Detecção de Facas: Um Modelo de Detecção de Objetos implantado no Triton Inference Sever baseado em reComputer
A inspeção de segurança é um alarme de segurança para a proteção de passageiros e dos setores de transporte, mantendo o perigo afastado, normalmente aplicada em aeroportos, estações de trem, estações de metrô, etc. No campo atual de inspeção de segurança, as máquinas de inspeção são implantadas nas passagens de entrada do transporte público. Em geral, é necessário que vários dispositivos funcionem ao mesmo tempo.
No entanto, o desempenho de detecção de itens proibidos em imagens de raio-x ainda não é ideal devido à sobreposição de objetos detectados durante a inspeção de segurança. Para isso, com base no módulo de remoção de oclusão no Triton Interface Sever, implantar um algoritmo de detecção de itens proibidos em imagens de raio-x pode oferecer uma forma de atuação melhor.
Assim, graças a Yanlu Wei, Renshuai Tao et al., fornecemos este projeto fundamental no qual vamos implantar um modelo de Deep Learning no reComputer J1010 que pode detectar itens proibidos (facas) com o Raspberry Pi e o reComputer J1010, onde usamos um reComputer J1010 como nosso servidor de inferência e dois Raspberry Pi para simular máquinas de inspeção de segurança enviando imagens. O reComputer 1020, reComputer J2011, reComputer J2012 e Nvidia Jetson AGX Xavier são todos suportados.
Primeiros Passos
Triton Inference Server fornece uma solução de inferência em nuvem e na borda, otimizada tanto para CPUs quanto para GPUs. O Triton suporta os protocolos HTTP/REST e GRPC que permitem que clientes remotos solicitem inferência para qualquer modelo gerenciado pelo servidor. Aqui vamos usar o Triton (Triton Inference Server) como nosso servidor local no qual o modelo de detecção será implantado.
Hardware
Hardware Necessário
Neste projeto, os dispositivos necessários são mostrados abaixo:
- Raspberry Pi 4B*2
- reComputer J1010
- Tela HDMI, mouse e teclado
- PC
Configuração de Hardware
Os dois Raspberry Pi e o reComputer devem estar ligados e todos devem estar na mesma rede. Neste projeto, usamos dois Raspberry Pi para simular o trabalho de máquinas de segurança, já que as máquinas de inspeção de segurança são usadas por múltiplos dispositivos na maioria dos casos. Portanto, ambos
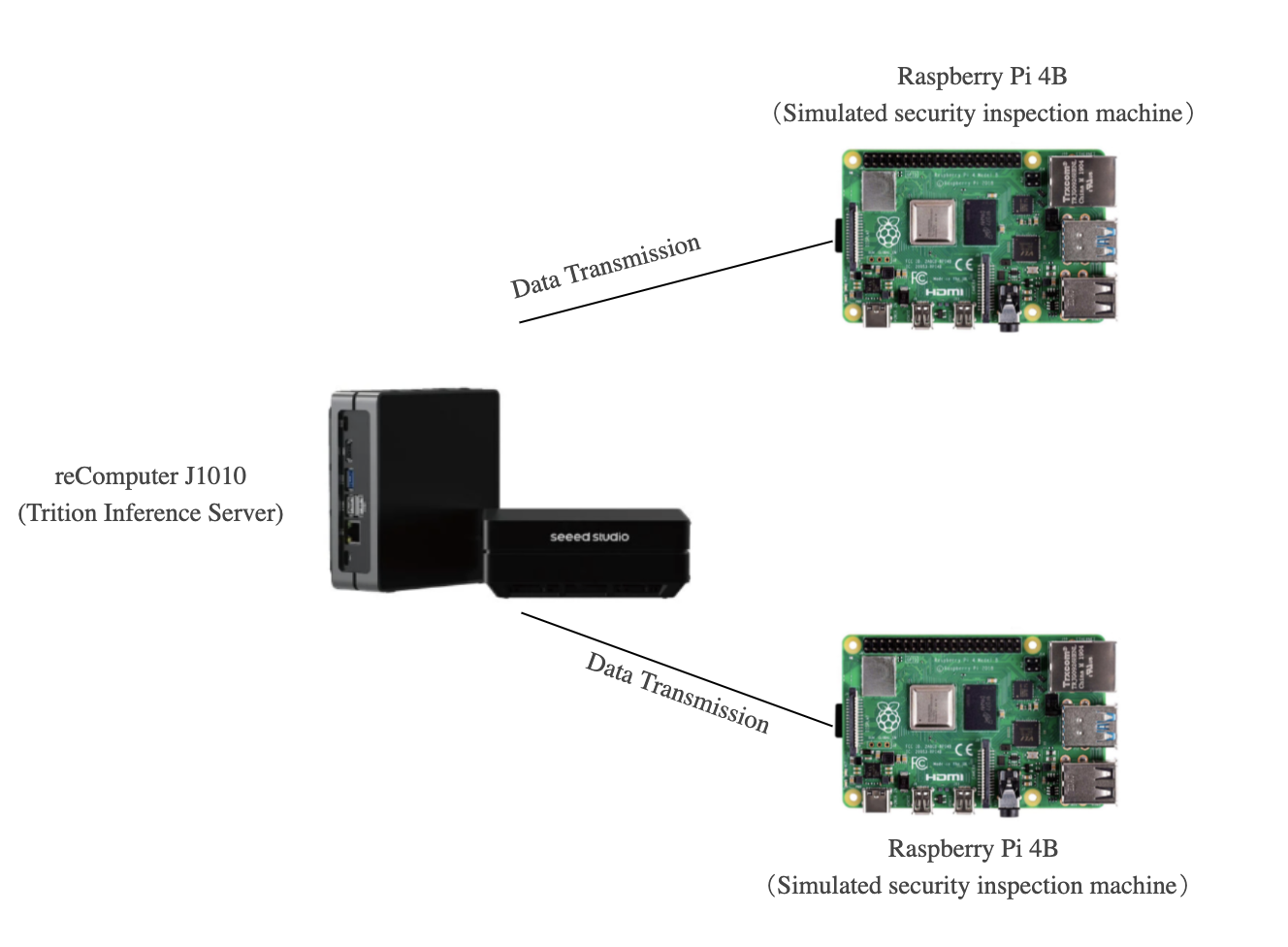
Apenas um Raspberry Pi também pode ser aplicado a este projeto. No entanto, a demonstração de detecção simultânea de facas em dois dispositivos pode oferecer melhores capacidades de batching dinâmico do Triton Inference Server. Nas próximas instruções, apresentaremos como configurar o software no Raspberry Pi e no reComputer J1010.
