Como executar localmente um LLM de texto‑para‑imagem no reComputer
Introdução
Um modelo texto‑para‑imagem é um tipo de modelo de inteligência artificial (IA) que gera imagens a partir de uma descrição textual. Esses modelos recebem uma entrada textual, como frases ou parágrafos descrevendo uma cena, e produzem uma imagem com base nessa descrição.
Esses modelos são treinados em grandes conjuntos de dados contendo pares de descrições de texto e imagens correspondentes, aprendendo a entender as relações entre informações textuais e visuais.
Modelos de texto‑para‑imagem tiveram um avanço significativo nos últimos anos, mas gerar imagens de alta qualidade e diversas que correspondam com precisão às descrições textuais ainda é uma tarefa desafiadora na pesquisa em IA.
Visão geral
Neste tutorial, vamos explorar várias maneiras de fazer o deploy e executar localmente um LLM texto‑para‑imagem:
- Criar o ambiente virtual (tanto TensorFlow quanto PyTorch)
- 1.1. Criar um exemplo com Keras Stable Diffusion
- 1.2. Criar um exemplo usando um dos modelos disponíveis no Hugging Face
- 1.3. Criar uma pequena API em Python que usaremos para gerar imagens chamando a API tanto para Keras quanto para Hugging Face
- Usando um container Nvidia.
Solução de problemas
Antes de começar, aqui estão alguns passos que podemos seguir para ter mais memória disponível.
-
Desativar a interface gráfica Desktop. Podemos usar o Jetson via SSH. Assim podemos economizar cerca de ~800MB de memória.
-
Desativar o ZRAM e usar Swap.
Você pode encontrar essas dicas no Nvidia Jetson AI Lab e ver como implementá‑las.
Requisitos
Para este tutorial, vamos precisar de um Nvidia Jetson Orin NX 16GB.

E precisamos garantir que TensorFlow e PyTorch estejam instalados – mas vou abordar isso aqui.
Passo 1 - Criar os ambientes virtuais
Keras pode usar TensorFlow ou PyTorch como backends. Hugging Face vai usar principalmente PyTorch
Vamos instalar TensorFlow e PyTorch.
As instruções de como instalar TensorFlow e PyTorch para o Jetson Orin NX estão no site da Nvidia.
Podemos instalar TensorFlow e PyTorch globalmente ou em um ambiente virtual. Vamos usar um ambiente virtual.
Ao usar um ambiente virtual não corremos o risco de misturar projetos ou versões de pacotes.
Esta é a melhor forma, embora o site da Nvidia prefira o método global.
TensorFlow
Crie o ambiente virtual (estou usando o nome kerasStableEnvironment porque vou usá‑lo para o exemplo com Keras. Use outro nome se quiser.)
sudo apt install python3.8-venv
python -m venv kerasStableEnvironment
Depois de criá‑lo, ative o ambiente virtual
source kerasStableEnvironment/bin/activate
Quando estiver ativo, você verá o nome dele antes do prompt

Entre no ambiente virtual
cd kerasStableEnvironment
Atualize o PIP e instale algumas dependências
pip install -U pip
pip install -U numpy grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast h5py astor termcolor protobuf keras-applications keras-preprocessing wrapt google-pasta setuptools testresources
Instale o TensorFlow para Jetpack 5.1.1
Para descobrir qual versão do JetPack temos, execute o seguinte comando:
dpkg -l | grep -i jetpack
e o resultado deve mostrar a versão do JetPack:

pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v511 tensorflow==2.12.0+nv23.05
Se você tiver outra versão do JetPack, consulte o site da Nvidia para a URL correta.
Agora, vamos verificar a instalação do TensorFlow
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
Isso deve retornar a seguinte linha:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
PyTorch
Vamos instalar algumas dependências
sudo apt install libopenblas-dev
Agora, instale o PyTorch para JetPack 5.1.1
pip install --no-cache https://developer.download.nvidia.com/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
Para verificar a instalação e se o CUDA está disponível
python -c "import torch; print(torch.cuda.is_available())"
Ele deve retornar True
Agora que temos tanto o TensorFlow quanto o PyTorch instalados, vamos instalar o Keras e criar uma imagem
1.1 Keras
Depois de instalar PyTorch e Tensorflow, agora estamos prontos para começar a criar imagens a partir de prompts de texto. Certifique‑se de que você ainda está no ambiente virtual.
KerasCV tem uma implementação (entre várias outras) do modelo texto‑para‑imagem da Stability.ai, o Stable Diffusion.
Usando a implementação do KerasCV, podemos usar algumas vantagens de desempenho, como compilação XLA e suporte a precisão mista.
Você pode ler mais no site do Keras
Instale o Keras e as dependências. Vamos usar essas versões porque elas funcionam com as versões do TensorFlow (ou PyTorch) que instalamos.
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
Abra seu editor preferido e digite o seguinte exemplo
vi generate_image.py
import keras_cv
import keras
from PIL import Image
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
prompt = "a cute magical flying dog, fantasy art, golden color, high quality, highly detailed, elegant, sharp focus, concept art, character concepts, digital painting, mystery, adventure"
image = model.text_to_image (prompt,
num_steps = 25, #image quality
batch_size = 1 # how many images to generate at once
)
Image.fromarray(image[0]).save("keras_generate_image.png")
Enquanto o script estiver executando, aqui estão algumas estatísticas
E depois de um tempo, aqui está o resultado

