Reconhecimento de Cena de Áudio do Wio Terminal com Edge Impulse e Microfone Integrado
Neste projeto aprenderemos como treinar e implantar um classificador de cenas de áudio com o Wio Terminal e o Edge Impulse. Para mais detalhes e um tutorial em vídeo, assista ao vídeo correspondente!
Processamento de som em computadores
A classificação de cena de áudio é uma tarefa em que o modelo de aprendizado de máquina precisa prever uma classe para um segmento de áudio, por exemplo, "um bebê chorando", "uma tosse", "um cachorro latindo" etc.
Som é uma vibração que se propaga (ou viaja) como uma onda acústica, através de um meio de transmissão como um gás, líquido ou sólido.

A fonte do som empurra as moléculas do meio ao redor, elas empurram as moléculas ao lado delas e assim por diante. Quando alcançam outro objeto, ele também vibra levemente – usamos esse princípio em um microfone. A membrana do microfone é empurrada para dentro pelas moléculas do meio e depois volta à sua posição original.
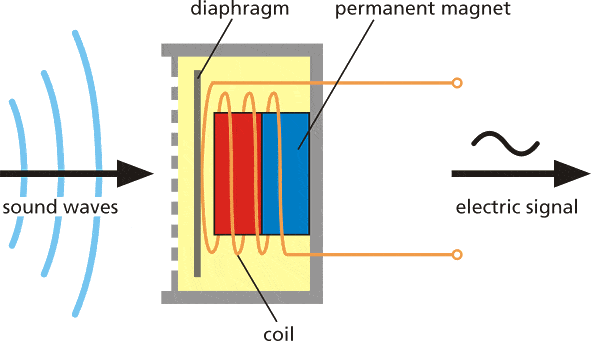
Isso gera corrente alternada no circuito, onde a tensão é proporcional à amplitude do som – quanto mais alto o som, mais ele empurra a membrana, gerando assim uma tensão maior. Em seguida, lemos essa tensão com um conversor analógico‑digital e a registramos em intervalos iguais – o número de vezes que fazemos a medição do som em um segundo é chamado de taxa de amostragem; por exemplo, uma taxa de amostragem de 8000 Hz significa fazer a medição 8000 vezes por segundo. A taxa de amostragem obviamente importa muito para a qualidade do som – se amostrarmos muito devagar podemos perder partes importantes. Os números usados para gravar o som digitalmente também importam – quanto maior o intervalo do número usado, mais “nuances” podemos preservar do som original. Isso é chamado de profundidade de bits de áudio – você talvez já tenha ouvido termos como som de 8 bits e som de 16 bits. Bem, é exatamente o que o nome diz – para som de 8 bits são usados inteiros sem sinal de 8 bits, que têm intervalo de 0 a 255. Para som de 16 bits são usados inteiros com sinal de 16 bits, ou seja, de -32768 a 32767. Certo, então no final temos uma sequência de números, com números maiores correspondendo às partes mais altas do som, e podemos visualizá‑lo assim – isto é 1 segundo de som de tiro gravado a 8000 Hz de frequência com profundidade de 8 bits (0–255).

Porém, não podemos fazer muita coisa com essa representação bruta de som – sim, podemos cortar e colar partes ou torná‑lo mais silencioso ou mais alto, mas para analisar o som ela é, bem, bruta demais. É aqui que entram a transformada de Fourier, a escala Mel, os espectrogramas e os coeficientes cepstrais. Para fins deste projeto, definiremos a transformada de Fourier como uma transformação matemática que nos permite decompor um sinal em suas frequências individuais e na amplitude dessas frequências.
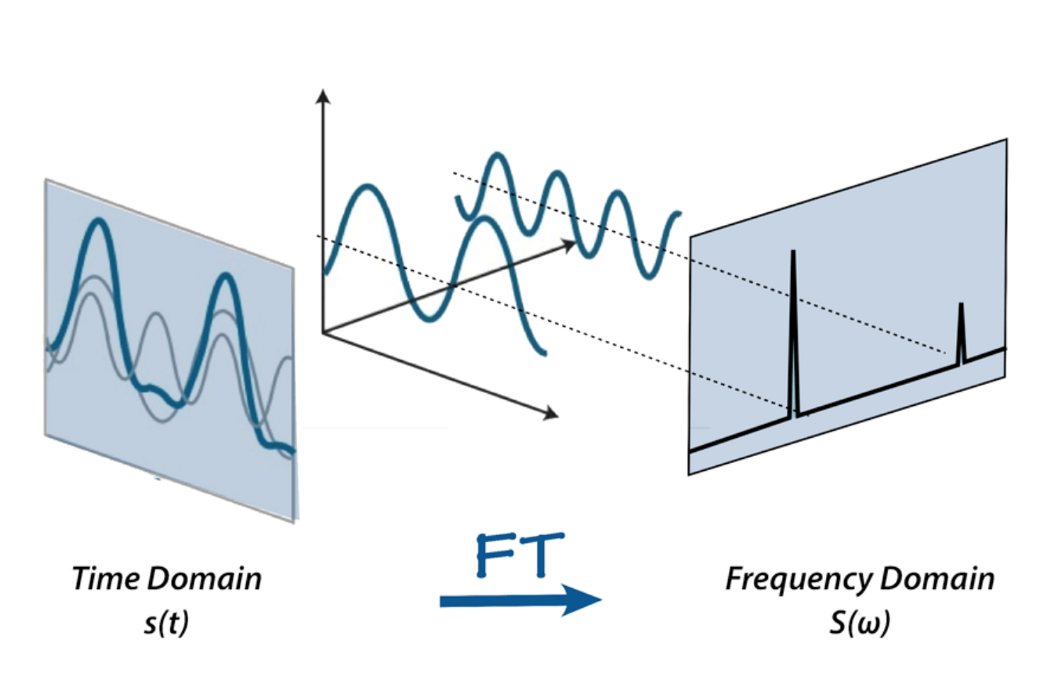
Ou, se você preferir usar uma metáfora – dado o smoothie, ela fornece a receita.
