reBot Arm 向け GR00T N1.7 のファインチューニングと Jetson Thor へのデプロイ
はじめに
この Wiki では、NVIDIA Isaac GR00T N1.7 をファインチューニングして reBot Arm B601 DM に対応させ、TensorRT アクセラレーションを用いて reComputer Robotics J601 上にデプロイする方法を説明します。
NVIDIA GR00T N1.7 は、最先端のエンドツーエンド Vision-Language-Action (VLA) 基盤モデルとして、エンボディドインテリジェンスの進化における大きな飛躍を示します。知覚と実行のギャップをシームレスに橋渡しし、ロボットが複雑な視覚入力や音声指示を、現実世界での物理的な動作へと直接変換できるようにします。新しい Cosmos Reason2-2B ビジョン・ランゲージモデルによって強化された GR00T N1.7 は、これまでにないレベルの環境認識を実現し、最先端の DiT (Diffusion Transformer) アクションデコーダにより、非常にスムーズなアクション生成と、現実世界の外乱に対する極めて高いロバスト性を提供します。

ハードウェア要件
- NVIDIA Jetson Thor(JetPack 7.x インストール済み)を搭載した reComputer Robotics J601
- reBot Arm B601 DM
- reBot Arm B601‑DM Leader 用 Star Arm 102
- USB-to-CAN アダプタ
- USB カメラ x2
- ロボットアーム用の電源および USB ケーブル
ハードウェア接続
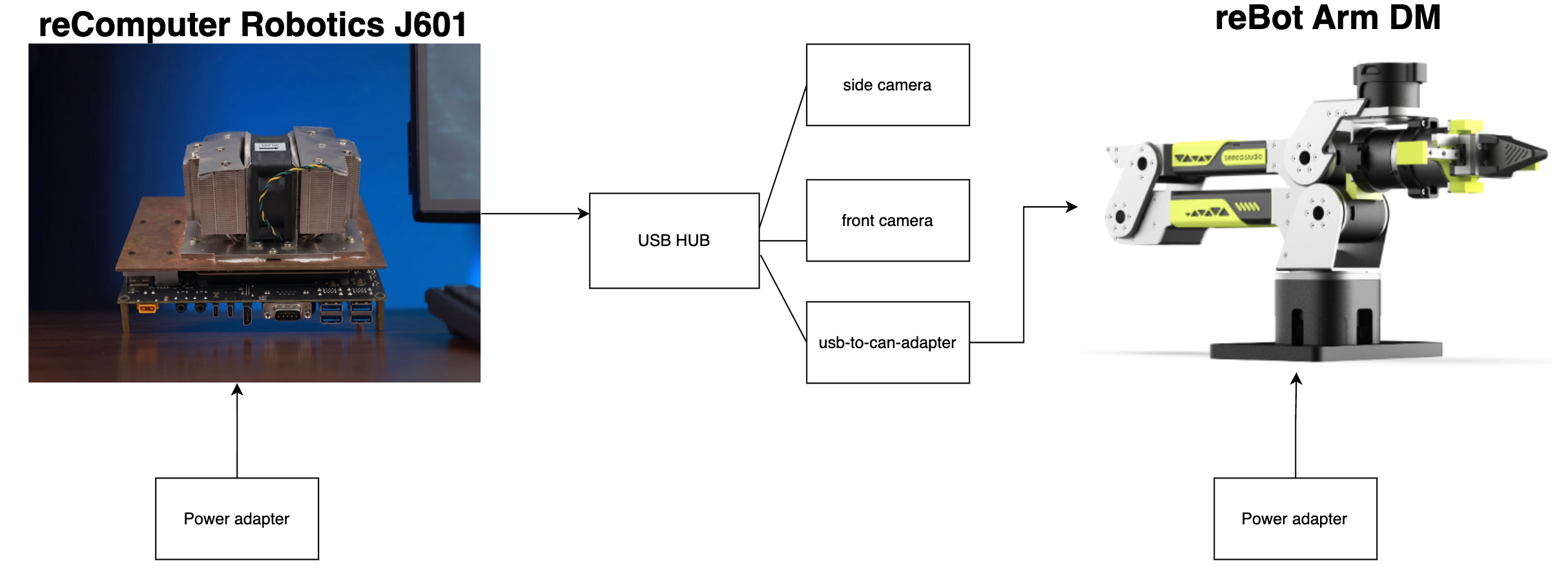
データ収集
独自の VLA モデルをデプロイしたい場合、まずはタスクに適したデータセットを収集してモデルをファインチューニングし、クロールタスクに適応できるようにする必要があります。環境構築とデータ収集については、この Wiki を参照してください。
モデルのファインチューニング
Python 環境の準備
ファインチューニング用サーバー(GPU 搭載 x86)上で、リポジトリをクローンし環境をセットアップします:
sudo apt install git-lfs && git lfs install
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
sudo apt-get update && sudo apt-get install -y ffmpeg
uv sync --python 3.10
cd /examples/SO100/
uv pip install -e .
