reSpeaker XVF3800 と Edge Impulse を用いた TinyML 音声認識
概要
TinyML を用いたキーワードスポッティング(KWS)システムにより、リアルタイムの音声コマンド検出でハンズフリー操作を実現します。高性能な ReSpeaker XVF3800 マイクアレイと高効率な XIAO ESP32S3、そして Edge Impulse プラットフォームを組み合わせることで、小型・低消費電力デバイスに音声認識機能をもたらします。学習、デプロイ、そしてリッスン——あなたのデバイスは常に次のコマンドを待ち受けます。
必要なハードウェア

データ収集
XIAO ESP32S3 搭載 ReSpeaker XVF3800 用 USB ファームウェアのインストール
オーディオデータの収集を開始する前に、ReSpeaker に USB ファームウェアを書き込み、USB マイクとして動作できるようにしておきます。
Python 環境のセットアップ
次に、音声データを収集するために、ノート PC またはデスクトップ PC 上に python 環境を構築する必要があります。ここでは respeaker-env を作成します。
python -m venv respeaker-env
source respeaker-env/bin/activate
必要なライブラリをインストールします:
pip install sounddevice scipy numpy
ReSpeaker デバイス ID の確認
正しいマイク入力から録音するために、ReSpeaker マイクのデバイスインデックスを特定する必要があります。
import sounddevice as sd
devices = sd.query_devices()
for i, device in enumerate(devices):
print(f"Device {i}: {device['name']} (input channels: {device['max_input_channels']})")
ReSpeaker に対応するデバイス名(ReSpeaker XVF3800 USB 4-Mic Array などの名称)を探し、そのインデックス番号(例:Device 2)をメモしておきます。
音声サンプルの録音
次のスクリプトを使用すると、人物とコマンド/キーワードごとに整理されたラベル付き音声サンプルを録音できます。
import os
import sounddevice as sd
from scipy.io.wavfile import write
# === Settings ===
SAMPLERATE = 16000
CHANNELS = 1 # Mono input
DURATION = 10 # seconds
DEVICE_INDEX = 2 # Replace with correct device index
def record_audio(filename, samplerate=SAMPLERATE, channels=CHANNELS, duration=DURATION, device=DEVICE_INDEX):
print(f"Recording '{filename}' for {duration} seconds...")
recording = sd.rec(int(duration * samplerate),
samplerate=samplerate,
channels=channels,
dtype='int32',
device=device)
sd.wait()
write(filename, samplerate, recording)
print(f"Saved: {filename}")
def get_next_filename(directory, label):
existing = [f for f in os.listdir(directory) if f.startswith(label) and f.endswith('.wav')]
index = len(existing) + 1
return os.path.join(directory, f"{label}.{index}.wav")
def collect_samples():
while True:
sample_name = input("Enter sample name (e.g., PersonA): ").strip()
if not sample_name:
print("Sample name cannot be empty.")
continue
sample_dir = os.path.join(os.getcwd(), sample_name)
os.makedirs(sample_dir, exist_ok=True)
print(f"Directory created: {sample_dir}")
while True:
label = input("Enter sound/voice to record (e.g., yes, no): ").strip()
if not label:
print("Label cannot be empty.")
continue
while True:
filename = get_next_filename(sample_dir, label)
record_audio(filename)
cont = input("Record another sample for this label? (yes/no): ").strip().lower()
if cont != 'yes':
break
next_label = input("Do you want to record a different label? (yes/no): ").strip().lower()
if next_label != 'yes':
break
next_sample = input("Do you want to create a new sample? (yes/no): ").strip().lower()
if next_sample != 'yes':
print("Audio collection completed.")
