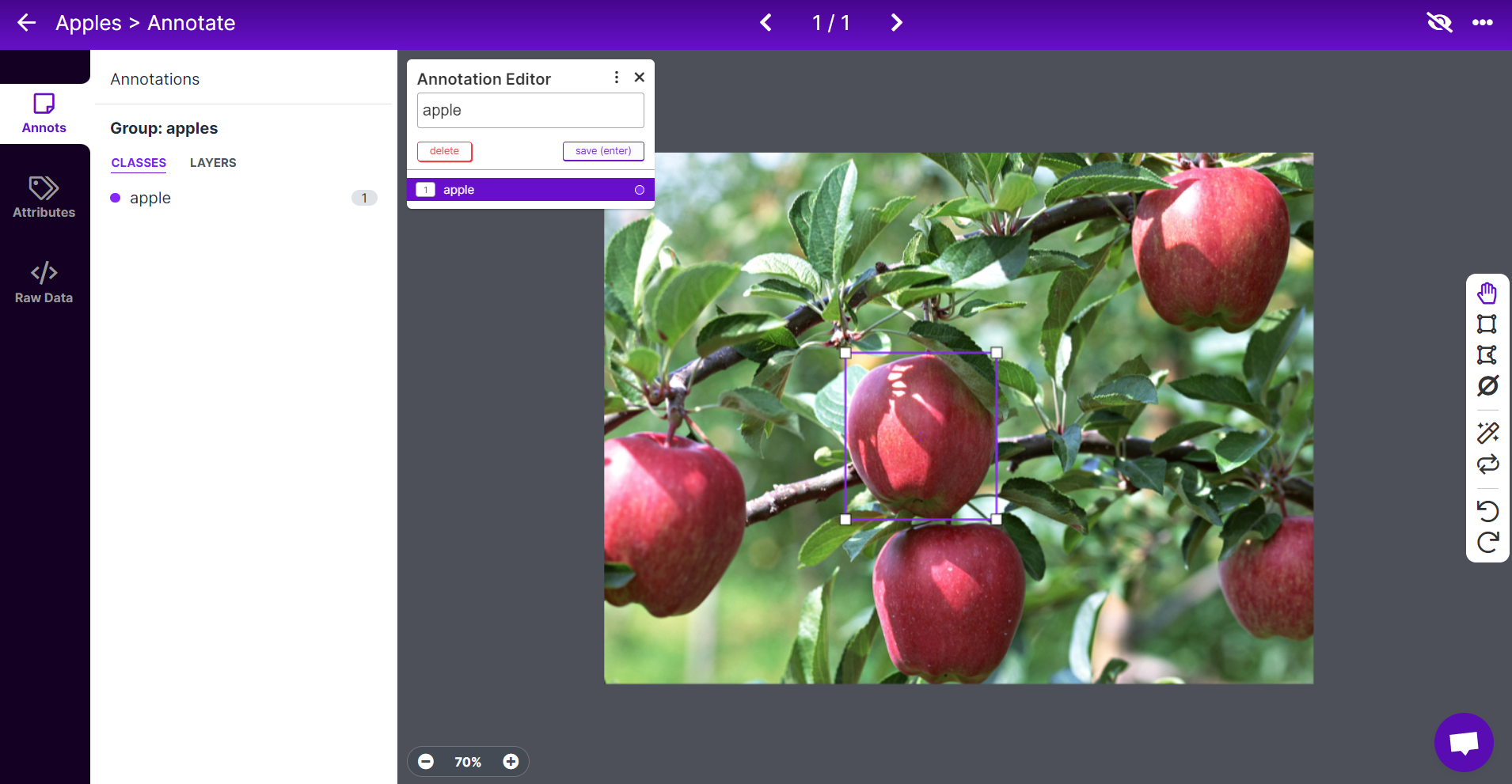
- ステップ8. 残りのリンゴについても同じことを繰り返します
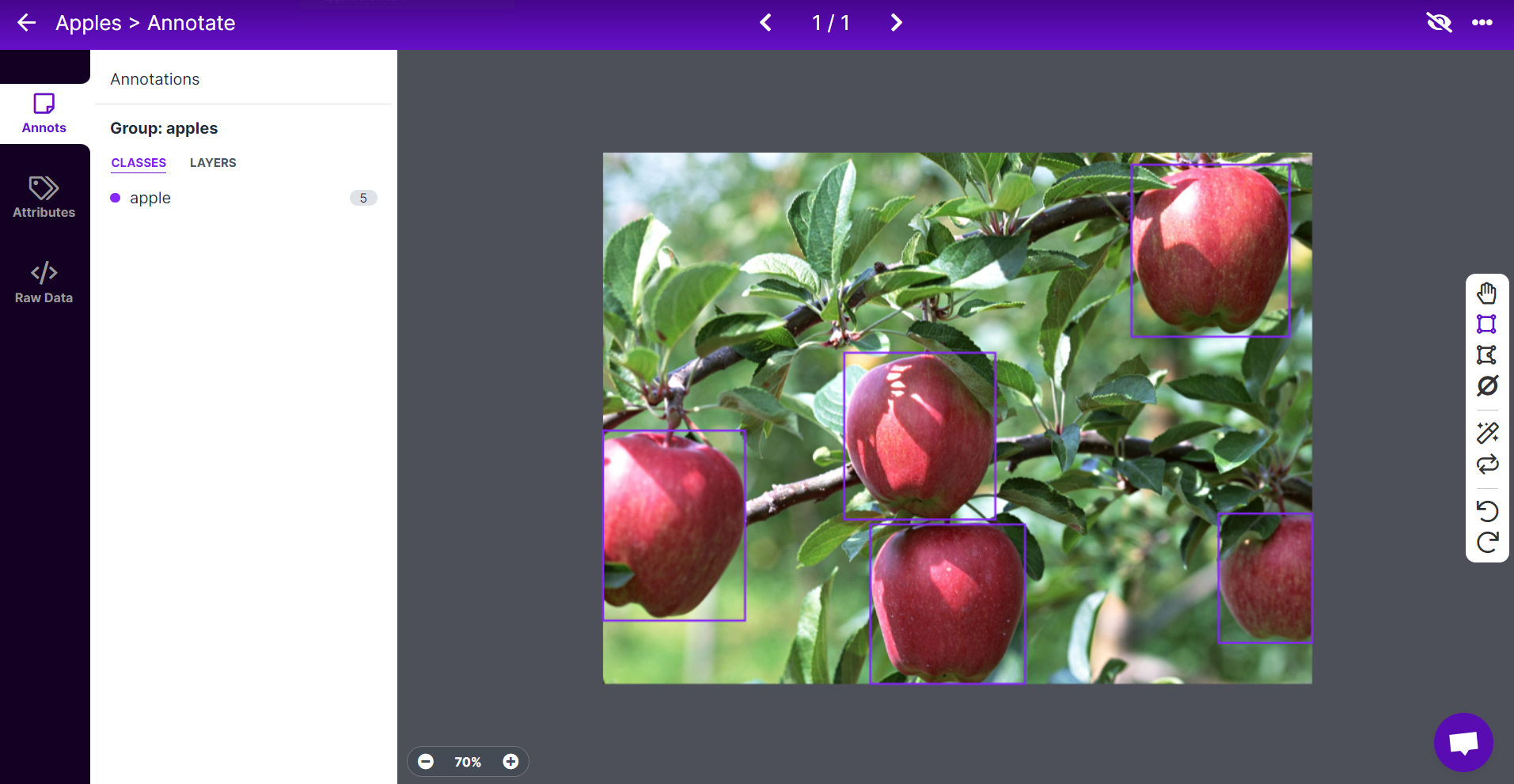
注意: 画像内に見えるすべてのリンゴにラベルを付けるようにしてください。リンゴの一部だけが見える場合も、それにもラベルを付けるようにしてください。
- ステップ9. データセット内のすべての画像のアノテーションを続けます
RoboflowにはLabel Assistという機能があり、事前にラベルを予測できるため、ラベル付けがはるかに高速になります。ただし、すべてのオブジェクトタイプで機能するわけではなく、選択されたタイプのオブジェクトでのみ機能します。この機能をオンにするには、Label Assistボタンを押し、モデルを選択し、クラスを選択して、画像をナビゲートして予測されたラベルとバウンディングボックスを確認するだけです
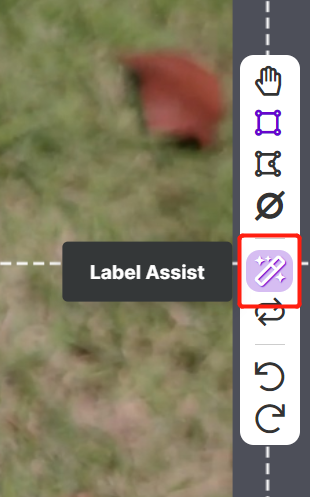
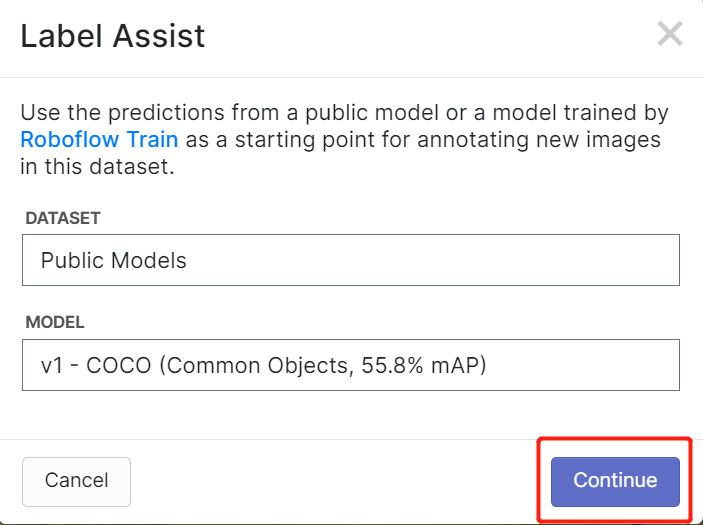