データセット変換
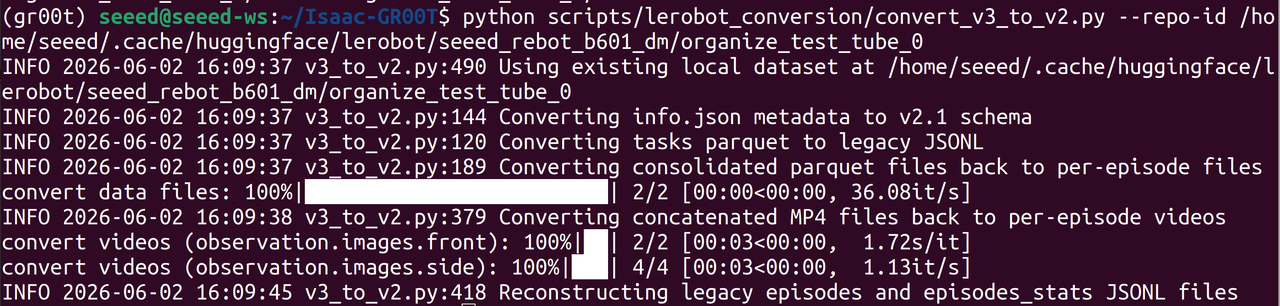
LeRobot フレームワークで収集したデータセットは v3.0 形式ですが、GR00T が必要とするのは v2.0 形式です。Isaac-GR00T リポジトリに含まれる変換スクリプトを実行します:
cd <path-to-isaac-gr00t>
uv run --project scripts/lerobot_conversion \
python scripts/lerobot_conversion/convert_v3_to_v2.py \
--repo-id /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/organize_test_tube
ファイルパスは自身のデータセットパスに置き換えてください。
実行後、これまでに収集した LeRobot データセットは v3.0 から v2.0 形式へダウングレードされます。
その後、次の modality.json ファイルを、変換後データセットの meta フォルダ内にコピーします:
modality.json(クリックして展開)
{
"state": {
"single_arm": {
"start": 0,
"end": 6
},
"gripper": {
"start": 6,
"end": 7
}
},
"action": {
"single_arm": {
"start": 0,
"end": 6
},
"gripper": {
"start": 6,
"end": 7
}
},
"video": {
"front": {
"original_key": "observation.images.front"
},
"side": {
"original_key": "observation.images.side"
}
},
"annotation": {
"human.task_description": {
"original_key": "task_index"
}
}
}
GR00T N1.7 のファインチューニング
データセットの準備ができたら、ファインチューニングスクリプトを実行します:
cd <path-to-isaac-gr00t>
uv pip uninstall deepspeed
export MAX_STEPS=10000
export SAVE_STEPS=5000
bash examples/finetune.sh \
--base-model-path nvidia/GR00T-N1.7-3B \
--dataset-path /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/organize_test_tube_0 \
--modality-config-path examples/SO100/so100_config.py \
--embodiment-tag NEW_EMBODIMENT \
--output-dir ~/output
ファイルパスは自身のデータセットおよび出力ディレクトリのパスに置き換えてください。
今回のトレーニングデータセットは比較的小さいため、計算資源を節約する目的で学習ステップ数を減らすことができます。
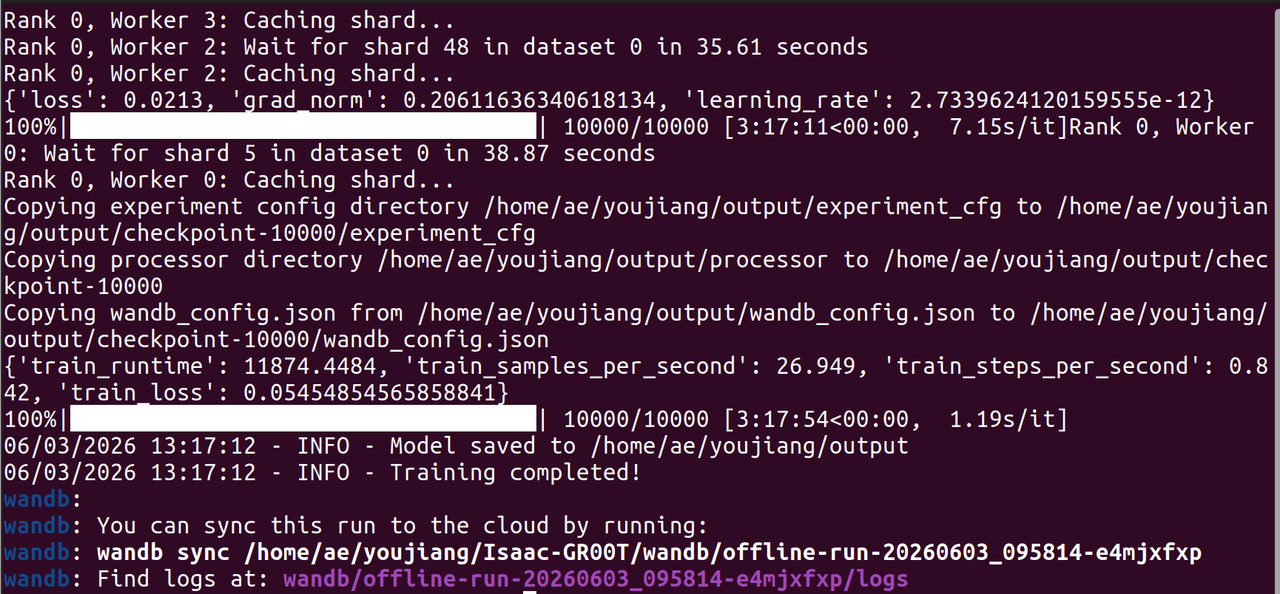
トレーニング完了後、--output-dir ディレクトリ内にファインチューニング済みの GR00T N1.7 モデルファイルが生成されます。

Jetson へのデプロイ
権限の取得
Hugging Face からモデルやデータセットをダウンロードするには、事前に必要なリポジトリへのアクセス権を付与する必要があります。
Hugging Face CLI をインストールし、ログインします:
uv tool install -U "huggingface_hub[cli]"
# Log in to your Hugging Face account and input your token
hf auth login
以下のリンクにアクセスし、必要なモデルのダウンロード権限を取得します: 🔗 https://huggingface.co/nvidia/Cosmos-Reason2-2B
リポジトリのクローン
# Install git-lfs
sudo apt install git-lfs && git lfs install
# Clone the repository
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
git submodule update --init --recursive
