Wio Terminal 内蔵加速度センサーを使用した Edge Impulse 継続的な動作認識
このチュートリアルでは、機械学習を使用して Wio Terminal 上で動作認識システムを構築します。ルールベースのプログラミングでは解決が難しい課題ですが、人々は毎回同じ方法でジェスチャーを行うわけではありません。しかし、機械学習はこれらの変動を容易に処理できます。このチュートリアルでは、実際のセンサーから高頻度データを収集する方法、信号処理を使用してデータをクリーンアップする方法、ニューラルネットワーク分類器を構築する方法、そしてデバイスにモデルをデプロイする方法を学びます。このチュートリアルの終わりには、Edge Impulse を使用して組み込みデバイスに機械学習を適用する確かな理解を得ることができます。
このチュートリアルのビデオ版もあります:
1. 前提条件
このチュートリアルを進めるには、対応するデバイスが必要です。まず Wio Terminal Edge Impulse チュートリアルを確認してください。
Wio Terminal 以外にも以下の対応デバイスがあります。
デバイスがスタジオ内の Devices に接続されている場合、次のステップに進むことができます:
Edge Impulse は、既に製品化されている組み込みデバイスを含む、あらゆるデバイスからデータを取り込むことができます。Ingestion service のドキュメントを参照してください。
2. 最初のデータを収集する
デバイスが接続されている状態で、データを収集できます。スタジオで Data acquisition タブに移動します。このタブはすべての生データが保存される場所であり、デバイスがリモート管理 API に接続されている場合、新しいデータのサンプリングを開始する場所でもあります。
Record new data の下で、デバイスを選択し、ラベルを idle に設定し、サンプルの長さを 5000 に設定し、センサーを Built-in accelerometer に設定し、周波数を 62.5Hz に設定します。これにより、10秒間データを記録し、記録されたデータに idle というラベルを付けることを示します。必要に応じて後でこれらのラベルを編集することもできます。
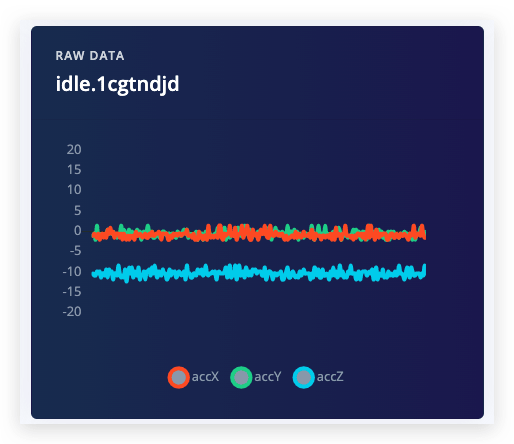
