AIモデルの変換と量子化

reCameraのAIモデル変換ツールは現在、PyTorch、ONNX、TFLite、Caffeなどのフレームワークをサポートしています。他のフレームワークのモデルはONNX形式に変換する必要があります。他の深層学習アーキテクチャからONNXにモデルを変換する方法については、ONNX公式ウェブサイトを参照してください:https://github.com/onnx/tutorials。
reCameraにAIモデルをデプロイするフロー図を以下に示します。
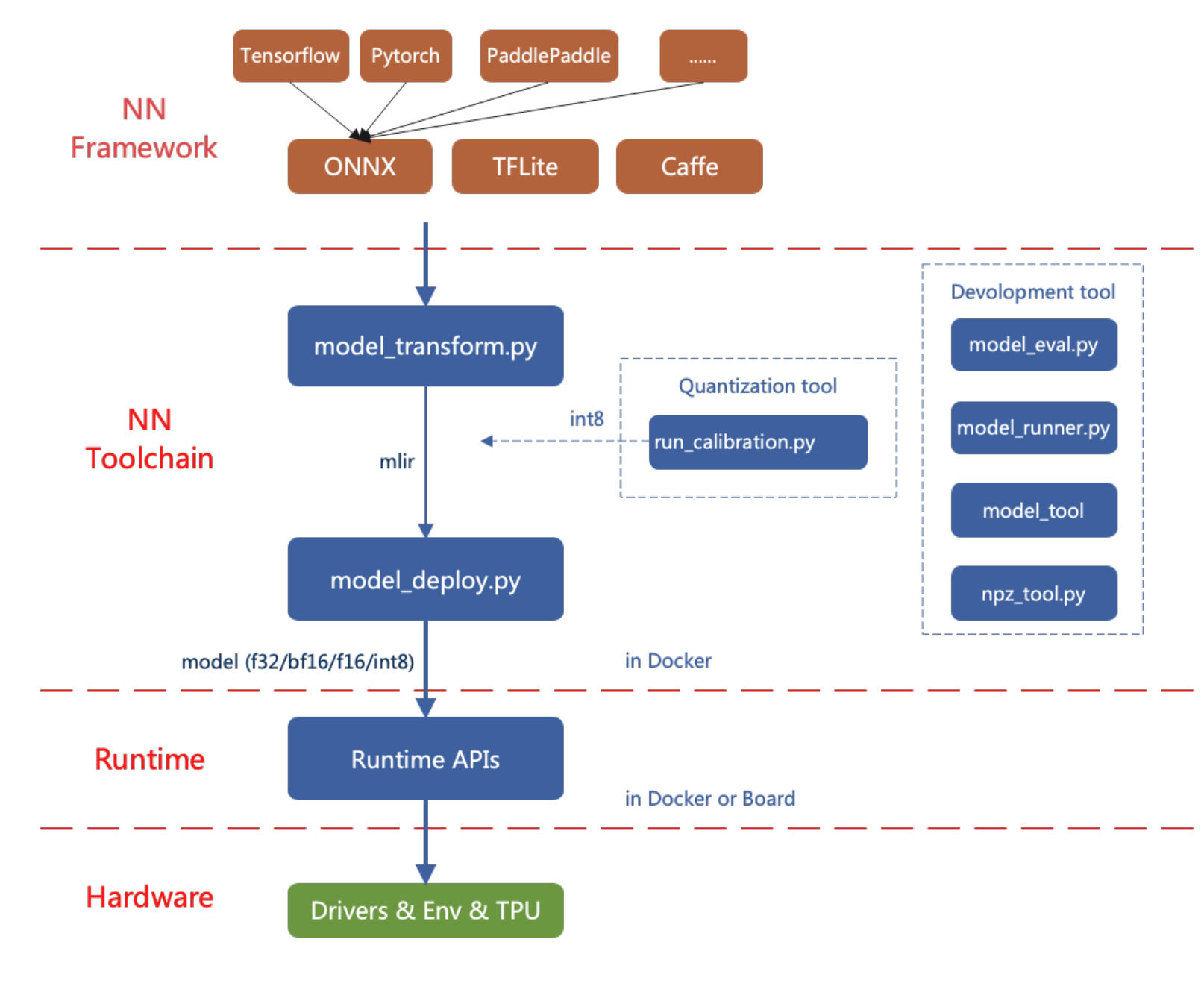
この記事では、簡単な例を通してreCameraのAIモデル変換ツールの使用方法を紹介します。
作業環境のセットアップ
方法1:Dockerイメージでのインストール(推奨)
DockerHub(こちらをクリック)から必要なイメージをダウンロードし、バージョン3.1の使用を推奨します:
docker pull sophgo/tpuc_dev:v3.1
初回にDockerを使用する場合は、インストールと設定のために以下のコマンドを実行できます(初回セットアップ時のみ必要):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
次に、現在のディレクトリに以下のようにコンテナを作成します:
docker run --privileged --name MyName -v $PWD:/workspace -it sophgo/tpuc_dev:v3.1
*"MyName"を希望するコンテナ名に置き換えてください
Dockerコンテナ内でpipを使用してtpu_mlirをインストールします。方法1と同様です:
pip install tpu_mlir[all]==1.7
方法2: ローカルインストール
まず、現在のシステム環境が以下の要件を満たしているかを確認してください:
要件を満たしていない場合やインストールに失敗した場合は、方法2を選択してモデル変換ツールをインストールしてください。
pipを使用してtpu_mlirをインストール:
pip install tpu_mlir==1.7
tpu_mlirが必要とする依存関係は、異なるフレームワークからのモデルを処理する際に変わります。ONNXまたはTorchによって生成されたモデルファイルの場合、以下のコマンドを使用して追加の依存関係をインストールしてください:
pip install tpu_mlir[onnx]==1.7
pip install tpu_mlir[torch]==1.7
現在、5つの設定がサポートされています:onnx、torch、tensorflow、caffe、paddle。または、以下のコマンドを使用してすべての依存関係をインストールできます:
pip install tpu_mlir[all]==1.7
tpu_mlir-{version}.whl ファイルがローカルに既に存在する場合は、以下のコマンドを使用してインストールすることもできます:
pip install path/to/tpu_mlir-{version}.whl[all]
AIモデルをcvimodel形式に変換・量子化する
ONNXの準備
reCameraはすでにYOLOシリーズをローカル推論に適応させています。そのため、このセクションではyolo11n.onnxを例として、ONNXモデルをcvimodelに変換する方法を説明します。
cvimodelはreCamera上でローカル推論に使用されるAIモデル形式です。
PyTorch、TFLite、Caffeモデルの変換・量子化方法は、このセクションと同じです。
