Orin Nano / NX 8GB での Jetson-Claw 入門

このWikiでは、Jetson Orin Nano 8GB と Jetson Orin NX 8GB 向けの、実践的な Jetson-Claw スターター構成について説明します。スタック全体は Jetson 上でローカル動作します。nanobot をインストールし、モデル読み込みを安全にするためにスワップ領域を拡張し、CUDA 対応で llama.cpp をコンパイルし、Qwen3.5 4B GGUF モデルをダウンロードし、nanobot のバックエンドをローカルの llama.cpp に切り替え、最後にボットを Feishu に接続して、チャットから制御できるようにします。
より大規模な OpenClaw デプロイと比べると、nanobot はこのエントリーレベルの Jetson-Claw 構成により適しています。はるかに軽量で、起動が速く、コードが読みやすく変更しやすく、すでに Feishu と OpenAI 互換のローカルバックエンド をサポートしているためです。8 GB の Jetson では、ランタイムのオーバーヘッドが小さいほどローカルモデル自体に使えるメモリが増えます。後で、より大きなプラグインエコシステムや重いマルチコンポーネントワークフローが必要になった場合でも、OpenClaw に移行できます。
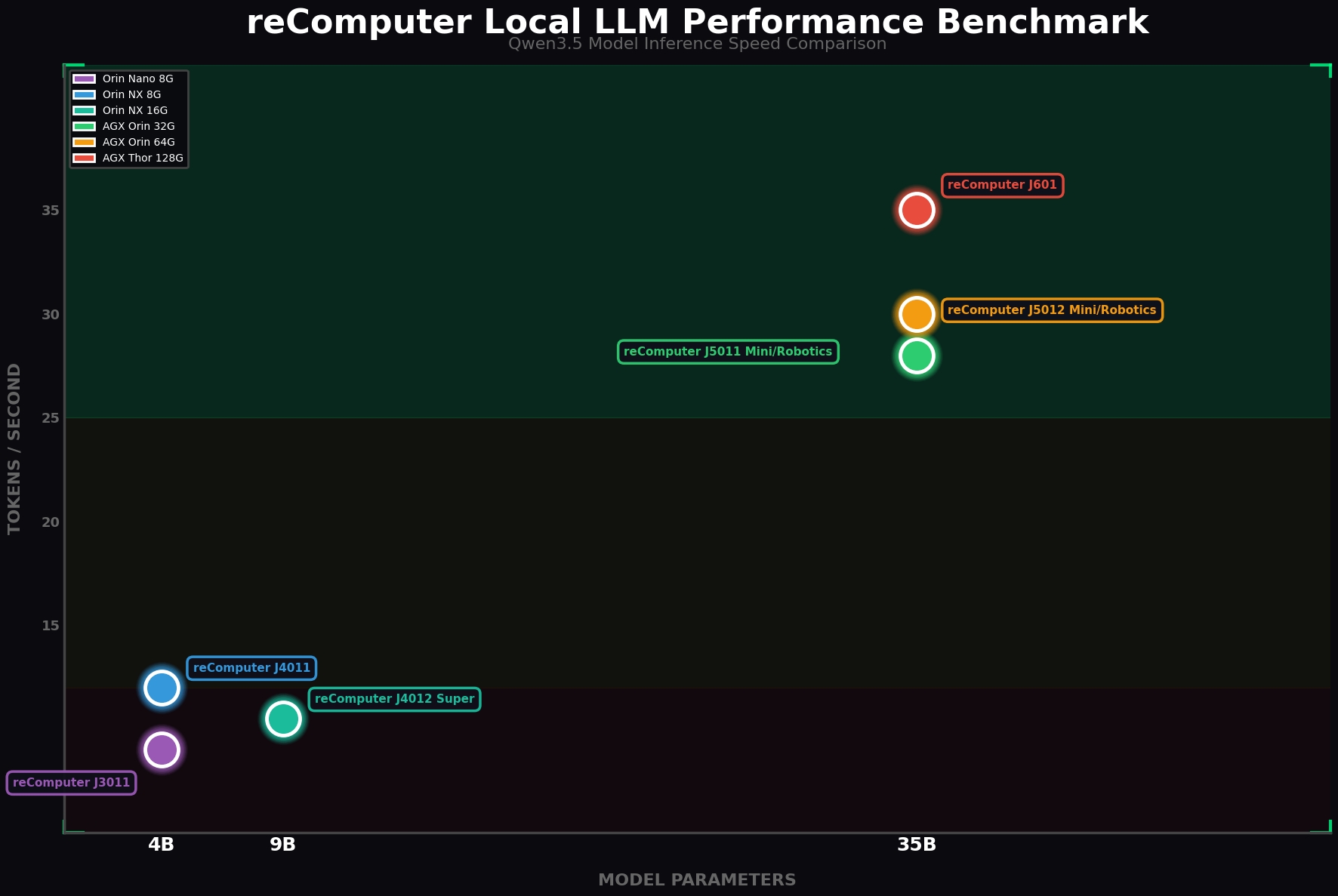
ベンチマーク
ここでは、Jetson 各モジュールにおけるローカル LLM の性能を一覧にしています。検証の結果、4B モデルは、特定のタスクを実行できるシステムを構築するのに最適な選択であることがわかりました。モデルのパラメータ数が大きいほど、性能は向上します。このベンチマークを参考にして、自分のニーズに合った reComputer を選択してください。
構築するもの
nanobotをベースにした軽量ローカル AI アシスタント- Jetson 上で動作する
llama.cppOpenAI 互換 HTTP サーバ - ローカルの
Qwen3.5 4BGGUF モデル - プライベートチャットやグループメンションから制御できる、Feishu 連携 Jetson ボット
前提条件
- Jetson Orin Nano 8GB または Jetson Orin NX 8GB を 1 台
- JetPack 6.x がすでにインストールされていること
- パッケージおよびモデルをダウンロードするためのインターネット接続
