reCamera による AI 音声インタラクション
はじめに
このプロジェクトでは、自然言語を通じて reCamera と対話する方法をデモします。ビジュアル推論によって音声録音がトリガーされた後、reCamera は録音データをサーバーに送信し、完全な STT (Speech-to-Text) → LLM (Large Language Model Reasoning) → TTS (Text-to-Speech) パイプラインで処理します。合成された音声は再生のために reCamera に戻され、自然な音声対話を実現します。
「見る」だけでなく、「理解し」「話す」こともできるカメラが欲しいと思ったことはありませんか?本プロジェクトのアーキテクチャを通じて、reCamera のマイクとスピーカーを利用することで、このデバイスは単なるビジュアルツールではなく、自然な会話が可能なインテリジェントアシスタントになります。これには、以下に挙げるようなシナリオが含まれますが、これらに限定されるものではありません。
-
スマート入退室管理アシスタント:入口に reCamera を設置し、訪問者は音声だけで本人確認の登録、伝言の残置、案内の取得などを行うことができ、追加のインタラクティブスクリーンは不要です。
-
工場の安全点検パートナー:産業環境において、作業者の手がふさがっている場合でも、ジェスチャーで音声インタラクションをトリガーし、AI アシスタントに設備の状態や操作マニュアルを尋ねたり、異常を報告したりできます。
-
アクセシビリティ支援インタラクション:視覚障害者や身体の不自由なユーザーに音声操作の入り口を提供し、簡単なジェスチャートリガーを通じてデバイスと自然言語で会話し、周囲の情報を取得したりコマンドを送信したりできるようにします。
-
教育・展示ガイド:博物館や展示ホールにおいて、来場者はジェスチャーで音声インタラクションをトリガーし、AI アシスタントに展示物の情報を尋ね、パーソナライズされたガイドツアーを受けることができます。
デモ動画
システムアーキテクチャ