Passo 1.2 - Hugging Face
Hugging Face é como o Github para Machine Learning. Ele permite que desenvolvedores criem, façam deploy, compartilhem e treinem seus modelos de ML.
O Hugging Face também é conhecido pela sua biblioteca Transformers em Python, que facilita o processo de baixar e treinar modelos de ML.
Vamos usar alguns dos modelos disponíveis. Vá até o Hugging Face e escolha ver os modelos.
No lado esquerdo, você tem filtros que nos permitem escolher que tipo de modelos queremos ver.
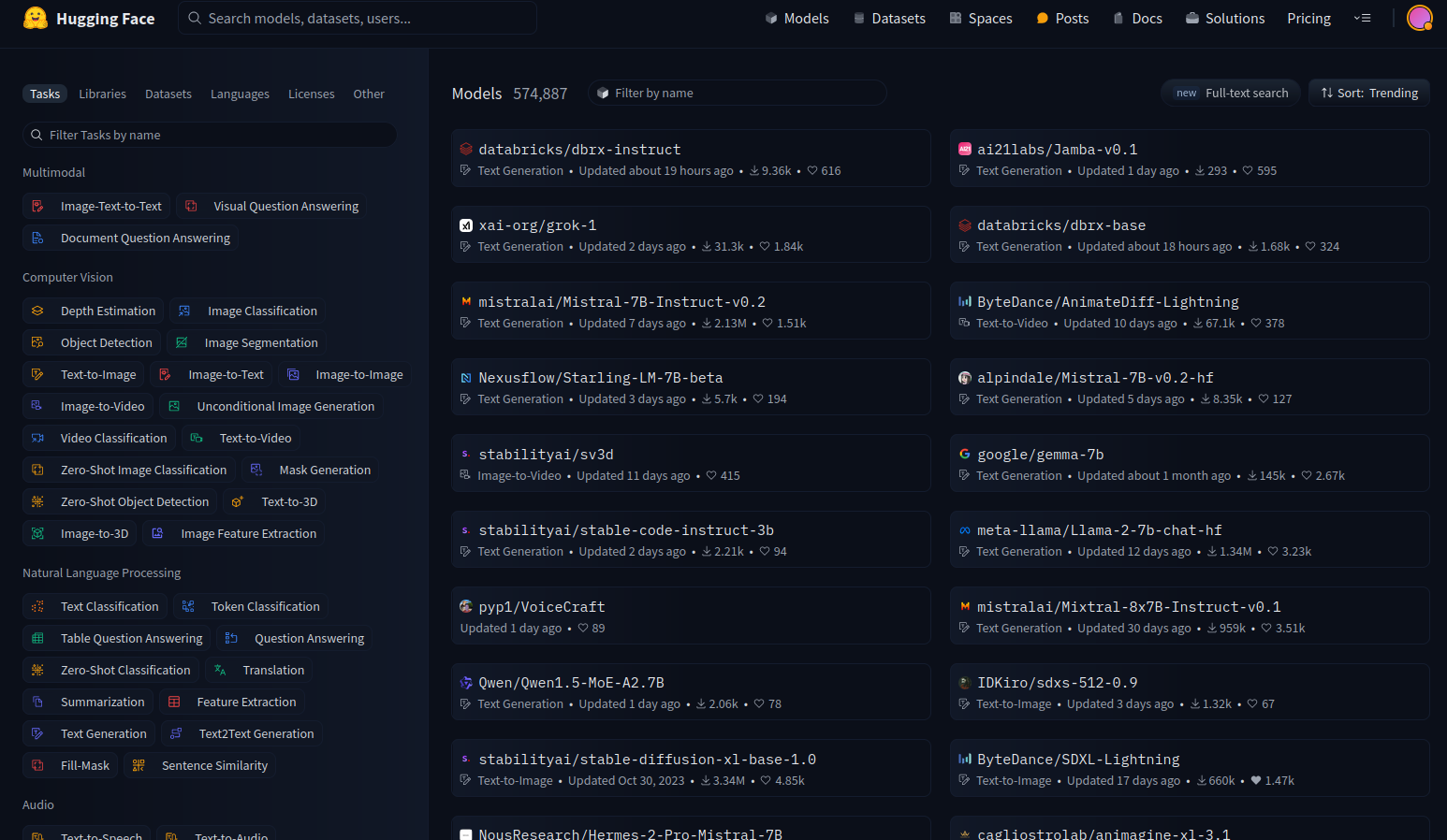
Há muitos modelos disponíveis, mas vamos nos concentrar nos modelos texto‑para‑imagem.
Ambiente virtual
Crie um ambiente virtual, como fizemos acima, para que possamos usar o Hugging Face sem bagunçar versões de pacotes ou instalar pacotes de que não precisamos.
python -m venv huggingfaceTesting
source huggingfaceTesting/bin/activate
Depois de criar o ambiente virtual, vamos entrar nele. Instale o PyTorch usando as instruções acima.
cd huggingfaceTesting
Modelo
O Hugging Face tem muitos modelos texto‑para‑imagem. Embora teoricamente eles devam funcionar com o nosso Jetson, eles não funcionam.
stable-diffusion-v1-5
Vou testar o stable-diffusion-v1-5 da Runaway.
No card do modelo, eles têm todas as informações necessárias para trabalhar com o modelo.