Software
Aqui usamos o conjunto de dados de imagens de raio-x como nossos dados de entrada que serão colocados no Raspberry Pi. Depois disso, o reComputer enviará os resultados de inferência processados para o Raspberry Pi. Ao final, o Raspberry Pi concluirá o trabalho final e exibirá na tela, ou seja, a última camada do modelo de inferência será implantada no Raspberry Pi.
Configurar o Raspberry Pi
Aqui mostraremos como configurar os softwares necessários no Raspberry Pi, incluindo
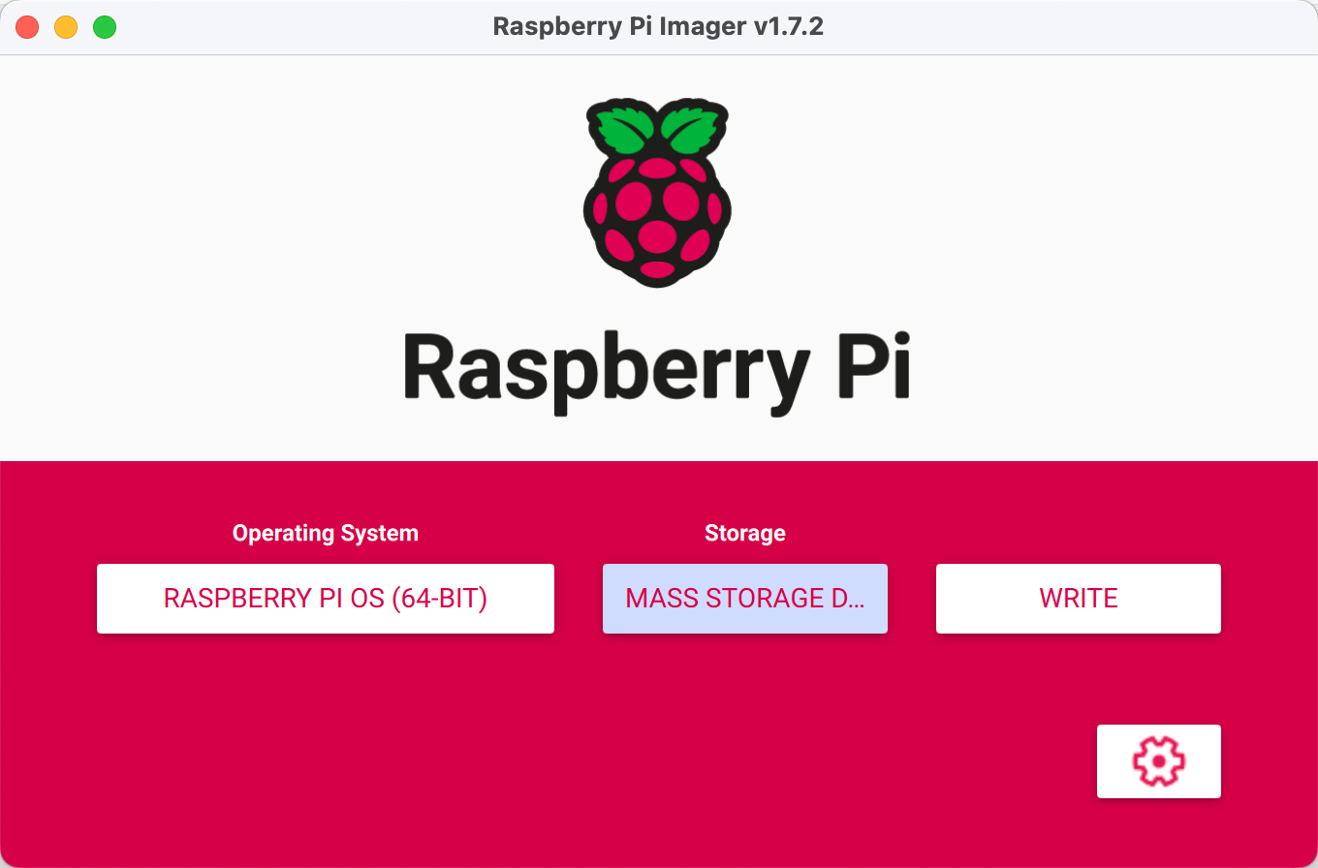
Passo 1. Instale o sistema Raspbian Buster e faça a configuração básica a partir do site oficial. Neste projeto, usamos RASPBERRY PI OS (64 bit) como nosso sistema operacional.
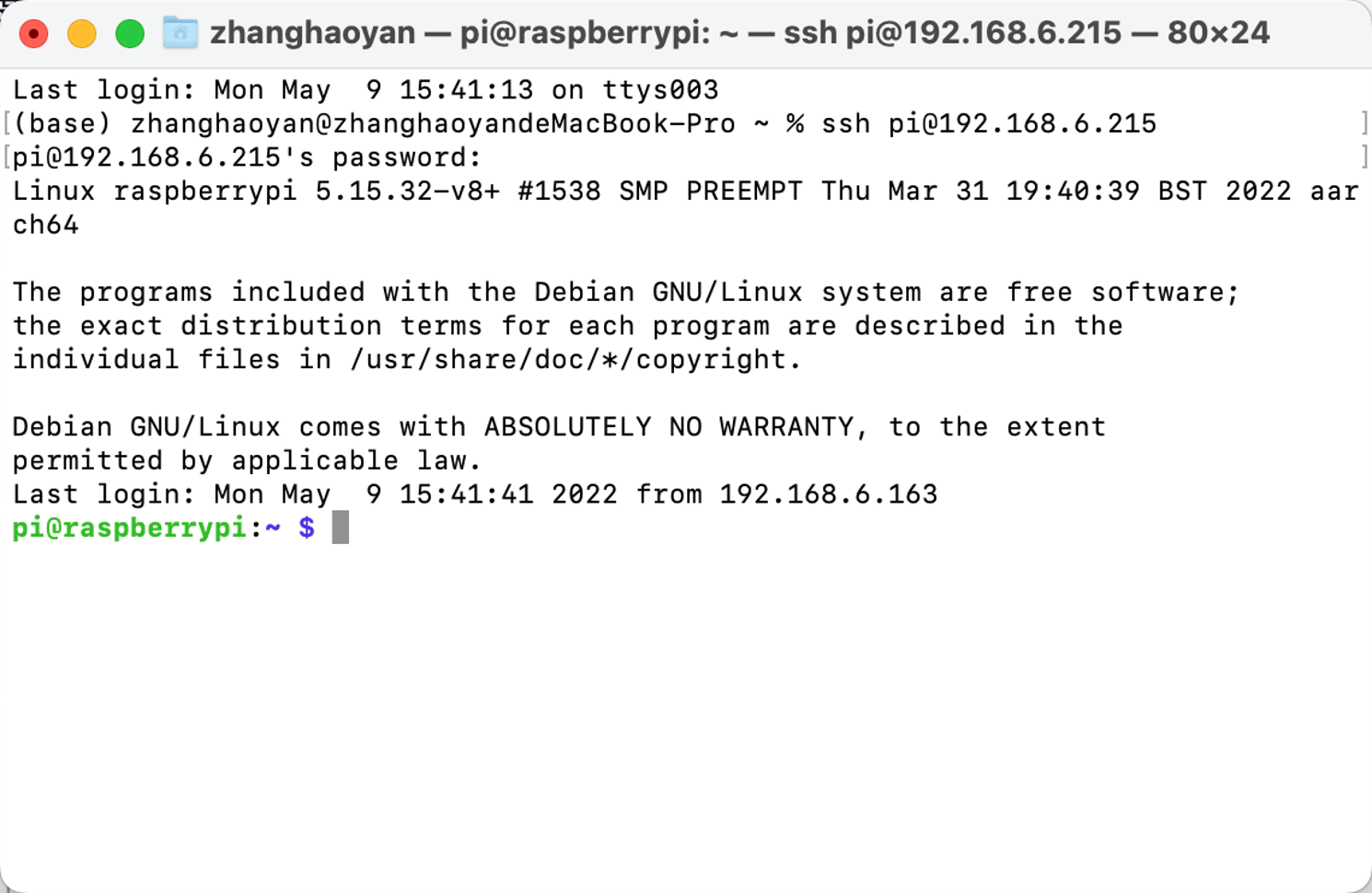
Passo 2. Configure a porta SSH do Raspberry Pi (opcional).
