Estação meteorológica inteligente Wio Terminal Tensorflow Lite Micro com BME280
Neste projeto vamos usar o Wio Terminal e o Tensorflow Lite para Microcontroladores para criar uma estação meteorológica inteligente, capaz de prever o tempo e a precipitação nas próximas 24 horas com base em dados locais do sensor ambiental BME280.

Para mais detalhes e elementos visuais, assista ao vídeo correspondente!
Você aprenderá como aplicar técnicas de otimização de modelo, que permitirão não apenas executar uma rede neural convolucional de tamanho médio, mas também ter essa interface gráfica elegante e a conexão WiFi rodando tudo ao mesmo tempo por dias e meses seguidos!

Este é o resultado final; você pode ver que há os valores atuais de temperatura, umidade e pressão atmosférica exibidos na tela, junto com o nome da cidade, o tipo de tempo previsto e a chance de precipitação prevista – e na parte inferior da tela há um campo de saída de log, que você pode reutilizar facilmente para exibir informações de clima extremo ou outras informações relevantes. Embora já pareça bom e útil assim, há muitas coisas que você pode adicionar – por exemplo, a saída de notícias/tweets mencionada acima na tela ou o uso do modo de sono profundo para economizar energia e torná-la alimentada por bateria e assim por diante.
Neste projeto vamos lidar com dados de séries temporais, como já fizemos várias vezes antes – a única grande diferença desta vez é que o período de tempo é muito maior para a previsão do tempo. Vamos fazer uma medição a cada hora e realizar a previsão com base em 24 horas de dados. Além disso, como vamos prever o tipo médio de tempo para as próximas 24 horas, também vamos prever a chance de precipitação para as próximas 24 horas, com o mesmo modelo. Para isso, utilizaremos o Keras Functional API e um modelo com múltiplas saídas.
Dentro do modelo com múltiplas saídas haverá “um tronco”, comum para ambas as saídas, que vai “se ramificar” em duas saídas diferentes. O principal benefício de usar um modelo multi‑saída em comparação com dois modelos independentes aqui é que os dados e as características aprendidas usadas para prever o tipo de tempo e a chance de precipitação são altamente relacionados.
Se você estiver fazendo este projeto no Windows, a primeira coisa que você precisará fazer é baixar a versão nightly do Arduino IDE, pois a versão estável atual 1.18.3 não irá compilar sketches com muitas dependências de biblioteca (o problema é que o comando do linker durante a compilação excede o comprimento máximo no Windows).
Em segundo lugar, você precisa garantir que tenha a versão 1.8.2 das definições de placa Seeed SAMD no Arduino IDE.
Por fim, como estamos usando uma rede neural convolucional e a construímos com o Keras API, ela contém uma operação não suportada pela versão estável atual do Tensorflow Micro. Pesquisando as issues do Tensorflow no Github, encontrei um pull request para adicionar essa operação (EXPAND_DIMS) à lista de operações disponíveis, mas ele não havia sido mesclado ao branch master no momento da produção deste vídeo. Você pode executar git clone no repositório Tensorflow, mudar para o branch do PR e compilar a biblioteca do Arduino executando ./tensorflow/lite/micro/tools/ci_build/test_arduino.sh em uma máquina Linux – a biblioteca resultante pode ser encontrada em tensorflow/lite/micro/tools/make/gen/arduino_x86_64/prj/tensorflow_lite.zip. Alternativamente, você pode baixar a biblioteca já compilada do repositório Github deste projeto e colocá‑la na pasta de bibliotecas de sketches do Arduino – apenas certifique‑se de ter apenas uma biblioteca Tensorflow lite de cada vez!
Entendendo os dados
Tudo começa com os dados, é claro. Para este tutorial usaremos um conjunto de dados meteorológicos facilmente disponível no Kaggle, Historical Hourly Weather Data 2012-2017. A sede da Seeed EDU está localizada em Shenzhen, uma cidade no sul da China – e essa cidade está ausente do conjunto de dados, então escolhemos uma cidade que está localizada em latitude semelhante e também tem um clima subtropical – Miami.
