ReSpeaker Mic Array v3.0

ReSpeaker Mic Array v3.0は、ReSpeaker Mic Array v2.0に続く、Seeed StudioのUSBマイクロフォンアレイの次世代製品です。v2.0はXMOSのXVF-3000チップセットをベースに構築され、v1.0からの大幅なアップグレードとして設計されましたが、v3.0は物理的なマイクロフォン数が少なくなっても、音質とアルゴリズム性能の向上に焦点を当てています。
v2.0の4マイクアレイと比較して、v3.0も4つのマイクロフォンを使用していますが、改良された内蔵音声処理アルゴリズムを統合し、前世代よりもクリアな遠距離音声キャプチャと優れたノイズ処理を提供します。v3.0では、v2.0のWM8960コーデックをTLV320AIC3104コーデックに置き換え、より高品質な音声キャプチャに貢献しています。
v2.0がReSpeaker Coreと組み合わせて使用されることが多く、開発ボードとして使用されていたのに対し、v3.0はよりプラグアンドプレイ型のUSBデバイスです。Windows、macOS、Linuxとの完全な互換性を提供するUSB Audio Class 1.0のサポートという点ではv2.0と似ていますが、追加のハードウェアを必要とせずに、すぐに使える音声インターフェース性能に調整されています。
機能面では、両方ともAEC(音響エコーキャンセレーション)、VAD(音声活動検出)、DOA(到来方向)、ビームフォーミング、ノイズ抑制などの遠距離音声キャプチャと音声強化アルゴリズムをサポートしていますが、v3.0のアルゴリズム最適化により、実際のノイズの多い環境でよりクリアな音声を提供します。
LEDシステムは両バージョンとも12個のプログラマブルRGB LEDのままですが、v3.0は新しいUSB 4 Mic Arrayデザインをモデルとしており、v2.0の開発者向けフォームファクターよりも小さくシンプルでありながら、主要なプロフェッショナル音声インターフェース機能を保持しています。

![]()
バージョン
| 製品バージョン | 変更点 | リリース日 |
|---|---|---|
| ReSpeaker Mic Array v1.0 | 初期版 | 2016年8月15日 |
| ReSpeaker Mic Array v2.0 | XVSM-2000の製造終了により、MCUをXVF-3000に変更し、マイクを7個から4個に削減。 | 2018年1月25日 |
| ReSpeaker Mic Array v3.0 | コーデックをTLV320AIC3104に変更 | 2021年1月19日 |
機能
- 遠距離音声キャプチャ
- USB Audio Class 1.0 (UAC 1.0) サポート
- 4つのマイクロフォンアレイ
- 12個のプログラマブルRGB LEDインジケータ
- 音声アルゴリズムと機能
- 音声活動検出
- 到来方向推定
- ビームフォーミング
- ノイズ抑制
- 残響除去
- 音響エコーキャンセレーション
仕様
- XMOSのXVF-3000
- 4つの高性能デジタルマイクロフォン
- 遠距離音声キャプチャサポート
- オンチップ音声アルゴリズム
- 12個のプログラマブルRGB LEDインジケータ
- マイクロフォン: ST MP34DT01TR-M
- 感度: -26 dBFS (無指向性)
