LeRobot を使った SO-ARM100 および SO-ARM101 ロボットアーム入門
はじめに
SO-10xARM は、TheRobotStudio によって立ち上げられた完全オープンソースのロボットアームプロジェクトです。フォロワーアームとリーダーロボットアームを含み、詳細な3Dプリントファイルと操作ガイドも提供しています。LeRobot は、PyTorch 上で実世界ロボティクス向けのモデル、データセット、ツールを提供することに注力しています。その目的はロボティクスの参入障壁を下げ、誰もがデータセットや事前学習済みモデルを共有することで貢献し、恩恵を受けられるようにすることです。LeRobot は、模倣学習を中心に、実世界で検証された最先端の手法を統合しています。人間が収集したデモンストレーションを含むデータセット、事前学習済みモデル群、シミュレーション環境を備えており、ユーザーはロボットの組み立てを行わなくてもすぐに始めることができます。今後数週間で、現在入手可能な中で最も低コストかつ高性能なロボットに対する実世界ロボティクスのサポートをさらに拡充していく予定です。
プロジェクト概要
SO-ARM10x と reComputer Jetson AI インテリジェントロボットキットは、高精度なロボットアーム制御と強力なAIコンピューティングプラットフォームをシームレスに組み合わせ、包括的なロボット開発ソリューションを提供します。このキットは Jetson Orin または AGX Orin プラットフォームをベースに、SO-ARM10x ロボットアームと LeRobot AI フレームワークを組み合わせることで、教育、研究、産業オートメーションなど複数のシナリオに適用可能なインテリジェントロボットシステムをユーザーに提供します。 このWikiでは、SO ARM10x の組み立てとデバッグのチュートリアルを提供し、Lerobot フレームワーク内でのデータ収集と学習を実現します。

主な特長
- オープンソースかつ低コスト: TheRobotStudio によるオープンソースで低コストなロボットアームソリューションです。
- LeRobot との統合: LeRobot プラットフォーム との統合を前提に設計されています。
- 豊富な学習リソース: 組み立ておよびキャリブレーションガイド、テスト・データ収集・学習・デプロイのチュートリアルなど、包括的なオープンソース学習リソースを提供し、ユーザーがロボットアプリケーションを迅速に立ち上げ、開発できるよう支援します。
- Nvidia との互換性: reComputer Mini J4012 Orin NX 16 GB でこのアームキットをデプロイできます。
- マルチシーンでの応用: 教育、科学研究、自動化生産、ロボティクスなどの分野に適用でき、さまざまな複雑なタスクにおいて効率的かつ高精度なロボット動作を実現するのに役立ちます。
新着情報:
- 配線の最適化: SO-ARM100 と比較して、SO-ARM101 は配線が改善されており、以前ジョイント3で発生していた断線問題を防止します。新しい配線設計では、関節の可動範囲も制限されなくなりました。
- リーダーアームの異なるギア比: リーダーアームは最適化されたギア比を持つモーターを使用するようになり、性能が向上し、外部ギアボックスが不要になりました。
- 新機能のサポート: リーダーアームは、フォロワーアームをリアルタイムで追従できるようになりました。これは、今後導入される学習ポリシーにおいて、人間が介入してロボットの動作を修正できるようにするために重要です。
Seeed Studio はハードウェア自体の品質にのみ責任を負います。チュートリアルは公式ドキュメントに厳密に従って更新されています。ソフトウェアの問題や環境依存関係の問題が発生し解決できない場合は、本チュートリアル末尾の FAQ セクションを確認するほか、速やかにLeRobot プラットフォーム または LeRobot Discord チャンネル に問題を報告してください。
仕様
| タイプ | SO-ARM100 | SO-ARM101 | ||
|---|---|---|---|---|
| Arm Kit | Arm Kit Pro | Arm Kit | Arm Kit Pro | |
| リーダーアーム | 全関節に 1:345 のギア比を持つ 12x ST-3215- C001 (7.4V) モーター | 全関節に 1:345 のギア比を持つ 12x ST-3215-C018/ST-3215-C047 (12V) モーター | ジョイント2専用の 1:345 のギア比を持つ 1x ST-3215- C001 (7.4V) モーター | |
| フォロワーアーム | SO-ARM100 と同じ | |||
| 電源 | 5.5 mm × 2.1 mm DC 5 V 4 A | 5.5 mm × 2.1 mm DC 12 V 2 A | 5.5 mm × 2.1 mm DC 5 V 4 A | 5.5 mm × 2.1 mm DC 12 V 2 A(フォロワーアーム) |
| 角度センサー | 12ビット磁気エンコーダ | |||
| 推奨動作温度 | 0 °C ~ 40 °C | |||
| 通信方式 | UART | |||
| 制御方法 | PC | |||
Arm Kit バージョンを購入した場合、両方の電源は 5V です。Arm Kit Pro バージョンを購入した場合は、リーダーロボットアームのキャリブレーションおよびすべての手順には 5V 電源を使用し、フォロワーロボットアームのキャリブレーションおよびすべての手順には 12V 電源を使用してください。
部品表(BOM)
| 部品 | 数量 | 同梱 |
|---|---|---|
| サーボモーター | 12 | ✅ |
| モーター制御ボード | 2 | ✅ |
| USB-C ケーブル 2 本 | 1 | ✅ |
| 電源2 | 2 | ✅ |
| テーブルクランプ | 4 | ✅ |
| アームの3Dプリント部品 | 1 | オプション |
初期システム環境
Ubuntu x86 の場合:
- Ubuntu 22.04
- CUDA 12+
- Python 3.10
- Torch 2.6+
Jetson Orin の場合:
- Jetson JetPack 6.0 および 6.1、6.1 はサポートされていません
- Python 3.10
- Torch 2.3+
目次
3D プリントガイド
SO101 の公式アップデートに伴い、SO100 は今後サポートされず、公式の方針によりソースファイルは削除されますが、ソースファイルは依然として当社のMakerworldで見つけることができます。ただし、以前に SO100 を購入したユーザーについては、チュートリアルとインストール方法は引き続き互換性があります。SO101 のプリントは、SO100 のモーターキットの取り付けと完全に互換性があります。
ステップ 1: プリンタを選ぶ
提供されている STL ファイルは、多くの FDM プリンタでそのまま印刷できます。以下はテスト済みで推奨される設定ですが、他の設定でも動作する可能性があります。
- 材料: PLA+
- ノズル径と精度: 0.4mm ノズル径で 0.2mm レイヤー高さ、または 0.6mm ノズルで 0.4mm レイヤー高さ。
- インフィル密度: 15%
ステップ 2: プリンタをセットアップする
- プリンタ固有の手順に従ってプリンタをキャリブレーションし、ベッドレベリングが正しく設定されていることを確認します。
- プリントベッドを清掃し、ほこりや油分が付着していないことを確認します。水やその他の液体でベッドを清掃した場合は、ベッドを乾かしてください。
- プリンタで推奨されている場合は、標準的なスティックのりを使用し、ベッドのプリント領域全体に薄く均一な層を塗布します。ダマになったり、ムラが出たりしないように注意してください。
- プリンタ固有の手順に従ってプリンタフィラメントを装填します。
- プリンタ設定が上記で提案したものと一致していることを確認します(ほとんどのプリンタには複数の設定があるため、最も近いものを選択してください)。
- サポートは「どこでも」有効にしますが、水平方向に対して 45 度を超える傾斜は無視するように設定します。
- 水平軸を持つネジ穴の中にはサポートが入らないようにします。
ステップ 3: パーツを印刷する
リーダーまたはフォロワー用のすべてのパーツは、サポートを最小限に抑えるために z 方向が上になるよう正しく向きを揃えた単一ファイルに、簡単に 3D プリントできる形でまとめられています。
-
Ender など、プリンタベッドサイズが 220mm x 220mm の場合は、次のファイルを印刷します:
-
Prusa/Up など、プリンタベッドサイズが 205mm x 250mm の場合:
LeRobot をインストールする
pytorch や torchvision などの環境は、使用している CUDA に基づいてインストールする必要があります。
- Miniconda をインストールします: Jetson の場合:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
または、X86 Ubuntu 22.04 の場合:
mkdir -p ~/miniconda3
cd miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all
- lerobot 用に新しい conda 環境を作成して有効化します
conda create -y -n lerobot python=3.10 && conda activate lerobot
- Lerobot をクローンします:
git clone https://github.com/Seeed-Projects/lerobot.git ~/lerobot
- miniconda を使用している場合は、環境内に ffmpeg をインストールします:
conda install ffmpeg -c conda-forge
これは通常、libsvtav1 エンコーダでコンパイルされた、プラットフォーム向けの ffmpeg 7.X をインストールします。libsvtav1 がサポートされていない場合(ffmpeg -encoders でサポートされているエンコーダを確認)、次のことができます:
- [任意のプラットフォーム] 次のコマンドを使用して ffmpeg 7.X を明示的にインストールします:
conda install ffmpeg=7.1.1 -c conda-forge
- [Linux のみ] ffmpeg のビルド依存関係をインストールし、libsvtav1 を有効にしてソースから ffmpeg をコンパイルし、
which ffmpegで確認できる、インストールに対応した ffmpeg バイナリを使用していることを確認します。
このようなエラーが発生した場合は、このコマンドも使用できます。
- feetech モーター用の依存関係付きで LeRobot をインストールします:
cd ~/lerobot && pip install -e ".[feetech]"
Jetson Jetpack 6.0 以降のデバイスの場合(このステップを実行する前に、ステップ 5 から Pytorch-gpu と Torchvision を必ずインストールしてください):
conda install -y -c conda-forge "opencv>=4.10.0.84" # Install OpenCV and other dependencies through conda, this step is only for Jetson Jetpack 6.0+
conda remove opencv # Uninstall OpenCV
pip3 install opencv-python==4.10.0.84 # Then install opencv-python via pip3
conda install -y -c conda-forge ffmpeg
conda uninstall numpy
pip3 install numpy==1.26.0 # This should match torchvision
- Pytorch と Torchvision を確認する
pip で lerobot 環境をインストールすると、元の Pytorch と Torchvision がアンインストールされ、CPU 版の Pytorch と Torchvision がインストールされるため、Python で確認を行う必要があります。
import torch
print(torch.cuda.is_available())
出力結果が False の場合は、公式サイトのチュートリアル に従って Pytorch と Torchvision を再インストールする必要があります。
Jetson デバイスを使用している場合は、このチュートリアル に従って Pytorch と Torchvision をインストールしてください。
モーターを設定する
- SO101
SO-ARM101 のサーボのキャリブレーションおよび初期化プロセスは、方法とコードの両方の点で SO-ARM100 と同じです。ただし、SO-ARM101 のリーダーアームの最初の 3 つの関節のギア比は SO-ARM100 とは異なるため、それらを区別して慎重にキャリブレーションすることが重要です。
モーターを設定するには、リーダーアーム用に 1 つのバスサーボアダプタと 6 個のモーターを割り当て、同様にフォロワーアーム用にもう 1 つのバスサーボアダプタと 6 個のモーターを割り当てます。どのモーターがフォロワー F 用かリーダー L 用か、また ID が 1 から 6 のどれなのかを各モーターに記入してラベル付けしておくと便利です。F1–F6 を Follower Arm の関節 1〜6、L1–L6 を Leader Arm の関節 1〜6 を表すものとして使用します。対応するサーボモデル、関節の割り当て、およびギア比の詳細は次のとおりです:
| サーボモデル | ギア比 | 対応する関節 |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
ここで、5V または 12V の電源をモーターバスに接続する必要があります。STS3215 7.4V モーターには 5V、STS3215 12V モーターには 12V を使用します。リーダーアームは常に 7.4V モーターを使用するため、12V と 7.4V のモーターが混在している場合は、誤ってモーターを焼損させないよう、正しい電源を接続していることに注意してください。次に、モーターバスを USB 経由でコンピュータに接続します。USB は電源を供給しないため、電源と USB の両方を接続する必要があることに注意してください。

以下はコードによるキャリブレーション手順です。上の画像の配線サーボを参照しながらキャリブレーションを行ってください
アームに対応する USB ポートを見つける 各アームに対して正しいポートを見つけるには、ユーティリティスクリプトを 2 回実行します:
lerobot-find-port
出力例:
Finding all available ports for the MotorBus.