- 少なくとも 20 GB の空きストレージを推奨
本ガイドでは、リファレンス Jetson プラットフォームとして reComputer Super J3011 を使用します。

現在 nanobot には Python 3.11 以降が必要なため、このガイドでは Jetson のデフォルトのシステム Python ではなく Miniconda 環境を使用します。
手順 1. nanobot をインストールする
まず、システム依存パッケージと Miniconda をインストールします。
sudo apt update
sudo apt install -y git curl wget build-essential cmake libcurl4-openssl-dev python3-pip
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
クリーンな Python 3.11 環境を作成し、nanobot をインストールします。
conda create -y -n jetson-claw python=3.11
conda activate jetson-claw
pip install -U pip
pip install nanobot-ai
ランタイムディレクトリを初期化します。
nanobot onboard
初期化後、メイン設定ファイルは次の場所にあります。
~/.nanobot/config.json
nanobot は OpenClaw に着想を得ていますが、Orin Nano / NX 8GB では通常、こちらのほうが良い出発点です。メモリオーバーヘッドが小さく、起動が速く、デバッグすべきコンポーネントも少ないためです。
手順 2. スワップ領域を増やす
8 GB の Jetson で 4B のローカルモデルを動かす場合、スワップを追加すると格段に安定します。これはモデル読み込みやコンパイル、長いコンテキストでの推論時に役立ちます。
sudo fallocate -l 8G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
echo '/var/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
swapon --show
より大きなコンテキストサイズや他のモデルで実験したい場合は、さらにスワップを増やしても構いません。
手順 3. CUDA 対応で llama.cpp をコンパイルする
CUDA のパスを設定します。
