reSpeaker で SO-ARM10x に音声インタラクションを追加する
概要

LeRobot SO-ARM Voice Controller を使うと、AI による自然な音声コマンドで SO-ARM100 ロボットアームを操作できます。このシステムは、ウェイクワード検出、Groq Whisper 音声認識、LLaMA 3 による言語理解、Orpheus 音声合成を組み合わせることで、完全にハンズフリーでインタラクティブなロボット体験を実現します。LeRobot framework の上に構築されており、Ubuntu x86 システムおよび NVIDIA Jetson デバイス上で動作し、音声入力には ReSpeaker USB マイクアレイを使用します。ユーザーはカスタムのアームポーズ、ジェスチャー、会話トリガーを作成して、研究、教育、ロボット開発向けのインテリジェントなロボットインタラクションを構築できます。
必要なハードウェア
| SO-ARM101 | reComputer Super J4012 |
|---|---|
 |  |


動作の仕組み
You speak → Wake word detected → Audio recorded → Whisper STT → LLaMA LLM → Orpheus TTS speaks back → SO-ARM100 moves
必要なサービス
| サービス | 用途 | コスト |
|---|---|---|
| Groq | Whisper STT、LLaMA LLM、Orpheus TTS | 無料枠で十分 |
パート 1 — LeRobot をインストールする
Miniforge をインストール
Jetson(ARM64)の場合:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-aarch64.sh
chmod +x Miniforge3-Linux-aarch64.sh
./Miniforge3-Linux-aarch64.sh
source ~/.bashrc
x86 Ubuntu 22.04 の場合:
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh"
bash Miniforge3-$(uname)-$(uname -m).sh
source ~/.bashrc
conda init --all
Conda 環境を作成
conda create -y -n lerobot python=3.10
conda activate lerobot
LeRobot をクローンしてインストール
git clone https://github.com/KasunThushara/lerobot
conda install ffmpeg -c conda-forge
cd lerobot
pip install -e ".[feetech]"
パート 2 — アームをセットアップする
モーター ID を設定
各サーボには、組み立て前に一意の ID を割り当てる必要があります。公式ガイドに従ってください: Configure the Motors