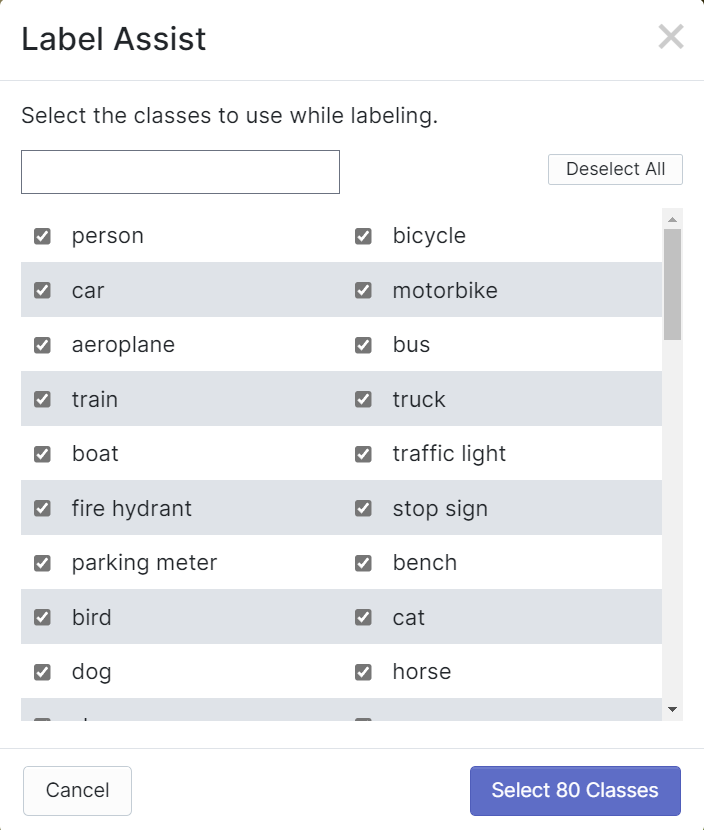
上記のように、言及された80クラスのアノテーションの予測のみを支援できます。画像に上記のオブジェクトクラスが含まれていない場合、ラベルアシスト機能を使用することはできません。
- ステップ10. ラベル付けが完了したら、Add images to Datasetをクリックします

- ステップ11. 次に、「Train、Valid、Test」間で画像を分割します。分布のデフォルトのパーセンテージを保持し、Add Imagesをクリックします
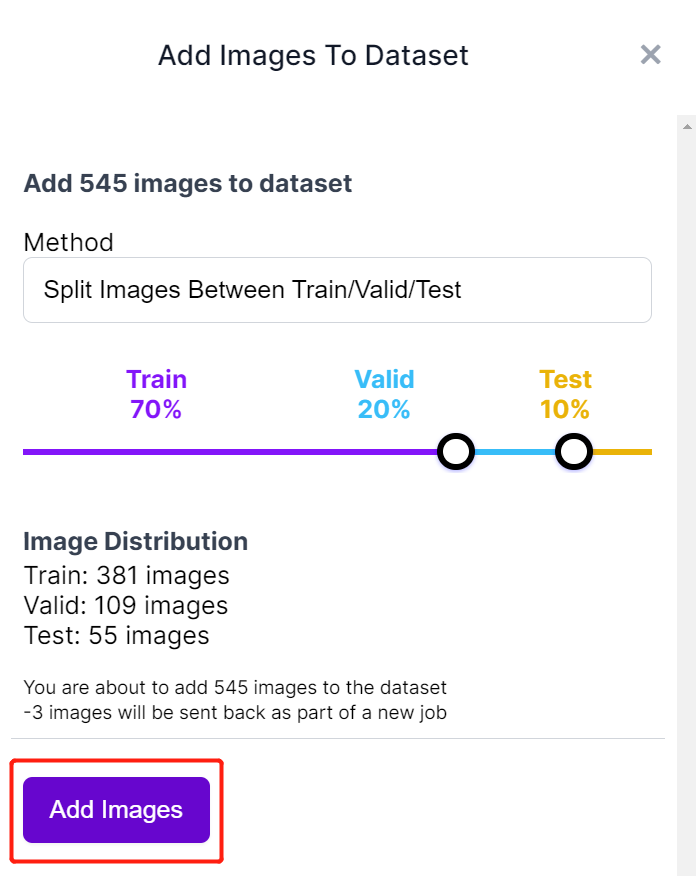
- ステップ12. Generate New Versionをクリックします

- ステップ13. 必要に応じてPreprocessingとAugmentationを追加できます。ここでは、Resizeオプションを192x192に変更します
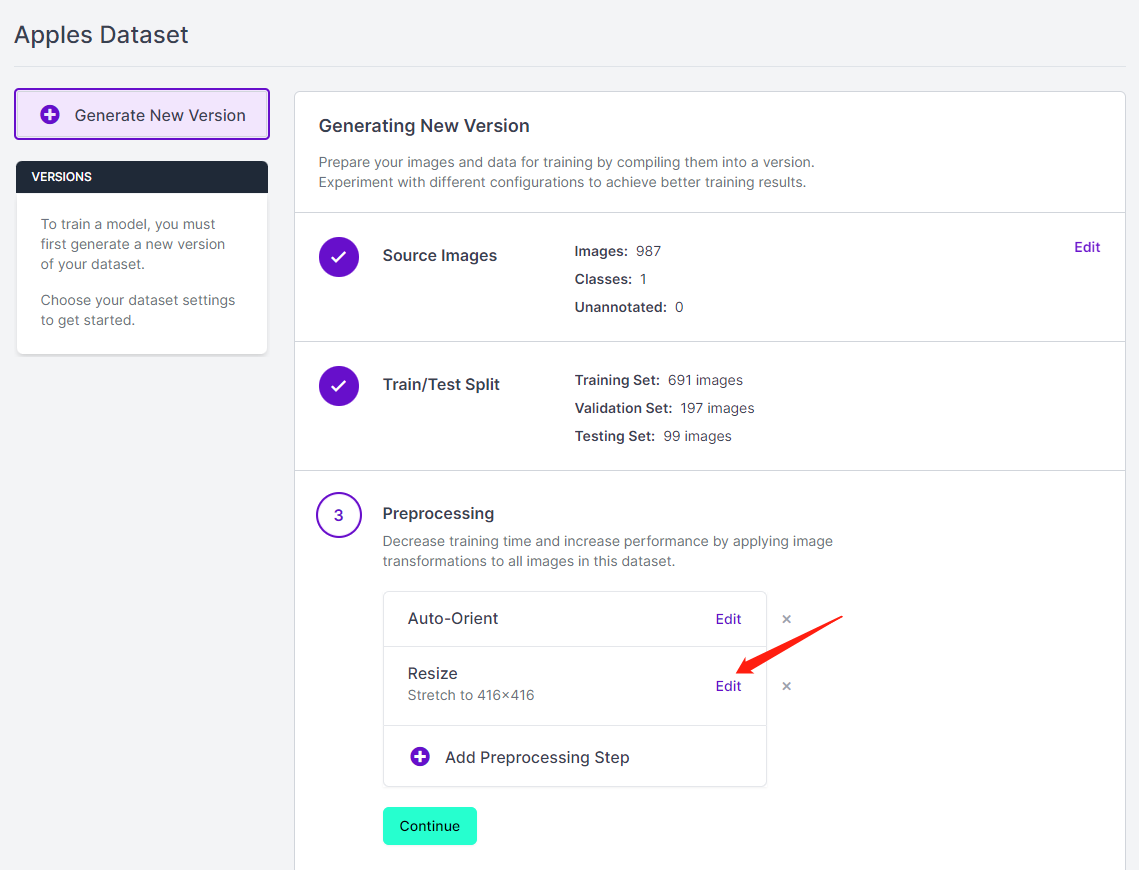
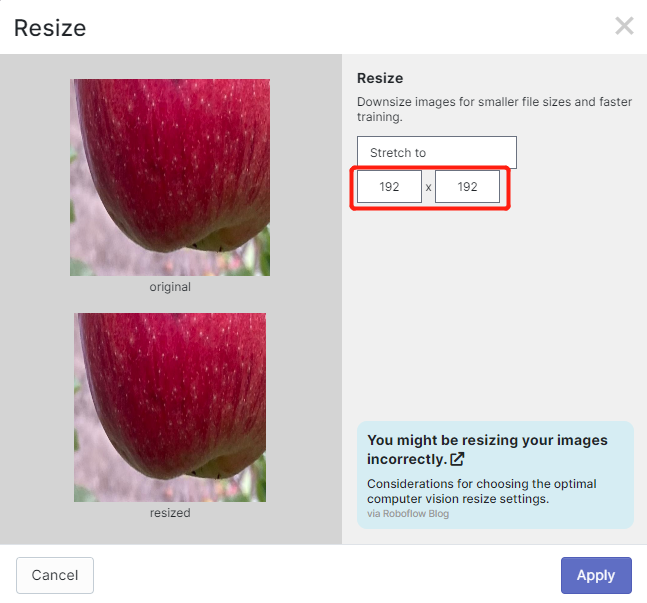
