Apache Kafkaを活用したリアルタイムIoTデータ処理ノード
私たちの最先端処理ノードKafka-ESP32は、Apache KafkaとESP32C6マイクロコントローラーの力を組み合わせて、IoTデータストリームを処理するための効率的なソリューションを提供します。XIAO ESP32C6とDHT20環境センサーを使用することで、データが収集され、ESP32C6を介してApache Kafkaにシームレスに送信されます。Kafkaの高スループット、低レイテンシメッセージング機能により、リアルタイムデータ処理と分析が可能になり、その分散アーキテクチャにより簡単にスケーラビリティを実現できます。Kafka-ESP32は、カスタムアプリケーションと統合の開発を可能にし、今日のデータ駆動型環境でIoTアセットを管理・活用する方法を革新します。
必要な材料
この例では、XIAO ESP32C6とGrove DHT20温湿度センサーを使用して、AWS IoT CoreのSageMakerタスクを完了する方法を紹介します。以下は、このルーチンを完了するために必要なすべてのハードウェアデバイスです。



Docker インストール
なぜ Docker を使用するのでしょうか?Docker は単一のマシン上で複数のコンピューターの環境をシミュレートし、アプリケーションを非常に簡単にデプロイできるからです。そのため、このプロジェクトでは Docker を使用して環境をセットアップし、効率を向上させます。
ステップ 1. Docker をダウンロード
お使いのコンピューターに応じて、異なるタイプのインストーラーをダウンロードしてください。こちらをクリックしてジャンプしてください。
お使いのコンピューターが Windows の場合、ステップ 2 を完了するまで docker をインストールしないでください。
ステップ 2. WSL(Windows Subsystem for Linux) をインストール
このステップは Windows 用です。お使いのコンピューターが Mac または Linux の場合、このステップをスキップできます。
- 管理者として以下のコードを実行してください。
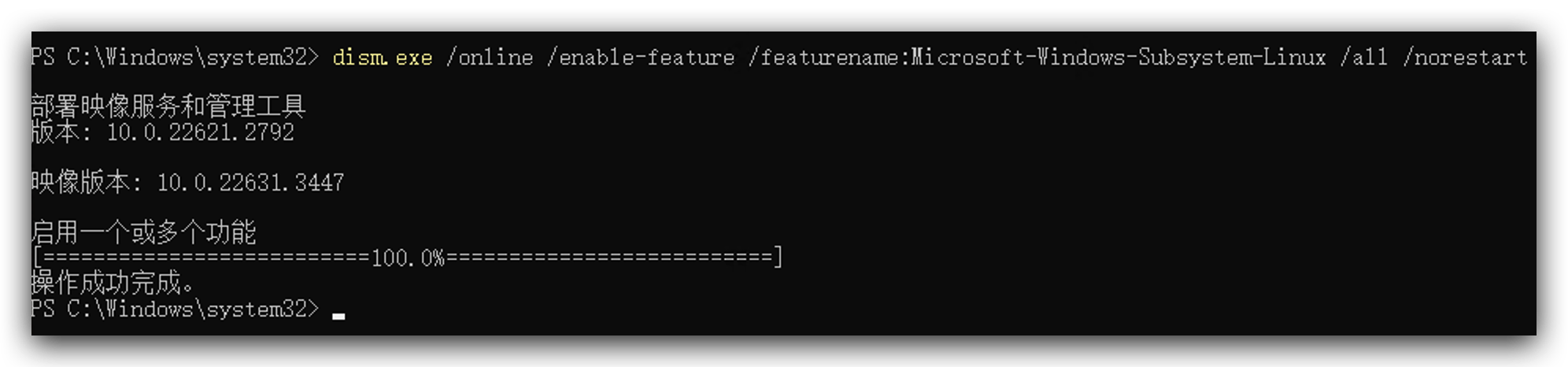