Start sampling をクリックした後、デバイスを上下に連続的に動かします。約12秒後、デバイスはサンプリングを完了し、ファイルを Edge Impulse にアップロードします。スタジオの 'Collected data' の下に新しい行が表示されます。それをクリックすると、生データがグラフ化されて表示されます。開発ボードの加速度センサーには3つの軸があるため、それぞれの軸に対応する3つの異なる線が表示されます。
後でデータを小さなウィンドウに分割するため、連続的な動きを行うことが重要です。
機械学習は大量のデータで最も効果を発揮するため、単一のサンプルでは不十分です。ここで独自のデータセットを構築する時です。例えば、以下の3つのクラスを使用し、各クラスで約3分間のデータを記録します:
- Idle - 作業中に机の上に置いている状態。
- Wave - デバイスを左右に振る動作。
- Circle - 円を描く動作。
動作にバリエーションを持たせることを忘れないでください。例えば、ゆっくりした動きと速い動きを両方行い、ボードの向きを変えてください。ユーザーがデバイスをどのように使用するかは予測できません。約10秒間のサンプルを収集するのが最適です。
3. インパルスの設計
トレーニングセットが準備できたら、インパルスを設計することができます。インパルスは生データを取り込み、小さなウィンドウに分割し、信号処理ブロックを使用して特徴を抽出し、学習ブロックを使用して新しいデータを分類します。信号処理ブロックは、同じ入力に対して常に同じ値を返し、生データを処理しやすくするために使用されます。一方、学習ブロックは過去の経験から学習します。
このチュートリアルでは、「スペクトル分析」信号処理ブロックを使用します。このブロックはフィルターを適用し、信号のスペクトル分析を行い、周波数とスペクトルパワーデータを抽出します。その後、これらのスペクトル特徴を使用して、3つのクラス(アイドル、円、波)を区別する「ニューラルネットワーク」学習ブロックを使用します。
スタジオで Create impulse に移動し、ウィンドウサイズを 2000 に設定します(2000 ms のテキストをクリックして正確な値を入力できます)。ウィンドウの増加を 80 に設定し、Spectral Analysis と Neural Network (Keras) ブロックを追加します。その後、Save impulse をクリックします。
