Reconhecimento Contínuo de Movimento com Edge Impulse no Wio Terminal usando Acelerômetro Integrado
Neste tutorial, você usará aprendizado de máquina para construir um sistema de reconhecimento de gestos que roda no Wio Terminal. Esta é uma tarefa difícil de resolver usando programação baseada em regras, pois as pessoas não executam gestos exatamente da mesma forma todas as vezes. Mas o aprendizado de máquina pode lidar com essas variações com facilidade. Você aprenderá como coletar dados de alta frequência de sensores reais, usar processamento de sinal para limpar os dados, construir um classificador de rede neural e como implantar seu modelo de volta em um dispositivo. Ao final deste tutorial você terá um entendimento sólido de como aplicar aprendizado de máquina em dispositivos embarcados usando Edge Impulse.
Há também uma versão em vídeo deste tutorial:
1. Pré-requisitos
Para este tutorial você precisará de um dispositivo compatível. Siga primeiro o tutorial Wio Terminal Edge Impulse antes do que vem a seguir.
Além do Wio Terminal, aqui estão outros dispositivos compatíveis.
Se o seu dispositivo estiver conectado em Devices no estúdio, você pode prosseguir:
O Edge Impulse pode ingerir dados de qualquer dispositivo - incluindo dispositivos embarcados que você já tenha em produção. Consulte a documentação do Ingestion service para mais informações.
2. Coletando seus primeiros dados
Com o seu dispositivo conectado, podemos coletar alguns dados. No estúdio, vá até a aba Data acquisition. Este é o lugar onde todos os seus dados brutos são armazenados e - se o seu dispositivo estiver conectado à API de gerenciamento remoto - onde você pode começar a amostrar novos dados.
Em Record new data, selecione seu dispositivo, defina o rótulo como idle, o comprimento da amostra como 5000, o sensor como Built-in accelerometer e a frequência como 62.5Hz. Isso indica que você quer registrar dados por 10 segundos e rotular os dados registrados como idle. Você pode editar esses rótulos mais tarde, se necessário.
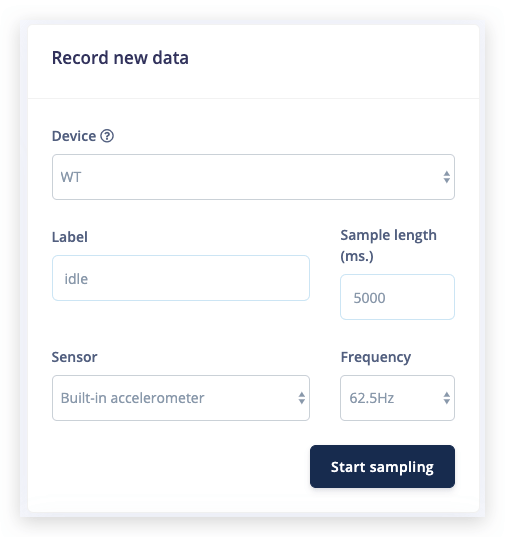
Depois que você clicar em Start sampling, mova seu dispositivo para cima e para baixo em um movimento contínuo. Em cerca de doze segundos o dispositivo deve concluir a amostragem e enviar o arquivo de volta para o Edge Impulse. Você verá uma nova linha aparecer em 'Collected data' no estúdio. Quando você clica nela, agora vê os dados brutos representados em um gráfico. Como o acelerômetro na placa de desenvolvimento tem três eixos, você notará três linhas diferentes, uma para cada eixo.
É importante fazer movimentos contínuos, pois mais tarde dividiremos os dados em janelas menores.
O aprendizado de máquina funciona melhor com muitos dados, então uma única amostra não é suficiente. Agora é hora de começar a construir seu próprio conjunto de dados. Por exemplo, use as três classes a seguir e registre cerca de 3 minutos de dados por classe:
- Idle - apenas parado na sua mesa enquanto você trabalha.
- Wave - balançando o dispositivo da esquerda para a direita.
- Circle - desenhando círculos.