['/dev/ttyACM0', '/dev/ttyACM1']
Remove the usb cable from your MotorsBus and press Enter when done.
[...Disconnect corresponding leader or follower arm and press Enter...]
The port of this MotorsBus is /dev/ttyACM1
Reconnect the USB cable.
USB を抜くことを忘れないでください。そうしないとインターフェースが検出されません。
フォロワーアームのポートを特定する際の出力例(Mac では /dev/tty.usbmodem575E0031751、Linux では /dev/ttyACM0 など):
リーダーアームのポートを特定する際の出力例(/dev/tty.usbmodem575E0032081、または Linux では /dev/ttyACM1 など):
USB ポートへのアクセス権を付与する必要がある場合は、次を実行します:
sudo chmod 666 /dev/ttyACM0
sudo chmod 666 /dev/ttyACM1
モーターを設定する
リーダーモーター(ST-3215-C046, C044, 001)のキャリブレーションには 5V 電源を使用してください。
| Leader Arm 関節 6 のキャリブレーション | Leader Arm 関節 5 のキャリブレーション | Leader Arm 関節 4 のキャリブレーション | Leader Arm 関節 3 のキャリブレーション | Leader Arm 関節 2 のキャリブレーション | Leader Arm 関節 1 のキャリブレーション |
|---|---|---|---|---|---|
 |  |  |  |  |  |
Arm Kit バージョン(ST-3215-C001)を購入した場合は 5V 電源を使用してください。Arm Kit Pro バージョンを購入した場合は、12V 電源を使用してサーボ(ST-3215-C047/ST-3215-C018)をキャリブレーションしてください。
| Follower Arm 関節 6 のキャリブレーション | Follower Arm 関節 5 のキャリブレーション | Follower Arm 関節 4 のキャリブレーション | Follower Arm 関節 3 のキャリブレーション | Follower Arm 関節 2 のキャリブレーション | Follower Arm 関節 1 のキャリブレーション |
|---|---|---|---|---|---|
 |  |  |  |  |  |
繰り返しになりますが、サーボジョイントのIDと減速比が、SO-ARM101 のものと厳密に一致していることを必ず確認してください。
コンピュータからのUSBケーブルと電源をフォロワーアームのコントローラボードに接続します。その後、次のコマンドを実行します。
lerobot-setup-motors \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 # <- paste here the port found at previous step
次の指示が表示されます。
Connect the controller board to the 'gripper' motor only and press enter.
指示に従い、グリッパーのモーターを接続します。このとき、ボードに接続されているモーターがそのモーターだけであり、かつそのモーター自体がまだ他のモーターとデイジーチェーン接続されていないことを確認してください。[Enter] を押すと、そのモーターの ID とボーレートがスクリプトによって自動的に設定されます。
その後、次のメッセージが表示されます。
'gripper' motor id set to 6
続いて次の指示が表示されます。
Connect the controller board to the 'wrist_roll' motor only and press enter.
コントローラボードから 3 ピンケーブルを取り外して構いませんが、反対側はグリッパーモーターに接続したままで問題ありません。すでに正しい位置にあります。次に、別の 3 ピンケーブルを手首ロールモーターに接続し、それをコントローラボードに接続します。前のモーターと同様に、ボードに接続されているモーターがそのモーターだけであり、かつそのモーター自体が他のどのモーターとも接続されていないことを確認してください。
指示に従って、各モーターに対して同じ操作を繰り返してください。
Enter を押す前に、各ステップで配線を確認してください。例えば、ボードを操作している間に電源ケーブルが外れてしまうことがあります。
完了するとスクリプトは終了し、その時点でモーターは使用可能な状態になります。各モーターから次のモーターへ 3 ピンケーブルを接続し、最初のモーター(id=1 の「shoulder pan」)からのケーブルをコントローラボードに接続します。コントローラボードはアームのベースに取り付けることができます。
リーダーアームについても同じ手順を実行します。
lerobot-setup-motors \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM0 # <- paste here the port found at previous step
組み立て
- SO-ARM101 のデュアルアーム組み立て手順は SO-ARM100 と同じです。唯一の違いは、SO-ARM101 ではケーブルクリップが追加されていることと、リーダーアームのジョイントサーボの減速比が異なることです。そのため、SO100 と SO101 のどちらも、以下の内容を参照して組み立てることができます。
- 組み立て前に、モーターモデルと減速比をもう一度確認してください。SO100 を購入した場合は、このステップは無視して構いません。SO101 を購入した場合は、以下の表を確認し、F1〜F6 と L1〜L6 を区別してください。
| サーボモデル | 減速比 | 対応するジョイント |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
SO101 Arm Kit Standard Edition を購入した場合、すべての電源は 5V です。SO101 Arm Kit Pro Edition を購入した場合、リーダーアームは各ステップで 5V 電源を使用してキャリブレーションおよび動作させる必要があり、フォロワーアームは各ステップで 12V 電源を使用してキャリブレーションおよび動作させる必要があります。
リーダーアームの組み立て
| ステップ 1 | ステップ 2 | ステップ 3 | ステップ 4 | ステップ 5 | ステップ 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| ステップ 7 | ステップ 8 | ステップ 9 | ステップ 10 | ステップ 11 | ステップ 12 |
 |  |  |  |  |  |
| ステップ 13 | ステップ 14 | ステップ 15 | ステップ 16 | ステップ 17 | ステップ 18 |
 |  |  |  |  |  |
| ステップ 19 | ステップ 20 | ||||
 |  |
フォロワーアームの組み立て
- フォロワーアームの組み立て手順は、基本的にリーダーアームと同じです。唯一の違いは、ステップ 12 以降のエンドエフェクタ(グリッパーとハンドル)の取り付け方法です。
| ステップ 1 | ステップ 2 | ステップ 3 | ステップ 4 | ステップ 5 | ステップ 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| ステップ 7 | ステップ 8 | ステップ 9 | ステップ 10 | ステップ 11 | ステップ 12 |
 |  |  |  |  |  |
| ステップ 13 | ステップ 14 | ステップ 15 | ステップ 16 | ステップ 17 | |
 |  |  |  |  |
キャリブレーション
SO100 と SO101 のコードは互換性があります。SO100 のユーザーは、SO101 のパラメータとコードをそのまま利用して動作させることができます。
SO101 Arm Kit Standard Edition を購入した場合、すべての電源は 5V です。SO101 Arm Kit Pro Edition を購入した場合、リーダーアームは各ステップで 5V 電源を使用してキャリブレーションおよび動作させる必要があり、フォロワーアームは各ステップで 12V 電源を使用してキャリブレーションおよび動作させる必要があります。
次に、SO-10x ロボットに電源とデータケーブルを接続し、キャリブレーションを行う必要があります。これは、リーダーアームとフォロワーアームが同じ物理位置にあるときに、同じ位置値を持つようにするためです。このキャリブレーションは、ある SO-10x ロボットで学習したニューラルネットワークを別の SO-10x ロボットでも動作させるために不可欠です。ロボットアームを再キャリブレーションする必要がある場合は、~/.cache/huggingface/lerobot/calibration/robots または ~/.cache/huggingface/lerobot/calibration/teleoperators 配下のファイルを削除してから、ロボットアームを再キャリブレーションしてください。そうしないと、エラーが表示されます。ロボットアームのキャリブレーション情報は、このディレクトリ配下の JSON ファイルに保存されます。
PC(Linux)および Jetson デバイスでは、最初に接続した USB デバイスは通常 ttyACM0 に、2 番目は ttyACM1 にマッピングされます。コマンドを実行する前に、どのポートがリーダーとフォロワーにマッピングされているかを必ず再確認してください。
フォロワーアームの手動キャリブレーション
6つのロボットサーボのインターフェースを3ピンケーブルで接続し、シャーシサーボをサーボドライブプレートに接続してから、次のコマンドまたはAPIサンプルを実行してロボットアームをキャリブレーションします:
まずインターフェース権限を付与します
sudo chmod 666 /dev/ttyACM*
次にフォロワーアームをキャリブレーションします
lerobot-calibrate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \# <- The port of your robot
--robot.id=my_awesome_follower_arm # <- Give the robot a unique name
以下のビデオはキャリブレーションの方法を示しています。まず、すべての関節が可動範囲の中央になる位置にロボットを移動させる必要があります。その後、Enterキーを押したら、各関節を可動範囲全体にわたって動かしてください。
リーダーアームの手動キャリブレーション
同じ手順でリーダーアームをキャリブレーションし、次のコマンドまたはAPIサンプルを実行します:
lerobot-calibrate \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \# <- The port of your robot
--teleop.id=my_awesome_leader_arm # <- Give the robot a unique name
(オプション)Seeed Studio SoARM クイックツールによる中立位置キャリブレーション
ロボットのキャリブレーションや動作中に、次のようなエラーが表示される場合があります:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)
これは通常、サーボの現在位置/ゼロオフセットが異常で、読み取られる角度が想定範囲を超えていることを意味します。その場合、Seeed Studio の SoARM ツールを使用して中立位置キャリブレーション(現在位置を書き込み、中立値 2048 に設定)を行い、その後にアーム全体のキャリブレーションをやり直すことができます。
