Watcher To Open Interpreter クイックスタート

パート1. Open Interpreterとは
Open Interpreterは、ユーザーが自然言語コマンドを使用してさまざまなプログラミング言語でコードを実行できるようにすることで、ユーザーとコンピューターの間の相互作用を促進するオープンソースツールです。これは橋渡しの役割を果たし、ユーザーが平易な言語で指示を書くことを可能にし、インタープリターがそれを実行可能なコードに翻訳します。これにより生産性が向上し、特にコーディング構文に慣れていない人にとってプログラミングがより身近になります。
パート2. Node-REDでの操作
このパートでは、作業を完了するために4つのモジュールが必要です。SenseCap Watcher OpenSteam、function、http request、debugモジュールです。
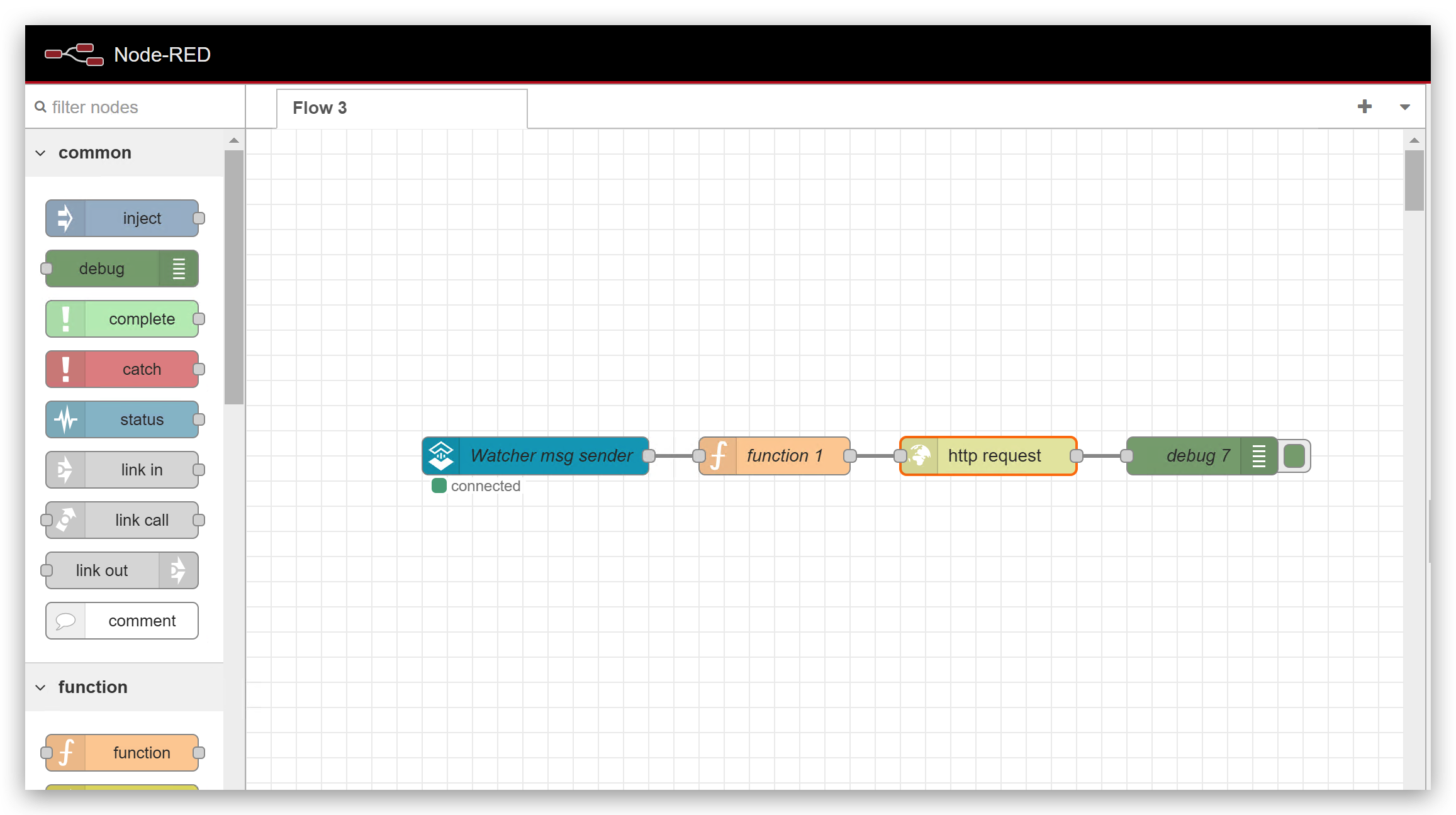