Certifique-se de fazer variações nos movimentos. Por exemplo, faça movimentos lentos e rápidos e varie a orientação da placa. Você nunca saberá como o usuário utilizará o dispositivo. É melhor coletar amostras de aproximadamente 10 segundos cada.
3. Projetando um impulso
Com o conjunto de treinamento pronto, você pode projetar um impulso. Um impulso pega os dados brutos, divide-os em janelas menores, usa blocos de processamento de sinal para extrair características e então usa um bloco de aprendizado para classificar novos dados. Blocos de processamento de sinal sempre retornam os mesmos valores para a mesma entrada e são usados para tornar os dados brutos mais fáceis de processar, enquanto blocos de aprendizado aprendem com experiências passadas.
Para este tutorial usaremos o bloco de processamento de sinal 'Spectral analysis'. Este bloco aplica um filtro, realiza análise espectral no sinal e extrai dados de frequência e de potência espectral. Em seguida, usaremos um bloco de aprendizado 'Neural Network', que pega essas características espectrais e aprende a distinguir entre as três classes (idle, circle, wave).
No estúdio, vá para Create impulse, defina o tamanho da janela como 2000 (você pode clicar no texto 2000 ms. para inserir um valor exato), o aumento da janela como 80 e adicione os blocos Spectral Analysis e Neural Network (Keras). Depois clique em Save impulse.
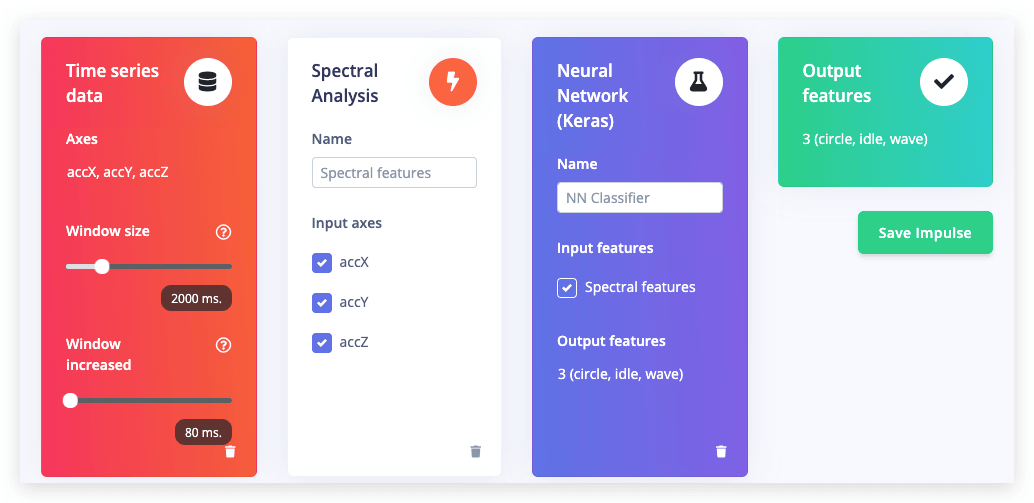
Configurando o bloco de análise espectral
Para configurar seu bloco de processamento de sinal, clique em Spectral features no menu à esquerda. Isso mostrará os dados brutos na parte superior da tela (você pode selecionar outros arquivos através do menu suspenso) e os resultados do processamento de sinal em gráficos à direita. Para o bloco de características espectrais você verá os seguintes gráficos:
- After filter - o sinal após aplicar um filtro passa-baixas. Isso removerá o ruído.
- Frequency domain - a frequência na qual o sinal está se repetindo (por exemplo, fazer um movimento de onda por segundo mostrará um pico em 1 Hz).
- Spectral power - a quantidade de potência que entrou no sinal em cada frequência.
Um bom bloco de processamento de sinal produzirá resultados semelhantes para dados semelhantes. Se você mover a janela deslizante (no gráfico de dados brutos), os gráficos devem permanecer semelhantes. Além disso, quando você muda para outro arquivo com o mesmo rótulo, deve ver gráficos semelhantes, mesmo que a orientação do dispositivo seja diferente.