Há muito material na Internet sobre transformada de Fourier, por exemplo este artigo do betterexplained.com e um vídeo do 3Blue1Gray – confira para saber mais sobre FFT.
É assim que nosso som fica depois de aplicar a transformada de Fourier – as barras mais altas correspondem a frequências de maior amplitude.

Isso é ótimo! Agora podemos fazer coisas mais interessantes com o sinal de áudio – por exemplo, eliminar as frequências menos importantes para comprimir o arquivo de áudio ou remover o ruído ou talvez o som de voz etc. Mas isso ainda não é bom o suficiente para reconhecimento de áudio e fala – ao fazer a transformada de Fourier perdemos toda a informação do domínio do tempo, o que não é bom para sinais não periódicos, como a fala humana. Porém, somos espertos e simplesmente aplicamos a transformada de Fourier várias vezes na amostra de sinal, essencialmente fatiando‑a e depois costurando os dados de múltiplas transformadas de Fourier de volta na forma de um espectrograma.
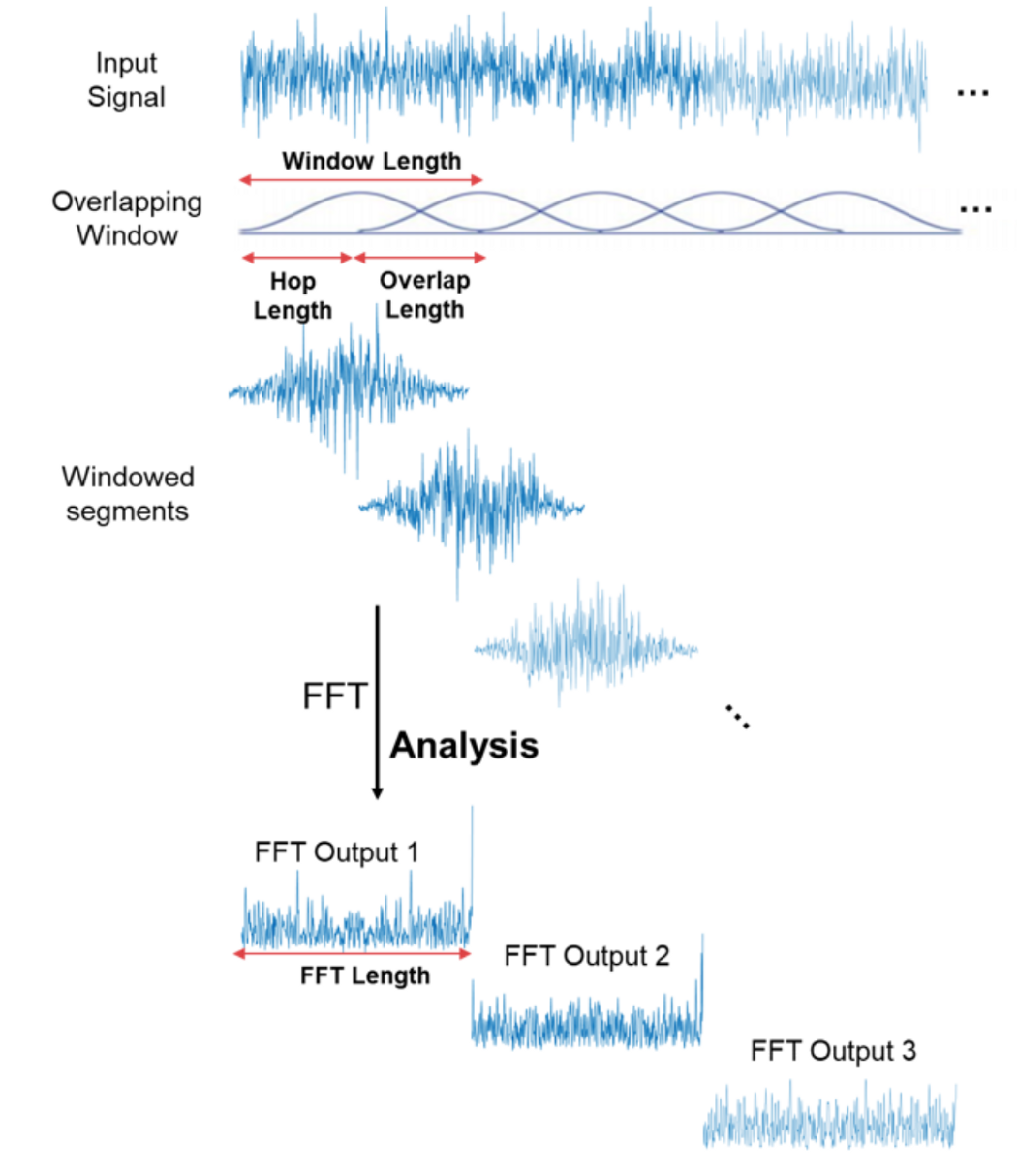
Aqui o eixo x é o tempo, o eixo y é a frequência e a amplitude de uma frequência é expressa por meio de uma cor; cores mais brilhantes correspondem a amplitudes maiores.