Antes de implantar o ambiente, podemos abrir a porta SSH do Raspberry Pi e acessá-lo remotamente usando a interface SSH no PC.
Aviso: certifique-se de que o PC e o Raspberry Pi estejam na mesma LAN.
Passo 3. Configure o ambiente Python.
Precisamos implantar os ambientes necessários para o modelo de inferência como Python, PyTorch, Tritonclient e TorchVision e, para exibição de imagens, o OpenCV no Raspberry Pi. Fornecemos as instruções abaixo:
Python
Podemos executar python –V e garantir que a versão do Python seja 3.9.2. Precisamos instalar PyTorch, Torchclient e TorchVision cujas versões correspondam ao Python 3.9.2. Você pode consultar aqui para baixar e instalar.
PyTorch
Se a versão do Python estiver correta, podemos agora instalar o Pytorch.
Aviso: antes de instalar o Pytorch, precisamos verificar a versão do Raspbian.
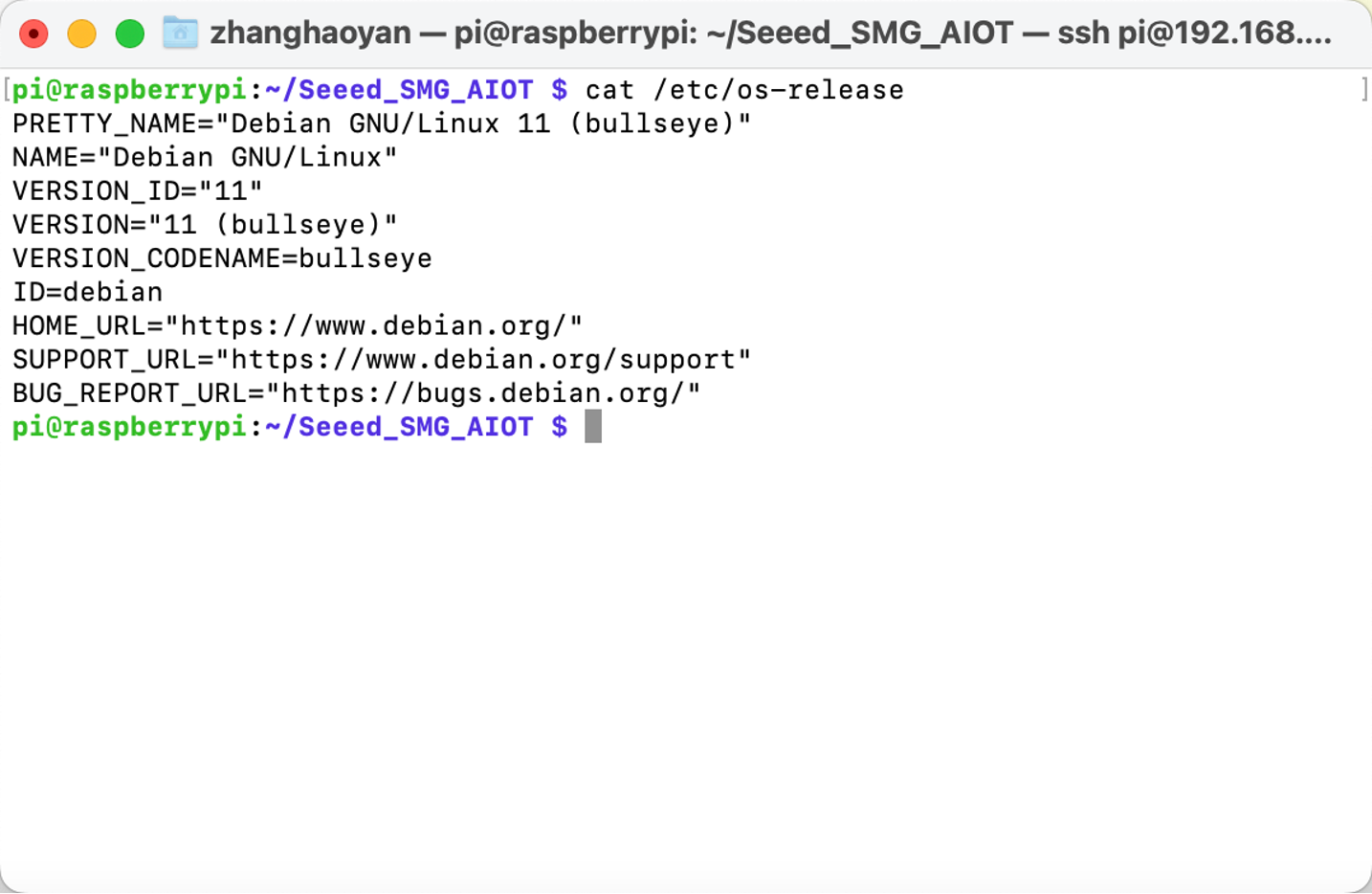
Execute o comando abaixo para instalar o Pytorch:
# get a fresh start
sudo apt-get update
sudo apt-get upgrade
