reSpeaker Flex Pico-voice によるウェイクワード制御と NLU
はじめに
Picovoice はデバイス上で動作する音声 AI を専門とする企業で、ウェイクワード検出、音声認識(speech-to-text)、インテント認識などのフルスタック技術を提供しており、クラウドに依存せずに組み込み機器やエッジデバイス上でローカルに動作します。これらのソリューションは、低レイテンシ、プライバシー保護、クロスプラットフォーム展開を前提に設計されており、IoT やロボットシステムに適しています。
Porcupine は Picovoice の軽量かつ高精度なウェイクワード検出エンジンで、ディープニューラルネットワークを用いて構築され、組み込みシステム向けに最適化されています。常時待ち受けするアプリケーションを、低い計算コストを維持しながら実現でき、マイコン、Raspberry Pi、モバイル、デスクトップなどのプラットフォームで動作します。
Picovoice Rhino は、音声コマンドをテキスト変換を経由せずに直接構造化されたインテントへと変換する speech-to-intent エンジンです。音声認識と自然言語理解を 1 ステップのディープラーニング手法で組み合わせることで、精度向上とレイテンシ削減を実現します。
NLP、NLU、STT とは?
自然言語処理(NLP)は、機械が人間の言語を処理できるようにする広い分野であり、その中の一部である自然言語理解(NLU)は、特にその言語から意味やインテントを抽出することに焦点を当てています。Speech-to-Text(STT)は話された音声をテキストに変換し、そのテキストは通常 NLU に渡されてユーザーの意図が理解されます。Picovoice Rhino は、STT をスキップして音声から直接インテント(speech-to-intent)へ変換するという別のアプローチを取り、効率と精度を向上させています。
キーワード(ウェイクワード)検出(例:「Hey device」)は、システムを起動する最初のステップであり、起動後は STT → NLU のパイプライン、もしくは speech-to-intent(Rhino)が使用されてコマンドを理解し実行します。
目的
このデモでは、Picovoice Porcupine を用いたウェイクワード検出が、Raspberry Pi 上での効率的な speech-to-intent 処理のために Picovoice Rhino とどのように連携するかを紹介します。システムはまずキーワードを待ち受けて起動し、一度トリガーされると、重いクラウド処理に依存することなく、話されたコマンドを直接実行可能なインテントに変換します。このアプローチは低リソースの組み込みデバイス向けに高度に最適化されており、ロボット工学やエッジ AI アプリケーションに最適です。低レイテンシなリアルタイム音声インタラクションを可能にし、制約のあるハードウェア上でも高速かつ信頼性の高い動作を実現します。
必要なハードウェア

ウェイクワード検出
ロボティクス向け組み込みシステムにおけるウェイクワードは、イベント駆動型処理を可能にし、デバイスを低消費電力のリスニング状態に保ち、必要なときにのみ重い音声処理を有効化できるようにします。これにより、マイコンやエッジデバイスのようなリソースに制約のあるハードウェアでの CPU、メモリ、電力消費が大幅に削減されます。また、オーディオパイプラインにおけるゲーティングメカニズムとして機能し、不要なノイズをフィルタリングして、音声認識や制御ロジックの不必要な起動を防ぎます。プライバシーの観点からも、ウェイクワード検出により、明示的なユーザー意図が検出された後にのみ音声が収集・送信され、多くのデータ処理をデバイス上に留めることができます。さらに、人とロボットのインタラクションを改善し、自然な起動トリガーを提供することで、環境音の会話と、ロボットに向けられたコマンドとを区別するのに役立ちます。
