YOLOv5とRoboflowを使用したFew-Shot物体検出
はじめに
YOLOは、利用可能な最も有名な物体検出アルゴリズムの一つです。少数のサンプルでの訓練のみを必要とし、高速な訓練時間と高精度を提供します。このwikiでは、これらの機能を一つずつ実演し、データを収集し、ラベル付けし、訓練し、最終的に訓練されたデータを使用して物体を検出する完全な機械学習パイプラインをステップバイステップで説明します。訓練されたモデルをNVIDIA Jetsonプラットフォームなどのエッジデバイス上で実行します。また、カスタムデータセットと公開データセットの使用の違いも比較します。
YOLOv5とは?
YOLOは「You Only Look Once」の略語です。これは、リアルタイムで画像内の様々な物体を検出し認識するアルゴリズムです。Ultralytics YOLOv5はYOLOの最新バージョンで、現在はPyTorchフレームワークに基づいています。

Few-shot物体検出とは?
従来、機械学習モデルを訓練したい場合、約17112枚の画像で構成されるPascal VOC 2012データセットなどの公開データセットを使用します。しかし、転移学習を使用してYOLOv5でfew-shot物体検出を実現し、非常に少数の訓練サンプルのみを必要とします。これをこのwikiで実演します。
サポートされるハードウェア
YOLOv5は以下のハードウェアでサポートされています:
-
NVIDIAの公式開発キット:
- NVIDIA® Jetson Nano Developer Kit
- NVIDIA® Jetson Xavier NX Developer Kit
- NVIDIA® Jetson AGX Xavier Developer Kit
- NVIDIA® Jetson TX2 Developer Kit
-
NVIDIAの公式SoM:
- NVIDIA® Jetson Nano module
- NVIDIA® Jetson Xavier NX module
- NVIDIA® Jetson TX2 NX module
- NVIDIA® Jetson TX2 module
- NVIDIA® Jetson AGX Xavier module
-
Seedのキャリアボード:
- Jetson Mate
- Jetson SUB Mini PC
- Jetson Xavier AGX H01 Kit
- A203 Carrier Board
- A203 (Version 2) Carrier Board
- A205 Carrier Board
- A206 Carrier Board
前提条件
-
上記のいずれかのJetsonデバイスで、すべてのSDKコンポーネントがインストールされた最新のJetPack v4.6.1が動作していること(インストールの参考についてはこのwikiを確認してください)
-
ホストPC
- ローカル訓練にはLinux PC(できればUbuntu)が必要
- クラウド訓練は任意のOSのPCから実行可能
はじめに
Jetsonプラットフォームなどのエッジデバイスで最初の物体検出プロジェクトを実行するには、単純に4つの主要なステップが必要です!
-
データセットの収集または公開されているデータセットの使用
- データセットの手動収集
- 公開されているデータセットの使用
-
Roboflowを使用したデータセットの注釈付け
-
ローカルPCまたはクラウドでの訓練
- ローカルPC(Linux)での訓練
- Google Colabでの訓練
-
Jetsonデバイスでの推論
データセットの収集または公開データセットの使用
物体検出プロジェクトの最初のステップは、トレーニング用のデータを取得することです。公開されているデータセットをダウンロードするか、独自のデータセットを作成することができます!通常、公開データセットは教育や研究目的で使用されます。しかし、検出したい物体が公開データセットに含まれていない特定の物体検出プロジェクトを構築したい場合は、独自のデータセットを構築することをお勧めします。
データセットの手動収集
まず、認識したい物体のビデオ映像を録画することをお勧めします。物体のすべての角度(360度)をカバーし、異なる環境、異なる照明、異なる天候条件で物体を配置することを確認する必要があります。 録画した総ビデオは9分間で、4.5分が花、残りの4.5分が葉です。録画は以下のように分類できます:

- 朝の通常天候
- 朝の風の強い天候
- 朝の雨天
- 昼の通常天候
- 昼の風の強い天候
- 昼の雨天
- 夕方の通常天候
- 夕方の風の強い天候
- 夕方の雨天
注意: 後で、このビデオ映像を一連の画像に変換して、トレーニング用のデータセットを作成します。
公開データセットの使用
COCOデータセット、Pascal VOCデータセットなど、多数の公開データセットをダウンロードできます。Roboflow Universeは、幅広いデータセットを提供する推奨プラットフォームで、コンピュータビジョンモデルの構築に利用できる90,000以上のデータセットと6600万以上の画像があります。また、Googleでオープンソースデータセットを検索して、利用可能な様々なデータセットから選択することもできます。
Roboflowを使用したデータセットのアノテーション
次に、持っているデータセットのアノテーションに移ります。アノテーションとは、検出したい各物体の周りに長方形のボックスを描き、ラベルを割り当てることです。Roboflowを使用してこれを行う方法を説明します。
Roboflowは、オンラインベースのアノテーションツールです。ここでは、以前に録画したビデオ映像を直接Roboflowにインポートでき、一連の画像としてエクスポートされます。このツールは、データセットを「トレーニング、検証、テスト」に分散するのに役立つため、非常に便利です。また、このツールでは、ラベル付け後にこれらの画像にさらなる処理を追加できます。さらに、ラベル付けされたデータセットをYOLOV5 PyTorch形式に簡単にエクスポートでき、これはまさに私たちが必要とするものです!
-
ステップ1. こちらをクリックしてRoboflowアカウントにサインアップします