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
-
こちらからこのツールをダウンロードし、ダブルクリックしてインストールします。
-
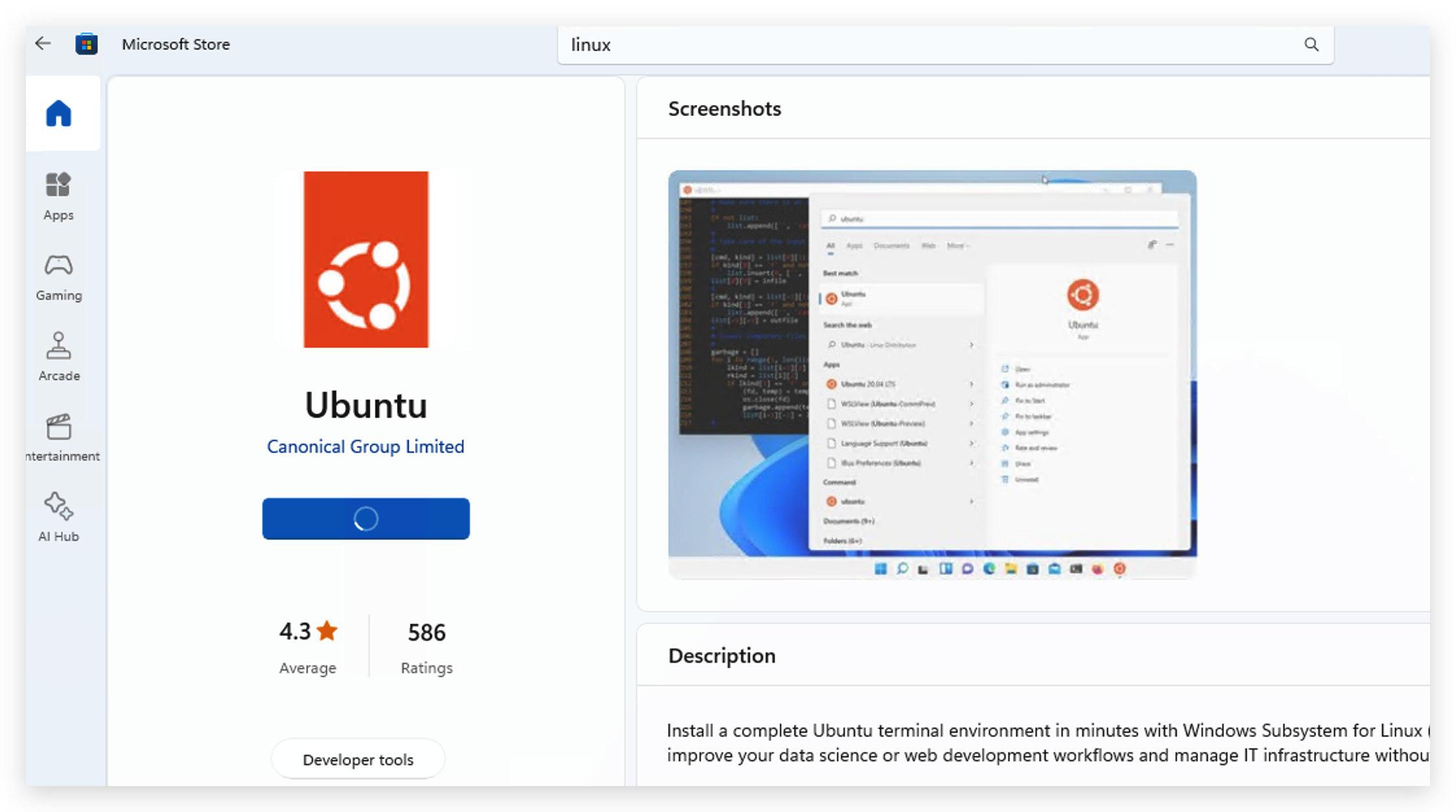
Microsoft Storeに移動して、お好みのLinuxバージョンを検索してダウンロードします。ここではUbuntuをインストールしました。
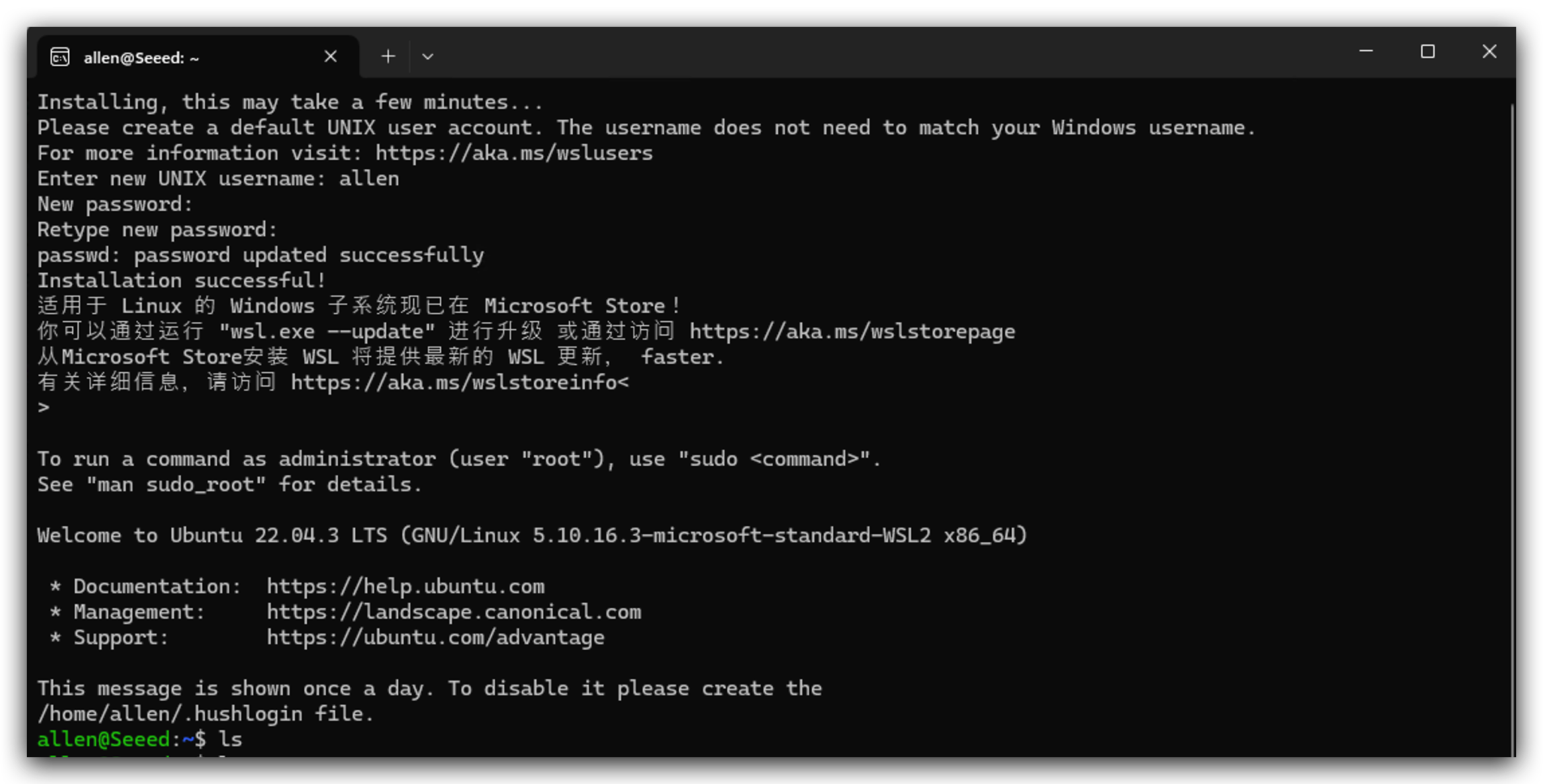
- Linuxをインストールした後、それを開いてユーザー名とパスワードを設定し、初期化のために1分ほど待つ必要があります。
- 以下の指示に従ってWSLを使用します。
- WSLをインストールした後、dockerインストーラーをダブルクリックしてインストールできます。以下の画像が表示されれば動作しています。
サービスのデプロイ
開始する前に、このプロジェクトの各サービスの機能を紹介したいと思います。
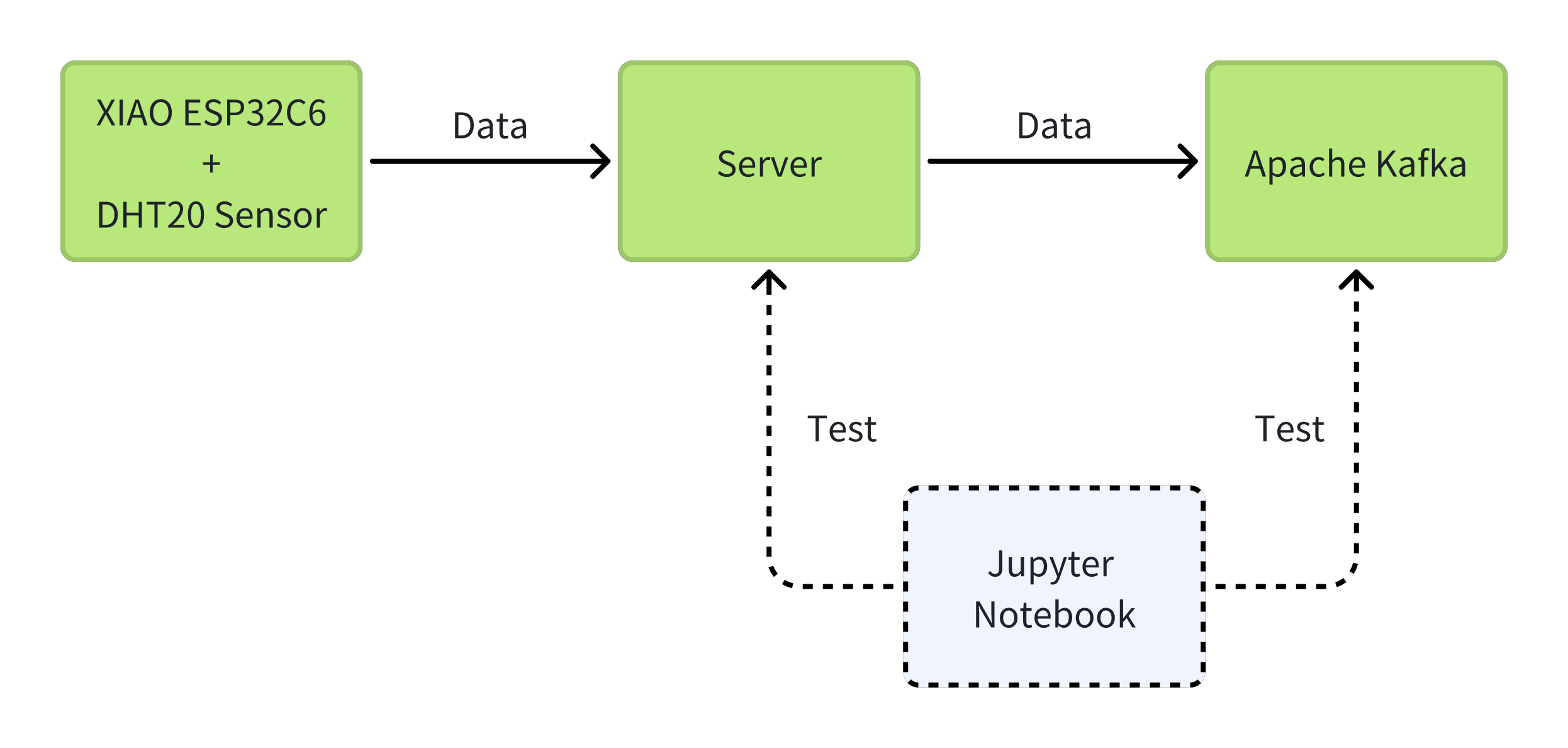
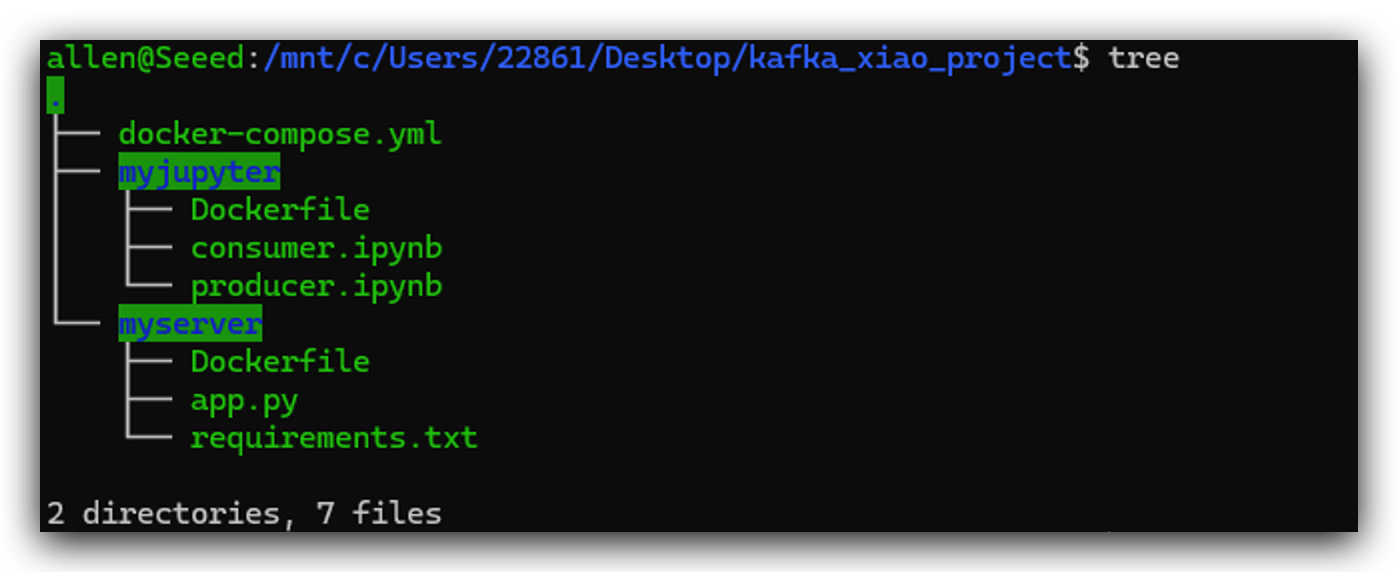
こちらは参考用のプロジェクトディレクトリ構造です。以下の手順でこれらのファイルを一つずつ作成します。各ファイルの位置は非常に重要です。このディレクトリ構造を参照することを強くお勧めします。kafka_xiao_projectディレクトリを作成し、これらのファイルを含めてください。
ステップ3. Pythonサーバーのデプロイ
MCUデバイスの性能不足により、kafkaのクライアントとして直接使用することはできません。そのため、データ転送を行うサーバーを構築する必要があります。このステップでは、Pythonでシンプルなサーバーを構築します。XIAO ESP32C6は主にDHT20から環境データを収集し、サーバーに送信します。
- まず、サーバーが行う処理であるapp.pyファイルを作成する必要があります。
from flask import Flask
from kafka import KafkaProducer, KafkaConsumer
app = Flask(__name__)
