WatcherのAI機能をローカルにデプロイする

SenseCAP Watcherは、空間内の異常を監視し、その後アクションを実行するのに役立つAIウォッチャーです。WatcherはSenseCraft AIサービスを利用できますが、独自のデバイスでAI機能をローカルにデプロイするオプションも提供し、より大きな制御、プライバシー、柔軟性を提供します。
この包括的なガイドでは、ローカルデバイスでWatcherのAIサービスを設定およびデプロイするプロセスを順を追って説明します。Windows PC、macOSマシン、またはNVIDIA® Jetson AGX Orinを使用している場合でも、独自の環境でWatcherのAI機能の力を活用するのに役立つステップバイステップの手順を提供します。
このガイド全体を通して、必要なソフトウェアとハードウェアの準備、サポートされている各プラットフォームのデプロイプロセス、およびWatcherのローカルAIサービスを効果的に活用して新しい可能性を解き放ち、生産性を向上させる方法について説明します。このガイドの最後までに、独自のデバイスでWatcherのAI機能を活用する方法をしっかりと理解し、ニーズに合わせたインテリジェントでパーソナライズされたソリューションを作成できるようになります。
ソフトウェアの準備
Watcherのローカルデプロイ機能を利用するには、ユーザーはまず必要なソフトウェアをダウンロードする必要があります。ソフトウェアパッケージには、Watcherアプリケーションとデバイス AIサービスコンポーネントが含まれており、ユーザーがローカルAIサービスを設定および構成できるようになります。
ユーザーは以下のダウンロードリンクからWatcher APPをダウンロードできます:
- Windows用:
- macOS用:
- Linux用:
お使いのオペレーティングシステムに基づいて適切なダウンロードリンクを選択してください。Watcher APPはWindows、macOS、および主要なLinuxディストリビューションと互換性があり、異なるプラットフォーム間でシームレスなエクスペリエンスを保証します。
ハードウェアの準備