Muito bem! Já podemos fazer reconhecimento de som agora? Não! Sim! Talvez! Um espectrograma normal contém informação demais se só nos importamos com o reconhecimento de sons que o ouvido humano pode escutar. Estudos mostraram que os humanos não percebem frequências em uma escala linear. Somos melhores em detectar diferenças em frequências mais baixas do que em frequências mais altas. Por exemplo, podemos facilmente notar a diferença entre 500 e 1000 Hz, mas dificilmente seremos capazes de notar a diferença entre 10000 e 10500 Hz, apesar de a distância entre os dois pares ser a mesma. Em 1937, Stevens, Volkmann e Newmann propuseram uma unidade de altura tonal tal que distâncias iguais em altura soassem igualmente distantes para o ouvinte. Isso é chamado de escala mel.
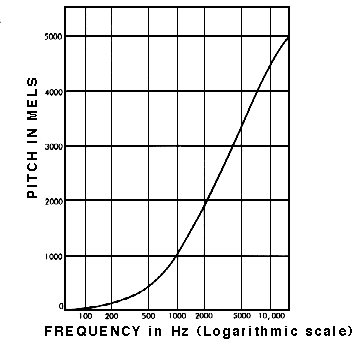
Um espectrograma mel é um espectrograma em que as frequências são convertidas para a escala mel.

Há mais etapas envolvidas no reconhecimento de fala – por exemplo, os coeficientes cepstrais, que mencionamos acima – iremos discuti‑los em projetos posteriores. É hora de finalmente começar com a implementação prática.
Aquisição de dados de treinamento
O sinal de áudio precisa ser amostrado em uma taxa de amostragem muito alta, 8000 Hz ou, idealmente, 16000 Hz. A ferramenta Edge Impulse Data Forwarder é lenta demais para lidar com essa taxa de amostragem, então precisaremos usar um firmware dedicado de coleta de dados para obter os dados para este projeto. Baixe uma nova versão do firmware do Wio Terminal para Edge Impulse com suporte a microfone e grave‑o no seu dispositivo, conforme descrito na página Getting started with Edge Impulse. Depois disso, crie um novo projeto na plataforma Edge Impulse, inicie o serviço de ingestão edge-impulse
edge-impulse-daemon
Se você já usou o edge-impulse-daemon antes, será necessário adicionar --clean ao comando acima para limpar os dados do projeto.
Em seguida, faça login com suas credenciais e escolha o projeto que você acabou de criar. Vá até a aba Data Acquisition e você poderá começar a obter amostras de dados.
Teremos três classes de dados:
• background
• coughing
• crying
Registre 10 amostras para cada classe, com duração de 5000 milissegundos cada. Você pode gravar os sons reproduzidos pelos alto‑falantes do computador (exceto para a classe background), mas se tiver a oportunidade de gravar sons reais, será ainda melhor.
Para a classe background grave sons que não devem ser classificados como tosse ou choro, por exemplo, pessoas conversando, ausência de sons, ar‑condicionado/ventilador e assim por diante.

30 amostras é um número assustadoramente pequeno, então também vamos enviar mais alguns dados. Basta baixar os sons da Internet, remostrálos para 16000 Hz e salvá‑los no formato .wav com este script de conversão
import librosa
import sys
import soundfile as sf
input_filename = sys.argv[1]
output_filename = sys.argv[2]
data, samplerate = librosa.load(input_filename, sr=16000)
print(data.shape, samplerate)
sf.write(output_filename, data, samplerate, subtype='PCM_16')
Copie o código e cole‑o em um documento de texto (use Notepad++, IDLE IDE ou outra IDE adequada. Não use o Bloco de Notas padrão do Windows).
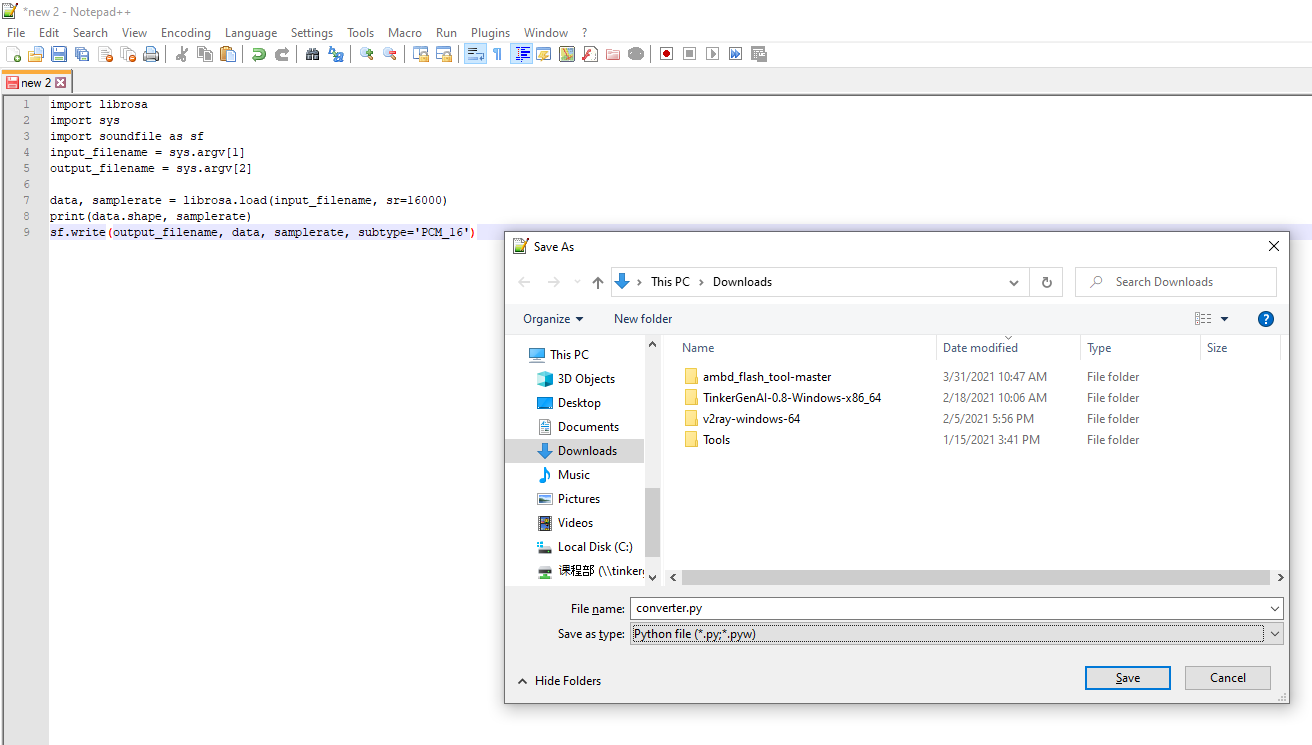
Salve o documento como converter.py e, em seguida, a partir do ambiente Anaconda, execute
python converter.py name-of-the-downloaded-file class_name.number.wav

Você pode encontrar arquivos de som de exemplo já convertidos para o formato correto no repositório Github deste projeto. Em seguida, divida todas as amostras de som para deixar apenas os trechos “interessantes” – faça isso para cada classe, exceto para background.