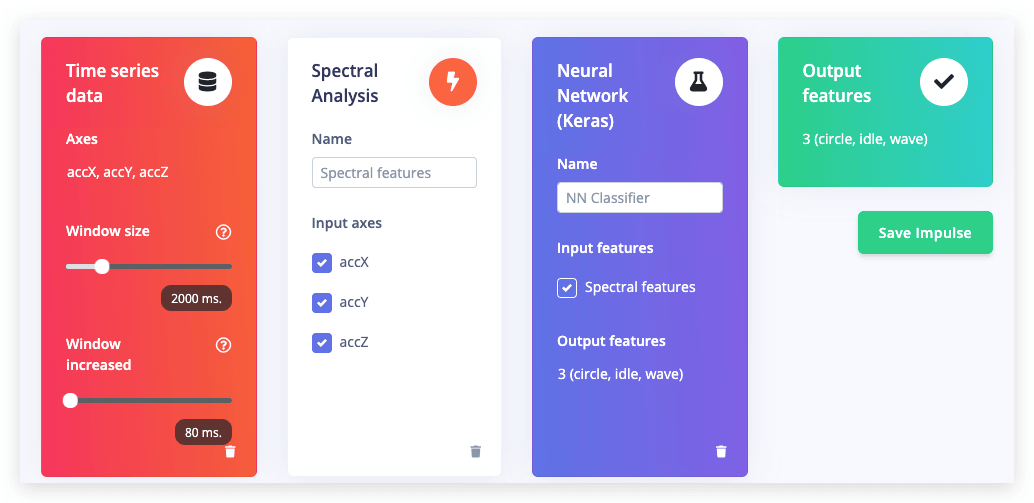
スペクトル分析ブロックの設定
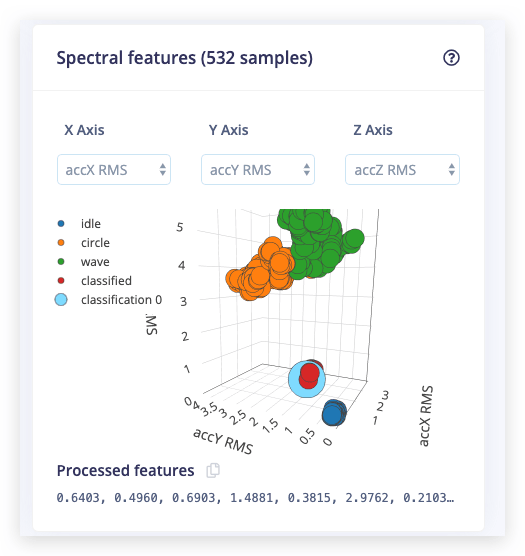
信号処理ブロックを設定するには、左側のメニューで Spectral features をクリックします。これにより、画面上部に生データが表示され(ドロップダウンメニューから他のファイルを選択できます)、右側に信号処理の結果がグラフとして表示されます。スペクトル特徴ブロックでは以下のグラフが表示されます:
- After filter - ローパスフィルターを適用した後の信号。このフィルターはノイズを除去します。
- Frequency domain - 信号が繰り返される周波数(例:1秒間に1回の波動を作る場合、1 Hzでピークが表示されます)。
- Spectral power - 各周波数に投入された信号のパワー量。
良好な信号処理ブロックは、類似のデータに対して類似の結果を生成します。スライディングウィンドウ(生データグラフ上)を移動させても、グラフは類似したままであるべきです。また、同じラベルの別のファイルに切り替えた場合でも、デバイスの向きが異なっていても類似したグラフが表示されるはずです。
結果に満足したら、Save parameters をクリックします。これにより、Feature generation 画面に移動します。ここでは以下を行います:
- 生データをすべてウィンドウサイズとウィンドウ増加に基づいて分割します。
- これらのウィンドウすべてにスペクトル特徴ブロックを適用します。
Generate features をクリックしてプロセスを開始します。
その後、Feature explorer が読み込まれます。これは、生成されたすべてのウィンドウに対して抽出された特徴のプロットです。このグラフを使用して、データセット全体を比較できます。例えば、X軸に最初のピークの高さをプロットし、Y軸に0.5 Hzから1 Hzの間のスペクトルパワーをプロットすることができます。目視でデータをいくつかの軸で分離できる場合、機械学習モデルもそれを行うことができる可能性が高いです。
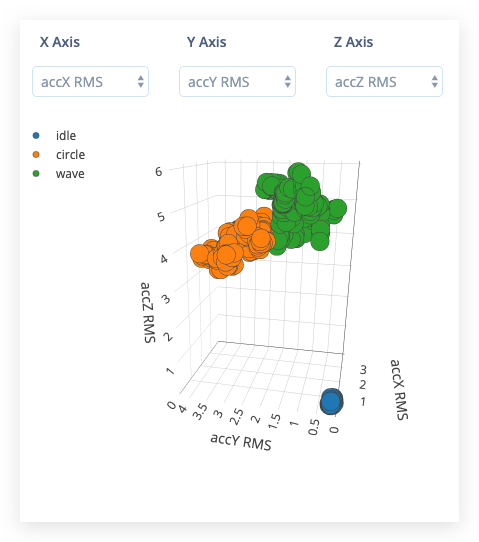
ニューラルネットワークの設定