reSpeaker Flex のような高度なマイクアレイシステムとウェイクワードを併用することで、具現化ロボット(embodied systems)において効率的かつ信頼性の高い音声インタラクションを実現できます。ウェイクワードは、必要なときにのみフルの音声処理を有効化し、組み込みハードウェアでの電力消費と CPU 使用率を削減します。マイクアレイはこれを補完し、ビームフォーミング、ノイズ抑圧、Circular マイクアレイでの方向検出を提供することで、騒がしい環境でも高精度なウェイクワード認識を可能にします。この組み合わせにより、誤検出が最小限に抑えられ、システム全体の応答性が向上します。また、明示的に呼びかけられたときにのみデバイスが反応し、正しい話者にフォーカスできるため、人とロボットのインタラクションも向上します。
Pico-voice でウェイクワードを使う方法
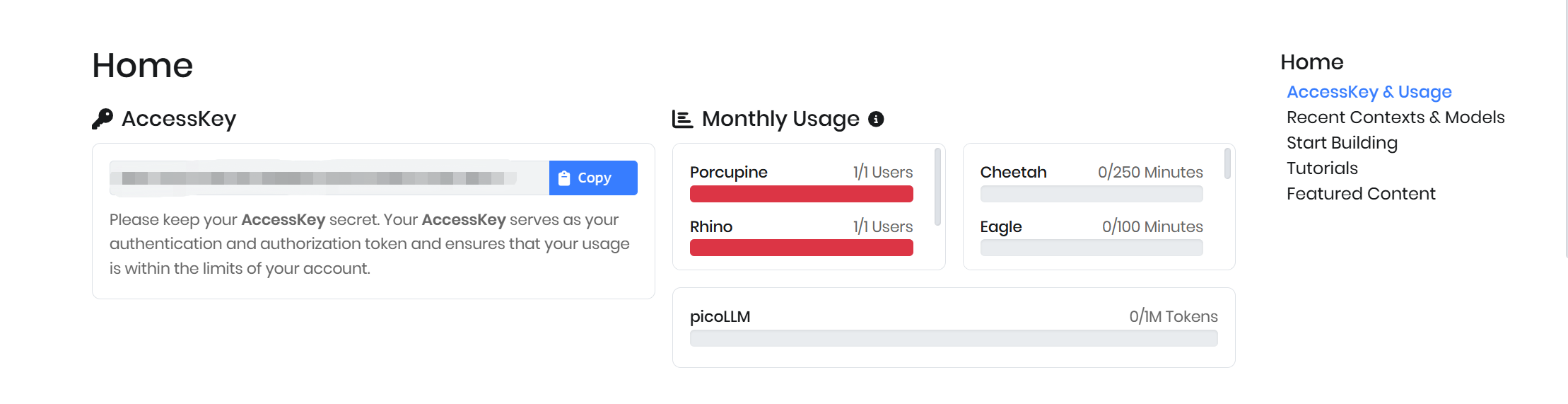
Picovoice にサインアップすると、Access Key を取得できます。
オプション A : 組み込みキーワード
Porcupine は、AMERICANO、BLUEBERRY、BUMBLEBEE、GRAPEFRUIT、GRASSHOPPER、PICOVOICE、PORCUPINE、TERMINATOR、JARVIS などの複数の組み込みウェイクワードオプションを提供しており、有効な Access Key があればそのまま利用できます。この Access Key を用いることで、カスタムモデルを学習させることなく、これらのキーワードを簡単にアプリケーションへ統合できます。
この構成では、ホストデバイスとして Raspberry Pi 5 を使用し、ウェイクワード検出はデバイス上でローカルに実行されます。XMOS ベースのマイクロフォンシステムには USB audio firmware が書き込まれており、OS から標準的なオーディオ入力デバイスとして認識されます。
まず、Porcupine のライブラリと依存パッケージを環境にインストールする必要があります。
pip install pvporcupine
インストール後、サンプルコードを使用してオーディオレコーダーを初期化し、選択したキーワードを読み込み、ウェイクワードを継続的に待ち受けることができます。キーワードが検出されると、録音や音声コマンド処理などの後続のアクションをトリガーできます。
import pvporcupine
from pvrecorder import PvRecorder
access_key = "YOUR_ACCESS_KEY"
porcupine = pvporcupine.create(
access_key=access_key,
keywords=["porcupine"]
)
recorder = PvRecorder(device_index=-1, frame_length=porcupine.frame_length)
recorder.start()
print("Listening...")
while True:
pcm = recorder.read()
result = porcupine.process(pcm)
if result >= 0:
print("Wake word detected!")