ここでは、トレーニングに192x192のサイズを使用するため、画像サイズを192x192に変更します。これによりトレーニングが高速化されます。そうしないと、トレーニングプロセス中にすべての画像を192x192に変換する必要があり、より多くのCPUリソースを消費してトレーニングプロセスが遅くなります。
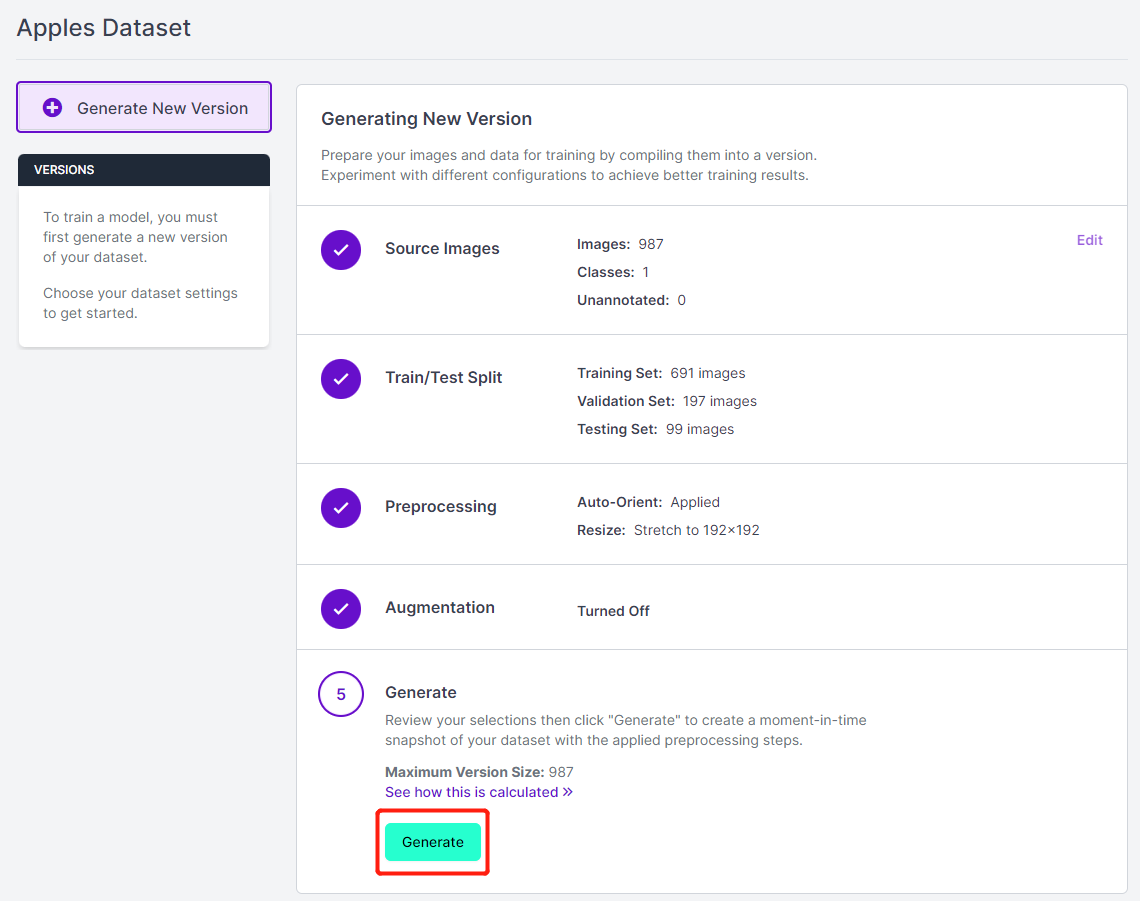
- ステップ 14. 次に、残りのデフォルト設定で進み、Generateをクリックします
- ステップ 15. Exportをクリックし、FormatとしてYOLO v5 PyTorchを選択し、show download codeを選択してContinueをクリックします
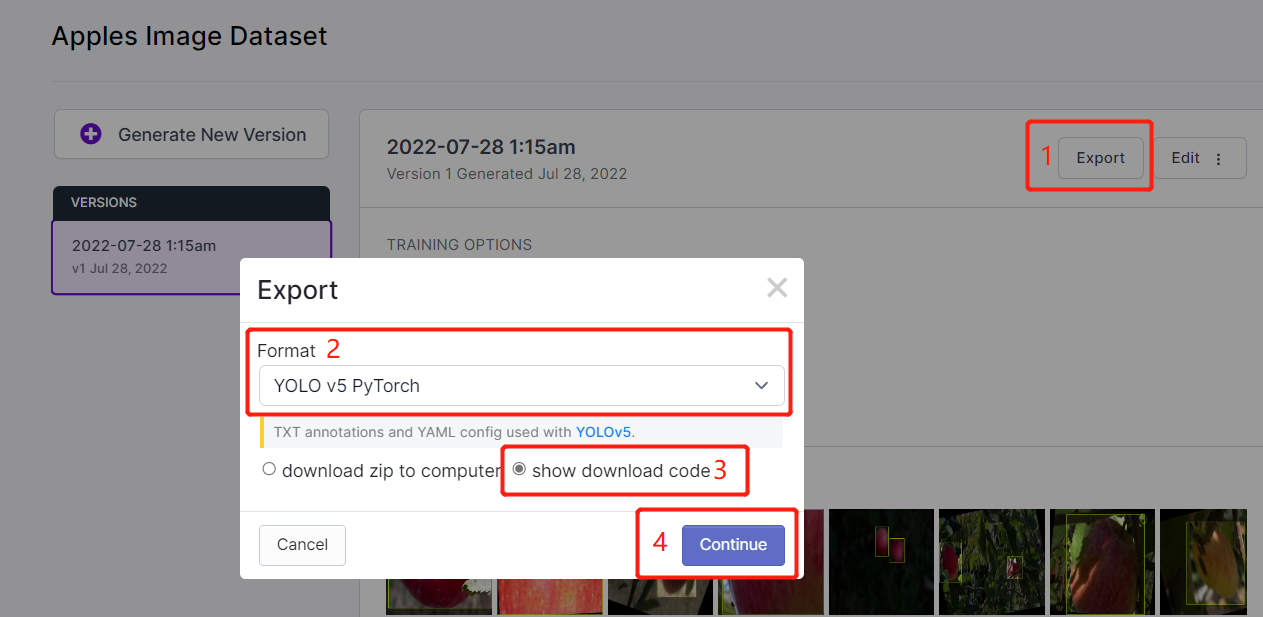
これにより、後でGoogle Colabトレーニング内で使用するコードスニペットが生成されます。このウィンドウをバックグラウンドで開いたままにしておいてください。
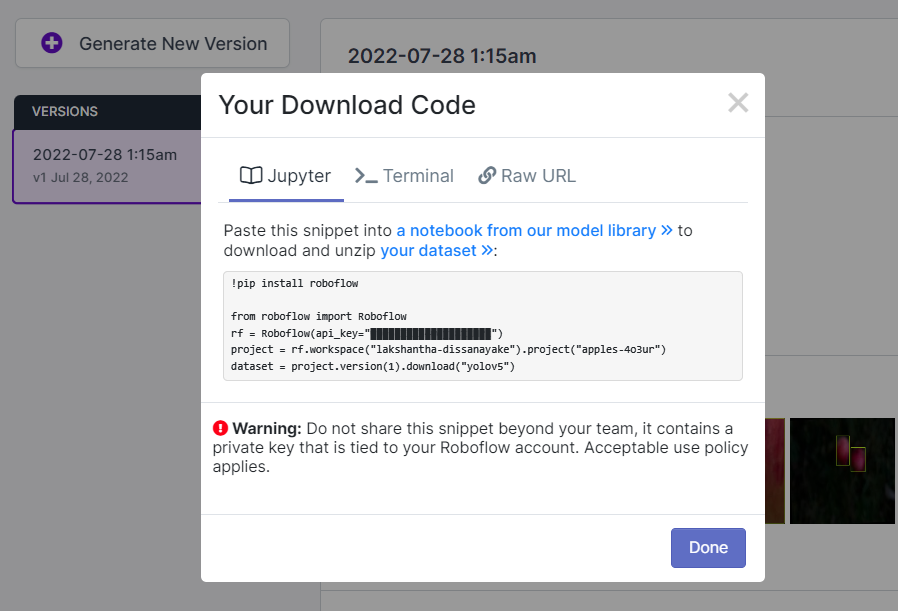
