YOLOv8でカスタム分類モデルを訓練・デプロイする
はじめに
このガイドでは、YOLOv8を使用してカスタム分類モデルを訓練・デプロイする方法を説明します。
概要
YOLOv8をインストールする仮想環境を作成し、roboflowから分類モデルをダウンロードして、それを訓練・デプロイします。
画像分類
画像分類はコンピュータビジョンの最もシンプルなタスクで、画像を事前定義されたクラスの1つに分類することです。 出力として得られるのは、単一のクラスラベルと信頼度スコアです。
画像分類は、画像内のオブジェクトの位置を知る必要がなく、画像がどのクラスに属するかを知るだけで十分な場合に有用です。
必要な材料
ハードウェアセットアップ
このチュートリアルでは、Nvidia Jetson Orin NX 16GBが必要です。

ソフトウェアセットアップ
- reComputerにJetPack 6.0がインストールされていること
- データセットをダウンロードするためのRoboflowアカウント
reComputerの準備
Seeed StudioのreComputer J4012は、Jetson Orin NX 16GBです。 これは強力なマシンですが、Tegra Linuxには多くの機能が含まれており、グラフィカルモードで起動します。これを変更しましょう。
私はVScodeとX転送を有効にしたSSHターミナルを使用して、リモートで例とプログラミングを実行します。 X転送は、リモートコンピュータではなく、接続の私たちの側でいくつかのグラフィカルアプリケーションを実行できるSSHのオプションです。
モニター、キーボード、マウスでreComputerに接続する場合は、次のステップをスキップしてください。
起動モードの変更

これで問題ありませんが、グラフィックスは必要なく、アイドルモードでは約1.5GBのメモリを消費しています。

代わりにコマンドラインで起動するように設定します。
sudo systemctl set-default multi-user
現在、私たちのreComputerは起動時にCLIで起動します。 必要に応じて今すぐ再起動することもできますし、1つのコマンドでCLIに入ることもできます。
sudo systemctl isolate multi-user
1.5GBのメモリ使用量から700MBまで削減できました。機械学習を使用する際は、メモリの1バイトも無駄にできません。
電力モードの変更
デフォルトでは、reComputerはレベル2 - 15Wで動作しているはずです。 MLモデルの訓練や推論を行う際、フルパワーで実行できれば、より良いパフォーマンスが得られるでしょう。
変更方法を学びましょう。
/etc/nvpmodel.confファイルに、利用可能な電力モードが記載されています。
< POWER_MODEL ID=0 NAME=MAXN >
< POWER_MODEL ID=1 NAME=10W >
< POWER_MODEL ID=2 NAME=15W >
< POWER_MODEL ID=3 NAME=25W >
その後、sudo nvpmodel -m <電力モデル番号> を使用して電力モードを変更できます。そして、このスレッドの投稿によると、設定は再起動後も保持されます。
現在どの電力レベルにいるかを確認するには、
sudo nvpmodel -q