以下はyolo11n.onnxのダウンロードリンクです。リンクをクリックしてモデルをダウンロードし、さらなる使用のためにWorkspaceにコピーできます。
モデルをダウンロード: yolo11n.onnxをダウンロード このONNXファイルは、IRバージョンやOpsetバージョンを変更する必要なく、以下のセクションの例で直接使用できます。
現在、このwikiのONNXはIRバージョン8およびOpsetバージョン17に基づいています。2024年12月以降にUltralyticsの例から変換されたONNXファイルの場合、より高いバージョンのため、後続のプロセスで問題が発生する可能性があります。
Netronを使用してONNXファイルの情報を確認できます:
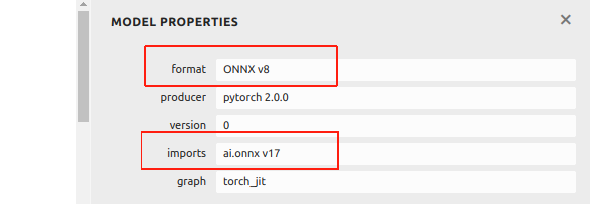
ONNXファイルがIR v8およびOpset v17より高い場合、ダウングレードを支援する例を提供します。 まず、pipを使用してonnxをインストールします:
pip install onnx
ONNXファイルのバージョンを変更するプログラムをGitHubからプルします:
git clone https://github.com/jjjadand/ONNX_Downgrade.git
cd ONNX_Downgrade/
入力と出力のモデルファイルパスをコマンドライン引数として提供してスクリプトを実行します:
python downgrade_onnx.py <input_model_path> <output_model_path> --target_ir_version <IR_version> --target_opset_version <Opset_version>
<input_model_path>: ダウングレードしたい元のONNXモデルのパス。<output_model_path>: ダウングレードされたモデルが保存されるパス。- --target_ir_version
<IR_version>: オプション。ダウングレード先のIRバージョン。デフォルトは8。 - --target_opset_version
<Opset_version>: オプション。ダウングレード先のOpsetバージョン。デフォルトは17。
例えば、デフォルトバージョン(IR v8、Opset v17)を使用する場合:
python downgrade_onnx.py model_v12.onnx model_v8.onnx
これにより model_v12.onnx が読み込まれ、IR バージョン 8 にダウングレードし、opset バージョン 17 を設定し、検証を行い、新しいモデルを model_v8.onnx として保存します。
カスタムバージョンの使用(IR v9、Opset v11):
python downgrade_onnx.py model_v12.onnx model_v9.onnx --target_ir_version 9 --target_opset_version 11
これにより model_v12.onnx が読み込まれ、IR バージョン 9 にダウングレードし、opset バージョン 11 を設定し、検証を行い、新しいモデルを model_v9.onnx として保存します。
- エラーを避けるため、IR v8 と Opset v17 を使用した ONNX の使用を推奨します。
ワークスペースの準備
tpu-mlir と同じレベルに model_yolo11n ディレクトリを作成します。画像ファイルは通常、モデルの訓練データセットの一部であり、後続の量子化プロセス中のキャリブレーションに使用されます。
