独自の AI モデルをトレーニングして Grove - Vision AI にデプロイする
産業用センサーへのアップグレード可能
SenseCAP S2110 コントローラー と S2100 データロガー を使用することで、Grove を簡単に LoRaWAN® センサーに変えることができます。Seeed はプロトタイピングを支援するだけでなく、SenseCAP シリーズの堅牢な産業用センサーを使用してプロジェクトを拡張する可能性も提供します。
IP66 ハウジング、Bluetooth 設定、グローバル LoRaWAN® ネットワークとの互換性、内蔵 19 Ah バッテリー、そしてアプリからの強力なサポートにより、SenseCAP S210x は産業用途に最適な選択肢となります。このシリーズには、土壌水分、空気温度と湿度、光強度、CO2、EC、そして 8-in-1 気象ステーション用のセンサーが含まれています。次の成功する産業プロジェクトに最新の SenseCAP S210x をお試しください。
| SenseCAP 産業用センサー | |||
 |  |  | |
| S2100 データロガー | S2101 空気温度 & 湿度 | S2102 光強度 | S2103 空気温度 & 湿度 & CO2 |
 |  |  |  |
| S2104 土壌水分 & 温度 | S2105 土壌水分 & 温度 & EC | S2110 LoRaWAN® コントローラー | S2120 8-in-1 気象ステーション |
概要
このウィキでは、特定のアプリケーション向けに独自のAIモデルをトレーニングし、それをGrove - Vision AI Moduleに簡単にデプロイする方法を説明します。それでは始めましょう!
ハードウェアの紹介
このウィキ全体を通じて、主にGrove - Vision AI Moduleを使用します。まずは、このハードウェアについて理解を深めましょう。
Grove - Vision AI モジュール
Grove Vision AI Moduleは、親指サイズのAIカメラで、カスタマイズされたセンサーが搭載されており、人検出やその他のカスタマイズモデルのための機械学習アルゴリズムがすでにインストールされています。このモジュールは、数分で簡単にデプロイおよび表示でき、超低消費電力モードで動作します。また、2つの信号伝送方法と複数のオンボードモジュールを提供しており、AI対応カメラの入門に最適です。

ソフトウェアの紹介
このウィキでは、以下のソフトウェア技術を使用します。
- Roboflow - アノテーション用
- YOLOv5 - トレーニング用
- TensorFlow Lite - 推論用

Roboflowとは?
Roboflowは、オンラインベースのアノテーションツールです。このツールを使用すると、画像に簡単にアノテーションを追加し、さらに画像を処理して、YOLOV5 PyTorchやPascal VOCなどのさまざまな形式でラベル付きデータセットをエクスポートできます。また、Roboflowにはユーザーが利用できる公開データセットも用意されています。
YOLOv5とは?
