データセットからXIAO ESP32S3へのモデル展開
このデータセットをXIAO ESP32S3で動作する完全に機能するモデルに変換する包括的なチュートリアルへようこそ。このガイドでは、Roboflowの直感的なツールを使用してデータセットにラベルを付ける初期ステップから始まり、Google Colabの協調環境内でのモデルトレーニングまでの道のりを進んでいきます。
その後、SenseCraft Model Assistantを使用してトレーニング済みモデルを展開する段階に進みます。これは、トレーニングと実世界のアプリケーションの間のギャップを埋めるプロセスです。このチュートリアルの終わりまでに、XIAO ESP32S3で動作するカスタムモデルを手に入れるだけでなく、モデルの予測結果を解釈し活用するための知識も身に付けることができます。
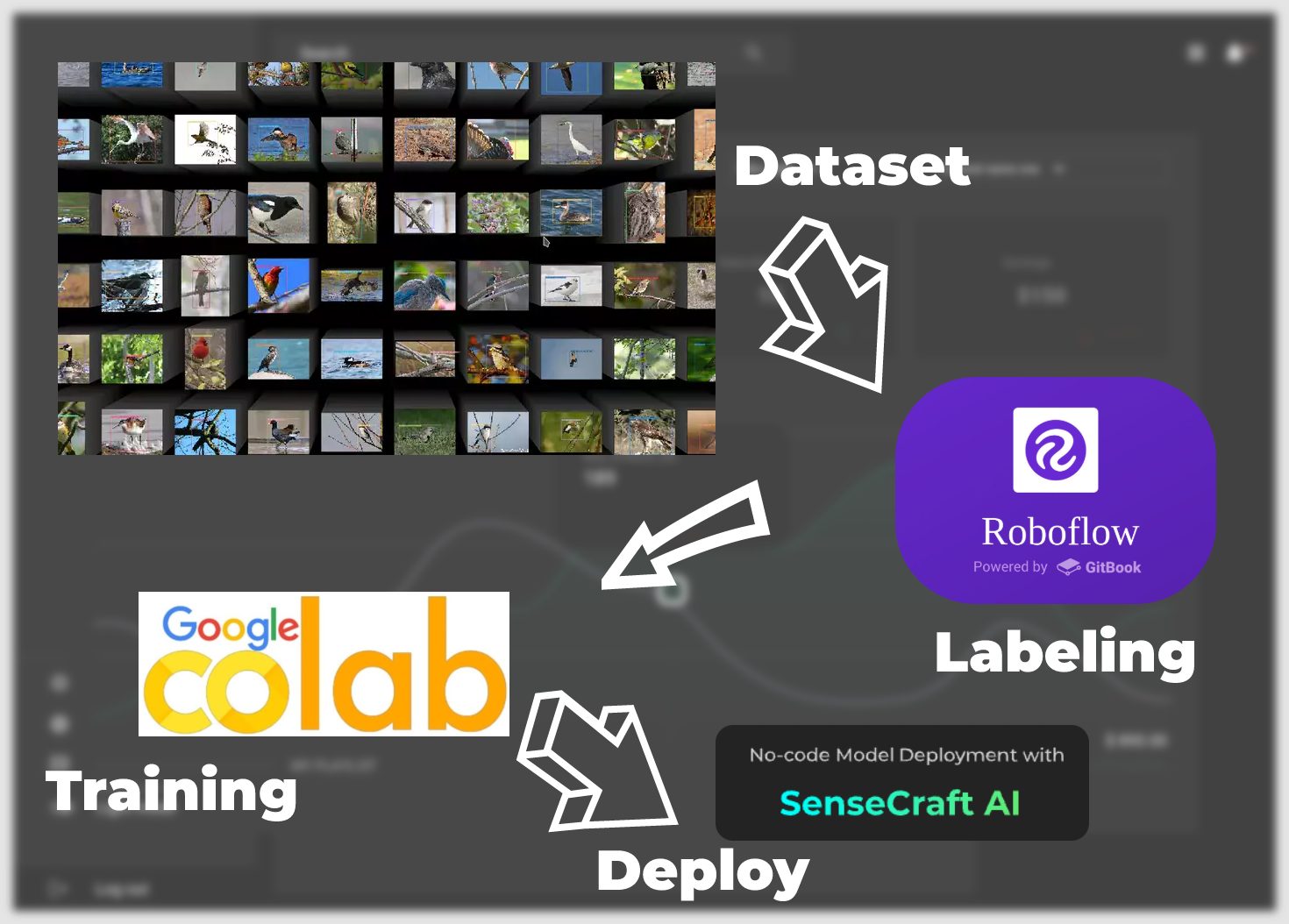
データセットからモデル展開まで、以下の主要なステップを実行します。
-
ラベル付きデータセット —— この章では、モデルにトレーニングできるデータセットを取得する方法に焦点を当てます。主に2つの方法があります。1つ目はRoboflowコミュニティが提供するラベル付きデータセットを使用する方法、もう1つは独自のシナリオ固有の画像をデータセットとして使用する方法ですが、手動でラベリングを行う必要があります。
-
トレーニングデータセットエクスポートモデル —— この章では、Google Colabプラットフォームを使用して、最初のステップで取得したデータセットに基づいて、XIAO ESP32S3に展開できるモデルをトレーニングして取得する方法に焦点を当てます。
-
SenseCraft Model Assistantを介したモデルのアップロード —— このセクションでは、エクスポートされたモデルファイルを使用して、SenseCraft Model AssistantでXIAO ESP32S3にモデルをアップロードする方法について説明します。
-
モデルの一般的なプロトコルとアプリケーション —— 最後に、SenseCraft AIの統一データ通信フォーマットを紹介し、デバイスとモデルの最大限の可能性を活用して、シナリオに適したアプリケーションを作成できるようにします。
それでは、データに命を吹き込むエキサイティングなプロセスを始めましょう。
必要な材料
開始する前に、以下の機器を準備する必要があります。


このチュートリアルでは、XIAO ESP32S3 の標準版とSense版の両方を使用できますが、標準版では カメラ拡張ボードが使用できないため、Sense版の使用をお勧めします。
ラベル付きデータセット
このセクションでは、ユーザーが自由にデータセットを選択できます。これには、コミュニティの写真や独自に撮影したシーンの写真が含まれます。このチュートリアルでは、2つの主要なシナリオを紹介します。1つ目は、Roboflow コミュニティが提供する既製のラベル付きデータセットを使用することです。もう1つは、自分で撮影した高解像度画像を使用してデータセットにラベルを付けることです。ニーズに応じて、以下の異なるチュートリアルをお読みください。
ステップ1:無料のRoboflowアカウントを作成する
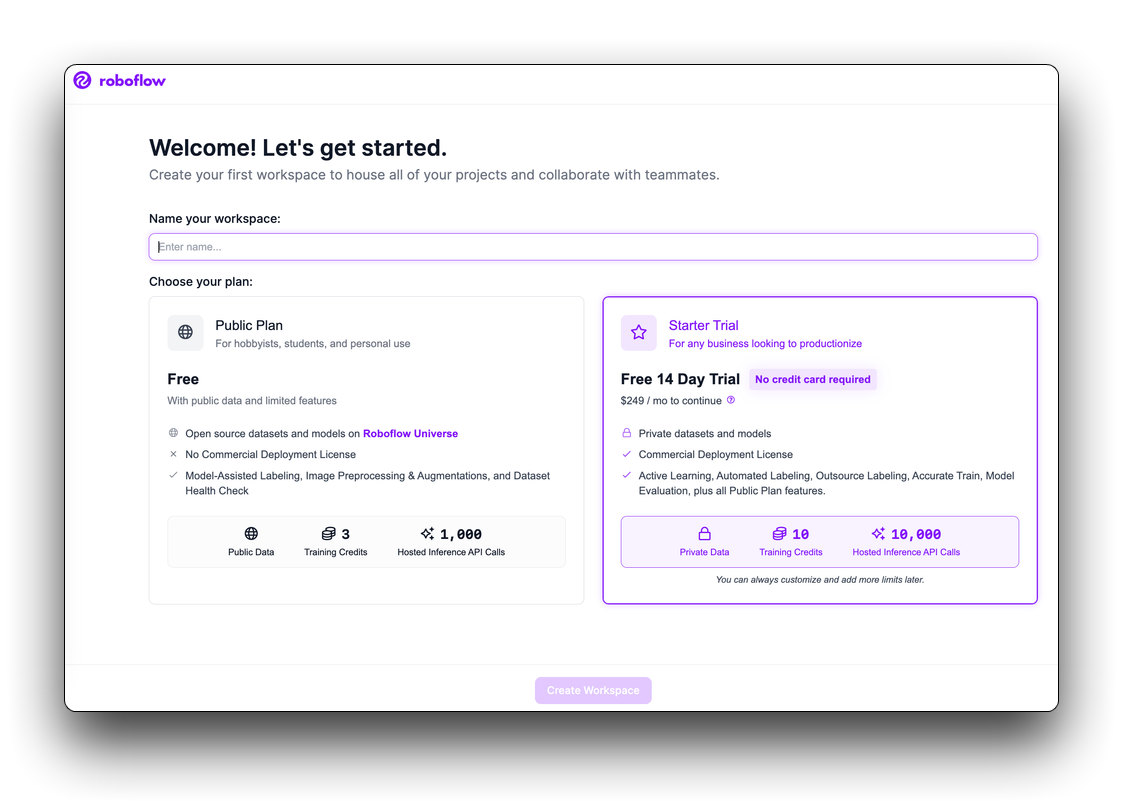
Roboflowは、コンピュータビジョンソリューションのラベル付け、トレーニング、デプロイに必要なすべてを提供します。開始するには、無料のRoboflowアカウントを作成してください。
利用規約を確認して同意すると、2つのプランのうち1つを選択するよう求められます:パブリックプランとスタータープランです。
次に、ワークスペースに協力者を招待するよう求められます。これらの協力者は、画像の注釈付けやワークスペース内のビジョンプロジェクトの管理を手伝うことができます。ワークスペースに人を招待した後(希望する場合)、プロジェクトを作成できるようになります。
データセットの取得方法を選択する
- Roboflowを使用してラベル付きデータセットをダウンロード
- 独自の画像をデータセットとして使用
Roboflowから直接使用に適したデータセットを選択するには、データセットのサイズ、品質、関連性、ライセンスなどの側面を考慮して、プロジェクトの要件に最も適したデータセットを決定する必要があります。
ステップ2. Roboflow Universeを探索する
Roboflow Universeは、さまざまなデータセットを見つけることができるプラットフォームです。Roboflow Universeのウェブサイトにアクセスして、利用可能なデータセットを探索してください。