# install the dependencies
sudo apt-get install python3-pip libjpeg-dev libopenblas-dev libopenmpi-dev libomp-dev
# above 58.3.0 you get version issues
sudo -H pip3 install setuptools==58.3.0
sudo -H pip3 install Cython
# install gdown to download from Google drive
sudo -H pip3 install gdown
# Buster OS
# download the wheel
gdown https://drive.google.com/uc?id=1gAxP9q94pMeHQ1XOvLHqjEcmgyxjlY_R
# install PyTorch 1.11.0
sudo -H pip3 install torch-1.11.0a0+gitbc2c6ed-cp39-cp39-linux_aarch64.whl
# clean up
rm torch-1.11.0a0+gitbc2c6ed-cp39-cp39m-linux_aarch64.whl
Após uma instalação bem-sucedida, podemos verificar o PyTorch com os seguintes comandos após iniciar o python:
import torch as tr
print(tr.__version__)
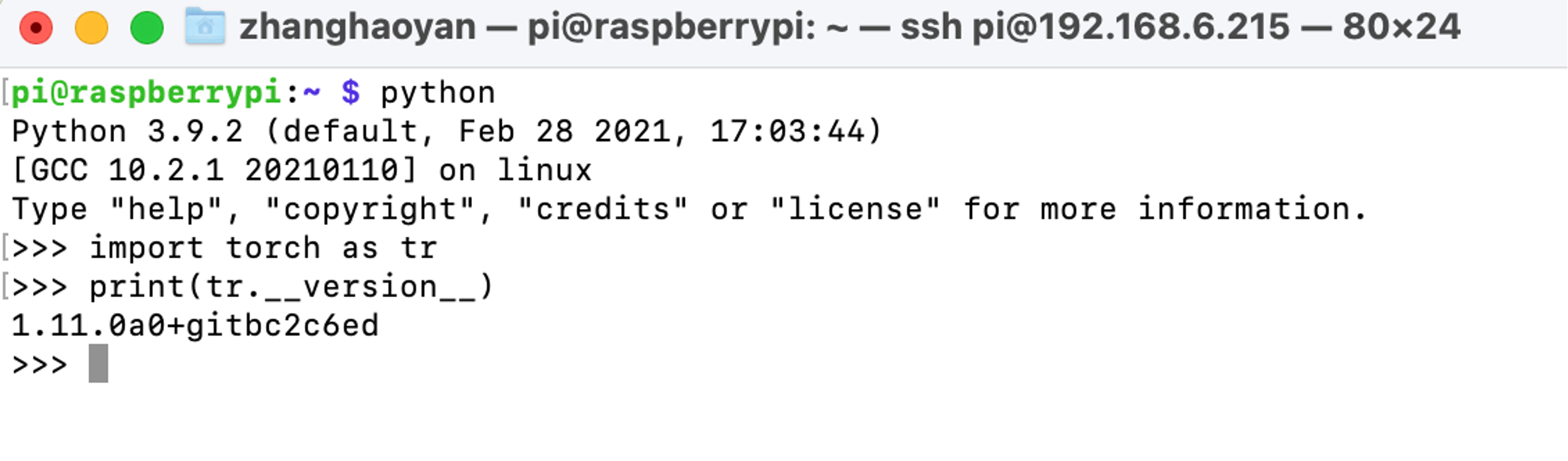
Aviso: pacotes wheel do PyTorch para Raspberry Pi 4 podem ser encontrados em https://github.com/Qengineering/PyTorch-Raspberry-Pi-64-OS
Tritonclient
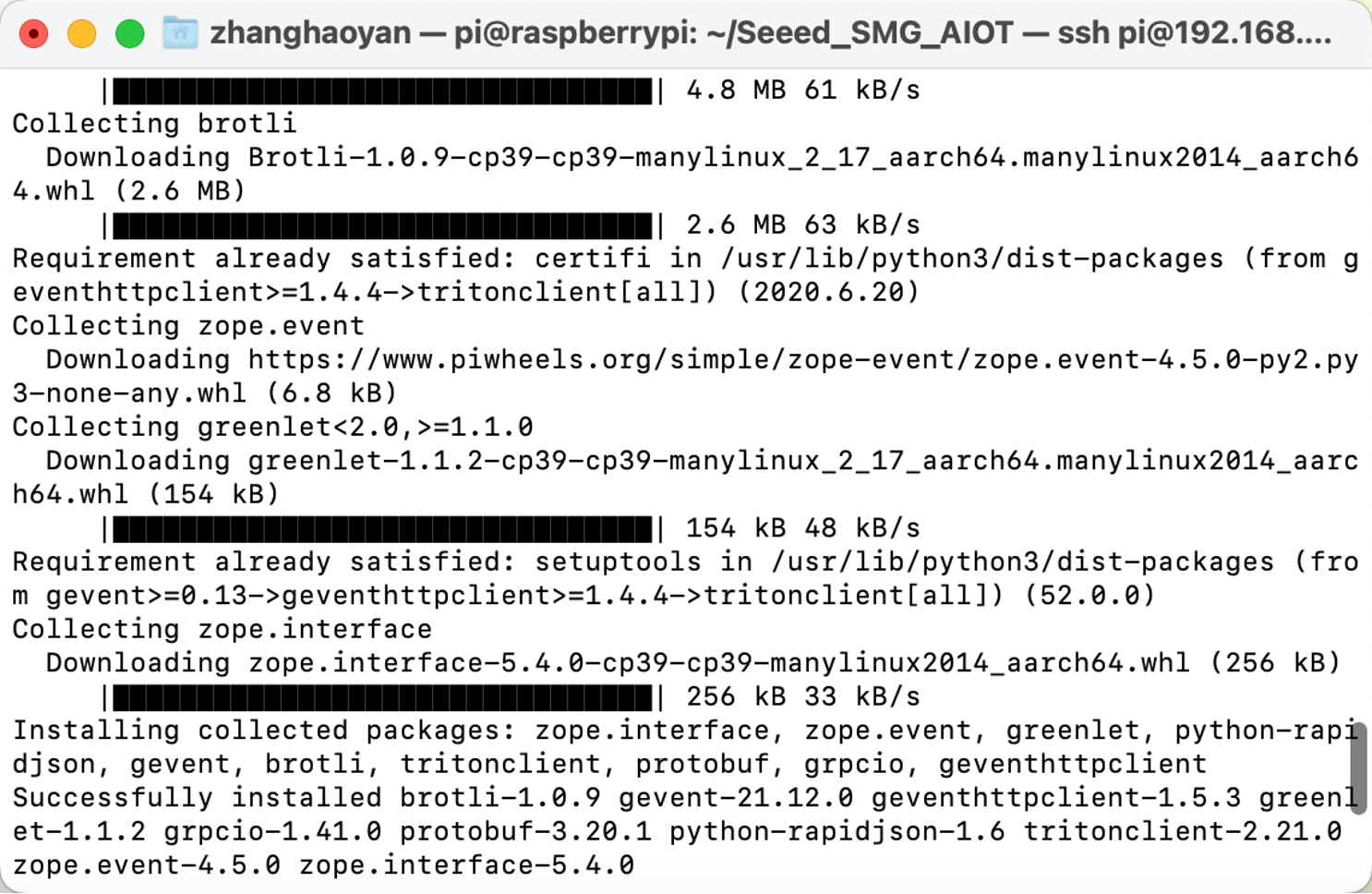
Podemos executar pip3 install tritonclient[all] para baixar o Tritonclient.