YOLOは「You Only Look Once(1回見るだけ)」の略です。このアルゴリズムは、リアルタイムで画像内のさまざまなオブジェクトを検出および認識します。UltralyticsのYOLOv5は、PyTorchフレームワークに基づいたYOLOのバージョンです。
TensorFlow Liteとは?
TensorFlow Liteは、オープンソースで製品対応のクロスプラットフォーム深層学習フレームワークです。TensorFlowで事前トレーニングされたモデルを、速度やストレージに最適化できる特別な形式に変換します。この特別な形式のモデルは、AndroidやiOSを使用するモバイルデバイスや、Raspberry PiやマイクロコントローラーなどのLinuxベースの組み込みデバイスでエッジ推論を行うためにデプロイできます。
ウィキの構成
このウィキは、以下の3つの主要セクションに分かれています。
- 公開データセットを使用して独自のAIモデルをトレーニングする
- 独自のデータセットを使用して独自のAIモデルをトレーニングする
- トレーニング済みAIモデルをGrove - Vision AI Moduleにデプロイする
最初のセクションでは、最小限の手順で独自のAIモデルを構築する最速の方法を説明します。2番目のセクションでは、独自のAIモデルを構築するために時間と労力が必要ですが、その知識は確実に価値があります。3番目のセクションでは、最初または2番目のセクションの後にAIモデルをデプロイする方法を説明します。
このウィキを進めるには、以下の2つの方法があります。
ただし、最初は1つ目の方法を進め、その後2つ目の方法に進むことをお勧めします。
1. 公開データセットを使用して独自のAIモデルをトレーニングする
オブジェクト検出プロジェクトの最初のステップは、トレーニング用のデータを取得することです。公開されているデータセットをダウンロードするか、独自のデータセットを作成することができます。
では、オブジェクト検出を始める最も速くて簡単な方法は何でしょうか?それは...公開データセットを使用することです。これにより、自分でデータを収集して注釈を付ける時間を大幅に節約できます。これらの公開データセットはすでに注釈が付けられているため、AIビジョンアプリケーションに集中する時間を増やすことができます。
ハードウェアの準備
- Grove - Vision AI Module
- USB Type-C ケーブル
- インターネット接続が可能な Windows/ Linux/ Mac
ソフトウェアの準備
- 追加のソフトウェアを準備する必要はありません
公開されている注釈付きデータセットを使用する
COCOデータセット、Pascal VOCデータセットなど、公開されているデータセットをいくつかダウンロードできます。Roboflow Universeは推奨されるプラットフォームで、幅広いデータセットを提供しており、90,000以上のデータセットと66+百万枚の画像がコンピュータビジョンモデルの構築に利用可能です。また、Googleで「オープンソースデータセット」を検索するだけで、さまざまなデータセットから選択できます。
-
ステップ1. このURLにアクセスして、Roboflow Universeで公開されているApple Detectionデータセットを取得します。
