Wio Terminal Edge Impulse 内蔵マイクによるオーディオシーン認識
このプロジェクトでは、Wio TerminalとEdge Impulseを使用してオーディオシーン分類器をトレーニングおよびデプロイする方法を学びます。 詳細やビデオチュートリアルについては、対応するビデオをご覧ください!
コンピュータにおける音声処理
オーディオシーン分類は、機械学習モデルがオーディオセグメントのクラスを予測するタスクです。例えば、「泣いている赤ちゃん」、「咳」、「犬の鳴き声」などです。
音は、ガス、液体、固体などの伝達媒体を通じて音波として伝播(または移動)する振動です。

音の発生源が周囲の媒体分子を押し、それが隣接する分子を押し続けます。そして最終的に他の物体に到達すると、それもわずかに振動します。この原理をマイクロフォンで利用しています。マイクロフォンの膜は媒体分子によって内側に押され、元の位置に戻ります。
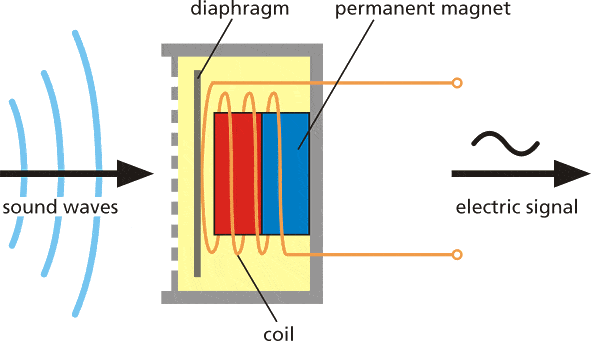
これにより回路内で交流電流が生成され、電圧は音の振幅に比例します。音が大きいほど膜を強く押し、より高い電圧を生成します。この電圧をアナログ-デジタル変換器で読み取り、一定間隔で記録します。1秒間に音を測定する回数をサンプリングレートと呼びます。例えば、8000 Hzのサンプリングレートでは1秒間に8000回測定します。サンプリングレートは音質に非常に重要です。サンプリングが遅すぎると重要な部分を見逃す可能性があります。音をデジタルで記録するために使用される数値も重要です。使用される数値の範囲が広いほど、元の音からより多くの「ニュアンス」を保存できます。これをオーディオビット深度と呼びます。例えば、8ビット音声や16ビット音声という用語を聞いたことがあるかもしれません。これはそのままの意味で、8ビット音声では範囲が0から255の符号なし8ビット整数が使用されます。16ビット音声では範囲が-32768から32767の符号付き16ビット整数が使用されます。最終的に、音の大きな部分に対応する大きな数値を持つ数値列が得られます。これを次のように視覚化できます。これは8000 Hzの周波数で8ビット深度(0-255)で記録された1秒間の銃声の音です。

しかし、この生の音声表現ではあまり多くのことはできません。部分を切り取ったり貼り付けたり、音を静かにしたり大きくしたりすることはできますが、音声を分析するにはあまりにも生の状態です。ここでフーリエ変換、メルスケール、スペクトログラム、ケプストラム係数が登場します。このプロジェクトの目的のために、フーリエ変換を信号を個々の周波数とその振幅に分解する数学的変換として定義します。
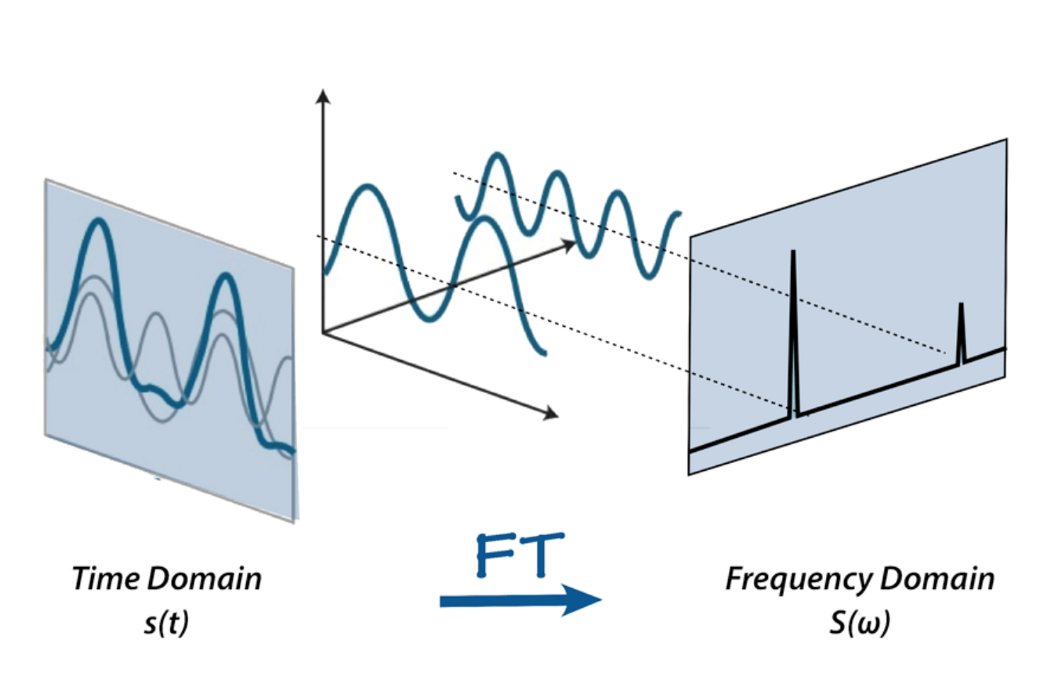
または、比喩を使うならば、スムージーを与えるとそのレシピを出力するようなものです。
フーリエ変換についてはインターネット上に多くの資料があります。例えば、betterexplained.comのこの記事や3Blue1Grayのビデオをチェックして、FFTについてさらに詳しく学んでください。
フーリエ変換を適用した後の音声はこのように見えます。バーが高いほど振幅が大きい周波数を示しています。

素晴らしいですね!これでオーディオ信号でより興味深いことができます。例えば、最も重要でない周波数を排除してオーディオファイルを圧縮したり、ノイズを除去したり、声の音を取り除いたりすることができます。しかし、これでもオーディオや音声認識には十分ではありません。フーリエ変換を行うことで、時間領域の情報をすべて失ってしまいます。これは人間の音声のような非周期的信号には良くありません。しかし、私たちは賢いので、信号サンプルに対してフーリエ変換を複数回行い、基本的にそれをスライスして、複数のフーリエ変換から得られたデータをスペクトログラムの形で再び結合します。
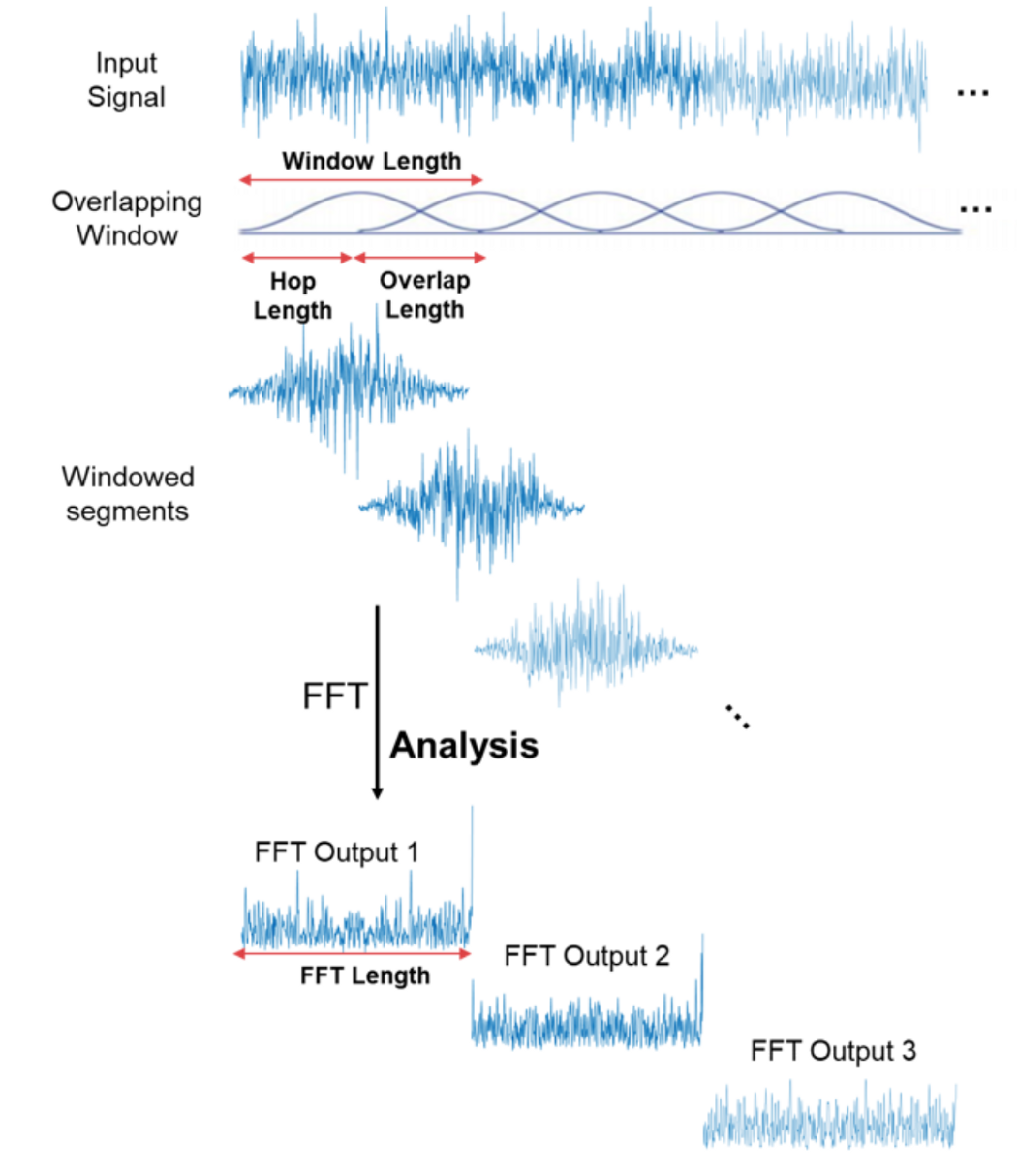