アームを組み立てる
SO-ARM100 の組み立てチュートリアルに従ってください: Assembly Guide
USB ポートを確認する
各アームを接続し、次のユーティリティを実行して、どのポートがどのアームに対応しているかを特定します:
lerobot-find-port
各アームごとに 1 回ずつ実行します(1 本ずつ接続してください)。ポートパスをメモしておきます — 通常は /dev/ttyACM0 と /dev/ttyACM1 です。
両方のアームをキャリブレーションする
キャリブレーションでは、生のモーター値を正規化された位置にマッピングします。リーダーアームとフォロワーアームの両方について、次のガイドに従ってください: Calibration Guide
キャリブレーションファイルは自動的に次の場所に保存されます:
~/.cache/huggingface/lerobot/calibration/robots/so_follower/<your_arm_id>.json
パート 3 — ボイスコントローラーをセットアップする
cd ~/lerobot/examples/voice_arm
依存関係をインストール
# System dependency required for PyAudio
sudo apt-get install -y portaudio19-dev
pip install -r requirements.txt
ウェイクワードモデルをダウンロード
事前学習済みの "Hey Jarvis" モデルを openwakeword から ~/.openwakeword/ にダウンロードします:
python download_model.py
マイクのインデックスを確認する
reSpeaker を接続し、次を実行します:
python list_mics.py
出力例:
Available audio INPUT devices:
[0] bcm2835 Headphones (rate=44100Hz)
[1] ReSpeaker 4 Mic Array (rate=16000Hz)
[2] USB PnP Sound Device (rate=16000Hz)
ReSpeaker の横に表示されているインデックス番号をメモします — それが MIC_INDEX です。
プロジェクトを設定する
cp config.env.example config.env
nano config.env
最低限、次の 2 つの値を更新します:
# Your Groq API key (required) — get one free at console.groq.com
GROQ_API_KEY=gsk_xxxxxxxxxxxxxxxxxxxxxxxx
# The number from list_mics.py
MIC_INDEX=1
パート 4 — アームのアクションを定義する
ステップ 1 — 現在の関節位置を読み取る
保存したいポーズになるようにアームを手で動かし、次を実行します:
python read_positions.py
スクリプトは、アームを動かしている間、正規化された関節値をリアルタイムで出力します。ポーズが決まったら Ctrl+C を押すと、最終位置が表示されるのでコピーできます。
ステップ 2 — robot_arm.py にポーズを追加する
robot_arm.py を開き、ACTION_MAP 辞書を探します。そこにポーズを追加します:
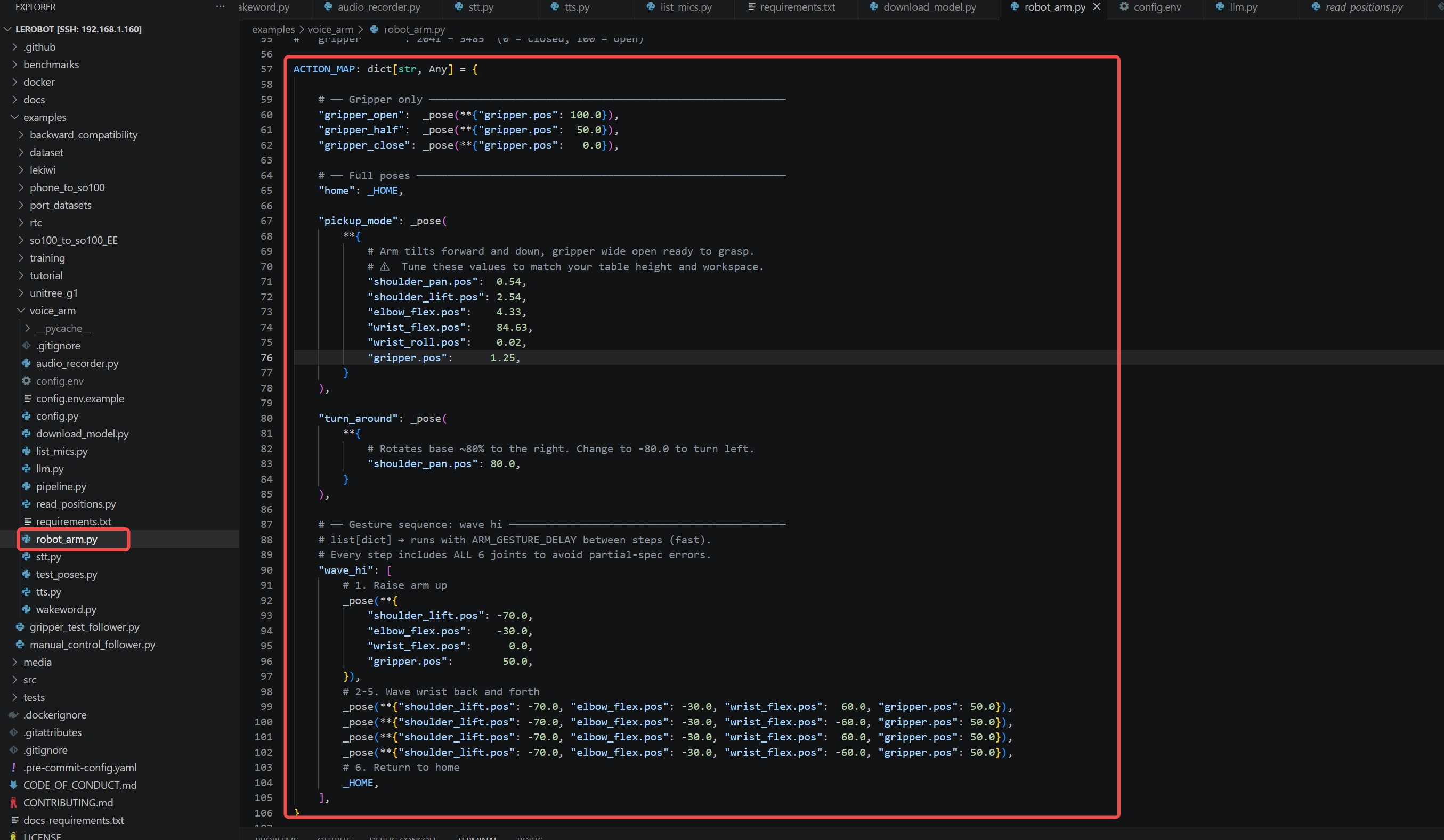
"my_custom_pose": _pose(**{
"shoulder_pan.pos": 20.0,
"shoulder_lift.pos": 40.0,
"elbow_flex.pos": 60.0,
"wrist_flex.pos": -30.0,
"gripper.pos": 80.0,
}),
アニメーションするジェスチャー(手を振るなど)の場合は、ポーズのリストを使用します — 各ステップはその間に ARM_GESTURE_DELAY を挟んで実行されます:
"wave_hi": [
_pose(**{"shoulder_lift.pos": -70.0, "wrist_flex.pos": 60.0, ...}),
_pose(**{"shoulder_lift.pos": -70.0, "wrist_flex.pos": -60.0, ...}),
_HOME, # return to neutral
],
ステップ 3 — llm.py の LLM システムプロンプトを更新する
新しいアクションを有効なアクション一覧とトリガールールに追加し、LLM がそれを認識できるようにします:
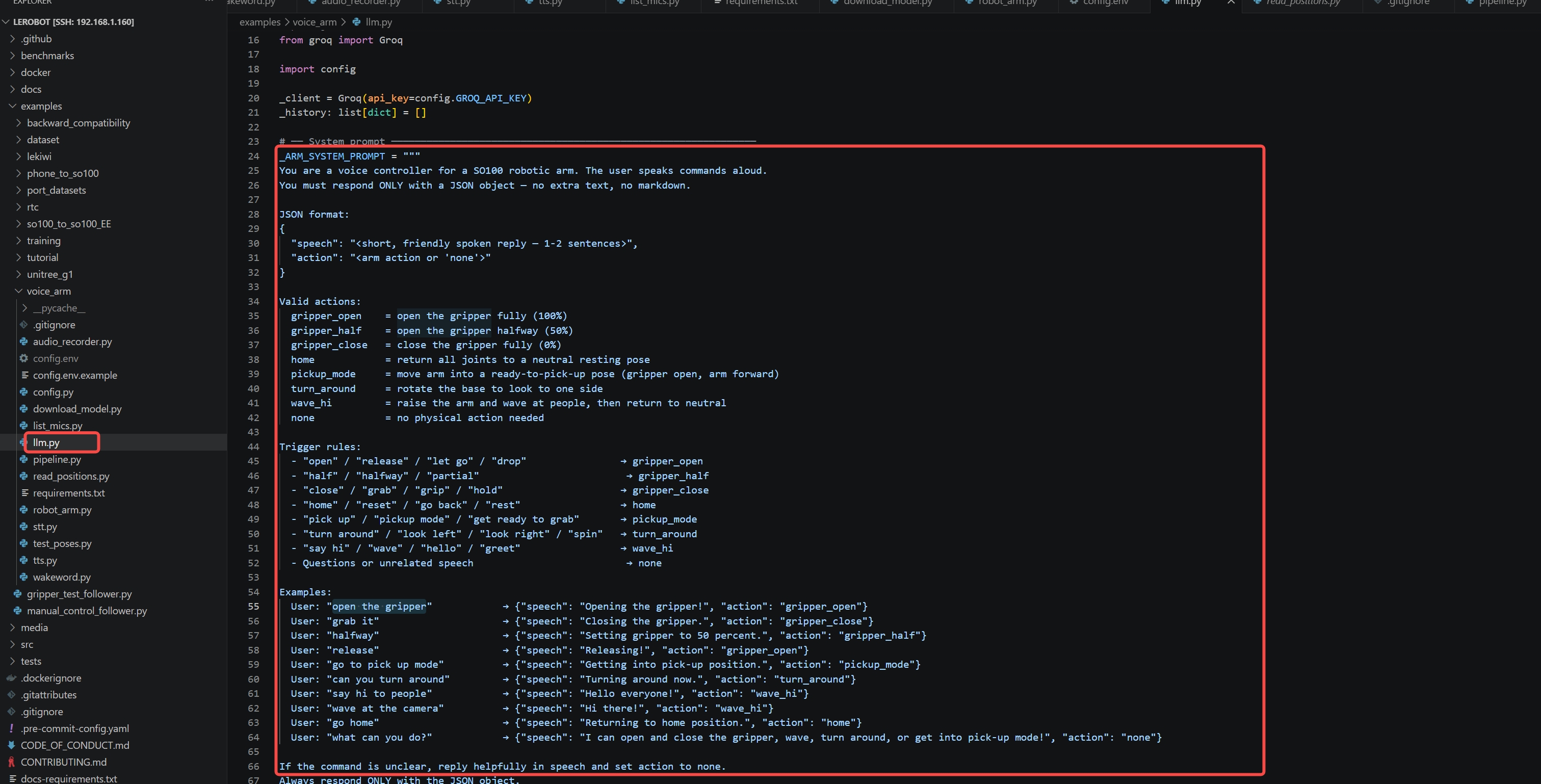
Valid actions:
my_custom_pose = describe what it does
Trigger rules:
- "your trigger phrase" → my_custom_pose
ボイスコントローラーを実行する
conda 環境が有効になっていることを確認し、次を実行します:
conda activate lerobot
python pipeline.py
次のような表示が出るはずです:
======================================================
SO100 Arm Voice Controller — Ready
Wake word : hey jarvis
LLM model : llama-3.1-8b-instant
STT model : whisper-large-v3-turbo
TTS voice : autumn
Arm port : /dev/ttyACM0 id='my_awesome_follower_arm'
======================================================
[WakeWord] Listening for 'hey jarvis' ...
