Primeiros passos com o Jetson Mate

Jetson Mate é uma placa carrier que pode instalar até 4 SoMs Nvidia Jetson Nano/NX. Há um switch gigabit de 5 portas na placa que permite que os 4 SoMs se comuniquem entre si. Todos os 3 SoMs periféricos podem ser ligados ou desligados separadamente. Com um carregador PD de 65W com 2 portas para SoMs Jetson Nano ou um carregador PD de 90W com 2 portas para SoMs Jetson NX, e um cabo Ethernet, os desenvolvedores podem facilmente construir o seu próprio Cluster Jetson.
Recursos
- Fácil de montar e configurar
- Potente e compacto
- Acompanha um gabinete e uma ventoinha dedicados
Especificações
| Especificação | -- |
|---|---|
| Alimentação | 65w PD |
| Dimensões | 110mm x 110mm |
| Switch onboard | Microchip KSZ9896CTXC |
Visão geral do hardware
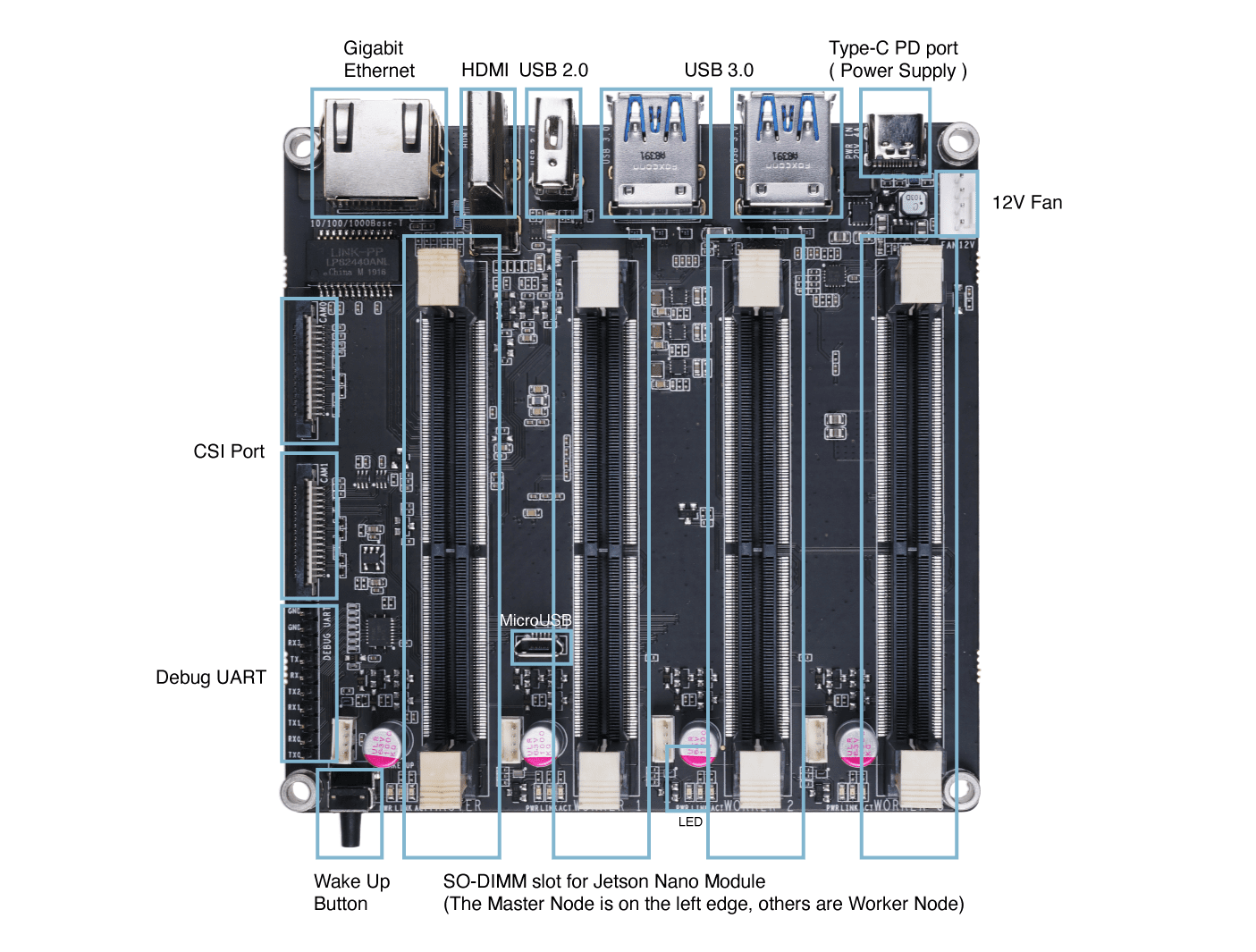