- 音響過負荷点: 120 dBSPL
- SNR: 61 dB
- 電源: Micro USBまたは拡張ヘッダーから5V DC
- 寸法: 70mm (直径)
- 3.5mmオーディオジャック出力ソケット
- 消費電力: 5V、LED点灯時180mA、LED消灯時170mA
- 最大サンプルレート: 16Khz
ハードウェア概要

-
① XMOS XVF-3000: 音響エコーキャンセレーション(AEC)、ビームフォーミング、残響除去、ノイズ抑制、ゲイン制御を含む高度なDSPアルゴリズムを統合しています。
-
② デジタルマイクロフォン: MP34DT01-Mは、容量性センシング素子とICインターフェースで構築された、超小型、低消費電力、無指向性のデジタルMEMSマイクロフォンです。
-
③ RGB LED: 3色RGB LED。
-
④ USBポート: 電源を供給し、マイクアレイを制御します。
-
⑤ 3.5mmヘッドフォンジャック: オーディオ出力。このポートにアクティブスピーカーやヘッドフォンを接続できます。
-
⑥ TLV320AIC3104: TLV320AIC3104は、8Ωの負荷に対してチャンネルあたり1Wを提供するクラスDスピーカードライバーを搭載した低消費電力ステレオコーデックです。
システム図
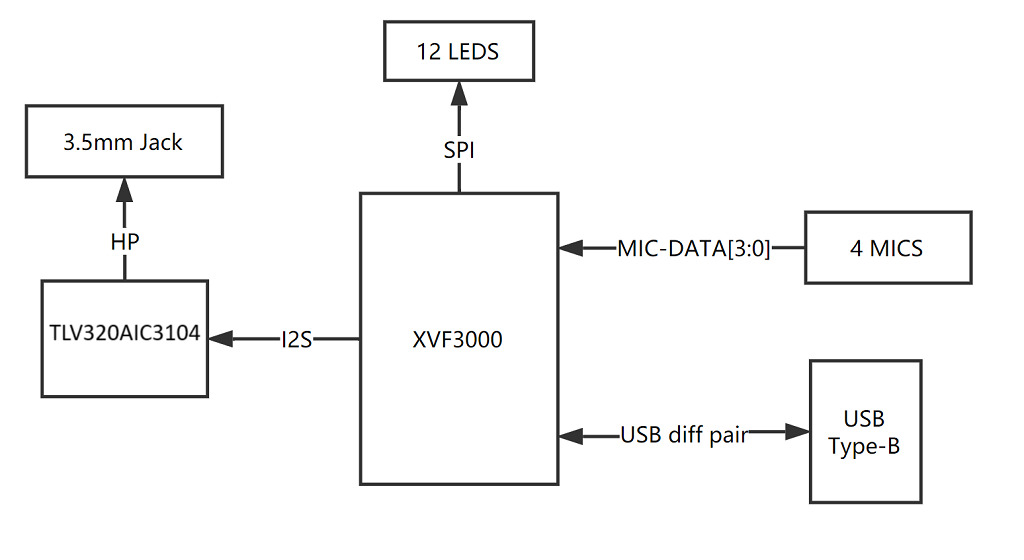
ピンマップ

寸法
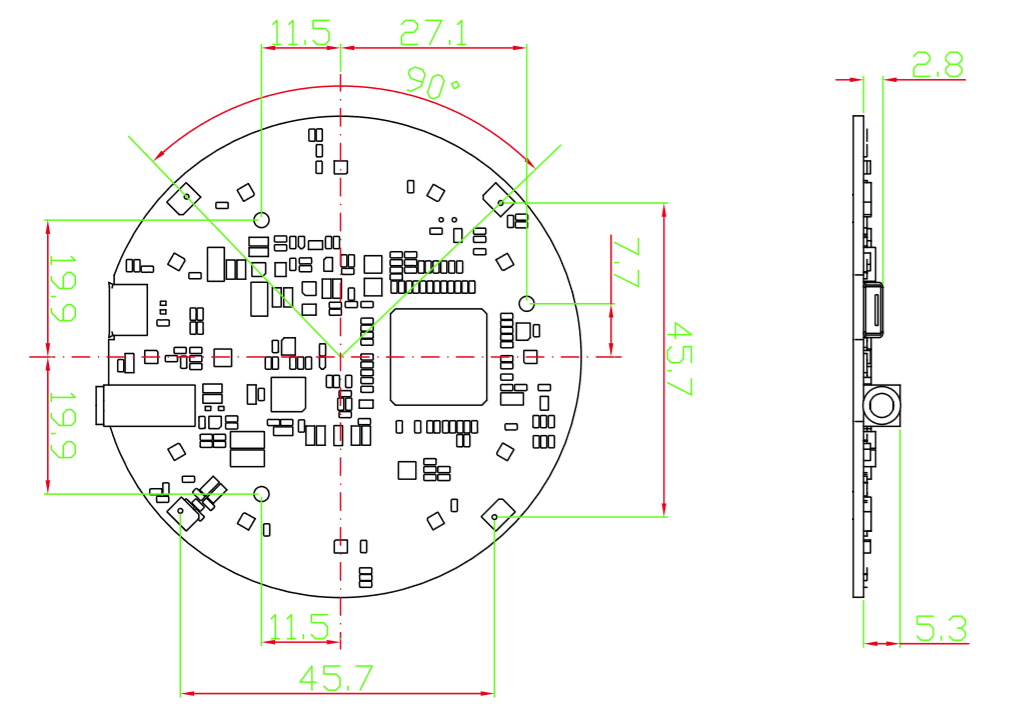
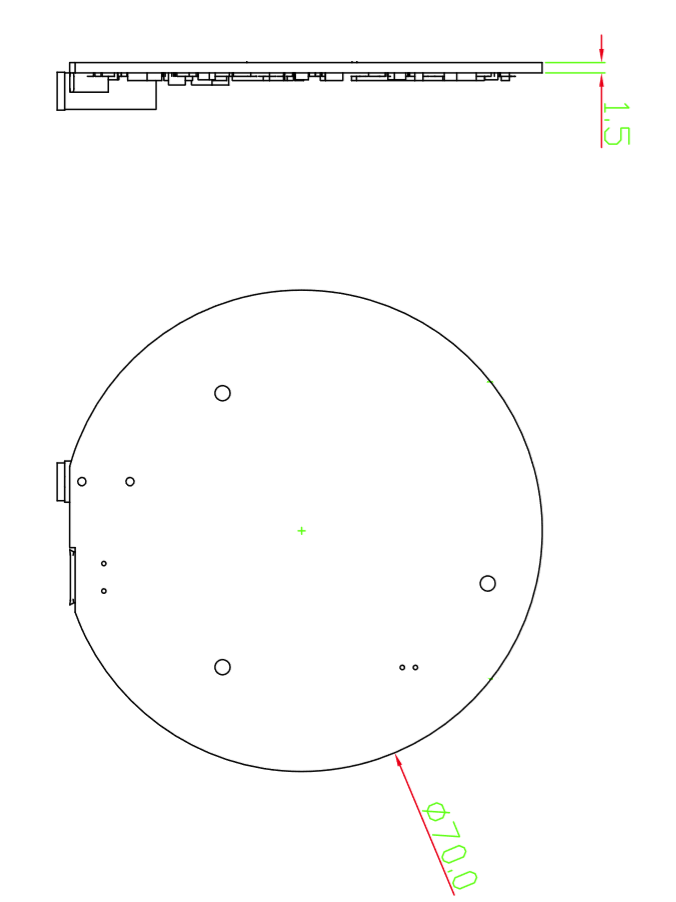
アプリケーション
- USB音声キャプチャ
- スマートスピーカー
- インテリジェント音声アシスタントシステム
- ボイスレコーダー
- 音声会議システム
- 会議通信機器
- 音声対話ロボット
- 車載音声アシスタント
- その他の音声インターフェースシナリオ
はじめに
ReSpeaker Mic Array v3.0は、Windows、Mac、Linuxシステム、Androidと互換性があります。以下のスクリプトはPython2.7でテストされています。
Androidについては、Raspberry上のemteria.OS(Android 7.1)でテストしました。マイクアレイv3.0をRaspberry PiのUSBポートに接続し、ReSpeakerマイクアレイv3.0をオーディオデバイスとして選択しました。以下は音声録音画面です。

以下は音声再生画面です。ReSpeakerマイクアレイv3.0の3.5mmオーディオジャックにスピーカーを接続し、録音した音声を聞くことができます。

ファームウェアの更新
2つのファームウェアがあります。1つは1チャンネルデータを含み、もう1つは6チャンネルデータを含みます(工場出荷時ファームウェア)。以下は違いの表です。
| ファームウェア | チャンネル | 注記 |
|---|---|---|
| 1_channel_firmware.bin | 1 | ASR用の処理済みオーディオ |
| 6_channels_firmware.bin | 6 | チャンネル0: ASR用の処理済みオーディオ チャンネル1: mic1生データ チャンネル2: mic2生データ チャンネル3: mic3生データ チャンネル4: mic4生データ チャンネル5: 統合再生 |
