Wio Terminal Tensorflow Lite Microを使用したBME280によるインテリジェント気象ステーション
このプロジェクトでは、Wio TerminalとTensorflow Lite for Microcontrollersを使用して、BME280環境センサーからのローカルデータに基づいて、次の24時間の天気と降水量を予測できるインテリジェント気象ステーションを作成します。

詳細やビジュアルについては、対応する動画をご覧ください!
モデル最適化技術を適用する方法を学びます。この技術により、中規模の畳み込みニューラルネットワークを実行するだけでなく、この洗練されたGUIやWiFi接続を同時に数日から数ヶ月間実行することが可能になります。

これが最終結果です。画面には現在の温度、湿度、大気圧の値が表示されており、都市名、予測された天気の種類、予測された降水確率も表示されています。また、画面の下部にはログ出力フィールドがあり、これを簡単に再利用して極端な天気情報やその他の関連情報を表示することができます。この状態でも見た目が良く、実用的ですが、自分で追加できることがたくさんあります。例えば、前述のニュースやツイートを画面に表示したり、ディープスリープモードを使用してエネルギーを節約し、バッテリー駆動にするなどです。
このプロジェクトでは、以前に何度も扱った時系列データを使用しますが、今回は天気予測のために時間の範囲が大幅に広がります。1時間ごとに測定を行い、24時間分のデータで予測を行います。また、次の24時間の平均的な天気の種類を予測するだけでなく、同じモデルを使用して次の24時間の降水確率も予測します。そのために、Keras Functional APIとマルチ出力モデルを活用します。
マルチ出力モデルでは、両方の出力に共通する「ステム」があり、そこから2つの異なる出力に「分岐」します。ここで2つの独立したモデルを使用する代わりにマルチ出力モデルを使用する主な利点は、天気の種類と降水確率を予測するために使用されるデータと学習された特徴が非常に関連していることです。
このプロジェクトをWindowsで作成する場合、最初に行うべきことはArduino IDEのナイトリーバージョンをダウンロードすることです。現在の安定版1.18.3では、多くのライブラリ依存関係を含むスケッチをコンパイルできません(問題は、コンパイル中にリンカーコマンドがWindowsでの最大長を超えることです)。
次に、Arduino IDEでSeeed SAMDボード定義の1.8.2バージョンを確保する必要があります。
最後に、畳み込みニューラルネットワークを使用し、Keras APIで構築しているため、現在の安定版Tensorflow Microではサポートされていない操作が含まれています。GithubのTensorflowの問題を調べたところ、この操作(EXPAND_DIMS)を利用可能な操作のリストに追加するためのプルリクエストがあることがわかりましたが、この動画を作成した時点ではマスターにマージされていませんでした。Tensorflowリポジトリをgit cloneし、PRブランチに切り替えてLinuxマシンで./tensorflow/lite/micro/tools/ci_build/test_arduino.shを実行してArduinoライブラリをコンパイルすることができます。結果のライブラリはtensorflow/lite/micro/tools/make/gen/arduino_x86_64/prj/tensorflow_lite.zipにあります。あるいは、このプロジェクトのGithubリポジトリから既にコンパイルされたライブラリをダウンロードし、Arduinoスケッチのライブラリフォルダに配置することもできます。ただし、同時に1つのTensorflow Liteライブラリのみを保持するようにしてください!