WatcherのAI機能をローカルにデプロイする際にスムーズで最適なエクスペリエンスを確保するには、デバイスが最小ハードウェア要件を満たす必要があります。これらの要件はオペレーティングシステムによって異なります。以下は、サポートされている各プラットフォームのハードウェア要件です:
| Windows | Mac | Linux (arm64) | |
|---|---|---|---|
| グラフィックスカード(推奨構成) | GeForece RTX2070 | Apple M1 16 GB | GeForece RTX2070 |
| RAM(最小構成) | 8 GB | 16 GB | 8 GB |
| ストレージ(最小構成) | 20 GB | 20 GB | 20 GB |
これらは最小要件であり、より高い仕様を持つことでWatcherのAIサービスのパフォーマンスと応答性を大幅に向上させることができることに注意することが重要です。複数のAIサービスを同時にデプロイしたり、大量のデータを処理したりする予定がある場合は、より高度なハードウェア構成を持つデバイスの使用をお勧めします。
パフォーマンスの考慮事項
WatcherのローカルにデプロイされたAIサービスのパフォーマンスは、デバイスのハードウェア仕様によって異なる場合があります。以下は一般的なパフォーマンスガイドラインです:
- RAM:より多くのRAMにより、よりスムーズなマルチタスクが可能になり、より複雑なAIモデルと大きなデータセットを処理できます。
- グラフィックスカード:RTX2070のような専用グラフィックスカードは、特にコンピュータビジョンとディープラーニングを含むタスクにおいて、AI計算を大幅に加速できます。
- ストレージ:AIモデル、データセット、生成された出力を保存するには十分なストレージ容量が不可欠です。推奨される20 GBのストレージは、WatcherのAIサービスに十分なスペースを確保します。
WatcherのAIサービスをローカルにデプロイする際は、特定の使用ケースと使用予定のAIモデルの複雑さを考慮することが重要です。リアルタイム処理が必要な場合や、リソース集約的なタスクを処理する予定がある場合は、最適なパフォーマンスを確保するために、より高性能なハードウェア構成を選択することをお勧めします。
上記のハードウェア要件を満たし、パフォーマンス要因を考慮することで、ローカルデバイスでWatcherのAI機能のスムーズで効率的なデプロイを確保できます。