ここでx軸は時間、y軸は周波数、周波数の振幅は色で表されます。明るい色ほど振幅が大きいことを示します。

非常に良いですね!これで音声認識ができるのでしょうか?いいえ!はい!たぶん! 通常のスペクトログラムには、人間の耳で聞こえる音を認識するだけならば、情報が多すぎます。研究によると、人間は周波数を線形スケールで認識していないことが示されています。私たちは低い周波数の違いを高い周波数よりも検出するのが得意です。例えば、500 Hzと1000 Hzの違いは簡単にわかりますが、10000 Hzと10500 Hzの違いはほとんどわかりません。両者の間隔は同じであるにもかかわらずです。 1937年、Stevens、Volkmann、Newmannは、ピッチの単位を提案しました。この単位では、ピッチの等しい距離が聞き手にとって等しく離れているように感じられます。これをメルスケールと呼びます。
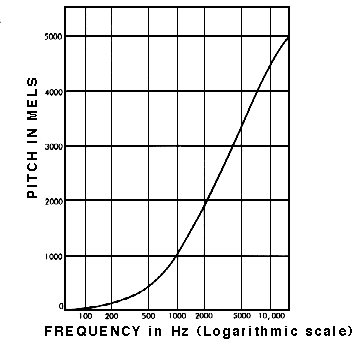
メルスペクトログラムとは、周波数がメルスケールに変換されたスペクトログラムのことです。

音声認識にはさらに多くのステップが必要です。例えば、前述したケプストラム係数などです。これらについては後のプロジェクトで詳しく説明します。それでは、いよいよ実際の実装を始めましょう。
トレーニングデータの取得
音声信号は非常に高いサンプリングレートでサンプリングする必要があります。8000 Hz、理想的には16000 Hzです。Edge Impulse Data Forwarderツールはこのサンプリングレートを処理するには遅すぎるため、このプロジェクトのデータを取得するには専用のデータ収集ファームウェアを使用する必要があります。マイクサポート付きのWio Terminal Edge Impulseファームウェアの新しいバージョンをダウンロードし、Edge Impulseの始め方ページで説明されているようにデバイスにフラッシュしてください。その後、Edge Impulseプラットフォームで新しいプロジェクトを作成し、Edge Impulseのデータ取り込みサービスを起動します。
edge-impulse-daemon
以前にedge-impulse-daemonを使用したことがある場合は、上記のコマンドに--cleanを追加してプロジェクトデータをクリアする必要があります。
次に、資格情報でログインし、作成したばかりのプロジェクトを選択します。「Data Acquisition」タブに移動して、データサンプルの取得を開始できます。
データは以下の3つのクラスに分類されます:
- background(背景音)
- coughing(咳)
- crying(泣き声)
各クラスについて10個のサンプルを記録し、それぞれのサンプルの長さは5000ミリ秒です。コンピュータのスピーカーから再生される音を記録することもできます(backgroundクラスを除く)。ただし、実際の音を記録する機会がある場合は、それがさらに良いでしょう。
backgroundクラスでは、咳や泣き声として分類されるべきではない音を記録します。例えば、人々の会話、無音、エアコンやファンの音などです。

30個のサンプルは非常に少ないため、さらに多くのデータをアップロードします。インターネットから音声をダウンロードし、それを16000 Hzにリサンプリングして、このコンバータースクリプトを使用して.wav形式で保存します。
import librosa
import sys
import soundfile as sf
input_filename = sys.argv[1]
output_filename = sys.argv[2]
data, samplerate = librosa.load(input_filename, sr=16000)
print(data.shape, samplerate)