-
ステップ2. Create AccountをクリックしてRoboflowアカウントを作成します。
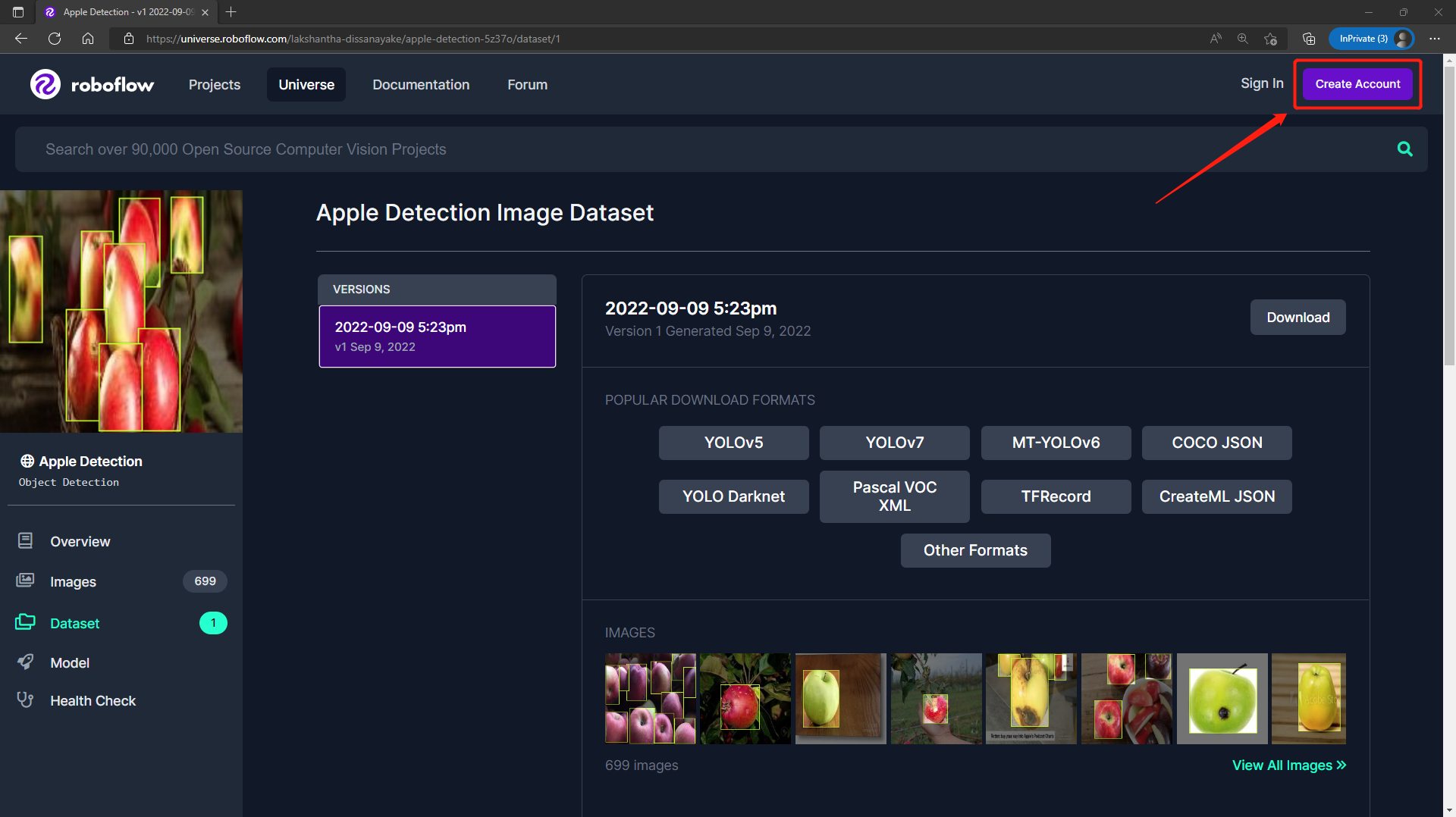
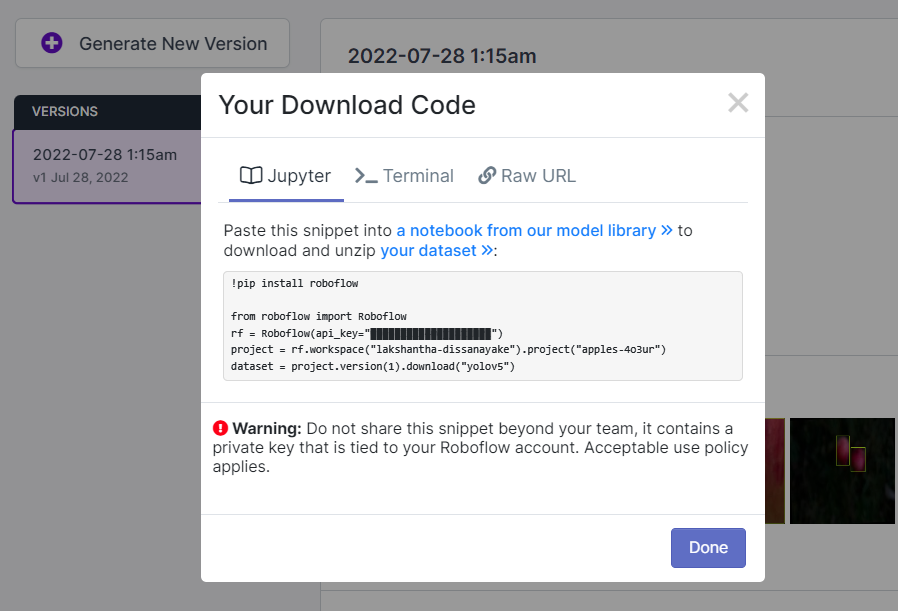
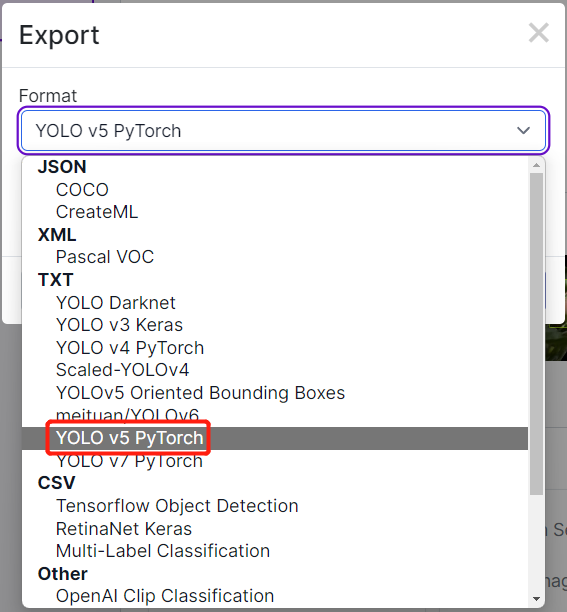
- ステップ3. Downloadをクリックし、YOLO v5 PyTorchをFormatとして選択し、show download codeをクリックしてContinueをクリックします。
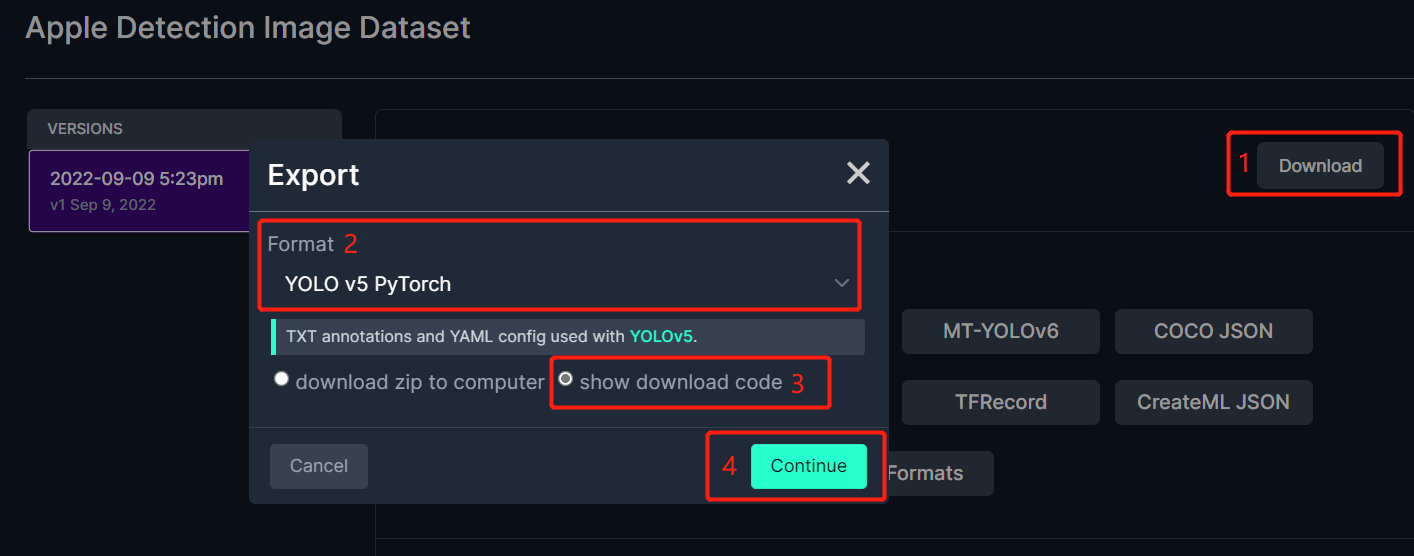
これにより、後でGoogle Colabトレーニング内で使用するコードスニペットが生成されます。このウィンドウをバックグラウンドで開いたままにしてください。
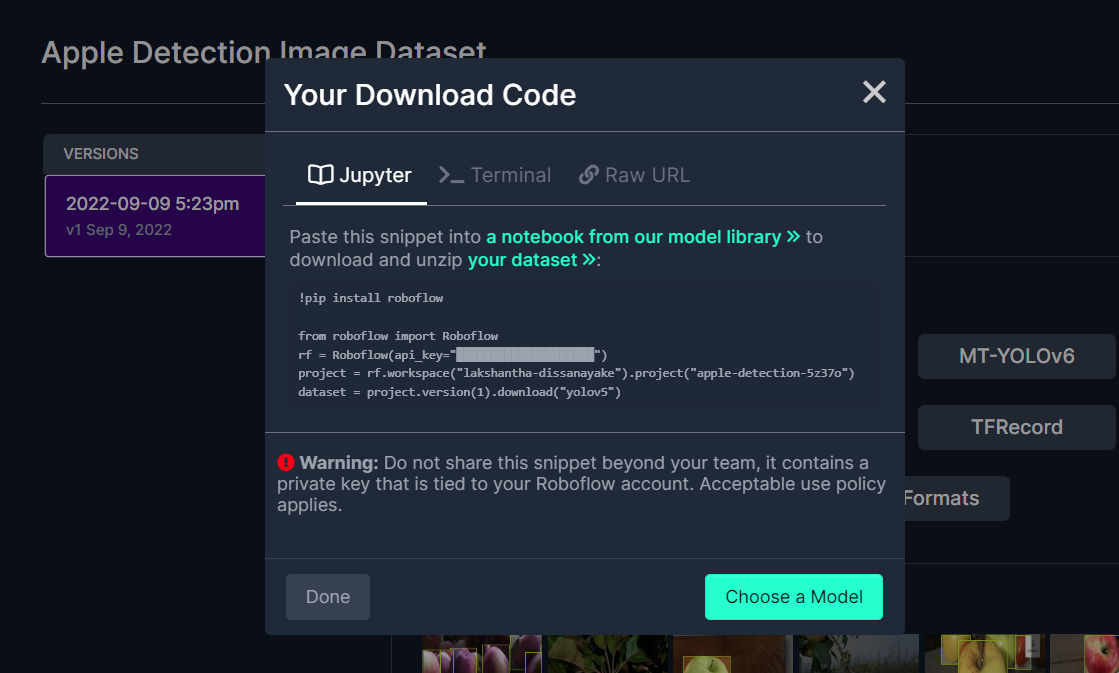
Google ColabでYOLOv5を使用してトレーニングする
公開データセットを選択した後、データセットをトレーニングする必要があります。ここでは、Google Colaboratory環境を使用してクラウド上でトレーニングを行います。また、Colab内でRoboflow APIを使用してデータセットを簡単にダウンロードします。
こちらをクリックして、すでに準備されたGoogle Colabワークスペースを開き、ワークスペースに記載されている手順を確認し、コードセルを順番に実行してください。
注意: Google Colabのステップ4のコードセルでは、上記で説明したRoboflowからコードスニペットを直接コピーできます。
以下の内容を順に説明します:
- トレーニング環境のセットアップ
- データセットのダウンロード
- トレーニングの実行
- トレーニング済みモデルのダウンロード
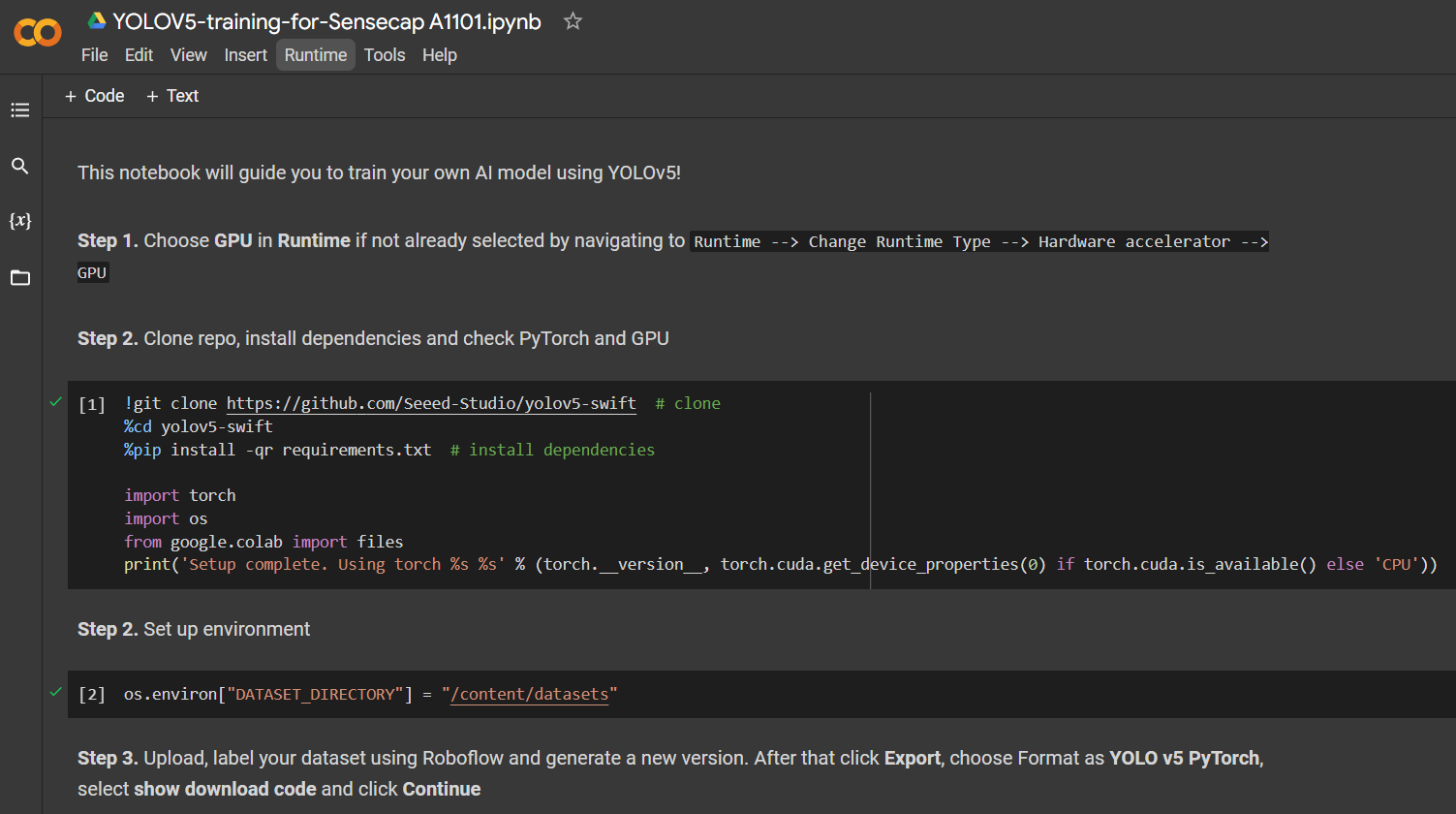
699枚の画像を含むApple Detectionデータセットの場合、Google ColabでNVIDIA Tesla T4 GPU(16GB GPUメモリ)を使用してトレーニングプロセスを完了するのに約7分かかりました。
上記のColabプロジェクトに従った場合、デバイスに一度に4つのモデルをロードできることがわかります。ただし、1回にロードできるモデルは1つだけです。これはユーザーによって指定され、後でこのWikiで説明されます。
デプロイと推論
トレーニング済みAIモデルをGrove - Vision AI Moduleにデプロイして推論を実行する方法を説明するセクション3に直接ジャンプしたい場合は、こちらをクリック。
Roboflowを使用してデータセットに注釈を付ける
独自のデータセットを使用する場合、データセット内のすべての画像に注釈を付ける必要があります。注釈を付けるとは、検出したい各オブジェクトの周りに矩形ボックスを描き、それらにラベルを割り当てることを意味します。これをRoboflowを使用して行う方法を説明します。
