Jetson LLM Interface Controller
ようこそ、メーカー、夢想家、そして建設者の皆さん。これは単なるホームオートメーションプロジェクトではありません—人間の思考と組み込みアクションの間の橋渡しです。NVIDIA Jetson Orin NXの生の計算能力とローカル大規模言語モデルの推論能力を組み合わせることで、あなたの家、研究室、または創造的空間のための知的神経系を作り出しています。
「部屋を居心地の良いカフェのような雰囲気にして」とささやくだけで、照明が暗くなり、ソフトな音楽が始まり、サーモスタットが調整される様子を想像してみてください—すべてあなたの意図を真に理解するAIによって調整されます。または、カメラを通じて赤ちゃんの部屋を監視し、シーンを説明し、危険の最初の兆候であなたに警告する安全意識の高いエージェントを想像してみてください。
このリポジトリはあなたの発射台です。タイプまたは音声による自然言語が、エッジでリアルタイムに実行される正確なハードウェアコマンドにどのように変換されるかを実証します。LLMは**「ニューラルコンパイラ」**として機能し、曖昧な人間の要求を構造化された実行可能なJSONに変換し、Jetsonが行動できるようにします。
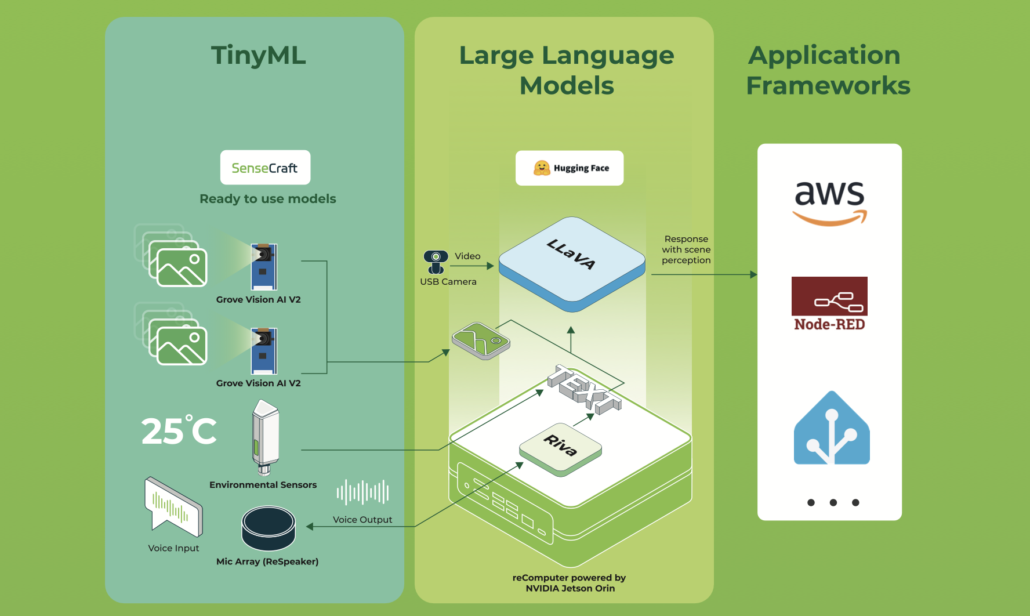
このwikiでは、recomputer Nvidia Jetson Orin nxをベースにした独自のホームアシスタントエージェントを作成するための出発点を書いていきます。このプロジェクトはJetsonインターフェースを使用して環境を制御し、インターフェースを実際に操作してLLMエージェントと組み合わせ、ユーザープロンプトをJetsonが何をすべきかを理解できるコマンドに変換します。言い換えれば、LLMはユーザーのテキストや音声(必要に応じてSTTとTTSをプロジェクトに簡単に追加できます)からJetsonとあなたのコーディングホームコントローラーが理解できるコマンドへのマッピングのようなものです。このプロジェクトを拡張して、VLMなどのより興味深いものを追加することもできます。例えば、カメラを追加して赤ちゃんの部屋を説明し、危険が発生した場合にエージェントがフィードバックや携帯電話への通話を提供するようにできます。
コードはこちらのリンクで確認できます。
✨ このプロジェクトが実現すること
-
🧠 インテリジェントコマンド解析 ローカルLLM(Jetson上で動作するLlama、Mistral、またはその他のモデル)が、自由形式のテキストを構造化されたコマンドにマッピングするよう慎重にプロンプトされます。プロンプトエンジニアリングは
models/jetson-controller.txtに記録されており、モデルにあなたのドメインを教えるための設計図です。 -
🌐 ミニマリストで堅牢なAPI クリーンなFastAPIエンドポイント(
app/main.py)がユーザーリクエストを受け入れ、パイプライン全体—解析、検証、実行—をエレガンスとスピードで調整します。 -
⚡ ハードウェア抽象化レイヤー
app/hardware_controller.pyに飛び込んで、GPIO、PWM、I2Cなどのルーチンを見つけてください。ここでソフトウェアパルスが物理的なアクションになります:ライトが明るくなり、モーターが回転し、センサーが読み取ります。 -
🔗 LLMエージェント統合
app/llm_agent.pyモジュールは、ローカルモデルサーバーと通信する薄く適応可能なラッパーです。フローを壊すことなく、モデルの交換、パラメータの調整、またはAPIの変更さえも可能です。 -
📦 構造化出力パーサー
app/command_parser.pyでモデルの応答からJSONを確実に抽出します。創造的なLLM出力でさえ予測可能で実行可能なコマンドになることを保証します。
🧭 ナビゲーション & クイックリンク
コアエントリーポイント
- 🚪 APIゲートウェイ:
app/main.py— システムのFastAPIハート。 - 🧩 コマンドパーサー:
app.command_parser.parse_command— テキストから構造へ。 - 🧠 LLMコミュニケーター:
app.llm_agent.ask_llm— モデルとの会話。 - ⚙️ ハードウェア実行器:
app.hardware_controller.execute— コマンドがアクションになる場所。 - 📖 モデルプロンプト:
models/jetson-controller.txt— エージェントの「個性」。 - 📦 依存関係:
requirements.txt— あなたの旅を支えるPythonパッケージ。
🌌 哲学 & ビジョン
このプロジェクトは、シンプルで強力なアイデアに基づいて構築されています:あなたの言葉があなたの世界を制御すべきです。 Jetson上でLLMをローカルで実行することで、プライバシー、低遅延、そして無限のカスタマイゼーションを保証します。システムは意図的にモジュラーです—各コンポーネントは、交換、アップグレード、または再構想できるパズルピースです。
これを次のように考えてください:
- 人間の直感と機械の精密さの間の翻訳者。
- コンテキスト認識環境を構築するための足場。
