TensorRTを使用してNVIDIA JetsonにYOLOv8をデプロイ
このwikiガイドでは、YOLOv8モデルをNVIDIA Jetsonプラットフォームにデプロイし、TensorRTを使用して推論を実行する方法を説明します。ここでは、Jetsonプラットフォームでの推論性能を最大化するためにTensorRTを使用します。
以下のような様々なコンピュータビジョンタスクを紹介します:
- 物体検出
- 画像セグメンテーション
- 画像分類
- ポーズ推定
- 物体追跡

前提条件
- Ubuntu ホストPC(ネイティブまたはVMware Workstation Playerを使用したVM)
- reComputer JetsonまたはJetPack 5.1.1以上を実行している他のNVIDIA Jetsonデバイス
このwikiはreComputer J4012およびNVIDIA Jetson orin NX 16GBモジュールを搭載したreComputer Industrial J4012[https://www.seeedstudio.com/reComputer-Industrial-J4012-p-5684.html]でテストおよび検証されています
JetsonにJetPackをフラッシュ
JetsonデバイスがJetPackシステムでフラッシュされていることを確認する必要があります。NVIDIA SDK Managerまたはコマンドラインを使用してデバイスにJetPackをフラッシュできます。
Seeed Jetson搭載デバイスのフラッシュガイドについては、以下のリンクを参照してください:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
このwikiで検証したバージョンであるため、JetPackバージョン5.1.1をフラッシュするようにしてください
1行のコードでJetsonにYOLOV8をデプロイ!
JetsonデバイスにJetPackをフラッシュした後、以下のコマンドを実行するだけでYOLOv8モデルを実行できます。これにより、まず必要なパッケージと依存関係をダウンロードしてインストールし、環境をセットアップし、YOLOv8から事前訓練済みモデルをダウンロードして、物体検出、画像セグメンテーション、ポーズ推定、画像分類タスクを実行します!
wget files.seeedstudio.com/YOLOv8-Jetson.py && python YOLOv8-Jetson.py
上記スクリプトのソースコードはこちらで確認できます
事前学習済みモデルの使用
YOLOv8を始める最も速い方法は、YOLOv8が提供する事前学習済みモデルを使用することです。ただし、これらはPyTorchモデルであるため、Jetsonで推論を行う際にはCPUのみを利用します。JetsonでこれらのモデルをGPU上で実行して最高のパフォーマンスを得たい場合は、このwikiのセクションに従ってPyTorchモデルをTensorRTにエクスポートできます。
- Object Detection
- Image Classification
- Image Segmentation
- Pose Estimation
- Object Tracking
YOLOv8は、COCOデータセットで入力画像サイズ640x640で学習された、物体検出用の5つの事前学習済みPyTorchモデル重みを提供しています。以下で確認できます
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
参考: https://docs.ultralytics.com/tasks/detect
上記の表から希望するモデルを選択してダウンロードし、以下のコマンドを実行して画像に対する推論を実行できます
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' show=True
モデルについては、yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.ptのいずれかに変更することができ、関連する事前訓練済みモデルがダウンロードされます