Docker セットアップ(推奨)
Thor は CUDA 13 と Python 3.12 を使用しており、x86 や Orin とは異なる依存関係スタックが必要です。JetPack 7.1 でテスト済みです。Thor 上で実行する方法は 2 通りあり、Docker(推奨)またはベアメタルでの実行が可能です。
リポジトリのルートから Thor 用コンテナをビルドします:
cd docker && sudo bash build.sh --profile=thor
ファインチューニング済みモデルをダウンロードします(ホスト上で 1 回だけ実行):
uv run hf download nvidia/GR00T-N1.7-LIBERO \
--include "libero_10/config.json" \
"libero_10/embodiment_id.json" \
"libero_10/model-*.safetensors" \
"libero_10/model.safetensors.index.json" \
"libero_10/processor_config.json" \
"libero_10/statistics.json" \
--local-dir checkpoints/GR00T-N1.7-LIBERO
インタラクティブな Docker セッションを開始します(複数ステップの TRT 作業に推奨):
# Add Docker to the user group
sudo usermod -aG docker $USER
docker run -it --rm --runtime nvidia --gpus all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--network host \
-v "$(pwd)":/workspace/repo \
-v "${HF_HOME:-${HOME}/.cache/huggingface}":/root/.cache/huggingface \
-w /workspace/repo \
-e HF_TOKEN="${HF_TOKEN:-}" \
gr00t-thor \
bash
ベアメタルセットアップ
Docker を使用したくない場合は、依存関係を直接インストールすることもできます:
bash scripts/deployment/thor/install_deps.sh
# In each new shell
source .venv/bin/activate
source scripts/activate_thor.sh
環境の検証
PyTorch 推論を実行して、環境が正しく構成されているか確認できます。
スクリプトを実行する前に、あらかじめ Hugging Face アカウントにログインし、トークンを入力しておく必要があります。
# Run inference on demo trajectories using PyTorch (no TRT setup needed):
uv run python scripts/deployment/standalone_inference_script.py \
--model-path checkpoints/GR00T-N1.7-LIBERO/libero_10 \
--dataset-path demo_data/libero_demo \
--embodiment-tag LIBERO_PANDA \
--traj-ids 0 1 2 3 4 \
--inference-mode pytorch \
--action-horizon 8
データセット形式の変換
GR00T は LeRobot v2.1 形式のデータセットのみをサポートしています。しかし、LeRobot フレームワークでデータを収集する際に使用されるデータセット形式は v3.0 です。Jetson 上で TensorRT による高速化エンジンモデルをエクスポートするには、GR00T のトレーニング時と同じ形式にデータセットを変換する必要があります。
次の変換スクリプトを Isaac-GR00T リポジトリ内の scripts/convert_v3_to_v2.py として配置します:
convert_v3_to_v2.py(クリックして展開)
#!/usr/bin/env python3
"""
LeRobot v3.0 to v2.1 Format Converter for Seeed REBOT-B601-DM Dataset
Converts a LeRobot v3.0 dataset to v2.1 format compatible with GR00T's
LeRobotEpisodeLoader.
