GPT-OSS reComputer Jetson上でのライブ実行
はじめに
これは単純な技術移植の演習をはるかに超えたものです - エッジで何が可能かを探求するものです。この記事では、20Bパラメータのオープンソース大規模言語モデルが、Nvidia Jetson Orin Nxのようなエッジデバイス上でどのように動作するかを実演します。

NVIDIA Jetsonシリーズは、優れた電力効率とコンパクトなフォームファクターで有名な、プレミアムエッジコンピューティングプラットフォームとして位置づけられています。一方、GPT-OSS-20Bは、自由に利用可能なオープンソース大規模言語モデルの最先端を表しています。これらの融合は、エッジデバイスの未開拓の可能性を示すだけでなく、オフラインAIアプリケーションの新しい可能性を開拓します。
前提条件
- reComputer Super J4012
このwikiでは、reComputer Super J4012を使用して以下のタスクを実行しますが、他のJetsonデバイスを使用して試すこともできます。

後続のステップでは、Jetson上で複数のPython環境を設定することになります。JetsonデバイスにCondaをインストールすることをお勧めします:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
llama.cppのインストール
まず、Jetsonにllama.cpp推論エンジンをインストールする必要があります。JetsonのターミナルウィンドウでNext以下のコマンドを実行してください。
sudo apt update
sudo apt install -y build-essential cmake git
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel
コンパイル後、llama.cppのすべての実行可能ファイルがbuild/binに生成されます。
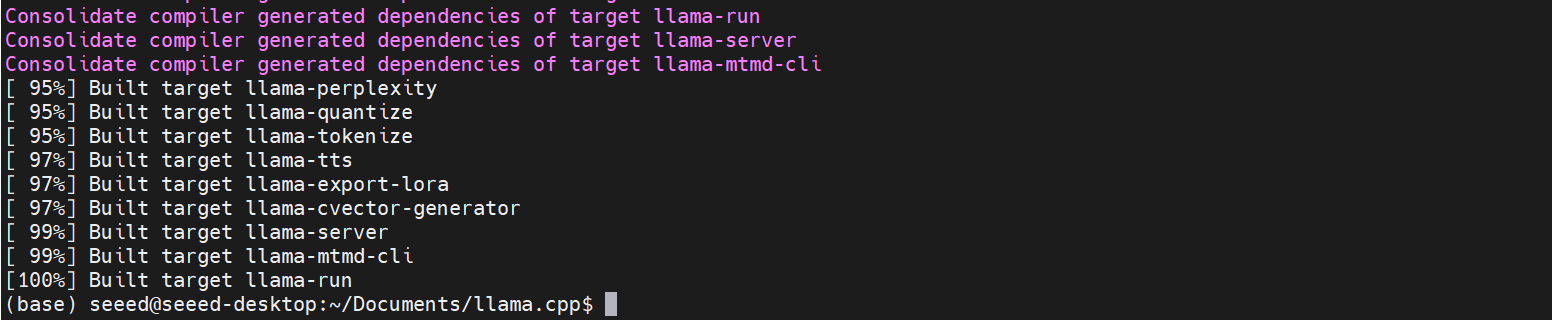
ビルドプロセスは通常約2時間かかります。
GPT-OSSモデルの準備
ステップ1. HuggingfaceからGPT-OSS-20Bをダウンロードし、Jetsonにアップロードします。

ステップ2. モデル変換に必要な依存関係をインストールします。
conda create -n gpt-oss python=3.10
conda activate gpt-oss
cd /home/seeed/Documents/llama.cpp # cd `path_of_llama.cpp`
pip install .
