Primeiros Passos com Edge Impulse no Wio Terminal

Edge Impulse permite que desenvolvedores criem a próxima geração de soluções de dispositivos inteligentes com Machine Learning embarcado. Machine Learning bem na borda permitirá o uso valioso dos 99% dos dados de sensores que hoje são descartados devido a limitações de custo, largura de banda ou energia.
Agora, o Wio Terminal é oficialmente suportado pelo Edge Impulse. Vamos ver como iniciar o Wio Terminal com Machine Learning na borda!
Instalando dependências
Para configurar o Wio Terminal no Edge Impulse, você precisará instalar o seguinte software:
- Node.js v12 ou superior.
- Arduino CLI
- O Edge Impulse CLI e um monitor serial. Instale abrindo o prompt de comando ou terminal e execute:
npm install -g edge-impulse-cli
Problemas ao instalar o CLI? Consulte Installation and troubleshooting para mais referências.
Conectando ao Edge Impulse
Com todo o software instalado, é hora de conectar a placa de desenvolvimento ao Edge Impulse.
1. Conecte a placa de desenvolvimento ao seu computador
Conecte o Wio Terminal ao seu computador. Entre no modo bootloader deslizando o interruptor de energia duas vezes rapidamente. Para mais referências, consulte também aqui.

Uma unidade externa chamada Arduino deve aparecer no seu PC. Arraste os arquivos de firmware uf2 do Edge Impulse baixados para a unidade Arduino. Agora, o Edge Impulse está carregado no Seeeduino Wio Terminal!
NOTA: Aqui está o código-fonte do Wio Terminal Edge Impulse; você também pode compilar o firmware a partir daqui.
2. Configurando chaves
No prompt de comando ou terminal, execute:
edge-impulse-daemon
NOTA: Ao conectar a um novo dispositivo, execute edge-impulse-daemon --clean para remover o cache anterior.
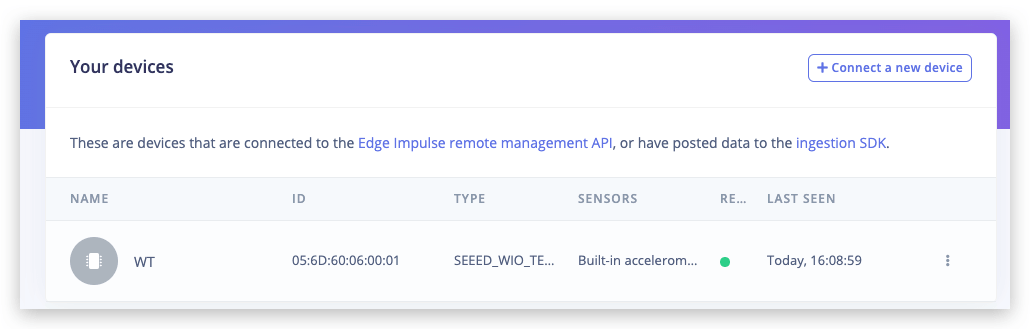
3. Verificando se o dispositivo está conectado
É isso! Seu dispositivo agora está conectado ao Edge Impulse. Para verificar, vá para o seu projeto Edge Impulse e clique em Devices. O dispositivo será listado ali.
Para o seu primeiro projeto, vamos treinar e implantar rapidamente uma rede neural simples para classificar gestos de pedra-papel-tesoura com apenas um único sensor de luz. Para mais detalhes e tutorial em vídeo, assista ao vídeo correspondente!
Aquisição de dados de treinamento
Vá para a aba Data acquisition. Defina o comprimento da amostra para cerca de 10000 ms ou 10 segundos e crie 10 amostras para cada gesto, balançando a mão nas proximidades do Wio Terminal.

Este é um conjunto de dados pequeno, mas também temos uma rede neural minúscula, então o underfitting é mais provável do que o overfitting neste caso em particular.
Underfitting: Diz-se que um modelo estatístico ou um algoritmo de machine learning apresenta underfitting quando não consegue capturar a tendência subjacente dos dados; isso acontece (entre outros casos) quando o tamanho do modelo é pequeno demais para desenvolver uma regra geral para dados que têm grande variedade e muito ruído.
Overfitting: Diz-se que um modelo estatístico está com overfitting quando ele começa a aprender a partir do ruído e de entradas de dados imprecisas em nosso conjunto de dados. Isso acontece quando você tem um modelo grande e um conjunto de dados relativamente pequeno – o modelo pode simplesmente “decorar” todos os pontos de dados sem generalizar.
Ao coletar amostras, é importante fornecer diversidade para que o modelo consiga generalizar melhor; por exemplo, tenha amostras com direções, velocidades e distâncias diferentes em relação ao sensor. Em geral, a rede só pode aprender a partir dos dados presentes no conjunto de dados – portanto, se as únicas amostras que você tiver forem gestos movendo-se da esquerda para a direita acima do sensor, você não deve esperar que o modelo treinado consiga reconhecer gestos movendo-se da direita para a esquerda ou para cima e para baixo.
Construindo um modelo de machine learning
Depois de coletar as amostras, é hora de projetar um “impulse”. Aqui, Impulse é a palavra que o Edge Impulse usa para denotar o pipeline de processamento de dados – treinamento. Clique em Create Impulse e defina Window length para 1000 ms e Window length increase para 50 ms.