Roboflowはオンラインベースの注釈ツールです。ここでは、録画したビデオ映像を直接Roboflowにインポートし、一連の画像にエクスポートすることができます。このツールは非常に便利で、データセットを「トレーニング、検証、テスト」に分配するのを助けてくれます。また、ラベル付け後にこれらの画像にさらに処理を追加することも可能です。さらに、このツールはラベル付けされたデータセットをYOLOV5 PyTorch形式に簡単にエクスポートでき、これがまさに必要なものです!
このWikiでは、リンゴを含む画像のデータセットを使用して、後でリンゴを検出し、カウントを行います。
-
ステップ1. こちらをクリックしてRoboflowアカウントにサインアップします。
-
ステップ2. Create New Projectをクリックしてプロジェクトを開始します。
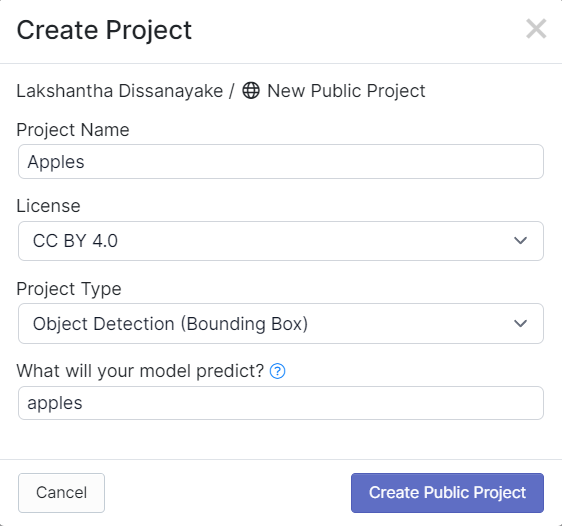
- ステップ 3. プロジェクト名を入力し、ライセンス (CC BY 4.0) と プロジェクトタイプ (Object Detection (Bounding Box)) をデフォルトのままにします。What will your model predict? の列には、アノテーショングループ名を入力します。例えば、ここでは apples を選択します。この名前はデータセット内のすべてのクラスを強調する必要があります。最後に、Create Public Project をクリックします。
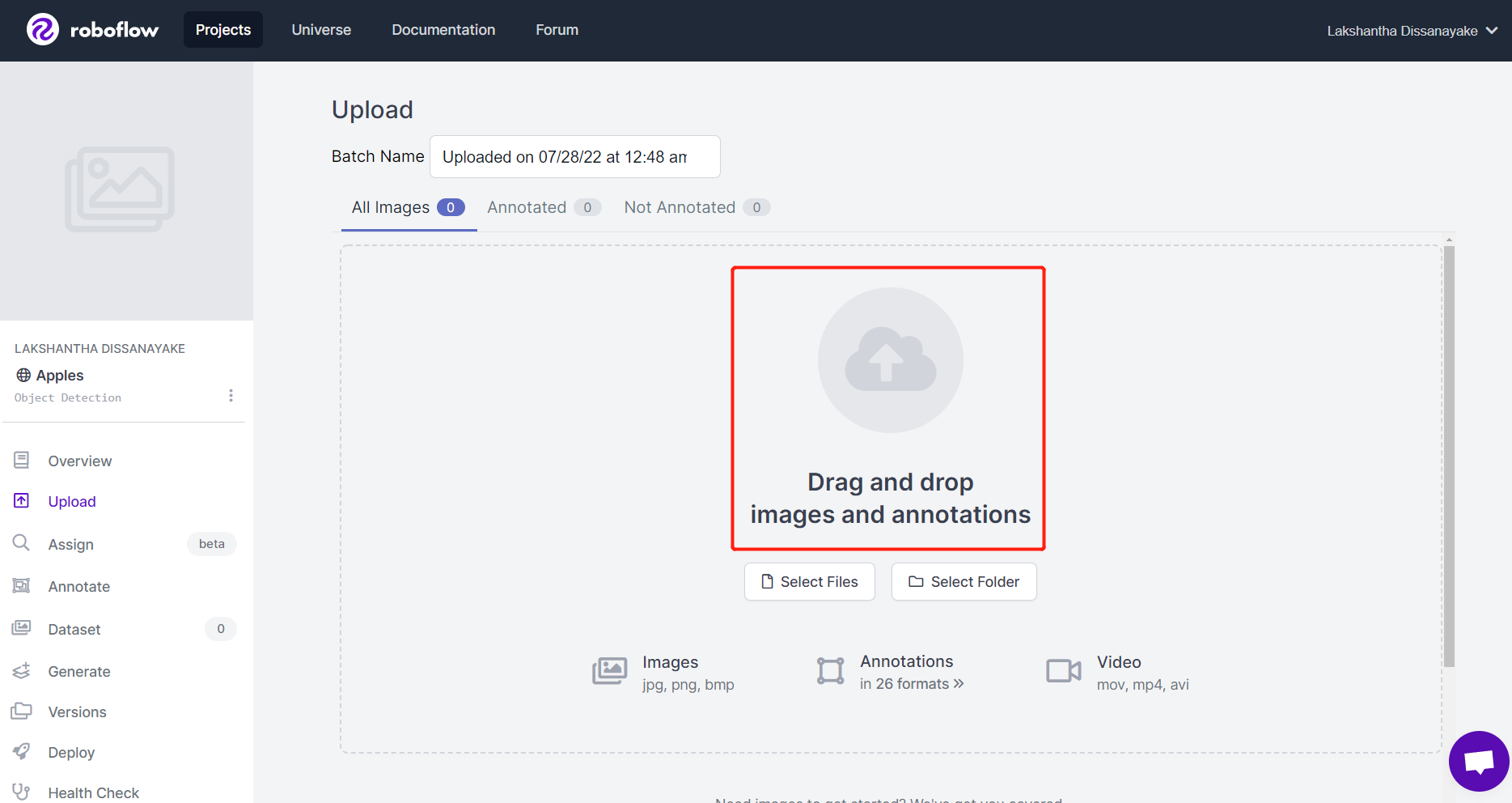
- ステップ 4. Grove - Vision AI Module を使用してキャプチャした画像をドラッグ&ドロップします。
- ステップ 5. 画像が処理されたら、Finish Uploading をクリックします。画像がアップロードされるまでしばらく待ちます。
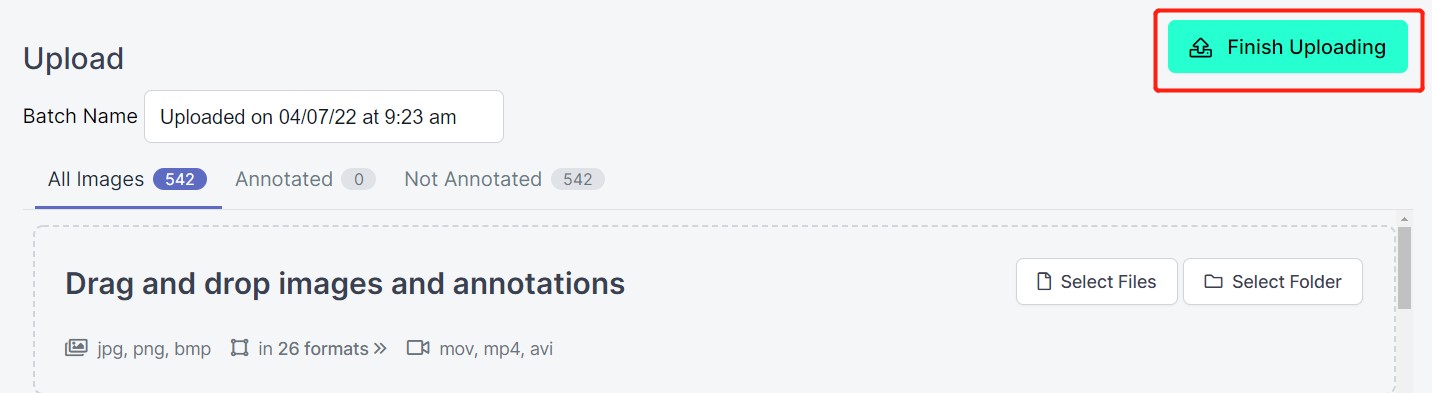
- ステップ 6. 画像がアップロードされたら、Assign Images をクリックします。
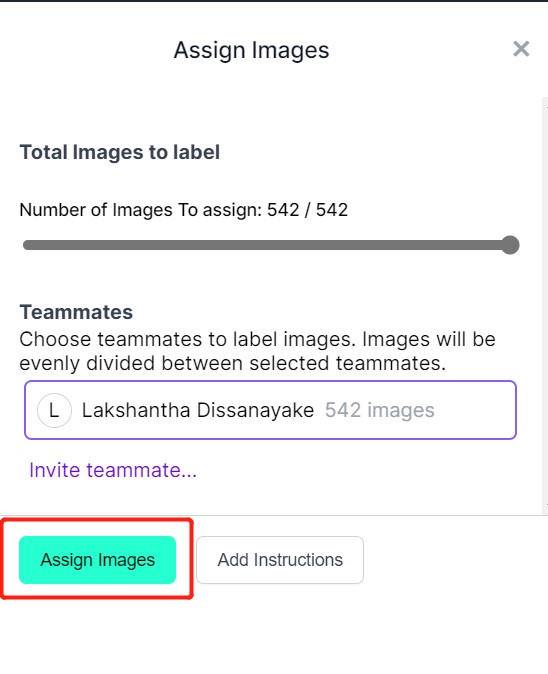
- ステップ 7. 画像を選択し、リンゴの周りに矩形ボックスを描画し、ラベルを apple に設定して ENTER を押します。
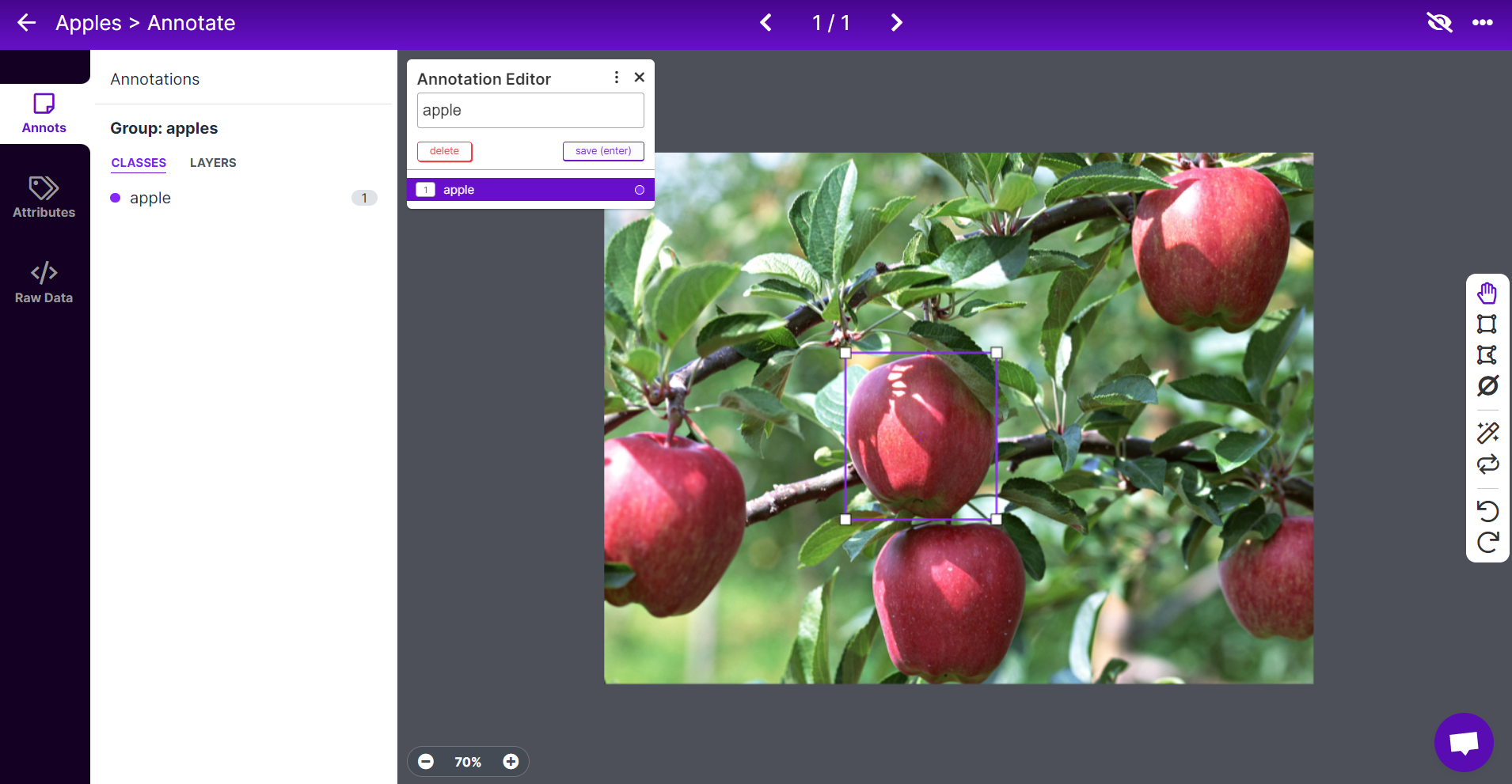
- ステップ 8. 残りのリンゴについても同じ操作を繰り返します。
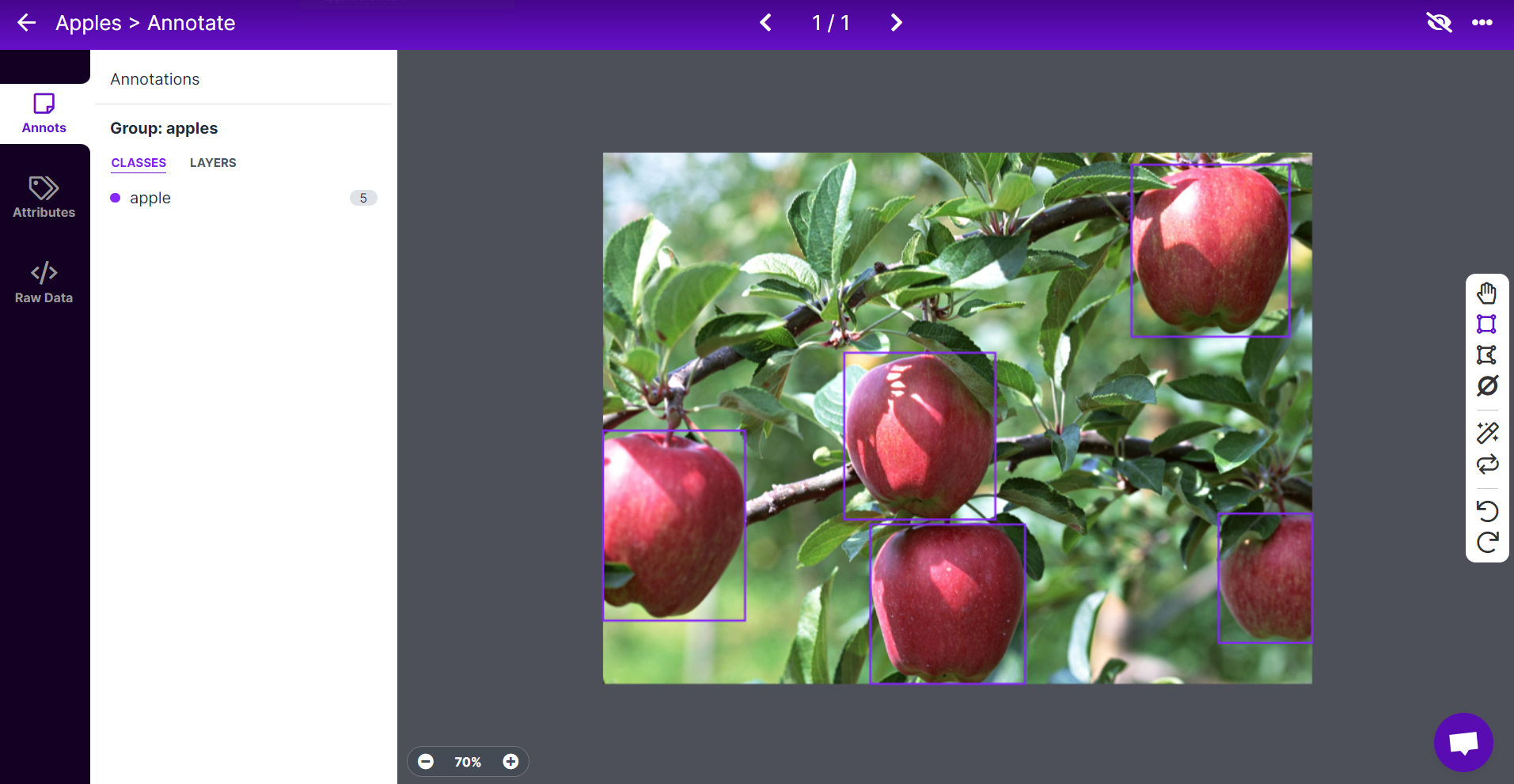
注意: 画像内に見えるすべてのリンゴをラベル付けするようにしてください。リンゴの一部しか見えない場合でも、その部分をラベル付けするようにしてください。
- ステップ 9. データセット内のすべての画像をアノテーションし続けます。
Roboflow には Label Assist という機能があり、ラベルを事前に予測してラベル付けをより迅速に行えるようにします。ただし、この機能はすべてのオブジェクトタイプに対応しているわけではなく、特定のオブジェクトタイプにのみ対応しています。この機能をオンにするには、Label Assist ボタンを押し、モデルを選択し、クラスを選択して、画像をナビゲートして予測されたラベルとバウンディングボックスを確認します。