Depois que a coleta de dados estiver concluída, é hora de escolher os blocos de processamento e definir nosso modelo de rede neural.
Construindo um modelo de aprendizado de máquina
Entre os blocos de processamento vemos três opções familiares – a saber, Raw, Spectral Analysis, que é basicamente a transformada de Fourier do sinal, Spectrogram e MFE (bancos de energia em frequência Mel) – que correspondem às quatro etapas de processamento de áudio que descrevemos anteriormente!
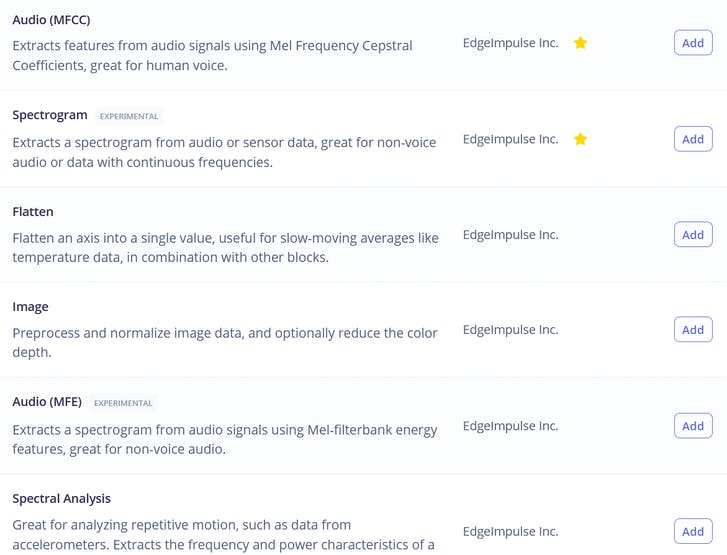
Se você gosta de experimentar, pode tentar usar todos eles nos seus dados, exceto talvez Raw, que terá dados demais para nossa rede neural relativamente pequena. Para o propósito desta lição, vamos apenas usar a melhor opção para esta tarefa, que é MFE ou bancos de energia em frequência mel (Mel-Frequency Energy). Depois de calcular as features, vá para a aba NN classifier e escolha uma arquitetura de modelo adequada. As duas opções que temos são usar 1D Conv e 2D Conv. Ambas funcionarão, mas, se possível, devemos sempre optar por um modelo menor, já que vamos querer implantá-lo em um dispositivo embarcado. Ao escrever os materiais para este curso, executamos 4 experimentos diferentes, 1D Conv/2D Conv com features MFE e MFCC e os resultados deles estão nesta tabela.

O melhor modelo foi a rede 1D Conv com bloco de processamento MFE. Ajustando os parâmetros de MFE (aumentando o stride para 0,02 e diminuindo a frequência baixa para 0) alcançamos uma acurácia de 89,4% no conjunto de validação.
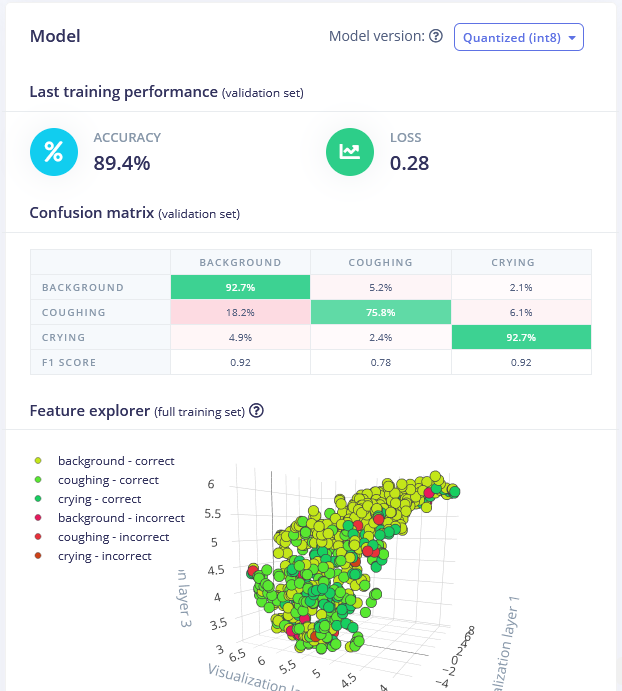
Você pode encontrar o modelo treinado aqui e testá-lo você mesmo. Embora ele seja bom em distinguir sons de choro do fundo, a acurácia de detecção de tosse é um pouco baixa e pode exigir obter mais amostras.