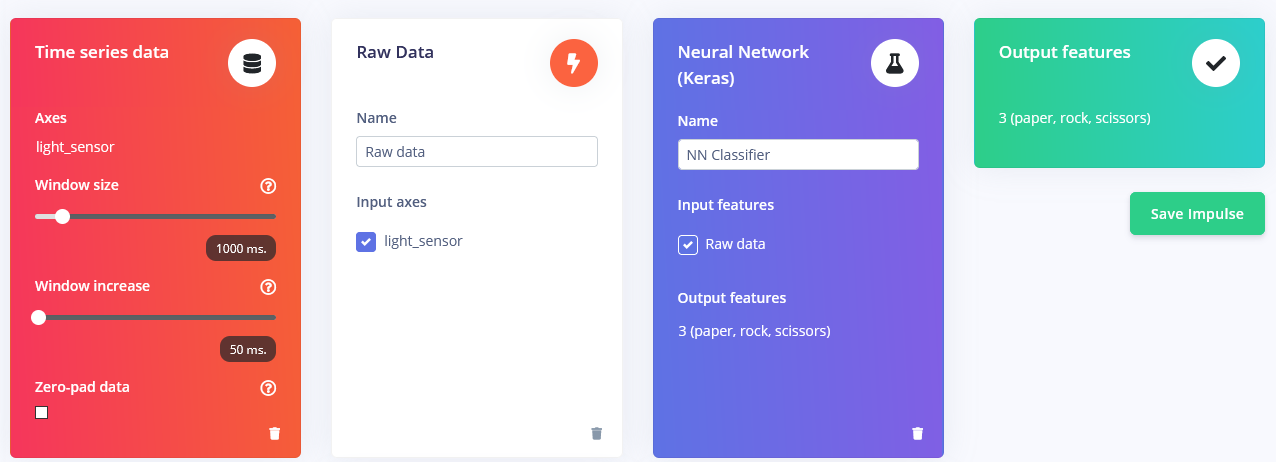
Essas configurações significam que, a cada vez que uma inferência é executada, vamos fazer medições do sensor por 1000 ms – quantas medições seu dispositivo fará depende da frequência. Durante a coleta de dados, você definiu a frequência de amostragem para 40 Hz, ou 40 vezes por 1 segundo. Então, resumindo, seu dispositivo vai reunir 40 amostras de dados dentro da janela de tempo de 1000 ms e depois pegar esses valores, pré-processá-los e alimentá-los à rede neural para obter o resultado da inferência. Claro que usamos o mesmo tamanho de janela durante o treinamento. Para este projeto de prova de conceito, vamos tentar três blocos de pré-processamento diferentes com parâmetros padrão (exceto por adicionar scaling) – bloco Flatten, que calcula Average, Min, Max e outras funções dos dados brutos dentro da janela de tempo.
bloco Spectral Features, que extrai as características de frequência e potência de um sinal ao longo do tempo.
e o bloco Raw data, que, como você provavelmente já imaginou, apenas alimenta dados brutos no bloco de aprendizado da NN (opcionalmente normalizando os dados).