sf.write(output_filename, data, samplerate, subtype='PCM_16')
コードをコピーしてテキストドキュメントに貼り付けます(Notepad++、IDLE IDE、またはその他の適切なIDEを使用してください。Windowsのデフォルトのメモ帳は使用しないでください)。
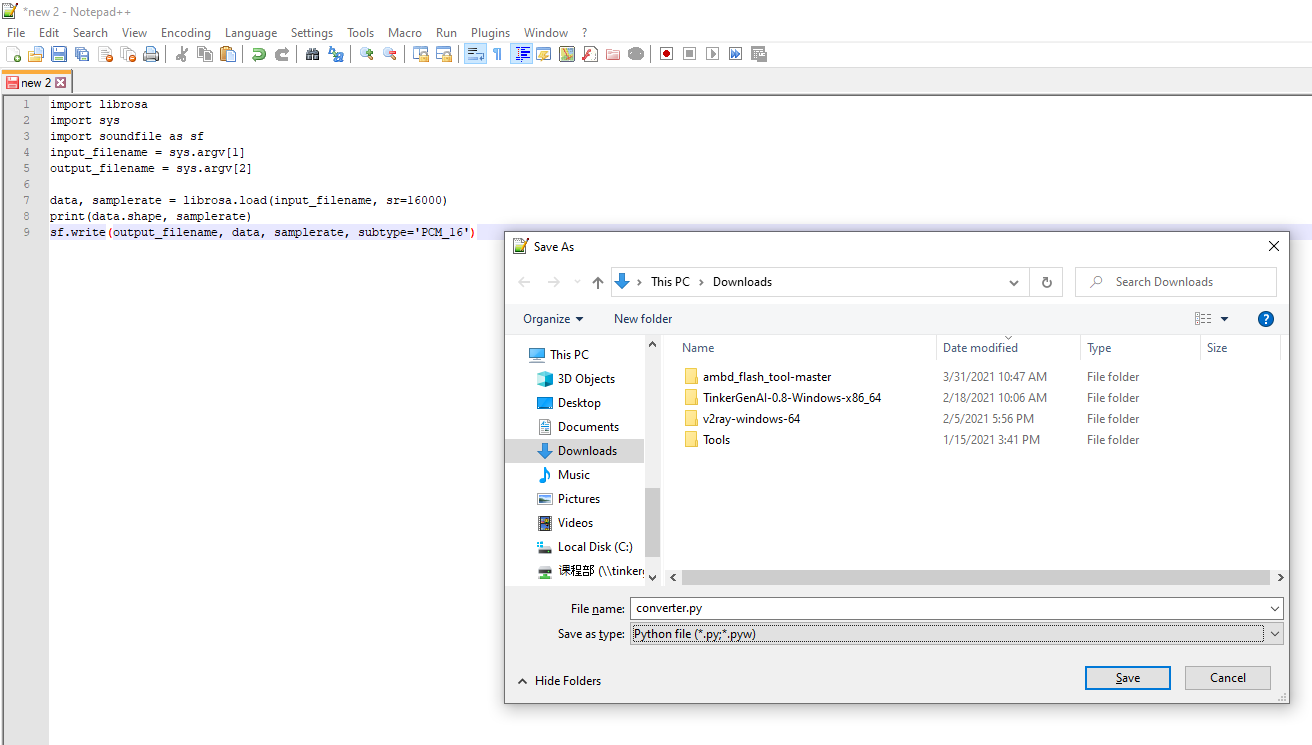
ドキュメントをconverter.pyとして保存し、Anaconda環境から以下を実行します。
python converter.py name-of-the-downloaded-file class_name.number.wav

このプロジェクトのGithubリポジトリには、すでに正しい形式に変換された音声ファイルの例が見つかります。 次に、すべての音声サンプルを分割して「興味深い」部分だけを残します。これはbackgroundクラスを除くすべてのクラスに対して行います。
データ収集が完了したら、処理ブロックを選択し、ニューラルネットワークモデルを定義する時です。
機械学習モデルの構築
処理ブロックの中には、Raw、Spectral Analysis(信号のフーリエ変換に相当)、Spectrogram、MFE(Mel-Frequency Energyバンク)という3つの馴染みのあるオプションがあります。これらは、前述した音声処理の4つの段階に対応しています!
実験が好きな方は、Rawを除いてすべてのオプションをデータに使用してみることができます。Rawは小規模なニューラルネットワークにはデータ量が多すぎるためです。このレッスンでは、このタスクに最適なオプションであるMFE(Mel-Frequency Energyバンク)を使用します。特徴量を計算した後、NN分類器タブに移動して適切なモデルアーキテクチャを選択します。選択肢は1D Convと2D Convの2つです。どちらも機能しますが、可能であれば常に小さいモデルを選択するべきです。これは、組み込みデバイスにデプロイする必要があるためです。このコースの資料を作成する際に、MFEおよびMFCC特徴量を使用して1D Conv/2D Convの4つの異なる実験を実施しました。その結果は以下の表に示されています。

最適なモデルはMFE処理ブロックを使用した1D Convネットワークでした。MFEパラメータを調整することで(具体的にはストライドを0.02に増加させ、低周波数を0に減少させる)、検証データセットで89.4%の精度を達成しました。
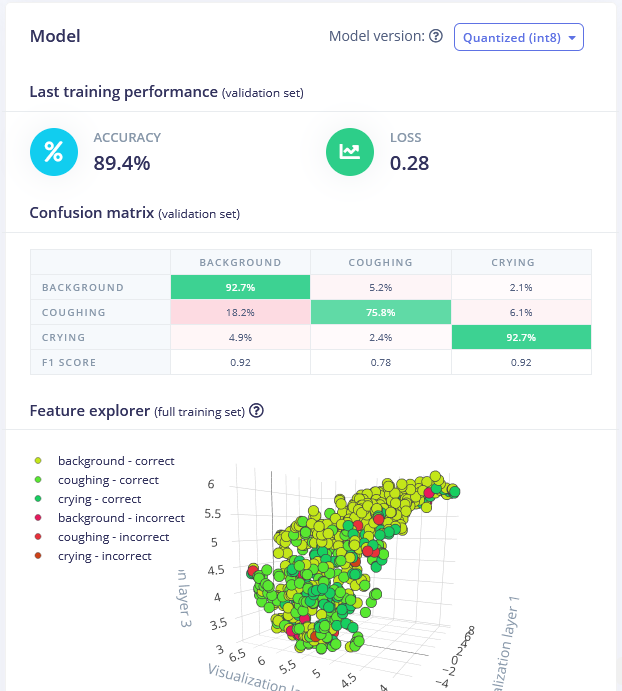
トレーニング済みモデルはこちらで見つけることができ、自分で試すことができます。このモデルは背景音から泣き声を区別するのに優れていますが、咳の音を検出する精度はやや低く、より多くのサンプルを収集する必要があるかもしれません。
Wio Terminalへのデプロイ
トレーニングでモデルの精度に満足したら、Live分類タブで新しいデータをテストし、その後Wio Terminalにデプロイします。Arduinoライブラリとしてダウンロードし、Arduinoライブラリフォルダに配置して、Examples -> プロジェクト名 -> nano_33_ble_sense_microphone_continuousを開きます。このデモはArduino Nano 33 BLEをベースにしており、PDMライブラリを使用します。Wio Terminalでは、DMA(Direct Memory Access)コントローラーを使用してADC(アナログ-デジタルコンバーター)からサンプルを取得し、MCUを介さずに推論バッファに保存します。
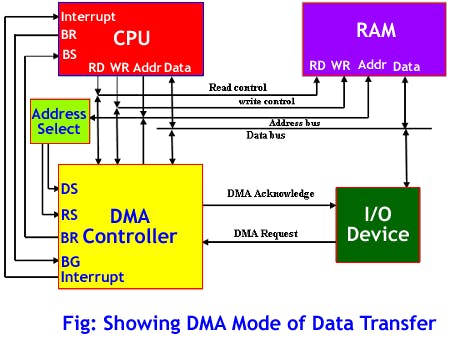
これにより、音声サンプルを収集しながら推論を同時に実行することが可能になります。PDMライブラリからDMAへの音声データ収集を変更するためには、いくつかの変更を加える必要があります。説明中に迷った場合は、コース資料にある完全なサンプルコードを参照してください。