-
ステップ2. Create New Projectをクリックしてプロジェクトを開始します
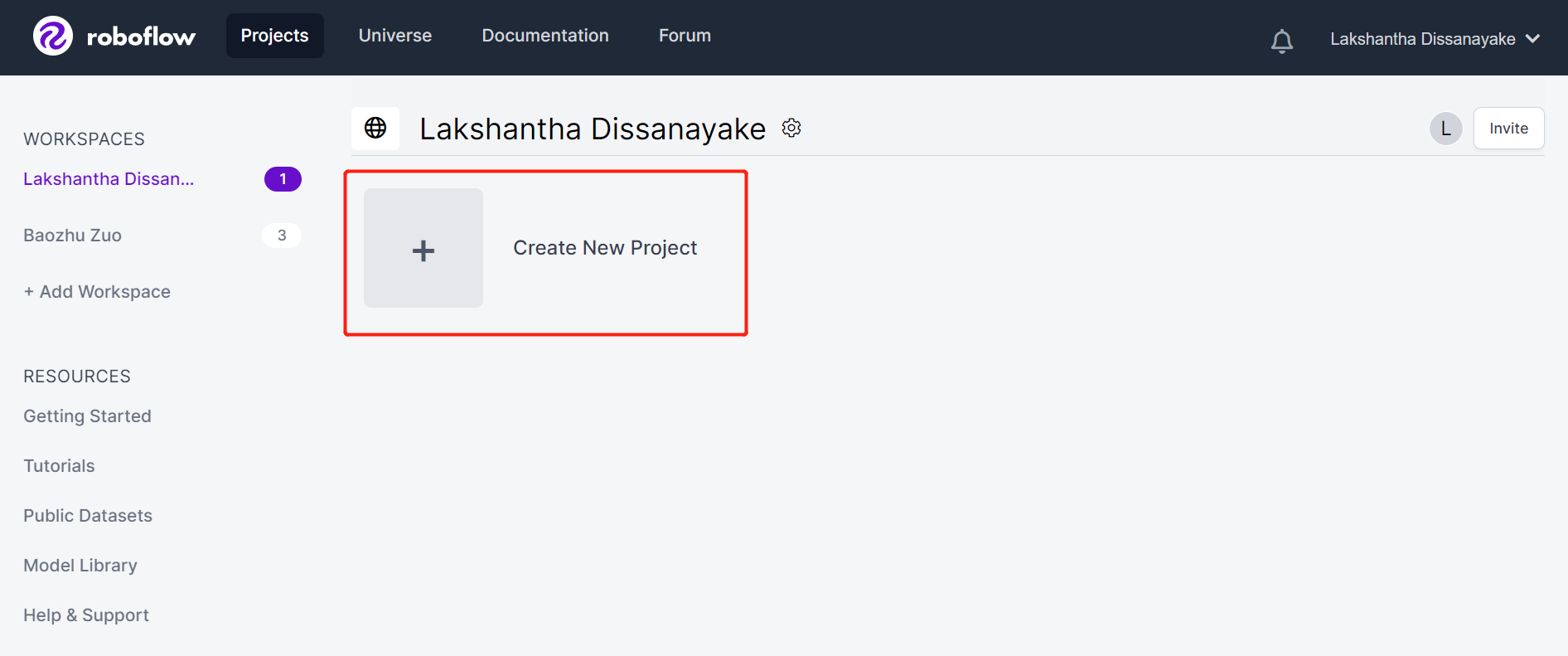
- ステップ3. Project Nameを入力し、**License (CC BY 4.0)とProject type (Object Detection (Bounding Box))**をデフォルトのままにします。What will your model predict?列の下で、アノテーショングループ名を入力します。例えば、私たちの場合はplantsを選択します。この名前は、データセットのすべてのクラスを強調する必要があります。最後に、Create Public Projectをクリックします。
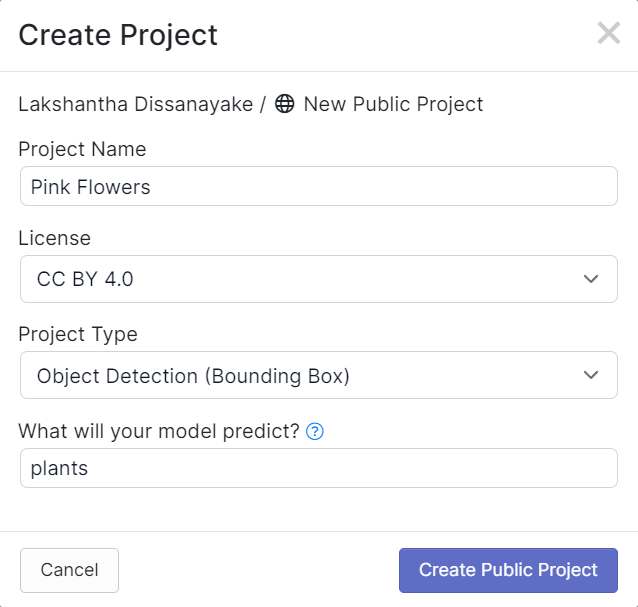
- ステップ4. 以前に録画したビデオ映像をドラッグアンドドロップします
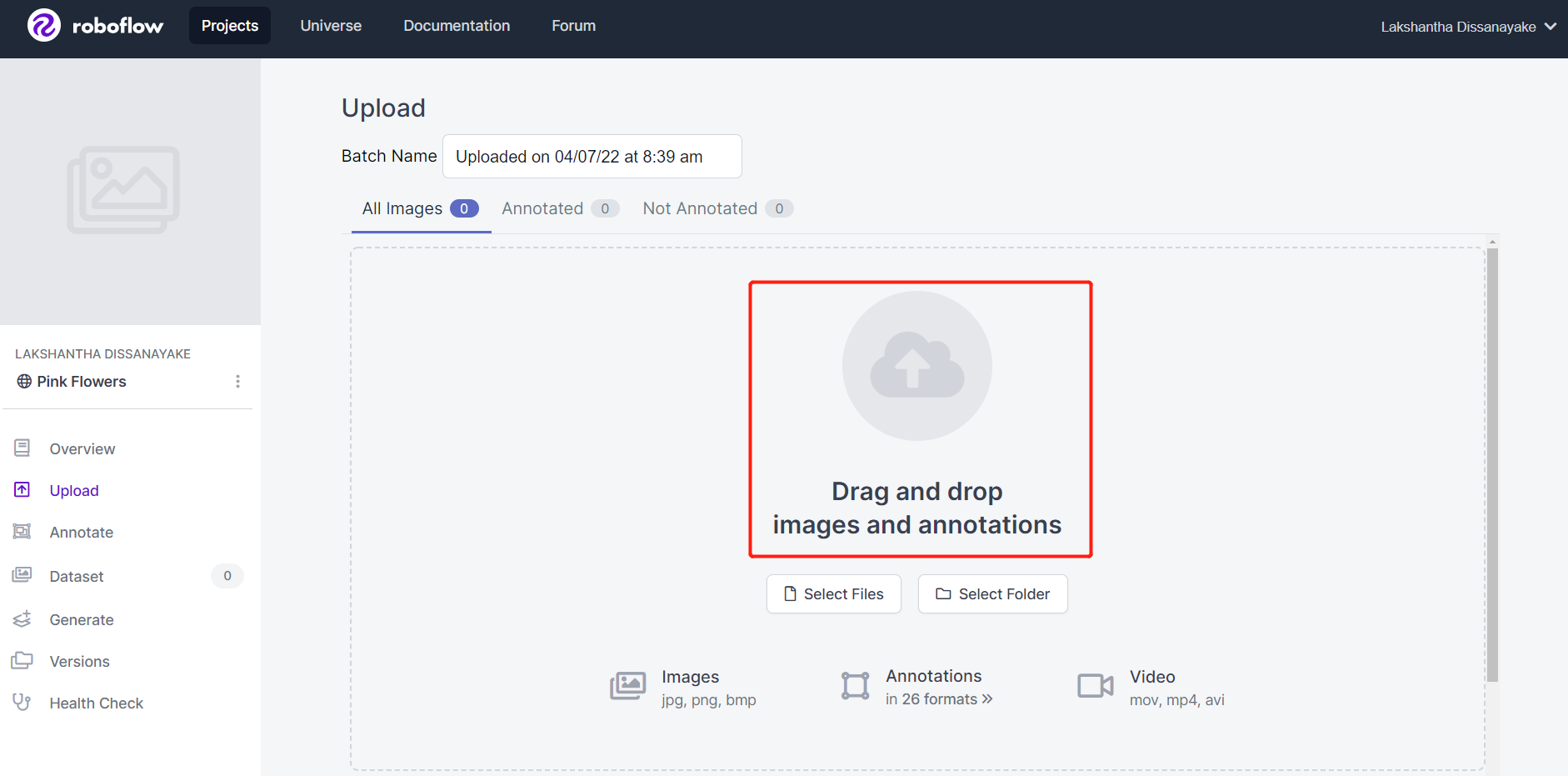
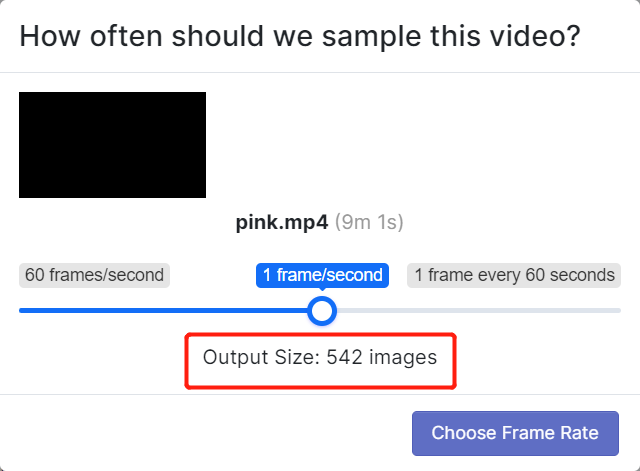
- ステップ5. ビデオが一連の画像に分割されるようにフレームレートを選択します。ここでは、デフォルトのフレームレート1 frame/secondを使用し、これにより合計542枚の画像が生成されます。スライダーをスクラブしてフレームレートを選択したら、Choose Frame Rateをクリックします。このプロセスが完了するまで数秒から数分(ビデオの長さによって異なります)かかります。
- ステップ6. 画像が処理された後、Finish Uploadingをクリックします。画像がアップロードされるまで辛抱強く待ちます。
- ステップ7. 画像がアップロードされた後、Assign Imagesをクリックします
- ステップ8. 画像を選択し、花の周りに長方形のボックスを描き、ラベルをpink flowerとして選択し、ENTERを押します
- ステップ9. 残りの花についても同じことを繰り返します
- ステップ10. 葉の周りに長方形のボックスを描き、ラベルをleafとして選択し、ENTERを押します
- ステップ11. 残りの葉についても同じことを繰り返します
注意: 画像内に見えるすべての物体にラベルを付けるようにしてください。物体の一部だけが見える場合も、それにラベルを付けるようにしてください。
- ステップ12. データセット内のすべての画像のアノテーションを続けます
RoboflowにはLabel Assistという機能があり、事前にラベルを予測できるため、ラベル付けがはるかに高速になります。ただし、すべての物体タイプで機能するわけではなく、選択された物体タイプでのみ機能します。この機能をオンにするには、Label Assistボタンを押し、モデルを選択し、クラスを選択して、画像をナビゲートして境界ボックス付きの予測ラベルを確認するだけです
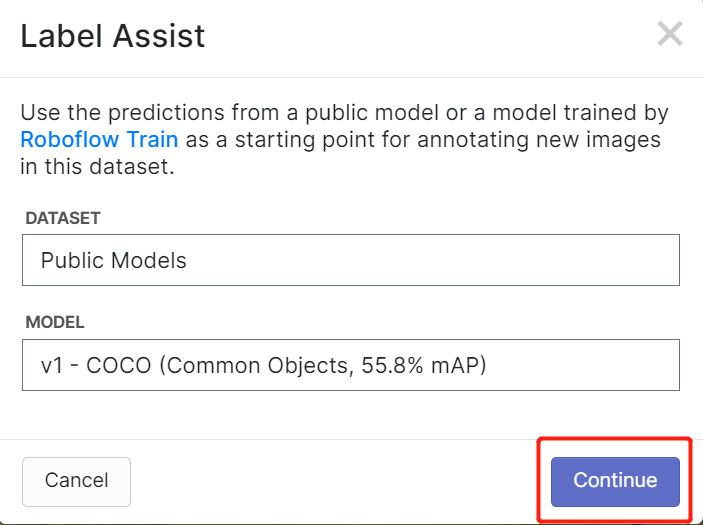
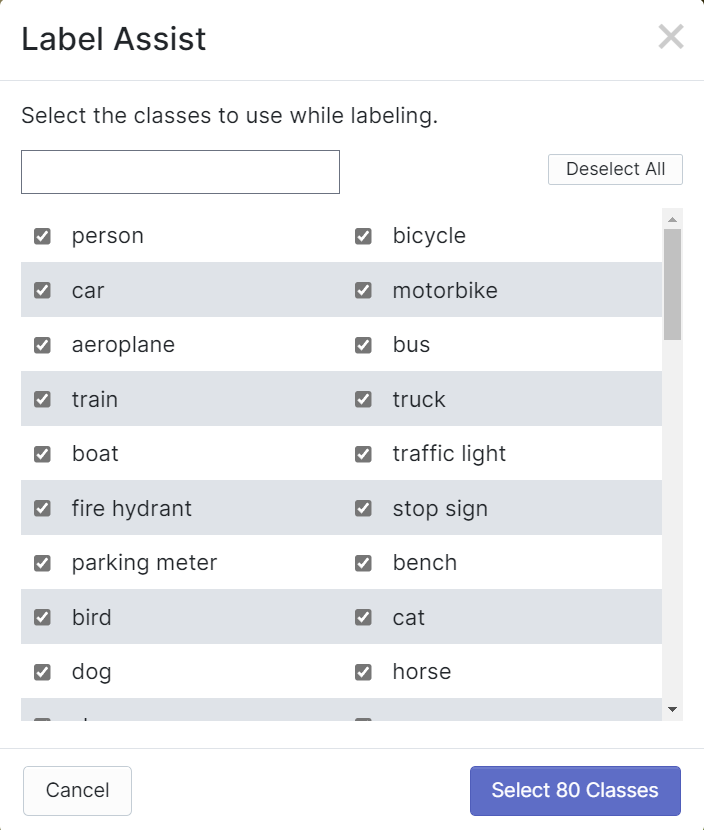
上記のように、これは上記で言及された80クラスの予測アノテーションを支援することしかできません。画像に上記のオブジェクトクラスが含まれていない場合、ラベルアシスト機能を使用することはできません。
- ステップ 13. ラベリングが完了したら、Add images to Dataset をクリックします

- ステップ 14. 次に、画像を「Train、Valid、Test」に分割します。分布のデフォルトパーセンテージを保持し、Add Images をクリックします
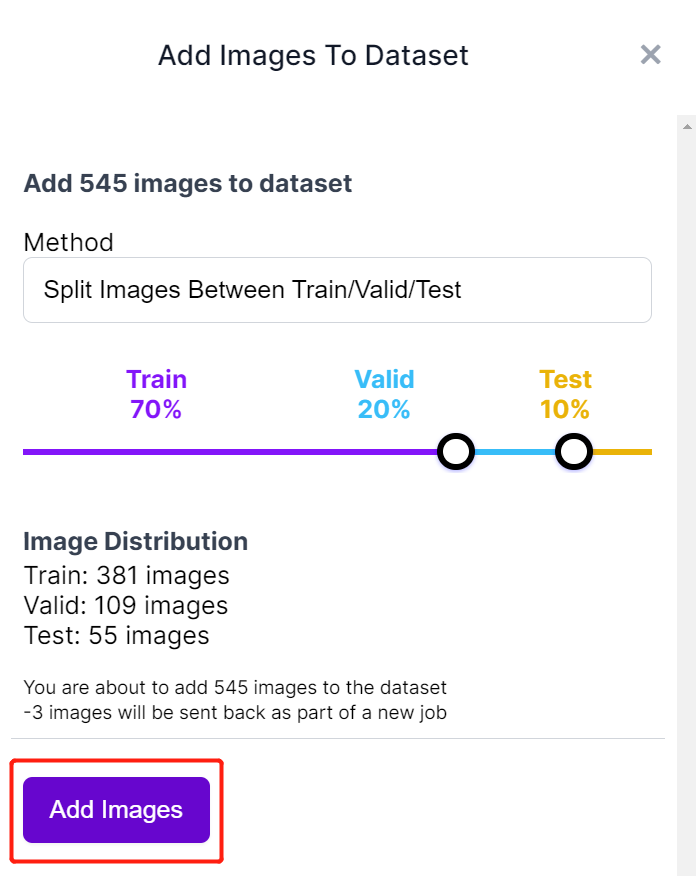
- ステップ 15. Generate New Version をクリックします

- ステップ 16. 必要に応じて Preprocessing と Augmentation を追加できます。ここでは Resize オプションを削除し、元の画像サイズを保持します
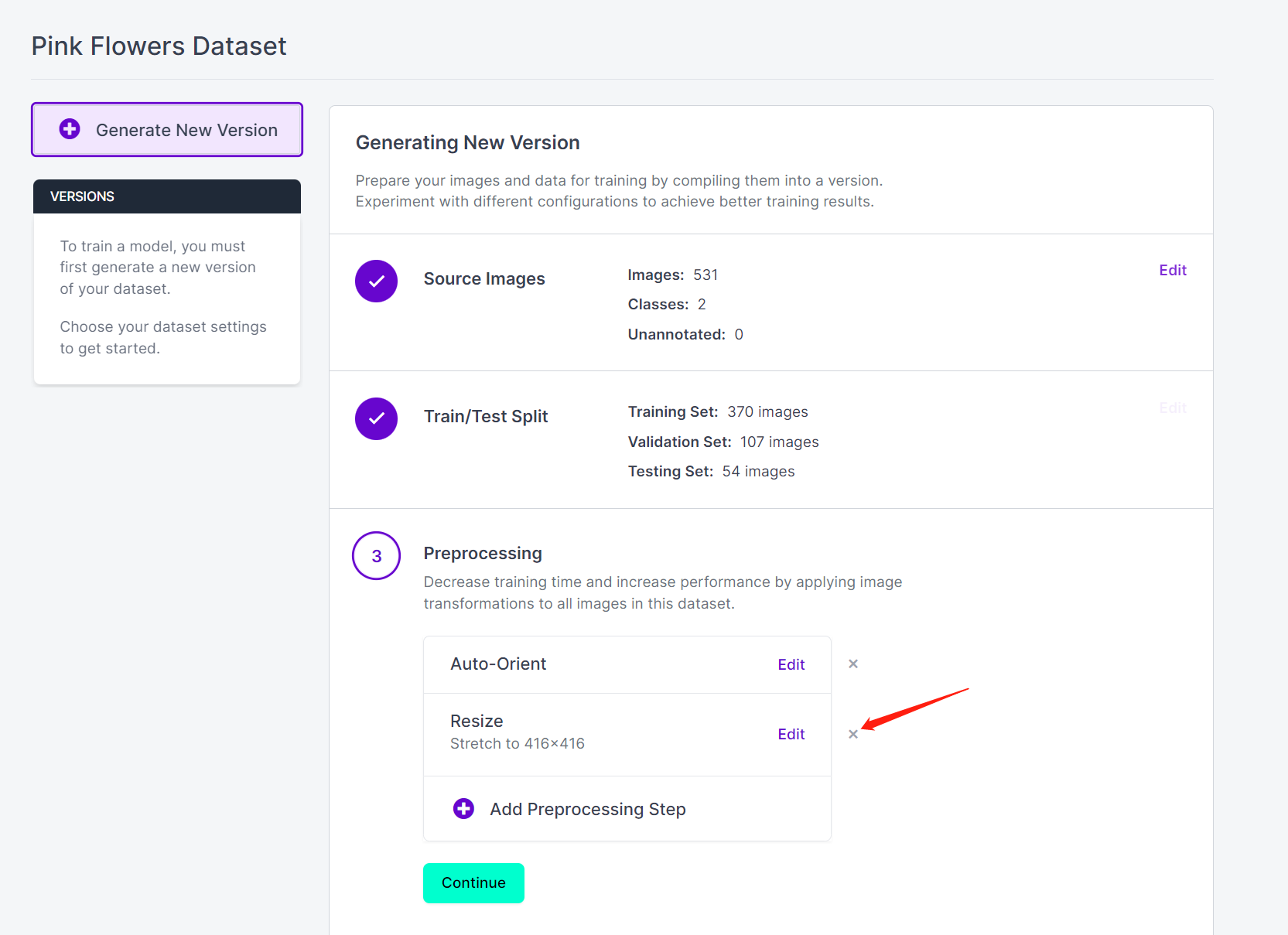
- ステップ 17. 次に、残りのデフォルト設定で進み、Generate をクリックします
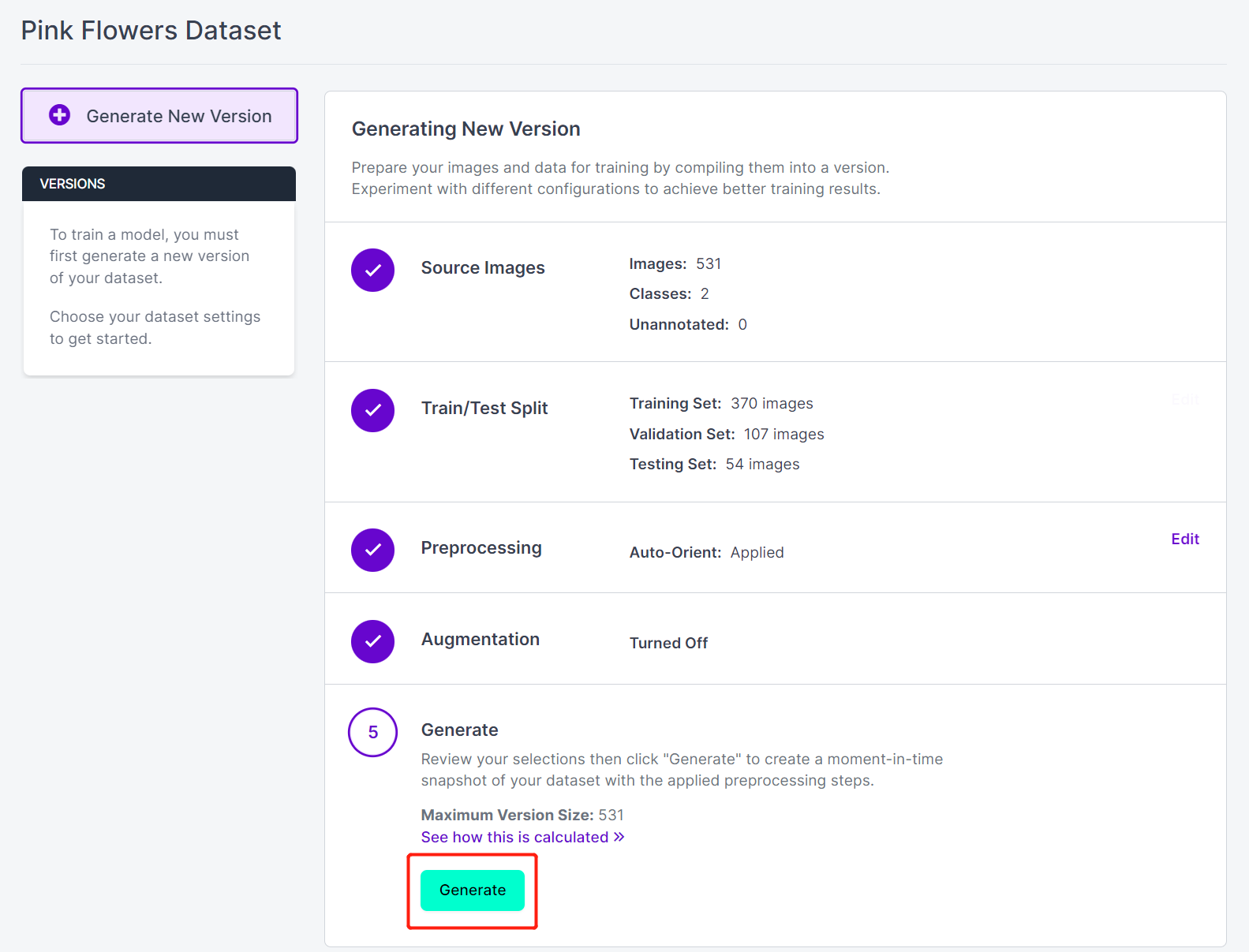
- ステップ 18. Export をクリックします
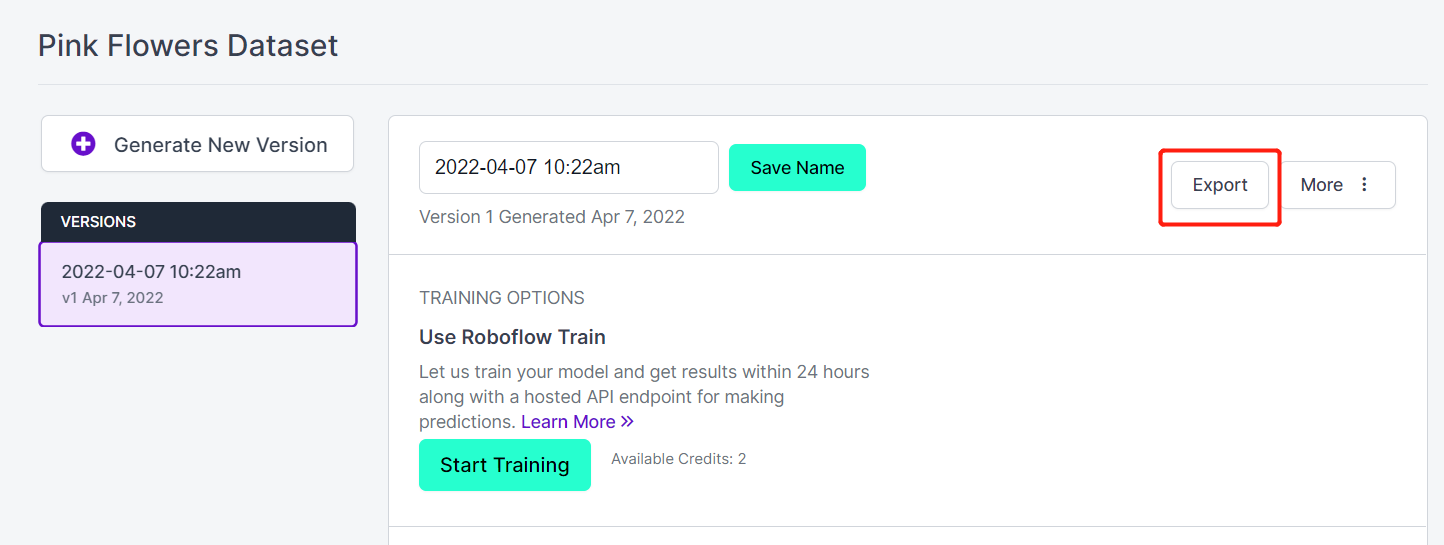
- ステップ 19. download zip to computer を選択し、「Select a Format」で YOLO v5 PyTorch を選択して Continue をクリックします
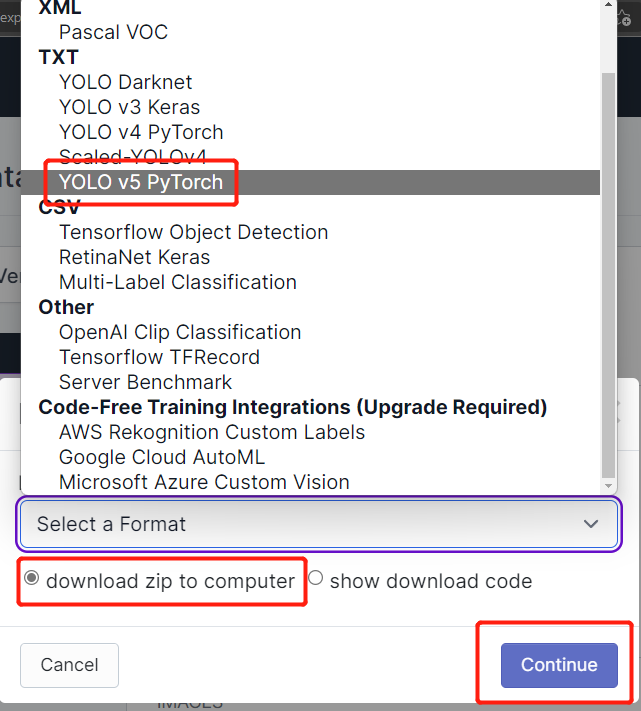
- ステップ 20. その後、.zip ファイルがコンピューターにダウンロードされます。この.zipファイルは後でトレーニングに必要になります。
ローカルPCまたはクラウドでのトレーニング
データセットのアノテーションが完了したら、データセットをトレーニングする必要があります。トレーニングには2つの方法を紹介します。1つの方法はオンライン(Google Colab)ベース、もう1つの方法はローカルPC(Linux)ベースです。
Google Colabトレーニングでは、2つの方法を使用します。最初の方法では、Ultralytics HUBを使用してデータセットをアップロードし、Colabでトレーニングを設定し、トレーニングを監視し、トレーニング済みモデルを取得します。2番目の方法では、Roboflow APIを介してRoboflowからデータセットを取得し、Colabでトレーニングしてモデルをダウンロードします。
Ultralytics HUBでGoogle Colabを使用
Ultralytics HUBは、コードを一行も知らなくてもモデルをトレーニングできるプラットフォームです。データをUltralytics HUBにアップロードし、モデルをトレーニングして実世界にデプロイするだけです!高速で、シンプルで、使いやすいです。誰でも始められます!