TorchVision
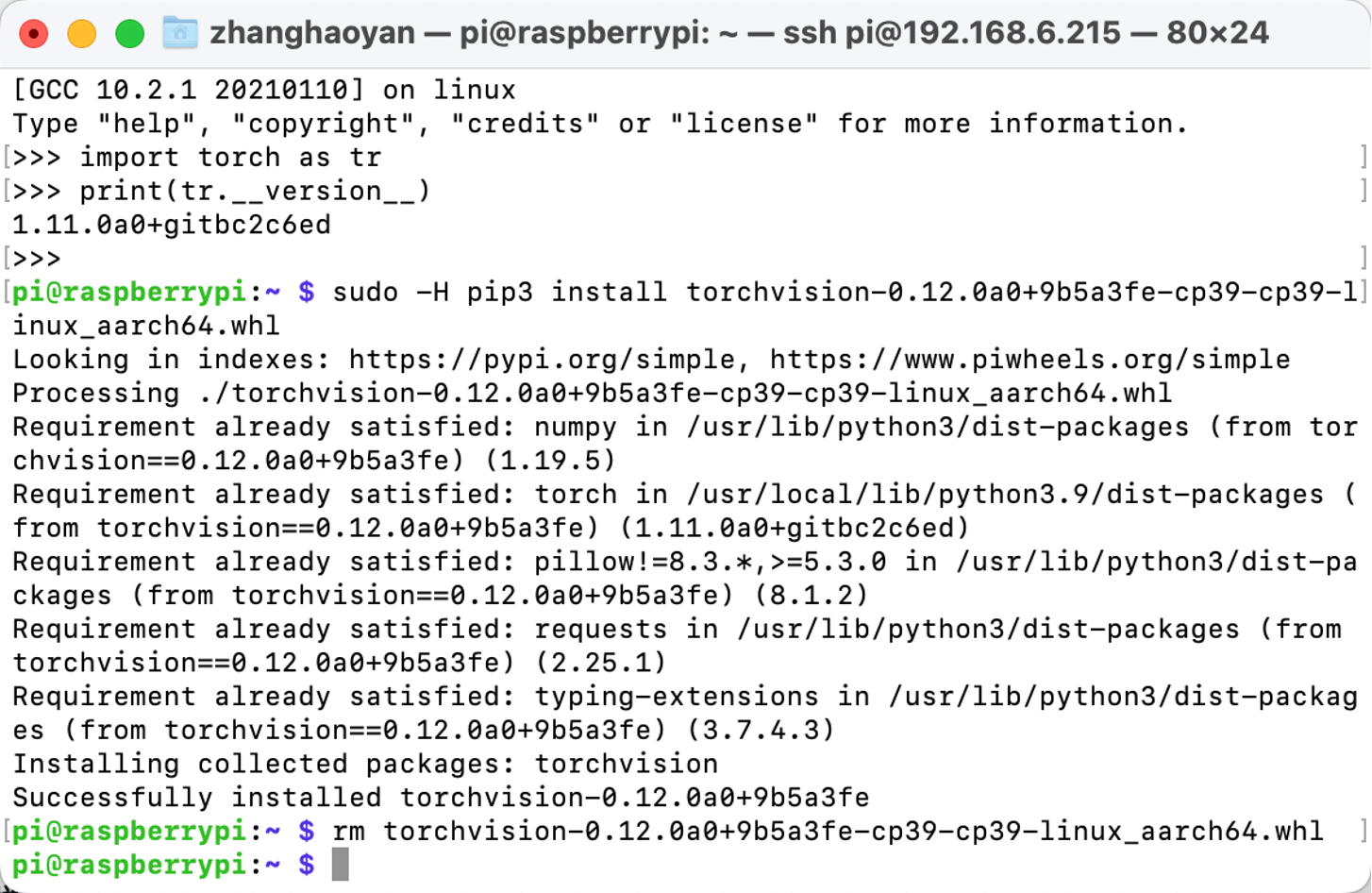
Depois que o Pytorch for instalado, podemos seguir para a instalação do Torchvision. Aqui estão os comandos:
# download the wheel
gdown https://drive.google.com/uc?id=1oDsJEHoVNEXe53S9f1zEzx9UZCFWbExh
# install torchvision 0.12.0
sudo -H pip3 install torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
# clean up
rm torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
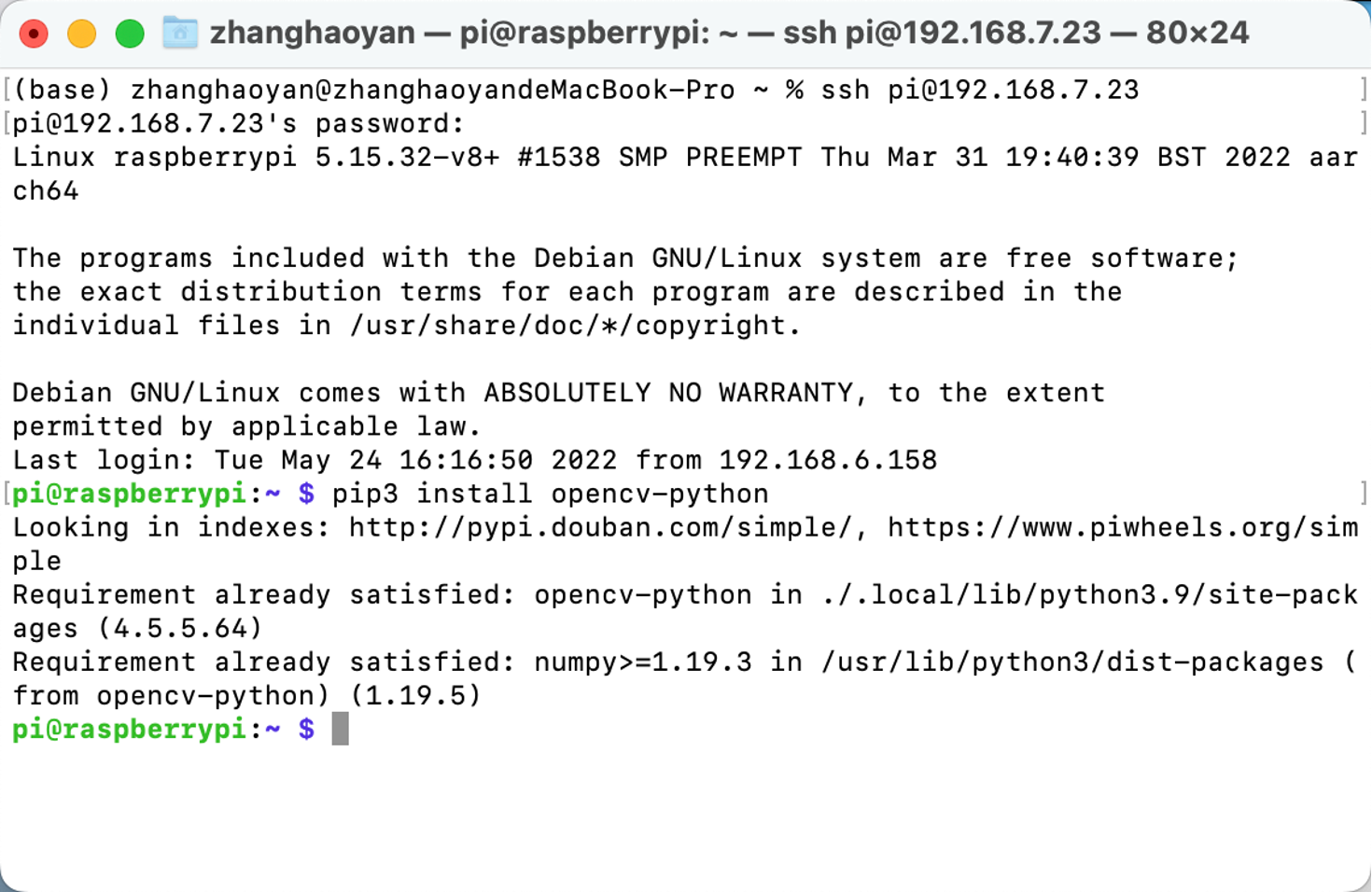
OpenCV
Podemos executar diretamente pip3 install opencv-python para instalar o OpenCV:
Configurar o reComputer J1010
Neste projeto, vamos implantar o Triton Inference Server no reComputer J1010. A fim de melhorar a interatividade e a praticidade de implantação do modelo treinado, vamos converter o modelo para o formato ONXX.