ターミナルで以下のコマンドを入力してください:
git clone -b v1.7 --depth 1 https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
使用可能なONNXファイルを取得した後、作成したWorkspaceディレクトリに配置してください。ディレクトリ構造は以下の通りです:
model_yolo11n
├── COCO2017
├── image
└── Workspace
└──yolo11n.onnx
後続のステップは、あなたの Workspace で実行されます。
ONNX から MLIR へ
ONNXからMLIRへの変換は、モデル変換プロセスの中間ステップです。reCamera上での推論に適したモデルを取得する前に、まずONNXモデルをMLIR形式に変換する必要があります。このMLIRファイルは、reCameraの推論エンジン用に最適化された最終モデルを生成するためのブリッジとして機能します。
入力が画像の場合、転送前にモデルの前処理について知る必要があります。モデルが前処理済みのnpzファイルを入力として使用する場合、前処理を考慮する必要はありません。前処理プロセスは以下のように定式化されます(xは入力を表します):
y = (x − mean) × scale
yolo11の正規化範囲は**[0, 1]で、公式yolo11の画像はRGBです。各値は1/255で乗算され、meanとscaleに変換される際にそれぞれ0.0, 0.0, 0.0と0.0039216, 0.0039216, 0.0039216**に対応します。meanとscaleのパラメータは、各特定モデルで使用される正規化方法によって決定されるため、モデルによって異なります。
ターミナルで以下のモデル変換コマンドを参照できます:
model_transform \
--model_name yolo11n \
--model_def yolo11n.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
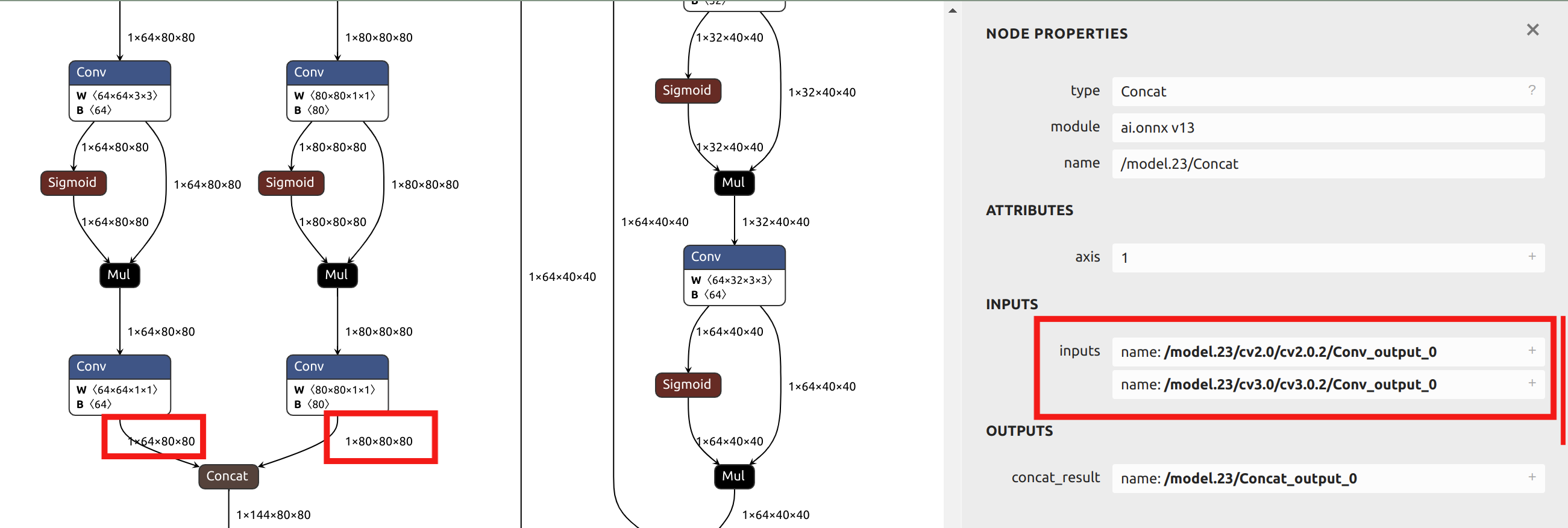
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../image/dog.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
mlir ファイルに変換した後、${model_name}_in_f32.npz ファイルが生成されます。これは後続のモデルの入力ファイルです。
--output_names パラメータの選択について、この例のYOLO11モデル変換では、output0という名前の最終出力を選択しません。代わりに、モデルのheadの前にある6つの出力をパラメータとして選択します。ONNX ファイルを Netron にインポートしてモデル構造を確認できます。
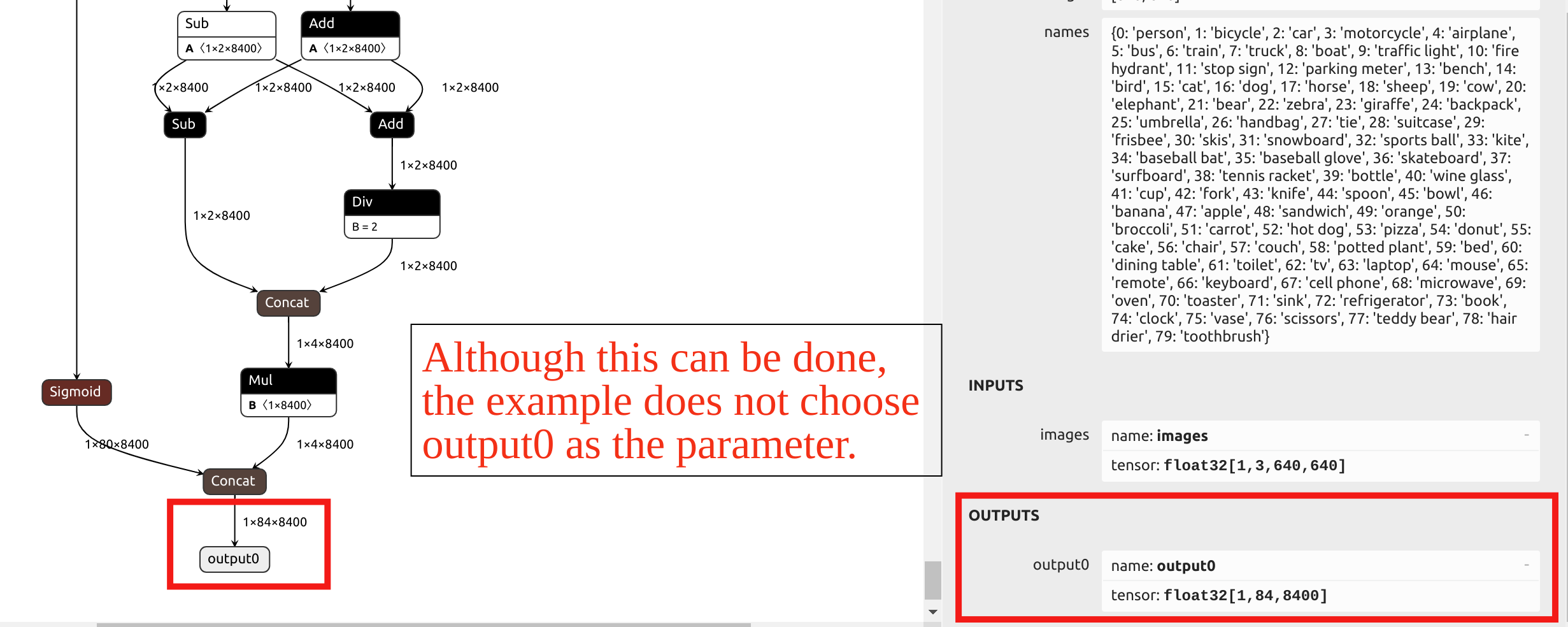
YOLOの head 内の演算子は INT8 量子化後の精度が非常に低くなります。最終的な output0 をパラメータとして選択した場合、混合精度量子化が必要になります。
この記事の後続セクションでは混合精度量子化の例を提供し、このセクションでは単一量子化精度を例として使用するため、head の前の出力をパラメータとして選択します。Netron でONNXモデルを可視化することで、6つの出力名の位置を確認できます:
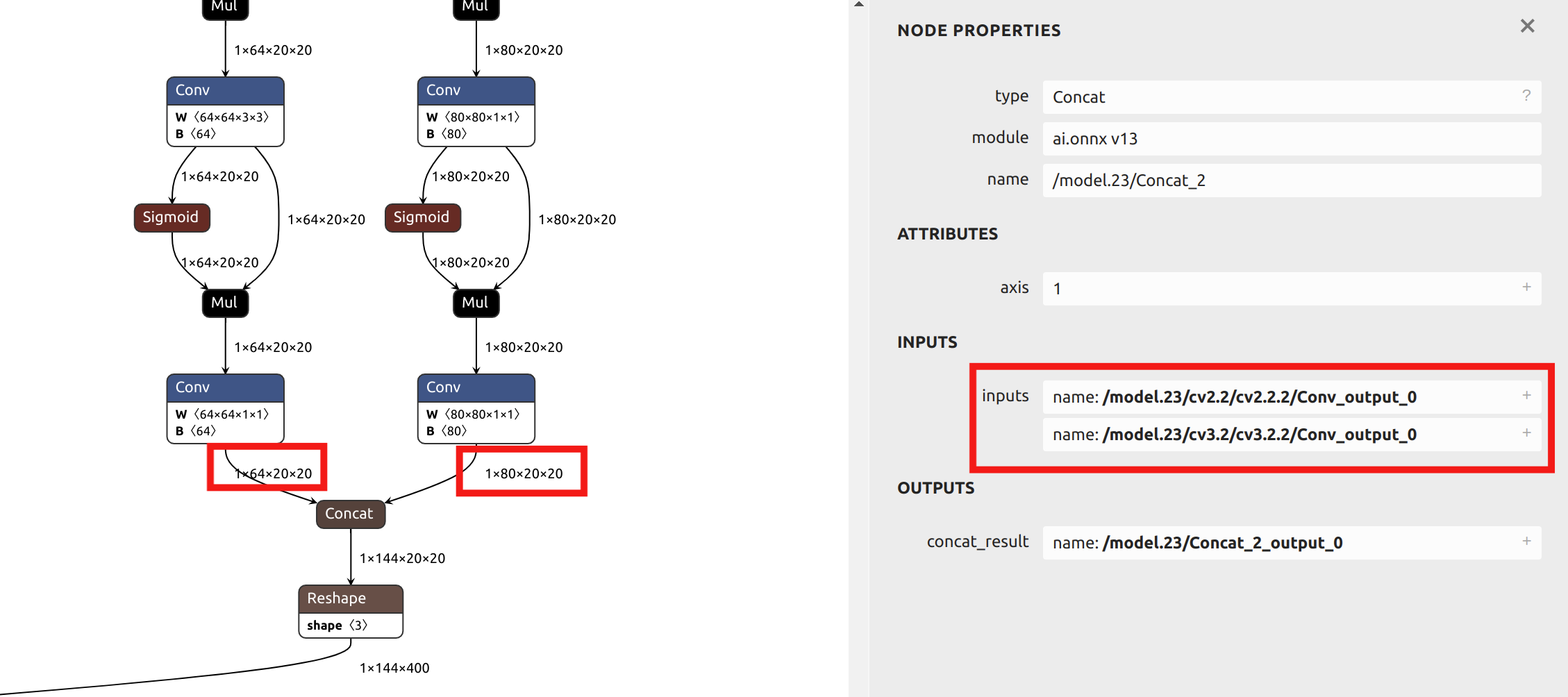
model_transform の主要パラメータの説明:
| パラメータ名 | 必須? | 説明 |
|---|---|---|
| model_name | はい | モデル名を指定します。 |
| model_def | はい | '.onnx'、'.tflite'、'.prototxt'などのモデル定義ファイルを指定します。 |
| input_shapes | いいえ | 入力形状を指定します。例:[[1,3,640,640]]。複数の入力をサポートできる二次元配列。 |
| input_types | いいえ | int32などの入力タイプを指定します。複数の入力はカンマで区切ります。デフォルトはfloat32です。 |
| resize_dims | いいえ | 元の画像をリサイズする寸法を指定します。指定されない場合、モデルの入力サイズにリサイズされます。 |
| keep_aspect_ratio | いいえ | リサイズ時にアスペクト比を保持するかどうか。デフォルトはfalse。trueの場合、不足部分はゼロパディングされます。 |
| mean | いいえ | 画像の各チャンネルの平均値。デフォルトは0,0,0,0です。 |
| scale | いいえ | 画像の各チャンネルのスケール値。デフォルトは1.0,1.0,1.0です。 |
| pixel_format | いいえ | 画像タイプ。'rgb'、'bgr'、'gray'、'rgbd'のいずれかを指定できます。デフォルトは'bgr'です。 |
| channel_format | いいえ | 画像入力のチャンネルタイプ。'nhwc'または'nchw'を指定できます。非画像入力の場合は'none'を使用します。デフォルトは'nchw'です。 |
| output_names | いいえ | 出力名を指定します。指定されない場合、モデルのデフォルト出力名が使用されます。 |
| test_input | いいえ | 画像、npy、npzファイルなどの検証用入力ファイルを指定します。指定されない場合、精度検証は実行されません。 |
| test_result | いいえ | 検証結果の出力ファイルを指定します。 |
| excepts | いいえ | 検証から除外するネットワーク層をカンマ区切りで指定します。 |
| mlir | はい | 出力MLIRファイル名とパスを指定します。 |
MLIR から F16 cvimodel
mlirからF16精度のcvimodelに変換したい場合は、ターミナルで以下の参考コマンドを入力できます:
model_deploy \
--mlir yolo11n.mlir \
--quant_input \
--quantize F16 \
--customization_format RGB_PACKED \
--processor cv181x \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--fuse_preprocess \
--tolerance 0.99,0.9 \
--model yolo11n_1684x_f16.cvimodel
変換が成功すると、推論に直接使用できるFP16精度のcvimodelファイルが得られます。INT8精度または混合精度のcvimodelファイルが必要な場合は、以下の記事の後続セクションの内容を参照してください。
model_deployの主要パラメータの説明:
| パラメータ名 | 必須? | 説明 |
|---|---|---|
| mlir | はい | MLIRファイル |