デバイスベンチマーク
以下は、一部のデバイスでAIサービスをデプロイした後の応答時間です。
| デバイス | Windows 10 32GB with GeForce RTX4060 Graphics Card | Windows 10 16GB with non-Graphics Card | Mac Mini M1 (16 GB) | NVIDIA® Jetson AGX Orin 32GB |
|---|---|---|---|---|
| タスク分析時間 | 5s | 17m14s | 36s | 18s |
| 画像分析時間 | 4s | 4m10s | 8s | 7s |
AI関連タスクにおいてNVIDIA Jetson AGXシリーズ製品をRTX 4090のようなコンシューマーグレードのグラフィックスカードと比較すると、Jetson AGXシリーズはいくつかの主要な利点を提供します:
-
産業グレードの信頼性:Jetson AGXシリーズ製品は産業および商業アプリケーション向けに設計されており、これは平均故障間隔(MTBF)が長いことを意味します。これらは問題に遭遇することなく、24時間365日連続して動作するように構築されています。対照的に、RTX 4090のようなコンシューマーグレードのグラフィックスカードは、このような要求の厳しい24時間体制の動作向けに設計されておらず、同じレベルの信頼性を提供しない場合があります。
-
コンパクトサイズと低消費電力:Jetson AGXシリーズ製品は、組み込みおよびエッジコンピューティングアプリケーションを念頭に置いて設計されています。高性能コンシューマーグラフィックスカードと比較して、より小さなフォームファクターを持ち、消費電力が少なくなっています。これにより、スペースに制約のある環境での展開により適しており、全体的な運用コストを削減します。低消費電力はまた、発熱量の減少を意味し、これは組み込みシステムにとって重要であり、冷却要件を最小限に抑えるのに役立ちます。