Implantando no Wio Terminal
Depois que tivermos nosso modelo e estivermos satisfeitos com sua acurácia no treinamento, podemos testá-lo em novos dados na aba Live classification e então implantá-lo no Wio Terminal. Nós o baixaremos como biblioteca Arduino, colocaremos na pasta de bibliotecas do Arduino e abriremos Examples -> nome do seu projeto -> nano_33_ble_sense_microphone_continuous. A demonstração é baseada no Arduino Nano 33 BLE e usa a biblioteca PDM. Para o Wio Terminal vamos depender do DMA, ou controlador de Acesso Direto à Memória (Direct Memory Access), para obter amostras do ADC (Conversor Analógico-Digital) e salvá-las no buffer de inferência sem envolvimento do MCU.
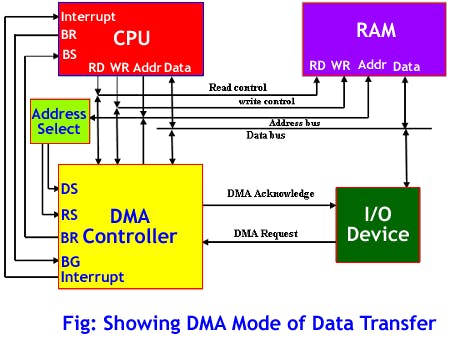
Isso nos permitirá coletar as amostras de som e executar a inferência ao mesmo tempo. Há bastantes mudanças que precisamos fazer para alterar a coleta de dados de som da biblioteca PDM para DMA; se você se sentir um pouco perdido durante a explicação, dê uma olhada no código de exemplo completo, que você pode encontrar nos materiais do curso. Exclua a biblioteca PDM do sketch
#include <PDM.h>
Adicione a estrutura de descritor do DMA e outras constantes de configuração logo após a última declaração include
// Settings
#define DEBUG 1 // Enable pin pulse during ISR
enum {ADC_BUF_LEN = 4096}; // Size of one of the DMA double buffers
static const int debug_pin = 1; // Toggles each DAC ISR (if DEBUG is set to 1)
// DMAC descriptor structure
typedef struct {
uint16_t btctrl;
uint16_t btcnt;
uint32_t srcaddr;
uint32_t dstaddr;
uint32_t descaddr;
} dmacdescriptor;
Então, logo antes da função setup, crie variáveis para os arrays de buffer, variáveis voláteis para passar os valores entre a função de callback da ISR e o código principal e também um filtro Butterworth passa-alta, que aplicaremos ao sinal para eliminar a maior parte do componente DC no sinal do microfone.
// Globals - DMA and ADC
volatile uint8_t recording = 0;
volatile boolean results0Ready = false;
volatile boolean results1Ready = false;
uint16_t adc_buf_0[ADC_BUF_LEN]; // ADC results array 0
uint16_t adc_buf_1[ADC_BUF_LEN]; // ADC results array 1
volatile dmacdescriptor wrb[DMAC_CH_NUM] __attribute__ ((aligned (16))); // Write-back DMAC descriptors
dmacdescriptor descriptor_section[DMAC_CH_NUM] __attribute__ ((aligned (16))); // DMAC channel descriptors
dmacdescriptor descriptor __attribute__ ((aligned (16))); // Place holder descriptor
//High pass butterworth filter order=1 alpha1=0.0125
class FilterBuHp1
{
public:
FilterBuHp1()
{
v[0]=0.0;
}
private:
float v[2];
public:
float step(float x) //class II
{
v[0] = v[1];
v[1] = (9.621952458291035404e-1f * x)
+ (0.92439049165820696974f * v[0]);
return
(v[1] - v[0]);
}
};
FilterBuHp1 filter;
Depois disso, adicione três blocos de código – o primeiro é uma função de callback, chamada pela ISR (Interrupt Service Routine) toda vez que um dos dois buffers é preenchido. Dentro dessa função lemos elementos do buffer de gravação (aquele que acabou de ser preenchido), processamos e colocamos em um buffer de inferência.
/*******************************************************************************
* Interrupt Service Routines (ISRs)
*/
/**
* @brief Copy sample data in selected buf and signal ready when buffer is full
*
* @param[in] *buf Pointer to source buffer
* @param[in] buf_len Number of samples to copy from buffer
*/
static void audio_rec_callback(uint16_t *buf, uint32_t buf_len) {
static uint32_t idx = 0;
// Copy samples from DMA buffer to inference buffer
if (recording) {
for (uint32_t i = 0; i < buf_len; i++) {
// Convert 12-bit unsigned ADC value to 16-bit PCM (signed) audio value
inference.buffers[inference.buf_select][inference.buf_count++] = filter.step(((int16_t)buf[i] - 1024) * 16);
// Swap double buffer if necessary
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
O próximo bloco contém a própria ISR – ela é executada por um temporizador em um determinado período de tempo; dentro dessa função verificamos se o canal 1 do DMAC foi suspenso – se tiver sido suspenso, isso significa que um dos buffers para dados do microfone foi preenchido e precisamos copiar os dados dele, alternar para o outro buffer e reiniciar o ADC do DMAC.