Você precisará escolher uma cidade que pelo menos se assemelhe ao clima onde você mora – é claro que o modelo treinado com dados de Miami e depois implantado em Chicago no inverno não fornecerá previsões corretas.
Construindo um modelo de aprendizado de máquina
Para a etapa de processamento de dados e treinamento do modelo, vamos abrir o Jupyter Notebook que você pode encontrar nos materiais do curso. A maneira mais fácil de executar esse notebook é enviá‑lo para o Google Colab, pois ele já possui todos os pacotes instalados e prontos para uso.
Como alternativa, você pode executar o notebook localmente – para isso, primeiro instale todas as dependências necessárias no ambiente virtual executando
pip install -r requirements.txt
com o ambiente virtual ml que você criou anteriormente ativado. Em seguida, execute o comando jupyter notebook no mesmo ambiente, o que abrirá o servidor de notebooks no seu navegador padrão.
Os Jupyter Notebooks são uma ótima maneira de explorar e apresentar dados, pois permitem ter texto e código executável no mesmo ambiente. O fluxo de trabalho geral é explicado nas seções de texto do Notebook.
Implantando no Wio Terminal
O modelo que você treinou na última etapa foi convertido em um array de bytes, que contém a estrutura e os pesos do modelo e agora pode ser carregado no Wio Terminal junto com o código C++.
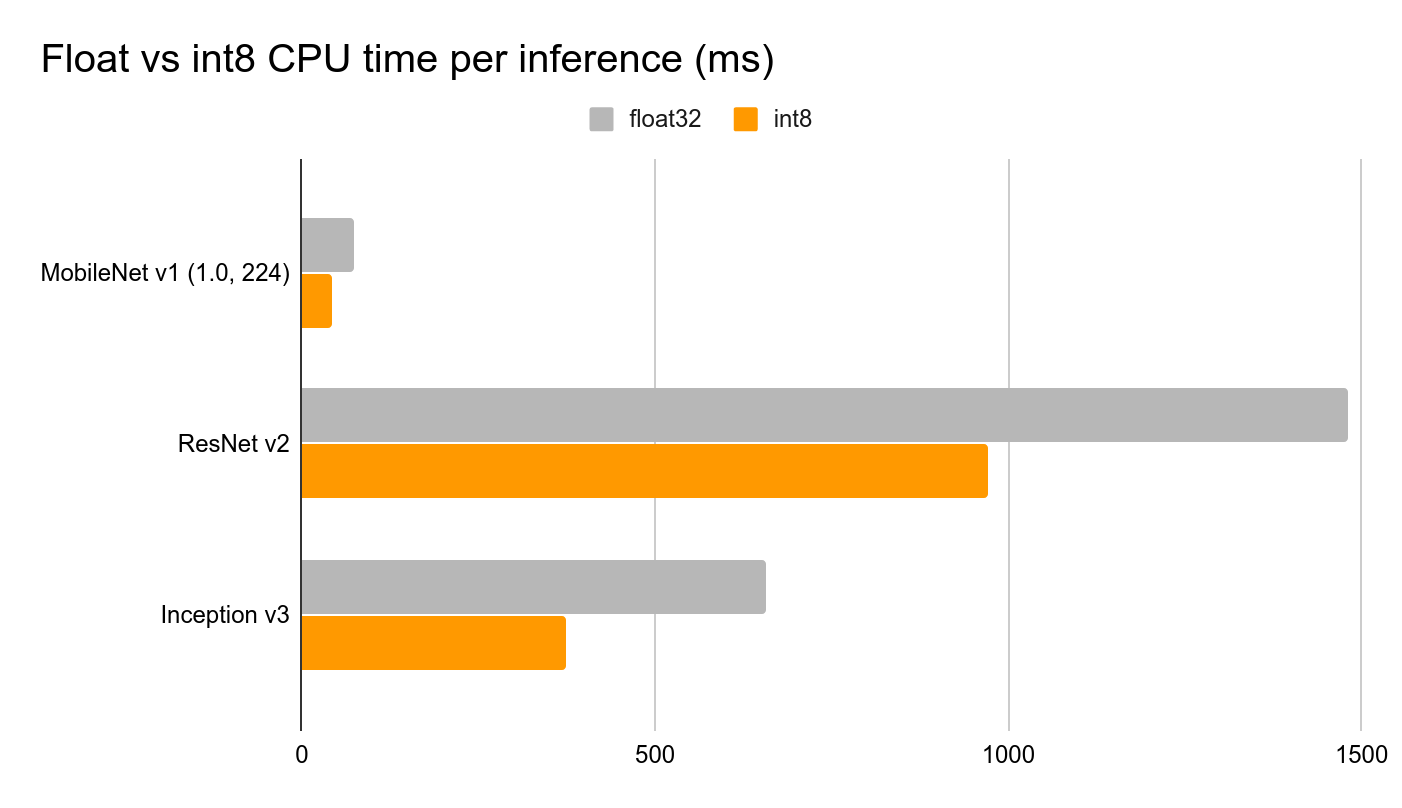
O Tensorflow Lite para Microcontroladores inclui o interpretador do modelo, que é projetado para ser leve e rápido. O interpretador usa uma ordenação estática do grafo e um alocador de memória personalizado (menos dinâmico) para garantir carga, inicialização e latência de execução mínimas. Os dados colocados nos buffers de entrada são alimentados ao grafo do modelo e, quando a inferência é concluída, os resultados são colocados no buffer de saída. Para reduzir o tamanho do modelo e diminuir o tempo de inferência, realizamos duas otimizações importantes: • Realizar quantização totalmente inteira, alterando os pesos do modelo, entradas e saídas de números de ponto flutuante de 32 bits (cada um ocupando 32 bits de memória) para números inteiros de 8 bits (cada um ocupando apenas 8 bits), reduzindo assim o tamanho em um fator de 4.
• Usar micro_mutable_op_resolver e especificar as operações que temos na rede neural, para compilar nosso código apenas com as operações necessárias para executar o modelo, em vez de usar all_ops_resolver, que inclui todas as operações suportadas pelo interpretador atual do Tensorflow Lite para Microcontroladores.