-
ステップ 1. このリンクにアクセスして、無料のUltralytics HUBアカウントにサインアップします
-
ステップ 2. 認証情報を入力し、メールでサインアップするか、Google、GitHub、またはAppleアカウントで直接サインアップします
Ultralytics HUBにログインすると、以下のようなダッシュボードが表示されます
-
ステップ 3. 以前にRoboflowからダウンロードしたzipファイルを解凍し、含まれているすべてのファイルを新しいフォルダに入れます
-
ステップ 4. データセットyamlとルートフォルダ(以前に作成したフォルダ)が同じ名前を共有していることを確認してください。例えば、yamlファイルをpinkflowers.yamlと名前を付けた場合、ルートフォルダはpinkflowersと名前を付ける必要があります。
-
ステップ 5. pinkflowers.yamlファイルを開き、trainとvalディレクトリを以下のように編集します
train: train/images
val: valid/images
- ステップ 6. ルートフォルダを .zip として圧縮し、ルートフォルダと同じ名前を付けます(この例では pinkflowers.zip)
これで、Ultalytics HUB にアップロードする準備ができたデータセットが完成しました。
- ステップ 7. Datasets タブをクリックし、Upload Dataset をクリックします
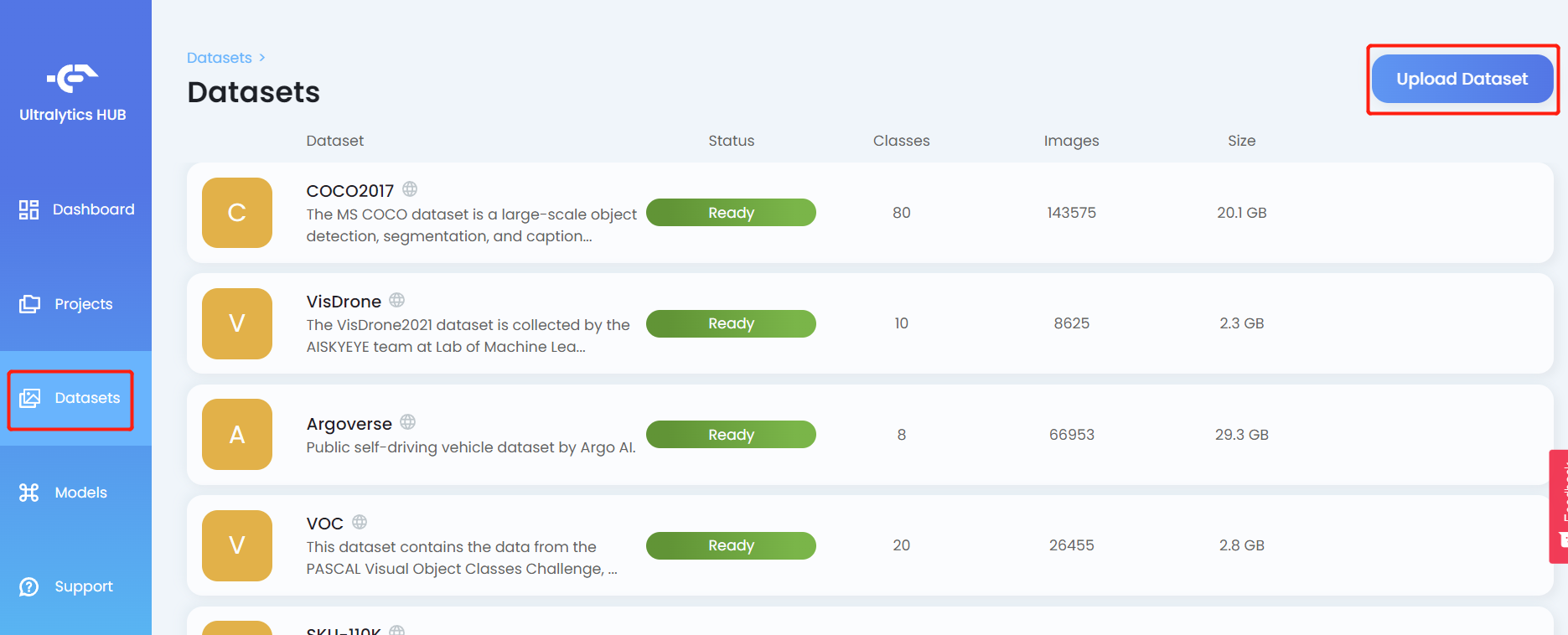
- ステップ 8. データセットの Name を入力し、必要に応じて Description を入力し、Dataset フィールドの下に先ほど作成した .zip ファイルをドラッグ&ドロップして、Upload Dataset をクリックします
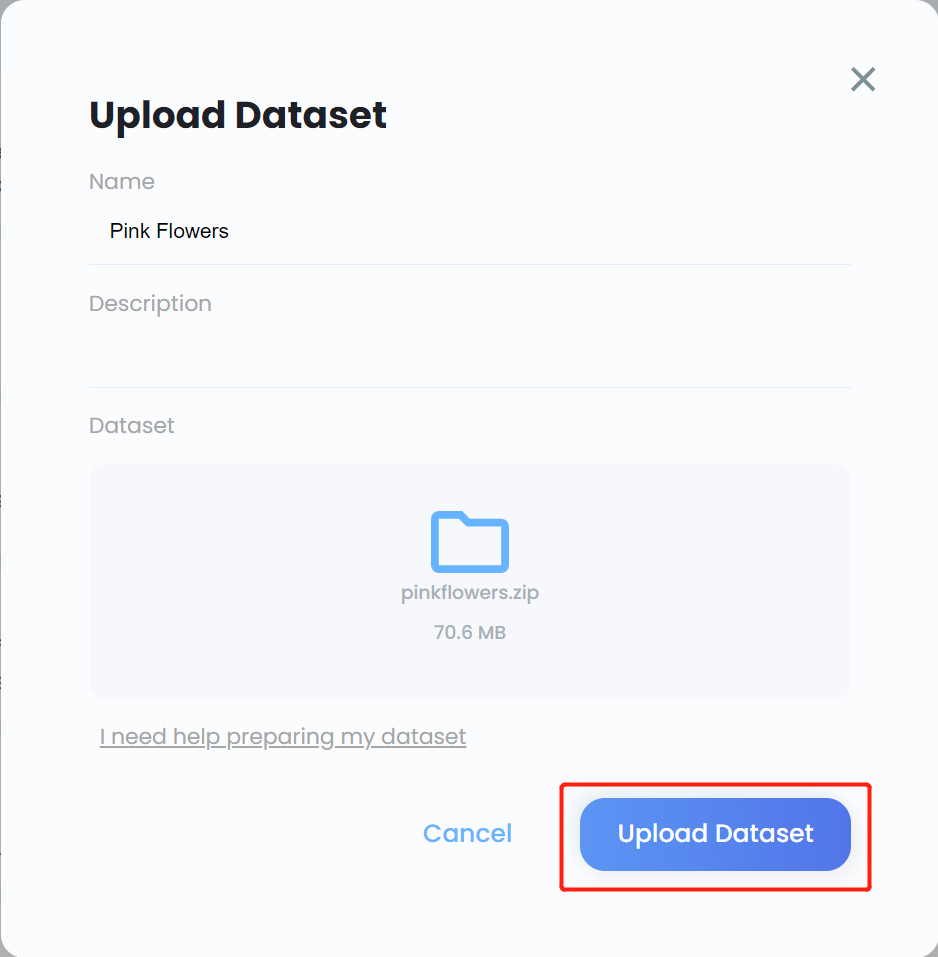
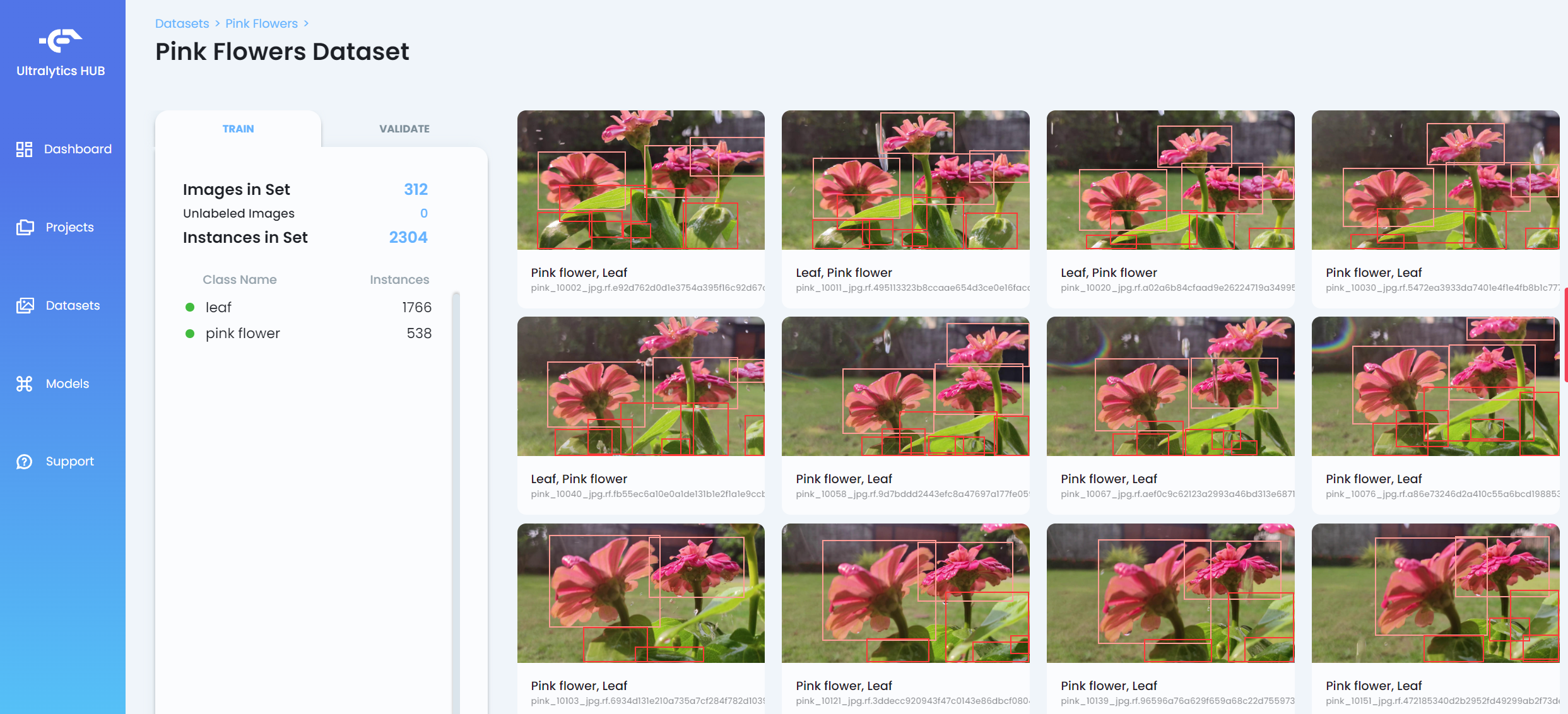
- ステップ 9. データセットがアップロードされた後、データセットをクリックしてデータセットの詳細な情報を表示します
- ステップ 10. Projects タブをクリックし、Create Project をクリックします