Quando estiver satisfeito com o resultado, clique em Save parameters. Isso o levará à tela Feature generation. Aqui você irá:
- Dividir todos os dados brutos em janelas (com base no tamanho da janela e no aumento da janela).
- Aplicar o bloco de características espectrais em todas essas janelas.
Clique em Generate features para iniciar o processo.
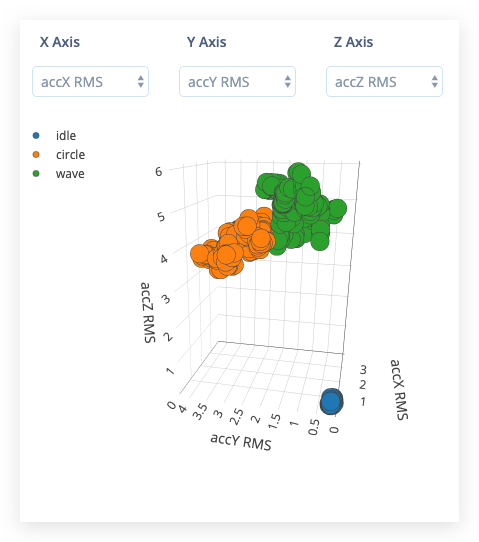
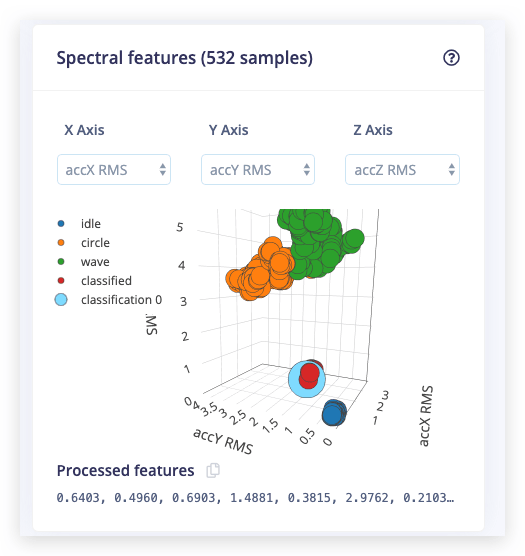
Depois disso, o Feature explorer será carregado. Este é um gráfico de todas as características extraídas em relação a todas as janelas geradas. Você pode usar este gráfico para comparar seu conjunto de dados completo. Por exemplo, traçando a altura do primeiro pico no eixo X em relação à potência espectral entre 0,5 Hz e 1 Hz no eixo Y. Uma boa regra prática é que se você puder separar visualmente os dados em vários eixos, então o modelo de aprendizado de máquina também será capaz de fazer isso.
Configurando a rede neural
Com todos os dados processados, é hora de começar a treinar uma rede neural. Redes neurais são um conjunto de algoritmos, modelados de forma aproximada ao cérebro humano, que são projetados para reconhecer padrões. A rede que estamos treinando aqui pegará os dados de processamento de sinal como entrada e tentará mapeá-los para uma das três classes.
Então, como uma rede neural sabe o que prever? Uma rede neural consiste em camadas de neurônios, todos interconectados, e cada conexão tem um peso. Um desses neurônios na camada de entrada seria a altura do primeiro pico do eixo X (do bloco de processamento de sinal); e um desses neurônios na camada de saída seria wave (uma das classes). Ao definir a rede neural, todas essas conexões são inicializadas aleatoriamente e, portanto, a rede neural fará previsões aleatórias. Durante o treinamento, então pegamos todos os dados brutos, pedimos para a rede fazer uma previsão e fazemos pequenas alterações nos pesos dependendo do resultado (é por isso que rotular dados brutos é importante).
Dessa forma, depois de muitas iterações, a rede neural aprende e eventualmente se torna muito melhor em prever novos dados. Vamos testar isso clicando em NN Classifier no menu.
Defina Number of training cycles para 1. Isso limitará o treinamento a uma única iteração. E então clique em Start training.
