Jetpack6.2 に TensorRT Edge-LLM をデプロイする
TensorRT Edge-LLM とは?
TensorRT Edge-LLM は、組み込みプラットフォーム上で大規模言語モデル(LLM)および Vision-Language Model(VLM)を推論するための、NVIDIA の高性能な C++ 推論ランタイムです。NVIDIA Jetson や NVIDIA DRIVE プラットフォームなどのリソース制約のあるデバイス上で、最先端の言語モデルを効率的にデプロイすることができます。
TensorRT Edge-LLM は、幅広い最先端モデルをサポートしています:
-
大規模言語モデル:Llama 3.x、Qwen 2/2.5/3、DeepSeek-R1 Distilled
-
Vision-Language Model:Qwen2/2.5/3-VL、InternVL3-1B-hf、InternVL3-2B-hf、Phi-4-Multimodal
-
量子化:FP16、FP8(SM89+)、INT4 AWQ/GPTQ、NVFP4(SM100+)
サポートされているモデルの完全な一覧、精度要件、およびプラットフォーム互換性については、Supported Models を参照してください。https://nvidia.github.io/TensorRT-Edge-LLM/0.6.0/user_guide/getting_started/supported-models.html
TensorRT Edge-LLM は主に JetPack 7.x ソフトウェアスタック向けに設計されています。しかし、NVIDIA は専用の互換リリースを通じて JetPack 6.2 への互換性サポートを公式に文書化しています。本ガイドでは、JetPack 6.2 上で TensorRT Edge-LLM をデプロイし、検証するためのワークフローについて説明します。