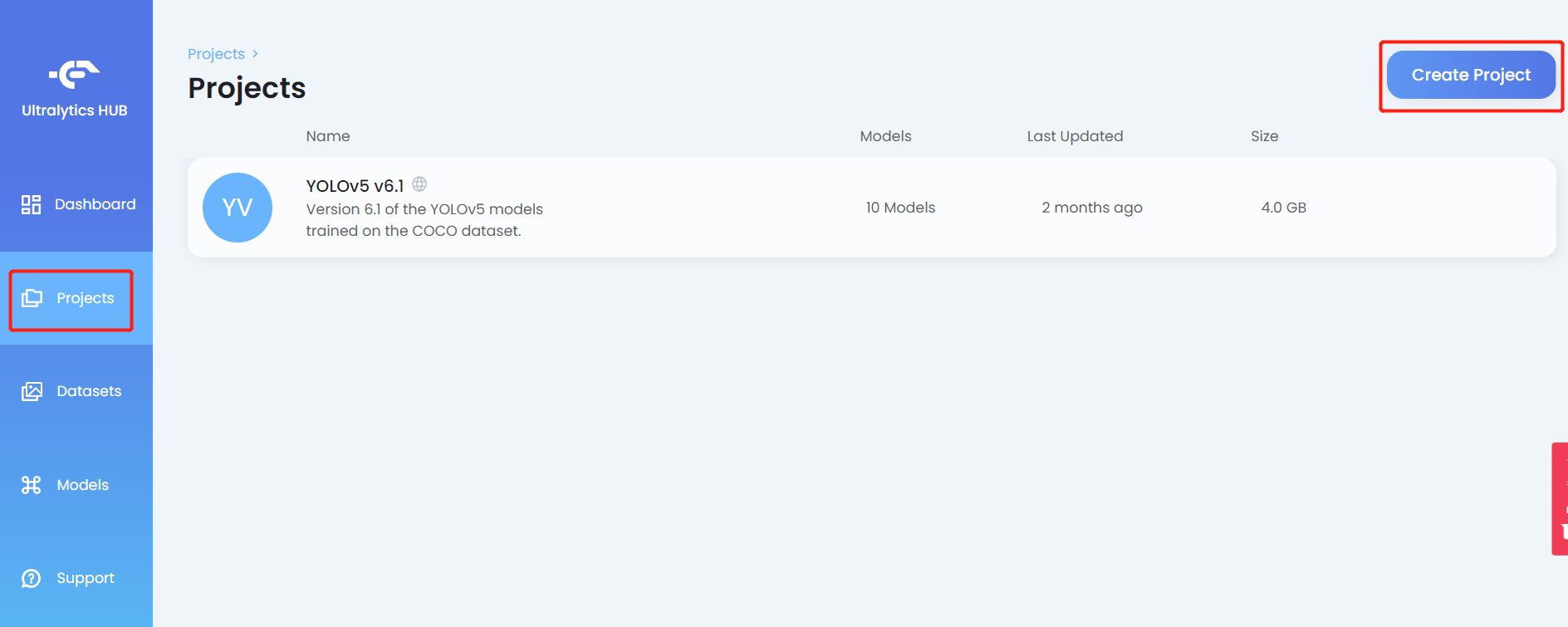
- ステップ 11. プロジェクトの Name を入力し、必要に応じて Description を入力し、必要に応じて cover image を追加して、Create Project をクリックします
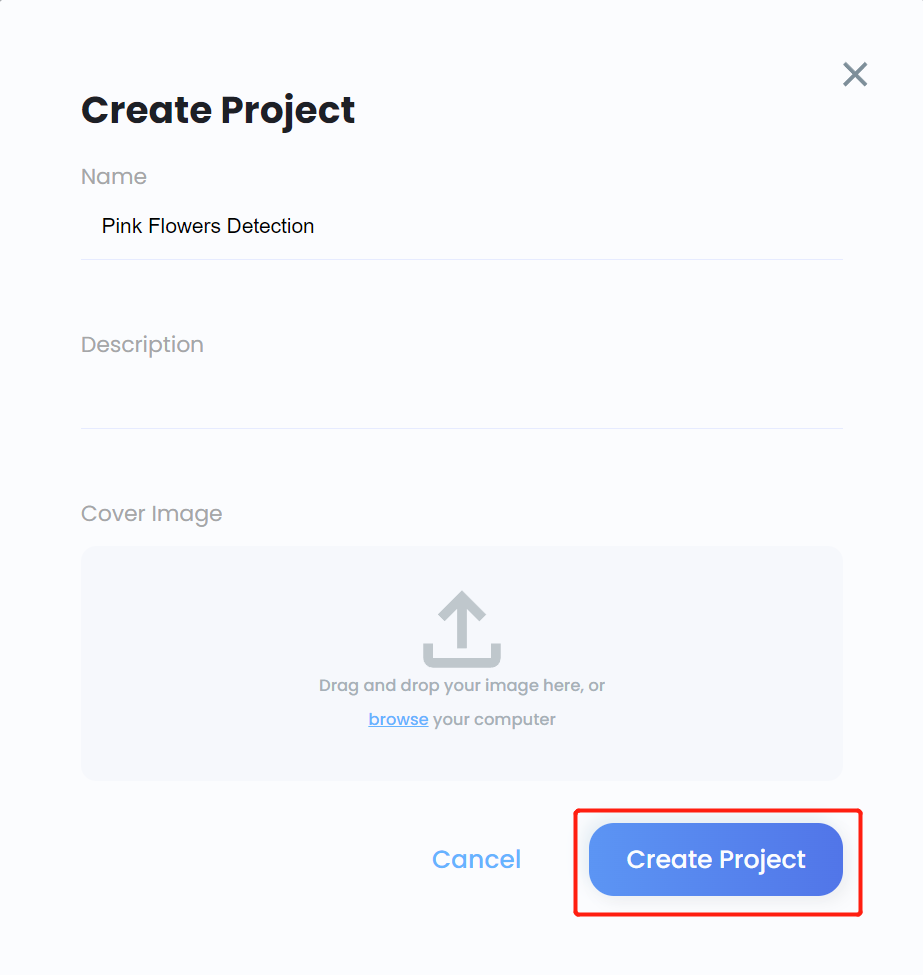
- ステップ 12. 新しく作成されたプロジェクトに入り、Create Model をクリックします

- ステップ 13. Model name を入力し、事前学習済みモデルとして YOLOv5n を選択し、Next をクリックします
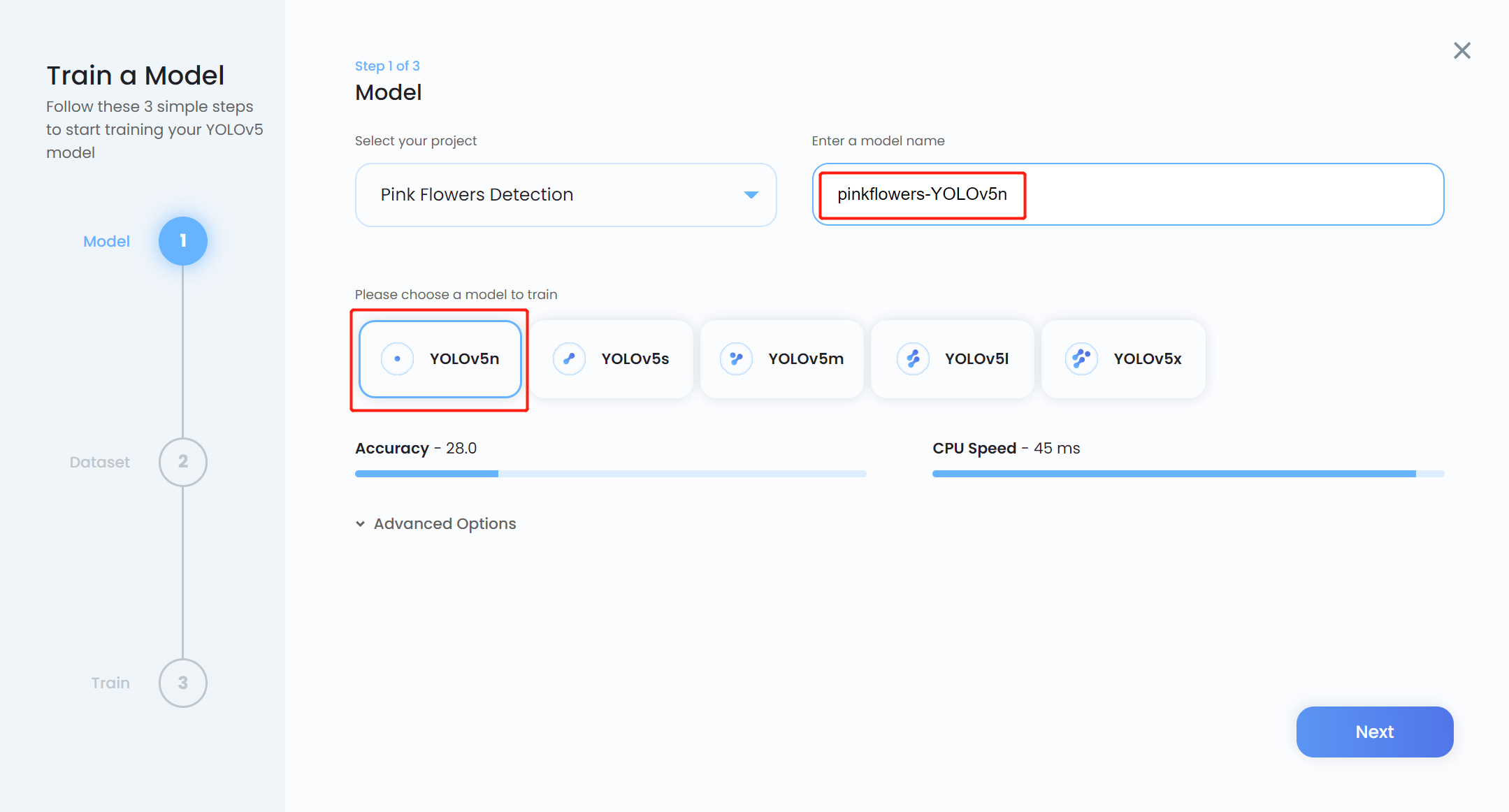
注意: 通常、YOLOv5n6 は Jetson プラットフォームなどのエッジデバイスでの使用に適しているため、事前学習済みモデルとして推奨されます。しかし、Ultralytics HUB はまだそれをサポートしていません。そのため、少し似たモデルである YOLOv5n を使用します。
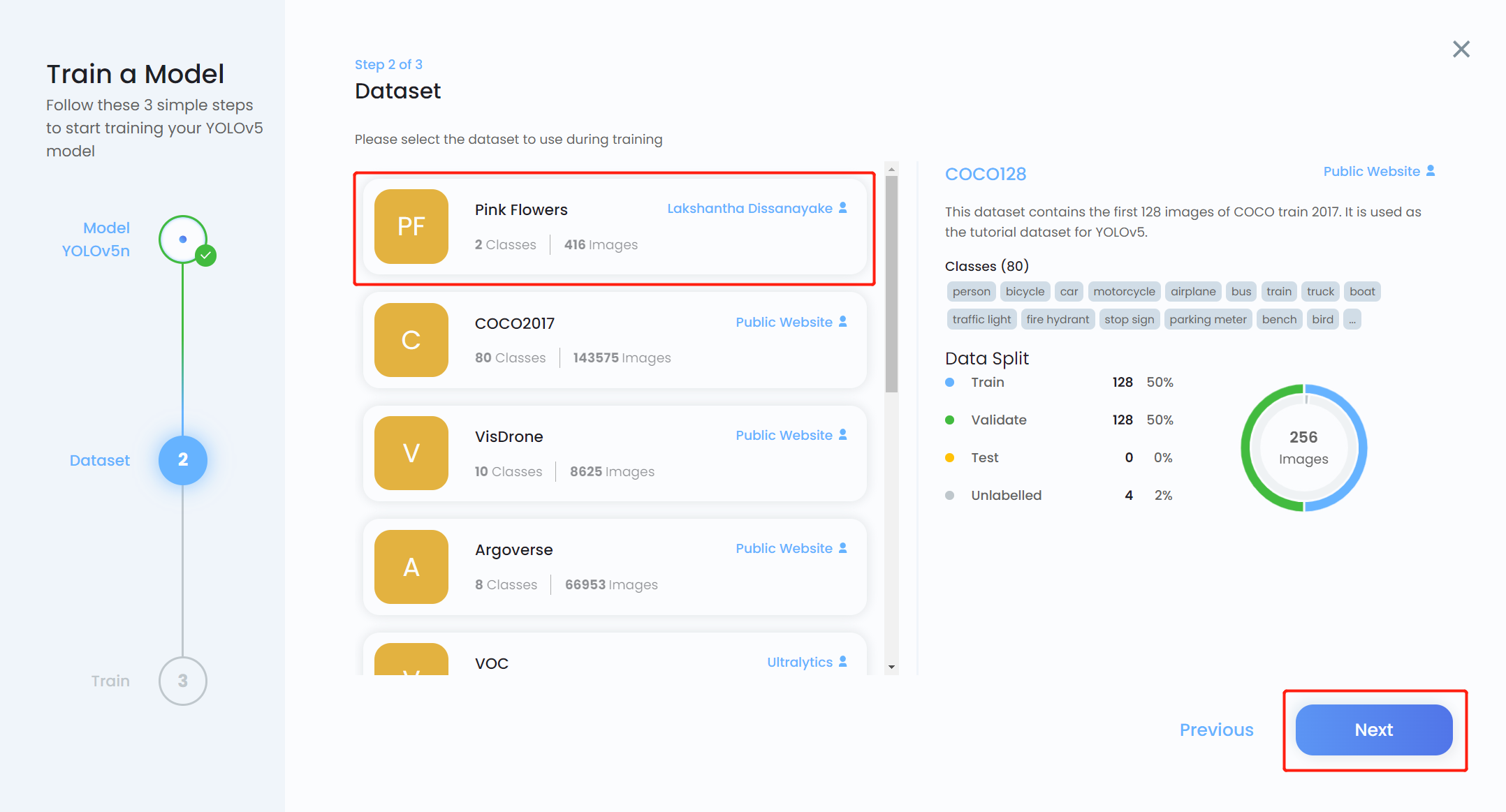
- ステップ 14. 先ほどアップロードしたデータセットを選択し、Next をクリックします
- ステップ 15. 学習プラットフォームとして Google Colab を選択し、Advanced Options ドロップダウンメニューをクリックします。ここで学習の設定を変更できます。例えば、エポック数を 300 から 100 に変更し、他の設定はそのままにします。Save をクリックします
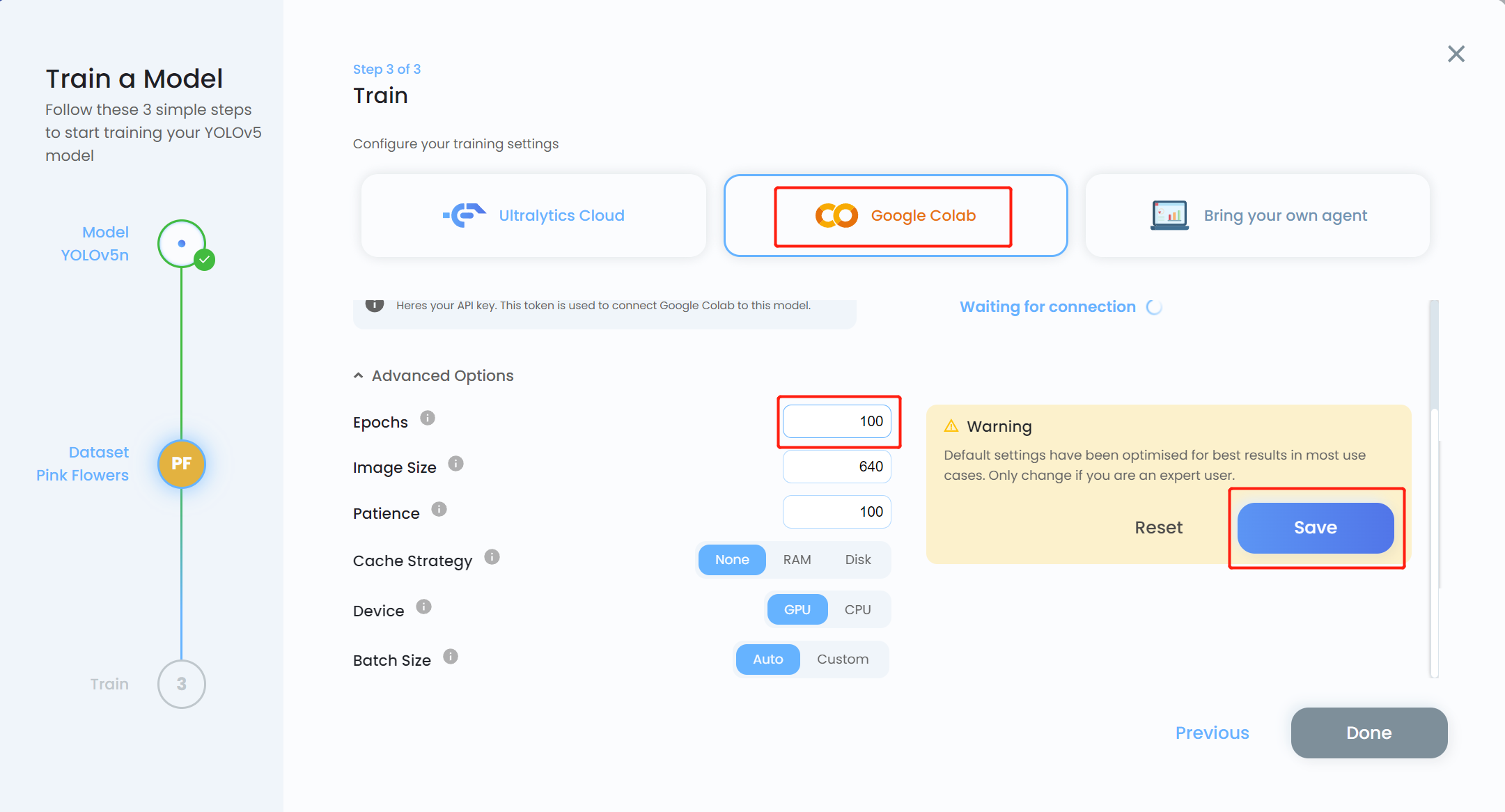
注意: ローカル学習を行う予定の場合は、Bring your own agent を選択することもできます
- ステップ 16. API key をコピーし、Open Colab をクリックします
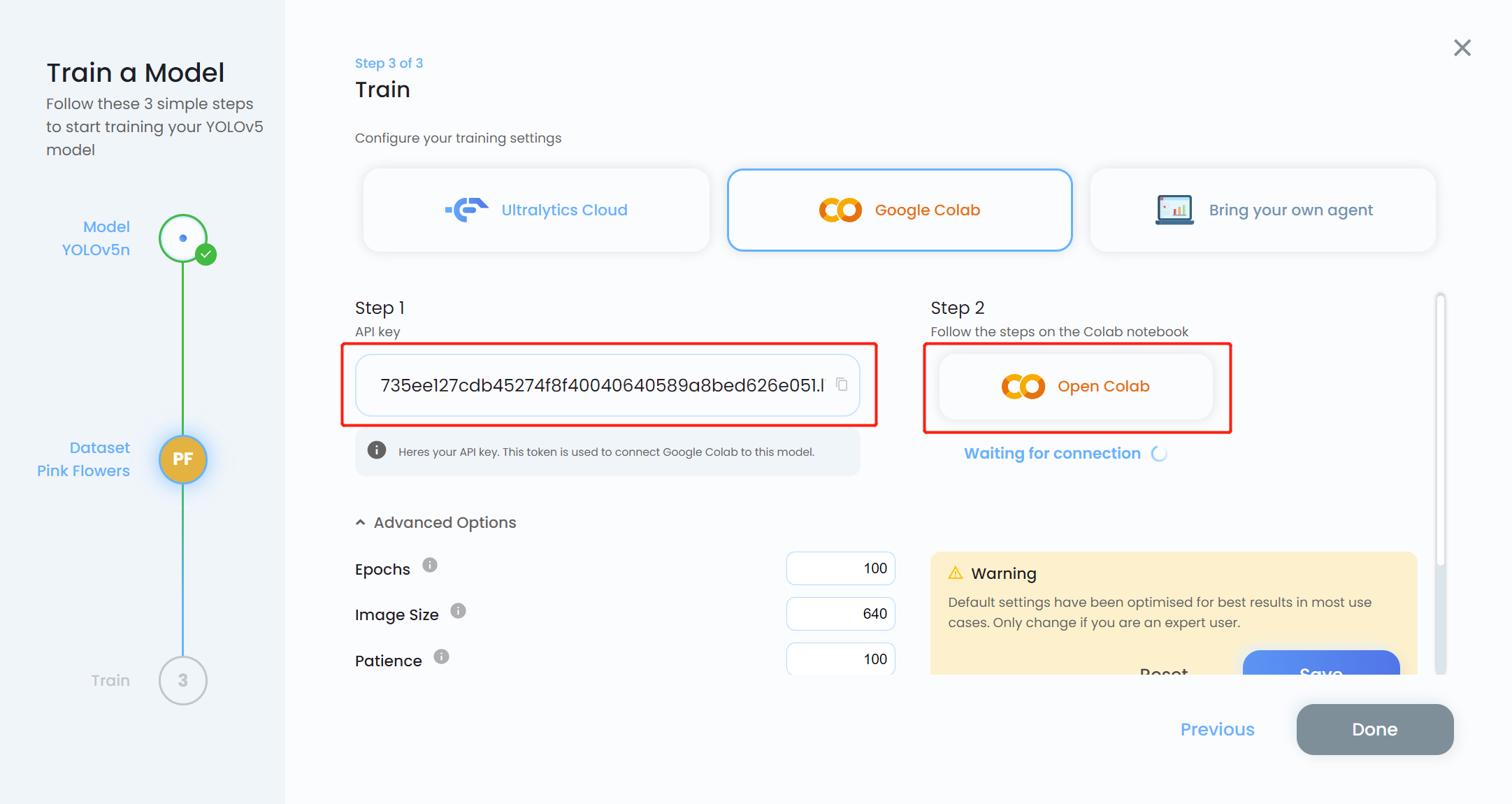
- ステップ 17. MODEL_KEY を先ほどコピーした API key に置き換えます
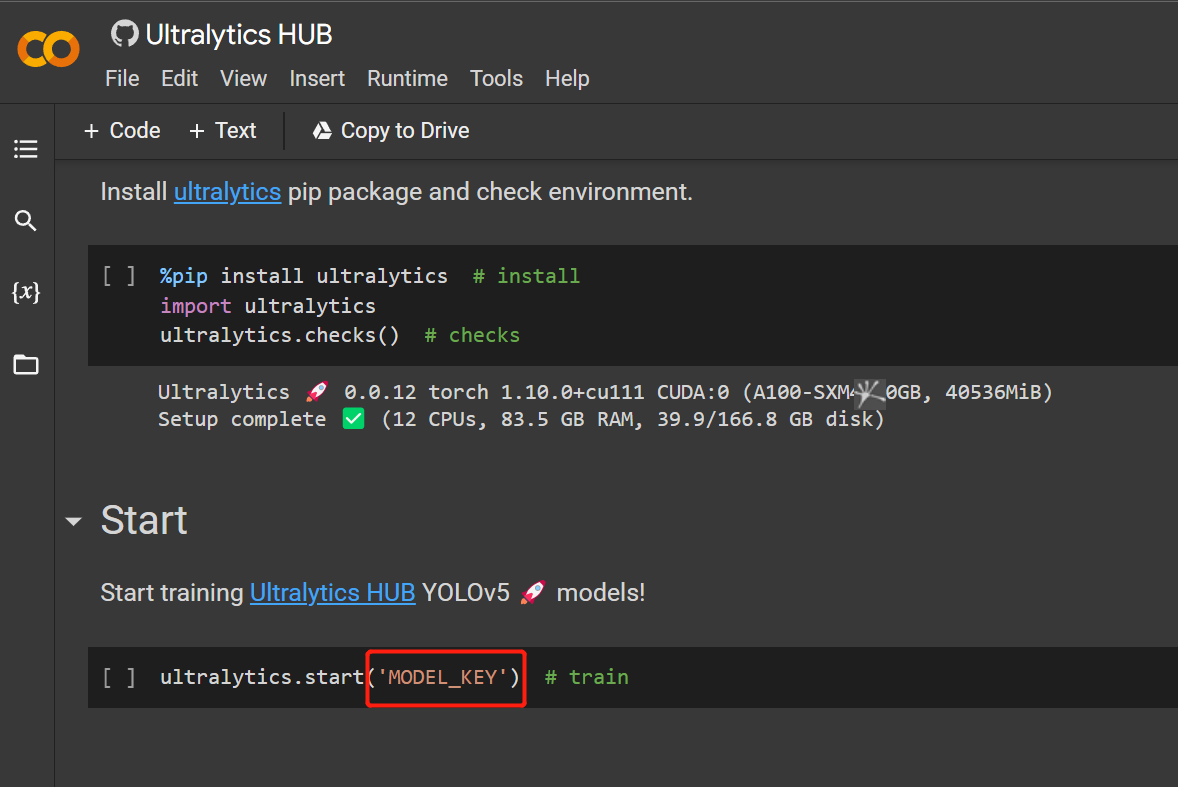
- ステップ 18.