これらの利点に加えて、Jetson AGXシリーズは、AIワークロード用に最適化された包括的なソフトウェアスタックを提供し、開発者がAIアプリケーションを効率的に作成およびデプロイすることを容易にします。産業グレードの信頼性、コンパクトサイズ、低消費電力、最適化されたソフトウェアスタックの組み合わせにより、Jetson AGXシリーズは、特にRTX 4090のようなコンシューマーグレードのグラフィックスカードと比較した場合、AI関連プロジェクトおよびアプリケーションにとって魅力的な選択肢となります。
Windowsでのデプロイ
WindowsデバイスでWatcherのAI機能をデプロイするには、以下の簡単な手順に従ってください。
ステップ1. コンピューターのダウンロードフォルダーまたは指定された場所でダウンロードした.exeファイルを見つけます。.exeファイルをダブルクリックしてインストールプロセスを開始します。インストールウィザードがセットアッププロセスをガイドします。インストール中に追加の選択や設定を行う必要はありません。
ステップ2. インストールが完了したら、Watcherアプリケーションを起動します。初回起動時に、使用したいAIモデルを選択するよう求められます。Watcherは2つのオプションを提供します。
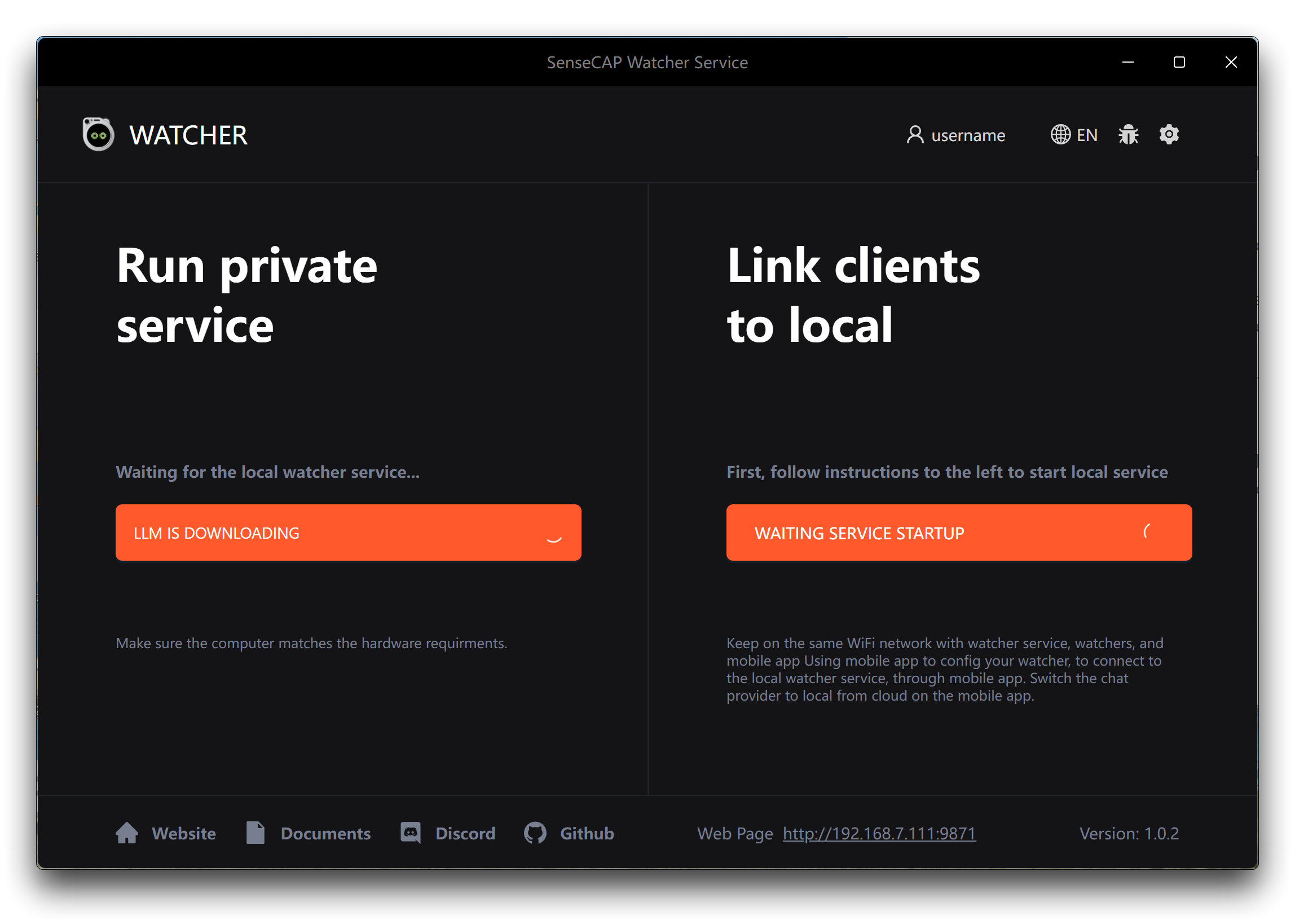
- Llama 3.1 + LLaVA:このオプションを選択した場合、下のApplyボタンをクリックして、必要なAIモデルと関連ファイルのダウンロードを開始します。これらの追加ダウンロードは約10 GBのサイズになる可能性があるため、時間がかかる場合があります。中断や不完全なダウンロードを避けるために、モデルダウンロードプロセス中は安定した高速インターネット接続を確保してください。
- OpenAI: OpenAIのモデルを使用したい場合は、事前にOpenAI APIキーを準備する必要があります。有効なAPIキーとOpenAIモデルを使用するのに十分なクレジットがあることを確認してください。プロンプトが表示されたら、APIキーを入力してWatcherがOpenAIのサービスを使用するように設定してください。
あなたのニーズとリソースに最も適したオプションを選択してください。十分なストレージ容量と信頼性の高いインターネット接続がある場合、Llama 3.1 + LLaVAオプションは自己完結型のソリューションを提供します。OpenAIモデルの柔軟性とパワーを好み、APIキーが準備できている場合は、OpenAIオプションを選択してください。