JetPack 6.2 システムに対しては、TensorRT Edge-LLM v0.6.0 が推奨かつ検証済みのリリースです。
デプロイのワークフローは、次の 2 段階で構成されます:
-
x86 Linux ホストでのモデル準備
NVIDIA GPU を搭載した x86 Linux ワークステーション上で、対象の大規模言語モデル(LLM)を量子化し、TensorRT Edge-LLM ツールチェーンを使用して ONNX 形式にエクスポートします。
-
Jetson 上でのエンジン生成
エクスポートされた ONNX モデルを Jetson デバイスに転送し、TensorRT Edge-LLM によってデプロイとランタイム実行用の最適化された TensorRT 推論エンジンを生成します。
パート 1:モデル準備(GPU 搭載 x86 ホスト)
Python エクスポートパイプラインは、モデルの変換と量子化を行います。これは NVIDIA GPU を搭載した x86 Linux システム上で実行する必要があります。
システム要件
-
プラットフォーム:x86-64 Linux システム
-
推奨 OS:Ubuntu 22.04, 24.04
-
GPU:Compute Capability 8.0 以上(Ampere 以降)の NVIDIA GPU
-
CUDA:12.x または 13.x
-
Python:3.10 以上
メモリ要件(デプロイしたいモデルのサイズに依存します)
GPU メモリ(VRAM):
-
一般的な目安:ほとんどの処理でモデルサイズの約 2~3 倍、FP8 ONNX エクスポートではモデルサイズの約 5~6 倍
-
小規模モデル(0.6B~3B):8~16GB
-
大規模モデル(7B~8B):20~48GB
-
超大規模モデル(13B 以上):48GB 以上
CPU メモリ(RAM):
-
一般的な目安:ほとんどの処理でモデルサイズの約 2~3 倍、FP8 ONNX エクスポートでは 約 18~20 倍 のモデルサイズ
-
小規模モデル(0.6B~3B):8~16GB(FP8 ONNX エクスポートでは 48GB 以上)