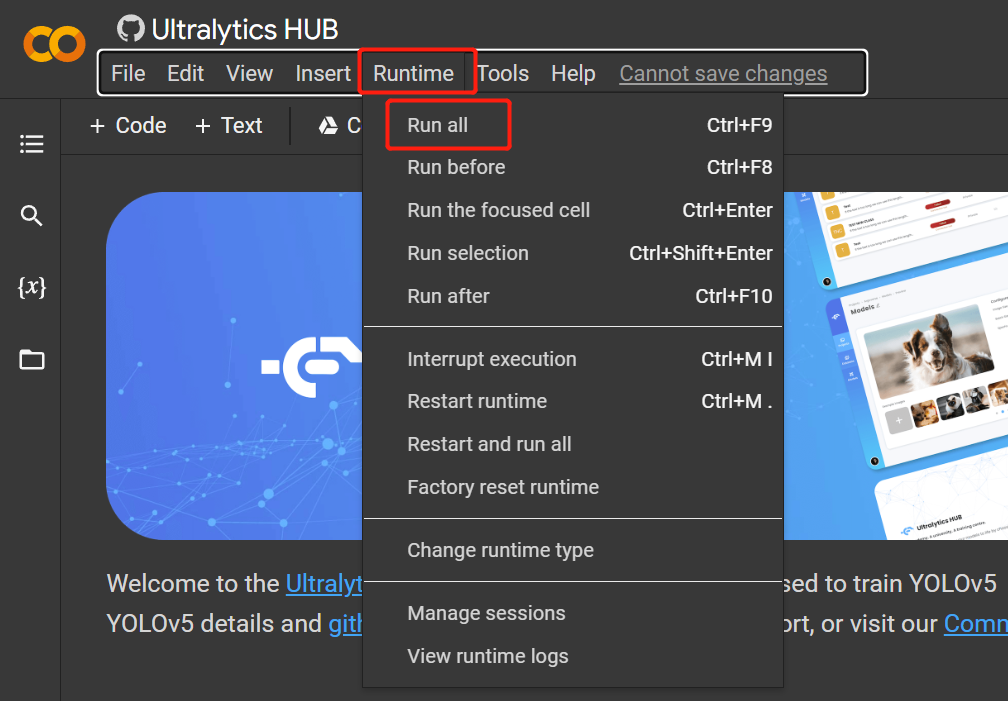
Runtime > Rull Allをクリックして、すべてのコードセルを実行し、学習プロセスを開始します
- ステップ 19. Ultralytics HUB に戻り、青色になったら Done をクリックします。Colab が Connected と表示されることも確認できます。
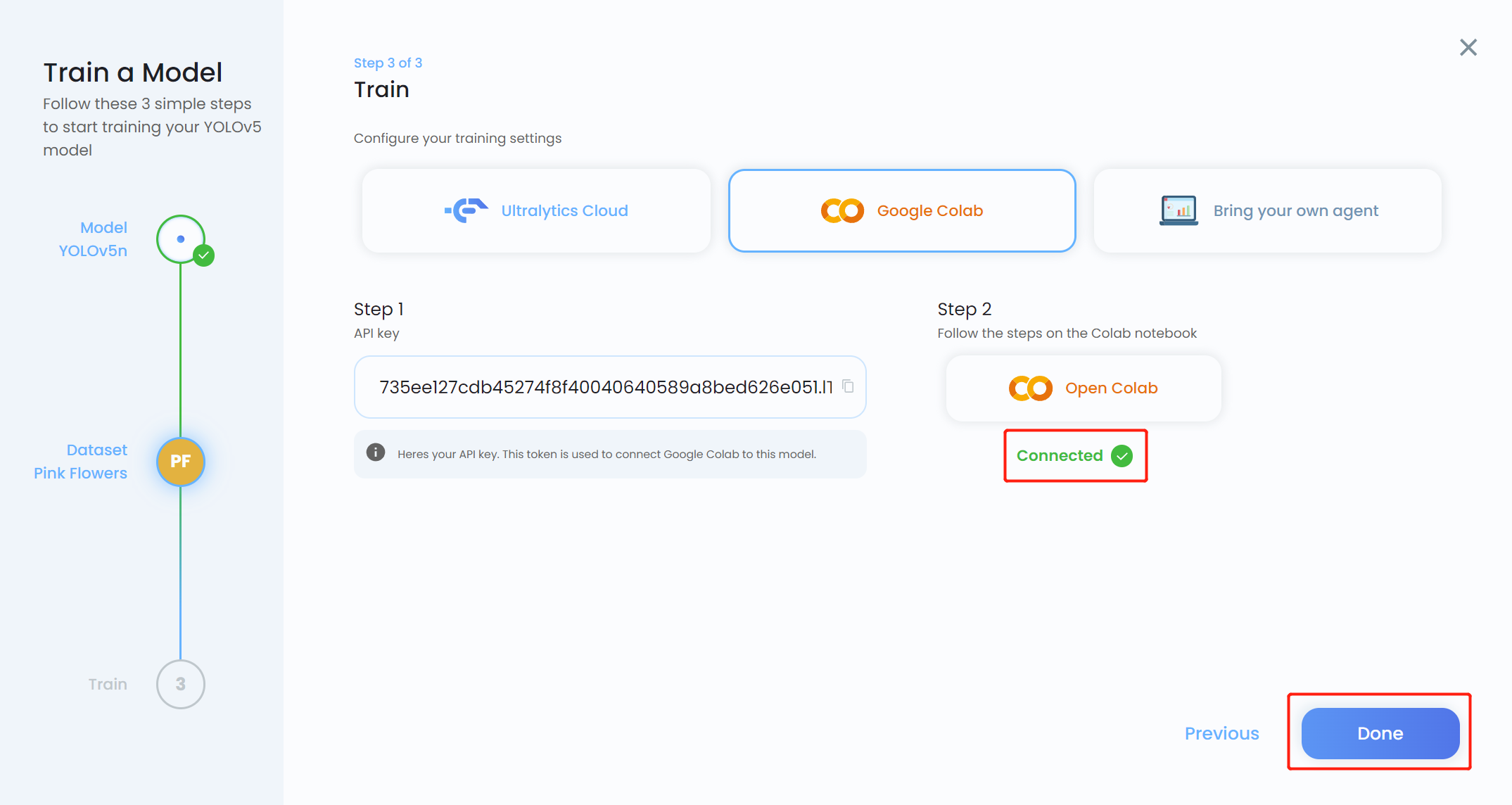
これで HUB で学習の進行状況を確認できます
- ステップ 20. 学習が完了したら、PyTorch をクリックして学習済みモデルを PyTorch 形式でダウンロードします。PyTorch は Jetson デバイスで推論を実行するために必要な形式です
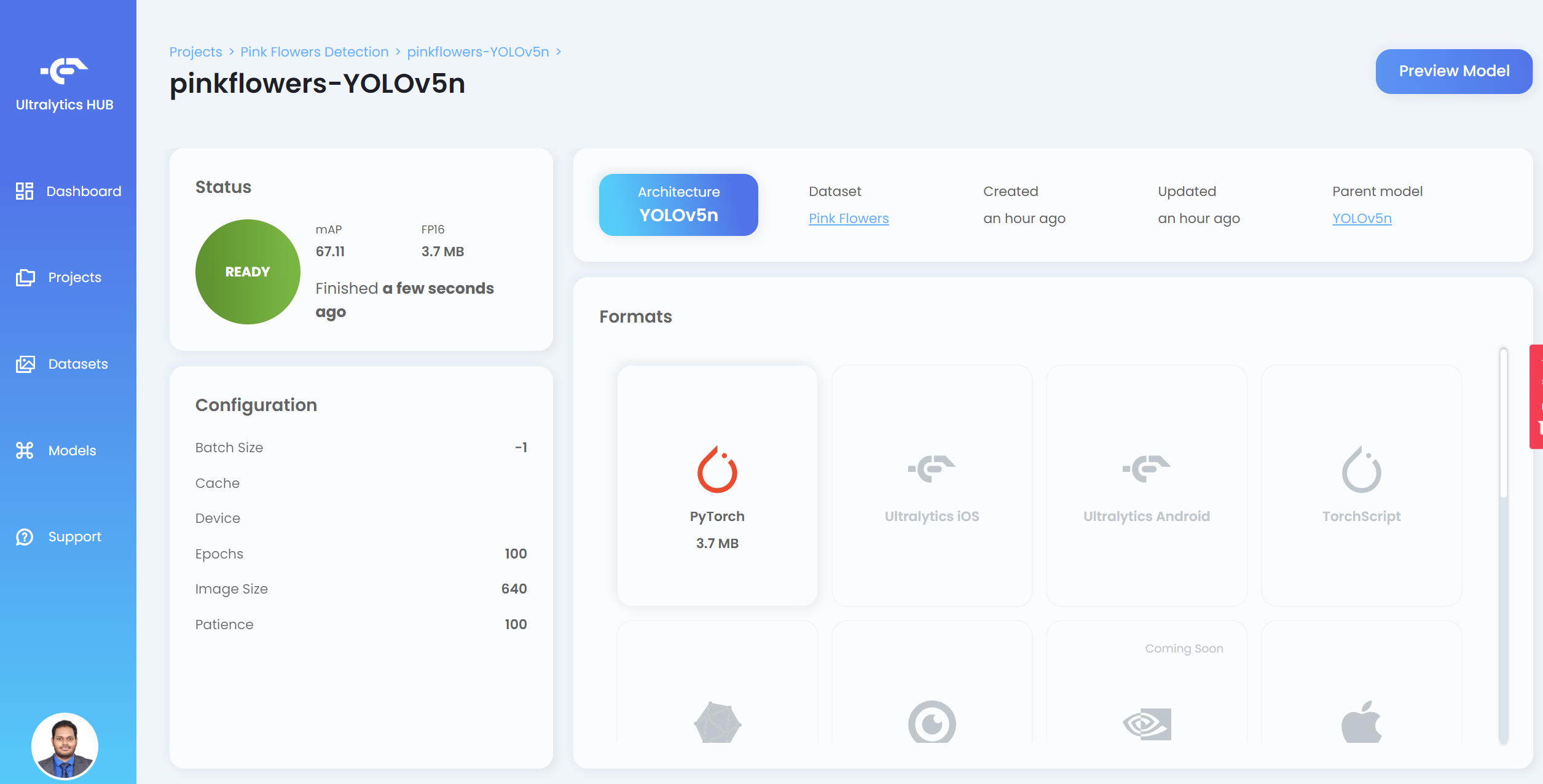
注意: Formats の下に表示されている他の形式にもエクスポートできます
Google Colab に戻ると、以下のような詳細を確認できます:
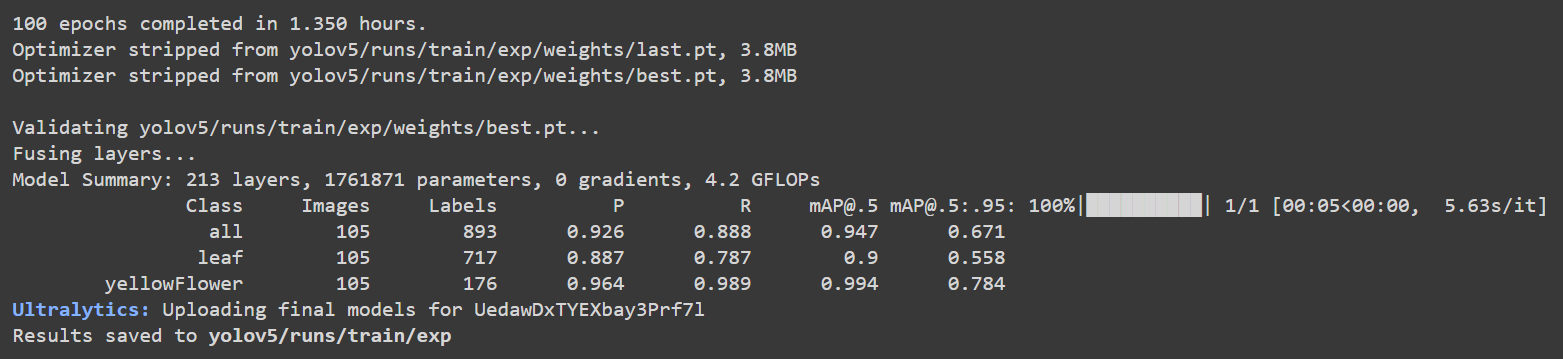
ここで精度 [email protected] は葉で約 90%、花で 99.4% であり、全体の精度 [email protected] は約 94.7% です。
Roboflow api を使用した Google Colab の使用
ここでは Google Colaboratory 環境を使用してクラウドで学習を実行します。さらに、Colab 内で Roboflow api を使用してデータセットを簡単にダウンロードします。
- ステップ 1. こちら をクリックして、すでに準備された Google Colab ワークスペースを開き、ワークスペースに記載されている手順を実行します
学習が完了すると、以下のような出力が表示されます:
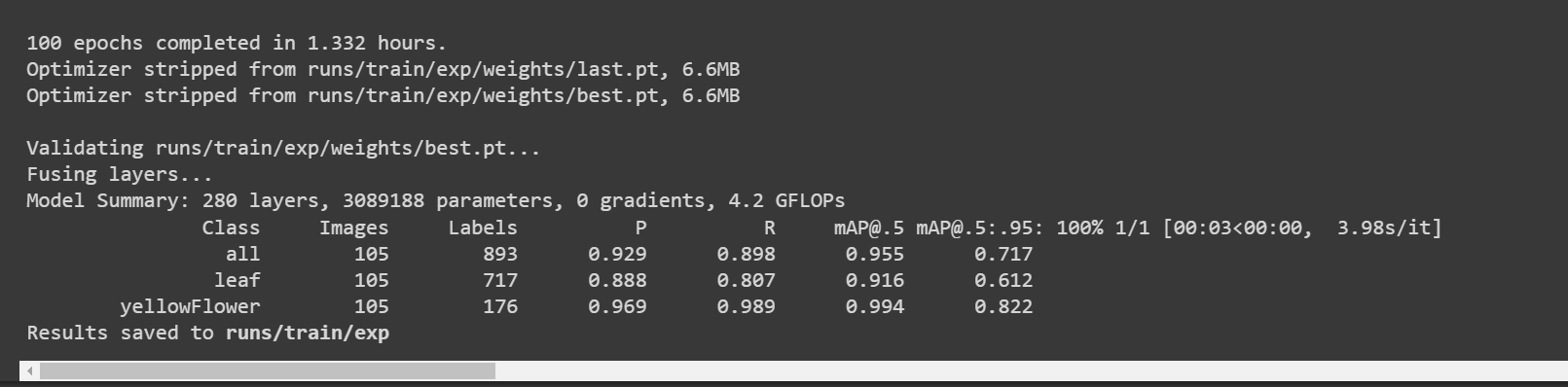
ここで精度 [email protected] は葉で約 91.6%、花で 99.4% であり、全体の精度 [email protected] は約 95.5% です。
- ステップ 2. Files タブの下で、
runs/train/exp/weightsに移動すると、best.pt というファイルが表示されます。これが学習から生成されたモデルです。このファイルをダウンロードして Jetson デバイスにコピーしてください。これは後で Jetson デバイスでの推論に使用するモデルです。
ローカル PC の使用
ここでは Linux OS を搭載した PC を学習に使用できます。この wiki では Ubuntu 20.04 PC を使用しました。
- ステップ 1. YOLOv5 リポジトリ をクローンし、Python>=3.7.0 環境で requirements.txt をインストールします
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
- ステップ 2. 先ほど Roboflow からダウンロードした .zip ファイルを yolov5 ディレクトリにコピー&ペーストし、展開します
# example
cp ~/Downloads/pink-flowers.v1i.yolov5pytorch.zip ~/yolov5
unzip pink-flowers.v1i.yolov5pytorch.zip
- ステップ 3. data.yamlファイルを開き、trainとvalディレクトリを以下のように編集する
train: train/images
val: valid/images
- ステップ 4. 以下を実行してトレーニングを開始します
python3 train.py --data data.yaml --img-size 640 --batch-size -1 --epoch 100 --weights yolov5n6.pt
私たちのデータセットは比較的小さい(約500枚の画像)ため、転移学習はゼロから学習するよりも良い結果を生み出すことが期待されます。私たちのモデルは、'weights'引数にモデル名(yolov5n6)を渡すことで、事前学習済みCOCOモデルの重みで初期化されました。ここではyolov5n6を使用しました。これはエッジデバイスに理想的だからです。ここで画像サイズは640x640に設定されています。バッチサイズは**-1を使用します。これにより最適なバッチサイズが自動的に決定されるからです。ただし、「GPU メモリが不足しています」というエラーが発生した場合は、バッチサイズを32**、または16に選択してください。好みに応じてエポックを変更することもできます。
学習が完了すると、以下のような出力が表示されます:

ここで精度[email protected]は葉と花でそれぞれ約90.6%と99.4%であり、全体の精度[email protected]は約95%です。
- ステップ 5.