- SenseCap Watcher OpenSteamモジュール: WatcherからNode-REDにメッセージを取得します。
- functionモジュール: データを処理して必要なメッセージを取得します。
- http requestモジュール: httpプロトコル経由でOpen Interpreterにメッセージを送信します。
- debugモジュール: 全体のワークフローをデバッグして、すべてが正常に動作しているかを確認します。
以下の手順で、これらのモジュールの設定方法を説明します。
ステップ1. SenseCap Watcher OpenSteamモジュールの設定
まず最初に、以下のビデオに従ってWatcherでタスクを実行する必要があります。詳細を知りたい場合はこちらをクリックしてください。
WatcherからNode_REDにメッセージを送信する方法がまだわからない場合は、こちらをクリックしてください。
ステップ2. functionモジュールの設定
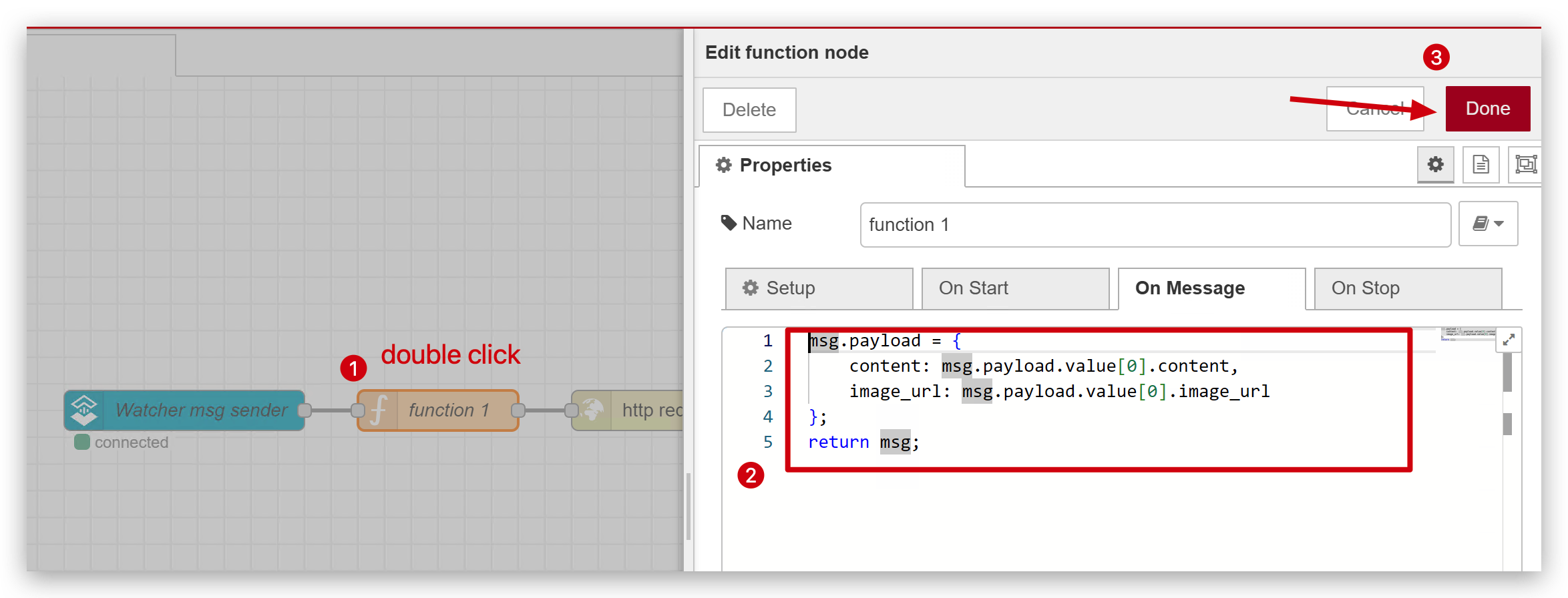
msg.payload = {
content: msg.payload.value[0].content,
image_url: msg.payload.value[0].image_url
};
return msg;
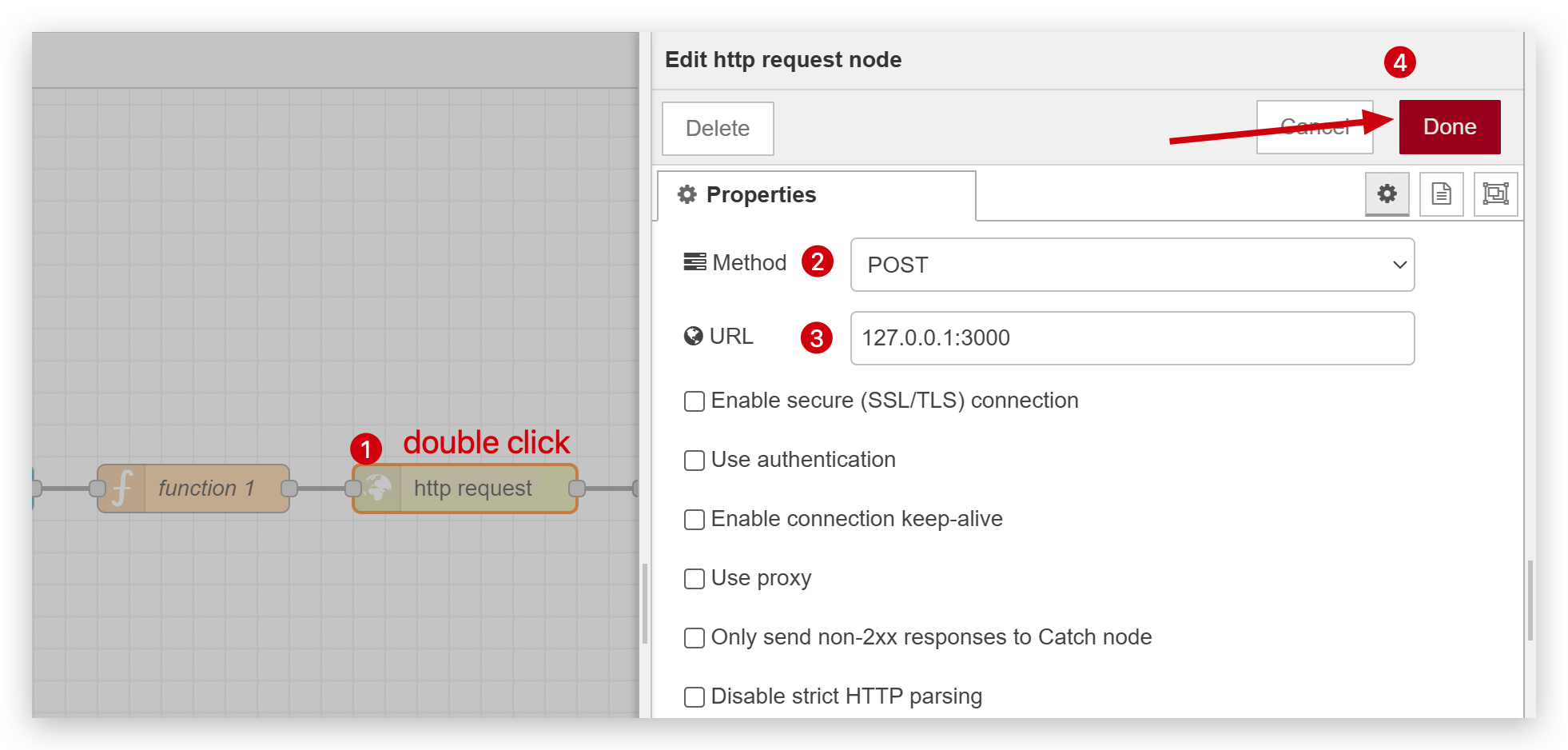
ステップ3. HTTPリクエストモジュールの設定
セキュリティのためにPOSTリクエストを使用し、ポート3000に送信します。後でOpen Interpreterを使用してポート3000をリッスンし続けます。
ステップ4. デバッグモジュールの設定
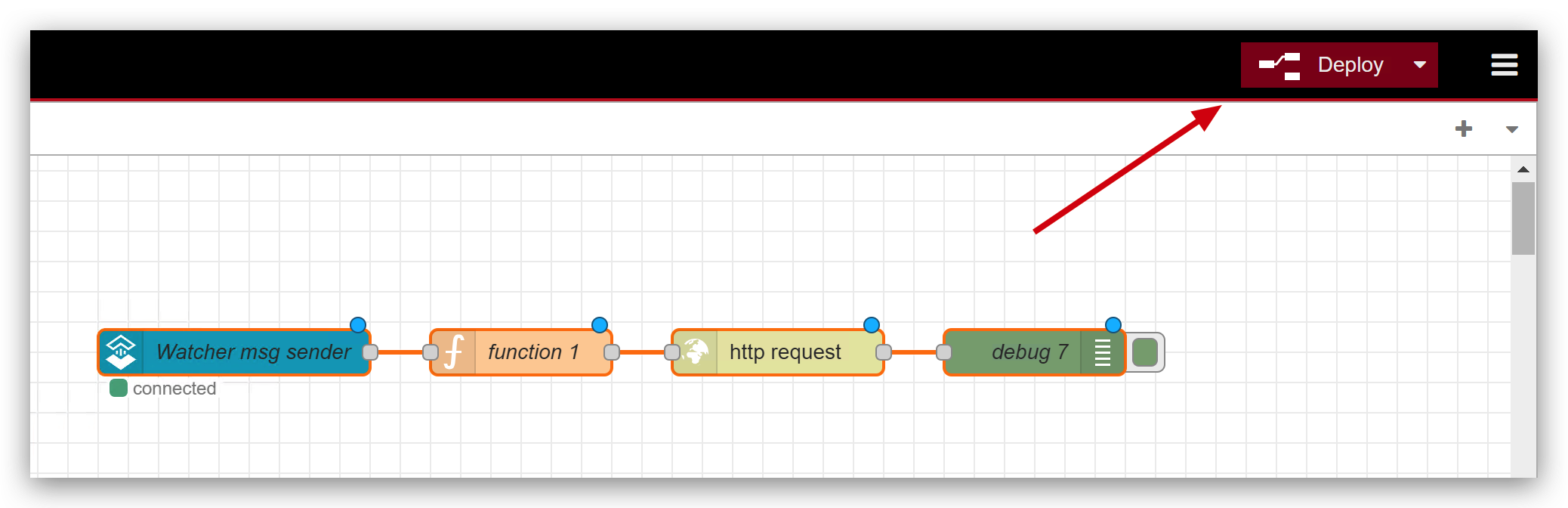
以下の画像のように選択してください。
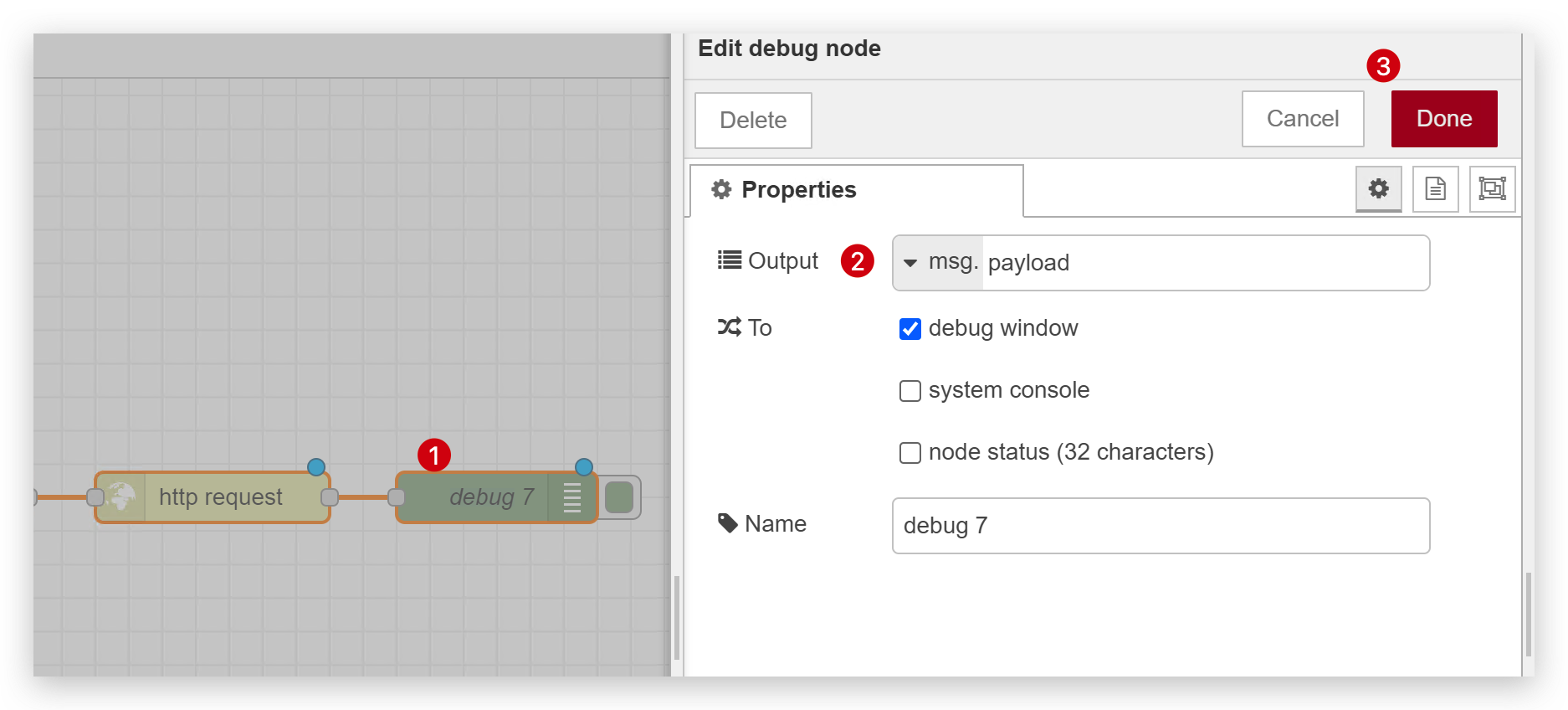