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
llama.cpp をクローンしてビルドします。
git clone https://github.com/ggml-org/llama.cpp.git ~/llama.cpp
cd ~/llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --parallel
コンパイル後、メインの実行ファイルは次のディレクトリに配置されます。
~/llama.cpp/build/bin
次のコマンドで、サーバ用バイナリが準備できているかを素早く確認できます。
~/llama.cpp/build/bin/llama-server --help
手順 4. Qwen3.5 4B GGUF の重みをダウンロードする
本ガイドでは、8 GB Jetson デバイスでのメモリ使用量と応答品質のバランスが良い Q4_K_M GGUF 量子化を使用します。
Hugging Face CLI をインストールします。
conda activate jetson-claw
pip install -U "huggingface_hub[cli]"
mkdir -p ~/llama.cpp/models/Qwen3.5-4B-GGUF
次に、以下のモデルページを開き、Q4_K_M GGUF ファイルを ~/llama.cpp/models/Qwen3.5-4B-GGUF/ にダウンロードします。
Hugging Face のページで Qwen3.5-4B.Q4_K_M.gguf ファイルを選択します。
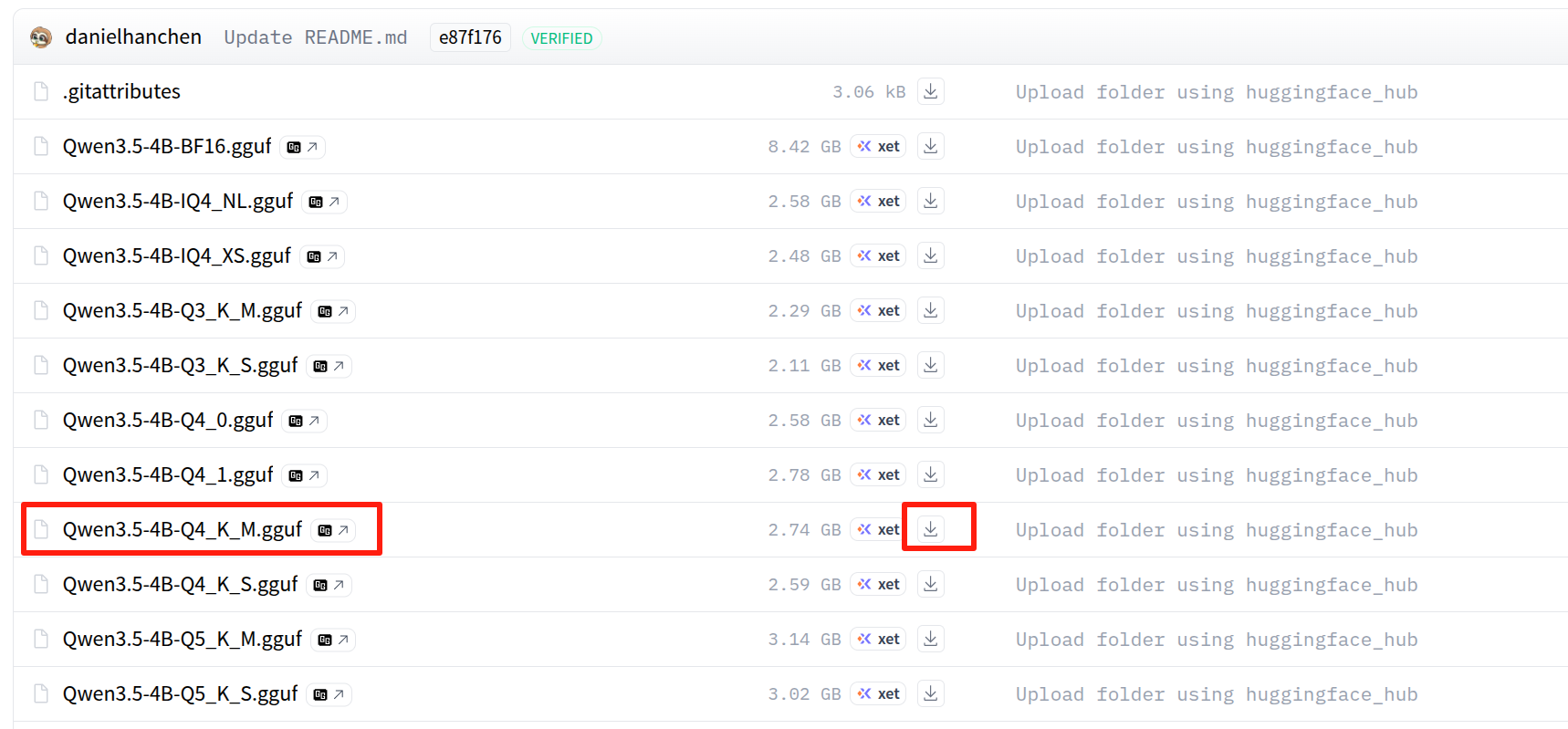
リポジトリ側のファイル名が本ガイドの例と同じであれば、次のようにしてダウンロードすることもできます。
huggingface-cli download \
unsloth/Qwen3.5-4B-GGUF \
Qwen3.5-4B.Q4_K_M.gguf \
--local-dir ~/llama.cpp/models/Qwen3.5-4B-GGUF
ファイル名が異なる場合は、後述する起動コマンド内のパスをそのファイル名に合わせて更新してください。ここでの例では、モデルファイルを次のように想定しています。
~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf
手順 5. ローカルバックエンドとして llama.cpp を起動する