システム全体は、reCamera 側 と PC サーバー側 の 2 つの部分が連携して完結します。アーキテクチャは次のとおりです。
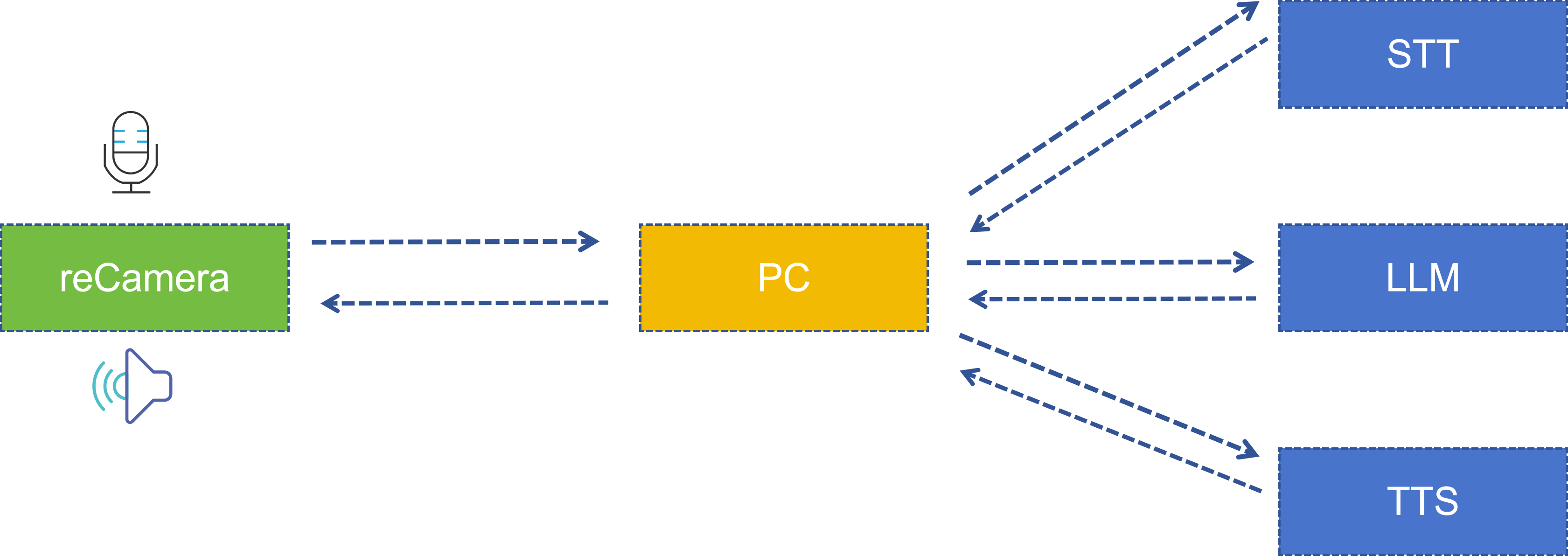
| ステージ | 実行場所 | 使用技術 / モデル | 説明 |
|---|---|---|---|
| ポーズ検出 | reCamera | YOLO11n Pose | 17 個の人体キーポイントを検出 |
| ポーズ判定 | reCamera (Node-RED Function) | カスタムロジック | 肩と肘のキーポイント間距離を比較 |
| 録音 / 再生 | reCamera | arecord / aplay | 16kHz モノラル PCM |
| 音声認識 (STT) | PC サーバー | iFlytek 音声ディクテーション API | 音声からテキストへ変換 |
| 大規模モデル推論 (LLM) | PC サーバー | Spark 大規模モデル Spark Lite | インテリジェントな応答を生成 |
| 音声合成 (TTS) | PC サーバー | iFlytek 音声合成 API | テキストから音声へ変換 |
ハードウェアの準備
このデモを実行するには、以下のハードウェアが必要です。
- reCamera デバイス 1 台(すべての reCamera バリアントに対応)
- PC 1 台(音声処理サービスを実行するため、reCamera と同一 LAN 上にある必要があります)
デプロイ要件に応じて、任意のバージョンの reCamera を選択できます。
- reCamera 2002 シリーズ (Wi-Fi)
- reCamera Gimbal
- reCamera HQ PoE (Ethernet + PoE)
注意: PoE バージョンは Wi-Fi をサポートしておらず、PoE 対応スイッチを介して同一ローカルネットワークに接続する必要があります。
| reCamera 2002 シリーズ | reCamera Gimbal | reCamera HQ PoE |