| quantize | はい | 量子化タイプ(F32/F16/BF16/INT8) |
| processor | はい | 使用するプラットフォームに依存します。2024年版のreCameraでは「cv181x」をパラメータとして選択します。 |
| calibration_table | いいえ | キャリブレーションテーブルのパス。INT8量子化の場合に必要 |
| tolerance | いいえ | MLIR量子化とMLIR fp32推論結果間の最小類似度の許容値 |
| test_input | いいえ | 検証用の入力ファイル。画像、npy、またはnpzファイルが可能。指定されない場合は検証は実行されません |
| test_reference | いいえ | mlir許容値を検証するための参照データ(npz形式)。各オペレータの結果です |
| compare_all | いいえ | 設定された場合、すべてのテンソルを比較します |
| excepts | いいえ | 検証から除外する必要があるネットワーク層の名前。カンマで区切ります |
| op_divide | いいえ | 大きなopを複数の小さなopに分割してionメモリ節約の目的を達成しようとします。特定のモデルに適用されます |
| model | はい | 出力モデルファイルの名前(パスを含む) |
| skip_validation | いいえ | cvimodelの正確性検証をスキップしてデプロイメント効率を向上させます。cvimodel検証はデフォルトで有効です |
コンパイル後、yolo11n_1684x_f16.cvimodel という名前のファイルが生成されます。量子化されたモデルは精度がわずかに低下する可能性がありますが、より軽量で推論速度が高速になります。
MLIR から INT8 cvimodel へ
キャリブレーションテーブルの生成
INT8 モデルに変換する前に、キャリブレーションを実行してキャリブレーションテーブルを取得する必要があります。
入力データの数は状況に応じて約100から1000です。
その後、キャリブレーションテーブルを使用して対称または非対称の cvimodel を生成します。対称モデルが既に要件を満たしている場合は、非対称モデルの性能が対称モデルよりもわずかに劣るため、一般的に非対称モデルの使用は推奨されません。
以下は、COCO2017 から既存の100枚の画像を使用してキャリブレーションを実行する例です:
run_calibration \
yolo11n.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolo11n_calib_table
上記のコマンドを実行すると、yolo11n_calib_table という名前のファイルが生成されます。これは、後続の INT8 モデルのコンパイルの入力ファイルとして使用されます。
run_calibration の主要パラメータの説明:
| パラメータ | 必須? | 説明 |
|---|---|---|
| N/A | はい | MLIRファイルを指定 |
| dataset | いいえ | 入力サンプルディレクトリを指定。パスには対応する画像、npz、またはnpyファイルが含まれます |
| data_list | いいえ | サンプルリストを指定。datasetまたはdata_listのいずれかを選択する必要があります |
| input_num | いいえ | キャリブレーションサンプル数を指定。0に設定すると、すべてのサンプルが使用されます |