break
if __name__ == "__main__":
collect_samples()
フォルダ構成の例
/PersonA
├── red.1.wav
├── red.2.wav
├── blue.1.wav
└── blue.2.wav
/PersonB
├── red.1.wav
└── green.1.wav
各人物のフォルダにはラベル付きの .wav ファイルが含まれており、後で Edge Impulse にアップロードしてモデル学習に使用します。
Edge Impulse への音声データのアップロードと準備
ReSpeaker XVF3800 を使って生の音声サンプルを収集し、ラベルごとに整理したら、次のステップとして、それらを Edge Impulse Studio にアップロードし、キーワードスポッティングモデルの学習用に処理します。
Edge Impulse で新しいプロジェクトを作成
-
Edge Impulse にアクセスし、ログインします(初めての場合はサインアップします)。
-
"Create new project" をクリックします。
-
プロジェクト名を入力します(例:"Voice Command KWS")。
既存の音声サンプルをアップロード
収集したデータをアップロードするには:
- 1.Data Acquisition タブに移動します。
- 2.右上の "Upload existing data" をクリックします。
- 3.フォルダ内の .wav ファイルを選択してアップロードします。
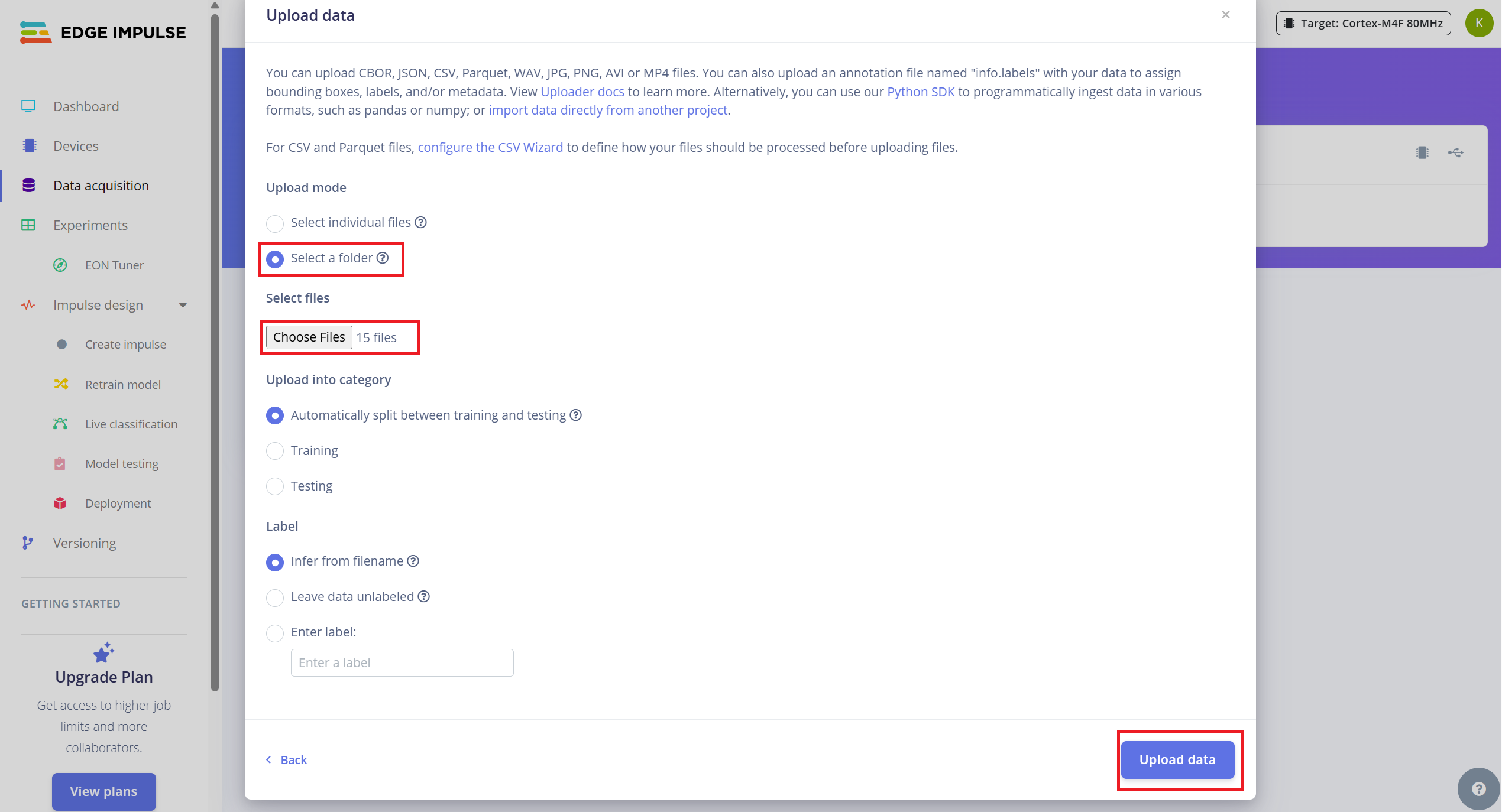
- 4.データを自動的に学習用とテスト用に分割するオプションを有効にします(Edge Impulse ではおよそ 80/20 の分割を推奨しています)。
10 秒の音声を 1 秒サンプルに分割
Edge Impulse は、キーワードスポッティングにおいて 1 秒の音声クリップで最も良く動作します。元のサンプルは 10 秒単位で録音されているため、それぞれを複数の 1 秒サンプルに分割する必要があります。
次の手順に従います:
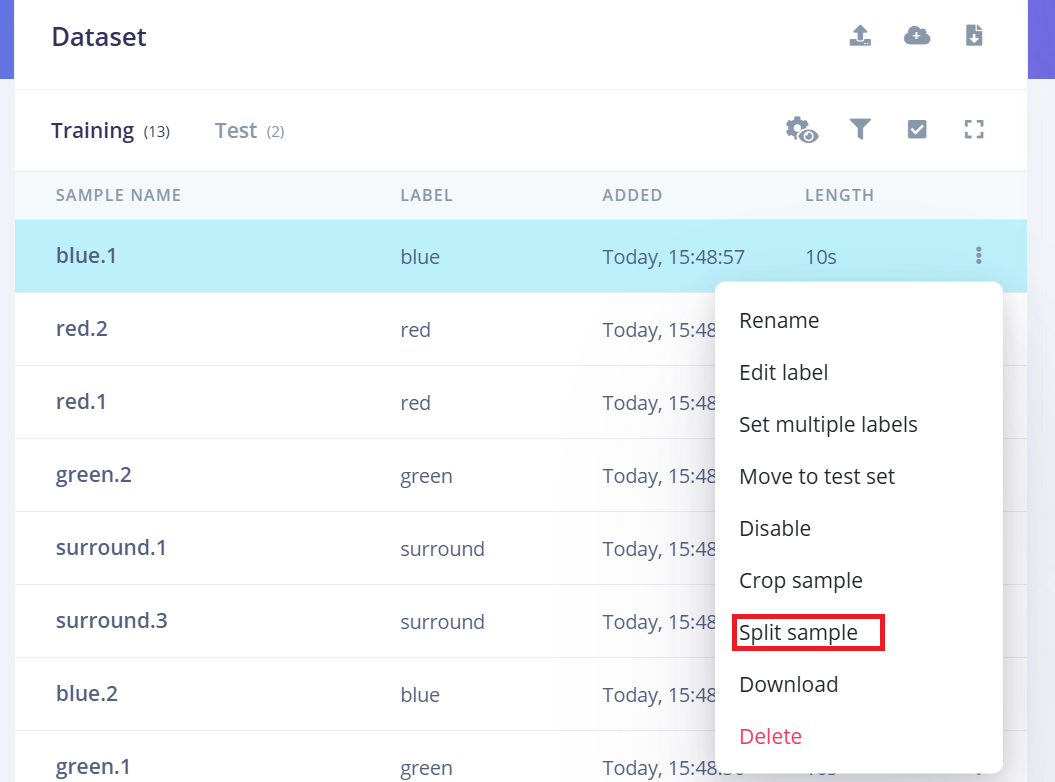
- 1.アップロード後、Data Acquisition ページに移動します。
- 2.サンプル(例:yes.1.wav)を見つけ、そのサンプルの横にある 三つの点(…) をクリックします。