Usage:
python convert_v3_to_v2.py \
--input /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test \
--output /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2
The converter:
1. Reads episodes from meta/episodes/chunk-*/file-*.parquet
2. Splits data parquet into per-episode parquet files (v2.1 naming)
3. Extracts video clips per episode from v3.0 continuous MP4 files
4. Generates meta/modality.json, meta/tasks.jsonl, meta/episodes.jsonl
"""
import argparse
import json
import os
import shutil
import subprocess
from pathlib import Path
import pandas as pd
def _val(x):
"""Convert pyarrow/pandas scalar to native Python value."""
if hasattr(x, "item"):
return x.item()
elif hasattr(x, "tolist"):
return x.tolist()
return x
# ============================================================================
# 1. meta/modality.json
# ============================================================================
MODALITY_JSON = {
"video": {
"down_size": {
"type": "video",
"original_key": "observation.images.down_size"
},
"up_side": {
"type": "video",
"original_key": "observation.images.up_side"
}
},
"state": {
"single_arm": {
"start": 0,
"end": 6,
"original_key": "observation.state"
},
"gripper": {
"start": 6,
"end": 7,
"original_key": "observation.state"
}
},
"action": {
"single_arm": {
"start": 0,
"end": 6,
"original_key": "action"
},
"gripper": {
"start": 6,
"end": 7,
"original_key": "action"
}
},
"annotation": {
"language.language_instruction": {
"original_key": "task_index"
}
}
}
# ============================================================================
# 2. Convert tasks.parquet -> tasks.jsonl
# ============================================================================
def convert_tasks(input_dir: Path, output_dir: Path):
"""Convert tasks.parquet to tasks.jsonl."""
eps_dir = input_dir / "meta" / "episodes"
task_text = "unknown"
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, row in df_eps.iterrows():
tasks_val = row.get("tasks", None)
if tasks_val is not None:
if hasattr(tasks_val, "tolist"):
tasks_val = tasks_val.tolist()
if isinstance(tasks_val, (list, tuple)) and len(tasks_val) > 0:
task_text = str(tasks_val[0])
break
if task_text != "unknown":
break
if task_text != "unknown":
break
tasks_path = input_dir / "meta" / "tasks.parquet"
df_tasks = pd.read_parquet(tasks_path, engine="pyarrow")
tasks = []
for _, row in df_tasks.iterrows():
ti_val = row["task_index"]
ti = int(ti_val.item()) if hasattr(ti_val, "item") else int(ti_val)
tasks.append({"task_index": ti, "task": task_text})
tasks_path_out = output_dir / "meta" / "tasks.jsonl"
with open(tasks_path_out, "w") as f:
for t in tasks:
f.write(json.dumps(t) + "\n")
print(f" Created tasks.jsonl ({len(tasks)} tasks)")
# ============================================================================
# 3. Convert episodes -> episodes.jsonl
# ============================================================================
def convert_episodes(input_dir: Path, output_dir: Path):
"""Convert episodes parquet files to episodes.jsonl."""
eps_dir = input_dir / "meta" / "episodes"
all_eps = []
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df = pd.read_parquet(pf, engine="pyarrow")
for _, row in df.iterrows():
def get(v):
val = row[v]
if hasattr(val, "tolist"):
val = val.tolist()
return val
tasks_val = get("tasks")
if isinstance(tasks_val, (list, tuple)) and len(tasks_val) > 0:
tasks_str = [str(tasks_val[0])]
else:
tasks_str = ["unknown"]
ep = {
"episode_index": int(get("episode_index")),
"length": int(get("length")),
"tasks": tasks_str,
}
all_eps.append(ep)
all_eps.sort(key=lambda x: x["episode_index"])
eps_path_out = output_dir / "meta" / "episodes.jsonl"
with open(eps_path_out, "w") as f:
for ep in all_eps:
f.write(json.dumps(ep) + "\n")
print(f" Created episodes.jsonl ({len(all_eps)} episodes)")
# ============================================================================
# 4. Split data parquet -> per-episode parquet files (v2.1 naming)
# ============================================================================
def convert_data_parquet(input_dir: Path, output_dir: Path):
"""
Split combined data parquet files into per-episode parquet files.
