TensorRTとDeepStream SDKサポートを使用してNVIDIA JetsonにYOLOv8をデプロイ
このガイドでは、訓練されたAIモデルをNVIDIA Jetsonプラットフォームにデプロイし、TensorRTとDeepStream SDKを使用して推論を実行する方法について説明します。ここでは、Jetsonプラットフォームでの推論性能を最大化するためにTensorRTを使用します。

前提条件
- Ubuntu ホストPC(ネイティブまたはVMware Workstation Playerを使用したVM)
- reComputer JetsonまたはJetPack 4.6以上を実行するその他のNVIDIA Jetsonデバイス
JetPackバージョンに対応するDeepStreamバージョン
YOLOv8をDeepStreamと連携させるために、このDeepStram-YOLOリポジトリを使用しており、これは異なるバージョンのDeepStreamをサポートしています。そのため、正しいバージョンのDeepStreamに応じて正しいバージョンのJetPackを使用するようにしてください。
| DeepStreamバージョン | JetPackバージョン |
|---|---|
| 6.2 | 5.1.1 |
| 5.1 | |
| 6.1.1 | 5.0.2 |
| 6.1 | 5.0.1 DP |
| 6.0.1 | 4.6.3 |
| 4.6.2 | |
| 4.6.1 | |
| 6.0 | 4.6 |
このwikiを検証するために、reComputer J4012上で動作するJetPack 5.1.1システムにDeepStream SDK 6.2をインストールしました。
JetsonにJetPackをフラッシュする
Jetsonデバイスに、CUDA、TensorRT、cuDNNなどのSDKコンポーネントを含むJetPackシステムがフラッシュされていることを確認する必要があります。NVIDIA SDK Managerまたはコマンドラインを使用してJetPackをデバイスにフラッシュできます。
Seeed Jetson搭載デバイスのフラッシュガイドについては、以下のリンクを参照してください:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
DeepStreamをインストールする
JetsonデバイスにDeepStreamをインストールする方法は複数あります。詳細についてはこのガイドを参照してください。ただし、成功かつ簡単なインストールを保証できるため、SDK Managerを使用してDeepStreamをインストールすることをお勧めします。
SDK managerを使用してDeepStreamをインストールする場合、システム起動後にDeepStreamの追加依存関係である以下のコマンドを実行する必要があります
sudo apt install \
libssl1.1 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstreamer-plugins-base1.0-dev \
libgstrtspserver-1.0-0 \
libjansson4 \
libyaml-cpp-dev
必要なパッケージのインストール
- ステップ 1. Jetsonデバイスのターミナルにアクセスし、pipをインストールしてアップグレードします
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- ステップ2. 以下のリポジトリをクローンします
git clone https://github.com/ultralytics/ultralytics.git
- ステップ3. requirements.txtを開く
cd ultralytics
vi requirements.txt
- ステップ 4. 以下の行を編集します。ここでは、まず
iを押して編集モードに入る必要があります。ESCを押してから:wqと入力して保存して終了します
# torch>=1.7.0
# torchvision>=0.8.1
注意: torch と torchvision は後でインストールされるため、現在は除外されています。
- ステップ 5. 必要なパッケージをインストールする
pip3 install -r requirements.txt
インストーラーが古い python-dateutil パッケージについて警告する場合は、以下のコマンドでアップグレードしてください
pip3 install python-dateutil --upgrade
PyTorchとTorchvisionのインストール
JetsonプラットフォームはARM aarch64アーキテクチャをベースとしているため、pipからPyTorchとTorchvisionをインストールすることはできません。そのため、事前にビルドされたPyTorch pipホイールを手動でインストールし、Torchvisionをソースからコンパイル/インストールする必要があります。
すべてのPyTorchとTorchvisionのリンクにアクセスするには、このページをご覧ください。
以下はJetPack 5.0以降でサポートされているバージョンの一部です。
PyTorch v1.11.0
Python 3.8を使用したJetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0)でサポート
file_name: torch-1.11.0-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl
PyTorch v1.12.0
Python 3.8を使用したJetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0)でサポート
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- ステップ 1. お使いのJetPackバージョンに応じて、以下の形式でtorchをインストールします
wget <URL> -O <file_name>
pip3 install <file_name>
例えば、ここではJP5.0.2を実行しているため、PyTorch v1.12.0を選択します
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- ステップ 2. インストールしたPyTorchのバージョンに応じてtorchvisionをインストールします。例えば、PyTorch v1.12.0を選択した場合、Torchvision v0.13.0を選択する必要があります
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
PyTorchのバージョンに応じてインストールする必要があるtorchvisionの対応バージョンのリストは以下の通りです:
- PyTorch v1.11 - torchvision v0.12.0
- PyTorch v1.12 - torchvision v0.13.0
より詳細なリストが必要な場合は、このリンクをご確認ください。
DeepStream YOLOv8の設定
- ステップ 1. 以下のリポジトリをクローンします
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- ステップ 2. リポジトリを以下のコミットにチェックアウトする
cd DeepStream-Yolo
git checkout 68f762d5bdeae7ac3458529bfe6fed72714336ca
- ステップ 3. DeepStream-Yolo/utils から gen_wts_yoloV8.py を ultralytics ディレクトリにコピーします
cp utils/gen_wts_yoloV8.py ~/ultralytics
- ステップ 4. ultralytics リポジトリ内で、YOLOv8 releases から pt ファイル をダウンロードします(YOLOv8s の例)
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt
注意: カスタムモデルを使用することができますが、エンジンを正しく生成するために、cfg および weights/wts ファイル名に YOLO モデル参照 (yolov8_) を保持することが重要です。
- ステップ 5. cfg、wts、および labels.txt(利用可能な場合)ファイルを生成します(YOLOv8s の例)
python3 gen_wts_yoloV8.py -w yolov8s.pt
注意: 推論サイズを変更するには(デフォルト: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- ステップ 6. 生成された cfg、wts、および labels.txt(生成された場合)ファイルを DeepStream-Yolo フォルダにコピーします
cp yolov8s.cfg ~/DeepStream-Yolo
cp yolov8s.wts ~/DeepStream-Yolo
cp labels.txt ~/DeepStream-Yolo
- ステップ 7. DeepStream-Yolo フォルダを開き、ライブラリをコンパイルします
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- ステップ 8. あなたのモデルに応じて config_infer_primary_yoloV8.txt ファイルを編集します(80クラスのYOLOv8sの例)
[property]
...
custom-network-config=yolov8s.cfg
model-file=yolov8s.wts
...
num-detected-classes=80
...
