Treine e Faça Deploy do Seu Próprio Modelo de IA no Grove - Vision AI
Atualizável para Sensores Industriais
Com o controlador SenseCAP S2110 controller e o registrador de dados S2100 data logger, você pode facilmente transformar o Grove em um sensor LoRaWAN®. A Seeed não apenas ajuda você com a criação de protótipos, como também oferece a possibilidade de expandir seu projeto com a série SenseCAP de robustos industrial sensors.
O invólucro IP66, configuração via Bluetooth, compatibilidade com a rede global LoRaWAN®, bateria interna de 19 Ah e o poderoso suporte do APP tornam o SenseCAP S210x a melhor escolha para aplicações industriais. A série inclui sensores para umidade do solo, temperatura e umidade do ar, intensidade da luz, CO2, EC e uma estação meteorológica 8 em 1. Experimente o mais recente SenseCAP S210x no seu próximo projeto industrial de sucesso.







Visão geral
Neste wiki, vamos ensinar como treinar seu próprio modelo de IA para a sua aplicação específica e, em seguida, fazer o deploy dele facilmente no Grove - Vision AI Module. Vamos começar!
Introdução ao hardware
Vamos usar principalmente o Grove - Vision AI Module ao longo deste wiki. Então, primeiro, vamos nos familiarizar com o hardware.
Grove - Vision AI Module
Grove Vision AI Module representa uma câmera de IA do tamanho de um polegar, um sensor personalizado que já tem instalado o algoritmo de ML para detecção de pessoas e outros modelos personalizados. Sendo facilmente implantado e exibido em poucos minutos, funciona em modo de consumo ultrabaixo de energia e fornece duas formas de transmissão de sinal e múltiplos módulos onboard, o que o torna perfeito para começar com câmeras habilitadas com IA.

Introdução ao software
Utilizaremos as seguintes tecnologias de software neste wiki
- Roboflow - para anotação
- YOLOv5 - para treinamento
- TensorFlow Lite - para inferência

O que é Roboflow?
Roboflow é uma ferramenta de anotação baseada online. Esta ferramenta permite que você anote facilmente todas as suas imagens, adicione processamento adicional a essas imagens e exporte o conjunto de dados rotulado em diferentes formatos, como YOLOV5 PyTorch, Pascal VOC e mais! O Roboflow também possui conjuntos de dados públicos prontamente disponíveis para os usuários.
O que é YOLOv5?
YOLO é uma abreviação do termo “You Only Look Once”. É um algoritmo que detecta e reconhece vários objetos em uma imagem em tempo real. Ultralytics YOLOv5 é a versão do YOLO baseada no framework PyTorch.
O que é TensorFlow Lite?
TensorFlow Lite é um framework de deep learning multiplataforma, pronto para produção e de código aberto, que converte um modelo pré-treinado em TensorFlow para um formato especial que pode ser otimizado para velocidade ou armazenamento. O modelo nesse formato especial pode ser implantado em dispositivos de borda, como celulares usando Android ou iOS, ou dispositivos embarcados baseados em Linux, como Raspberry Pi ou Microcontroladores, para realizar a inferência na Borda.
Estrutura do wiki
Este wiki será dividido em três seções principais
- Treine seu próprio modelo de IA com um conjunto de dados público