@app.route('/favicon.ico')
def favicon():
return '', 204
@app.route('/<temperature>/<humidity>')
def send_data(temperature, humidity):
producer = KafkaProducer(bootstrap_servers='kafka:9092')
data = f'Temperature: {temperature}, Humidity: {humidity}'
producer.send('my_topic', data.encode('utf-8'))
return f'Temperature: {temperature}, Humidity: {humidity}'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)
- requirements.txt を作成します。これは依存関係ライブラリです。
flask
kafka-python
- Dockerfileを作成する
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
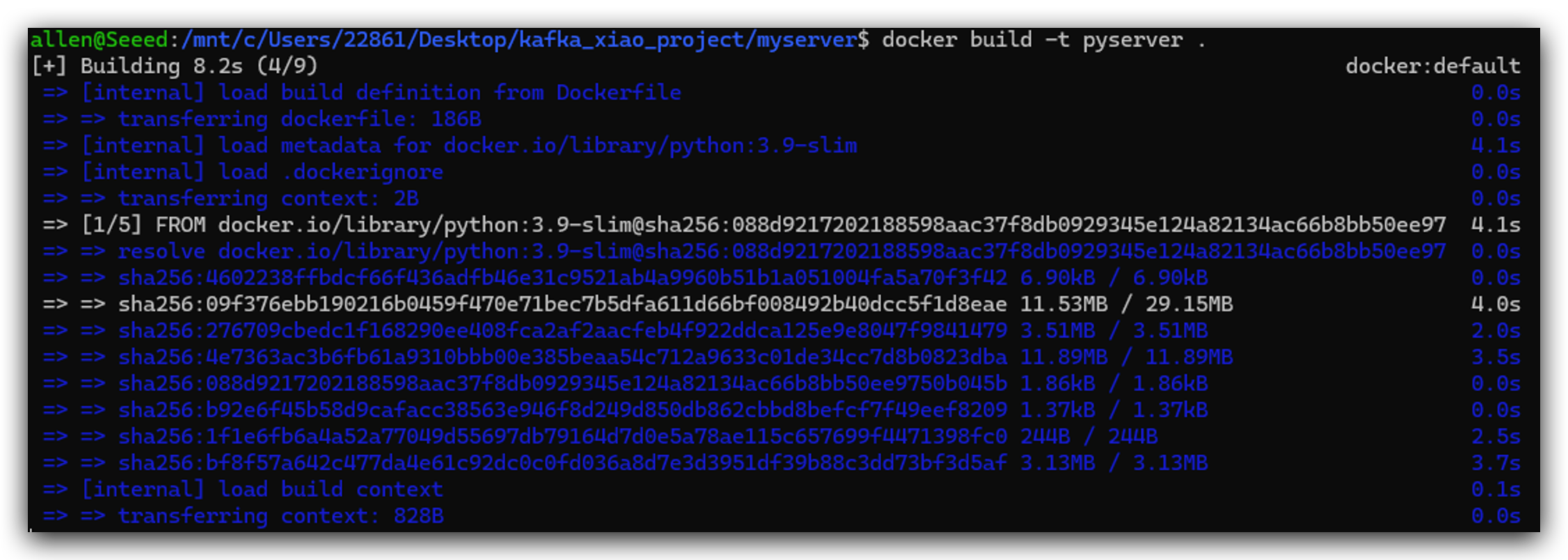
- これら3つのファイルを作成した後、以下のコードを実行してDockerイメージをビルドできます。
docker build -t pyserver .
ステップ4. Jupyter Notebookのデプロイ
Jupyter Notebookは主にデバッグに使用され、非常に優れたツールです。また、PythonでKafkaを操作することもできます。
- まずDockerfileを作成します。
FROM python:3.9
RUN pip install jupyter
WORKDIR /notebook
EXPOSE 8888
CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]
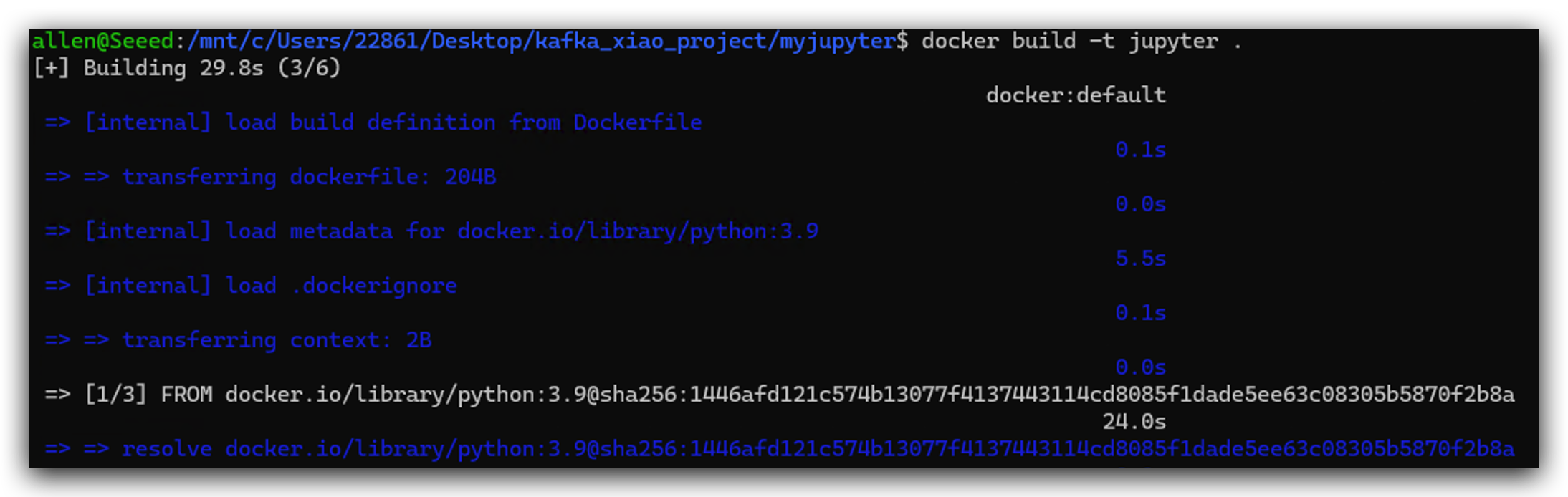
- jupyter dockerイメージをビルドします。
docker build -t jupyter .