- ステップ 9. deepstream_app_config.txt ファイルを編集する
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
- ステップ 10. deepstream_app_config.txt ファイル内のビデオソースを変更します。以下に示すように、デフォルトのビデオファイルが読み込まれています
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
推論の実行
deepstream-app -c deepstream_app_config.txt
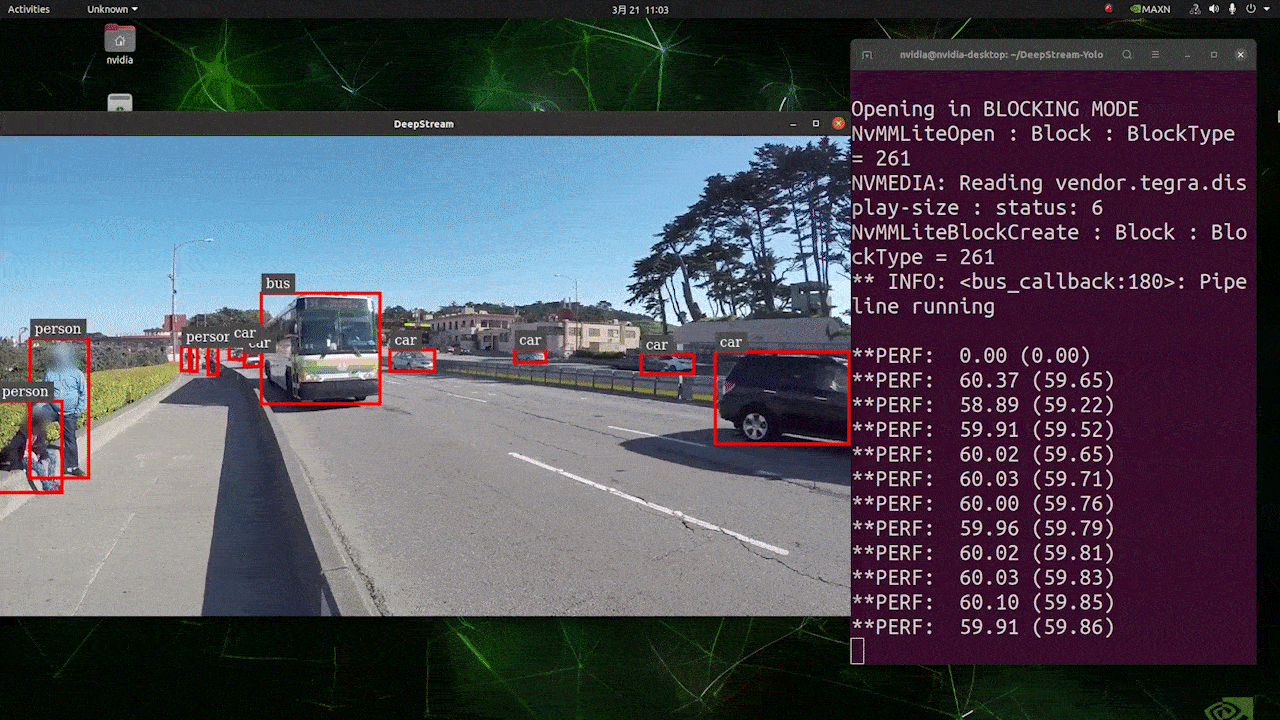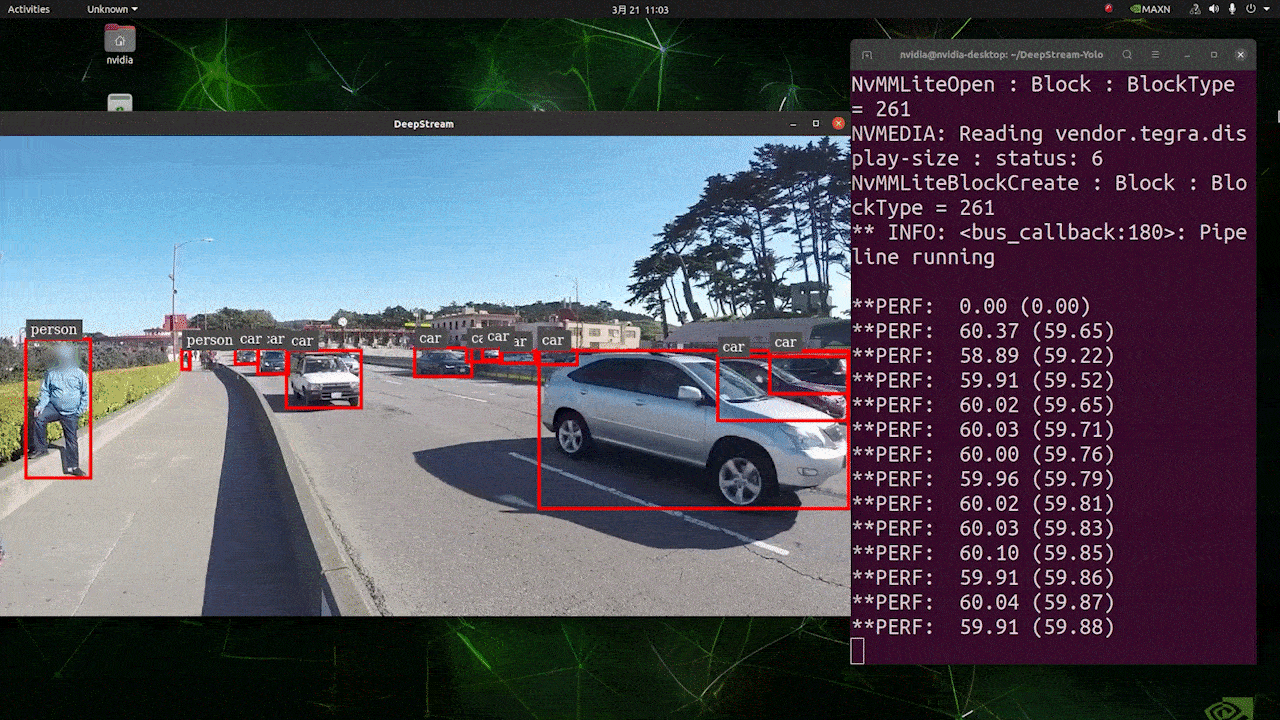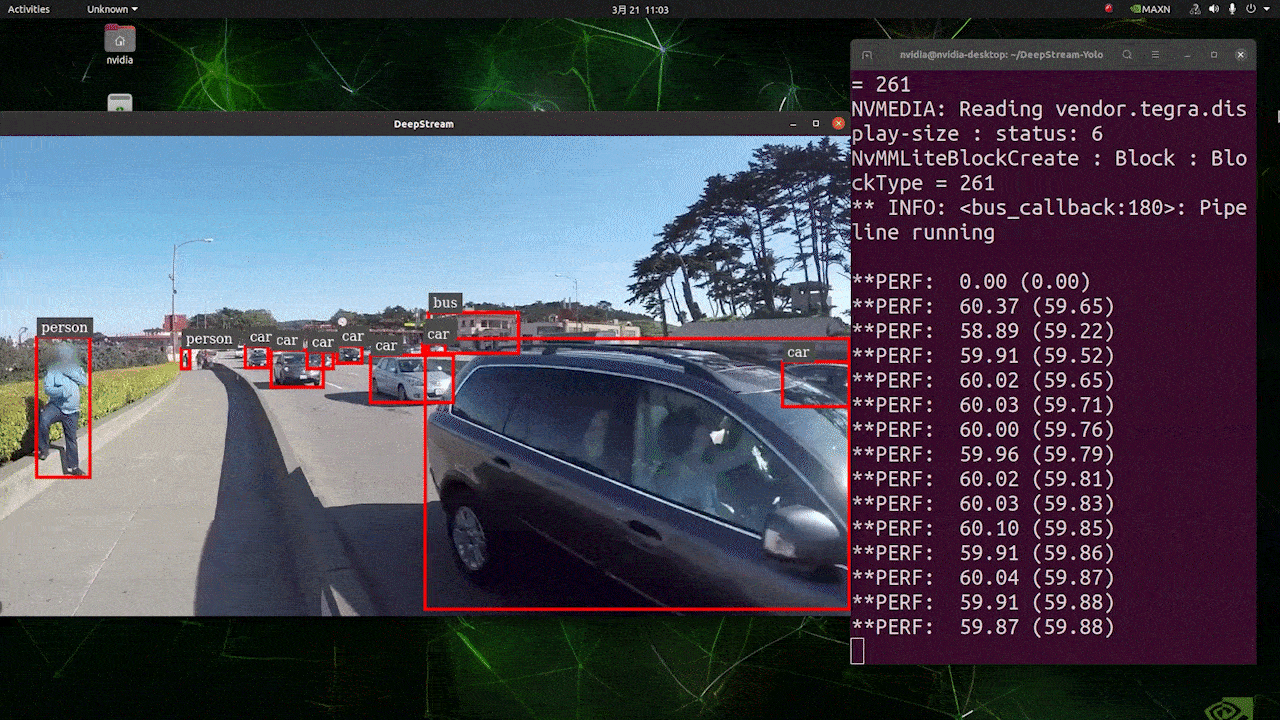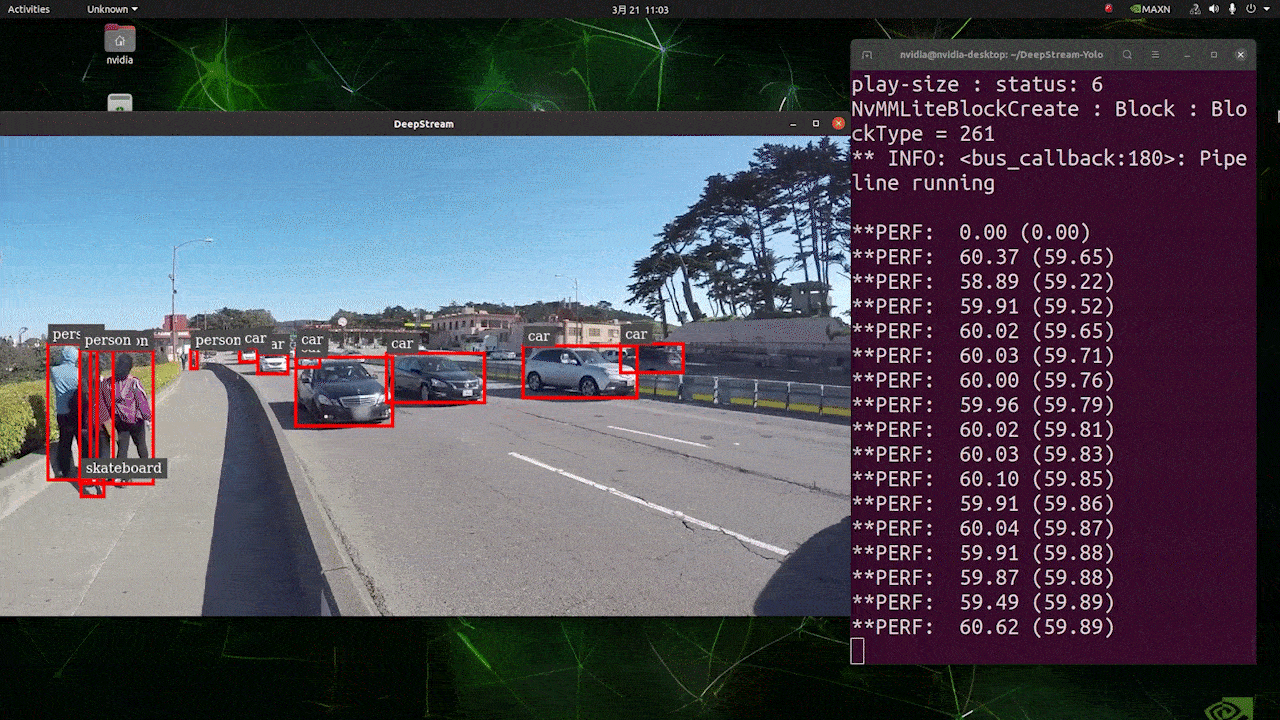
上記の結果は、Jetson AGX Orin 32GB H01 KitでFP32とYOLOv8s 640x640を使用して実行されています。FPSは約60であることがわかりますが、これは真のFPSではありません。なぜなら、deepstream_app_config.txtファイルの**[sink0]の下でtype=2を設定すると、FPSはモニターのfpsに制限され、このテストで使用したモニターは60Hzモニターだからです。ただし、この値をtype=1**に変更すると、最大FPSを取得できますが、ライブ検出出力はありません。