- Treine seu próprio modelo de IA com seu próprio conjunto de dados
- Faça o deploy do modelo de IA treinado no Grove - Vision AI Module
A primeira seção será a maneira mais rápida de construir seu próprio modelo de IA com o menor número de etapas. A segunda seção exigirá algum tempo e esforço para construir seu próprio modelo de IA, mas o conhecimento adquirido certamente valerá a pena. A terceira seção, sobre fazer o deploy do modelo de IA, pode ser feita após a primeira ou a segunda seção.
Portanto, há duas maneiras de seguir este wiki:
- Siga a seção 1 e depois a seção 3 - rápido de seguir
- Siga a seção 2 e depois a seção 3 - lento de seguir
No entanto, incentivamos que siga o primeiro método primeiro e depois passe para o segundo.
1. Treine seu próprio modelo de IA com um conjunto de dados público
O primeiro passo de um projeto de detecção de objetos é obter dados para o treinamento. Você pode baixar conjuntos de dados disponíveis publicamente ou criar seu próprio conjunto de dados!
Mas qual é a maneira mais rápida e fácil de começar com detecção de objetos? Bem... Usar conjuntos de dados públicos pode economizar muito tempo que você, de outra forma, gastaria coletando dados por conta própria e anotando-os. Esses conjuntos de dados públicos já vêm anotados, permitindo que você tenha mais tempo para se concentrar em suas aplicações de visão de IA.
Preparação de hardware
- Grove - Vision AI Module
- Cabo USB Tipo-C
- Windows/ Linux/ Mac com acesso à internet
Preparação de software
- Não é necessário preparar software adicional
Use um conjunto de dados anotado disponível publicamente
Você pode baixar vários conjuntos de dados disponíveis publicamente, como o COCO dataset, Pascal VOC dataset e muitos outros. O Roboflow Universe é uma plataforma recomendada que fornece uma ampla variedade de conjuntos de dados e possui 90,000+ datasets with 66+ million images disponíveis para construir modelos de visão computacional. Além disso, você pode simplesmente pesquisar open-source datasets no Google e escolher entre uma variedade de conjuntos de dados disponíveis.
-
Passo 1. Visite este URL para acessar um conjunto de dados de Detecção de Maçãs disponível publicamente no Roboflow Universe
-
Passo 2. Clique em Create Account para criar uma conta Roboflow
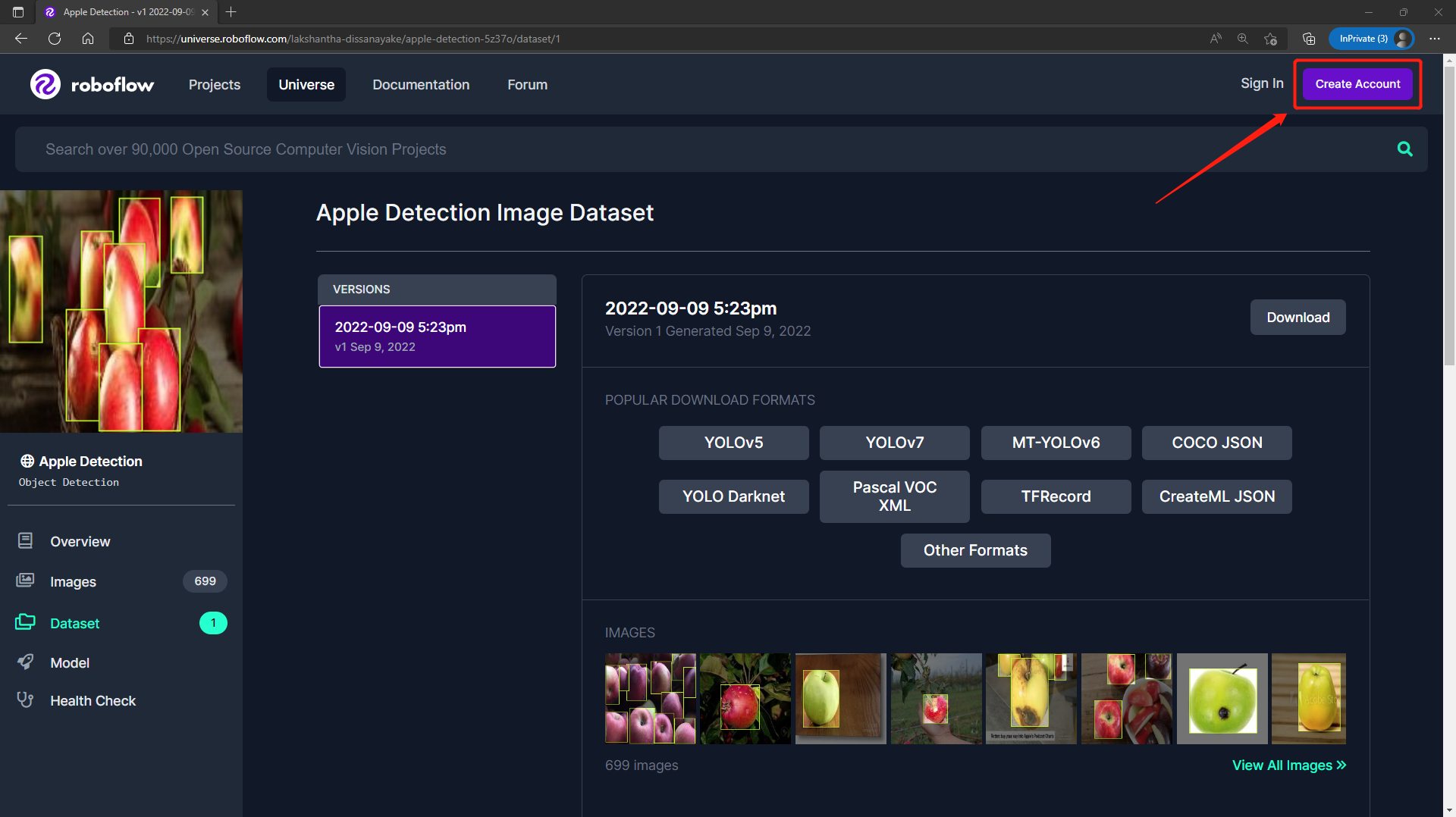
- Passo 3. Clique em Download, selecione YOLO v5 PyTorch como o Format, clique em show download code e clique em Continue
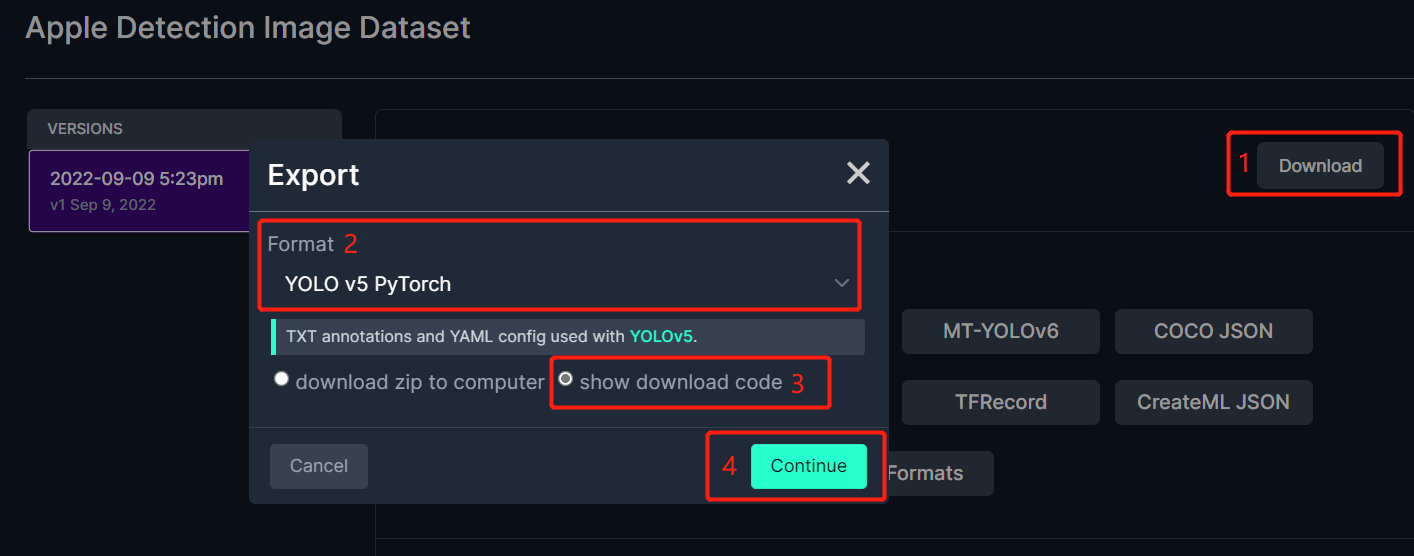
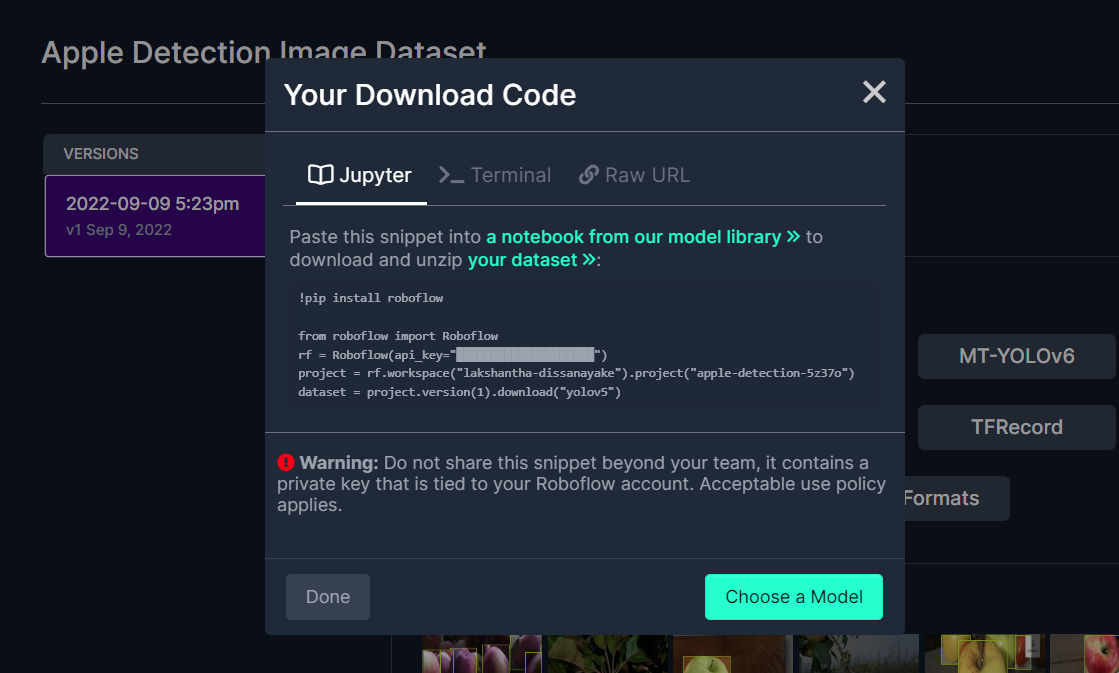
Isso irá gerar um trecho de código que usaremos mais tarde durante o treinamento no Google Colab. Portanto, mantenha essa janela aberta em segundo plano.
Treinar usando YOLOv5 no Google Colab
Depois de escolhermos um conjunto de dados público, precisamos treinar o conjunto de dados. Aqui usamos um ambiente Google Colaboratory para realizar o treinamento na nuvem. Além disso, usamos a API do Roboflow dentro do Colab para baixar facilmente nosso conjunto de dados.
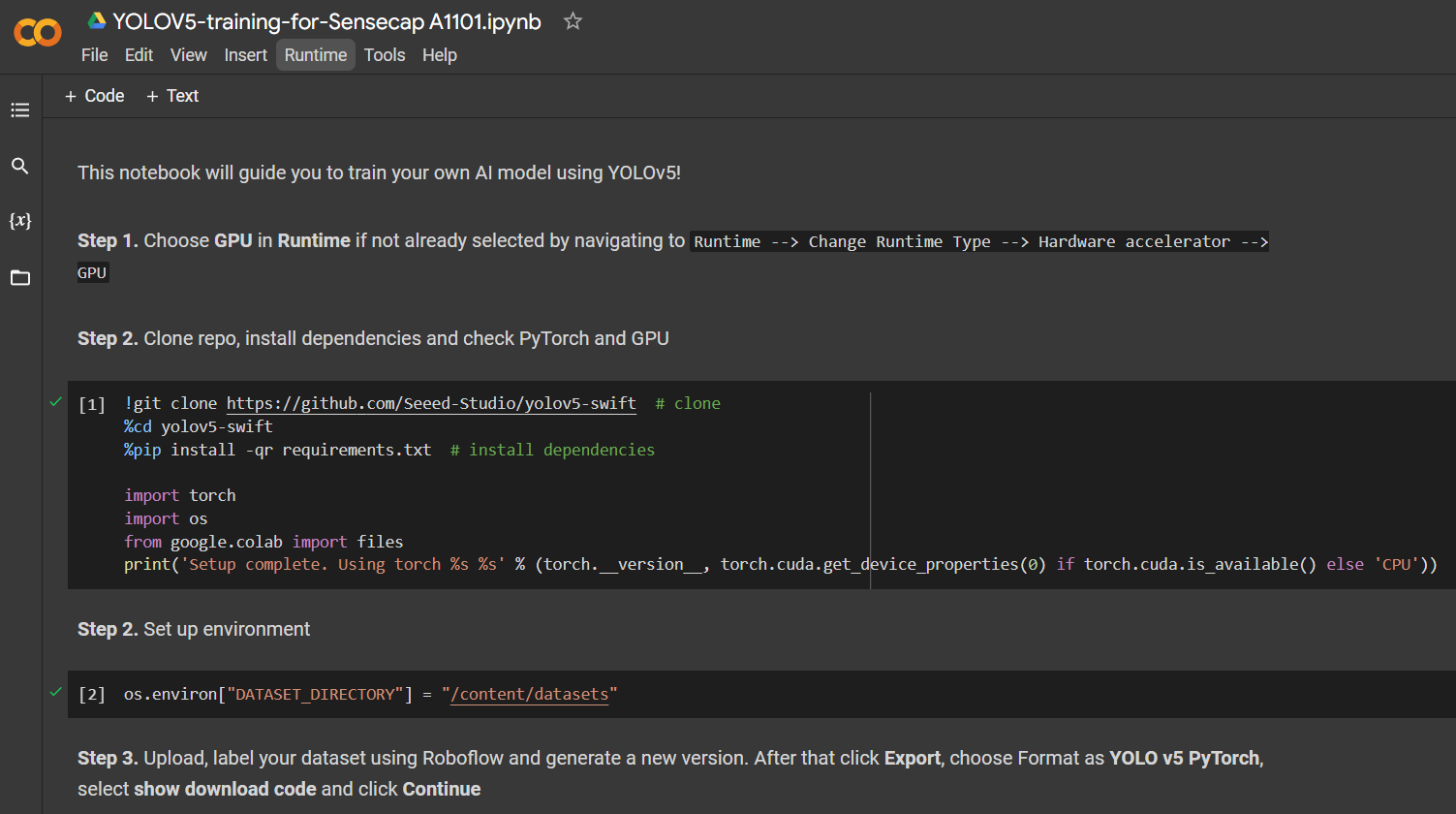
Clique aqui para abrir um workspace do Google Colab já preparado, siga as etapas mencionadas no workspace e execute as células de código uma por uma.