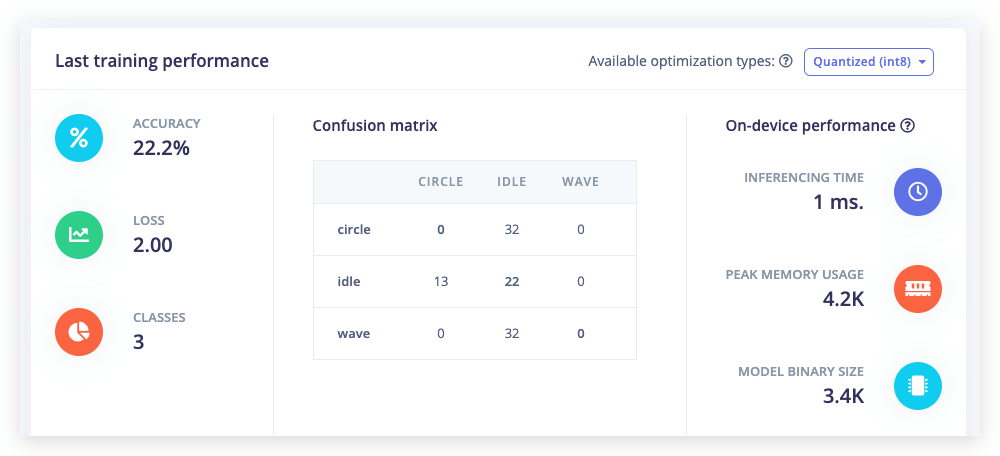
Agora mude Number of training cycles para 2 e você verá o desempenho aumentar. Finalmente, mude Number of training cycles para 100 ou mais e deixe o treinamento terminar. Você acabou de treinar sua primeira rede neural!
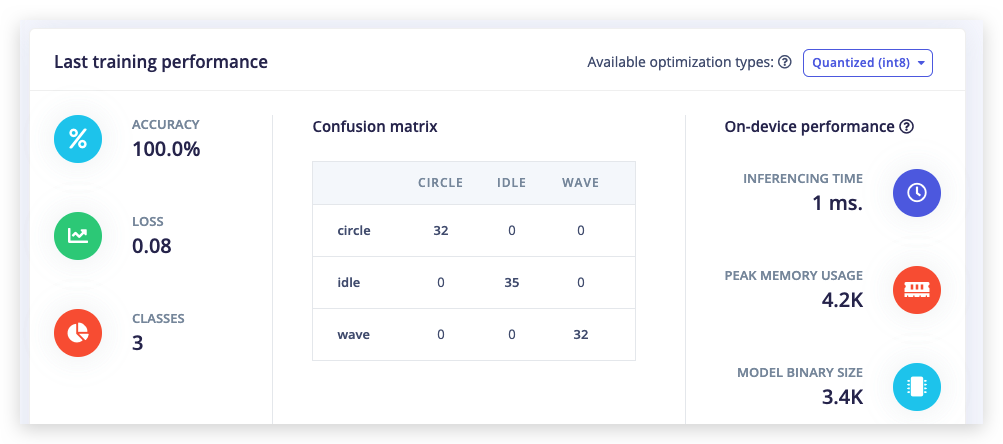
Você pode acabar com uma precisão de 100% após treinar por 100 ciclos de treinamento. Isso não é necessariamente algo bom, pois pode ser um sinal de que a rede neural está ajustada demais para o conjunto de teste específico e pode ter um desempenho ruim em novos dados (overfitting). A melhor maneira de reduzir isso é adicionando mais dados ou reduzindo a taxa de aprendizado.
4. Classificando novos dados
Pelas estatísticas da etapa anterior, sabemos que o modelo funciona com nossos dados de treinamento, mas quão bem a rede se sairia com novos dados? Clique em Live classification no menu para descobrir. Seu dispositivo deve (assim como na etapa 2) aparecer como online em Classify new data. Defina o Sample length para 5000 (5 segundos), clique em Start sampling e comece a fazer movimentos. Depois disso, você receberá um relatório completo sobre o que a rede achou que você fez.