| tune_num | いいえ | チューニングサンプル数を指定。デフォルトは10 |
| histogram_bin_num | いいえ | ヒストグラムのビン数。デフォルトは2048 |
| o | はい | キャリブレーションテーブルファイルを出力 |
INT8対称量子化cvimodelへのコンパイル
yolo11n_cali_table ファイルを取得した後、以下のコマンドを実行して INT8 対称量子化モデルに変換します:
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
コンパイル後、yolo11n_1684x_int8_sym.cvimodelという名前のファイルが生成されます。INT8に量子化されたモデルは、F16/BF16に量子化されたモデルと比較して、より軽量で推論速度が高速です。
クイックテスト
reCameraのNode-REDを使用して可視化し、変換されたyolo11n_1684x_int8_sym.cvimodelを素早く検証できます。以下の例動画に示すように、いくつかのノードを設定するだけです:
クイック検証のために、modelノードでyolo11n_1684x_int8_sym.cvimodelを選択する必要があります。modelノードをダブルクリックし、"Upload"をクリックして量子化されたモデルをインポートし、次に"Done"をクリックし、最後に"Deploy"をクリックします。
previewノードでINT8量子化モデルの推論結果を確認できます。正しい変換と量子化方法で得られたcvimodelは依然として信頼性があります:
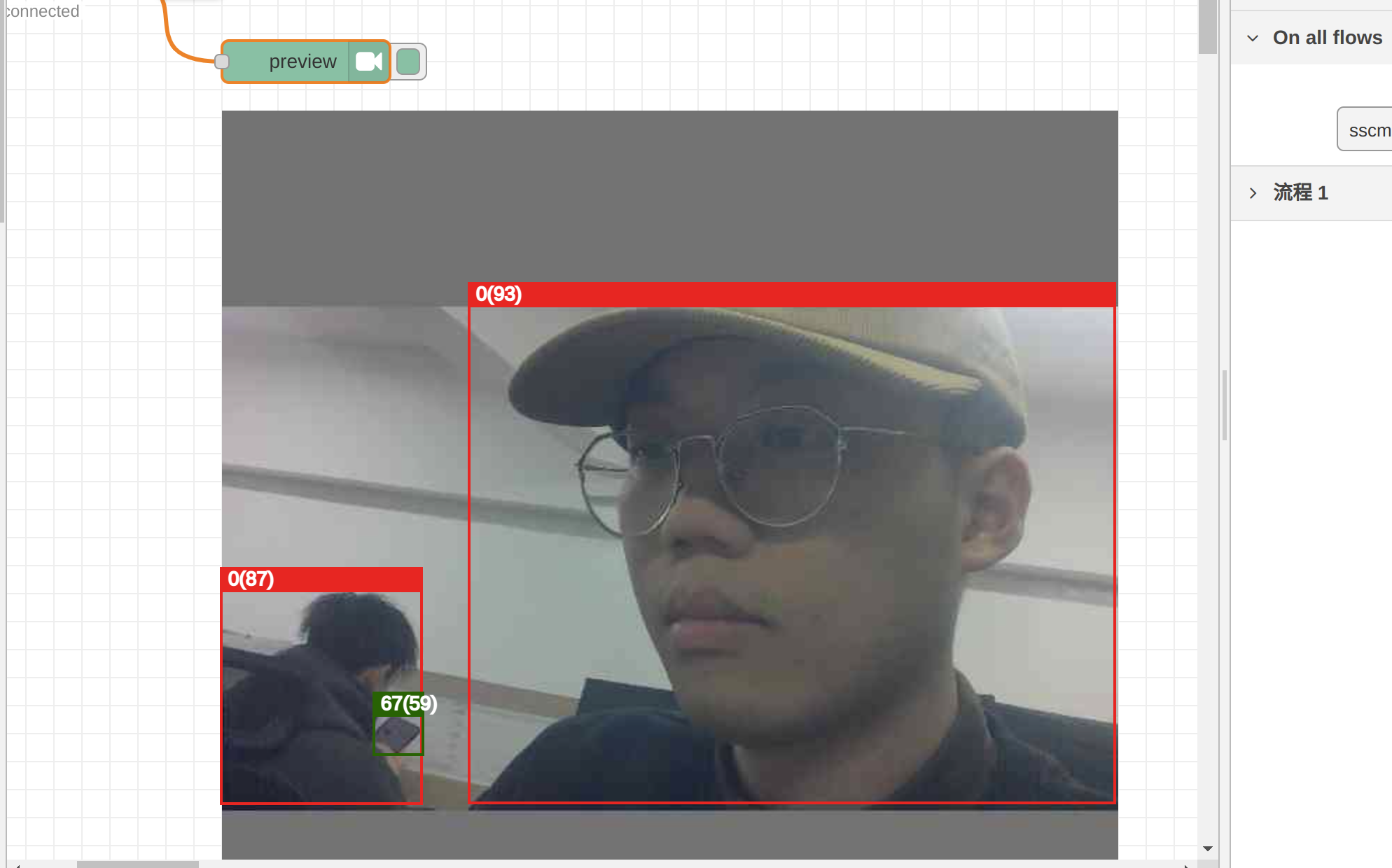
現在、reCameraのNode-REDは限られた数のモデルのプレビューテストのみをサポートしています。将来的には、より多くのモデルに対応する予定です。カスタムモデルをNode-REDにインポートする場合、または例で示したような指定された出力テンソルを設定しない場合、cvimodelが正しくても、Node-REDのバックエンドはプレビューテストをサポートしません。
様々なモデルの前処理と後処理に関するチュートリアルをリリース予定ですので、独自のコードを書いてカスタムcvimodelを推論できるようになります。
混合精度量子化
モデル内の特定の層の精度が量子化の影響を受けやすいが、それでもより高速な推論速度が必要な場合、単一精度量子化はもはや適切ではない可能性があります。このような場合、混合精度量子化がより良い解決策となります。量子化に敏感な層についてはF16/BF16量子化を選択し、精度損失が最小限の層についてはINT8を使用できます。
次に、yolov5s.onnxを例として、モデルを混合精度cvimodelに素早く変換・量子化する方法を説明します。このセクションを読む前に、記事の前のセクションを必ず読んでください。このセクションの操作は、前述の内容に基づいて構築されています。
以下はyolov5s.onnxのダウンロードリンクです。リンクをクリックしてモデルをダウンロードし、さらなる使用のためにワークスペースにコピーできます。
モデルをダウンロード: yolov5s.onnxをダウンロード
モデルをダウンロードした後、次のステップのためにworkspaceに配置してください。
mkdir model_yolov5s && cd model_yolov5s
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir workspace && cd workspace