Passo 1. Instale o Jetpack 4.6.1 no reComputer J1010.
Passo 2. Crie uma nova pasta “opi/1” em “home/server/docs/examples/model_repository ”. e então baixe o model.onnx treinado e convertido e coloque-o na pasta “1”.
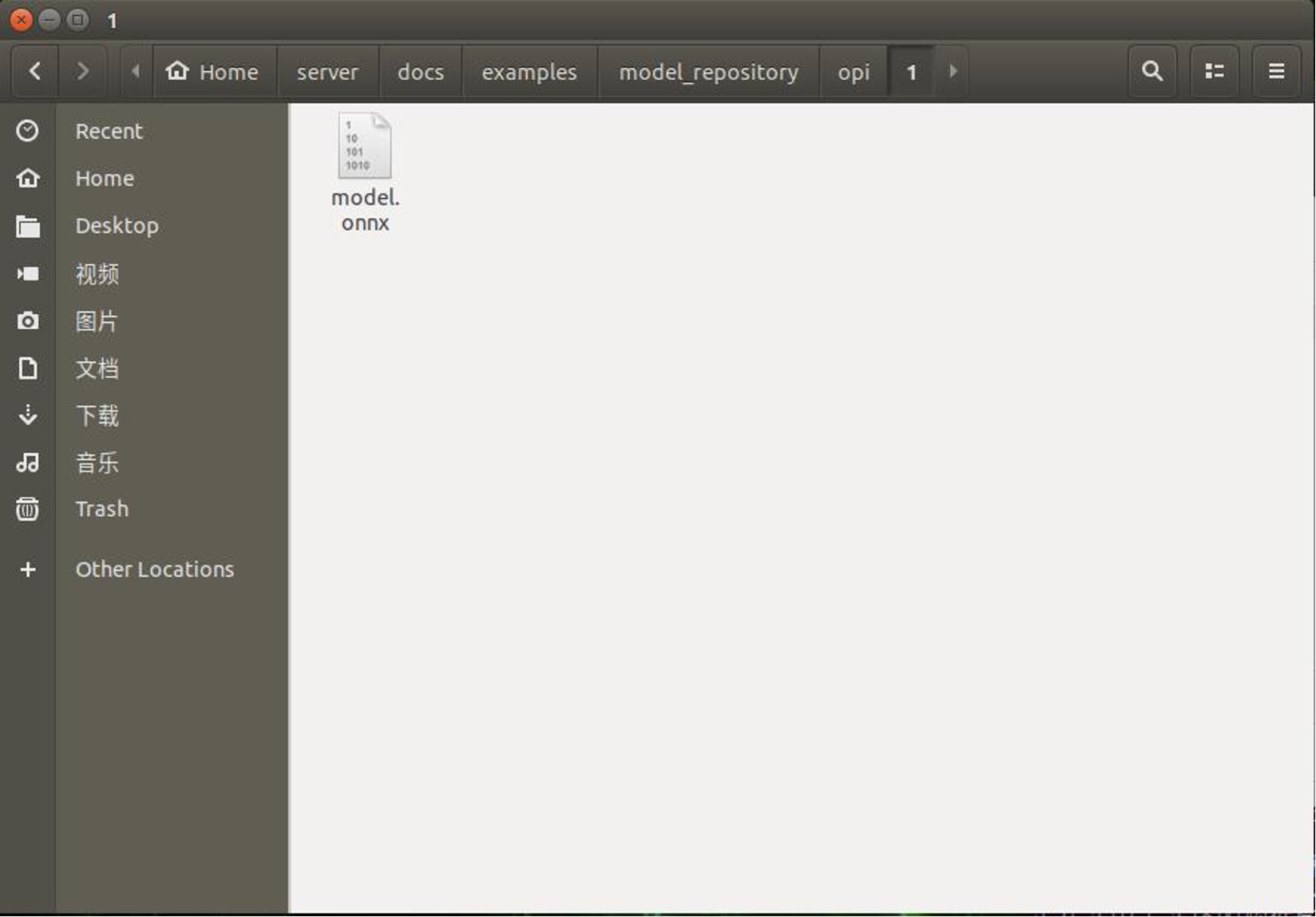
Se você precisar de outro servidor geral, pode executar os seguintes passos.
Abra um novo Terminal e execute
git clone https://github.com/triton-inference-server/server
cd ~/server/docs/examples
sh fetch_models.sh
Passo 3. Instale a versão do Triton para JetPack 4.6.1 que é fornecida no arquivo tar anexado: tritonserver2.21.0-jetpack5.0.tgz.