1) GitHub からツールをクローンし、依存関係をインストールする
git clone https://github.com/Seeed-Projects/Seeed_RoboController.git
cd Seeed_RoboController
pip install -r requirements.txt
2) 中立位置キャリブレーションと検証
スクリプトの場所:
src/tools/servo_middle_calibration.py:中立位置キャリブレーション(現在位置を 2048 として書き込む)src/tools/servo_disable.py:サーボトルクを無効化(手で関節を回しやすくする)src/tools/servo_center_test.py:2048 に移動してキャリブレーション結果を検証
次の順番で実行します(コマンドは対話的にポートの選択を求めます):
- (オプション)トルクを無効化して、手動で関節を調整:
python -m src.tools.servo_disable
- 中立位置キャリブレーションを実行(現在位置を 2048 に設定):
python -m src.tools.servo_middle_calibration
- 検証:サーボを 2048 に移動し、想定どおりの中立位置に戻るか確認:
python -m src.tools.servo_center_test
中立位置キャリブレーションが完了したら、上記の lerobot-calibrate 手順に戻り、アーム全体のキャリブレーションをやり直します。
テレオペレーション
シンプルなテレオペ これでロボットをテレオペレーションする準備が整いました!次のシンプルなスクリプトを実行します(カメラには接続せず、表示もしません):
ロボットに関連付けられた id はキャリブレーションファイルの保存に使用されます。同じ構成を使用する場合、テレオペレーション、記録、評価の際には同じ id を使用することが重要です。
sudo chmod 666 /dev/ttyACM*
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm
teleoperate コマンドは自動的に次の処理を行います:
- 不足しているキャリブレーションを検出し、キャリブレーション手順を開始します。
- ロボットとテレオペデバイスに接続し、テレオペレーションを開始します。
カメラを追加する
RealSense D435i/D405 を使用する場合
RealSense 深度カメラは LeRobot に RGB-D 認識機能を提供し、物体認識、点群再構成、テーブルトップマニピュレーションなどのタスクに適しています。ここで推奨するモデルは RealSense D405 と RealSense D435i です。
RealSense D405

RealSense D405 は短距離用のステレオ深度カメラで、テーブルトップロボットマニピュレーションなどの高精度な近距離タスク向けに設計されており、一般的な動作距離は 7 cm ~ 50 cm です。
RealSense D435i

RealSense D435i は深度センシング、RGB イメージング、IMU を組み合わせており、3D 再構成、SLAM、ロボット環境認識などの中距離〜近距離アプリケーションに適しています。
1. カメラブランチに切り替える
現在のカメラサポートは DepthCameraSupport ブランチで利用できます:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
現在のブランチを確認します:
git branch --show-current
期待される出力:
DepthCameraSupport
2. LeRobot を編集可能モードでインストール
RealSense のみを使用する場合:
pip install -e ".[realsense]"
3. カメラを検出する
lerobot-find-cameras realsense
このステップでは次の情報が出力されます:
- カメラモデル
- シリアル番号
- USB 情報
- デフォルトのストリーム設定
4. RealSense の例
デュアル RealSense テスト:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
d435i_color: {
type: realsense_d435i_color,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d435i_depth: {
type: realsense_d435i_depth,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
max_depth_m: 2.0,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
},
d405_color: {
type: realsense_d405_color,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d405_depth: {
type: realsense_d405_depth,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
depth_alpha: 0.03,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. パラメータに関する注意
depth_alphaは深度画像のスケーリング係数を制御し、表示結果や対象距離範囲に応じて調整できます。- 3台以上の深度カメラを接続する場合は、全体の安定性を高めるために
fpsを15に下げることを推奨します。 - 安定性とリアルタイム性のバランスを取るため、解像度は
640x480に保つことを推奨します。
Orbbec Gemini2/Gemini336 カメラを使用する場合

Orbbec Gemini 2 はロボットアプリケーション向けの高性能 RGB-D カメラで、正確な深度とカラーのアライメントを備えた同期 RGB および深度ストリームを提供します。ステレオ深度センシングと内蔵 6 軸 IMU を組み合わせることで、物体検出、3D 認識、マッピング、ナビゲーションなどのロボットタスクに非常に適しています。コンパクトな設計と完全な Orbbec SDK サポートにより、研究用途と実環境での導入の両方に適しています。

Gemini 336 は Gemini 330 シリーズの新しいメンバーです。Gemini 335 の優れた深度性能を受け継ぎつつ、反射の多い屋内エリア、高ダイナミックシーンの暗部、明るい屋外環境における深度画像品質をさらに向上させています。ロボットアプリケーションにおいては、認識、自己位置推定、マニピュレーションなどのタスクに対して、より安定した高品質の深度データを提供できます。
1. カメラブランチに切り替える
現在のカメラサポートは DepthCameraSupport ブランチで利用できます:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
現在のブランチを確認します:
git branch --show-current
期待される出力:
DepthCameraSupport
2. LeRobot を編集可能モードでインストール
Orbbec のみを使用する場合:
pip install -e ".[orbbec]"
3. カメラを検出する
lerobot-find-cameras orbbec
このステップでは次の情報が出力されます:
- カメラモデル
- シリアル番号
- USB 情報
- デフォルトのストリーム設定
4. Orbbec の例
シングル Orbbec テスト:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
orbbec_color: {
type: orbbec_color,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
rotation: 0,
warmup_s: 1
},
orbbec_depth: {
type: orbbec_depth,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 400,
fps: 30,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. パラメータに関する注意事項
depth_alphaは深度画像のスケーリング係数を制御します。まずは0.2を目安に設定し、その後表示結果に基づいて微調整してください。- 3 台以上の深度カメラを接続する場合は、安定性を高めるために
fpsを15に下げることを推奨します。 - より安定した表示とデータ転送のために、解像度は
640x480に保つことを推奨します。
6. よくある問題
次のようなエラーが表示される場合:
No Orbbec camera found for 'XXXX'
通常は、設定内のシリアル番号が現在接続されているデバイスと一致していないことを意味します。次を実行します:
lerobot-find-cameras orbbec
その後、実際の serial を確認し、コマンド内の serial_number_or_name を更新してください。
通常のカメラを使用する場合
SO100 と SO101 のコードは互換性があります。SO100 のユーザーは、SO101 のパラメータとコードをそのまま利用して動作させることができます。
カメラをインスタンス化するには、カメラ識別子が必要です。この識別子は、コンピュータを再起動したりカメラを再接続したりすると変わる場合があり、この挙動は主にオペレーティングシステムに依存します。
システムに接続されているカメラのインデックスを確認するには、次のスクリプトを実行します:
lerobot-find-cameras opencv # or realsense for Intel Realsense cameras
ターミナルには次のような情報が出力されます。
--- Detected Cameras ---
Camera #0:
Name: OpenCV Camera @ 0
Type: OpenCV
Id: 0
Backend api: AVFOUNDATION
Default stream profile:
Format: 16.0
Width: 1920
Height: 1080
Fps: 15.0
--------------------
(more cameras ...)
各カメラで撮影された画像は、outputs/captured_images ディレクトリ内に保存されています。
Intel RealSense カメラを macOS で使用する場合、次のようなエラーが発生することがあります:OSError finding RealSense cameras: failed to set power state sudo。これは同じコマンドを権限付きで実行することで解決できます。なお、macOS で RealSense カメラを使用する場合は不安定であることに注意してください。
その後、次のコードを実行することで、テレオペレーション中にコンピュータ上でカメラ映像を表示できるようになります。これは、最初のデータセットを記録する前にセットアップを準備するのに役立ちます。
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
カメラがさらに多い場合は、--robot.cameras を変更してカメラを追加できます。index_or_path の形式は、python -m lerobot.find_cameras opencv によって出力されるカメラ ID の末尾の数字によって決まることに注意してください。
fourcc: "MJPG" 形式の画像は圧縮されています。より高い解像度を試すこともできますし、YUYV 形式を試すこともできます。ただし後者では画像の解像度と FPS が低下し、その結果ロボットアームの動作にラグが生じます。現在、MJPG 形式では、1920*1080 の解像度で 30FPS を維持しながら 3 台のカメラをサポートできます。とはいえ、同じ USB ハブ経由で 2 台のカメラを 1 台のコンピュータに接続することは依然として推奨されません。