Linux用: マイクアレイはUSB DFUをサポートしています。USBを通じてファームウェアを更新するためのPythonスクリプトdfu.pyを開発しました。
sudo apt-get update
sudo pip install pyusb click
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
sudo python dfu.py --download MicArrayV3_firmware/6_channels_dfu_4.0.0_firmware.bin # The 6 channels version
# if you want to use 1 channel,then the command should be like:
sudo python dfu.py --download MicArrayV3_firmware/1_channel_dfu_4.0.0_firmware.bin
Windows/Mac用: Windows/MacとLinux仮想マシンを使用してファームウェアを更新することはお勧めしません。
開封デモ
以下は6チャンネルファームウェアを使用したアコースティックエコーキャンセレーション例です。
- ステップ1. USBケーブルをPCに接続し、オーディオジャックをスピーカーに接続します。

- ステップ2. PC側でマイクアレイv3.0を出力デバイスとして選択します。
- ステップ3. Audacityを起動して録音を開始します。
- ステップ4. まずPC側で音楽を再生し、その後話します。
- ステップ5. 以下のようなAudacity画面が表示されます。各チャンネルの音声を聞くにはSoloをクリックしてください。

チャンネル0音声(アルゴリズムで処理済み):
チャンネル1音声(Mic1生データ):
チャンネル5音声(再生データ):
以下はDOAとAECに関するビデオです。
DFUとLED制御ドライバーのインストール
- Windows: 音声録音と再生はデフォルトで正常に動作します。Libusb-win32ドライバーは、WindowsでLEDとDSPパラメータを制御するためにのみ必要です。便利なツール - Zadigを使用して、
SEEED DFUとSEEED Controlの両方にlibusb-win32ドライバーをインストールします(ReSpeaker Mic ArrayはWindowsデバイスマネージャーに2つのデバイスとして表示されます)。

libusb-win32が選択されていることを確認してください。WinUSBやlibusbKではありません。
- MAC: ドライバーは不要です。
- Linux: ドライバーは不要です。
チューニング
Linux/Mac/Windows用: 内蔵アルゴリズムのいくつかのパラメータを設定できます。
- 全パラメータリストを取得するには、詳細についてはFAQを参照してください。
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
python tuning.py -p
- 例#1、自動ゲイン制御(AGC)をオフにすることができます:
python tuning.py AGCONOFF 0
- 例#2、DOA角度を確認できます。
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
LEDの制御