Primeiros passos
!!!Note Neste guia, o Ubuntu 18.04 LTS está instalado no PC host. Atualmente, a gravação do SO usando o NVIDIA SDK Manager não é suportada pelo Ubuntu 20.04. Portanto, certifique-se de usar Ubuntu 18.04 ou 16.04. Além disso, se você estiver executando Ubuntu em uma máquina virtual, é recomendado usar o VMware Workstation Player, pois nós o testamos. Não é recomendado usar o Oracle VM VirtualBox, pois ele falha ao gravar o SO.
Hardware necessário
- Jetson Mate
- Módulo(s) Jetson Nano/ NX
- Cabo Micro - USB
- Adaptador de energia de 65W ou 90W com cabo USB Tipo-C
- PC host com Ubuntu 18.04 ou 16.04 instalado
Configuração de hardware
- Passo 1. Insira um módulo Jetson Nano/ NX no Nó Mestre

- Passo 2. Conecte um cabo micro-USB do Jetson Mate ao PC

- Passo 3. Conecte um jumper entre os pinos BOOT e GND para modo de recuperação

-
Passo 4. Conecte o Jetson Mate a um adaptador de energia e ligue o Jetson Mate pressionando o botão WAKE
-
Passo 5. Remova o jumper depois que o Jetson Mate ligar
-
Passo 6. Abra uma janela de terminal no PC host e execute o seguinte
lsusb

Se a saída incluir 0955:7f21 NVidia Corp., o Jetson Mate entrou no modo de recuperação
Configuração de software
Se você estiver usando módulos com cartão micro-SD do Kit de Desenvolvedor, sugerimos que você instale e configure o sistema seguindo este guia para Jetson Nano, este guia para Jetson Nano 2GB e este guia para Jetson Xavier NX
Se você estiver usando módulos com armazenamento eMMC, use o SDK Manager oficial da NVIDIA e siga os passos abaixo
- Passo 1. Baixe o NVIDIA SDK Manager clicando aqui
Nota: Escolha a versão relevante de acordo com o sistema operacional do PC host. Escolhemos Ubuntu aqui porque o PC host usado neste guia está executando Ubuntu 18.04

-
Passo 2. Crie uma conta ou faça login no NVIDIA Developer Program Membership
-
Passo 3. Instale o NVIDIA SDK Manager
Nota: Clique duas vezes no arquivo baixado para instalá-lo
- Passo 4. Abra o NVIDIA SDK Manager e você notará que ele detecta automaticamente o módulo Jetson Nano/ NX conectado

-
Passo 5. Selecione o módulo conectado
-
Passo 6. Na janela de configuração, desmarque Host Machine.

Nota: Aqui o DeepStream SDK também está desmarcado. Mas se você planeja instalá-lo também, pode marcá-lo. No entanto, os 16GB do módulo eMMC não serão suficientes para instalar este SDK.
-
Passo 7. Clique em CONTINUE TO STEP 02
-
Passo 8. Revise os componentes necessários e marque I accept the terms and conditions of the license agreements

Nota: Se você quiser apenas instalar o Jetson OS, pode desmarcar Jetson SDK Components
-
Passo 9. Clique em CONTINUE TO STEP 03
-
Passo 10. Quando a seguinte mensagem de erro aparecer, clique em Create

- Passo 11. Comece a baixar e gravar

- Passo 12. Depois que o download e a gravação do SO forem concluídos, você verá a seguinte saída

-
Passo 13. Desligue o Jetson Mate
-
Passo 14. Abra uma janela de terminal no PC host e instale o minicom, que é um aplicativo de terminal serial
sudo apt update
sudo apt install minicom
Nota: Usaremos este aplicativo para estabelecer uma conexão serial entre o PC host e o Jetson Mate
- Passo 15. Ligue o Jetson Mate ainda conectado ao PC via cabo micro - USB, e insira o seguinte para identificar a porta serial conectada
dmesg | grep tty