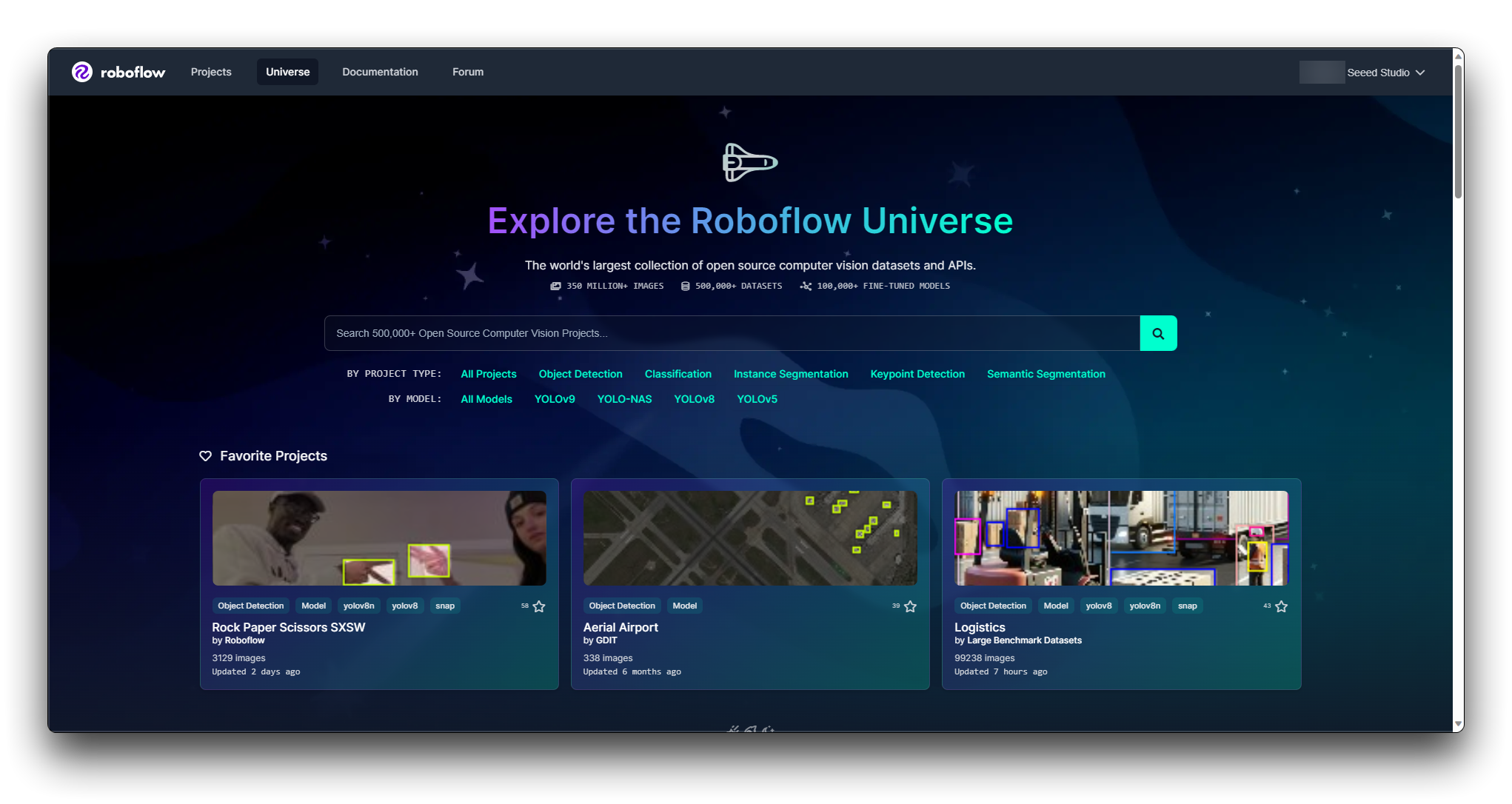
Roboflowは、データセットを見つけるのに役立つフィルターと検索機能を提供しています。ドメイン、クラス数、注釈タイプなどでデータセットをフィルタリングできます。これらのフィルターを活用して、条件に合うデータセットを絞り込んでください。
ステップ3. 個別のデータセットを評価する
候補リストができたら、各データセットを個別に評価してください。以下を確認してください:
注釈の品質:注釈が正確で一貫しているかを確認してください。
データセットのサイズ:モデルが効果的に学習できる十分な大きさでありながら、処理しきれないほど大きくないことを確認してください。
クラスバランス:データセットは理想的には各クラスに対してバランスの取れた例数を持つべきです。
ライセンス:データセットのライセンスを確認して、意図した通りに使用できることを確認してください。
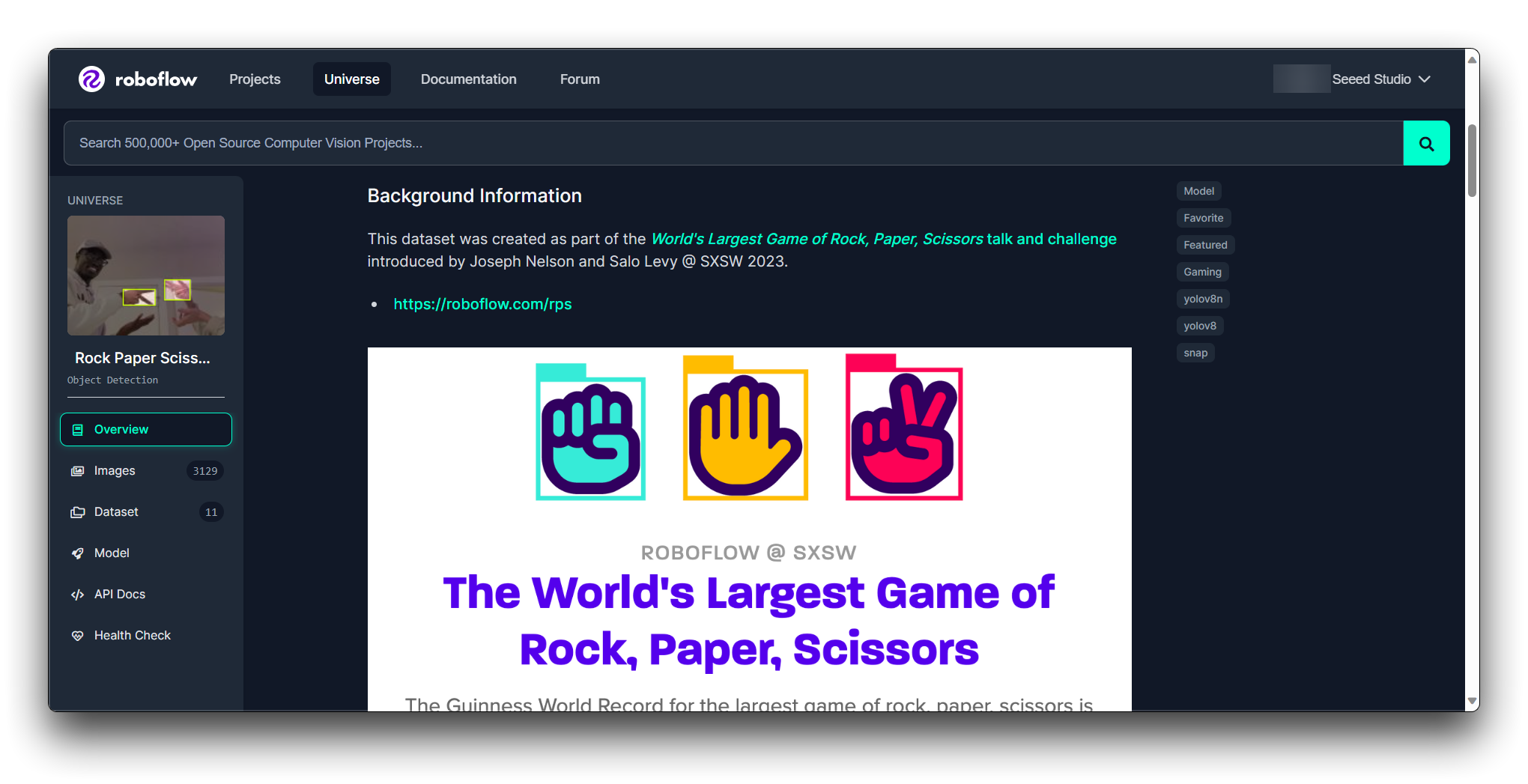
ドキュメント:データセットに付属するドキュメントやメタデータを確認して、その内容と既に適用されている前処理ステップをよりよく理解してください。
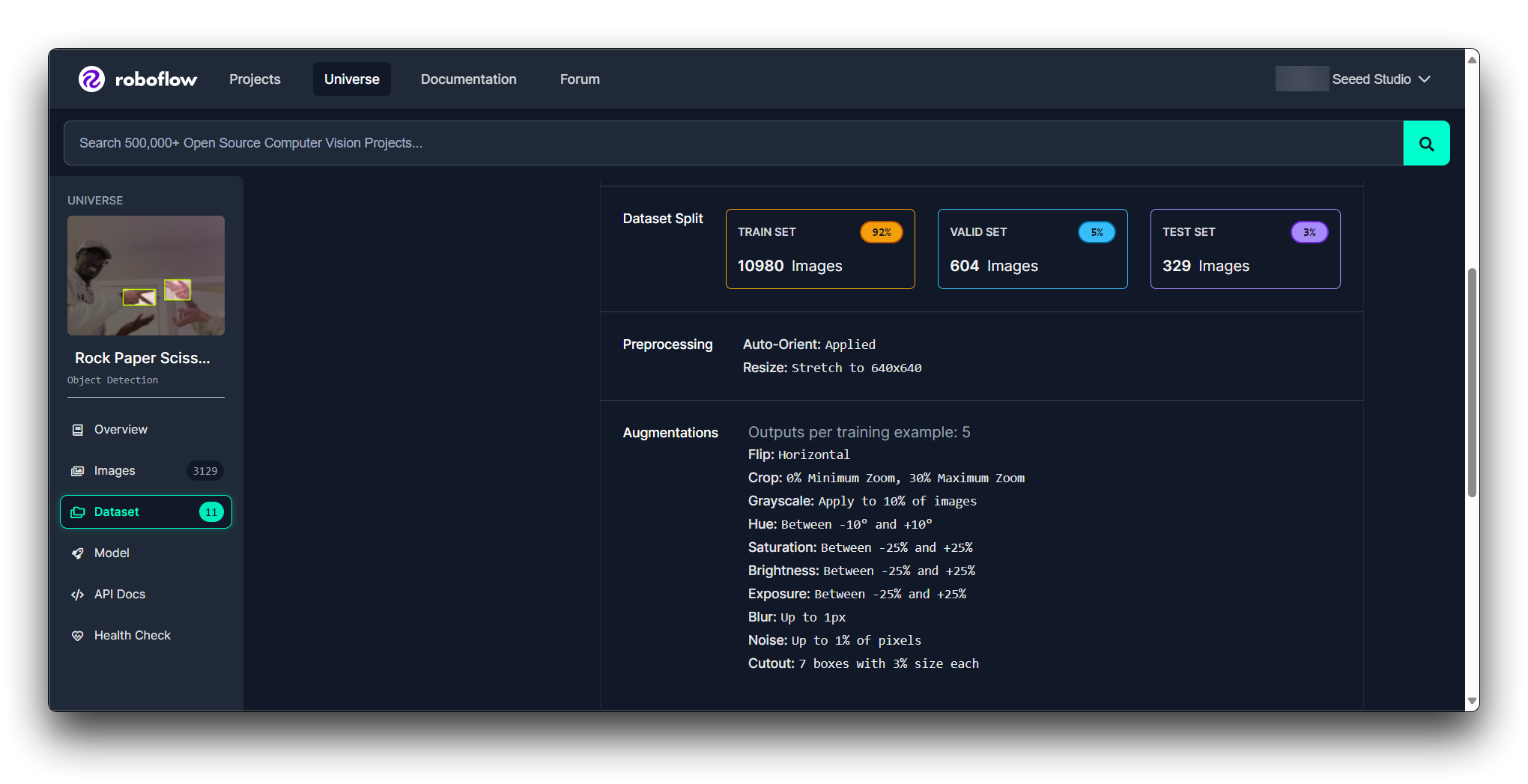
**Roboflow Health Check**を通じてモデルの状態を確認できます。
ステップ4. サンプルをダウンロードする
選択したデータセットが見つかったら、それをダウンロードして使用するオプションがあります。Roboflowでは通常、データセットのサンプルをダウンロードできます。サンプルをテストして、ワークフローとうまく統合でき、モデルに適しているかを確認してください。
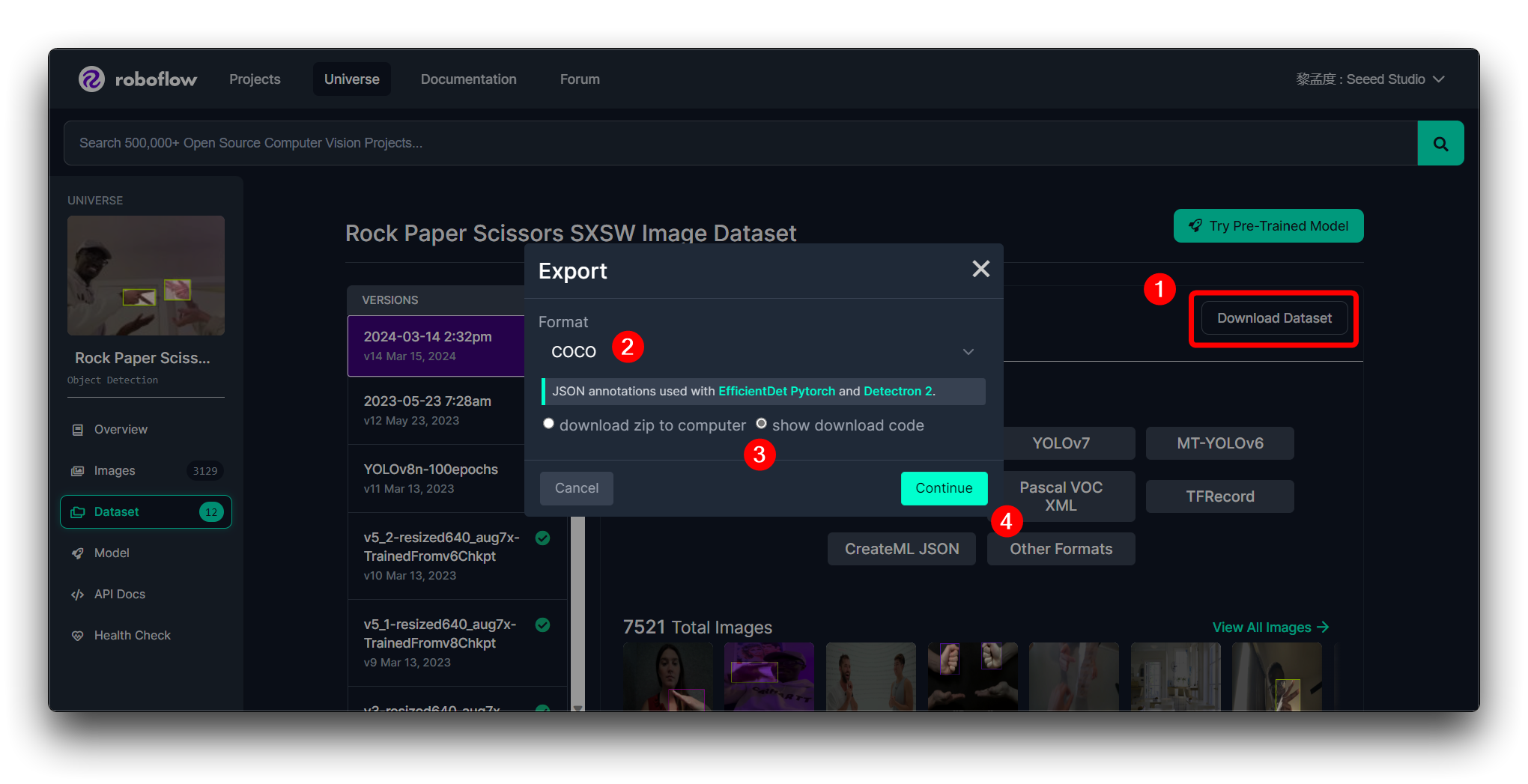
後続のステップを続行するために、以下に示す形式でデータセットをエクスポートすることをお勧めします。
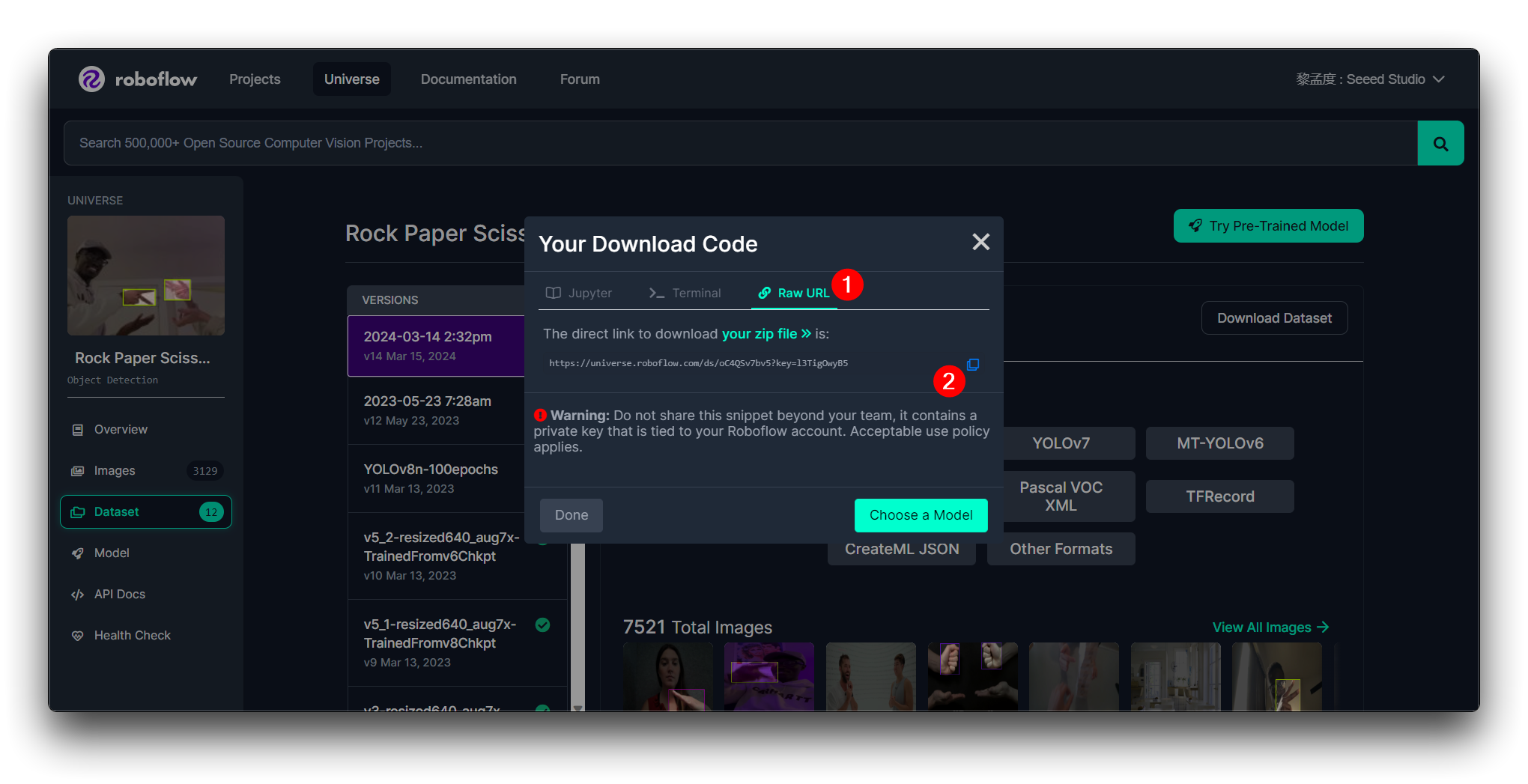
その後、このモデルのRaw URLが取得できます。これを安全に保管してください。後でモデルトレーニングステップでこのリンクを使用します。
Roboflowを初めて使用し、データセットの選択について全く判断がつかない場合、データセットでモデルをトレーニングして初期テストを実行し、パフォーマンスを確認するステップが不可欠かもしれません。これにより、データセットが要件を満たすかどうかを判断できます。
データセットが要件を満たし、初期テストで良好なパフォーマンスを示した場合、プロジェクトに適している可能性が高いです。そうでなければ、検索を続けるか、より多くの画像でデータセットを拡張することを検討する必要があるかもしれません。
ここでは、じゃんけんのジェスチャー画像をデモとして使用し、Roboflowでの画像アップロード、ラベル付け、データセットエクスポートのタスクを案内します。
データセットの写真撮影にはXIAO ESP32S3の使用を強くお勧めします。これはXIAO ESP32S3に最適です。XIAO ESP32S3 Senseで写真を撮影するサンプルプログラムは、以下のWikiリンクで確認できます。
ステップ2. 新しいプロジェクトの作成と画像のアップロード
Roboflowにログインしたら、Create Projectをクリックします。
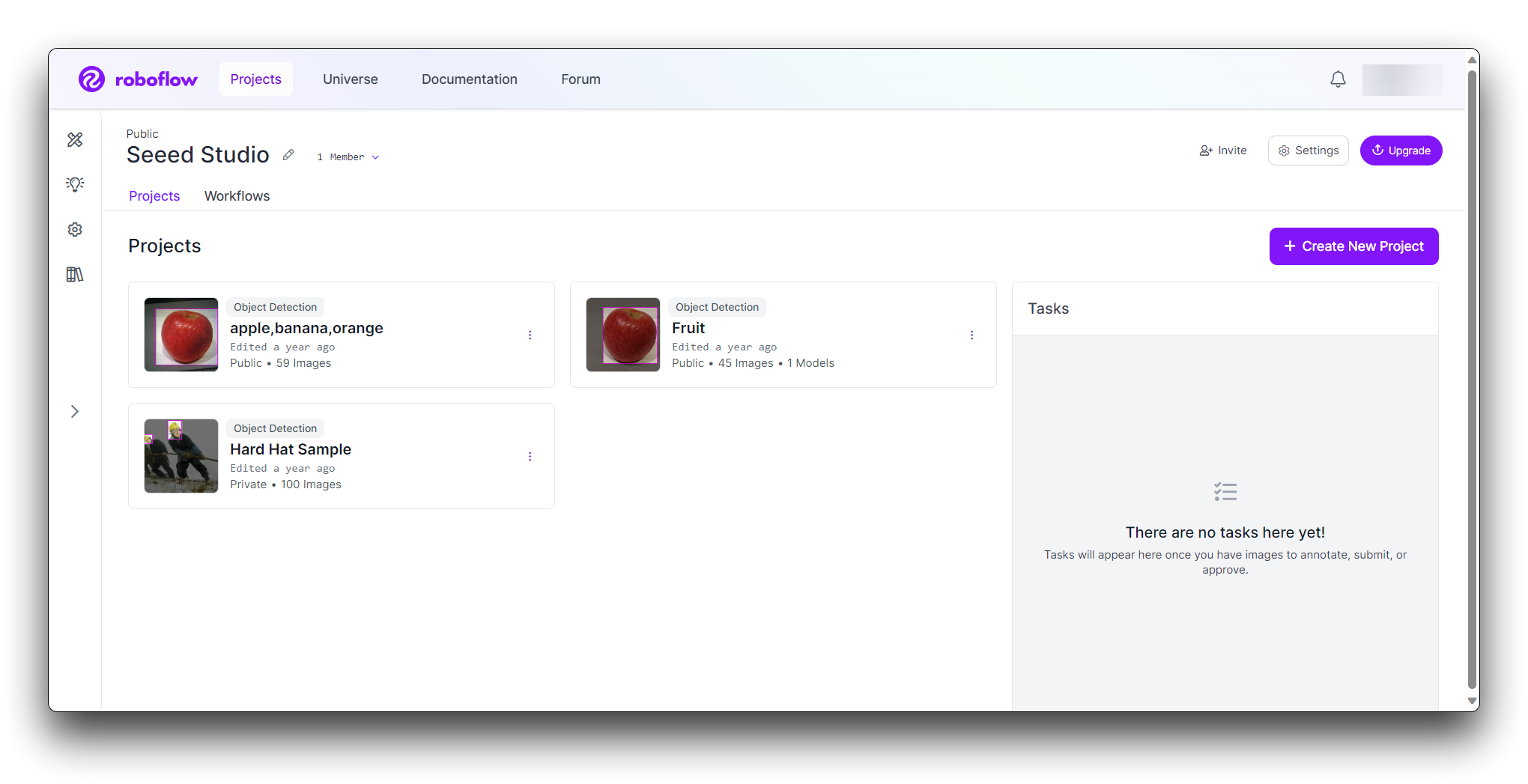
プロジェクトに名前を付けます(例:「Rock-Paper-Scissors」)。プロジェクトをObject Detectionとして定義します。Output LabelsをCategoricalに設定します(Rock、Paper、Scissorsは異なるカテゴリであるため)。
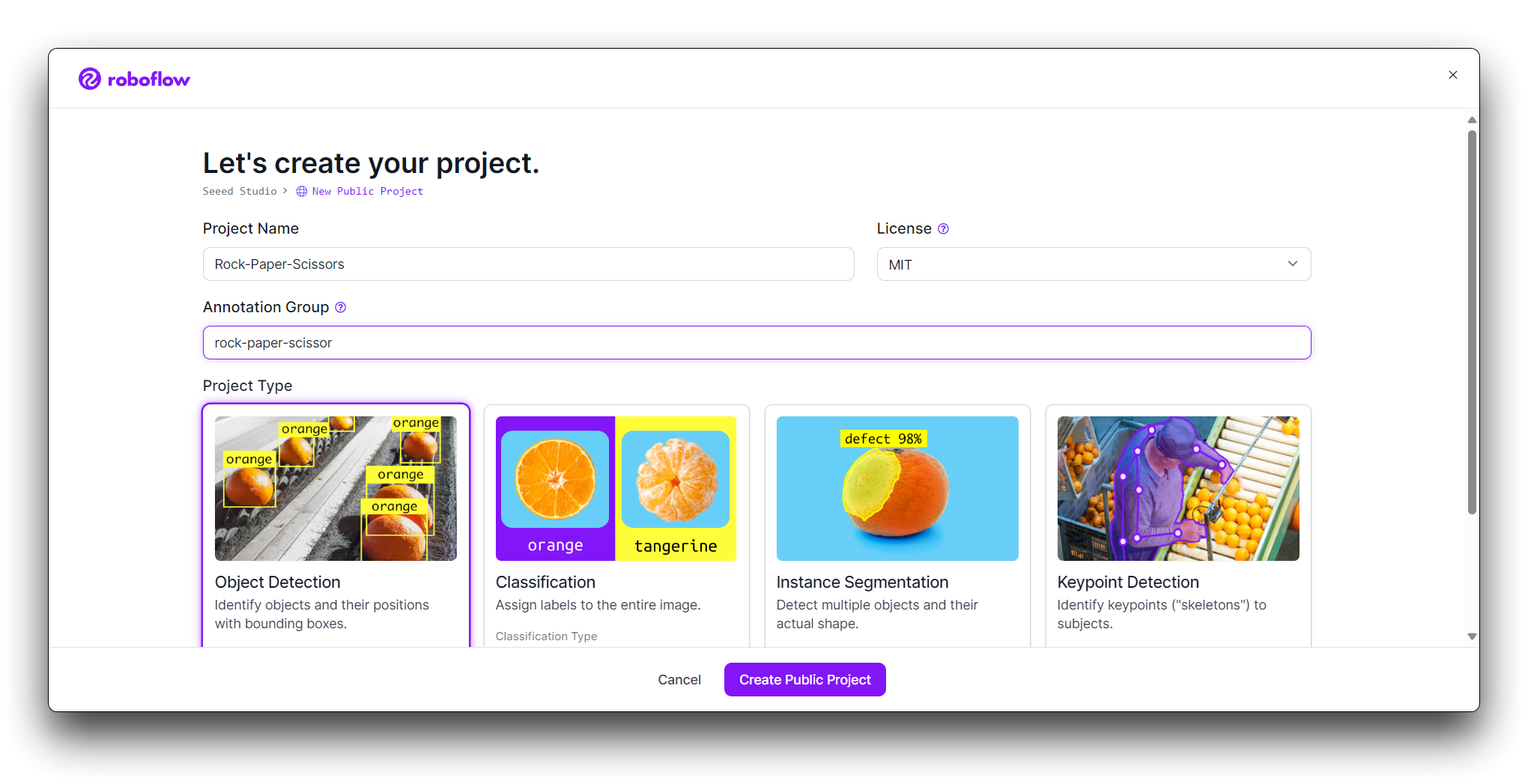
次に、手のジェスチャー画像をアップロードします。
じゃんけんのグー、パー、チョキのジェスチャーの画像を収集します。様々な背景と照明条件を含むようにしてください。プロジェクトページで「Add Images」をクリックします。
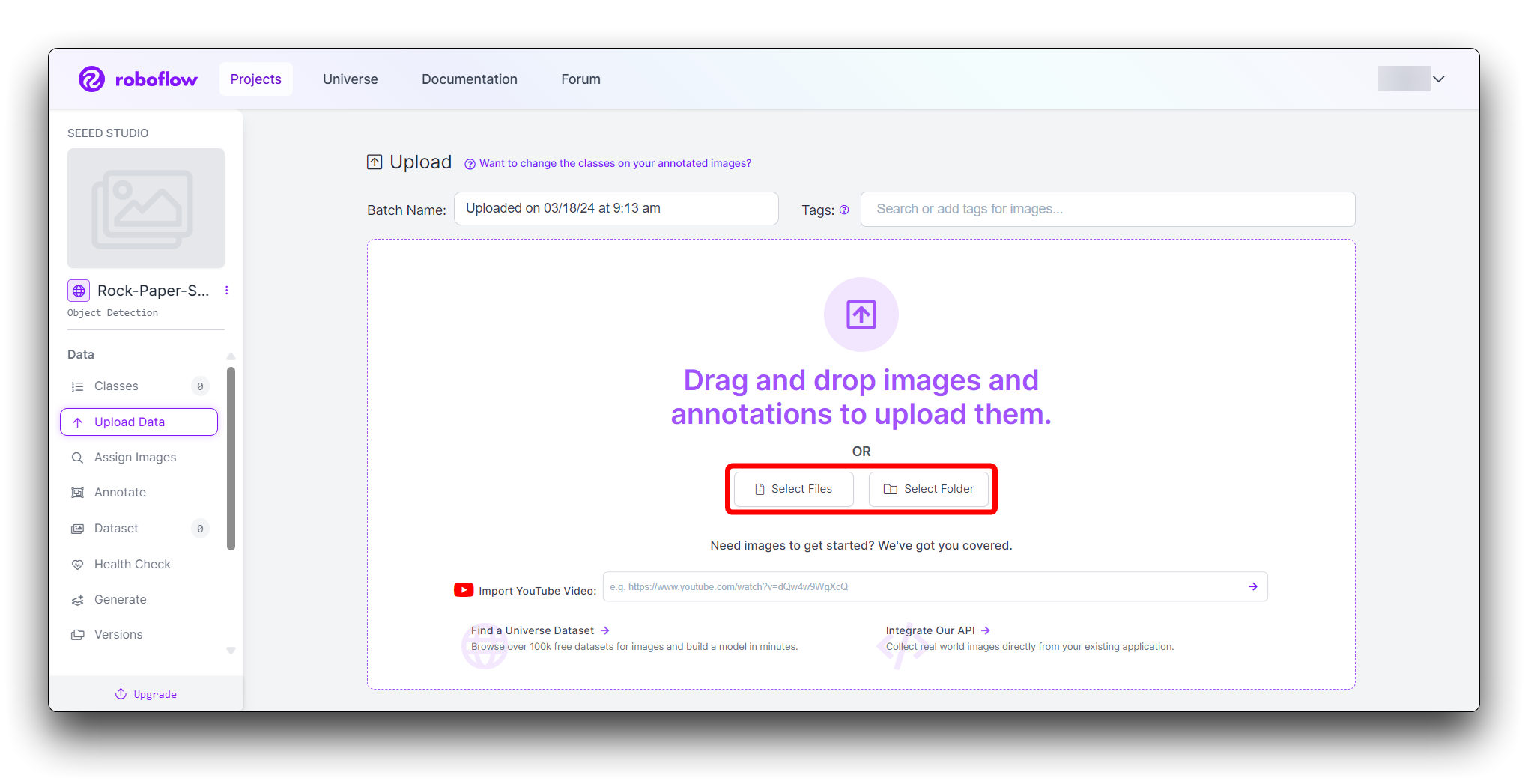
画像をドラッグ&ドロップするか、コンピューターから選択できます。堅牢なデータセットのために、各ジェスチャーの画像を少なくとも100枚アップロードしてください。
データセットのサイズはどのように決定されるのでしょうか?