例えば、サイドカメラを追加したい場合:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
fourcc: "MJPG" 形式の画像は圧縮されています。より高い解像度を試すこともできますし、YUYV 形式を試すこともできます。ただし後者では画像の解像度と FPS が低下し、その結果ロボットアームの動作にラグが生じます。現在、MJPG 形式では、1920*1080 の解像度で 30FPS を維持しながら 3 台のカメラをサポートできます。とはいえ、同じ USB ハブ経由で 2 台のカメラを 1 台のコンピュータに接続することは依然として推奨されません。
このようなバグが見つかった場合。
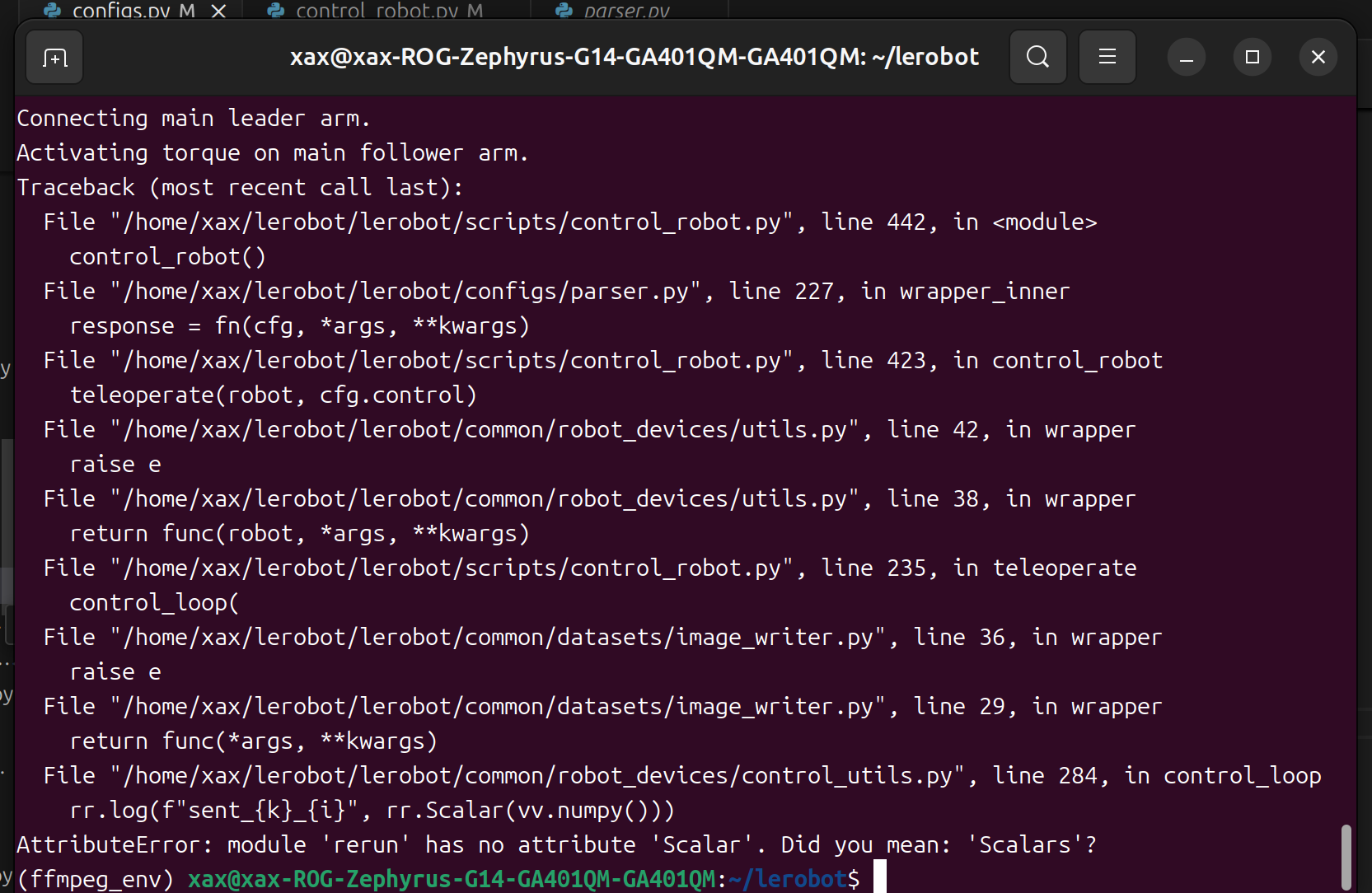
問題を解決するには、rerun のバージョンをダウングレードしてください。
pip3 install rerun-sdk==0.23
データセットを記録する
- データセットをローカルに保存したい場合は、そのまま次を実行できます:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=seeedstudio123/test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=false \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
このうち、repo_id は任意に変更でき、push_to_hub=false とします。最終的に、データセットはホームフォルダ内の ~/.cache/huggingface/lerobot ディレクトリに保存され、そこで前述の seeedstudio123/test フォルダが作成されます。
- Hugging Face Hub の機能を使ってデータセットをアップロードしたい場合で、まだ行っていない場合は、Hugging Face settings から作成できる書き込み権限付きトークンを使ってログインしていることを確認してください:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential
これらのコマンドを実行するために、Hugging Face のリポジトリ名を変数に保存します:
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER
5 エピソードを記録し、データセットを Hub にアップロードします:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=true \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
次のような行が多数表示されます:
INFO 2024-08-10 15:02:58 ol_robot.py:219 dt:33.34 (30.0hz) dtRlead: 5.06 (197.5hz) dtWfoll: 0.25 (3963.7hz) dtRfoll: 6.22 (160.7hz) dtRlaptop: 32.57 (30.7hz) dtRphone: 33.84 (29.5hz)
Record 関数
record 関数は、ロボットの動作中にデータを取得および管理するための一連のツールを提供します。
1. データ保存
- データは
LeRobotDataset形式で保存され、記録中にディスクへ書き込まれます。 - デフォルトでは、記録後にデータセットはあなたの Hugging Face ページにプッシュされます。
- アップロードを無効にするには、
--dataset.push_to_hub=Falseを使用します。
2. チェックポイントと再開
- 記録中にチェックポイントが自動的に作成されます。
- 中断後に再開するには、
--resume=trueを付けて同じコマンドを再実行します。
⚠️ 重要な注意:再開する場合、--dataset.num_episodes には「データセット全体の目標エピソード数」ではなく、「追加で記録したいエピソード数」を設定してください。
- 最初から記録をやり直したい場合は、データセットのディレクトリを手動で削除してください。
3. 記録パラメータ
コマンドライン引数を使ってデータ記録の流れを設定します:
| Parameter | 説明 | デフォルト |
|---|---|---|
| --dataset.episode_time_s | 1 エピソードあたりの時間(秒) | 60 |
| --dataset.reset_time_s | 各エピソード後の環境リセット時間(秒) | 60 |
| --dataset.num_episodes | 記録するエピソードの総数 | 50 |
4. 記録中のキーボード操作
キーボードショートカットを使ってデータ記録の流れを制御します:
| Key | 動作 |
|---|---|
| → (右矢印) | 現在のエピソード/リセットを早期終了し、次へ進む。 |
| ← (左矢印) | 現在のエピソードをキャンセルし、録り直す。 |
| ESC | セッションを即座に停止し、動画をエンコードしてデータセットをアップロードする。 |
キーボードが動作しない場合は、別バージョンの pynput をインストールする必要があるかもしれません。
pip install pynput==1.6.8
データ収集のヒント
- タスクの提案:さまざまな位置にある物体を把持し、ビンの中に置く。
- 規模:50 エピソード以上を記録する(位置ごとに 10 エピソード)。
- 一貫性:
- カメラを固定する。
- 同じ把持動作を維持する。
- 操作対象の物体がカメラ映像内に見えるようにする。
- 段階的な拡張:
- 新しい位置、手法、カメラ調整などのバリエーションを加える前に、まずは確実な把持を実現する。
- 失敗を防ぐため、複雑さを急激に増やさない。
💡 経験則:カメラ画像だけを見て、自分自身でタスクを実行できる状態であるべきです。
この重要なトピックをさらに深く知りたい場合は、良いデータセットとは何かについて執筆したブログ記事を参照してください。
トラブルシューティング
Linux 固有の問題:
録画中に右矢印/左矢印/ESC キーが反応しない場合:
$DISPLAY環境変数が設定されているか確認します(pynput limitations を参照)。
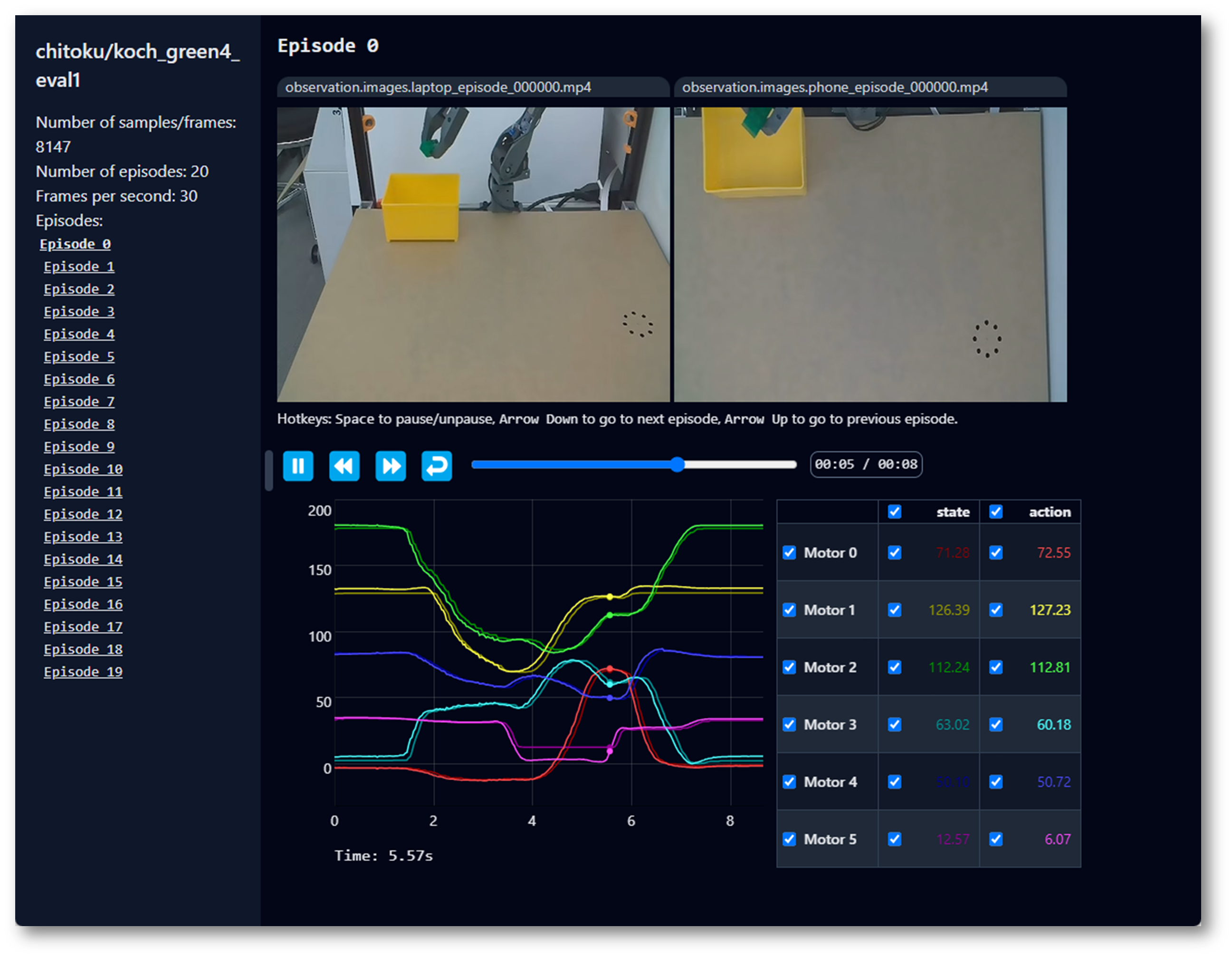
データセットを可視化する
SO100 と SO101 のコードは互換性があります。SO100 のユーザーは、SO101 のパラメータとコードをそのまま利用して動作させることができます。
--control.push_to_hub=true を指定してデータセットを Hub にアップロードした場合、次のコマンドで表示されるリポジトリ ID をコピー&ペーストして、オンラインでデータセットを可視化 できます:
echo ${HF_USER}/so101_test
--dataset.push_to_hub=false を指定してアップロードしなかった場合でも、次のコマンドでローカルに可視化できます:
lerobot-dataset-viz \
--repo-id ${HF_USER}/so101_test \
--dataset.push_to_hub=false を指定してアップロードした場合でも、次のコマンドでローカルに可視化できます:
lerobot-dataset-viz \
--repo-id seeed_123/so101_test \
ここで、seeed_123 はデータ収集時に定義したカスタムの repo_id 名です。
エピソードをリプレイする
SO100 と SO101 のコードは互換性があります。SO100 のユーザーは、SO101 のパラメータとコードをそのまま利用して動作させることができます。
便利な機能として replay 関数があります。これを使うと、記録した任意のエピソードや、公開されている任意のデータセットのエピソードをリプレイできます。この機能により、ロボットの動作の再現性をテストしたり、同一モデルのロボット間での転移性を評価したりできます。
以下のコマンド、または API のサンプルを使って、ロボット上で最初のエピソードをリプレイできます:
lerobot-replay \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.episode=0
ロボットは、記録したものと同様の動きを再現するはずです。
学習と評価
ACT
ACT を参照してください
ロボットを制御するポリシーを学習するには、lerobot-train スクリプトを使用します。
学習
lerobot-train \
--dataset.repo_id=${HF_USER}/so101_test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--steps=300000
ローカルデータセットで学習したい場合は、repo_id がデータ収集時に使用したものと一致していることを確認し、--policy.push_to_hub=False を追加してください。
lerobot-train \
--dataset.repo_id=seeedstudio123/test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--policy.push_to_hub=false\
--steps=300000
内容を説明します:
- データセットの指定:パラメータ
--dataset.repo_id=${HF_USER}/so101_testによってデータセットを指定します。 - 学習ステップ数:
--steps=300000を使って学習ステップ数を変更します。アルゴリズムのデフォルトは 800000 ステップであり、タスクの難易度や学習中の loss を観察しながら調整できます。 - ポリシータイプ:
policy.type=actによってポリシーを指定します。同様に、[act,diffusion,pi0,pi0fast,pi0fast,sac,smolvla] などのポリシーを切り替えることができ、その場合はconfiguration_act.pyから設定が読み込まれます。重要な点として、このポリシーは、モータ状態・モータアクション・カメラ数といった情報がすでにデータセットに保存されているため、ロボット(例:laptopやphone)に自動的に適応します。 - デバイスの選択:Nvidia GPU 上で学習しているため
policy.device=cudaを指定していますが、Apple Silicon で学習する場合はpolicy.device=mpsを使用できます。 - 可視化ツール:学習チャートを Weights and Biases で可視化するために
wandb.enable=trueを指定します。これは任意ですが、使用する場合はwandb loginを実行してログインしていることを確認してください。
評価
SO100 と SO101 のコードは互換性があります。SO100 のユーザーは、SO101 のパラメータとコードをそのまま利用して動作させることができます。
ポリシーのチェックポイントを入力として、lerobot/record.py の record 関数を使用できます。例えば、次のコマンドを実行して 10 エピソード分の評価を記録します:
lerobot-record \
--robot.type=so100_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ up: {type: opencv, index_or_path: /dev/video10, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: intelrealsense, serial_number_or_name: 233522074606, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_so100 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=${HF_USER}/my_policy
例えば次のようになります:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/train/act_so101_test/checkpoints/last/pretrained_model