|---|---|---|
 |  |  |
デモのセットアップ
ステップ 1: reCamera の設定
まず、公式の入門ガイドに従って reCamera の基本設定を完了してください:reCamera Getting Started
初期セットアップが完了したら、デバイスの電源がオンになっており、ネットワークに正しく接続されていることを確認します。 次に、ブラウザからアドレス 192.168.42.1 にアクセスして reCamera にログインし、Node-RED ワークスペースに入ります。
下図のように Node-RED のフローインターフェースに正常にアクセスできれば、設定は完了です。

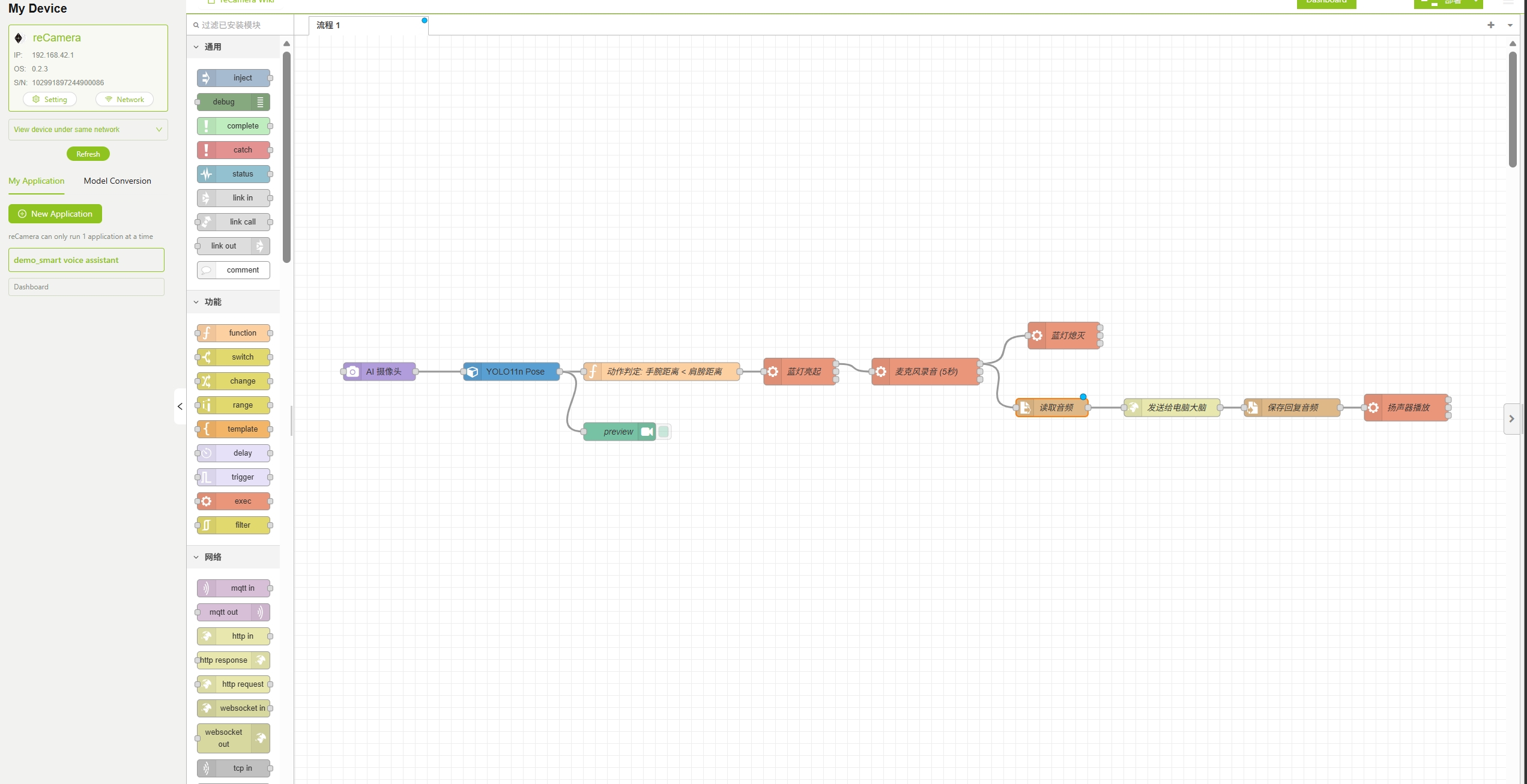
ステップ 2: Node-RED ワークフローのインポート
このデモでは、インテリジェント音声アシスタントに必要なすべてのノードと接続があらかじめ設定された、事前構成済みのワークフローファイル を提供しています。 以下の手順に従っていくつかの設定を行い、このプロジェクトを正しく実行できるようにする必要があります。
新しいアプリケーションを作成し、SenseCraft AI Platform から AI Voice Assistant のワークフローファイルをダウンロードして、reCamera に直接インポートします。SenseCraft AI のチュートリアルについては、Access SenseCraft AI reCamera Dashboard のリンクを参照してください。
下図のように Node-RED のフローインターフェースに正常にアクセスできれば、ワークフローは正常にインポートされています。
ステップ 3: ワークフローパラメータの設定
ワークフローをインポートした後、実際のネットワーク環境とシステム設定に応じて、以下の 3.1 から 3.5 のセクション内のパラメータを変更する必要があります。
3.1 Model ノード