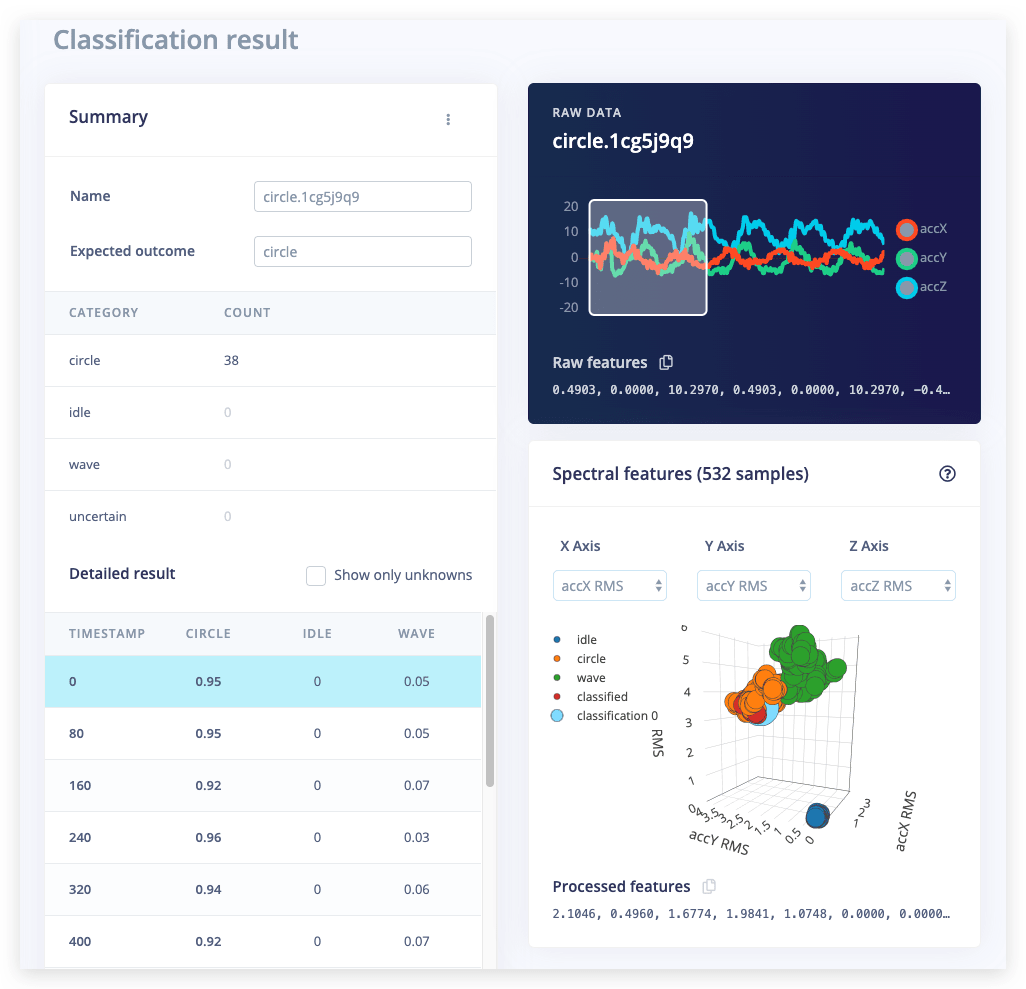
Se a rede teve um ótimo desempenho, fantástico! Mas e se ela teve um desempenho ruim? Pode haver uma variedade de motivos, mas os mais comuns são:
- Não há dados suficientes. Redes neurais precisam aprender padrões em conjuntos de dados e, quanto mais dados, melhor.
- Os dados não se parecem com outros dados que a rede já viu antes. Isso é comum quando alguém usa o dispositivo de uma forma que você não adicionou ao conjunto de teste. Você pode adicionar o arquivo atual ao conjunto de teste clicando e selecionando Move to training set. Certifique-se de atualizar o rótulo em
Data acquisitionantes de treinar. - O modelo não foi treinado o suficiente. Aumente o número de épocas para
200e veja se o desempenho aumenta (o arquivo classificado é armazenado e você pode carregá-lo por meio deClassify existing validation sample). - O modelo está com overfitting e, portanto, tem um desempenho ruim em novos dados. Tente reduzir a taxa de aprendizado ou adicionar mais dados.