一般的に、タスクモデル、タスクの複雑さ、データの純度など、様々な要因に依存します。例えば、人体検出モデルは多数の人々を含み、範囲が広く、タスクがより複雑であるため、より多くのデータを収集する必要があります。 別の例として、ジェスチャー検出モデルは「グー」「チョキ」「パー」の3種類のみを検出する必要があり、必要なカテゴリが少ないため、収集されるデータセットは約500枚程度です。
ステップ3: 画像のアノテーション
アップロード後、手のジェスチャーにラベルを付けて画像にアノテーションを行う必要があります。
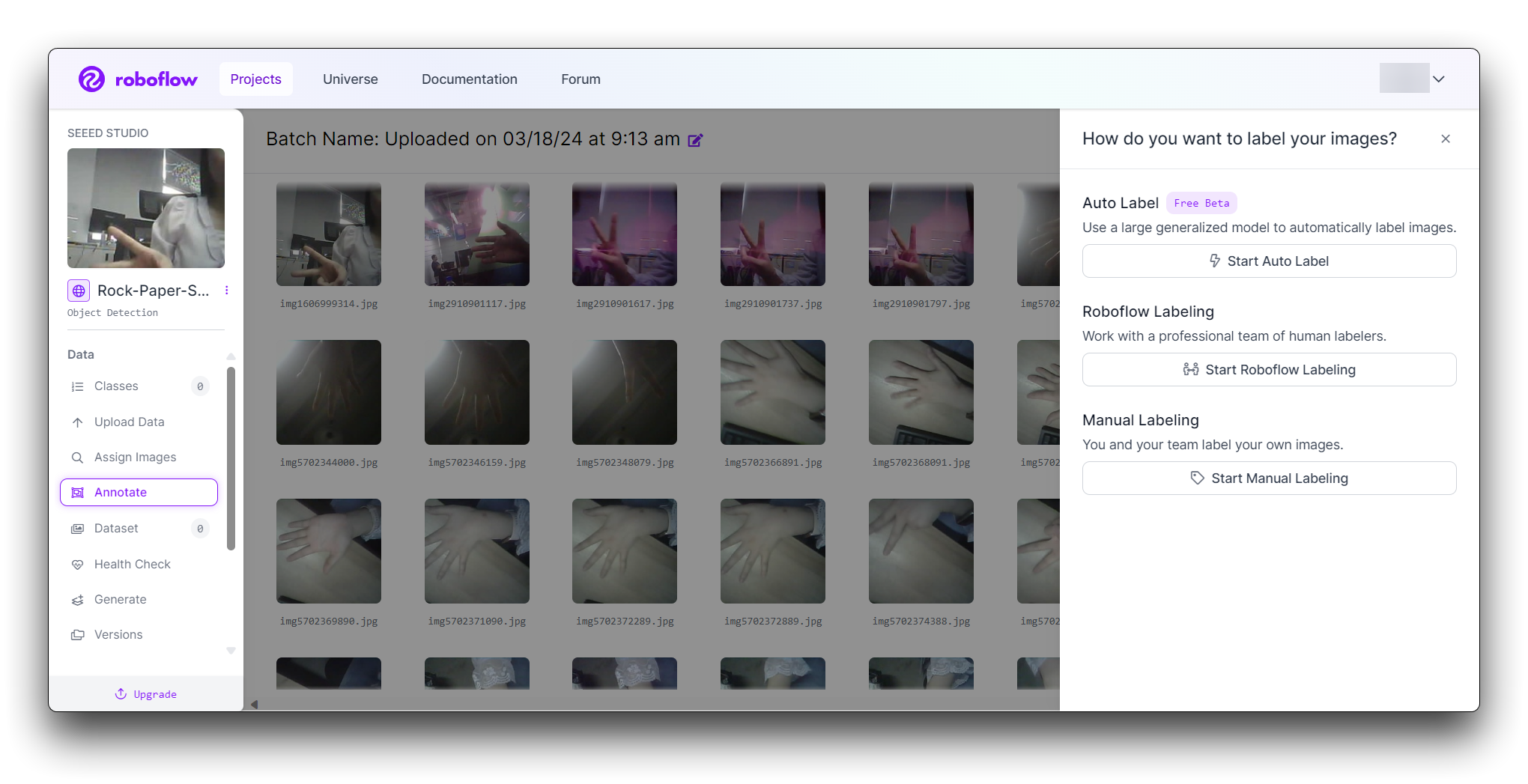
Roboflowは画像にラベルを付ける3つの異なる方法を提供しています:Auto Label、Roboflow Labeling、Manual Labelingです。
- Auto Label:大規模な汎用モデルを使用して画像に自動的にラベルを付けます。
- Roboflow Labeling:プロの人間ラベラーチームと協力します。最小ボリュームなし。事前コミットメントなし。バウンディングボックスアノテーションは$0.04から、ポリゴンアノテーションは$0.08から開始されます。
- Manual Labeling:あなたとあなたのチームが独自に画像にラベルを付けます。
以下では、最も一般的に使用される手動ラベリングの方法について説明します。
「Manual Labeling」ボタンをクリックします。Roboflowがアノテーションインターフェースを読み込みます。
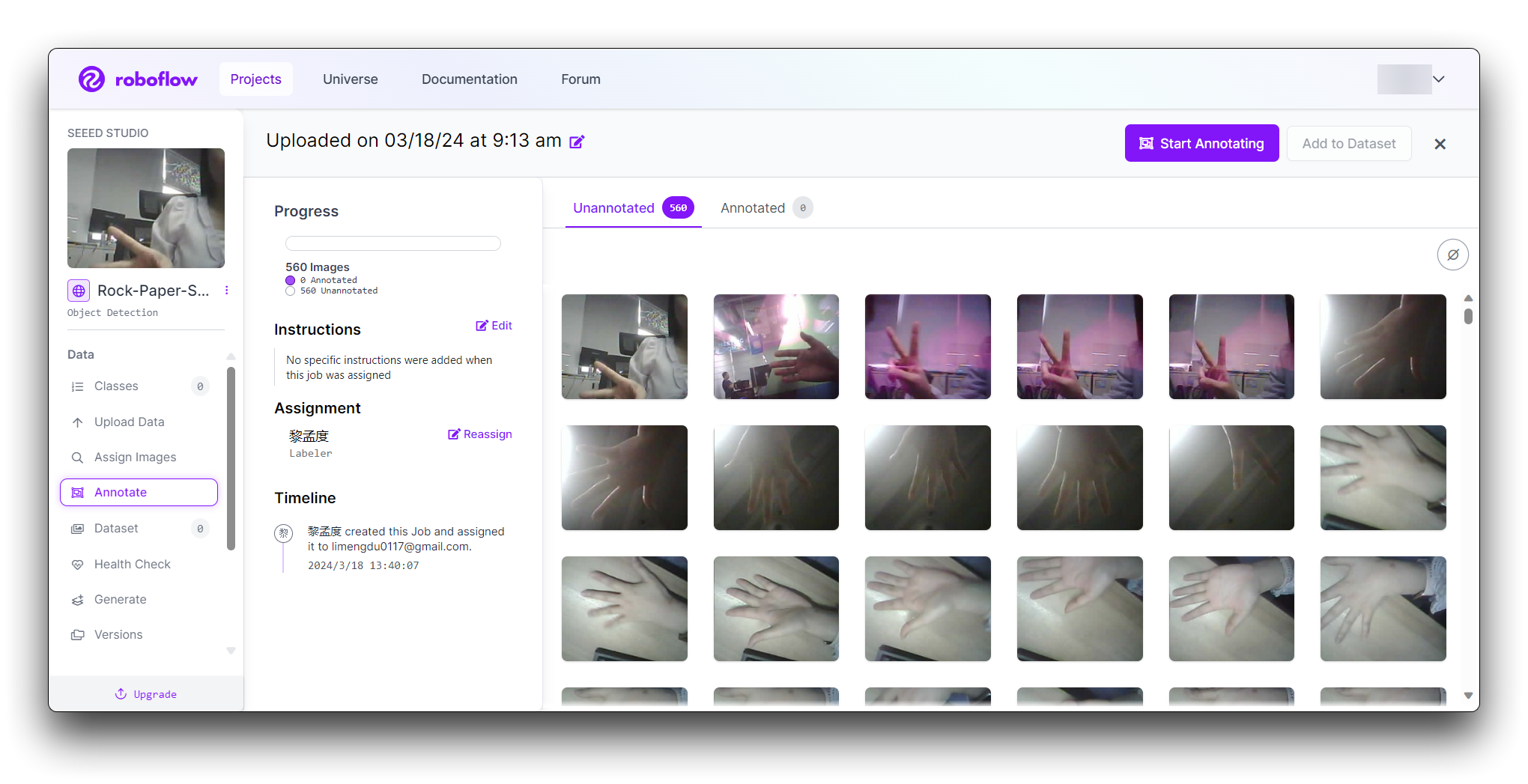
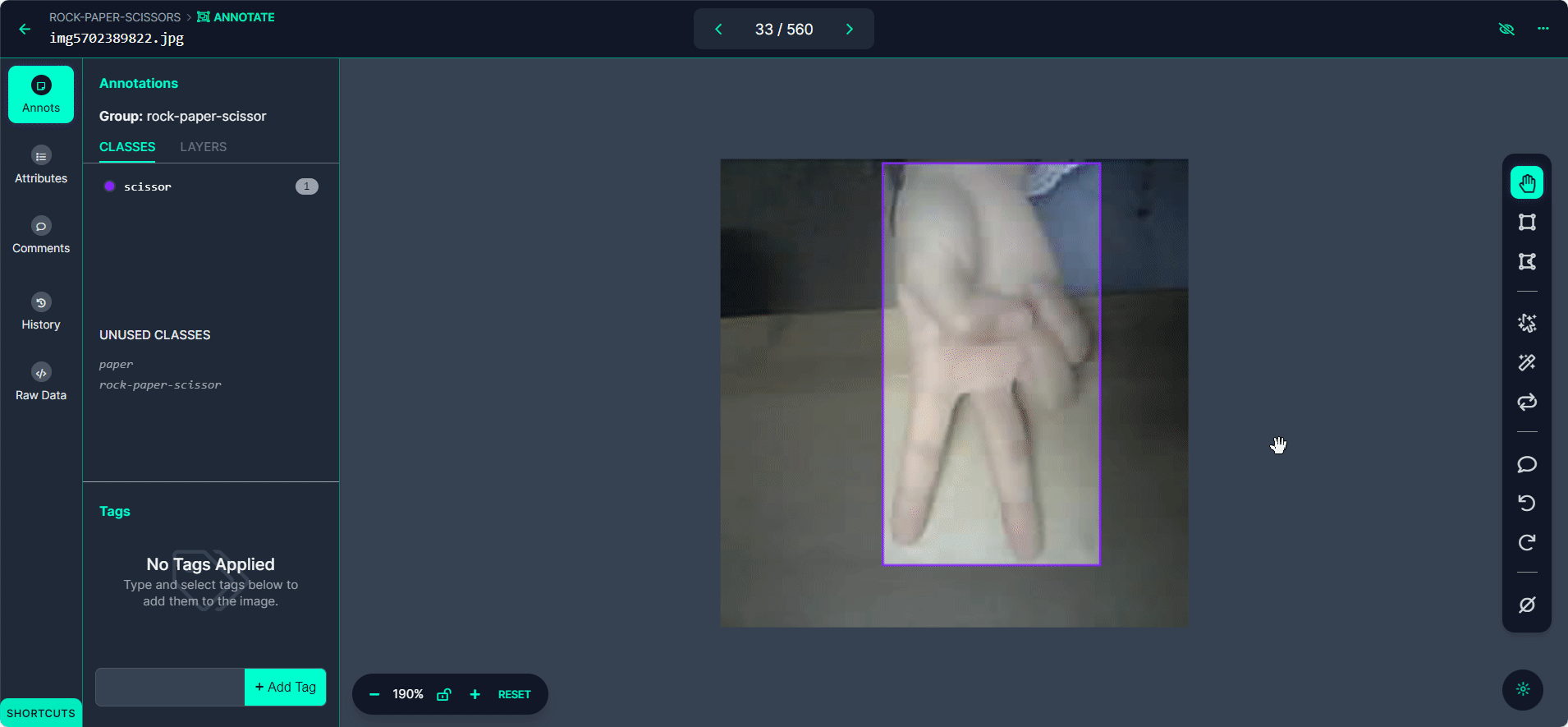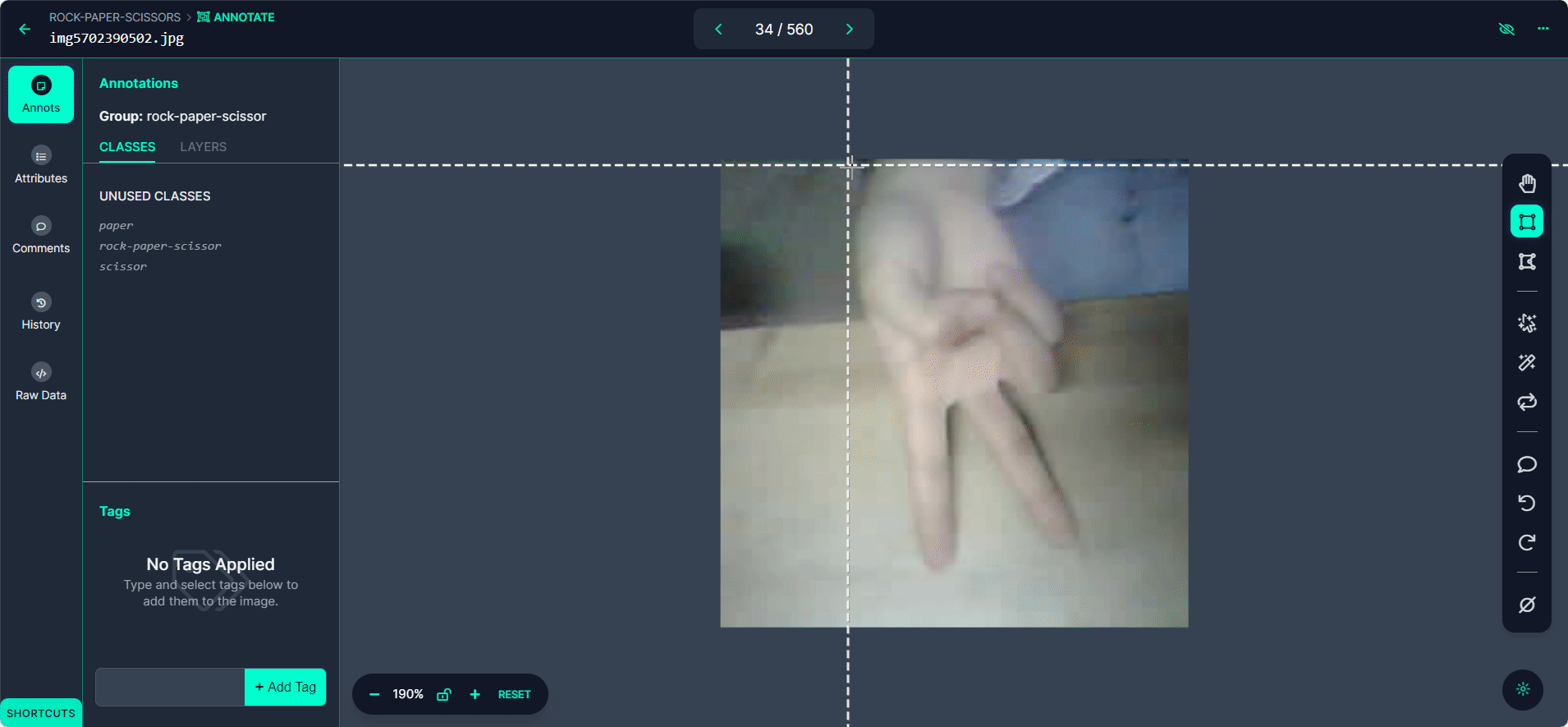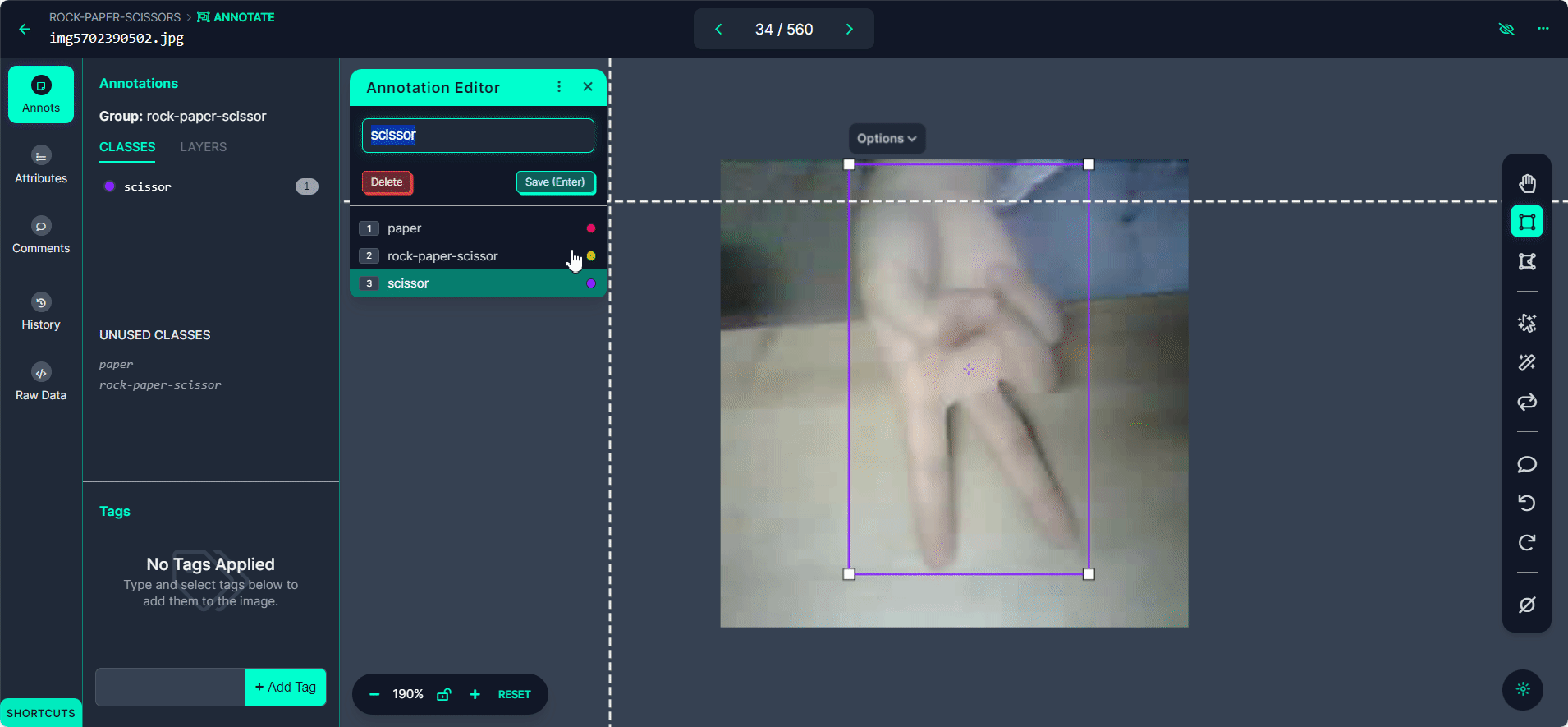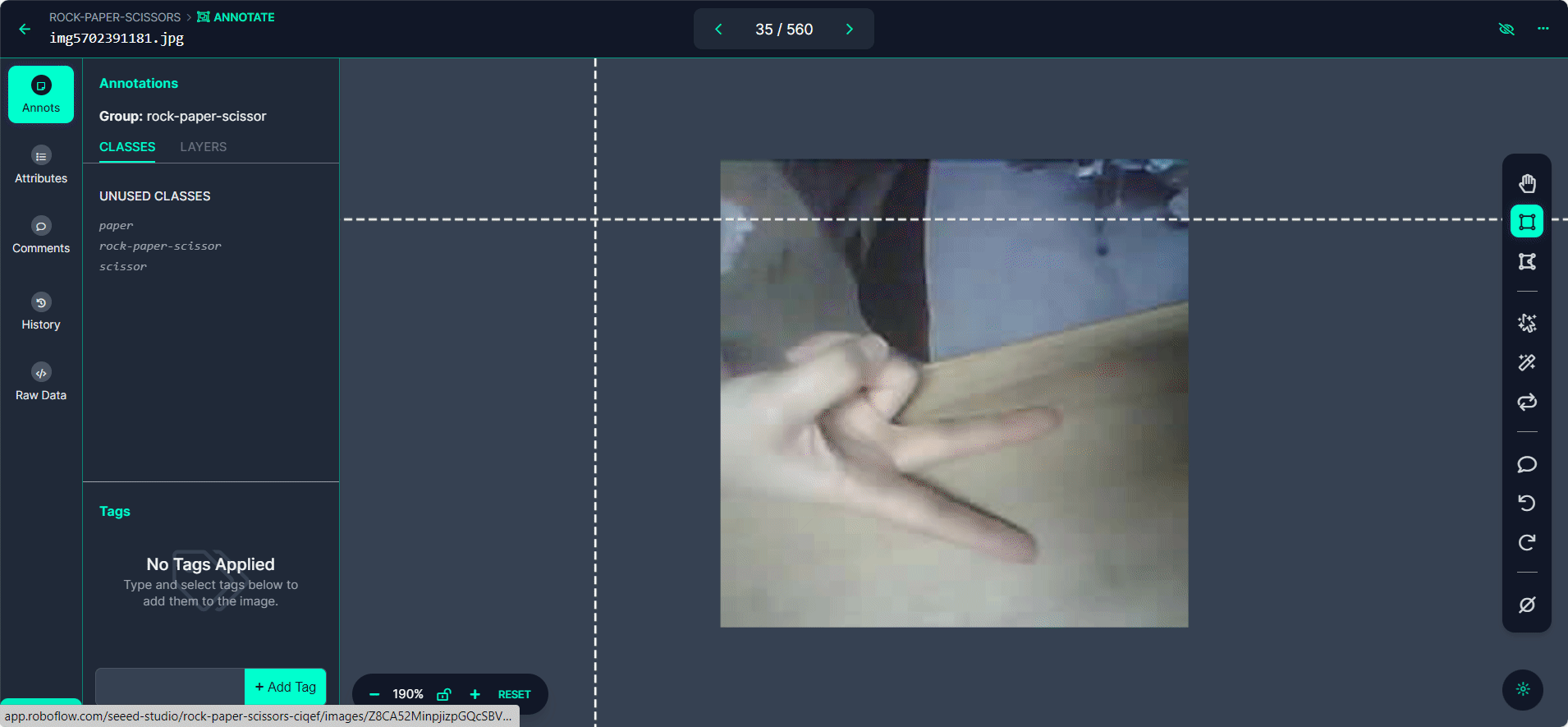
