reComputer Jetson での分散 llama.cpp(RPC モード)

NVIDIA Jetson のようなエッジデバイスで大規模言語モデル(LLM)を実行することは、メモリと計算の制約により困難な場合があります。このガイドでは、llama.cpp の RPC バックエンドを使用して複数の reComputer Jetson デバイス間で LLM 推論を分散し、より要求の厳しいワークロードに対する水平スケーリングを可能にする方法を説明します。
前提条件
- JetPack 6.x+ がインストールされ、CUDA ドライバが正常に動作する 2 台の reComputer Jetson デバイス
- 両方のデバイスが同じローカルネットワーク上にあり、互いに
pingできること - ローカルマシン(クライアント)に ≥ 64 GB RAM、リモートノードに ≥ 32 GB RAM
1. ソースコードのクローン
ステップ 1. llama.cpp リポジトリをクローンします:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
2. ビルド依存関係のインストール
ステップ 1. パッケージリストを更新し、必要な依存関係をインストールします:
sudo apt update
sudo apt install -y build-essential cmake git libcurl4-openssl-dev python3-pip
3. RPC + CUDA バックエンドでのビルド
ステップ 1. RPC と CUDA サポートで CMake を設定します:
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_RPC=ON \
-DCMAKE_BUILD_TYPE=Release
ステップ 2. 並列ジョブでコンパイルします:
cmake --build build --parallel # Multi-core parallel compilation
4. Python 変換ツールのインストール
ステップ 1. Python パッケージを開発モードでインストールします:
pip3 install -e .
5. モデルのダウンロードと変換
この例では TinyLlama-1.1B-Chat-v1.0 を使用します:
モデルリンク: https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