すべてのデータが処理されたら、ニューラルネットワークのトレーニングを開始する時です。ニューラルネットワークは、人間の脳をゆるやかにモデル化したアルゴリズムのセットで、パターンを認識するように設計されています。ここでトレーニングするネットワークは、信号処理データを入力として受け取り、それを3つのクラスのいずれかにマッピングしようとします。
では、ニューラルネットワークはどのようにして予測を行うのでしょうか?ニューラルネットワークは、ニューロンの層で構成されており、すべてが相互接続されており、各接続には重みがあります。入力層のニューロンの1つは、X軸の最初のピークの高さ(信号処理ブロックから)であり、出力層のニューロンの1つは「波」(クラスの1つ)です。ニューラルネットワークを定義する際、これらの接続はすべてランダムに初期化されるため、ニューラルネットワークはランダムな予測を行います。トレーニング中に生データをすべて取り込み、ネットワークに予測を行わせ、その結果に応じて重みを微調整します(これが生データのラベル付けが重要である理由です)。
この方法で、多くの反復を経てニューラルネットワークは学習し、新しいデータの予測が非常に上手になります。これを試すには、メニューで NN Classifier をクリックします。
Number of training cycles を 1 に設定します。これによりトレーニングが1回の反復に制限されます。そして Start training をクリックします。
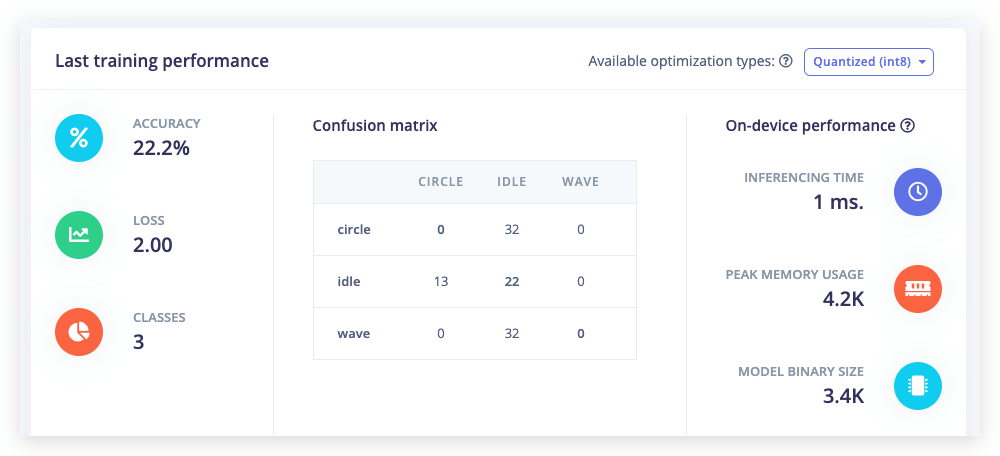
次に Number of training cycles を 2 に変更すると、パフォーマンスが向上するのがわかります。最後に Number of training cycles を 100 以上に設定してトレーニングを完了させます。これで初めてニューラルネットワークをトレーニングしました!
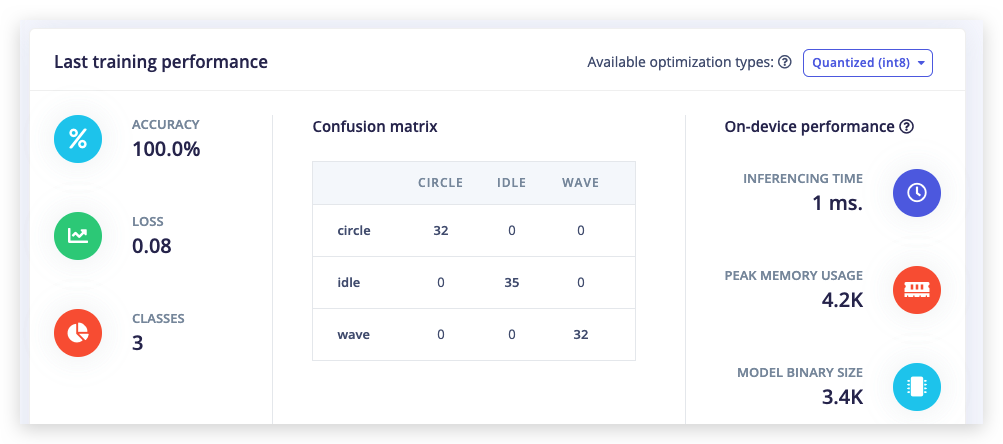
100回のトレーニングサイクル後に100%の精度を達成することがあります。これは必ずしも良いことではありません。ニューラルネットワークが特定のテストセットに過度に適合しており、新しいデータに対しては性能が低下する可能性がある(過学習)ことを示している場合があります。これを軽減する最善の方法は、データを追加するか、学習率を下げることです。
4. 新しいデータの分類