ウェブカメラを接続して以下のコマンドを実行することもできます
yolo detect predict model=yolov8n.pt source='0' show=True
上記のコマンドを実行する際にエラーが発生した場合は、コマンドの最後に「device=0」を追加してみてください

上記は reComputer J4012/ reComputer Industrial J4012 で実行され、640x640 入力で訓練された YOLOv8s モデルを使用し、TensorRT FP16 精度を使用しています。
YOLOv8 は、ImageNet で 224x224 の入力画像サイズで訓練された、画像分類用の 5 つの事前訓練済み PyTorch モデル重みを提供しています。以下で確認できます
| Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
参考: https://docs.ultralytics.com/tasks/classify
お好みのモデルを選択し、以下のコマンドを実行して画像に対する推論を実行できます
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' show=True
モデルについては、yolov8s-cls.pt、yolov8m-cls.pt、yolov8l-cls.pt、yolov8x-cls.ptのいずれかに変更でき、関連する事前訓練済みモデルがダウンロードされます
ウェブカメラを接続して以下のコマンドを実行することもできます
yolo classify predict model=yolov8n-cls.pt source='0' show=True
上記のコマンドを実行する際にエラーが発生した場合は、コマンドの最後に「device=0」を追加してみてください
(224推論での更新)
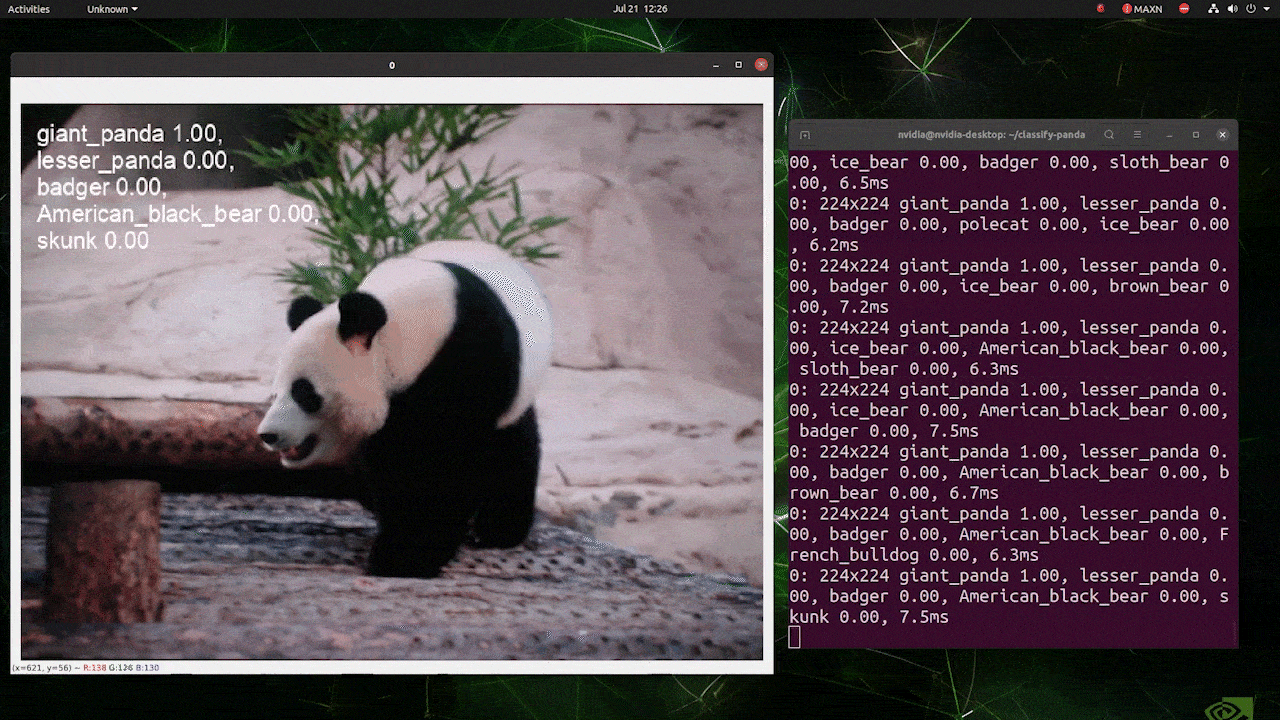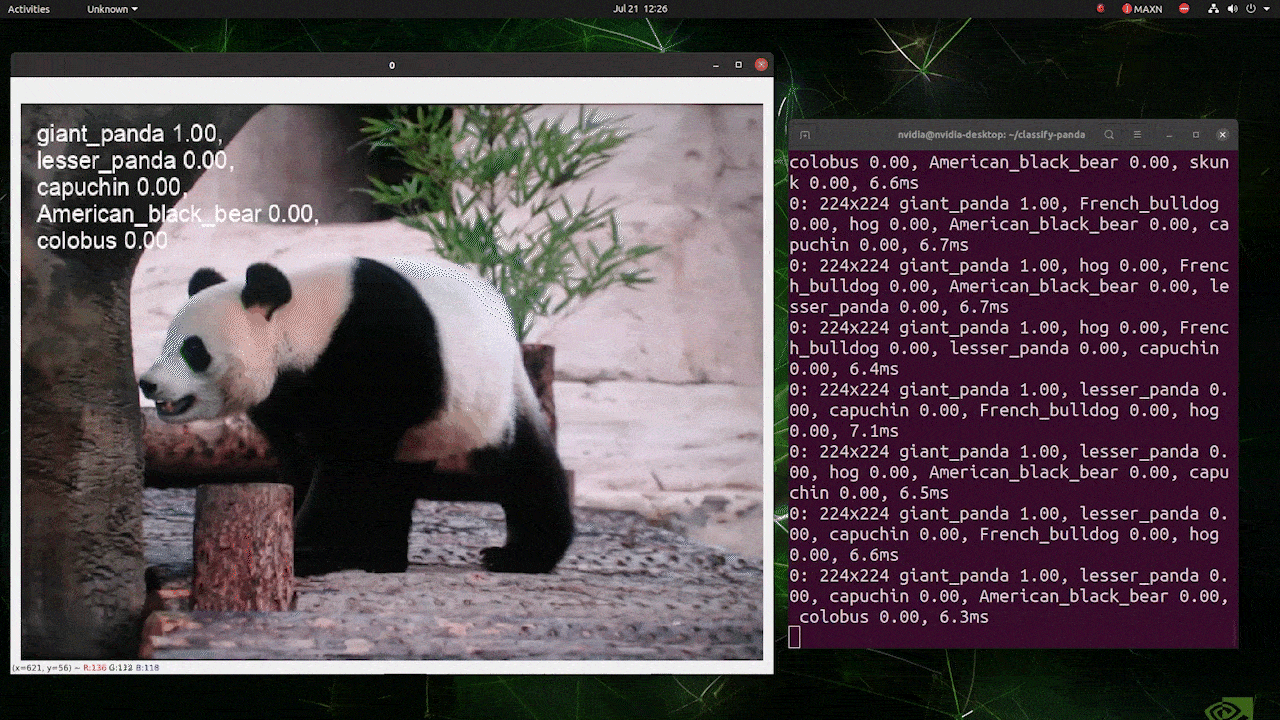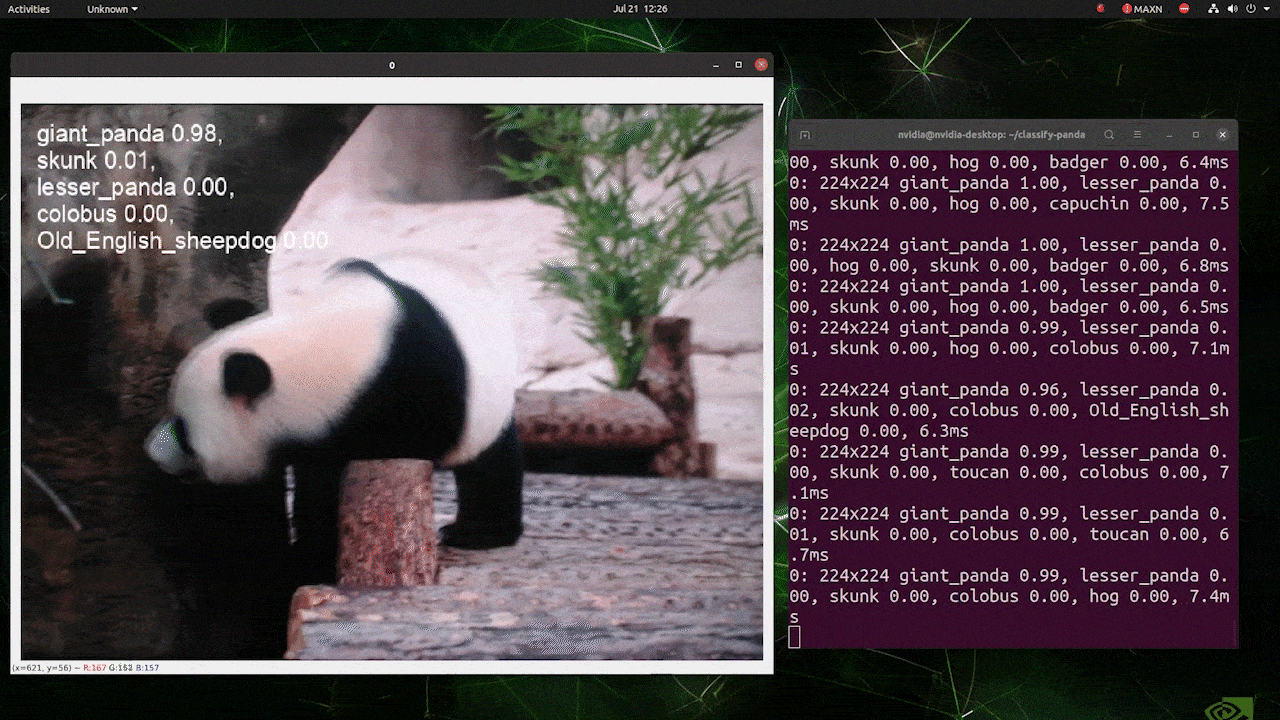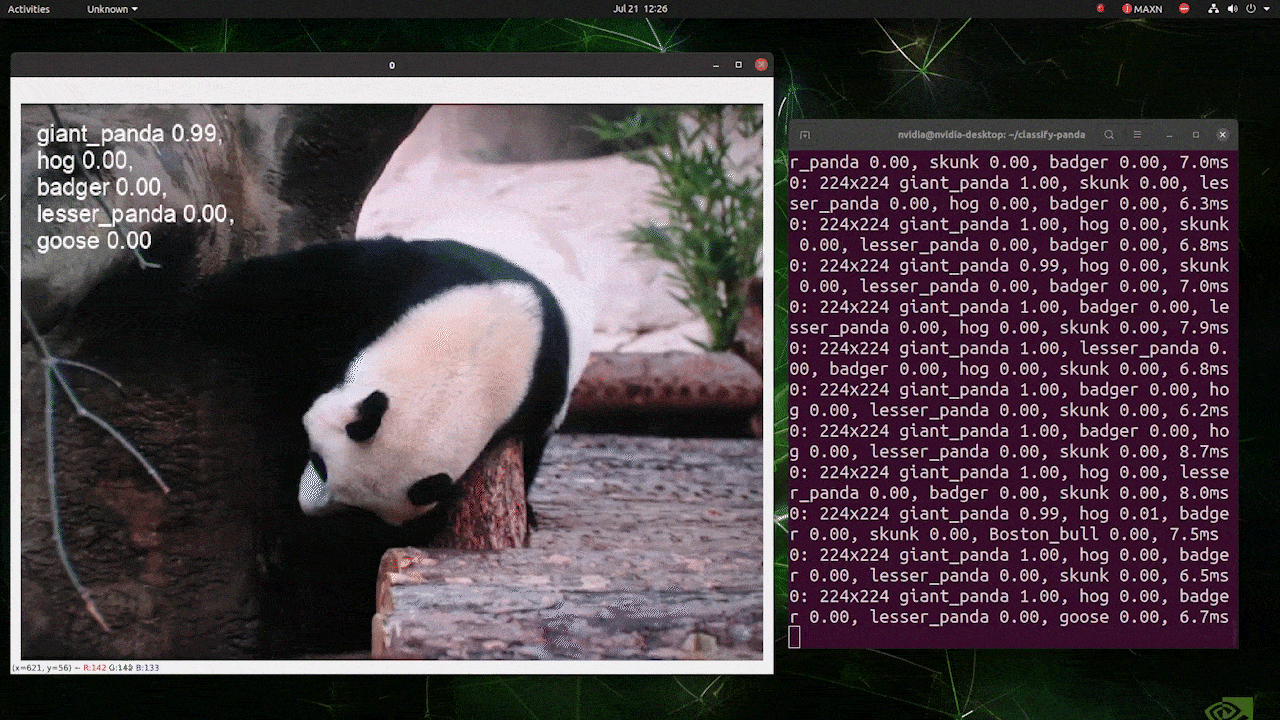
上記はreComputer J4012/ reComputer Industrial J4012で実行され、224x224入力で訓練されたYOLOv8s-clsモデルを使用し、TensorRT FP16精度を使用しています。また、TensorRTエクスポートでの推論コマンド内で引数imgsz=224を渡すことを確認してください。推論エンジンはTensorRTモデルを使用する際、デフォルトで640画像サイズを受け入れるためです。
YOLOv8は、COCOデータセットで入力画像サイズ640x640で訓練された、画像セグメンテーション用の5つの事前訓練済みPyTorchモデル重みを提供しています。以下で確認できます
| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
参考: https://docs.ultralytics.com/tasks/segment
お好みのモデルを選択し、以下のコマンドを実行して画像で推論を実行できます
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' show=True
モデルについては、yolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.ptのいずれかに変更することができ、関連する事前訓練済みモデルがダウンロードされます
ウェブカメラを接続して以下のコマンドを実行することもできます
yolo segment predict model=yolov8n-seg.pt source='0' show=True
上記のコマンドを実行する際にエラーが発生した場合は、コマンドの最後に「device=0」を追加してみてください