Google ColabでYOLOv5を使用したトレーニング
データセットのアノテーションが完了したら、データセットをトレーニングする必要があります。Google Colab上で実行されるYOLOv5を使用してAIモデルをトレーニングする方法を説明しているこの部分にジャンプしてください。
3. トレーニング済みモデルをデプロイして推論を実行する
次に、トレーニングの最後に取得したmodel-1.uf2をSenseCAP A1101に移動します。
-
ステップ 1. 最新バージョンのGoogle ChromeまたはMicrosoft Edgeブラウザをインストールして開きます
-
ステップ 2. USB Type-CケーブルでSenseCAP A1101をPCに接続します
- ステップ 3. SenseCAP A1101のブートボタンをダブルクリックして、マスストレージモードに入ります
この後、ファイルエクスプローラーにSENSECAPとして新しいストレージドライブが表示されます
- ステップ 4. model-1.uf2ファイルをSENSECAPドライブにドラッグアンドドロップします
uf2のコピーがドライブに完了すると、ドライブが消えます。これは、uf2がモジュールに正常にアップロードされたことを意味します。
注意: 4つのモデルファイルが準備できている場合は、各モデルを1つずつドラッグアンドドロップできます。最初のモデルをドロップし、コピーが完了するまで待ち、再度ブートモードに入り、2番目のモデルをドロップするという具合に進めます。SenseCAP A1101に1つのモデル(インデックス1)のみをロードした場合、そのモデルがロードされます。
-
ステップ 5. SenseCAP Mate Appを開きます。お持ちでない場合は、お使いのOSに応じてモバイルフォンにダウンロードしてインストールしてください
-
ステップ 6. アプリを開き、Config画面でVision AI Sensorを選択します

- ステップ 7. SenseCap A1101の設定ボタンを3秒間長押しして、Bluetoothペアリングモードに入ります

- ステップ 8. Setupをクリックすると、近くのSenseCAP A1101デバイスのスキャンが開始されます
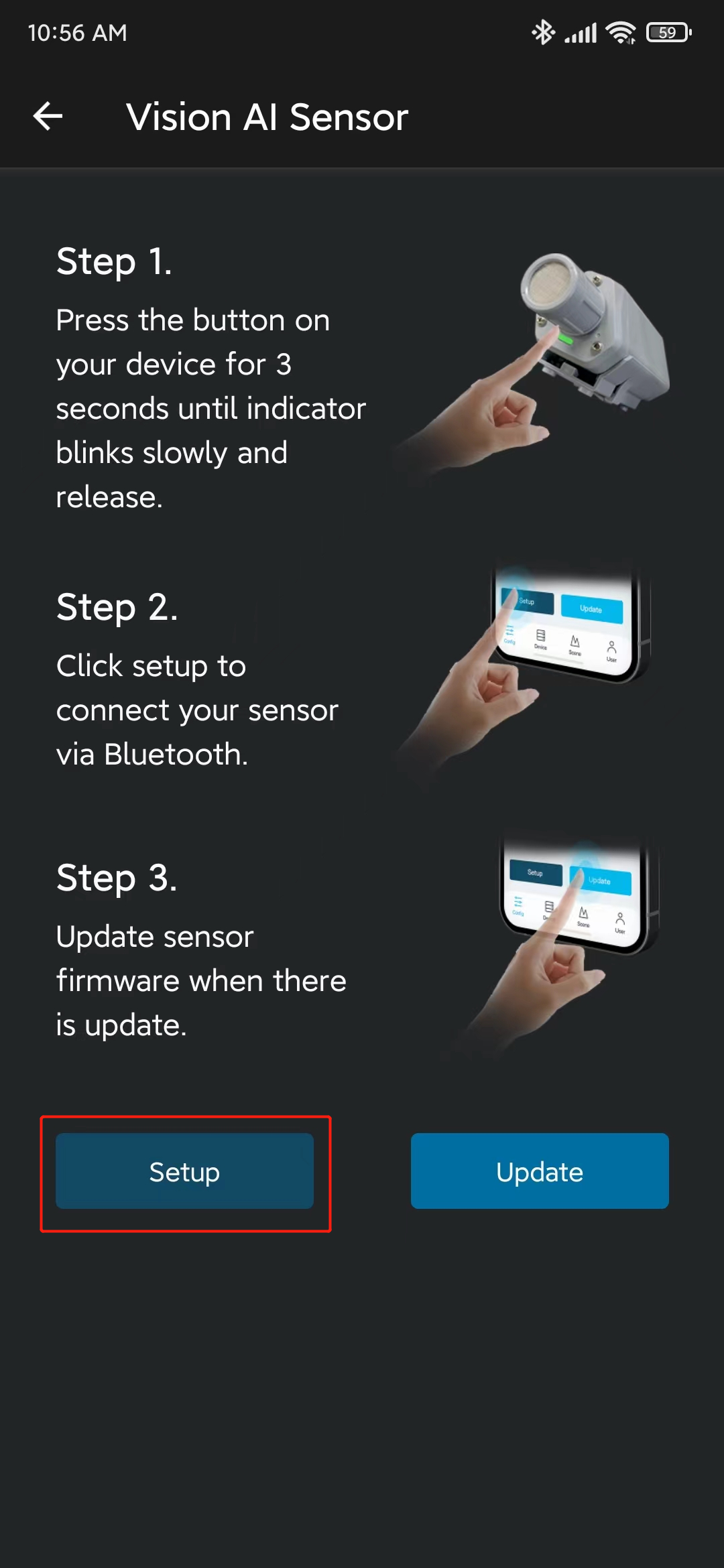