- 3.メニューから "Split sample" を選択します。
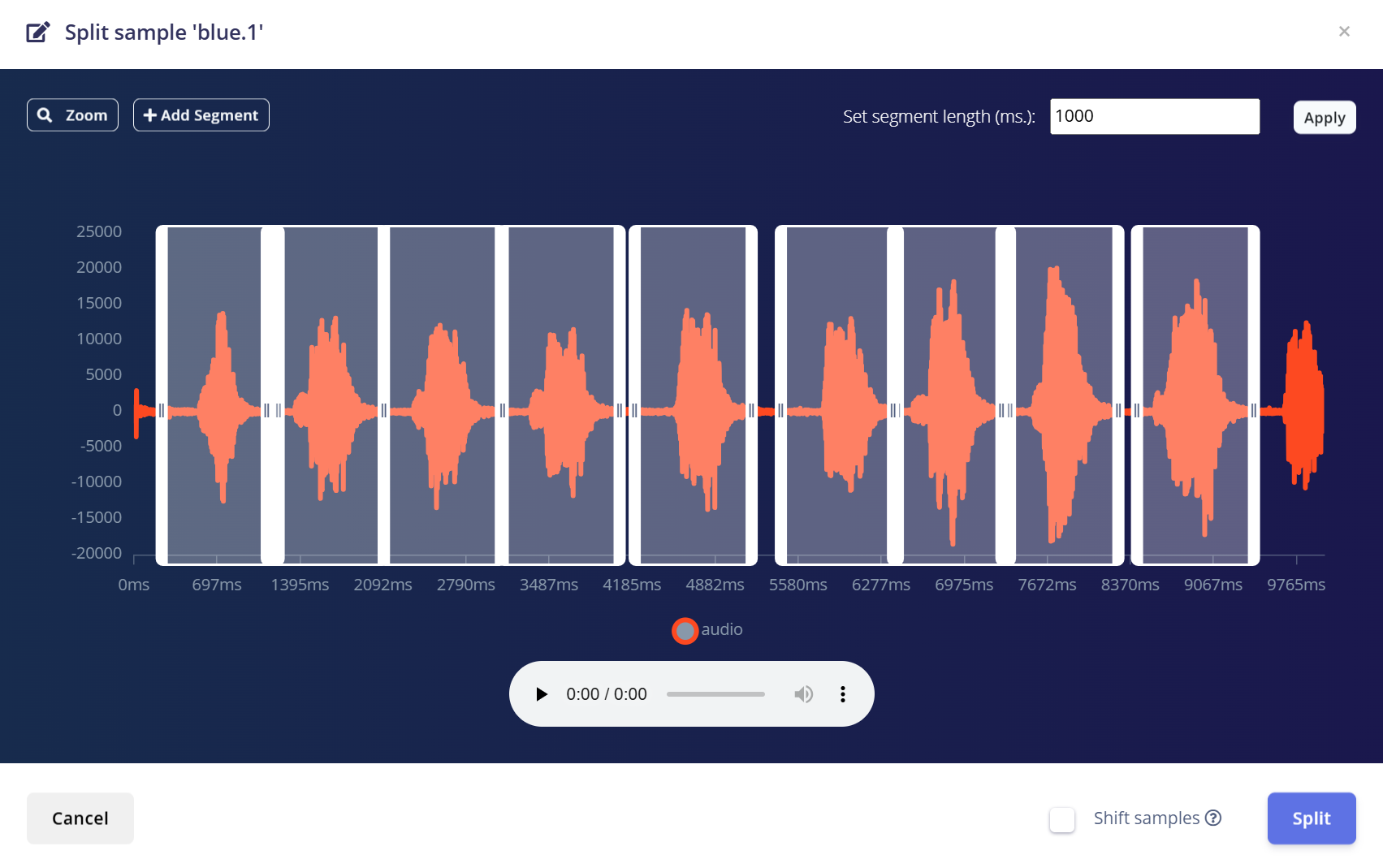
- 4.ツールを使って波形を 1 秒セグメントに分割します。
- a.ドラッグしてセグメントを調整したり、必要に応じて追加/削除することができます。
- 5.Save and Split をクリックします。
この処理を、すべてのクラスのすべての 10 秒サンプル(学習用・テスト用の両方)に対して繰り返します。
これにより、データセットが適切な形式に整えられ、高精度なモデルを学習するために最適化されます。
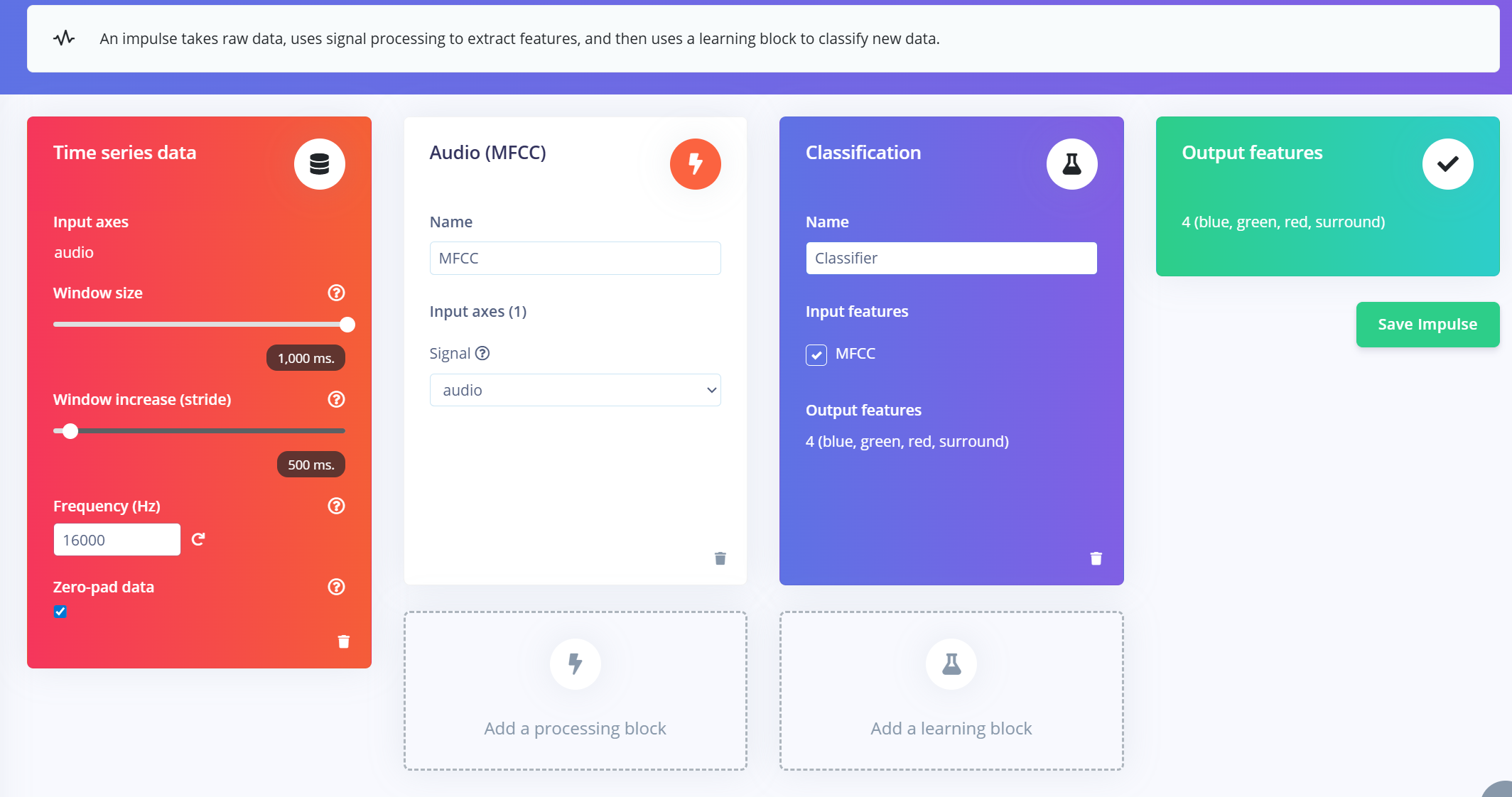
Impulse の作成(前処理 / モデル定義)
Edge Impulse における impulse とは、生データを学習済み機械学習モデルへと変換するエンドツーエンドのパイプラインを定義するものです。これには、信号処理、特徴抽出、そして分類のための 学習ブロック が含まれます。
Impulse を作成
- 1.Edge Impulse プロジェクト内の "Impulse Design" タブに移動します。
- 2.“Create Impulse” をクリックします。
- 3.入力ウィンドウを設定します:
- a.Window size: 1000 ms(1 秒)
- b.Window increase: 500 ms(データ拡張のためのオーバーラップウィンドウ)
- c."Zero-pad data" を有効化:これは、特にサンプル分割時にノイズトリミングが適用される場合に、800ms などの短いセグメントをゼロでパディングするのに役立ちます。
MFCC 特徴抽出器を追加
Impulse ウィンドウを作成したら:
- 1.“Add a processing block” をクリックし、MFCC (Mel Frequency Cepstral Coefficients) を選択します。
- a.MFCC は、音声信号を音声の周波数パターンを表す 2D 特徴に変換するために広く用いられている手法です。
- b.これらの特徴は、音声ベースの認識モデルに最適です。
- 2.MFCC パラメータを設定します(ほとんどの場合、デフォルトで問題ありません):
- a.Output shape: 13 x 49 x 1