-
--policy.pathパラメータは、ポリシー学習結果の重みファイルへのパスを示します(例:outputs/train/act_so101_test/checkpoints/last/pretrained_model)。モデル学習結果の重みファイルを Hub にアップロードした場合は、モデルリポジトリ(例:${HF_USER}/act_so100_test)を使用することもできます。 -
データセット名
dataset.repo_idはeval_で始まります。この操作により、評価時の動画とデータが別々に記録され、seeed/eval_test123のようなeval_で始まるフォルダに保存されます。 -
評価フェーズ中に
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'が発生した場合は、まずeval_で始まるフォルダを削除してから、再度プログラムを実行してください。 -
mean is infinity. You should either initialize with stats as an argument or use a pretrained modelが発生した場合、--robot.camerasパラメータ内の front や side などのキーワードは、データセット収集時に使用したものと厳密に一致している必要があることに注意してください。
SmolVLA
SmolVLA は、Hugging Face が提供するロボティクス向け軽量ファウンデーションモデルです。LeRobot データセット上で簡単にファインチューニングできるよう設計されており、開発を加速させるのに役立ちます。
環境をセットアップする
次のコマンドを実行して SmolVLA の依存関係をインストールします:
pip install -e ".[smolvla]"
自分のデータで SmolVLA をファインチューニングする
smolvla_base(事前学習済み 4.5 億パラメータモデル)を使用し、自分のデータでファインチューニングします。モデルを 20k ステップ学習するには、単一の A100 GPU でおおよそ 4 時間かかります。ステップ数は、性能とユースケースに応じて調整してください。
GPU デバイスがない場合は、Google Colab 上のノートブックを使って学習できます。
--dataset.repo_id を使って、トレーニングスクリプトにデータセットを渡します。インストールをテストしたい場合は、SmolVLA Paper 用に収集したデータセットの 1 つを使用する、次のコマンドを実行してください。
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--job_name=my_smolvla_training \
--policy.device=cuda \
--wandb.enable=true
GPU に余裕があり、読み込み時間が短いままであれば、小さいバッチサイズから始めて徐々に増やしていくことができます。
ファインチューニングは一種のアートです。ファインチューニング用オプションの全体像を確認するには、次を実行してください:
lerobot-train --help
ファインチューニングしたモデルを評価し、リアルタイムで動かす
エピソードを記録する場合と同様に、HuggingFace Hub にログインしておくことを推奨します。対応する手順は Record a dataset を参照してください。ログイン後は、次のようにしてセットアップ上で推論を実行できます:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \ # <- Use your port
--robot.id=my_blue_follower_arm \ # <- Use your robot id
--robot.cameras="{ front: {type: opencv, index_or_path: 8, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \ # <- Use your cameras
--dataset.single_task="Grasp a lego block and put it in the bin." \ # <- Use the same task description you used in your dataset recording
--dataset.repo_id=${HF_USER}/eval_DATASET_NAME_test \ # <- This will be the dataset name on HF Hub
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
# <- Teleop optional if you want to teleoperate in between episodes \
# --teleop.type=so100_leader \
# --teleop.port=/dev/ttyACM0 \
# --teleop.id=my_red_leader_arm \
--policy.path=HF_USER/FINETUNE_MODEL_NAME # <- Use your fine-tuned model
評価セットアップに応じて、評価スイートで記録する継続時間とエピソード数を設定できます。
LIBERO
LIBERO は、生涯にわたるロボット学習を研究するために設計されたベンチマークです。ロボットは工場で一度だけ事前学習されるのではなく、時間の経過とともに人間のユーザーと一緒に学習と適応を続ける必要がある、という考え方に基づいています。この継続的な適応は、意思決定における生涯学習(LLDM)と呼ばれ、真にパーソナライズされたヘルパーロボットを構築するための重要なステップです。
LIBERO で評価する
LeRobot では、LIBERO をフレームワークに移植し、主に軽量な Vision-Language-Action モデルである SmolVLA を評価するために使用しました。
LIBERO は現在、マルチ評価対応シミュレーションの一部となっており、フラグを 1 つ付けるだけで、単一のタスクスイートまたは複数のスイートを同時に対象としてポリシーをベンチマークできます。
LIBERO をインストールするには、LeRobot の公式手順に従った後、次を実行します:pip install -e ".[libero]"
単一スイートでの評価
1 つの LIBERO スイート上でポリシーを評価します:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object \
--eval.batch_size=2 \
--eval.n_episodes=3
--env.taskはスイート(libero_object、libero_spatialなど)を選択します。--eval.batch_sizeは並列実行する環境数を制御します。--eval.n_episodesは実行するエピソードの総数を設定します。
マルチスイートでの評価
複数のスイートにまたがってポリシーを一度にベンチマークします:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object,libero_spatial \
--eval.batch_size=1 \
--eval.n_episodes=2
- マルチスイート評価には、
--env.taskにカンマ区切りのリストを渡します。
トレーニングコマンド例
lerobot-train \
--policy.type=smolvla \
--policy.repo_id=${HF_USER}/libero-test \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_10 \
--output_dir=./outputs/ \
--steps=100000 \
--batch_size=4 \
--eval.batch_size=1 \
--eval.n_episodes=1 \
--eval_freq=1000 \
レンダリングに関する注意
LeRobot はシミュレーションに MuJoCo を使用します。トレーニングや評価の前にレンダリングバックエンドを設定する必要があります:
export MUJOCO_GL=egl→ ヘッドレスサーバー向け(例:HPC、クラウド)
Pi0
Pi0 を参照してください
pip install -e ".[pi]"
トレーニング
lerobot-train \
--policy.type=pi0 \
--dataset.repo_id=seeed/eval_test123 \
--job_name=pi0_training \
--output_dir=outputs/pi0_training \
--policy.pretrained_path=lerobot/pi0_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--policy.dtype=bfloat16 \
--steps=20000 \
--policy.device=cuda \
--batch_size=32 \
--wandb.enable=false
評価
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi0_training/checkpoints/last/pretrained_model
Pi0.5
Pi0.5 を参照してください
pip install -e ".[pi]"
トレーニング
lerobot-train \
--dataset.repo_id=seeed/eval_test123 \
--policy.type=pi05 \
--output_dir=outputs/pi05_training \
--job_name=pi05_training \
--policy.pretrained_path=lerobot/pi05_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--wandb.enable=false \
--policy.dtype=bfloat16 \
--steps=3000 \
--policy.device=cuda \
--batch_size=32
評価
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi05_training/checkpoints/last/pretrained_model
GR00T N1.5
公式ドキュメントを参照してください:GR00T N1.5。
GR00T N1.5 は、より一般的なロボットの推論とスキル学習のための、NVIDIA によるオープンなファウンデーションモデルです。これはクロスエンボディメントモデルであり、言語や画像などのマルチモーダル入力を受け取り、異なる環境にまたがってマニピュレーションタスクを実行できます。
LeRobot では、重要なのはポリシータイプを --policy.type=groot に設定することです。GR00T N1.5 は環境要件が高く(FlashAttention に依存し、CUDA GPU を必要とします)、まず ACT / Pi0 をエンドツーエンドで動作させてから GR00T を試すことを推奨します。
インストール(重要)
現在の公式ドキュメントによると、GR00T N1.5 には flash-attn が必要であり、CUDA 対応ハードウェアでのみ使用できます。
推奨される手順:
- まずベース環境(Python、CUDA、ドライバなど)を準備します。この時点では
lerobotをインストールしないでください。 - 使用する CUDA バージョンに対応した PyTorch をインストールします(CUDA のバージョンによっては異なる
--index-urlが必要になる場合があります。PyTorch のインストールページに従ってください)。
pip install "torch>=2.2.1,<2.8.0" "torchvision>=0.21.0,<0.23.0"
flash-attnのビルド依存関係をインストールし、その後flash-attn自体をインストールします。
pip install ninja "packaging>=24.2,<26.0"