「Start Annotating」ボタンを選択します。各画像の手のジェスチャーの周りにバウンディングボックスを描画します。
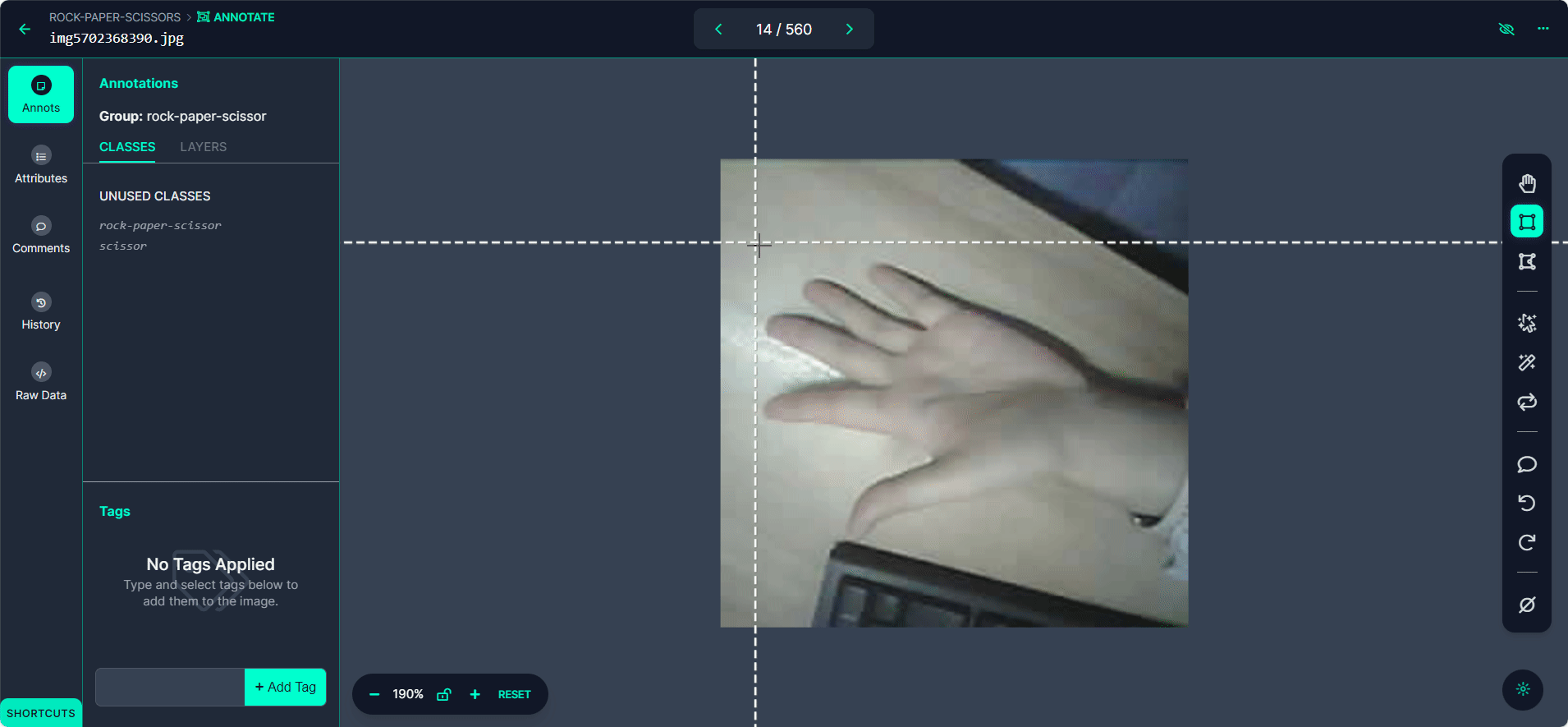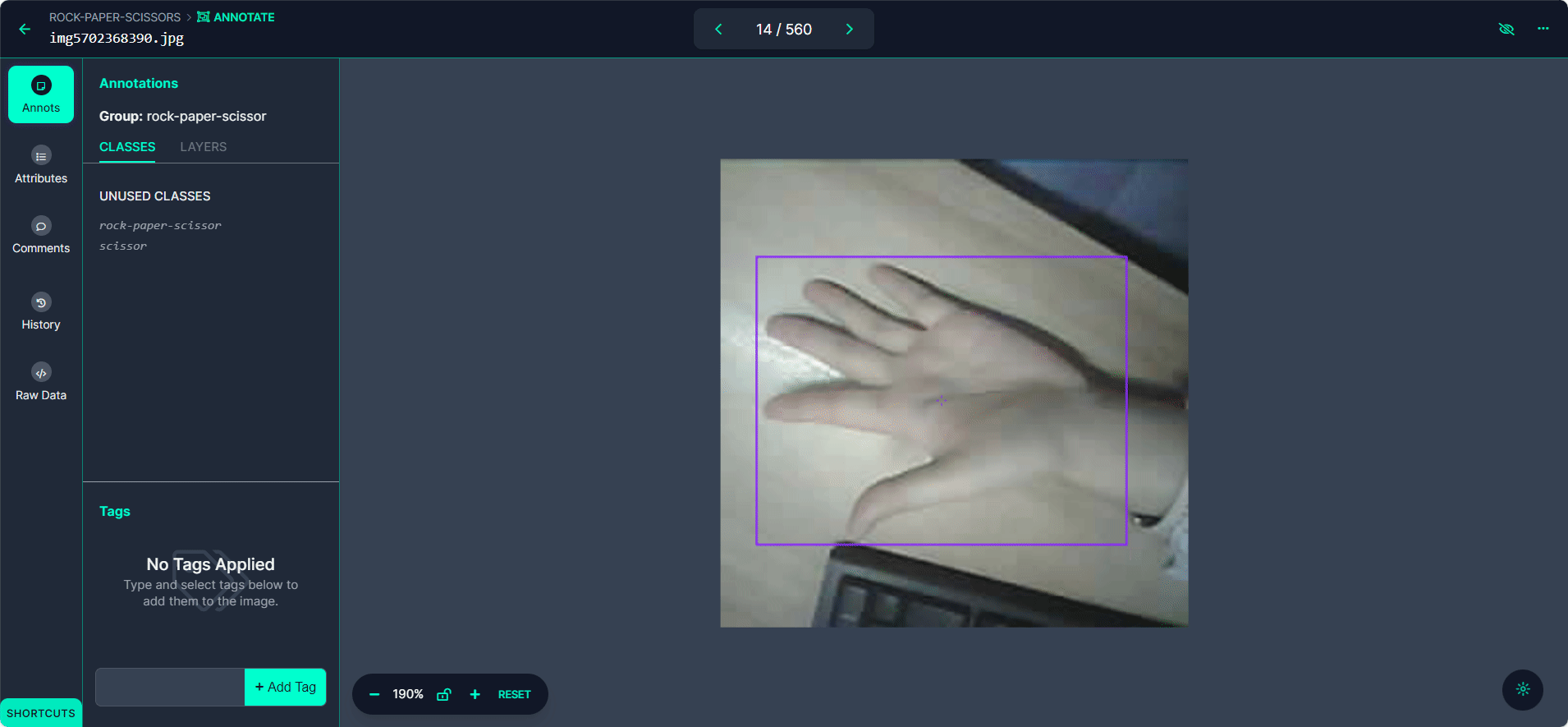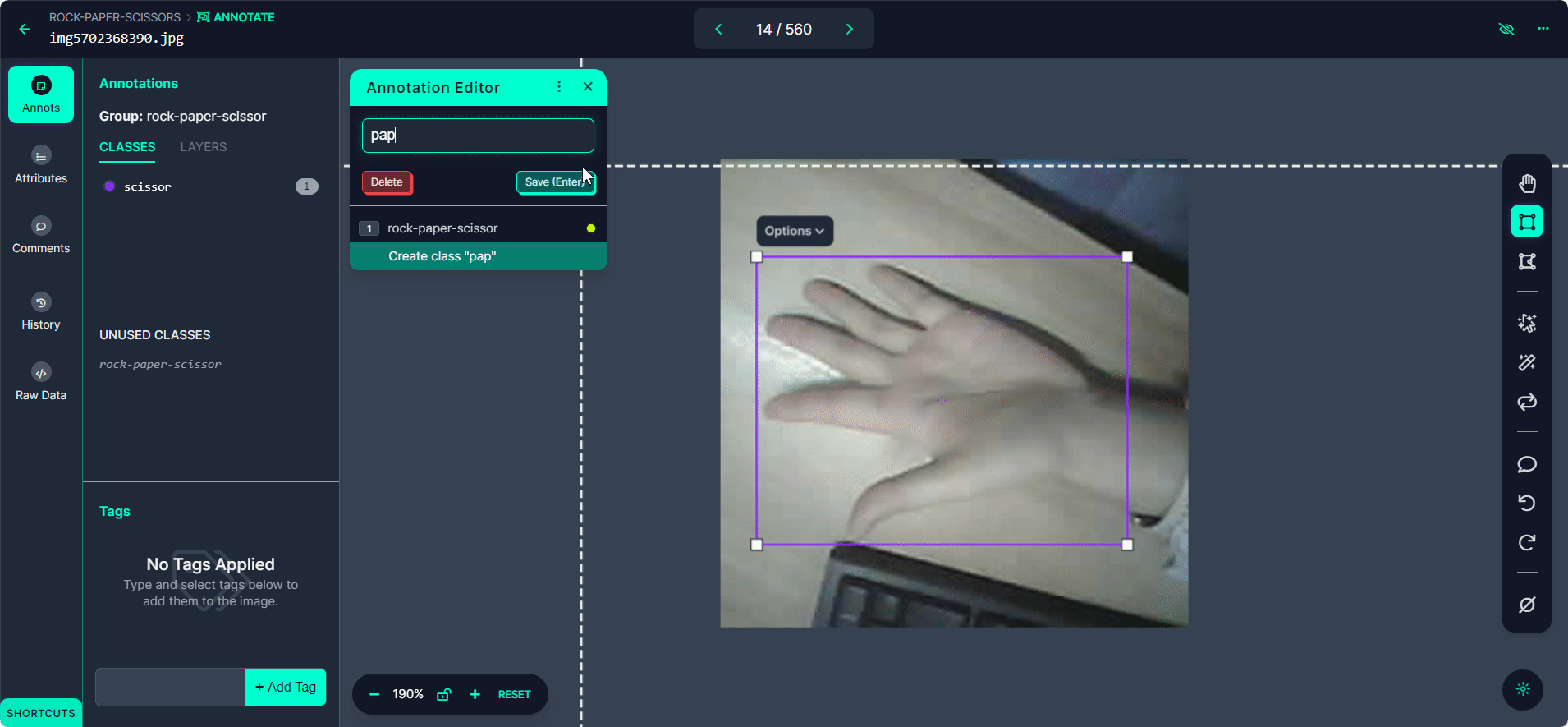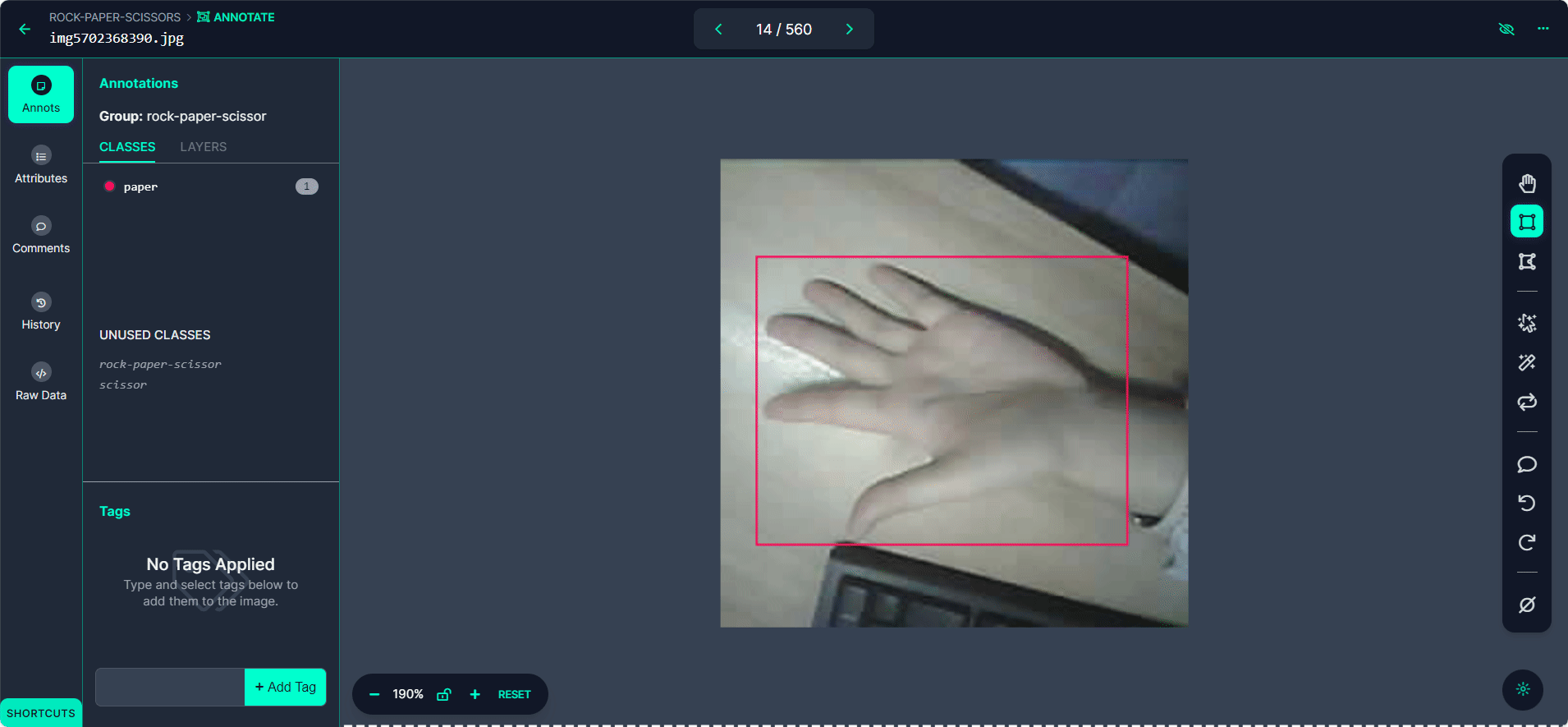
各バウンディングボックスを「Rock」、「Paper」、または「Scissors」としてラベル付けします。
「>」ボタンを使用してデータセット内を移動し、各画像に対してアノテーションプロセスを繰り返します。
ステップ4: アノテーションのレビューと編集
アノテーションが正確であることを確認することが重要です。
各画像をレビューして、バウンディングボックスが正しく描画され、ラベル付けされていることを確認します。間違いを見つけた場合は、アノテーションを選択してバウンディングボックスを調整するか、ラベルを変更します。
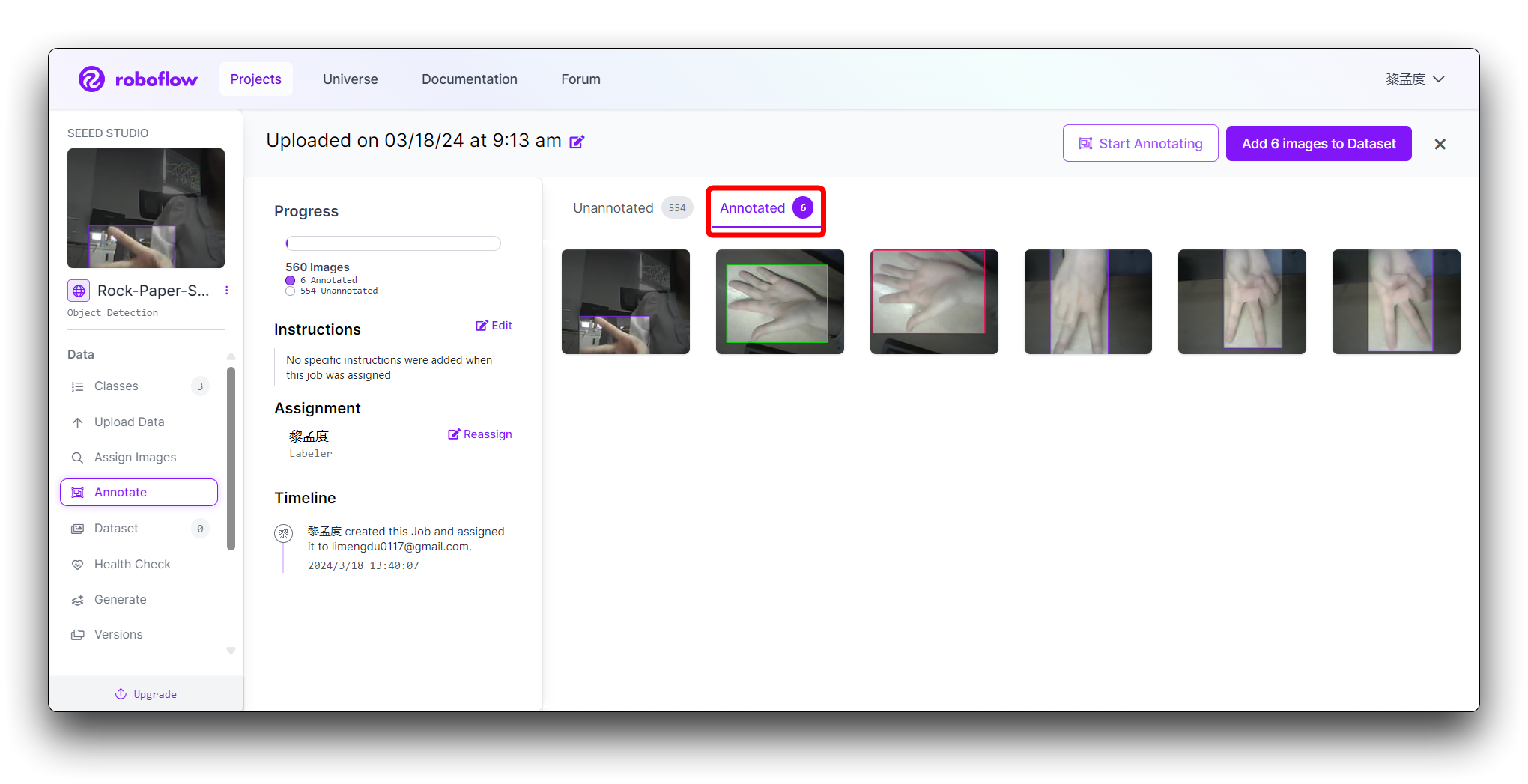
不正確なラベリングは訓練の全体的なパフォーマンスに影響し、一部のデータセットがラベリング要件を満たさない場合は破棄できます。以下に悪いラベリングの例を示します。

ステップ5: データセットの生成とエクスポート
すべての画像にアノテーションが完了したら、Annotateで右上角のAdd x images to Datasetボタンをクリックします。
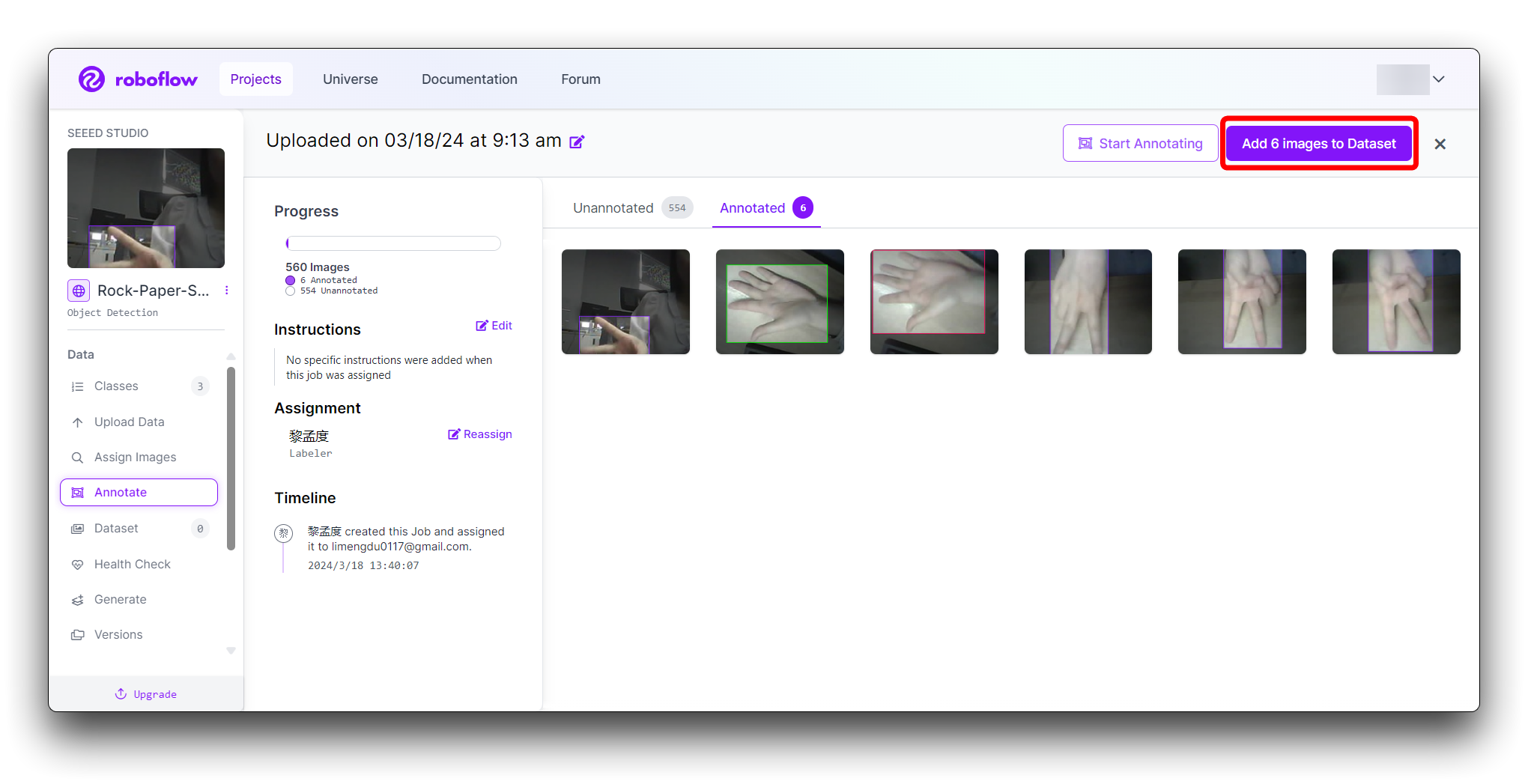
次に、新しいポップアップウィンドウの下部にあるAdd Imagesボタンをクリックします。
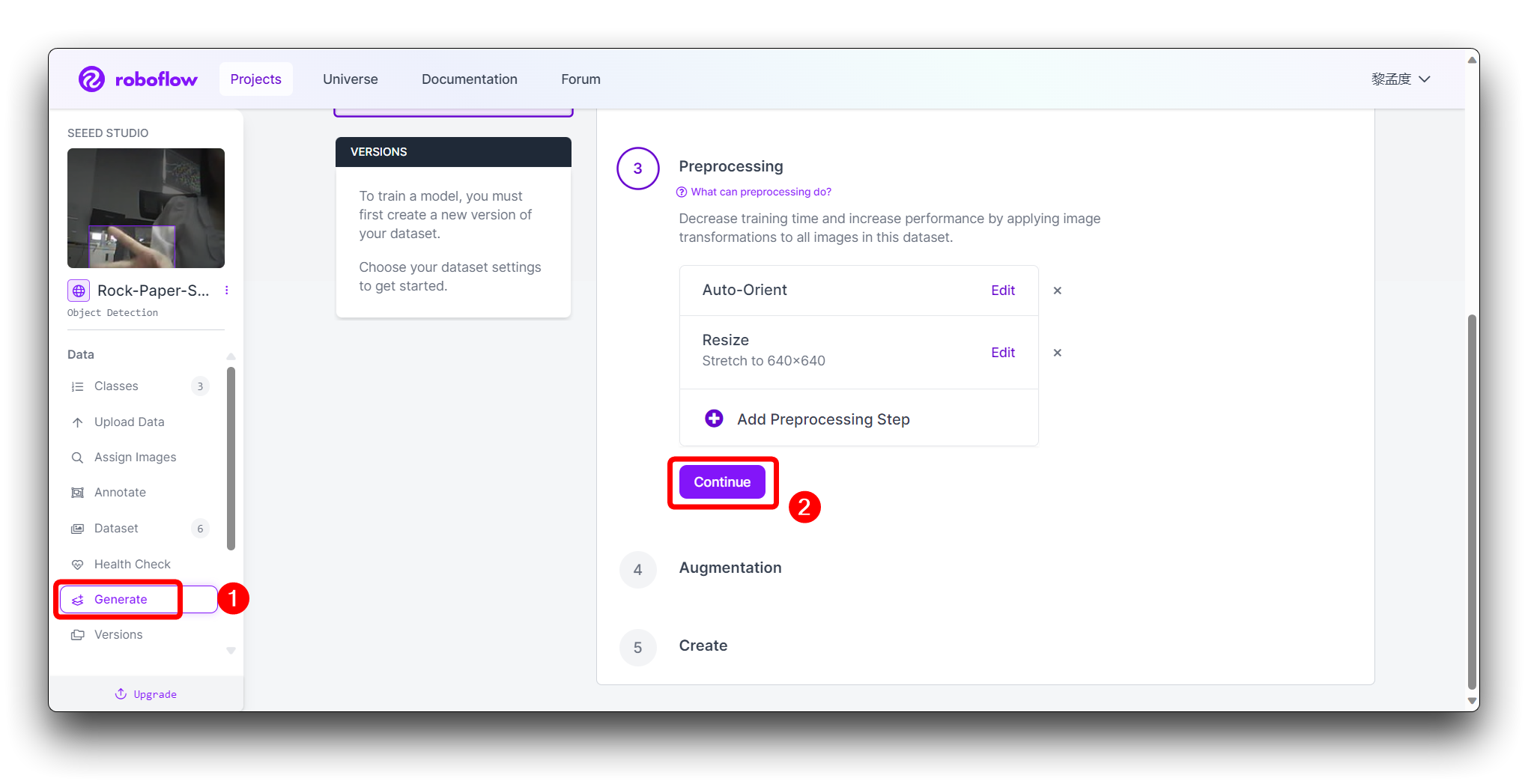
左のツールバーでGenerateをクリックし、3番目のPreprocessingステップでContinueをクリックします。