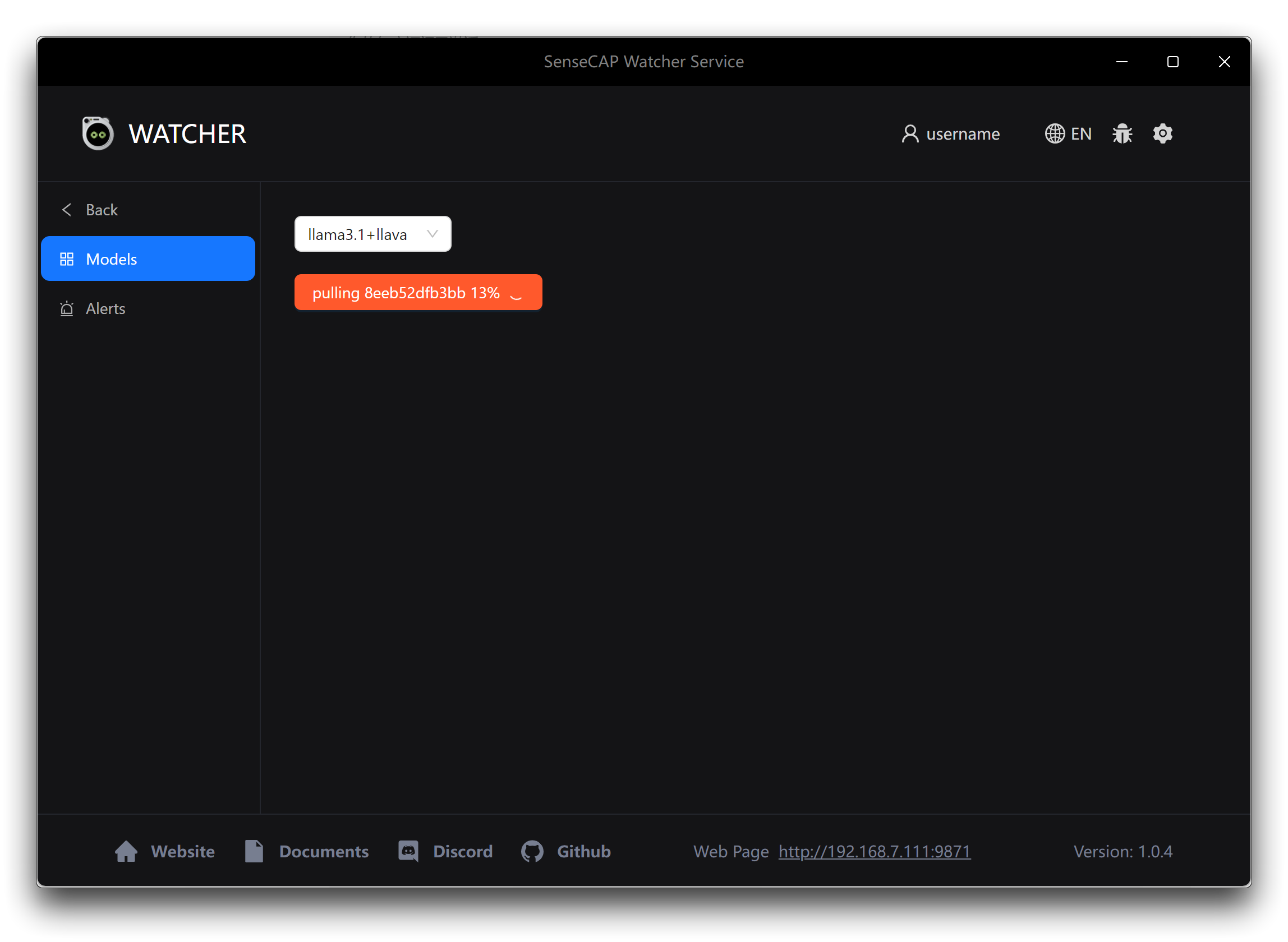
モデルファイルがダウンロードされインストールされると、WatcherはWindowsデバイスで使用する準備が整います。
macOSでのデプロイメント
macOSデバイスでWatcherのAI機能をデプロイするには、以下の手順に従ってください。
ステップ1. コンピューターのダウンロードフォルダまたは指定された場所でダウンロードした.dmgファイルを見つけます。.dmgファイルをダブルクリックして開きます。新しいウィンドウが表示され、インストールパッケージの内容が表示されます。
ステップ2. 新しいウィンドウで、Watcherアプリケーションアイコンとアプリケーションフォルダのエイリアスが表示されます。Watcherアプリケーションアイコンをクリックして、ウィンドウ内のアプリケーションフォルダエイリアスにドラッグします。この操作により、Watcherアプリケーションがコンピューターのアプリケーションフォルダにコピーされます。
コピープロセスが完了したら、.dmgウィンドウを閉じることができます。
ステップ3. アプリケーションを初回起動すると、Watcherは必要なAIモデルと関連ファイルのダウンロードを自動的に開始します。これらの追加ダウンロードは約10GBのサイズになる可能性があるため、時間がかかる場合があります。モデルダウンロードプロセス中に中断や不完全なダウンロードを避けるため、安定した高速インターネット接続があることを確認してください。
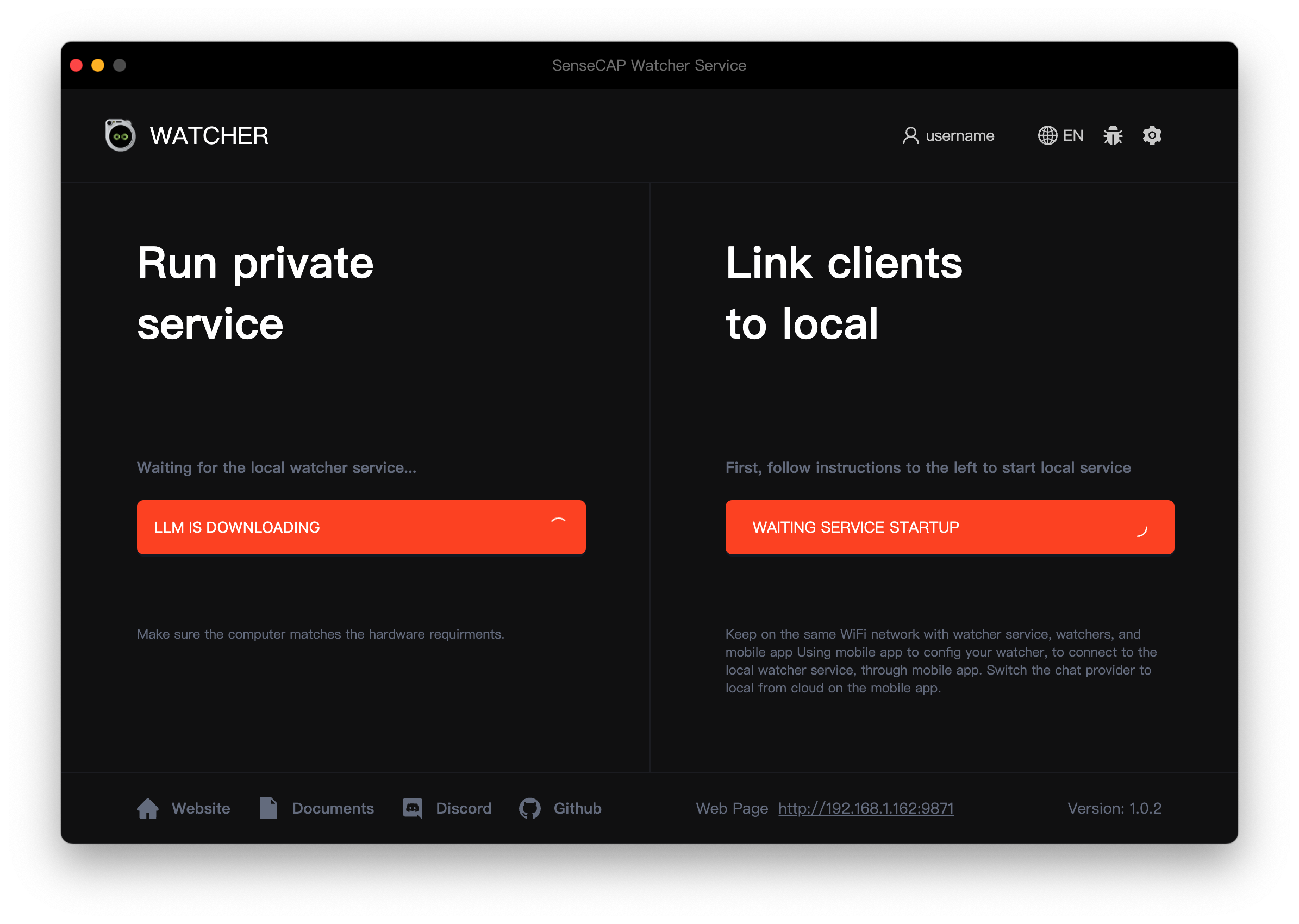
-
Llama 3.1 + LLaVA: このオプションを選択した場合、下のApplyボタンをクリックして必要なAIモデルと関連ファイルのダウンロードを開始します。これらの追加ダウンロードは約10GBのサイズになる可能性があるため、時間がかかる場合があります。モデルダウンロードプロセス中に中断や不完全なダウンロードを避けるため、安定した高速インターネット接続があることを確認してください。
-