pip install "flash-attn>=2.5.9,<3.0.0" --no-build-isolation
python -c "import flash_attn; print(f'Flash Attention {flash_attn.__version__} imported successfully')"
grootのオプション依存関係(lerobot[groot])付きで LeRobot をインストールします。
pip install "lerobot[groot]"
もし flash-attn のインストールに失敗する場合、主な原因は通常、(1) PyTorch と CUDA の不整合、(2) ビルド依存関係の不足、または (3) 環境が新しすぎる/古すぎる、のいずれかです。まず公式の GR00T ドキュメントと PyTorch のインストール手順を突き合わせて確認してください。
トレーニング(ファインチューニング)
公式ドキュメントでは、accelerate launch --multi_gpu ... を用いたマルチ GPU の例が提供されています。単一 GPU しかない場合でも、まずは単一プロセスの実行を動作させることから始めることができます(正確なサポート内容や引数は公式ドキュメントに依存します)。
accelerate launch \
--multi_gpu \
--num_processes=$NUM_GPUS \
$(which lerobot-train) \
--output_dir=$OUTPUT_DIR \
--save_checkpoint=true \
--batch_size=$BATCH_SIZE \
--steps=$NUM_STEPS \
--save_freq=$SAVE_FREQ \
--log_freq=$LOG_FREQ \
--policy.push_to_hub=true \
--policy.type=groot \
--policy.repo_id=$REPO_ID \
--policy.tune_diffusion_model=false \
--dataset.repo_id=$DATASET_ID \
--wandb.enable=true \
--wandb.disable_artifact=true \
--job_name=$JOB_NAME
ロボット上での検証(評価)
トレーニング後は、他のポリシーと同様に lerobot-record を使って評価とリプレイの記録を行うことができます。公式ドキュメントには両腕ロボットの例が含まれていますが、SO101 の単腕ユーザーは left_arm_port/right_arm_port のような引数は不要です。
lerobot-record \
--robot.type=bi_so_follower \
--robot.left_arm_port=/dev/ttyACM1 \
--robot.right_arm_port=/dev/ttyACM0 \
--robot.id=bimanual_follower \
--robot.cameras='{ right: {"type": "opencv", "index_or_path": 0, "width": 640, "height": 480, "fps": 30}, left: {"type": "opencv", "index_or_path": 2, "width": 640, "height": 480, "fps": 30}, top: {"type": "opencv", "index_or_path": 4, "width": 640, "height": 480, "fps": 30} }' \
--display_data=true \
--dataset.repo_id=${HF_USER}/eval_groot_bimanual \
--dataset.num_episodes=10 \
--dataset.single_task="Grab and handover the red cube to the other arm" \
--policy.path=${HF_USER}/groot-bimanual \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=10
ライセンス:Apache 2.0(元の GR00T リポジトリと同じ)。
(Optional) Parameter-Efficient Fine-Tuning (PEFT)
PEFT(Parameter-Efficient Fine-Tuning)は、大規模な事前学習済みモデルがすべてのパラメータを更新することなく新しいタスクに適応できるようにする手法とツールのファミリーです。事前学習済みの LeRobot ポリシー(例:SmolVLA、Pi0)では、多くの場合、小さな「アダプタ」パラメータセット(例:LoRA)のみを学習することで、VRAM 使用量と学習コストを削減しつつ、フルファインチューニングに近い性能を達成できます。
インストール
オプションの peft 依存関係付きで LeRobot をインストールした後、トレーニング時に PEFT 関連の引数を使用できます。
pip install -e ".[peft]"
pip install "lerobot[peft]"
より詳しい概念と手法については:🤗 PEFT documentation を参照してください。
例:SmolVLA を LoRA でファインチューニングする(LIBERO libero_spatial サブタスク)
この例では、HuggingFaceVLA/libero データセット上で lerobot/smolvla_base を LoRA によりファインチューニングします。引数名は LeRobot のバージョンに依存するため、lerobot-train --help も併せて確認することを推奨します。
lerobot-train \
--policy.path=lerobot/smolvla_base \
--policy.repo_id=${HF_USER}/my_libero_smolvla_peft \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_spatial \
--output_dir=outputs/train/my_libero_smolvla_peft \
--job_name=my_libero_smolvla_peft \
--policy.device=cuda \
--steps=10000 \
--batch_size=32 \
--optimizer.lr=1e-3 \
--peft.method_type=LORA \
--peft.r=64
主要な PEFT 引数
--peft.method_type: 使用する PEFT 手法を選択します。LoRA(Low-Rank Adapter)は最も一般的な選択肢の 1 つです。--peft.r: LoRA のランク。ランクを高くすると通常は表現力が増しますが、同時にパラメータ数と VRAM 使用量も増加します。
LoRA を挿入する層 / モジュールの選択(任意)
デフォルトでは、PEFT は通常、最も重要な射影層(例:attention の q_proj、v_proj)に LoRA を挿入し、状態 / 行動の射影もカバーする場合があります。カスタマイズしたい場合は、--peft.target_modules を使用します。
一般的なパターン:
- モジュール名のサフィックスのリストを指定する(例):
--peft.target_modules="['q_proj', 'v_proj']"
- 正規表現を指定する(例;モデル内の実際のモジュール名に合わせて調整してください):
--peft.target_modules='(model\\.vlm_with_expert\\.lm_expert\\..*\\.(down|gate|up)_proj|.*\\.(state_proj|action_in_proj|action_out_proj|action_time_mlp_in|action_time_mlp_out))'
一部モジュールを全結合で学習する(任意)
一部のモジュールを LoRA のみ挿入するのではなく完全に学習させたい場合は、--peft.full_training_modules を使用します。例えば state_proj のみを全結合で学習するには:
--peft.full_training_modules="['state_proj']"
学習率の目安(経験則)
LoRA の学習率は、フル微調整よりも約 10 倍高く設定されることが多いです。例えば、フル微調整で一般的に 1e-4 を使う場合、LoRA では 1e-3 から始められます。学習率スケジューラを使用する場合、最終的な学習率は参考値として 1e-4 前後になることが多いです。
(任意)Accelerate を用いたマルチ GPU 学習
学習手順
方法 1: CLI フラグを使用する。
lerobot環境にaccelerateをインストールします。
pip install accelerate
accelerate launchと--multi_gpuおよび--num_processesフラグを使ってマルチ GPU 学習を起動します。
accelerate launch \
--multi_gpu \
--num_processes=2 \
$(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
重要な accelerate フラグ:
--multi_gpu: マルチ GPU 学習を有効にします。--num_processes: 使用する GPU の数(通常はマシン上で利用可能な GPU の数と同じ)。--mixed_precision=fp16: fp16 の混合精度を使用します(ハードウェアが対応している場合は bf16 も使用できます)。
注意:bf16 にはハードウェアのサポートが必要であり、すべての GPU で利用できるわけではありません。
| 精度 | ハードウェアサポート |
|---|---|
| fp16 | ほぼすべての NVIDIA GPU でサポート |
| bf16 | 一部の新しい GPU(Ampere 以降)のみサポート |
GPU が bf16 をサポートしていない場合は、Accelerate の設定で fp16 を選択するか、明示的に fp16 を指定してください。
方法 2: accelerate の設定ファイルを使用する(任意)。
頻繁に複数 GPU で学習する場合は、設定を保存して、同じフラグを毎回入力しなくて済むようにできます。
accelerate config は、ハードウェア構成(GPU の数、混合精度など)を設定ファイルに保存し、その後 accelerate launch を実行する際にそれらのオプションを再入力しなくて済むようにします。LeRobot の学習ロジック自体は変更せず、CLI 入力の繰り返しを減らすだけです。
マルチ GPU をたまにしか使わない場合(あるいは今回が初めての場合)は、これをスキップしてもまったく問題ありません。
対話的な設定では、一般的な「単一マシン + 複数 GPU」のシナリオにおいて、典型的な選択肢は次のとおりです:
- Compute environment: This machine
- Number of machines: 1
- Number of processes: 使用したい GPU の数
- GPU ids to use: Enter キーを押す(すべての GPU を使用)
- Mixed precision: 可能であれば fp16 を優先し、GPU が対応していると分かっている場合のみ bf16 を選択
accelerate config
accelerate launch $(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
マルチ GPU がハイパーパラメータに与える影響(および調整方法)
LeRobot は、学習挙動を暗黙的に変更しないようにするため、GPU の数に応じて学習率や学習ステップ数を自動調整しません。これは、他の一部の分散学習フレームワークとは異なります。
マルチ GPU 用にハイパーパラメータを調整したい場合、一般的なアプローチは次のとおりです:
- ステップ数: 有効バッチサイズ(batch_size × num_gpus)が増加するため、同じ総サンプル数を保つには、ステップ数をおおよそ