ステップ 5. Docker クラスターの起動
docker-compose.yml を使用して docker クラスターを構築できます。docker-compose の各サービスは独立したコンピューターを表し、kafka-net を使用してそれらを相互に接続します。
- まず docker-compose.yml を作成する必要があります。
services:
zookeeper:
container_name: zookeeper
hostname: zookeeper
image: docker.io/bitnami/zookeeper
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- kafka-net
kafka:
container_name: kafka
hostname: kafka
image: docker.io/bitnami/kafka
ports:
- "9092:9092"
- "9093:9093"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_BROKER_ID=0
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
depends_on:
- zookeeper
networks:
- kafka-net
jupyter:
image: jupyter:latest
depends_on:
- kafka
volumes:
- ./myjupyter:/notebook
ports:
- "8888:8888"
environment:
- JUPYTER_ENABLE_LAB=yes
networks:
- kafka-net
pyserver:
image: pyserver:latest
depends_on:
- kafka
volumes:
- ./myserver/app.py:/app/app.py
ports:
- "5001:5001"
networks:
- kafka-net
networks:
kafka-net:
driver: bridge
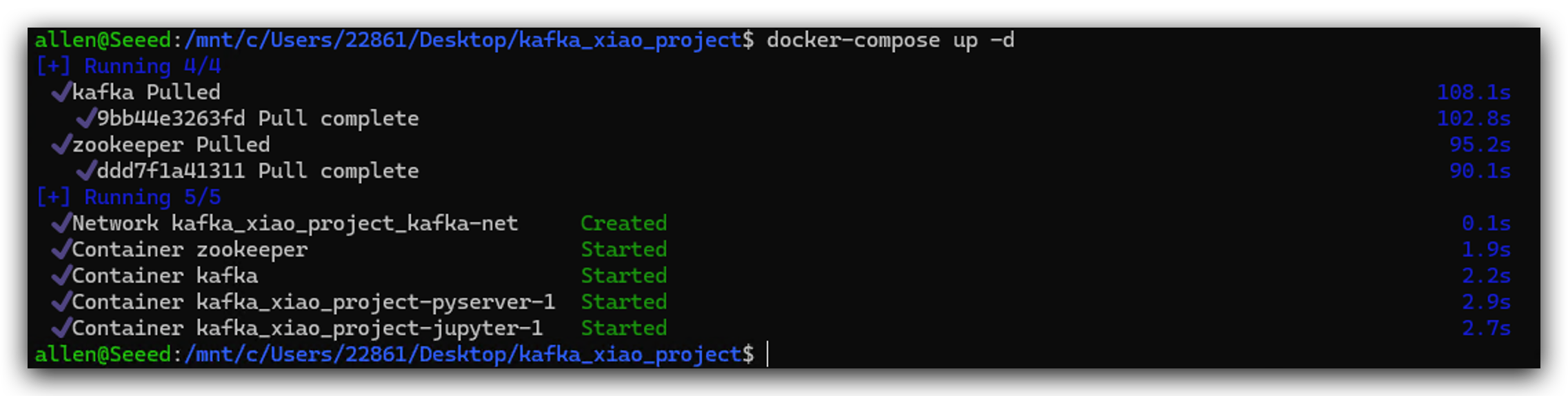
- 次に、以下のコマンドを実行してこのdockerクラスターを起動します。
docker-compose up -d