スケッチからPDMライブラリを削除します。
#include <PDM.h>
最後のinclude文の直後にDMAディスクリプタ構造体とその他の設定定数を追加します。
// 設定
#define DEBUG 1 // ISR中のピンパルスを有効化
enum {ADC_BUF_LEN = 4096}; // DMAダブルバッファのサイズ
static const int debug_pin = 1; // DAC ISRごとにトグル(DEBUGが1の場合)
// DMACディスクリプタ構造体
typedef struct {
uint16_t btctrl;
uint16_t btcnt;
uint32_t srcaddr;
uint32_t dstaddr;
uint32_t descaddr;
} dmacdescriptor;
次に、setup関数の直前にバッファ配列用の変数、ISRコールバックとメインコード間で値を渡すためのvolatile変数、そして信号に適用してマイク信号のDC成分をほとんど除去するためのハイパスバターワースフィルタを作成します。
// グローバル変数 - DMAとADC
volatile uint8_t recording = 0;
volatile boolean results0Ready = false;
volatile boolean results1Ready = false;
uint16_t adc_buf_0[ADC_BUF_LEN]; // ADC結果配列0
uint16_t adc_buf_1[ADC_BUF_LEN]; // ADC結果配列1
volatile dmacdescriptor wrb[DMAC_CH_NUM] __attribute__ ((aligned (16))); // 書き戻しDMACディスクリプタ
dmacdescriptor descriptor_section[DMAC_CH_NUM] __attribute__ ((aligned (16))); // DMACチャネルディスクリプタ
dmacdescriptor descriptor __attribute__ ((aligned (16))); // プレースホルダディスクリプタ
// ハイパスバターワースフィルタ order=1 alpha1=0.0125
class FilterBuHp1
{
public:
FilterBuHp1()
{
v[0]=0.0;
}
private:
float v[2];
public:
float step(float x) // クラスII
{
v[0] = v[1];
v[1] = (9.621952458291035404e-1f * x)
+ (0.92439049165820696974f * v[0]);
return
(v[1] - v[0]);
}
};
FilterBuHp1 filter;
その後、3つのコードブロックを追加します。最初のコードブロックは、ISR(割り込みサービスルーチン)によって呼び出されるコールバック関数で、2つのバッファのいずれかが満杯になるたびに実行されます。この関数内では、録音バッファ(今満杯になったもの)から要素を読み取り、それらを処理して推論バッファに格納します。
/*******************************************************************************
* 割り込みサービスルーチン(ISR)
*/
/**
* @brief 選択されたバッファ内のサンプルデータをコピーし、バッファが満杯になったら準備完了を通知
*
* @param[in] *buf ソースバッファへのポインタ
* @param[in] buf_len バッファからコピーするサンプル数