上記で使用したのと同じビデオソースと同じモデルについて、[sink0]の下でtype=1に変更した後、以下の結果を得ることができます。
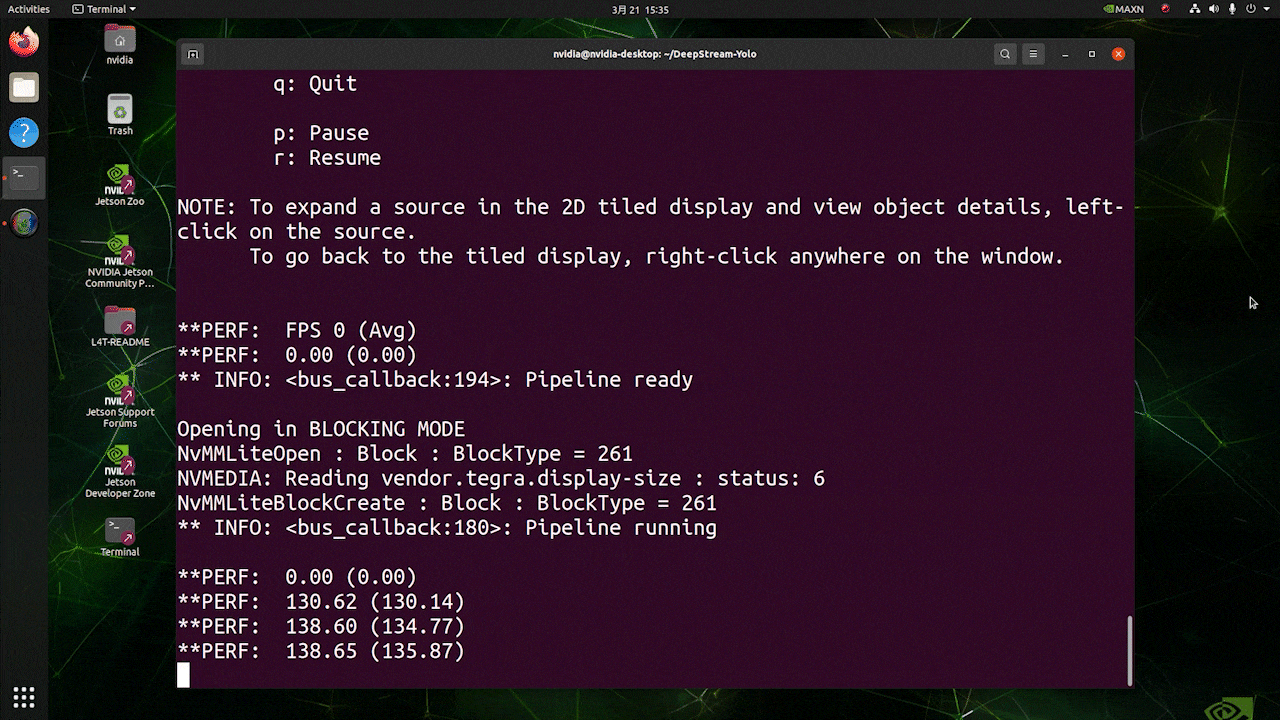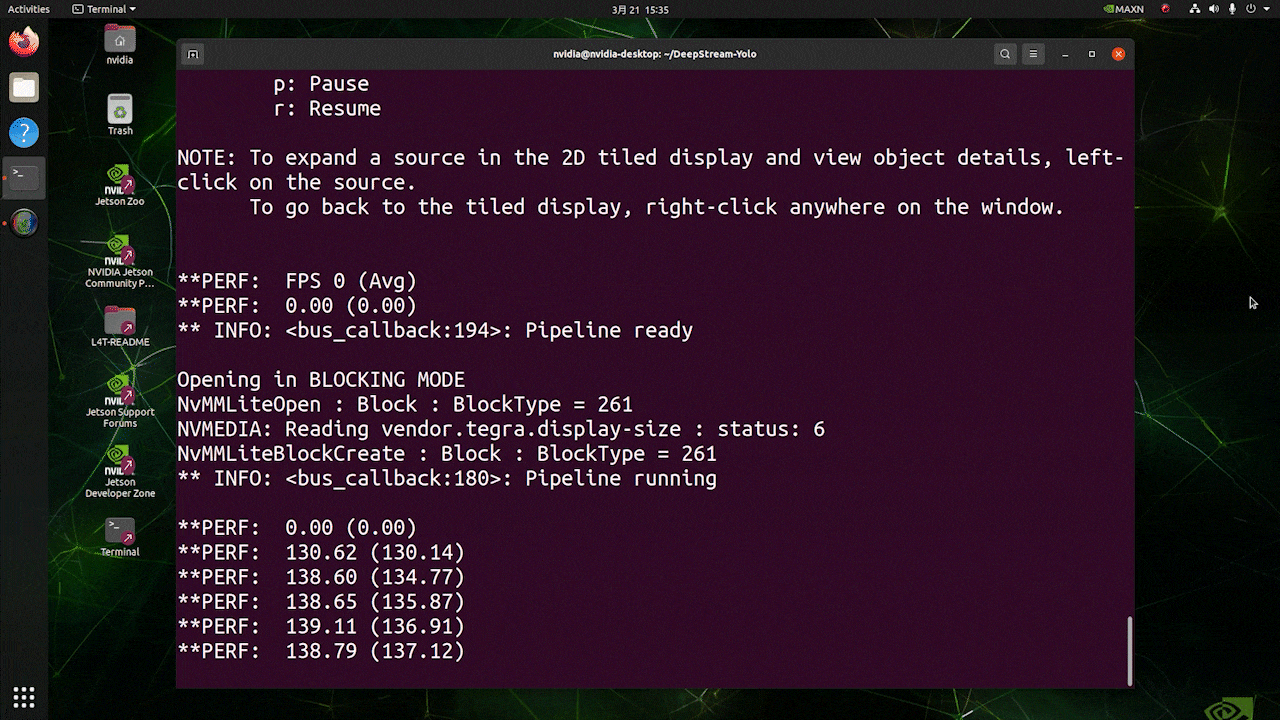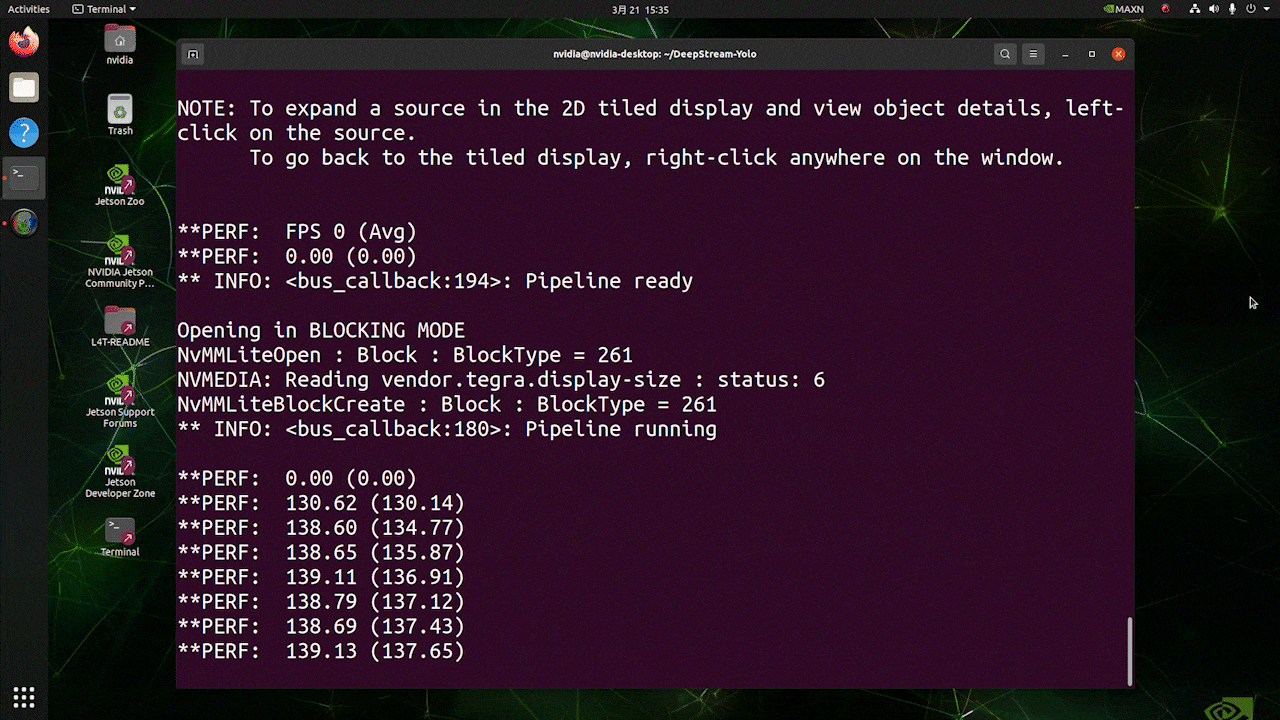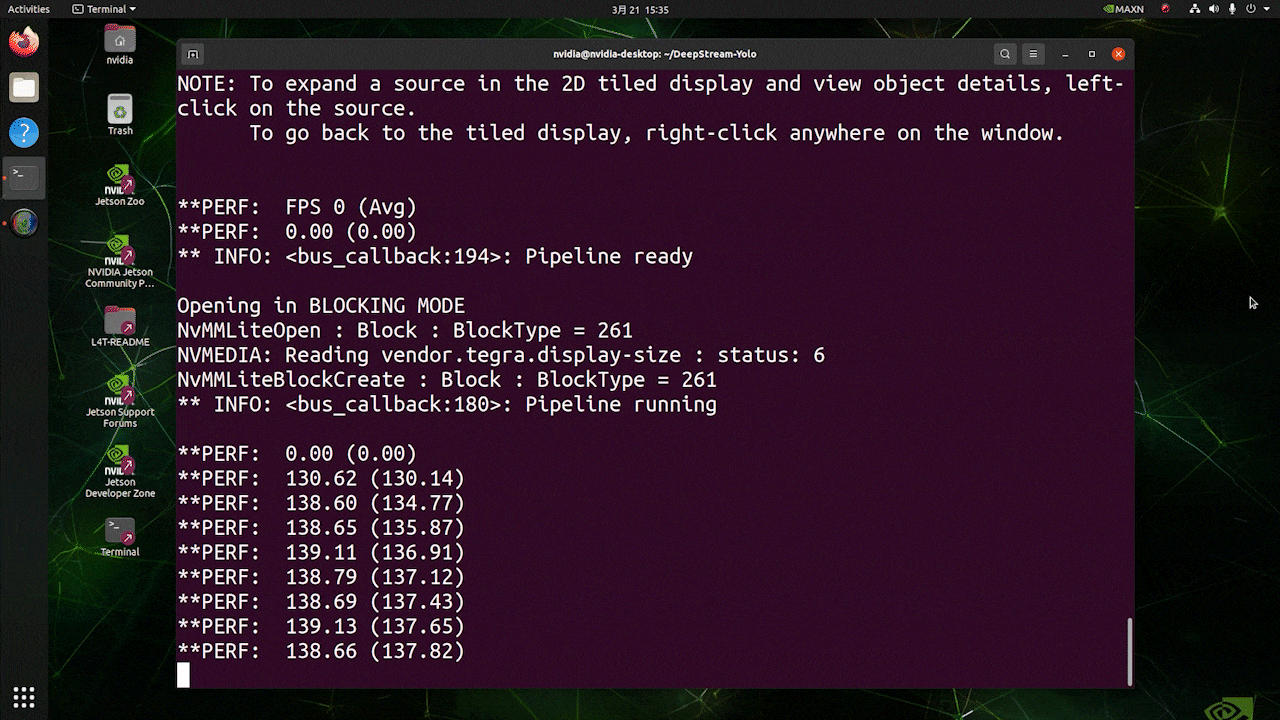
ご覧のように、実際のfps値に関連する約139のfpsを得ることができます。
INT8キャリブレーション
推論にINT8精度を使用したい場合は、以下の手順に従う必要があります
- ステップ1. OpenCVをインストール
sudo apt-get install libopencv-dev
- ステップ 2. OpenCVサポートを有効にしてnvdsinfer_custom_impl_Yoloライブラリをコンパイル/再コンパイルする
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
-
ステップ 3. COCOデータセットについて、val2017をダウンロードし、展開してDeepStream-Yoloフォルダに移動します
-
ステップ 4. キャリブレーション画像用の新しいディレクトリを作成します
mkdir calibration
- ステップ 5. 以下を実行して、COCOデータセットから1000枚のランダムな画像を選択してキャリブレーションを実行します
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