ポートが占有されている可能性があります。ポートを5001から5002などに変更するか、ポートを占有しているアプリケーションを閉じることができます。
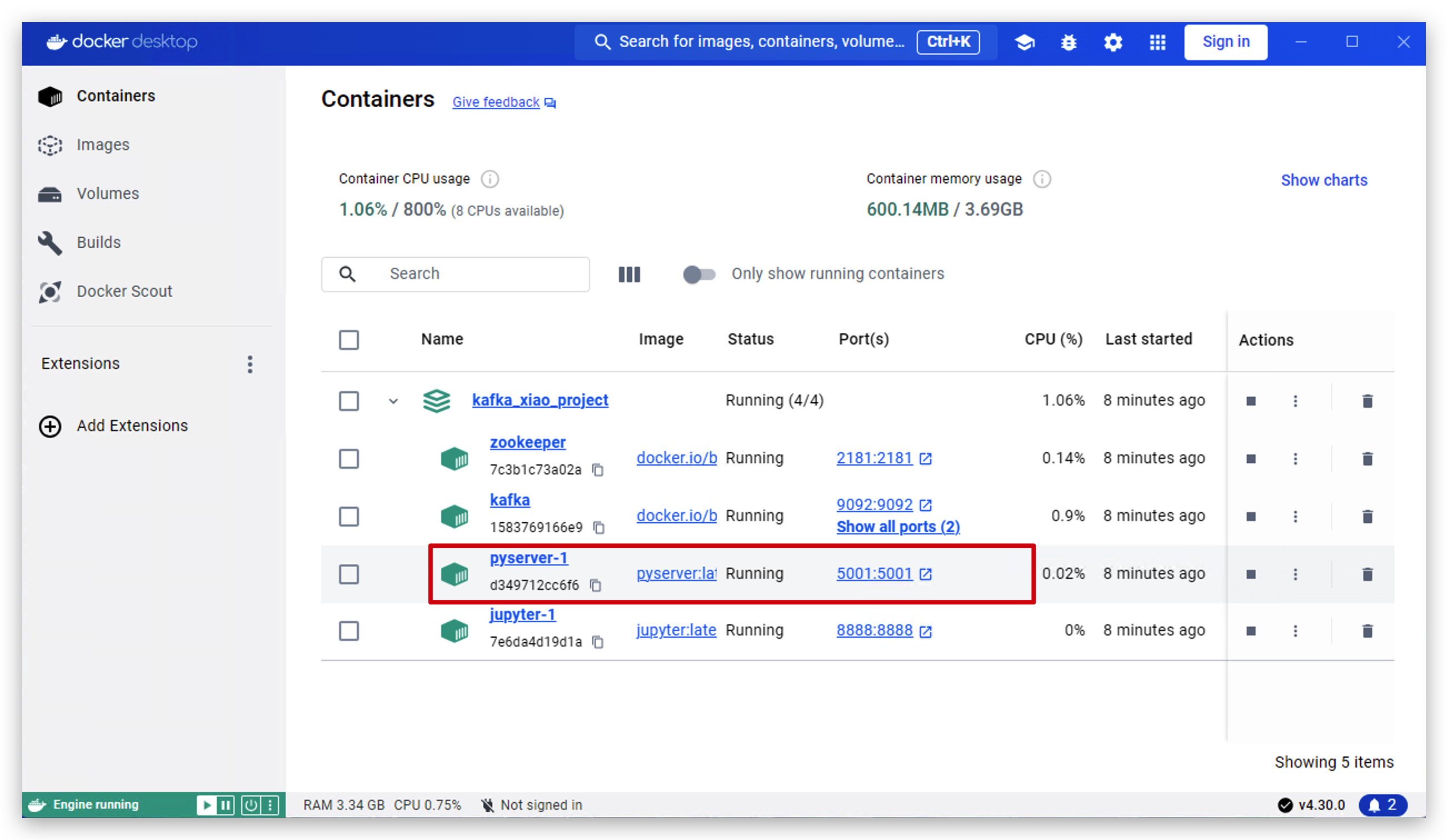
- 次のいくつかの操作で、正常に動作するかどうかをテストします。まず、ソフトウェア docker desktop を開き、pyserver をクリックします。
- これで、サーバーが
http://127.0.0.1:5001で実行されています。このリンクをクリックして開きます。
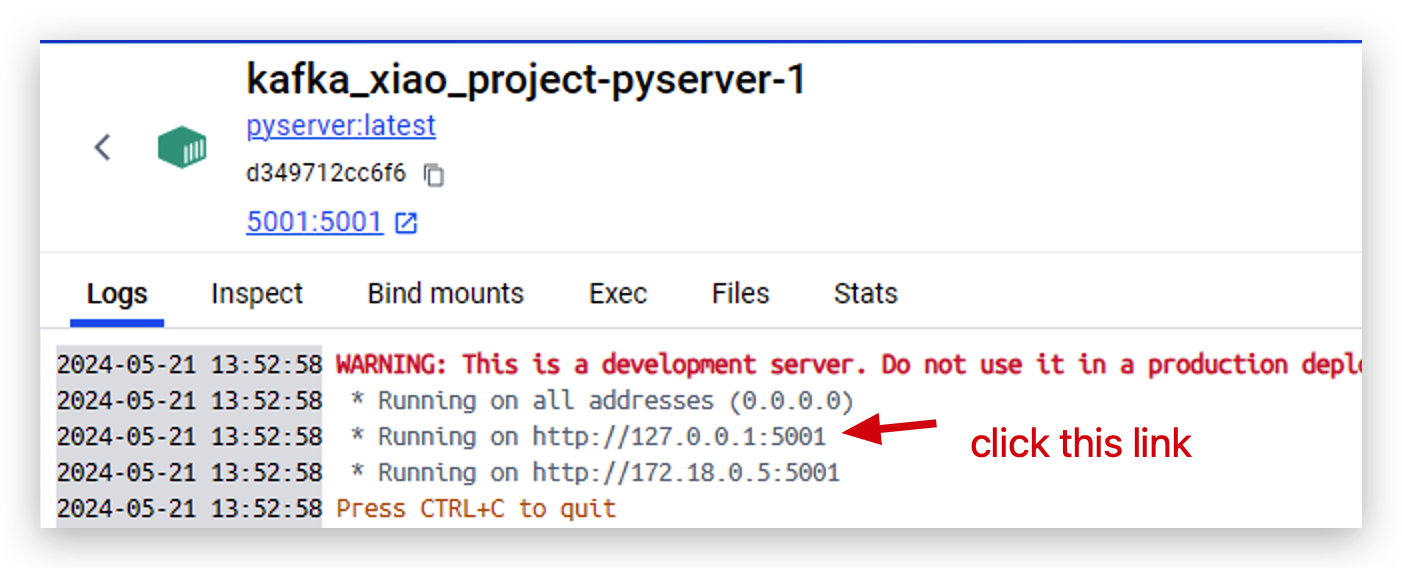
- そして、dockerクラスターが正常に動作しているかをテストするために、このような形式で2つのパラメータを入力します。
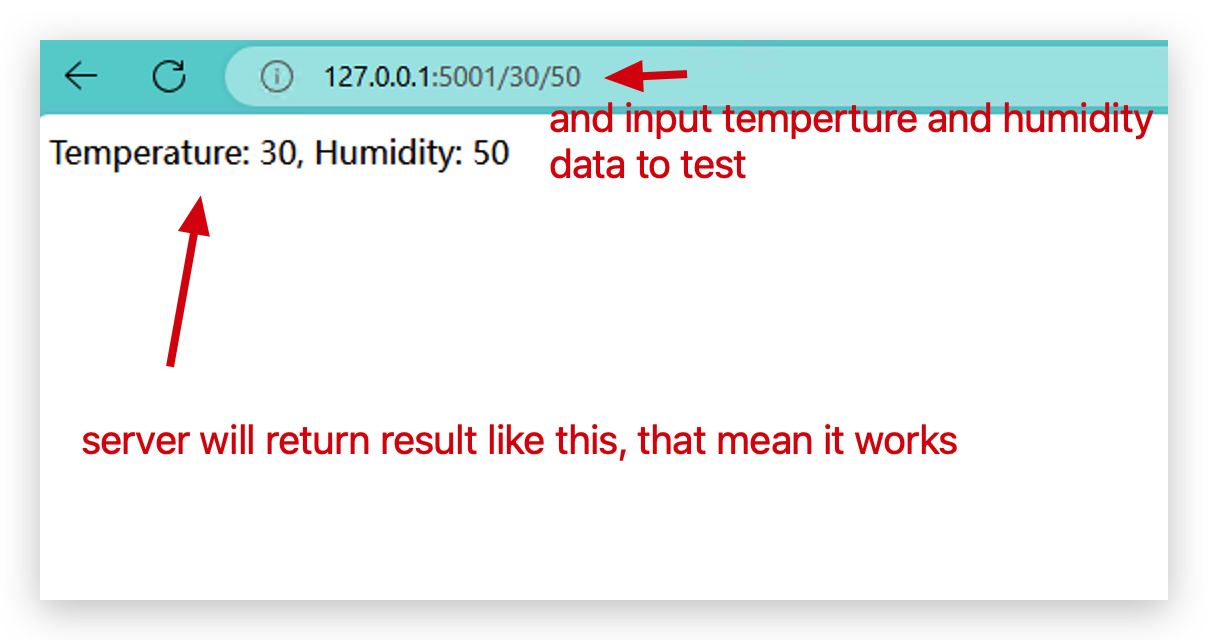
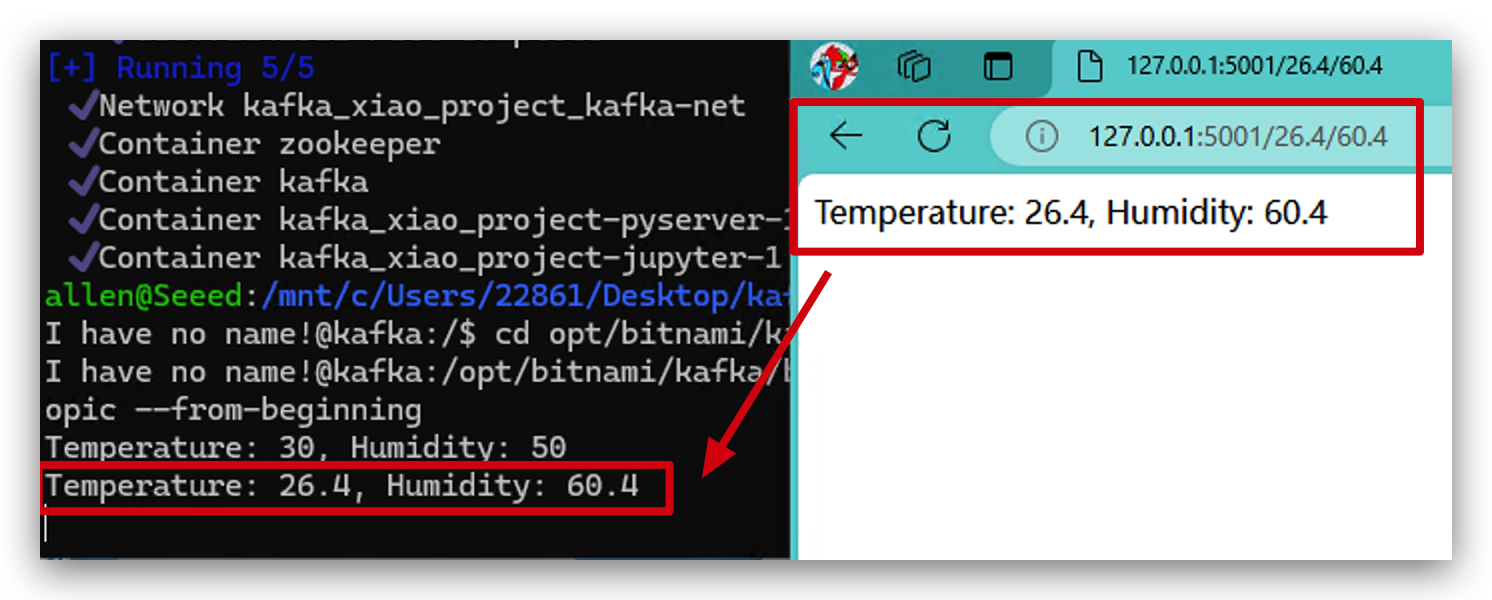
- データがKafkaに送信されたかどうかを確認するために、Kafkaの内部を見てみます。
docker exec -it kafka bash
cd opt/bitnami/kafka/bin/
kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic my_topic --from-beginning

- 異なるパラメータで再度試すことができ、データが即座にKafkaに送信されることが確認できます。これで、おめでとうございます!Dockerクラスターが完璧に動作しています。
ステップ7. PythonでKafkaをテストする
このステップは主にPythonを使用してKafkaを操作する方法についてです。このステップをスキップすることもできます。プロジェクト全体の動作には影響ありません。
- Docker Desktopを開き、jupyterをクリックします。
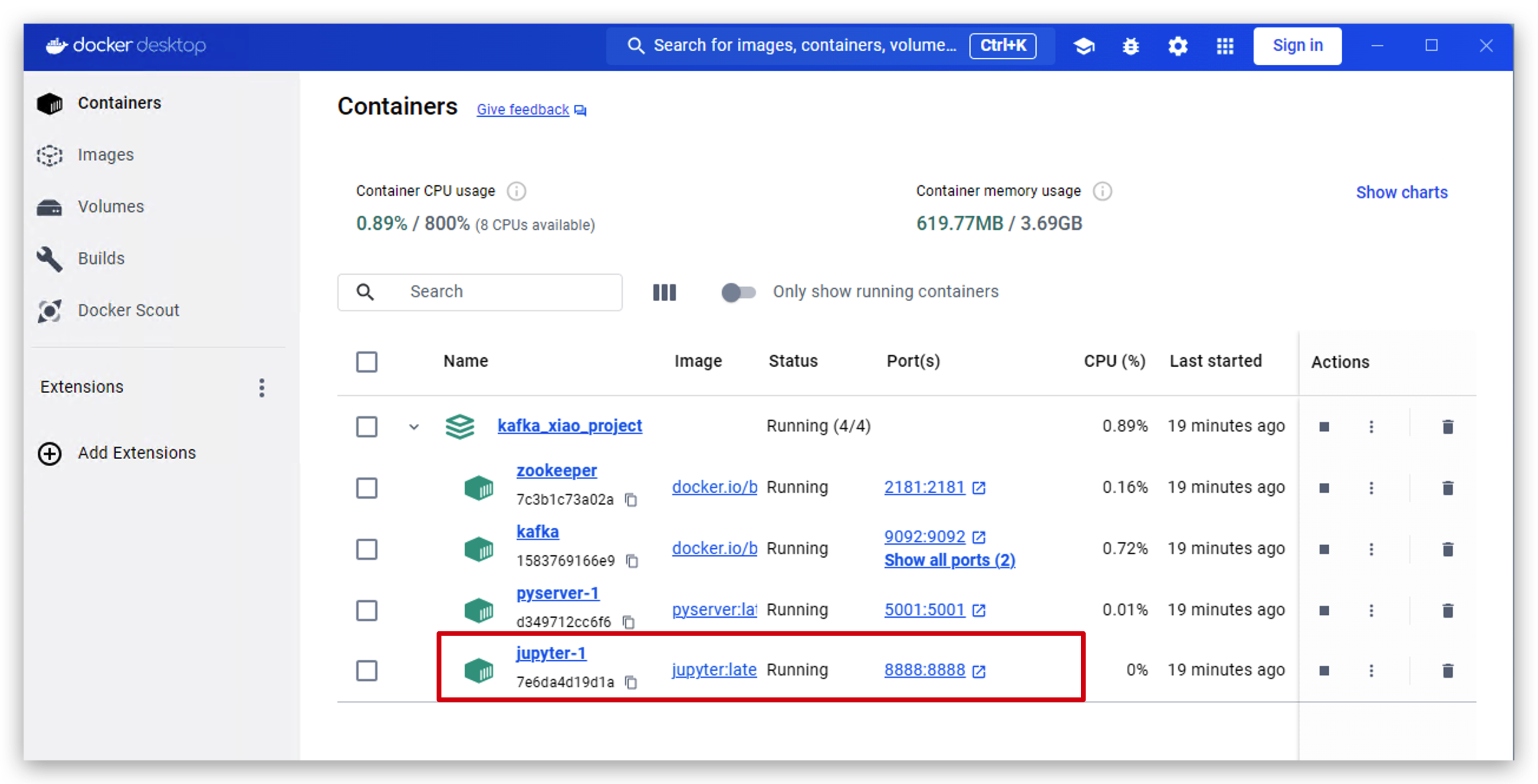
- このリンクをクリックしてjupyterにアクセスします。
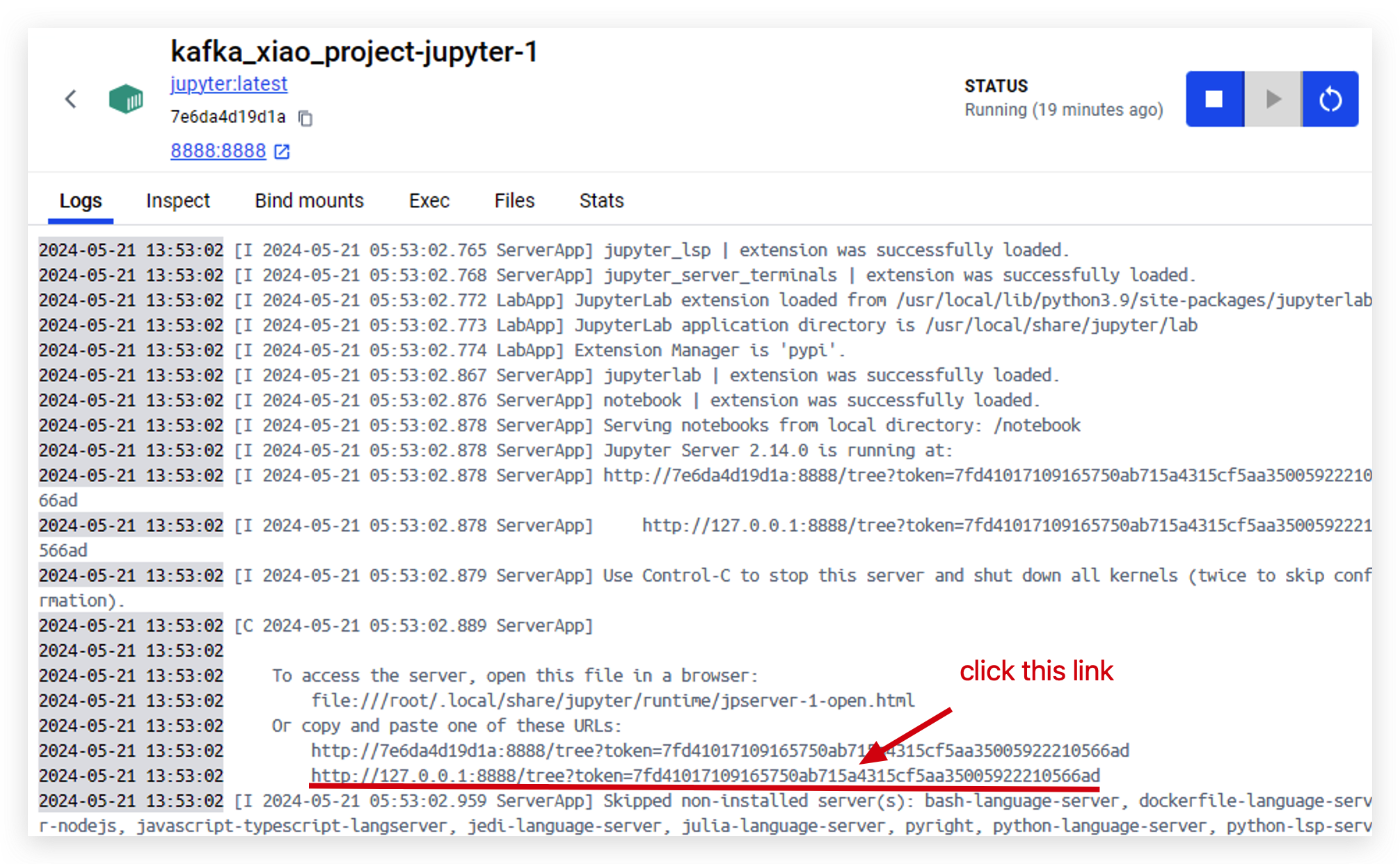
- jupyterに正常にアクセスすると、このページが表示されます。
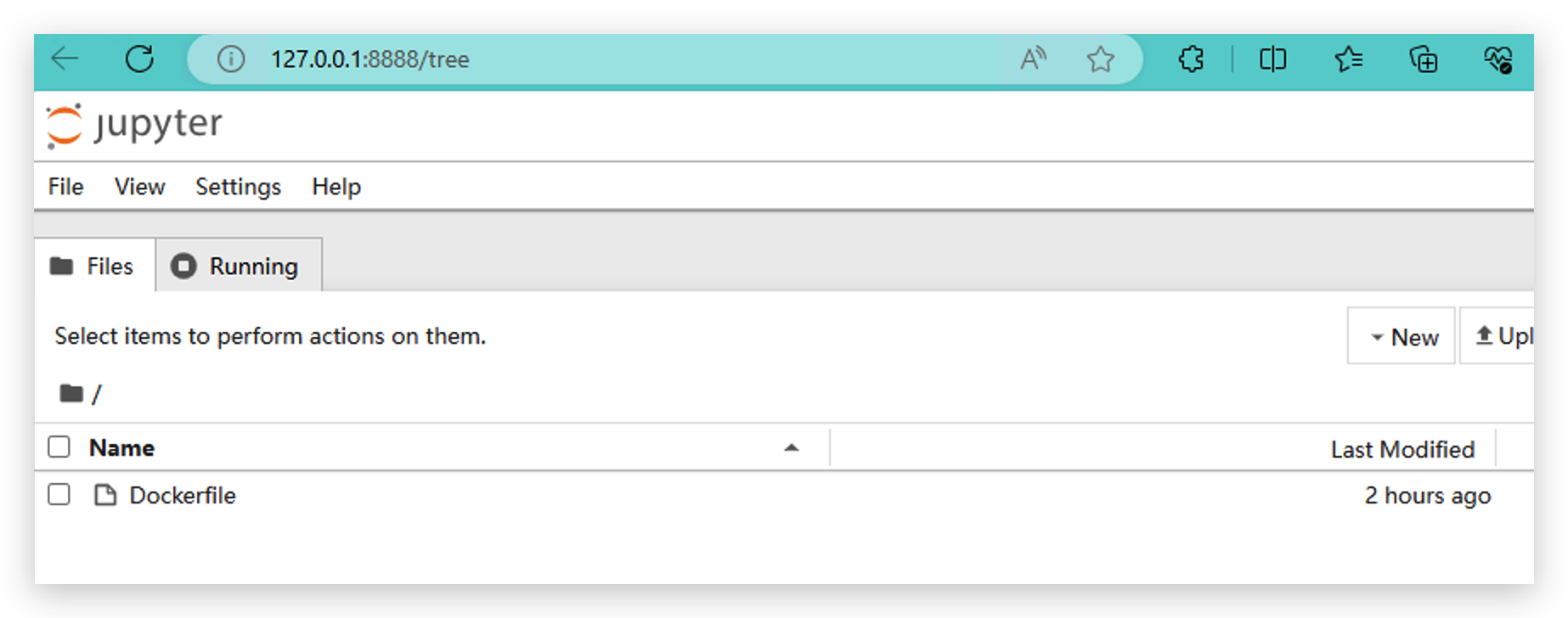
- 右クリックしてNew Notebookを作成し、Python3(ipykernel)を使用します。