ワークフロー内の Model ノードには、いくつかの事前学習済みモデルが用意されています。ここでさまざまなモデルパラメータを選択・設定できます。このデモでは、人のポーズを検出するために YOLO11n Pose モデルを使用します。
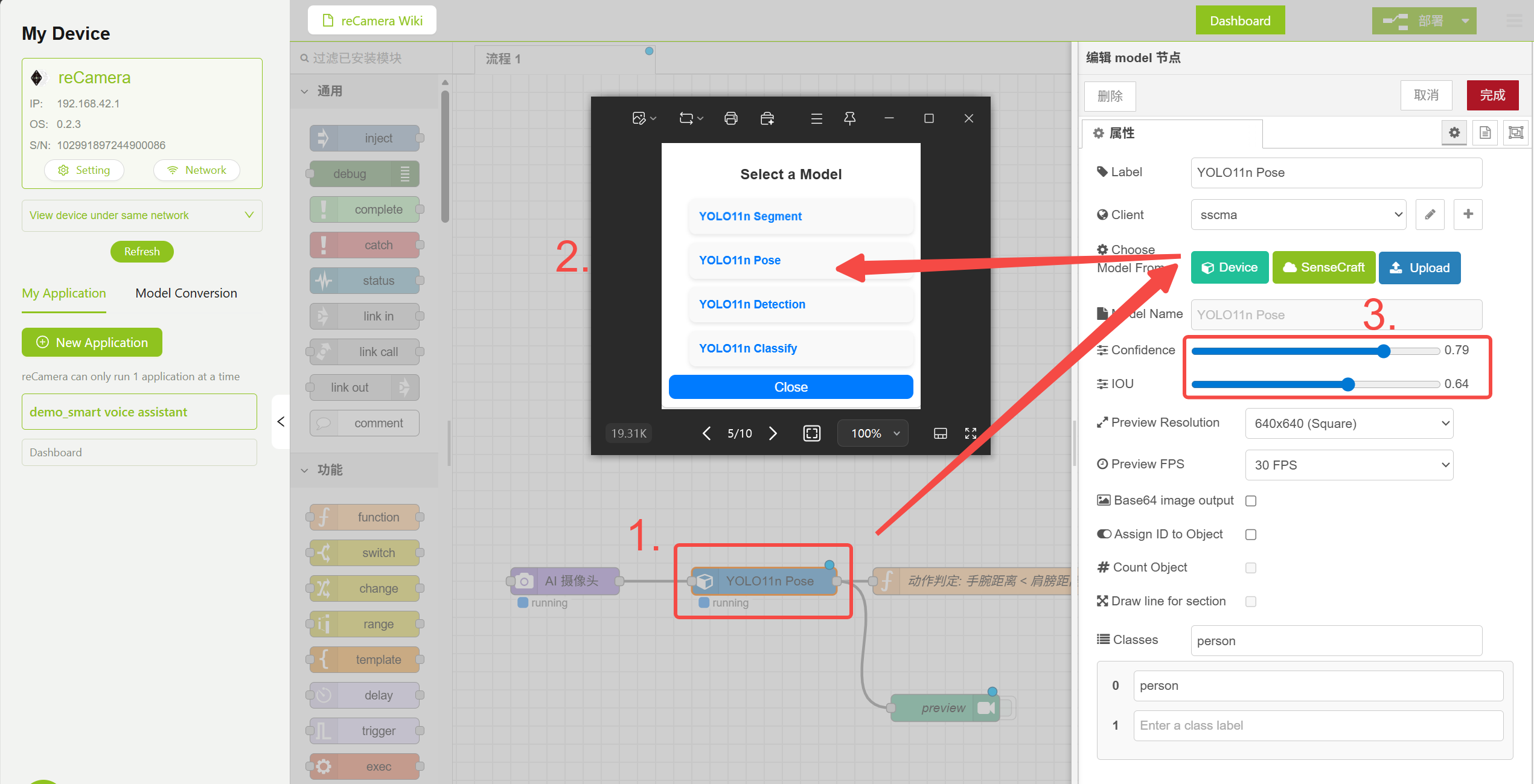
Model ノードの設定
3.2 Model ノード — ポーズ判定ロジック
Function ノードにはポーズ判定ロジックが含まれており、肩のキーポイント間距離 と 肘のキーポイント間距離 を比較して、音声インタラクションをトリガーするかどうかを判断します。Model ノード内の Confidence と IOU パラメータを調整して誤検出を減らしたり、以下の Function ノード内のロジックコードを変更して、追加機能を実装したりできます。
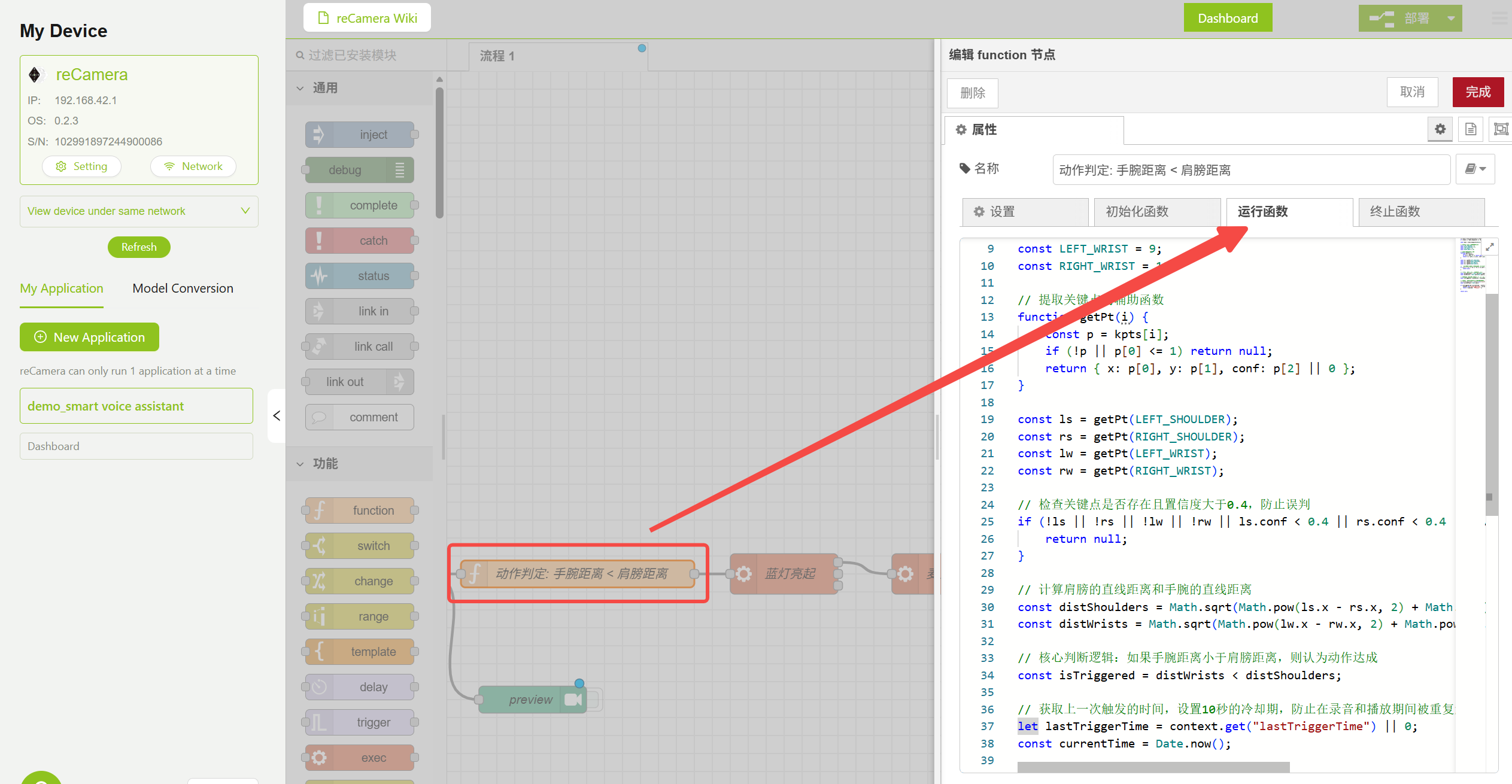
ポーズ判定 Function ノードの設定
3.3 Exec ノード — LED 制御と録音
このワークフローでは、Exec ノード を使用してシステムコマンドを実行し、LED の制御と録音を行います。該当するノードをダブルクリックし、実際の設定に合わせて reCamera の root パスワードを変更してください。
echo "your_Password" | sudo -S sh -c 'echo 1 > /sys/class/leds/blue/brightness'
- 青色 LED のオン / オフ(録音開始を示す)
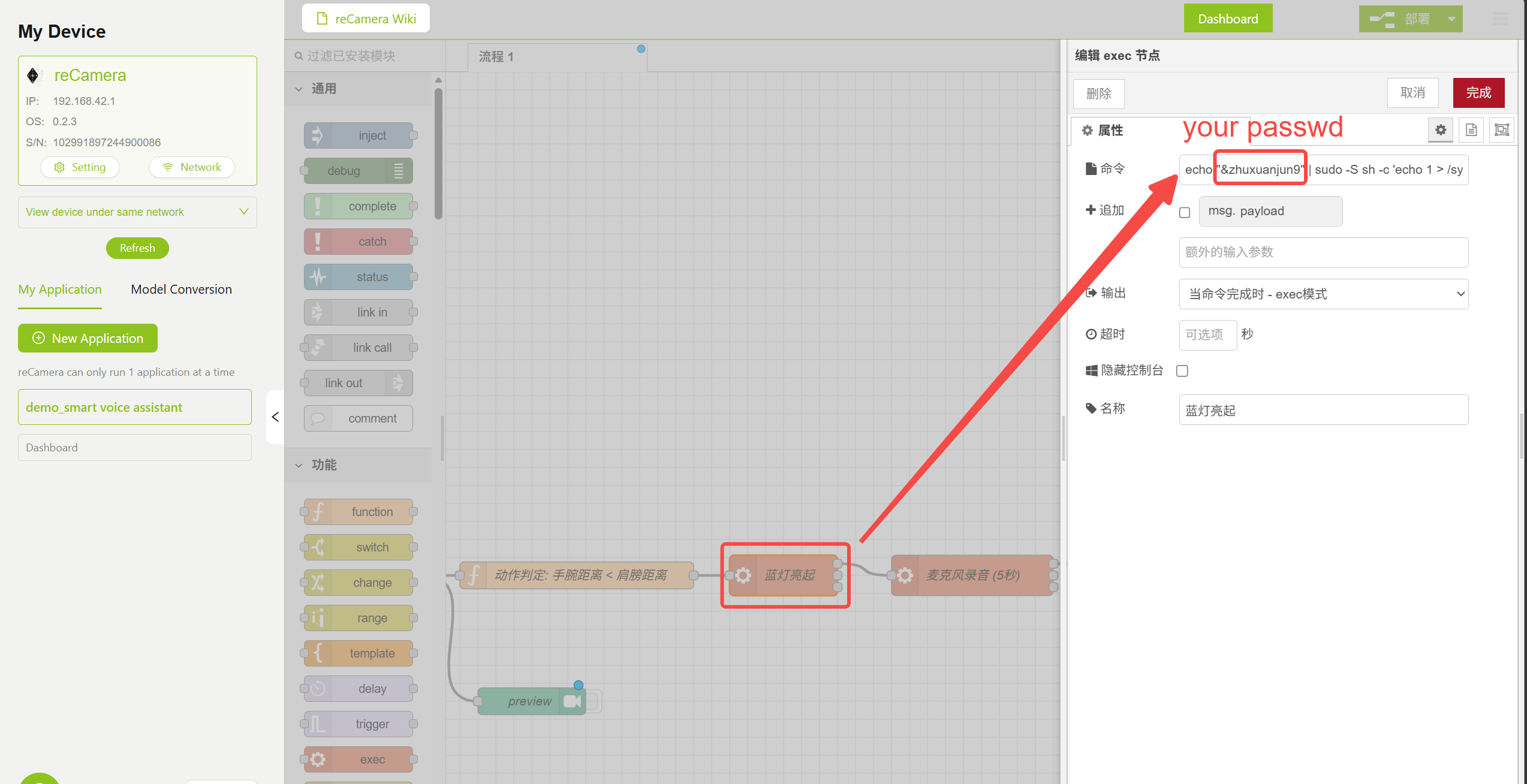
LED 点灯ノードのパラメータ設定
3.4 HTTP Request ノード — 音声送信先アドレス
ワークフロー内で HTTP Request ノードを見つけ、URL を PC サーバーのアドレスに変更します。これには、ステップ 4 を完了して先に server.py を実行しておく必要があり、その後、下図の該当箇所にアドレスを入力します。
http://<PC_IP_ADDRESS>:5000/interact