1 / num_gpusに比例して減らすことができます。
accelerate launch --num_processes=2 $(which lerobot-train) \
--batch_size=8 \
--steps=50000 \
--dataset.repo_id=lerobot/pusht \
--policy=act
- 学習率: 各ステップで使用されるサンプル数が増えるため、多くの場合、学習率を GPU の数に線形に比例させてスケールできます: new_lr = single_gpu_lr × num_gpus
accelerate launch --num_processes=2 $(which lerobot-train) \
--optimizer.lr=2e-4 \
--dataset.repo_id=lerobot/pusht \
--policy=act
これらは厳密なルールではなく、一般的なヒューリスティックです。よく分からない場合は、学習が安定している限り、学習率やステップ数を変更せずにそのままにしておいても構いません。
高度な設定やトラブルシューティングについては、Accelerate のドキュメントを参照してください:Accelerate。
(任意)非同期推論
非同期推論が有効になっていない場合、LeRobot の制御フローは 従来型の逐次 / 同期推論 として理解できます:ポリシーがまず一連のアクションチャンクを予測し、それを実行し、その後になって次の予測を待ちます。
大きなモデルでは、次のアクションチャンクを待つ間にロボットが目に見えて一時停止することがあります。
非同期推論の目的は、現在のアクションチャンクをロボットに実行させながら、次のチャンクを先行して計算することで、待ち時間を減らし応答性を向上させることです。
非同期推論は、ACT、OpenVLA、Pi0、SmolVLA などの チャンクベースのアクションポリシー を含む、LeRobot がサポートするポリシーに適用できます。
推論が実際の制御から切り離されるため、非同期推論は、より強力な計算リソースを持つマシンをロボットの推論に活用するのにも役立ちます。
非同期推論の詳細については、Hugging Face のブログを参照してください。
まず、いくつかの基本概念を紹介します:
-
クライアント: ロボットアームとカメラに接続し、観測データ(画像やロボットの姿勢など)を収集してサーバーに送信し、サーバーから返されるアクションチャンクを受け取って順番に実行します。
-
サーバー: 計算リソースを提供するデバイスです。カメラデータとロボットアームのデータを受け取り、推論(すなわち計算)を行ってアクションチャンクを生成し、それをクライアントに送り返します。ロボットアームとカメラに接続された同じデバイスでも、同一ローカルネットワーク上の別のコンピュータでも、インターネット上のクラウドサーバーでも構いません。
-
アクションチャンク: サーバー側でのポリシー推論によって得られる、ロボットアームのアクションコマンド列です。
非同期推論の 3 つのデプロイシナリオ
- 単一マシンでのデプロイ
ロボット、カメラ、クライアント、サーバーがすべて同じデバイス上にあります。
これは最も単純なケースです:サーバーは 127.0.0.1 で待ち受けでき、クライアントも 127.0.0.1:port に接続できます。公式ドキュメントのコマンド例はこのシナリオを想定しています。
- LAN 内でのデプロイ
ロボットとカメラは軽量なデバイスに接続され、ポリシーサーバーは同じローカルネットワーク内の別の高性能マシン上で動作します。
この場合、サーバーは他のマシンからアクセス可能なアドレスで待ち受ける必要があり、クライアントも 127.0.0.1 ではなくサーバーの LAN IP に接続する必要があります。
- ネットワーク越し / クラウドでのデプロイ
ポリシーサーバーはインターネット上で公開アクセス可能なクラウドホスト上で動作し、クライアントはパブリックインターネット経由で接続します。
この方法では、クラウドホストのより強力な GPU を利用できます。ネットワーク環境が良好な場合、往復のネットワーク時間(ネットワークレイテンシ)は推論時間と比べて相対的に小さい場合もありますが、これは実際のネットワーク環境に依存します。
セキュリティに関する注意:LeRobot の非同期推論パイプラインには、認証されていない gRPC + pickle デシリアライズに関連するリスクがあります。サーバー上に重要な情報や重要なサービスがある場合、パブリックなデプロイでサービスをインターネットに直接公開することは推奨されません。より安全な方法は、VPN や SSH トンネリングを使用するか、少なくともセキュリティグループで許可する送信元 IP を自分のクライアントのパブリック IP にできるだけ制限することです。
非同期推論デプロイの始め方
ステップ 1: 環境構築
まず、非同期推論に必要な追加依存関係を pip でインストールします。クライアントとサーバーの両方で、追加依存関係付きの lerobot をインストールする必要があります:
pip install -e ".[async]"
ステップ 2: ネットワーク設定と確認
- プロキシの問題
現在のターミナルでプロキシが設定されていて接続が異常な挙動を示す場合は、一時的にプロキシ環境変数を解除できます:
unset http_proxy https_proxy ftp_proxy all_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY ALL_PROXY
注意:上記のコマンドは現在のターミナルセッションにのみ影響します。別のターミナルウィンドウを開いた場合は、再度実行する必要があります。
- ファイアウォール / セキュリティグループでポートを開く
単一マシンでのデプロイ:通常はこの手順を省略できます。
LAN デプロイ:サーバー側で待ち受けポートを開く必要があります。
LAN 構成で待ち受けポートを開く例(サーバー側で実行):
sudo ufw allow 8080/tcp
クラウドデプロイ:クラウドサーバーのセキュリティグループでこのポートを開く必要があり、送信元 IP は可能な限り制限することを推奨します。
クラウドサーバー上で実行している場合:
サーバー管理コンソールのセキュリティグループでポート 8080 を開放するか、すでに開いている別のポートを使用してください。クラウドサービスプラットフォームごとに操作方法が異なるため、クラウドプロバイダのドキュメントを参照してください。
- IP アドレスを確認する
単一マシンでのデプロイの場合、このステップはスキップできます(単一マシンの IP アドレスは常に 127.0.0.1 です)。
LAN デプロイの場合:
サーバー側の LAN IP アドレスを確認して覚えておく必要があります。クライアントが接続する際に入力すべきなのは、policy_server を実行しているマシンの LAN IP であり、クライアント自身の IP ではありません。
Linux / Jetson / Raspberry Pi:
hostname -I
複数のアドレスが表示される場合は、一般的に現在の LAN ネットワークインターフェースに対応するもの(例:192.168.x.x)を選択します。
次のコマンドを使うこともできます:
ip addr
現在接続されているネットワークインターフェースの inet フィールドを確認します。
Windows:
ipconfig
IPv4 Address . . . . . . . . . . . : 192.168.14.140 のようなフィールドを探します。これがそのマシンの LAN IP アドレスです。
macOS:
ifconfig
現在接続されているネットワークインターフェースに対応する inet フィールドを探します。これが LAN IP アドレスです。
サーバー側の LAN IP アドレスを覚えておく必要があります。ここではこれを <LAN IP address> と表記します。
クラウドサーバーでのデプロイの場合:
サーバーのコントロールパネルでパブリック IP を探します。通常、次のいずれかの名称になっています:
Public IPv4
External IP
Public IP address
EIP
Public IP
パブリック IP アドレスを覚えておく必要があります。ここではこれを<server public IP>と表記します。
- 接続テスト
単一マシンでのデプロイ:このステップはスキップできます
LAN / クラウドデプロイ:クライアント側からサーバーポートに到達できるかテストすることを推奨します。テスト例は次のとおりです:
LAN 例:クライアント側で実行
nc -vz <LAN IP address> 8080
クラウド例:クライアント側で実行
nc -vz <server public IP> 8080
ステップ 3: サービスを起動する
シナリオ A: 単一マシンでのデプロイ
1 つのターミナルでローカルサービスを起動します:
python -m lerobot.async_inference.policy_server \
--host=127.0.0.1 \
--port=8080
正常に起動したら、このターミナルは開いたままにしておく必要があります。別のコマンドを実行するには、新しいターミナルを開いてください。
シナリオ B: LAN デプロイ
サーバー側で実行:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
この場合、クライアントが接続する際の --server_address にはサーバー側の LAN IP アドレス、つまり <LAN IP address>:8080 を指定する必要があります。
シナリオ C: クラウドサーバーでのデプロイ
サーバー側で実行:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
この場合、クライアントが接続する際の --server_address にはサーバーのパブリック IP アドレス、つまり <server public IP>:8080 を指定する必要があります。
ステップ 4: 推論パラメータを選択する
クライアント側で実行:
python -m lerobot.async_inference.robot_client \
--server_address=<ip address>:8080 \
--robot.type=so100_follower \
--robot.port=/dev/tty.usbmodem585A0076841 \
--robot.id=follower_so100 \
--robot.cameras="{ laptop: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, phone: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
--task="dummy" \
--policy_type=your_policy_type \
--pretrained_name_or_path=user/model \
--policy_device=cuda \
--actions_per_chunk=50 \
--chunk_size_threshold=0.5 \
--aggregate_fn_name=weighted_average \
--debug_visualize_queue_size=True
パラメータの説明:
--server_address
policy サーバーのアドレスとポートを指定します。<ip address> には 127.0.0.1(ローカルマシン)、<LAN IP address>(LAN)、または<server public IP>(クラウドサーバー)を指定します。
--robot.type, --robot.port, --robot.id, --robot.cameras
ハードウェアデバイスのパラメータです。これらはデータセット収集時に使用したパラメータと一致させる必要があります。
--task
タスクの説明です。SmolVLA のようなビジョン・ランゲージポリシーは、タスクテキストに基づいて行動のターゲットを判断できます。
--policy_type
ここを具体的なポリシー名に置き換えます。例:
-
smolvla
-
act
-
--pretrained_name_or_path