上記はreComputer J4012/ reComputer Industrial J4012で実行され、640x640入力でトレーニングされたYOLOv8s-segモデルを使用し、TensorRT FP16精度を使用しています。
YOLOv8は、COCO keypointsデータセットで入力画像サイズ640x640でトレーニングされた、ポーズ推定用の6つの事前トレーニング済みPyTorchモデル重みを提供しています。以下で確認できます
| Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
参考: https://docs.ultralytics.com/tasks/pose
お好みのモデルを選択し、以下のコマンドを実行して画像で推論を実行できます
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg'
ここでモデルについては、yolov8s-pose.pt、yolov8m-pose.pt、yolov8l-pose.pt、yolov8x-pose.pt、yolov8x-pose-p6のいずれかに変更することができ、関連する事前訓練済みモデルがダウンロードされます
また、ウェブカメラを接続して以下のコマンドを実行することもできます
yolo pose predict model=yolov8n-pose.pt source='0'
上記のコマンドを実行する際にエラーが発生した場合は、コマンドの末尾に「device=0」を追加してみてください

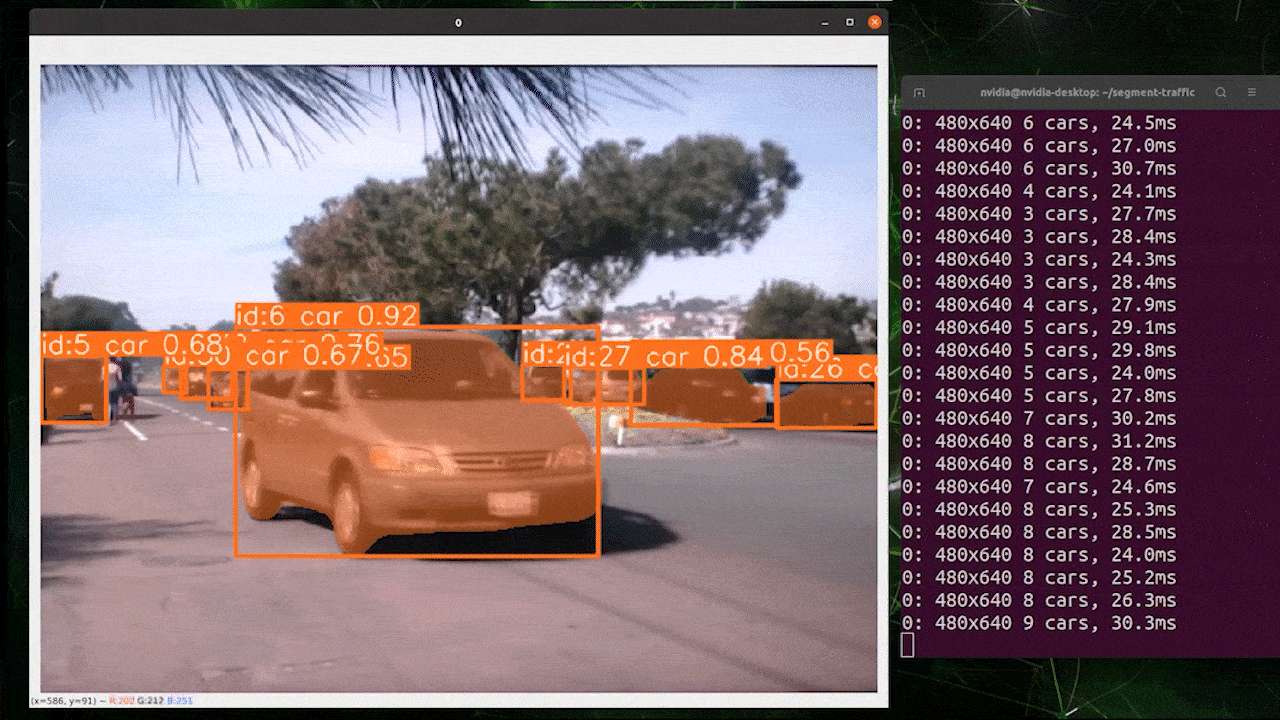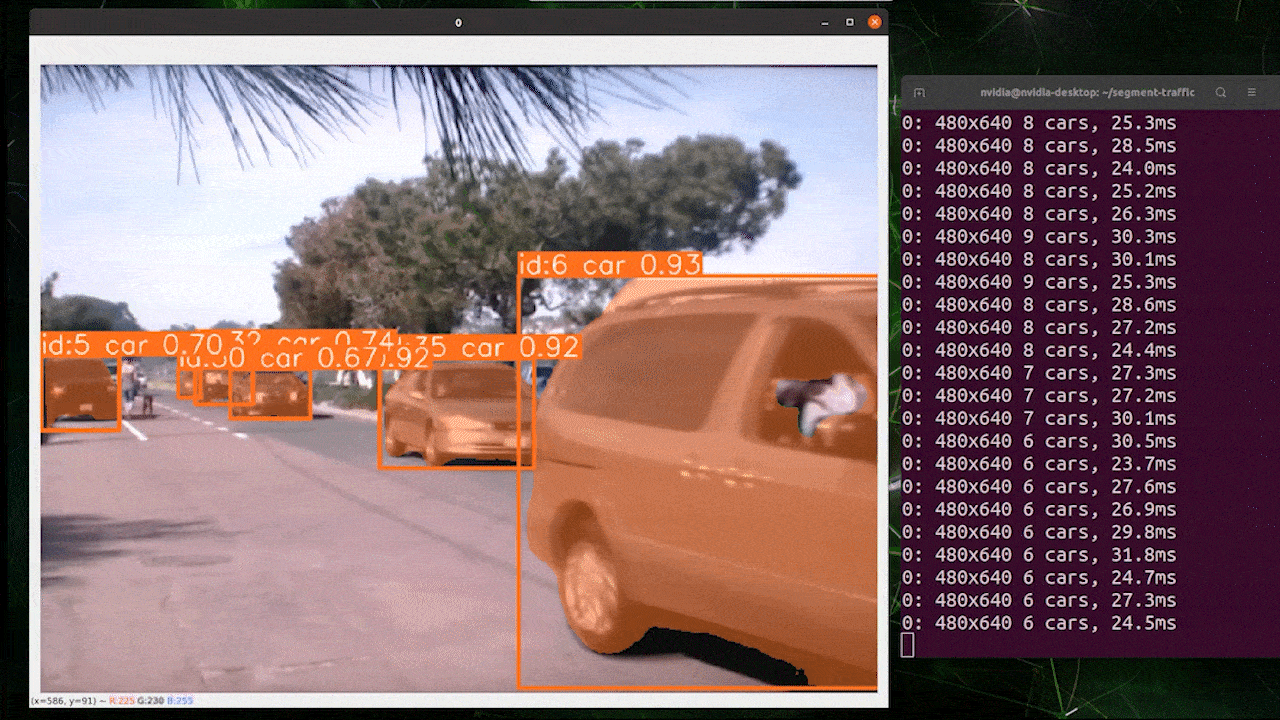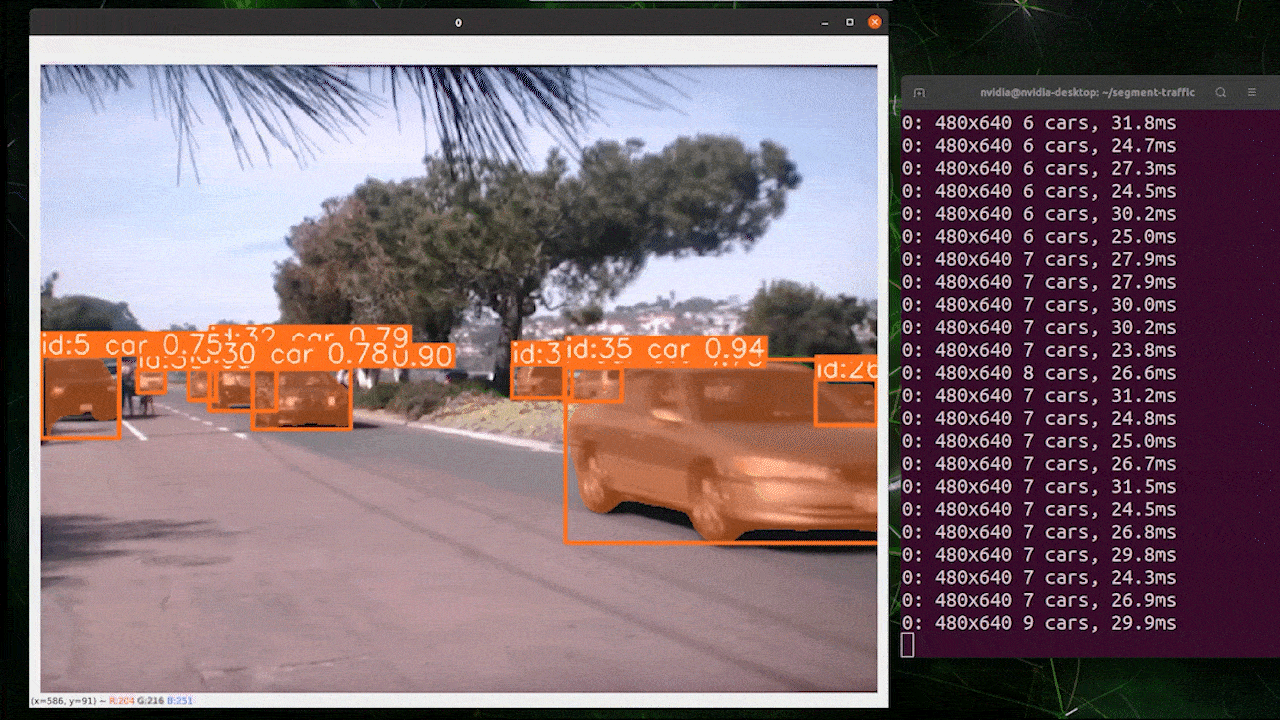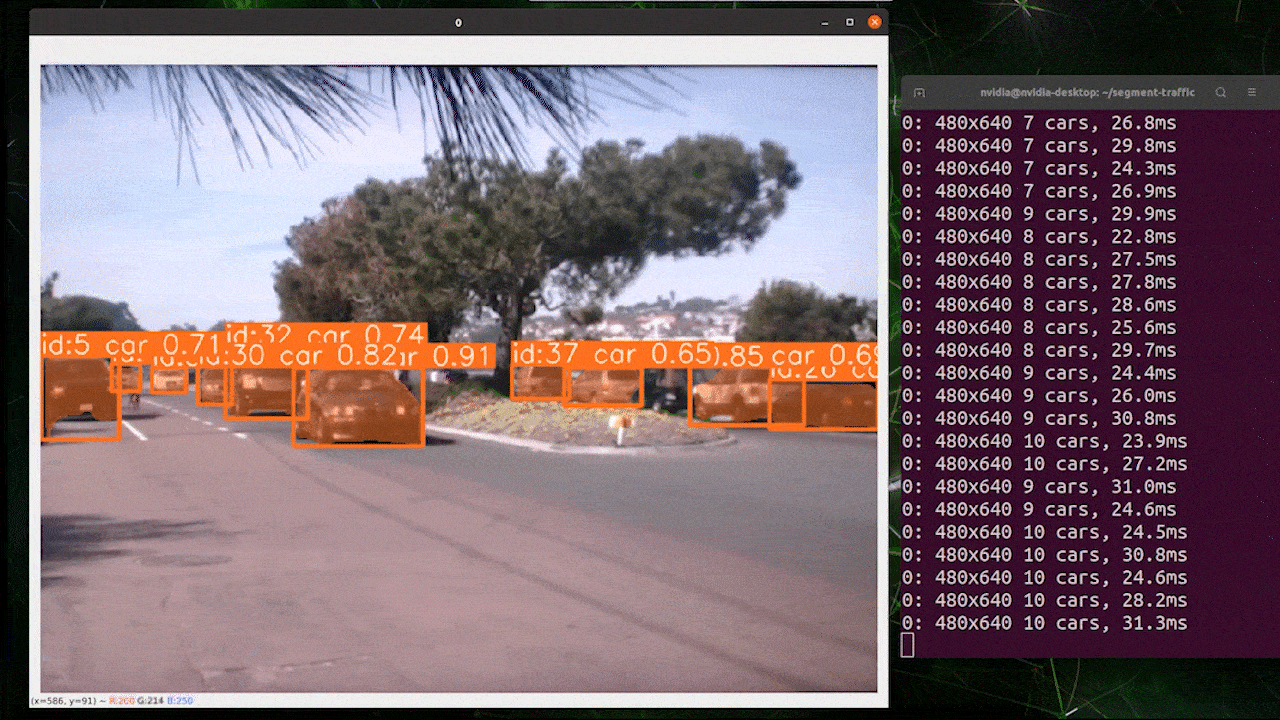
オブジェクトトラッキングは、オブジェクトの位置とクラスを識別し、ビデオストリーム内でその検出に一意のIDを割り当てるタスクです。
基本的に、オブジェクトトラッキングの出力は、オブジェクトIDが追加されたオブジェクト検出と同じです。
参考: https://docs.ultralytics.com/modes/track
オブジェクト検出/画像セグメンテーションに基づいて希望するモデルを選択し、以下のコマンドを実行してビデオで推論を実行できます
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc"
ここでモデルについては、yolov8n.pt、yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.pt、yolov8n-seg.pt、yolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.ptのいずれかに変更でき、関連する事前訓練済みモデルがダウンロードされます
ウェブカメラを接続して以下のコマンドを実行することもできます
yolo track model=yolov8n.pt source="0"
上記のコマンドを実行する際にエラーが発生した場合は、コマンドの最後に「device=0」を追加してみてください

TensorRTを使用して推論速度を向上させる
前述したように、JetsonでYOLOv8モデルを実行する際の推論速度を向上させたい場合は、まず元のPyTorchモデルをTensorRTモデルに変換する必要があります。
以下の手順に従って、YOLOv8 PyTorchモデルをTensorRTモデルに変換してください。
これは前述した4つのコンピュータビジョンタスクすべてに対応しています
- ステップ1. モデルパスを指定してエクスポートコマンドを実行する
yolo export model=<path_to_pt_file> format=engine device=0
例えば:
yolo export model=yolov8n.pt format=engine device=0
cmakeに関するエラーが発生した場合は、無視してください。TensorRTのエクスポートが完了するまでお待ちください。数分かかる場合があります