pip install kafka-pythonを実行してkafka-pythonライブラリをインストールします。
- そのライブラリをインストールした後、jupyterを再起動する必要があります。
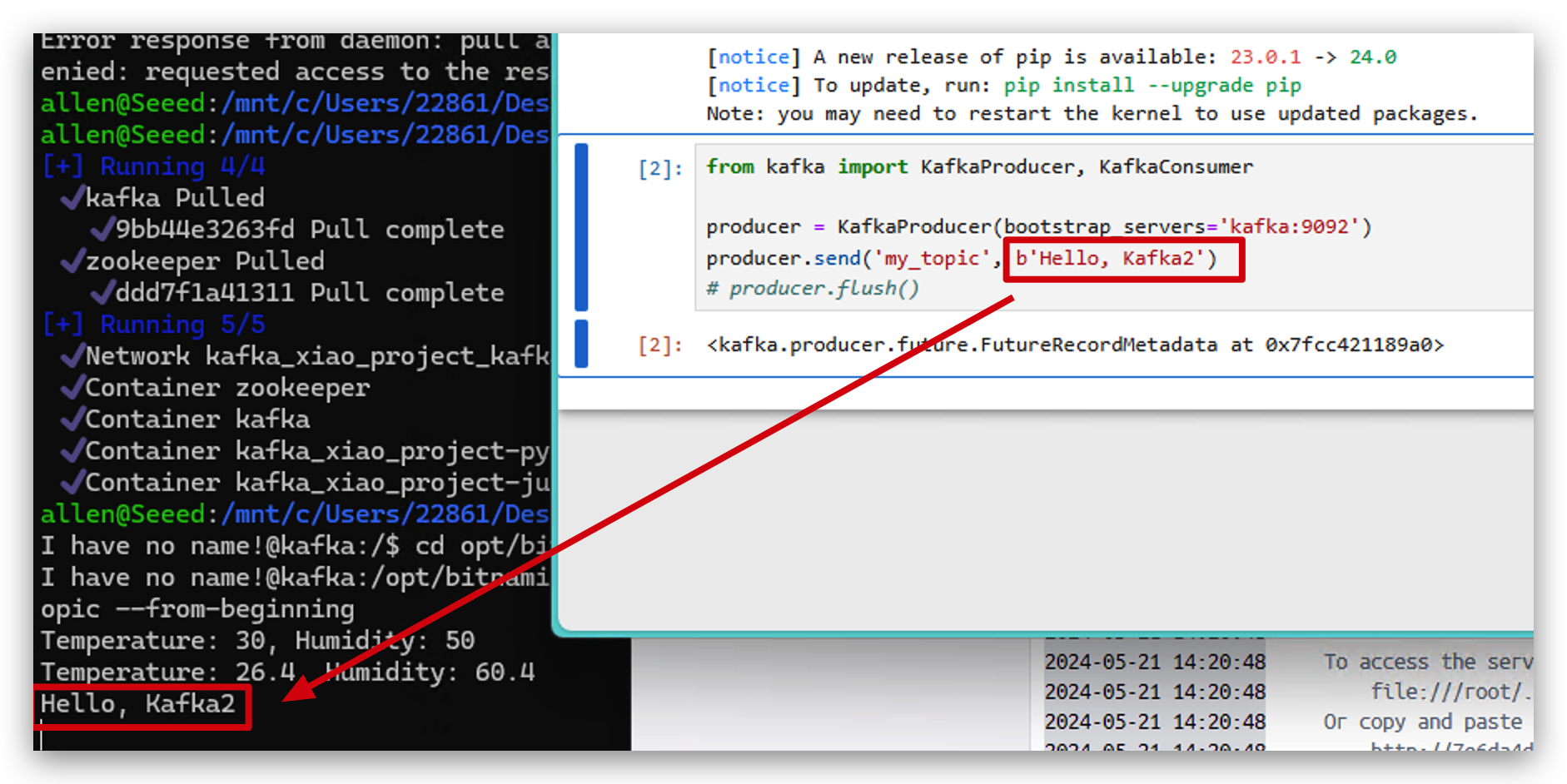
- 次に、以下のコードを実行してPythonでKafkaにデータを送信します。
from kafka import KafkaProducer, KafkaConsumer
#initialize producer
producer = KafkaProducer(bootstrap_servers='localhost:9093')
#send message
producer.send('my_topic', b'Hello, Kafka2')
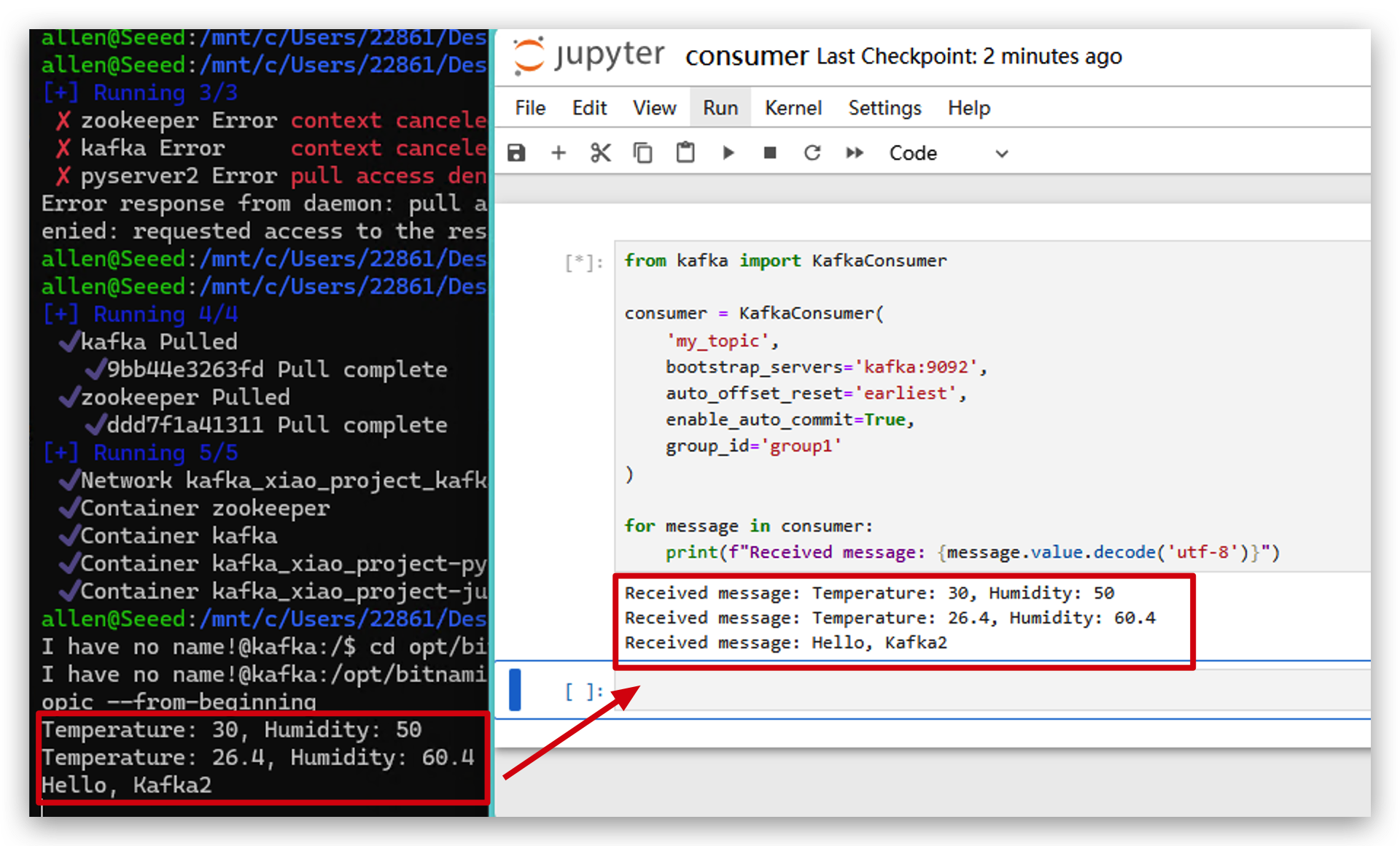
- また、これらのデータをkafkaで確認することもできます。
from kafka import KafkaConsumer
# initialize consumer
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers='localhost:9093',
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='group1'
)
# receive data and print
for message in consumer:
print(f"Received message: {message.value.decode('utf-8')}")
XIAO ESP32C6 と Apache Kafka
Kafka は、大規模なデータストリームのリアルタイム処理を可能にする分散ストリーミングプラットフォームです。システム間でのデータのパブリッシュ・サブスクライブメッセージングを可能にし、フォルトトレラント性、永続性、高スループットを提供します。Kafka は、様々な分野でリアルタイムデータパイプラインとストリーミングアプリケーションの構築に広く使用されています。
今回は、XIAO ESP32C6 と DHT20 温湿度センサーを使用してデータを収集し、リアルタイムで Kafka に送信します。
ステップ 8. データを収集して Apache Kafka に送信する
- 以下のコードを Arduino IDE にコピーしてください。
#include <WiFi.h>
#include <HTTPClient.h>
//Change to your wifi name and password here.
const char* ssid = "Maker_2.4G";
const char* password = "15935700";
//Change to your computer IP address and server port here.
const char* serverUrl = "http://192.168.1.175:5001";
void setup() {
Serial.begin(115200);
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) {
delay(1000);
Serial.println("Connecting to WiFi...");
}
Serial.println("Connected to WiFi");
}
void loop() {
if (WiFi.status() == WL_CONNECTED) {
HTTPClient http;
//Create access link
String url = serverUrl;
url += "/";
url += "30.532"; // tempertature
url += "/";
url += "60.342"; // humidity
http.begin(url);
int httpResponseCode = http.GET();
//Get http response and print
if (httpResponseCode == 200) {
String response = http.getString();
Serial.println("Server response:");
Serial.println(response);
} else {
Serial.print("HTTP error code: ");
Serial.println(httpResponseCode);
}
http.end();
} else {
Serial.println("WiFi disconnected");
}
delay(5000); // access server in every 5s.