Nota: No Google Colab, na célula de código em Step 4, você pode copiar diretamente o trecho de código do Roboflow conforme mencionado acima
Ele irá conduzir você pelos seguintes passos:
- Configurar um ambiente para treinamento
- Baixar um conjunto de dados
- Executar o treinamento
- Baixar o modelo treinado
Para um conjunto de dados de detecção de maçãs com 699 imagens, o processo de treinamento levou cerca de 7 minutos para ser concluído no Google Colab, rodando em uma GPU NVIDIA Tesla T4 com 16GB de memória de GPU.
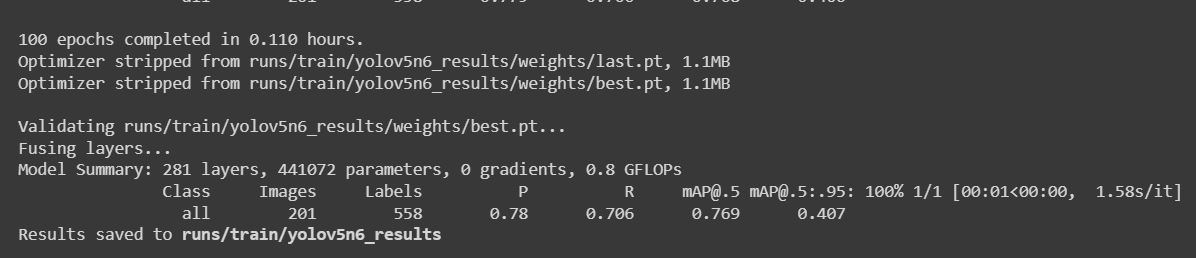
Se você seguiu o projeto Colab acima, sabe que pode carregar 4 modelos no dispositivo de uma só vez. No entanto, observe que apenas um modelo pode ser carregado por vez. Isso pode ser especificado pelo usuário e será explicado mais adiante neste wiki.
Implantar e fazer inferência
Se você quiser ir diretamente para a seção 3, que explica como implantar o modelo de IA treinado no Grove - Vision AI Module e realizar inferência, clique aqui.
Anotar o conjunto de dados usando Roboflow
Se você usar seu próprio conjunto de dados, precisará anotar todas as imagens do seu conjunto de dados. Anotar significa simplesmente desenhar caixas retangulares em volta de cada objeto que queremos detectar e atribuir a eles rótulos. Explicaremos como fazer isso usando o Roboflow.
Roboflow é uma ferramenta de anotação baseada na web. Aqui podemos importar diretamente as filmagens de vídeo que gravamos para o Roboflow e elas serão exportadas como uma série de imagens. Essa ferramenta é muito conveniente porque nos permite ajudar a distribuir o conjunto de dados em "treinamento, validação e teste". Além disso, essa ferramenta nos permite adicionar processamento adicional a essas imagens depois de rotulá-las. Além disso, ela pode facilmente exportar o conjunto de dados rotulado no formato YOLOV5 PyTorch format que é exatamente o que precisamos!
