Como treinar e implantar YOLOv8 no reComputer
Introdução
Diante de desafios cada vez mais complexos e dinâmicos, a aplicação de inteligência artificial oferece novas formas de resolver problemas e tem contribuído de forma significativa para o desenvolvimento sustentável da sociedade global e para a melhoria da qualidade de vida das pessoas. Normalmente, antes de implantar algoritmos de inteligência artificial, o design e o treinamento dos modelos de IA ocorrem em servidores de computação de alto desempenho. Após a conclusão do treinamento do modelo, ele é exportado para dispositivos de computação de borda para inferência na borda. Na verdade, todos esses processos podem ocorrer diretamente em dispositivos de computação de borda. Especificamente, tarefas como preparação de conjuntos de dados, treinamento de redes neurais, validação de redes neurais e implantação de modelos podem ser realizadas em dispositivos de borda. Isso não apenas garante a segurança dos dados, como também economiza os custos associados à compra de dispositivos adicionais.

Neste documento, treinamos e implantamos um modelo de detecção de objetos para cenas de tráfego no reComputer J4012. Este documento usa o algoritmo de detecção de objetos YOLOv8 como exemplo e fornece uma visão geral detalhada de todo o processo. Observe que todas as operações descritas abaixo ocorrem no dispositivo de computação de borda Jetson, garantindo que o dispositivo Jetson tenha um sistema operacional instalado que seja JetPack 5.0 ou superior.
Conjunto de dados
O processo de aprendizado de máquina envolve encontrar padrões dentro de dados fornecidos e, em seguida, usar uma função para capturar esses padrões. Portanto, a qualidade do conjunto de dados afeta diretamente o desempenho do modelo. De modo geral, quanto melhor a qualidade e a quantidade de dados de treinamento, melhor será o modelo treinado. Portanto, a preparação do conjunto de dados é crucial.
Existem vários métodos para coletar o conjunto de dados de treinamento. Aqui, são apresentados dois métodos: 1. Fazer o download de conjuntos de dados públicos de código aberto já anotados. 2. Coletar e anotar dados de treinamento. Por fim, consolide todos os dados para preparar a fase subsequente de treinamento.
Baixar conjuntos de dados públicos
Conjuntos de dados públicos são recursos padronizados de dados compartilhados, amplamente usados em pesquisa de aprendizado de máquina e inteligência artificial. Eles fornecem aos pesquisadores referências padrão para avaliar o desempenho de algoritmos, promovendo a inovação e a colaboração na área. Esses conjuntos de dados impulsionam a comunidade de IA em direção a uma direção mais aberta, inovadora e sustentável.
Existem muitas plataformas onde você pode baixar conjuntos de dados gratuitamente, como Roboflow, Kaggle, e outras. Aqui, baixamos um conjunto de dados anotado relacionado a cenas de tráfego, Traffic Detection Project, do Kaggle.
A estrutura de arquivos após a extração é a seguinte:
archive
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.jpg
│ │ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.txt
│ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.jpg
│ │ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.txt
│ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.txt
│ ├── ...
└── valid
├── images
│ ├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.jpg
│ ├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.jpg
│ ├── ...
└── labels
├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.txt
├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.txt
├──...
Cada imagem tem um arquivo de texto correspondente que contém as informações completas de anotação dessa imagem. O arquivo data.json registra os locais dos conjuntos de treinamento, teste e validação, e você precisa modificar os caminhos:
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']
Coletando e anotando dados
Quando conjuntos de dados públicos não conseguem atender aos requisitos do usuário, é preciso considerar a coleta e criação de conjuntos de dados personalizados adaptados a necessidades específicas. Isso pode ser feito coletando, anotando e organizando dados relevantes. Para fins de demonstração, capturei e salvei três imagens do YouTube , e tentei usar o Label Studio para anotar as imagens.