USBを通じてReSpeaker Mic Array V2のLEDを制御することができます。USBデバイスにはVendor Specific Class Interfaceがあり、USB Control Transferを通じてデータを送信するために使用できます。私たちはpyusb python libraryを参考にして、usb_pixel_ring python libraryを開発しました。
LED制御コマンドはpyusbのusb.core.Device.ctrl_transfer()によって送信され、そのパラメータは以下の通りです:
ctrl_transfer(usb.util.CTRL_OUT | usb.util.CTRL_TYPE_VENDOR | usb.util.CTRL_RECIPIENT_DEVICE, 0, command, 0x1C, data, TIMEOUT)
usb_pixel_ring APIの一覧です。
| Command | Data | API | Note |
|---|---|---|---|
| 0 | [0] | pixel_ring.trace() | トレースモード、LEDの変化はVADとDOAに依存 |
| 1 | [red, green, blue, 0] | pixel_ring.mono() | モノモード、すべてのRGB LEDを単一色に設定、例:赤(0xFF0000)、緑(0x00FF00)、青(0x0000FF) |
| 2 | [0] | pixel_ring.listen() | リッスンモード、トレースモードと似ているが、LEDをオフにしない |
| 3 | [0] | pixel_ring.speak() | 待機モード |
| 4 | [0] | pixel_ring.think() | スピークモード |
| 5 | [0] | pixel_ring.spin() | スピンモード |
| 6 | [r, g, b, 0] * 12 | pixel_ring.custimize() | カスタムモード、各LEDを独自の色に設定 |
| 0x20 | [brightness] | pixel_ring.set_brightness() | 明度設定、範囲:0x00~0x1F |
| 0x21 | [r1, g1, b1, 0, r2, g2, b2, 0] | pixel_ring.set_color_palette() | カラーパレット設定、例:pixel_ring.set_color_palette(0xff0000, 0x00ff00)をpixel_ring.think()と組み合わせて使用 |
| 0x22 | [vad_led] | pixel_ring.set_vad_led() | 中央LED設定:0 - オフ、1 - オン、その他 - VADに依存 |
| 0x23 | [volume] | pixel_ring.set_volume() | ボリューム表示、範囲:0 ~ 12 |
| 0x24 | [pattern] | pixel_ring.change_pattern() | パターン設定、0 - Google Homeパターン、その他 - Echoパターン |
Linux用: LEDを制御する例です。以下のコマンドに従ってデモを実行してください。
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring
sudo python setup.py install
sudo python examples/usb_mic_array.py
以下は usb_mic_array.py のコードです。
import time
from pixel_ring import pixel_ring
if __name__ == '__main__':
pixel_ring.change_pattern('echo')
while True:
try:
pixel_ring.wakeup()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.speak()
time.sleep(6)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
time.sleep(1)
Windows/Mac用: LEDを制御する例を以下に示します。
- ステップ1. pixel_ringをダウンロードします。
git clone https://github.com/respeaker/pixel_ring.git
cd pixel_ring/pixel_ring
- ステップ2. 以下のコードで led_control.py を作成し、'python led_control.py' を実行します
from usb_pixel_ring_v2 import PixelRing
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
print dev
if dev:
pixel_ring = PixelRing(dev)
while True:
try:
pixel_ring.wakeup(180)
time.sleep(3)
pixel_ring.listen()
time.sleep(3)
pixel_ring.think()
time.sleep(3)
pixel_ring.set_volume(8)
time.sleep(3)
pixel_ring.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixel_ring.off()
画面に「None」と表示される場合は、libusb-win32ドライバーを再インストールしてください。
DOA(到来方向)
Windows/Mac/Linux用: DOAを表示する例です。緑色のLEDが音声方向のインジケーターです。角度については、ハードウェア概要を参照してください。
- ステップ1. usb_4_mic_arrayをダウンロードします。
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- ステップ 2. usb_4_mic_array フォルダの下に以下のコードで DOA.py を作成し、'python DOA.py' を実行します
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.direction
while True:
try:
print Mic_tuning.direction
time.sleep(1)
except KeyboardInterrupt:
break
- Step 3. We will see the DOA as below.