ローカルの OpenAI 互換 API サーバを起動します。
conda activate jetson-claw
cd ~/llama.cpp
./build/bin/llama-server \
-m ~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf \
--alias qwen3.5-4b-local \
-t 6 \
-c 40960 \
--n-gpu-layers 40 \
--reasoning off \
--reasoning-format none \
--host 127.0.0.1 \
--port 8080
推奨パラメータの補足:
--alias qwen3.5-4b-local: ローカルモデルに、nanobotから参照しやすいクリーンな API モデル名を与えます-t 6: エントリーレベルの Jetson デバイスに適した、中程度の CPU スレッド数を使用します-c 40960: 大きなコンテキストウィンドウを提供しますが、メモリが厳しい場合は減らしてください--n-gpu-layers 40: 可能な限り多くのレイヤーを Jetson GPU にオフロードします--reasoning off: 出力をシンプルに保ち、スターター構成で不要なオーバーヘッドを抑えます
メモリ不足が原因でサーバが起動できない場合は、まず -c を 16384 に下げ、その後 --n-gpu-layers を減らしてみてください。
別のターミナルで API を検証します。
curl http://127.0.0.1:8080/v1/models
手順 6. nanobot を llama.cpp を使うように設定する
設定ファイルを開きます。
nano ~/.nanobot/config.json
次に、以下のセクションを自分の設定にマージします。
{
"agents": {
"defaults": {
"workspace": "~/.nanobot/workspace",
"model": "qwen3.5-4b-local",
"provider": "custom",
"maxTokens": 8192,
"contextWindowTokens": 40960,
"temperature": 0.1,
"maxToolIterations": 40,
"reasoningEffort": null
}
},
"channels": {
"sendProgress": true,
"sendToolHints": false,
"feishu": {