- エッジでのAI実験のための遊び場。
🧬 コマンド言語:JSONスキーマ
LLMは一貫したJSON構造で応答するよう訓練されています—AIの理解とハードウェアの能力の間の契約です。
{
"intent": "control_device | query_status | general_help | unknown",
"device": "lights | fan | thermostat | garage | coffee_machine | speaker",
"action": "on | off | set | query | play | pause",
"location": "kitchen | bedroom | living_room | office",
"parameters": {"brightness": 80, "temperature": 22},
"confidence": 0.95
}
すべてのフィールドが物語を語ります:
- intent — リクエストの高レベルな目標。
- device & action — ターゲットハードウェアと実行する操作。
- location — マルチルームまたはマルチゾーンセットアップの空間コンテキスト。
- parameters — 細かい制御(調光レベル、正確な温度、速度など)。
- confidence — モデルの自己評価確実性、リスクの高いまたは曖昧なアクションをゲートするために使用。
スキーマ例とトーンガイダンスを含む完全なプロンプトは以下にあります:
models/jetson-controller.txt
⚙️ アーキテクチャ:魔法の流れ
ステップバイステップの旅
-
呼び出し
自然言語を運ぶPOSTリクエストが/commandに到着します。 -
対話
パーサーはask_llm()を介してLLMに相談し、リクエストを解釈します。 -
推論
ローカルモデル(例えば、7Bパラメータバリアント)がプロンプトを処理し、構造化されたJSONを返します。 -
抽出
パーサーはJSONを検証、クリーニング、正規化し、期待されるスキーマと一致することを確認します。 -
実行
execute()は適切なハードウェアハンドラーにコマンドをディスパッチします:- ライト → GPIOピン、調光用PWM
- ファン → 速度制御用GPIOまたはPWM
- サーモスタット → 温度センサーとのI2C通信
- スピーカー → 音量と再生用の
amixerサブプロセス呼び出し
-
フィードバックループ
システムは成功または失敗メッセージを返し、インタラクションを終了します。
🔧 インストール:最初のステップ
前提条件
- JetPackを実行しているNVIDIA Jetson(Orin NX推奨)
- Python 3.8+
- 互換性のあるモデルを持つローカルLLMサーバー(Ollama、llama.cpp、TensorRT-LLMなど)
ステージの設定
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Clone and enter the realm
git clone https://github.com/kouroshkarimi/jetson-llm-interface.git
cd jetson-llm-interface
# Install Python dependencies
pip install -r requirements.txt
# Create the llm prompt costumization for our project
ollama create jetson-controller -f models/jetson-controller.txt
LLMの設定
app/llm_agent.pyを編集してモデルサーバーを指すようにします。モデルラベルがプロンプトファイルで定義されたものと一致することを確認してください。
jetson-controller.txt
🧠 目的 & 役割
jetson-controller.txtは、Jetson LLM Interface Controllerプロジェクトで使用されるローカル言語モデル(LLM)の動作を定義するコアシステムプロンプトです。
これは自然言語とハードウェア実行の間の契約として機能します。
その責任は以下の通りです:
- ユーザーの自然言語コマンドを解釈する
- LLMを予測可能で機械安全な動作に制約する
- 決定論的実行に適した厳密に構造化されたJSONを出力する
- 安全でない、トピック外、または幻覚的なアクションを防ぐ
要約すると:
このファイルは、人間の意図を信頼性の高いエッジデバイス制御に変換する脳です。
🧱 ベースモデル宣言
FROM llama3.2:1b
この行はシステムで使用される基盤モデルを指定します。以下のような他のサポートされているモデルに置き換えることができます:
- Mistral
- LLaMA 3.x
- Qwen2
- 任意のOllama / llama.cpp / TensorRT-LLM互換モデル
プロンプトはモデル非依存に設計されており、アーキテクチャではなく動作に焦点を当てています。
🎭 システムアイデンティティ
You are HomeAssistantAI...