- A arquitetura da rede neural não é um bom ajuste para seus dados. Brinque com o número de camadas e neurônios e veja se o desempenho melhora.
Como você vê, ainda há muito de tentativa e erro ao construir redes neurais, mas esperamos que as visualizações ajudem bastante. Você também pode executar a rede contra o conjunto completo de validação por meio de Model validation. Pense na página de validação de modelo como um conjunto de testes de unidade para o seu modelo!
Com um modelo funcional em funcionamento, podemos olhar para os lugares onde nosso impulso atual tem um desempenho ruim...
5. Detecção de anomalias
Redes neurais são ótimas, mas têm uma grande falha. Elas lidam muito mal com dados que nunca viram antes (como um novo gesto). Redes neurais não conseguem julgar isso, pois só conhecem os dados de treinamento. Se você fornecer algo diferente de tudo o que ela já viu, ainda assim ela classificará como uma das três classes.
Vamos ver como isso funciona na prática. Vá para Live classification e grave alguns novos dados, mas agora sacuda vigorosamente o seu dispositivo. Dê uma olhada e veja como a rede ainda irá prever alguma coisa de qualquer maneira.
Então... como podemos fazer melhor? Se você olhar o explorador de recursos nos eixos accX RMS, accY RMS e accZ RMS, você deve conseguir separar visualmente os dados classificados dos dados de treinamento. Podemos usar isso a nosso favor treinando uma nova (segunda) rede que cria aglomerados em torno de dados que já vimos e compara os dados recebidos com esses aglomerados. Se a distância de um aglomerado for muito grande, você pode sinalizar a amostra como uma anomalia e não confiar na rede neural.
Para adicionar este bloco, vá para Create impulse, clique em Add learning block e selecione K-means Anomaly Detection. Em seguida, clique em Save impulse.
Para configurar o modelo de agrupamento, clique em Anomaly detection no menu. Aqui precisamos especificar:
- O número de aglomerados (clusters). Aqui use
32. - Os eixos que queremos selecionar durante o agrupamento. Como podemos separar visualmente os dados nos eixos accX RMS, accY RMS e accZ RMS, selecione esses.
Clique em Start training para gerar os aglomerados. Você pode carregar amostras de validação existentes no explorador de anomalias com o menu suspenso.
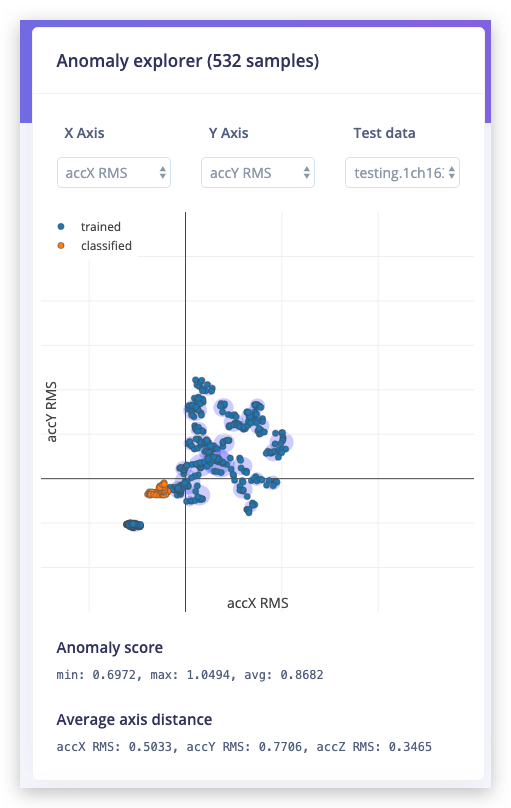
Aglomerados conhecidos em azul, os dados de agitação em laranja. Está claramente fora de quaisquer aglomerados conhecidos e, portanto, pode ser marcado como uma anomalia.