Para este wiki, usaremos um conjunto de dados com imagens contendo maçãs, para que possamos detectar maçãs posteriormente e também fazer contagem.
-
Passo 1. Clique aqui para se inscrever em uma conta Roboflow
-
Passo 2. Clique em Create New Project para iniciar nosso projeto
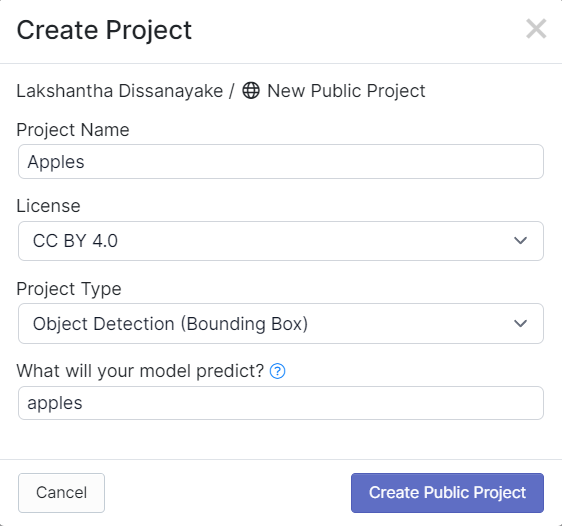
- Passo 3. Preencha Project Name, mantenha License (CC BY 4.0) e Project type (Object Detection (Bounding Box)) como padrão. Na coluna What will your model predict?, preencha um nome de grupo de anotação. Por exemplo, no nosso caso escolhemos apples. Esse nome deve destacar todas as classes do seu conjunto de dados. Por fim, clique em Create Public Project.
- Passo 4. Arraste e solte as imagens que você capturou usando o Grove - Vision AI Module
- Passo 5. Depois que as imagens forem processadas, clique em Finish Uploading. Aguarde pacientemente até que as imagens sejam enviadas.
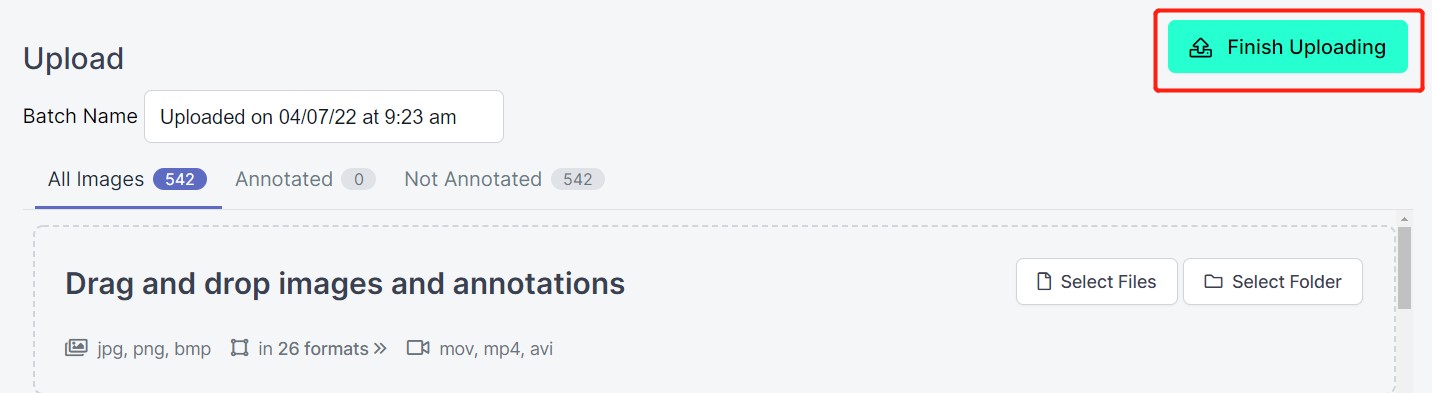
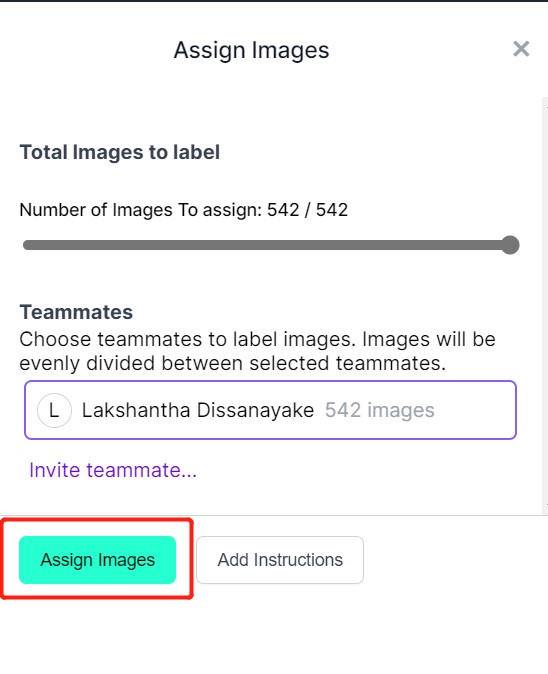
- Passo 6. Depois que as imagens forem enviadas, clique em Assign Images
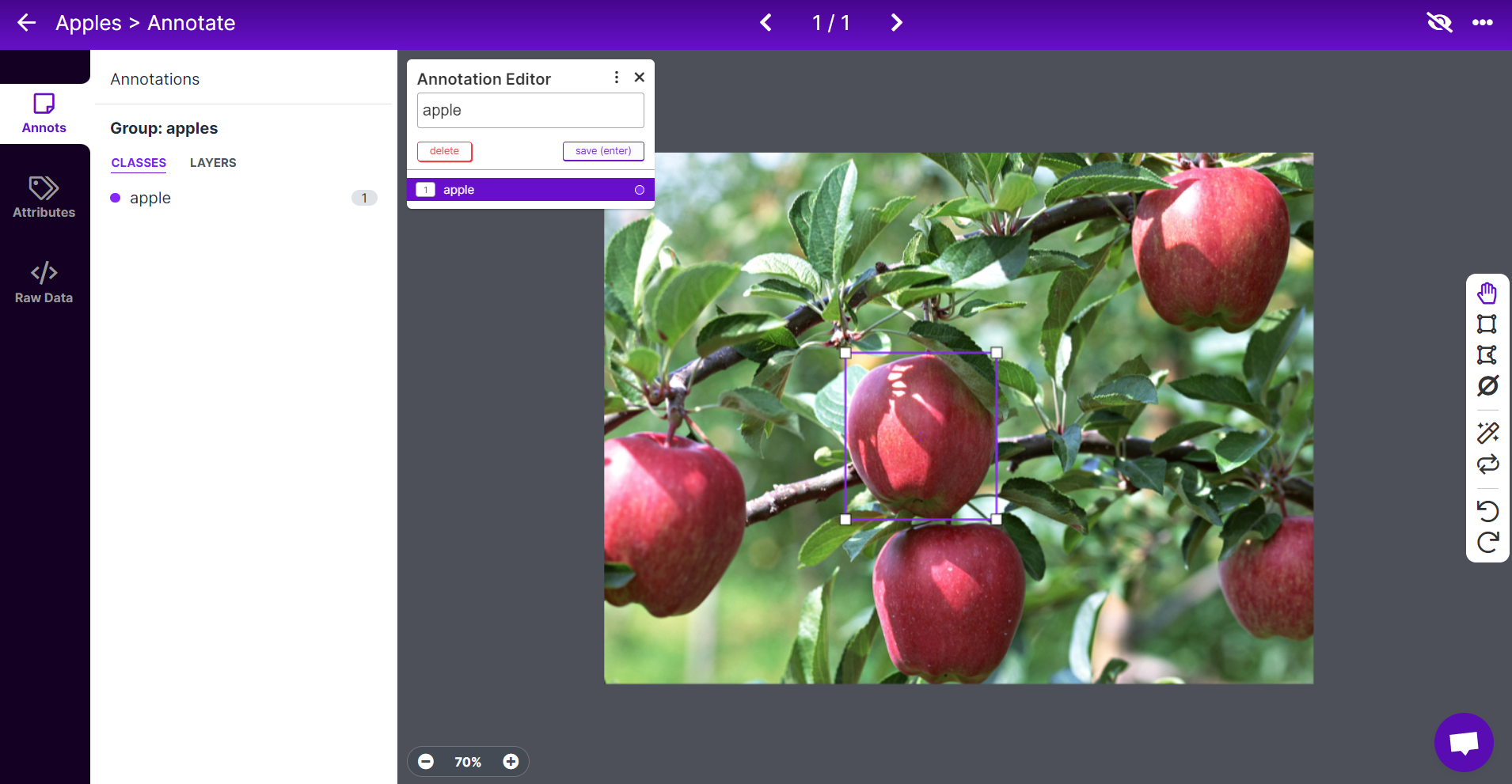
- Passo 7. Selecione uma imagem, desenhe uma caixa retangular ao redor de uma maçã, escolha o rótulo como apple e pressione ENTER
- Passo 8. Repita o mesmo para as demais maçãs
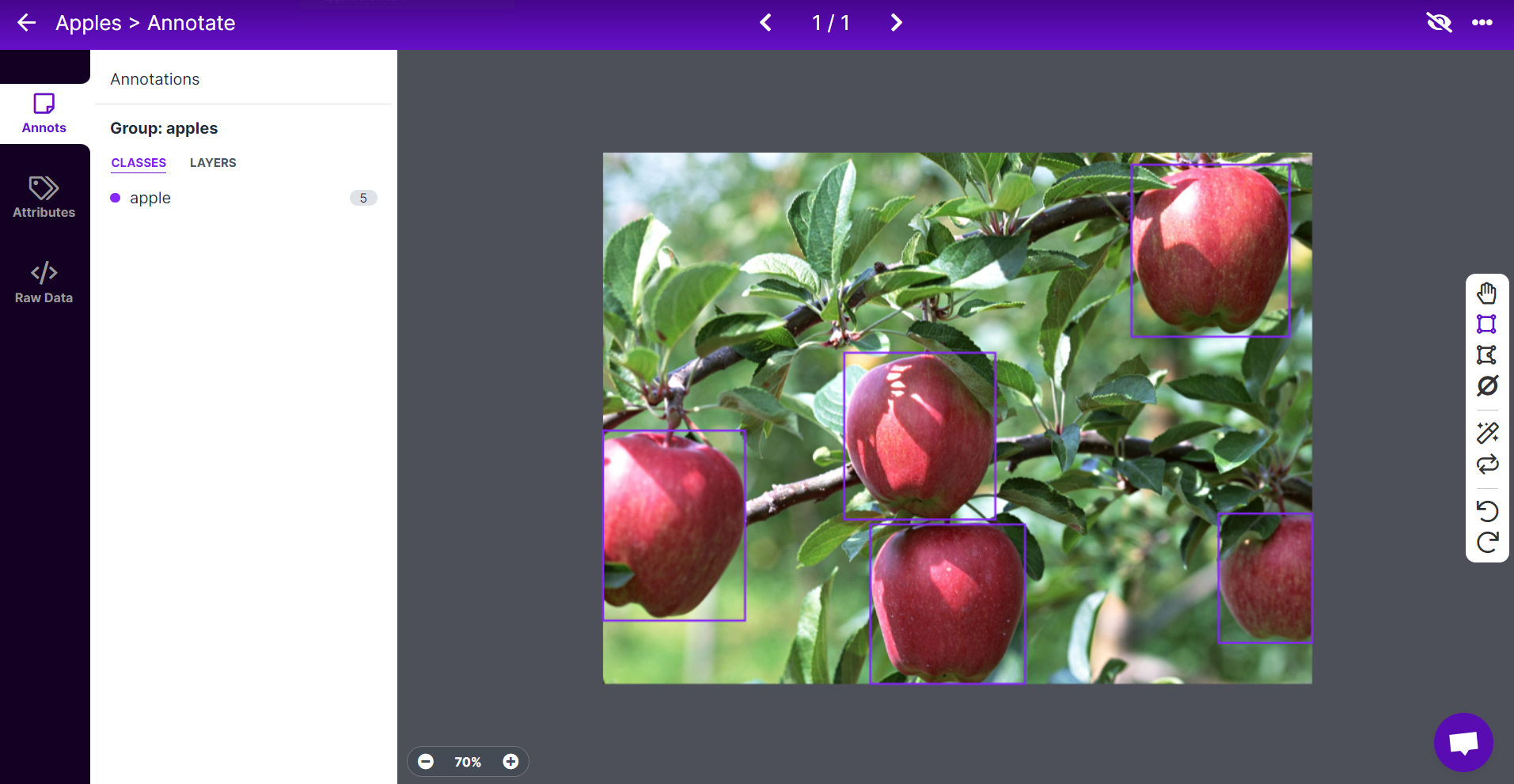
Nota: Tente rotular todas as maçãs que você vê dentro da imagem. Se apenas uma parte de uma maçã estiver visível, tente rotular essa parte também.