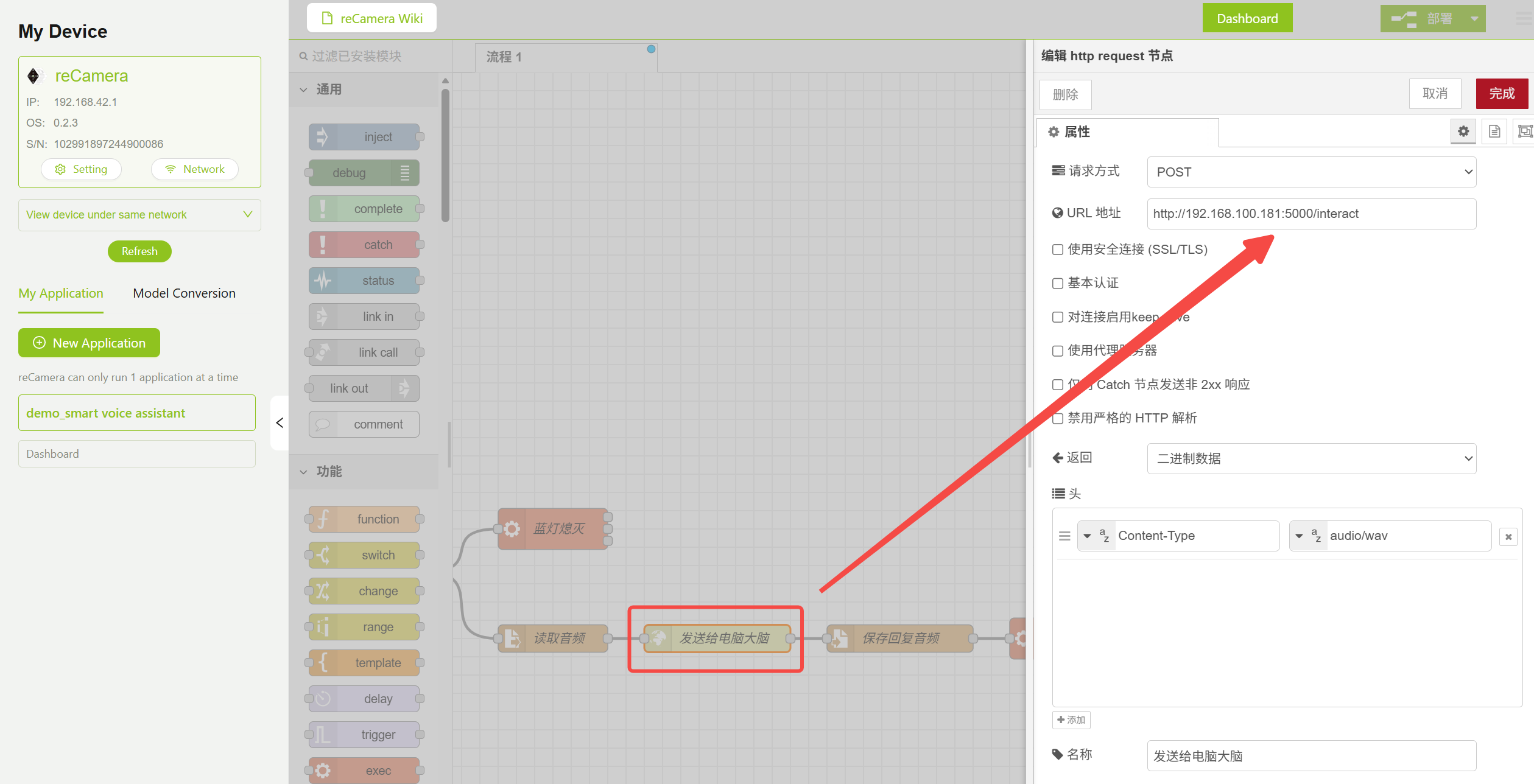
HTTP Request ノードのパラメータ設定
3.5 Exec ノード — 音声再生
返送された音声は aplay コマンドを通じて再生されます。TTS モデルの出力フォーマット(16kHz、モノラル、16 ビット)に一致するように、正しい音声パラメータを指定する必要があります。
aplay -D hw:1,0 -f S16_LE -c 1 -r 16000 /tmp/reply.wav
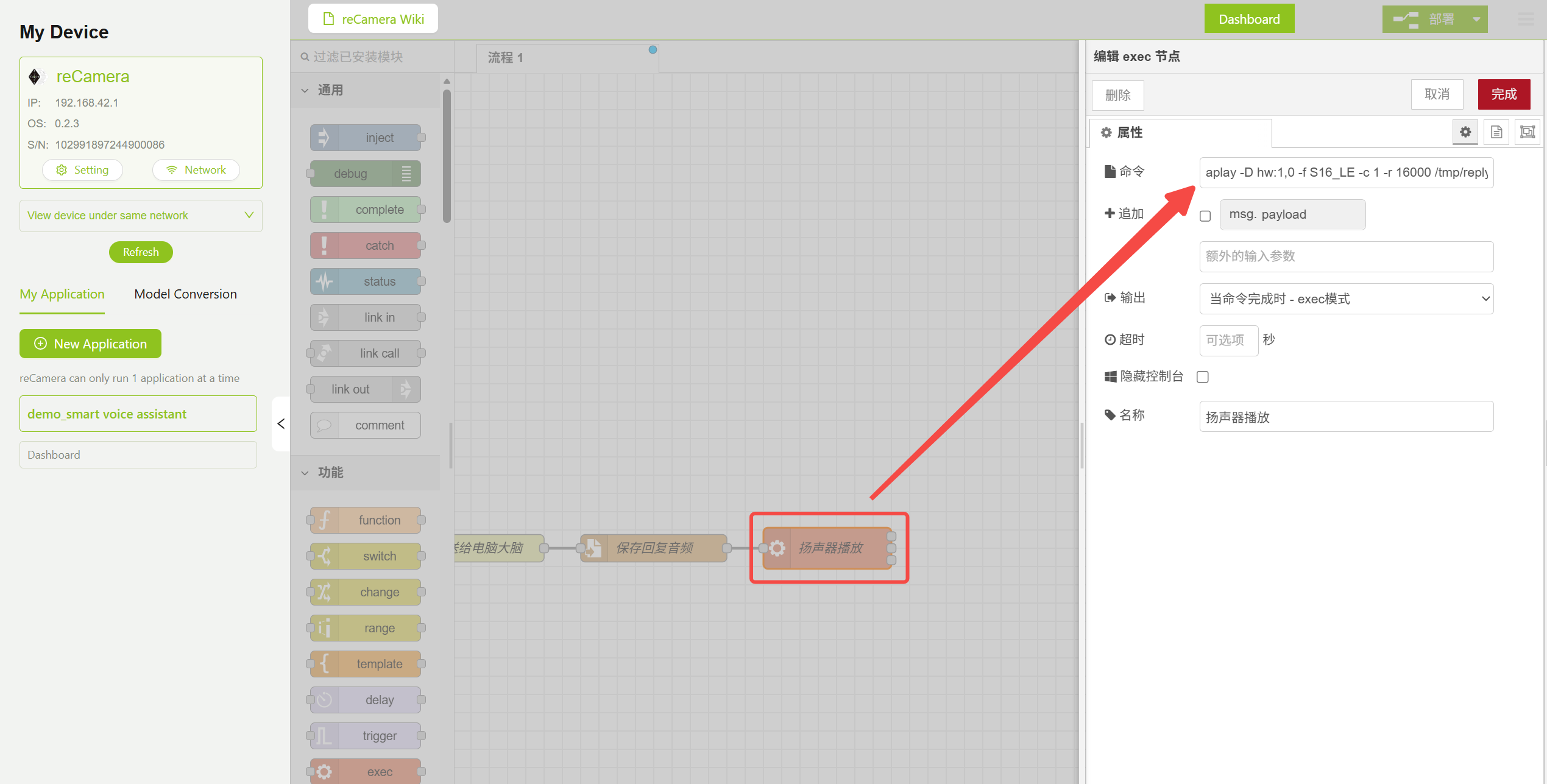
音声再生ノードのパラメータ設定
ステップ 4: PC 上に音声処理サービスをデプロイ
音声処理サービスは PC 上で動作し、STT → LLM → TTS の音声処理パイプライン全体を完了する役割を担います。
4.1 前提条件
PC に以下の環境がインストールされていることを確認してください:
- Python 3.8 以上
- pip パッケージマネージャ
4.2 コードの取得と依存関係のインストール
repository から AI Voice Assistant 用のサーバーサイド Python コードを取得します。プロジェクトコードを PC にダウンロードしたら、サービスディレクトリに移動して Python の依存関係をインストールします:
cd server/
pip install -r requirements.txt
主な依存関係は次のとおりです:
| パッケージ | 目的 |
|---|---|
| Flask | HTTP サービスフレームワーク |
| websocket-client | iFlytek API との通信 |
| certifi | SSL 証明書検証 |
| pydub | オーディオ処理 |
4.3 API キーの設定
サービスを実行する前に、iFlytek の API キーを設定する必要があります。iFlytek Open Platform にアクセスしてアカウントを登録し、次の 3 つのサービスを有効化してください:
| サービス | 目的 | 有効化リンク |
|---|---|---|
| 音声聞き取り (STT) | ユーザーの音声をテキストに変換 | iFlytek Speech Dictation |
| Spark 大規模モデル (LLM) | テキストに基づいてインテリジェントな応答を生成 | iFlytek Spark Large Model |
| 音声合成 (TTS) | 応答テキストを音声に変換 | iFlytek Speech Synthesis |
有効化後、server.py に API キーを入力します:
# 1. STT Speech Recognition Configuration
STT_APPID = "your_APPID"
STT_APISecret = "your_APISecret"
STT_APIKey = "your_APIKey"
# 2. TTS Speech Synthesis Configuration
TTS_APPID = "your_APPID"
TTS_APISecret = "your_APISecret"
TTS_APIKey = "your_APIKey"
# 3. LLM Spark Large Model Configuration (Spark Lite)
LLM_APPID = "your_APPID"
LLM_APISecret = "your_APISecret"
LLM_APIKey = "your_APIKey"
このデモでは Spark Lite モデル(無料)を使用しています。必要に応じて、より高性能なモデルバージョンに切り替えたり、他社の大規模モデルを使用したりすることもできます。
4.4 サービスの起動
python server.py

サーバー起動ログ
サービスが起動すると、reCamera からの音声リクエストを待機します。PC のファイアウォールでポート 5000 への受信接続が許可されていること、PC と reCamera が同一 LAN 上にあることを確認してください。ステップ 5: デモを実行する