前のステップで得た統計から、モデルがトレーニングデータに対して機能することは分かりましたが、ネットワークが新しいデータに対してどれほどの性能を発揮するかはどうでしょうか?メニューの「Live classification」をクリックして確認してみましょう。デバイスは(ステップ2と同様に)「Classify new data」の下でオンラインとして表示されるはずです。Sample lengthを5000(5秒)に設定し、Start samplingをクリックして動作を開始してください。その後、ネットワークがあなたの動作をどのように認識したかの完全なレポートが得られます。
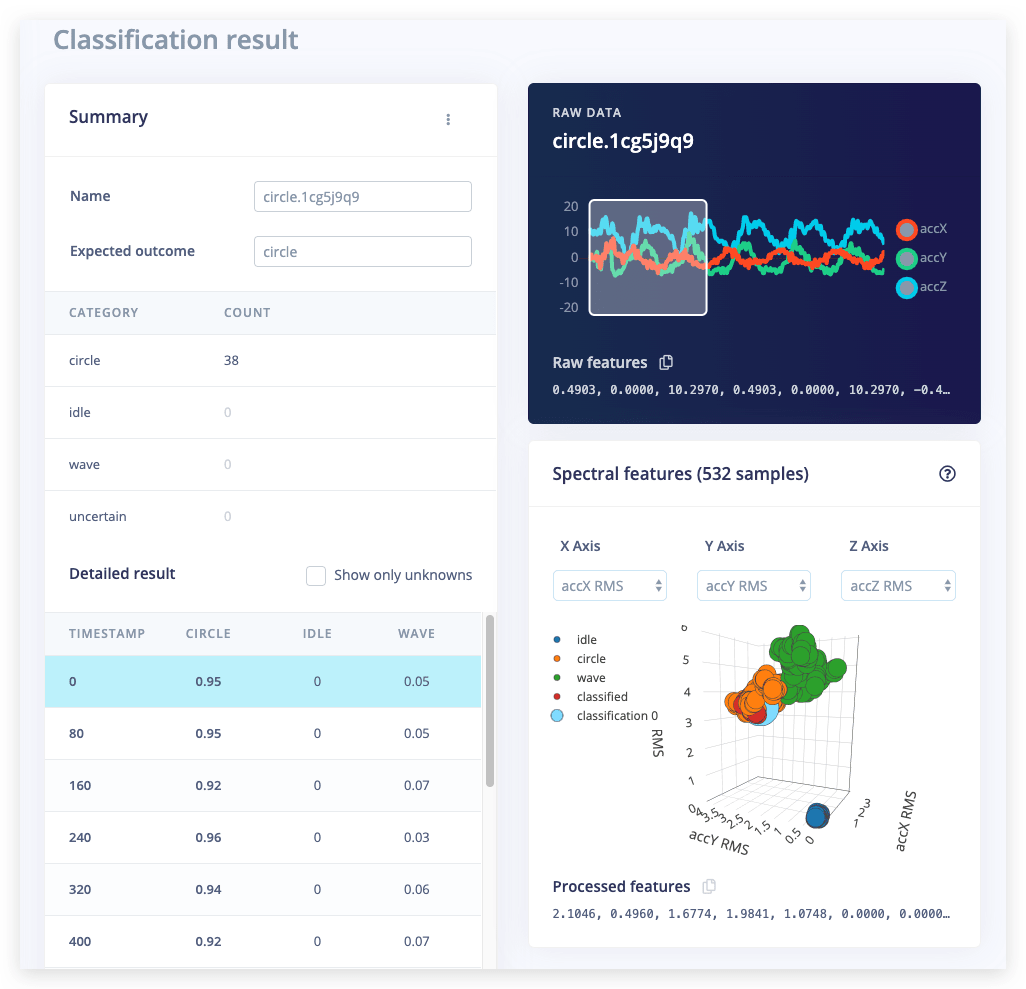
ネットワークが素晴らしい性能を発揮した場合は、素晴らしいですね!しかし、もし性能が悪かった場合はどうでしょうか?いくつかの理由が考えられますが、最も一般的なものは以下の通りです:
- データが不足している。ニューラルネットワークはデータセット内のパターンを学習する必要があり、データが多ければ多いほど良いです。
- データがネットワークが以前に見たデータと似ていない。これは、デバイスをテストセットに追加していない方法で使用した場合によく見られます。現在のファイルをテストセットに追加するにはクリックして、Move to training setを選択します。トレーニング前に
Data acquisitionの下でラベルを更新することを忘れないでください。 - モデルが十分にトレーニングされていない。エポック数を
200に増やして性能が向上するか確認してください(分類されたファイルは保存されており、Classify existing validation sampleを通じてロードできます)。 - モデルが過学習しており、新しいデータに対して性能が悪い。学習率を下げるか、データを追加してみてください。
- ニューラルネットワークのアーキテクチャがデータに適していない。層やニューロンの数を調整して性能が向上するか確認してください。
ニューラルネットワークを構築する際にはまだ多くの試行錯誤が必要ですが、可視化が大いに役立つことを願っています。また、Model validationを通じてネットワークを完全な検証セットに対して実行することもできます。モデル検証ページは、モデルの単体テストのセットと考えてください!
