Primeiros passos com inferência Roboflow em dispositivos NVIDIA® Jetson
Este guia wiki explica como fazer o deploy de modelos de IA de forma simples usando o servidor de inferência do Roboflow em execução em dispositivos NVIDIA Jetson. Aqui usaremos o Roboflow Universe para selecionar um modelo já treinado, fazer o deploy do modelo no dispositivo Jetson e executar inferência em um stream de webcam ao vivo!
Roboflow Inference é a forma mais simples de usar e fazer deploy de modelos de visão computacional, fornecendo uma API HTTP do Roboflow usada para executar inferência. A inferência Roboflow oferece suporte a:
- Detecção de objetos
- Segmentação de imagem
- Classificação de imagem
e modelos base como CLIP e SAM.
Pré-requisitos
- PC host com Ubuntu (nativo ou VM usando VMware Workstation Player)
- reComputer Jetson ou qualquer outro dispositivo NVIDIA Jetson
Este wiki foi testado e verificado em um reComputer J4012 e reComputer Industrial J4012 alimentados pelo módulo NVIDIA Jetson Orin NX 16GB
Gravar o JetPack no Jetson
Agora você precisa garantir que o dispositivo Jetson esteja gravado com um sistema JetPack. Você pode usar o NVIDIA SDK Manager ou a linha de comando para gravar o JetPack no dispositivo.
Para guias de gravação de dispositivos Jetson alimentados pela Seeed, consulte os links abaixo:
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- A206 Carrier Board
- A603 Carrier Board
- A607 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
- reComputer Indsutrial
- reServer Industrial
Certifique-se de gravar a versão 5.1.1 do JetPack porque essa é a versão que verificamos para este wiki
Acesse mais de 50.000 modelos no Roboflow Universe
O Roboflow oferece mais de 50.000 modelos de IA prontos para uso para que qualquer pessoa possa começar com deploy de visão computacional da forma mais rápida. Você pode explorá-los todos no Roboflow Universe. O Roboflow Universe também oferece mais de 200.000 conjuntos de dados, nos quais você pode usar esses conjuntos de dados para treinar um modelo nos servidores em nuvem do Roboflow ou então trazer seu próprio conjunto de dados, usar a ferramenta online de anotação de imagens do Roboflow e iniciar o treinamento.
-
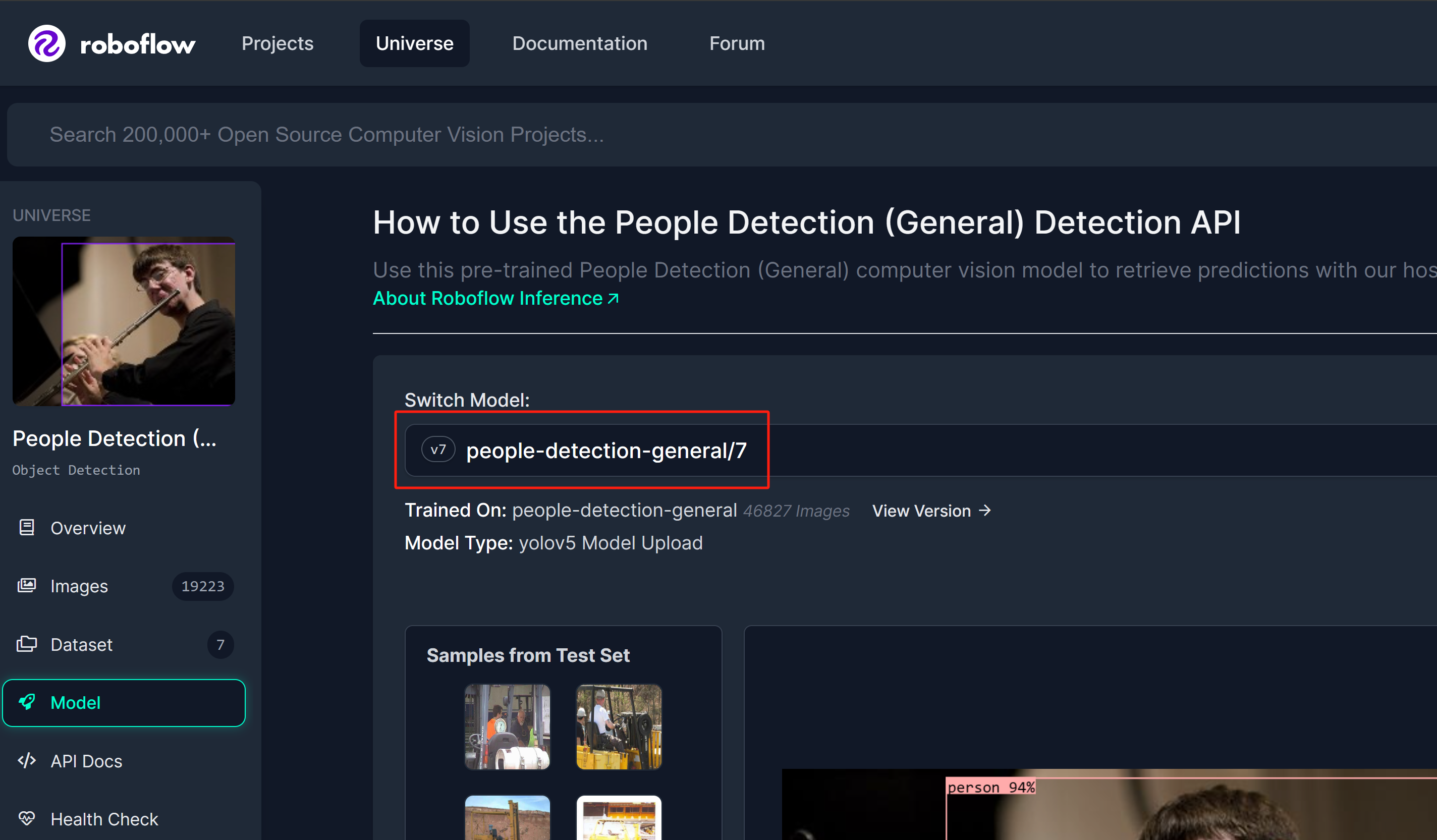
Passo 1: Usaremos um modelo de detecção de pessoas do Roboflow Universe como referência
-
Passo 2: Aqui o nome do modelo seguirá o formato "model_name/version". Neste caso, é people-detection-general/7. Usaremos este nome de modelo mais tarde neste wiki quando começarmos a inferência.