v3.0: data/chunk-000/file-000.parquet contains ALL episodes' data
v2.1: data/chunk-000/episode_000000.parquet (one per episode)
"""
data_dir = input_dir / "data"
output_data = output_dir / "data"
eps_dir = input_dir / "meta" / "episodes"
ep_data_map = {}
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, erow in df_eps.iterrows():
ei = int(_val(erow["episode_index"]))
dci = int(_val(erow["data/chunk_index"]))
dfi = int(_val(erow["data/file_index"]))
ep_data_map[ei] = (dci, dfi)
chunk_files = {}
for chunk_dir in sorted(data_dir.iterdir()):
if not chunk_dir.is_dir():
continue
chunk_idx = int(chunk_dir.name.split("-")[1])
files = {}
for pf in sorted(chunk_dir.glob("*.parquet")):
file_idx = int(pf.stem.split("-")[1])
files[file_idx] = pf
chunk_files[chunk_idx] = files
for chunk_idx, files in sorted(chunk_files.items()):
output_chunk = output_data / f"chunk-{chunk_idx:03d}"
output_chunk.mkdir(parents=True, exist_ok=True)
ep_chunks = {}
for ep_idx, (dci, dfi) in sorted(ep_data_map.items()):
if dci == chunk_idx:
ep_chunks[ep_idx] = files[dfi]
for ep_idx, parquet_path in sorted(ep_chunks.items()):
df = pd.read_parquet(parquet_path, engine="pyarrow")
ep_rows = df[df["episode_index"] == ep_idx]
cols_to_keep = [c for c in ep_rows.columns if c in ("action", "observation.state", "task_index")]
ep_rows = ep_rows[cols_to_keep].reset_index(drop=True)
out_name = f"episode_{ep_idx:06d}.parquet"
out_path = output_chunk / out_name
ep_rows.to_parquet(out_path, engine="pyarrow", index=False)
total_eps = len(list(output_data.glob("chunk-*/episode_*.parquet")))
print(f" Converted data: {total_eps} episode parquet files")
# ============================================================================
# 5. Extract video clips per episode
# ============================================================================
def convert_videos(input_dir: Path, output_dir: Path):
"""
Extract per-episode video clips from v3.0 continuous MP4 files.
v3.0: videos/{cam}/chunk-{chunk:03d}/file-{file:03d}.mp4 (continuous, multi-episode)
v2.1: videos/{cam}/chunk-{chunk:03d}/episode_{ep:06d}.mp4 (one per episode)
"""
videos_dir = input_dir / "videos"
output_videos = output_dir / "videos"
camera_keys = [
"observation.images.down_size",
"observation.images.up_side",
]
eps_dir = input_dir / "meta" / "episodes"
ep_video_map = {}
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, row in df_eps.iterrows():
ei = int(_val(row["episode_index"]))
ep_video_map[ei] = {}
for cam in camera_keys:
ep_video_map[ei][cam] = {
"chunk": int(_val(row[f"videos/{cam}/chunk_index"])),
"file": int(_val(row[f"videos/{cam}/file_index"])),
"from_ts": float(_val(row[f"videos/{cam}/from_timestamp"])),
"to_ts": float(_val(row[f"videos/{cam}/to_timestamp"])),
}
all_tasks = [(ep_idx, cam) for ep_idx, cam_data in sorted(ep_video_map.items()) for cam in camera_keys]
total = len(all_tasks)
done = 0
errors = 0
for ep_idx, cam in all_tasks:
vinfo = ep_video_map[ep_idx][cam]
src_name = f"file-{vinfo['file']:03d}.mp4"
src = videos_dir / cam / f"chunk-{vinfo['chunk']:03d}" / src_name
dest = output_videos / cam / f"chunk-{vinfo['chunk']:03d}" / f"episode_{ep_idx:06d}.mp4"
dest.parent.mkdir(parents=True, exist_ok=True)
if dest.exists():
done += 1
print(f"\r Extracting clips: {done}/{total} (errors: {errors})", end="", flush=True)
continue
duration = vinfo["to_ts"] - vinfo["from_ts"]
start = vinfo["from_ts"]
cmd = [
"ffmpeg", "-y",
"-ss", str(start),
"-i", str(src),
"-t", str(duration),
"-c:v", "libx264",
"-crf", "18",
"-preset", "fast",
"-an",
str(dest),
]
result = subprocess.run(cmd, capture_output=True, text=True)
done += 1
if result.returncode != 0:
errors += 1
print(f"\n ERROR ep{ep_idx} {cam}: {result.stderr[-300:]}")
print(f"\r Extracting clips: {done}/{total} (errors: {errors})", end="", flush=True)
print()
print(f" Extracted {total - errors} video clips ({len(ep_video_map)} episodes x {len(camera_keys)} cameras)")
# ============================================================================
# 6. Generate v2.1 info.json
# ============================================================================
def convert_info_json(input_dir: Path, output_dir: Path):
"""Update info.json for v2.1 format."""