/**
* Interrupt Service Routine (ISR) for DMAC 1
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// Check if DMAC channel 1 has been suspended (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// Debug: make pin high before copying buffer
#if DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// Restart DMAC on channel 1 and clear SUSP interrupt flag
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// See which buffer has filled up, and dump results into large buffer
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// Flip to next buffer
count = (count + 1) % 2;
// Debug: make pin low after copying buffer
#if DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
O próximo bloco contém os dados de configuração para o ADC DMAC e o temporizador que controla a ISR (Interrupt Service Routine)
// Configure DMA to sample from ADC at regular interval
void config_dma_adc() {
// Configure DMA to sample from ADC at a regular interval (triggered by timer/counter)
DMAC->BASEADDR.reg = (uint32_t)descriptor_section; // Specify the location of the descriptors
DMAC->WRBADDR.reg = (uint32_t)wrb; // Specify the location of the write back descriptors
DMAC->CTRL.reg = DMAC_CTRL_DMAENABLE | DMAC_CTRL_LVLEN(0xf); // Enable the DMAC peripheral
DMAC->Channel[1].CHCTRLA.reg = DMAC_CHCTRLA_TRIGSRC(TC5_DMAC_ID_OVF) | // Set DMAC to trigger on TC5 timer overflow
DMAC_CHCTRLA_TRIGACT_BURST; // DMAC burst transfer
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_0 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_1 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
// Configure NVIC
NVIC_SetPriority(DMAC_1_IRQn, 0); // Set the Nested Vector Interrupt Controller (NVIC) priority for DMAC1 to 0 (highest)
NVIC_EnableIRQ(DMAC_1_IRQn); // Connect DMAC1 to Nested Vector Interrupt Controller (NVIC)
// Activate the suspend (SUSP) interrupt on DMAC channel 1
DMAC->Channel[1].CHINTENSET.reg = DMAC_CHINTENSET_SUSP;
// Configure ADC
ADC1->INPUTCTRL.bit.MUXPOS = ADC_INPUTCTRL_MUXPOS_AIN12_Val; // Set the analog input to ADC0/AIN2 (PB08 - A4 on Metro M4)
while(ADC1->SYNCBUSY.bit.INPUTCTRL); // Wait for synchronization
ADC1->SAMPCTRL.bit.SAMPLEN = 0x00; // Set max Sampling Time Length to half divided ADC clock pulse (2.66us)
while(ADC1->SYNCBUSY.bit.SAMPCTRL); // Wait for synchronization
ADC1->CTRLA.reg = ADC_CTRLA_PRESCALER_DIV128; // Divide Clock ADC GCLK by 128 (48MHz/128 = 375kHz)
ADC1->CTRLB.reg = ADC_CTRLB_RESSEL_12BIT | // Set ADC resolution to 12 bits
ADC_CTRLB_FREERUN; // Set ADC to free run mode
while(ADC1->SYNCBUSY.bit.CTRLB); // Wait for synchronization
ADC1->CTRLA.bit.ENABLE = 1; // Enable the ADC
while(ADC1->SYNCBUSY.bit.ENABLE); // Wait for synchronization
ADC1->SWTRIG.bit.START = 1; // Initiate a software trigger to start an ADC conversion
while(ADC1->SYNCBUSY.bit.SWTRIG); // Wait for synchronization
// Enable DMA channel 1
DMAC->Channel[1].CHCTRLA.bit.ENABLE = 1;
// Configure Timer/Counter 5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // Enable perhipheral channel for TC5
GCLK_PCHCTRL_GEN_GCLK1; // Connect generic clock 0 at 48MHz
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // Set TC5 to Match Frequency (MFRQ) mode
TC5->COUNT16.CC[0].reg = 3000 - 1; // Set the trigger to 16 kHz: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // Wait for synchronization
// Start Timer/Counter 5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // Enable the TC5 timer
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // Wait for synchronization
}
Adicione a condição de depuração no topo da função de configuração:
// Configure pin to toggle on DMA interrupt
#if DEBUG
pinMode(debug_pin, OUTPUT);
#endif
Em seguida, na função setup, depois de run_classifier_init(); adicione o seguinte código que cria buffers de inferência, configura o DMA e inicia a gravação definindo a variável global volátil recording como 1.
// Create double buffer for inference
inference.buffers[0] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE * sizeof(int16_t));
if (inference.buffers[0] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 0");
return;
}
inference.buffers[1] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE *
sizeof(int16_t));
if (inference.buffers[1] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 1");
free(inference.buffers[0]);
return;
}
// Set inference parameters
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = EI_CLASSIFIER_SLICE_SIZE;
inference.buf_ready = 0;
// Configure DMA to sample from ADC at 16kHz (start sampling immediately)
config_dma_adc();
// Start recording to inference buffers
recording = 1;
}
Delete PDM.end(); e free(sampleBuffer); da função microphone_inference_end(void) e também das funções microphone_inference_start(uint32_t n_samples) e pdm_data_ready_inference_callback(void), já que não estamos as utilizando.
Depois de compilar e enviar o código, abra o monitor Serial e você verá as probabilidades de cada classe sendo impressas. Reproduza alguns sons ou tussa perto do Wio Terminal para verificar a precisão!