runs/train/exp/weightsに移動すると、best.ptというファイルが表示されます。これは学習から生成されたモデルです。このファイルをJetsonデバイスにコピー・ペーストしてください。これは後でJetsonデバイスでの推論に使用するモデルだからです。

Jetsonデバイスでの推論
TensorRTの使用
今度は、Jetsonデバイスを使用して、以前の学習で生成されたモデルの助けを借りて画像上で推論(オブジェクト検出)を実行します。ここではNVIDIA TensorRTを使用してJetsonプラットフォームでの推論性能を向上させます。
- ステップ 1. Jetsonデバイスのターミナルにアクセスし、pipをインストールしてアップグレードします
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- ステップ 2. 以下のリポジトリをクローンします
git clone https://github.com/ultralytics/yolov5
- ステップ 3. requirements.txt を開く
cd yolov5
vi requirements.txt
- ステップ4. 以下の行を編集します。ここでは、まず i を押して編集モードに入る必要があります。ESC を押してから :wq と入力して保存して終了します
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
注意: matplotlib と numpy の固定バージョンを含めて、後でYOLOv5を実行する際にエラーが発生しないようにしています。また、torchとtorchvisionは後でインストールされるため、現在は除外されています。
- ステップ 5. 以下の依存関係をインストールする
sudo apt install -y libfreetype6-dev
- ステップ 6. 必要なパッケージをインストールする
pip3 install -r requirements.txt
- ステップ 7. torchをインストールする
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- ステップ 8. torchvisionをインストール
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- ステップ 9. 以下のリポジトリをクローンしてください
cd ~
git clone https://github.com/wang-xinyu/tensorrtx
-
ステップ 10. 前回のトレーニングから best.pt ファイルを yolov5 ディレクトリにコピーする
-
ステップ 11. tensorrtx/yolov5 から gen_wts.py を yolov5 ディレクトリにコピーする
cp tensorrtx/yolov5/gen_wts.py yolov5
- ステップ 12. PyTorchの**.ptファイルから.wts**ファイルを生成する
cd yolov5
python3 gen_wts.py -w best.pt -o best.wts
- ステップ 13. tensorrtx/yolov5 に移動します
cd ~
cd tensorrtx/yolov5
- ステップ 14. vi テキストエディタで yololayer.h を開く
vi yololayer.h
- ステップ 15. CLASS_NUM をあなたのモデルが訓練されたクラス数に変更します。この例では、2 です
CLASS_NUM = 2
- ステップ 16. 新しい build ディレクトリを作成し、その中に移動します
mkdir build
cd build
- ステップ 17. 以前に生成されたbest.wtsファイルをこのbuildディレクトリにコピーする
cp ~/yolov5/best.wts .
- ステップ 18. コンパイルする
cmake ..
make
- ステップ 19. モデルをシリアライズする
sudo ./yolov5 -s [.wts] [.engine] [n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw]
#example
sudo ./yolov5 -s best.wts best.engine n6
ここではn6を使用します。これはNVIDIA Jetsonプラットフォームなどのエッジデバイスに推奨されているためです。ただし、Ultralytics HUBを使用してトレーニングを設定する場合は、n6がまだHUBでサポートされていないため、nのみ使用できます。
-
ステップ 20. モデルに検出させたい画像をtensorrtx/yolov5/imagesなどの新しいフォルダにコピーします
-
ステップ 21. 以下のように画像をデシリアライズして推論を実行します
sudo ./yolov5 -d best.engine images
以下は、Jetson Nano と Jetson Xavier NX で実行した推論時間の比較です。
Jetson Nano
ここでは量子化を FP16 に設定しています
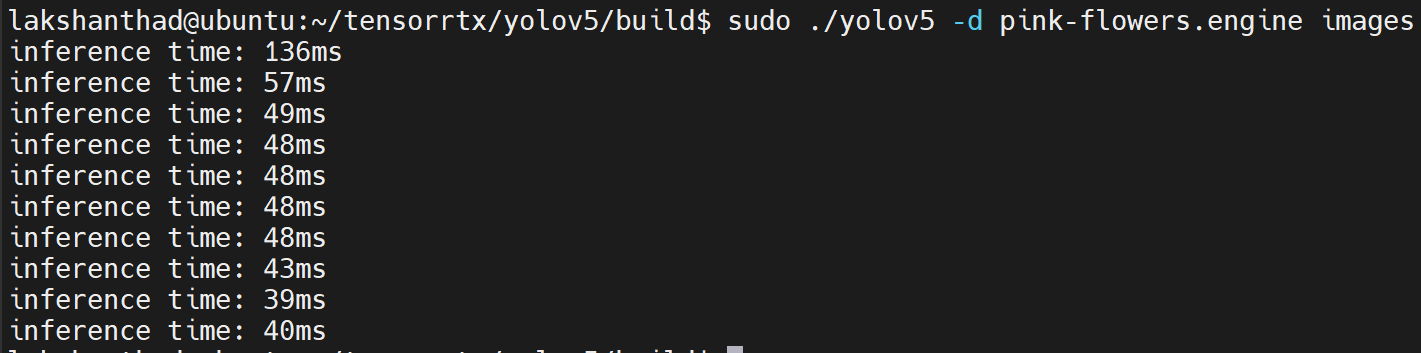
上記の結果から、平均を約 47ms とすることができます。この値をフレーム毎秒に変換すると:1000/47 = 21.2766 = 21fps となります。
Jetson Xavier NX
ここでは量子化を FP16 に設定しています
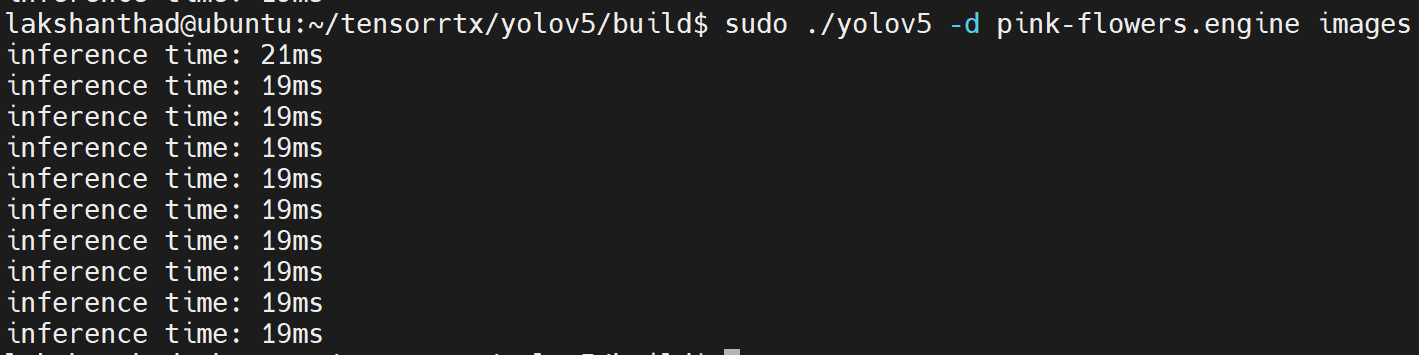
上記の結果から、平均を約 20ms とすることができます。この値をフレーム毎秒に変換すると:1000/20 = 50fps となります。
また、オブジェクトが検出された出力画像は以下のようになります:


TensorRT と DeepStream SDK の使用
ここでは、NVIDIA TensorRT と NVIDIA DeepStream SDK を使用して、動画映像で推論を実行します
- ステップ 1. Jetson デバイスに SDK Components と DeepStream SDK が適切にインストールされていることを確認してください。(インストールの参考についてはこの wiki を確認してください)
注意: すべての SDK コンポーネントと DeepStream SDK をインストールするには、NVIDIA SDK Manager を使用することを推奨します
- ステップ 2. Jetson デバイスのターミナルにアクセスし、pip をインストールしてアップグレードします
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- ステップ 3. 以下のリポジトリをクローンします
git clone https://github.com/ultralytics/yolov5
- ステップ 4. requirements.txt を開く
cd yolov5
vi requirements.txt
- ステップ 5. 以下の行を編集します。ここでは、まず i を押して編集モードに入る必要があります。ESC を押してから :wq と入力して保存して終了します
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
注意: 後でYOLOv5を実行する際にエラーが発生しないよう、matplotlibとnumpyの固定バージョンを含めています。また、torchとtorchvisionは後でインストールするため、現時点では除外されています。
- ステップ 6. 以下の依存関係をインストールする
sudo apt install -y libfreetype6-dev