ステップ3. モデル変換プロセスを実行します。
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <path_of_input_model> <path_of_output_model>
ステップ4. モデル量子化。
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <path_of_f16_gguf_model> <path_of_output_model> <quantization_method>
llama.cppでGPT-OSSを起動する
これで、Jetsonターミナルで推論プログラムの起動を試すことができます。
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
必要に応じてモデルパスを置き換えてください。
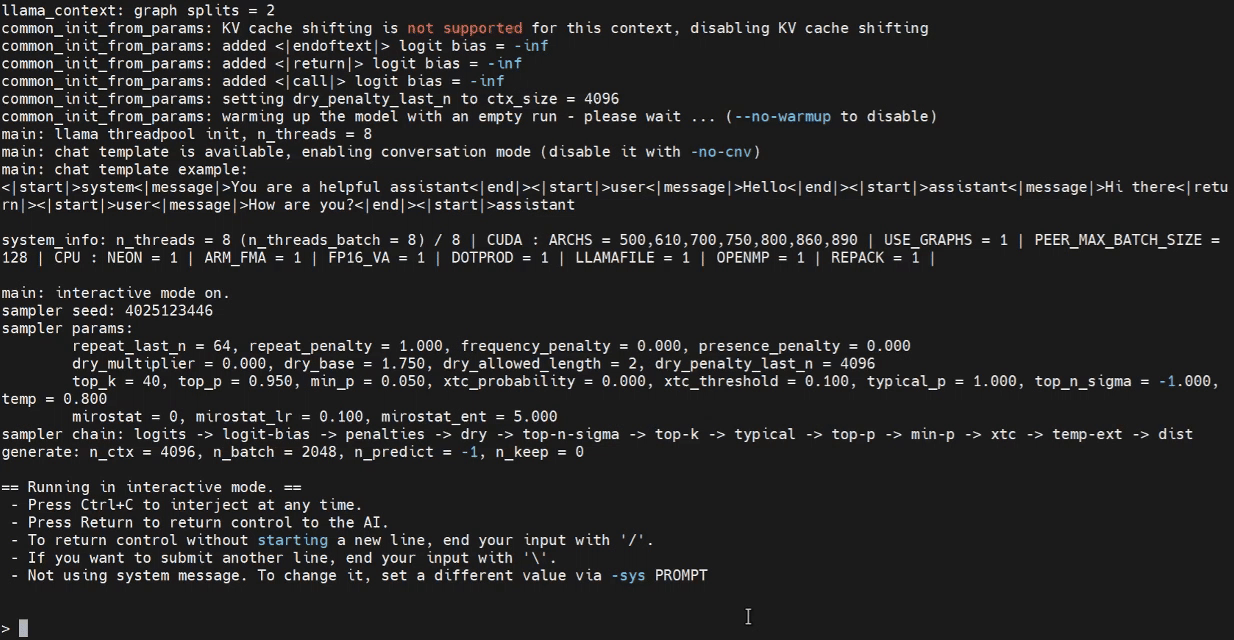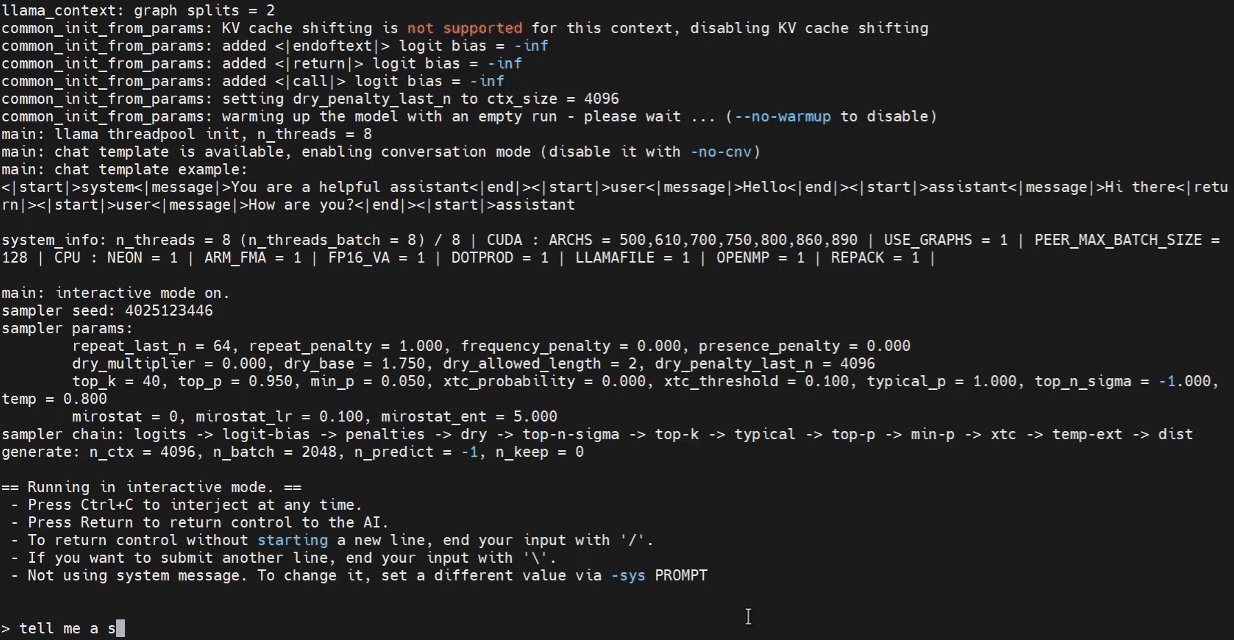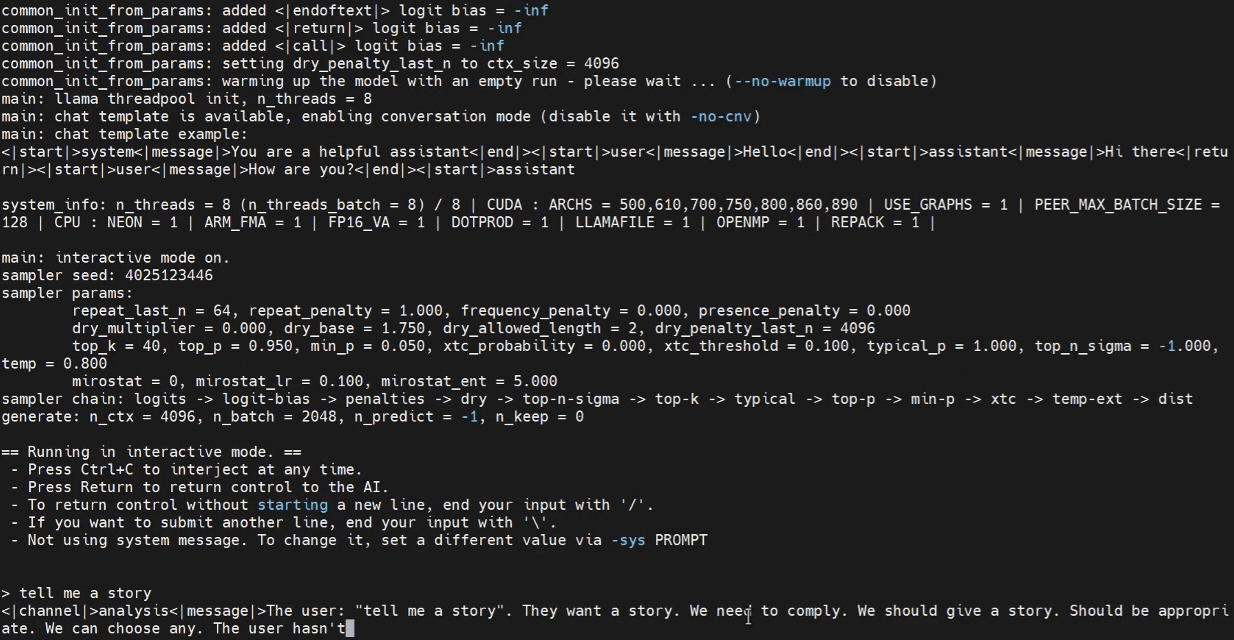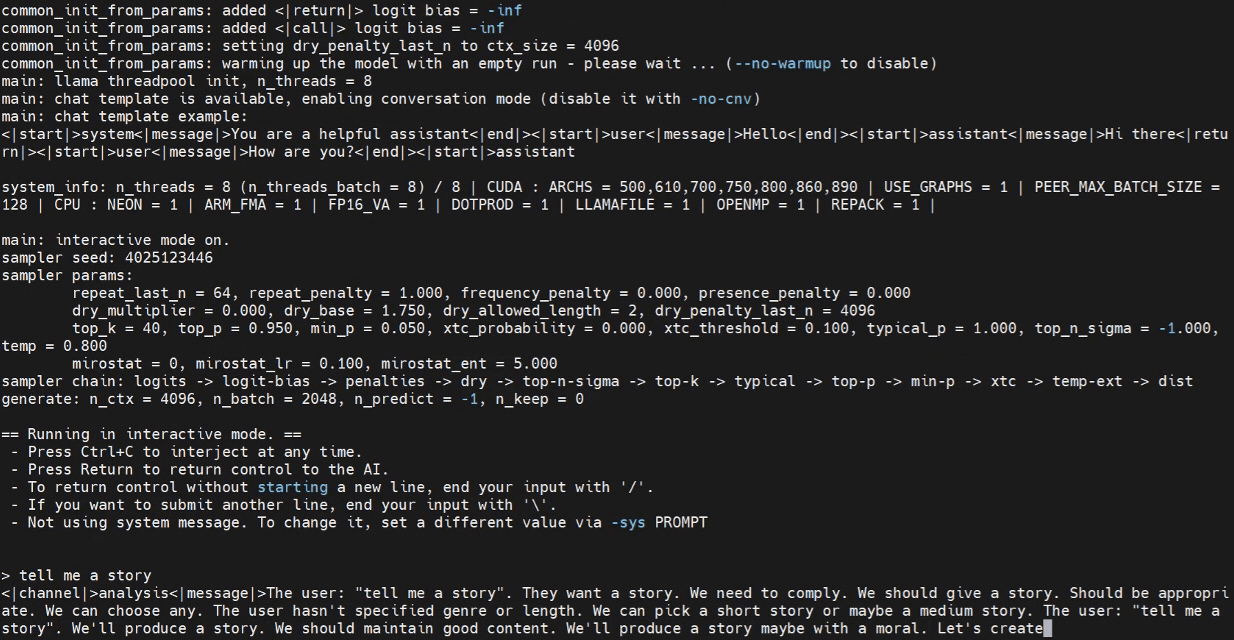
WebUIでの推論(オプション)
UIインターフェースを通じてモデルにアクセスしたい場合は、Jetson上にOpenWebUIをインストールしてこれを実現できます。 Jetsonで新しいターミナルを開き、以下のコマンドを入力してください:
conda create -n open-webui python=3.11
conda activate open-webui
pip install open-webui
open-webui serve
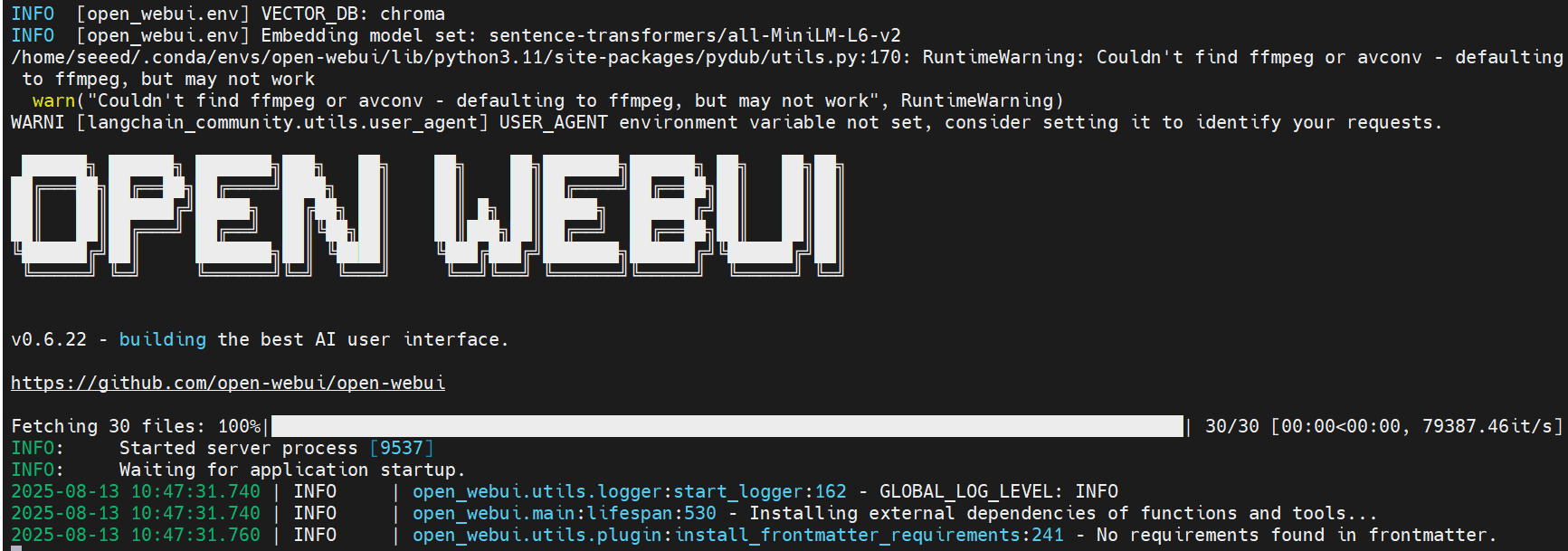