設定が完了したら、Deployすることを忘れないでください。
パート3. Open Interpreterでの操作
続行する前に、前提条件としてコンピューターにPython開発環境が必要です。
まだお持ちでない場合は、こちらをご参照ください。
ステップ5. Open Interpreterのインストール
Pythonをインストールした後、PythonでOpen Interpreterを簡単にインストールできます。コマンド一つだけです。
pip install open-interpreter
ステップ6. Open Interpreterを開始する
Interpreterには2つのモードがあります:オンラインモードとローカルモードです。デフォルトでは、Interpreterはオンラインモードを選択し、OpenAI ChatGPT gpt-4-turbo API Keyを使用します。ローカルモードに設定することもできますが、その場合はモデルをダウンロードしてローカルで実行する必要があります。
オンラインモードをお勧めします。オンラインモードはローカルモードよりもはるかに高速で賢く、ローカルモードはしばしば停止することがあるためです。
オンラインモード
- 開始する前に、OpenAI API Keyが必要です。OpenAI GPT-4の有料メンバーの場合は、こちらをクリックして取得できます。
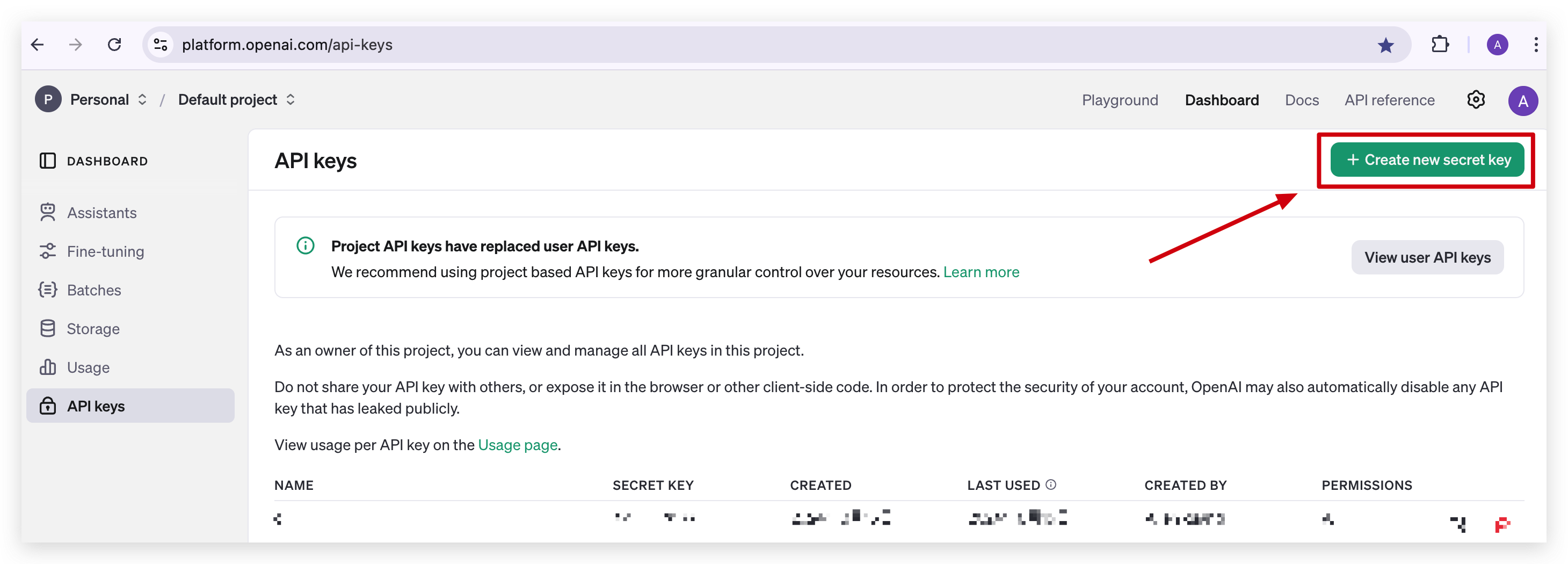
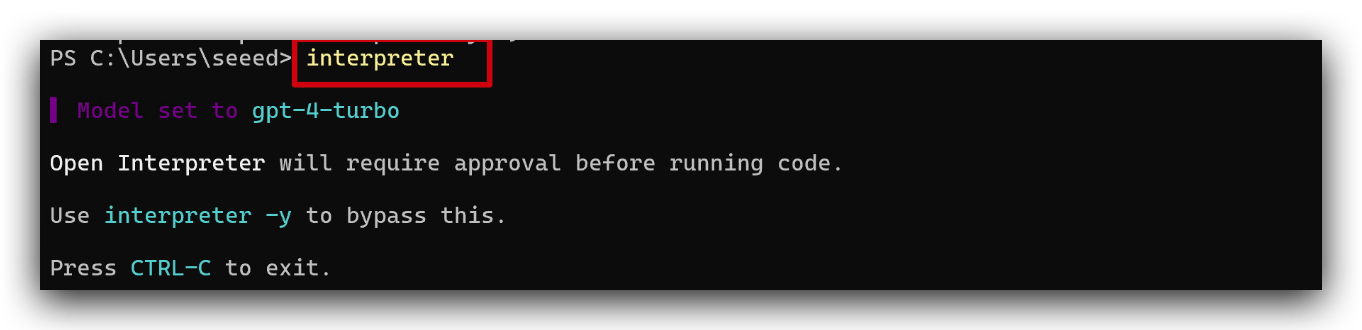
- その後、
interpreterコマンドを入力して開始し、API Keyの入力が求められます。その後、モデルをgpt-4-turboに正常に設定します。
ローカルモード
- 開始する前に、ローカルで実行するためのモデルをダウンロードする必要があります。ここではOllamaをお勧めします。こちらをクリックしてジャンプ。 このアプリケーションをダウンロードしてインストールしてください。