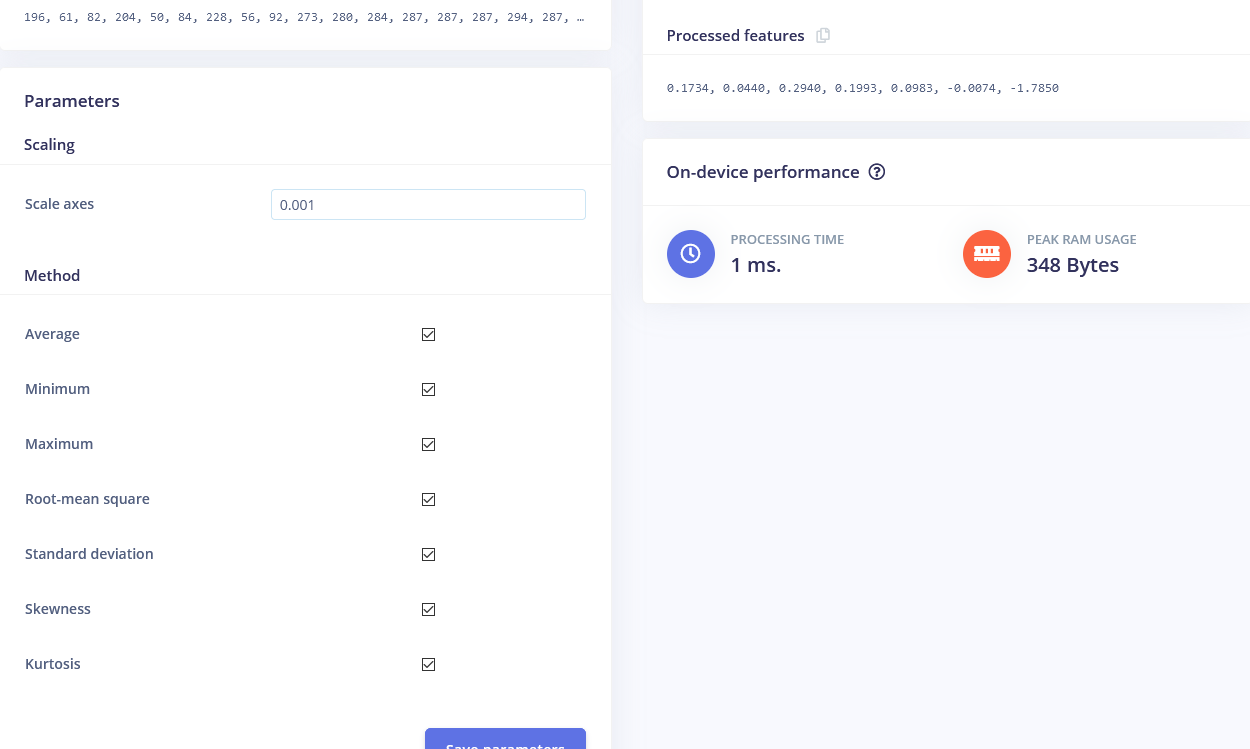
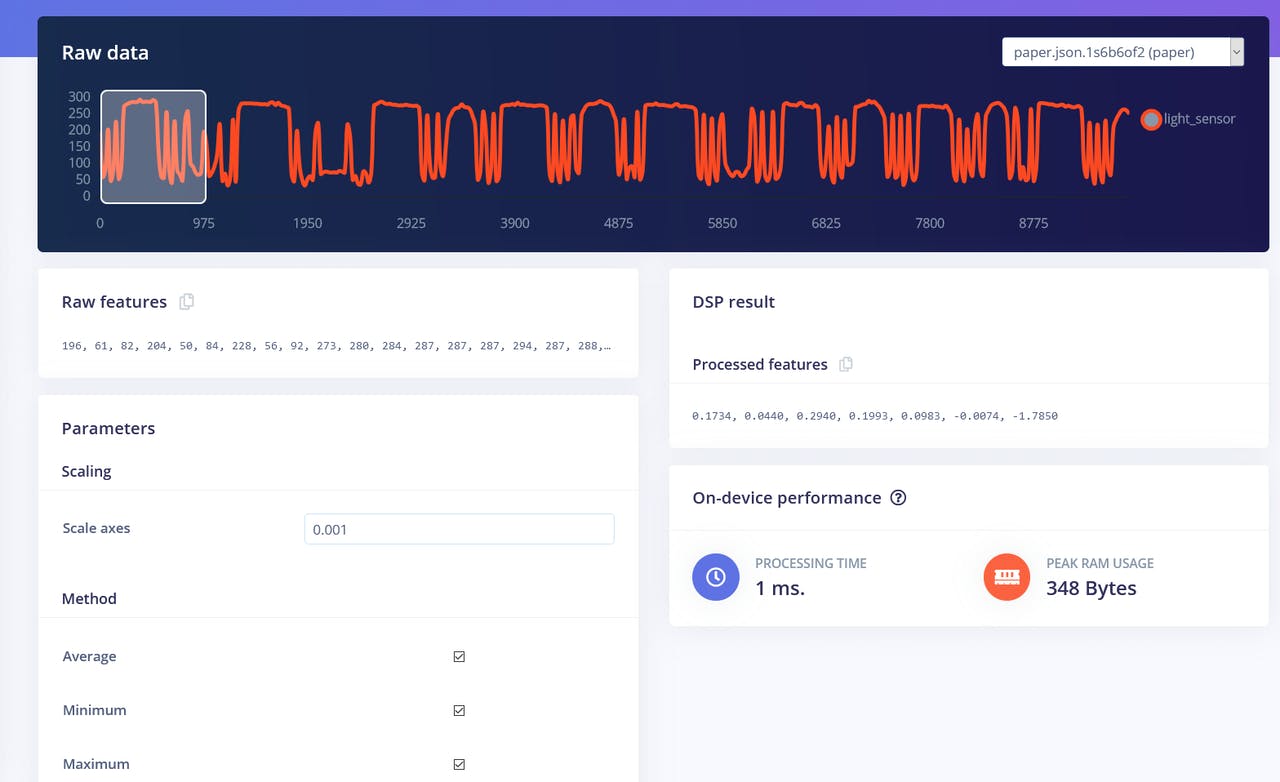
Vamos começar com o bloco Flatten. Adicione esse bloco e depois adicione Neural Network (Keras) como bloco de aprendizado, marque Flatten como features de entrada e clique em Save Impulse. Vá para a próxima aba, que tem o nome do bloco de processamento que você escolheu – Flatten. Lá, insira 0.001 em scaling e deixe os outros parâmetros iguais. Clique em Save parameters e depois em Generate features.
A visualização de features é uma ferramenta particularmente útil na interface web do Edge Impulse, pois permite que os usuários obtenham insights gráficos sobre como os dados ficam após o pré-processamento. Por exemplo, estes são dados após o bloco de processamento Flatten:
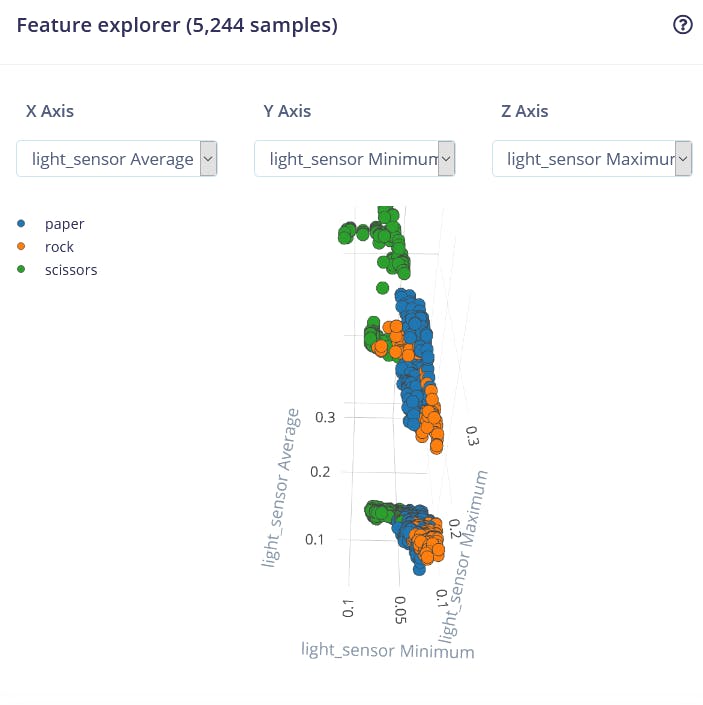
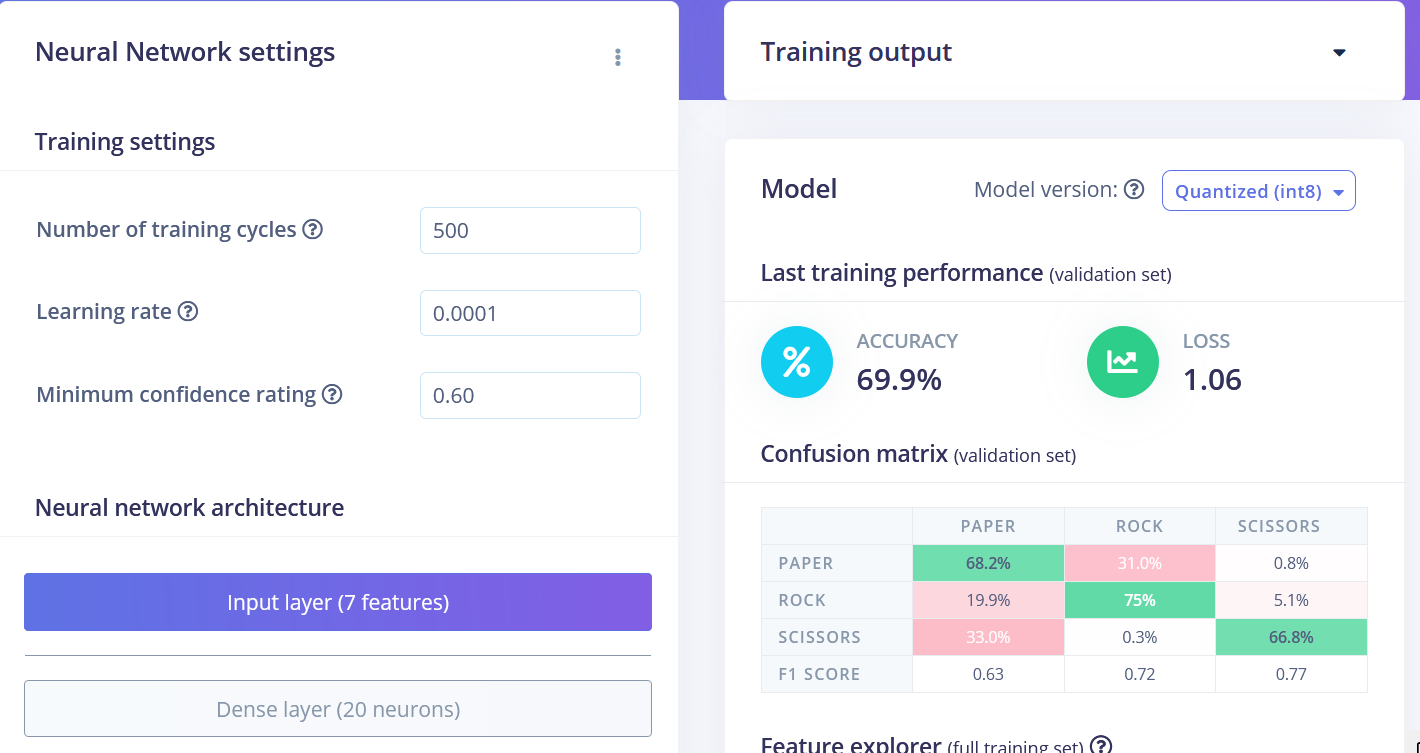
Podemos ver que os pontos de dados para diferentes classes estão aproximadamente separados, mas há muita sobreposição entre rock e outras classes, o que causará problemas e baixa precisão