Nota: Aqui o nome da porta é ttyACM0
- Passo 16. Conecte-se ao Jetson Mate usando o minicom
sudo minicom -b 9600 -D /dev/ttyACM0
Nota: -b é taxa de baud e -D é o dispositivo
- Passo 17. Passe pela configuração inicial do Jetson OS

- Passo 18. Após a conclusão da configuração, volte para a janela do SDK Manager, insira o nome de usuário e senha definidos para o Jetson Mate e clique em Install

Nota: Use o nome de usuário e a senha definidos na configuração inicial
Agora ele começará a baixar e instalar os componentes do SDK

Você verá a seguinte saída quando o SDK Manager tiver baixado e instalado com sucesso os componentes necessários

- Passo 19. Grave todos os módulos Jetson Nano/ NX restantes que você tiver
Nota: Todos os módulos só podem ser gravados quando instalados no nó mestre. Portanto, você deve gravar e configurar os módulos um por um no nó mestre.
Iniciar o cluster
- Passo 1. Conecte um cabo Ethernet do roteador ao Jetson Mate
Nota: Certifique-se de que o PC e o Jetson Mate estejam conectados ao mesmo roteador
- Passo 2. Acesse o Jetson Mate usando o minicom como explicado antes, enquanto o micro-USB estiver conectado ao PC host e digite o seguinte para obter os endereços IP dos módulos conectados ao Jetson Mate
ifconfig
- Passo 3. Digite o seguinte no terminal do PC host para estabelecer uma conexão SSH
Nota: Substitua user pelo seu nome de usuário do Jetson Nano/ NX e 192.xxx.xx.xx pelo endereço IP do seu Jetson Nano/ NX
Nota: Você também pode se conectar aos nós substituindo o endereço IP pelo hostname deles
Criar um cluster Kubernetes com Jetson Mate
Kubernetes é um sistema de orquestração de contêineres em nível empresarial, projetado desde o início para ser cloud-native. Ele se tornou a plataforma de contêineres em nuvem de fato, continuando a se expandir à medida que abraça novas tecnologias, incluindo virtualização nativa de contêiner e computação serverless.
Kubernetes gerencia contêineres e muito mais, desde microescala na borda até escala massiva, em ambientes de nuvem públicos e privados. É uma escolha perfeita para um projeto de "nuvem privada em casa", fornecendo tanto uma orquestração de contêiner robusta quanto a oportunidade de aprender sobre uma tecnologia tão demandada e tão totalmente integrada à nuvem que seu nome é praticamente sinônimo de "computação em nuvem".
Neste tutorial, usamos um mestre e três workers. Nos passos a seguir, indicaremos em negrito se o software está em execução no master, no worker ou em worker e master.
configurar o Docker
worker e master, precisamos configurar o runtime do Docker para usar "nvidia" como padrão.
modifique o arquivo /etc/docker/daemon.json
{
"default-runtime" : "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
Reinicie o daemon do Docker:
sudo systemctl daemon-reload && sudo systemctl restart docker
Valide o runtime padrão do Docker como NVIDIA:
sudo docker info | grep -i runtime
Aqui está um exemplo de saída:
Runtimes: nvidia runc
Default Runtime: nvidia
Instalando o Kubernetes
worker e master, instale kubelet, kubeadm e kubectl:
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the Kubernetes repo
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt update && sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
Desative o swap. Você precisa desativá-lo toda vez que reiniciar.
sudo swapoff -a
Compile o deviceQuery, que usaremos nas etapas a seguir.
cd /usr/local/cuda/samples/1_Utilities/deviceQuery && sudo make
cd
Configurar o Kubernetes
master, inicialize o cluster:
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
A saída mostra os comandos que você deve executar para implantar uma rede de pods no cluster, bem como os comandos para ingressar no cluster. Se tudo for bem-sucedido, você deverá ver algo semelhante a isto no final da saída:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