-
大規模モデル(7B~8B):20~48GB(FP8 ONNX エクスポートでは 128GB 以上)
-
超大規模モデル(13B 以上):48GB 以上
注: FP8 ONNX エクスポートでは、内部処理のために現在、CPU(モデルサイズの最大 20 倍)および GPU(モデルサイズの最大 6 倍)のメモリを大幅に多く必要とします。これは既知の問題であり、現在積極的に最適化が進められています。
インストール
-
リポジトリをクローン
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
Python パッケージをインストール
仮想環境の使用を推奨します:
python3 -m venv venv
source venv/bin/activateその後、ソフトウェアをインストールします:
pip3 install . -
インストールを検証
tensorrt-edgellm-export-llm --help
tensorrt-edgellm-quantize-llm --help
パラメータの説明が表示されれば、TensorRT Edge-LLM は正常にインストールされています。
エクスポートと量子化
軽量な例として Qwen3-0.6B を使用してみましょう:
注:実際のコマンドは、特定のフォルダ構成によって異なる場合があります。
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
mkdir -p $WORKSPACE_DIR
cd $WORKSPACE_DIR
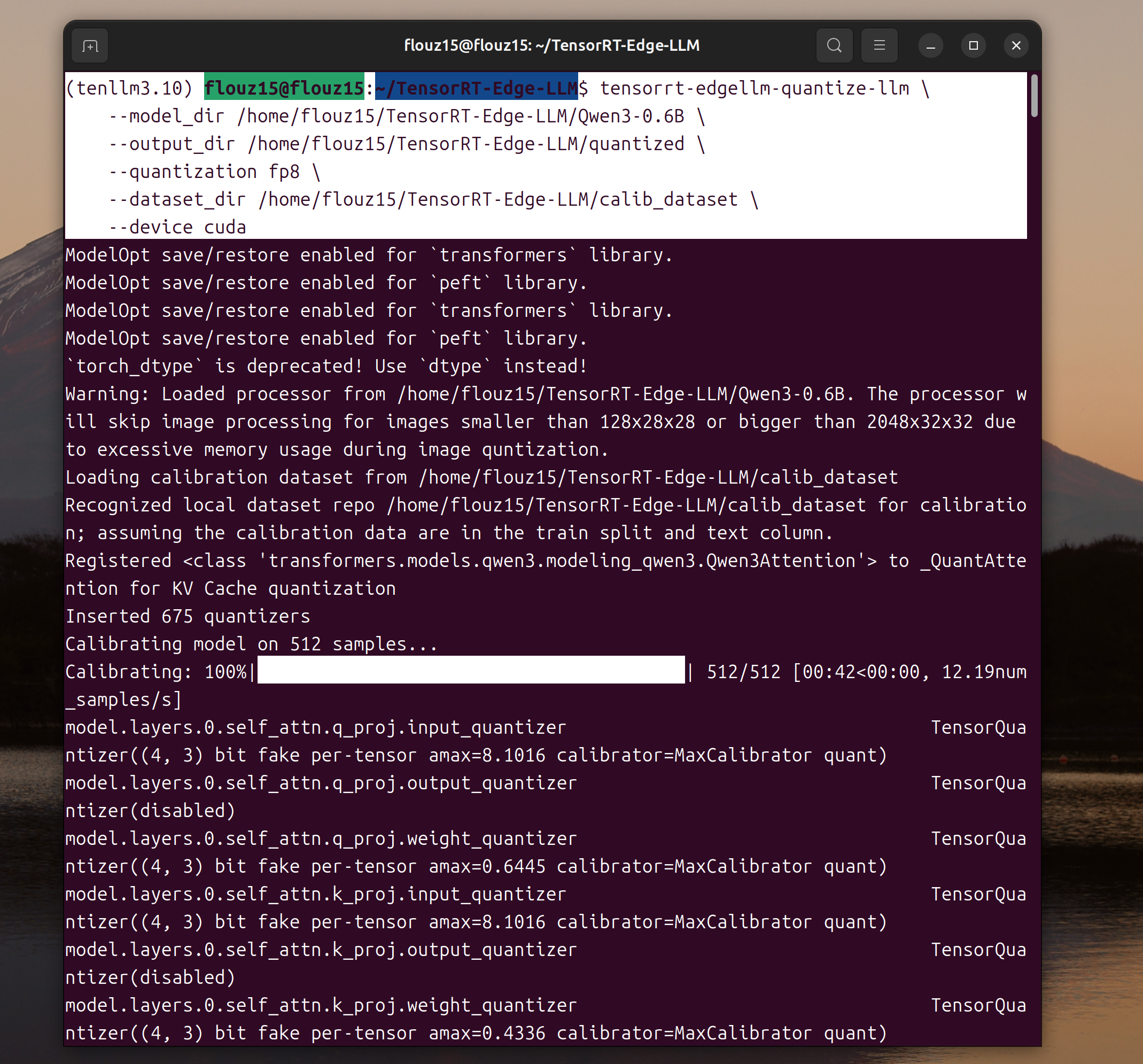
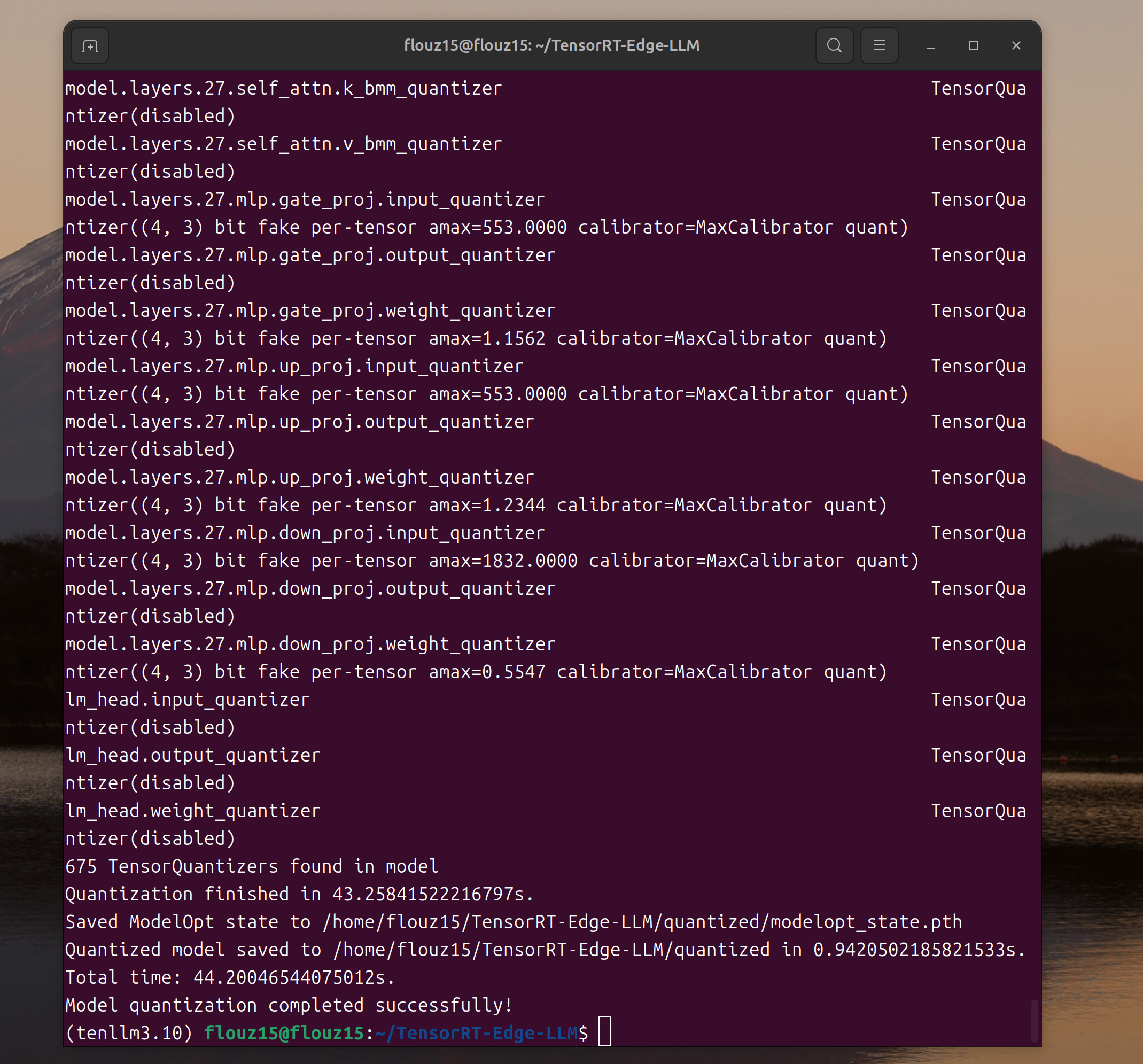
# Step 1: Quantize to FP8 (downloads model automatically)
tensorrt-edgellm-quantize-llm \