モデルの訓練のために最大パワーモードを選択しましょう
sudo nvpmodel -m 0

再起動後、フルパワーで動作していることを確認できます

モデルの訓練
モデルの訓練には、YOLOv8を使用します。以下は、CUDAサポート付きでインストールするために必要な手順です。 また、roboflowアカウントも必要になります。
モデル
鳥を分類するモデルを作成します。 これは、私の庭に設置予定のスマートバードフィーダープロジェクトの一部で、そこで餌を食べている鳥がどのような鳥なのかを知りたいと思っています。
これは分類タスクなので、写真内の鳥の位置を知る必要はありません。
分類データセットまたはモデルである限り、お好みの別のデータセットを使用することもできます
私の地域に住んでいて、私の近くでよく見かける12種類の鳥を調達し、Roboflowで分類データセットを作成しました。
識別しようとしている鳥の種類は以下の通りです:
- ツバメ
- キクイタダキ
- サヨナキドリ
- ズアオアトリ
- イワツバメ
- ゴシキヒワ
- アオカワラヒワ
- セリン
- イエスズメ
- スペインスズメ
- ニシイワツバメ
- ハクセキレイ
データセットを選択し、roboflowからダウンロードしてください。 データセットを選択したら、「Download Dataset」を選択します。- そのためにはアカウントが必要です。
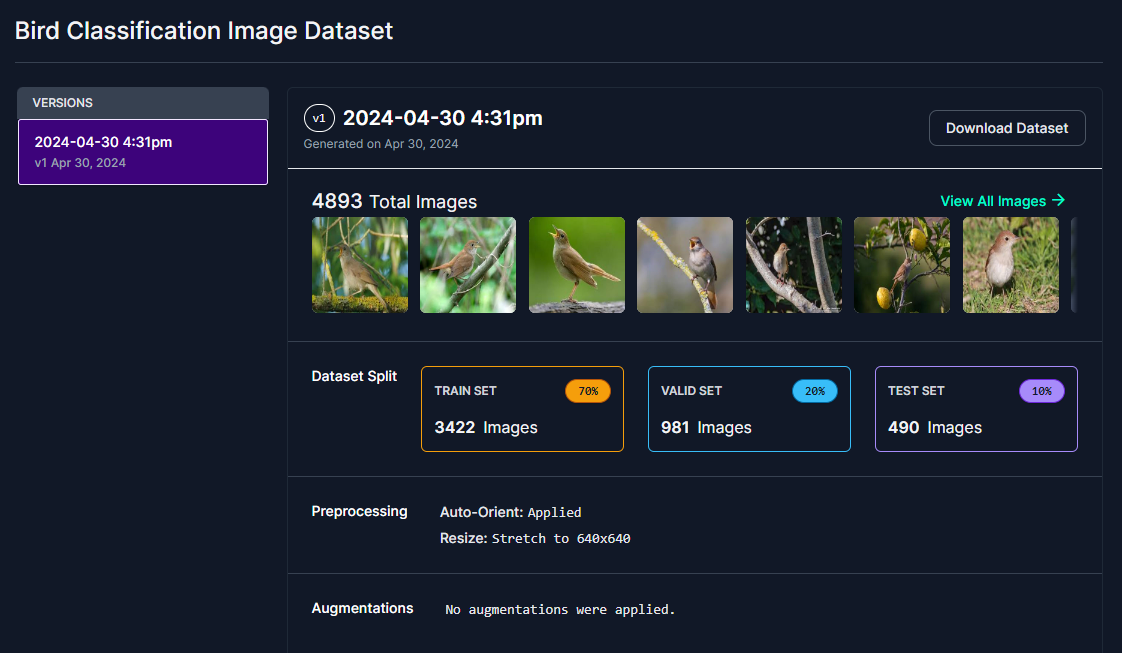
次に、フォーマットでFolder Structureを選択し、show download codeを選択します。
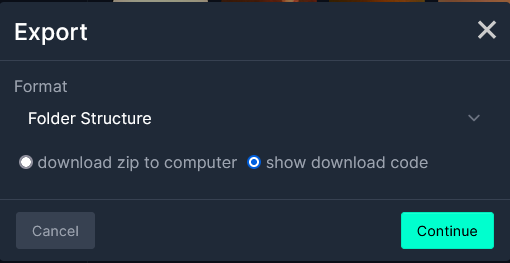
次に、Jupyter Notebookを使用する場合はJupyterを、ターミナルで行う予定の場合はTerminalを選択します。
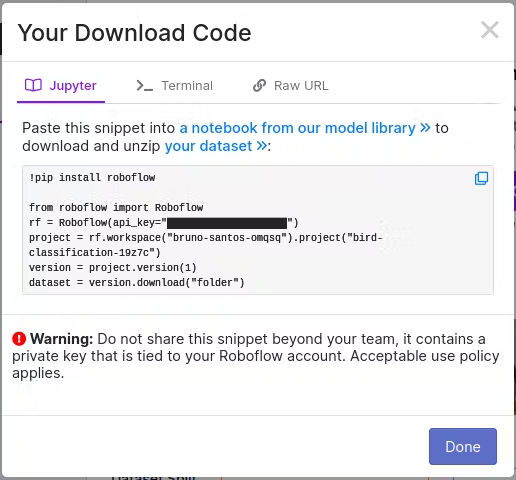
Jupyter Notebookで使用するため、Jupyterを選択しました。コードをコピーしてください。
環境の作成
仮想環境を作成し、PyTorchをインストールし、YOLOv8をインストールします。 YOLOv8ドキュメントのヒントによると、最初にPyTorchをインストールしてからultralyticsをインストールする方が良いとされています。
また、VSCodeで使用するためにjupyterlabパッケージもインストールしています。ノートブックはこのチュートリアルに添付されています。
まず、いくつかの依存関係をインストールしましょう。
注意: YOLOv8を使用するため、通常は必要のない手順を実行する必要があります。
NVIDIA deep learningドキュメントに従ってTorchをインストールするだけで、CUDAサポート付きのTorchを使用できます。
PyTorchを通常通りPIPでインストールした場合、CUDAサポートは含まれません。
依存関係
sudo apt install libopenblas-dev cuda-toolkit libcudnn8 tensorrt python3-libnvinfer nvidia-l4t-dla-compiler
Python仮想環境を作成する
python -m venv birdClassificationModel
エラーが発生した場合、それは python3-venv パッケージがインストールされていないためです。インストールして、上記のコマンドを繰り返しましょう。
sudo apt install python3-venv
Activate the virtual environment
source birdClassificationModel/bin/activate
あなたは、それがアクティブであることを確認できます。なぜなら、その名前があなたのプロンプトの前に表示されるからです。
YOLOv8
事前に、そしてドキュメントのヒントに従って、まずPyTorchをインストールしましょう。