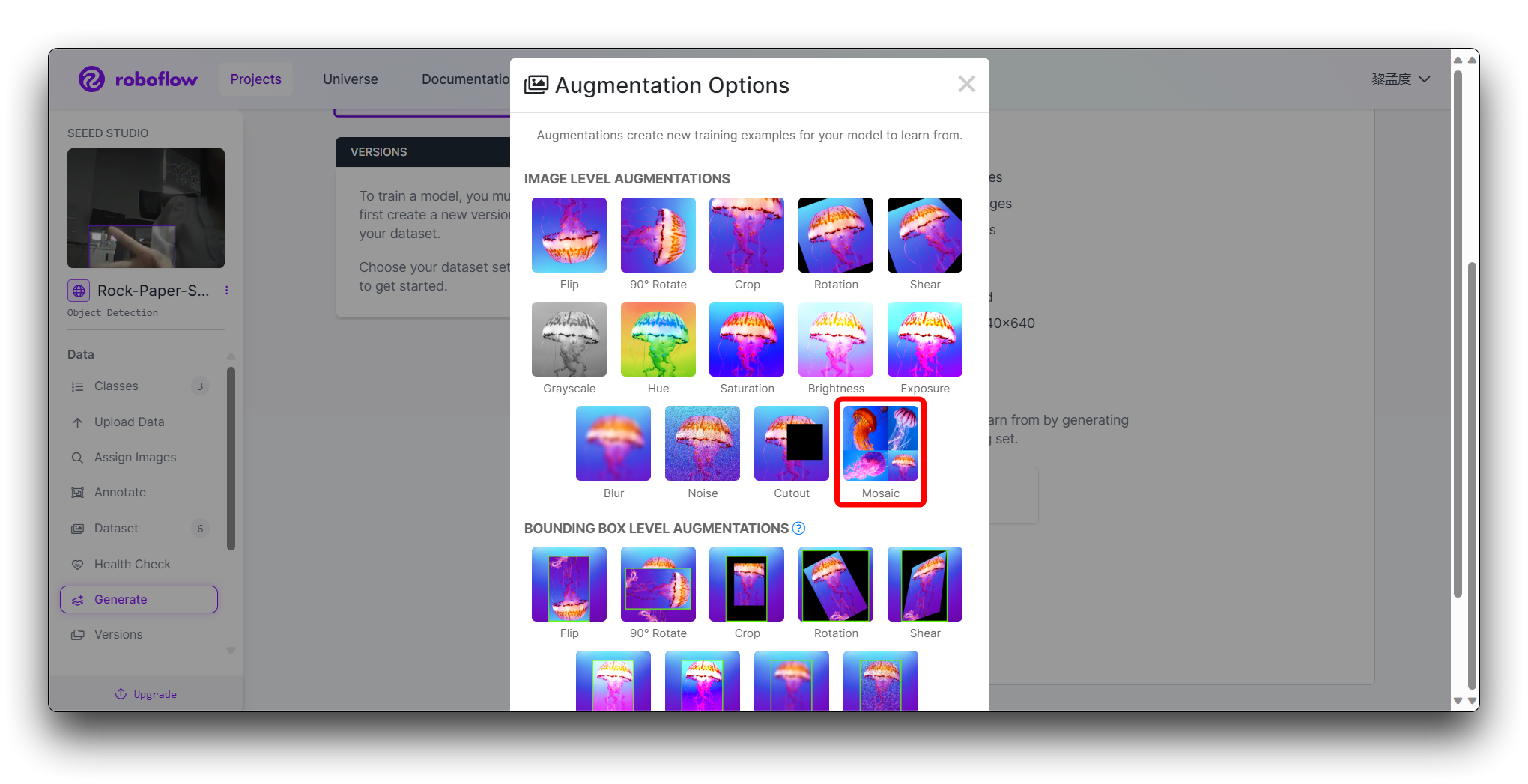
ステップ4のAugmentationで、汎化を向上させるMosaicを選択します。
最終的なCreateステップでは、Roboflowのブーストに従って画像数を合理的に計算してください。一般的に、画像が多いほど、モデルの訓練に時間がかかります。ただし、画像が多いからといって必ずしもモデルがより正確になるわけではなく、主にデータセットが十分に良いかどうかに依存します。
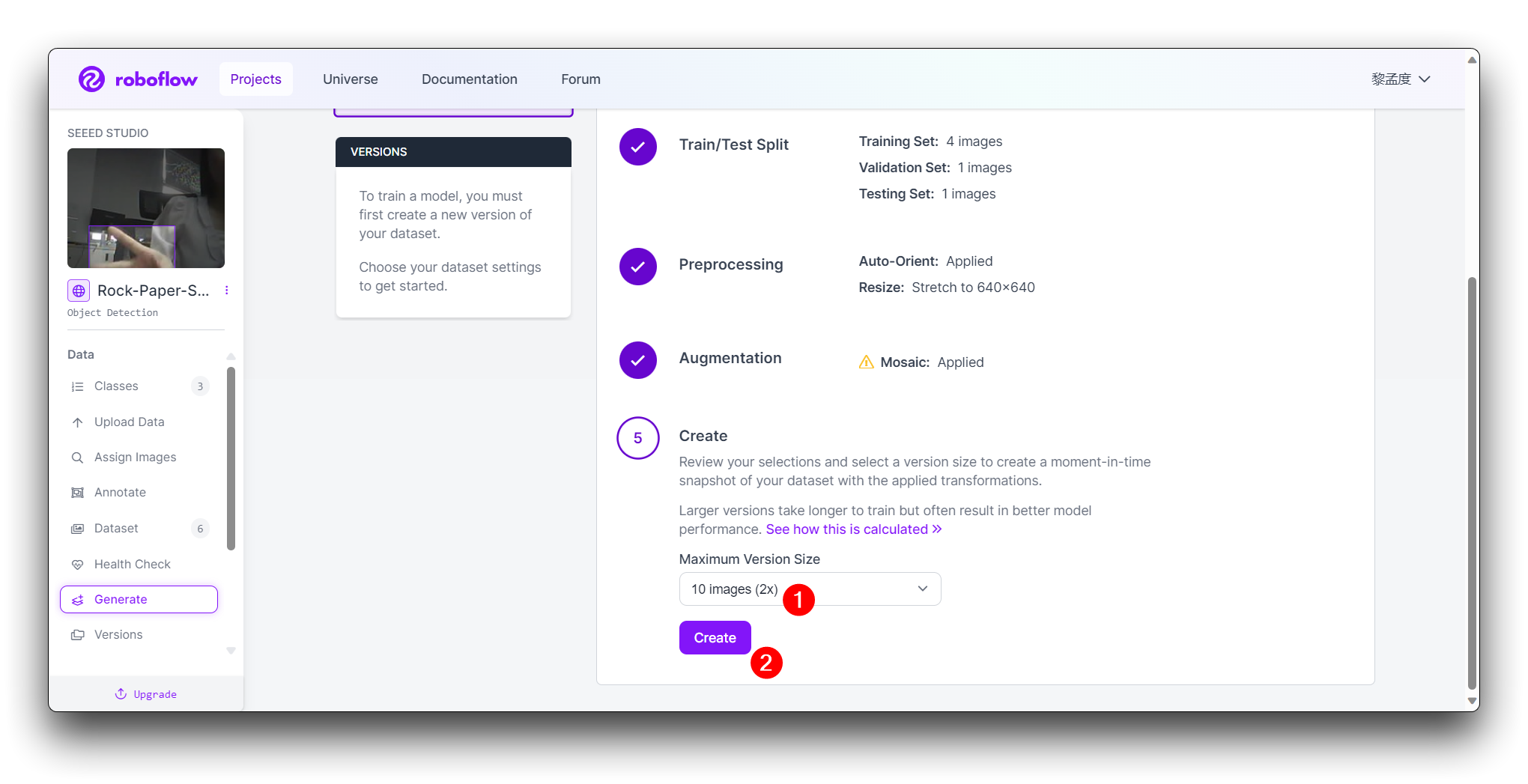
Create をクリックして、データセットのバージョンを作成します。Roboflowが画像とアノテーションを処理し、バージョン管理されたデータセットを作成します。データセットが生成された後、Export Dataset をクリックします。トレーニングするモデルの要件に合致する COCO フォーマットを選択します。
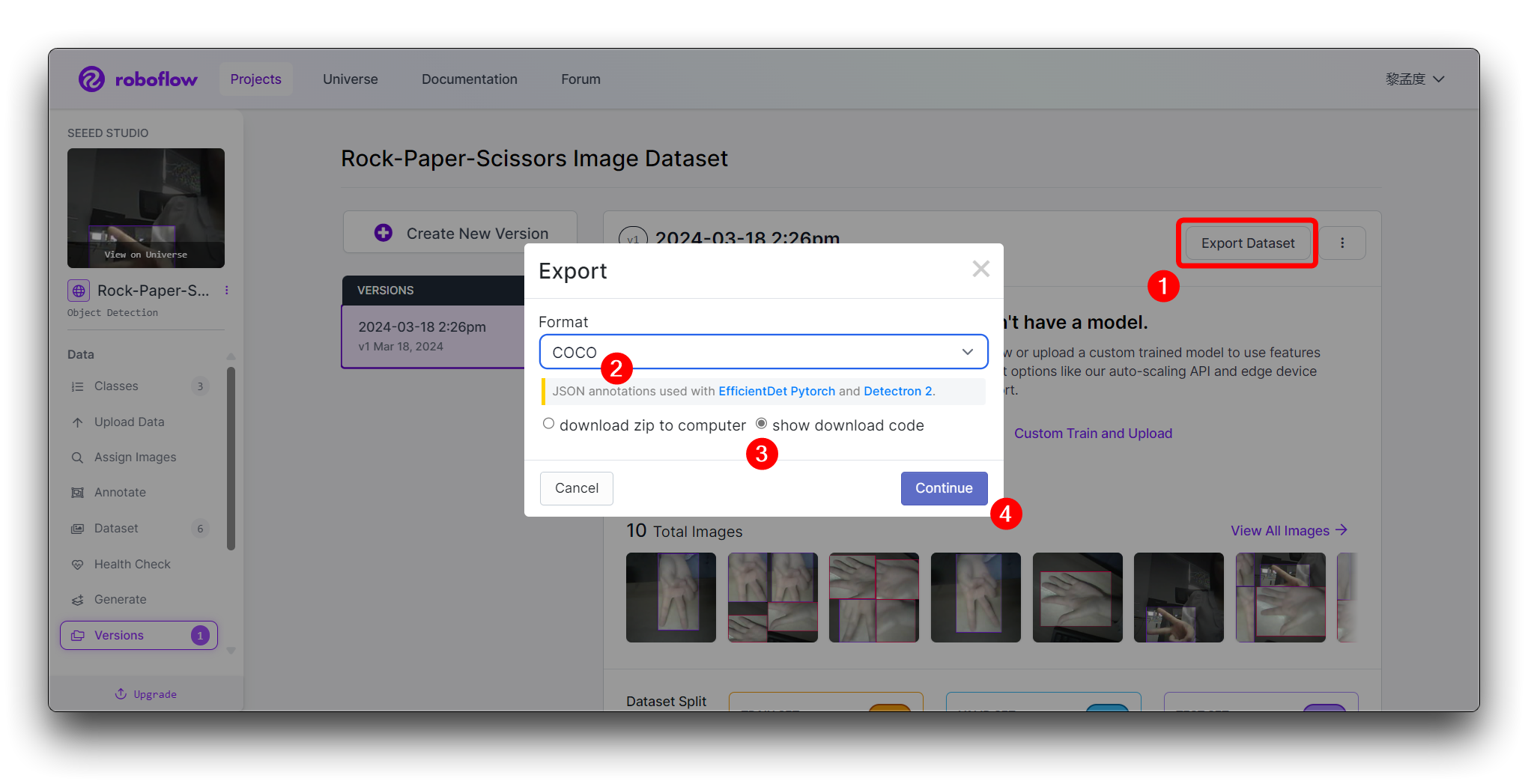
Continue をクリックすると、このモデルのRaw URLが表示されます。このリンクを保存しておいてください。後のモデルトレーニングステップで使用します。
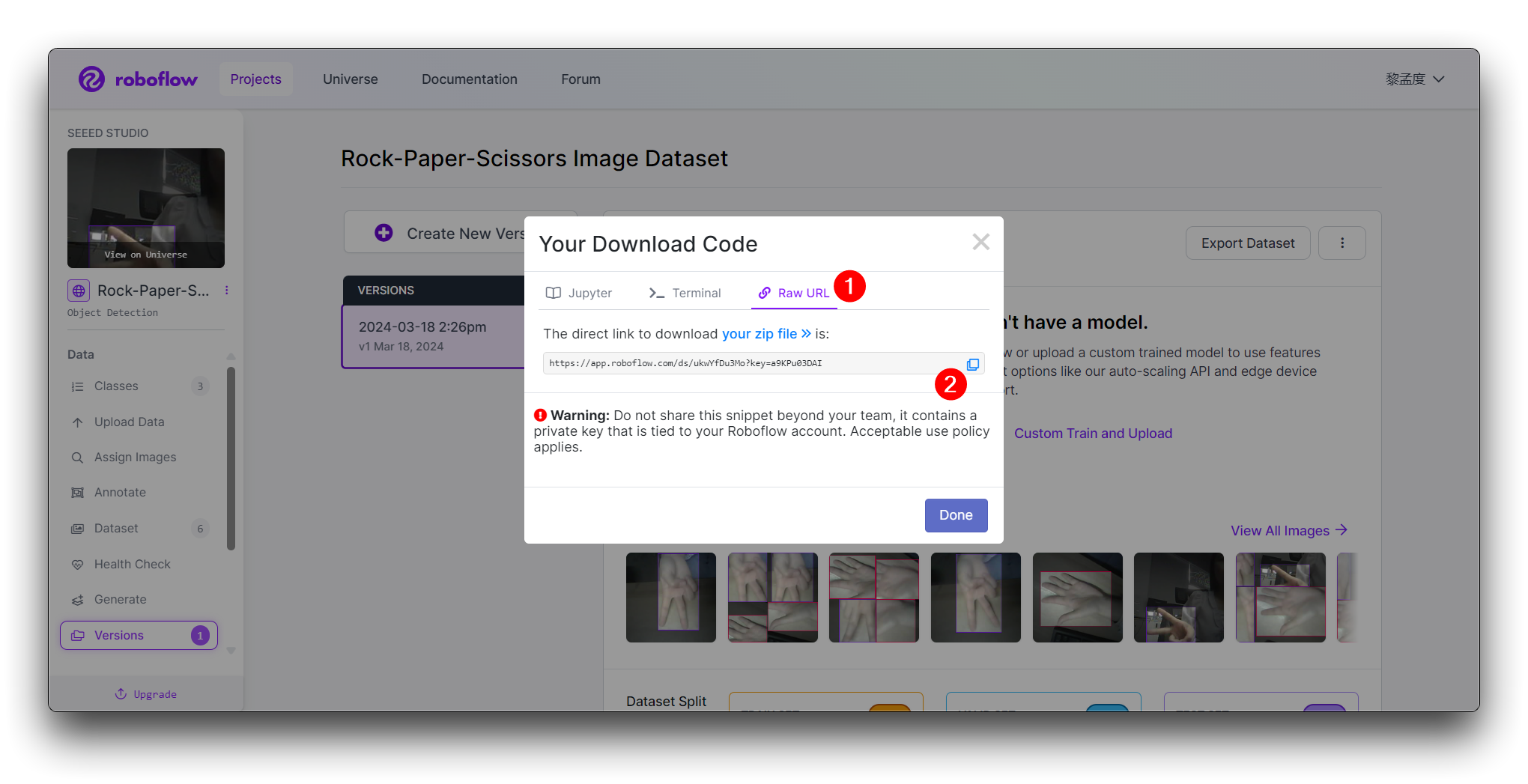
おめでとうございます!Roboflowを使用して、じゃんけんの手のジェスチャー検出モデル用のデータセットのアップロード、アノテーション、エクスポートに成功しました。データセットの準備ができたので、Google Colabなどのプラットフォームを使用して機械学習モデルのトレーニングに進むことができます。
将来のモデルの精度を向上させるために、データセットを多様で適切にアノテーションされた状態に保つことを忘れないでください。モデルトレーニングの成功を祈り、AIの力で手のジェスチャー分類を楽しんでください!