最初のステップは、モデルを .mlir ファイルに変換することです。YOLO の head では混合精度量子化を使用する際の精度損失が最小限であるため、以前のアプローチとは異なり、--output_names パラメータでは head の前の出力ではなく、最終的な出力名を選択します。Netron で ONNx を可視化します:
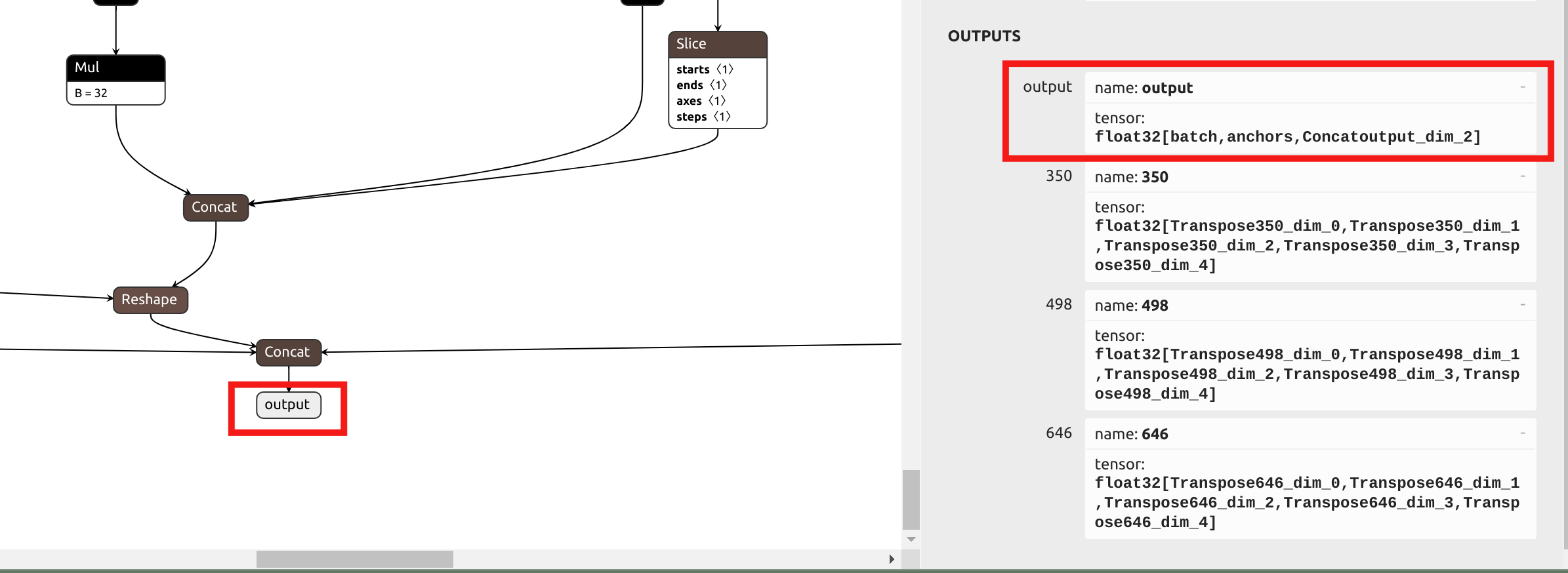
yolov5 の正規化パラメータは yolo11 と同じであるため、model_transform の以下のコマンドを取得できます:
model_transform \
--model_name yolov5s \
--model_def yolov5s.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names output \
--test_input ../image/dog.jpg \
--test_result yolov5s_top_outputs.npz \
--mlir yolov5s.mlir
次に、キャリブレーションテーブルも生成する必要があります。この手順は前のセクションと同じです:
run_calibration \
yolov5s.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolov5s_calib_table
int8対称量子化yolo11モデルを変換したセクションとは異なり、model_deployを実行する前に、混合精度量子化テーブルを生成する必要があります。参考コマンドは以下の通りです:
run_qtable \
yolov5s.mlir \
--dataset ../COCO2017 \
--calibration_table yolov5s_calib_table \
--processor cv181x \
--min_layer_cos 0.99 \
--expected_cos 0.999 \
-o yolov5s_qtable
run_qtable のパラメータ説明を以下の表に示します:
| パラメータ | 必須? | 説明 |
|---|---|---|
| N/A | はい | MLIRファイルを指定 |
| dataset | いいえ | 入力サンプルディレクトリを指定、画像、npz、またはnpyファイルを含む |
| data_list | いいえ | サンプルリストを指定;dataset または data_list のいずれかを選択する必要があります |
| calibration_table | はい | 入力キャリブレーションテーブル |
| processor | はい | 使用するプラットフォームに依存します。2024年版のreCameraでは「cv181x」をパラメータとして選択します。 |
| fp_type | いいえ | 混合精度の浮動小数点精度タイプを指定、auto、F16、F32、BF16をサポート;デフォルトはauto |
| input_num | いいえ | 入力サンプル数を指定;デフォルトは10 |
| expected_cos | いいえ | 最終ネットワーク出力層の最小期待コサイン類似度を指定;デフォルトは0.99 |
| min_layer_cos | いいえ | 各層の出力の最小コサイン類似度を指定;この閾値を下回る値は浮動小数点計算を使用;デフォルトは0.99 |
| debug_cmd | いいえ | 開発用のデバッグコマンド文字列を指定;デフォルトは空 |