- Passo 9. Continue anotando todas as imagens do conjunto de dados
O Roboflow possui um recurso chamado Label Assist, no qual ele pode prever os rótulos antecipadamente para que sua rotulagem seja muito mais rápida. No entanto, ele não funciona com todos os tipos de objetos, mas sim com um tipo selecionado de objetos. Para ativar esse recurso, você só precisa pressionar o botão Label Assist, selecionar um modelo, selecionar as classes e navegar pelas imagens para ver os rótulos previstos com caixas delimitadoras
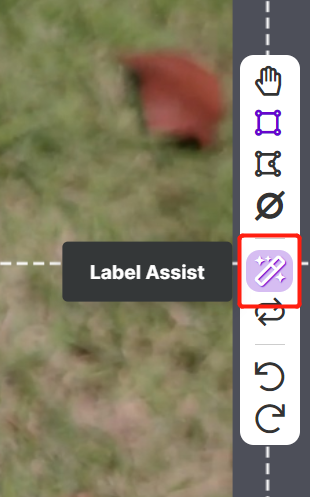
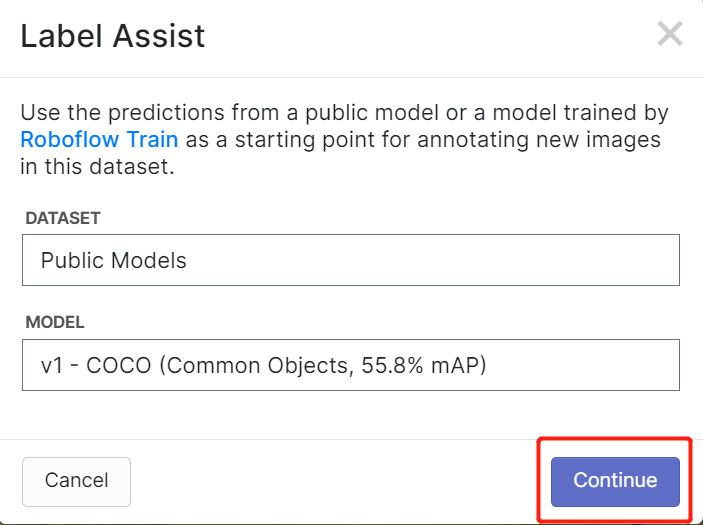
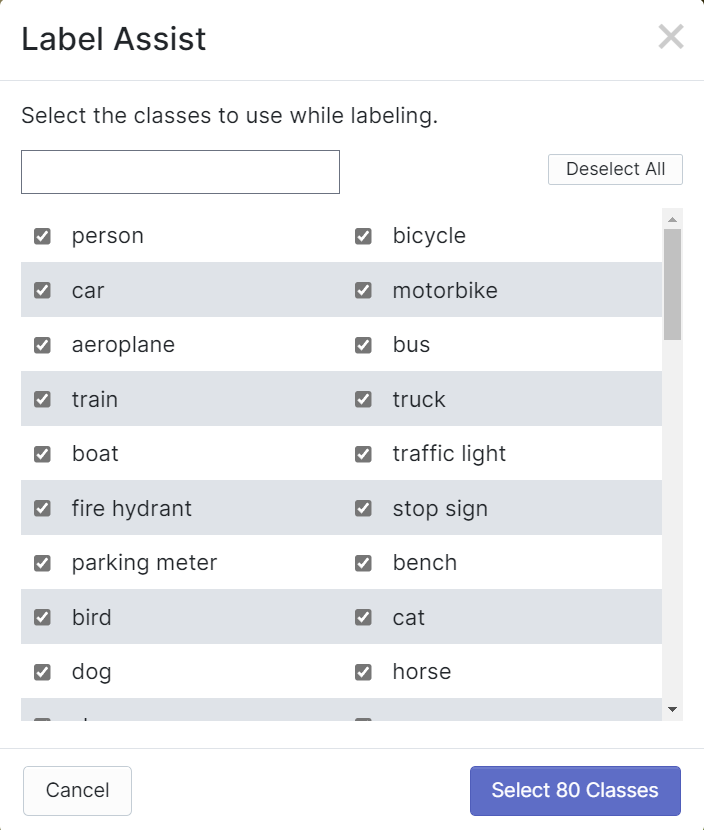
Como você pode ver acima, ele só pode ajudar a prever anotações para as 80 classes mencionadas. Se suas imagens não contiverem as classes de objetos acima, você não poderá usar o recurso de assistência de rótulos.
- Passo 10. Quando a rotulagem estiver concluída, clique em Add images to Dataset

- Passo 11. Em seguida, vamos dividir as imagens entre "Train, Valid and Test". Mantenha as porcentagens padrão para a distribuição e clique em Add Images
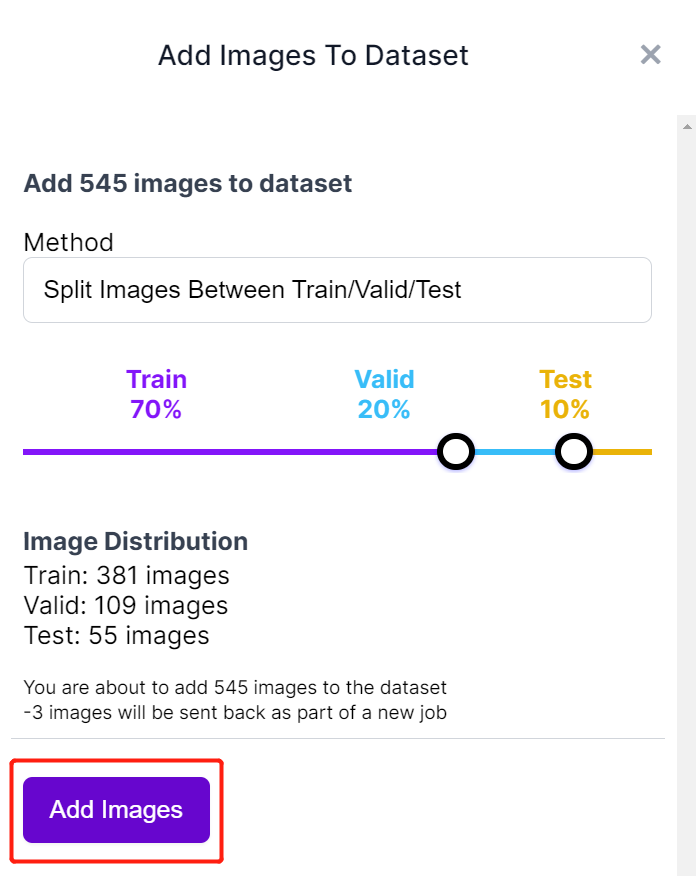
- Passo 12. Clique em Generate New Version

- Passo 13. Agora você pode adicionar Preprocessing e Augmentation se preferir. Aqui nós vamos alterar a opção Resize para 192x192
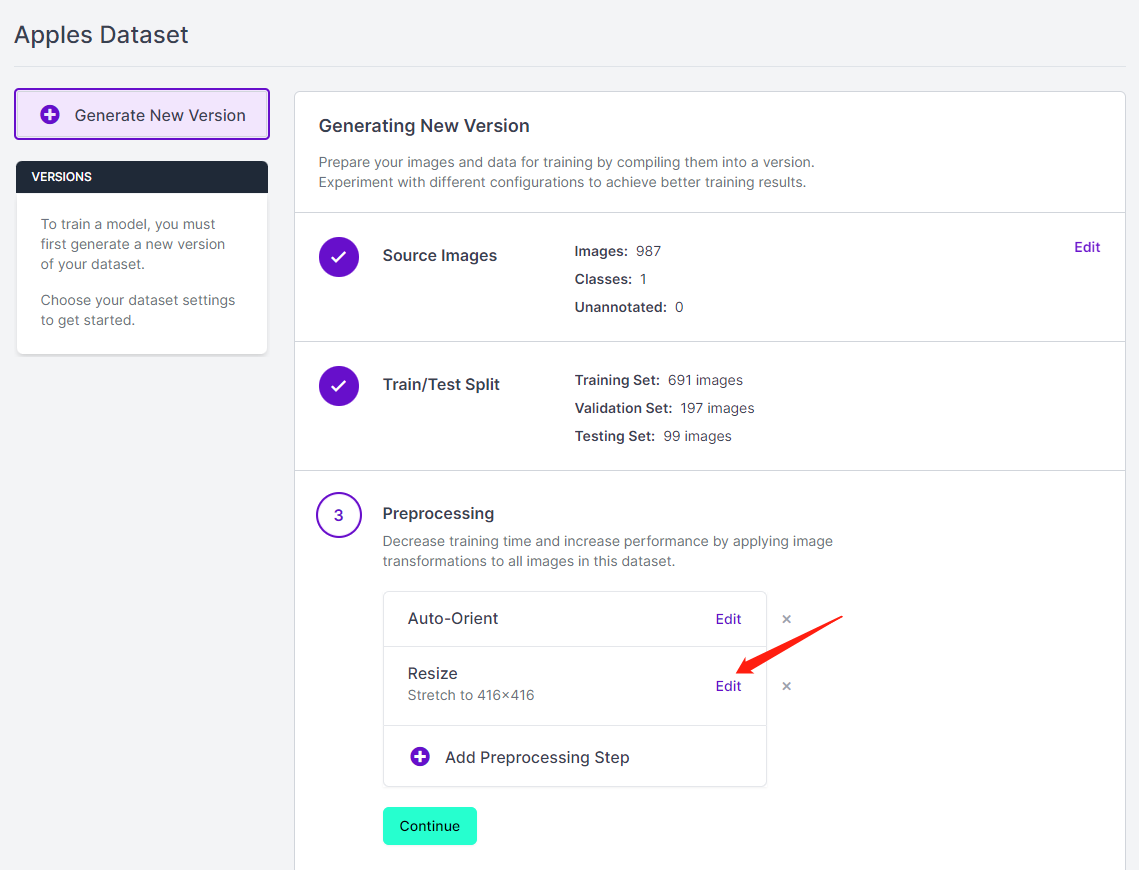
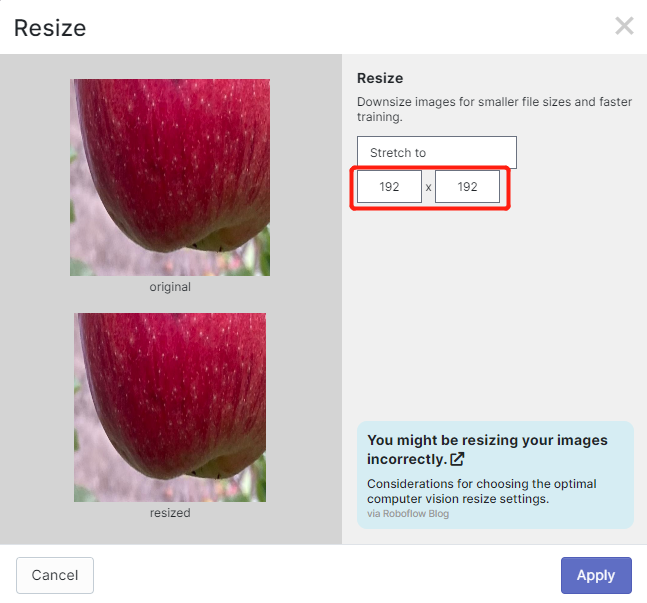
Aqui mudamos o tamanho da imagem para 192x192 porque usaremos esse tamanho para o treinamento e o treinamento será mais rápido. Caso contrário, será necessário converter todas as imagens para 192x192 durante o processo de treinamento, o que consome mais recursos de CPU e deixa o processo de treinamento mais lento.