porcupine.delete()
recorder.stop()
recorder.delete()
オプション B: カスタムキーワード
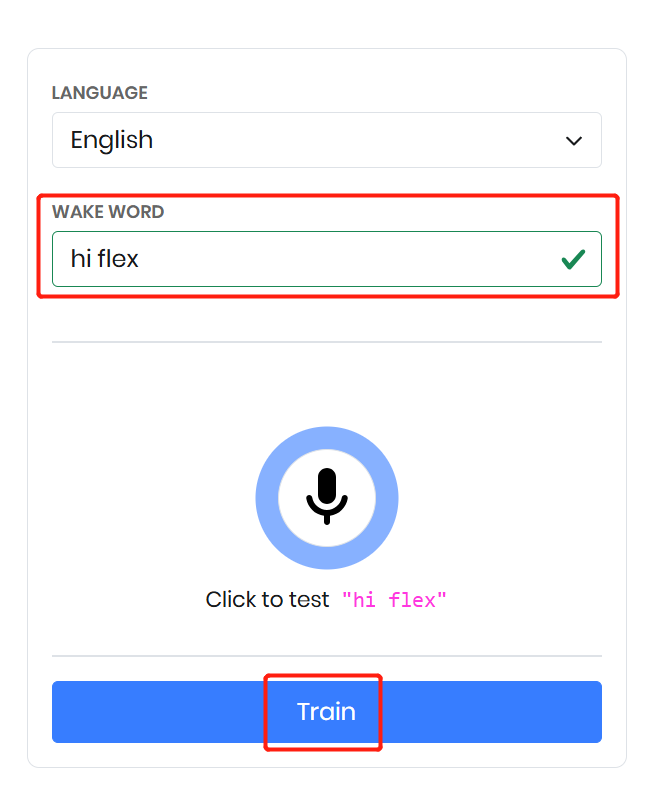
Picovoice Console を開き、カスタムウェイクワードのページに移動します。使用したい言語を選択し、「hi flex」のようなウェイクワードを定義します。コンソール内でウェイクワードをテストし、その検出性能を確認できます。
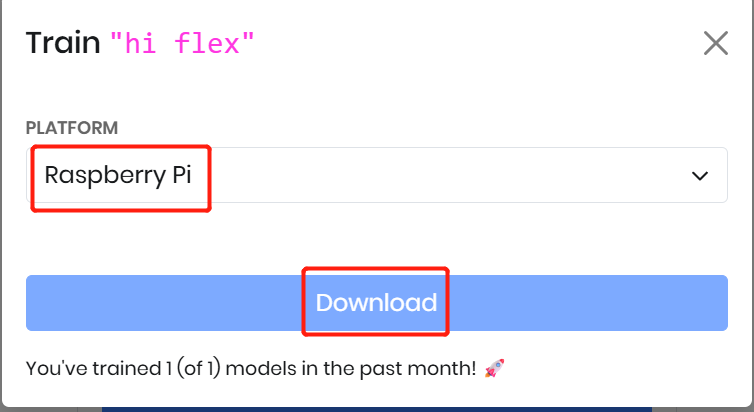
設定に満足したら、Train をクリックしてモデルを生成します。その後、ターゲットプラットフォームを選択します。ここでは Raspberry Pi を選びます。最後に生成された .ppn ファイルをダウンロードします。このファイルをアプリケーション内で使用して、カスタムウェイクワード検出を行います。
サンプルコード
import pvporcupine
from pvrecorder import PvRecorder
access_key = "YOUR_ACCESS_KEY"
porcupine = pvporcupine.create(
access_key=access_key,