OpenAI: OpenAIのモデルを使用したい場合は、事前にOpenAI APIキーを準備する必要があります。有効なAPIキーとOpenAIモデルを使用するのに十分なクレジットがあることを確認してください。プロンプトが表示されたら、APIキーを入力してWatcherがOpenAIのサービスを使用するように設定してください。
あなたのニーズとリソースに最も適したオプションを選択してください。十分なストレージ容量と信頼性の高いインターネット接続がある場合、Llama 3.1 + LLaVAオプションは自己完結型のソリューションを提供します。OpenAIモデルの柔軟性とパワーを好み、APIキーが準備できている場合は、OpenAIオプションを選択してください。
モデルファイルがダウンロードされインストールされると、WatcherはmacOSデバイスで使用する準備が整います。
NVIDIA® Jetson AGX Orin / Linuxでのデプロイメント
NVIDIA® Jetson AGX OrinまたはLinuxデバイスでWatcherのAI機能をデプロイするには、以下の手順に従ってください。
ステップ1. Jetson AGX OrinまたはLinuxデバイスでターミナルウィンドウを開きます。
ステップ2. cdコマンドを使用して、ダウンロードした.debファイルが配置されているディレクトリに移動します。以下のコマンドを実行してWatcherをインストールします。
sudo dpkg -i watcher_service_x.x.x_arm64.deb
watcher_service_x.x.x_arm64.debをダウンロードした.debファイルの実際の名前に置き換えてください。インストールプロセスが開始されます。インストールを承認するためにシステムパスワードの入力を求められる場合があります。インストールが完了するまで待ちます。ターミナルには進行状況と追加情報が表示されます。
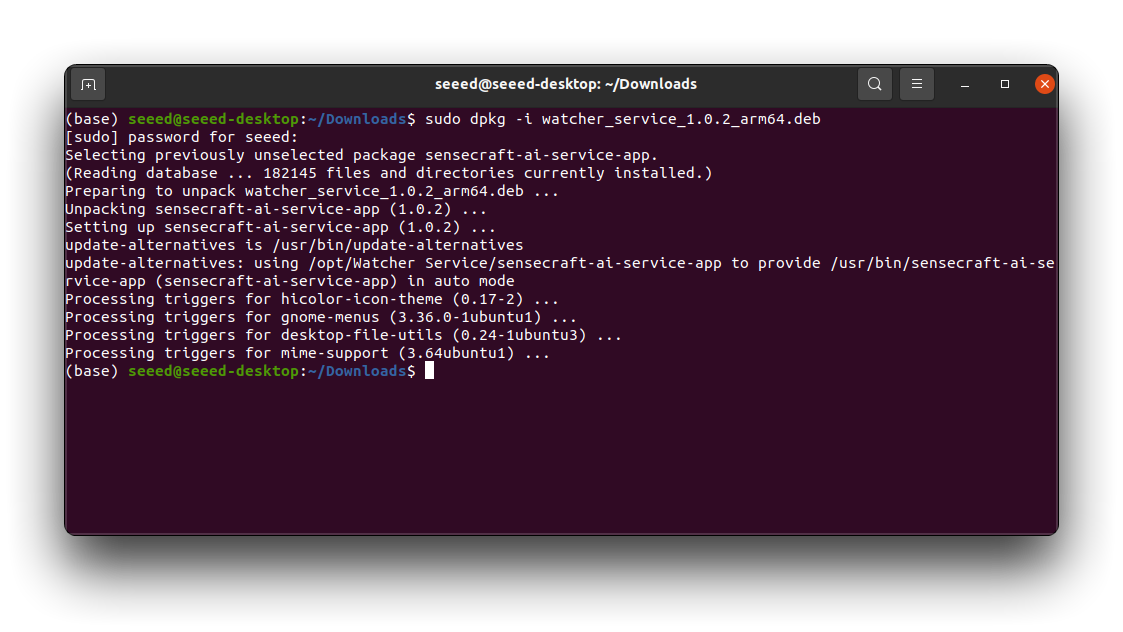
ステップ3. インストールが完了したら、ターミナルでwatcherと入力するか、アプリケーションランチャーで見つけることでWatcherを起動できます。
-
Llama 3.1 + LLaVA: このオプションを選択した場合、下のApplyボタンをクリックして必要なAIモデルと関連ファイルのダウンロードを開始します。これらの追加ダウンロードは約10GBのサイズになる可能性があるため、時間がかかる場合があります。モデルダウンロードプロセス中に中断や不完全なダウンロードを避けるため、安定した高速インターネット接続があることを確認してください。