Vamos usar a biblioteca diffusers do Hugging Face. Dentro do ambiente virtual (e com ele ativado) instale as dependências.
pip install diffusers transformers accelerate
Agora que temos todas as dependências instaladas, vamos testar o modelo. Usando seu editor favorito, copie o código a seguir (também disponível na página do card do modelo):
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a master jedi cat in star wars holding a lightsaber, wearing a jedi cloak hood, dramatic, cinematic lighting"
image = pipe(prompt).images[0]
image.save("cat_jedi.png")
Vamos testar o modelo.
python stableDiffusion.py
Lembre-se: Isso ocupa muito espaço. Os checkpoints do modelo estão sendo baixados. Isso será feito apenas uma vez.

Depois de um tempo, aqui está o resultado

SDXL-Turbo
Aqui está outro modelo que podemos testar. SDXL Turbo da Stability AI. Copie o seguinte código
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "full body, cat dressed as a Viking, with weapon in his paws, battle coloring, glow hyper-detail, hyper-realism, cinematic"
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
image.save("sdxl-turbo.png")
Este prompt foi retirado de um artigo no Medium escrito por Daria Wind
Este aqui é realmente rápido para gerar uma imagem. Leva quase 30s, desde a execução do script até ele encerrar. Aqui está o resultado

Também podemos testar outros modelos, como modelos treinados especificamente para anime ou cyberpunk.
Haverá alguns modelos que não vão funcionar. Isso pode ser por vários fatores - memória, CPUs disponíveis ou até memória Swap.
Passo 1.3 - Criar uma pequena API
Agora vamos criar uma pequena API com Flask para usar para gerar uma imagem dado um prompt e retorná-la para quem chamou.
Imagine que você tem o Jetson em execução e quer poder gerar uma imagem chamando uma API - seu LLM pessoal de image-to-text.
Já existem projetos que fazem isso (como o que vamos ver mais tarde), mas nada supera fazer você mesmo.
Vamos criar um novo Ambiente Virtual
python -m venv imageAPIGenerator
Ative o ambiente e entre nele
source imageAPIGenerator/bin/activate
cd imageAPIGenerator
Vamos usar Flask para isso. FlasK é um framework de aplicações web escrito em Python. Ele é pequeno o suficiente para o nosso propósito.
Instale o Flask.
pip install Flask
Depois de instalá-lo, vamos instalar todas as outras dependências de que precisamos. Apenas para fins de demonstração, vamos usar Keras, porque ele tem menos dependências.
Instale o TensorFlow. Siga as instruções acima. Em seguida, instale o Keras.
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
Agora, vamos começar a escrever nossa aplicação.
vi app.py
Para aqueles que não sabem o que Flask é ou faz, vamos tentar um pequeno exemplo.
from flask import Flask
app = Flask (__name__)
@app.route("/generate_image")
def generate_image_api():
return "<h2>Hello World !</h2>"
if __name__ == "__main__":
app.run(host='',port=8080)
Para executar, rode o script python:
python app.py
Você deverá ver o seguinte:

Agora, abra um navegador e tente acessar seu dispositivo Jetson com a porta 8080.