- 正常にインストールしたら、PowerShell(またはTerminal)で
ollamaを実行すると、以下の画像のようになります。その後、ollama run llama3.1を実行してモデルllama3.1をダウンロードして実行します。
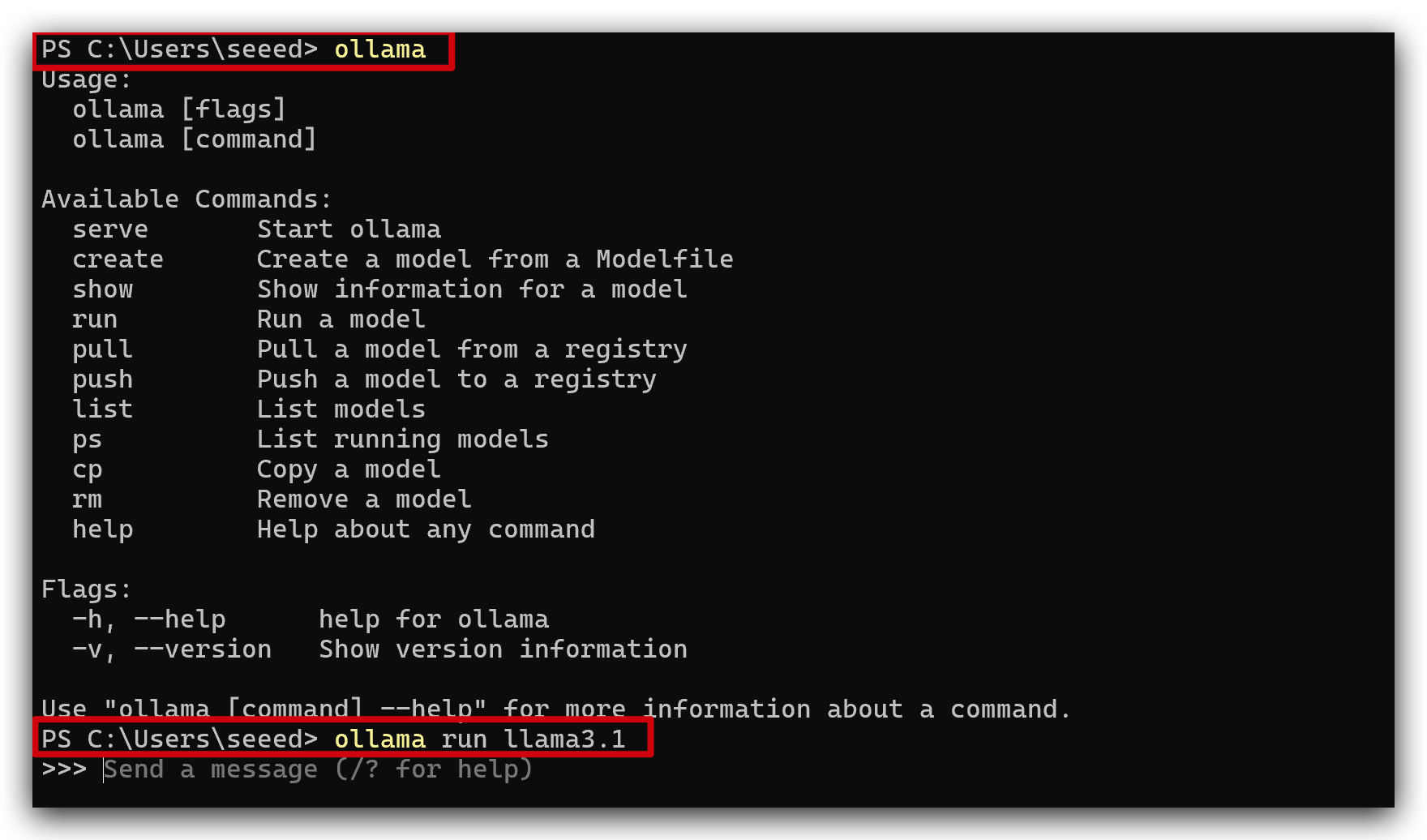
- 他のモデルを試したい場合は、こちらをクリックしてジャンプ。
ollama run xxxを実行するだけです。
- モデルのインストールと実行が正常に完了したら、続行できます。
interpreter -lコマンドを入力してInterpreterに入り、ollamaとllama3.1(先ほどダウンロードしたモデル)を選択します。
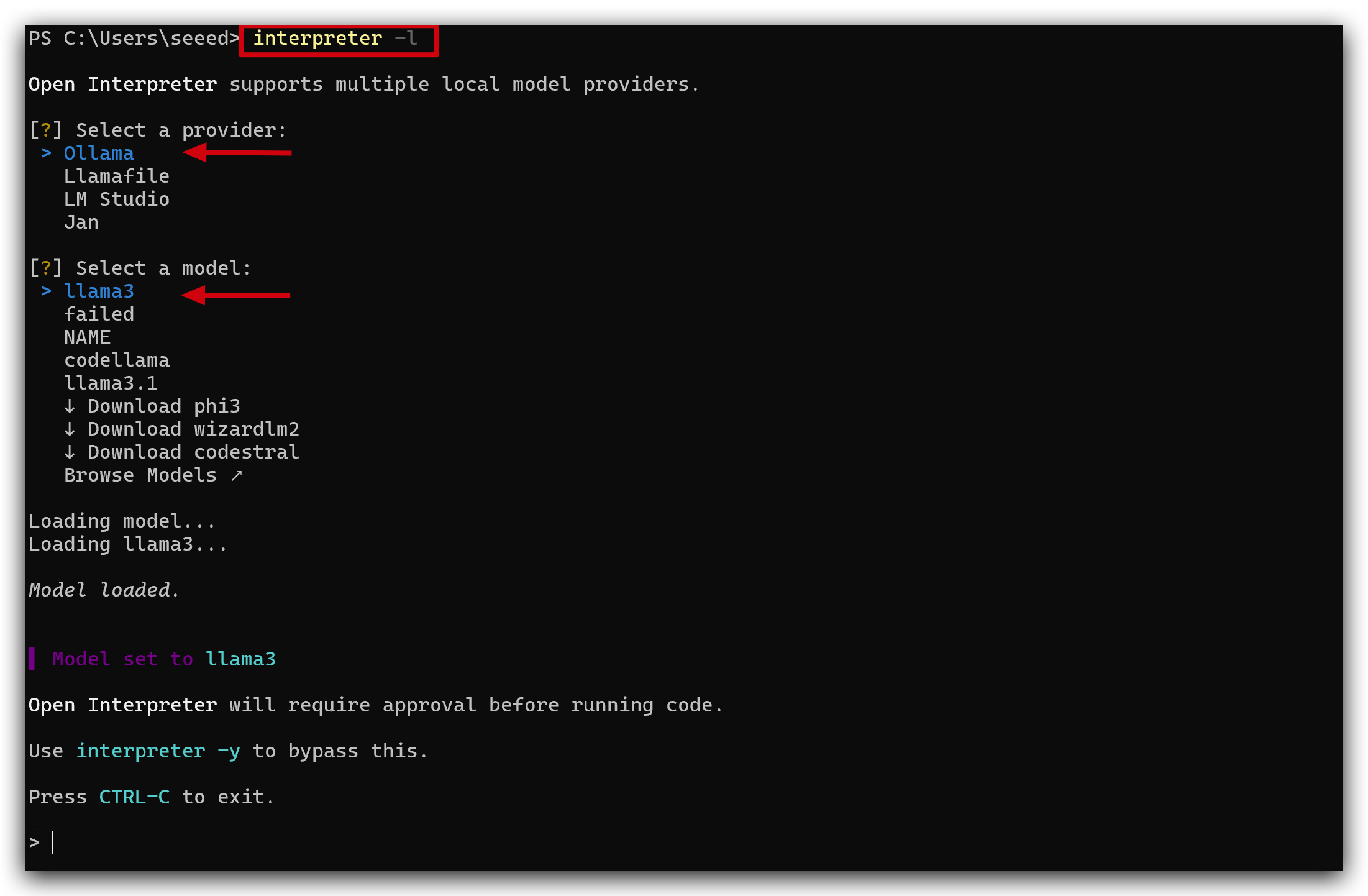
ステップ7. コマンドを実行する