注意: NVIDIAは良好な精度を得るために少なくとも500枚の画像を推奨しています。この例では、より良い精度を得るために1000枚の画像が選択されています(画像数が多いほど精度が向上します)。INT8_CALIB_BATCH_SIZEの値を高くすると、より高い精度とより高速なキャリブレーション速度が得られます。GPUメモリに応じて設定してください。head -1000から設定できます。例えば、2000枚の画像の場合、head -2000とします。このプロセスには長時間かかる場合があります。
- ステップ 6. 選択されたすべての画像でcalibration.txtファイルを作成する
realpath calibration/*jpg > calibration.txt
- ステップ 7. 環境変数を設定する
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- ステップ 8. config_infer_primary_yoloV8.txt ファイルを更新する
変更前
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
から
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
-
ステップ 9. 推論を実行する前に、前述のように deepstream_app_config.txt ファイルの [sink0] の下で type=2 を設定して、最大fps性能を得ます。
-
ステップ 10. 推論を実行します
deepstream-app -c deepstream_app_config.txt
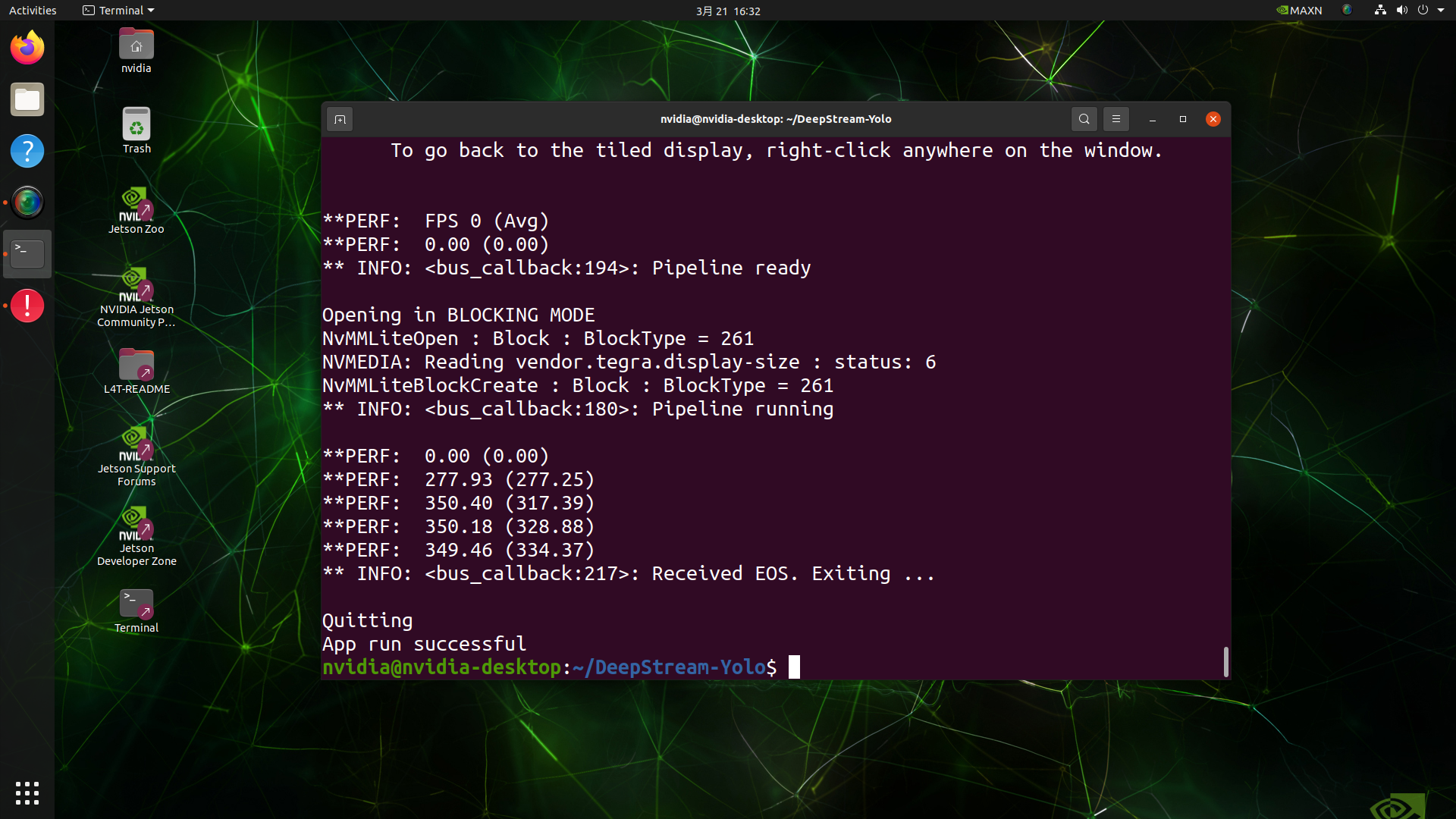
ここで約350のFPS値を取得しました!
マルチストリーム設定
NVIDIA DeepStream では、単一の設定ファイルで複数のストリームを簡単にセットアップして、マルチストリーム映像解析アプリケーションを構築できます。このwikiの後半では、高いFPSパフォーマンスを持つモデルがマルチストリームアプリケーションにどのように役立つかを、いくつかのベンチマークとともに実演します。
ここでは9つのストリームを例に取り上げます。deepstream_app_config.txt ファイルを変更します。
- ステップ 1. [tiled-display] セクション内で、行と列を3と3に変更して、9つのストリームで3x3グリッドを作成できるようにします
[tiled-display]
rows=3
columns=3
- ステップ 2. [source0] セクション内で、num-sources=9 を設定し、さらに uri を追加します。ここでは、現在のサンプル動画ファイルを8回複製して、合計9つのストリームを作成します。ただし、アプリケーションに応じて異なる動画ストリームに変更することができます
[source0]
enable=1
type=3
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
num-sources=9