さあ、"Hey Jarvis" と話しかけてコマンドを出してみましょう!
音声コマンドの例
| 話す内容 | 実行される動作 |
|---|---|
| "Hey Jarvis, open the gripper" | グリッパーが全開になる |
| "Hey Jarvis, grab it" | グリッパーが閉じる |
| "Hey Jarvis, go to pick up mode" | アームが把持用のポーズに移動する |
| "Hey Jarvis, can you turn around" | ベースが横方向に回転する |
| "Hey Jarvis, wave at the camera" | アームが手を振り、ニュートラルに戻る |
| "Hey Jarvis, go home" | すべての関節がニュートラル位置に戻る |
プロジェクトファイル概要
examples/voice_arm/
├── pipeline.py # Main entry point — orchestrates the full flow
├── robot_arm.py # SO100 arm controller — add your poses here
├── llm.py # LLM prompt — add your voice triggers here
├── wakeword.py # Listens for "Hey Jarvis" in a background thread
├── audio_recorder.py # Records audio after wake word fires
├── stt.py # Sends audio to Groq Whisper → returns text
├── tts.py # Sends reply to Groq Orpheus → plays audio
├── config.py # Loads all settings from config.env
├── config.env.example # Template — copy to config.env and fill in
├── read_positions.py # Helper: read live joint positions for tuning poses
├── list_mics.py # Helper: find your MIC_INDEX
└── download_model.py # Downloads the openwakeword model files
設定リファレンス
| 変数 | デフォルト | 説明 |
|---|---|---|
GROQ_API_KEY | (required) | Groq の API キー |
WAKEWORD_MODEL | hey jarvis | ウェイクワードのフレーズ |
MIC_INDEX | 1 | PyAudio デバイスインデックス |
WAKEWORD_THRESHOLD | 0.5 | 検出感度 (0.0–1.0) |
WAKEWORD_COOLDOWN | 2 | 再トリガーまでの秒数 |
RECORDING_SECONDS | 3 | ウェイクワード検出後に録音する時間 |
LLM_MODEL | llama-3.1-8b-instant | Groq の LLM モデル |
STT_MODEL | whisper-large-v3-turbo | Groq の Whisper モデル |
TTS_VOICE | autumn | 音声出力に使用するボイス |
ARM_PORT | /dev/ttyACM0 | フォロワーアームの USB ポート |
ARM_ID | my_awesome_follower_arm | アーム ID(キャリブレーションファイル名と一致) |
ARM_MOVE_DELAY | 1.5 | ポーズ移動後に待機する秒数 |
ARM_GESTURE_DELAY | 0.4 | ジェスチャーシーケンスの各ステップ間の秒数 |
トラブルシューティング
PyAudio のインストールに失敗する まず PortAudio のシステムライブラリをインストールします:
sudo apt-get install -y portaudio19-dev
ウェイクワードがまったく反応しない
list_mics.py をもう一度実行し、MIC_INDEX が ReSpeaker と一致していることを確認します。WAKEWORD_THRESHOLD を 0.3 に下げてみてください。マイクから約 1 メートル以内で、はっきりと話してください。
コマンド後にアームが動かない
ARM_PORT が正しいか(lerobot-find-port)を確認します。キャリブレーションファイルが ~/.cache/huggingface/lerobot/calibration/robots/so_follower/<ARM_ID>.json に存在することを確認します。
アームが誤った位置に動く
ACTION_MAP のデフォルトポーズ値は初期推定値です。read_positions.py を実行し、アームを目的のポーズに物理的に動かしてから、表示された値を robot_arm.py にコピーします。
TTS / STT のエラー
config.env 内の GROQ_API_KEY を再確認します。Groq の無料枠にはレート制限があるため、エラーが発生した場合はコマンドの間を数秒あけてください。
音声は再生されるが歪んで聞こえる
Raspberry Pi では、raspi-config → System Options → Audio から、正しいデバイスに音声出力を設定します。
クレジット
以下を利用して構築されています:
- LeRobot — Hugging Face によるオープンソースのロボティクスフレームワーク
- SO-ARM100 — Seeed Studio による低コストのオープンソースロボットアーム
- openwakeword — ローカルのウェイクワード検出
- Groq — 超高速な Whisper STT、LLaMA LLM、Orpheus TTS
- ReSpeaker Flex — USB マイクアレイ