- PC 上で
server.pyが起動して動作していることを確認します - Node-RED で Deploy をクリックしてフローをデプロイします
- reCamera の前に立ち、腕組み のジェスチャーを行います(肩の距離が肘の距離より短い状態)
- reCamera の 青色 LED が点灯し、録音開始を示します
- マイクに向かって質問を話します
- 青色 LED が消灯すると、reCamera は音声をサーバーに送信し、応答を受信した後に再生します。
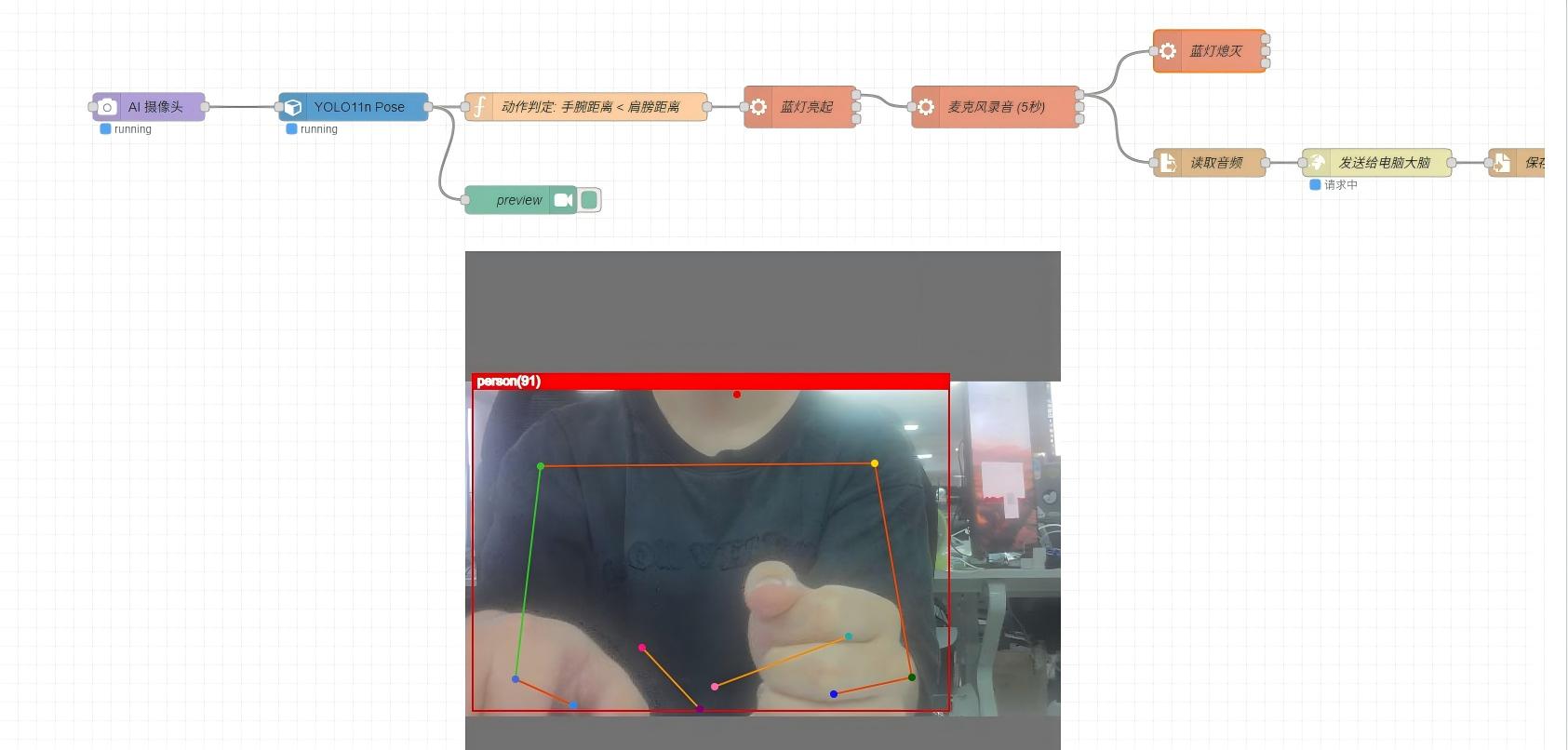
音声対話フローのトリガー
Received reCamera audio,length:160044 bytes
User said:Hi,who are you?
LLM is thinking……
LLM reply:Hi,I′m the voice assistant on your smart camera reCamera.I'm here to help you with any questions or concerns you may have.
Generating speech……
Speech delivered! Waiting for next interaction.
192.168.4.53--[11/Jun/2026 16:38:14]"POST /interact HTTP/1.1" 200 -

サーバーログ
ワークフローの詳細
全体のワークフローの高レベルなロジックは次のとおりです:
-
ビデオ入力とポーズ検出 カメラが連続的にビデオフレームを取得し、YOLO11 ポーズ推定モデルが人体のキーポイント(肩、肘、手首など合計 17 点)を検出します。
-
ジェスチャートリガー判定 Function ノードが左右の肩のキーポイント間の距離と、左右の肘のキーポイント間の距離を計算します。肩の距離 < 肘の距離 のとき、トリガージェスチャー(腕組みポーズ)と判定します。
-