Obter a chave de API do Roboflow
Agora precisamos obter uma chave de API do Roboflow para que o servidor de inferência do Roboflow funcione.
-
Passo 1: Cadastre-se para uma nova conta Roboflow inserindo suas credenciais
-
Passo 2: Faça login na conta, navegue até
Projects > Workspaces > <your_workspace_name> > Roboflow APIe clique em Copy ao lado da seção "Private API Key"
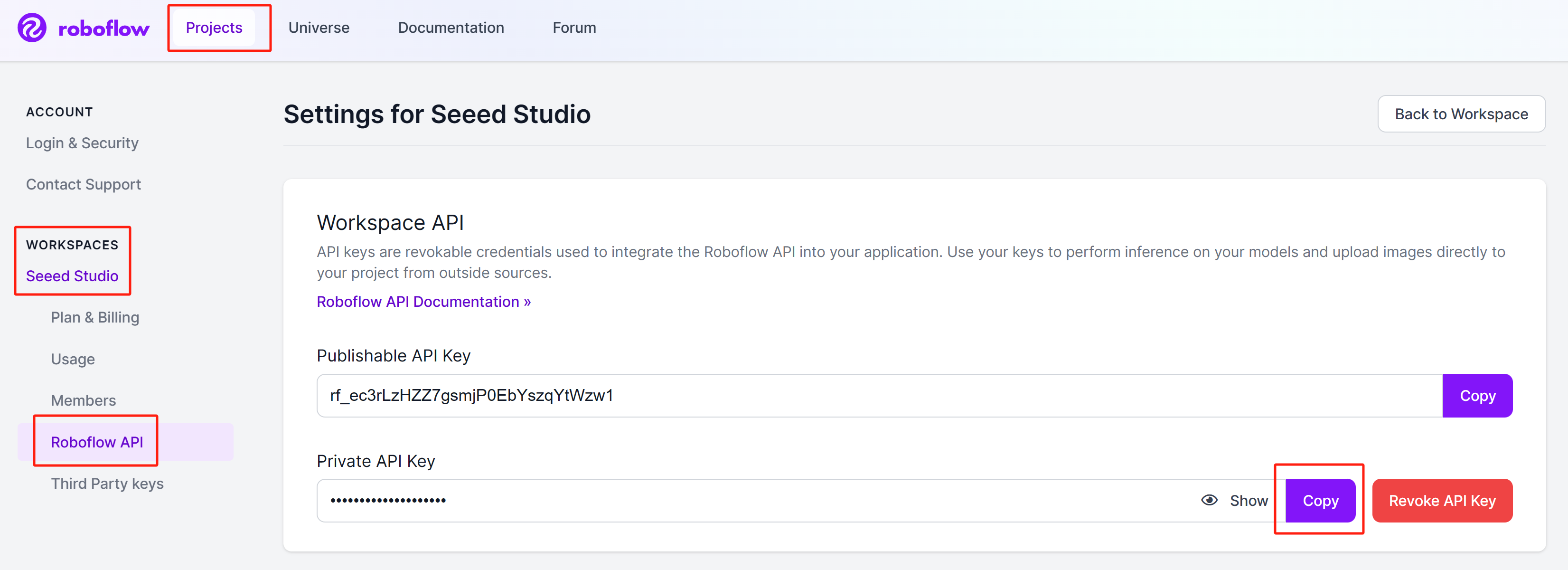
Guarde essa chave privada porque vamos precisar dela mais tarde.
Executando o servidor de inferência Roboflow
Você pode começar com a inferência Roboflow em NVIDIA Jetson de 3 maneiras diferentes.
- Usando pacote pip - Usar o pacote pip será a forma mais rápida de começar, porém você precisará instalar componentes do SDK (CUDA, cuDNN, TensorRT) junto com o JetPack.