pi@raspberrypi:~/usb_4_mic_array $ sudo python doa.py
184
183
175
105
104
104
103
VAD (音声アクティビティ検出)
Windows/Mac/Linux用: VADを確認する例を以下に示します。赤色LEDがVADのインジケーターです。
- ステップ1. usb_4_mic_arrayをダウンロードします。
git clone https://github.com/respeaker/usb_4_mic_array.git
cd usb_4_mic_array
- ステップ 2. usb_4_mic_array フォルダの下に以下のコードで VAD.py を作成し、'python VAD.py' を実行します
from tuning import Tuning
import usb.core
import usb.util
import time
dev = usb.core.find(idVendor=0x2886, idProduct=0x0018)
#print dev
if dev:
Mic_tuning = Tuning(dev)
print Mic_tuning.is_voice()
while True:
try:
print Mic_tuning.is_voice()
time.sleep(1)
except KeyboardInterrupt:
break
- ステップ3. 以下のようにDOAが表示されます。
pi@raspberrypi:~/usb_4_mic_array $ sudo python VAD.py
0
0
0
1
0
1
0
VADの閾値については、GAMMAVAD_SRを使用して設定することもできます。詳細についてはTuningを参照してください。
音声の抽出
USB経由で音声を抽出するためにPyAudio pythonライブラリを使用します。
Linux向け: 以下のコマンドを使用して音声を録音または再生できます。
arecord -D plughw:1,0 -f cd test.wav # record, please use the arecord -l to check the card and hardware first
aplay -D plughw:1,0 -f cd test.wav # play, please use the aplay -l to check the card and hardware first
arecord -D plughw:1,0 -f cd |aplay -D plughw:1,0 -f cd # record and play at the same time
また、Pythonスクリプトを使用して音声を抽出することもできます。
- ステップ1、以下のスクリプトを実行してMic Arrayのデバイスインデックス番号を取得する必要があります:
sudo pip install pyaudio
cd ~
nano get_index.py
- ステップ2、以下のコードをコピーしてget_index.pyに貼り付けます。
Python 3を使用している場合は、このファイルが使用に適しています get_index.py
import pyaudio
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
numdevices = info.get('deviceCount')
for i in range(0, numdevices):
if (p.get_device_info_by_host_api_device_index(0, i).get('maxInputChannels')) > 0:
print "Input Device id ", i, " - ", p.get_device_info_by_host_api_device_index(0, i).get('name')
-
ステップ3、
Ctrl+Xを押して終了し、Y を押して保存します。 -
ステップ4、'sudo python get_index.py' を実行すると、以下のようにデバイスIDが表示されます。
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0): USB Audio (hw:1,0)
- ステップ5、
RESPEAKER_INDEX = 2をインデックス番号に変更します。Pythonスクリプト record.py を実行して音声を録音します。
import pyaudio
import wave
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 2 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(RESPEAKER_CHANNELS)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
- ステップ6. 6チャンネルからチャンネル0のデータを抽出したい場合は、以下のコードに従ってください。他のチャンネルXについては、[0::6]を[X::6]に変更してください。
import pyaudio
import wave
import numpy as np
RESPEAKER_RATE = 16000
RESPEAKER_CHANNELS = 6 # change base on firmwares, 1_channel_firmware.bin as 1 or 6_channels_firmware.bin as 6
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 3 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 3
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
# extract channel 0 data from 6 channels, if you want to extract channel 1, please change to [1::6]
a = np.fromstring(data,dtype=np.int16)[0::6]
frames.append(a.tostring())
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
For Windows:
- Step 1. We run below command to install pyaudio.
pip install pyaudio
- ステップ 2. get_index.py を使用してデバイスインデックスを取得します。
C:\Users\XXX\Desktop>python get_index.py
Input Device id 0 - Microsoft Sound Mapper - Input
Input Device id 1 - ReSpeaker 4 Mic Array (UAC1.0)
Input Device id 2 - Internal Microphone (Conexant I)
- ステップ3. record.pyのデバイスインデックスとチャンネルを変更し、音声を抽出します。
C:\Users\XXX\Desktop>python record.py
* recording
* done recording
「Error: %1 is not a valid Win32 application.」が表示される場合は、Python Win32版をインストールしてください。
MAC の場合:
- Step 1. 以下のコマンドを実行して pyaudio をインストールします。
pip install pyaudio
- ステップ 2. get_index.py を使用してデバイスインデックスを取得します。
MacBook-Air:Desktop XXX$ python get_index.py
Input Device id 0 - Built-in Microphone
Input Device id 2 - ReSpeaker 4 Mic Array (UAC1.0)
- ステップ3. record.pyのデバイスインデックスとチャンネルを変更し、音声を抽出します。
MacBook-Air:Desktop XXX$ python record.py
2018-03-24 14:53:02.400 Python[2360:16629] 14:53:02.399 WARNING: 140: This application, or a library it uses, is using the deprecated Carbon Component Manager for hosting Audio Units. Support for this will be removed in a future release. Also, this makes the host incompatible with version 3 audio units. Please transition to the API's in AudioComponent.h.