OpenWebUIの起動により依存関係がインストールされ、モデルがダウンロードされます —— しばらくお待ちください。
セットアップが完了すると、ターミナルに以下のようなログが表示されるはずです。
次に、ブラウザを開いて http://<ip-of-jetson>:8080 にアクセスし、Open WebUIを起動します。
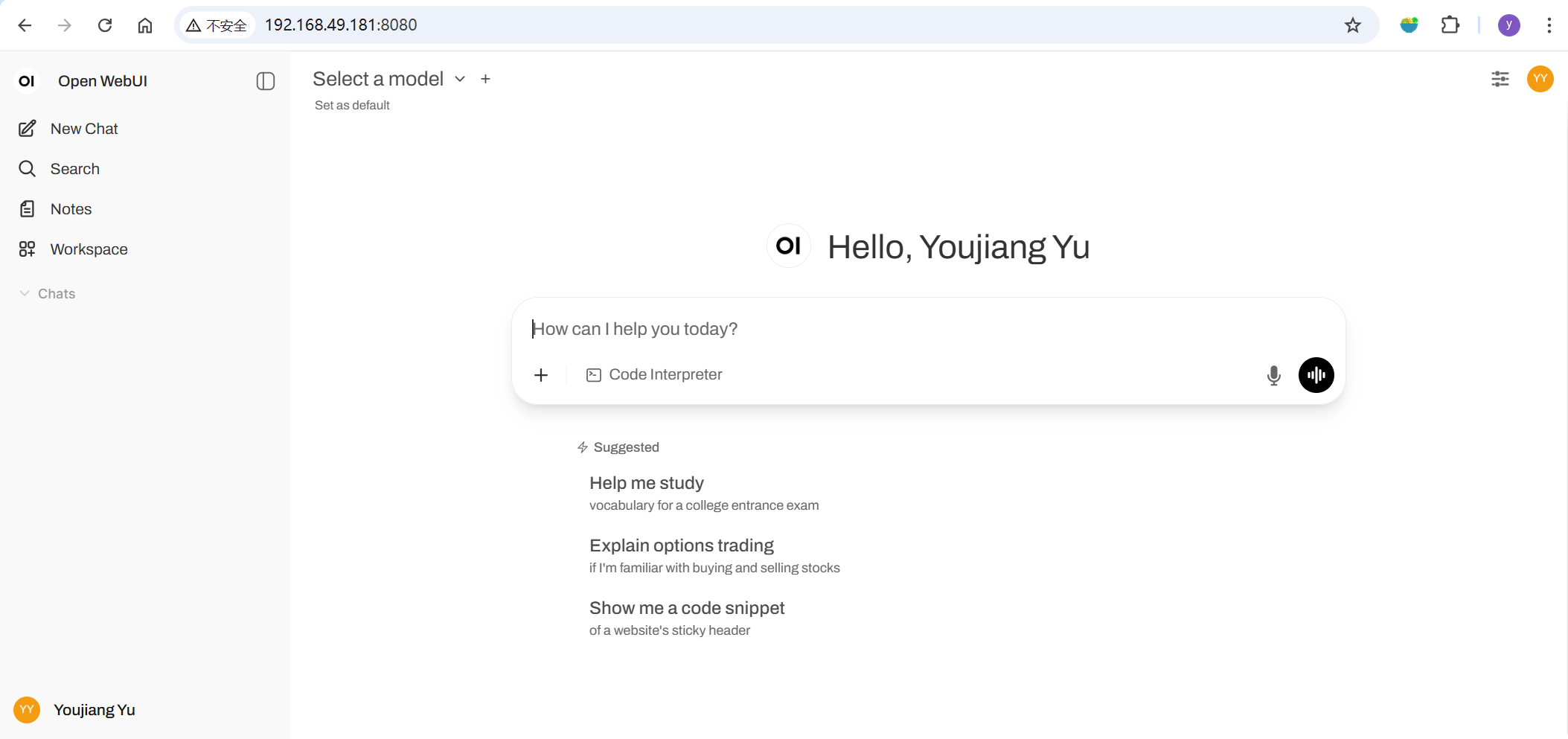
初回起動の場合は、指示に従ってアカウントを設定してください。
⚙️ 管理者設定 → 接続 → OpenAI接続に移動し、URLを http://127.0.0.1:8081 に設定します。保存すると、Open WebUIはローカルのLlama.cppサーバーをバックエンドとして使用し始めます!
効果実演
最後に、NVIDIA Jetson Orin NX上でのGPT-OSS-20Bモデルの実際の推論性能を動画デモンストレーションで紹介します。
参考文献
- https://hyd.ai/2025/03/07/llamacpp-on-jetson-orin-agx/
- https://docs.openwebui.com/getting-started/quick-start/starting-with-llama-cpp
- https://github.com/open-webui/open-webui
- https://huggingface.co/openai/gpt-oss-20b
- https://www.seeedstudio.com/tag/nvidia.html
技術サポート & 製品ディスカッション
弊社製品をお選びいただき、ありがとうございます!弊社製品での体験が可能な限りスムーズになるよう、さまざまなサポートを提供いたします。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルをご用意しています。