この値は、サーバー側のモデルパス、または Hugging Face 上のモデルパスに置き換える必要があります。
--policy_device
サーバー側で使用する推論デバイスを指定します。
cuda、mps、cpu のいずれかを指定できます。
--actions_per_chunk=50
1 回の推論で出力されるアクション数を指定します。
この値が大きいほど:
利点:アクションバッファに十分な余裕ができ、枯渇しにくくなる 欠点:予測ホライズンが長くなり、制御誤差がより顕著に蓄積する可能性がある
--chunk_size_threshold=0.5
次のアクションチャンクをサーバーに要求するタイミングを指定します。
これはしきい値で、通常 0〜1 の範囲です。
現在のアクションキューの残り割合がこのしきい値を下回ったときに、クライアントが事前に新しい観測を送信し、次のアクションチャンクを要求する、というイメージで理解できます。
ここで 0.5 に設定しているのは、次のことを意味します:
現在のアクションチャンクが半分ほど消費されたとき
クライアントが次のアクションチャンクの要求を開始する
この値が大きいほど、リクエスト送信の頻度が高くなり、システムの応答性は向上しますが、サーバーへの負荷も増加します。
この値が小さいほど、挙動は同期推論に近づきます。
--aggregate_fn_name=weighted_average
重なり合うアクション区間を集約する方法を指定します。
非同期推論では、古いアクションチャンクがまだ完全に実行されていないうちに、新しいアクションチャンクがすでに到着している場合があります。
その場合、2 つのチャンクは時間区間の一部で重なり合うため、それらを最終的に実行されるアクションに統合するための集約関数が必要になります。
weighted_average の意味は:
重なり合う部分を重み付き平均で融合する、ということです。
これにより、通常はアクションの切り替えがよりスムーズになり、急激な変化が減少します。
--debug_visualize_queue_size=True
実行時にアクションキューのサイズを可視化するかどうかを指定します。
有効にすると、キューが頻繁に底をついていないかをより直感的に確認でき、actions_per_chunk や chunk_size_threshold のチューニングに役立ちます。
ステップ 5: ロボットの挙動に応じてパラメータを調整する
非同期推論では、同期推論には存在しない、調整が必要な追加パラメータが 2 つあります:
パラメータ 推奨初期値 説明
actions_per_chunk 50 ポリシーが一度に出力するアクション数。典型的な値:10〜50。
chunk_size_threshold 0.5 アクションキューの残り割合が chunk_size_threshold 以下になったときに、クライアントが新しいアクションチャンクのリクエストを送信します。値の範囲は [0, 1] です。
--debug_visualize_queue_size=True の場合、実行時にアクションキューサイズの変化がプロットされます。
非同期推論でバランスを取るべきなのは、サーバーがアクションチャンクを生成する速度が、クライアントがアクションチャンクを消費する速度以上であることです。そうでない場合、アクションキューが空になり、ロボットが再びカクつき始めます(キューの可視化では、曲線が下限に張り付く形で確認できます)。
サーバーがアクションチャンクを生成する速度は、モデルサイズ、デバイスタイプ、VRAM / メモリ、GPU の計算性能などの要因に影響されます。
クライアントがアクションチャンクを消費する速度は、設定された実行 fps によって決まります。
キューが頻繁に空になる場合は、actions_per_chunk を増やす、chunk_size_threshold を増やす、または fps を下げる必要があります。
キューの曲線が頻繁に変動していても、キュー内の残りアクションが常に十分である場合は、chunk_size_threshold を適切に下げることができます。
一般的には:
actions_per_chunk の経験的な範囲は 10〜50
chunk_size_threshold の経験的な範囲は 0.5〜0.7 であり、チューニングの際は 0.5 から始めて徐々に増やしていくことを推奨します
次のようなエラーが発生した場合:
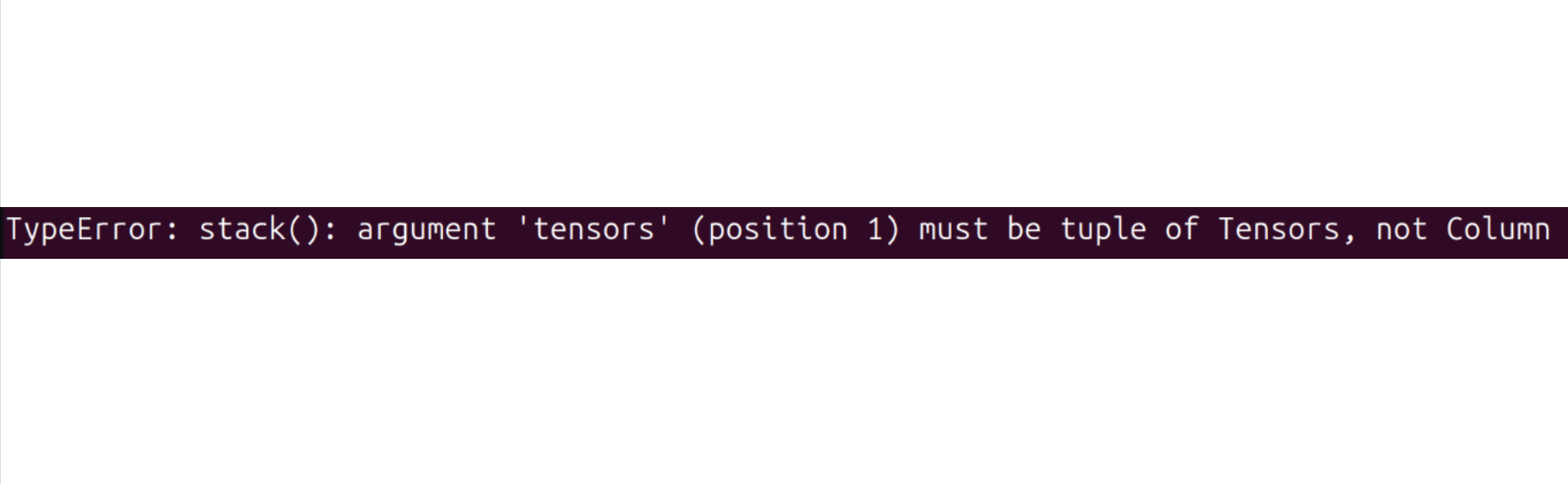
次のコマンドを実行して解決を試みてください:
pip install datasets==2.19
トレーニングには数時間かかるはずです。outputs/train/act_so100_test/checkpoints にチェックポイントが生成されます。
チェックポイントからトレーニングを再開するには、act_so101_test ポリシーの last チェックポイントから再開するためのコマンド例を以下に示します:
lerobot-train \
--config_path=outputs/train/act_so101_test/checkpoints/last/pretrained_model/train_config.json \
--resume=true
ポリシーチェックポイントをアップロードする
トレーニングが完了したら、次のコマンドで最新のチェックポイントをアップロードします:
huggingface-cli upload ${HF_USER}/act_so101_test \
outputs/train/act_so101_test/checkpoints/last/pretrained_model
中間チェックポイントをアップロードすることもできます:
CKPT=010000
huggingface-cli upload ${HF_USER}/act_so101_test${CKPT} \
outputs/train/act_so101_test/checkpoints/${CKPT}/pretrained_model
FAQ
-
このドキュメント / チュートリアルに従う場合は、推奨されている GitHub リポジトリ
https://github.com/Seeed-Projects/lerobot.gitを git clone してください。本ドキュメントで推奨しているリポジトリは検証済みの安定版です。一方、公式の Lerobot リポジトリは常に最新バージョンへ更新されており、データセットバージョンの違いやコマンドの違いなど、予期せぬ問題が発生する可能性があります。 -
サーボ ID のキャリブレーション時に次のようなエラーが発生した場合:
`Motor ‘gripper’ was not found, Make sure it is connected`通信ケーブルがサーボに正しく接続されているか、電源が正しい電圧を供給しているかを慎重に確認してください。
-
次のような状況が発生した場合:
Could not connect on port "/dev/ttyACM0"ls /dev/ttyACM*を実行したときに ACM0 が存在する場合は、シリアルポートの権限付与を忘れていることを意味します。ターミナルでsudo chmod 666 /dev/ttyACM*を入力して修正してください。 -
次のような状況が発生した場合:
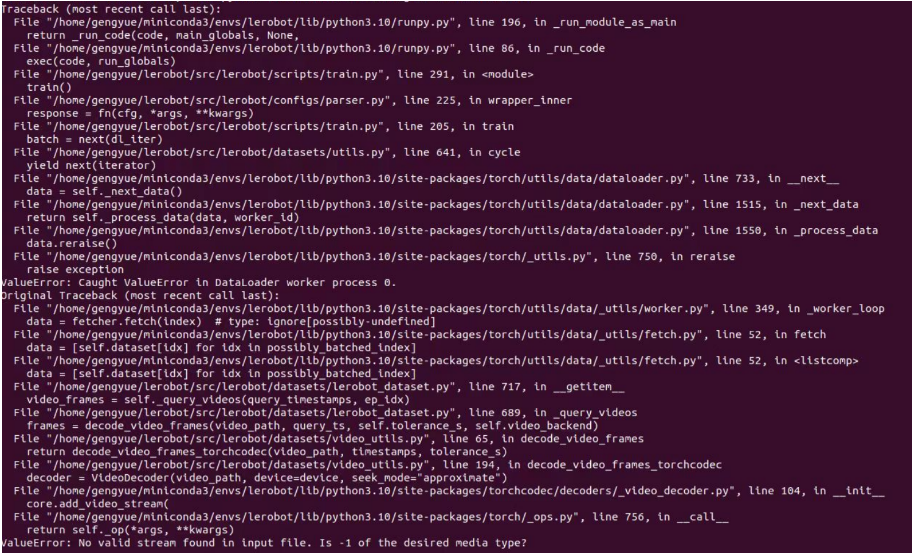
No valid stream found in input file. Is -1 of the desired media type?conda install ffmpeg=7.1.1 -c conda-forgeを使用して ffmpeg 7.1.1 をインストールしてください。
-
次のような状況が発生した場合:
ConnectionError: Failed to sync read 'Present_Position' on ids=[1,2,3,4,5,6] after 1 tries. [TxRxResult] There is no status packet!対応するポート上のロボットアームの電源が入っているか、バスサーボのデータケーブルが緩んでいたり外れていたりしないかを確認する必要があります。もしサーボのランプが点灯していない場合は、その一つ前のサーボのケーブルが緩んでいることを意味します。
-
ロボットアームのキャリブレーション時に次のエラーが発生した場合:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)ロボットアームの電源を切って再起動し、その後もう一度キャリブレーションを試してください。この方法は、キャリブレーション中に MAX 角度が数万という値に達した場合にも使用できます。これでも解決しない場合は、該当するサーボを再キャリブレーションする必要があります。中央値のキャリブレーションと ID の書き込みを含みます。
-
評価フェーズ中に次のような状況が発生した場合:
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'まず
eval_で始まるフォルダを削除してから、プログラムを再度実行してください。 -
評価フェーズ中に次のような状況が発生した場合:
`mean` is infinity. You should either initialize with `stats` as an argument or use a pretrained model--robot.camerasパラメータ内の "front" や "side" などのキーワードは、データセット収集時に使用したものと厳密に一致している必要があることに注意してください。 -
ロボットアームの一部を修理または交換した場合は、
~/.cache/huggingface/lerobot/calibration/robotsまたは~/.cache/huggingface/lerobot/calibration/teleoperators配下のファイルを完全に削除し、ロボットアームを再キャリブレーションしてください。そうしないと、キャリブレーション情報がこれらのディレクトリ内の JSON ファイルに保存されているため、エラーメッセージが表示される可能性があります。 -
50 セットのデータで ACT をトレーニングするには、RTX 3060(8GB)を搭載したノート PC で約 6 時間、RTX 4090 または A100 GPU を搭載したコンピュータでは約 2~3 時間かかります。
-
データ収集中は、カメラの位置、角度、および周囲の照明が安定していることを確認してください。カメラに映り込む不安定な背景や歩行者の量を減らしてください。デプロイ環境の変化が大きすぎると、ロボットアームが正しく把持できなくなる可能性があります。
-
データ収集コマンドでは、十分なデータを収集できるように
num-episodesパラメータが設定されていることを確認してください。途中で手動で一時停止しないでください。データの平均値と分散はデータ収集完了後にのみ計算され、これらはトレーニングに必要です。 -
プログラムが USB カメラから画像データを読み取れないと表示する場合は、USB カメラがハブ経由で接続されていないことを確認してください。USB カメラはデバイスに直接接続し、高速な画像伝送速度を確保する必要があります。
-
AttributeError: module 'rerun' has no attribute 'scalar'. Did you mean: 'scalars'?のようなバグが見つかった場合は、rerun のバージョンをダウングレードすることで問題を解決できます。
pip3 install rerun-sdk==0.23
解決できないソフトウェアの問題や環境依存の問題が発生した場合は、このチュートリアルの最後にある FAQ セクションを確認することに加えて、速やかに LeRobot platform または LeRobot Discord channel に問題を報告してください。
引用
TheRobotStudio プロジェクト: SO-ARM10x
Huggingface プロジェクト: Lerobot
Dnsty: Jetson Containers
技術サポート & 製品ディスカッション
当社の製品をお選びいただきありがとうございます。私たちは、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じて選択できるよう、複数のコミュニケーションチャネルを用意しています。