- ステップ 7. 必要なパッケージをインストールする
pip3 install -r requirements.txt
- ステップ 8. torchをインストールする
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- ステップ 9. torchvisionをインストールする
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- ステップ 10. 以下のリポジトリをクローンしてください
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- ステップ 11. DeepStream-Yolo/utils から gen_wts_yoloV5.py を yolov5 ディレクトリにコピーします
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- ステップ 12. yolov5 リポジトリ内で、YOLOv5 リリースから pt ファイル をダウンロードします(YOLOv5s 6.1 の例)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- ステップ 13. cfg と wts ファイルを生成する
python3 gen_wts_yoloV5.py -w yolov5s.pt
注意: 推論サイズを変更するには(デフォルト: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- ステップ 14. 生成された cfg と wts ファイルを DeepStream-Yolo フォルダにコピーします
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo
- ステップ 15. DeepStream-Yolo フォルダを開き、ライブラリをコンパイルします
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
- ステップ 16. あなたのモデルに従って config_infer_primary_yoloV5.txt ファイルを編集してください
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...
- ステップ 17. deepstream_app_configファイルを編集する
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt
- ステップ 18. 推論を実行する
deepstream-app -c deepstream_app_config.txt
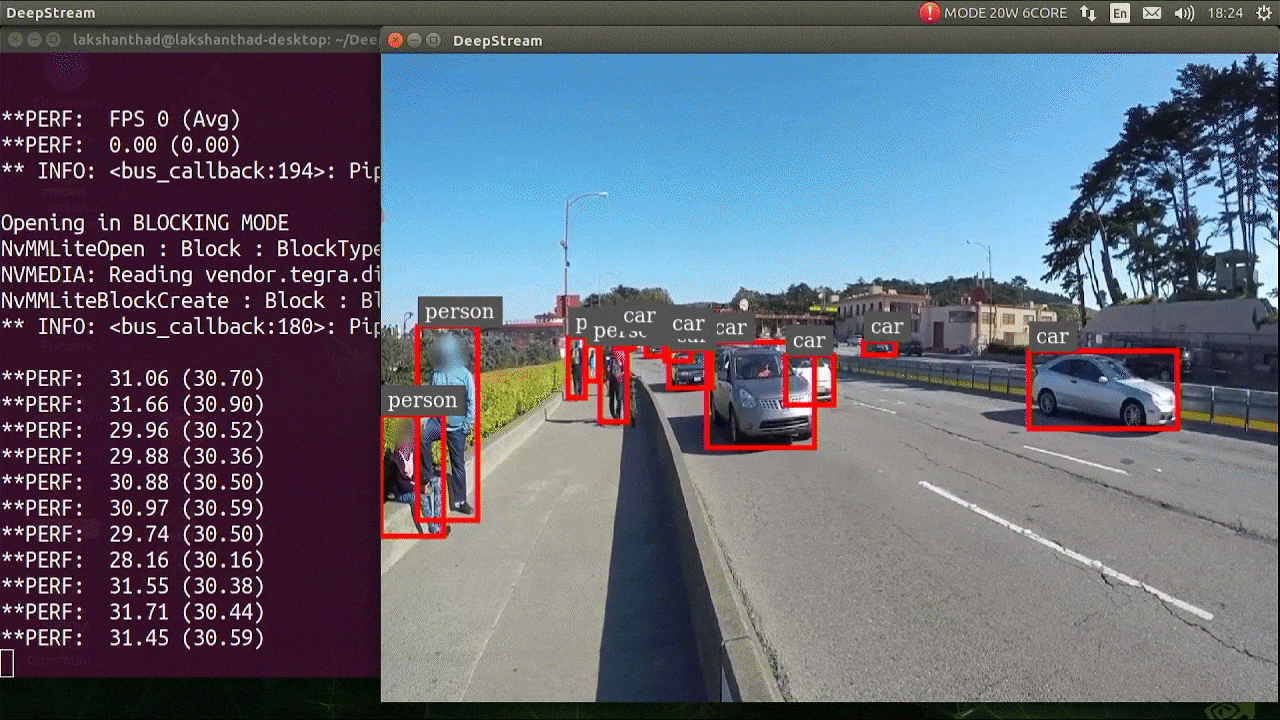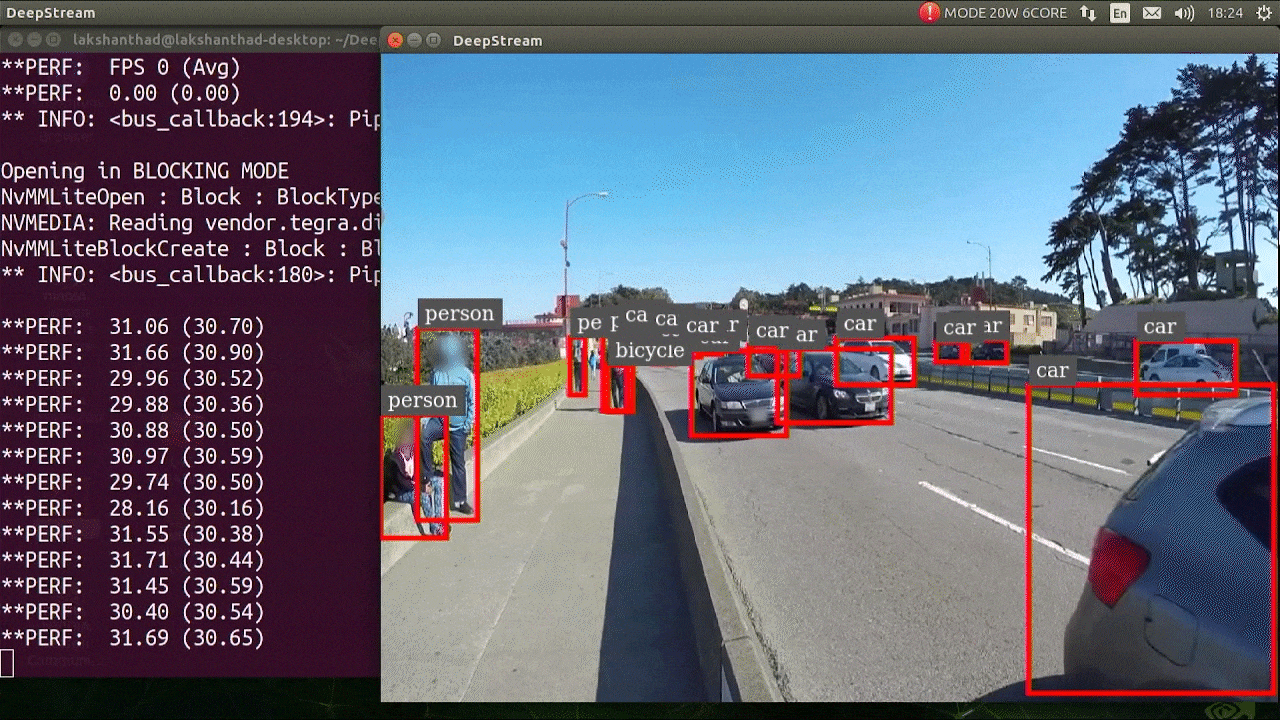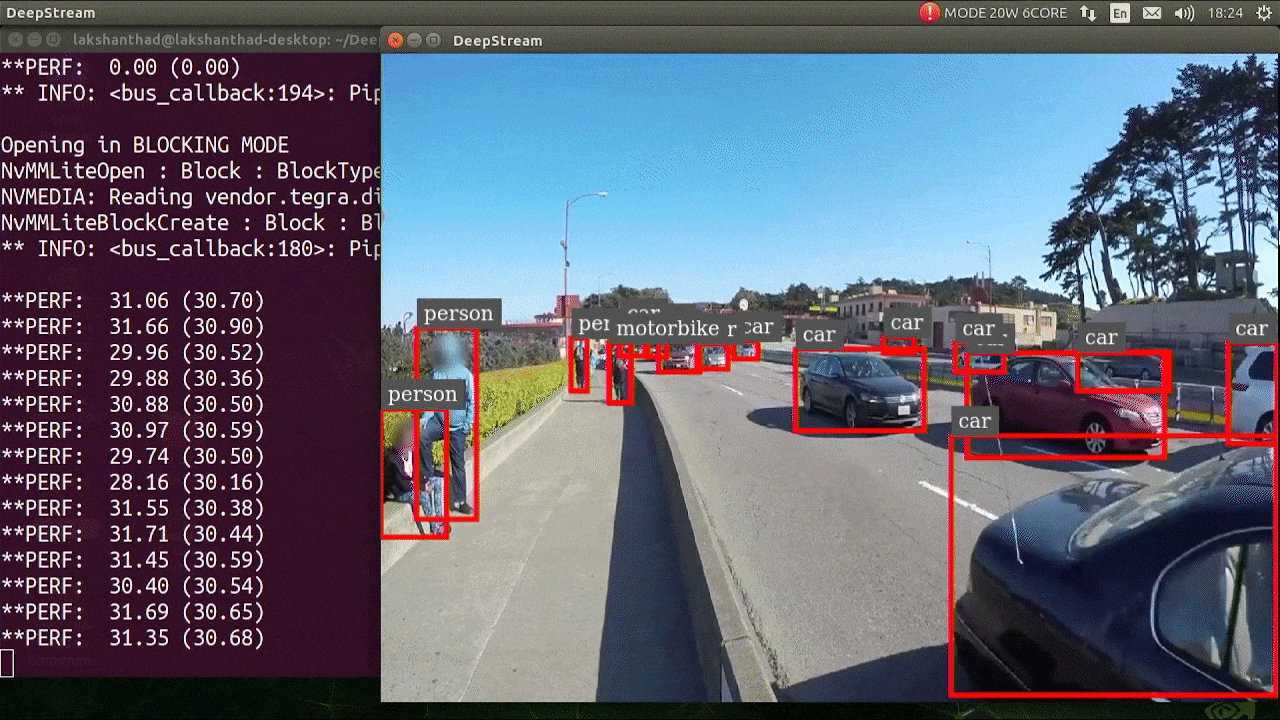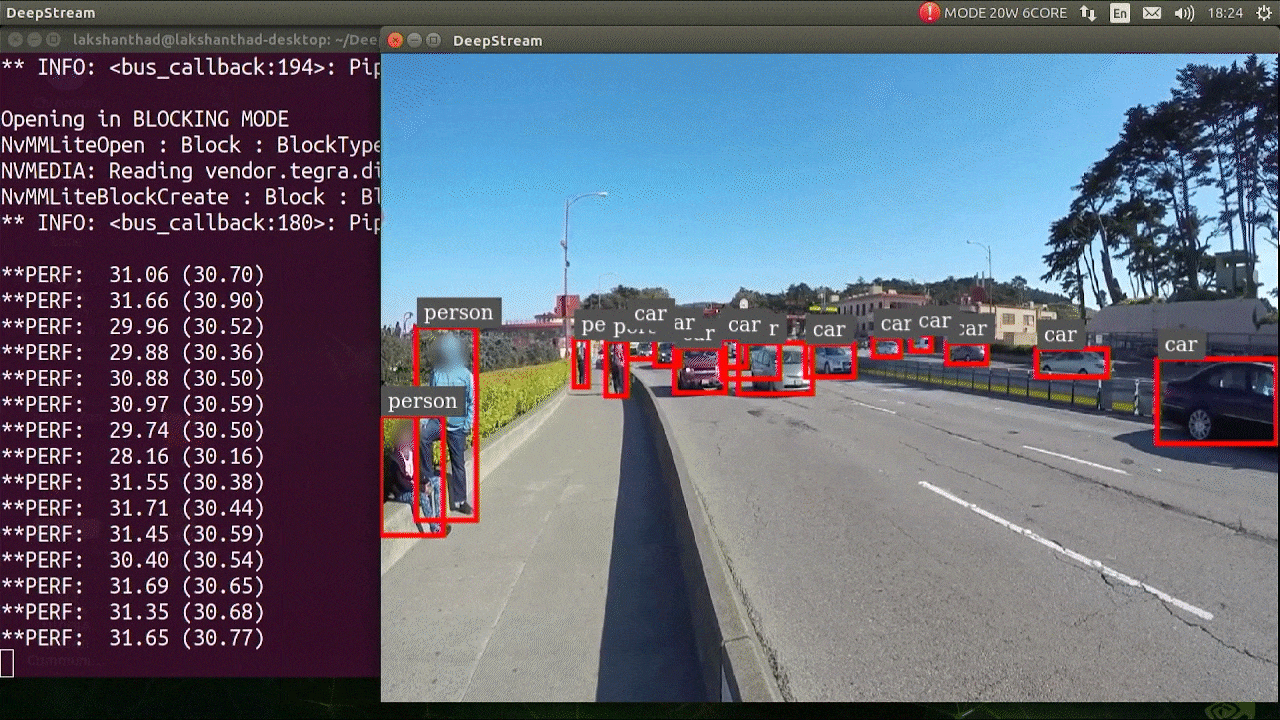
上記の結果は Jetson Xavier NX で FP32 と YOLOv5s 640x640 を使用して実行されています。FPS は約 30 であることがわかります。
INT8 キャリブレーション
推論にINT8精度を使用したい場合は、以下の手順に従う必要があります
- ステップ 1. OpenCVをインストール
sudo apt-get install libopencv-dev
- ステップ 2. OpenCV サポートを有効にして nvdsinfer_custom_impl_Yolo ライブラリをコンパイル/再コンパイルする
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
-
ステップ 3. COCOデータセットについて、val2017をダウンロードし、展開してDeepStream-Yoloフォルダに移動します
-
ステップ 4. キャリブレーション画像用の新しいディレクトリを作成します
mkdir calibration
- ステップ 5. 以下を実行して、COCOデータセットから1000枚のランダムな画像を選択してキャリブレーションを実行します
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
注意: NVIDIAは良好な精度を得るために少なくとも500枚の画像を推奨しています。この例では、より良い精度を得るために1000枚の画像が選択されています(画像数が多いほど精度が向上します)。INT8_CALIB_BATCH_SIZEの値を高くすると、より高い精度とより高速なキャリブレーション速度が得られます。GPUメモリに応じて設定してください。head -1000から設定できます。例えば、2000枚の画像の場合はhead -2000です。この処理には長時間かかる場合があります。
- ステップ 6. 選択したすべての画像でcalibration.txtファイルを作成する
realpath calibration/*jpg > calibration.txt
- ステップ 7. 環境変数を設定する
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- ステップ 8. config_infer_primary_yoloV5.txt ファイルを更新する
変更前
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
から
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
- ステップ 9. 推論を実行する
deepstream-app -c deepstream_app_config.txt
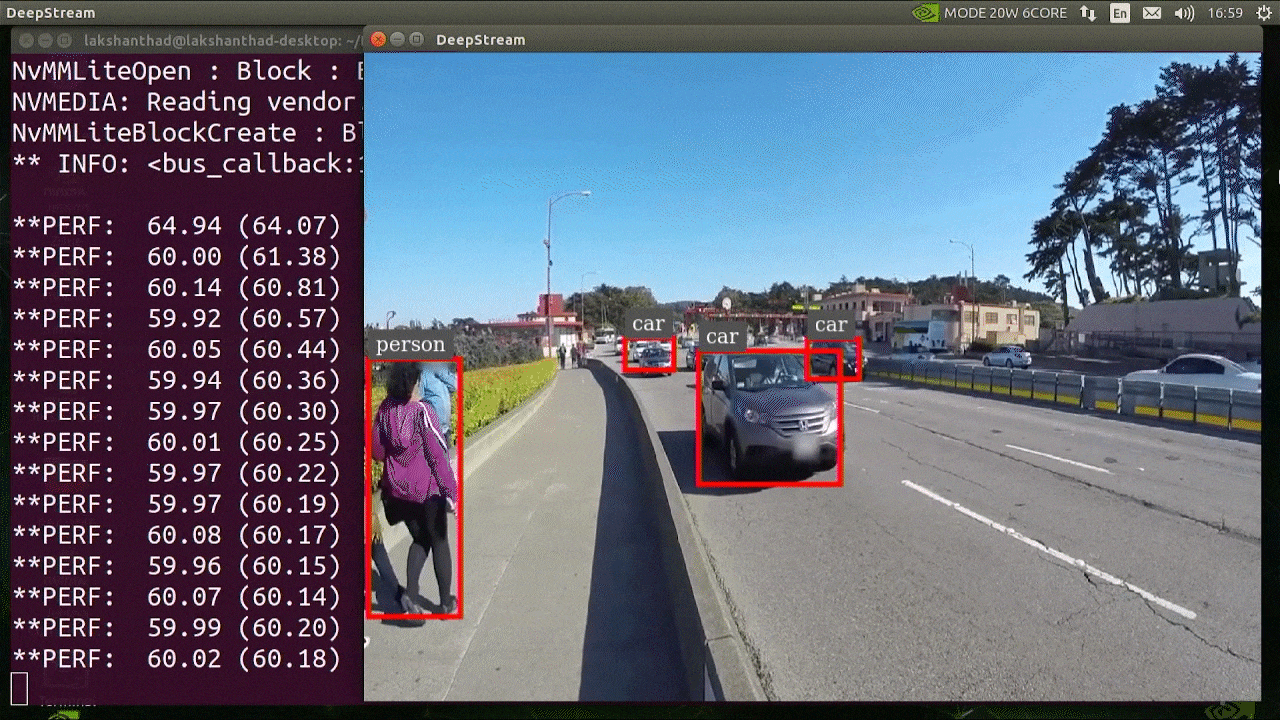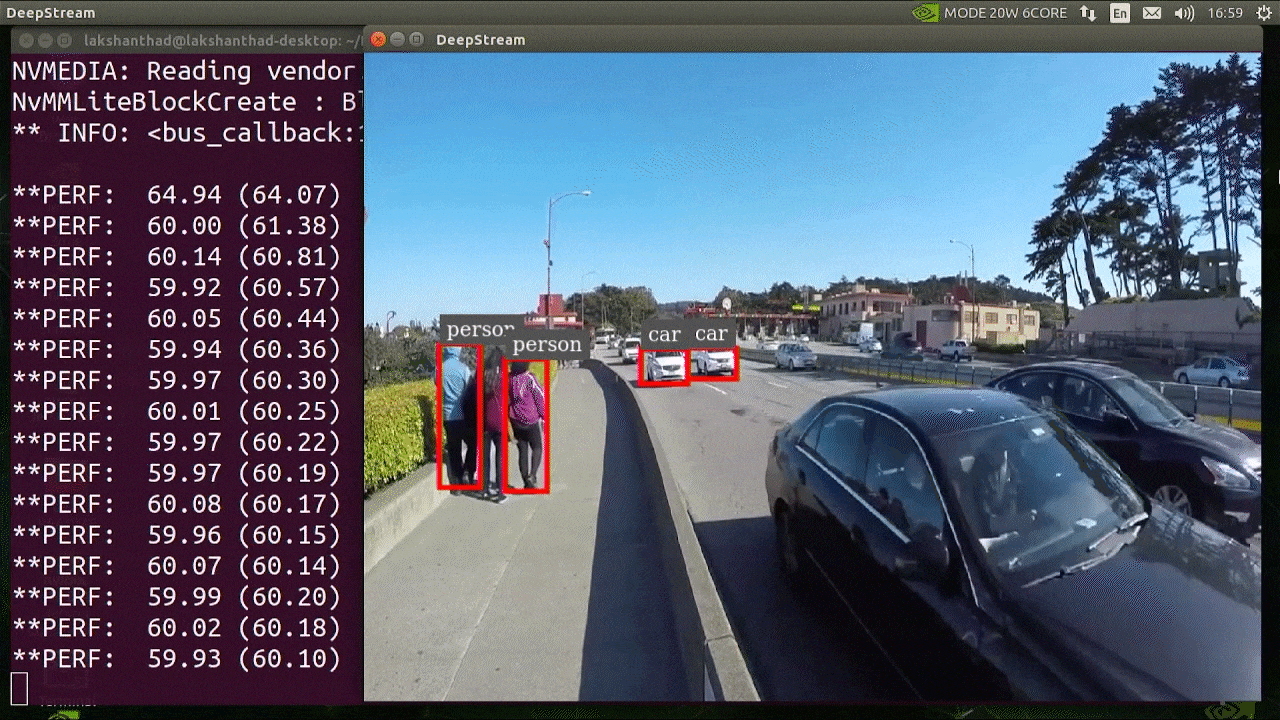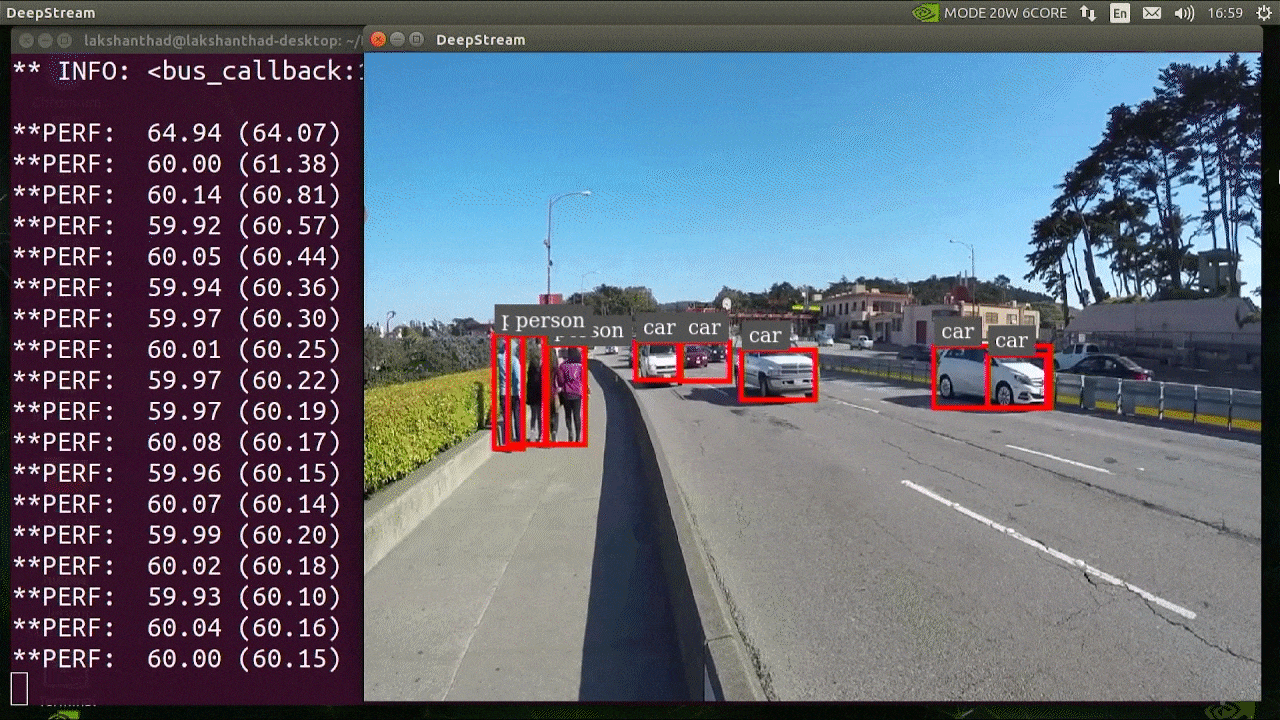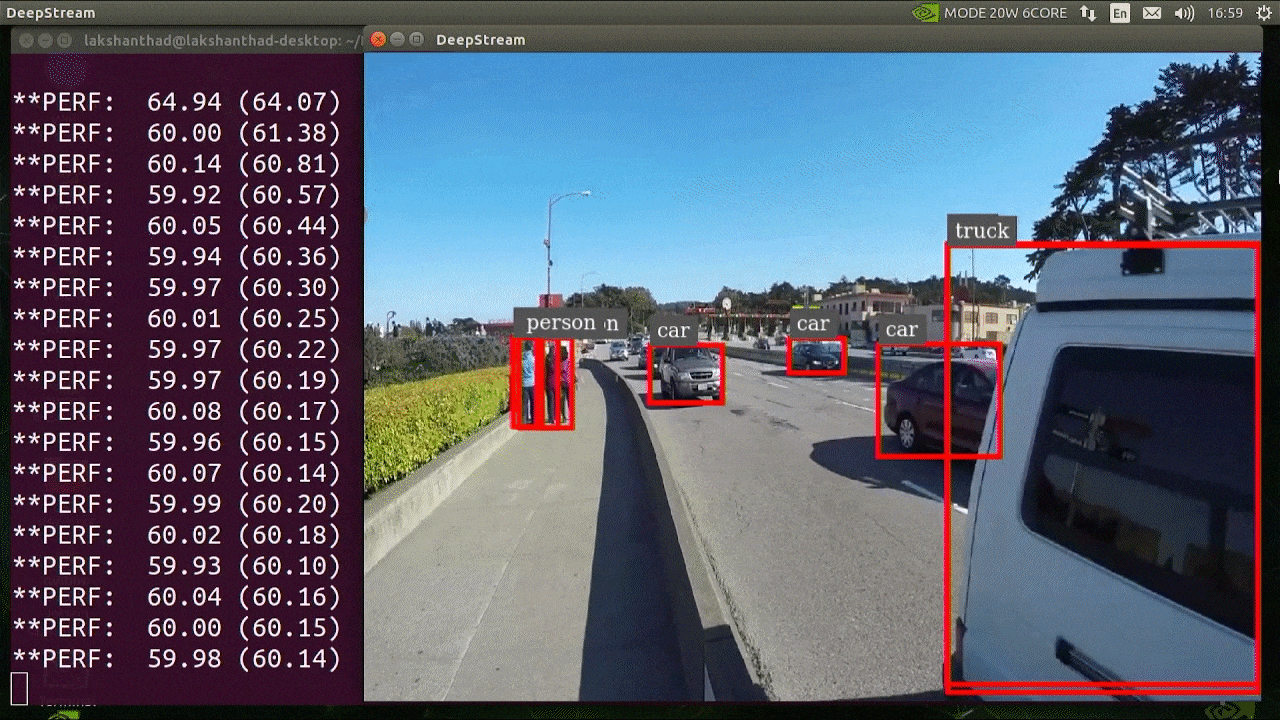
上記の結果はJetson Xavier NXでINT8とYOLOv5s 640x640を使用して実行されています。FPSが約60であることがわかります。
ベンチマーク結果
以下の表は、Jetson Xavier NXで異なるモデルがどのように動作するかをまとめています。
| モデル名 | 精度 | 推論サイズ | 推論時間 (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
パブリックデータセットとカスタムデータセットの使用比較
ここでは、パブリックデータセットと独自のカスタムデータセットを使用した場合の、トレーニングサンプル数とトレーニング時間の違いを比較します。
トレーニングサンプル数
カスタムデータセット
このwikiでは、植物データセットを最初にビデオとして収集し、その後Roboflowを使用してビデオを一連の画像に変換しました。ここでは542枚の画像を取得しましたが、これはパブリックデータセットと比較すると非常に小さなデータセットです。
パブリックデータセット
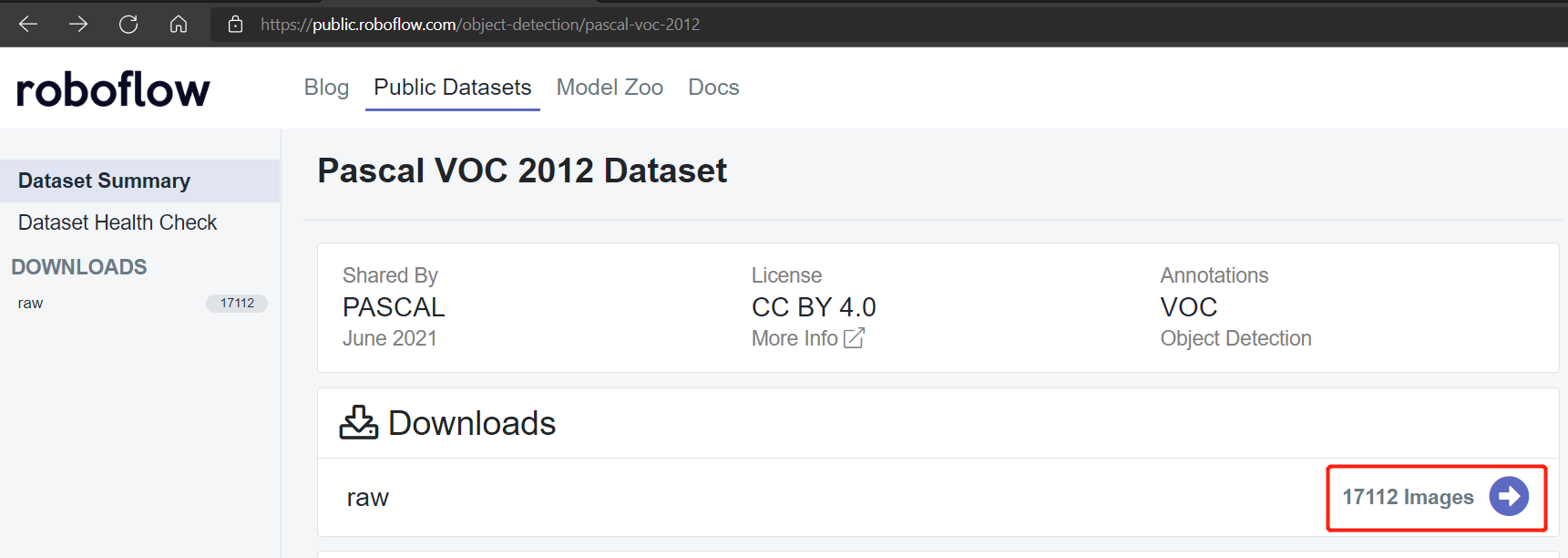
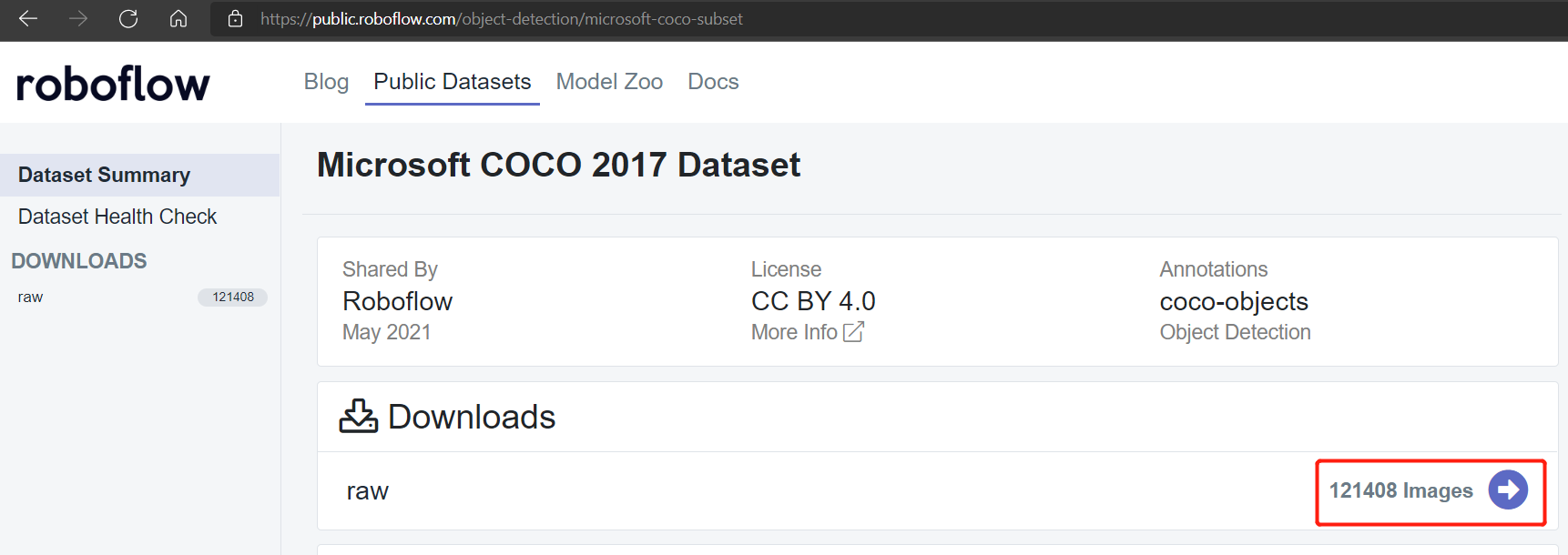
Pascal VOC 2012やMicrosoft COCO 2017データセットなどのパブリックデータセットには、それぞれ約17112枚と121408枚の画像があります。
Pascal VOC 2012データセット
Microsoft COCO 2017データセット
トレーニング時間
ローカルトレーニング