*/
static void audio_rec_callback(uint16_t *buf, uint32_t buf_len) {
static uint32_t idx = 0;
// DMAバッファから推論バッファへのサンプルコピー
if (recording) {
for (uint32_t i = 0; i < buf_len; i++) {
// 12ビットの符号なしADC値を16ビットPCM(符号付き)オーディオ値に変換
inference.buffers[inference.buf_select][inference.buf_count++] = filter.step(((int16_t)buf[i] - 1024) * 16);
// 必要に応じてダブルバッファを切り替え
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
次のブロックには ISR(割り込みサービスルーチン)が含まれています。この関数は一定の時間間隔でタイマーによって実行されます。この関数内では、DMAC チャネル 1 が一時停止(SUSP)しているかどうかを確認します。一時停止している場合、マイクデータ用のバッファのいずれかが満杯になったことを意味し、そのデータをコピーし、別のバッファに切り替えて DMAC ADC を再起動する必要があります。
/**
* DMAC 1 の割り込みサービスルーチン (ISR)
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// DMAC チャネル 1 が一時停止(SUSP)しているか確認
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// デバッグ: バッファコピー前にピンを HIGH に設定
#if DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// チャネル 1 の DMAC を再起動し、一時停止割り込みフラグをクリア
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// どのバッファが満杯になったか確認し、大きなバッファに結果をダンプ
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// 次のバッファに切り替え
count = (count + 1) % 2;
// デバッグ: バッファコピー後にピンを LOW に設定
#if DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
次のブロックには、ADC DMAC と ISR(割り込みサービスルーチン)を制御するタイマーの設定データが含まれています。
// ADC を定期的にサンプリングするための DMA 設定
void config_dma_adc() {
// ADC を定期的にサンプリングするための DMA 設定(タイマー/カウンターによるトリガー)
DMAC->BASEADDR.reg = (uint32_t)descriptor_section; // デスクリプタの場所を指定
DMAC->WRBADDR.reg = (uint32_t)wrb; // 書き戻しデスクリプタの場所を指定
DMAC->CTRL.reg = DMAC_CTRL_DMAENABLE | DMAC_CTRL_LVLEN(0xf); // DMAC ペリフェラルを有効化
DMAC->Channel[1].CHCTRLA.reg = DMAC_CHCTRLA_TRIGSRC(TC5_DMAC_ID_OVF) | // TC5 タイマーオーバーフローで DMAC をトリガー
DMAC_CHCTRLA_TRIGACT_BURST; // DMAC バースト転送