O que fizemos foi importar a classe Flask
import Flask
Em seguida criamos uma instância da classe Flask
app = Flask(__name__)
Depois criamos um decorator de rota para dizer ao Flask qual URL irá disparar nossa função
@app.route("/generate_image")
Ao usar generate_image na URL, vamos disparar nossa função
def generate_image_api():
return "<h2>Hello World !</h2>"
Também podemos usar curl para acessar nossa API
curl http://192.168.2.230:8080/generate_image

Agora que sabemos como criar uma API, vamos nos aprofundar e escrevê-la.
vi app.py
E cole o código
from flask import Flask, request, send_file
import random, string
import keras_cv
import keras
from PIL import Image
#define APP
app = Flask (__name__)
#option for keras
keras.mixed_precision.set_global_policy("mixed_float16")
# generate custom filename
def generate_random_string(size):
"""Generate a random string of specified size."""
return ''.join(random.choices(string.ascii_letters + string.digits, k=size))
"""
This is the function that will generate the image
and save it using a random created filename
"""
def generate_image(prompt):
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
image = model.text_to_image (prompt,
num_steps = 25,
batch_size = 1
)
# image filename
filename = generate_random_string(10) + ".png"
Image.fromarray(image[0]).save(filename)
return filename # return filename to send it to client
#define routes
# Use this to get the prompt. we're going to receive it using GET
@app.route("/generate_image", methods=["GET"])
def generate_image_api():
# get the prompt
prompt = request.args.get("prompt")
if not prompt:
# let's define a default prompt
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image_name = generate_image(prompt)
return send_file(image_name, mimetype='image/png')
if __name__ == "__main__":
app.run(host='0.0.0.0',port=8080)
LEMBRE-SE: Este não é um código pronto para a Internet. Não temos nenhuma medida de segurança.
Vamos executá-lo.
Em um navegador, digite a URL http://jetsonIP:8080/generate_image e aguarde.
Se não dermos um prompt, ele usará o padrão que definimos.
No CLI, você pode ver a imagem sendo gerada