para essas duas classes. Depois de gerar e inspecionar as features, vá para a aba NN CLassifier. Treine uma rede totalmente conectada simples com 2 camadas ocultas, 20 e 10 neurônios em cada camada oculta por 500 épocas com taxa de aprendizado de 1e-4. Após o término do treinamento, você verá os resultados de teste em uma matriz de confusão, semelhante a esta:
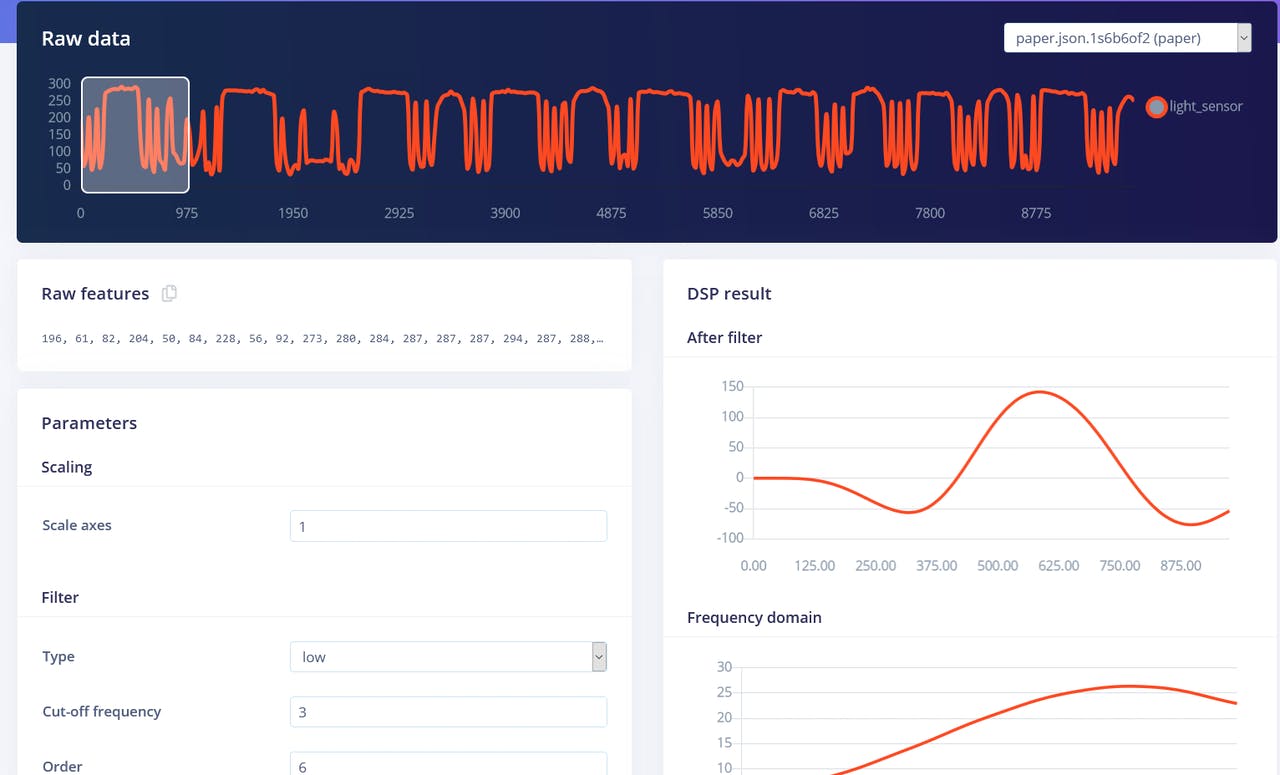
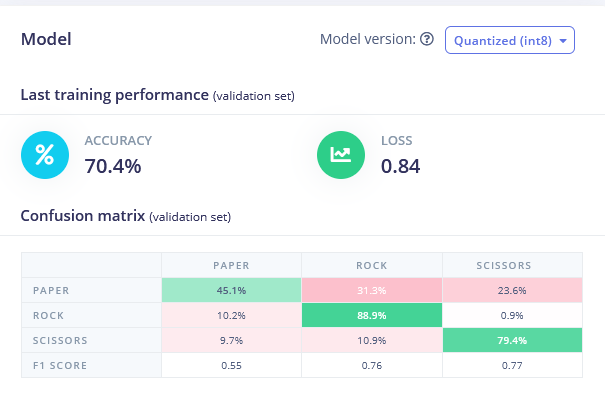
Volte para a aba Create Impulse, exclua o bloco Flatten e escolha o bloco Spectral Features, gere as features (lembre-se de definir scaling para 0.001!) e treine a Neural network com os dados de Spectral features. Você deve ver uma leve melhora.
Tanto os blocos Flatten quanto Spectral Features na verdade não são os melhores métodos de processamento para a tarefa de reconhecimento de gestos de pedra-papel-tesoura. Se pensarmos bem, para classificar gestos de pedra-papel-tesoura só precisamos contar quantas vezes e por quanto tempo o sensor de luz recebeu valores “abaixo do normal”. Se for uma vez por um tempo relativamente longo – então é rock (punho passando acima dos sensores). Se for duas vezes, então é scissors. Qualquer coisa além disso é paper. Parece fácil, mas preservar os dados de série temporal é realmente importante para que a rede neural consiga aprender essa relação nos pontos de dados. Ambos os blocos de processamento Flatten e Spectral Features removem a relação temporal dentro de cada janela – o bloco Flatten simplesmente transforma os valores brutos, que inicialmente estão em sequência, em valores de Average, Min, Max etc. calculados sobre todos os valores na janela de tempo, independentemente da ordem deles. O bloco Spectral Features extrai as características de frequência e potência e a razão pela qual ele não funcionou tão bem para esta tarefa em particular provavelmente é que a duração de cada gesto é muito curta. Portanto, a maneira de obter o melhor desempenho é usar o bloco Raw data, que preservará os dados de série temporal. Dê uma olhada no projeto de exemplo em que usamos Raw data e uma rede Convolutional 1D, um tipo de rede mais especializado em comparação com a totalmente conectada. Conseguimos alcançar 92,4% de precisão nos mesmos dados!
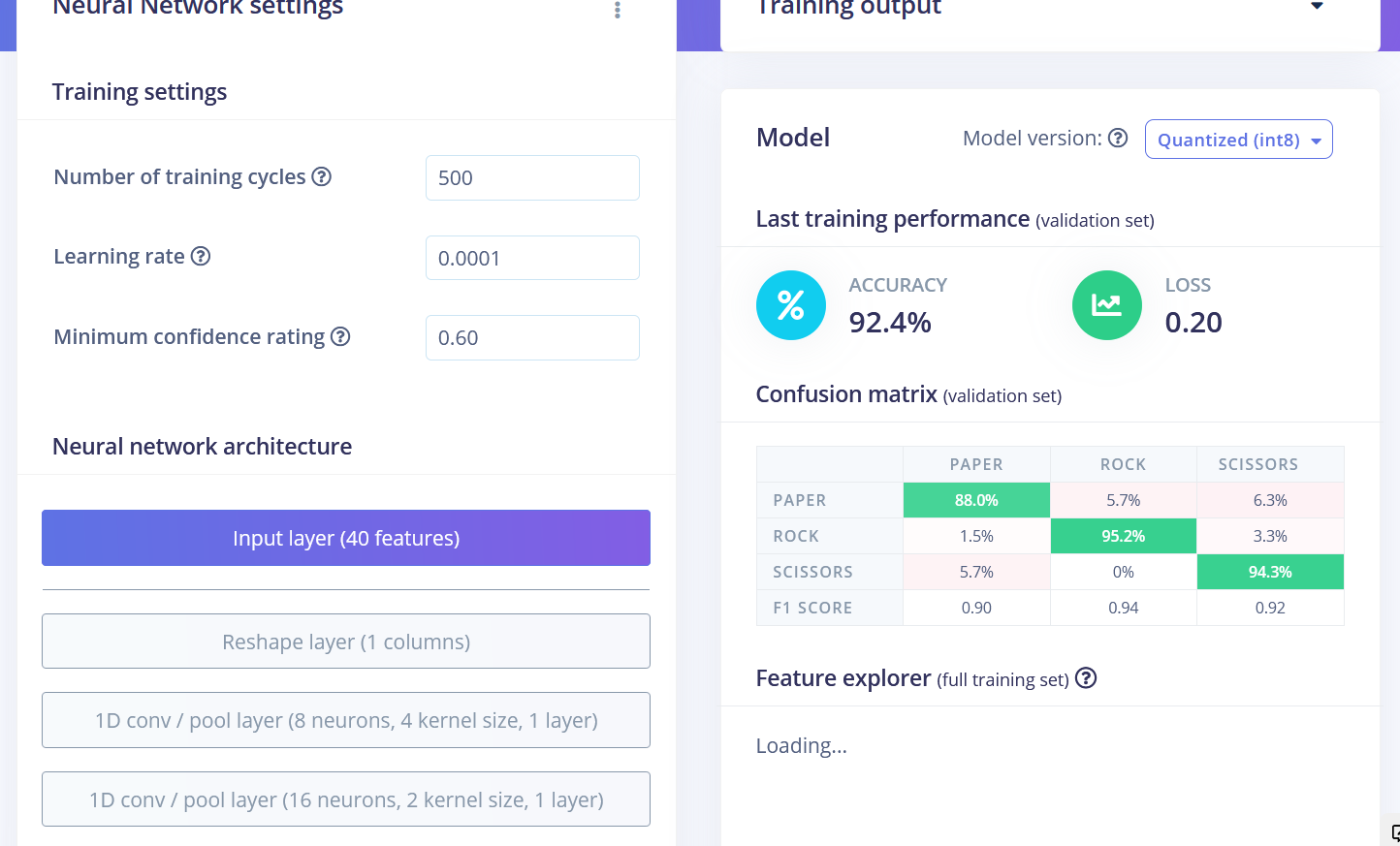
Os resultados finais após o treinamento foram
• Flatten FC 69,9 % de precisão
• Características espectrais FC 70,4 % de acurácia
• Dados brutos Conv1D 92,4 % de acurácia
Após o treinamento, você pode testar o modelo usando a aba Live classification, que coletará uma amostra de dados do dispositivo e a classificará com o modelo hospedado no Edge Impulse. Testamos com três gestos diferentes e vimos que a acurácia é satisfatória para uma prova de conceito.
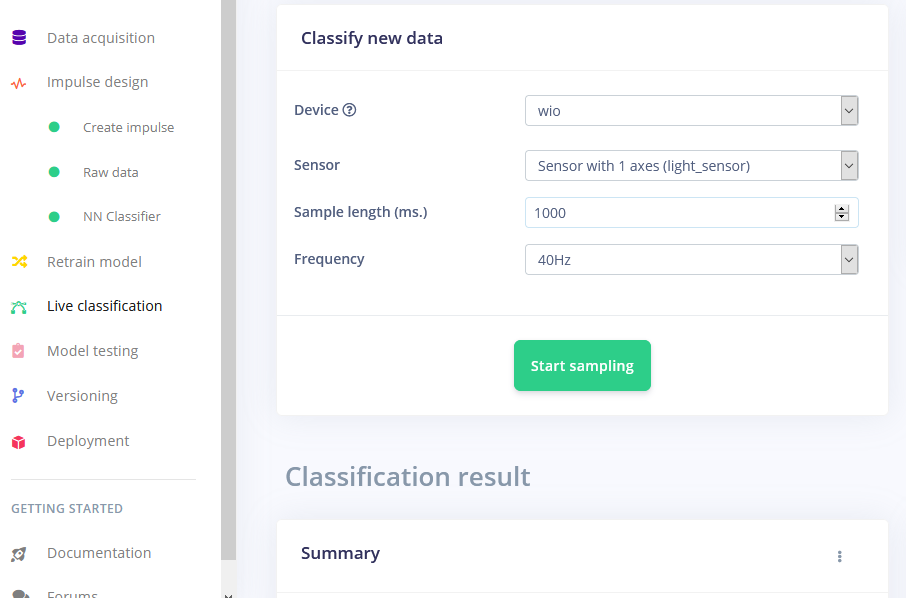
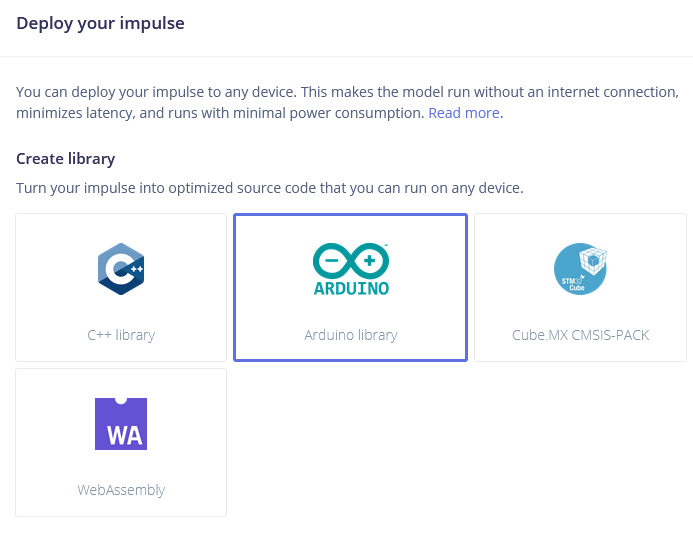
Implantando no Wio Terminal
O próximo passo é a implantação no dispositivo. Depois de clicar na aba Deployment, escolha a biblioteca Arduino e faça o download.
Extraia o arquivo e coloque-o na pasta de bibliotecas do Arduino. Abra a IDE do Arduino e escolha o sketch static buffer (localizado em File -> Examples -> nome do seu projeto -> static_buffer), que já possui todo o código padrão para classificação com o seu modelo. Legal!