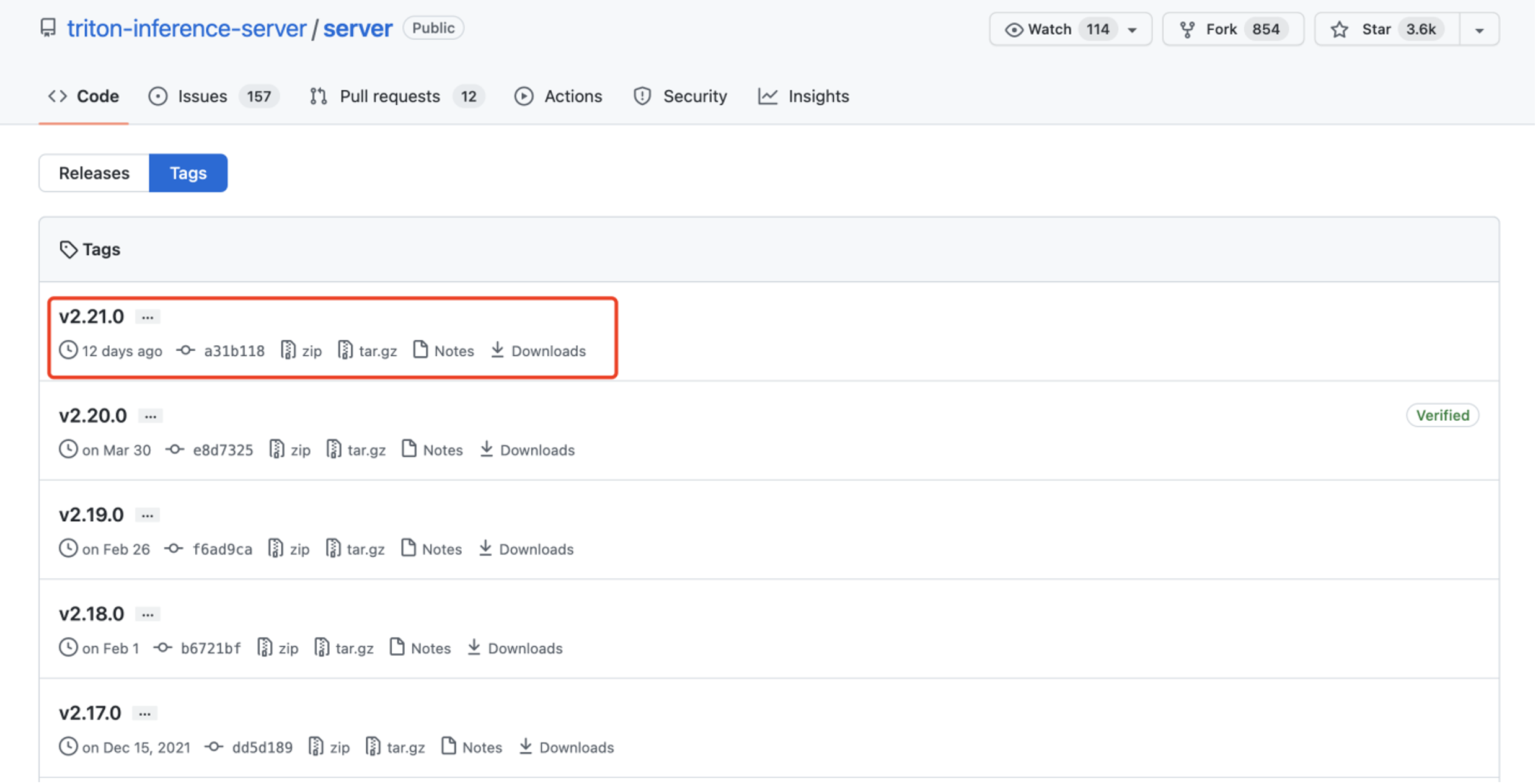
O arquivo tar aqui contém o executável do servidor Triton e bibliotecas compartilhadas, incluindo as bibliotecas cliente C++ e Python e exemplos. Para mais informações sobre como instalar e usar o Triton no JetPack você pode consultar aqui.
Passo 4. Execute o seguinte comando:
mkdir ~/TritonServer && tar -xzvf tritonserver2.19.0-jetpack4.6.1.tgz -C ~/TritonServer
cd ~/TritonServer/bin
./tritonserver --model-repository=/home/seeed/server/docs/examples/model_repository --backend-directory=/home/seeed/TritonServer/backends --strict-model-config=false --min-supported-compute-capability=5.3
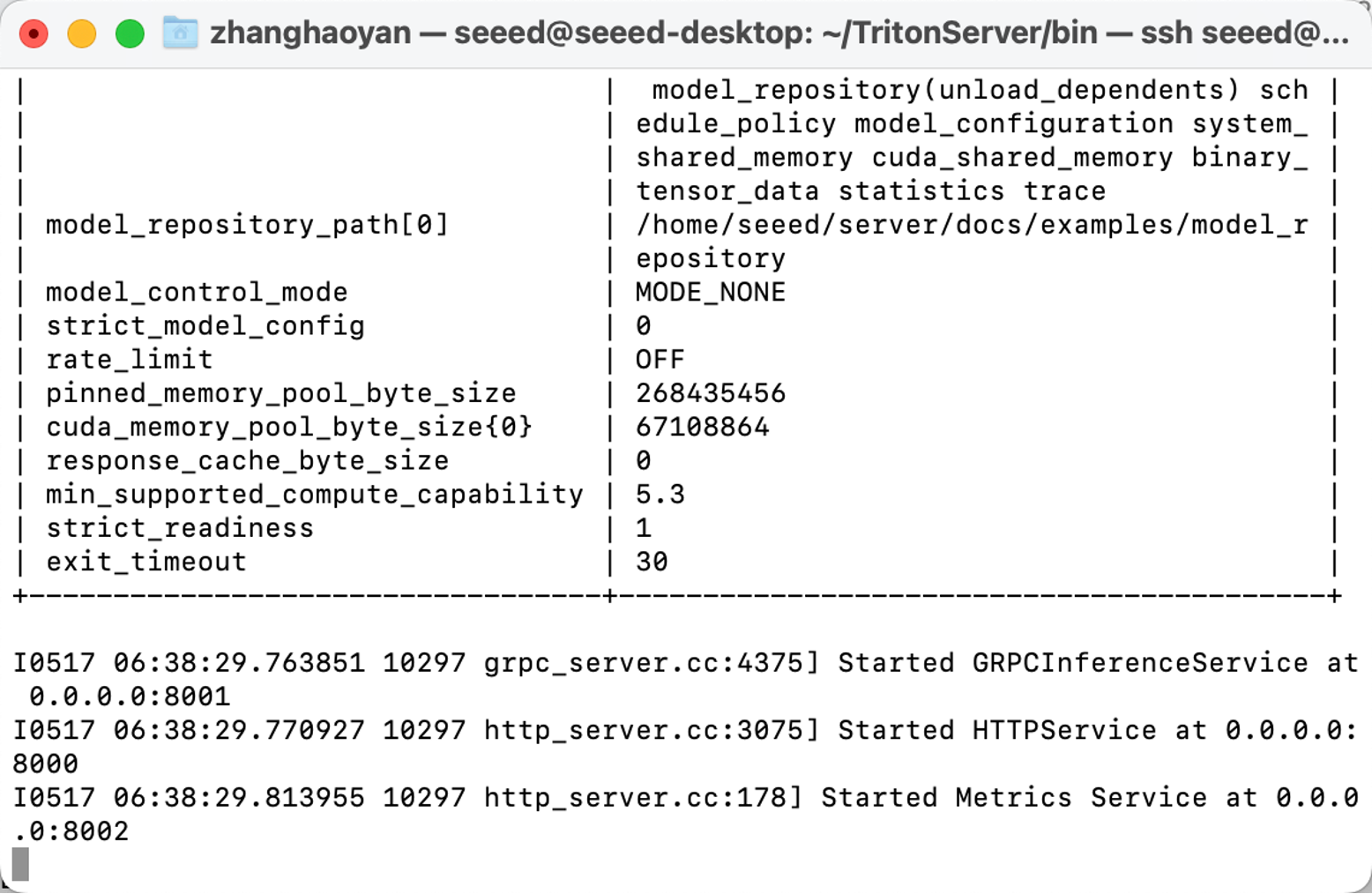
Agora, concluímos todas as preparações.