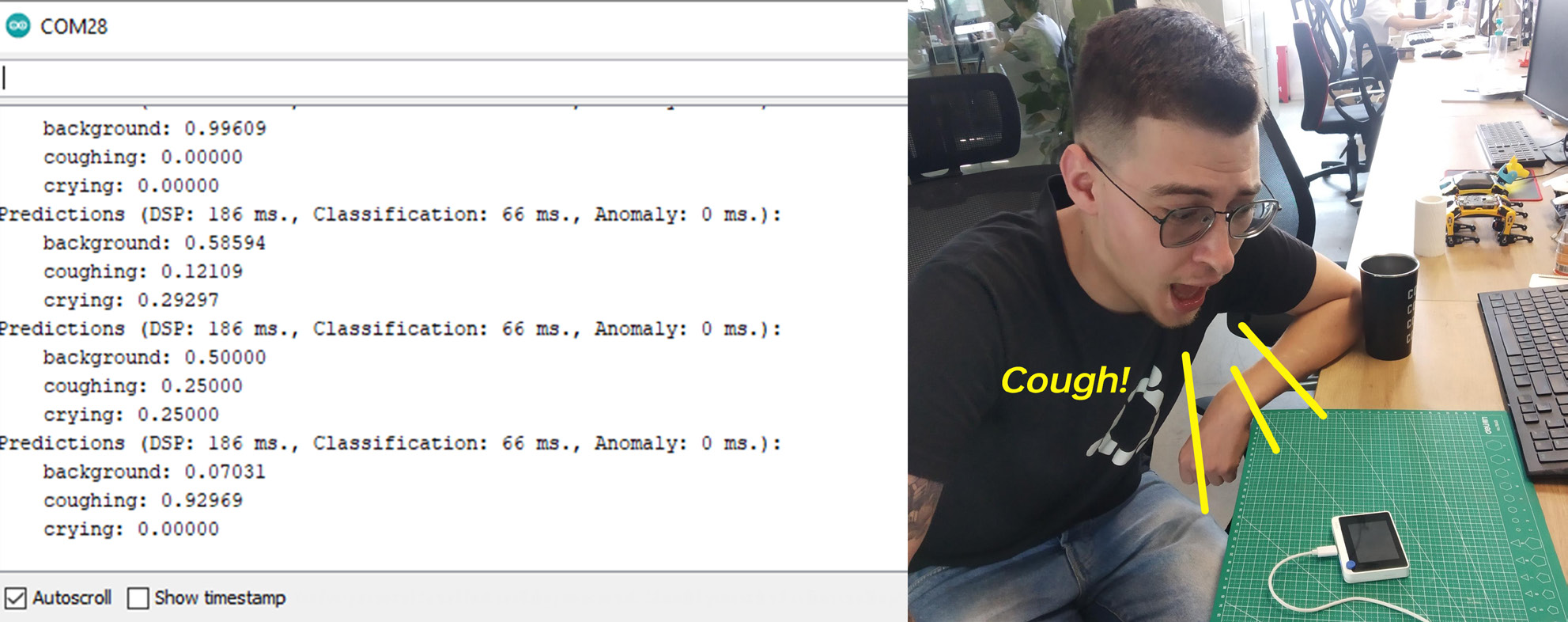
Integração com Blynk
Como o Wio Terminal pode se conectar à Internet, podemos pegar este demo simples e transformá-lo em uma aplicação IoT real com o Blynk.
Blynk é uma plataforma que permite criar rapidamente interfaces para controlar e monitorar seus projetos de hardware a partir de seus dispositivos iOS e Android. Neste caso, usaremos o Blynk para enviar notificações para nosso smartphone se o Wio Terminal detectar quaisquer sons com os quais devamos nos preocupar. Para começar com o Blynk, baixe o app, registre uma nova conta e crie um novo projeto. Adicione um elemento de notificação push a ele e pressione o botão play.

Em seguida, certifique-se de que você configurou as bibliotecas e o firmware de WiFi do Wio Terminal, de acordo com o guia aqui. Baixe a biblioteca Blynk conforme descrito naquele tutorial.
Depois, teste sua configuração compilando e enviando o exemplo simples de botão – certifique-se de alterar o SSID do WiFi, a senha e o seu token de API do Blynk, que você pode obter no app.
#define BLYNK_PRINT Serial
#include <rpcWiFi.h>
#include <WiFiClient.h>
#include <BlynkSimpleWioTerminal.h>
char auth[] = "token";
char ssid[] = "ssid";
char pass[] = "password";
void checkPin()
{
int isButtonPressed = !digitalRead(WIO_KEY_A);
if (isButtonPressed) {
Serial.println("Button is pressed.");
Blynk.notify("Yaaay... button is pressed!");
}
}
void setup()
{
Serial.begin(115200);
Blynk.begin(auth, ssid, pass);
pinMode(WIO_KEY_A, INPUT_PULLUP);
}
void loop()
{
Blynk.run();
checkPin();
}
Se o código compilar e o teste for bem-sucedido (pressionar o botão superior esquerdo no Wio Terminal fizer com que uma notificação push apareça no seu telefone), então você pode seguir para a próxima etapa.