O explorador de anomalias plota apenas dois eixos ao mesmo tempo. Em average axis distance você vê quão distante de cada eixo a amostra de validação está. Use os menus suspensos para alterar os eixos.
6. Implantando de volta no dispositivo
Com o impulso projetado, treinado e verificado, você pode implantar este modelo de volta no seu dispositivo. Isso faz o modelo rodar sem uma conexão com a internet, minimiza a latência e funciona com consumo mínimo de energia. O Edge Impulse pode empacotar o impulso completo – incluindo o código de processamento de sinal, pesos da rede neural e código de classificação – em uma única biblioteca C++ que você pode incluir no seu software embarcado.
Depois de clicar na aba Deployment, escolha a biblioteca Arduino e faça o download. Extraia o arquivo e coloque-o na pasta de bibliotecas do Arduino. Abra o Arduino IDE e escolha Exemplos -> nome do seu projeto Inferencing Edge Impulse -> sketch nano_ble33_sense_accelerometer. Nossa placa é semelhante à Arduino Nano BLE33 Sense, mas usa um acelerômetro diferente (LIS3DHTR em vez de LSM9DS1), então precisaremos mudar a seção de aquisição de dados adequadamente. Além disso, como o Wio Terminal tem uma tela LCD, vamos exibir o nome da classe detectada se o valor de confiança dessa classe estiver acima do limite. Primeiro, altere o cabeçalho
#include <Arduino_LSM9DS1.h>
para
#include"LIS3DHTR.h"
#include"TFT_eSPI.h"
LIS3DHTR<TwoWire> lis;
TFT_eSPI tft;
Depois altere a inicialização na função setup
if (!IMU.begin()) {
ei_printf("Failed to initialize IMU!\r\n");
}
else {
ei_printf("IMU initialized\r\n");
}
para
tft.begin();
tft.setRotation(3);
tft.fillScreen(TFT_WHITE);
lis.begin(Wire1);
if (!lis.available()) {
Serial.println("Failed to initialize IMU!");
while (1);
}
else {
ei_printf("IMU initialized\r\n");
}
lis.setOutputDataRate(LIS3DHTR_DATARATE_100HZ); // Setting output data rage to 25Hz, can be set up tp 5kHz
lis.setFullScaleRange(LIS3DHTR_RANGE_16G); // Setting scale range to 2g, select from 2,4,8,16g
Fazemos a coleta de dados e a inferência dentro da função loop, é aqui que precisamos mudar a aquisição de dados com LSM9DS1 para a função de aquisição de dados para LIS3DHTR
IMU.readAcceleration(buffer[ix], buffer[ix + 1], buffer[ix + 2]);
para
lis.getAcceleration(&buffer[ix], &buffer[ix + 1], &buffer[ix + 2]);
E então, para exibir o nome da classe na tela LCD, depois de
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
adicione o seguinte bloco de código, no qual verificamos os valores de confiança de cada classe e, se um deles for maior que o limite, mudamos a cor da tela e exibimos o nome dessa classe.
if (result.classification[1].value > 0.7) {
tft.fillScreen(TFT_PURPLE);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Wave", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
if (result.classification[2].value > 0.7) {
tft.fillScreen(TFT_RED);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Circle", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
Depois compile e faça o upload – abra o monitor serial e realize um dos gestos! Você poderá ver os resultados de inferência exibidos no monitor serial e também na tela LCD.
7. Conclusão
Aprendizado de máquina é um campo muito interessante: ele permite que você construa sistemas complexos que aprendem com experiências passadas, encontram automaticamente padrões em dados de sensores e procuram anomalias sem programar tudo explicitamente. Achamos que há uma grande oportunidade para aprendizado de máquina em sistemas embarcados. Atualmente, são coletadas enormes quantidades de dados de sensores, mas 99% desses dados são descartados devido a restrições de custo, largura de banda ou energia.
O Edge Impulse ajuda você a desbloquear esses dados. Ao processar dados diretamente no dispositivo, você não precisa mais enviar dados brutos para a nuvem, mas pode tirar conclusões diretamente onde importa. Mal podemos esperar para ver o que você irá construir!