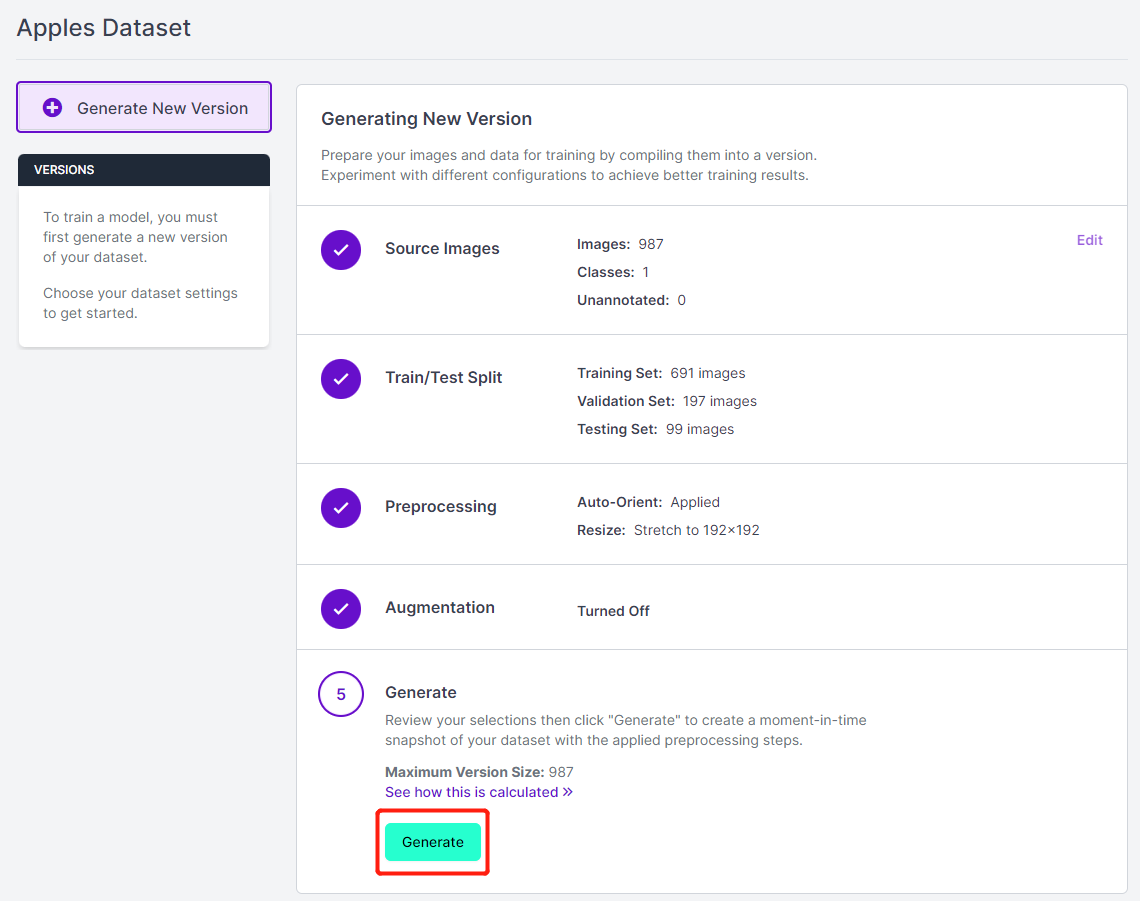
- Passo 14. Em seguida, prossiga com os demais padrões e clique em Generate
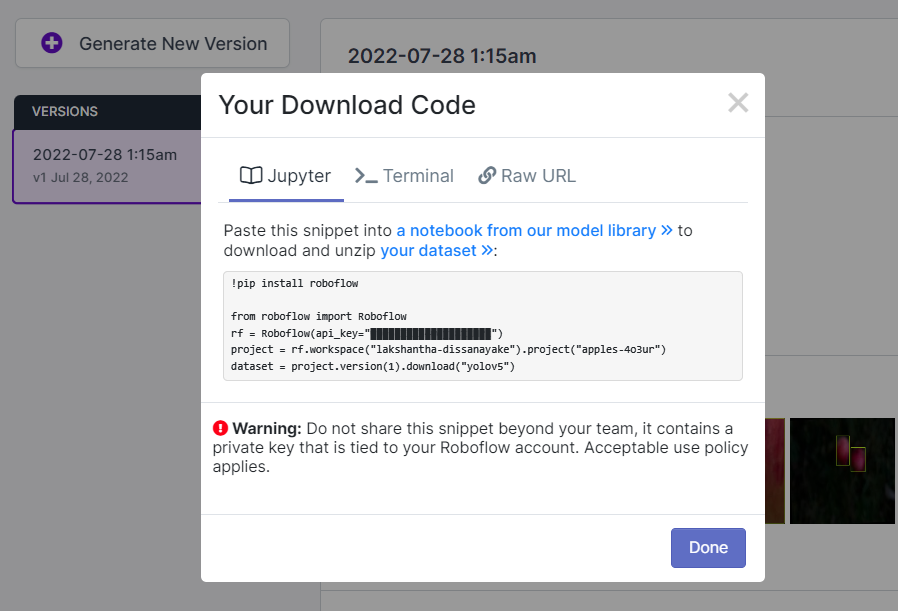
- Passo 15. Clique em Export, selecione Format como YOLO v5 PyTorch, selecione show download code e clique em Continue
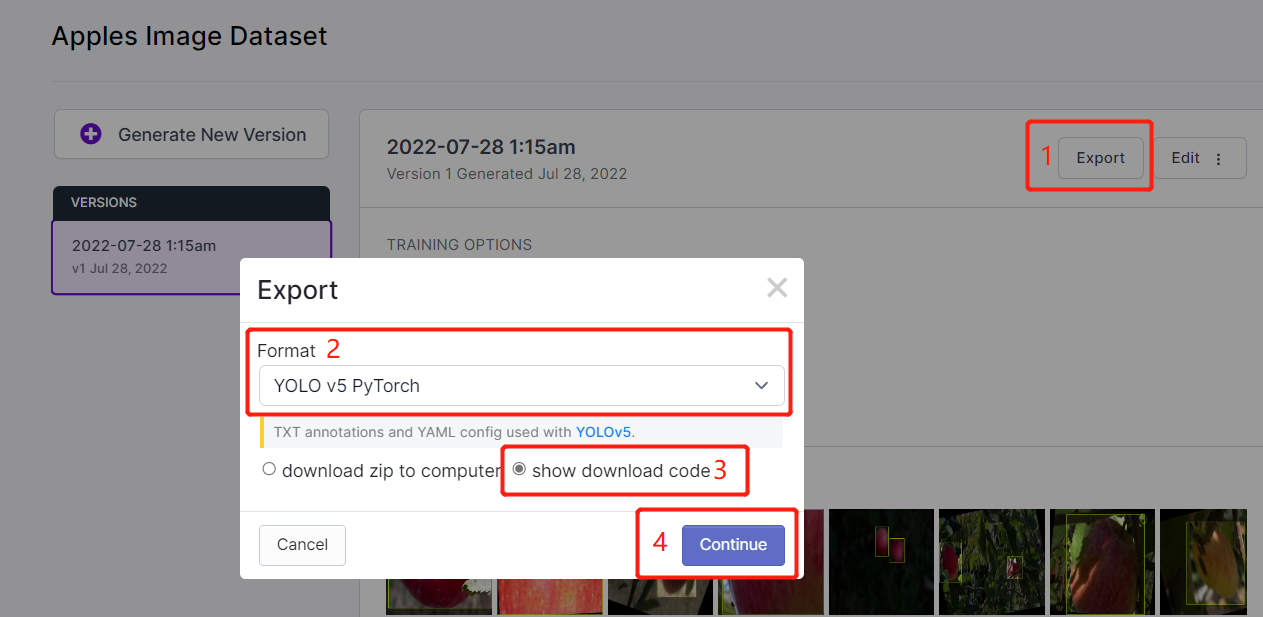
Isso irá gerar um trecho de código que usaremos mais tarde dentro do treinamento no Google Colab. Portanto, mantenha esta janela aberta em segundo plano.