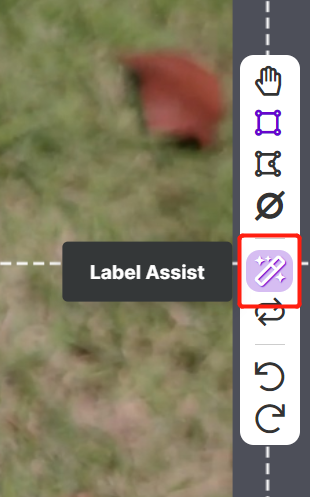
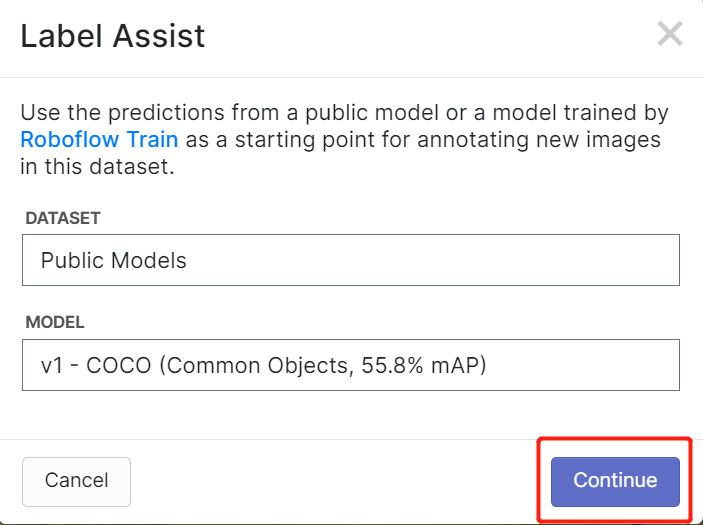
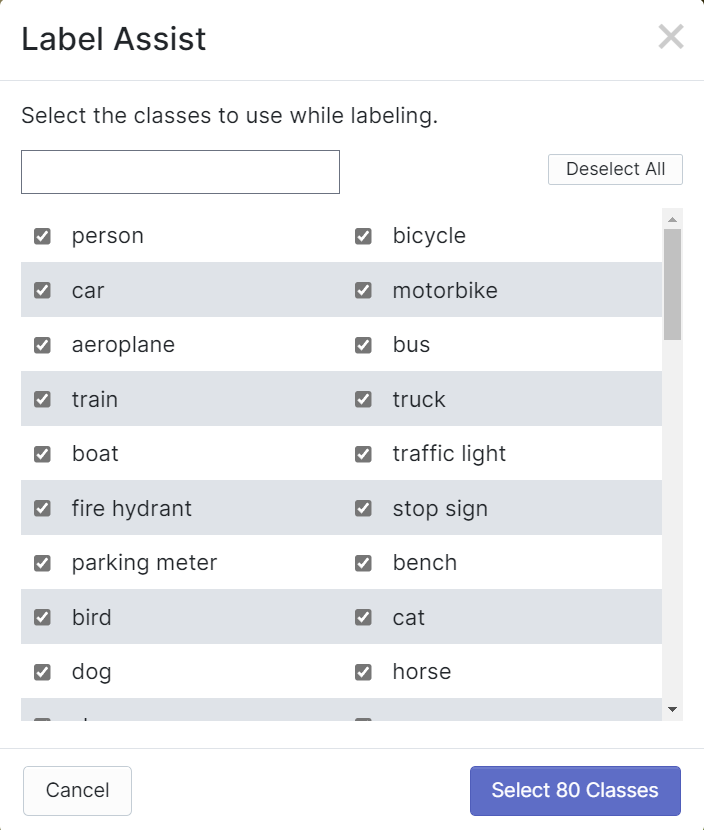
上記のように、この機能は80クラスに対してのみアノテーション予測を支援できます。画像にこれらのクラスに該当するオブジェクトが含まれていない場合、Label Assist 機能を使用することはできません。
- ステップ 10. ラベル付けが完了したら、Add images to Dataset をクリックします。

- ステップ 11. 次に、画像を「Train, Valid, Test」に分割します。分布のデフォルトの割合を保持し、Add Images をクリックします。
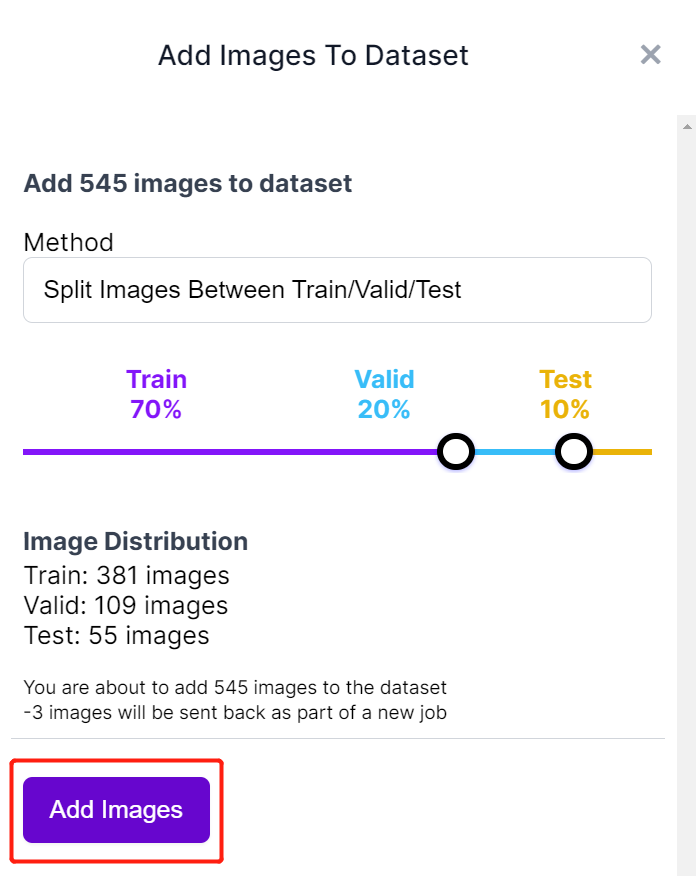
- ステップ 12. Generate New Version をクリックします。

- ステップ 13. 必要に応じて Preprocessing と Augmentation を追加します。ここでは Resize オプションを 192x192 に変更します。
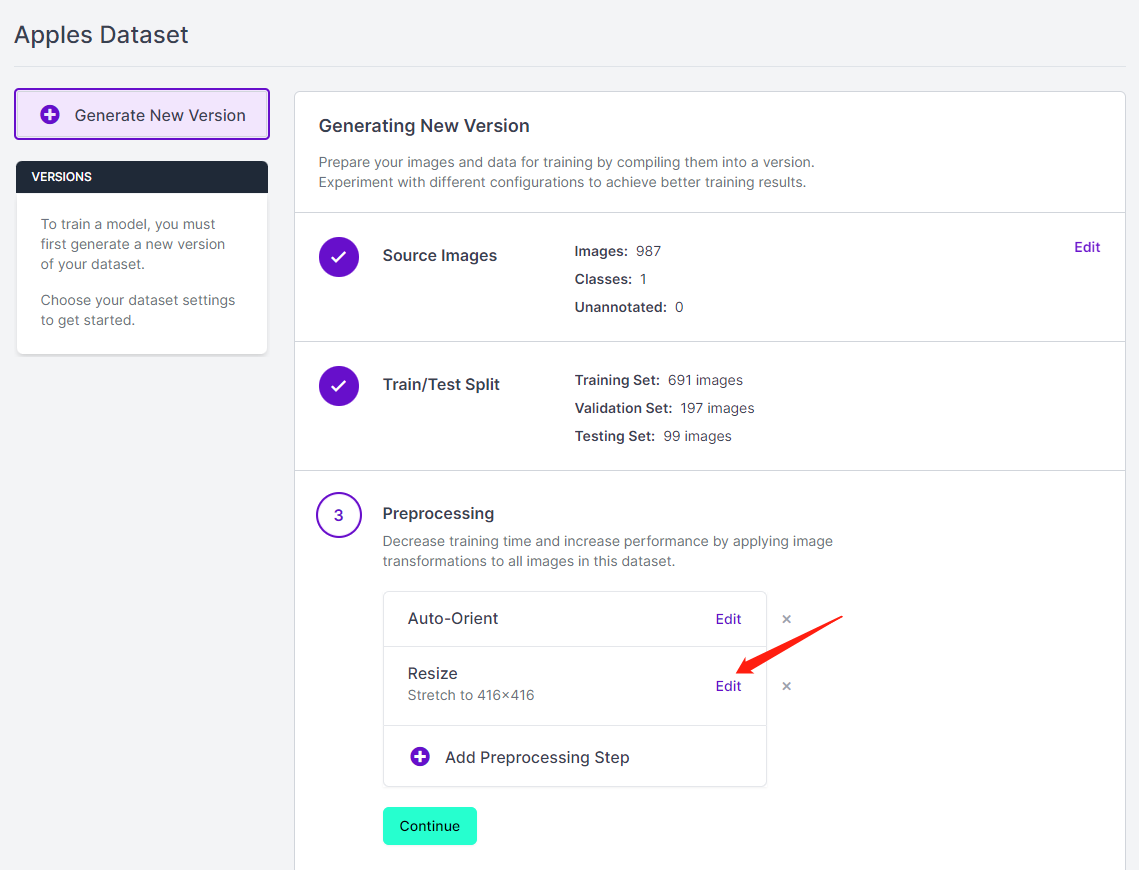
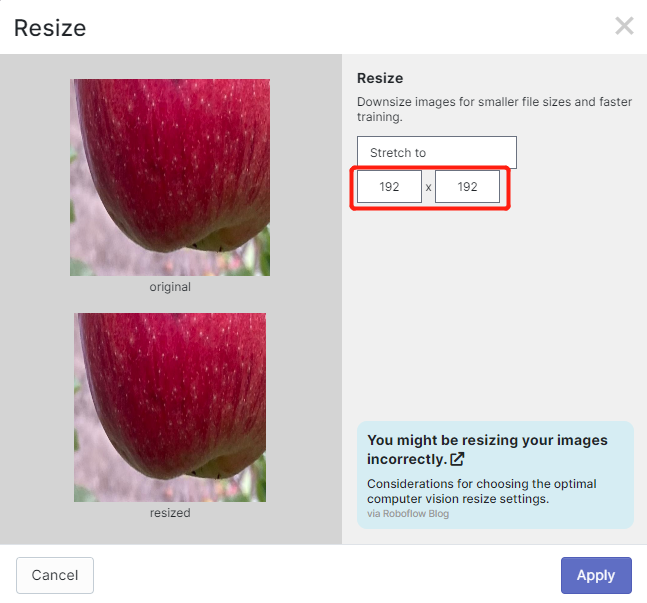
ここでは画像サイズを 192x192 に変更します。このサイズを使用してトレーニングを行うため、トレーニングがより速くなります。そうしない場合、トレーニングプロセス中にすべての画像を 192x192 に変換する必要があり、CPUリソースをより多く消費し、トレーニングプロセスが遅くなります。
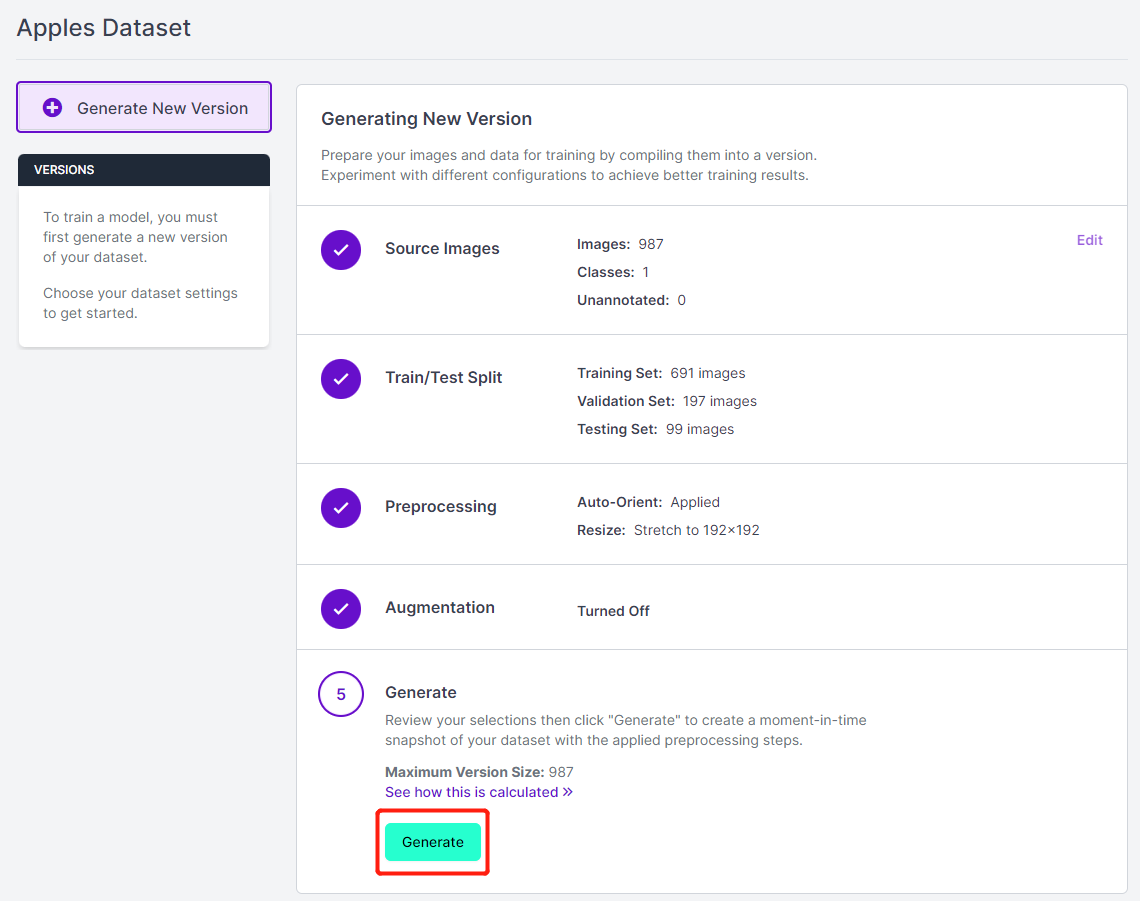
- ステップ 14. 残りのデフォルト設定を保持し、Generate をクリックします。
- ステップ 15. Exportをクリックし、FormatをYOLO v5 PyTorchに選択し、show download codeを選択してContinueをクリックします。
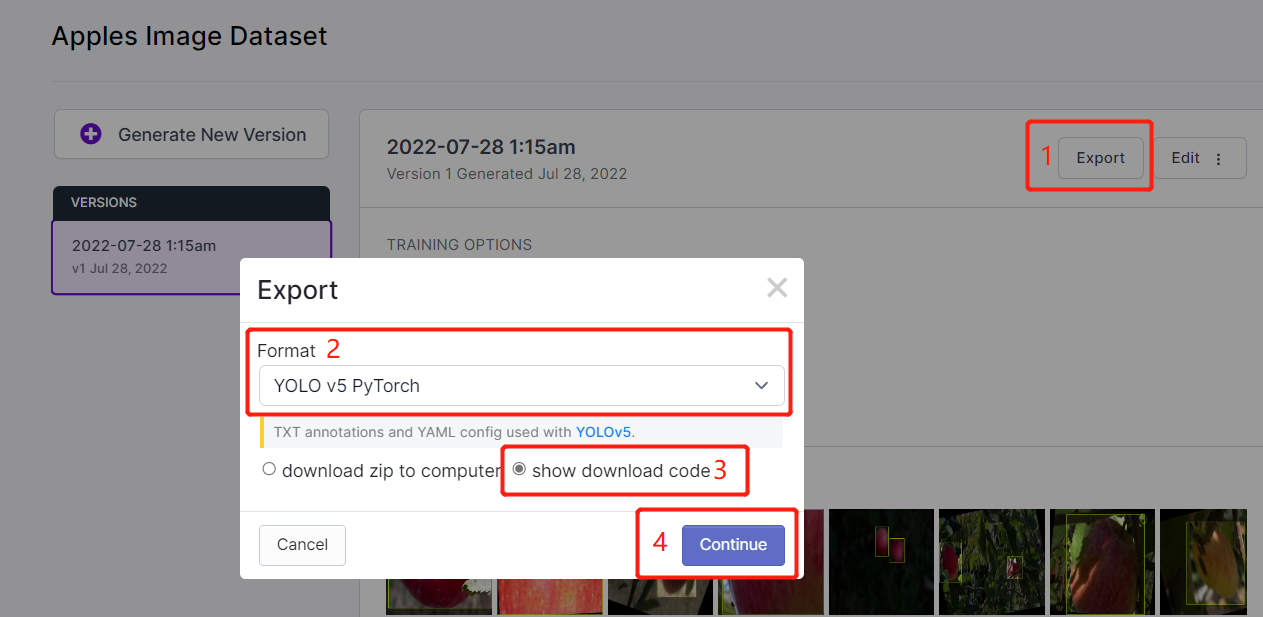
これにより、後でGoogle Colabのトレーニング内で使用するコードスニペットが生成されます。このウィンドウをバックグラウンドで開いたままにしておいてください。
Google ColabでYOLOv5を使用してトレーニングする
データセットのアノテーションが完了したら、次にデータセットをトレーニングする必要があります。こちらのセクションに進み、Google Colab上でYOLOv5を使用してAIモデルをトレーニングする方法を確認してください。
3. トレーニング済みモデルをデプロイして推論を実行する
Grove - Vision AI モジュール
次に、トレーニングの最後で得られたmodel-1.uf2をGrove - Vision AI Moduleに移動します。ここでは、Grove - Vision AI ModuleをWio Terminalに接続して推論結果を確認します。