- Usando Docker Hub - Usar o Docker Hub será um pouco mais lento porque primeiro ele fará o pull de uma imagem Docker de cerca de 19GB. No entanto, você não precisa instalar componentes do SDK porque a imagem Docker já os terá.
- Usando build Docker local - Usar build Docker local é uma extensão do método Docker Hub, em que você pode alterar o código-fonte da imagem Docker de acordo com a aplicação desejada (como habilitar precisão TensorRT com INT8).
Antes de prosseguir para executar o servidor de inferência Roboflow, você precisa obter um modelo de IA para fazer a inferência e uma chave de API do Roboflow. Primeiro passaremos por isso.
- Pacote pip
- Docker Hub
- Build Docker Local
Usando pacote pip
- Passo 1: Se você apenas gravar o dispositivo Jetson com Jetson L4T, precisará instalar primeiro os componentes do SDK
sudo apt update
sudo apt install nvidia-jetpack -y
- Passo 2: Execute os comandos abaixo no terminal para instalar o pacote pip do servidor de inferência Roboflow
sudo apt update
sudo apt install python3-pip -y
pip install inference-gpu
- Passo 3: Execute o comando abaixo e substitua pela sua Private API Key do Roboflow que você obteve antes
export ROBOFLOW_API_KEY=your_key_here
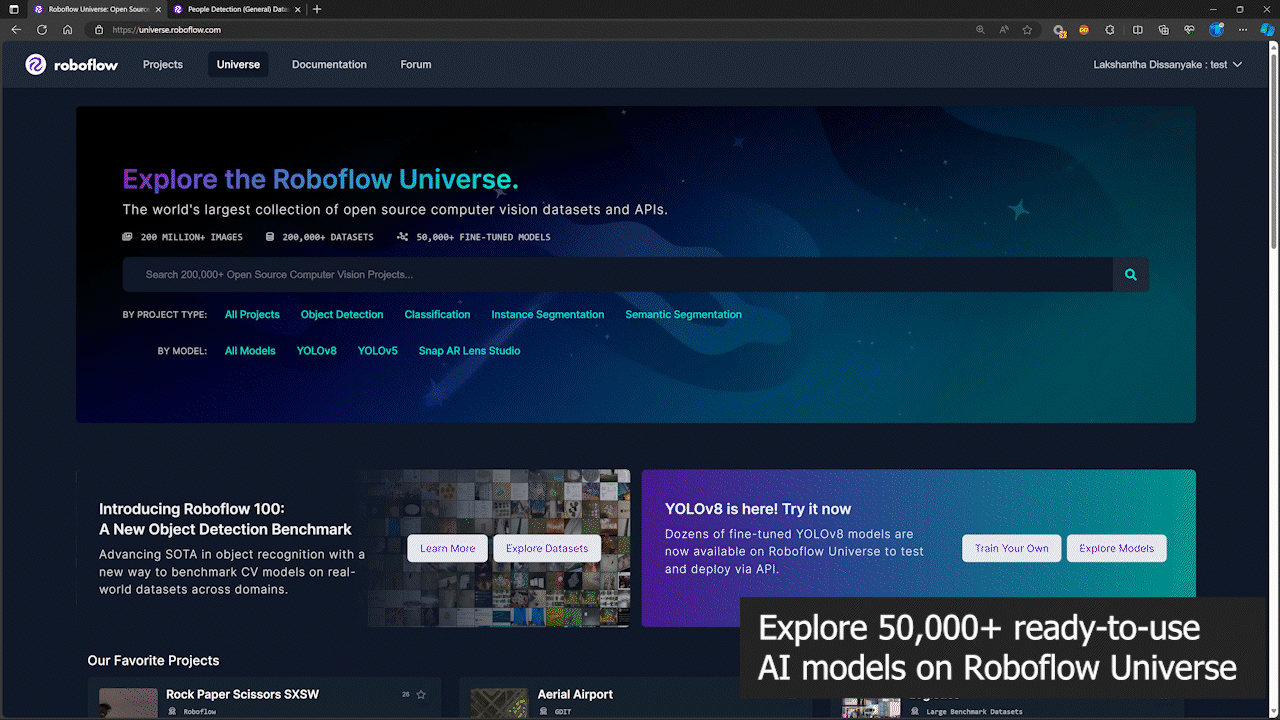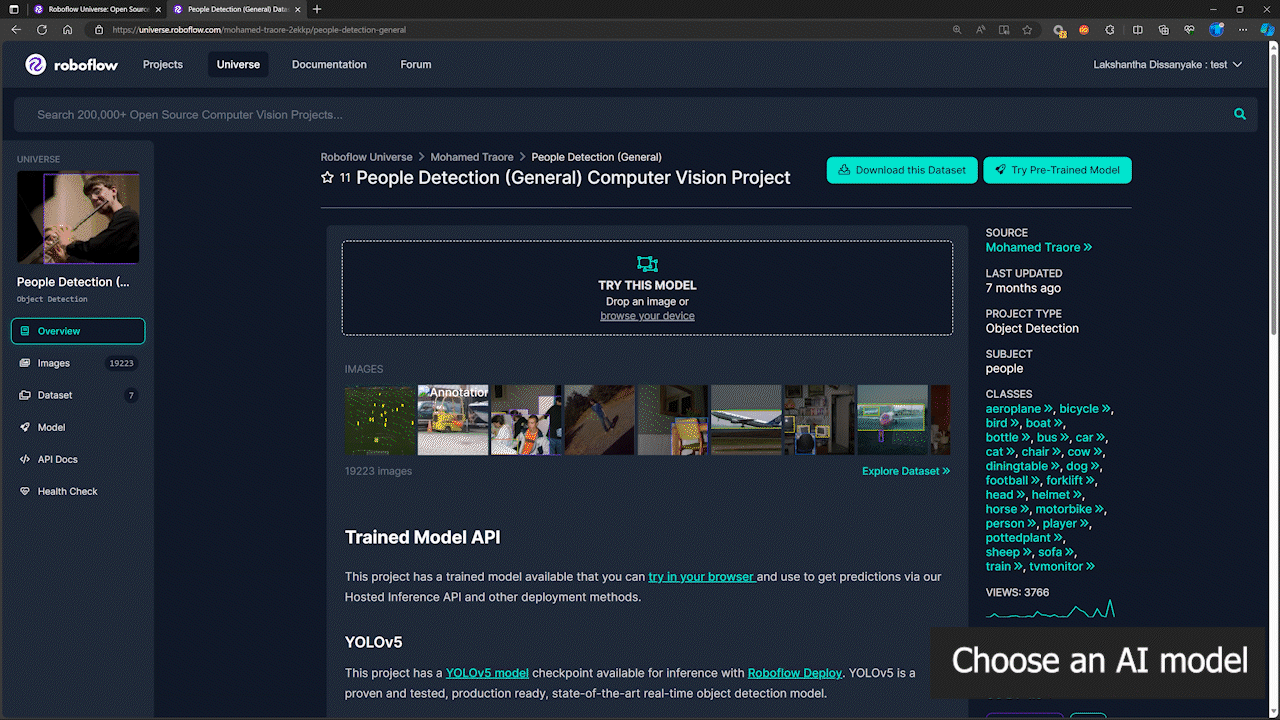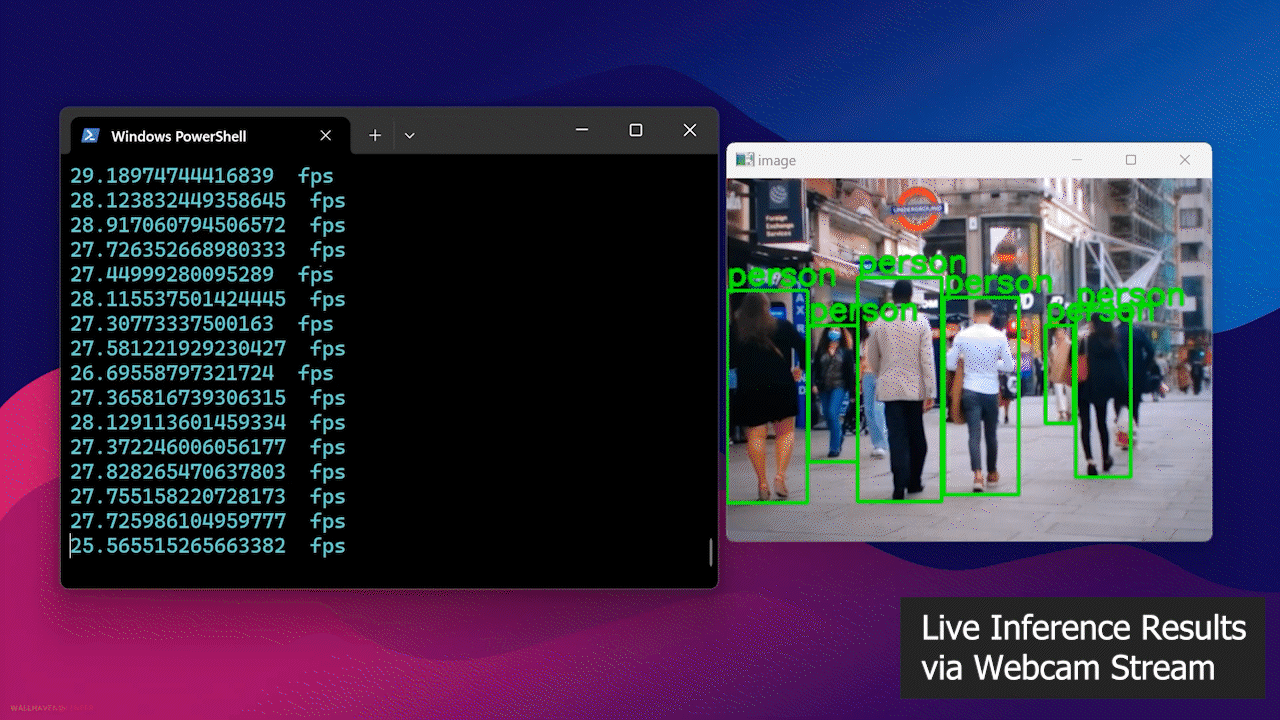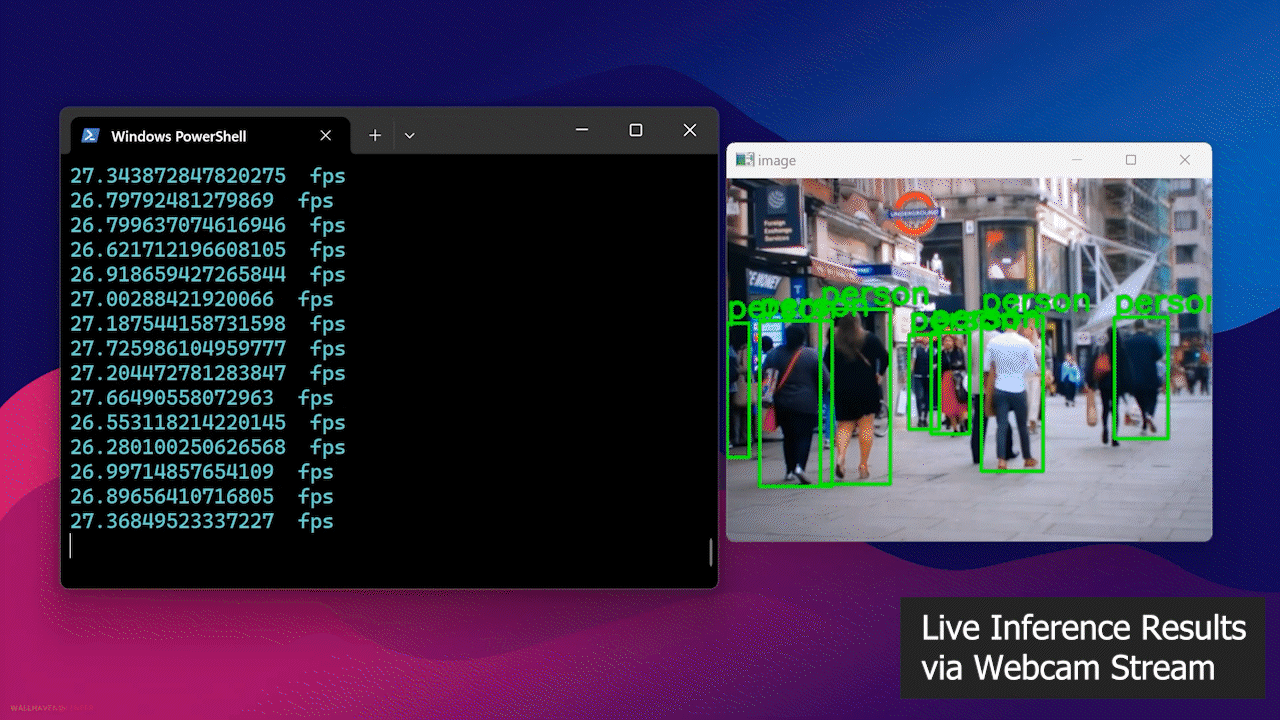
- Passo 4: Conecte uma webcam ao dispositivo Jetson e execute o seguinte script Python para rodar um modelo open source de detecção de pessoas no stream da sua webcam