TensorRTモデルファイル(.engine)が作成された後、以下のような出力が表示されます
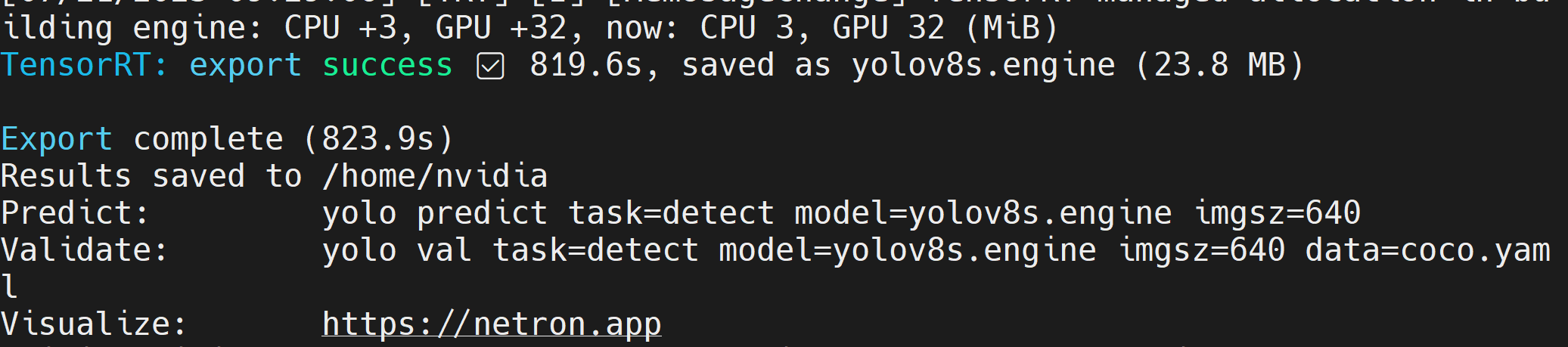
- ステップ 2. 追加の引数を渡したい場合は、以下の表に従って実行できます
| キー | 値 | 説明 |
|---|---|---|
| imgsz | 640 | スカラーまたは(h, w)リストとしての画像サイズ、例:(640, 480) |
| half | False | FP16量子化 |
| dynamic | False | 動的軸 |
| simplify | False | モデルの簡素化 |
| workspace | 4 | ワークスペースサイズ(GB) |
例えば、PyTorchモデルをFP16量子化でTensorRTモデルに変換したい場合は、以下のように実行します
yolo export model=yolov8n.pt format=engine half=True device=0
モデルのエクスポートが正常に完了したら、検出、分類、セグメンテーション、姿勢推定の4つのタスクすべてを実行する際に、yoloのpredictコマンド内の**model=**引数でこのモデルを直接置き換えることができます。
例えば、物体検出の場合:
yolo detect predict model=yolov8n.engine source='0' show=True
独自のAIモデルを持ち込む
データ収集とラベリング
特定のAIアプリケーションがあり、そのアプリケーションに適した独自のAIモデルを持ち込みたい場合は、独自のデータセットを収集し、ラベル付けを行い、YOLOv8を使用してトレーニングすることができます。
自分でデータを収集したくない場合は、すぐに利用できる公開データセットを選択することもできます。COCOデータセット、Pascal VOCデータセットなど、多数の公開データセットをダウンロードできます。Roboflow Universeは、幅広いデータセットを提供する推奨プラットフォームで、コンピュータビジョンモデルの構築に利用できる90,000以上のデータセットと6,600万以上の画像が利用可能です。また、Googleでオープンソースデータセットを検索し、利用可能な様々なデータセットから選択することもできます。
独自のデータセットがあり、画像にアノテーションを付けたい場合は、Roboflowが提供するアノテーションツールの使用をお勧めします。詳細については、このwikiの部分に従ってください。また、アノテーションについてはRoboflowのこのガイドに従うこともできます。
トレーニング
ここでは、モデルをトレーニングする3つの方法があります。
-
最初の方法はUltralytics HUBを使用することです。RoboflowをUltralytics HUBに簡単に統合できるため、すべてのRoboflowプロジェクトがトレーニングにすぐに利用できるようになります。ここでは、トレーニングプロセスを簡単に開始し、リアルタイムでトレーニングの進行状況を表示するGoogle Colabノートブックを提供しています。
-
2番目の方法は、トレーニングプロセスを簡単にするために私たちが作成したGoogle Colabワークスペースを使用することです。ここでは、Roboflow APIを使用してRoboflowプロジェクトからデータセットをダウンロードします。
-
3番目の方法は、トレーニングプロセスにローカルPCを使用することです。ここでは、十分に強力なGPUがあることを確認し、データセットを手動でダウンロードする必要があります。
- Ultralytics HUB + Roboflow + Google Colab
- Roboflow + Google Colab
- Roboflow + ローカルPC
ここでは、Ultralytics HUBを使用してRoboflowプロジェクトを読み込み、Google Colabでトレーニングを行います。
-
ステップ1. このURLにアクセスし、Ultralyticsアカウントにサインアップします
-