録音プロセス トリガー後:青色 LED を点灯 → 音声を録音 → 青色 LED を消灯。
-
音声処理と対話生成 録音完了後、オーディオデータは HTTP Request を介して PC 上の Flask サービスに POST され、次を実行します:
- STT: iFlytek Speech Dictation API が音声をテキストに変換
- LLM: Spark 大規模モデル (Spark Lite) がユーザー入力に基づいてインテリジェントな応答を生成
- TTS: iFlytek Speech Synthesis API が応答テキストを音声に変換
-
音声再生 PC は WAV オーディオを返し、reCamera は
aplayコマンドで応答音声を再生します。
注意事項
- 現在の録音間隔は 10 秒 に設定されています。STT → LLM → TTS の処理時間がこの間隔を超える場合、複数回のトリガーによってパイプラインが輻輳する可能性があります。処理時間を短縮するため、LLM の応答語数を制御することを推奨します(現在のシステムプロンプトでは 50 語以下に制限しています)。
- 輻輳によって CPU が応答しなくなる場合は、Model ノードの Confidence 属性を調整して誤検出を減らし、トリガー頻度を制御してください。
aplayで返却された音声を再生する際は、必ず正しいパラメータ(-f S16_LE -c 1 -r 16000)を指定してください。そうしないと、正常に再生されない場合があります。具体的なパラメータについては、TTS で生成された音声を参照してください。
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。特定のカスタマイズ目標に関するガイダンスが必要な場合や、ワークフローをさらに拡張したい場合は、いつでもお気軽にお問い合わせください。製品をできるだけスムーズにご利用いただけるよう、さまざまなレベルのサポートを提供しています。お好みやニーズに応じて選べる複数のコミュニケーションチャネルをご用意しています。