* recording
* done recording
FAQ
Q1: Parameters of built-in algorithms
pi@raspberrypi:~/usb_4_mic_array $ python tuning.py -p
name type max min r/w info
-------------------------------
AECFREEZEONOFF int 1 0 rw Adaptive Echo Canceler updates inhibit.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
AECNORM float 16 0.25 rw Limit on norm of AEC filter coefficients
AECPATHCHANGE int 1 0 ro AEC Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
AECSILENCELEVEL float 1 1e-09 rw Threshold for signal detection in AEC [-inf .. 0] dBov (Default: -80dBov = 10log10(1x10-8))
AECSILENCEMODE int 1 0 ro AEC far-end silence detection status.
0 = false (signal detected)
1 = true (silence detected)
AGCDESIREDLEVEL float 0.99 1e-08 rw Target power level of the output signal.
[−inf .. 0] dBov (default: −23dBov = 10log10(0.005))
AGCGAIN float 1000 1 rw Current AGC gain factor.
[0 .. 60] dB (default: 0.0dB = 20log10(1.0))
AGCMAXGAIN float 1000 1 rw Maximum AGC gain factor.
[0 .. 60] dB (default 30dB = 20log10(31.6))
AGCONOFF int 1 0 rw Automatic Gain Control.
0 = OFF
1 = ON
AGCTIME float 1 0.1 rw Ramps-up / down time-constant in seconds.
CNIONOFF int 1 0 rw Comfort Noise Insertion.
0 = OFF
1 = ON
DOAANGLE int 359 0 ro DOA angle. Current value. Orientation depends on build configuration.
ECHOONOFF int 1 0 rw Echo suppression.
0 = OFF
1 = ON
FREEZEONOFF int 1 0 rw Adaptive beamformer updates.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
FSBPATHCHANGE int 1 0 ro FSB Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
FSBUPDATED int 1 0 ro FSB Update Decision.
0 = false (FSB was not updated)
1 = true (FSB was updated)
GAMMAVAD_SR float 1000 0 rw Set the threshold for voice activity detection.
[−inf .. 60] dB (default: 3.5dB 20log10(1.5))
GAMMA_E float 3 0 rw Over-subtraction factor of echo (direct and early components). min .. max attenuation
GAMMA_ENL float 5 0 rw Over-subtraction factor of non-linear echo. min .. max attenuation
GAMMA_ETAIL float 3 0 rw Over-subtraction factor of echo (tail components). min .. max attenuation
GAMMA_NN float 3 0 rw Over-subtraction factor of non- stationary noise. min .. max attenuation
GAMMA_NN_SR float 3 0 rw Over-subtraction factor of non-stationary noise for ASR.
[0.0 .. 3.0] (default: 1.1)
GAMMA_NS float 3 0 rw Over-subtraction factor of stationary noise. min .. max attenuation
GAMMA_NS_SR float 3 0 rw Over-subtraction factor of stationary noise for ASR.
[0.0 .. 3.0] (default: 1.0)
HPFONOFF int 3 0 rw High-pass Filter on microphone signals.