私はJetPack 6.0を使用しており、これにはNVIDIA Jetson Linux 36.3とCUDA 12.2が付属しています。 まずPIPをアップグレードしましょう
pip install -U pip
YOLOv8で使用できるようにTorchをインストールするには、NVIDIAフォーラムの手順に従う必要があります。
これは仮想環境をアクティブにした状態で行われるため、その中にインストールされます。 NVIDIAからTorchバージョン2.3をダウンロード
wget https://nvidia.box.com/shared/static/mp164asf3sceb570wvjsrezk1p4ftj8t.whl -O torch-2.3.0-cp310-cp310-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev libomp-dev
pip3 install 'Cython<3'
pip install numpy torch-2.3.0-cp310-cp310-linux_aarch64.whl
この後、torchvisionをコンパイルしましょう。wheelからインストールした場合、CUDAサポートが含まれません。
ブランチバージョンは、インストールされたTorchバージョン用です。詳細はフォーラムページで確認できます。
仮想環境をアクティブにしておく必要があることを忘れないでください。そうすることで、すべてがその環境にインストールされます。
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libopenblas-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.18.0 https://github.com/pytorch/vision torchvision
cd torchvision/
export BUILD_VERSION=0.18.0
python setup.py install
しばらくすると、コンパイルとインストールが完了します。
インストール後、Cudaが利用可能かどうか確認してみましょう。
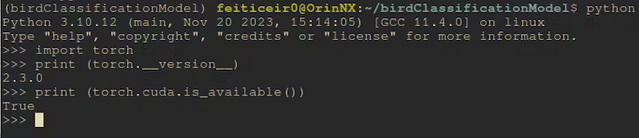
コマンドラインから
python -c "import torch;print (torch.cuda.is_available())"
これは True を返すはずです
YOLOv8 をインストール
CUDA サポート付きの PyTorch がインストールされたので、YOLOv8 をインストールする際に、CUDA サポートなしの新しいパッケージ(同じバージョンであっても)をインストールしようとする代わりに、インストール済みのバージョンを使用します。
pip install ultralytics
roboflowとjupyterlabをインストールしましょう
pip install roboflow jupyterlab
それでは、データセットをダウンロードしましょう。 ノートブックを使用している場合は、そこのコードを置き換えるだけです。
rf = Roboflow(api_key="<your_api_key>")
project = rf.workspace("bruno-santos-omqsq").project("bird-classification-19z7c")
version = project.version(1)
dataset = version.download("folder")
モデルをダウンロードした後、3つのディレクトリ(test、train、valid)のセットが得られ、それぞれに各クラスから一定数の画像が含まれています。各クラスの各画像は、それぞれ独自のディレクトリに配置されています。 これは画像分類用なので、画像にラベルを付ける必要はありません。 YOLOv8は、後で作成する設定ファイルからだけでなく、ディレクトリからもクラスを認識します。