keyword_paths=["/home/pi/porcupine_env/hi-flex_en_raspberry-pi_v4_0_0.ppn"]
)
recorder = PvRecorder(device_index=-1, frame_length=porcupine.frame_length)
recorder.start()
print("Listening...")
while True:
pcm = recorder.read()
result = porcupine.process(pcm)
if result >= 0:
print("Wake word detected!")
porcupine.delete()
recorder.stop()
recorder.delete()
Speech to Intent
Picovoice Rhino は、音声コマンドをテキスト変換を経由せずに直接構造化されたインテントへ変換する speech-to-intent エンジンです。1 ステップのディープラーニング手法を用いて音声認識と自然言語理解を組み合わせることで、精度を向上させつつレイテンシを低減します。 Rhino は リアルタイムのオンデバイス処理向けに最適化されており、オフラインで動作してネットワーク遅延がゼロであると同時に、すべての音声データをプライベートに保ちます。非常に効率的で、Raspberry Pi やマイコンのような組み込み・IoT システム向けに設計されています。 さらに Rhino では、開発者がインテントやスロットを含むカスタムコンテキストを定義できるため、システムが特定ドメインのコマンドを理解し、音声入力から直接アクションをトリガーできるようになります。
コンテキストを作成する
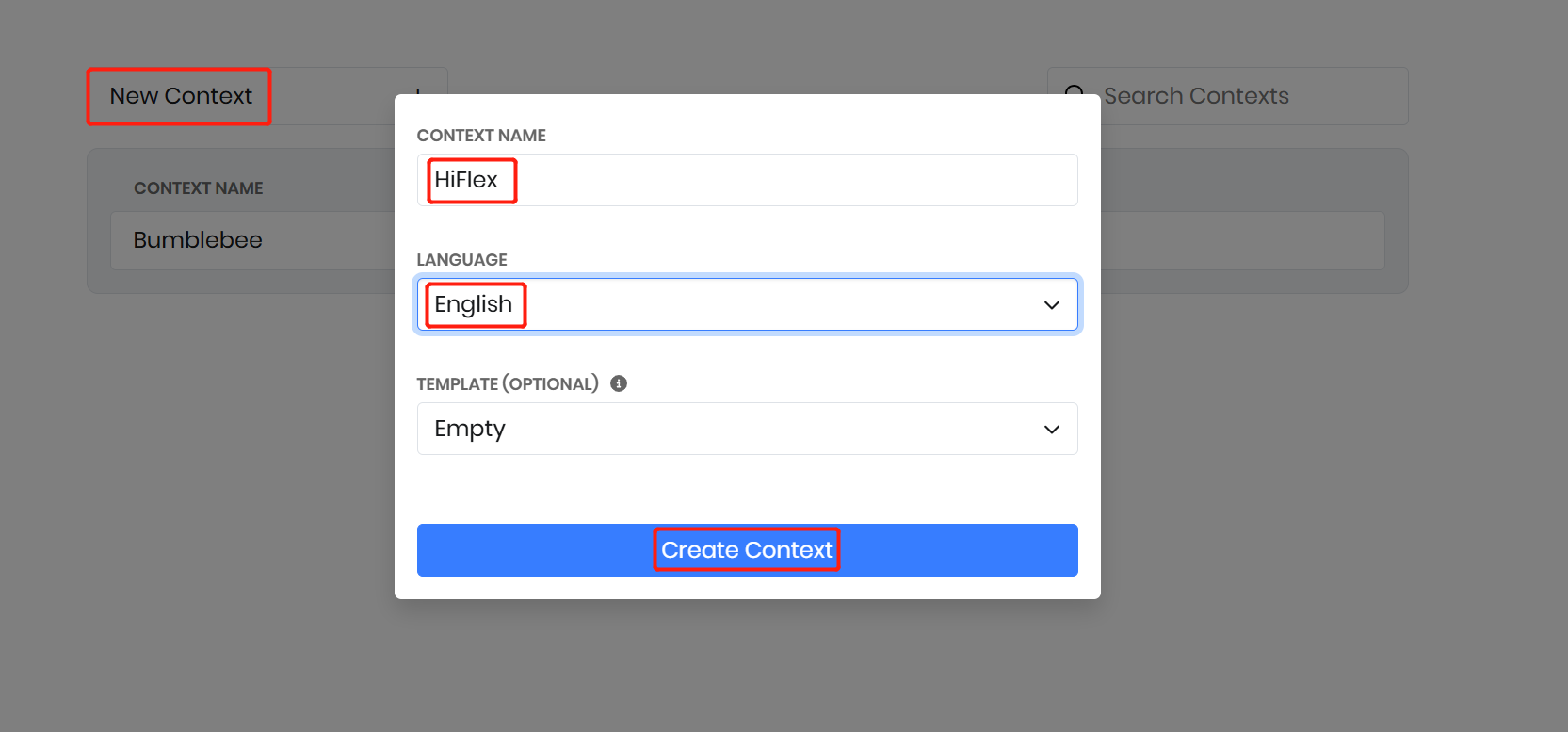
コンテキストは、特定ドメインにおける音声コマンド、インテント、およびスロットの集合を定義します。ここでは、音声コマンドで ReSpeaker Flex を制御するための 「Bumblebee」 コンテキストを作成します。Picovoice の Rhino Speech-to-Intent コンソールに移動し、「Empty」 テンプレートを使用して Bumblebee という名前の新しいコンテキストを作成します。
インテントを作成する
最上位レベルでは、コンテキストはドメイン内でのユーザーアクションを表すインテントの集合です。例えば、HiFlex コンテキスト内に「Gesture」というインテントを作成し、ジェスチャー関連の音声コマンドを表現します。