Interpreterで以下のコマンドを実行するために何度も試しましたが、Interpreterの反応は毎回同じではありません。
そのため、Interpreterの反応に応じて対話する必要があります。時には再起動して再試行する必要があります。
以下は、Open Interpreterに送信した私の自然言語コマンドです。
i want you to keep listening computer port 3000 and extract the image_url and open it in browser.
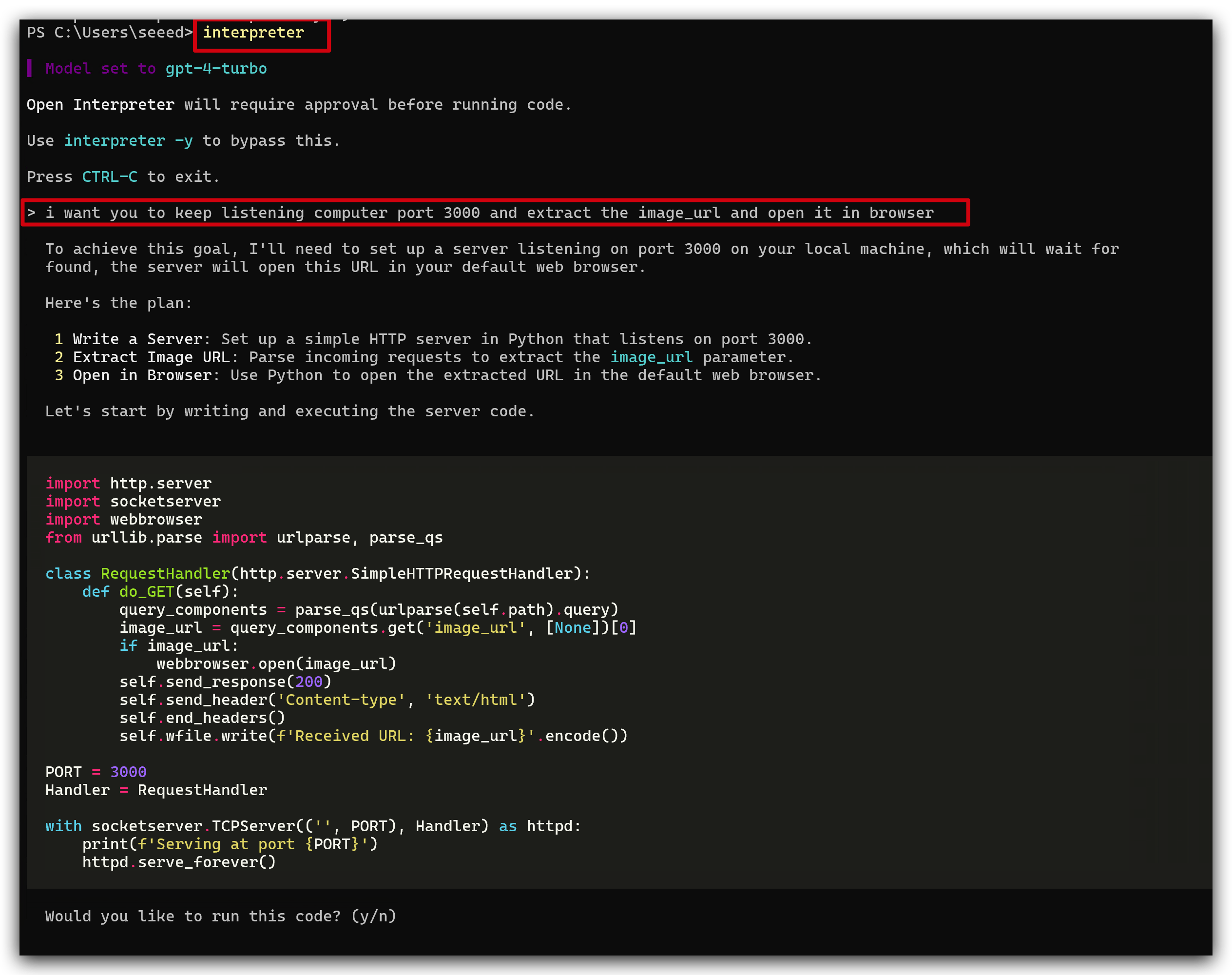
最初に、Interpreterは初期設定では簡単にするためGETリクエストのみをサポートしているが、私のリクエストはセキュリティのためPOSTであるため、サポートできないと言い、POSTリクエストを処理するようにサーバーを変更することを提案しました。私がyesと言うと、彼女は自動的に実行します。