注意: Arduinoを初めて使用する場合は、Getting Started with Arduinoを参照することを強くお勧めします。また、Arduino IDEでWio TerminalをセットアップするにはこのWikiを参照してください。
-
ステップ 1. 最新バージョンのGoogle ChromeまたはMicrosoft Edgeブラウザをインストールして開きます。
-
ステップ 2. USB Type-Cケーブルを使用してGrove - Vision AI ModuleをPCに接続します。

- ステップ 3. Grove - Vision AI Moduleのブートボタンをダブルクリックして、マスストレージモードに入ります。

これにより、ファイルエクスプローラーにGROVEAIという新しいストレージドライブが表示されます。
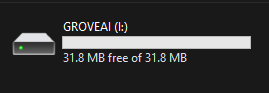
- ステップ 4. model-1.uf2ファイルをGROVEAIドライブにドラッグ&ドロップします。
uf2ファイルのコピーが完了すると、ドライブが消えます。これは、uf2がモジュールに正常にアップロードされたことを意味します。
注意: 4つのモデルファイルが準備できている場合は、それぞれのモデルを1つずつドラッグ&ドロップできます。最初のモデルをドロップし、コピーが完了するのを待ち、再度ブートモードに入り、次のモデルをドロップする、という手順を繰り返します。
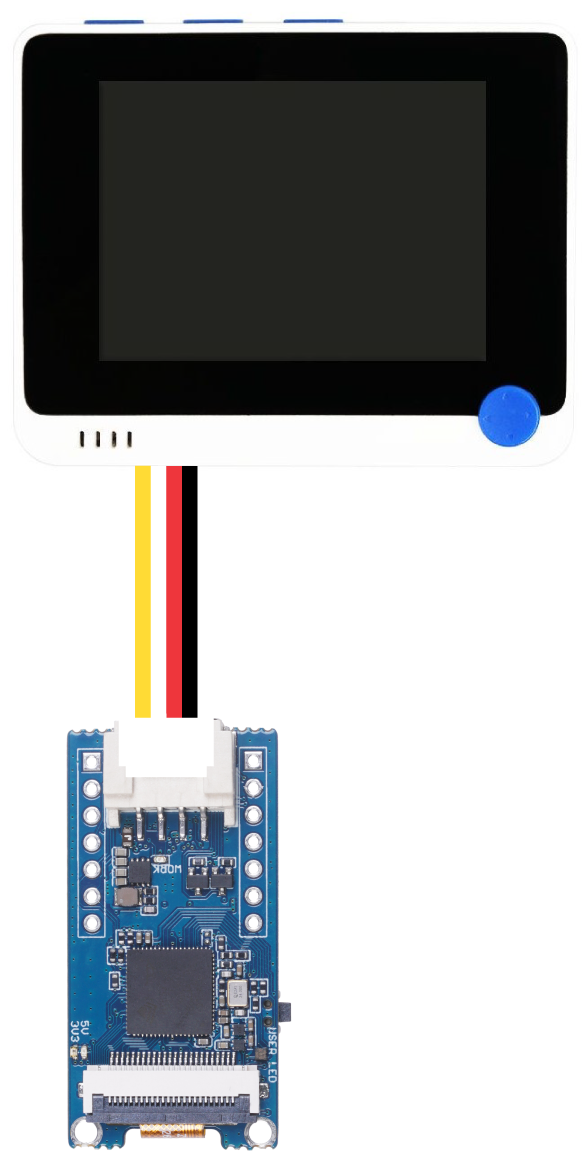
- ステップ 5. Grove - Vision AI ModuleをUSBでPCに接続したまま、Grove I2Cポートを介してWio Terminalに接続します。
-
ステップ 6. Seeed_Arduino_GroveAIライブラリをArduino IDEにインストールし、object_detection.inoの例を開きます。
-
ステップ 7. Grove - Vision AI Moduleに1つのモデル(インデックス1)だけをロードした場合、そのモデルがロードされます。ただし、複数のモデルをロードした場合は、**MODEL_EXT_INDEX_[value]**を変更することで使用するモデルを指定できます。valueには1, 2, 3, 4のいずれかの数字を指定します。
// 例:
if (ai.begin(ALGO_OBJECT_DETECTION, MODEL_EXT_INDEX_2))
上記のコードは、インデックス2のモデルをロードします。
- ステップ 8. 私たちはリンゴを検出するため、コードをこちらで少し変更します。
Serial.print("Number of apples: ");
- ステップ 9. Wio TerminalをPCに接続し、このコードをWio Terminalにアップロードし、Arduino IDEのシリアルモニターを115200のボーレートで開きます。
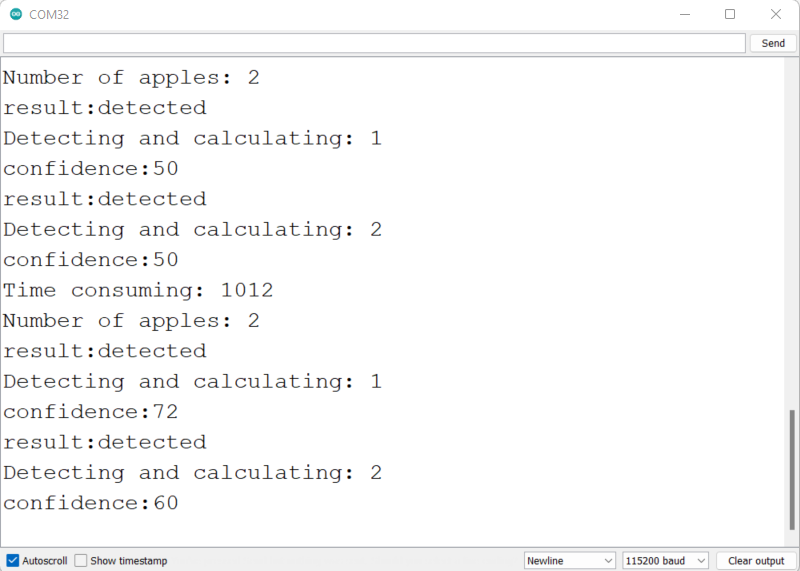
上記のように、シリアルモニターで検出情報を確認できます。
- ステップ 10. こちらをクリックして、検出結果を含むカメラストリームのプレビューウィンドウを開きます。