Treinar usando YOLOv5 no Google Colab
Depois de terminarmos de anotar o conjunto de dados, precisamos treiná-lo. Vá para esta parte que explica como treinar um modelo de IA usando YOLOv5 executando no Google Colab.
3. Implantar o modelo treinado e realizar inferência
Grove - Vision AI Module
Agora vamos mover o model-1.uf2 que obtivemos no final do treinamento para o Grove - Vision AI Module. Aqui vamos conectar o Grove - Vision AI Module ao Wio Terminal para visualizar os resultados da inferência.
Nota: Se esta é a sua primeira vez usando Arduino, recomendamos fortemente que você consulte Getting Started with Arduino. Além disso, siga este wiki para configurar o Wio Terminal para funcionar com a Arduino IDE.
-
Passo 1. Instale a versão mais recente do Google Chrome ou do navegador Microsoft Edge e abra-o
-
Passo 2. Conecte o Grove - Vision AI Module ao seu PC por meio de um cabo USB Tipo-C

- Passo 3. Dê um clique duplo no botão de boot do Grove - Vision AI Module para entrar no modo de armazenamento em massa

Depois disso, você verá um novo drive de armazenamento exibido no seu explorador de arquivos como GROVEAI
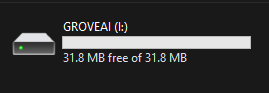
- Passo 4. Arraste e solte o arquivo model-1.uf2 no drive GROVEAI
Assim que o uf2 terminar de ser copiado para o drive, o drive desaparecerá. Isso significa que o uf2 foi enviado com sucesso para o módulo.
Nota: Se você tiver 4 arquivos de modelo prontos, poderá arrastar e soltar cada modelo um por um. Solte o primeiro modelo, aguarde até terminar a cópia, entre novamente no modo de boot, solte o segundo modelo e assim por diante.
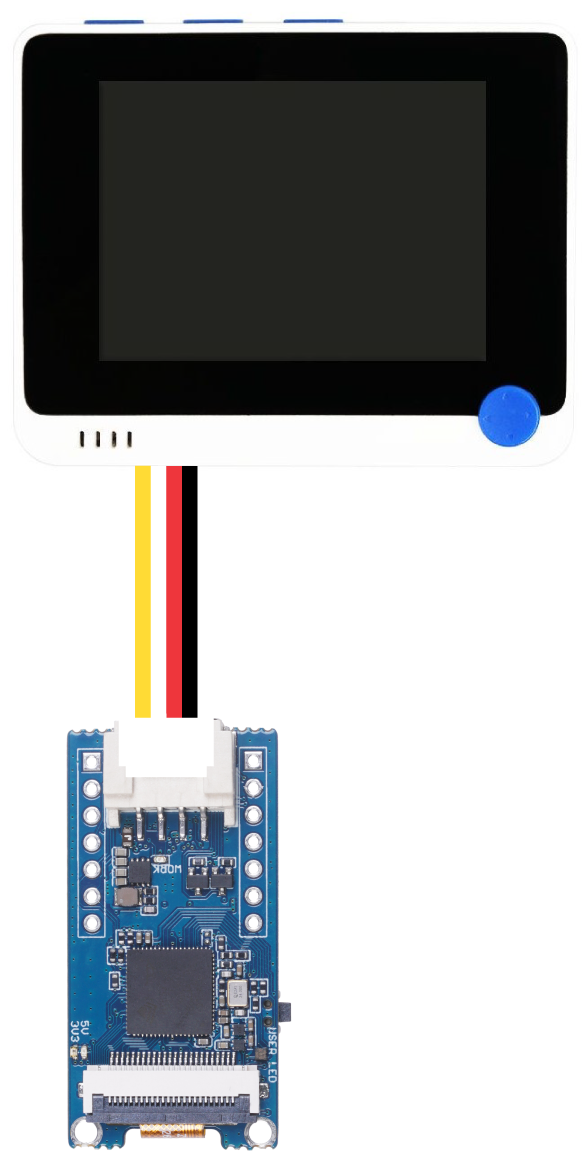
- Passo 5. Enquanto o Grove - Vision AI Module ainda estiver conectado ao PC usando USB, conecte-o ao Wio Terminal por meio da porta Grove I2C como a seguir
-
Passo 6. Instale a biblioteca Seeed_Arduino_GroveAI na Arduino IDE e abra o exemplo object_detection.ino
-
Passo 7. Se você tiver carregado apenas um modelo (com índice 1) no Grove - Vision AI Module, ele carregará esse modelo. No entanto, se você tiver carregado vários modelos, poderá especificar qual modelo usar alterando MODEL_EXT_INDEX_[value], onde o value pode assumir os dígitos 1,2,3 ou 4
// for example:
if (ai.begin(ALGO_OBJECT_DETECTION, MODEL_EXT_INDEX_2))
O acima irá carregar o modelo com índice 2
- Passo 8. Como estamos detectando maçãs, faremos uma pequena alteração no código aqui
Serial.print("Number of apples: ");
- Passo 9. Conecte o Wio Terminal ao PC, envie esse código para o Wio Terminal e abra o monitor serial da Arduino IDE com 115200 como taxa de baud
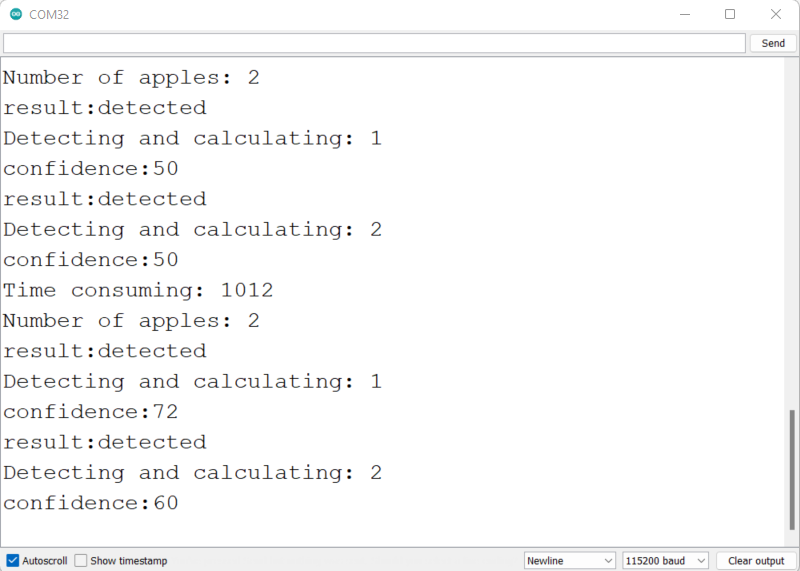
Você poderá ver as informações de detecção no monitor serial como acima.