E no navegador, depois de um tempo, podemos ver a imagem
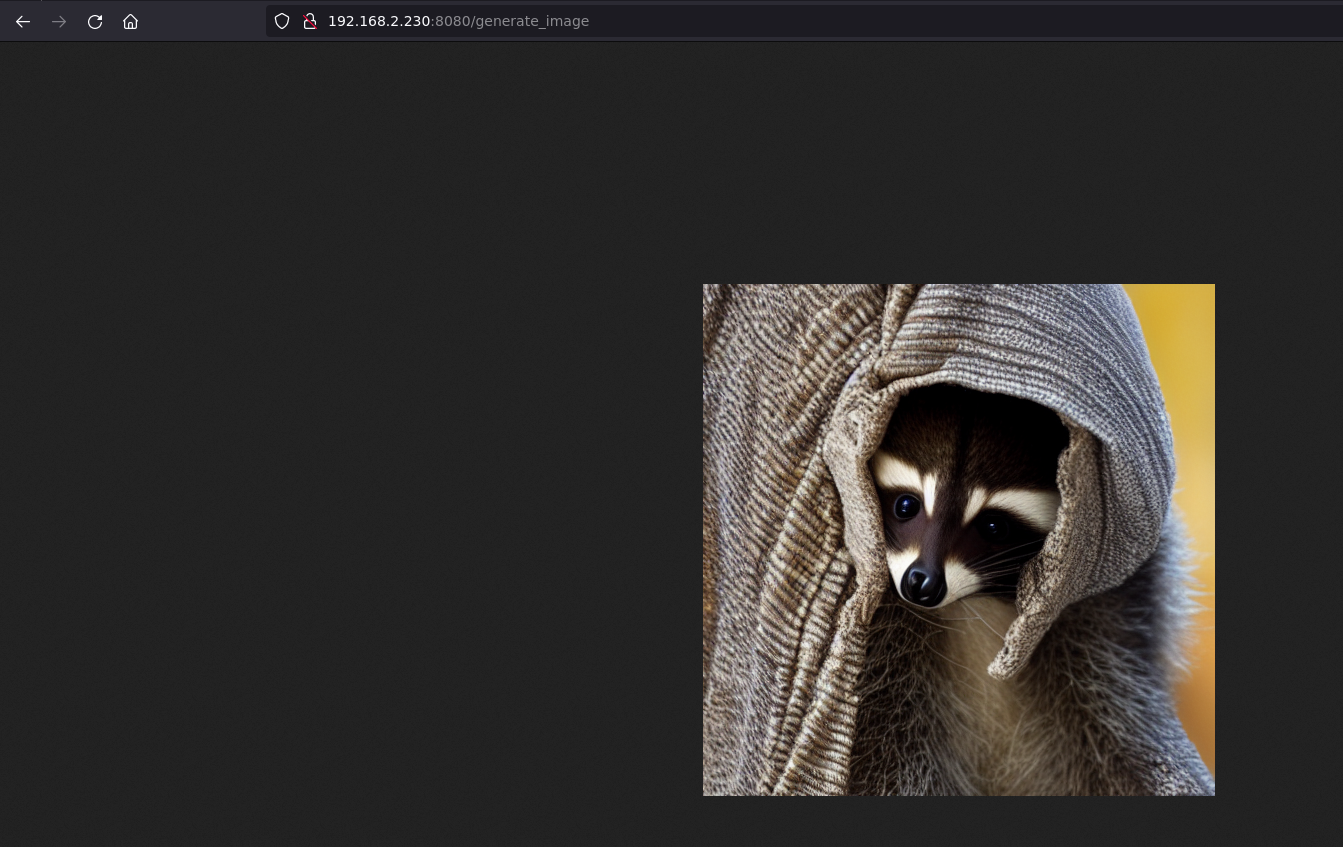
Também podemos ver que a imagem foi enviada
Também podemos usar curl para obter a imagem e salvá-la.
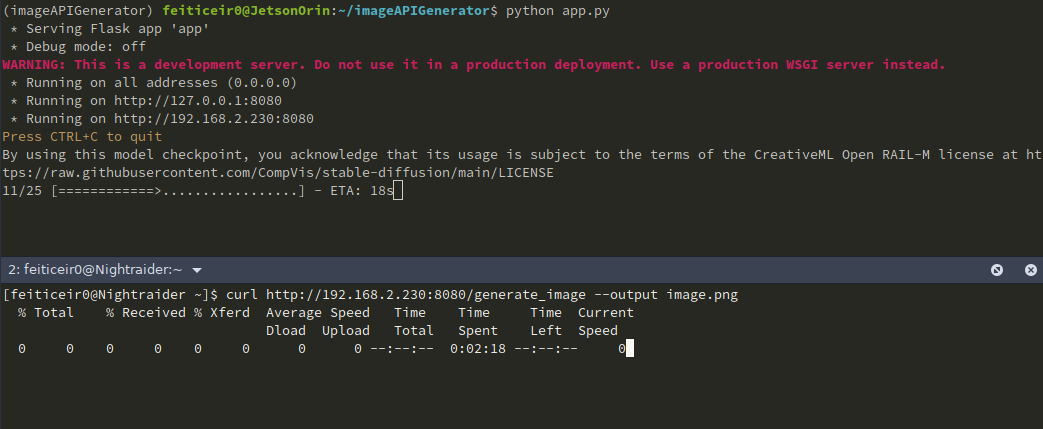
Se quisermos fornecer um prompt (como devemos), a URL ficará assim http://jetsonIP:8080/generate_image?prompt=<your_prompt>
Podemos expandir este exemplo para construir uma página melhor, como ter algumas caixas de texto para entrada do usuário, um fundo bonito, etc. Mas isso é para outro projeto.
Passo 2 - Nvidia LLM
Stable Diffusion v1.5
Podemos usar o projeto Jetson Containers para executar o stable-diffusion-webui usando AUTOMATIC1111. O projeto Jetson Containers é mantido por Dusty Franklin, um funcionário da NVIDIA.
A NVIDIA tem o projeto NVIDIA Jetson Generative AI Lab que possui muitos tutoriais de Machine Learning.
Vamos usar o tutorial de Stable Diffusion para isto.
Vamos clonar o repositório do github, entrar no repositório e instalar as dependências
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers/
sudo apt update; sudo apt install -y python3-pip
pip3 install -r requirements.txt
Agora que temos tudo que precisamos, vamos executar o container com o stable-diffusion-webui autotag
./run.sh $(./autotag stable-diffusion-webui)
Ele começará a executar o container.
Depois de um tempo, ele dirá que há um container compatível e perguntará se queremos prosseguir.
Found compatible container dustynv/stable-diffusion-webui:r35.3.1 (2024-02-02, 7.3GB) - would you like to pull it? [Y/n]
Ele começará a baixar o container.
Depois de terminar, ele fará o download do modelo e executará o servidor na porta 7860.
Aqui para mim não funcionou de primeira. Nenhum checkpoint aparecia para escolher, não importava quantas vezes eu apertasse o botão de atualizar.