}
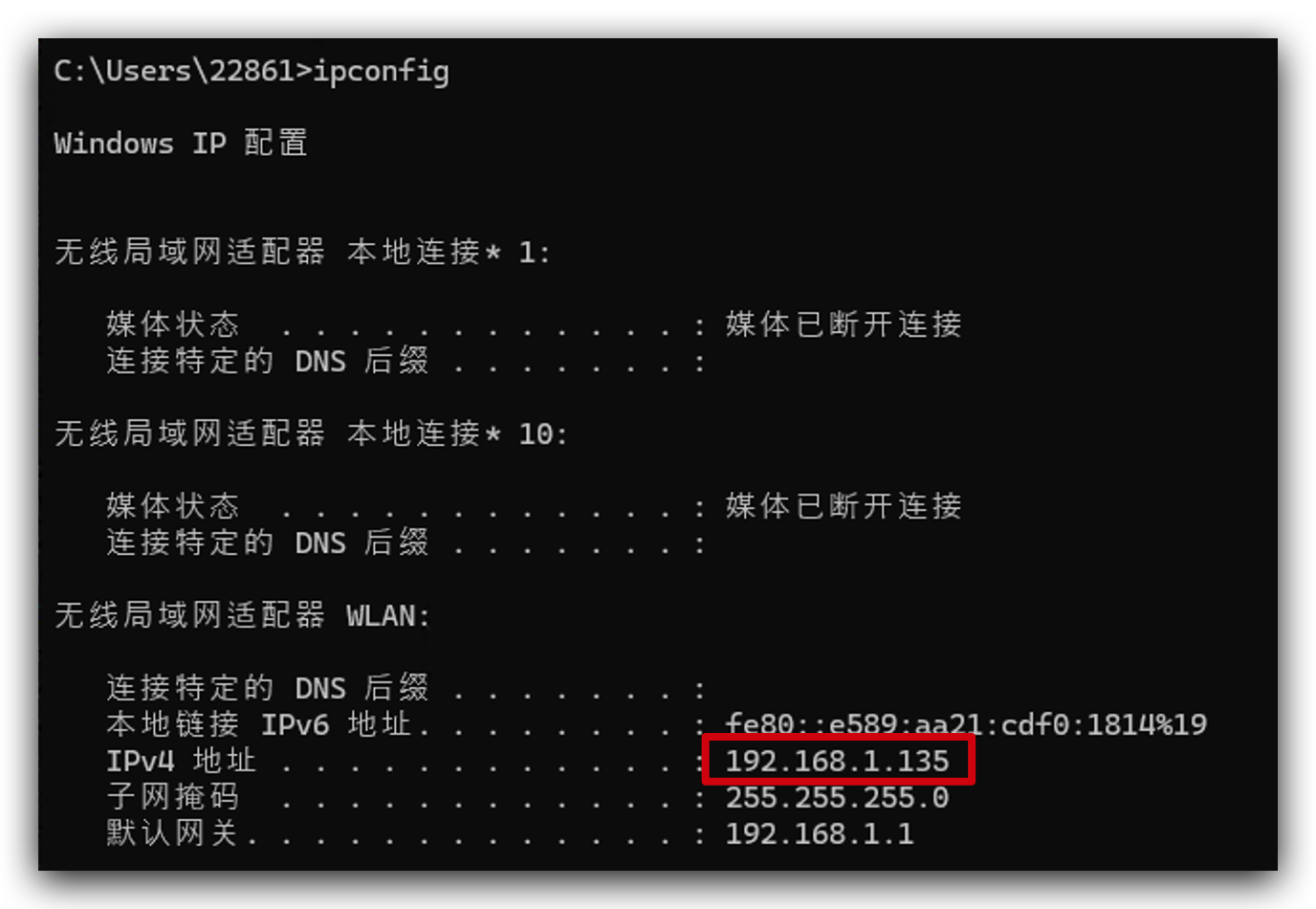
コンピュータのIPアドレスがわからない場合は、ipconfig(Windows)またはifconfig | grep net(MacまたはLinux)を実行して確認できます。
- Type-Cケーブルを使用してコンピュータをC6に接続し、Groveケーブルを使用してXIAO拡張ボードのI2CポートをDHT20センサーに接続します。

- 開発ボードを選択します。
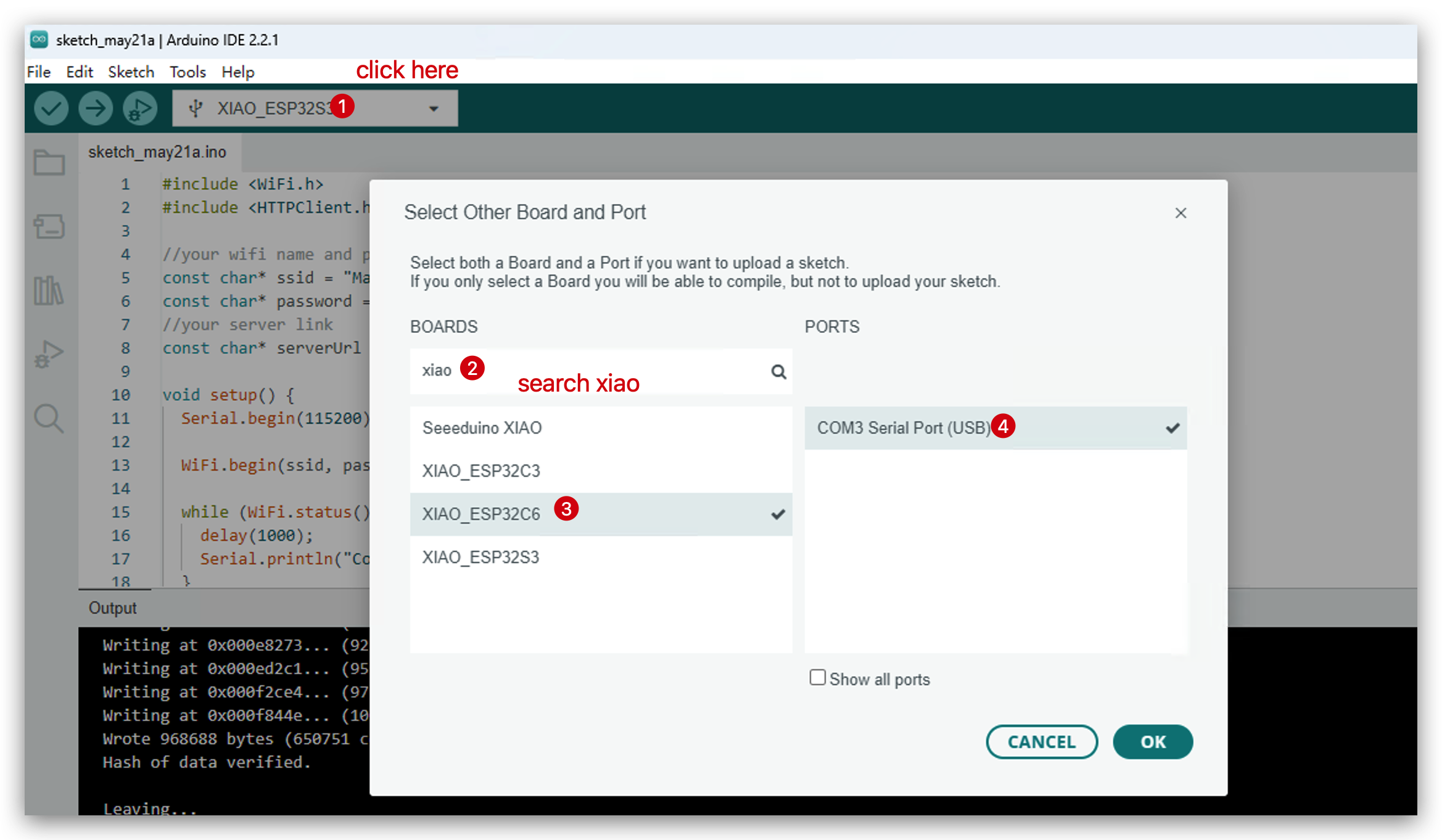
- コードをアップロードし、シリアルモニターを開きます。
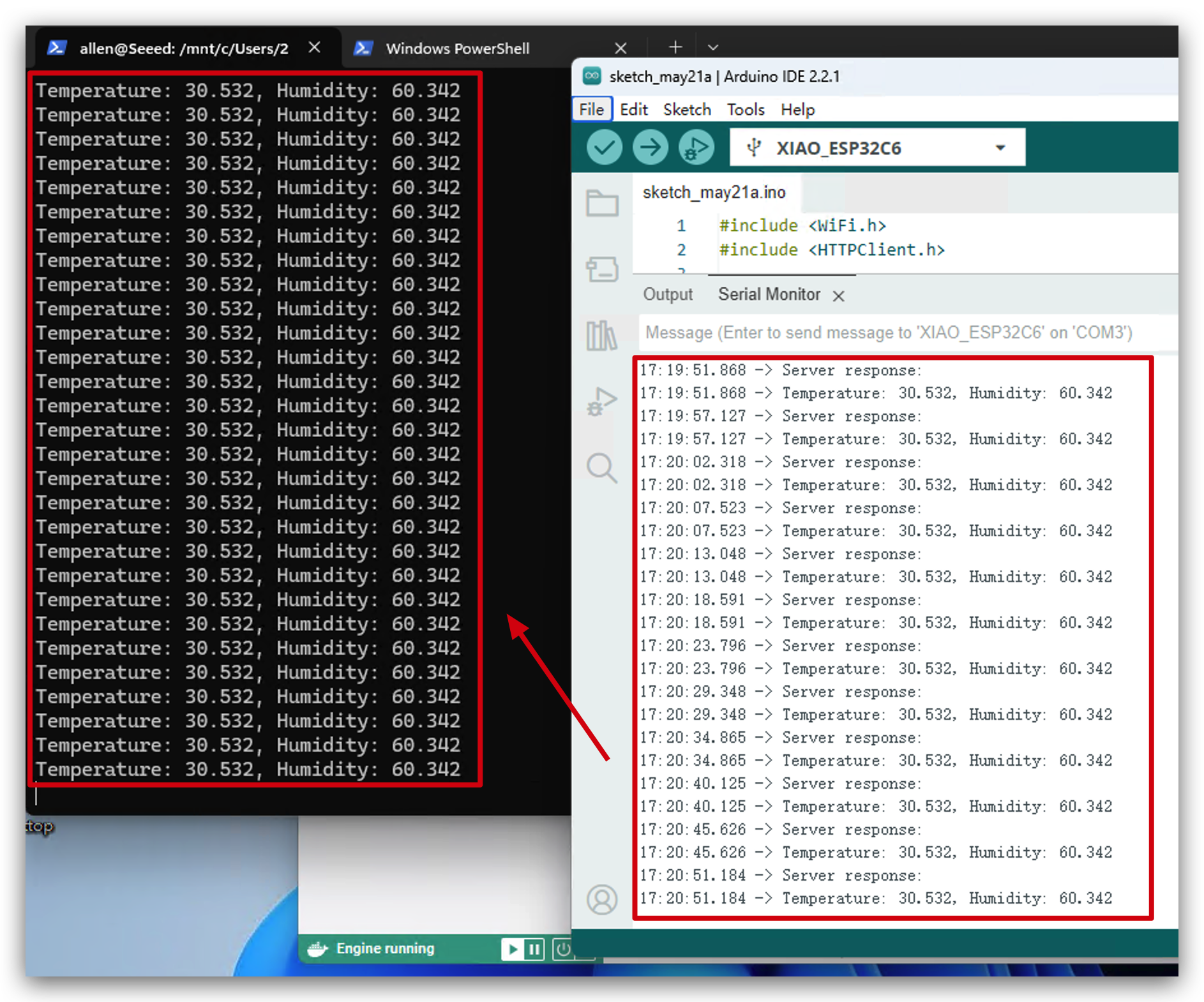
- kafkaが実行されているWindows PowerShellを開きます。環境データがKafkaに送信されているのが確認できます。おめでとうございます!このプロジェクトを正常に実行できました!
リソース
- [Link] Apache Kafka Introduction
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャンネルを用意しています。