- ステップ 9. 見つかったデバイスをクリックします
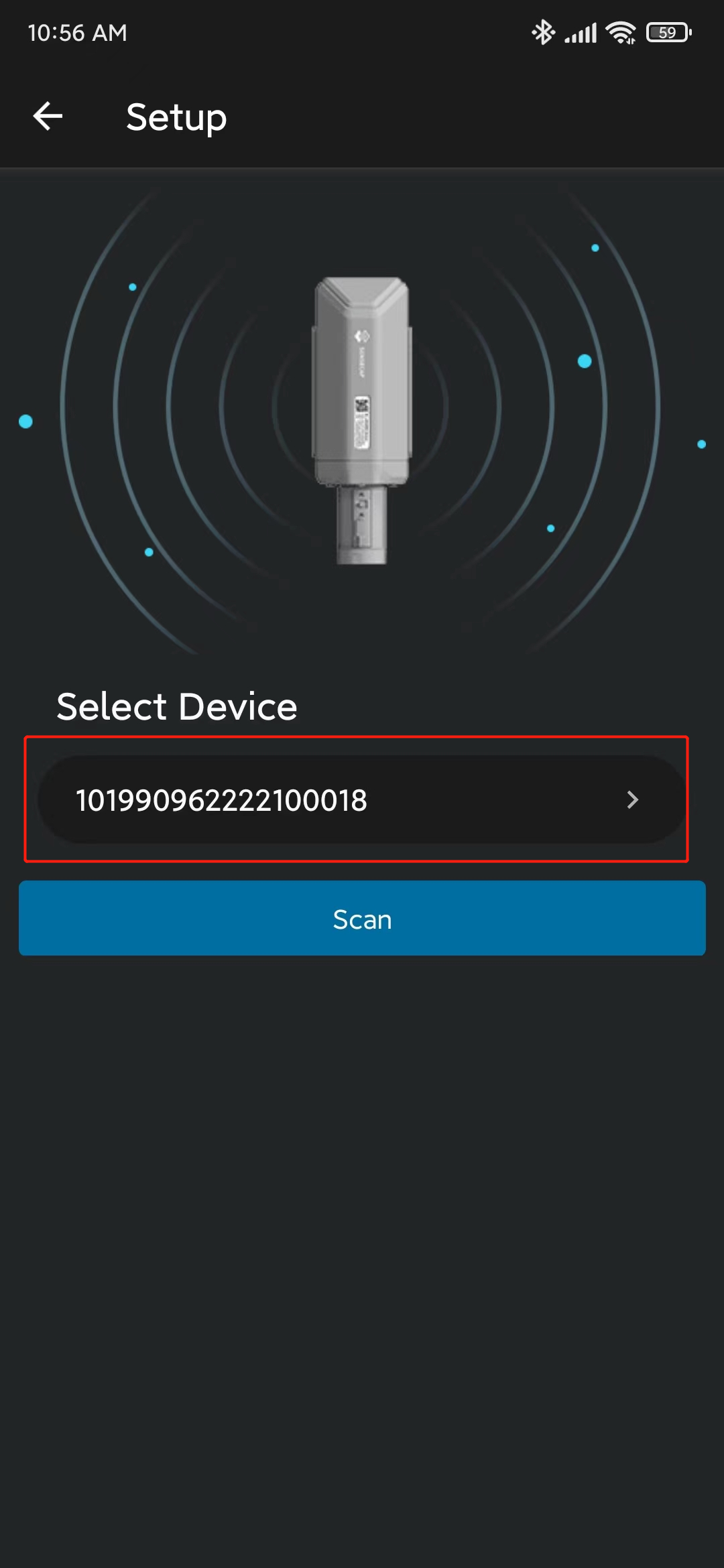
- ステップ 10. Settingsに移動し、Object Detectionが選択されていることを確認します。選択されていない場合は、選択してSendをクリックします
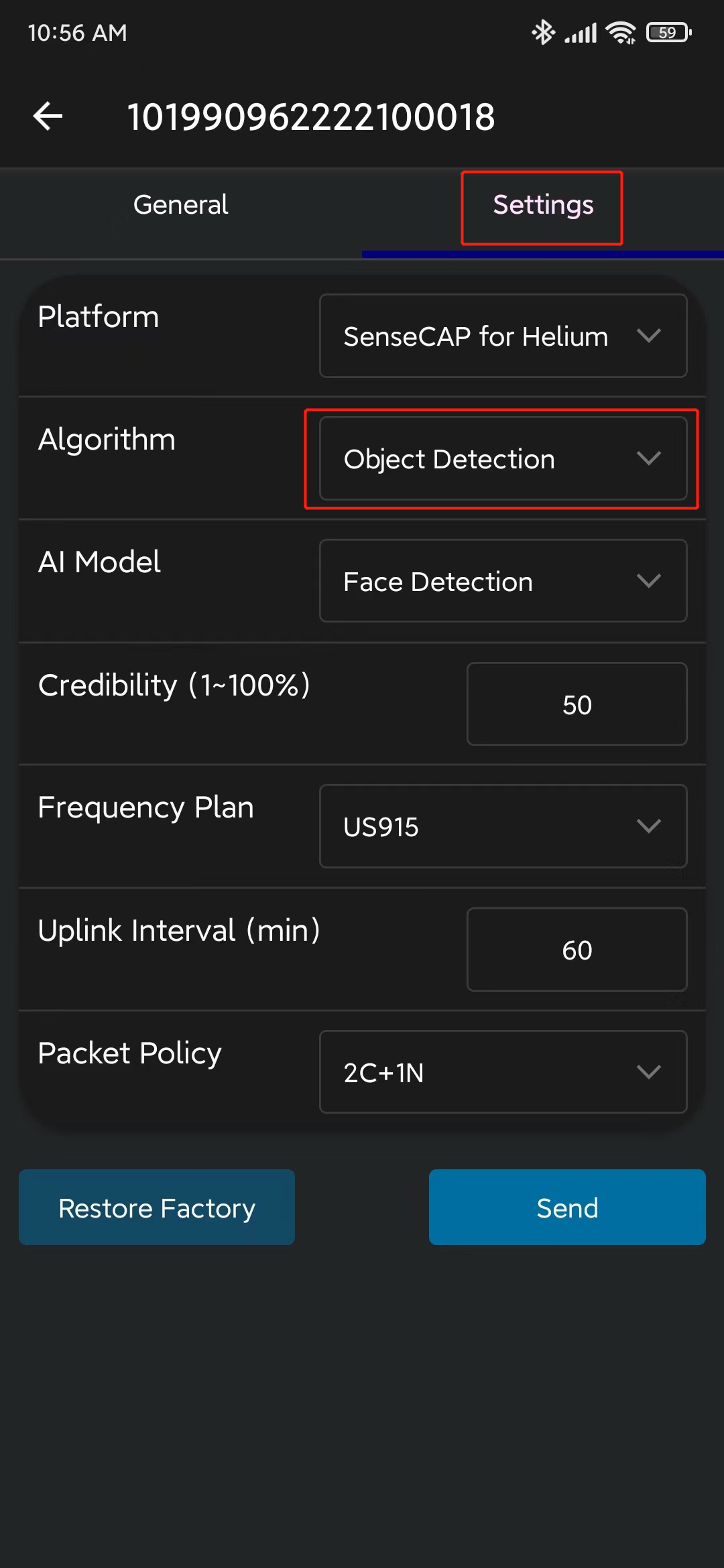
- ステップ 11. Generalに移動し、Detectをクリックします
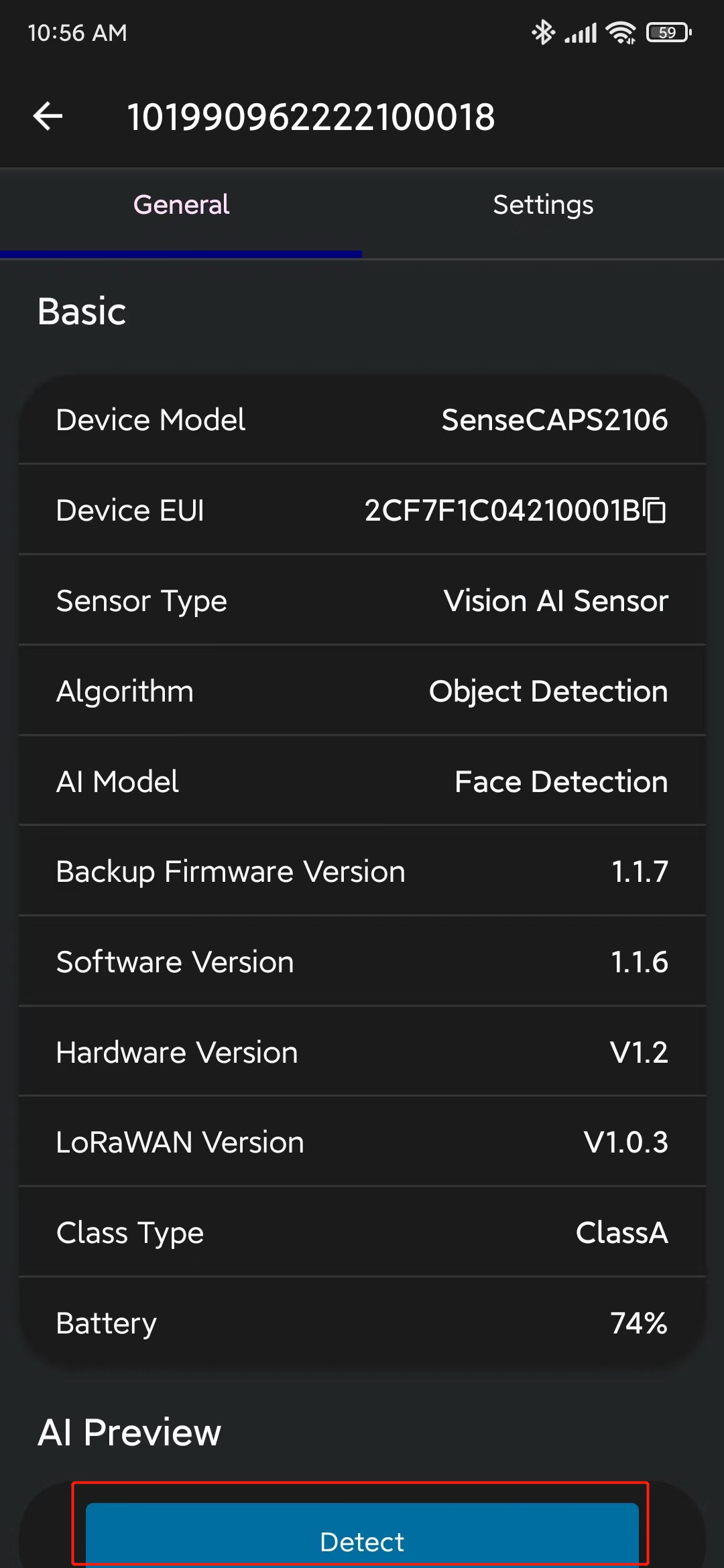
- ステップ 12. ここをクリックしてカメラストリームのプレビューウィンドウを開きます

- ステップ 13. Connectボタンをクリックします。ブラウザにポップアップが表示されます。SenseCAP Vision AI - Pairedを選択し、Connectをクリックします
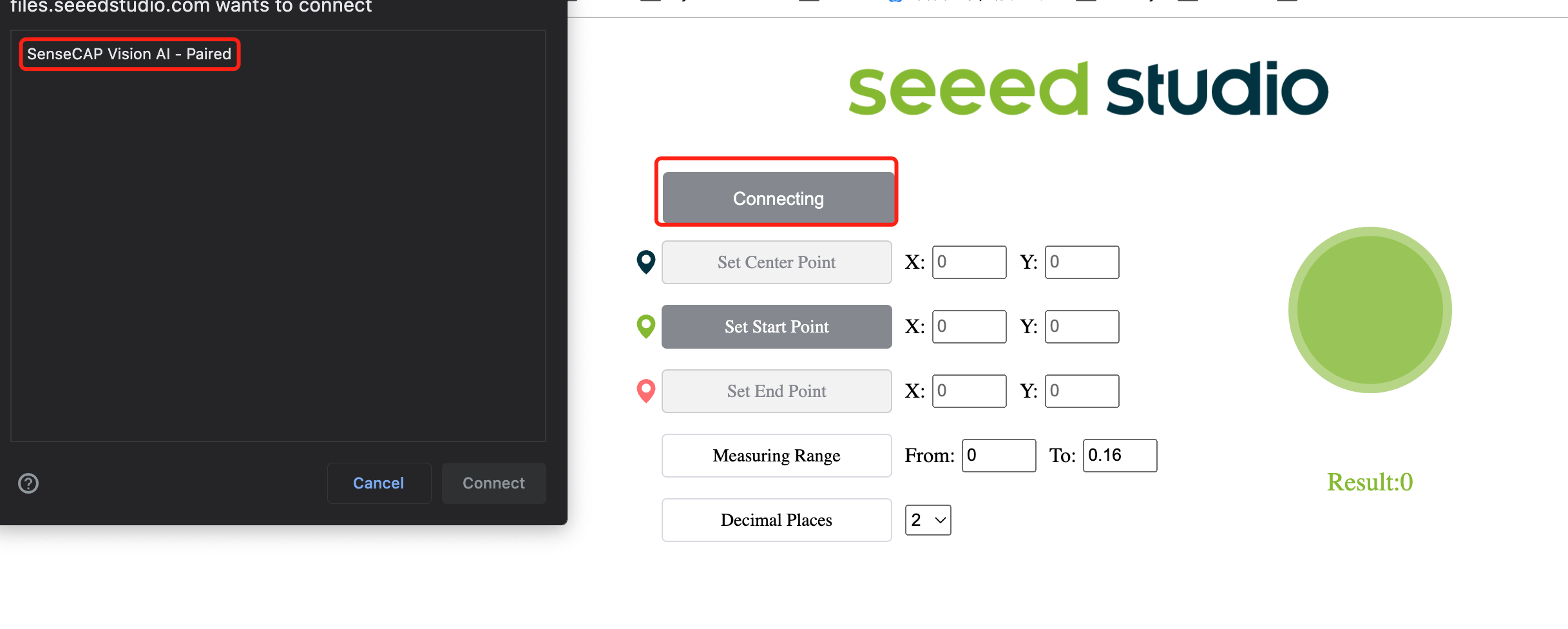
- ステップ 14. プレビューウィンドウを使用してリアルタイム推論結果を表示します!