-
OpenAI: OpenAIのモデルを使用したい場合は、事前にOpenAI APIキーを準備する必要があります。有効なAPIキーとOpenAIモデルを使用するのに十分なクレジットがあることを確認してください。プロンプトが表示されたら、APIキーを入力してWatcherがOpenAIのサービスを使用するように設定してください。
あなたのニーズとリソースに最も適したオプションを選択してください。十分なストレージ容量と信頼性の高いインターネット接続がある場合、Llama 3.1 + LLaVAオプションは自己完結型のソリューションを提供します。OpenAIモデルの柔軟性とパワーを好み、APIキーが準備できている場合は、OpenAIオプションを選択してください。
WindowsとmacOSのインストールと同様に、Watcherは必要なAIモデルと関連ファイルのダウンロードを自動的に開始します。
SenseCraft APPでローカルAIサービスの使用を設定する
SenseCraft APPでWatcherが提供するローカルAIサービスを使用するには、以下の簡潔な手順に従ってください:
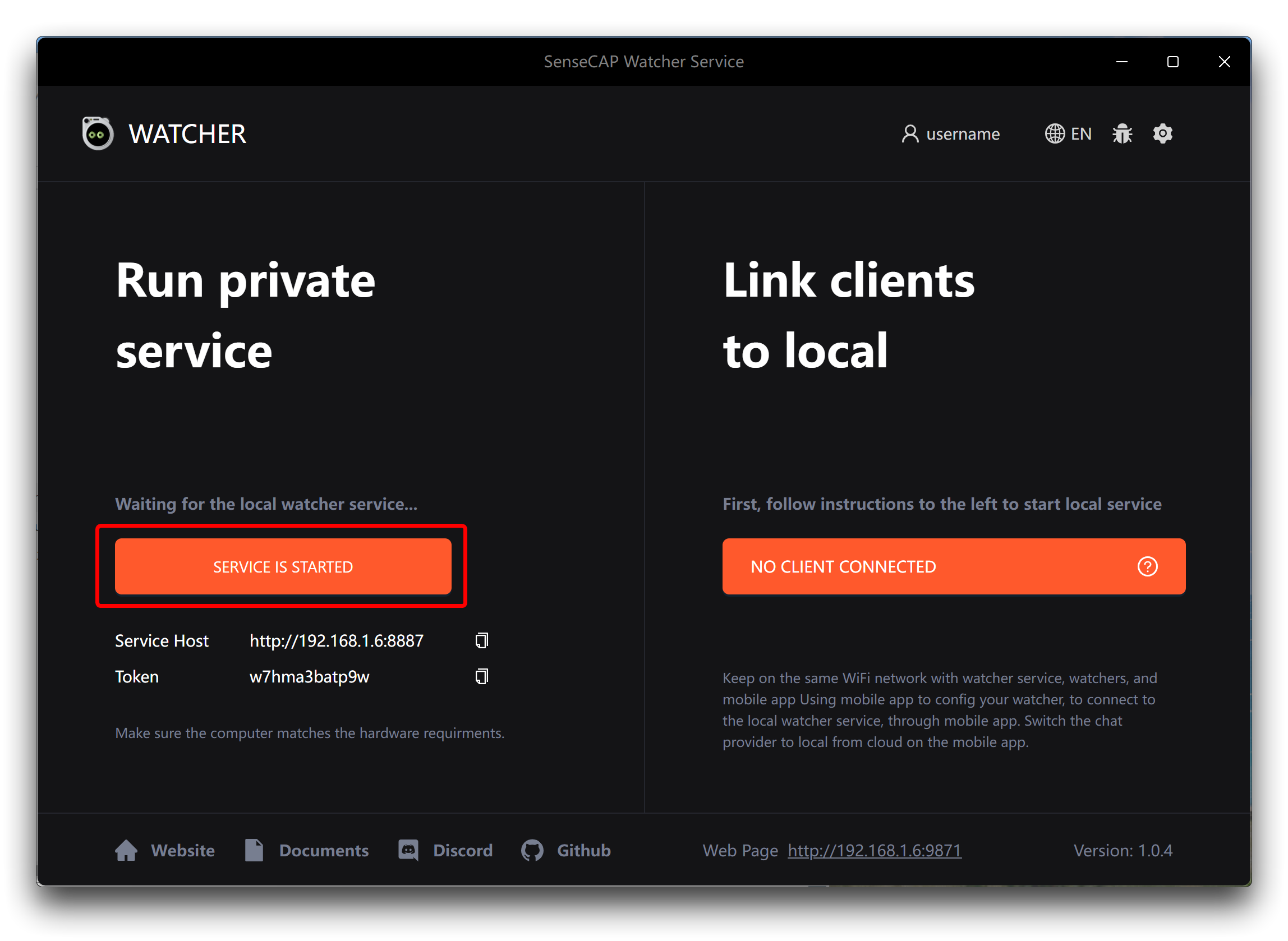
ステップ1. デバイスでWatcher APPを開き、左下セクションのStart Serviceボタンをクリックします。
ステップ2. SenseCraft APPで、Watcherインターフェースに移動し、右上角の設定ボタンをタップします。設定メニューからDevice AI Serviceを選択します。
ステップ3. Watcher APPのホーム画面からURLとTokenをコピーします。
ステップ4. SenseCraft APP内のDevice AI Service設定で、URLとTokenをそれぞれのフィールドに貼り付けます。
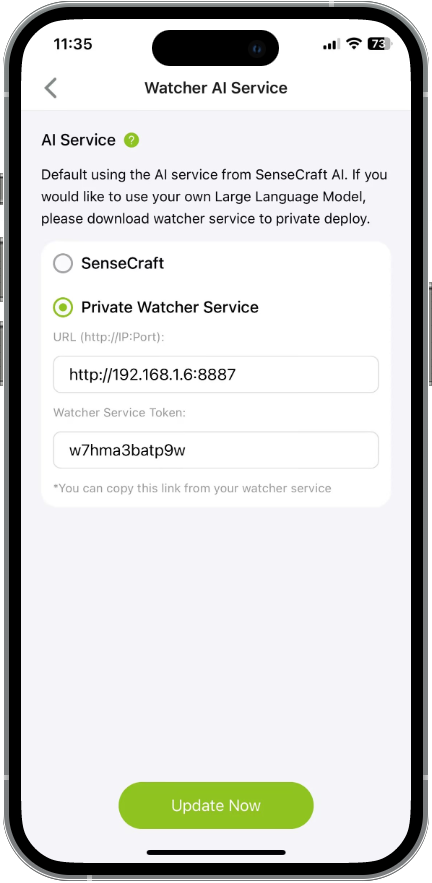
ステップ5. これで、SenseCraft APPを通じてWatcherにタスクを割り当てることができ、WatcherはローカルにデプロイされたAI機能を使用してそれらを処理します。