Operando o Programa
Como todos os ambientes necessários já estão implantados, podemos executar nosso projeto de acordo com as etapas a seguir.
Etapa 1. Baixar o modelo e os arquivos relacionados.
- Clonar o módulo do GitHub.
Abra um novo Terminal e execute:
git clone https://github.com/LemonCANDY42/Seeed_SMG_AIOT.git
cd Seeed_SMG_AIOT/
git clone https://github.com/LemonCANDY42/OPIXray.git
- Crie uma nova pasta “weights” para armazenar o peso treinado deste algoritmo “DOAM.pth”. Baixe o arquivo de peso e execute:
cd OPIXray/DOAMmkdir weights
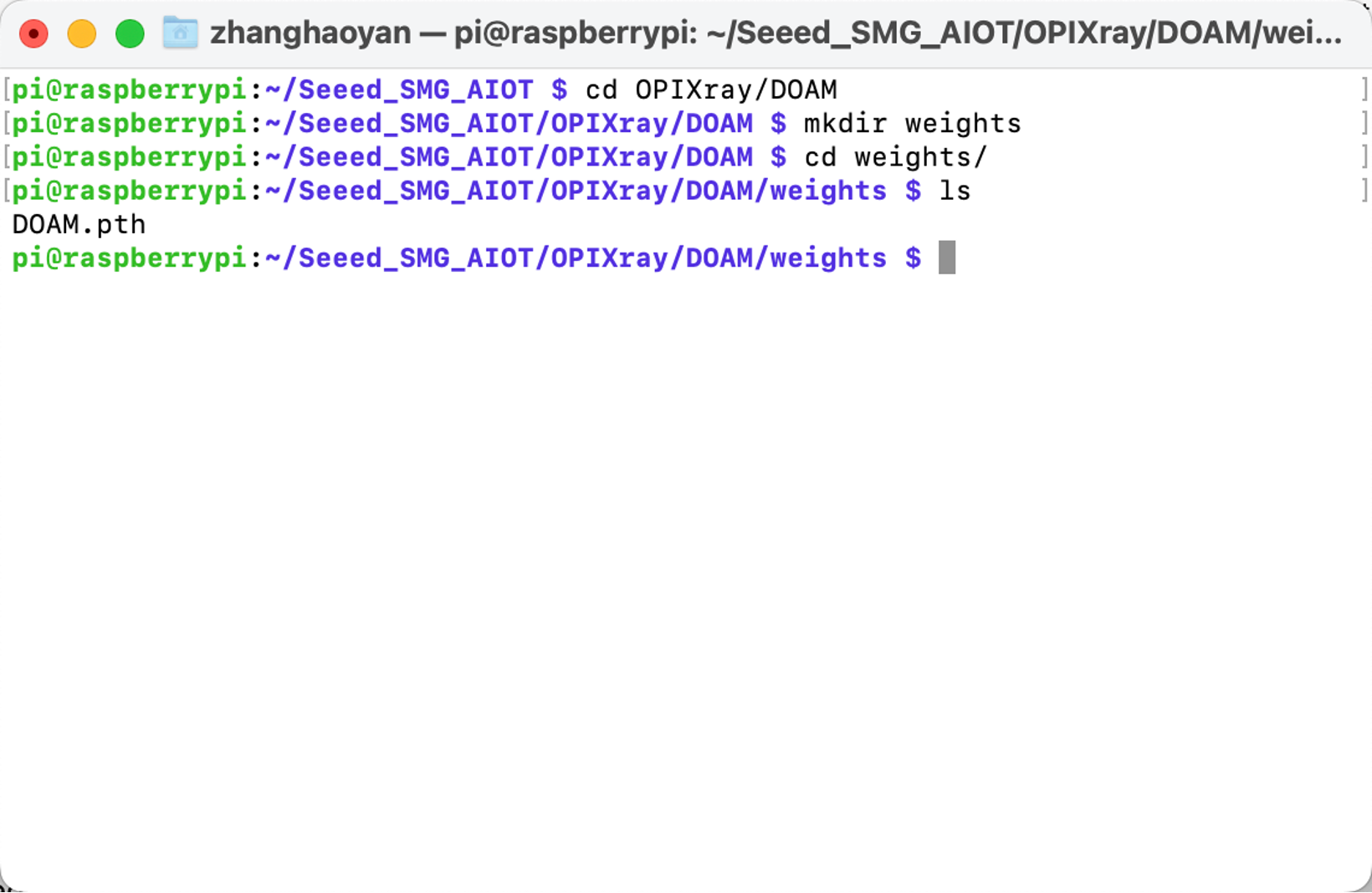
- Crie uma nova pasta “Dataset” para armazenar o conjunto de dados de imagens de raios X.
Etapa 2. Executar o modelo de inferência.
Execute python OPIXray_grpc_image_client.py -u 192.168.8.230:8001 -m opi Dataset
O resultado será mostrado como na figura abaixo:

Solução de Problemas
Ao iniciar o servidor Triton, você pode encontrar os seguintes erros:
- se houver erro com libb64.so.0d, execute:
sudo apt-get install libb64-0d
- se houver erro com libre2.so.2, execute:
sudo apt-get install libre2-dev
- se houver erro: creating server: Internal - failed to load all models, execute:
--exit-on-error=false
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para oferecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.