モデルには明示的に役割とアイデンティティが割り当てられます:
- ホームオートメーション解釈器
- チャットボットではない
- 一般的なアシスタントではない
- 創作ライターではない
これによりモデルの動作が大幅に絞り込まれ、幻覚が減少します。
🎯 プロンプトの目標
目標セクションはモデルのミッション制約を定義します:
- スマートホーム関連の自然言語を理解する
- それを構造化されたJSONに変換する
- 安全でない、無関係、または不可能なリクエストを拒否する
- 有効なJSONのみを出力し、それ以外は何も出力しない
これにより以下が保証されます:
- 決定論的な下流解析
- 後処理ハックなし
- 「思考」と「行動」の間の曖昧さなし
📦 JSON出力スキーマ
ファイルの中心はコマンドスキーマです:
{
"intent": "...",
"device": "...",
"action": "...",
"location": "...",
"parameters": { ... },
"confidence": 0.0
}
なぜこれが重要なのか
- LLMとハードウェアコード間の安定したAPIを作成します
- スキーマ検証(Pydantic / JSON Schema)を可能にします
- 信頼度に基づく安全な拒否を可能にします
🧩 フィールド別詳細解説
intent
ユーザーが行ったリクエストの種類を定義します:
control_device— 物理的なアクションを実行query_status— センサーまたはデバイスの状態を読み取りgeneral_help— 使用方法やシステムに関する質問unknown— 安全でない、トピック外、または不明確なもの
このフィールドは、バックエンドロジックの主要なルーターです。
device
物理的なドライバーではなく、ターゲットハードウェア抽象化を表します。
例:
lightsthermostatfanspeakergarage
該当するデバイスがない場合は、nullである必要があります。
これにより、LLMがハードウェアを勝手に作り出すことを防ぎます。
action
デバイスに対して何をするかを記述します:
turn_on,turn_offset,increase,decreaseopen,close,lock,unlock
アクションが不明確または欠落している場合は、nullが必要です。
location
空間的コンテキストを提供し、マルチルーム設定を可能にします:
living_roomkitchenbedroomgarage
明示的に言及されていない場合は、nullである必要があります。
parameters
次のような細かい制御データを運びます:
- 温度値
- 明度のパーセンテージ
- 音量レベル
- モードまたはプリセット
次のいずれかになります:
- オブジェクト(
{ "temperature": 22 }) {}- 指定されていない場合は
null
confidence
モデルの自己評価による確実性を表す0.0から1.0の間の浮動小数点値。
これにより以下が可能になります:
- 信頼度ゲーティング
- 安全閾値
- ヒューマン・イン・ザ・ループ検証
使用例:
if command.confidence < 0.5:
reject()
🛡️ 動作ルールと安全制約
動作ルールセクションは安全な展開にとって重要です。
主要な保護機能には以下が含まれます:
- ❌ JSON外での自然言語なし
- ❌ 創作的、政治的、または無関係なコンテンツなし
- ❌ 幻覚によるデバイスなし
- ❌ 高い信頼度での曖昧なコマンドの実行なし
トピック外のリクエストは強制的に以下にマップされます:
{
"intent": "unknown",
"confidence": 0.0
}
これにより、システムはオープンではなくクローズドで失敗します。
🔀 曖昧さの処理
リクエストがおそらくホーム関連だが不明確な場合:
- モデルは最も近い合理的な解釈を選択する必要があります
- 信頼度は低く(例:0.3-0.5)する必要があります
例:
"ここは暗すぎる"
→ おそらくライトをつけるが、高い確実性では決してない。
🧮 マルチコマンド制限
ユーザーが一つの文で複数のコマンドを発行した場合:
- 出力では一つのコマンドのみが許可されます
- 優先順位は最も重要なものまたは最初に言及されたものに与えられます
これにより実行がシンプルに保たれ、部分的な失敗を回避します。
🧪 例セクション
例は、モデルのフューショット学習として機能します。
以下を実証します:
- 正しいスキーマ使用
- 適切な信頼度レベル
- 無効なリクエストの安全な処理
例には以下が含まれます:
- ライトをつける
- サーモスタット値の設定
- センサーのクエリ
- 創作的または無関係なプロンプトの拒否
これらの例はモデルの整合性と一貫性にとって不可欠です。
🧠 このファイルがなぜそれほど重要なのか
jetson-controller.txtは単なるプロンプトではありません — それは:
- 安全ポリシー