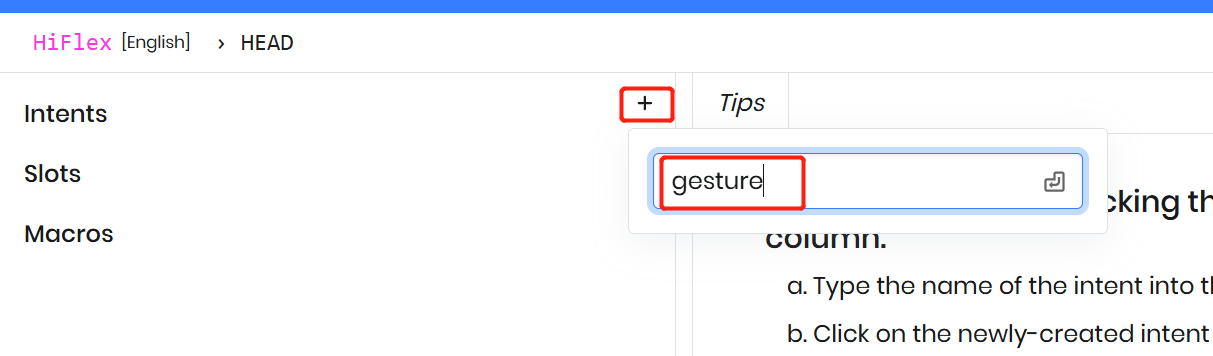
インテントに表現を追加する
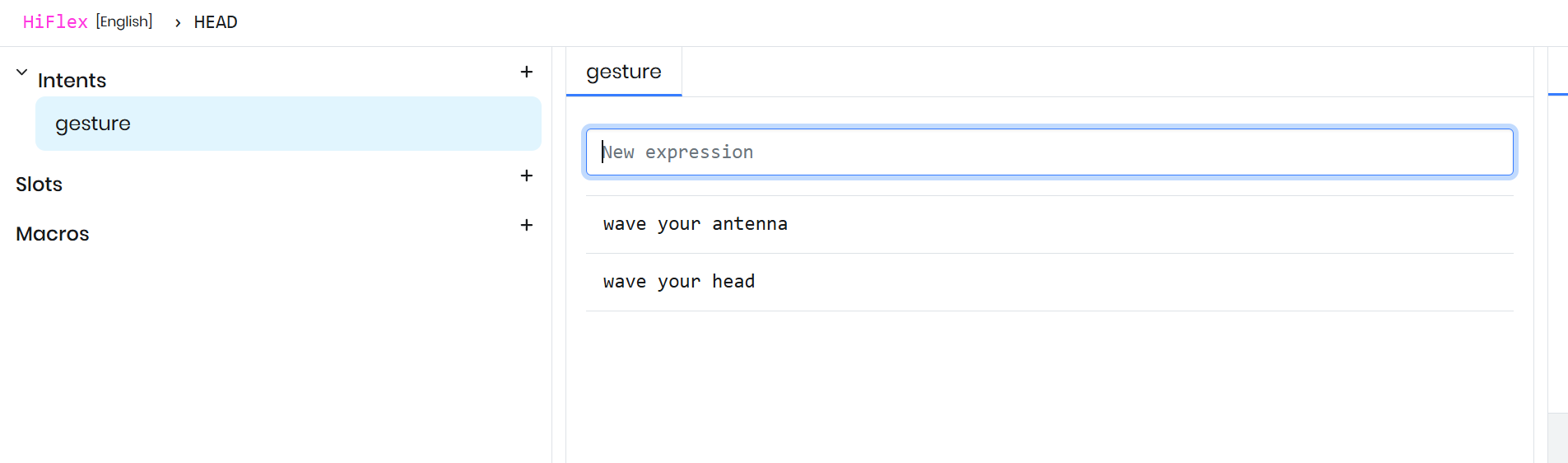
ユーザーは同じインテントを複数の言い回しで表現でき、その各バリエーションを表現(expression)と呼びます。Gesture インテントに対しては、「wave your head」や「shake your antenna」 のような表現を追加します。これらはいずれも同じアクションのグループに対応します。
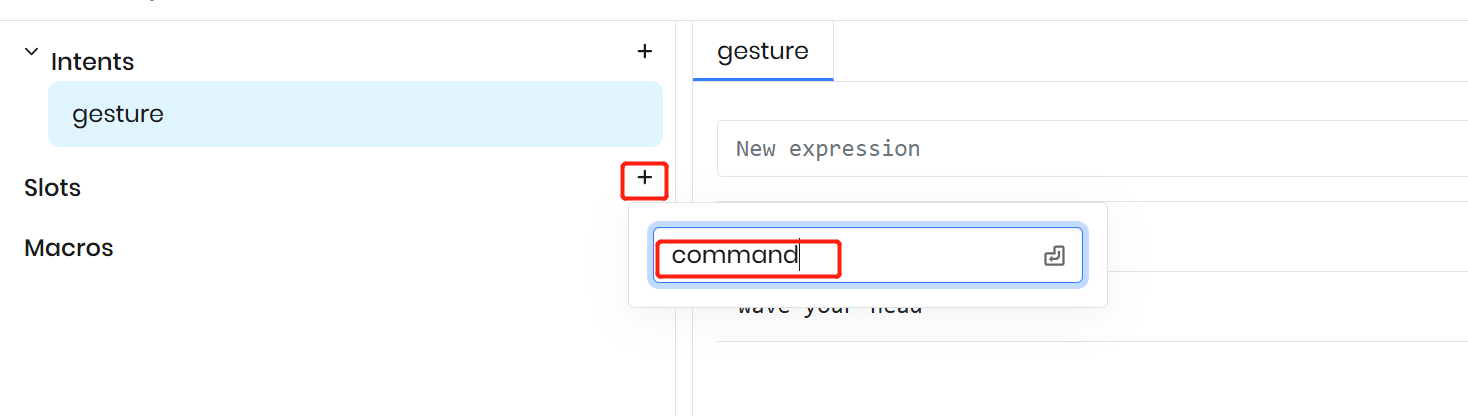
スロットを使って変数を取得する
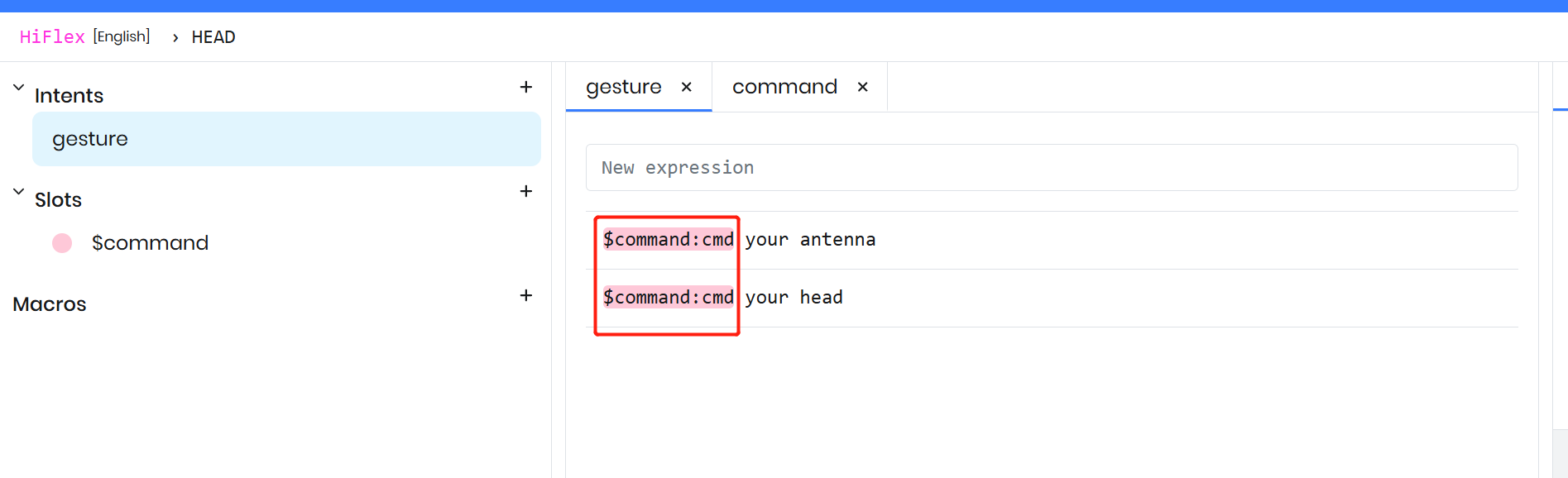
スロットを使用して、ユーザー発話内の可変部分を抽出します。この場合、“wave” や “shake” のような単語はコマンド内で変化する状態を表しているため、変数としてモデル化できます。これらのバリエーションを動的に取得するために、Rhino コンテキスト内に “commands” という名前のスロットを作成します。
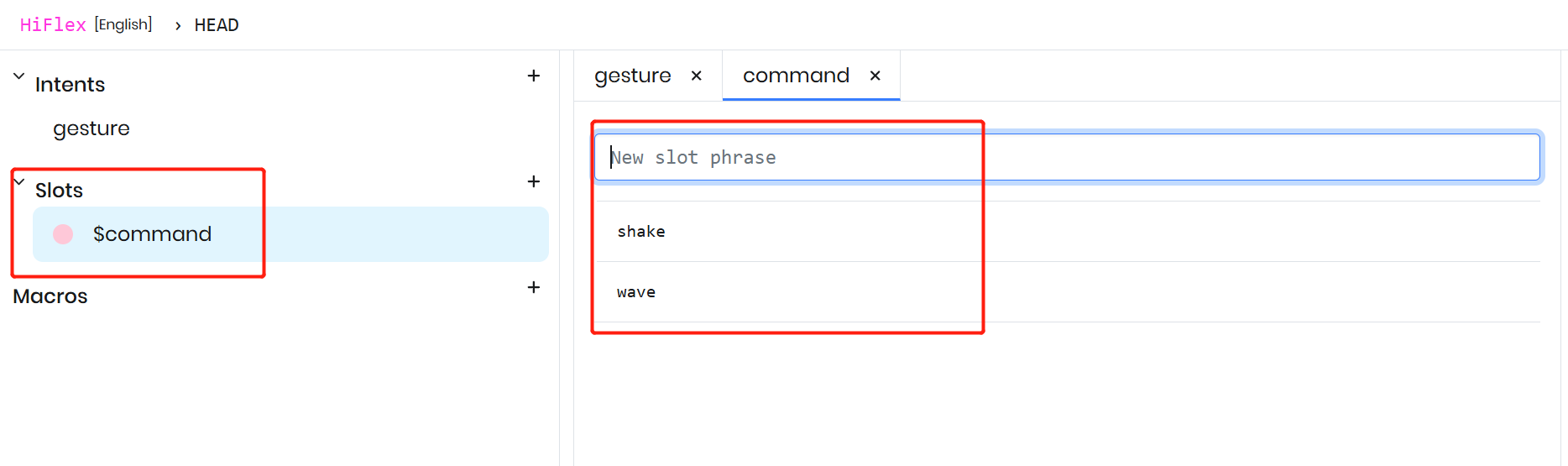