訓練
通常、データセットには画像とオブジェクトの座標を含むラベル(またはアノテーション)があります。これは分類タスクなので、そのようなものは必要ありません。画像がクラス名のディレクトリにそれぞれ配置されていればよいのです。
設定ファイルの準備
YOLOv8がクラスを認識するためには、設定ファイルが必要です。 このファイルは、.yaml拡張子でデータセットディレクトリ内に配置する必要があります。名前は重要ではありません。
cd <dataset_directory>
vi birdClassificationModel.yaml
ファイルに以下のテキストを挿入してください
train: train/
valid: valid/
test: test/
# number of classes
nc: 12
# class names
names: ["Barn Swallow","Common Firecrest","Common Nightingale","Eurasian Chaffinch","Eurasian Crag Martin","European Goldfinch","European Greenfinch","European Serin","House Sparrow","Spanish Sparrow","Western House Martin","white Wagtail"]
分類には、Ultralyticsから既に利用可能な事前訓練済みモデルの1つを使用します。
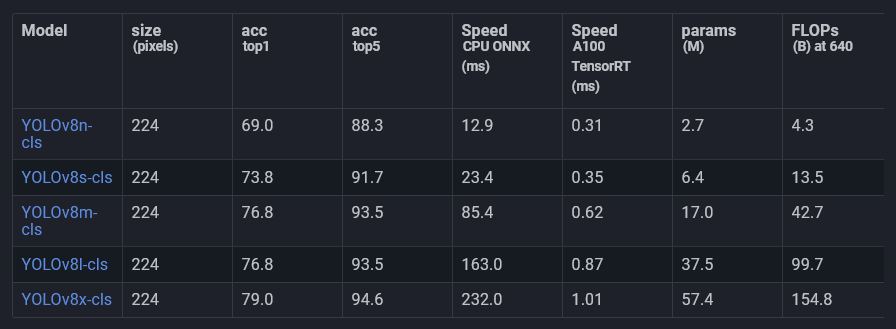
これらのモデルはImageNetで訓練されており、分類用にファインチューニングされています。 これを使用して、私たちのデータで訓練します。