上記のように、リンゴがバウンディングボックスで囲まれて検出されています。ここで「0」は同じクラスの各検出に対応しています。複数のクラスがある場合、0、1、2、3、4などと名前が付けられます。また、検出された各リンゴの信頼度スコア(上記のデモでは0.8と0.84)も表示されています!
ボーナスコンテンツ
より冒険的な気分になったら、wikiの残りの部分を引き続きフォローできます!
自分のPCでAIモデルをトレーニングできますか?
自分のPCを使用して物体検出モデルをトレーニングすることもできます。ただし、トレーニングのパフォーマンスは所有するハードウェアに依存します。また、トレーニング用にLinux OSを搭載したPCが必要です。このwikiではUbuntu 20.04 PCを使用しました。
- ステップ 1. yolov5-swift repoをクローンし、Python>=3.7.0環境でrequirements.txtをインストールします
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- ステップ 2. このwikiの手順を以前に実行したことがある場合、Robolflowでアノテーション後にデータセットをエクスポートしたことを覚えているかもしれません。また、Roboflow Universeでもデータセットをダウンロードしました。どちらの方法でも、データセットをどのような形式でダウンロードするかを尋ねる以下のようなウィンドウが表示されました。そこで今度は、download zip to computerを選択し、Formatの下でYOLO v5 PyTorchを選択してContinueをクリックしてください
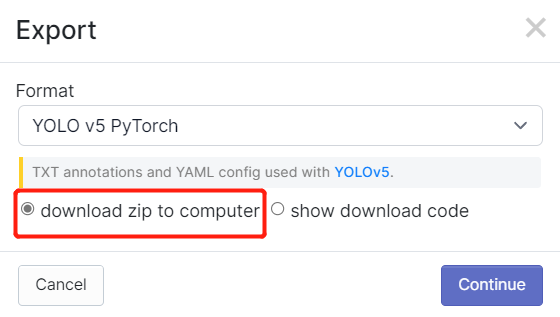
その後、.zipファイルがコンピューターにダウンロードされます
- ステップ 3. ダウンロードした.zipファイルをyolov5-swiftディレクトリにコピー&ペーストし、展開します
# example
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- ステップ 4. data.yamlファイルを開き、trainとvalディレクトリを以下のように編集する
train: train/images
val: valid/images
- ステップ 5. 私たちのトレーニングに適した事前訓練済みモデルをダウンロードする
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- ステップ 6. 以下を実行してトレーニングを開始します
ここでは、多数の引数を渡すことができます:
- img: 入力画像サイズを定義
- batch: バッチサイズを決定
- epochs: トレーニングエポック数を定義
- data: yamlファイルへのパスを設定
- cfg: モデル設定を指定
- weights: 重みへのカスタムパスを指定
- name: 結果名
- nosave: 最終チェックポイントのみを保存
- cache: より高速なトレーニングのために画像をキャッシュ
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
987枚の画像を含むりんご検出データセットの場合、6GBのGPUメモリを搭載したNVIDIA GeForce GTX 1660 Super GPUで動作するローカルPCでトレーニングプロセスを完了するのに約30分かかりました。

上記のColabプロジェクトに従った場合、デバイスに4つのモデルを一度にロードできることがわかります。ただし、一度にロードできるモデルは1つだけであることに注意してください。これはユーザーが指定でき、このwikiで後ほど説明します。
- ステップ 7.
runs/train/exp/weightsに移動すると、best.ptというファイルが表示されます。これがトレーニングから生成されたモデルです。

- ステップ 8. トレーニング済みモデルをTensorFlow Liteにエクスポートする
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- ステップ 9. TensorFlow Lite を UF2 ファイルに変換する
UF2 は Microsoft によって開発されたファイル形式です。Seeed はこの形式を使用して .tflite を .uf2 に変換し、tflite ファイルを Seeed が発売する AIoT デバイスに保存できるようにしています。現在、Seeed のデバイスは最大 4 つのモデルをサポートしており、各モデル(.tflite)は 1M 未満です。
-t を使用して、対応するインデックスに配置するモデルを指定できます。
例:
-t 1: インデックス 1-t 2: インデックス 2
# Place the model to index 1
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
デバイスに4つのモデルを一度にロードできますが、一度に読み込めるモデルは1つだけであることにご注意ください。これはユーザーが指定でき、このwikiで後ほど説明します。
- ステップ 10. これで model-1.uf2 という名前のファイルが生成されます。これがSenseCAP A1101モジュールにロードして推論を実行するファイルです!