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // 循環デスクリプタを設定
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // ADC0 RESULT レジスタから結果を取得
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // adc_buf_0 配列に結果を配置
descriptor.btcnt = ADC_BUF_LEN; // ビートカウント
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // ビートサイズは HWORD(16 ビット)
DMAC_BTCTRL_DSTINC | // 宛先アドレスをインクリメント
DMAC_BTCTRL_VALID | // デスクリプタが有効
DMAC_BTCTRL_BLOCKACT_SUSPEND; // ブロック転送後に DMAC チャネル 0 を一時停止
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // デスクリプタをデスクリプタセクションにコピー
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // 循環デスクリプタを設定
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // ADC0 RESULT レジスタから結果を取得
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // adc_buf_1 配列に結果を配置
descriptor.btcnt = ADC_BUF_LEN; // ビートカウント
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // ビートサイズは HWORD(16 ビット)
DMAC_BTCTRL_DSTINC | // 宛先アドレスをインクリメント
DMAC_BTCTRL_VALID | // デスクリプタが有効
DMAC_BTCTRL_BLOCKACT_SUSPEND; // ブロック転送後に DMAC チャネル 0 を一時停止
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // デスクリプタをデスクリプタセクションにコピー
// NVIC の設定
NVIC_SetPriority(DMAC_1_IRQn, 0); // DMAC1 の Nested Vector Interrupt Controller (NVIC) 優先度を 0(最高)に設定
NVIC_EnableIRQ(DMAC_1_IRQn); // DMAC1 を Nested Vector Interrupt Controller (NVIC) に接続
// DMAC チャネル 1 の一時停止(SUSP)割り込みを有効化
DMAC->Channel[1].CHINTENSET.reg = DMAC_CHINTENSET_SUSP;
// ADC の設定
ADC1->INPUTCTRL.bit.MUXPOS = ADC_INPUTCTRL_MUXPOS_AIN12_Val; // ADC0/AIN2(PB08 - Metro M4 の A4)をアナログ入力に設定
while(ADC1->SYNCBUSY.bit.INPUTCTRL); // 同期を待機
ADC1->SAMPCTRL.bit.SAMPLEN = 0x00; // 最大サンプリング時間を ADC クロックパルスの半分(2.66us)に設定
while(ADC1->SYNCBUSY.bit.SAMPCTRL); // 同期を待機
ADC1->CTRLA.reg = ADC_CTRLA_PRESCALER_DIV128; // ADC GCLK を 128 で分周(48MHz/128 = 375kHz)