ステップ2. 新しく作成したアカウントでサインインすると、以下のダッシュボードが表示されます
-
ステップ3. このURLにアクセスし、Roboflowアカウントにサインアップします
-
ステップ4. 新しく作成したアカウントでサインインすると、以下のダッシュボードが表示されます
-
ステップ5. 私たちが準備したこのwikiガイドに従って、新しいワークスペースを作成し、ワークスペース内に新しいプロジェクトを作成します。公式Roboflowドキュメントから詳細を学ぶには、こちらを確認することもできます。
-
ステップ6. ワークスペース内にいくつかのプロジェクトができると、以下のようになります
- ステップ7. Settingsに移動し、Roboflow APIをクリックします
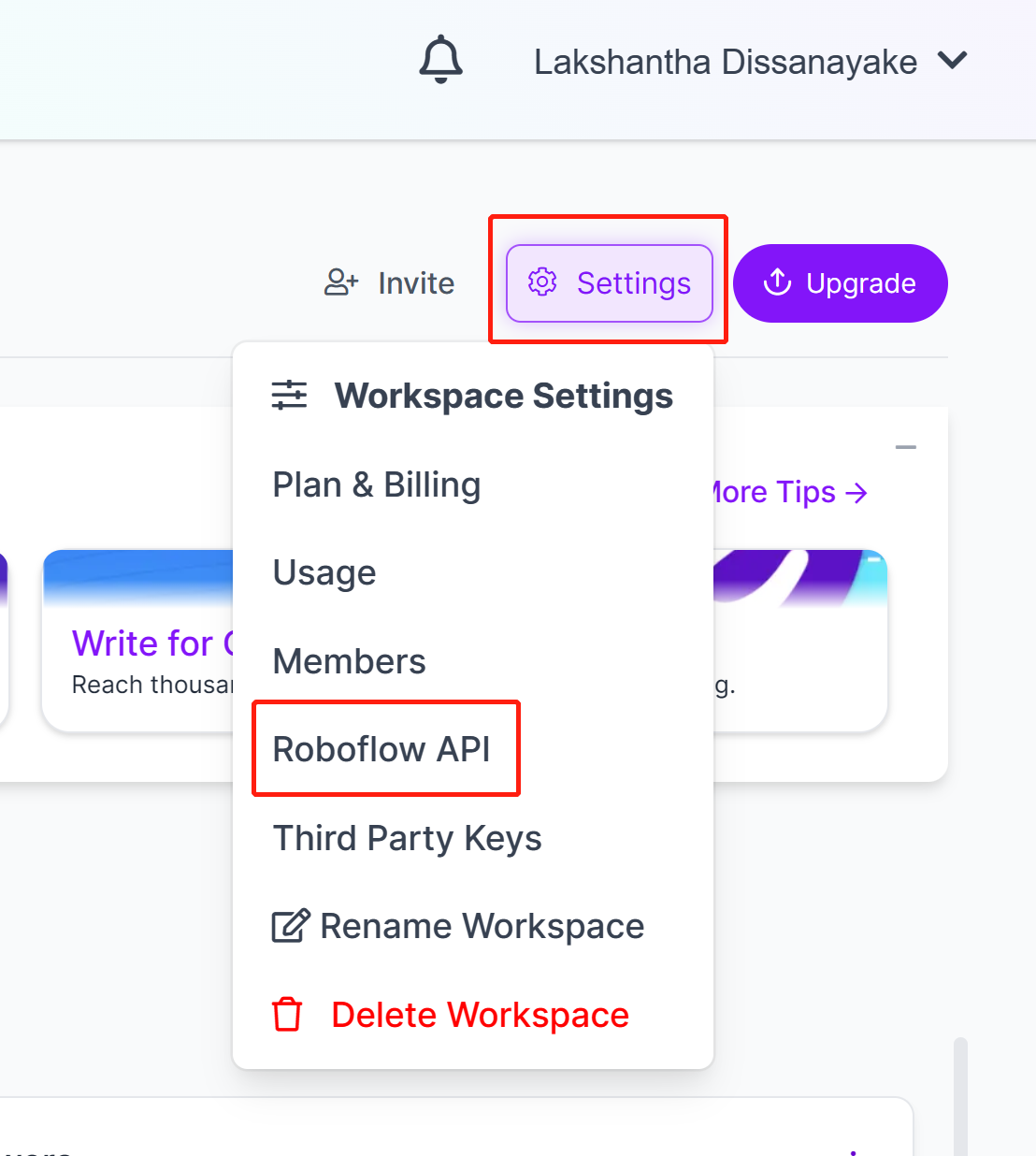
- ステップ8. copyボタンをクリックしてPrivate API Keyをコピーします
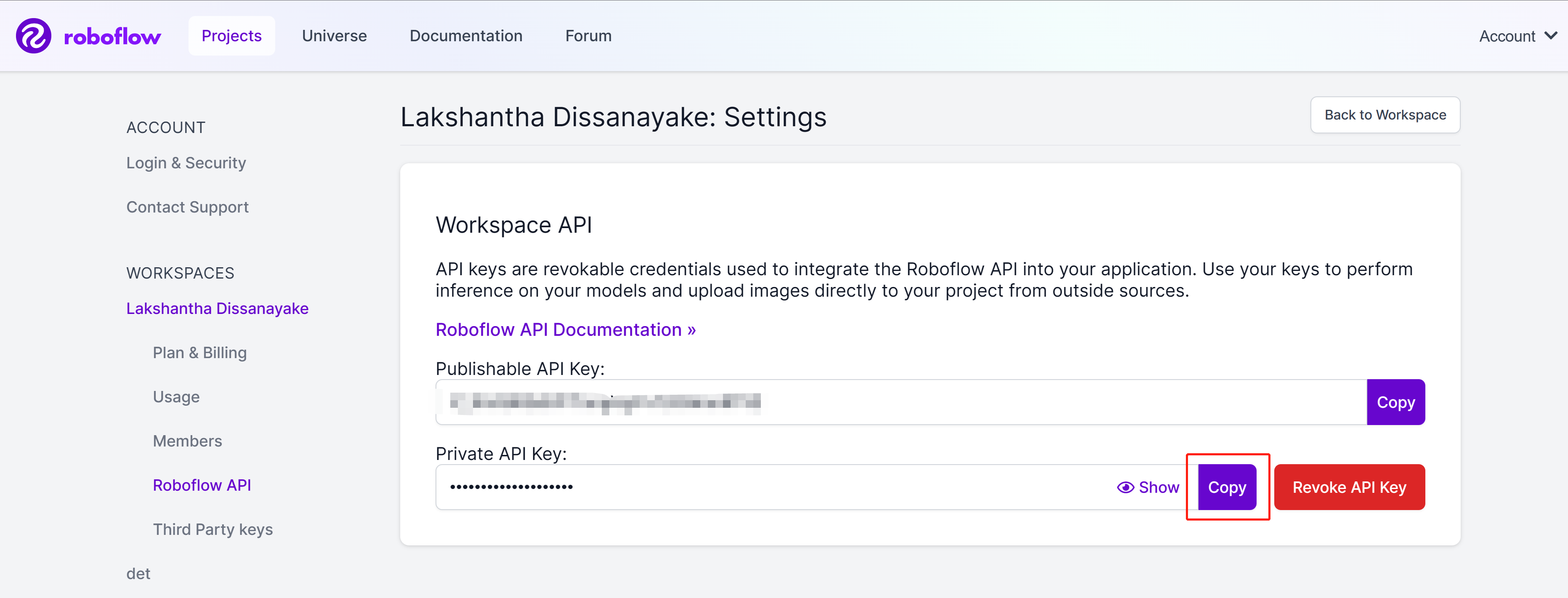
- ステップ9. Ultralytics HUBダッシュボードに戻り、Integrationsをクリックし、先ほどコピーしたAPI Keyを空の列に貼り付けてAddをクリックします
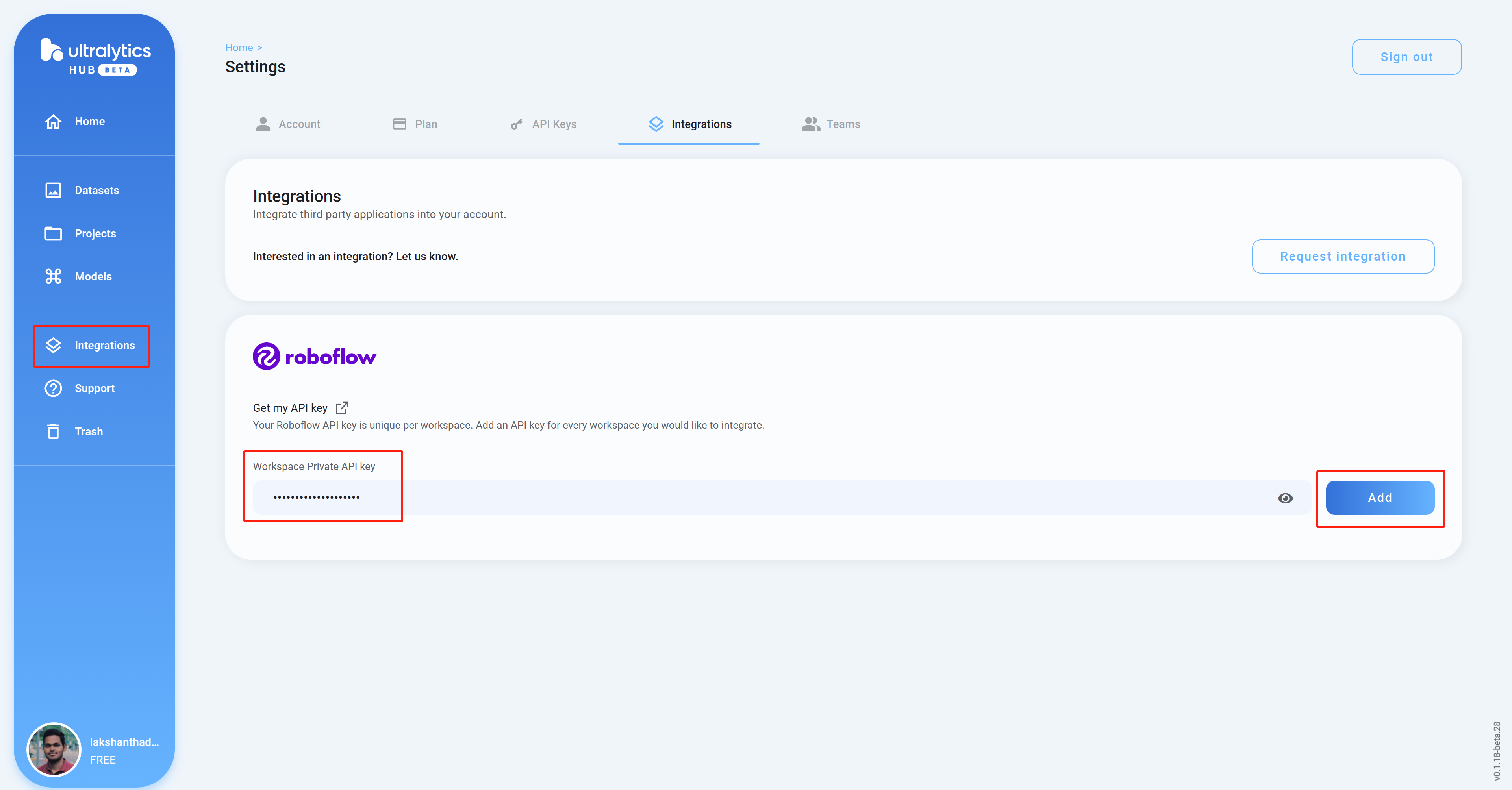
- ステップ10 ワークスペース名がリストに表示されていれば、統合が成功したことを意味します
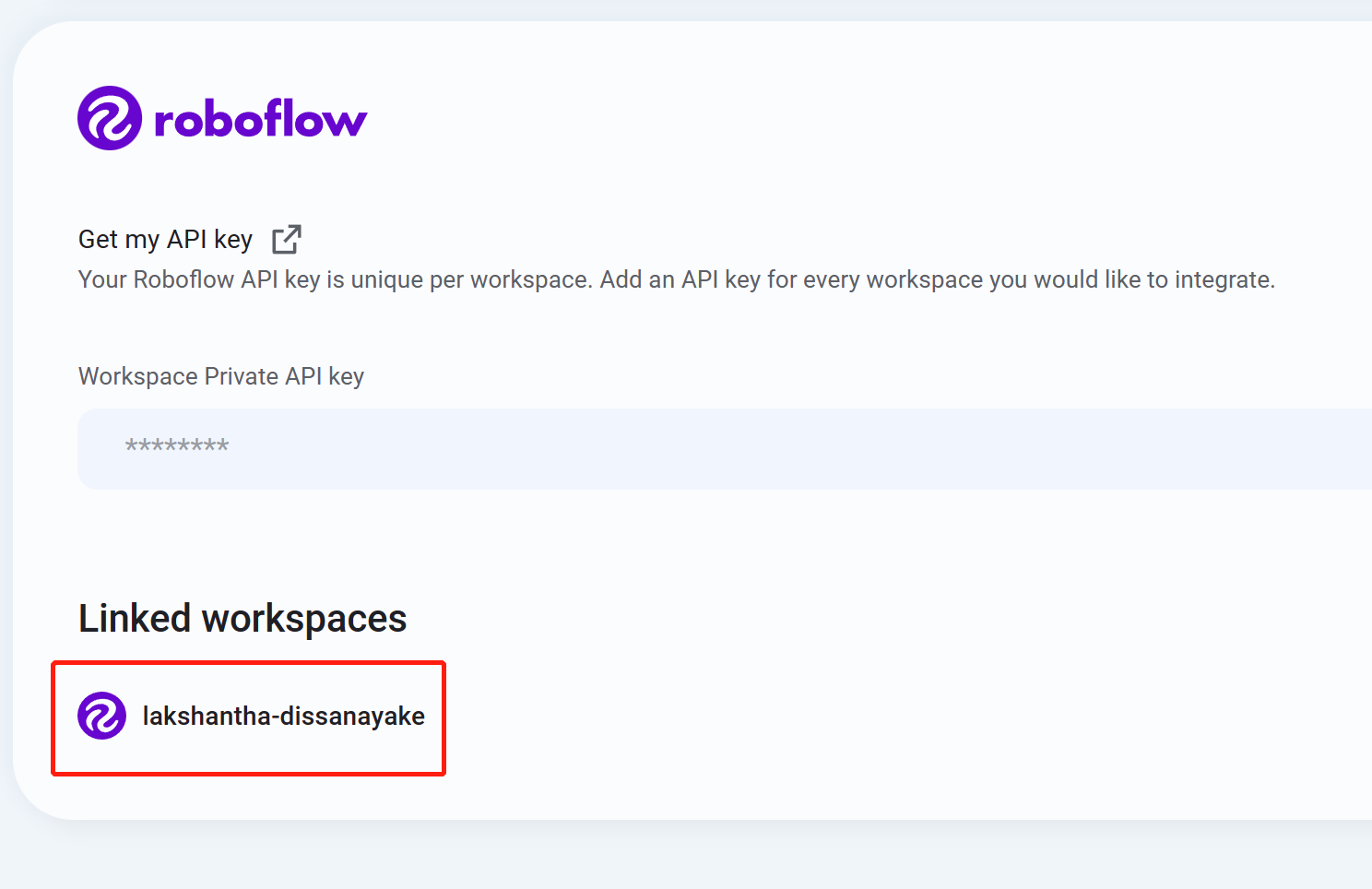
- ステップ11 Datasetsに移動すると、すべてのRoboflowプロジェクトがここに表示されます
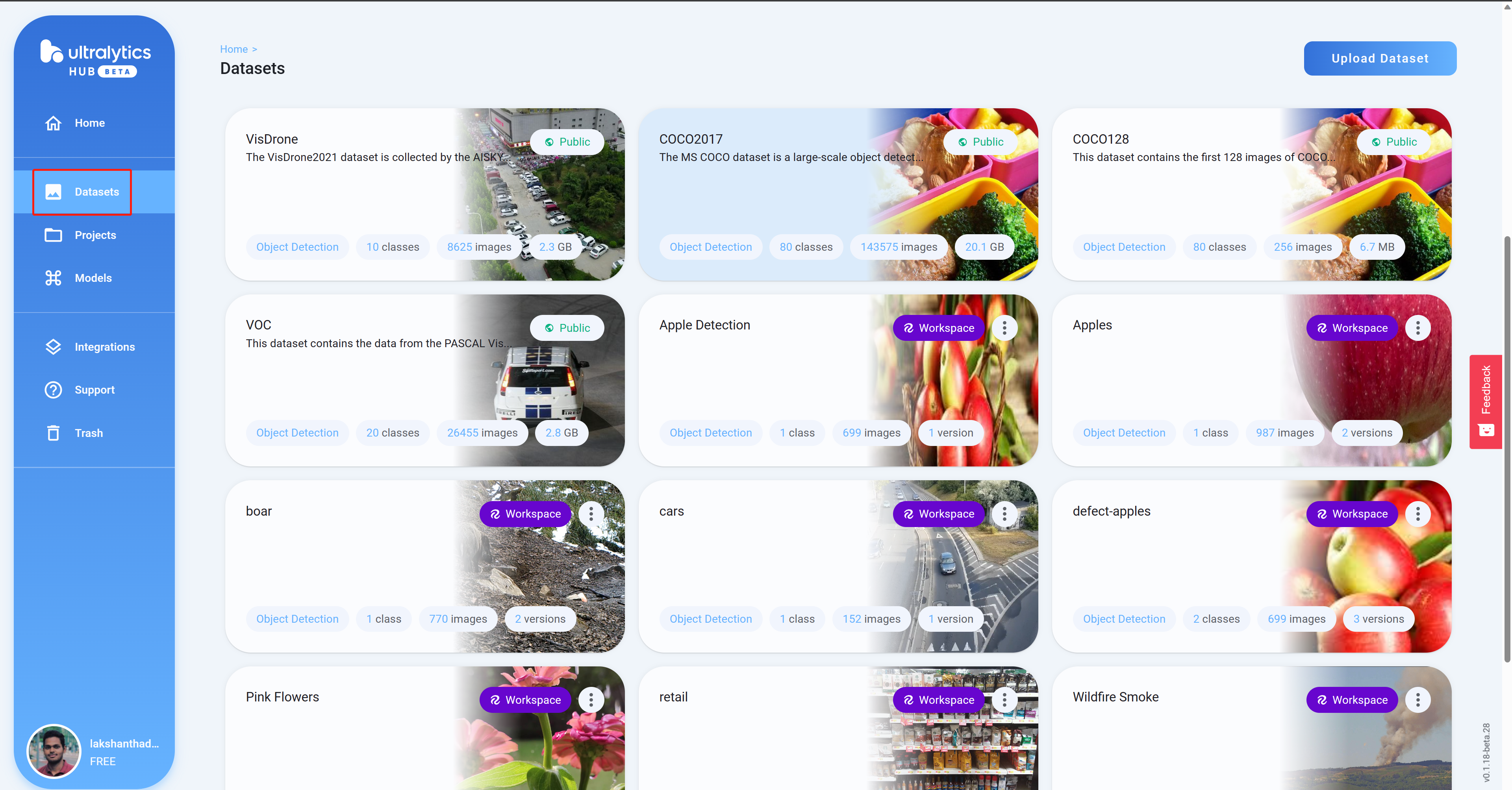
- ステップ12 プロジェクトをクリックして、データセットの詳細を確認します。ここでは、健康なリンゴと損傷したリンゴを検出できるデータセットを選択しました
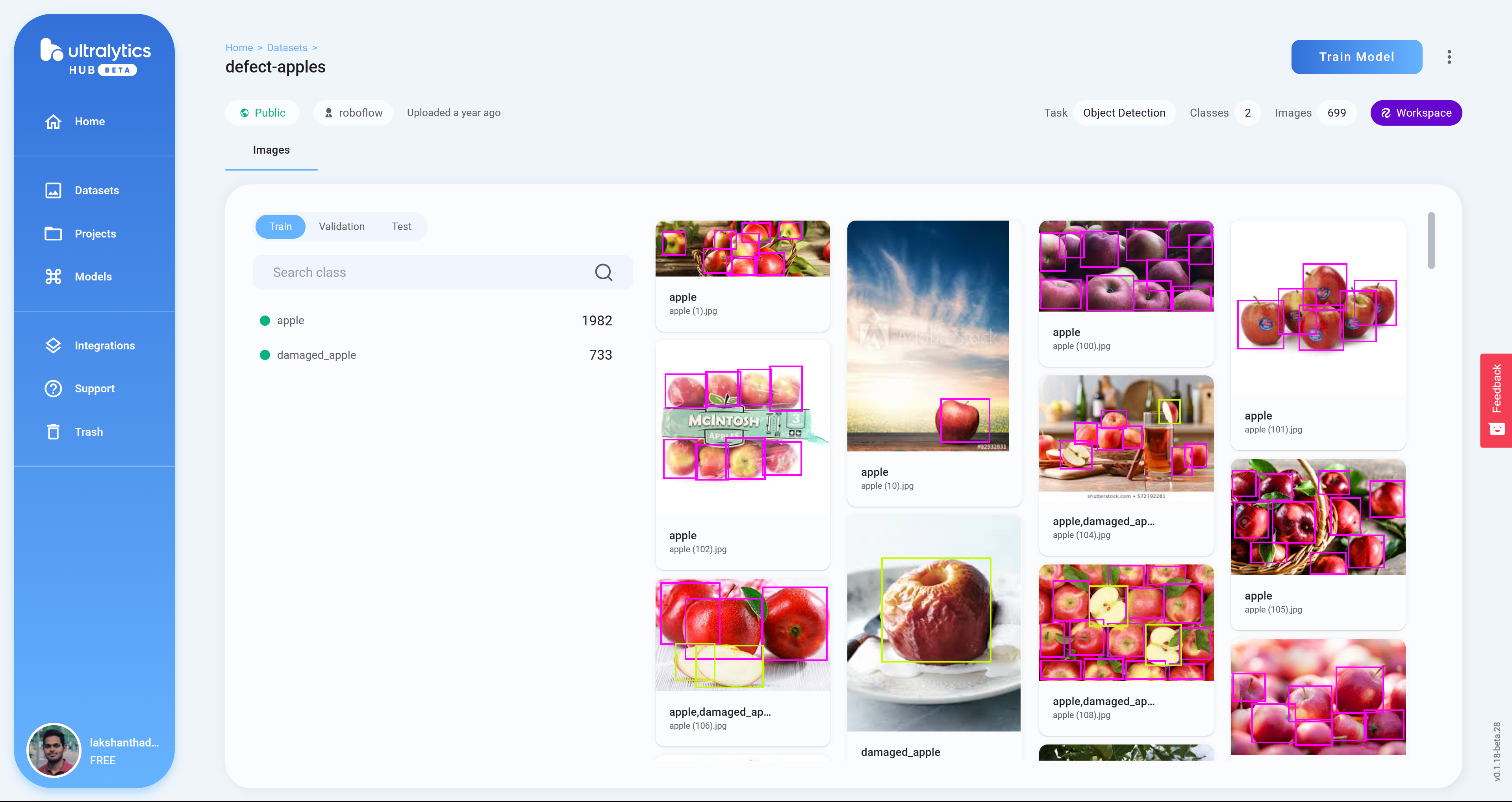
- ステップ13 Train Modelをクリックします
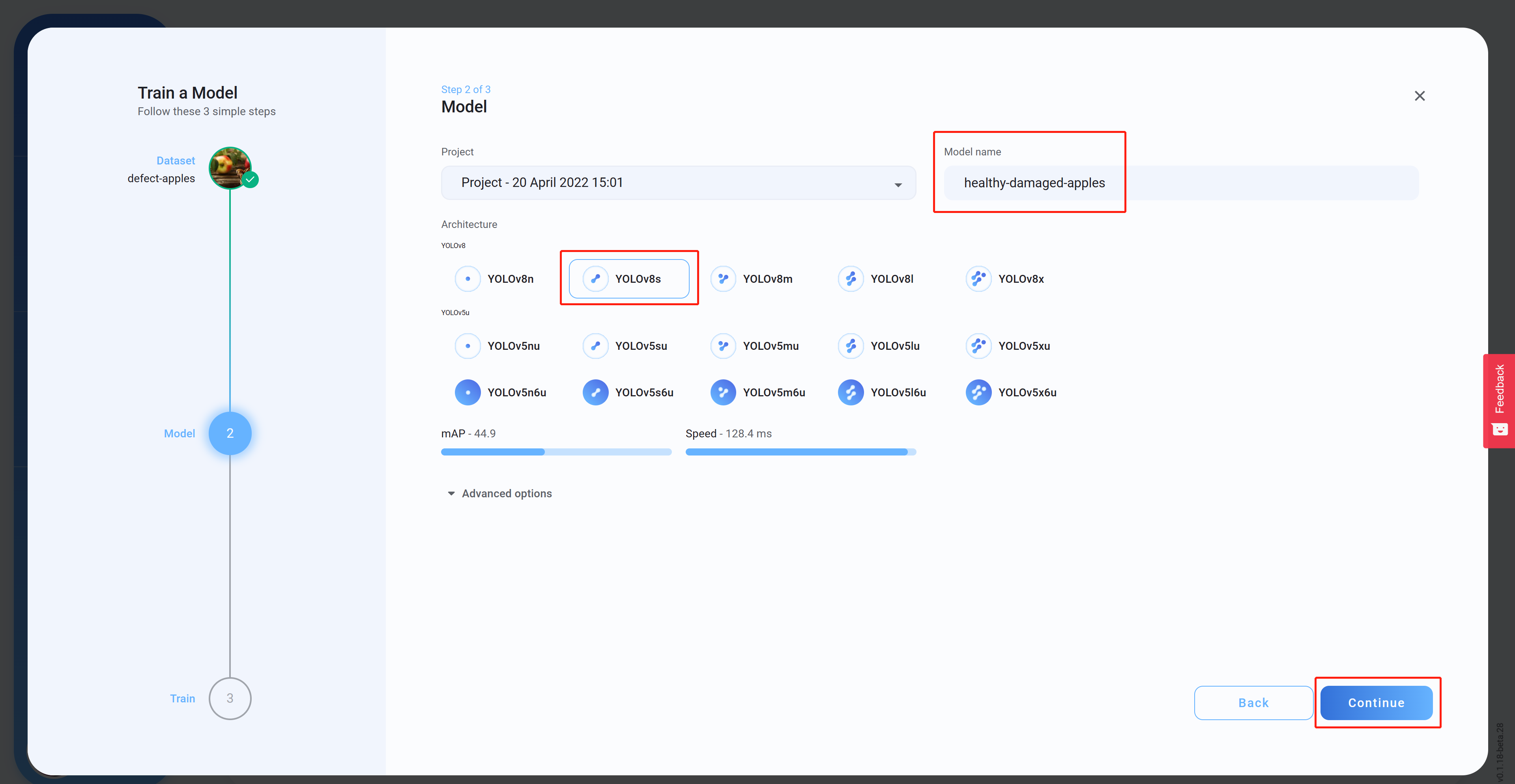
- ステップ14 Architectureを選択し、Model name(オプション)を設定してからContinueをクリックします。ここでは、モデルアーキテクチャとしてYOLOv8sを選択しました
- ステップ15 Advanced optionsで、お好みに応じて設定を構成し、Colabコード(これは後でColabワークスペースに貼り付けられます)をコピー&ペーストしてからOpen Google Colabをクリックします
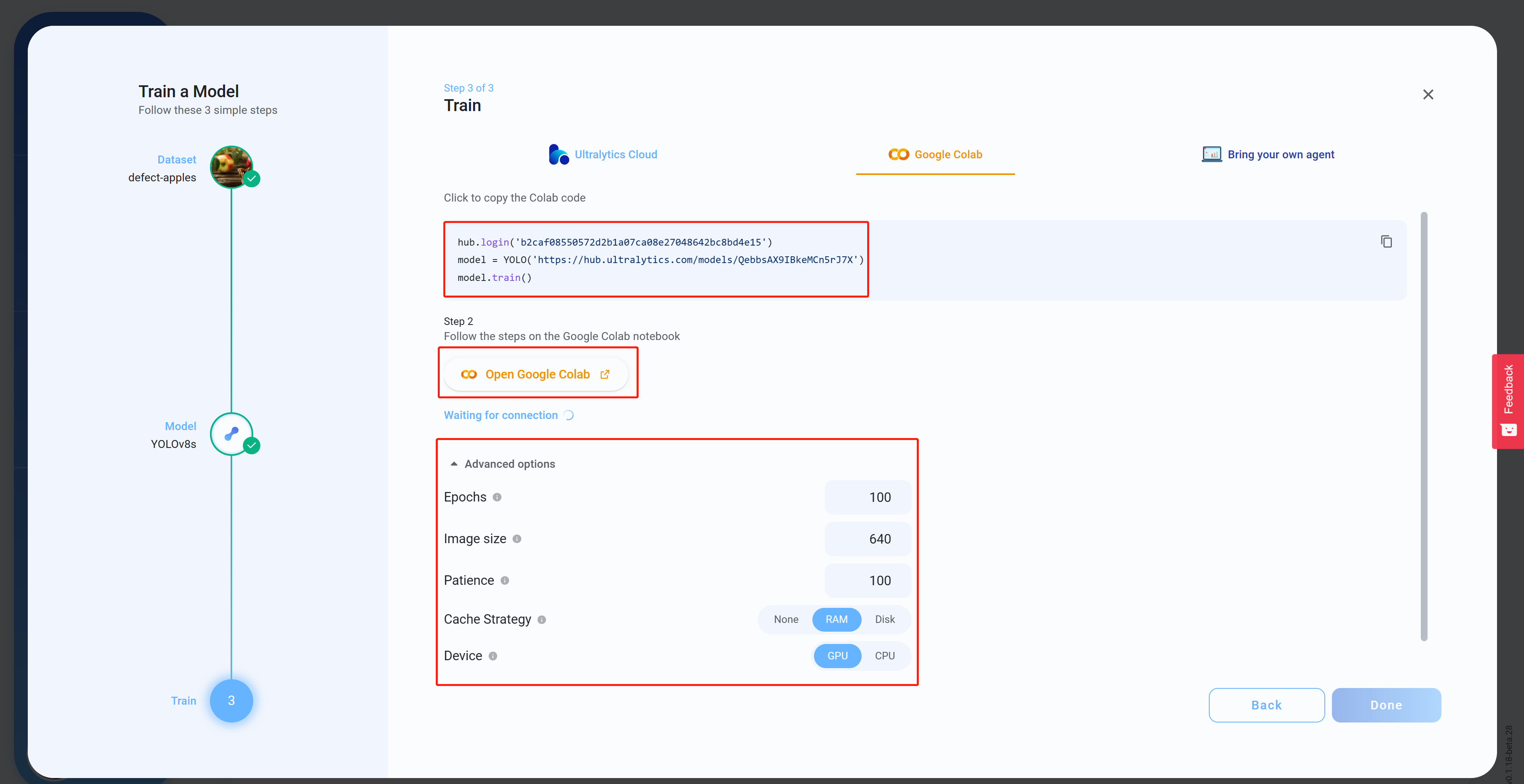
- ステップ16 まだサインインしていない場合は、Googleアカウントにサインインします
- ステップ 17
Runtime > Change runtime typeに移動します
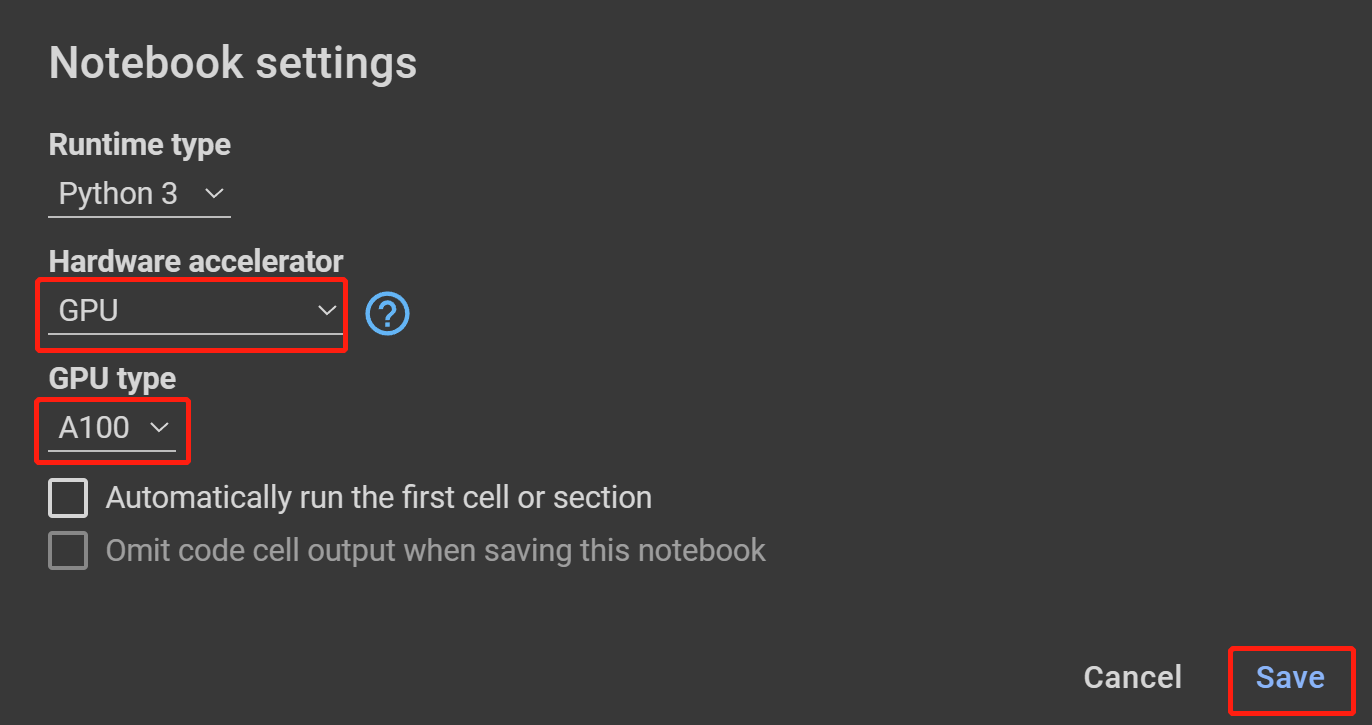
- ステップ 18 Hardware accelerator で GPU を選択し、GPU type で利用可能な最高のものを選択して Save をクリックします
- ステップ 19 Connect をクリックします
- ステップ 20 RAM, Disk ボタンをクリックしてハードウェアリソースの使用状況を確認します
- ステップ 21 Play ボタンをクリックして最初のコードセルを実行します
- ステップ 22 先ほど Ultralytics HUB からコピーしたコードセルを Start セクションの下に貼り付けて実行し、トレーニングを開始します
- ステップ 23 Ultralytics HUB に戻ると、Connected というメッセージが表示されます。Done をクリックします
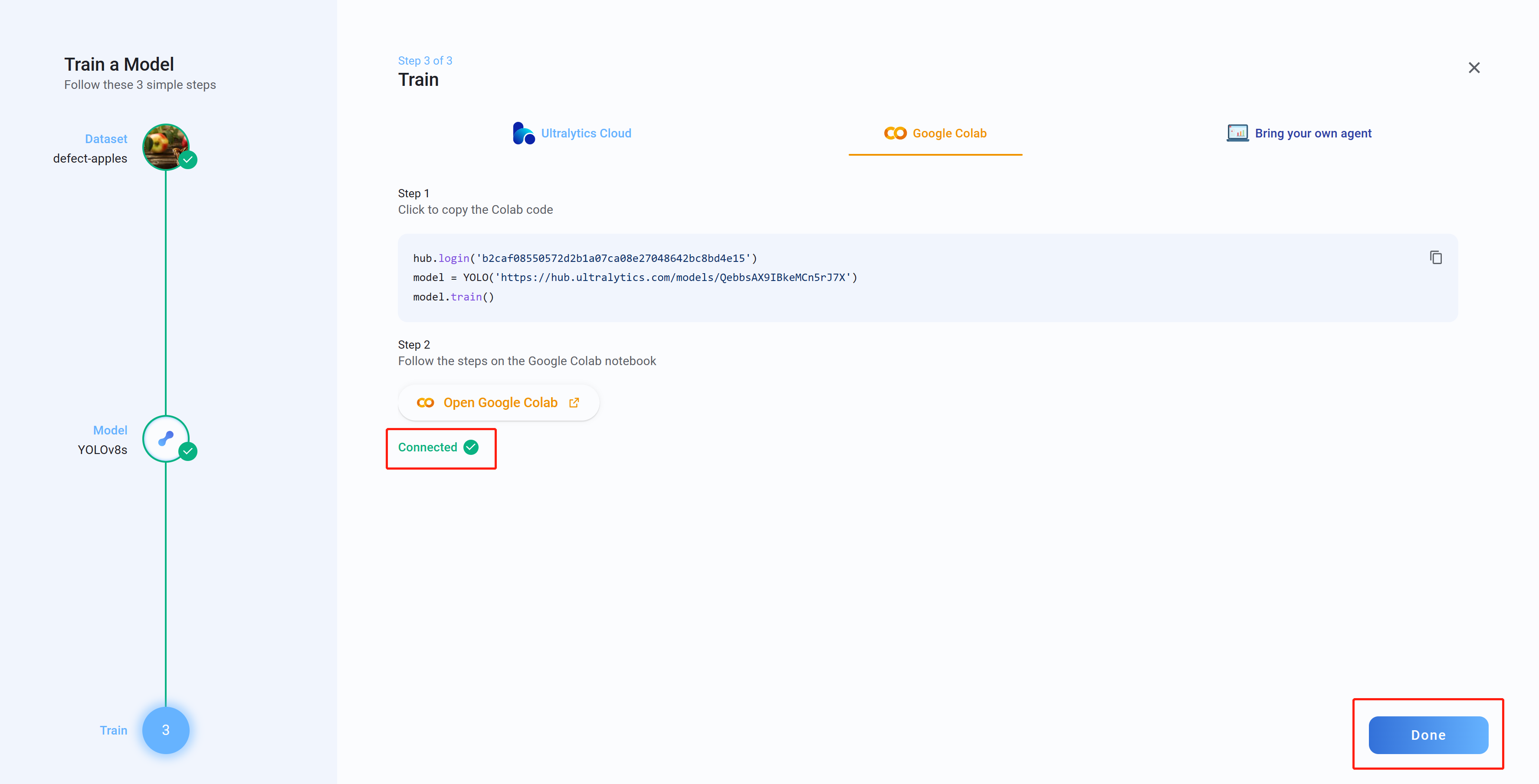
- ステップ 24 ここで、Google Colab でモデルがトレーニングされている間、Box Loss、Class Loss、Object Loss がリアルタイムで表示されます