--model_dir Qwen/Qwen3-0.6B \
--output_dir $MODEL_NAME/quantized \
--quantization fp8
# Step 2: Export to ONNX
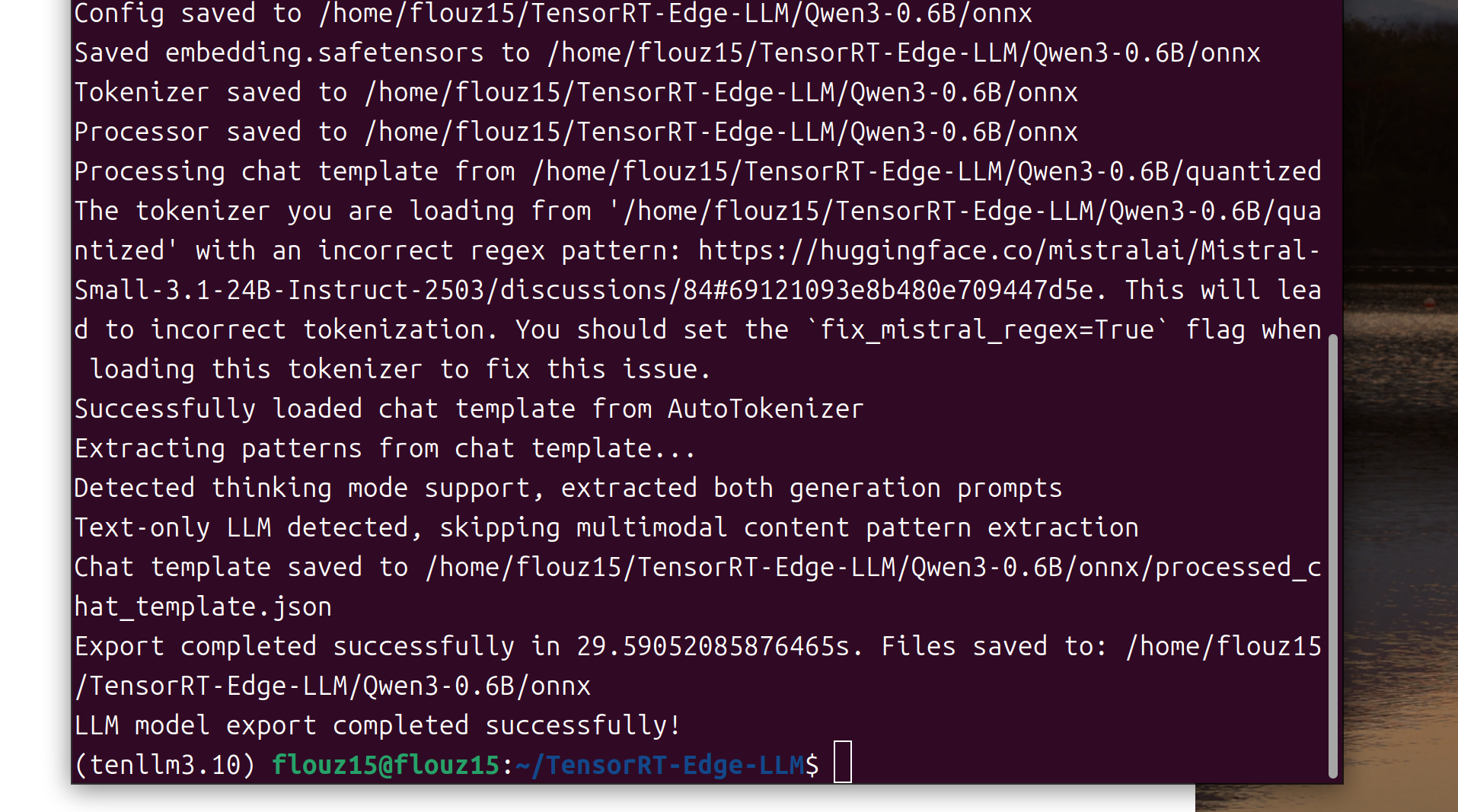
tensorrt-edgellm-export-llm \
--model_dir $MODEL_NAME/quantized \
--output_dir $MODEL_NAME/onnx
パート 2:エンジン生成(エッジ Jetson デバイス)
C++ ランタイムは、ターゲットのエッジデバイス上でモデルをビルドおよび実行します。これはターゲットプラットフォーム上、またはターゲットプラットフォーム向けにビルドする必要があります。
システム要件
ターゲットプラットフォーム:
-
NVIDIA Jetson Orin NX SUPER 16GB
-
JetPack 6.2
-
ディスク容量:ONNX ファイルおよび TensorRT エンジン用に 20~50GB
インストールとビルド
-
システム依存パッケージをインストール(エッジデバイス上)
sudo apt update
sudo apt install -y \
cmake \
build-essential \
git -
CUDA と TensorRT のインストールを確認
JetPack をインストールすると、TensorRT は /usr にインストールされているはずです
CUDA バージョンを確認
nvcc --version # Should show CUDA 12.6 -
リポジトリをクローン(エッジデバイス上)
cd ~
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
ビルドを構成
Jetson Thor デバイス上で、次のコマンドを使用してビルドを構成します:
mkdir build
cd build
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DTRT_PACKAGE_DIR=/usr \
-DCMAKE_TOOLCHAIN_FILE=cmake/aarch64_linux_toolchain.cmake \
-DEMBEDDED_TARGET=jetson-orin -
プロジェクトをビルド
make -j$(nproc)ビルド時間:ハードウェアに応じて約 1~2 分。
ビルドを検証
# Test C++ examples
./examples/llm/llm_build --help
./examples/llm/llm_inference --help
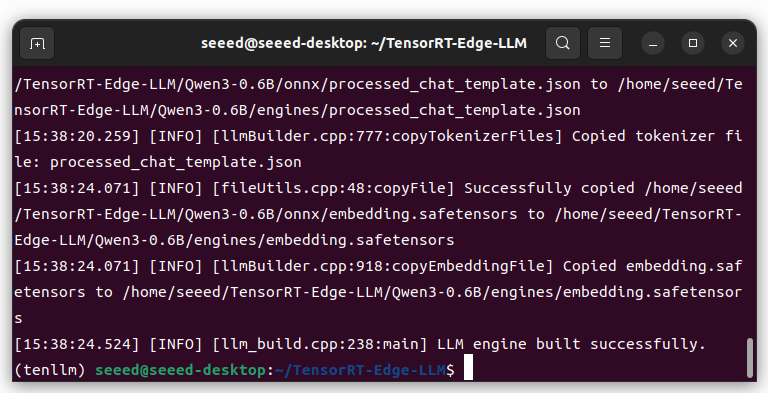
TensorRT エンジンをビルド
ホスト PC 上で生成された ONNX モデルディレクトリを Jetson デバイスにコピーします。
Jetson 上で:
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
cd ~/TensorRT-Edge-LLM
# Build engine
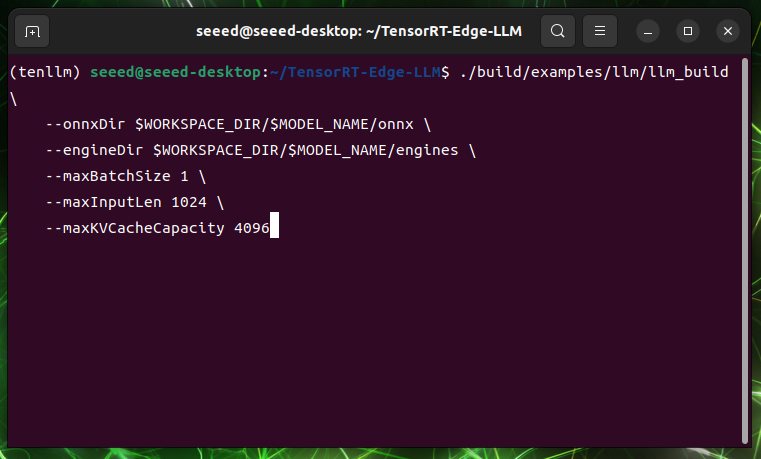
./build/examples/llm/llm_build \
--onnxDir $WORKSPACE_DIR/$MODEL_NAME/onnx \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--maxBatchSize 1 \
--maxInputLen 1024 \
--maxKVCacheCapacity 4096
推論を実行
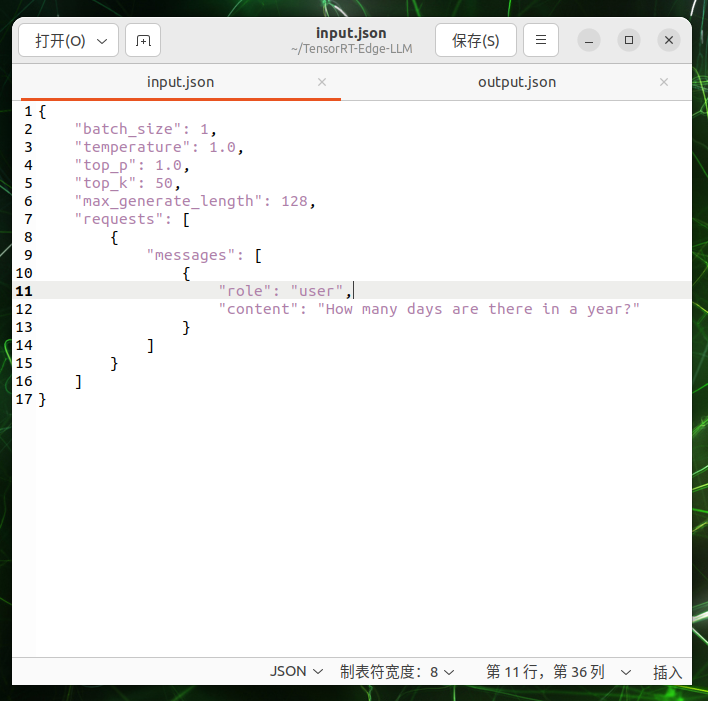
サンプルの質問を含む入力ファイルを作成します:
cat > $WORKSPACE_DIR/input.json << 'EOF'