ADC1->CTRLB.reg = ADC_CTRLB_RESSEL_12BIT | // ADC 解像度を 12 ビットに設定
ADC_CTRLB_FREERUN; // ADC をフリーランモードに設定
while(ADC1->SYNCBUSY.bit.CTRLB); // 同期を待機
ADC1->CTRLA.bit.ENABLE = 1; // ADC を有効化
while(ADC1->SYNCBUSY.bit.ENABLE); // 同期を待機
ADC1->SWTRIG.bit.START = 1; // ADC 変換を開始するためのソフトウェアトリガーを実行
while(ADC1->SYNCBUSY.bit.SWTRIG); // 同期を待機
// DMA チャネル 1 を有効化
DMAC->Channel[1].CHCTRLA.bit.ENABLE = 1;
// タイマー/カウンター 5 の設定
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // TC5 のペリフェラルチャネルを有効化
GCLK_PCHCTRL_GEN_GCLK1; // 汎用クロック 0(48MHz)に接続
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // TC5 をマッチ周波数(MFRQ)モードに設定
TC5->COUNT16.CC[0].reg = 3000 - 1; // トリガーを 16 kHz に設定: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // 同期を待機
// タイマー/カウンター 5 を開始
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // TC5 タイマーを有効化
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // 同期を待機
}
セットアップ関数の冒頭にデバッグ条件を追加します:
// DMA割り込み時にトグルするピンを設定
#if DEBUG
pinMode(debug_pin, OUTPUT);
#endif
次に、run_classifier_init();の後に以下のコードをセットアップ関数内に追加し、推論バッファを作成し、DMAを設定して、グローバル変数recordingを1に設定することで録音を開始します。
// 推論用のダブルバッファを作成
inference.buffers[0] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE * sizeof(int16_t));
if (inference.buffers[0] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 0");
return;
}
inference.buffers[1] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE *
sizeof(int16_t));
if (inference.buffers[1] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 1");
free(inference.buffers[0]);
return;
}
// 推論パラメータを設定
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = EI_CLASSIFIER_SLICE_SIZE;
inference.buf_ready = 0;
// DMAを設定してADCから16kHzでサンプリング(即座にサンプリング開始)
config_dma_adc();