"enabled": true,
"appId": "cli_xxx",
"appSecret": "xxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": ["*"],
"reactEmoji": "THUMBSUP",
"groupPolicy": "mention",
"replyToMessage": false
}
},
"providers": {
"custom": {
"apiKey": "no-key",
"apiBase": "http://127.0.0.1:8080/v1",
"extraHeaders": null
}
},
"gateway": {
"host": "0.0.0.0",
"port": 18790
}
}
この設定が機能する理由:
provider: "custom"は、nanobotに任意の OpenAI 互換バックエンドを使用させる指定ですapiBase: "http://127.0.0.1:8080/v1"はローカルのllama-serverを指しますmodel: "qwen3.5-4b-local"は、llama.cpp起動時に指定した--aliasの値と一致させます
素早くテストするには allowFrom: ["*"] が便利ですが、本番運用では検証後に自分の Feishu の open_id に置き換えてください。
手順 7. Feishu を nanobot に接続する
Feishu オープンプラットフォームで Feishu アプリケーションを作成します。
- https://open.feishu.cn/app を開く
- 自分のボットアプリケーションを新規作成または開く
- App ID と App Secret をコピーする
- それらを
channels.feishu.appIdおよびchannels.feishu.appSecretに貼り付ける
Long Connection モードでは、encryptKey と verificationToken は空のままで構いません。
後で認証情報が見つからなくなった場合は、次の場所に移動します。
- Feishu オープンプラットフォーム
- 自分のアプリケーション
Credentials & Basic Info
Feishu の権限をインポートする
ファイル・画像・リッチメッセージの処理を正しく動作させるには、以下の権限セットを次の場所からインポートします。
- Feishu オープンプラットフォーム
- 自分のアプリケーション