これらのファイルをダウンロードし、自作の TinyLlama-1.1B-Chat-v1.0 フォルダに配置してください。
ステップ 1. Hugging Face モデルを GGUF 形式に変換します:
# Assuming the model is already downloaded to ~/TinyLlama-1.1B-Chat-v1.0 using git-lfs or huggingface-cli
python3 convert_hf_to_gguf.py \
--outfile ~/TinyLlama-1.1B.gguf \
~/TinyLlama-1.1B-Chat-v1.0
6. 単一マシン推論の検証
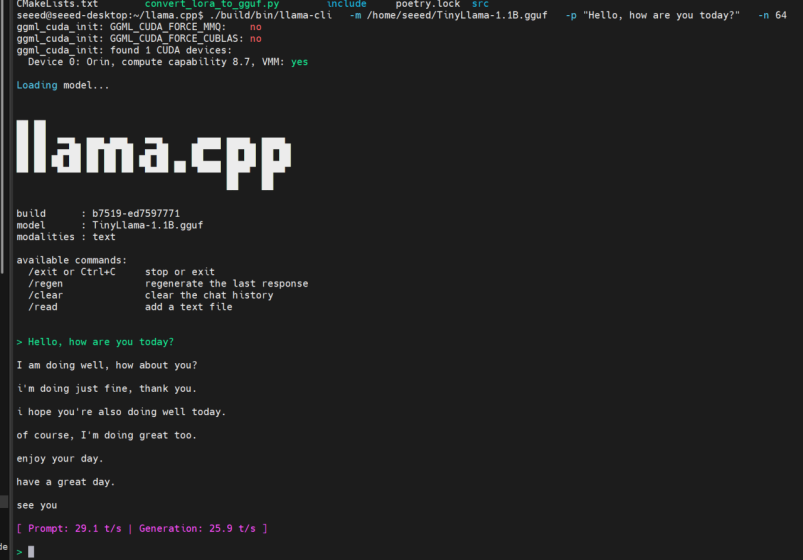
ステップ 1. 簡単なプロンプトでモデルをテストします:
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, how are you today?" \
-n 64
応答を受信した場合、モデルは正常に動作しています。
7. 分散 RPC 操作
7.1 ハードウェアトポロジーの例
| デバイス | RAM | 役割 | IP |
|---|---|---|---|
| マシン A | 64 GB | クライアント + ローカルサーバー | 192.168.100.2 |
| マシン B | 32 GB | リモートサーバー | 192.168.100.1 |
7.2 リモート RPC サーバーの開始(マシン B)
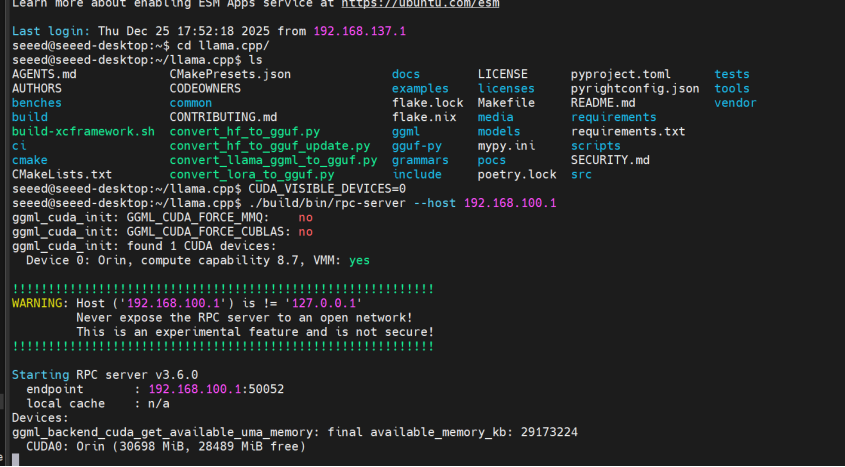
ステップ 1. リモートマシンに接続し、RPC サーバーを開始します:
ssh [email protected]
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server --host 192.168.100.1
サーバーはデフォルトでポート 50052 を使用します。カスタマイズするには、-p <port> を追加してください。
7.3 ローカル RPC サーバーの開始(マシン A)
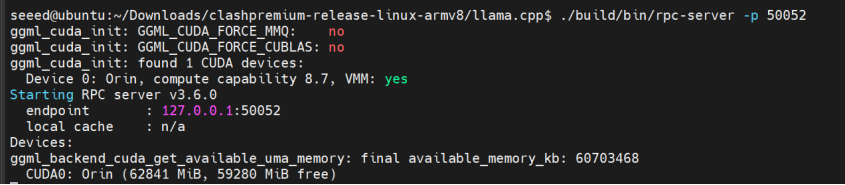
ステップ 1. ローカル RPC サーバーを開始します:
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server -p 50052
7.4 共同推論(マルチノード負荷)