これは転移学習として知られているものです。
私はYOLOv8l-clsモデルを使用します。おそらく他のモデルでも問題なく動作するでしょうが、リアルタイムが必要ないため、速度と精度のトレードオフになります。
それでは、YOLOv8 CLIインターフェースを使用してモデルを訓練しましょう
yolo task=classify mode=train model=yolov8l-cls.pt data=Bird-Classification-1 epochs=100
- task=classify : 画像を分類します
- mode=train : モデルを訓練しています
- model=yolov8l-cls.pt : 分類用の事前訓練済みモデルを使用しています
- data=Bird-Classification-1 : データセットが配置されているディレクトリです
- epochs=100 : モデルを訓練する期間です。
実行中の統計情報をjtop(tegra-stats)を使用して確認してみましょう。
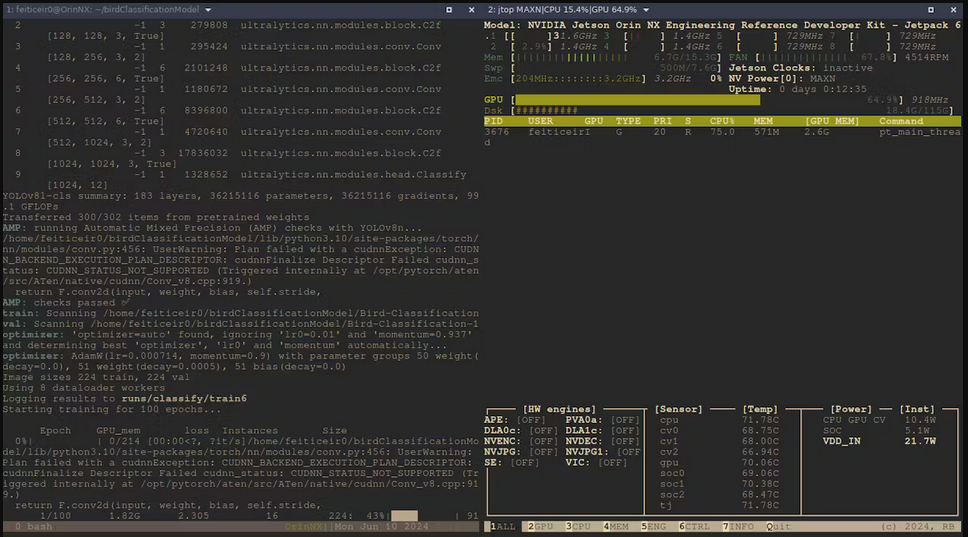
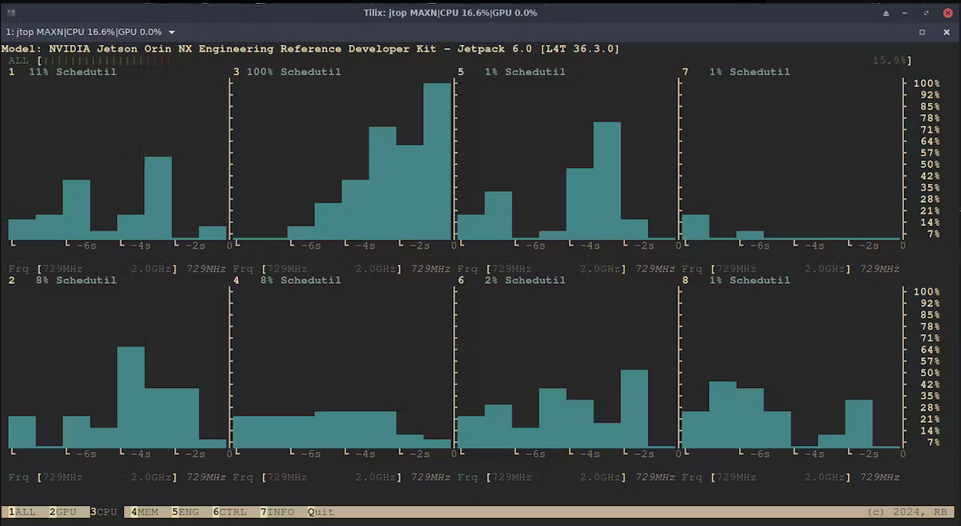
数時間後、訓練が完了しました。
それでは、モデルがどのように動作するか確認してみましょう。テストしてみます。
yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=Bird-Classification-1/test/**/*.jpg
これにより、yoloはテストディレクトリに移動し、各画像を予測しようとします。
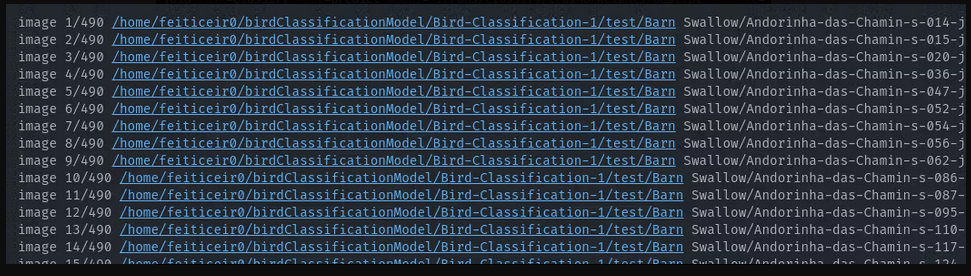