**ハードウェア準備**で推奨されているコンピューター構成をコンピューターが満たしていることを確認することが重要です。推奨構成を下回る場合、コンピューターが画像の1つを全力で分析している可能性があるため、認識結果とアラームメッセージを時間通りに受信できない場合があります。この時点で、Watcherは常に観察状態にあるように見えます。
これらの手順を完了することで、デバイス上でWatcherのAIサービスの力を直接活用でき、プライバシーの向上と独自の統合システムを便利にカスタマイズする能力を確保できます。WatcherのAI機能がローカルで実行されることで、データを自分の管理下に置きながら、高度なタスク、分析、自動化を安全かつ効率的に実行できます。
アプリケーションディレクトリでローカライズされたデプロイメント後のメッセージプッシュのための**HTTP Message Block**の使用に関するチュートリアルを引き続き追加していきますので、お楽しみに!
FAQ
SenseCap Watcher Serviceが動作しない
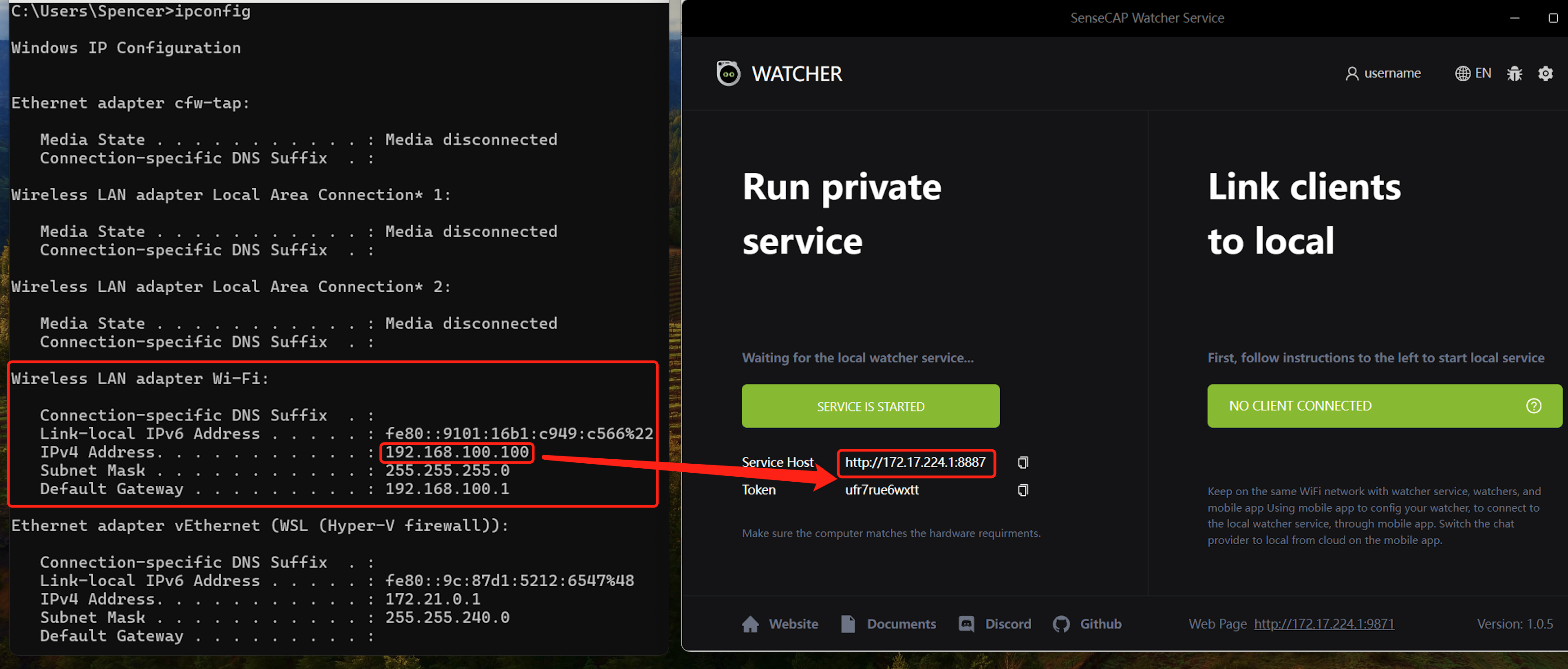
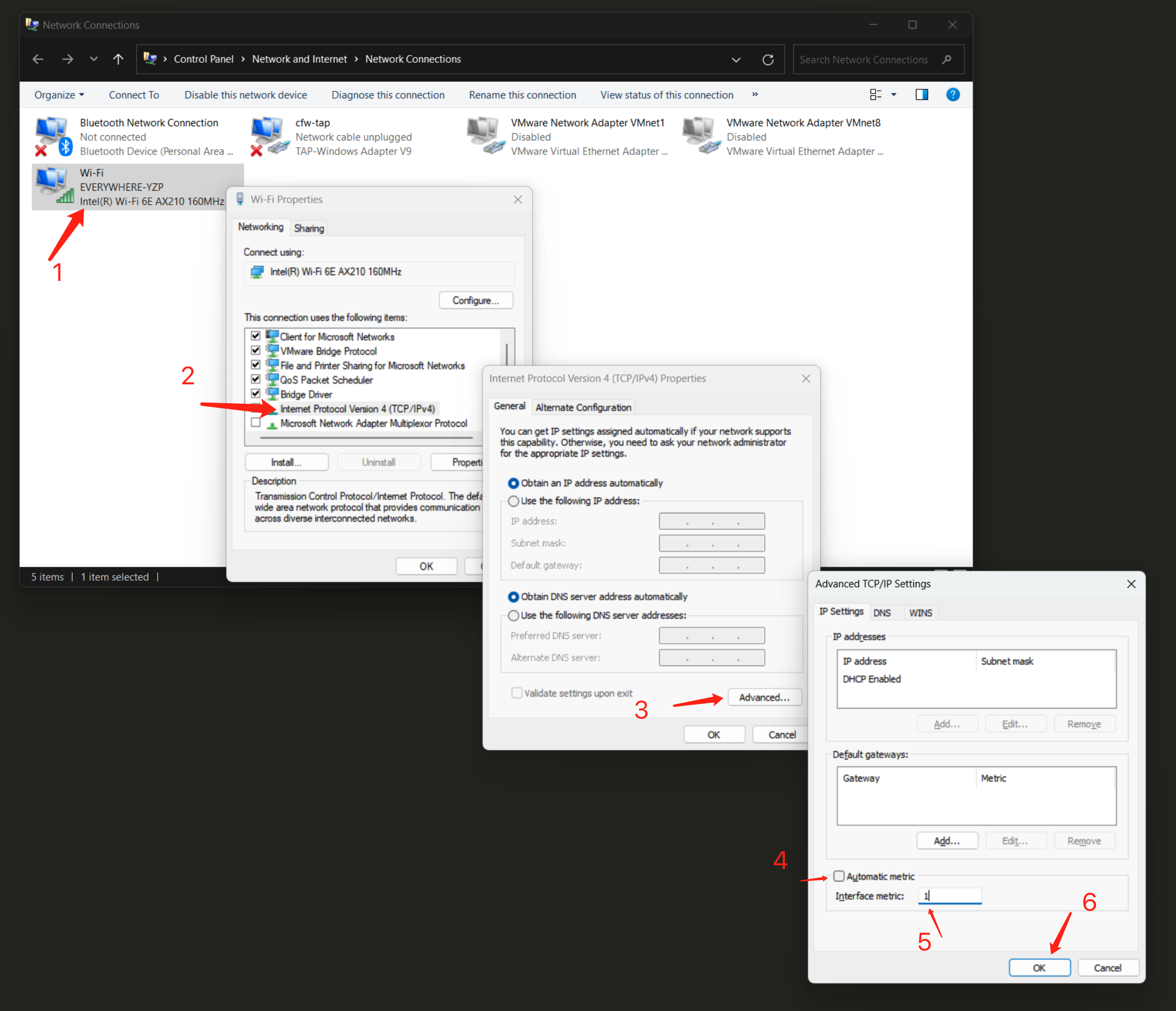
Service HostのIPはあなたのコンピューターのIPアドレスである必要があります。そうでない場合、SenseCAP Watcher Serviceは動作しません。以下の手順に従って修正する必要があります。
-
Win + Rを押す > "ncpa.cpl"と入力 > Enterを押す。
-
"Wi-Fi"またはEthernetを右クリック > "プロパティ"を選択。
-
IPv4またはIPv6をダブルクリック > "詳細設定"をクリック。
-
自動メトリックのチェックを外す > 1(または希望する数値)を入力 > OKをクリック。
技術サポート & 製品ディスカッション
弊社製品をお選びいただきありがとうございます!弊社製品での体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。さまざまな好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。