info_path = input_dir / "meta" / "info.json"
with open(info_path) as f:
info = json.load(f)
info["data_path"] = "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet"
info["video_path"] = "videos/{video_key}/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.mp4"
for key in ["data_files_size_in_mb", "video_files_size_in_mb", "splits"]:
info.pop(key, None)
info_path_out = output_dir / "meta" / "info.json"
with open(info_path_out, "w") as f:
json.dump(info, f, indent=2)
print(f" Created info.json")
# ============================================================================
# Main
# ============================================================================
def main():
parser = argparse.ArgumentParser(description="Convert LeRobot v3.0 dataset to v2.1 format")
parser.add_argument("--input", type=str, required=True, help="Input v3.0 dataset path")
parser.add_argument("--output", type=str, required=True, help="Output v2.1 dataset path")
args = parser.parse_args()
input_dir = Path(args.input)
output_dir = Path(args.output)
print(f"\nConverting LeRobot v3.0 -> v2.1")
print(f" Input: {input_dir}")
print(f" Output: {output_dir}")
(output_dir / "meta").mkdir(parents=True, exist_ok=True)
print("\n[1/6] Creating meta/modality.json...")
with open(output_dir / "meta" / "modality.json", "w") as f:
json.dump(MODALITY_JSON, f, indent=2)
print(" Created modality.json")
print("\n[2/6] Creating meta/tasks.jsonl...")
convert_tasks(input_dir, output_dir)
print("\n[3/6] Creating meta/episodes.jsonl...")
convert_episodes(input_dir, output_dir)
print("\n[4/6] Converting data parquet files...")
convert_data_parquet(input_dir, output_dir)
print("\n[5/6] Extracting video clips...")
convert_videos(input_dir, output_dir)
print("\n[6/6] Creating meta/info.json...")
convert_info_json(input_dir, output_dir)
print("\n[Done] Copying meta/stats.json...")
shutil.copy(input_dir / "meta" / "stats.json", output_dir / "meta" / "stats.json")
print(" Copied stats.json")
print(f"\nConversion complete: {output_dir}")
if __name__ == "__main__":
main()
変換スクリプトを実行します。例:
python3 scripts/convert_v3_to_v2.py \
--input /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test \
--output /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2
モデルを TensorRT エンジンとしてエクスポートする
環境を確認しデータセットを準備したら、ファインチューニング済みモデルを TensorRT エンジンとしてエクスポートし、Jetson Thor 上での推論を高速化できます。
cd Isaac-GR00T/
source .venv/bin/activate
source scripts/activate_thor.sh
python3 scripts/deployment/build_trt_pipeline.py \
--model-path /path/to/your/finetuned_model \
--dataset-path /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2 \
--embodiment-tag NEW_EMBODIMENT \
--output-dir ./seeed_rebot_b601_dm_deployment \
--precision bf16 \
--batch-size 1 \
--steps export,build
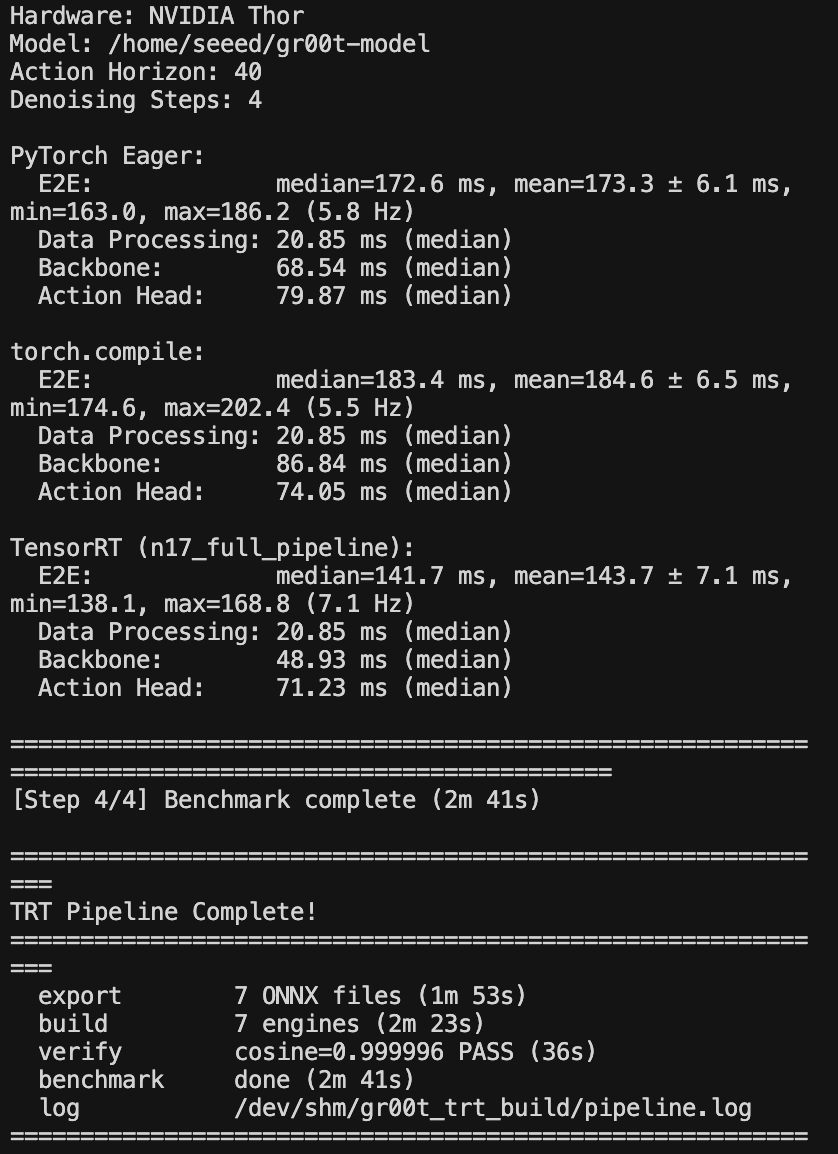
エンジン形式の高速化および最適化されたモデルファイルと、待機中に生成される中間変換済み ONNX ファイルを取得できます。
Jetson Thor での推論
この章では、TensorRT によってファインチューニングおよび高速化された GR00T N1.7 モデルを使用して、Jetson 上で推論を実行する方法を説明します。
推論サービスを起動する
次のスクリプトを使用してモデルサービスを起動します。TensorRT エンジンモデルの推論をサポートするために、元のスクリプトに軽微な変更を加えています。
run_gr00t_server.py(クリックして展開)
# SPDX-FileCopyrightText: Copyright (c) 2026 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
import importlib