Etapa 1. Coletar dados brutos:

Etapa 2. Instalar e executar a ferramenta de anotação:
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latest
Etapa 3. Criar um novo projeto e concluir a anotação conforme as instruções: Label Studio Reference Documentation
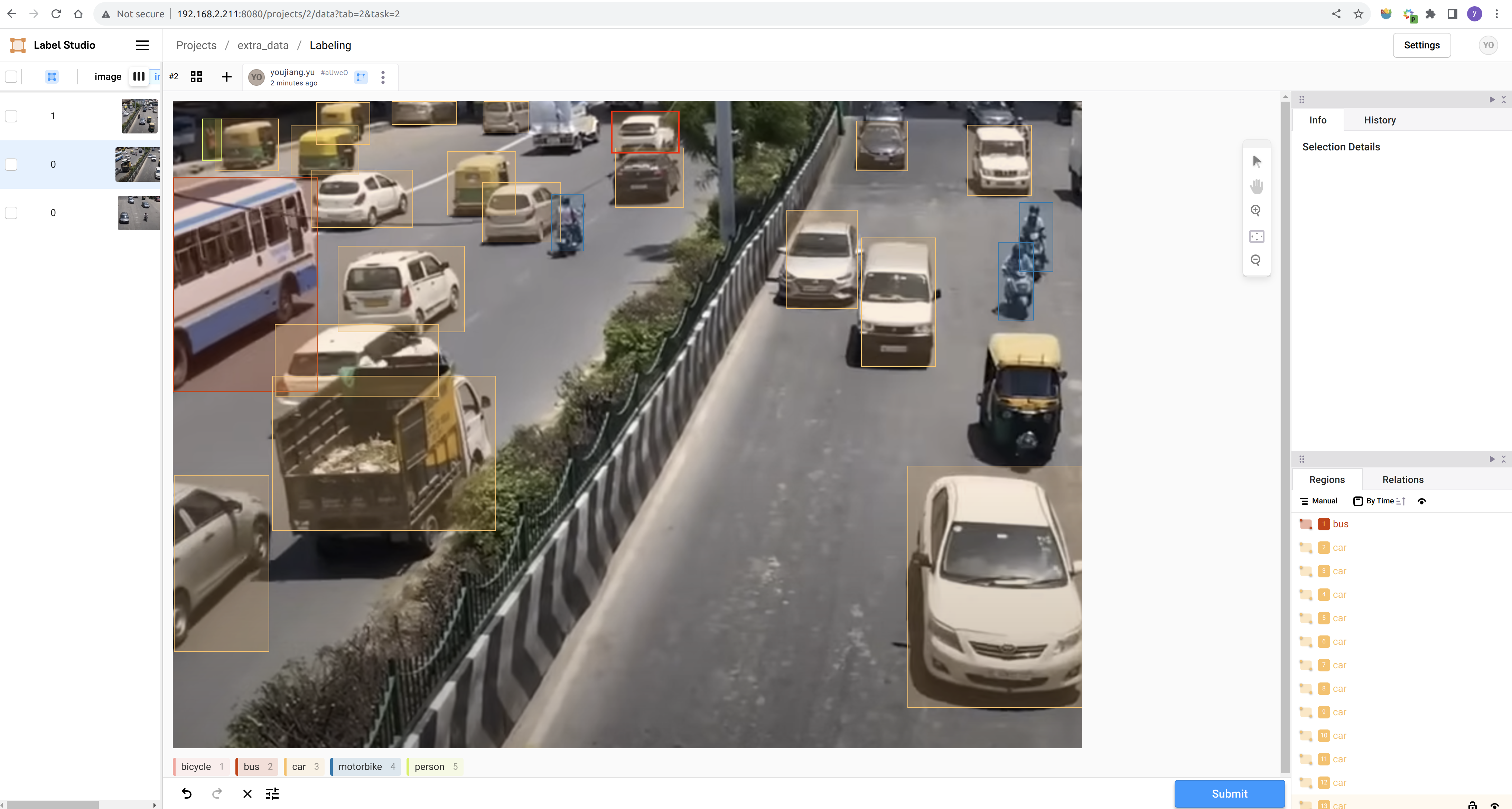
Após concluir a anotação, você pode exportar o conjunto de dados no formato YOLO e organizar os dados anotados junto com os dados baixados. A abordagem mais simples é copiar todas as imagens para a pasta train/images do conjunto de dados público e os arquivos de texto de anotação gerados para a pasta train/labels do conjunto de dados público.