0 = OFF
1 = ON - 70 Hz cut-off
2 = ON - 125 Hz cut-off
3 = ON - 180 Hz cut-off
MIN_NN float 1 0 rw Gain-floor for non-stationary noise suppression.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NN_SR float 1 0 rw Gain-floor for non-stationary noise suppression for ASR.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NS float 1 0 rw Gain-floor for stationary noise suppression.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
MIN_NS_SR float 1 0 rw Gain-floor for stationary noise suppression for ASR.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
NLAEC_MODE int 2 0 rw Non-Linear AEC training mode.
0 = OFF
1 = ON - phase 1
2 = ON - phase 2
NLATTENONOFF int 1 0 rw Non-Linear echo attenuation.
0 = OFF
1 = ON
NONSTATNOISEONOFF int 1 0 rw Non-stationary noise suppression.
0 = OFF
1 = ON
NONSTATNOISEONOFF_SR int 1 0 rw Non-stationary noise suppression for ASR.
0 = OFF
1 = ON
RT60 float 0.9 0.25 ro Current RT60 estimate in seconds
RT60ONOFF int 1 0 rw RT60 Estimation for AES. 0 = OFF 1 = ON
SPEECHDETECTED int 1 0 ro Speech detection status.
0 = false (no speech detected)
1 = true (speech detected)
STATNOISEONOFF int 1 0 rw Stationary noise suppression.
0 = OFF
1 = ON
STATNOISEONOFF_SR int 1 0 rw Stationary noise suppression for ASR.
0 = OFF
1 = ON
TRANSIENTONOFF int 1 0 rw Transient echo suppression.
0 = OFF
1 = ON
VOICEACTIVITY int 1 0 ro VAD voice activity status.
0 = false (no voice activity)
1 = true (voice activity)
Q2: ImportError: No module named usb.core
A2: Run sudo pip install pyusb to install the pyusb.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
Traceback (most recent call last):
File "tuning.py", line 5, in <module>
import usb.core
ImportError: No module named usb.core
pi@raspberrypi:~/usb_4_mic_array $ sudo pip install pyusb
Collecting pyusb
Downloading pyusb-1.0.2.tar.gz (54kB)
100% |████████████████████████████████| 61kB 101kB/s
Building wheels for collected packages: pyusb
Running setup.py bdist_wheel for pyusb ... done
Stored in directory: /root/.cache/pip/wheels/8b/7f/fe/baf08bc0dac02ba17f3c9120f5dd1cf74aec4c54463bc85cf9
Successfully built pyusb
Installing collected packages: pyusb
Successfully installed pyusb-1.0.2
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180
Q3: Raspberry alexa アプリケーションの例はありますか?
A3: はい、mic array v3.0 を raspberry の USB ポートに接続し、Raspberry Pi Quick Start Guide with Script に従って alexa との音声対話を行うことができます。
Q4: Mic array v3.0 と ROS システムの例はありますか?
A4: はい、Yuki が ReSpeaker Mic Array v2 と ROS (Robot Operating System) Middleware の統合 パッケージを共有してくれています。
Q5: 3.5mm オーディオポートで USB ポートと同様に信号を受信できるようにするにはどうすればよいですか?
A5: 新しいファームウェア をダウンロードし、ファームウェアの更新方法 に従って XMOS を書き込んでください。
リソース
- [PDF] ReSpeaker MicArray v3.0 回路図
- [PDF] ReSpeaker MicArray v3.0 製品概要
- [PDF] ReSpeaker MicArray v3.0 3D モデル
- [SKP] ReSpeaker MicArray v3.0 3D モデル
- [STP] ReSpeaker MicArray v3.0 3D モデル
- [PDF] XVF3000 製品概要
- [PDF] XVF3000 データシート
- [Github] ReSpeaker Mic Array v2 と ROS (Robot Operating System) Middleware
技術サポートと製品ディスカッション
弊社製品をお選びいただきありがとうございます!弊社製品での体験ができる限りスムーズになるよう、さまざまなサポートを提供いたします。さまざまな好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。