| global_compare_layers | いいえ | 最終出力比較のために置換する層を指定、例:'layer1,layer2' または 'layer1:0.3,layer2:0.7' |
| loss_table | いいえ | すべての層の浮動小数点タイプへの量子化損失値を保存するファイル名を指定;デフォルトはfull_loss_table.txt |
各レイヤーの前身レイヤーがその cos に基づいて対応する浮動小数点モードに変換された後、そのレイヤーに対して計算された cos 値がチェックされます。cos が依然として min_layer_cos パラメータより小さい場合、現在のレイヤーとその直接の後続レイヤーが浮動小数点演算を使用するように設定されます。
run_qtable は、隣接するレイヤーの各ペアを浮動小数点計算を使用するように設定した後、ネットワーク全体の出力の cos を再計算します。cos が指定された expected_cos パラメータを超えた場合、検索は終了します。したがって、より大きな expected_cos を設定すると、より多くのレイヤーが浮動小数点演算で試行されることになります。
最後に、model_deploy を実行して混合精度の cvimodel を取得します:
model_deploy \
--mlir yolov5s.mlir \
--quantize INT8 \
--quantize_table yolov5s_qtable \
--calibration_table yolov5s_calib_table \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--processor cv181x \
--model yolov5s_mix-precision.cvimodel
yolov5s_mix-precision.cvimodelを取得した後、model_toolを使用してモデルの詳細情報を表示できます:
model_tool --info yolov5s_mix-precision.cvimodel
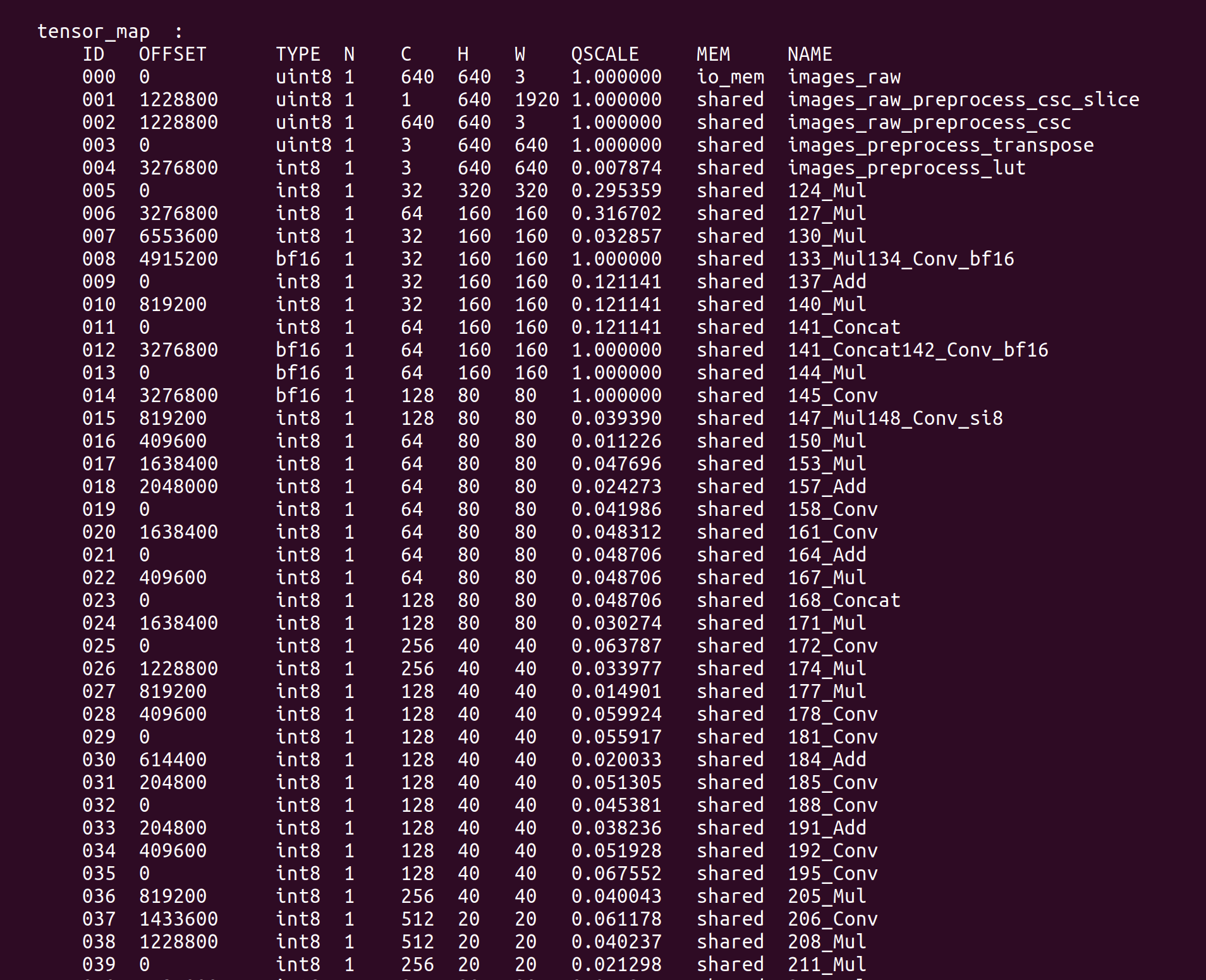
TensorMap や WeightMap などの重要な情報がターミナルに出力されます:
混合精度量子化されたYOLOv5モデルを検証するために、reCameraで例を実行できます。コンパイル済みのテスト例をプルします:
git clone https://github.com/jjjadand/yolov5_Test_reCamera.git
コンパイルされた例と yolov5s_mix-precision.cvimodel を FileZilla などのソフトウェアを使用して reCamera にコピーします。(reCamera の使用開始 を参照できます)
コピーが完了したら、reCamera ターミナルでコマンドを実行します:
cp /path/to/yolov5s_mix-precision.cvimodel /path/to/yolov5_Test_reCamera/solutions/sscma-model/build/
cd yolov5_Test_reCamera/solutions/sscma-model/build/
sudo ./sscma-model yolov5s_mix-precision.cvimodel Dog.jpg Out.jpg
Out.jogをプレビューすると、mixed-precision量子化されたyolov5モデルの推論結果は以下の通りです:

リソース
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。