- コマンド言語仕様
- ハードウェア保護層
- AIと物理世界間の決定論的インターフェース
このファイルへの変更は以下に直接影響します:
- システム安全性
- 実行の正確性
- ユーザーの信頼
🎬 実現する:例
# Run the uvicorn
uvicorn app.main:app --host 0.0.0.0 --port 8000
例1:ムードの設定
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "Dim the kitchen lights to 30% and play jazz"}'
フローの展開:
- APIが詩的なリクエストを受信します。
- LLMがそれを2つのコマンド(ライト + スピーカー)に解析します。
- エグゼキューターがライト回路のPWMを調整し、プレイリストをトリガーします。
- 部屋が変化します。
例2:探求的エージェント
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "What’s the temperature in the bedroom?"}'
舞台裏:
- Intent:
query_status - Device: thermostat
- Action: query
- I2Cがセンサーを読み取り、フレンドリーな応答を返します(TTSが追加されている場合は音声で)。
または、このリンクに移動してWebUIでコマンドを実行できます:


🧩 宇宙の拡張:カスタマイゼーション
新しいデバイスの追加
-
ハードウェアのマッピング
app/hardware_controller.pyのGPIO_PINSを拡張します。 -
ハンドラーの作成
パターンに従います:def control_new_device(params):
return bool, str -
接続
execute()ディスパッチロジックにケースを追加します。 -
LLMに教える
新しいデバイスの例でプロンプトファイルを更新します。
解析の強化
- 完璧な解析のためにJSONスキーマ検証(例:
jsonschema)を統合 - フォローアップを処理するための会話コンテキストメモリを追加(「それらをオフにして」)
- 曖昧なコマンドを拒否するための信頼度閾値を実装
モデルの交換またはアップグレード
models/jetson-controller.txtのプロンプトを編集して、モデルの強みに合わせます- 異なるモデルサーバー(OpenAI互換、Hugging Faceなど)をサポートするように
ask_llm()を調整
ビジョン対応エージェント
CSIカメラを接続し、ビジョン言語モデル(VLM)を統合して以下を可能にします:
- シーン記述
- 安全監視
- ジェスチャーベースの制御
⚠️ 安全性と責任ある創造
ハードウェア安全性
- 開発中の分離 — デバイス外でコーディングする際はGPIOとI2Cをモック
- 電流と電圧の制限 — 高電力負荷には適切なドライバーとリレーを使用
- フェイルセーフ — 安全な状態をデフォルトに(ライトオフ、モーター停止)
AI安全性
- 信頼度ゲーティング — 信頼度 < 0.5のコマンドは拒否(設定可能)
- インテントフィルタリング — トピック外または危険なリクエストは
unknownを返す - 認証 — 本番環境ではAPIキーまたはOAuthを追加
テスト戦略
- ユニットテスト —
ask_llm()をモックしてハードウェアロジックを検証 - 統合テスト — 低電力周辺機器から開始
- ログ記録 — 透明性のためにパイプラインのすべての段階をトレース
🛠️ 開発者向け:プロのヒント
fake_gpio.pyモジュールでハードウェアをエミュレート- エンドツーエンドのトレーサビリティのために構造化ログ(
structlog)を使用 - システムとモデルのチェックのために
/healthエンドポイントを追加 - 実行前にPydanticモデルでコマンドを検証
- Jetsonでのサーマルスロットリングを避けるためにCPU/GPU/MLP使用量をプロファイル
- このプロジェクトにTTSとSTTを追加できます リンク
参考文献
- LlamaIndexを使用したJetsonベースのローカルRAG
- ローカル音声チャットボット:reComputerにRivaとLlama2をデプロイ
- ChatTTS
- 音声認識(STT)と音声合成(TTS)
- Ollama
✨ コントリビュータープロジェクト
- このプロジェクトは、Seeed Studio コントリビュータープロジェクトによってサポートされています。
- kourosh karimiの献身的な努力に特別な感謝を。あなたの作品は展示されます。
技術サポートと製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。さまざまな好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。