データの理解
すべてはデータから始まります。このチュートリアルでは、Kaggle から入手可能な「Historical Hourly Weather Data 2012-2017」という天気データセットを使用します。Seeed EDU 本社は中国南部の都市、深圳に位置していますが、この都市はデータセットに含まれていないため、同じ緯度に位置し、亜熱帯気候を持つ都市であるマイアミを選びました。
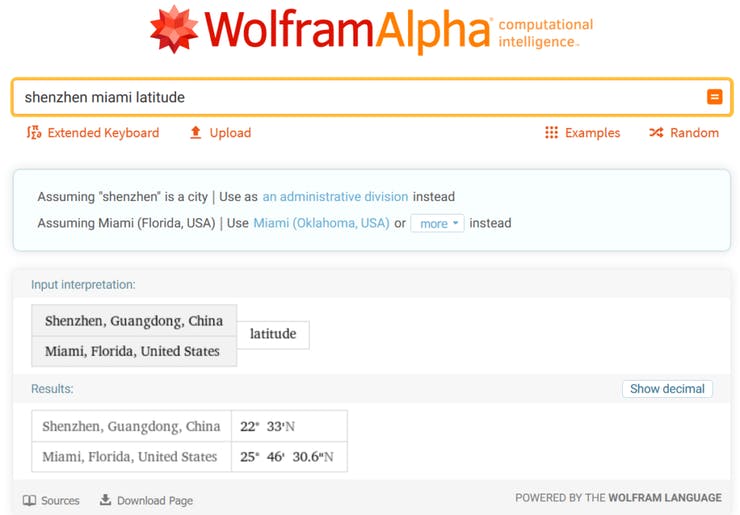
自分が住んでいる地域の気候に少なくとも似ている都市を選ぶ必要があります。言うまでもなく、マイアミのデータで訓練されたモデルを冬のシカゴで展開しても、正しい予測を出力することはできません。
機械学習モデルの構築
データ処理とモデル訓練のステップでは、コース資料に含まれている Jupyter Notebook を開きます。このノートブックを実行する最も簡単な方法は、Google Colab にアップロードすることです。Google Colab にはすでにすべてのパッケージがインストールされており、すぐに実行できます。
または、ノートブックをローカルで実行することもできます。その場合、まず仮想環境で以下のコマンドを実行して必要な依存関係をインストールしてください。
pip install -r requirements.txt
仮想環境を有効化した状態で、同じ環境で以下のコマンドを実行して Jupyter Notebook サーバーを起動します。
jupyter notebook
これにより、デフォルトのブラウザでノートブックサーバーが開きます。Jupyter Notebook は、テキストと実行可能なコードを同じ環境で扱えるため、データを探索し提示するのに非常に便利です。一般的なワークフローはノートブックのテキストセクションで説明されています。
Wio Terminal へのデプロイ
前のステップで訓練したモデルは、モデルの構造と重みを含むバイト配列に変換されました。このバイト配列を C++ コードと一緒に Wio Terminal にロードできます。
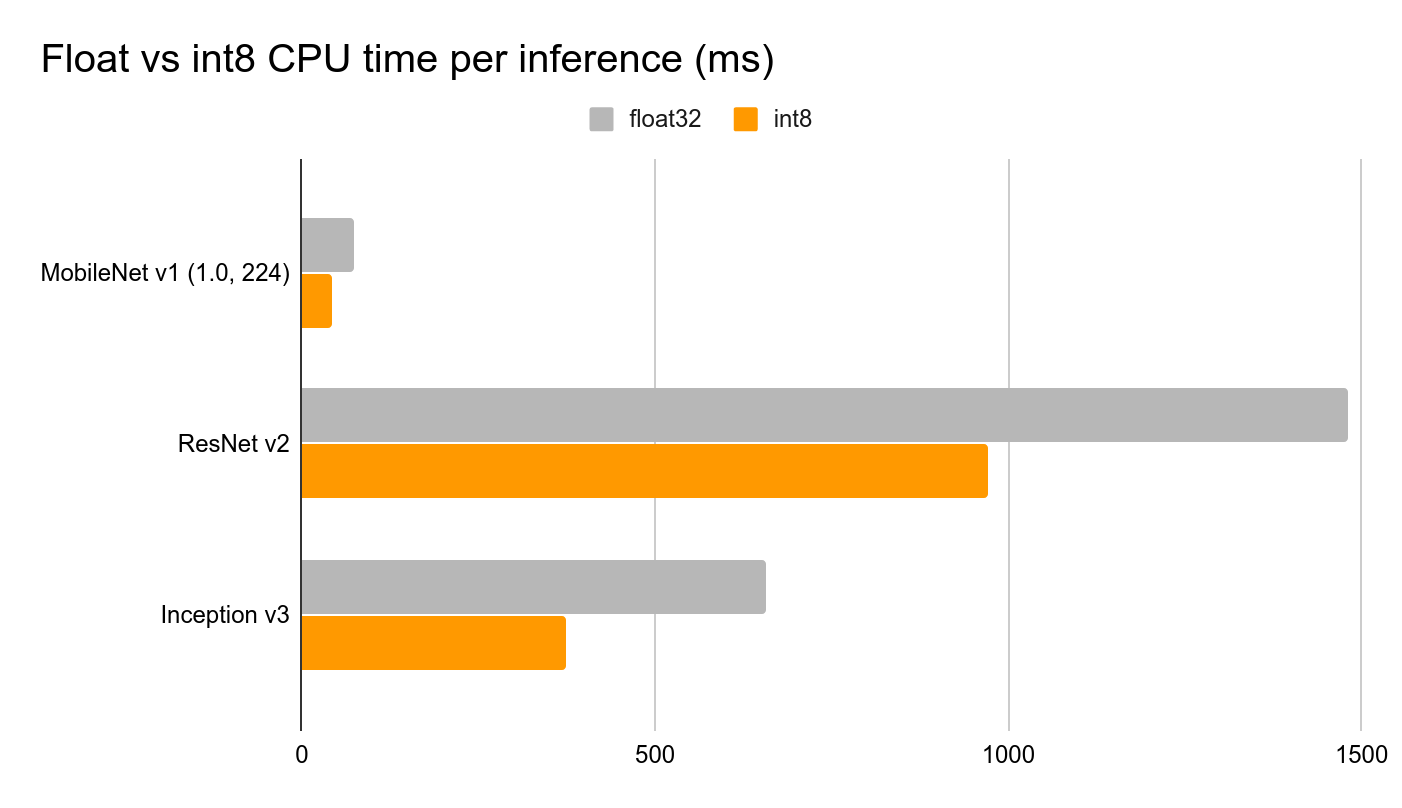
TensorFlow Lite for Microcontrollers には、軽量で高速なモデルインタープリタが含まれています。このインタープリタは、静的なグラフ順序とカスタム(動的ではない)メモリアロケータを使用して、ロード、初期化、および実行の遅延を最小限に抑えます。入力バッファに配置されたデータはモデルグラフに供給され、推論が終了すると結果が出力バッファに配置されます。 モデルのサイズを縮小し推論時間を短縮するために、以下の2つの重要な最適化を行います:
- 完全整数量子化を実行し、モデルの重み、入力、および出力を浮動小数点32(各32ビットのメモリを占有)から整数8(各8ビットのみを占有)に変更します。これによりサイズが4分の1に削減されます。
micro_mutable_op_resolverを使用してニューラルネットワーク内の操作を指定し、モデルを実行するために必要な操作のみを含むコードをコンパイルします。これにより、現在の TensorFlow Lite for Microcontrollers インタープリタがサポートするすべての操作を含むall_ops_resolverを使用する場合と比較して、デバイスのメモリを節約できます。