結果はすべて正しいです。今度は、モデルが一度も見たことのない2つの画像で試してみましょう。


yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=house_sparrow.jpg

yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=white_wagtail.jpg

これらの結果は素晴らしいと言えるでしょう。
モデルのエクスポート
推論にはモデルをそのまま使用できます。開いて使用するだけです。 より高速な推論時間を得るために、NVIDIA Jetson Orin NX上にいるのでTensorRTにエクスポートしたり、例えばONNXにエクスポートしたりできます。
このプロジェクトでより高速な推論時間が必要というわけではありません - リアルタイム動画で使用する予定はありません - しかし、使用しているプラットフォームの利点を活用できるのは良いことです。
残念ながら、仮想環境のためTensorRTにエクスポートできませんでした。何らかの理由で、Pythonでtensorrtをインポートできませんでしたが、仮想環境外では、tensorrtライブラリに問題はありませんでした。
ONNX
次のようにモデルをONNX形式にエクスポートできます
yolo export model='./runs/classify/train6/weights/best.pt' format=onnx imgsz=640
推論に使用できるbest.onnxが得られます。
ONNXを使用して推論を実行するには、onnxruntime_gpuホイールをインストールする必要があります。
JetPack 6.0でonnxruntime-gpuをインストールするには、Jetson Zooからダウンロードする必要があります。
onnxruntime_gpu 1.18.0をダウンロードします
Pythonバージョン(Python-3.10)用のpipホイールをダウンロードします
wget https://nvidia.box.com/shared/static/48dtuob7meiw6ebgfsfqakc9vse62sg4.whl -O onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
and then, install it
pip install onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
推論
写真
以下のコードを使用してbest.ptモデルで推論を実行し、結果を確認しました
# running inference
from ultralytics import YOLO
# load the model
bird_model = YOLO("./runs/classify/train6/weights/best.pt")
#run inference
results = bird_model("house_sparrow.jpg")[0]
# get class names
class_names = results.names
# get top class with more probability
top1 = results.probs.top1
# print the class name with the highest probability
print (f" The detected bird is: {class_names[top1]}")
上記のコードが行うことは、モデルを読み込み、画像で推論を実行し、結果をresults変数に保存することです。
resultsはultralytics.engine.results.Resultsオブジェクトで、1つのアイテムを持つリスト型であり、そのアイテムはResultsのインスタンスです。results変数の[0]は推論結果を保持し、これにより私たちが求める結果にアクセスできるようになります。
results = bird_model("house_sparrow.jpg")[0]
次に、結果を使用してクラス名を取得します。クラス名を知らないわけではありませんが、このようにすることで、このコードが他のモデルでも動作するようになります。
class_names = results.names
結果の1つは、より高い確率を持つTOP 1クラスを保持するtop1変数です。そのTOP1は、probsリストによって与えられます。
top1 = results.probs.top1
次に、鳥の種類であるべき最も高い確率のクラスを出力します。
print (f" The detected bird is: {class_names[top1]}")
The detected bird is: House Sparrow
カメラ
それでは、カメラを使用して推論を実行してみましょう。
JetsonはUSBカメラまたはRPIカメラを使用できます。USBカメラを接続します。
以下のコードは、カメラフィードを表示できるかどうかを確認します。
#Lets test if we can use a USB camera
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
cv2.imshow('Camera', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows
これは私のデスクトップコンピューターでの様子です。ssh -X username@jetson_ip を使用するだけで、X11ウィンドウがデスクトップに転送されます。これは私もLinuxを使用しているため機能します。WSLでも動作すると思います。
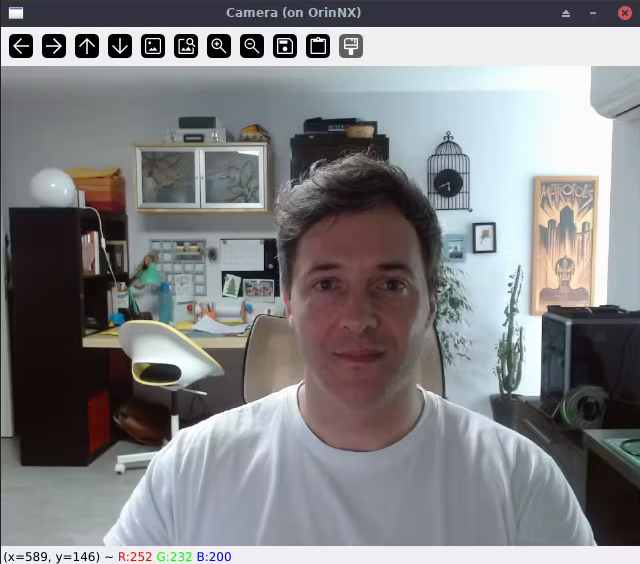
それでは、ビデオフィードで推論を実行し、より高い確率のクラスを表示してみましょう。
コードは以下の通りです
# again, save this code in a file a run it from the Jetson
import cv2
from ultralytics import YOLO
import time
#define confidence level
#only equal or above this level we say it's a class of bird
confidence = 0.95
# time when processed last frame
prev_frame = 0
# time processed current frame
cur_time = 0
# load the model
bird_model = YOLO("./runs/classify/train6/weights/best.pt")
# cv2 font
font = cv2.FONT_HERSHEY_SIMPLEX
# open camera
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
# to display fps
cur_frame = time.time()
fps = 1 / (cur_frame - prev_frame)
prev_frame = cur_frame
fps = int(fps)
fps = str(fps)
cv2.putText (img, fps, (550,50), font, 1, (124,10,120), 2, cv2.LINE_AA)
# inference current frame
results = bird_model(img, verbose=False)[0]
# get class names
class_names = results.names
# get top class with more probability
top1 = results.probs.top1
top1conf = results.probs.top1conf.tolist()
# we will only show the class name if the confidence is higher than defined level
# print the class name with the highest probability
if (top1conf >= confidence):
bird_class = class_names[top1]
print (f" The detected bird is: {class_names[top1]}")
# color is in BGR
confid = round(top1conf,2)
img = cv2.putText(img, bird_class, (50,50), font, 0.9, (0, 0, 255), 2, cv2.LINE_AA)
img = cv2.putText(img, "Conf: " + str(confid), (50,80), font, 0.6, (255, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('Camera', img)
else:
img = cv2.imshow('Camera', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows
ビデオフィードでの推論を示すビデオです
✨ コントリビュータープロジェクト
- このプロジェクトは Seeed Studio コントリビュータープロジェクトによってサポートされています。
- Bruno の努力に感謝し、あなたの作品は展示されます。
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを提供しています。