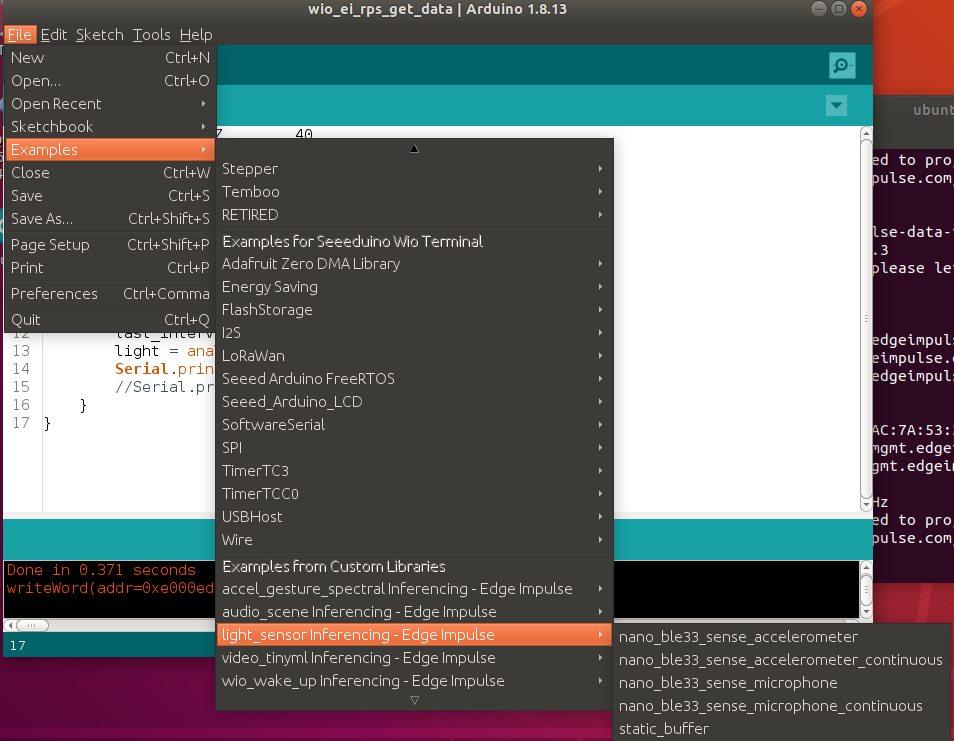
A única coisa que precisamos preencher é a aquisição de dados no dispositivo. Usaremos um simples laço for com delay para levar em conta a frequência (se você se lembra, tínhamos um delay de 25 ms ao coletar dados para o conjunto de treinamento).
int raw_feature_get_data(size_t offset, size_t length, float *out_ptr) {
float features[40];
for (byte i = 0; i < 40; i = i + 1)
{
features[i]=analogRead(WIO_LIGHT);
delay(25);
}
memcpy(out_ptr, features + offset, length * sizeof(float));
return 0;
}