import json
import os
from pathlib import Path
import sys
from gr00t.data.embodiment_tags import EmbodimentTag
from gr00t.data.types import ModalityConfig
from gr00t.policy.gr00t_policy import Gr00tPolicy
from gr00t.policy.replay_policy import ReplayPolicy
from gr00t.policy.server_client import PolicyServer
import tyro
DEFAULT_MODEL_SERVER_PORT = 5555
@dataclass
class ServerConfig:
"""Configuration for running the GR00T inference server."""
# Gr00t policy configs
model_path: str | None = None
"""Path to the model checkpoint directory"""
embodiment_tag: str = "new_embodiment"
"""Embodiment tag (name or value, case-insensitive). Run with --help to see known tags."""
device: str = "cuda"
"""Device to run the model on"""
# Replay policy configs
dataset_path: str | None = None
"""Path to the dataset for replay trajectory"""
modality_config_path: str | None = None
"""Path to the modality configuration file"""
execution_horizon: int | None = None
"""Policy execution horizon during inference. Required when --dataset-path is set (ReplayPolicy)."""
# Server configs
host: str = "0.0.0.0"
"""Host address for the server"""
port: int = DEFAULT_MODEL_SERVER_PORT
"""Port number for the server"""
strict: bool = True
"""Whether to enforce strict input and output validation"""
use_sim_policy_wrapper: bool = False
"""Whether to use the sim policy wrapper"""
# TensorRT inference configs
trt_engine_path: str = ""
"""Path to directory containing TensorRT engine files. If set, uses TRT inference instead of PyTorch."""
trt_mode: str = "n17_full_pipeline"
"""TRT mode: 'n17_full_pipeline', 'vit_llm_only', 'action_head', or 'dit_only'."""
def main(config: ServerConfig):
config.embodiment_tag = EmbodimentTag.resolve(config.embodiment_tag)
print("Starting GR00T inference server...")
print(f" Embodiment tag: {config.embodiment_tag}")
print(f" Model path: {config.model_path}")
print(f" Device: {config.device}")
print(f" Host: {config.host}")
print(f" Port: {config.port}")
if config.trt_engine_path:
print(f" TRT engines: {config.trt_engine_path}")
print(f" TRT mode: {config.trt_mode}")
# Create and start the server
if config.model_path is not None:
if config.model_path.startswith("/") and not os.path.exists(config.model_path):
raise FileNotFoundError(f"Model path {config.model_path} does not exist")
policy = Gr00tPolicy(
embodiment_tag=config.embodiment_tag,
model_path=config.model_path,
device=config.device,
strict=config.strict,
)
# Replace PyTorch modules with TensorRT engines if requested
if config.trt_engine_path:
deploy_dir = str(Path(__file__).resolve().parents[2] / "scripts" / "deployment")
if deploy_dir not in sys.path:
sys.path.insert(0, deploy_dir)
from trt_model_forward import setup_tensorrt_engines
setup_tensorrt_engines(policy, config.trt_engine_path, mode=config.trt_mode)
print(f" TensorRT engines loaded in '{config.trt_mode}' mode")
elif config.dataset_path is not None:
if config.execution_horizon is None:
raise ValueError(
"--execution-horizon is required when --dataset-path is set "
"(ReplayPolicy needs a positive integer to advance episodes)."