- ステップ 11. Connectボタンをクリックします。その後、ブラウザにポップアップが表示されます。Grove AI - Pairedを選択し、Connectをクリックします。
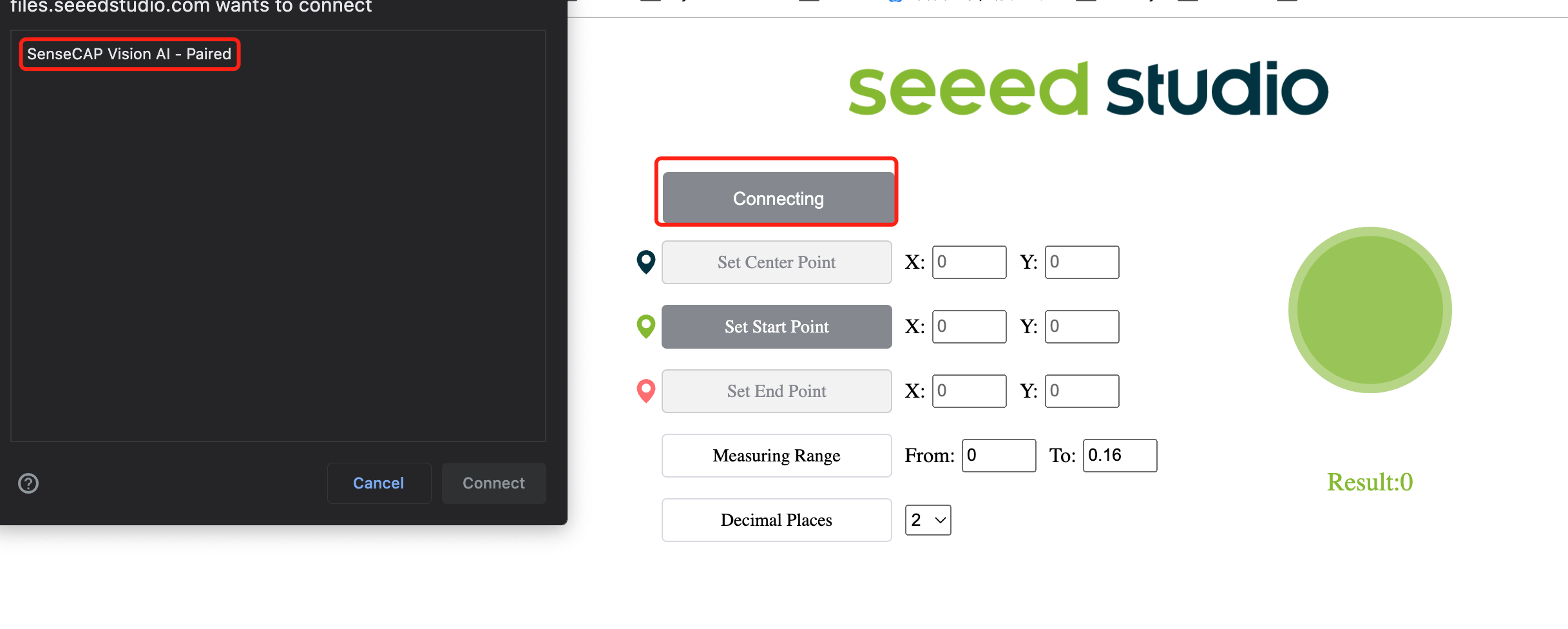
- ステップ 12. プレビューウィンドウを使用してリアルタイムの推論結果を確認しましょう!

上記のように、リンゴが検出され、それぞれのリンゴの周囲にバウンディングボックスが表示されています。「0」は同じクラスの各検出を表します。複数のクラスがある場合、それらは0,1,2,3,4といった名前で表示されます。また、検出されたリンゴの信頼度スコア(上記のデモでは0.8と0.84)が表示されています!
ボーナスコンテンツ
さらに冒険したい場合は、Wikiの残りの部分を続けて参照してください!
自分のPCでAIモデルをトレーニングできますか?
自分のPCを使用して物体検出モデルをトレーニングすることも可能です。ただし、トレーニングのパフォーマンスは使用するハードウェアに依存します。また、トレーニングにはLinux OSを搭載したPCが必要です。このWikiではUbuntu 20.04 PCを使用しています。
- ステップ 1. yolov5-swiftリポジトリをクローンし、Python>=3.7.0環境でrequirements.txtをインストールします
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- ステップ 2. このWikiの手順に従った場合、Roboflowでアノテーション後にデータセットをエクスポートしたことを覚えているかもしれません。また、Roboflow Universeでデータセットをダウンロードしました。どちらの方法でも、以下のようなウィンドウが表示され、データセットのダウンロード形式を選択するよう求められます。ここで、download zip to computerを選択し、FormatでYOLO v5 PyTorchを選択してContinueをクリックしてください。
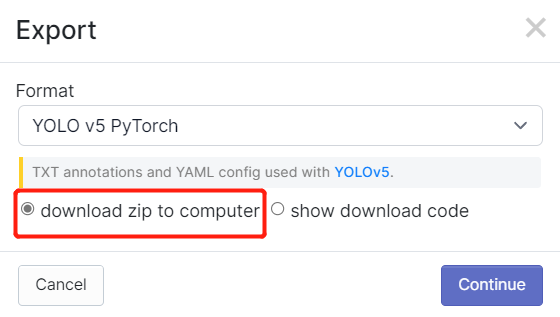
その後、.zipファイルがコンピュータにダウンロードされます。
- ステップ 3. ダウンロードした.zipファイルをyolov5-swiftディレクトリにコピー&ペーストし、解凍します
# 例
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- ステップ 4. data.yamlファイルを開き、trainおよびvalディレクトリを以下のように編集します
train: train/images
val: valid/images
- ステップ 5. トレーニングに適した事前学習済みモデルをダウンロードします
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- ステップ 6. 以下を実行してトレーニングを開始します
ここでは、いくつかの引数を渡すことができます:
- img: 入力画像サイズを定義
- batch: バッチサイズを設定
- epochs: トレーニングエポック数を定義