Descobri que eu estava com 100% do espaço ocupado.
feiticeir0@JetsonOrin:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p1 79G 79G 0 100% /
none 7,4G 0 7,4G 0% /dev
tmpfs 7,6G 0 7,6G 0% /dev/shm
tmpfs 1,6G 19M 1,5G 2% /run
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,6G 0 7,6G 0% /sys/fs/cgroup
/dev/loop0 162M 162M 0 100% /snap/chromium/2797
/dev/loop2 128K 128K 0 100% /snap/bare/5
/dev/loop1 70M 70M 0 100% /snap/core22/1125
/dev/loop3 65M 65M 0 100% /snap/cups/1025
/dev/loop4 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop6 162M 162M 0 100% /snap/chromium/2807
/dev/loop5 483M 483M 0 100% /snap/gnome-42-2204/174
/dev/loop7 35M 35M 0 100% /snap/snapd/21185
tmpfs 1,6G 4,0K 1,6G 1% /run/user/1000
Eu estava testando outros modelos e eles ocuparam todo o espaço. Se isso acontecer com você, apenas vá para o seu diretório home, para o diretório oculto de cache e exclua o diretório huggingface.
cd ~/.cache
rm -rf huggingface
Agora você deve ter espaço disponível. Ou simplesmente consiga um novo drive, com mais espaço. :)
Agora o modelo está sendo baixado.

E temos um checkpoint
Abra o seu navegador e acesse o endereço IP do seu Jetson e a porta para executar a webgui AUTOMATIC1111's Stable Diffusion
Agora podemos brincar com isso. Aqui estão algumas imagens criadas com o modelo padrão.
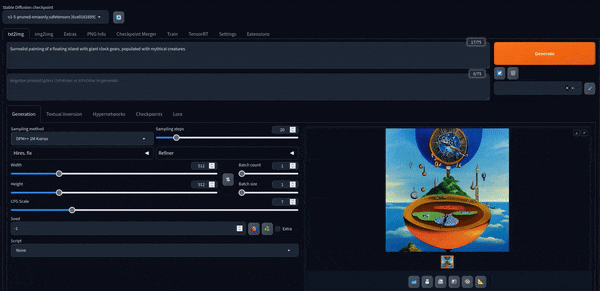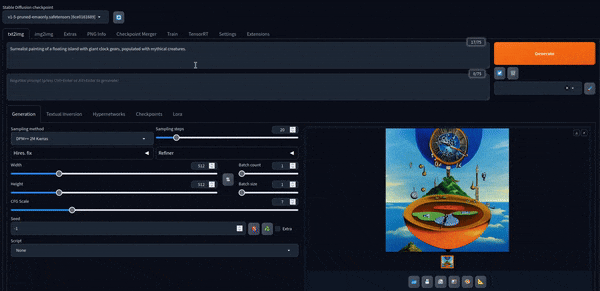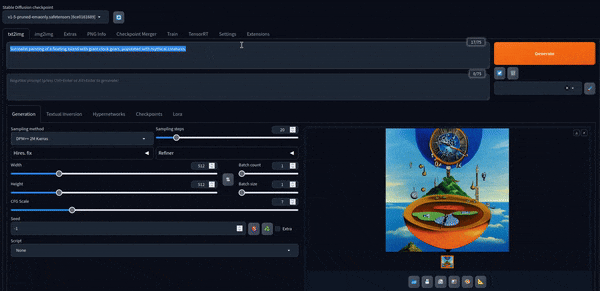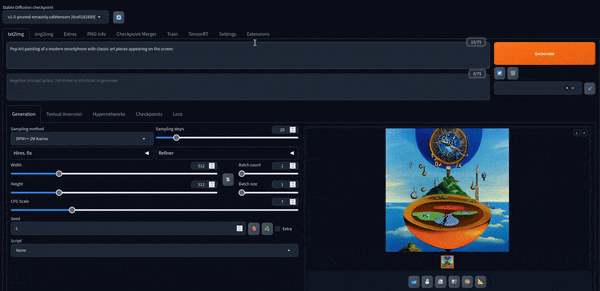
Stable Diffusion XL
AUTOMATIC1111 oferece suporte a outros modelos. Vamos tentar com o Stable Diffusion XL. Ele tem 6,6 bilhões de parâmetros.
Para adicionar outro modelo, e para ser mais fácil baixá-lo, vamos definir algumas variáveis, alterar permissões e baixar os modelos. Este é um exemplo do Tutorial da NVIDIA.
CONTAINERS_DIR=<where_jetson-containers_is_located>
MODEL_DIR=$CONTAINERS_DIR/data/models/stable-diffusion/models/Stable-diffusion/
sudo chown -R $USER $MODEL_DIR
Agora, baixe o modelo
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
Com os modelos baixados, vamos atualizar o menu suspenso de checkpoints se você tiver o contêiner em execução, ou iniciar o contêiner novamente.
Agora temos mais dois modelos disponíveis para nós.
Este é um exemplo gerado com o modelo XL, com o seguinte prompt:
Um retrato, modelo fashion usando roupas futuristas, em um ambiente de cobertura cyberpunk, com um fundo de cidade iluminada por neon, contra a luz do brilho vibrante da cidade, fotografia de moda