- Passo 10. Clique aqui para abrir uma janela de pré-visualização do fluxo da câmera com as detecções

- Passo 11. Clique no botão Connect. Em seguida, você verá um pop-up no navegador. Selecione Grove AI - Paired e clique em Connect
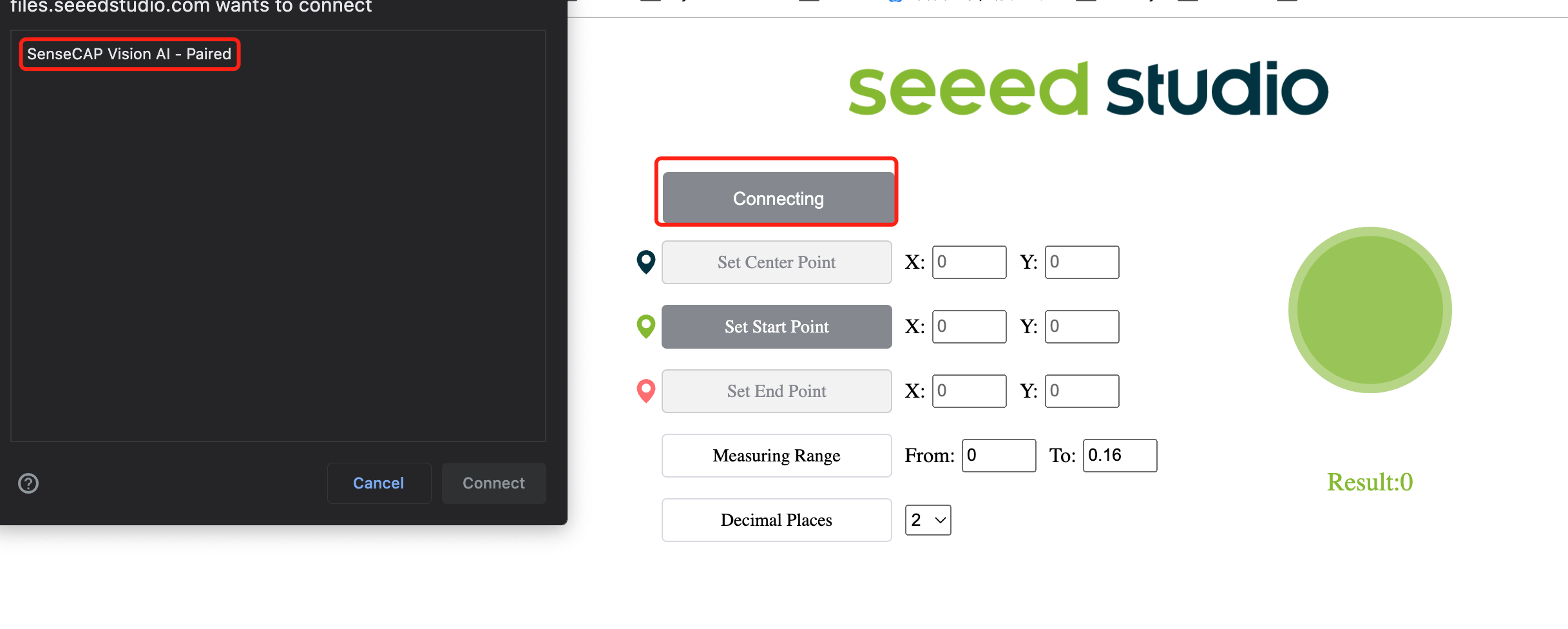
- Passo 12. Veja os resultados de inferência em tempo real usando a janela de pré-visualização!

Como você pode ver acima, as maçãs estão sendo detectadas com caixas delimitadoras ao redor delas. Aqui "0" corresponde a cada detecção da mesma classe. Se você tiver várias classes, elas serão nomeadas como 0,1,2,3,4 e assim por diante. Além disso, a pontuação de confiança para cada maçã detectada (0.8 e 0.84 na demonstração acima) está sendo exibida!
Conteúdo bônus
Se você se sentir mais aventureiro, pode continuar a seguir o restante do wiki!
Posso treinar um modelo de IA no meu PC?
Você também pode usar o seu próprio PC para treinar um modelo de detecção de objetos. No entanto, o desempenho do treinamento dependerá do hardware que você possui. Você também precisa ter um PC com um sistema operacional Linux para o treinamento. Usamos um PC com Ubuntu 20.04 para este wiki.
- Passo 1. Faça o clone do repositório yolov5-swift e instale o requirements.txt em um ambiente Python>=3.7.0
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- Passo 2. Se você seguiu os passos deste wiki antes, talvez se lembre de que exportamos o conjunto de dados após a anotação no Robolflow. Também no Roboflow Universe, fizemos o download do conjunto de dados. Em ambos os métodos, havia uma janela como a abaixo onde é perguntado qual tipo de formato para baixar o conjunto de dados. Então agora, selecione download zip to computer, em Format escolha YOLO v5 PyTorch e clique em Continue
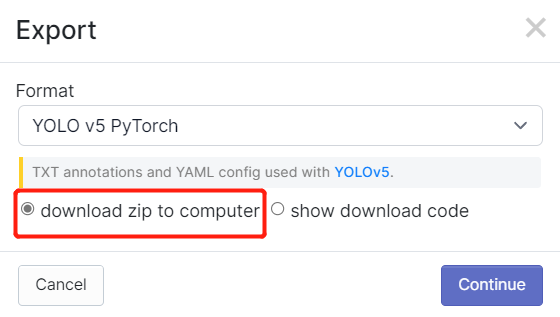
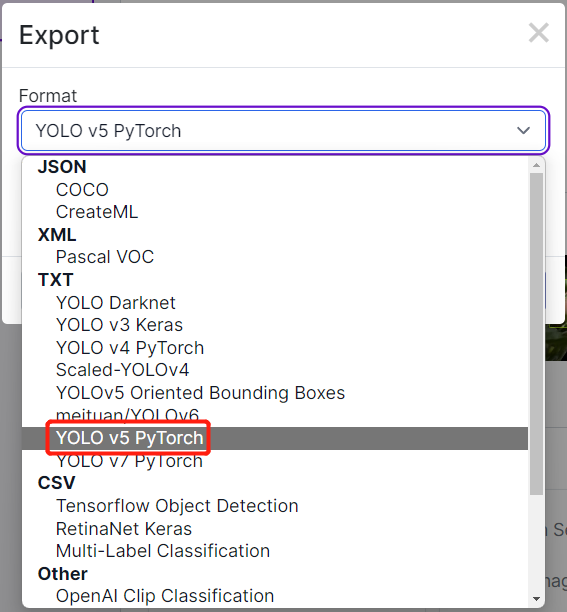
Depois disso, um arquivo .zip será baixado para o seu computador
- Passo 3. Copie e cole o arquivo .zip que baixamos no diretório yolov5-swift e extraia-o
# example
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- Passo 4. Abra o arquivo data.yaml e edite os diretórios train e val como segue
train: train/images
val: valid/images
- Passo 5. Baixe um modelo pré-treinado adequado para o nosso treinamento
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- Passo 6. Execute o seguinte para iniciar o treinamento
Aqui, podemos passar vários argumentos:
- img: define o tamanho da imagem de entrada
- batch: determina o tamanho do lote
- epochs: define o número de épocas de treinamento
- data: define o caminho para o nosso arquivo yaml
- cfg: especifica a configuração do nosso modelo
- weights: especifica um caminho personalizado para os pesos
- name: nomes dos resultados
- nosave: salva apenas o checkpoint final
- cache: coloca as imagens em cache para um treinamento mais rápido
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
Para um conjunto de dados de detecção de maçã com 987 imagens, o processo de treinamento levou cerca de 30 minutos em um PC local com GPU NVIDIA GeForce GTX 1660 Super com 6 GB de memória de GPU.

Se você seguiu o projeto Colab acima, sabe que pode carregar 4 modelos no dispositivo de uma só vez. No entanto, observe que apenas um modelo pode ser carregado por vez. Isso pode ser especificado pelo usuário e será explicado mais tarde neste wiki.
- Passo 7. Se você navegar até
runs/train/exp/weights, verá um arquivo chamado best.pt. Este é o modelo gerado a partir do treinamento.

- Passo 8. Exporte o modelo treinado para TensorFlow Lite
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- Passo 9. Converta o TensorFlow Lite em um arquivo UF2
UF2 é um formato de arquivo desenvolvido pela Microsoft. A Seeed usa esse formato para converter .tflite em .uf2, permitindo que arquivos tflite sejam armazenados nos dispositivos AIoT lançados pela Seeed. Atualmente, os dispositivos da Seeed suportam até 4 modelos, cada modelo (.tflite) tem menos de 1M.
Você pode especificar o modelo a ser colocado no índice correspondente com -t.
Por exemplo:
-t 1: índice 1-t 2: índice 2
# Place the model to index 1
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
Embora você possa carregar 4 modelos no dispositivo de uma só vez, observe que apenas um modelo pode ser carregado por vez. Isso pode ser especificado pelo usuário e será explicado mais tarde neste wiki.
- Passo 10. Agora um arquivo chamado model-1.uf2 será gerado. Este é o arquivo que carregaremos no Grove - Vision AI Module para realizar a inferência!
Recursos
-
[Página da Web] YOLOv5 Documentation
-
[Página da Web] Ultralytics HUB
-
[Página da Web] Roboflow Documentation
-
[Página da Web] TensorFlow Lite Documentation
Suporte Técnico & Discussão de Produto
Obrigado por escolher nossos produtos! Estamos aqui para oferecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos diversos canais de comunicação para atender a diferentes preferências e necessidades.