deepstream-app -c deepstream_app_config.txt コマンドでアプリケーションを再度実行すると、以下の出力が表示されます
trtexec ツール
samples ディレクトリには、trtexec と呼ばれるコマンドラインラッパーツールが含まれています。trtexec は、独自のアプリケーションを開発することなく TensorRT を使用するためのツールです。trtexec ツールには主に3つの目的があります:
- ランダムまたはユーザー提供の入力データでネットワークをベンチマークする
- モデルからシリアル化されたエンジンを生成する
- ビルダーからシリアル化されたタイミングキャッシュを生成する
ここでは、trtexec ツールを使用して、異なるパラメータでモデルを迅速にベンチマークできます。しかし、まず最初に onnx モデルが必要で、この onnx モデルは ultralytics yolov8 を使用して生成できます。
- ステップ 1. 以下を使用して ONNX をビルドします:
yolo mode=export model=yolov8s.pt format=onnx
- ステップ1. 以下のようにtrtexecを使用してエンジンファイルをビルドします:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
例えば:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
これにより、生成された**.engineファイルと共に以下のようなパフォーマンス結果が出力されます。デフォルトでは、ONNXをFP32**精度でTensorRT最適化ファイルに変換し、以下のような出力を確認できます
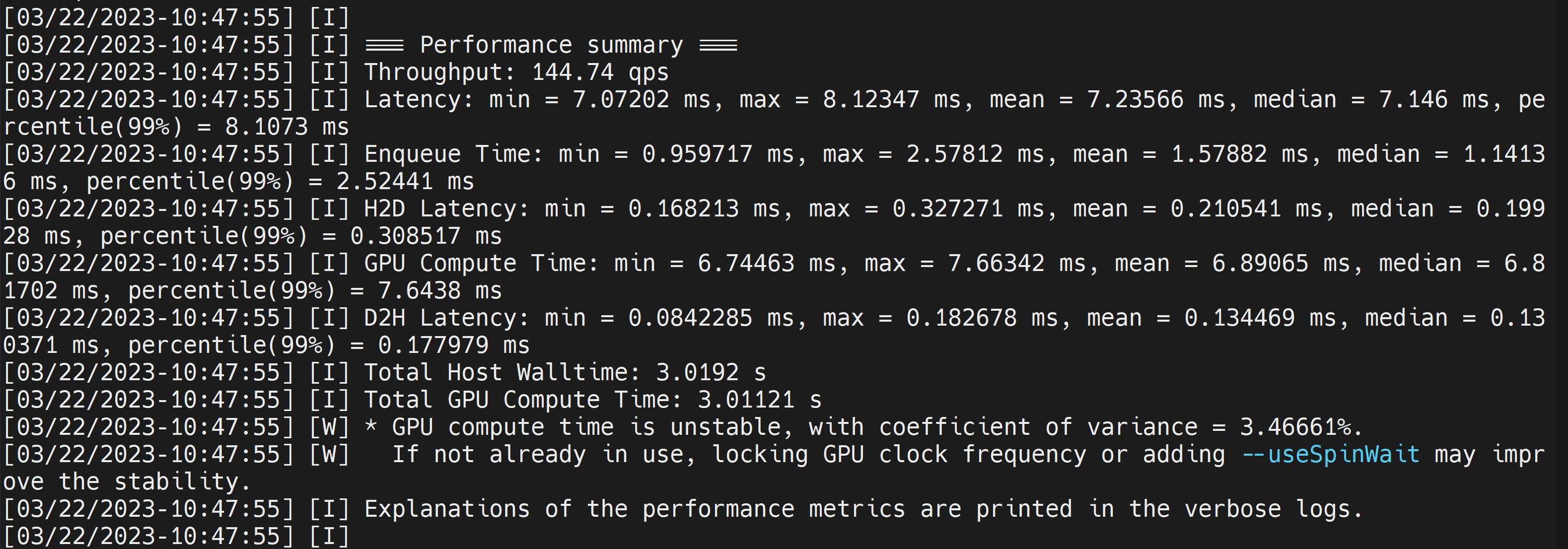
ここで平均レイテンシを7.2msとして取得でき、これは139FPSに相当します。これは前回のDeepStreamデモで得られたのと同じパフォーマンスです。
ただし、より良いパフォーマンスを提供するINT8精度が必要な場合は、上記のコマンドを以下のように実行できます
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
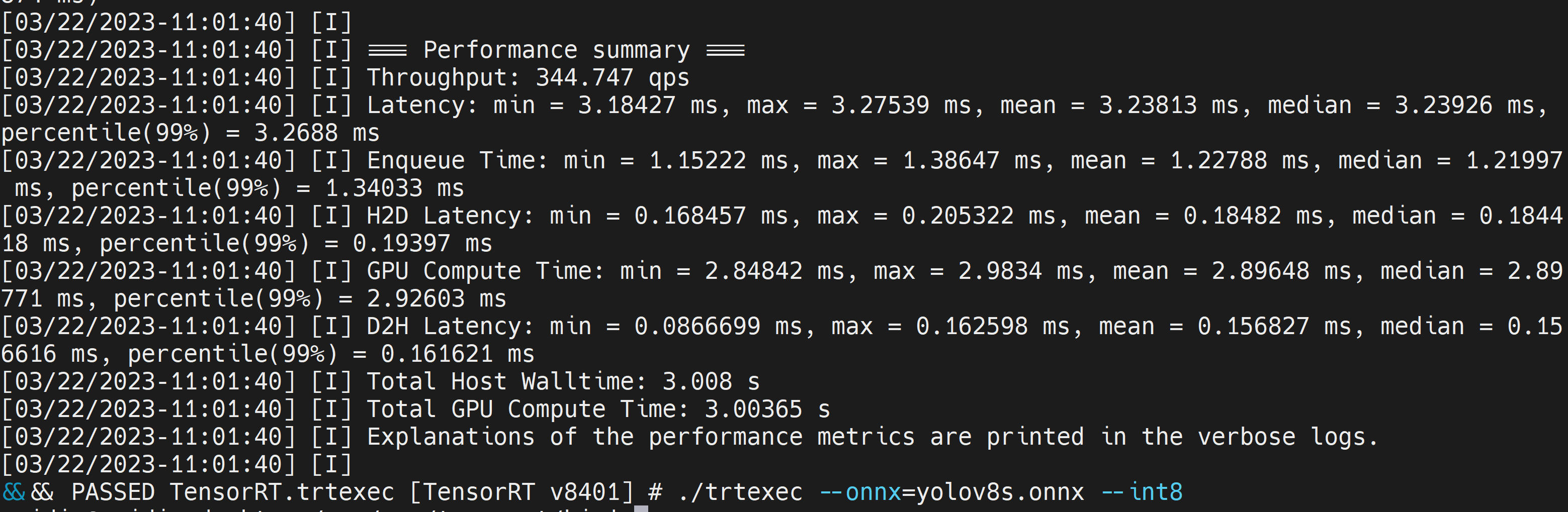
ここでは平均レイテンシを3.2msとして取ることができ、これは313FPSに相当します。
YOLOv8ベンチマーク結果
reComputer J4012、AGX Orin 32GB H01 Kit、reComputer J2021で動作する異なるYOLOv8モデルのパフォーマンスベンチマークを実施しました。
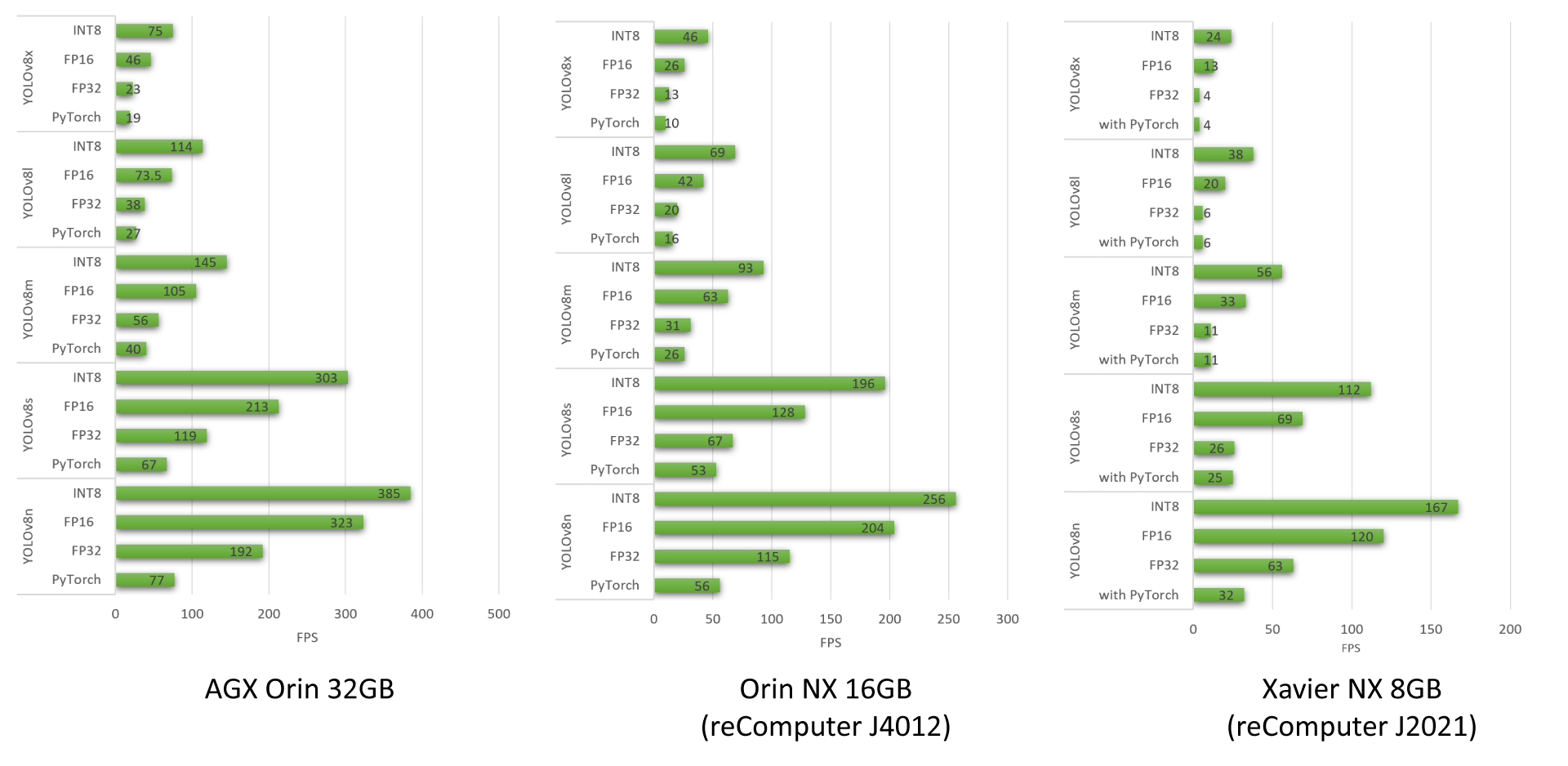
YOLOv8モデルを使用して実施したより多くのパフォーマンスベンチマークについて詳しく知りたい場合は、私たちのブログをご確認ください。
マルチストリームモデルベンチマーク
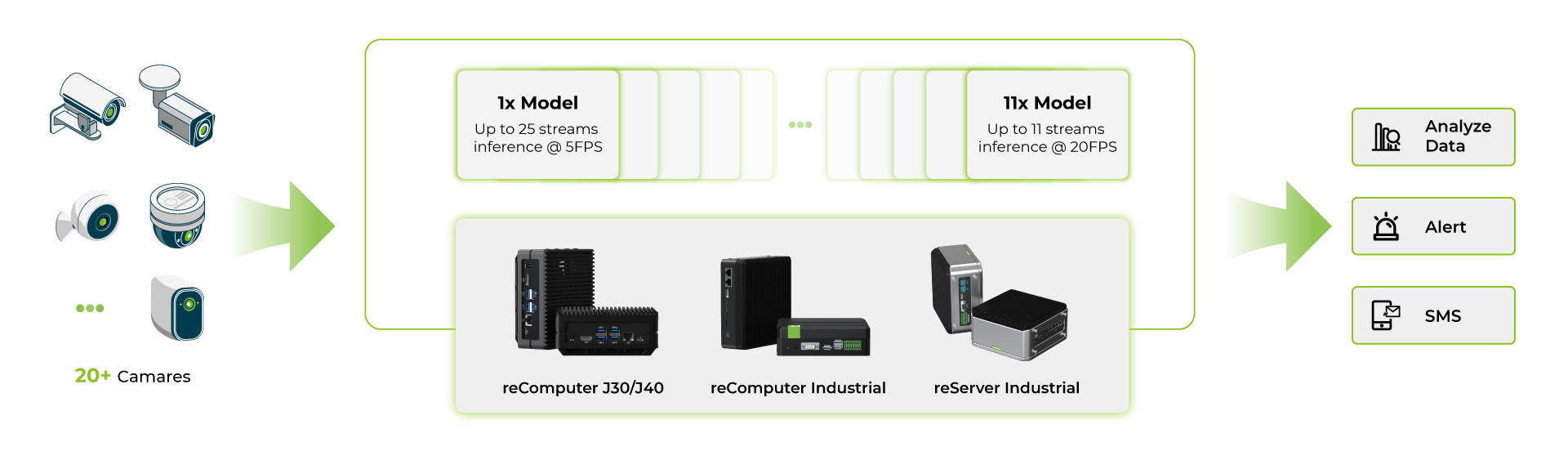
reComputer Jetson Orinシリーズ製品でいくつかのdeepstreamアプリケーションを実行した後、YOLOv8sモデルでベンチマークを実施しました。
- まず、単一のAIモデルを使用し、同じAIモデルで複数のストリームを実行しました
- 次に、複数のAIモデルを使用し、複数のAIモデルで複数のストリームを実行しました
これらのベンチマークはすべて以下の条件下で実施されました:
- YOLOv8s 640x640画像入力
- UIを無効化
- 最大電力と最大パフォーマンスモードをオン
これらのベンチマークから、最高性能のOrin NX 16GBデバイスでは、INT8の単一YOLOv8sモデルで約5fpsで約40台のカメラを使用でき、各ストリームにINT8の複数YOLOv8sモデルを使用する場合は約15fpsで約11台のカメラを使用できることがわかります。マルチモデルアプリケーションでは、デバイスのRAM制限により、また各モデルが相当量のRAMを消費するため、カメラの数は少なくなります。
要約すると、YOLOv8モデルのみでアプリケーションを実行せずにエッジデバイスを動作させる場合、Jetson Orin Nano 8GBは4-6ストリームをサポートでき、Jetson Orin NX 16GBは最大容量で16-18ストリームを管理できます。ただし、実際のアプリケーションでRAMリソースが使用されると、これらの数値は減少する可能性があります。したがって、これらの数値をガイドラインとして使用し、特定の条件下で独自のテストを実施することをお勧めします。
リソース
技術サポートと製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちの製品での体験ができるだけスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。