webcam.py
import cv2
import inference
import supervision as sv
annotator = sv.BoxAnnotator()
inference.Stream(
source="webcam",
model=" people-detection-general/7",
output_channel_order="BGR",
use_main_thread=True,
on_prediction=lambda predictions, image: (
print(predictions),
cv2.imshow(
"Prediction",
annotator.annotate(
scene=image,
detections=sv.Detections.from_roboflow(predictions)
)
),
cv2.waitKey(1)
)
)
Por fim, você verá o resultado a seguir
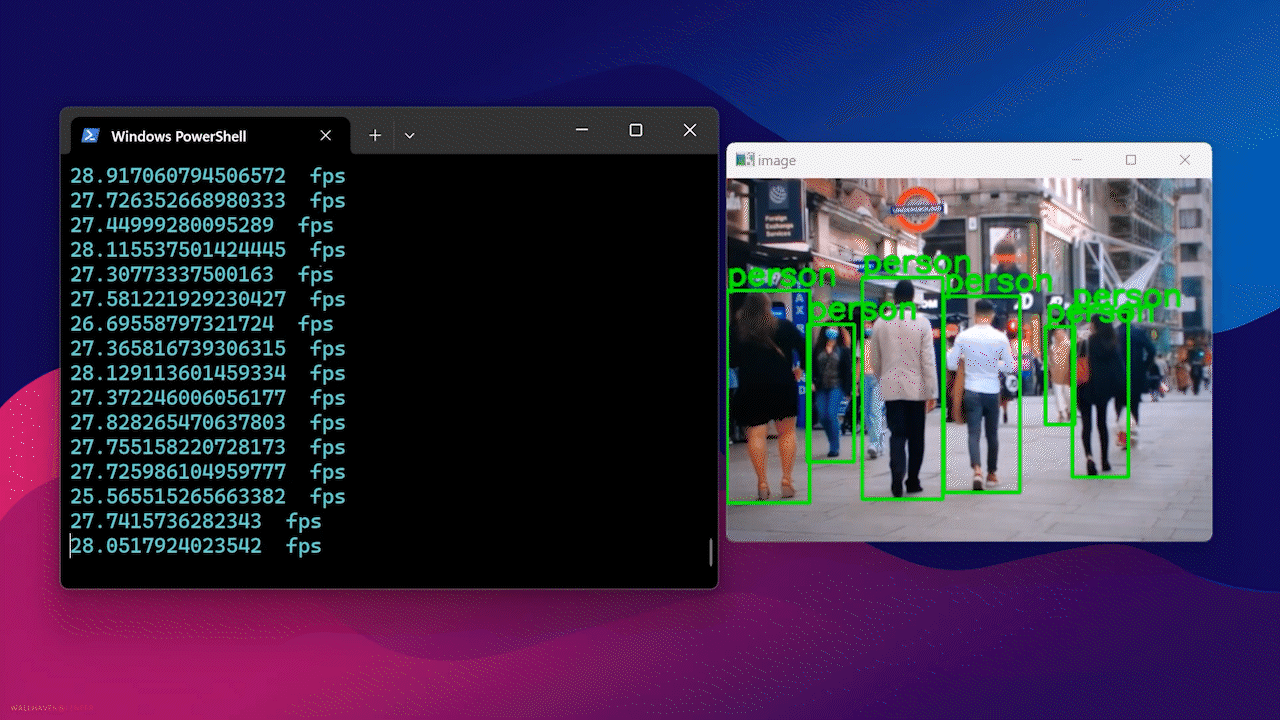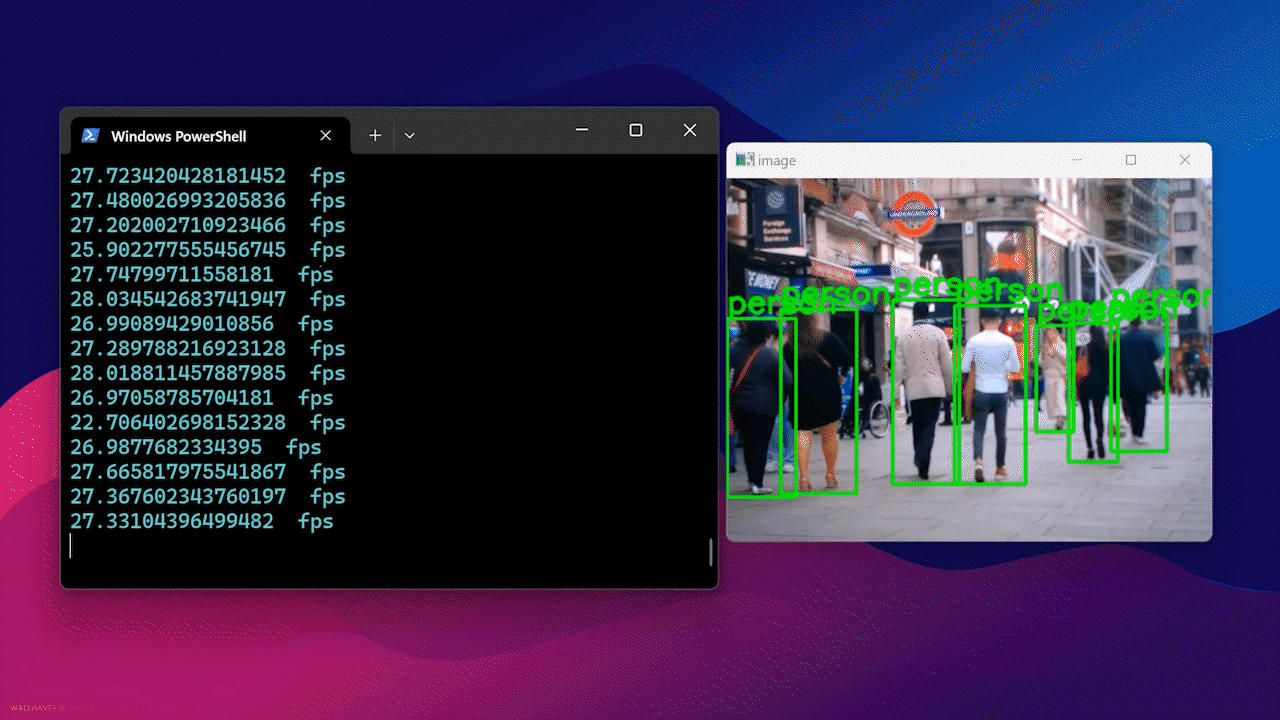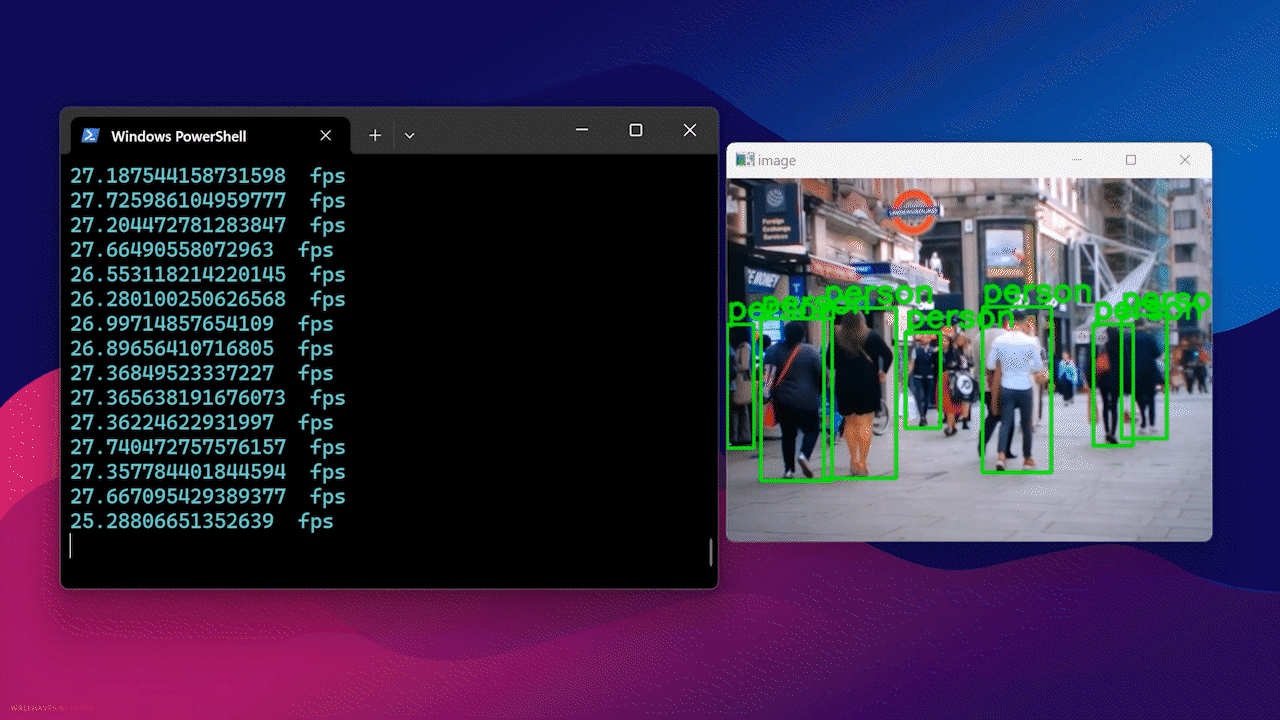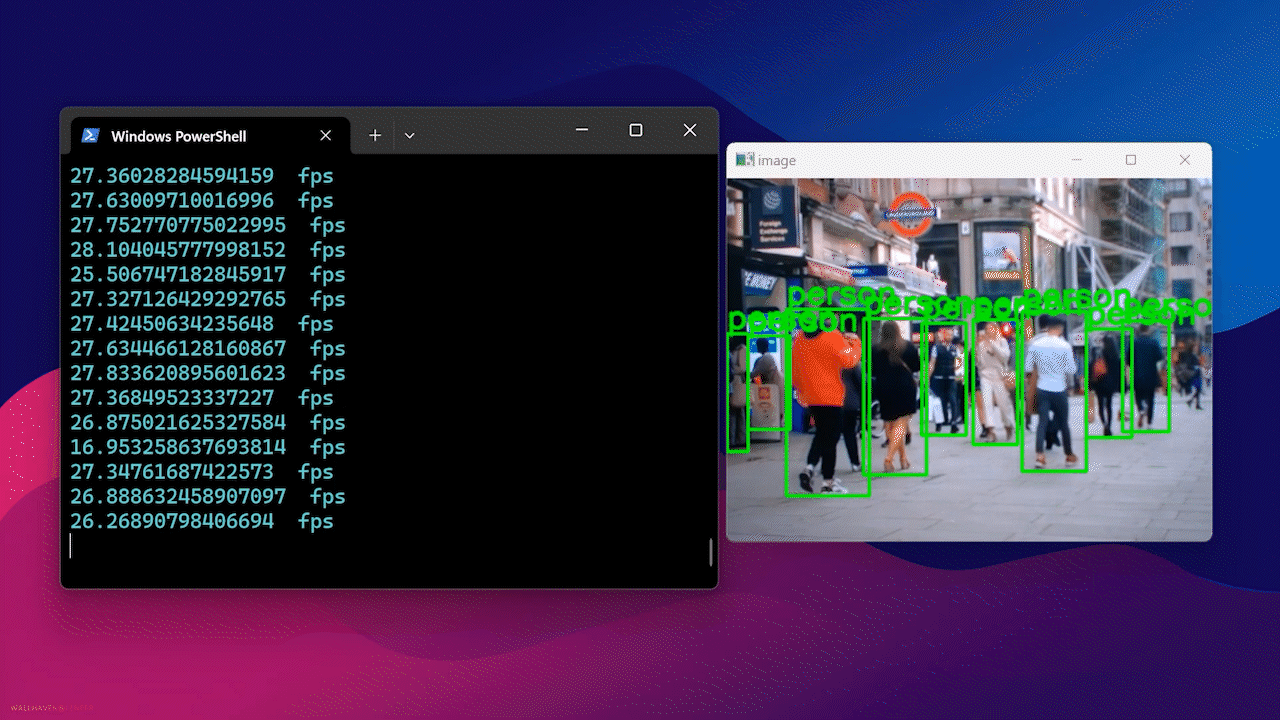
Usando Docker Hub
Para usar este método, gravar o dispositivo com Jetson L4T é suficiente. Isso usa uma arquitetura cliente-servidor em que o servidor de inferência Roboflow será executado em uma porta de rede específica no Jetson e você poderá acessar esse servidor de inferência usando qualquer PC na mesma rede ou até usar o próprio Jetson como servidor e cliente ao mesmo tempo.