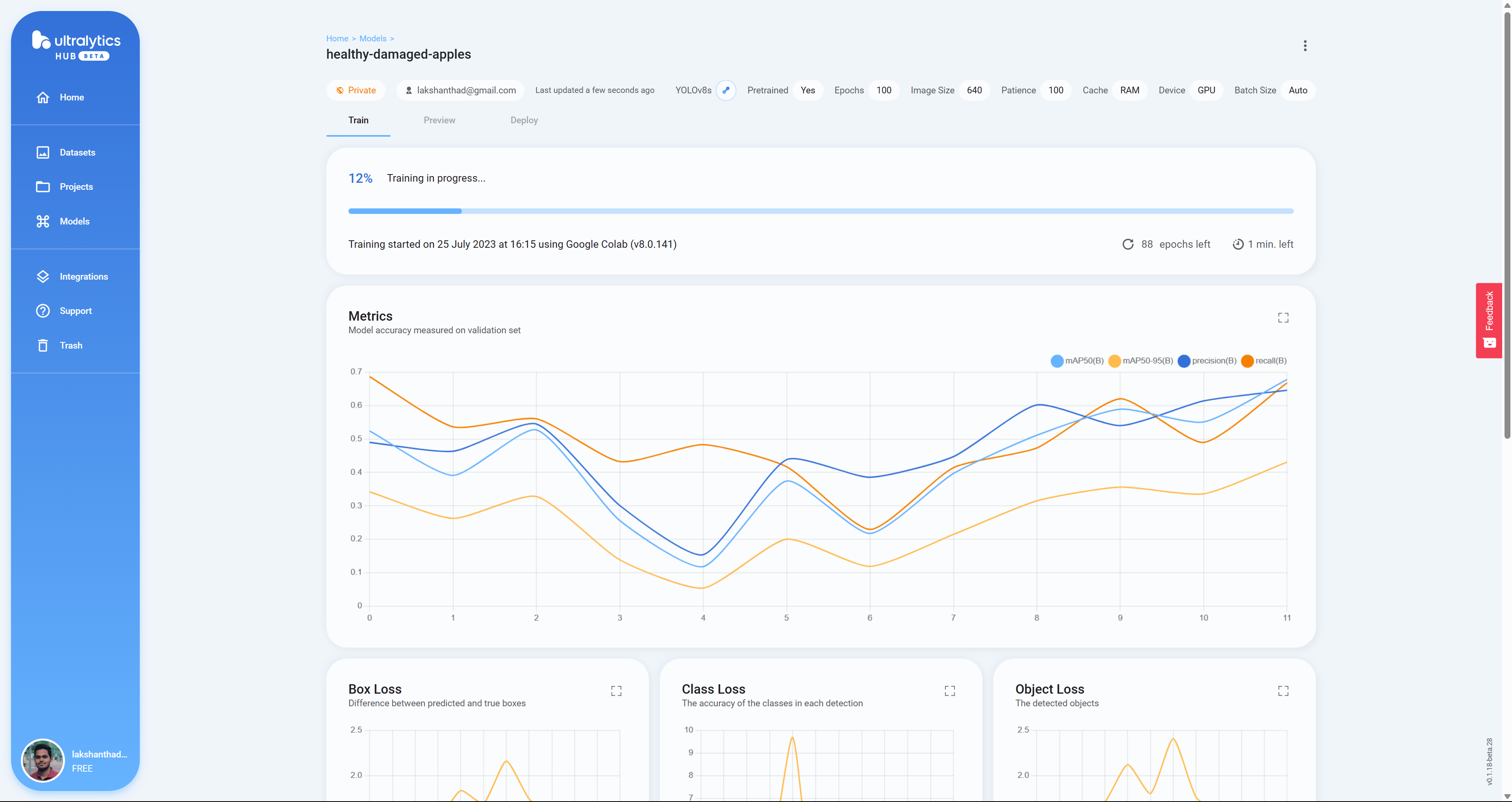
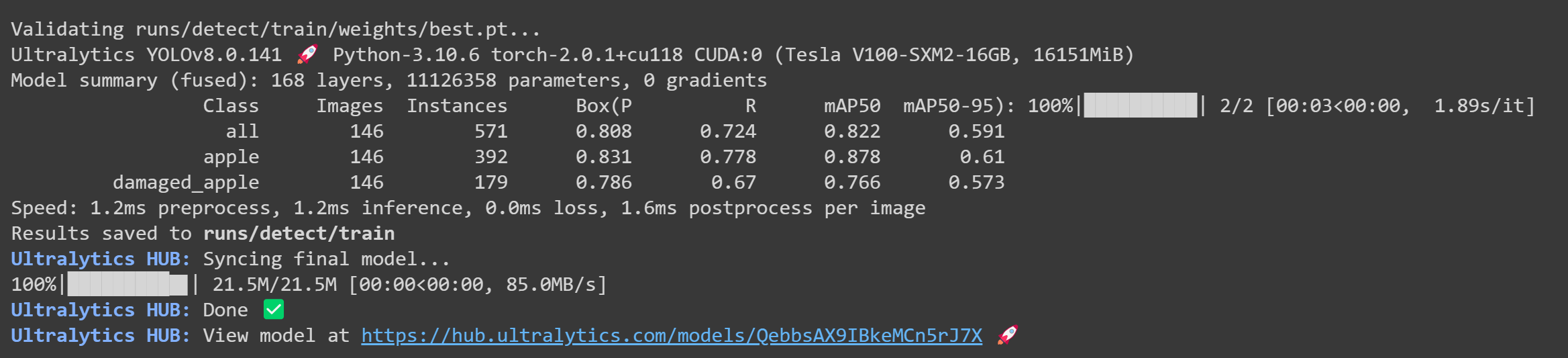
- ステップ 25 トレーニングが完了すると、Google Colab で以下の出力が表示されます
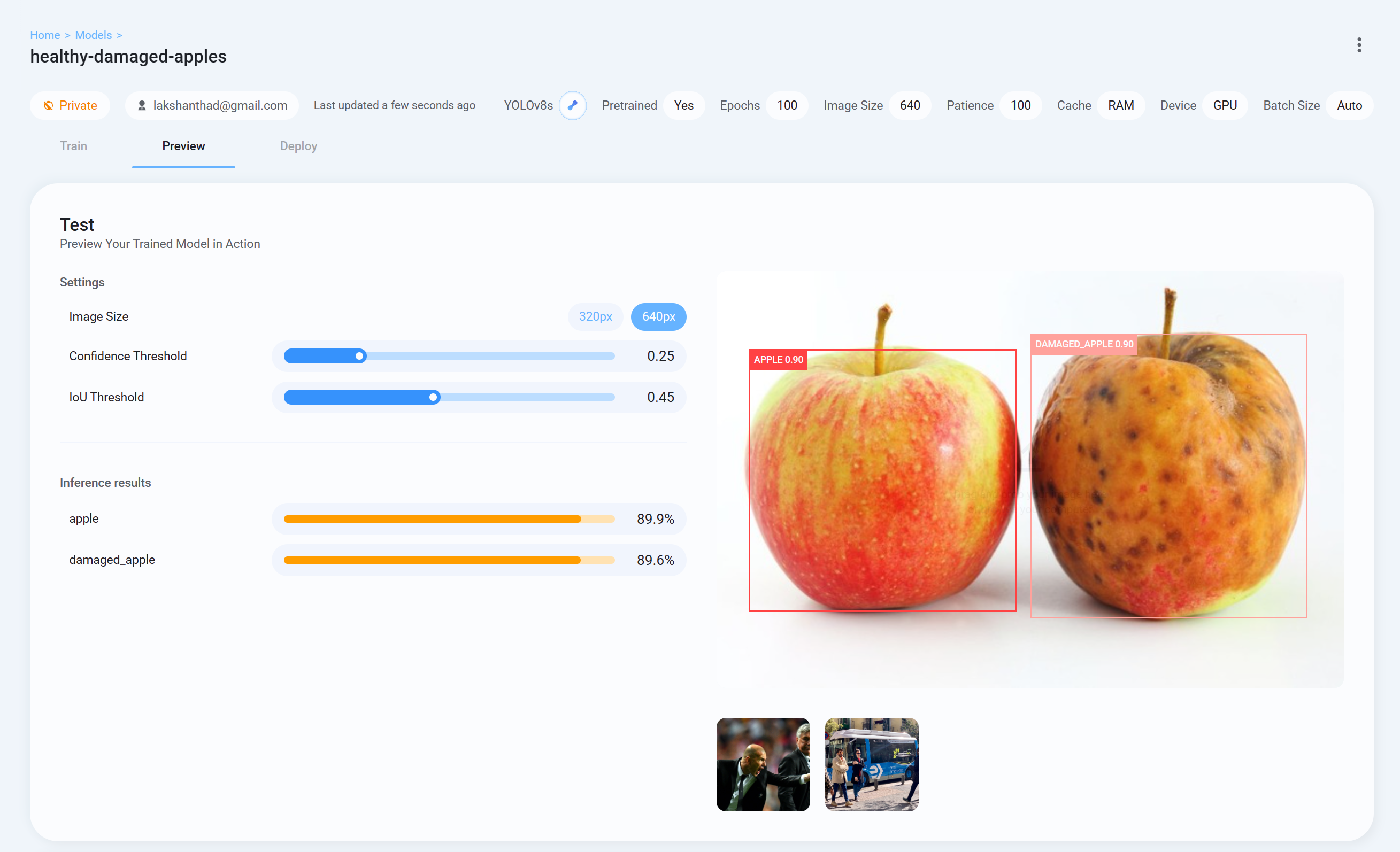
- ステップ 26 Ultralytics HUB に戻り、Preview タブに移動してテスト画像をアップロードし、トレーニング済みモデルの性能を確認します
- ステップ 26 最後に Deploy タブに移動し、YOLOv8 で推論するために好みの形式でトレーニング済みモデルをダウンロードします。ここでは PyTorch を選択しました。
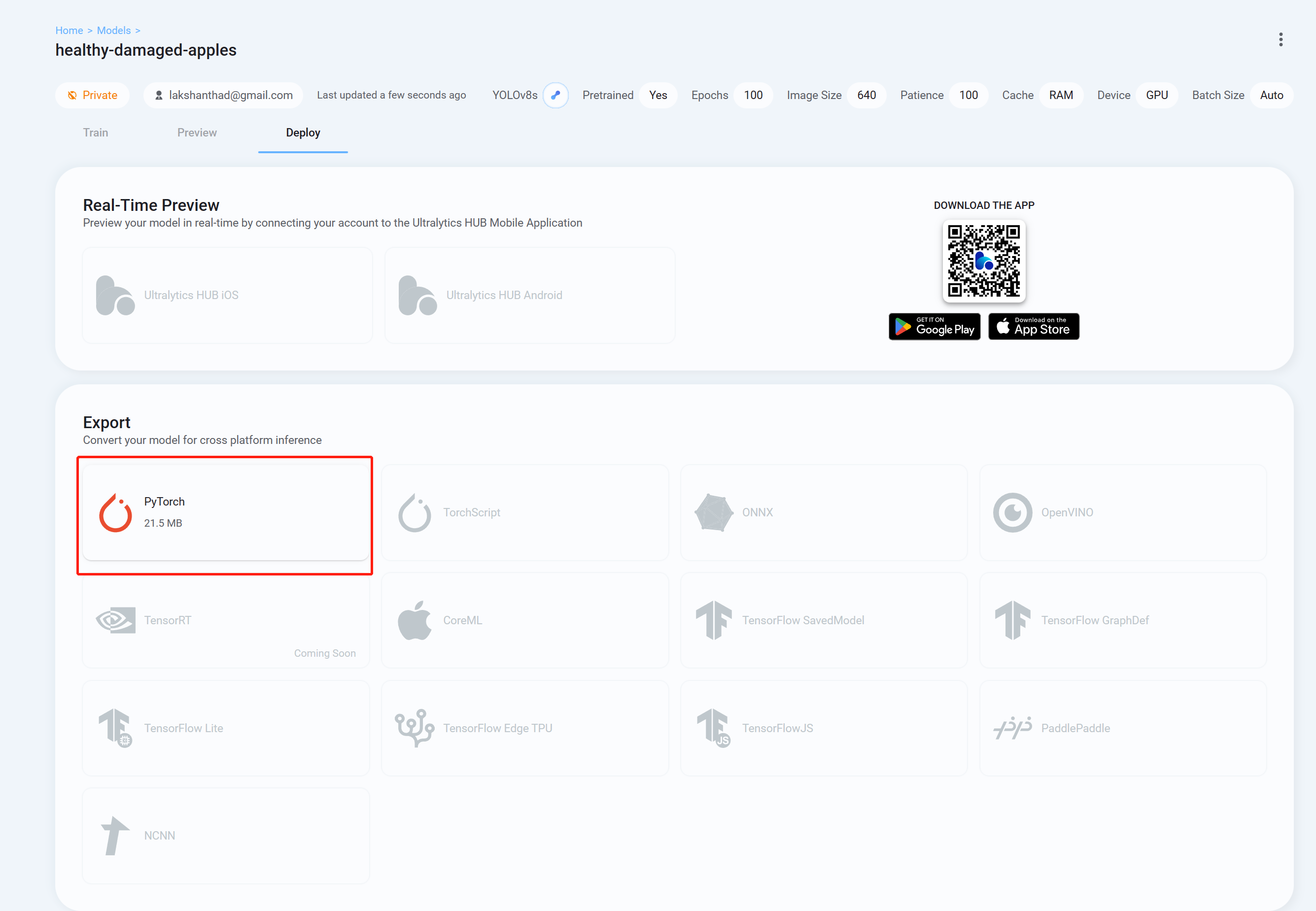
これで、ダウンロードしたモデルを、このwikiで以前に説明したタスクで使用できます。モデルファイルをあなたのモデルに置き換えるだけです。
例えば:
yolo detect predict model=<your_model.pt> source='0' show=True
ここでは、Google Colaboratory環境を使用してクラウド上でトレーニングを実行します。さらに、Colab内でRoboflow APIを使用してデータセットを簡単にダウンロードします。
- ステップ 1. こちらをクリックして、すでに準備されたGoogle Colabワークスペースを開き、ワークスペースに記載されている手順を実行してください
トレーニングが完了すると、以下のような出力が表示されます:
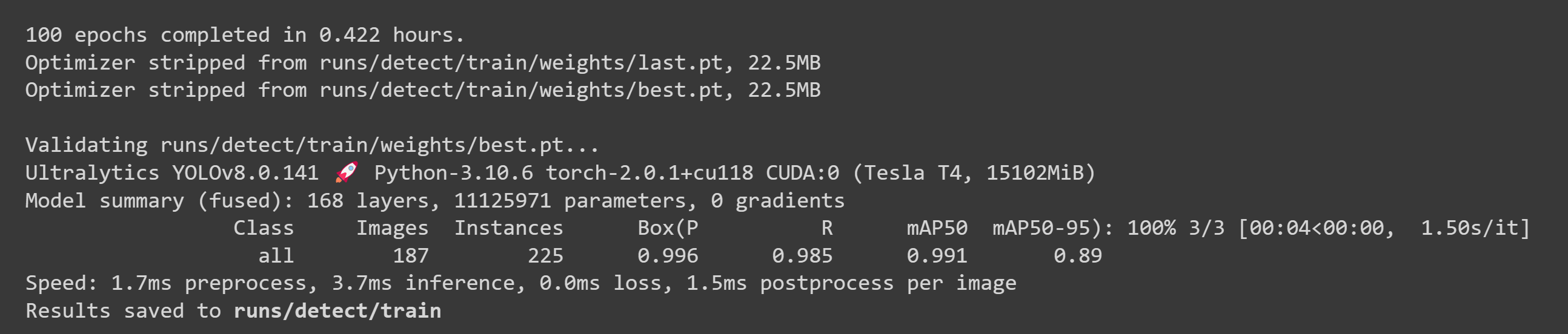
- ステップ 2. Filesタブで、
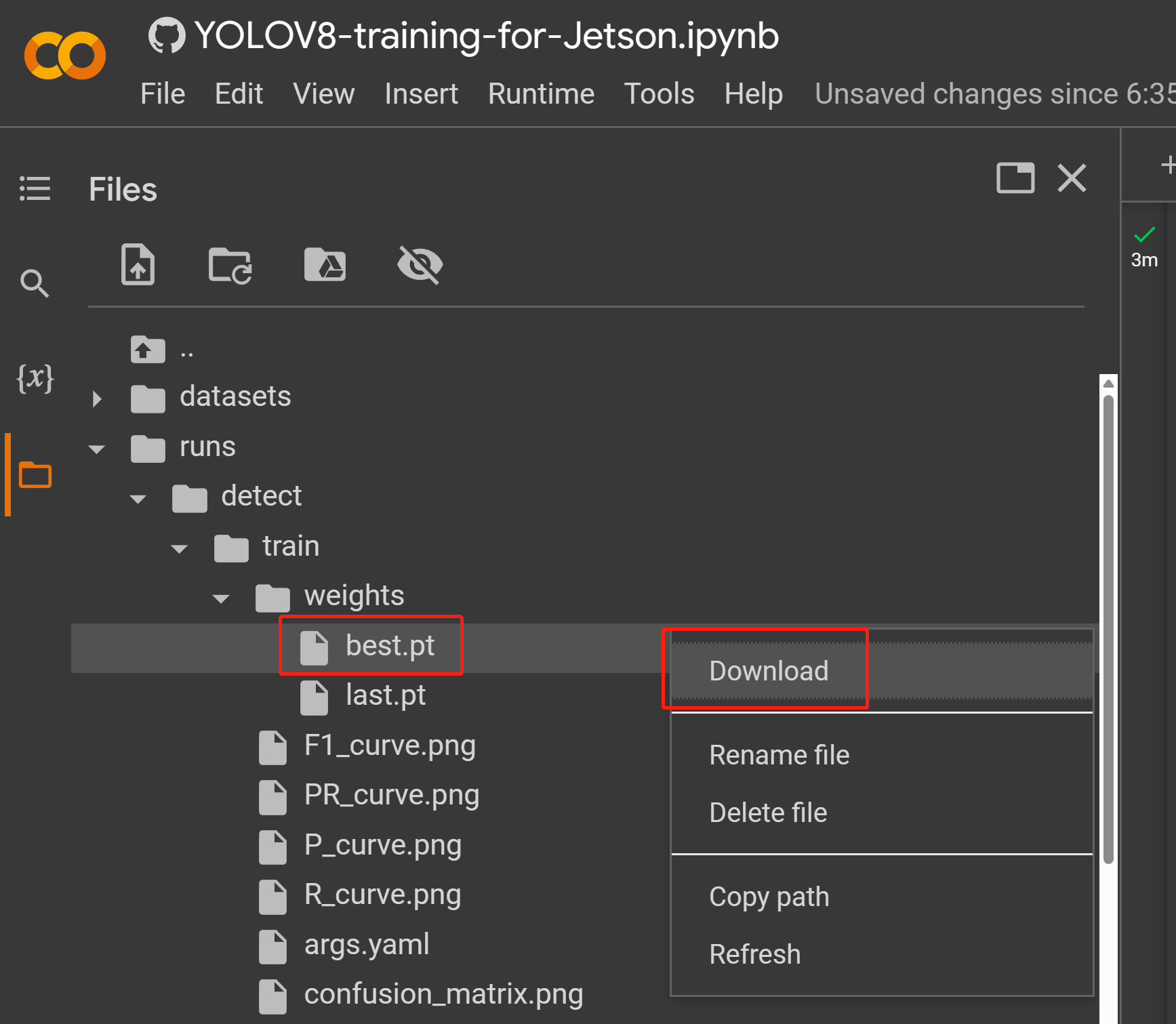
runs/train/exp/weightsに移動すると、best.ptというファイルが表示されます。これがトレーニングから生成されたモデルです。このファイルをダウンロードしてJetsonデバイスにコピーしてください。これは後でJetsonデバイス上での推論に使用するモデルです。
これで、ダウンロードしたモデルを、このwikiで以前に説明したタスクで使用できます。モデルファイルをあなたのモデルに置き換えるだけです。
例えば:
yolo detect predict model=<your_model.pt> source='0' show=True
ここでは、トレーニング用にLinux OSを搭載したPCを使用できます。このwikiではUbuntu 20.04 PCを使用しています。
- ステップ 1. システムにpipがない場合は、pipをインストールします
sudo apt install python3-pip -y
- ステップ 2. 依存関係と共にUltralyticsをインストールする
pip install ultralytics
- ステップ 3. Roboflowで、プロジェクト内のVersionsに移動し、Export Datasetを選択し、FormatをYOLOv8として選択し、download zip to computerを選択してContinueをクリックします
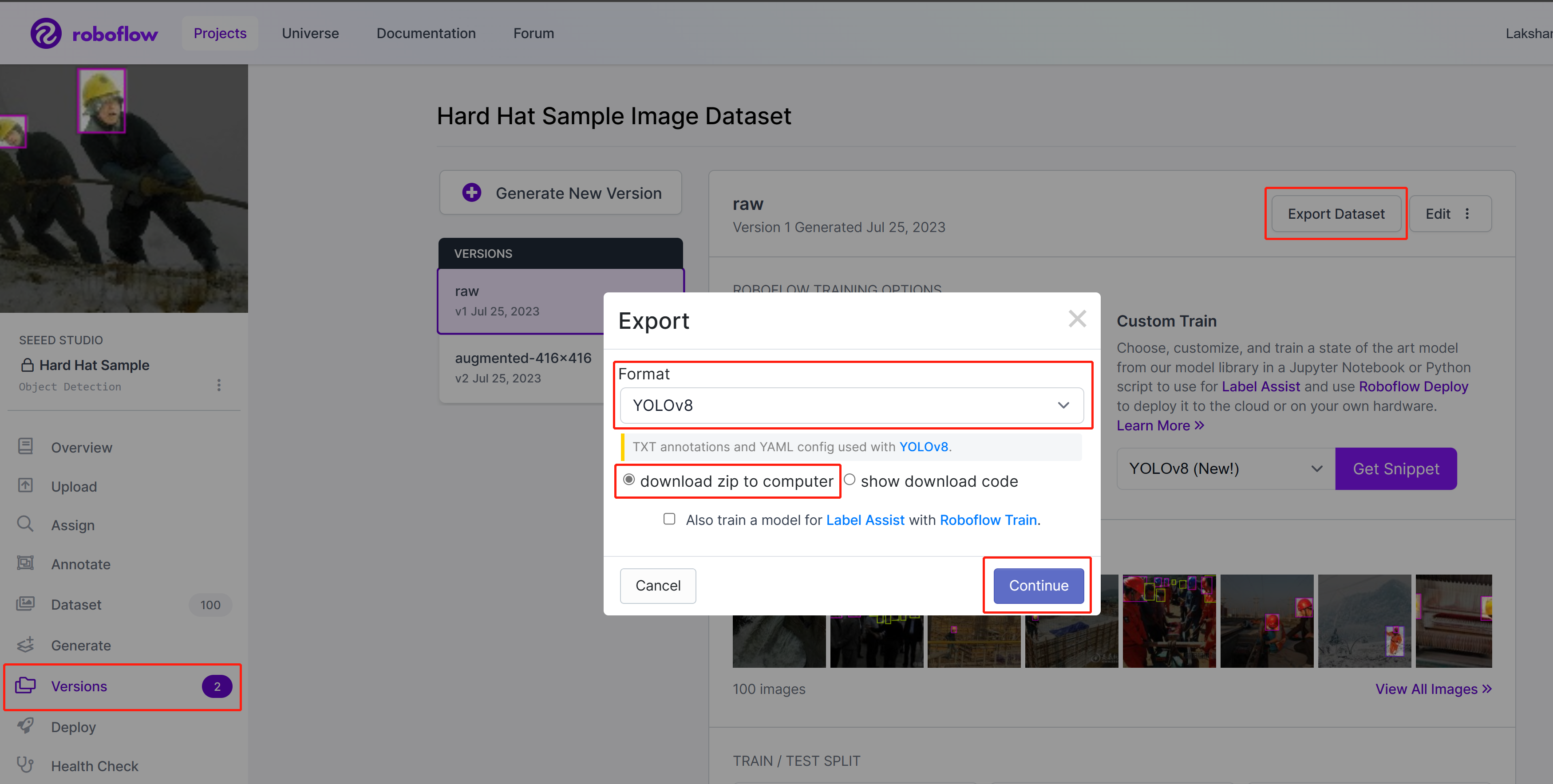
-
ステップ 4. ダウンロードしたzipファイルを展開します
-
ステップ 5. 以下を実行してトレーニングを開始します。ここで、path_to_yamlを、先ほど展開したzipファイル内にある.yamlファイルの場所に置き換える必要があります
yolo train data=<path_to_yaml> model=yolov8s.pt epochs=100 imgsz=640 batch=-1
ここで画像サイズは640x640に設定されています。batch-sizeは-1を使用しています。これにより最適なバッチサイズが自動的に決定されます。お好みに応じてエポック数も変更できます。ここでは事前学習済みモデルを任意の検出、セグメンテーション、分類、ポーズモデルに変更できます。