Certamente há maneiras melhores de implementar isso, por exemplo, um buffer de dados do sensor, o que nos permitiria realizar inferências com mais frequência. Mas chegaremos a isso em artigos posteriores desta série.
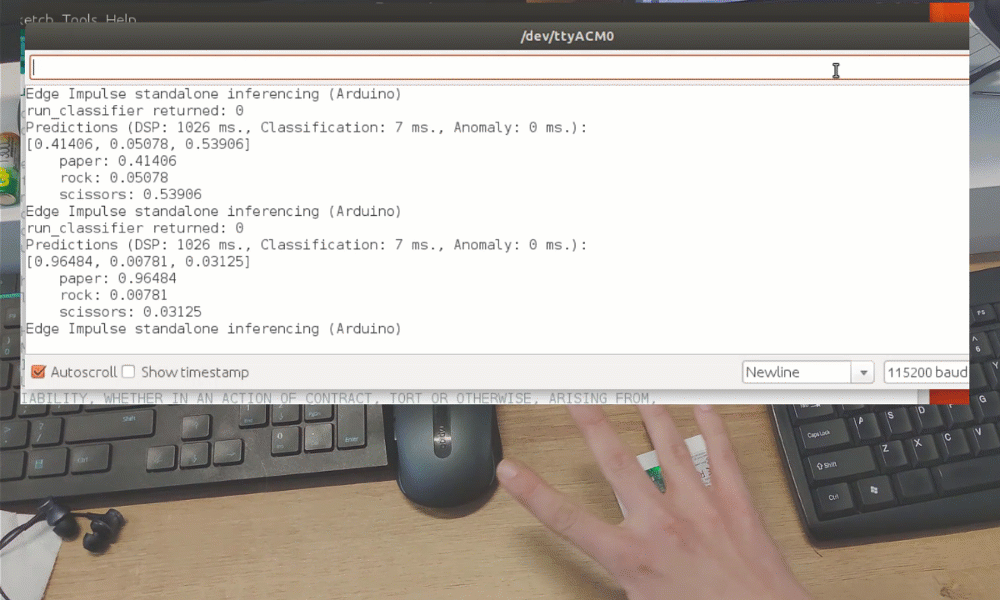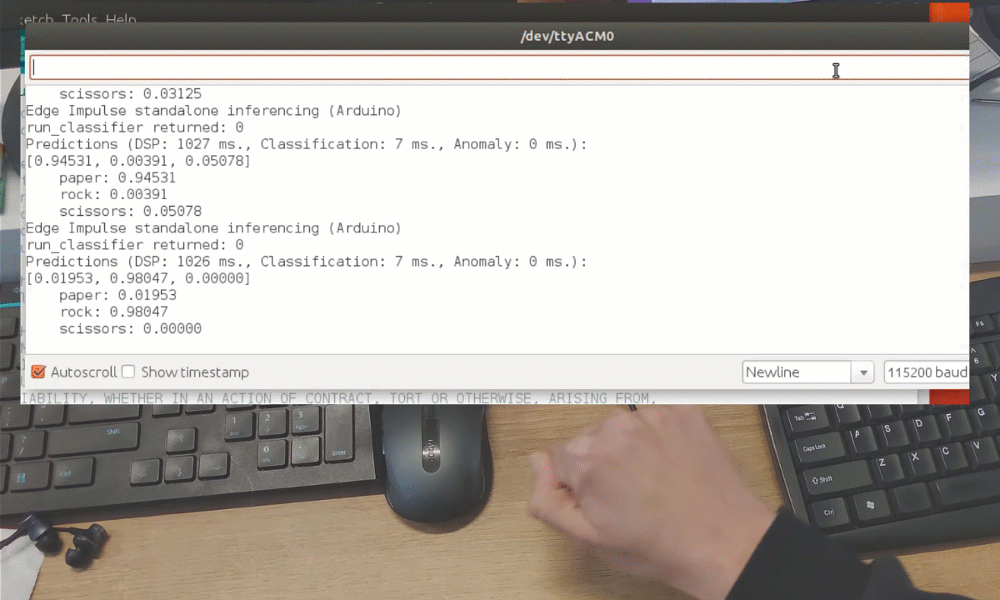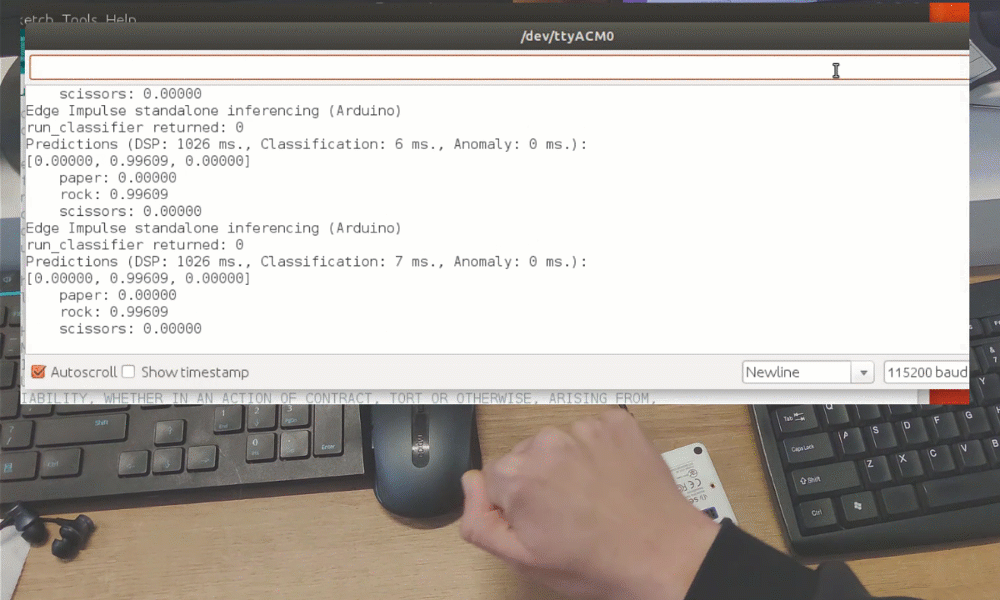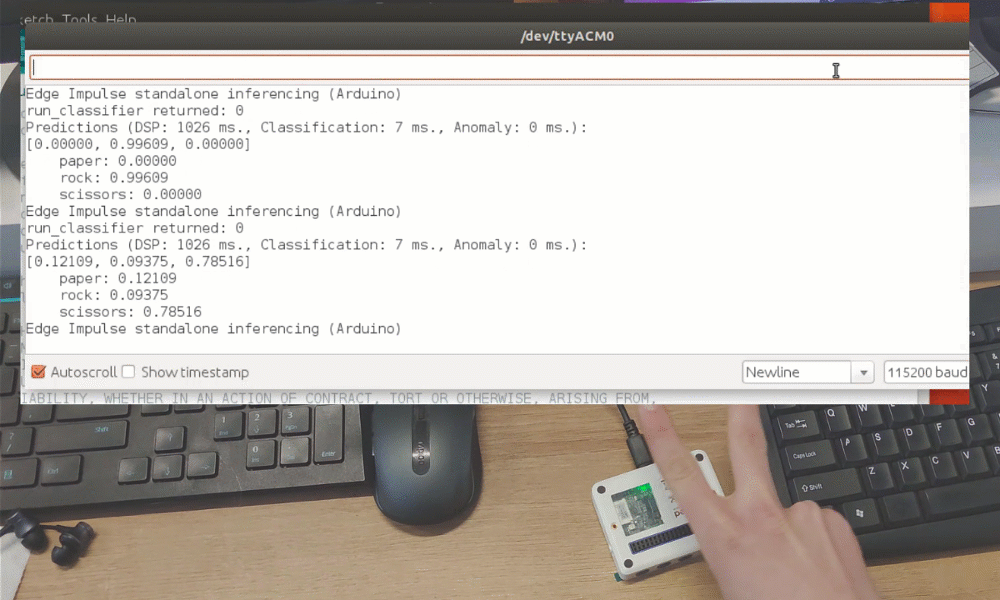
Embora tenha sido apenas uma demonstração de prova de conceito, isso realmente mostra que o TinyML está caminhando para algo grande. Você provavelmente sabia que é possível reconhecer gestos com um sensor de câmera, mesmo se a imagem for bastante reduzida. Mas reconhecer gestos com apenas 1 pixel é um nível totalmente diferente!