Usando as instruções da saída, execute os seguintes comandos:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Instale um add-on de rede de pods no nó do plano de controle. Use calico como o add-on de rede de pods:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Se você estiver na China, siga isto em vez disso:
kubectl apply -f https://gitee.com/wj204811/wj204811/raw/master/kube-flannel.yml
Certifique-se de que todos os pods estejam ativos e em execução:
kubectl get pods --all-namespaces
Aqui está um exemplo de saída:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-arm64-gz28t 1/1 Running 0 2m8s
kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s
kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s
kube-system etcd-#yourhost 1/1 Running 0 8m25s
kube-system kube-apiserver-#yourhost 1/1 Running 0 8m7s
kube-system kube-controller-manager-#yourhost 1/1 Running 0 8m3s
kube-system kube-proxy-6sh42 1/1 Running 0 9m7s
kube-system kube-scheduler-#yourhost 1/1 Running 0 8m26s
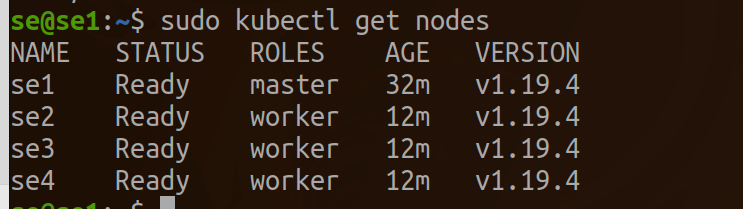
worker, una os nós de computação ao cluster; agora é hora de adicionar nós de computação ao cluster. Unir os nós de computação é apenas uma questão de executar o comando kubeadm join fornecido ao final da execução do comando kube init para inicializar o nó do Plano de Controle. Para o outro Jetson nano que você deseja adicionar ao seu cluster, faça login no host e execute o comando:
the cluster - your tokens and ca-cert-hash will vary
$ sudo kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
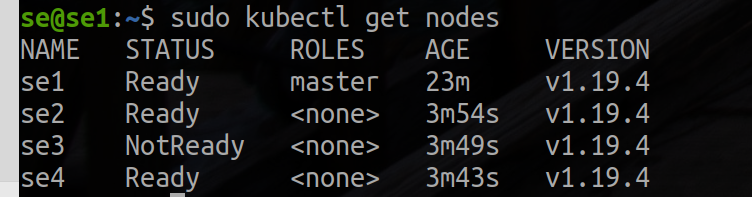
master, após concluir o processo de ingresso em cada nó, você deverá conseguir ver os novos nós na saída de kubectl get nodes:
kubectl get nodes
Aqui está um exemplo de saída:
marque como node para o worker.
kubectl label node se2 node-role.kubernetes.io/worker=worker
kubectl label node se3 node-role.kubernetes.io/worker=worker
kubectl label node se4 node-role.kubernetes.io/worker=worker
Validando uma instalação EGX 2.0 bem-sucedida
worker e master, para validar que a pilha EGX funciona como esperado, siga estas etapas para criar um arquivo yaml de pod. Se o comando get pods mostrar o status do pod como concluído, a instalação foi bem-sucedida. Você também pode verificar a execução bem-sucedida do arquivo cuda-samples.yaml verificando se a saída mostra Result=PASS. Crie um arquivo yaml de pod, adicione o seguinte conteúdo a ele e salve-o como samples.yaml:
nano cuda-samples.yaml
Adicione o seguinte conteúdo e salve-o como cuda-samples.yaml:
apiVersion: v1
kind: Pod
metadata:
name: nvidia-l4t-base
spec:
restartPolicy: OnFailure
containers:
- name: nvidia-l4t-base
image: "nvcr.io/nvidia/l4t-base:r32.4.2"
args:
- /usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
Crie um pod de GPU de exemplo:
sudo kubectl apply -f cuda-samples.yaml
Verifique se o pod de exemplos foi criado:
kubectl get pods
Valide os logs do pod de exemplo para dar suporte às bibliotecas CUDA:
kubectl logs nvidia-l4t-base
Aqui está um exemplo de saída:
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Xavier"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 7.2
Total amount of global memory: 7764 MBytes (8140709888 bytes)
( 6) Multiprocessors, ( 64) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 1109 MHz (1.11 GHz)
Memory Clock rate: 1109 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: Yes
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
Configurar o Jupyter no Kubernetes
worker e master, adicione o seguinte conteúdo e salve-o como jupyter.yaml:
nano jupyter.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: cluster-deployment
spec:
selector:
matchLabels:
app: cluster
replicas: 3 # tells deployment to run 3 pods matching the template
template:
metadata:
labels:
app: cluster
spec:
containers:
- name: nginx
image: helmuthva/jetson-nano-jupyter:latest
ports:
- containerPort: 8888
Crie um pod de GPU para o jupyter:
kubectl apply -f jupyter.yml
Verifique se o pod jupyter foi criado e está em execução:
kubectl get pod
Crie um Load Balancer Externo
kubectl expose deployment cluster-deployment --port=8888 --type=LoadBalancer