トレーニングが完了すると、以下のような出力が表示されます:
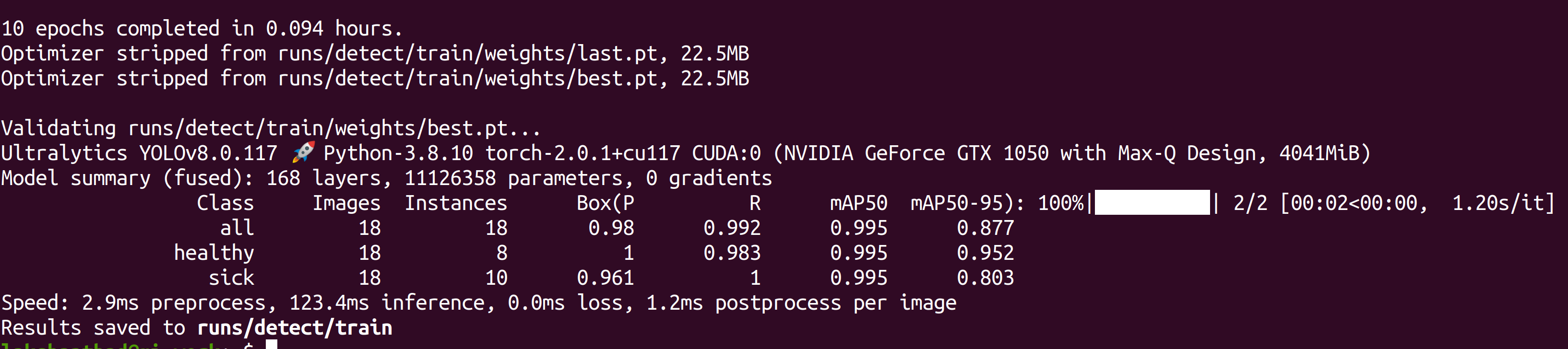
- ステップ 6. runs/detect/train/weightsの下に、best.ptというファイルが表示されます。これがトレーニングから生成されたモデルです。このファイルをダウンロードしてJetsonデバイスにコピーしてください。これが後でJetsonデバイスでの推論に使用するモデルです。

これで、ダウンロードしたモデルを、このwikiで以前に説明したタスクで使用できます。モデルファイルをあなたのモデルに置き換えるだけです。
例えば:
yolo detect predict model=<your_model.pt> source='0' show=True
パフォーマンスベンチマーク
準備
NVIDIA Jetson Orin NX 16GBモジュールを搭載したreComputer J4012/ reComputer Industrial J4012で動作するYOLOv8がサポートするすべてのコンピュータビジョンタスクについて、パフォーマンスベンチマークを実施しました。
samplesディレクトリには、trtexecというコマンドラインラッパーツールが含まれています。trtexecは、独自のアプリケーションを開発することなくTensorRTを使用するためのツールです。trtexecツールには3つの主要な目的があります:
- ランダムまたはユーザー提供の入力データでネットワークをベンチマークする
- モデルからシリアル化されたエンジンを生成する
- ビルダーからシリアル化されたタイミングキャッシュを生成する
ここでは、trtexecツールを使用して、異なるパラメータでモデルを迅速にベンチマークできます。しかし、まずonnxモデルが必要であり、このonnxモデルはultralytics yolov8を使用して生成できます。
- ステップ 1. 以下を使用してONNXをビルドします:
yolo mode=export model=yolov8s.pt format=onnx
- ステップ 2. 以下のようにtrtexecを使用してエンジンファイルをビルドします:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
例えば:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
これにより、生成された .engine ファイルと共に以下のようなパフォーマンス結果が出力されます。デフォルトでは、ONNX を FP32 精度で TensorRT 最適化ファイルに変換し、以下のような出力を確認できます
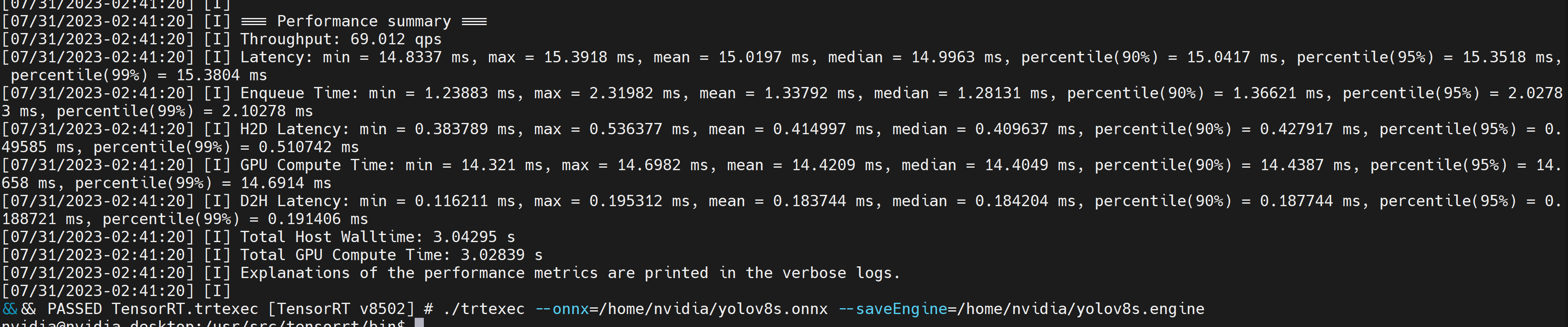
FP32 よりも優れたパフォーマンスを提供する FP16 精度を使用したい場合は、上記のコマンドを以下のように実行できます
./trtexec --onnx=/home/nvidia/yolov8s.onnx --fp16 --saveEngine=/home/nvidia/yolov8s.engine
ただし、FP16よりも優れたパフォーマンスを提供するINT8精度が必要な場合は、上記のコマンドを次のように実行できます
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
結果
以下に、reComputer J4012/ reComputer Industrial J4012で実行した4つのコンピュータビジョンタスクすべてから得られた結果をまとめます。
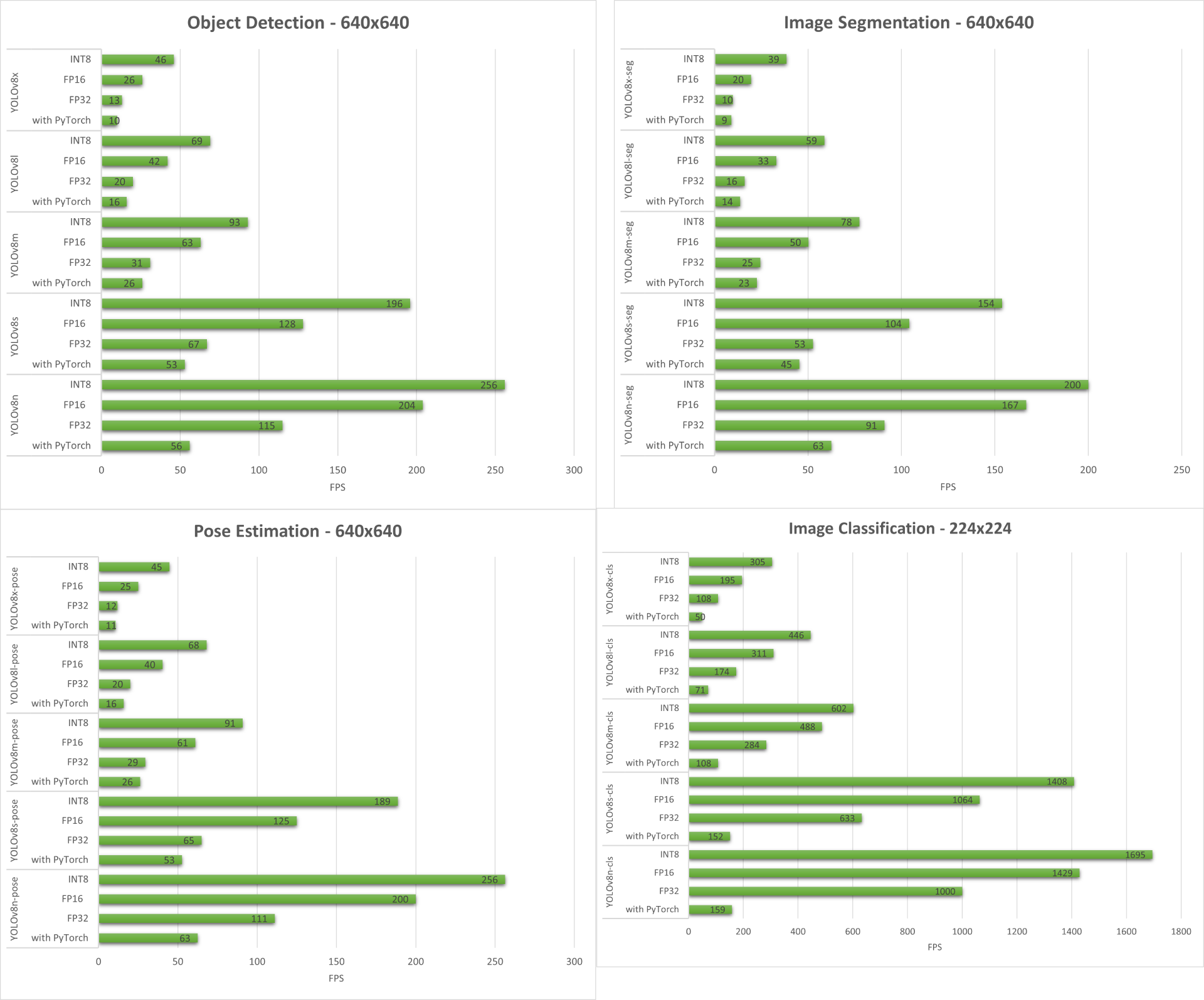
ボーナスデモ:YOLOv8を使用したエクササイズ検出・カウンター
YOLOv8-Poseモデルを使用して、YOLOv8でエクササイズ検出とカウントを行うポーズ推定デモアプリケーションを構築しました。このデモの詳細を学び、独自のJetsonデバイスにデプロイするには、こちらのプロジェクトをご確認ください!