既存の式を修正して、新しく作成したスロットを含めます。スロットを追加する際は、$ 記号を使ってスロットを示し、その後、オートコンプリートのドロップダウンから目的のスロットタイプを選択して名前を割り当てます。
準備ができたら、まず test をクリックしてテストします
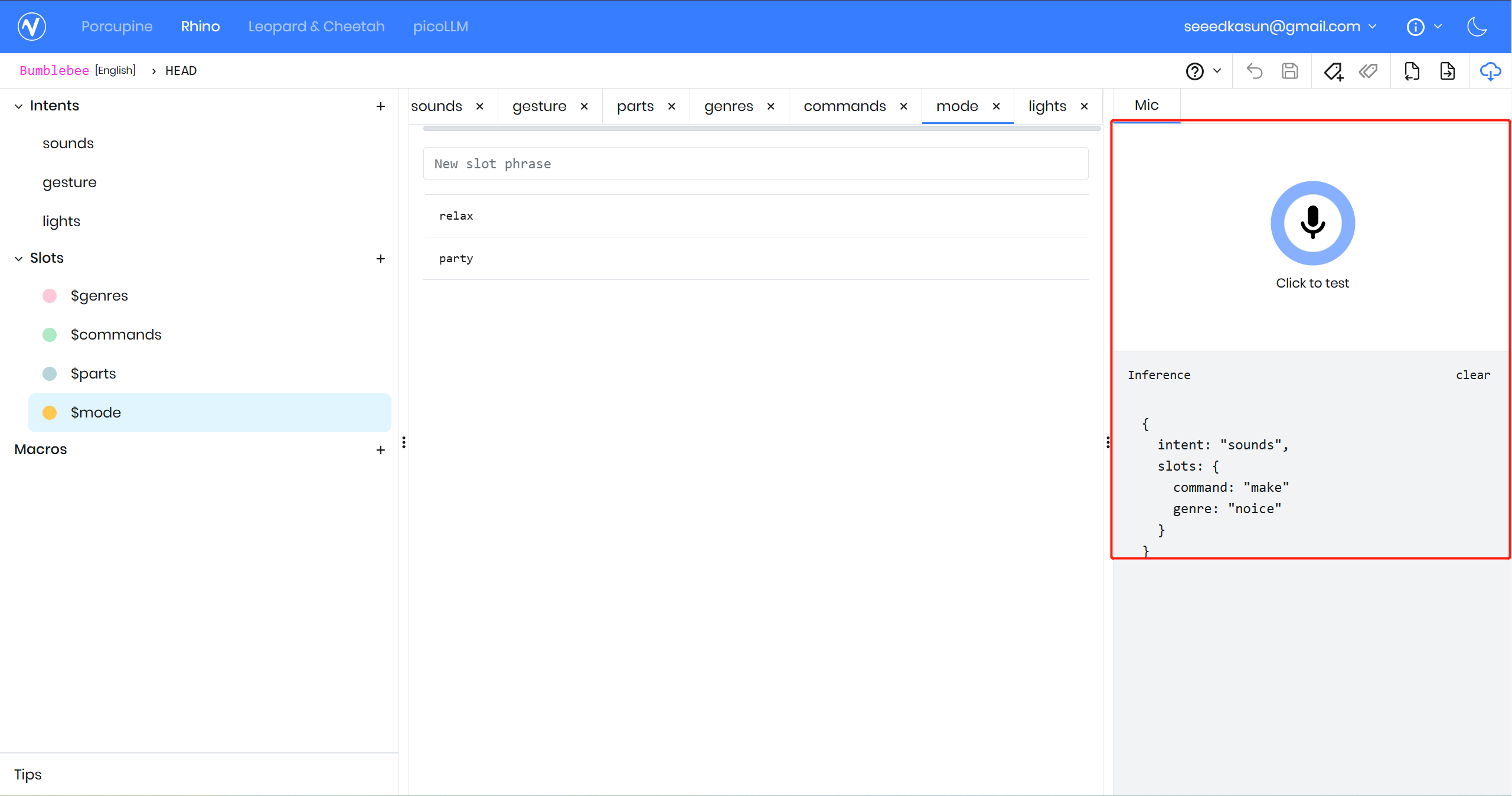
モデルをダウンロードしましょう
コンテキストの設計が完了したら、右上のダウンロードアイコンをクリックし、対象プラットフォームを選択してから “Download.” をクリックします。Picovoice Console はそのプラットフォーム向けの Rhino モデルを自動的にトレーニングし、通常は約 5〜10 秒で完了します。
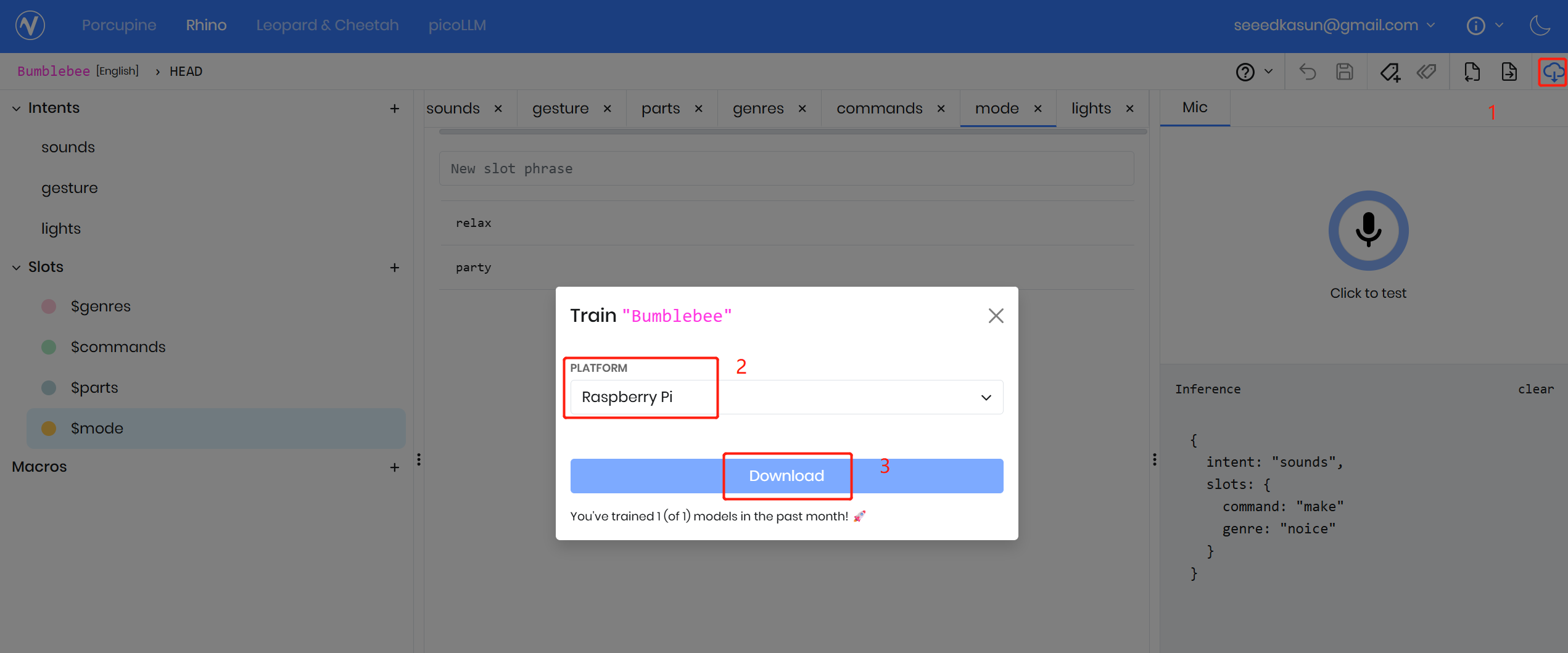
サンプルコード
import pvporcupine
import pvrhino
from pvrecorder import PvRecorder
access_key = "ACCESS KEY"
rhino = pvrhino.create(
access_key=access_key,
context_path="/home/pi/porcupine_env/Bumblebee_en_raspberry-pi_v4_0_0.rhn",
)
recorder = PvRecorder(device_index=-1, frame_length=rhino.frame_length)
recorder.start()
print("Listening...")
while True:
pcm = recorder.read()
is_finalized = rhino.process(pcm)
if is_finalized:
inference = rhino.get_inference()
if inference.is_understood:
print("Intent:", inference.intent)
print("Slots:", inference.slots)
else:
print("Didn't understand")
rhino.reset()
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。私たちは、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じてお選びいただけるよう、複数のコミュニケーションチャネルを用意しています。