Neste ponto, obtivemos os dados de treinamento por meio de dois métodos diferentes e os integramos. Se você quiser dados de treinamento de maior qualidade, há muitas etapas adicionais a considerar, como limpeza de dados, balanceamento de classes e outras. Como nossa tarefa é relativamente simples, vamos pular essas etapas por enquanto e prosseguir com o treinamento usando os dados obtidos acima.
Modelo
Nesta seção, faremos o download do código-fonte do YOLOv8 no reComputer e configuraremos o ambiente de execução.
Etapa 1. Use o seguinte comando para baixar o código-fonte:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
Etapa 2. Abra o requirements.txt e modifique o conteúdo relevante:
# Use the `vi` command to open the file
vi requirements.txt
# Press `a` to enter edit mode, and modify the following content:
torch>=1.7.0 --> # torch>=1.7.0
torchvision>=0.8.1 --> # torchvision>=0.8.1
# Press `ESC` to exit edit mode, and finally input `:wq` to save and exit the file.
Etapa 3. Execute os seguintes comandos para baixar as dependências necessárias do YOLO e instalar o YOLOv8:
pip3 install -e .
cd ..
Etapa 4. Instalar a versão Jetson do PyTorch:
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.cn/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
Etapa 5. Instalar o torchvision correspondente:
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.16.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
cd ..
Etapa 6. Use o seguinte comando para garantir que o YOLO foi instalado com sucesso:
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'
Treinar
O treinamento de modelo é o processo de atualização dos pesos do modelo. Ao treinar o modelo, algoritmos de aprendizado de máquina podem aprender a partir dos dados para reconhecer padrões e relacionamentos, possibilitando previsões e decisões sobre novos dados.
Etapa 1. Criar um script Python para treinamento:
vi train.py