Permission ManagementBulk Import
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"docs:document.content:read",
"event:ip_list",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource",
"sheets:spreadsheet",
"wiki:wiki:readonly"
],
"user": [
"aily:file:read",
"aily:file:write",
"im:chat.access_event.bot_p2p_chat:read"
]
}
}
権限をインポートした後:
- 新しいアプリバージョンを作成する
- アプリバージョンを公開する
そうしないと、新しく追加した権限が有効にならない場合があります。
ステップ 8. nanobot を起動して Feishu 制御をテストする
一つのターミナルで llama-server を実行したままにし、別のターミナルで nanobot を起動します:
conda activate jetson-claw
nanobot gateway
役に立つ確認項目:
nanobot status
nanobot channels status
次に、Feishu からボットにメッセージを送信します:
- プライベートチャットでは、ダイレクトメッセージを送信します
- グループチャットでは、
groupPolicy: "mention"を維持している場合、ボットをメンションします
もし allowFrom: ["*"] を使用した場合、ボットはすぐに返信するはずです。後でアクセスを制限したくなったら、まず 1 回メッセージを送り、nanobot のログで自分の open_id を確認し、その値で ["*"] を置き換えます。
オプション:Jetson-Claw のサンプルスキルを追加する
このスターターセットアップを、より実用的な Jetson-Claw デモにしたい場合は、サンプルのスキルセットを追加できます:
git clone https://github.com/jjjadand/JetsonClaw-SKILLS.git ~/JetsonClaw-SKILLS
mkdir -p ~/.nanobot/workspace/skills
cp -r ~/JetsonClaw-SKILLS/person-detection ~/.nanobot/workspace/skills/