Quando o treinamento do modelo terminar, crie um sketch vazio e salve‑o. Em seguida, copie o modelo que você treinou para a pasta do sketch e reabra o sketch. Altere o nome da variável do modelo e o comprimento do modelo para algo mais curto. Em seguida, use o código de wio_terminal_tfmicro_weather_prediction_static.ino, que você pode encontrar nos materiais do curso para testes.
Vamos passar pelas principais etapas que temos no código C++ Incluímos os cabeçalhos da biblioteca Tensorflow e o arquivo com o flatbuffer do modelo
#include <TensorFlowLite.h>
//#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/system_setup.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "model_Conv1D.h"
Observe como eu deixei micro_mutable_op_resolver.h comentado e all_ops_resolver.h habilitado – o cabeçalho all_ops_resolver.h compila todas as operações atualmente presentes no Tensorflow Micro e é conveniente para testes, mas, depois que você terminar os testes, é muito melhor mudar para micro_mutable_op_resolver.h para economizar memória do dispositivo – isso faz uma grande diferença.
Em seguida, definimos os ponteiros para o relatador de erros, modelo, tensores de entrada e saída e interpretador. Observe como nosso modelo tem duas saídas – uma para a quantidade de precipitação e outra para o tipo de tempo. Também definimos a tensor arena, que você pode pensar como um quadro de rascunho, contendo arrays de entrada, saída e intermediários – o tamanho necessário dependerá do modelo que você estiver usando e pode precisar ser determinado por experimentação.
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* input = nullptr;
TfLiteTensor* output_type = nullptr;
TfLiteTensor* output_precip = nullptr;
constexpr int kTensorArenaSize = 1024*25;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
Então, na função setup, há mais código padrão, como a instanciação do relatador de erros, resolvedor de operadores, interpretador, mapeamento do modelo, alocação de tensores e, por fim, verificação dos formatos dos tensores após a alocação. É aqui que o código pode gerar um erro em tempo de execução, se algumas das operações do modelo não forem suportadas pela versão atual da biblioteca Tensorflow Micro. Caso você tenha operações não suportadas, você pode ou mudar a arquitetura do modelo ou adicionar o suporte ao operador você mesmo, geralmente portando-o do Tensorflow Lite.
void setup() {
Serial.begin(115200);
while (!Serial) {delay(10);}
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(Conv1D_tflite);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// This pulls in all the operation implementations we need.