Configuração do servidor - Jetson
Execute o seguinte para baixar e executar o contêiner Docker do servidor de inferência Roboflow
sudo docker run --network=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1
Se você vir a seguinte saída, o servidor de inferência foi iniciado com sucesso

Configuração do cliente - Jetson/ PC
- Passo 1: Instale os pacotes necessários
sudo apt update
sudo apt install python3-pip -y
git clone https://github.com/roboflow/roboflow-api-snippets
cd Python/webcam
pip install -r requirements.txt
-
Passo 2: Crie um arquivo roboflow_config.json no mesmo diretório incluindo sua chave de API do Roboflow, nome do modelo. Você pode consultar o arquivo de exemplo roboflow_config.sample.json incluído neste repositório do GitHub
-
Passo 3: No mesmo dispositivo em uma janela de terminal diferente ou em outro PC na mesma rede que o Jetson, execute o seguinte script Python para rodar um modelo open source de detecção de pessoas no stream da sua webcam
python infer-simple.py
Usando build Docker local
Configuração do servidor - Jetson
Para usar este método, gravar o dispositivo com Jetson L4T é suficiente. Isso usa uma arquitetura cliente-servidor em que o servidor de inferência Roboflow será executado em uma porta de rede específica no Jetson e você poderá acessar esse servidor de inferência usando qualquer PC na mesma rede ou até usar o próprio Jetson como servidor e cliente ao mesmo tempo.
- Passo 1: Clone o repositório do servidor de inferência Roboflow
git clone https://github.com/roboflow/inference
- Passo 2: Entre no diretório "inference" e comece a compilar sua própria imagem Docker
cd inference
sudo docker build \
-f docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1 \
-t roboflow/roboflow-inference-server-jetson-5.1.1:seeed1 .
Aqui o texto após "-t" é o nome do contêiner que estamos construindo. Você pode dar qualquer nome a ele.
- Passo 3: Execute o comando abaixo para verificar se a imagem Docker que compilamos está listada
sudo docker ps

- Etapa 4: Inicie um contêiner Docker baseado na imagem Docker que você acabou de criar
docker run --privileged --net=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1:seeed1
Se você vir a seguinte saída, o servidor de inferência foi iniciado com sucesso

Configuração do cliente - Jetson/PC
Execute o seguinte script Python para rodar um modelo open-source de detecção de pessoas no fluxo da sua webcam webcam.py
import cv2
import base64
import requests
import time
upload_url = ("http://<ip_address_of_jetson>:9001/"
"people-detection-general/7"
"?api_key=xxxxxxxx"
"&stroke=5")
video = cv2.VideoCapture(0)
while True:
start = time.time()
ret, img = video.read()
if ret:
# Resize (while maintaining the aspect ratio) to improve speed and save bandwidth
height, width, channels = img.shape
scale = 416 / max(height, width)
img = cv2.resize(img, (round(scale * width), round(scale * height)))
# Encode image to base64 string
retval, buffer = cv2.imencode('.jpg', img)
img_str = base64.b64encode(buffer)
# Get prediction from Roboflow Infer API
resp = requests.post(upload_url, data=img_str, headers={
"Content-Type": "application/x-www-form-urlencoded"
}, stream=True)
resp = resp.json()
for bbox in resp["predictions"]:
img = cv2.rectangle(
img,
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2))),
(int(bbox['x']+(bbox['width']/2)), int(bbox['y']+(bbox['height']/2))),
(0, 255, 0),
2)
cv2.putText(
img, f"{bbox['class']}",
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2)-5)),
0, 0.9,
(0, 255, 0), thickness=2, lineType=cv2.LINE_AA
)
cv2.imshow('image', img)
print((1/(time.time()-start)), " fps")
if cv2.waitKey(1) == ord('q'):
break
video.release()
cv2.destroyAllWindows()
Observe que os elementos que precisam ser incluídos em upload_url no script são:
- Endereço IP do servidor de inferência do roboflow
- O modelo que você deseja executar
- Chave de API do roboflow
O modelo pode ser selecionado no universo do roboflow
Habilitar TensorRT
Por padrão, o servidor de inferência Roboflow está usando o runtime CUDA. Porém, se você quiser mudar para o runtime TensorRT para aumentar a velocidade de inferência, você pode adicionar o seguinte dentro do arquivo "inference/docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1" e criar a imagem Docker
ENV ONNXRUNTIME_EXECUTION_PROVIDERS=TensorrtExecutionProvider
Saiba mais
Roboflow oferece uma documentação muito detalhada e abrangente. Portanto, é altamente recomendável consultá-la aqui.
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para fornecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja o mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.