BootLoaderバージョンの確認
- BOOTボタンをダブルクリックし、リムーバブルドライブがマウントされるまで待ちます
- リムーバブルドライブ内のINFO_UF2.TXTを開きます

BootLoaderの更新
SenseCAP A1101がコンピューターに認識されず、ポート番号が表示されない場合は、BootLoaderを更新する必要があります。
- ステップ 1. Windows PCにBootLoader
.binファイルをダウンロードします。
以下のリンクから最新バージョンのBootLoaderファイルをダウンロードしてください。BootLoaderの名前は通常 tinyuf2-sensecap_vision_ai_vx.x.x.bin です。
これは、コンピューターとHimaxチップ間の接続を構築するBL702チップを制御するファームウェアです。最新バージョンのBootLoaderは、Vision AIがMacやLinuxで認識されない問題を修正しています。
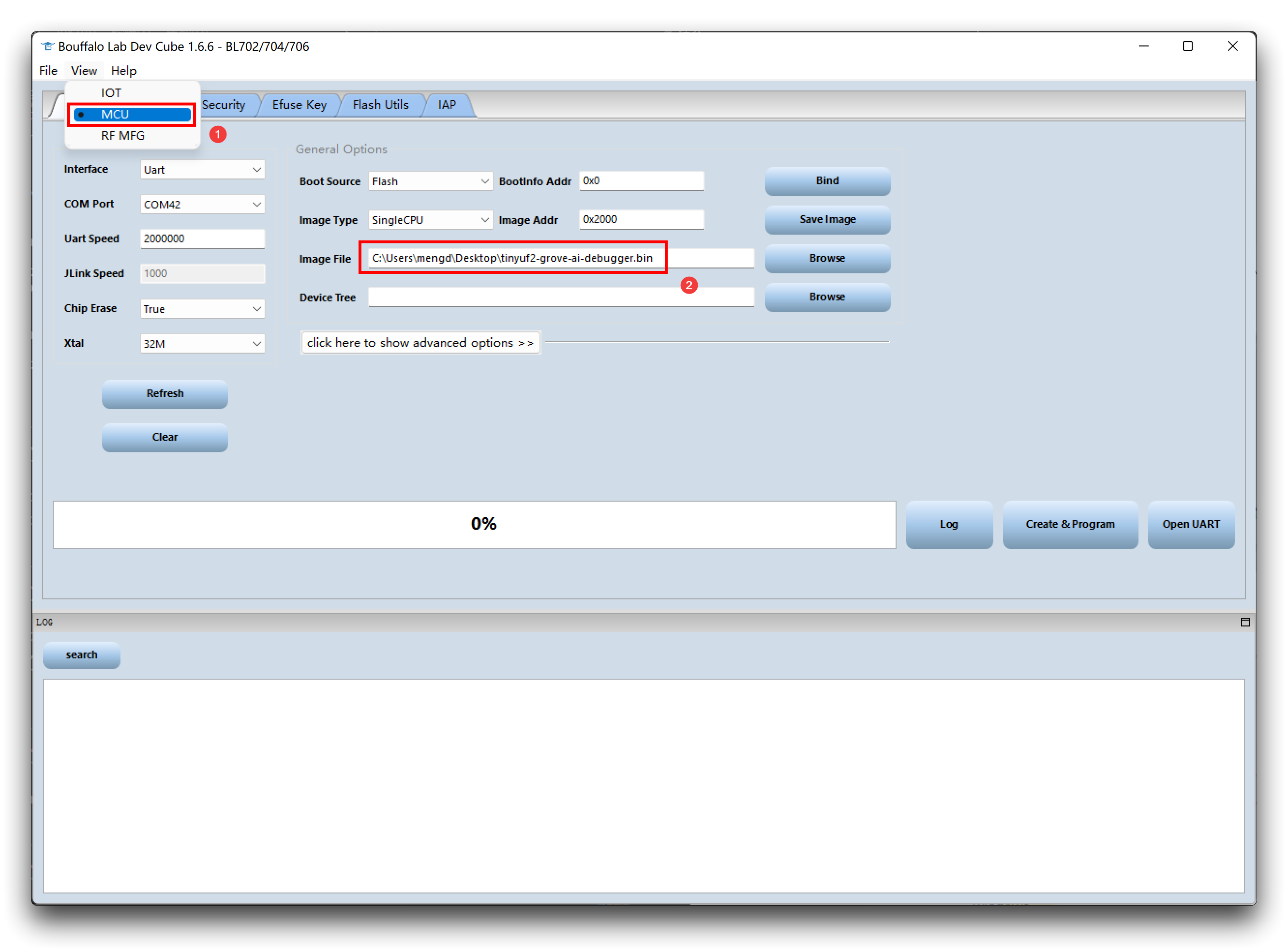
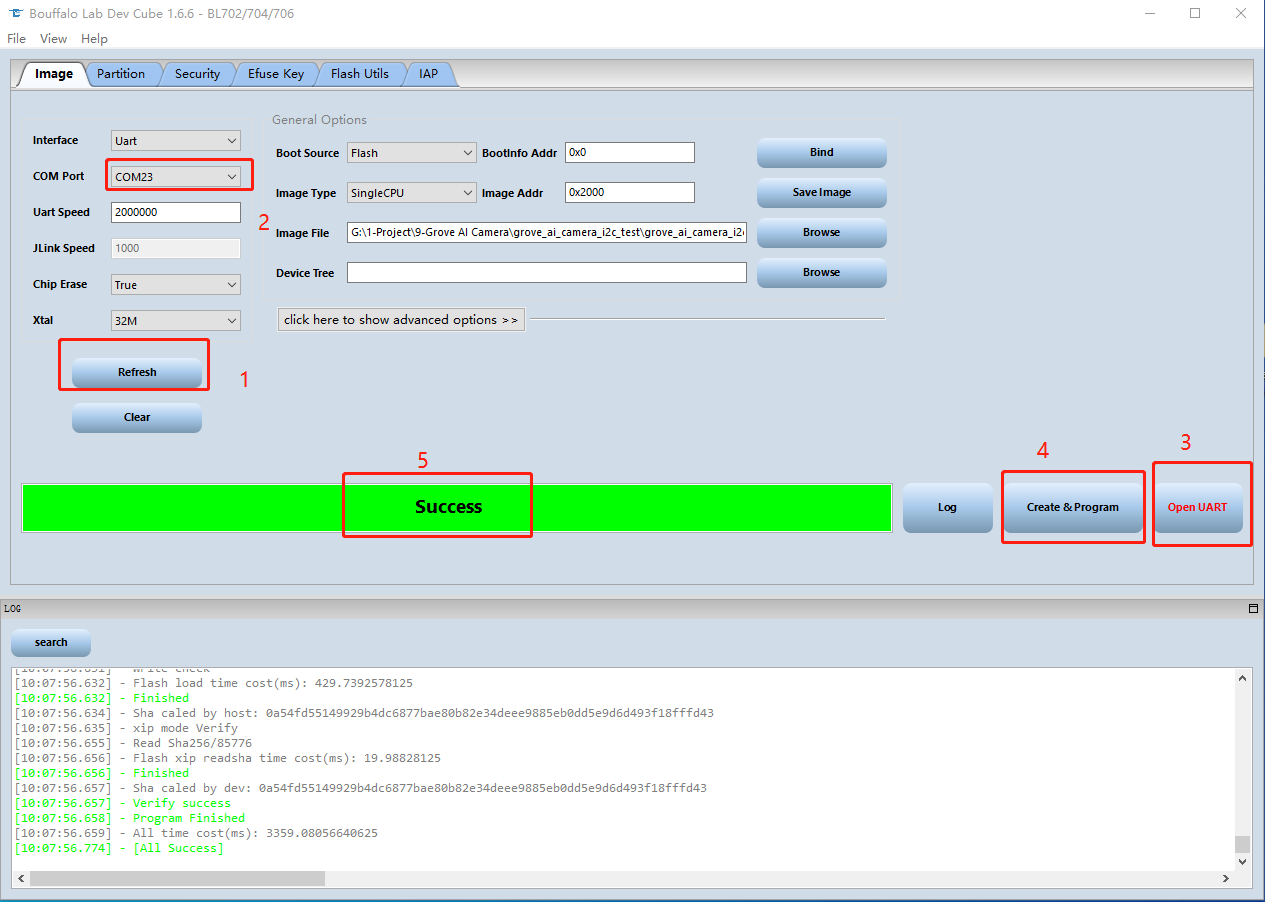
- ステップ 2. BLDevCube.exe ソフトウェアをダウンロードして開き、BL702/704/706 を選択し、Finish をクリックします。

- ステップ 3. View をクリックし、まず MCU を選択します。Image file に移動し、Browse をクリックして、先ほどダウンロードしたファームウェアを選択します。
-
ステップ 4. PCに他のデバイスが接続されていないことを確認します。次に、モジュールのBootボタンを押したまま、PCに接続します。
-
ステップ 5. PC上のBLDevCubeソフトウェアに戻り、Refresh をクリックして適切なポートを選択します。次に Open UART をクリックし、Chip Erase を True に設定してから Create&Program をクリックし、プロセスが完了するまで待ちます。
リソース
-
[Web Page] YOLOv5 Documentation
-
[Web Page] Ultralytics HUB
-
[Web Page] Roboflow Documentation
-
[Web Page] TensorFlow Lite Documentation
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを用意しています。