Pressione a para entrar no modo de edição e modifique o seguinte conteúdo:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)
Pressione ESC para sair do modo de edição e, por fim, digite :wq para salvar e sair do arquivo.
O método YOLO.train() possui muitos parâmetros de configuração; consulte a
documentation
para obter detalhes. Além disso, você pode usar uma abordagem CLI mais simplificada para iniciar o treinamento com base em seus requisitos específicos.
Passo 2. Inicie o treinamento com o seguinte comando:
python3 train.py
Em seguida, vem o longo processo de espera. Considerando a possibilidade de fechar a janela de conexão remota durante a espera, este tutorial usa o Tmux multiplexador de terminal. Assim, a interface que vejo durante o processo se parece com isto:
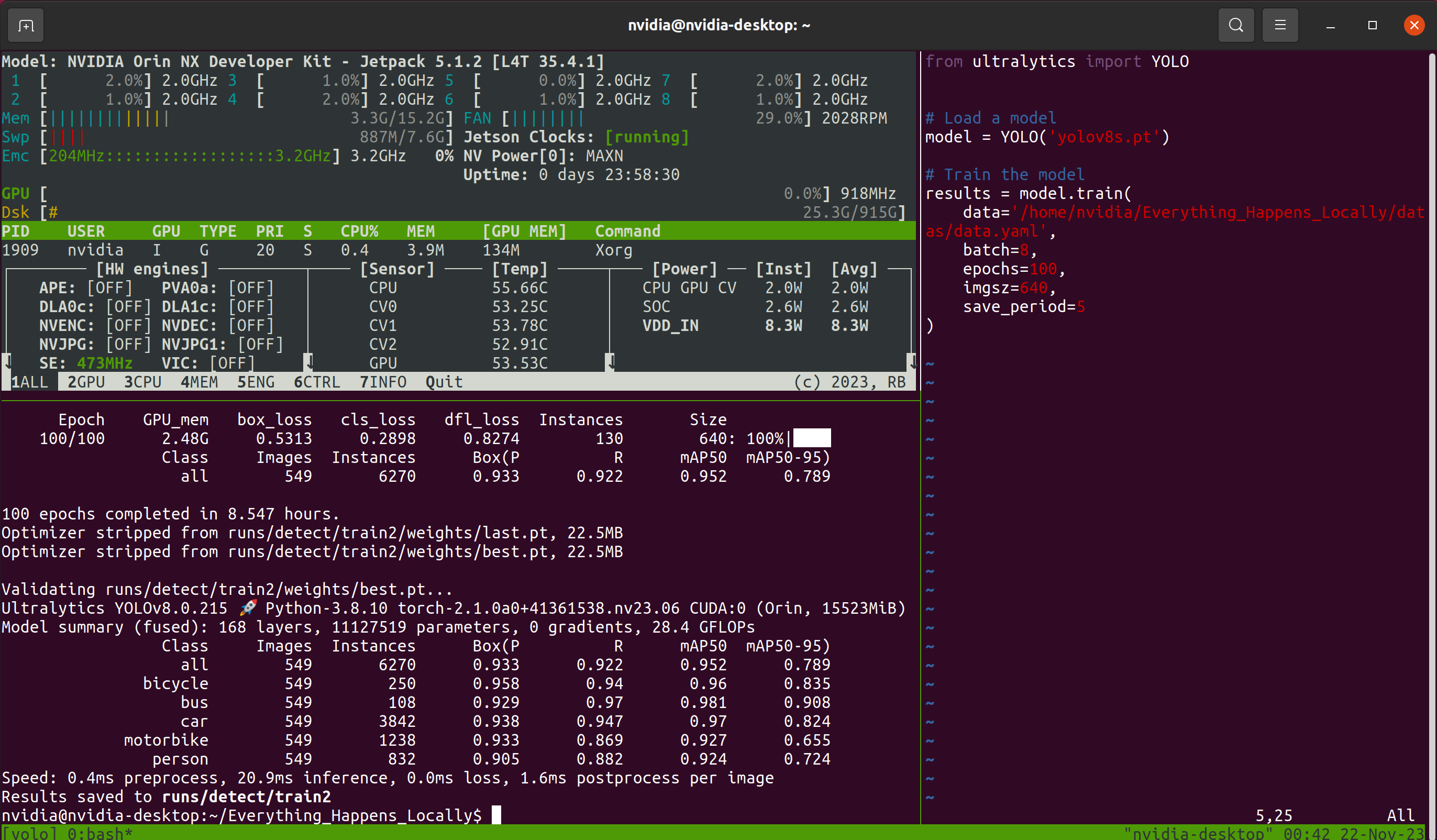
O uso do Tmux é opcional; o importante é que o modelo esteja treinando normalmente. Após a conclusão do programa de treinamento, você pode encontrar os arquivos de pesos do modelo salvos durante o processo de treinamento na pasta designada:

Validação
O processo de validação envolve usar uma parte dos dados para validar a confiabilidade do modelo. Esse processo ajuda a garantir que o modelo possa executar tarefas de forma precisa e robusta em aplicações do mundo real. Se você examinar atentamente as informações exibidas durante o processo de treinamento, notará que muitas validações estão intercaladas ao longo do treinamento. Esta seção não analisará o significado de cada métrica de avaliação, mas analisará a usabilidade do modelo examinando os resultados de predição.
Passo 1. Use o modelo treinado para fazer inferência em uma imagem específica:
yolo detect predict \
model='./runs/detect/train2/weights/best.pt' \
source='./datas/test/images/ant_sales-2615_png_jpg.rf.0ceaf2af2a89d4080000f35af44d1b03.jpg' \
save=True show=False
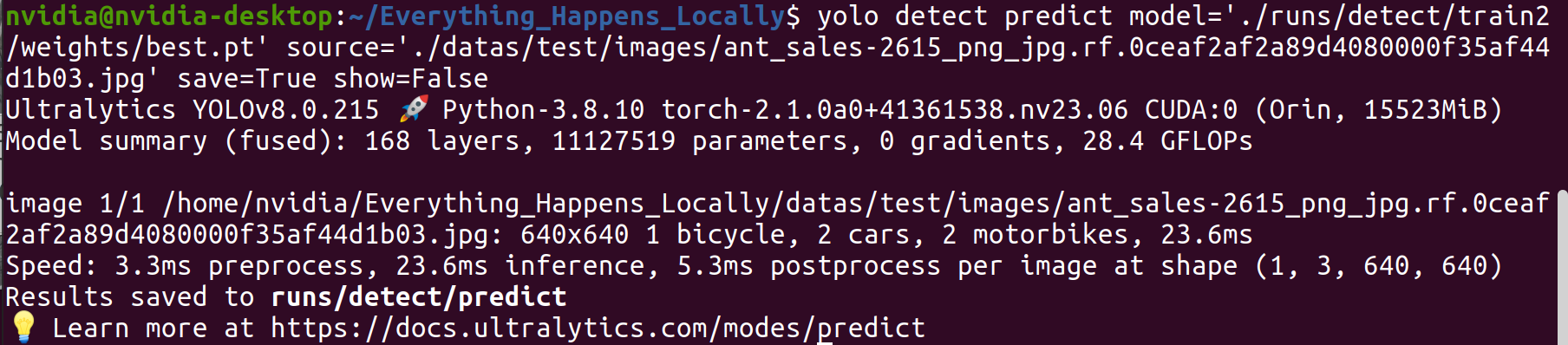
Passo 2. Examine os resultados da inferência.