トレーニングデータセットエクスポートモデル
ステップ 1. Colab Notebookへのアクセス
SenseCraft Model AssistantのWikiで、さまざまな種類のモデルGoogle Colabコードファイルを見つけることができます。どのコードを選択すべきかわからない場合は、モデルのクラス(物体検出または画像分類)に応じて、いずれかを選択できます。
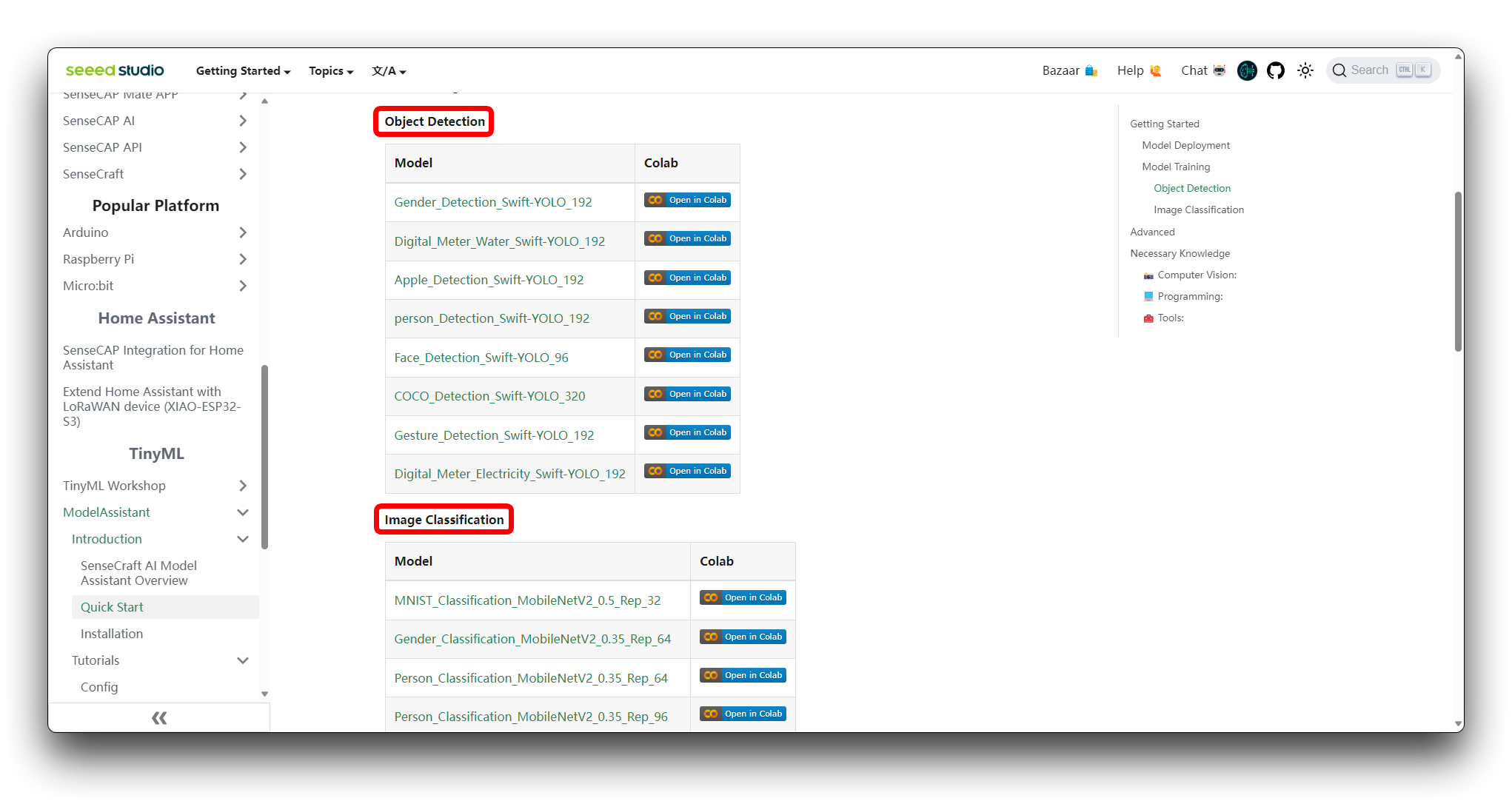
まだGoogleアカウントにサインインしていない場合は、Google Colabの全機能にアクセスするためにサインインしてください。
「Connect」をクリックして、Colabセッション用のリソースを割り当てます。

ステップ 2. Roboflowデータセットの追加
コードブロックを段階的に正式に実行する前に、コードが準備したデータセットを使用できるように、コードの内容を修正する必要があります。データセットをColabファイルシステムに直接ダウンロードするためのURLを提供する必要があります。
コード内の Download the dataset セクションを見つけてください。以下のサンプルプログラムが表示されます。
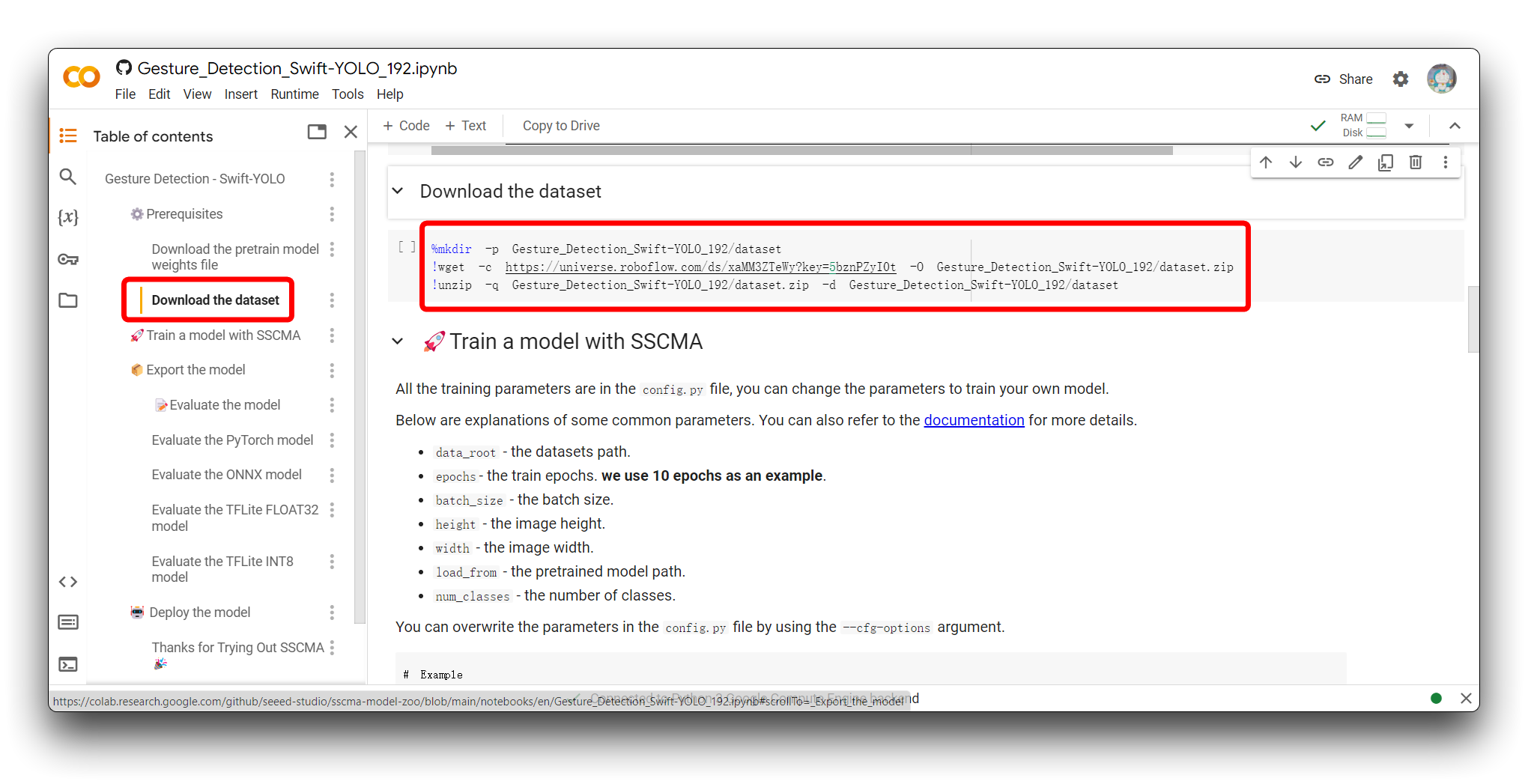
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset
このコードは、Google Colab環境内でディレクトリを作成し、Roboflowからデータセットをダウンロードして、新しく作成したディレクトリに解凍するために使用されます。各行の動作の詳細は以下の通りです:
-
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset:- この行は
Gesture_Detection_Swift-YOLO_192という新しいディレクトリとdatasetというサブディレクトリを作成します。-pフラグにより、ディレクトリが既に存在する場合にエラーを返さず、必要な親ディレクトリを作成することが保証されます。
- この行は
-
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip:- この行は
wgetというコマンドラインユーティリティを使用して、提供されたRoboflow URLからデータセットをダウンロードします。-cフラグにより、ダウンロードが中断された場合に再開できます。-Oフラグは、ダウンロードしたファイルの出力場所とファイル名を指定します。この場合はGesture_Detection_Swift-YOLO_192/dataset.zipです。
- この行は
-
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset:- この行は
unzipコマンドを使用して、dataset.zipファイルの内容を先ほど作成したdatasetディレクトリに展開します。-qフラグはunzipコマンドをクワイエットモードで実行し、ほとんどの出力メッセージを抑制します。
- この行は
Roboflowから独自のモデルリンクに対してこのコードをカスタマイズするには:
-
Gesture_Detection_Swift-YOLO_192を、データセットを保存したい希望のディレクトリ名に置き換えます。 -
Roboflowデータセット URL(
https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t)を、エクスポートしたデータセットへのリンクに置き換えます(これはラベル付きデータセットの最後のステップで取得したRaw URLです)。アクセスに必要な場合は、keyパラメータを含めるようにしてください。 -
必要に応じて
wgetコマンドの出力ファイル名を調整します(-O your_directory/your_filename.zip)。 -
unzipコマンドの出力ディレクトリが作成したディレクトリと一致し、ファイル名がwgetコマンドで設定したものと一致することを確認してください。
フォルダディレクトリGesture_Detection_Swift-YOLO_192の名前を変更する場合、変更前にコード内で使用されていた他のディレクトリ名も変更する必要があることに注意してください。そうしないとエラーが発生する可能性があります!
ステップ3. モデルパラメータの調整
次のステップは、モデルの入力パラメータを調整することです。「SSCMAでモデルを訓練する」セクションにジャンプすると、以下のコードスニペットが表示されます。
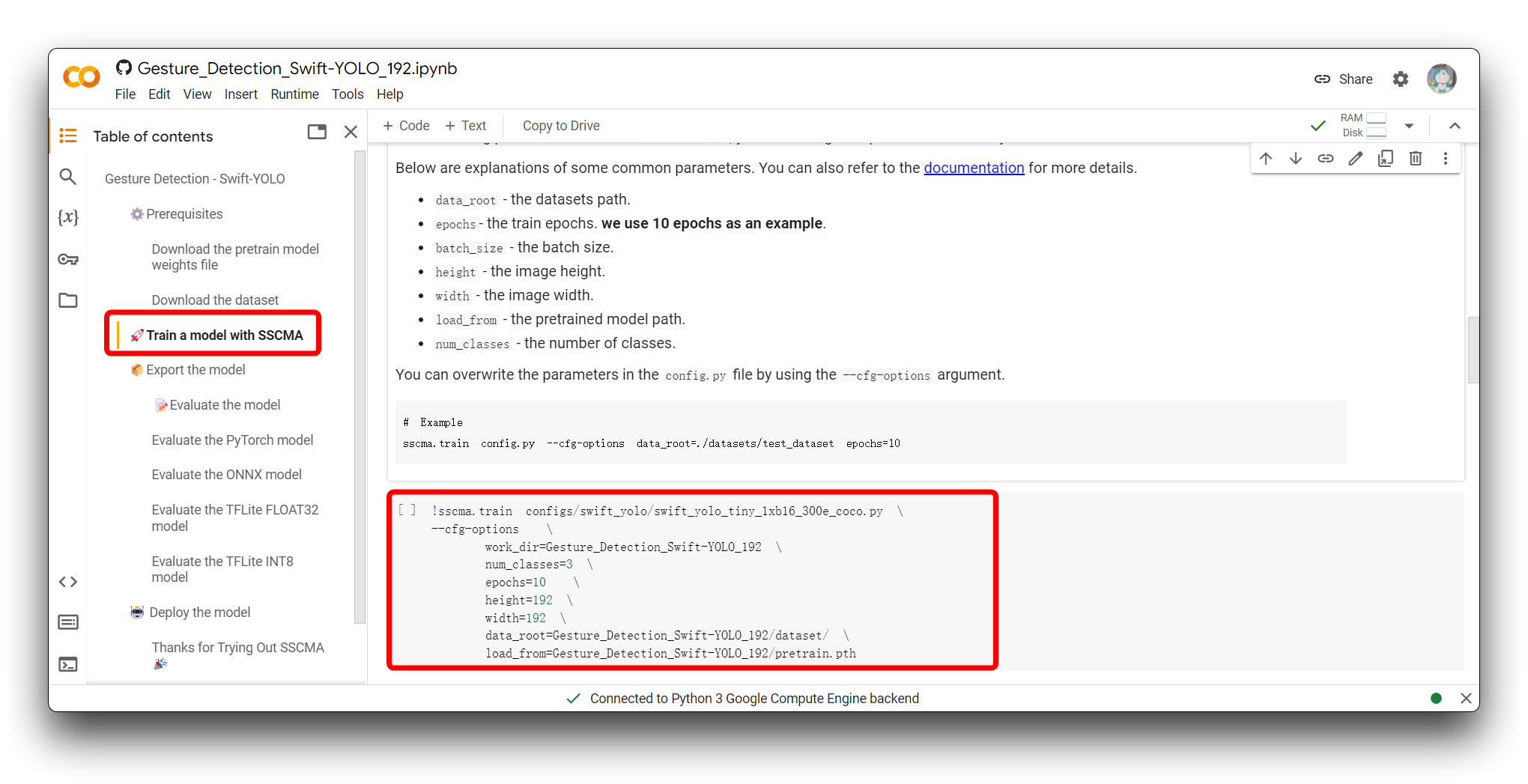
!sscma.train configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \
--cfg-options \
work_dir=Gesture_Detection_Swift-YOLO_192 \
num_classes=3 \
epochs=10 \
height=192 \
width=192 \
data_root=Gesture_Detection_Swift-YOLO_192/dataset/ \
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pth
このコマンドは、SSCMA(Seeed Studio SenseCraft Model Assistant)フレームワークを使用して、機械学習モデル、特にYOLO(You Only Look Once)モデルの訓練プロセスを開始するために使用されます。このコマンドには、訓練プロセスを設定するための様々なオプションが含まれています。各部分の機能は以下の通りです:
-
!sscma.trainは、SSCMAフレームワーク内で訓練を開始するコマンドです。 -
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pyは、モデルアーキテクチャ、訓練スケジュール、データ拡張戦略などの設定を含む訓練用の設定ファイルを指定します。 -
--cfg-optionsを使用すると、.pyファイルで指定されたデフォルト設定を、コマンドラインで提供する設定で上書きできます。 -
work_dir=Gesture_Detection_Swift-YOLO_192は、ログや保存されたモデルチェックポイントなどの訓練出力が保存されるディレクトリを設定します。 -
num_classes=3は、モデルが認識するように訓練されるクラス数を指定します。これは持っているタグの数に依存します。例えば、グー、パー、チョキの場合は3つのタグになります。 -
epochs=10は、実行する訓練サイクル(エポック)数を設定します。推奨値は50から100の間です。 -
height=192とwidth=192は、モデルが期待する入力画像の高さと幅を設定します。
Colabコードで画像サイズを変更することは実際にはお勧めしません。この値は、サイズ、精度、推論速度の組み合わせとして検証された、より適切なデータセットサイズだからです。このサイズではないデータセットを使用していて、精度を確保するために画像サイズの変更を検討したい場合は、240x240を超えないようにしてください。
-
data_root=Gesture_Detection_Swift-YOLO_192/dataset/は、訓練データが配置されているディレクトリへのパスを定義します。 -
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pthは、訓練を再開するか、転移学習の開始点として使用する事前訓練済みモデルチェックポイントファイルへのパスを提供します。
独自の訓練用にこのコマンドをカスタマイズするには、以下のようにします:
-
カスタム設定ファイルがある場合は、
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.pyを独自の設定ファイルへのパスに置き換えます。 -
work_dirを、訓練出力を保存したいディレクトリに変更します。 -