// NOLINTNEXTLINE(runtime-global-variables)
//static tflite::MicroMutableOpResolver<1> resolver;
static tflite::AllOpsResolver resolver;
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}
// Obtain pointers to the model's input and output tensors.
input = interpreter->input(0);
output_type = interpreter->output(1);
output_precip = interpreter->output(0);
Serial.println(input->dims->size);
Serial.println(input->dims->data[1]);
Serial.println(input->dims->data[2]);
Serial.println(input->type);
Serial.println(output_type->dims->size);
Serial.println(output_type->dims->data[1]);
Serial.println(output_type->type);
Serial.println(output_precip->dims->size);
Serial.println(output_precip->dims->data[1]);
Serial.println(output_precip->type);
}
Por fim, na função loop definimos um placeholder para valores INT8 quantizados e um array com valores float, que você pode copiar e colar do notebook Colab para comparação da inferência do modelo no dispositivo vs. no Colab.
void loop() {
int8_t x_quantized[72];
float x[72] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0};
Quantizamos os valores float para INT8 no laço for e os colocamos no tensor de entrada um por um:
for (byte i = 0; i < 72; i = i + 1) {
input->data.int8[i] = x[i] / input->params.scale + input->params.zero_point;
}
Em seguida, a inferência é realizada pelo interpretador Tensorflow Micro e, se nenhum erro for reportado, os valores são colocados nos tensores de saída.
// Run inference, and report any error
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed");
return;
}
Semelhante à entrada, a saída do modelo também é quantizada, então precisamos realizar a operação inversa e convertê-la de INT8 para float.
// Obtain the quantized output from model's output tensor
float y_type[4];
// Dequantize the output from integer to floating-point
int8_t y_precip_q = output_precip->data.int8[0];
Serial.println(y_precip_q);
float y_precip = (y_precip_q - output_precip->params.zero_point) * output_precip->params.scale;
Serial.print("Precip: ");
Serial.print(y_precip);
Serial.print("\t");
Serial.print("Type: ");
for (byte i = 0; i < 4; i = i + 1) {
y_type[i] = (output_type->data.int8[i] - output_type->params.zero_point) * output_type->params.scale;
Serial.print(y_type[i]);
Serial.print(" ");
}
Serial.print("\n");
}
Verifique e compare os valores para o mesmo ponto de dados; eles devem ser os mesmos para o modelo quantizado Tensorflow Lite no notebook Colab e o modelo Tensorflow Micro rodando no seu Wio Terminal.

Interface LVGL e WiFi
Agora o próximo passo é transformar isso de um demo em um projeto realmente útil. Abra o sketch wio_terminal_tfmicro_weather_prediction_static.ino dos materiais do curso e dê uma olhada em seu conteúdo.

O código é dividido em sketch principal, get_historical_data e partes de GUI. Como nosso modelo requer os dados das últimas 24 horas, precisaríamos esperar 24 horas para realizar a primeira inferência, o que é muito – para resolver esse problema, obtemos o clima das últimas 24 horas da API do openweathermap.com e podemos realizar a primeira inferência imediatamente após o dispositivo iniciar e então substituir os valores no buffer circular pela temperatura, umidade e pressão do sensor BME280 conectado ao conector Grove I2C do Wio Terminal. Para a GUI usamos LVGL, uma Little and Versatile Graphics Library.

Compile e faça o upload do código, certifique-se de alterar as credenciais de WiFi, sua localização e a chave de API do openweathermap.com no sketch antes de enviar. Após o upload, o dispositivo irá se conectar à Internet, obter os dados das últimas 24 horas para sua localização e realizar a primeira inferência. Em seguida, ele irá aguardar 1 hora antes de obter os valores do sensor BME280 conectado ao Wio Terminal – se nenhum sensor estiver conectado, o programa não irá inicializar.