- data: yamlファイルへのパスを設定
- cfg: モデル構成を指定
- weights: カスタムウェイトのパスを指定
- name: 結果の名前
- nosave: 最終チェックポイントのみ保存
- cache: 画像をキャッシュしてトレーニングを高速化
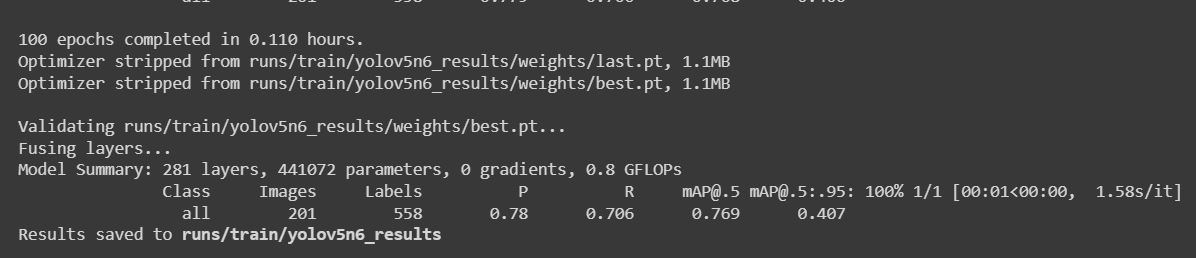
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
987枚の画像を含むリンゴ検出データセットの場合、NVIDIA GeForce GTX 1660 Super GPU(6GB GPUメモリ)を搭載したローカルPCでトレーニングプロセスを完了するのに約30分かかりました。

上記のColabプロジェクトに従った場合、デバイスに一度に4つのモデルをロードできることを知っているでしょう。ただし、1つのモデルのみロード可能であることに注意してください。これはユーザーによって指定可能であり、このWikiの後半で説明されます。
- ステップ 7.
runs/train/exp/weightsに移動すると、best.ptというファイルが表示されます。これがトレーニングから生成されたモデルです。

- ステップ 8. トレーニング済みモデルをTensorFlow Liteにエクスポートします
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- ステップ 9. TensorFlow LiteをUF2ファイルに変換します
UF2はMicrosoftによって開発されたファイル形式です。Seeedはこの形式を使用して.tfliteを.uf2に変換し、Seeedが発売したAIoTデバイスに.tfliteファイルを保存できるようにしています。現在、Seeedのデバイスは最大4つのモデルをサポートしており、各モデル(.tflite)は1M未満です。
モデルを対応するインデックスに配置するには、-tオプションを使用します。
例:
-t 1: インデックス1-t 2: インデックス2
# モデルをインデックス1に配置
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
一度にデバイスに4つのモデルをロードできますが、1つのモデルのみロード可能であることに注意してください。これはユーザーによって指定可能であり、このWikiの後半で説明されます。
- ステップ 10. model-1.uf2という名前のファイルが生成されます。このファイルをGrove - Vision AIモジュールにロードして推論を実行します!
リソース
-
[ウェブページ] YOLOv5 ドキュメント
-
[ウェブページ] Ultralytics HUB
-
[ウェブページ] Roboflow ドキュメント
-
[ウェブページ] TensorFlow Lite ドキュメント
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます!製品の使用体験がスムーズになるよう、さまざまなサポートを提供しております。異なる好みやニーズに対応するため、複数のコミュニケーションチャネルをご用意しています。