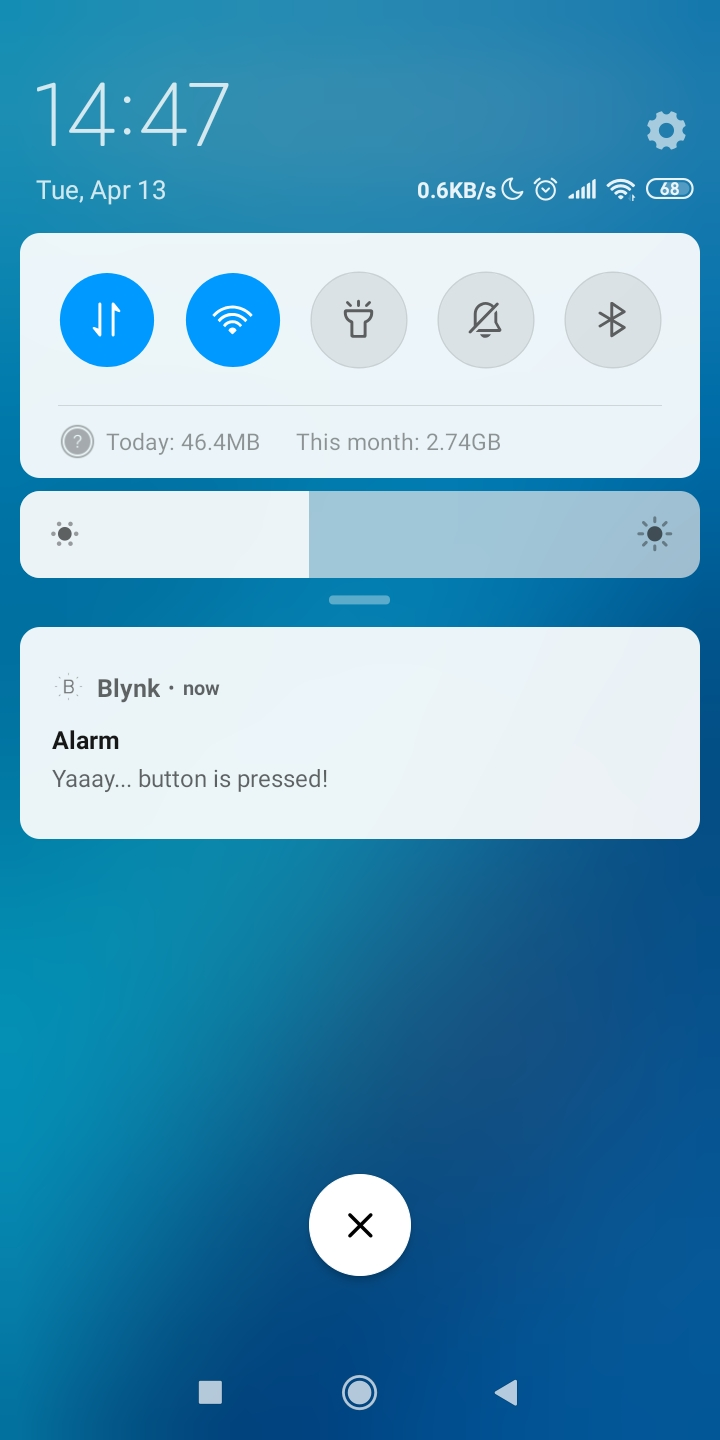
Vamos mover todo o código de inferência da rede neural para uma função separada e chamá-la na função loop() logo após Blynk.run(). De forma semelhante ao que fizemos antes, verificamos as probabilidades de predição da rede neural e, se forem maiores que o limite para uma determinada classe, chamamos a função Blynk.notify(), que, como você deve ter imaginado, envia uma notificação para o seu dispositivo móvel.
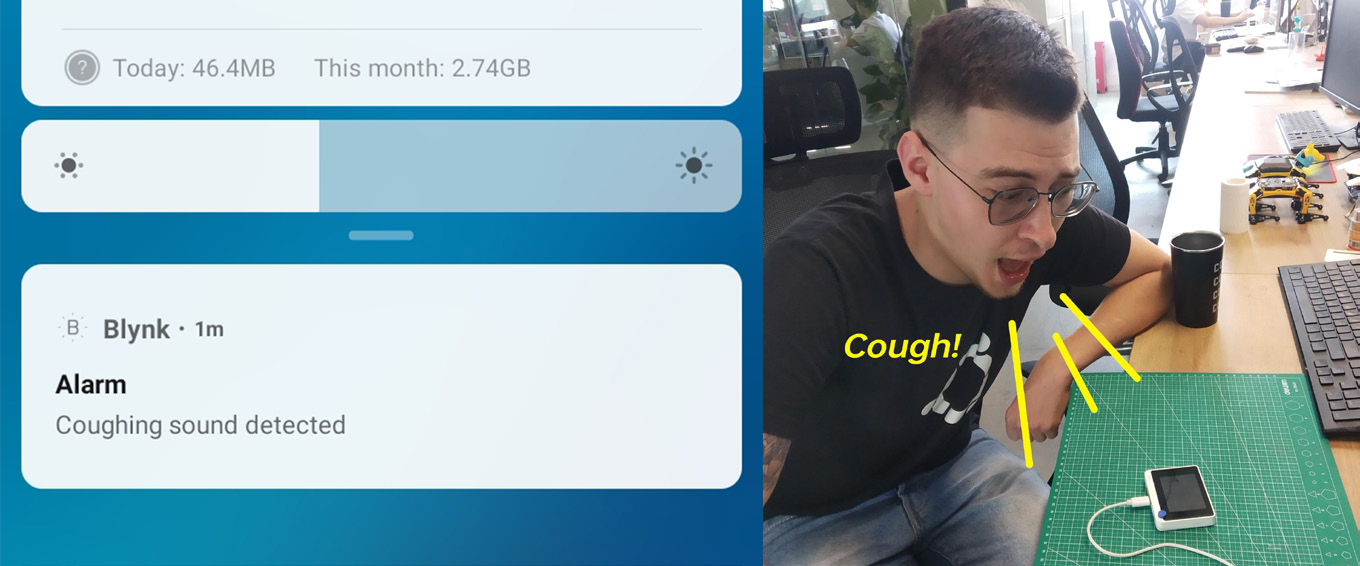
Encontre o código completo para a inferência da RN + notificação Blynk no repositório Github deste projeto.