A partir dos resultados da detecção, pode-se observar que o modelo treinado atinge o desempenho de detecção esperado.

Implantação
Implantação é o processo de aplicar um modelo de aprendizado de máquina ou de aprendizado profundo treinado em cenários do mundo real. O conteúdo apresentado acima validou a viabilidade do modelo, mas não considerou a eficiência de inferência do modelo. Na fase de implantação, é necessário encontrar um equilíbrio entre precisão de detecção e eficiência. O mecanismo de inferência TensorRT pode ser usado para melhorar a velocidade de inferência do modelo.
Passo 1. Para demonstrar visualmente o contraste entre os modelos leve e original, crie um novo arquivo inference.py usando a ferramenta vi para implementar a inferência em arquivo de vídeo. Você pode substituir o modelo de inferência e o vídeo de entrada modificando as linhas 8 e 9. A entrada neste documento é um vídeo que gravei com meu celular.
from ultralytics import YOLO
import os
import cv2
import time
import datetime
model = YOLO("/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt")
cap = cv2.VideoCapture('./sample_video.mp4')
save_dir = os.path.join('runs/inference_test', datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
output = cv2.VideoWriter(os.path.join(save_dir, 'result.mp4'), fourcc, fps, size)
while cap.isOpened():
success, frame = cap.read()
if success:
start_time = time.time()
results = model(frame)
annotated_frame = results[0].plot()
total_time = time.time() - start_time
fps = 1/total_time
cv2.rectangle(annotated_frame, (20, 20), (200, 60), (55, 104, 0), -1)
cv2.putText(annotated_frame, f'FPS: {round(fps, 2)}', (30, 50), 0, 0.9, (255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
print(f'FPS: {fps}')
cv2.imshow("YOLOv8 Inference", annotated_frame)
output.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
output.release()
Passo 2. Execute o seguinte comando e registre a velocidade de inferência antes da quantização do modelo:
python3 inference.py

O resultado indica que a velocidade de inferência do modelo antes da quantização é de 21,9 FPS
Passo 3. Gere o modelo quantizado:
pip3 install onnx
yolo export model=/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt format=engine half=True device=0
Após a conclusão do programa (cerca de 10–20 minutos), um arquivo .engine será gerado no mesmo diretório do modelo de entrada. Este arquivo é o modelo quantizado.

Passo 4. Teste a velocidade de inferência usando o modelo quantizado.
Aqui, você precisa modificar o conteúdo da linha 8 no script criado no Passo 1.
model = YOLO(<path to .pt>) --> model = YOLO(<path to .engine>)
Em seguida, execute novamente o comando de inferência:
python3 inference.py

Do ponto de vista da eficiência de inferência, o modelo quantizado apresenta uma melhoria significativa na velocidade de inferência.
Resumo
Este artigo fornece aos leitores um guia abrangente que abrange vários aspectos, desde a coleta de dados e o treinamento do modelo até a implantação. Importante ressaltar que todos os processos ocorrem no reComputer, eliminando a necessidade de GPUs adicionais por parte dos usuários.
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.