その後 nanobot gateway を再起動し、Jetson に USB カメラを接続して、Feishu 上のボットにカメラの前に人が映っているかどうかを確認するよう依頼します。
Feishu 監視フローの例
スキルをインストールした後、Feishu アプリからリクエストを送信して、Jetson-Claw にカメラ映像を確認させることができます:
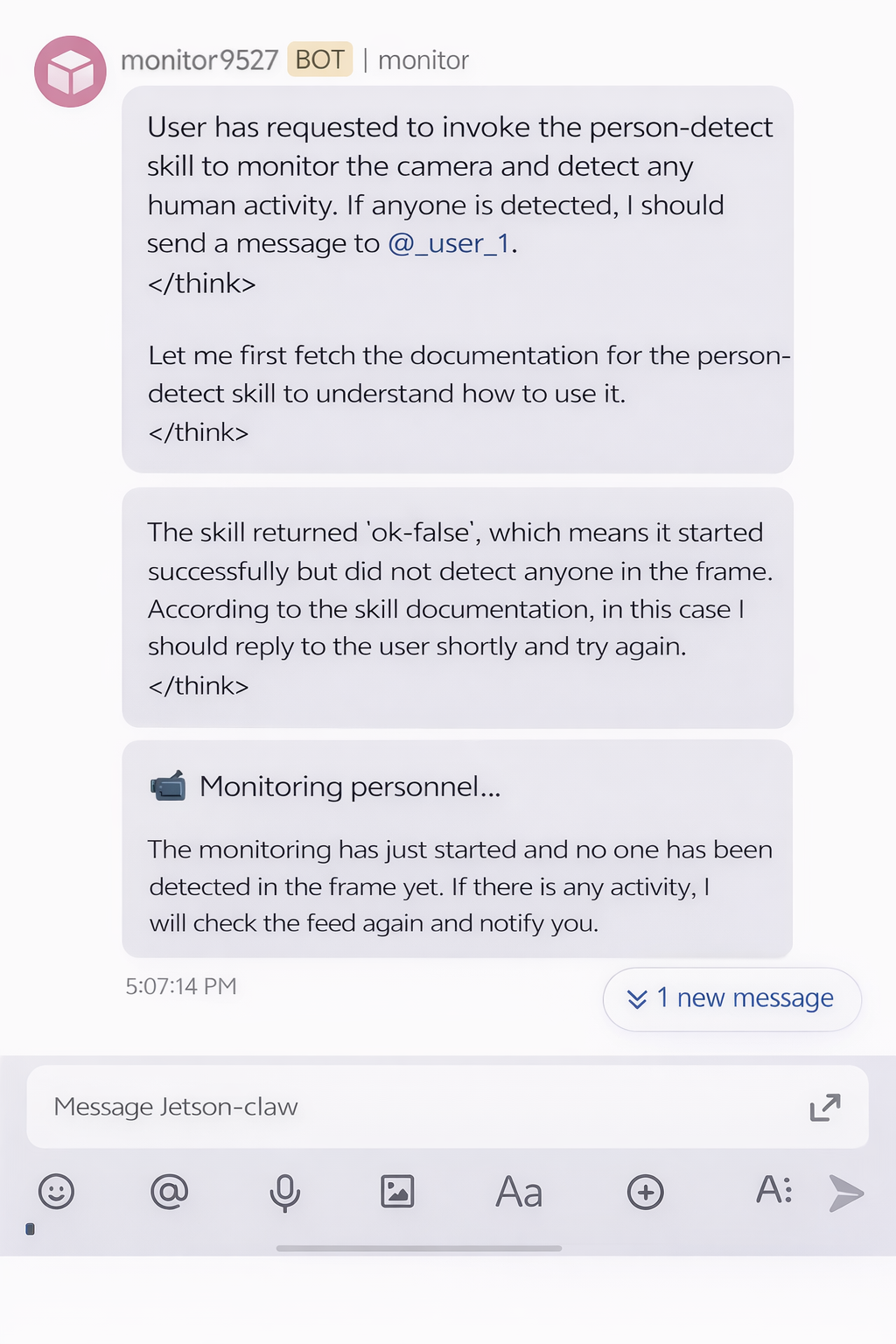
人が検出されない場合、監視結果は次のようになります:
人が検出された場合、Jetson-Claw は Feishu を通じてアラートを返すことができます:
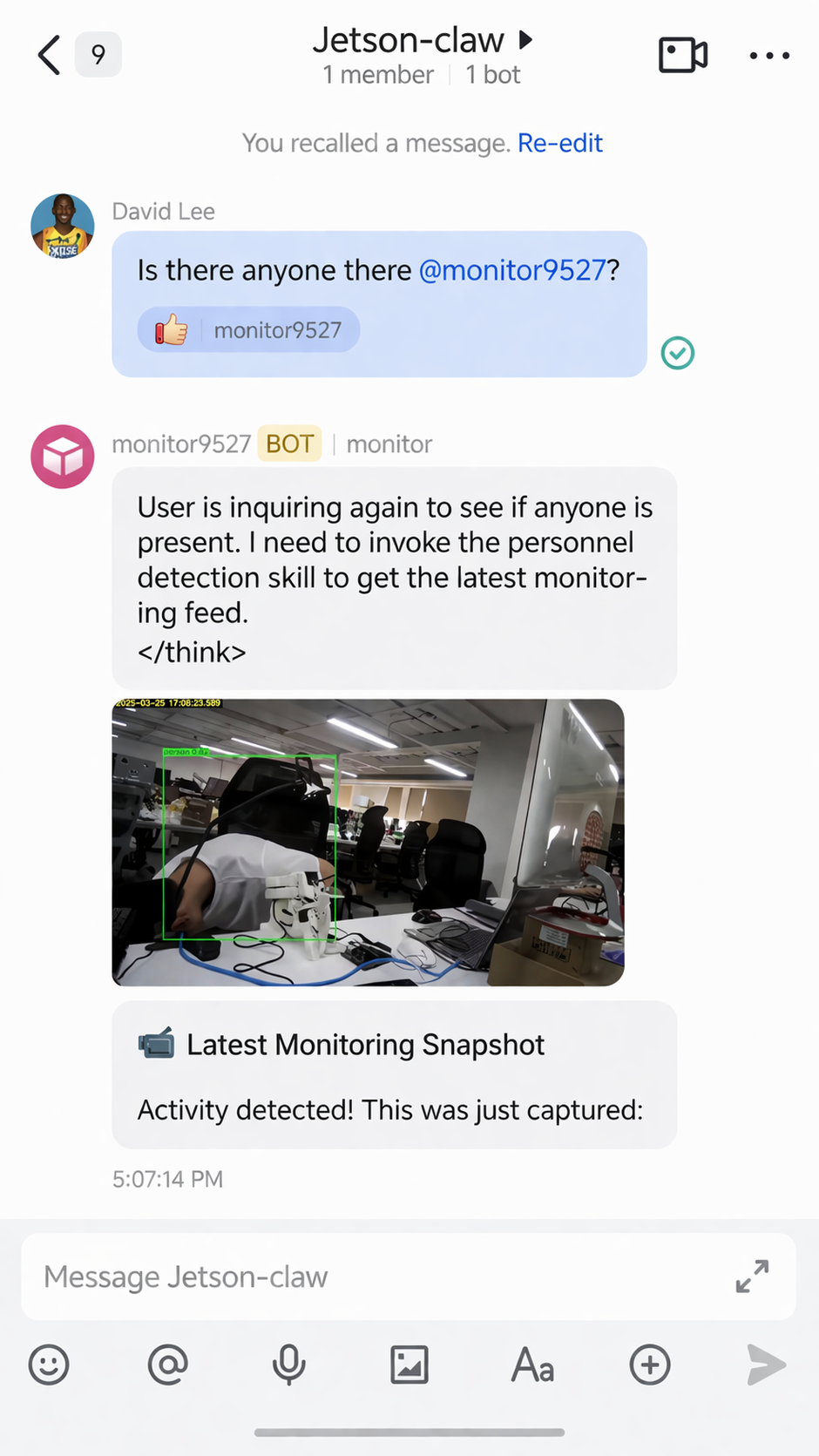
監視スキルは、取得した結果画像も返すことができます:

トラブルシューティング
nanobotのインストールに失敗する:Python 3.11 環境内にいることを確認してください- モデルの読み込み中に
llama-serverが終了する:スワップを増やすか、-cを小さくします - Feishu ボットが返信しない:App ID、App Secret、インポートした権限、公開済みアプリバージョンを確認します
- グループメッセージでボットが反応しない:
groupPolicyを確認し、ボットをメンションしていることを確認します - 応答が遅い:コンテキストサイズを小さくする、同時利用を減らす、またはより小さい量子化モデルを使用します
参考情報
- https://github.com/HKUDS/nanobot
- https://github.com/ggml-org/llama.cpp
- https://huggingface.co/unsloth/Qwen3.5-4B-GGUF/tree/main
- https://open.feishu.cn/app
- https://github.com/jjjadand/JetsonClaw-SKILLS
- https://wiki.seeedstudio.com/ja/local_openclaw_on_recomputer_jetson/
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。弊社は、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートをご提供しています。お好みやニーズに合わせて選べる複数のコミュニケーションチャネルをご用意しています。