動作するモデルが完成したら、現在のインパルスが性能を発揮できていない箇所を確認してみましょう...
5. 異常検知
ニューラルネットワークは非常に優れていますが、1つ大きな欠点があります。それは、これまでに見たことのないデータ(新しいジェスチャーなど)を扱うのが非常に苦手だということです。ニューラルネットワークはこれを判断することができません。トレーニングデータしか認識していないため、これまでに見たことのないデータを与えると、それでも3つのクラスのいずれかとして分類してしまいます。
これが実際にどのように機能するか見てみましょう。Live classificationに移動して新しいデータを記録しますが、今回はデバイスを激しく振ってみてください。ネットワークが何かしらを予測する様子を確認してみてください。
では...どうすれば改善できるでしょうか?accX RMS、accY RMS、accZ RMS軸の特徴エクスプローラーを見てみると、分類されたデータとトレーニングデータを視覚的に分離できるはずです。これを利用して、新しい(2つ目の)ネットワークをトレーニングし、これまでに見たデータの周りにクラスターを作成し、これらのクラスターに対して新しいデータを比較することができます。クラスターからの距離が大きすぎる場合、そのサンプルを異常としてフラグを立て、ニューラルネットワークを信頼しないようにすることができます。
このブロックを追加するには、Create impulseに移動し、Add learning blockをクリックしてK-means Anomaly Detectionを選択します。その後、Save impulseをクリックしてください。
クラスタリングモデルを構成するには、メニューのAnomaly detectionをクリックします。ここで以下を指定する必要があります:
- クラスターの数。ここでは
32を使用します。 - クラスタリング中に選択したい軸。accX RMS、accY RMS、accZ RMS軸でデータを視覚的に分離できるため、それらを選択します。
Start trainingをクリックしてクラスターを生成します。既存の検証サンプルをドロップダウンメニューを使用して異常エクスプローラーにロードすることができます。
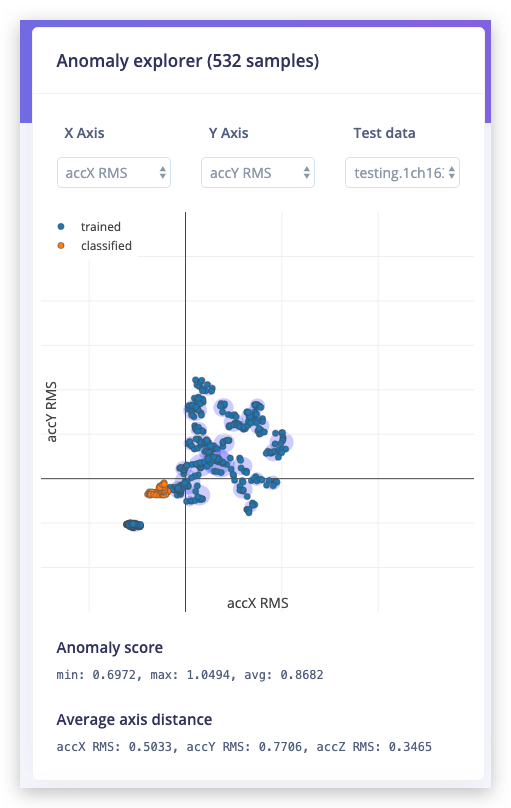
青色の既知のクラスター、オレンジ色の振動データ。明らかに既知のクラスターの外側にあり、異常としてタグ付けすることができます。
異常エクスプローラーは一度に2つの軸しかプロットしません。average axis distanceの下で、検証サンプルが各軸からどれだけ離れているかを確認できます。ドロップダウンメニューを使用して軸を変更してください。
6. デバイスへの再デプロイ
インパルスを設計し、トレーニングし、検証した後、このモデルをデバイスに再デプロイすることができます。これにより、モデルはインターネット接続なしで動作し、レイテンシーを最小化し、最小限の電力消費で動作します。Edge Impulseは、信号処理コード、ニューラルネットワークの重み、分類コードを含む完全なインパルスを1つのC++ライブラリにパッケージ化し、組み込みソフトウェアに含めることができます。
デプロイメントタブをクリックした後、Arduinoライブラリを選択してダウンロードします。アーカイブを解凍し、Arduinoのライブラリフォルダに配置します。Arduino IDEを開き、Examples -> プロジェクト名 Inferencing Edge Impulse -> nano_ble33_sense_accelerometerスケッチを選択します。私たちのボードはArduino Nano BLE33 Senseに似ていますが、異なる加速度センサー(LSM9DS1ではなくLIS3DHTR)を使用しているため、データ取得セクションを適切に変更する必要があります。また、Wio TerminalにはLCDスクリーンがあるため、検出されたクラスの信頼値が閾値を超えた場合、そのクラス名を表示します。 まず、ヘッダーを以下のように変更します。