Aqui você pode ver que o cluster jupyter tem acesso externo na porta 31262. Portanto, usamos http://se1.local:31262 para acessar o jupyter.
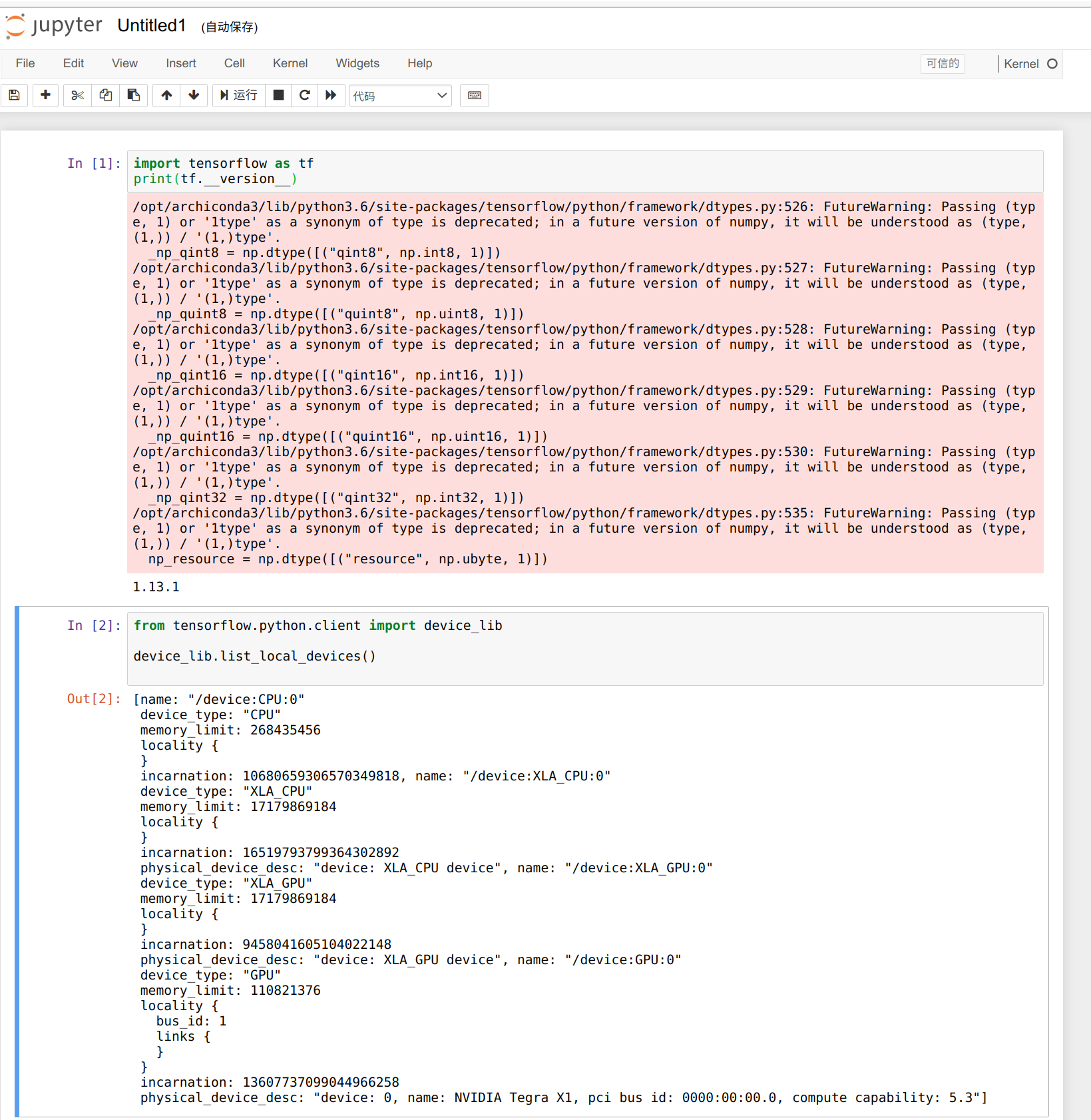
Podemos usar o código a seguir para verificar o número de GPUs disponíveis; temos apenas 3 workers, e o número de GPUs disponíveis é 3.
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
get_available_gpus()
Muito bem, aqui está o seu show.
Recursos
- [PDF] Jetson Mate Schematics
- [PDF] Jetson Mate PCB Top
- [PDF] Jetson Mate PCB Bottom
Suporte Técnico e Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para lhe fornecer diferentes formas de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.