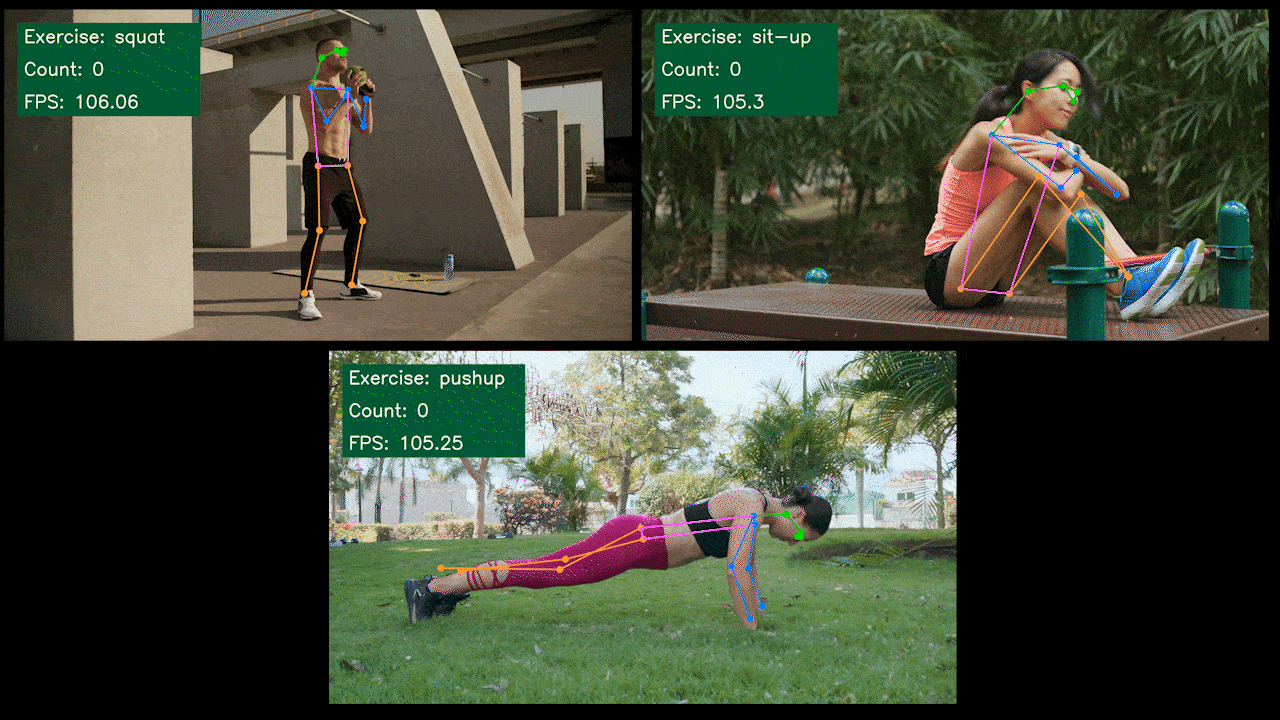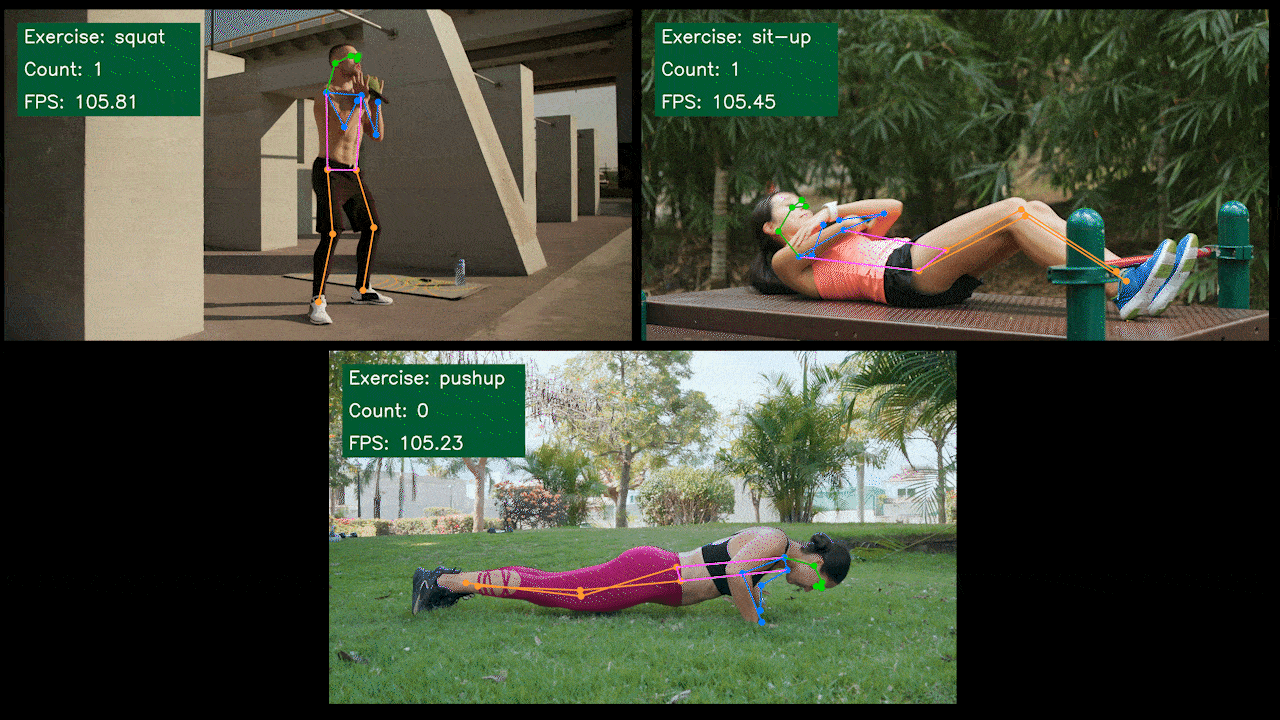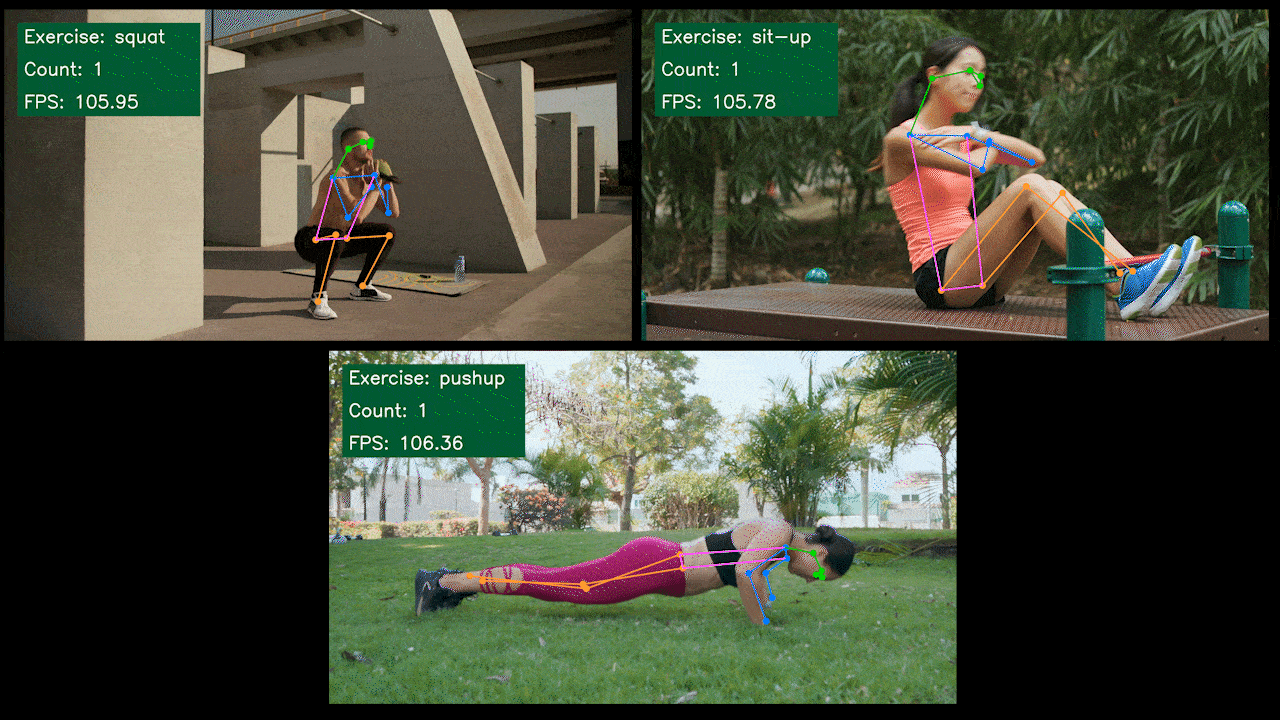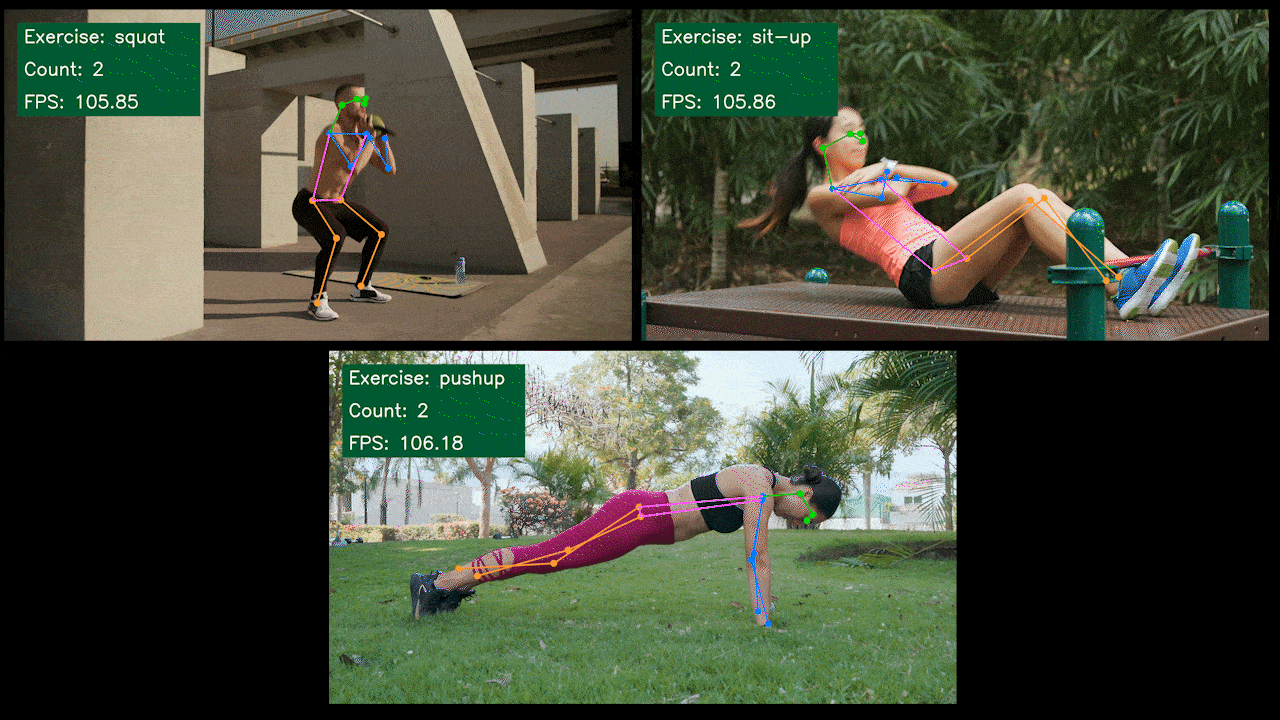
NVIDIA Jetson用YOLOv8の手動セットアップ
前述のワンラインスクリプトでエラーが発生した場合は、以下の手順を一つずつ実行してJetsonデバイスでYOLOv8を準備できます。
Ultralyticsパッケージのインストール
- ステップ1. Jetsonデバイスのターミナルにアクセスしてpipをインストールし、アップグレードします
sudo apt update
sudo apt install -y python3-pip -y
pip3 install --upgrade pip
- ステップ 2. Ultralyticsパッケージをインストールする
pip3 install ultralytics
- ステップ 3. numpy のバージョンを最新にアップグレードする
pip3 install numpy -U
- ステップ 4. デバイスを再起動する
sudo reboot
Torch と Torchvision のアンインストール
上記の ultralytics インストールにより、Torch と Torchvision がインストールされます。しかし、pip 経由でインストールされたこれら 2 つのパッケージは、ARM aarch64 アーキテクチャベースの Jetson プラットフォーム上では動作しません。そのため、事前にビルドされた PyTorch pip wheel を手動でインストールし、Torchvision をソースからコンパイル/インストールする必要があります。
pip3 uninstall torch torchvision
PyTorchとTorchvisionのインストール
このページにアクセスして、すべてのPyTorchとTorchvisionのリンクを確認してください。
以下はJetPack 5.0以降でサポートされているバージョンの一部です。
PyTorch v2.0.0
JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) でPython 3.8をサポート
file_name: torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl
PyTorch v1.13.0
JetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) でPython 3.8をサポート
file_name: torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v502/pytorch/torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl
- ステップ1. お使いのJetPackバージョンに応じて、以下の形式でtorchをインストールしてください pip3
wget <URL> -O <file_name>
pip3 install <file_name>
例えば、ここでは JP5.1.1 を実行しているため、PyTorch v2.0.0 を選択します
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl -O torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
- ステップ 2. インストールしたPyTorchのバージョンに応じてtorchvisionをインストールします。例えば、PyTorch v2.0.0を選択した場合、Torchvision v0.15.2を選択する必要があります
sudo apt install -y libjpeg-dev zlib1g-dev
git clone https://github.com/pytorch/vision torchvision
cd torchvision
git checkout v0.15.2
python3 setup.py install --user
PyTorchのバージョンに応じてインストールする必要があるtorchvisionバージョンの対応リストは以下の通りです:
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
より詳細なリストが必要な場合は、このリンクをご確認ください。
ONNXのインストールとNumpyのダウングレード
これはPyTorchモデルをTensorRTに変換したい場合にのみ必要です
- ステップ1. 必要なONNXをインストールします
pip3 install onnx
- ステップ 2. エラーを修正するために Numpy を低いバージョンにダウングレードする
pip3 install numpy==1.20.3
リソース
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャネルを用意しています。