num_classesを独自のデータセットのクラス数に合わせて更新します。これは持っているタグの数に依存します。例えば、グー、パー、チョキの場合は3つのタグになります。 -
epochsをモデルの希望する訓練エポック数に調整します。推奨値は50から100の間です。 -
heightとwidthをモデルの入力画像の寸法に合わせて設定します。 -
data_rootをデータセットのルートディレクトリを指すように変更します。 -
異なる事前訓練済みモデルファイルがある場合は、それに応じて
load_fromパスを更新します。
ステップ4. Google Colabコードを実行する
コードブロックを実行する方法は、コードブロックの左上角にある再生ボタンをクリックすることです。
ボタンをクリックするとコードブロックが実行され、すべてがうまくいけば、コードブロックの実行が完了したサイン - ブロックの左側にチェックマークが表示されます。図に示されているのは、最初のコードブロックの実行が完了した後の効果です。
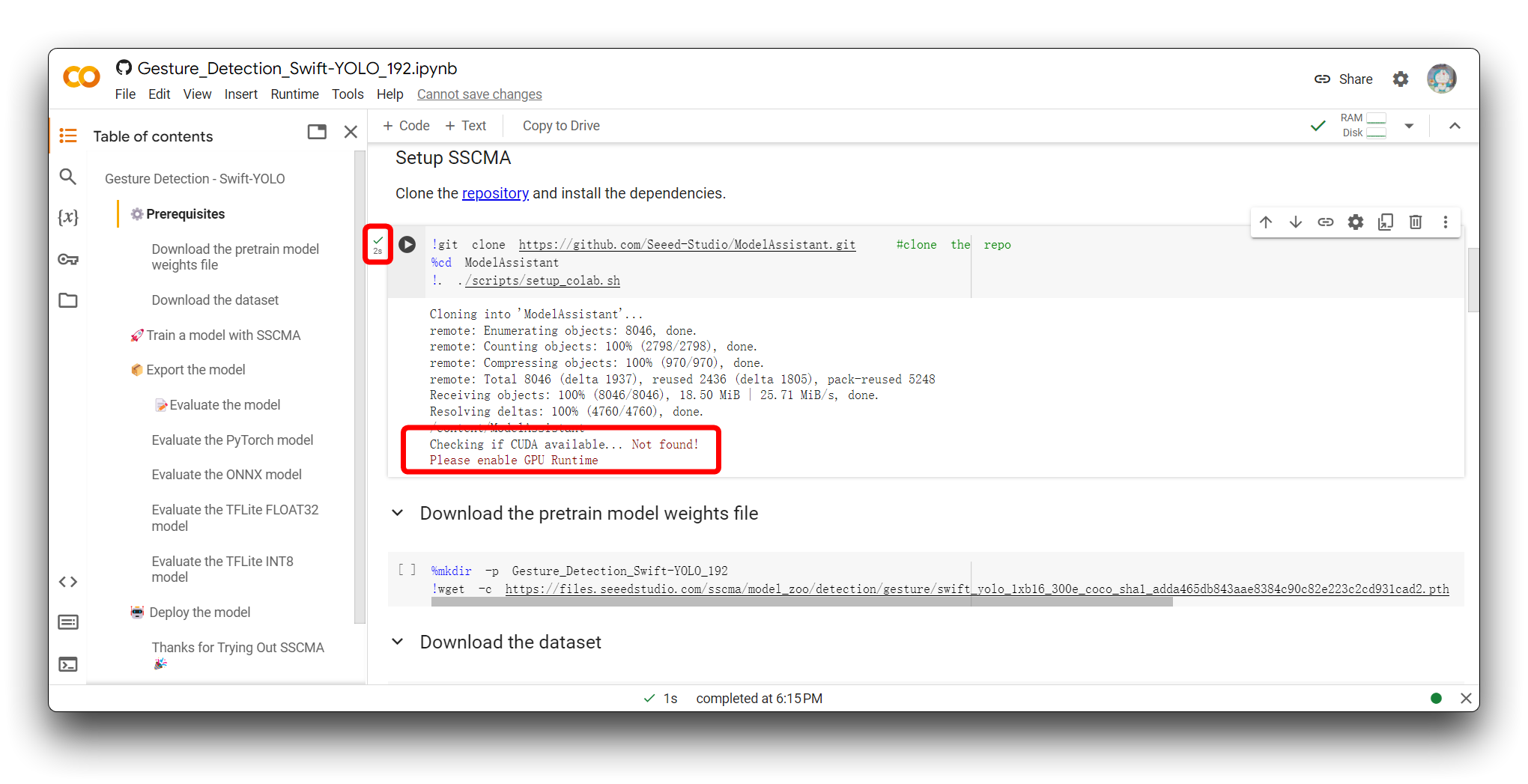
上の画像で私と同じエラーメッセージが表示された場合は、T4 GPU を使用していることを確認してください。このプロジェクトでは CPU を使用しないでください。
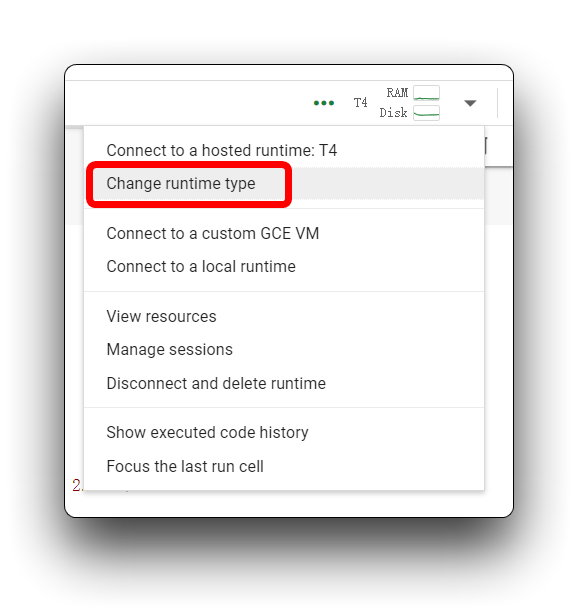
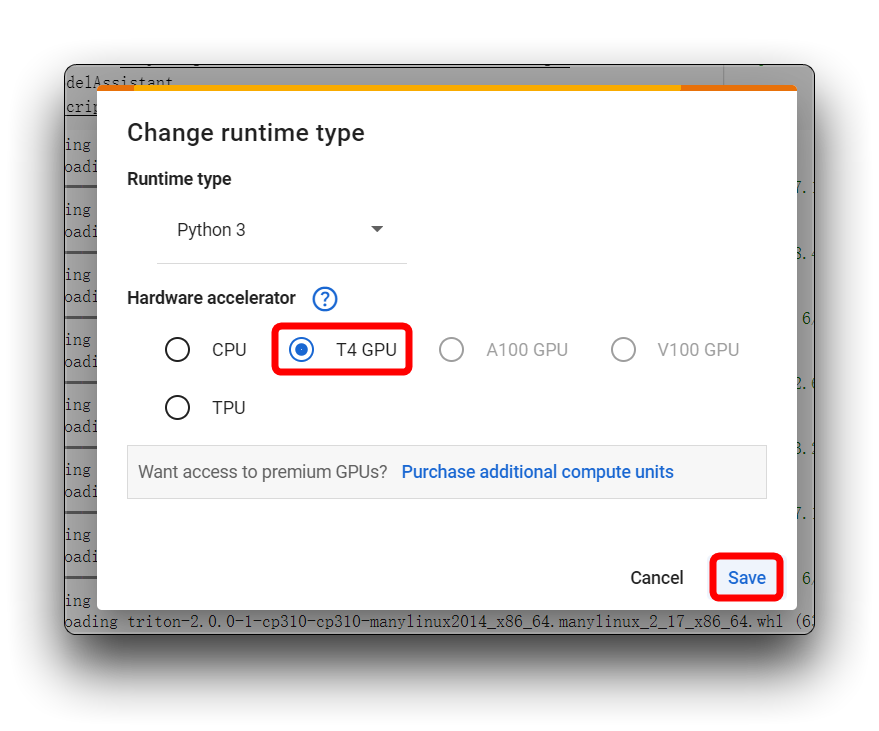
その後、コードブロックを再実行します。最初のコードブロックについて、すべてがうまくいけば、以下に示す結果が表示されます。
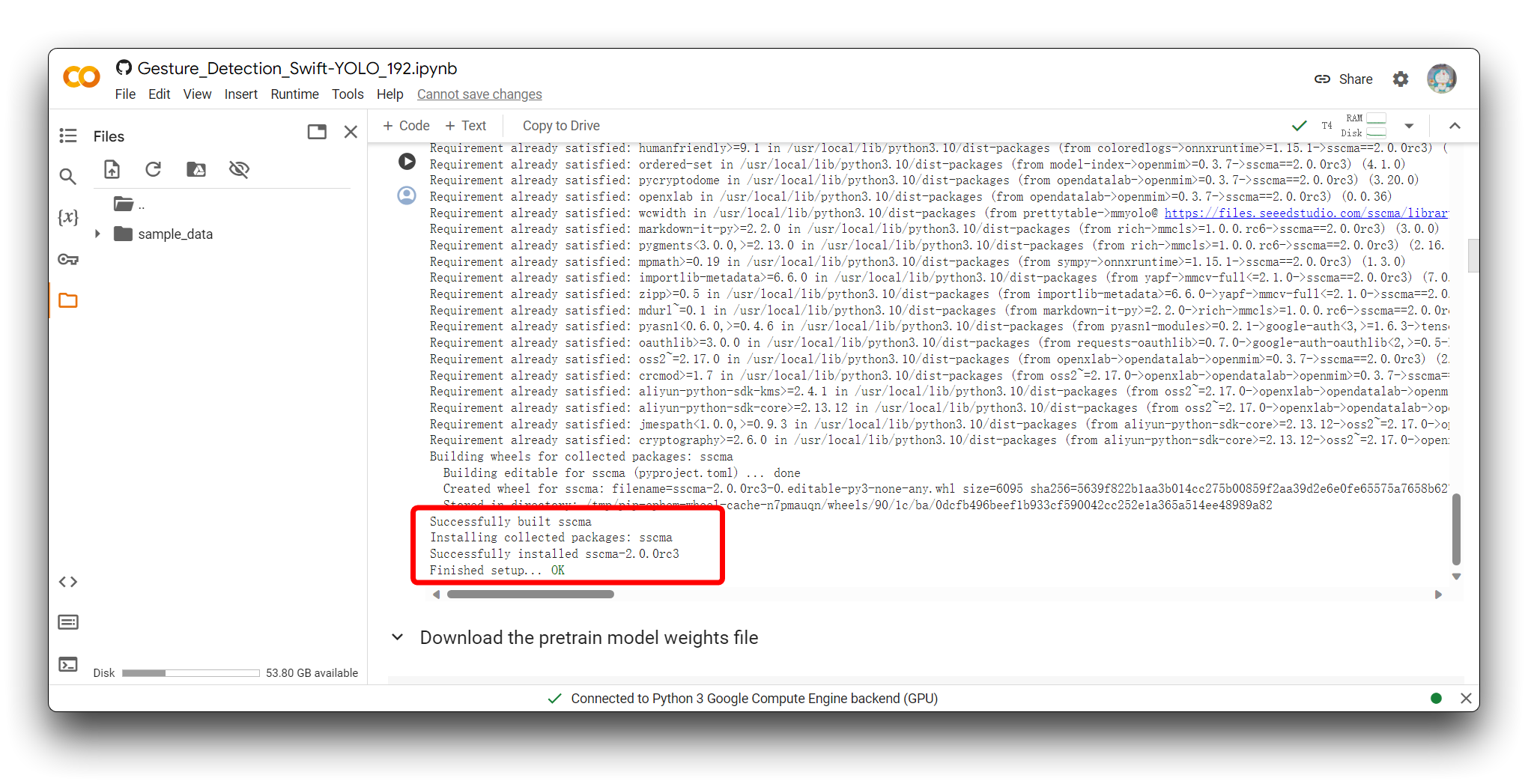
次に、Download the pretrain model weights file から Export the model まで、すべてのコードブロックを実行します。そして、各コードブロックにエラーがないことを確認してください。
コードに表示される警告は無視できます。
ステップ5. モデルを評価する
Evaluate the model セクションに到達したら、Evaluate the TFLite INT8 model コードブロックを実行するオプションがあります。
TFLite INT8 モデルの評価には、量子化されたモデルの予測を別のテストデータセットに対してテストして精度とパフォーマンスメトリクスを測定し、量子化がモデルの精度に与える影響を評価し、推論速度とリソース使用量をプロファイリングして、エッジデバイスの展開制約を満たすことを確認することが含まれます。
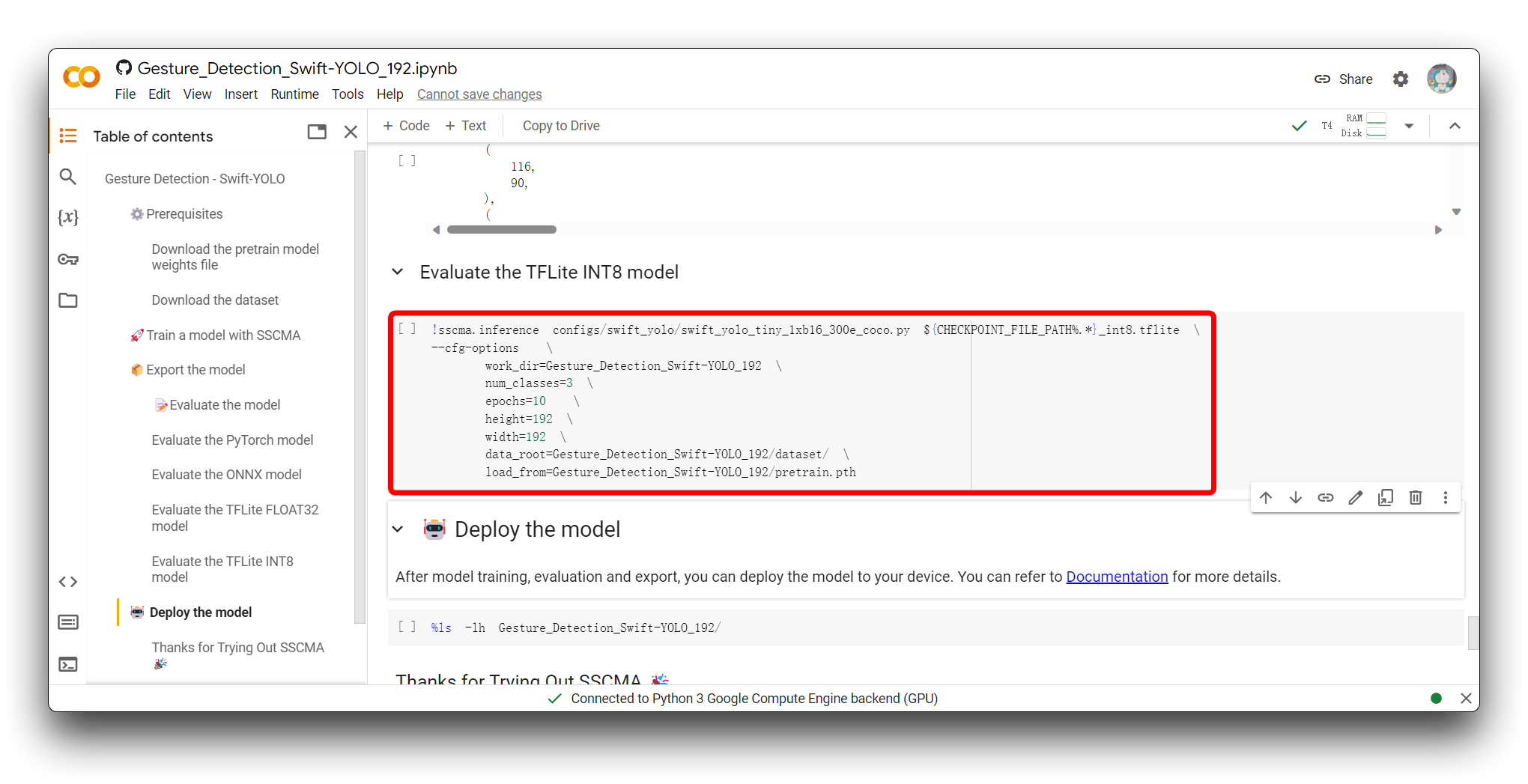
以下のスニペットは、このコードブロックを実行した後の結果の有効な部分です。
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.450
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.929
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.474
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.536
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.537
03/19 01:38:43 - mmengine - INFO - bbox_mAP_copypaste: 0.450 0.929 0.361 -1.000 0.474 0.456
{'coco/bbox_mAP': 0.45, 'coco/bbox_mAP_50': 0.929, 'coco/bbox_mAP_75': 0.361, 'coco/bbox_mAP_s': -1.0, 'coco/bbox_mAP_m': 0.474, 'coco/bbox_mAP_l': 0.456}
FPS: 128.350449 fram/s
評価結果には、一連の平均精度(AP)と平均再現率(AR)メトリクスが含まれており、これらは異なるIntersection over Union(IoU)閾値とオブジェクトサイズに対して計算され、物体検出モデルの性能を評価するために一般的に使用されます。
-
AP@[IoU=0.50:0.95 | area=all | maxDets=100] = 0.450
- このスコアは、0.50から0.95までのIoU閾値範囲(0.05刻み)におけるモデルの平均精度です。APが0.450であることは、この範囲でモデルが中程度の精度を持つことを示しています。これはCOCOデータセットで一般的に使用される重要なメトリクスです。
-
AP@[IoU=0.50 | area=all | maxDets=100] = 0.929
- IoU閾値0.50において、モデルは0.929の高い平均精度を達成しており、より寛容なマッチング基準の下で非常に正確にオブジェクトを検出することを示しています。
-
AP@[IoU=0.75 | area=all | maxDets=100] = 0.361
- より厳しいIoU閾値0.75では、モデルの平均精度は0.361に低下し、より厳密なマッチング基準の下での性能低下を示しています。
-
AP@[IoU=0.50:0.95 | area=small/medium/large | maxDets=100]
- APスコアは異なるサイズのオブジェクトで変化します。ただし、小さなオブジェクトのAPは-1.000であり、これは小さなオブジェクトの評価データの不足または小さなオブジェクト検出におけるモデル性能の低さを示している可能性があります。中サイズと大サイズのオブジェクトのAPスコアはそれぞれ0.474と0.456であり、モデルが中サイズと大サイズのオブジェクトを比較的よく検出することを示しています。
-
AR@[IoU=0.50:0.95 | area=all | maxDets=1/10/100]
- 異なる
maxDets値に対する平均再現率は0.515から0.529の範囲で非常に一貫しており、モデルが真陽性インスタンスの大部分を確実に検索することを示しています。
- 異なる
-
FPS: 128.350449 fram/s
- モデルは推論中に約128.35フレーム/秒の非常に高速な処理速度で画像を処理し、リアルタイムまたはほぼリアルタイムアプリケーションの可能性を示しています。
全体的に、モデルはIoU 0.50で優秀な性能を示し、IoU 0.75で中程度の性能を示します。中サイズと大サイズのオブジェクト検出では良好な性能を示しますが、小さなオブジェクトの検出に問題がある可能性があります。さらに、モデルは高速で推論を行うため、高速処理が必要なシナリオに適しています。アプリケーションで小さなオブジェクトの検出が重要な場合は、性能を向上させるためにモデルをさらに最適化するか、より多くの小さなオブジェクトデータを収集する必要があるかもしれません。
ステップ6. エクスポートされたモデルファイルのダウンロード
Export the modelセクションの後、様々な形式のモデルファイルが取得でき、これらはデフォルトでModelAssistantフォルダに保存されます。このチュートリアルでは、保存ディレクトリはGesture_Detection_Swift_YOLO_192です。
Google Colabがフォルダの内容を自動的に更新しない場合があります。この場合、左上角の更新アイコンをクリックしてファイルディレクトリを更新する必要があるかもしれません。
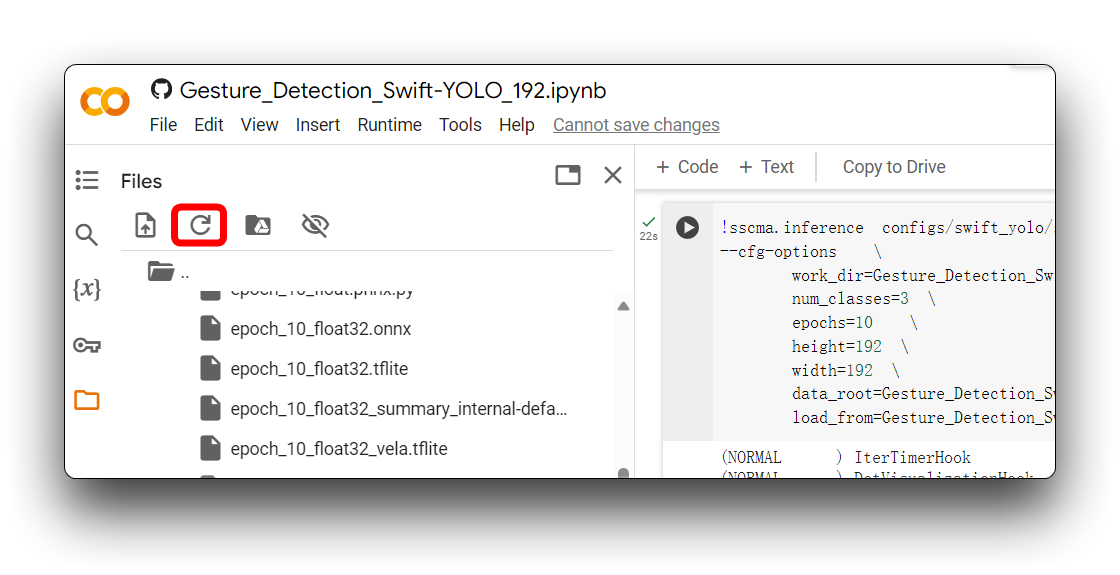
上記のディレクトリでは、.tfliteモデルファイルがXIAO ESP32S3とGrove Vision AI V2で利用可能です。XIAO ESP32S3 Senseの場合は、xxx_int8.tflite形式を使用するモデルファイルを必ず選択してください。XIAO ESP32S3 Senseでは他の形式は使用できません。
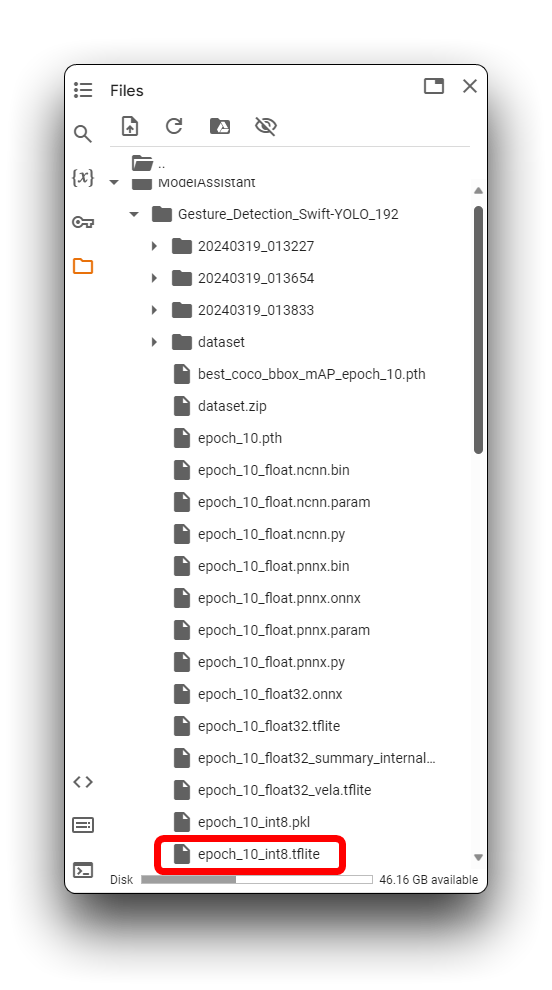
モデルファイルを見つけたら、できるだけ早くローカルコンピュータにダウンロードしてください。Google Colabは長時間アイドル状態が続くとストレージディレクトリを空にする可能性があります!