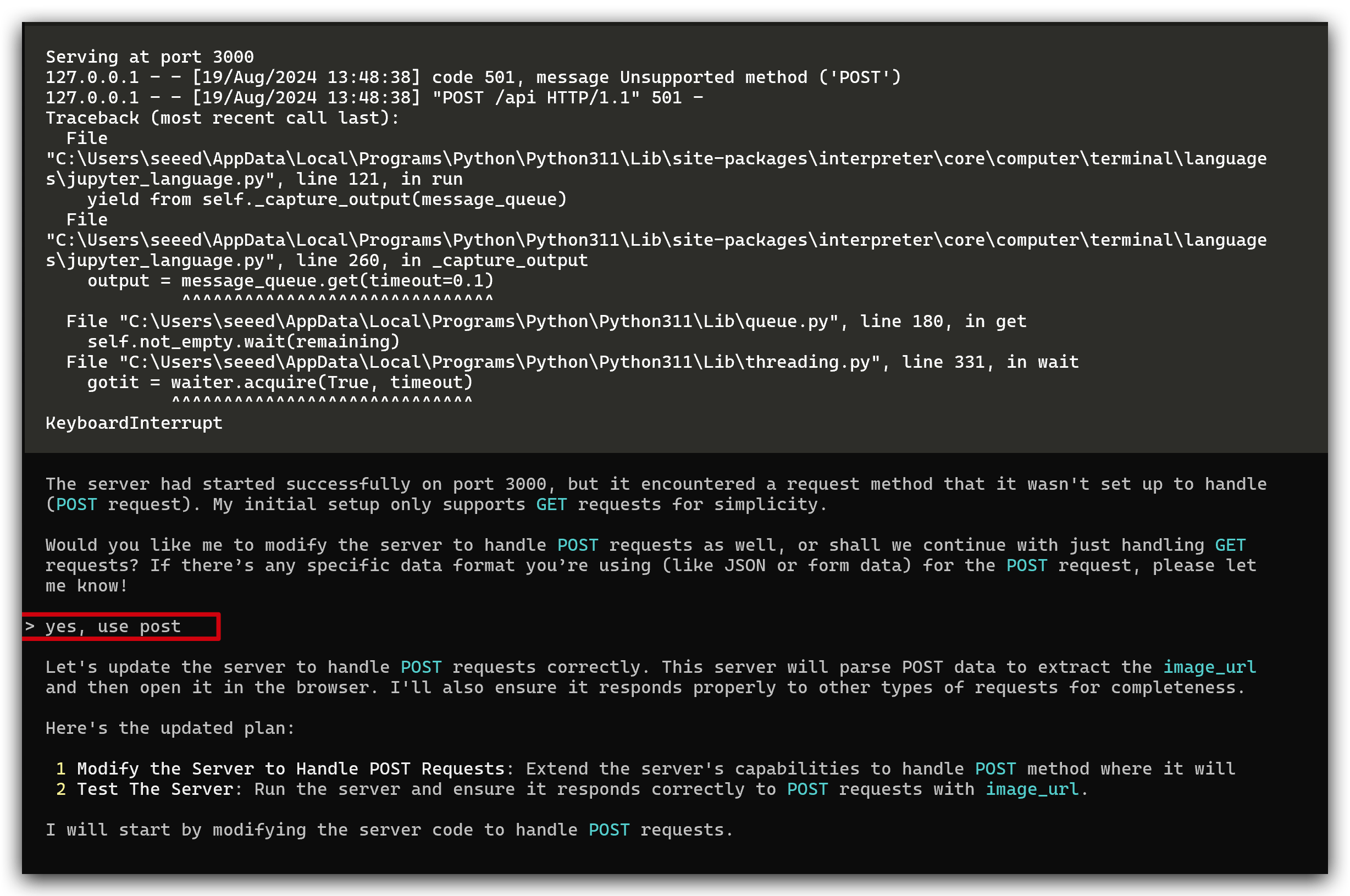
ご覧のとおり、コードは正常に実行され、ポート3000をリッスンしています。
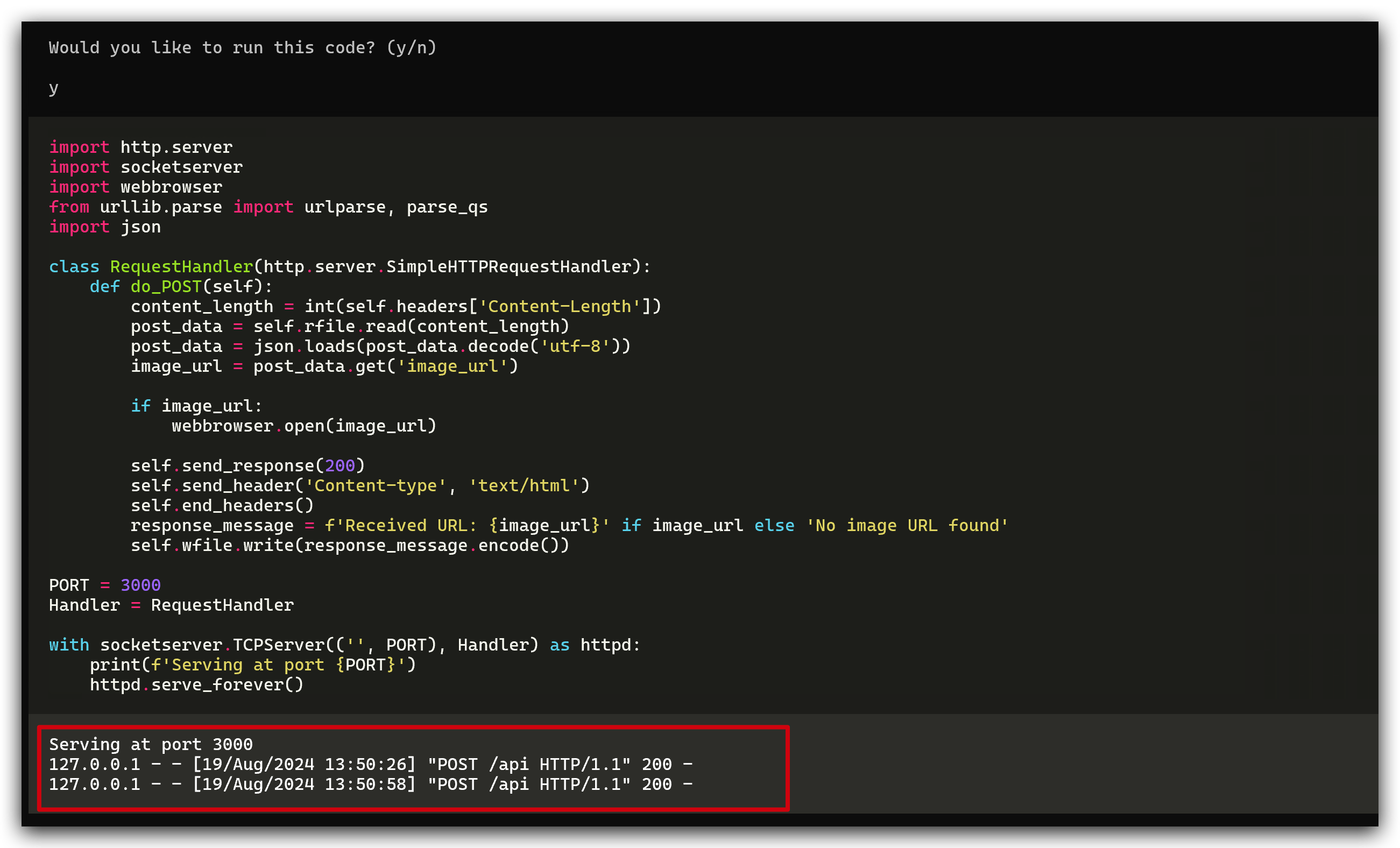
今度は、Watcherを使って自分自身を検出してみましょう。画像がキャプチャされ、ブラウザで自動的に開かれます。
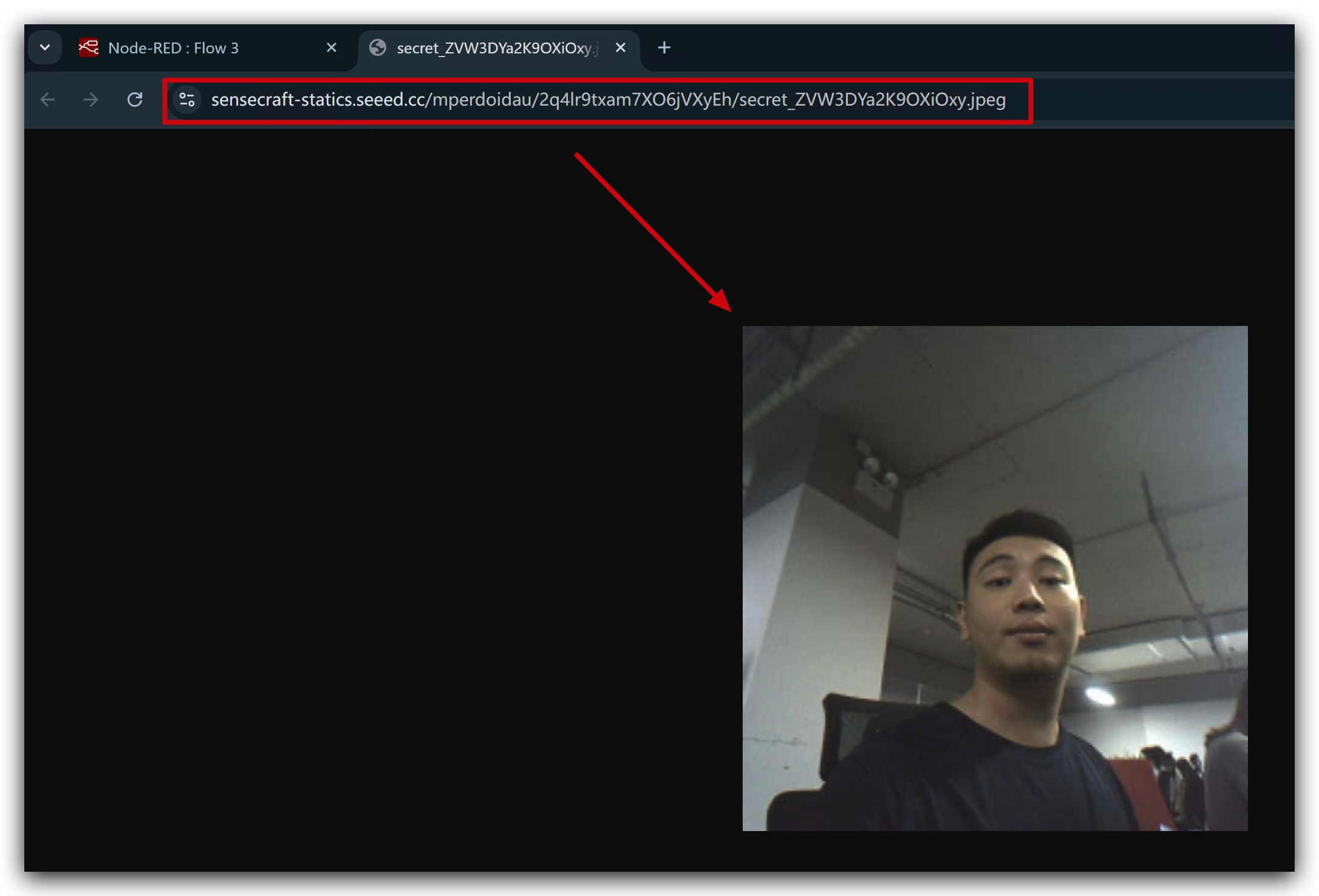
WatcherとOpen Interpreterアプリケーションの統合に成功したことをお祝いします!この成果は、あなたの献身とスキルを示す、旅路における重要な一歩です。今後、さらに魅力的な概念やツールを探求することができるでしょう。前方に待ち受ける挑戦と発見を受け入れ、このエキサイティングな冒険のすべての瞬間を楽しんでください!
技術サポート・製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。