ステップ 1. ローカルとリモートの両方の RPC サーバーを使用して推論を実行します:
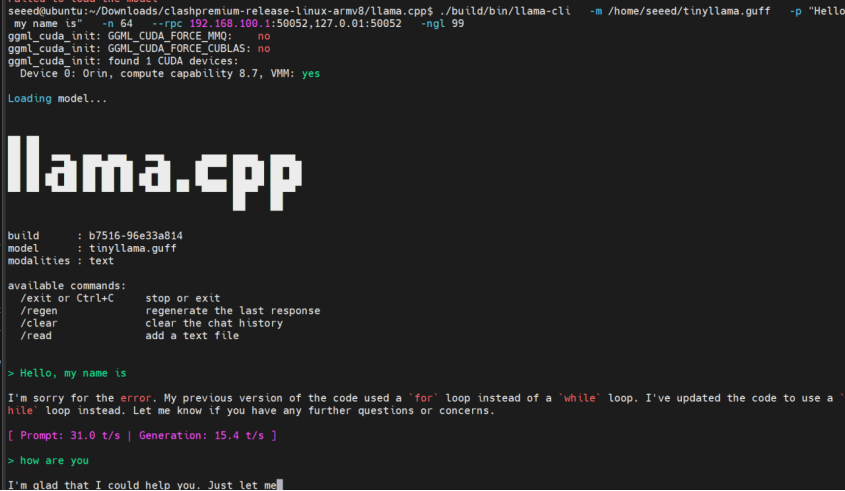
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, my name is" \
-n 64 \
--rpc 192.168.100.1:50052,127.0.0.1:50052 \
-ngl 99
-ngl 99 は 99% のレイヤーを GPU(RPC ノードとローカル GPU の両方)にオフロードします。
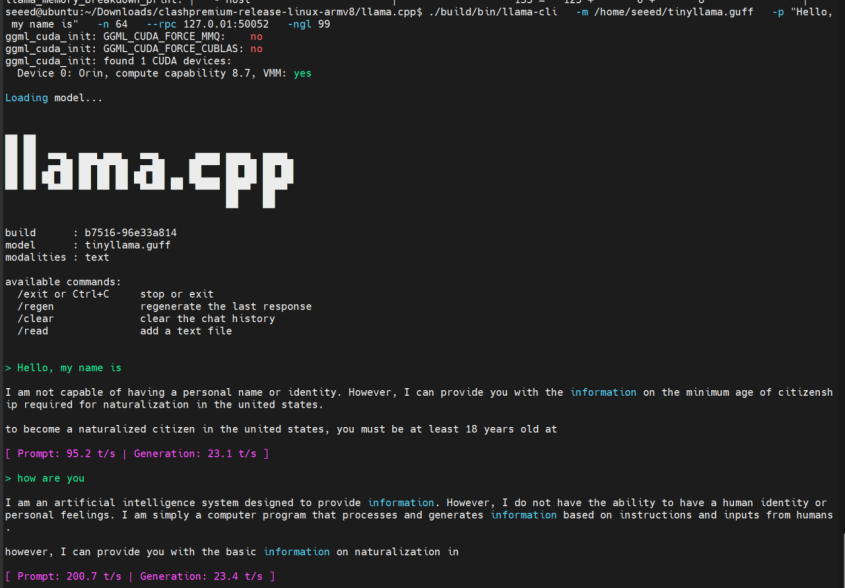
ローカルのみで実行したい場合は、--rpc からリモートアドレスを削除してください:
--rpc 127.0.0.1:50052
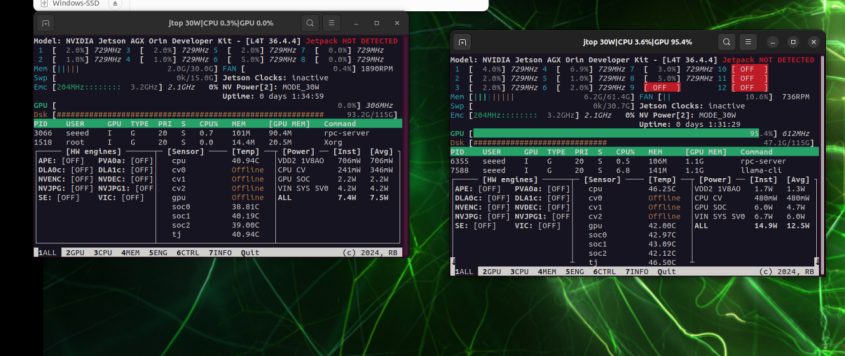
8. パフォーマンス比較
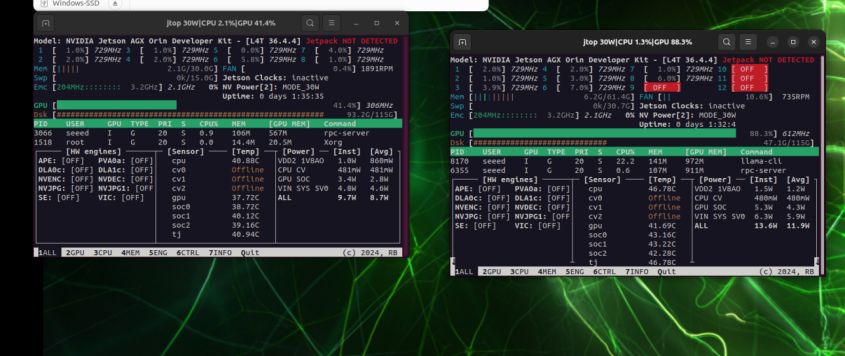
左:192.168.100.1 の GPU 使用率;右:192.168.100.2 の GPU 使用率
ローカルのみで実行する場合、GPU の負荷は単一のカードに集中します
9. トラブルシューティング
| 問題 | 解決策 |
|---|---|
| rpc-server 起動失敗 | ポートが占有されているか、ファイアウォールが 50052/tcp をブロックしていないか確認 |
| 推論速度の低下 | モデルが小さすぎる、ネットワーク遅延 > 計算利益;より大きなモデルまたは Unix ソケットモードを試す |
| メモリ不足エラー | -ngl 値を減らして GPU にオフロードするレイヤーを少なくするか、一部のレイヤーを CPU に保持 |
この設定により、llama.cpp の RPC バックエンドを使用して複数の Jetson デバイス間で LLM 推論の「水平スケーリング」を実現できます。より高いスループットを得るには、より多くの RPC ノードを追加するか、モデルを q4_0 や q5_k_m などの形式にさらに量子化することができます。
技術サポート & 製品ディスカッション
弊社製品をお選びいただき、ありがとうございます!弊社製品での体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。さまざまな好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。