モデルの訓練が終了したら、空のスケッチを作成して保存します。その後、訓練したモデルをスケッチフォルダにコピーし、スケッチを再度開きます。モデルの変数名とモデルの長さを短い名前に変更します。その後、コース資料に含まれている wio_terminal_tfmicro_weather_prediction_static.ino のコードを使用してテストします。
C++ コードの主なステップを確認してみましょう。 TensorFlow ライブラリのヘッダーとモデルのフラットバッファを含むファイルをインクルードします。
#include <TensorFlowLite.h>
//#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/system_setup.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "model_Conv1D.h"
micro_mutable_op_resolver.h をコメントアウトし、all_ops_resolver.h を有効にしていることに注意してください。all_ops_resolver.h ヘッダーは現在の TensorFlow Micro に存在するすべての操作をコンパイルするため、テストには便利ですが、テストが終了したら micro_mutable_op_resolver.h に切り替えることでデバイスのメモリを節約できます。これは大きな違いを生みます。
次に、エラーレポーター、モデル、入力および出力テンソル、インタープリタのポインタを定義します。モデルには降水量と天気タイプの2つの出力があることに注意してください。また、テンソルアリーナを定義します。テンソルアリーナは、入力、出力、および中間配列を保持する作業領域のようなもので、必要なサイズは使用するモデルによって異なり、実験によって決定する必要があります。
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* input = nullptr;
TfLiteTensor* output_type = nullptr;
TfLiteTensor* output_precip = nullptr;
constexpr int kTensorArenaSize = 1024*25;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
次に、setup 関数では、エラーレポーターのインスタンス化、操作リゾルバ、インタープリタの作成、モデルのマッピング、テンソルの割り当て、そして割り当て後のテンソル形状の確認などの定型的な処理を行います。この段階で、現在の TensorFlow Micro ライブラリのバージョンでサポートされていない操作がある場合、コードがランタイムエラーをスローする可能性があります。サポートされていない操作がある場合は、モデルのアーキテクチャを変更するか、通常は TensorFlow Lite からポーティングすることで操作のサポートを追加する必要があります。
void setup() {
Serial.begin(115200);
while (!Serial) {delay(10);}
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(Conv1D_tflite);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// This pulls in all the operation implementations we need.