- b.これにより、音声クリップが分類用の「画像」に変換されます。
学習ブロックを追加
- 1.“Add a learning block” をクリックし、“Classification (Keras)” を選択します。
- 2.これにより、MFCC 特徴に対して 画像分類 を行うカスタム 畳み込みニューラルネットワーク(CNN) が作成されます。
- 3.その後、NN Classifier タブに進み、モデルのカスタマイズと学習を行うことができます。
前処理(MFCC)
次のステップは、録音した音声からスペクトログラム画像を生成し、モデル学習に使用することです。デフォルトの DSP パラメータを使用することもできますが、本プロジェクトでは DSP Autotune 機能を活用し、より良い性能が得られるようパラメータを自動最適化します。
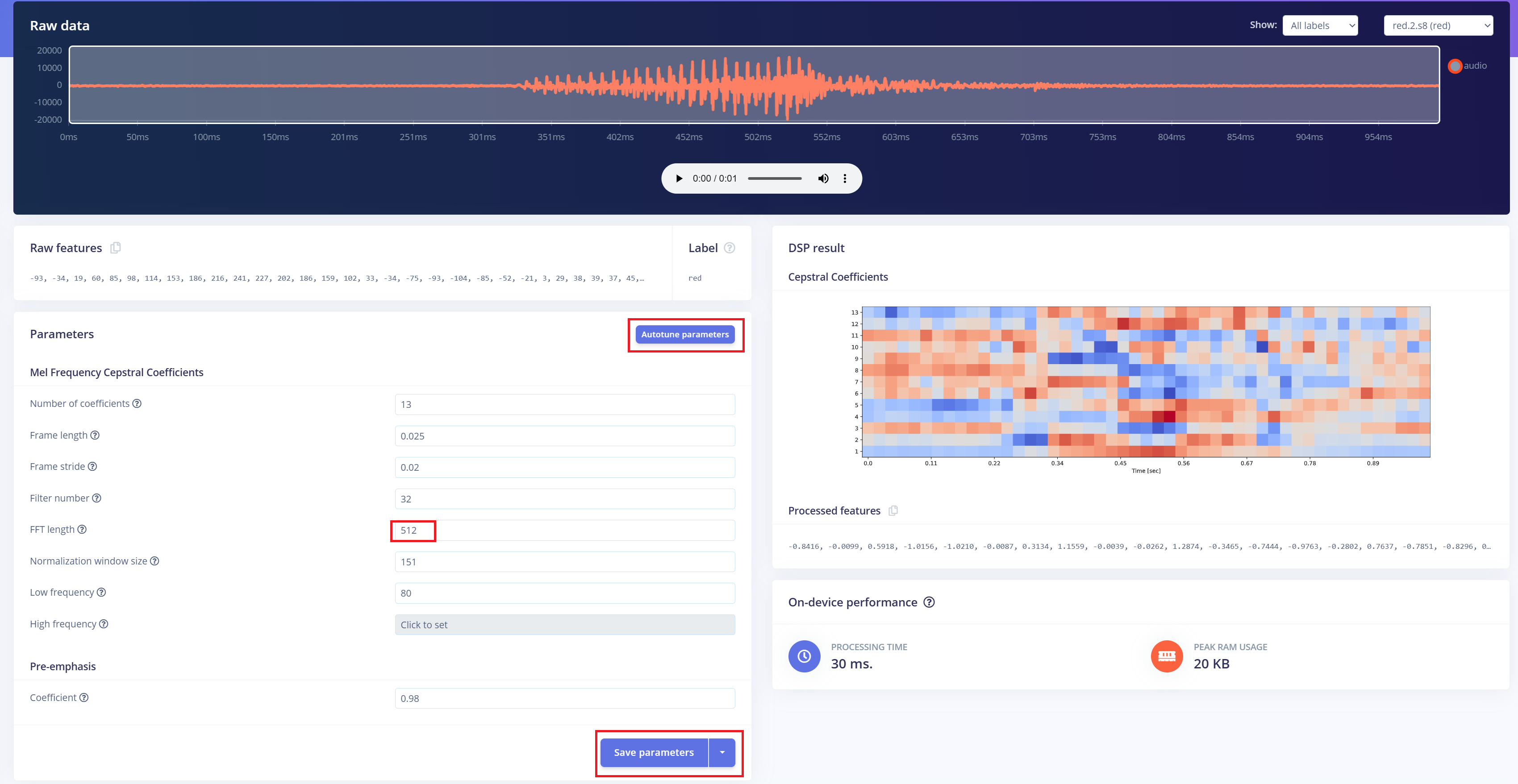
機械学習モデルの構築
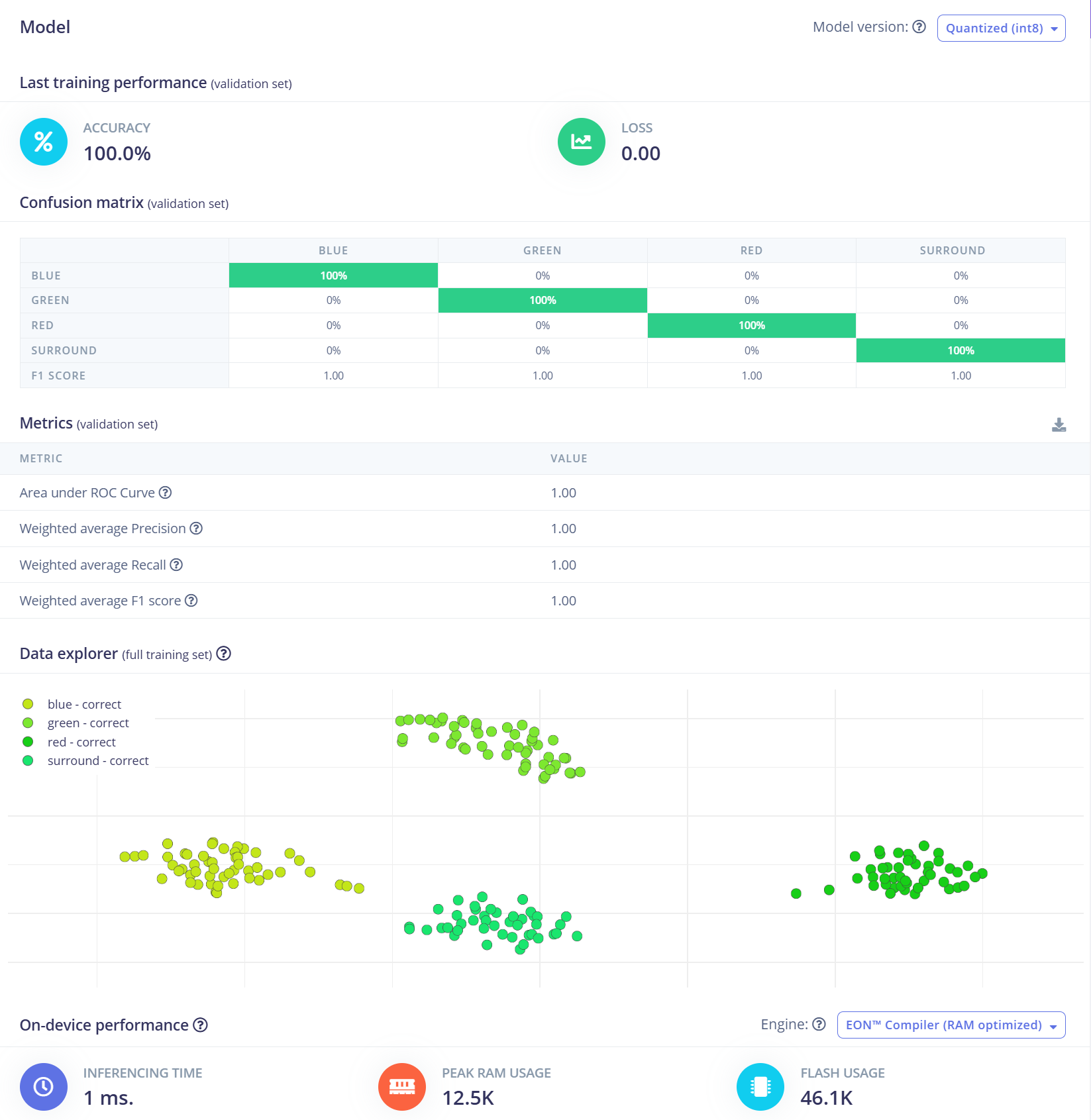
このプロジェクトでは、畳み込みニューラルネットワーク(CNN)モデルを使用します。アーキテクチャは、8 フィルタと 16 フィルタを持つ 2 つの Conv1D + MaxPooling レイヤーに続き、0.25 の Dropout レイヤーで構成されています。Flatten の後、最終の全結合レイヤーには 4 つのニューロンがあり、それぞれが 1 クラスを表します。 学習率 0.005、エポック数 100 でモデルを学習します。汎化性能とロバスト性を高めるために、背景ノイズなどのデータ拡張手法を適用します。初期結果は有望です。
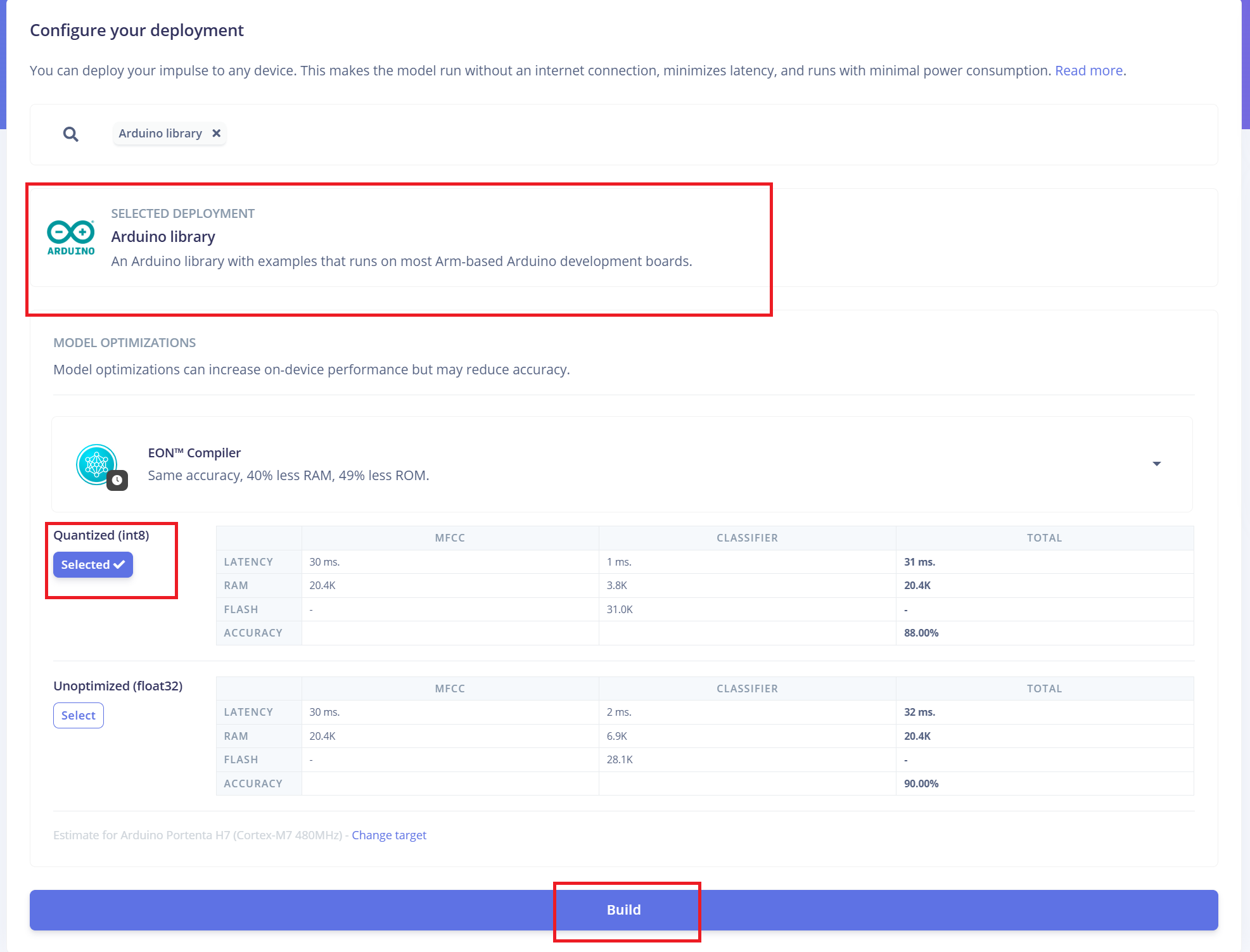
XIAO ESP32 S3 搭載 ReSpeaker XVF3800 へのデプロイ
Edge Impulse は、必要なすべてのライブラリ、前処理関数、および学習済みモデルを自動的に 1 つのダウンロード可能なパッケージにまとめます。 続行するには:
- 1.デプロイオプションとして "Arduino Library" を選択します。
- 2.下部で "Quantized (Int8)" フォーマットを選択します。
- 3.ライブラリを生成するために "Build" をクリックします。
ダウンロードが完了したら:
- 4.Arduino IDE を開き、Sketch メニューに移動します。
- 5."Include Library" > "Add .ZIP Library..." を選択します。
- 6.Edge Impulse からダウンロードした .zip ファイルを選択し、Arduino プロジェクトに追加します。
ファームウェアを I2S モードに切り替える
Arduino コードを書き込む前に、I2C プロトコル経由で通信できるように、ReSpeaker XVF3800 のファームウェアを I2S モードに切り替える必要があります。 Firmware Installation Guide
Arduino コードの統合
Edge Impulse が提供する Arduino コードは、ReSpeaker XVF3800 と XIAO ESP32S3 ハードウェアとの互換性を確保するために、いくつかの修正が必要になります。セットアップに応じて、GPIO ピン定義、I2S サンプリングレート、その他のハードウェア固有パラメータを更新してください。
#define EIDSP_QUANTIZE_FILTERBANK 0
#include <Kasun9603-project-1_inferencing.h> // Change with your one
#include "driver/i2s.h"
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
// ==== AUDIO CONFIG ====
#define I2S_PORT I2S_NUM_0
#define I2S_WS 7 // L/R clock
#define I2S_SD 43 // Serial Data In
#define I2S_SCK 8 // Bit Clock
#define SAMPLE_RATE 16000
#define I2S_SAMPLE_BITS 32
#define SAMPLE_BUFFER_SIZE 2048
// ==== INFERENCE STATE ====
typedef struct {
int16_t *buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static int32_t i2s_samples[SAMPLE_BUFFER_SIZE];