#include <Arduino_LSM9DS1.h>
から
#include"LIS3DHTR.h"
#include"TFT_eSPI.h"
LIS3DHTR<TwoWire> lis;
TFT_eSPI tft;
次に、setup関数内の初期化を以下のように変更します。
if (!IMU.begin()) {
ei_printf("Failed to initialize IMU!\r\n");
}
else {
ei_printf("IMU initialized\r\n");
}
から
tft.begin();
tft.setRotation(3);
tft.fillScreen(TFT_WHITE);
lis.begin(Wire1);
if (!lis.available()) {
Serial.println("Failed to initialize IMU!");
while (1);
}
else {
ei_printf("IMU initialized\r\n");
}
lis.setOutputDataRate(LIS3DHTR_DATARATE_100HZ); // 出力データレートを25Hzに設定、最大5kHzまで設定可能
lis.setFullScaleRange(LIS3DHTR_RANGE_16G); // スケール範囲を2gに設定、2,4,8,16gから選択可能
データ収集と推論はloop関数内で行います。ここで、LSM9DS1のデータ取得をLIS3DHTRのデータ取得関数に変更する必要があります。
IMU.readAcceleration(buffer[ix], buffer[ix + 1], buffer[ix + 2]);
を
lis.getAcceleration(&buffer[ix], &buffer[ix + 1], &buffer[ix + 2]);
に変更します。
そして、LCDスクリーンにクラス名を表示するために、以下のコードブロックを追加します。
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
の後に以下を追加します。このコードブロックでは、各クラスの信頼値をチェックし、いずれかが閾値を超えた場合、スクリーンの色を変更し、そのクラス名を表示します。
if (result.classification[1].value > 0.7) {
tft.fillScreen(TFT_PURPLE);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Wave", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
if (result.classification[2].value > 0.7) {
tft.fillScreen(TFT_RED);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Circle", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
その後、コンパイルしてアップロードします。シリアルモニターを開き、ジェスチャーを実行してください!推論結果がシリアルモニターに表示されるだけでなく、LCDスクリーンにも表示されます。
7. 結論
機械学習は非常に興味深い分野です。過去の経験から学び、センサーデータの中に自動的にパターンを見つけ、明示的にプログラムを組むことなく異常を検出する複雑なシステムを構築することが可能です。組み込みシステムにおける機械学習には大きな可能性があると考えています。現在収集されている膨大な量のセンサーデータのうち、99%はコスト、帯域幅、または電力制約のために破棄されています。
Edge Impulseはこのデータを活用する手助けをします。デバイス上で直接データを処理することで、生データをクラウドに送信する必要がなくなり、重要な場所で直接結論を導き出すことができます。皆さんがどのようなものを構築するのか、非常に楽しみにしています!