ここで実行した手順により、XIAO ESP32S3でサポートできるモデルファイルのエクスポートに成功しました。次に、モデルをデバイスにデプロイしましょう。
SenseCraft Model Assistantを使用してモデルをアップロードする
ステップ7. XIAO ESP32S3にカスタムモデルをアップロードする
次に、Model Assistantページに移動します。
XIAO ESP32S3を選択した後にデバイスを接続し、ページ下部のUpload Custom AI Modelを選択してください。
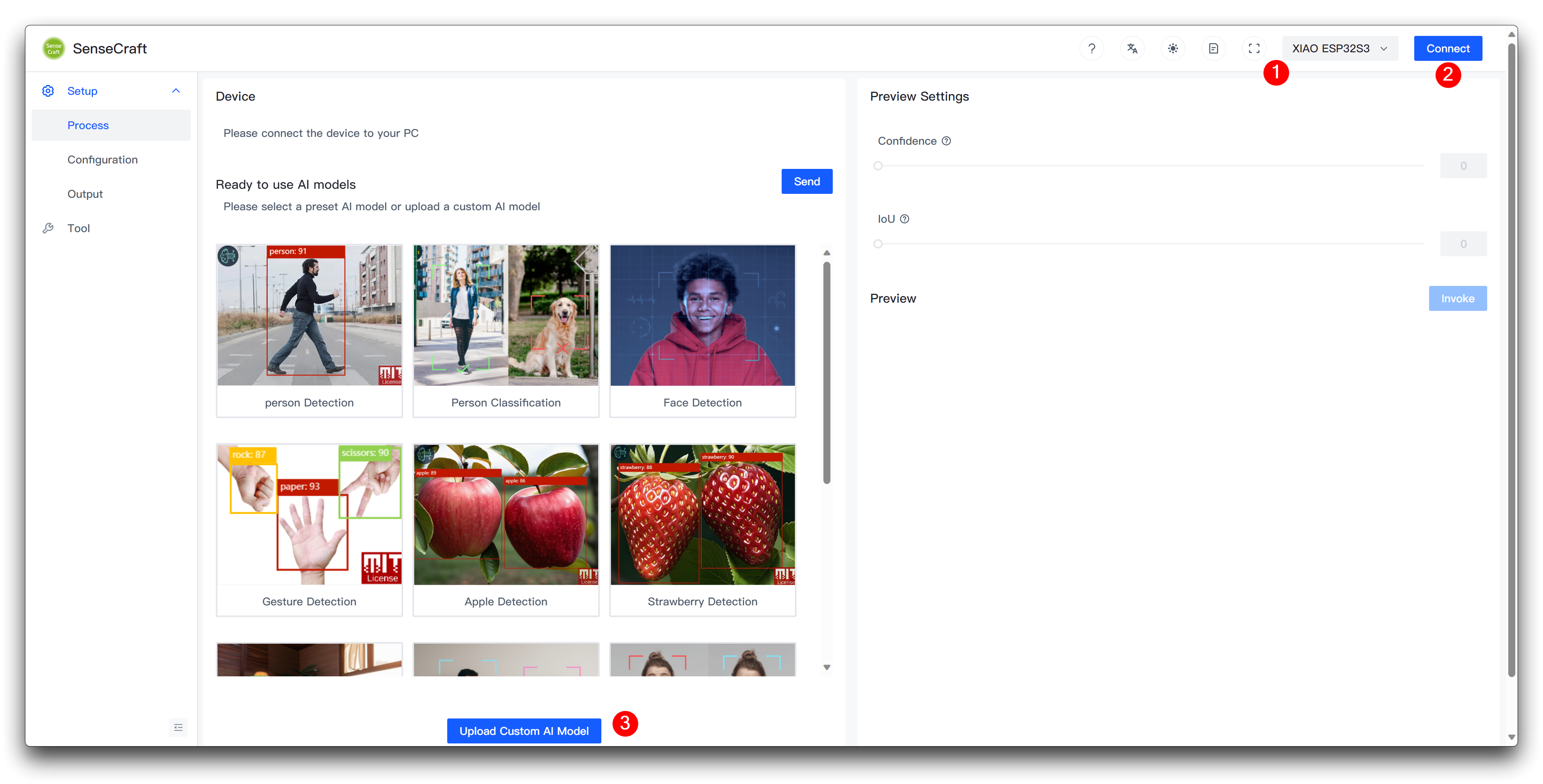
その後、モデル名、モデルファイル、ラベルを準備する必要があります。ここで、ラベルIDの要素がどのように決定されるかを強調したいと思います。
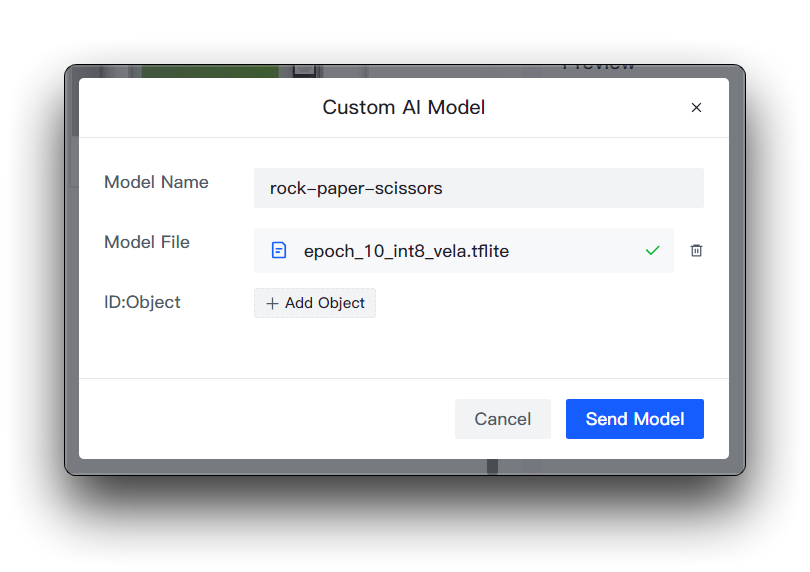
Roboflowのデータセットを直接ダウンロードしている場合
Roboflowのデータセットを直接ダウンロードした場合、Health Checkページで異なるカテゴリとその順序を確認できます。ここで入力された順序に従ってインストールしてください。
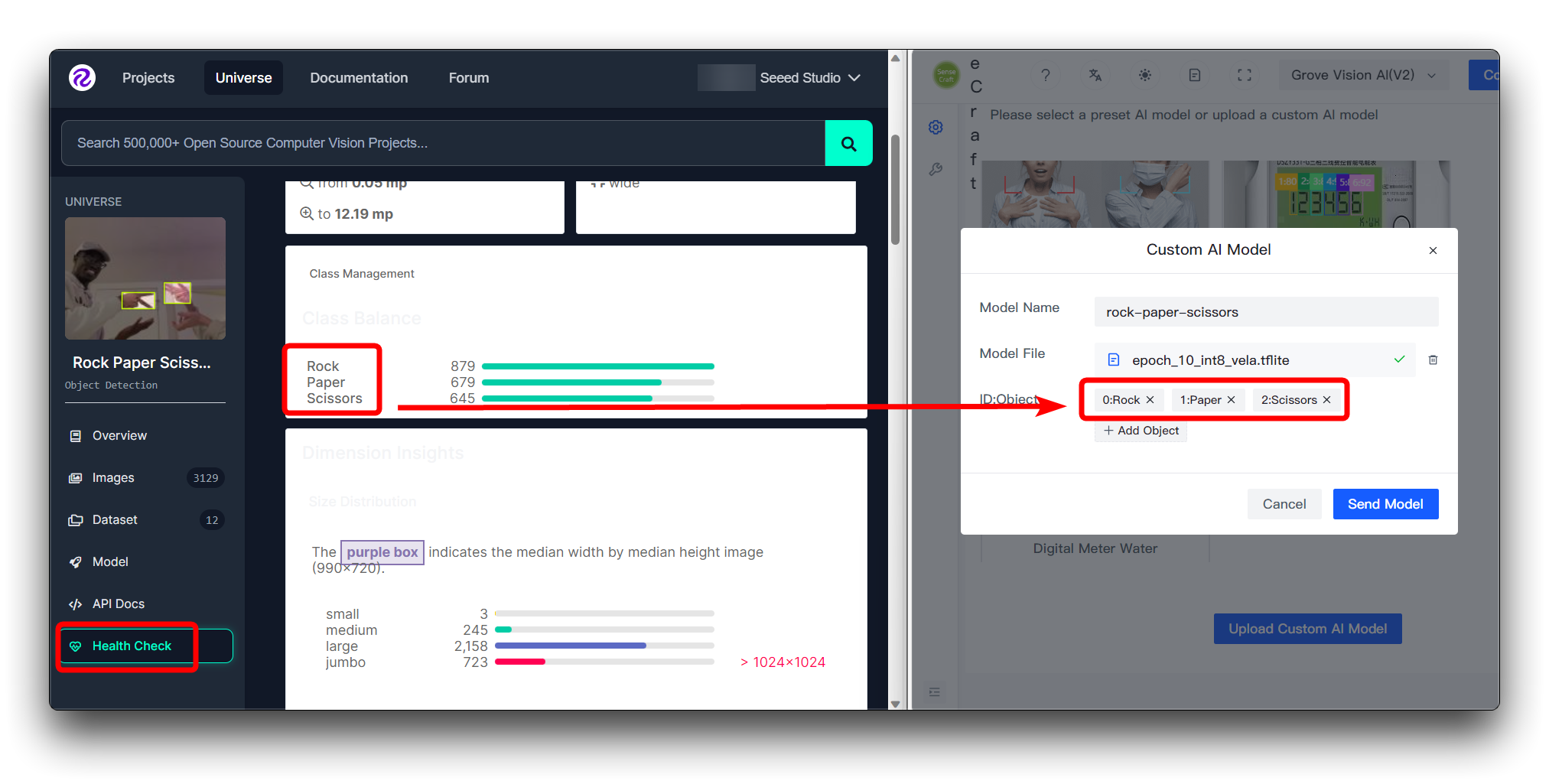
ID:Objectに数字を入力する必要はありません。カテゴリ名を直接入力するだけで、画像上のカテゴリの前の数字とコロンは自動的に追加されます。
カスタムデータセットを使用している場合
カスタムデータセットを使用している場合、Health Checkページで異なるカテゴリとその順序を確認できます。ここで入力された順序に従ってインストールしてください。
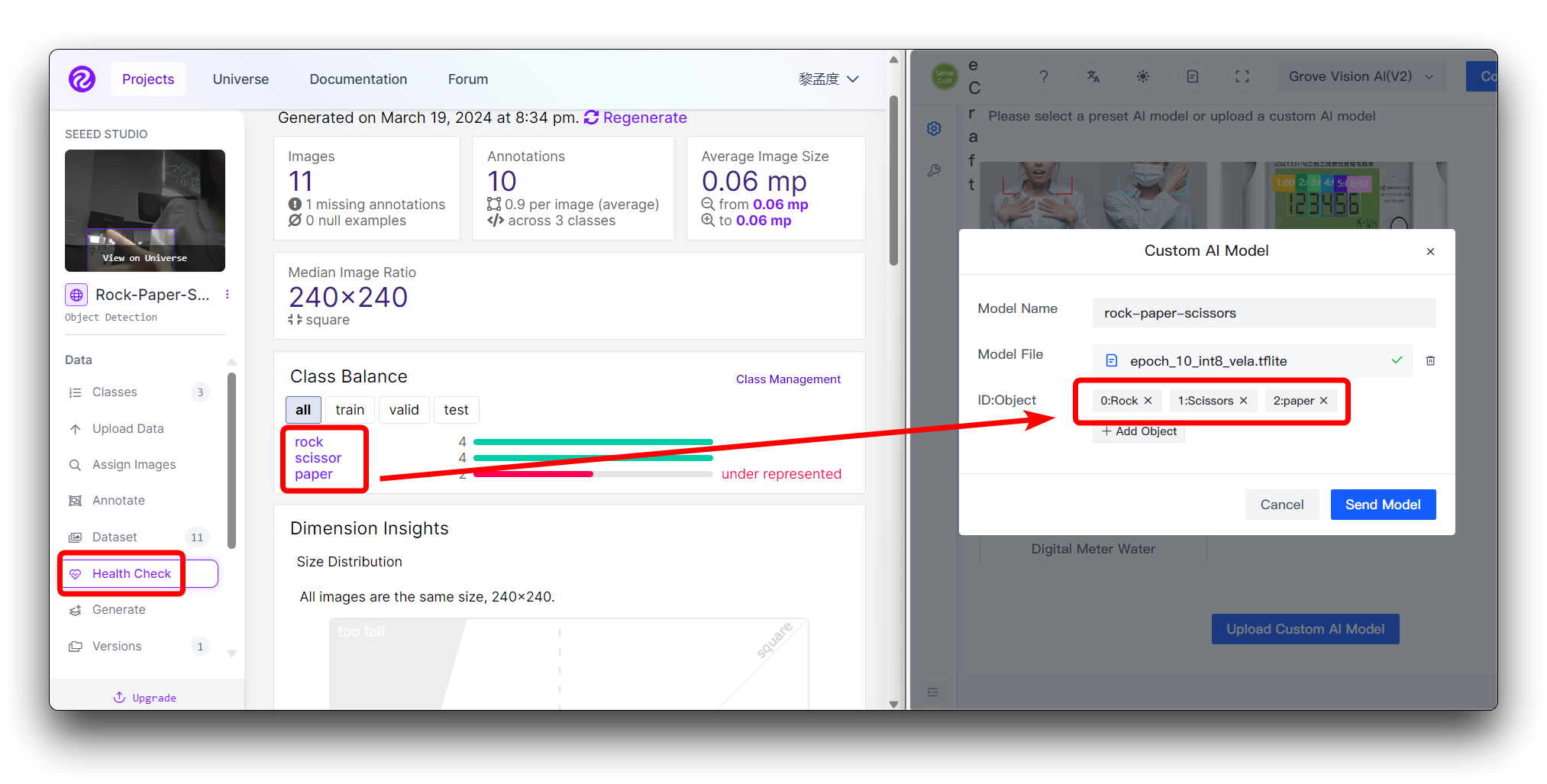
ID:Objectに数字を入力する必要はありません。カテゴリ名を直接入力するだけで、画像上のカテゴリの前の数字とコロンは自動的に追加されます。
その後、右下のSend Modelをクリックします。これには約3〜5分程度かかる場合があります。すべてが順調に進めば、上部のModel NameとPreviewウィンドウでモデルの結果を確認できます。
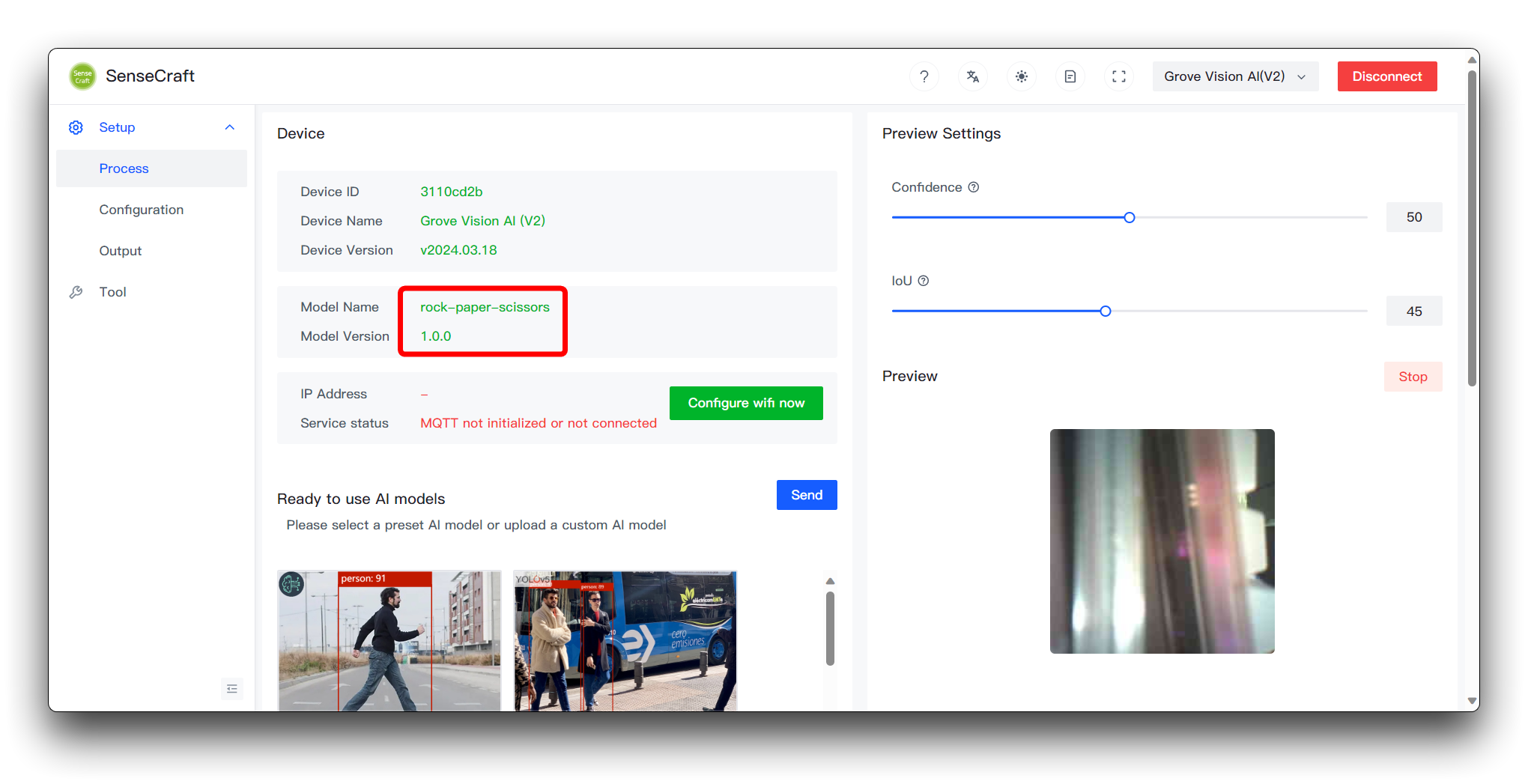
ここまで到達できたなら、おめでとうございます。独自のモデルを正常にトレーニングしてデプロイすることができました。
モデルの一般的なプロトコルとアプリケーション
カスタムモデルのアップロードプロセス中、視覚的にアップロードされるモデルファイルに加えて、デバイスに転送する必要があるデバイスのファームウェアもあります。デバイスのファームウェアには、モデル結果出力の形式を指定し、ユーザーがモデルで何ができるかを定める確立された通信プロトコルのセットがあります。
スペースの問題により、このwikiではこれらのプロトコルの詳細については展開しませんが、Githubのドキュメントを通じてこのセクションを詳しく説明します。より深い開発に興味がある場合は、こちらをご覧ください。
トラブルシューティング
1. 手順に従ったにも関わらず、モデルの結果が満足のいくものでない場合はどうすればよいですか?
モデルの認識精度が満足のいくものでない場合は、以下の側面を考慮して診断と改善を行うことができます:
-
データの品質と量
- 問題: データセットが小さすぎる、多様性に欠ける、またはアノテーションに不正確さがある可能性があります。
- 解決策: 訓練データのサイズと多様性を増やし、データクリーニングを実行してアノテーションエラーを修正します。
-
訓練プロセス
- 問題: 訓練時間が不十分、または学習率が不適切に設定されており、モデルが効果的に学習できない可能性があります。
- 解決策: 訓練エポック数を増やし、学習率やその他のハイパーパラメータを調整し、過学習を避けるために早期停止を実装します。
-
クラス不均衡
- 問題: 一部のクラスが他のクラスよりも大幅に多くのサンプルを持っており、モデルが多数派クラスに偏る原因となっています。
- 解決策: クラス重みを使用し、少数派クラスをオーバーサンプリングするか、多数派クラスをアンダーサンプリングしてデータのバランスを取ります。
徹底的な分析と的を絞った改善を実装することで、モデルの精度を段階的に向上させることができます。各修正後にモデルのパフォーマンスをテストするために検証セットを使用し、改善の効果を確実にすることを忘れないでください。
2. Wikiの手順に従った後、SenseCraftデプロイメントでInvoke failedメッセージが表示されるのはなぜですか?
Invoke failedが発生した場合、デバイスでの使用要件を満たさないモデルを訓練したことになります。以下の領域に焦点を当ててください。
- Colabの画像サイズを変更したかどうかを確認してください。デフォルトの圧縮サイズは192x192です。Grove Vision AI V2では、画像サイズを正方形として圧縮する必要があります。圧縮に非正方形サイズを使用しないでください。また、サイズが大きすぎないようにしてください (240x240以下を推奨)。
技術サポート & 製品ディスカッション
私たちの製品をお選びいただき、ありがとうございます!私たちは、お客様の製品体験が可能な限りスムーズになるよう、さまざまなサポートを提供しています。異なる好みやニーズに対応するため、複数のコミュニケーションチャネルを提供しています。