static bool record_status = true;
static bool debug_nn = false;
// ==== FUNCTION DECLARATIONS ====
static bool microphone_inference_start(uint32_t n_samples);
static bool microphone_inference_record(void);
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr);
static void audio_inference_callback(uint32_t n_bytes);
static void capture_samples(void *arg);
static int i2s_init();
static void i2s_deinit();
void setup() {
Serial.begin(115200);
while (!Serial);
ei_printf("XVF3800 Keyword Spotting Inference Start\n");
ei_printf("Model info:\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / (SAMPLE_RATE / 1000));
ei_printf("\tInterval: %.2f ms\n", EI_CLASSIFIER_INTERVAL_MS);
if (!microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT)) {
ei_printf("ERR: Audio buffer allocation failed.\n");
return;
}
ei_printf("Listening...\n");
}
void loop() {
if (!microphone_inference_record()) {
ei_printf("ERR: Failed to record audio.\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
ei_printf("Predictions:\n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" Anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
// ==== INFERENCE AND AUDIO HANDLING ====
static void audio_inference_callback(uint32_t n_bytes) {
for (uint32_t i = 0; i < n_bytes / sizeof(int32_t); i++) {
int16_t val = i2s_samples[i] >> 16; // Convert from 32-bit signed to 16-bit
inference.buffer[inference.buf_count++] = val;
if (inference.buf_count >= inference.n_samples) {
inference.buf_ready = 1;
inference.buf_count = 0;
}
}
}
static void capture_samples(void *arg) {
size_t bytes_read;
while (record_status) {
i2s_read(I2S_PORT, (char *)i2s_samples, SAMPLE_BUFFER_SIZE * sizeof(int32_t), &bytes_read, portMAX_DELAY);
if (bytes_read > 0) {
audio_inference_callback(bytes_read);
} else {
ei_printf("ERR: I2S read failed\n");
}
}
vTaskDelete(NULL);
}
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if (!inference.buffer) return false;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
if (i2s_init() != 0) {
ei_printf("ERR: I2S init failed\n");
return false;
}
xTaskCreate(capture_samples, "CaptureSamples", 4096, NULL, 1, NULL);
return true;
}
static bool microphone_inference_record(void) {
while (!inference.buf_ready) {
delay(10);
}
inference.buf_ready = 0;
return true;
}
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
static int i2s_init() {
i2s_config_t i2s_config = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = (i2s_bits_per_sample_t)I2S_SAMPLE_BITS,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 512,
.use_apll = false,
.tx_desc_auto_clear = false,
.fixed_mclk = 0
};
i2s_pin_config_t pin_config = {
.bck_io_num = I2S_SCK,
.ws_io_num = I2S_WS,
.data_out_num = -1,
.data_in_num = I2S_SD
};
esp_err_t err;
err = i2s_driver_install(I2S_PORT, &i2s_config, 0, NULL);
if (err != ESP_OK) return err;
err = i2s_set_pin(I2S_PORT, &pin_config);
if (err != ESP_OK) return err;
err = i2s_zero_dma_buffer(I2S_PORT);
return err;
}
static void i2s_deinit() {
i2s_driver_uninstall(I2S_PORT);
}
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます。私たちは、製品をできるだけスムーズにご利用いただけるよう、さまざまなサポートを提供しています。お好みやニーズに応じてお選びいただける、複数のコミュニケーションチャネルをご用意しています。