Experimente. Lembre-se de que pode não funcionar com algumas opções selecionadas.
Adicionando outros modelos
Também podemos adicionar muitos outros modelos. Além do Hugging Face, o Civitai é outro hub com mais modelos para escolher. O Civitai tem alguns modelos NSFW, então considere-se avisado.
Selecione o que você quiser, baixe os checkpoints e coloque-os no diretório de modelos
/home/<user>/<jetson-containers-location>/data/models/stable-diffusion/models/Stable-diffusion/
Vou baixar e testar um modelo chamado DreamShaper XL.
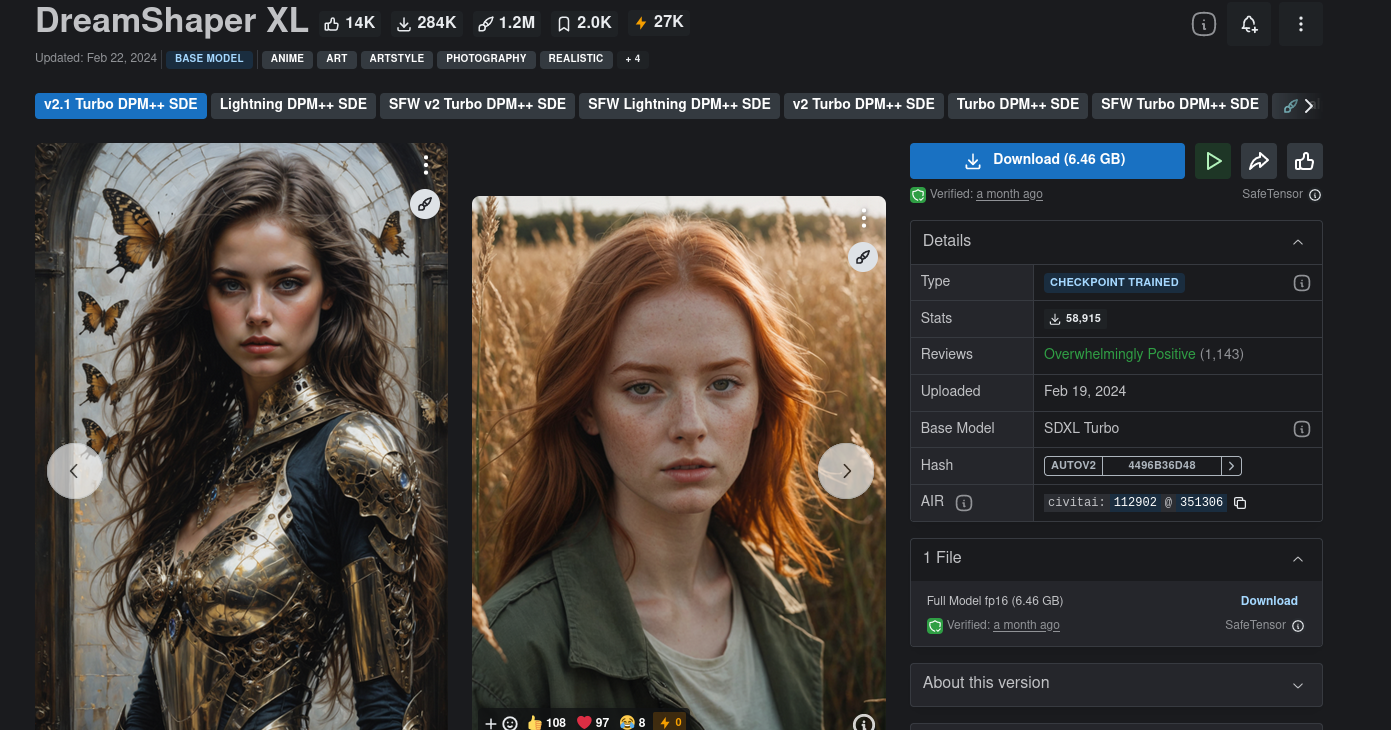
Lembre-se de que alguns modelos podem não funcionar.
Você precisa brincar com as configurações e ler o card do modelo para saber quais configurações podem funcionar melhor (se é que funcionam).
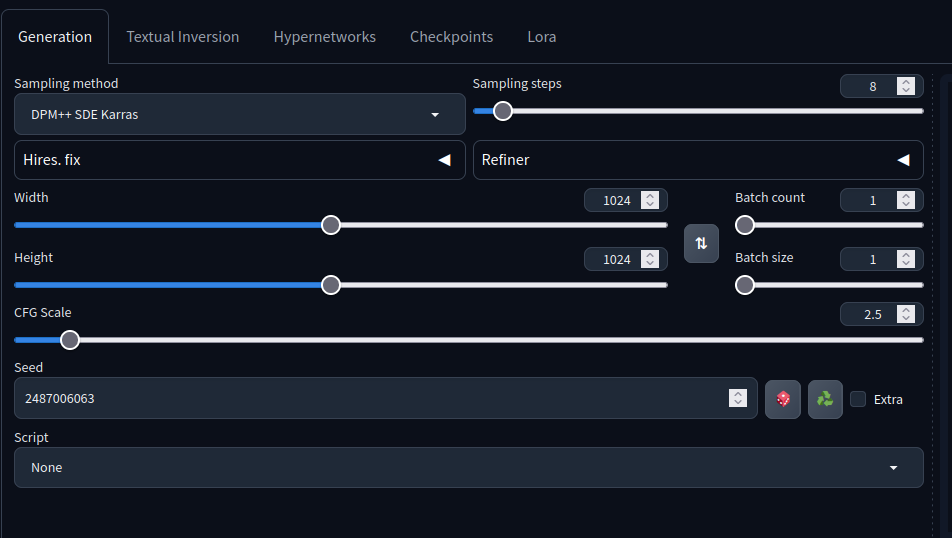
Por exemplo, este card de modelo diz que os passos de amostragem devem ser 4–8, o método de amostragem deve ser DPM++ SDE Karras, etc...
Baixe o checkpoint do modelo e adicione-o ao diretório acima.
Depois de atualizar, você deve ter o modelo pronto para selecionar. Ao selecionar, o AUTOMATIC1111 vai otimizar o modelo.
Se ele continuar sendo encerrado ou aparecer um erro, consiga mais espaço. Isso estava acontecendo comigo e, depois de conseguir mais espaço, tudo funcionou.
Usando o seguinte prompt
holding a staff, orbstaff
<lora:orbstaff:0.60>, ,(by Gabriel Isak and Adam Elsheimer:1.20), (by Jon Whitcomb and Bayard Wu and Malcolm Liepke0.80),8k , professional fashion shot
desta imagem, sem o prompt negativo, eu obtive o seguinte resultado

com estas configurações:
Lembra do prompt acima para a garota cyberpunk usando o modelo Stable Diffusion XL?
Aqui está uma nova imagem, com o mesmo prompt, gerada com o DreamShaper XL com as mesmas configurações acima

Como você pode ver, imagens maravilhosas podem ser criadas, desde que você conheça os parâmetros para ajustar. :)
Aprendi que imagens maiores tendem a produzir melhores resultados.
Espero que você tenha aprendido como gerar imagens usando o Nvidia Jetson NX 16GB e como usá-lo como um servidor para gerar imagens sob demanda.
✨ Projeto de Contribuidor
- Este projeto é apoiado pelo Projeto de Contribuidores da Seeed Studio.
- Obrigado aos esforços do Bruno e seu trabalho será exibido.
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para oferecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja o mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.