{
"batch_size": 1,
"temperature": 1.0,
"top_p": 1.0,
"top_k": 50,
"max_generate_length": 128,
"requests": [
{
"messages": [
{
"role": "user",
"content": "What is the capital of United States?"
}
]
}
]
}
EOF
"content"は LLM への入力です。エンジンを実行します:
cd ~/TensorRT-Edge-LLM
./build/examples/llm/llm_inference \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--inputFile $WORKSPACE_DIR/input.json \
--outputFile $WORKSPACE_DIR/output.json
出力を確認します:
# View the model response
cat $WORKSPACE_DIR/output.json
モデルの回答を含む JSON レスポンスが、次のように表示されるはずです:
{
"responses": [
{
"text": "The capital of the United States is Washington, D.C.",
"finish_reason": "stop"
}
]
}
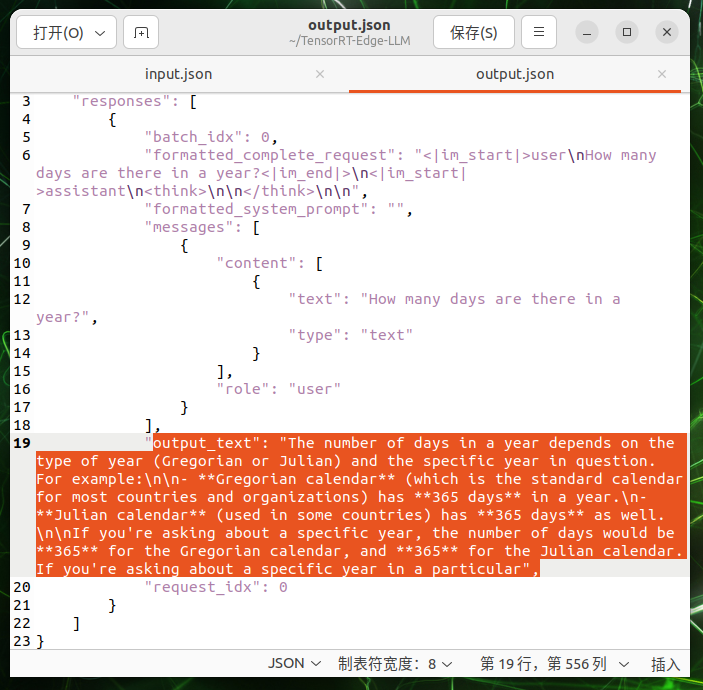
成功です! 🎉 エッジデバイス上で LLM 推論を実行することに成功しました!
技術サポートと製品ディスカッション
弊社製品をお選びいただきありがとうございます。私たちは、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じてお選びいただけるよう、複数のコミュニケーションチャネルをご用意しています。