// NOLINTNEXTLINE(runtime-global-variables)
//static tflite::MicroMutableOpResolver<1> resolver;
static tflite::AllOpsResolver resolver;
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}
// Obtain pointers to the model's input and output tensors.
input = interpreter->input(0);
output_type = interpreter->output(1);
output_precip = interpreter->output(0);
Serial.println(input->dims->size);
Serial.println(input->dims->data[1]);
Serial.println(input->dims->data[2]);
Serial.println(input->type);
Serial.println(output_type->dims->size);
Serial.println(output_type->dims->data[1]);
Serial.println(output_type->type);
Serial.println(output_precip->dims->size);
Serial.println(output_precip->dims->data[1]);
Serial.println(output_precip->type);
}
最後に、loop 関数内で、量子化された INT8 値のプレースホルダーと、Colab ノートブックからコピーしてデバイス上でのモデル推論と Colab での推論を比較するための float 値の配列を定義します。
void loop() {
int8_t x_quantized[72];
float x[72] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0};
for ループ内で float 値を INT8 に量子化し、それらを1つずつ入力テンソルに配置します。
for (byte i = 0; i < 72; i = i + 1) {
input->data.int8[i] = x[i] / input->params.scale + input->params.zero_point;
}
次に、Tensorflow Micro インタープリタによって推論が実行され、エラーが報告されなければ、値が出力テンソルに配置されます。
// 推論を実行し、エラーを報告
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed");
return;
}
入力と同様に、モデルの出力も量子化されているため、逆操作を行い、INT8 から float に変換する必要があります。
// モデルの出力テンソルから量子化された出力を取得
float y_type[4];
// 出力を整数から浮動小数点にデ量子化
int8_t y_precip_q = output_precip->data.int8[0];
Serial.println(y_precip_q);
float y_precip = (y_precip_q - output_precip->params.zero_point) * output_precip->params.scale;
Serial.print("Precip: ");
Serial.print(y_precip);
Serial.print("\t");
Serial.print("Type: ");
for (byte i = 0; i < 4; i = i + 1) {
y_type[i] = (output_type->data.int8[i] - output_type->params.zero_point) * output_type->params.scale;
Serial.print(y_type[i]);
Serial.print(" ");
}
Serial.print("\n");
}
同じデータポイントに対して値を確認し比較してください。量子化された Tensorflow Lite モデルの Colab ノートブックと、Tensorflow Micro モデルが Wio Terminal 上で動作している場合、値は同じであるはずです。

LVGL インターフェースと WiFi
次のステップは、デモから実際に役立つプロジェクトにすることです。コース資料から wio_terminal_tfmicro_weather_prediction_static.ino スケッチを開き、その内容を確認してください。

コードはメインスケッチ、get_historical_data、および GUI 部分に分かれています。モデルが過去24時間のデータを必要とするため、最初の推論を行うには24時間待つ必要がありますが、これは非常に長い時間です。この問題を解決するために、openweathermap.com API から過去24時間の天気データを取得し、デバイスが起動した直後に最初の推論を実行できます。その後、BME280 センサー(Wio Terminal の I2C Grove ソケットに接続)から温度、湿度、気圧の値を取得し、循環バッファ内の値を置き換えます。GUI には、Little and Versatile Graphics Library (LVGL) を使用しました。

コードをコンパイルしてアップロードする前に、WiFi の認証情報、場所、および openweathermap.com の API キーをスケッチ内で変更してください。アップロード後、デバイスはインターネットに接続し、指定した場所の過去24時間のデータを取得して最初の推論を実行します。その後、BME280 センサーから値を取得するまで1時間待機します。センサーが接続されていない場合、プログラムは初期化されません。