// 推論バッファへの録音を開始
recording = 1;
}
microphone_inference_end(void)関数からPDM.end();とfree(sampleBuffer);を削除します。また、microphone_inference_start(uint32_t n_samples)およびpdm_data_ready_inference_callback(void)関数も削除します。これらは使用しないためです。
コードをコンパイルしてアップロードした後、シリアルモニターを開くと、各クラスの確率が表示されます。Wio Terminalに向かって音を出したり咳をしたりして、精度を確認してください。
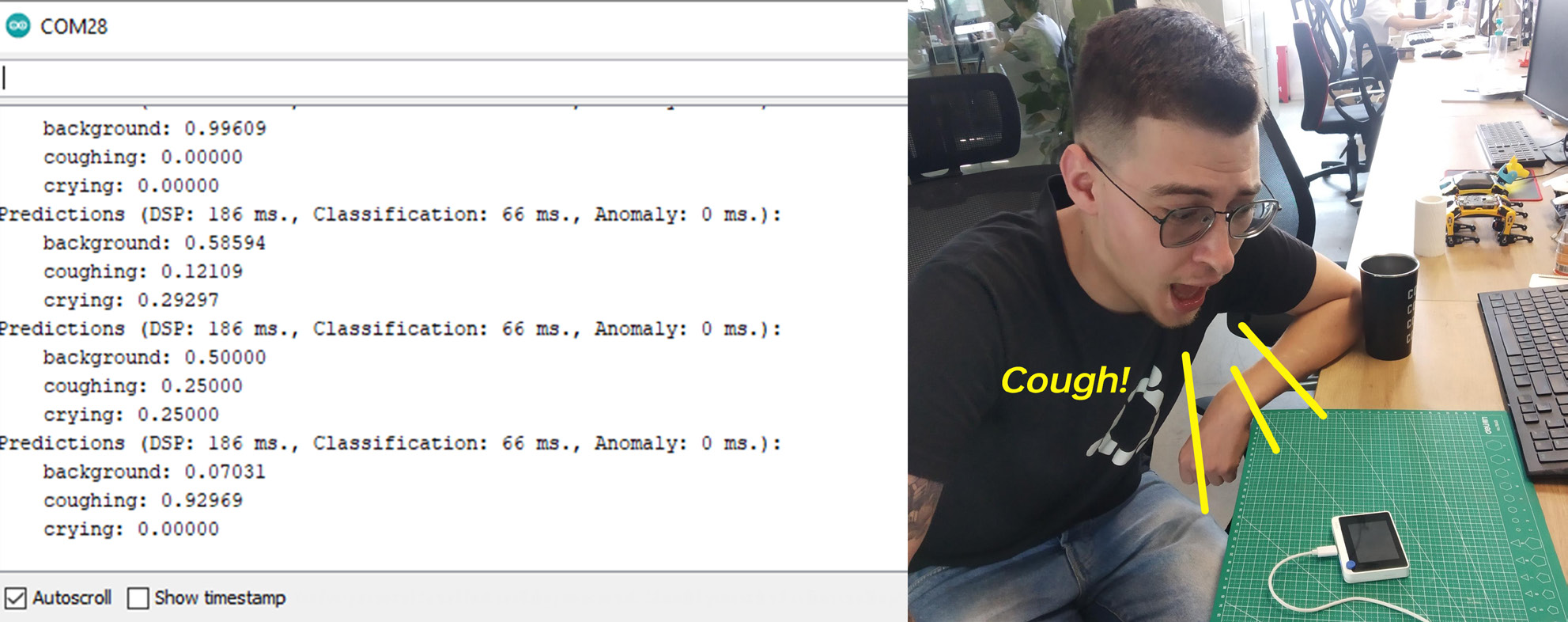
Blynk統合
Wio Terminalはインターネットに接続できるため、この簡単なデモを拡張して、Blynkを使用した実際のIoTアプリケーションにすることができます。
Blynkは、iOSやAndroidデバイスからハードウェアプロジェクトを制御および監視するためのインターフェースを迅速に構築できるプラットフォームです。この場合、Wio Terminalが注意すべき音を検出した場合にスマートフォンに通知を送るためにBlynkを使用します。
Blynkを始めるには、アプリをダウンロードし、新しいアカウントを登録して新しいプロジェクトを作成します。プッシュ通知要素を追加して、再生ボタンを押します。

次に、Wio TerminalのWiFiライブラリとファームウェアをこちらのガイドに従って設定してください。そのチュートリアルで説明されているようにBlynkライブラリをダウンロードします。
WiFiのSSID、パスワード、およびBlynk APIトークン(アプリで取得可能)を変更して、簡単なプッシュボタンの例をコンパイルしてアップロードしてセットアップをテストします。
#define BLYNK_PRINT Serial
#include <rpcWiFi.h>
#include <WiFiClient.h>
#include <BlynkSimpleWioTerminal.h>
char auth[] = "token";
char ssid[] = "ssid";
char pass[] = "password";
void checkPin()
{
int isButtonPressed = !digitalRead(WIO_KEY_A);
if (isButtonPressed) {
Serial.println("Button is pressed.");
Blynk.notify("Yaaay... button is pressed!");
}
}
void setup()
{
Serial.begin(115200);
Blynk.begin(auth, ssid, pass);
pinMode(WIO_KEY_A, INPUT_PULLUP);
}
void loop()
{
Blynk.run();
checkPin();
}
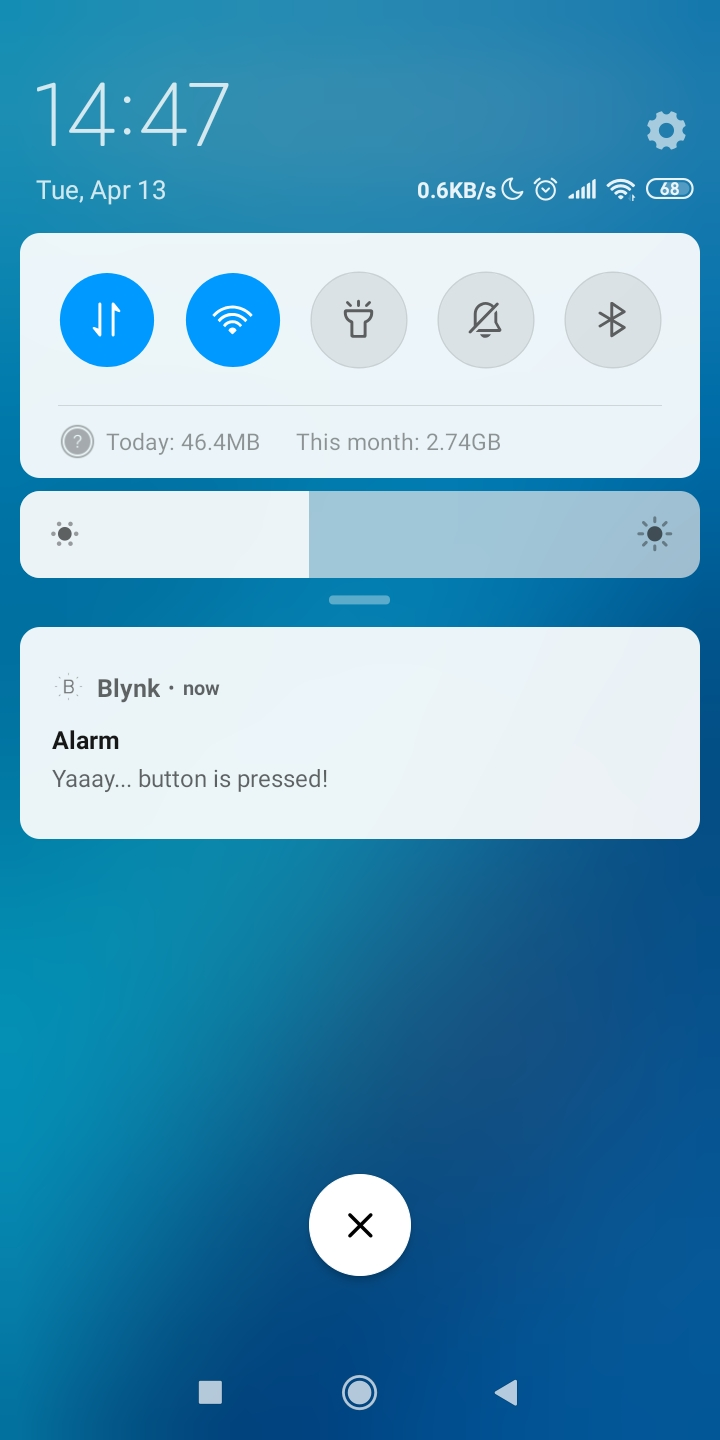
コードがコンパイルされ、テストが成功した場合(Wio Terminalの左上ボタンを押すとスマートフォンにプッシュ通知が表示される)、次のステージに進むことができます。
ニューラルネットワーク推論コードをすべて別の関数に移動し、loop()関数内でBlynk.run()の直後に呼び出します。以前と同様に、ニューラルネットワークの予測確率を確認し、特定のクラスの閾値を超えた場合、Blynk.notify()関数を呼び出します。この関数は、予想通りモバイルデバイスに通知を送ります。
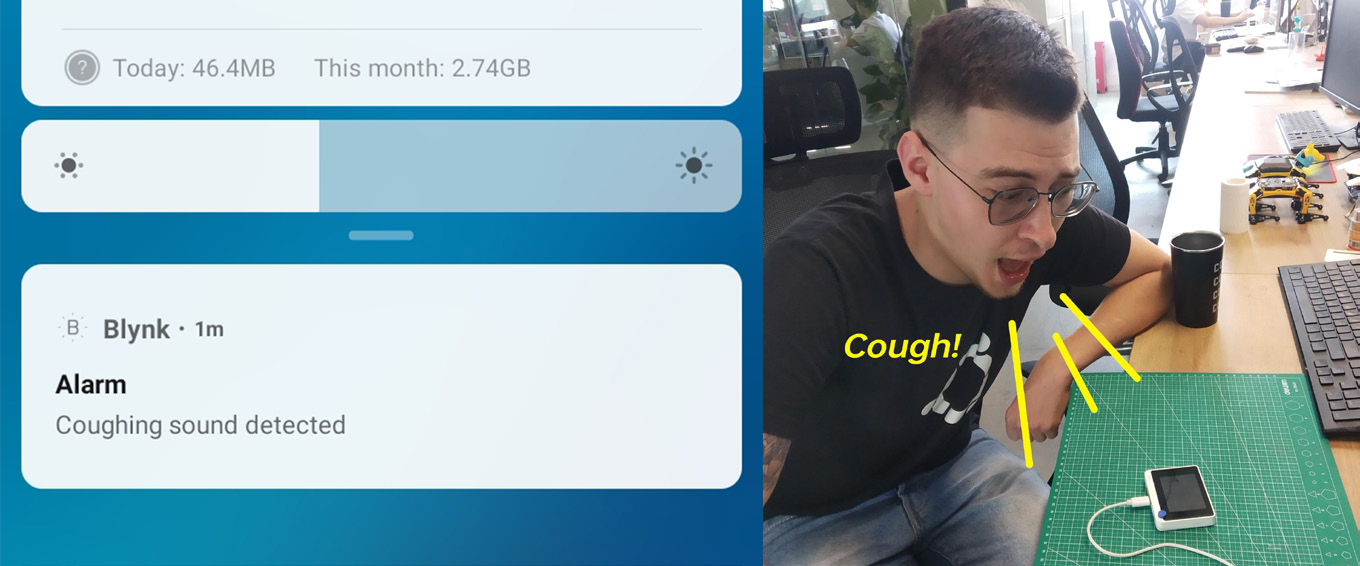
このプロジェクトのGitHubリポジトリで、NN推論とBlynk通知の完全なコードを確認してください。