)
if config.execution_horizon <= 0:
raise ValueError(
f"--execution-horizon must be positive; got {config.execution_horizon}."
)
modality_configs: dict[str, ModalityConfig] | None = None
if config.modality_config_path is not None:
config_path = Path(config.modality_config_path)
if config_path.suffix == ".py":
sys.path.append(str(config_path.parent))
importlib.import_module(config_path.stem)
print(f"Loaded modality config: {config_path}")
elif config_path.suffix == ".json":
with open(config.modality_config_path, "r") as f:
raw = json.load(f)
modality_configs = {k: ModalityConfig(**v) for k, v in raw.items()}
else:
raise ValueError(
f"Unsupported modality config format: {config_path.suffix}. Use .py or .json"
)
if modality_configs is None:
from gr00t.configs.data.embodiment_configs import MODALITY_CONFIGS
modality_configs = MODALITY_CONFIGS.get(config.embodiment_tag.value)
if modality_configs is None:
raise ValueError(
f"No built-in modality config for embodiment tag "
f"'{config.embodiment_tag.name}' (value='{config.embodiment_tag.value}'). "
f"Available tags: {sorted(MODALITY_CONFIGS.keys())}. "
f"Please provide --modality-config-path (JSON or .py) "
f"when using this tag with ReplayPolicy."
)
policy = ReplayPolicy(
dataset_path=config.dataset_path,
modality_configs=modality_configs,
execution_horizon=config.execution_horizon,
strict=config.strict,
)
else:
raise ValueError("Either model_path or dataset_path must be provided")
# Apply sim policy wrapper if needed
if config.use_sim_policy_wrapper:
from gr00t.policy.gr00t_policy import Gr00tSimPolicyWrapper
policy = Gr00tSimPolicyWrapper(policy)
server = PolicyServer(
policy=policy,
host=config.host,
port=config.port,
)
print(f"\n✓ Server ready — listening on {config.host}:{config.port}\n")
try:
server.run()
except KeyboardInterrupt:
print("\nShutting down server...")
if __name__ == "__main__":
config = tyro.cli(ServerConfig)
main(config)
TensorRT エンジンを使用して推論サーバーを実行します:
python gr00t/eval/run_gr00t_server.py \
--model-path /home/seeed/checkpoint-10000/ \
--embodiment-tag NEW_EMBODIMENT \
--trt-engine-path /dev/shm/gr00t_trt_build/engines \
--trt-mode n17_full_pipeline
モデルパスを、自分のファインチューニング済みモデルのチェックポイントパスに置き換えることを忘れないでください。
実機ロボットでの実行
ここでは、LeRobot 環境を使用してロボットアームを起動し、タスクを実行します。
cd /path/to/lerobot
source .venv/bin/activate
cd Isaac-GR00T/gr00t/eval/real_robot
git clone https://github.com/zibochen6/rebot-arm-dm.git
uv pip install -e .
uv pip install --no-deps -e ../../../../
ロボットアームを起動します:
python eval_rebot_arm_dm.py \
--robot.type=seeed_b601_dm_follower \
--robot.id=b601_dm_follower \
--robot.port=/dev/ttyACM0 \
--robot.can_adapter=damiao \
--robot.cameras='{ front: {type: opencv, index_or_path: /dev/video0, width: 640, height: 480, fps: 30}, side: {type: opencv, index_or_path: /dev/video2, width: 640, height: 480, fps: 30}}' \
--policy_host=localhost \
--policy_port=5555 \
--lang_instruction="Grab markers and place into pen holder." \
--action_smoothing_alpha=0.05 \
--action_smoothing_max_delta=20.0 \
--action_smoothing_gripper_alpha=0.1
最初の実行時に、ロボットアーム用のキャリブレーションファイルが見つからないというエラーが報告される場合があります。これは、reBot Arm を検証するために LeRobot を使用した際に生成されるキャリブレーションファイルの名前が follower1.json である一方で、プログラム側は b601_dm_follower.json を探しているためです。問題を解決するには、キャリブレーションファイルの名前を変更してください:
mv ~/.cache/huggingface/lerobot/calibration/robots/seeed_b601_dm_follower/follower1.json \
~/.cache/huggingface/lerobot/calibration/robots/seeed_b601_dm_follower/b601_dm_follower.json
参考資料
- 🔗 https://developer.nvidia.com/embedded/jetpack
- 🔗 https://github.com/NVIDIA/Isaac-GR00T/tree/main
- 🔗 https://huggingface.co/nvidia/GR00T-N1.7-LIBERO
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。私たちは、お客様が弊社製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じてお選びいただける、複数のコミュニケーションチャネルをご用意しています。