トレーニングは6GBメモリを搭載したNVIDIA GeForce GTX 1660 Superグラフィックスカードで実行されました。
カスタムデータセットでのローカルトレーニング
540枚画像データセット
以前に植物に対して実行したローカルトレーニングによると、以下の結果を得ました。
ここでは100エポック実行するのに2.2時間しかかかりませんでした。これはパブリックデータセットを使用したトレーニングと比較して高速です。
240枚画像データセット
データセットを240枚に削減して再度トレーニングを実行し、以下の結果を得ました。

ここでは100エポック実行するのに約1時間しかかかりませんでした。これはパブリックデータセットを使用したトレーニングと比較して高速です。
Pascal VOC 2012データセットでのローカルトレーニング
このシナリオでは、同じトレーニングパラメータを維持しながらPascal VOC 2012データセットをトレーニングに使用しました。1エポック実行するのに約**50分(0.846時間 * 60)**かかることがわかったため、1エポックでトレーニングを停止しました。

100エポックのトレーニング時間を計算すると、約50 * 100分 = 5000分 = 83時間かかることになり、これはカスタムデータセットのトレーニング時間よりもはるかに長くなります。
Microsoft COCO 2017データセットでのローカルトレーニング
このシナリオでは、同じトレーニングパラメータを維持しながらMicrosoft COCO 2017データセットをトレーニングに使用しました。1エポック実行するのに約7.5時間かかると推定されたため、1エポックが完了する前にトレーニングを停止しました。

100エポックのトレーニング時間を計算すると、約7.5時間 * 100 = 750時間かかることになり、これはカスタムデータセットのトレーニング時間よりもはるかに長くなります。
Google Colabトレーニング
トレーニングは12GBメモリを搭載したNVIDIA Tesla K80グラフィックスカードで実行されました。
カスタムデータセット
540枚画像データセット
540枚の画像を使用して以前に植物に対して実行したGoogle Colabトレーニングによると、以下の結果を得ました。
ここでは100エポック実行するのに約1.3時間しかかかりませんでした。これもパブリックデータセットを使用したトレーニングと比較して高速です。
240枚画像データセット
データセットを240枚に削減して再度トレーニングを実行し、以下の結果を得ました。
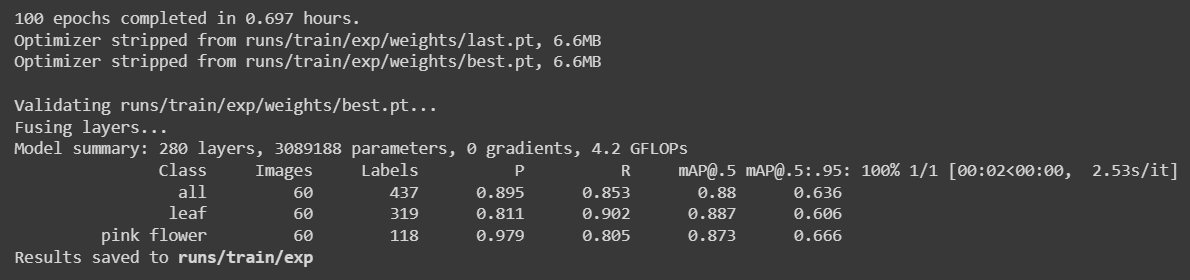
ここでは100エポック実行するのに約**42分(0.697時間 * 60)**しかかかりませんでした。これはパブリックデータセットを使用したトレーニングと比較して高速です。
Pascal VOC 2012データセットでのGoogle Colabトレーニング
このシナリオでは、同じトレーニングパラメータを維持しながらPascal VOC 2012データセットをトレーニングに使用しました。1エポック実行するのに約**9分(0.148時間 * 60)**かかることがわかったため、1エポックでトレーニングを停止しました。
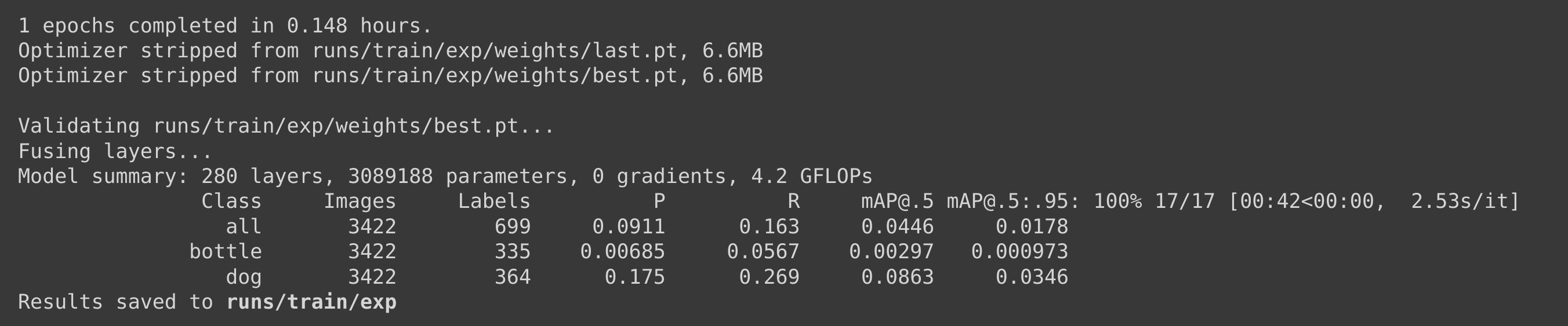
100エポックのトレーニング時間を計算すると、約9 * 100分 = 900分 = 15時間かかることになり、これはカスタムデータセットのトレーニング時間よりもはるかに長くなります。
Microsoft COCO 2017データセットでのGoogle Colabトレーニング
このシナリオでは、同じトレーニングパラメータを維持しながらMicrosoft COCO 2017データセットをトレーニングに使用しました。1エポック実行するのに約1.25時間かかると推定されたため、1エポックが完了する前にトレーニングを停止しました。

100エポックのトレーニング時間を計算すると、約1.25時間 * 100 = 125時間かかることになり、これはカスタムデータセットのトレーニング時間よりもはるかに長くなります。
トレーニングサンプル数とトレーニング時間の要約
| データセット | トレーニングサンプル数 | ローカルPC(GTX 1660 Super)でのトレーニング時間 | Google Colab(NVIDIA Tesla K80)でのトレーニング時間 |
|---|---|---|---|
| カスタム | 542 | 2.2時間 | 1.3時間 |
| 240 | 1時間 | 42分 | |
| Pascal VOC 2012 | 17112 | 83時間 | 15時間 |
| Microsoft COCO 2017 | 121408 | 750時間 | 125時間 |
事前学習済みチェックポイントの比較
以下の表から事前学習済みチェックポイントについて詳しく学ぶことができます。ここでは、Google Colabで学習し、Jetson NanoとJetson Xavier NXでYOLOv5n6を事前学習済みチェックポイントとして推論を行うシナリオをハイライトしています。
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | Speed Jetson Nano FP16 (ms) | Speed Jetson Xavier NX FP16 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | ||
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | ||
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | ||
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | ||
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | ||
| YOLOv5n6 | 640 | 71.7 | 95.5 | 153 | 8.1 | 2.1 | 47 | 20 | 3.1 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | ||
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | ||
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | ||
| YOLOv5x6 + [TTA] | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
参考: YOLOv5 GitHub
ボーナスアプリケーション
上記で説明したすべてのステップは、あらゆるタイプの物体検出アプリケーションに共通しているため、独自の物体検出アプリケーションではデータセットを変更するだけで済みます!
道路標識検出
ここでは、RoboflowからRoboflowの道路標識データセットを使用し、NVIDIA Jetsonで推論を実行しました!

山火事煙検出
ここでは、Roboflowの山火事煙データセットを使用し、NVIDIA Jetsonで推論を実行しました!

リソース
-
[Webページ] YOLOv5ドキュメント
-
[Webページ] Ultralytics HUB
-
[Webページ] Roboflowドキュメント
技術サポート & 製品ディスカッション
弊社製品をお選びいただき、ありがとうございます!弊社製品での体験が可能な限りスムーズになるよう、さまざまなサポートを提供いたします。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。