Reconhecimento de fala com Tensorflow Lite Micro no Wio Terminal – Conversão de fala em intenção
Uma abordagem tradicional para usar fala no controle de dispositivos/atendimento de solicitações do usuário é, primeiro, transcrever a fala em texto e depois analisar o texto em comandos/consultas em um formato adequado. Embora essa abordagem ofereça muita flexibilidade em termos de vocabulário e/ou cenários de aplicação, uma combinação de modelo de reconhecimento de fala e analisador dedicado não é adequada para os recursos limitados de microcontroladores.
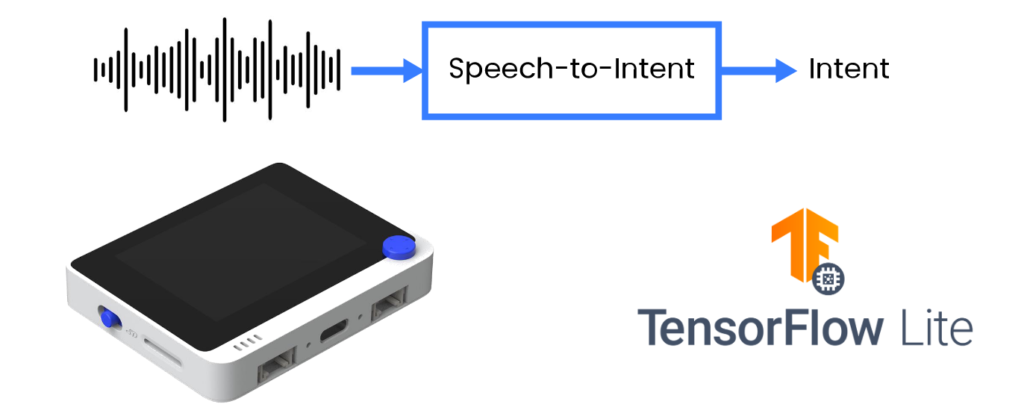
Fonte: Wio Terminal, Picovoice, Tensorflow Lite
Neste projeto vamos empregar um método mais eficiente e analisar diretamente as falas do usuário em uma saída acionável na forma de intenção/slots. Vamos compartilhar técnicas para treinar um modelo de conversão de fala em intenção para um domínio específico e implantá‑lo em uma placa de desenvolvimento baseada em Cortex M4F com microfone embutido, o Wio Terminal da Seeed Studio.
Para mais detalhes e materiais visuais, assista ao vídeo correspondente!
Existem diferentes tipos de tarefas de reconhecimento de fala – podemos dividi‑las grosseiramente em três grupos:
- Reconhecimento de fala contínua de grande vocabulário (LVCSR)
- Detecção de palavra‑chave
- Conversão de fala em intenção (Speech-to-Intent)
A detecção de palavra‑chave funciona bem em microcontroladores, é relativamente fácil de treinar com uma variedade de ferramentas open‑source no‑code disponíveis, por exemplo Edge Impulse, mas não lida bem com vocabulários grandes.
Se quisermos que um dispositivo execute uma ação útil com base na entrada de fala, precisamos combinar um modelo LVCSR e um analisador de linguagem natural baseado em texto – essa abordagem é robusta e relativamente fácil de implementar, dada a abundância de mecanismos de ASR disponíveis publicamente, mas não é adequada para rodar nem mesmo em SBCs, muito menos em microcontroladores.
Há uma terceira via, a conversão direta da fala em intenção analisada, baseada em um vocabulário de domínio específico. Vamos pegar como exemplo uma máquina de lavar inteligente ou lâmpadas inteligentes. Um modelo de conversão de fala em intenção, ao processar o enunciado “Normal cycle with low-spin”, produziria a intenção analisada, por exemplo
{ Intent: washClothes },
{ Slots: cycle: normal,
spin: low,
water: default }
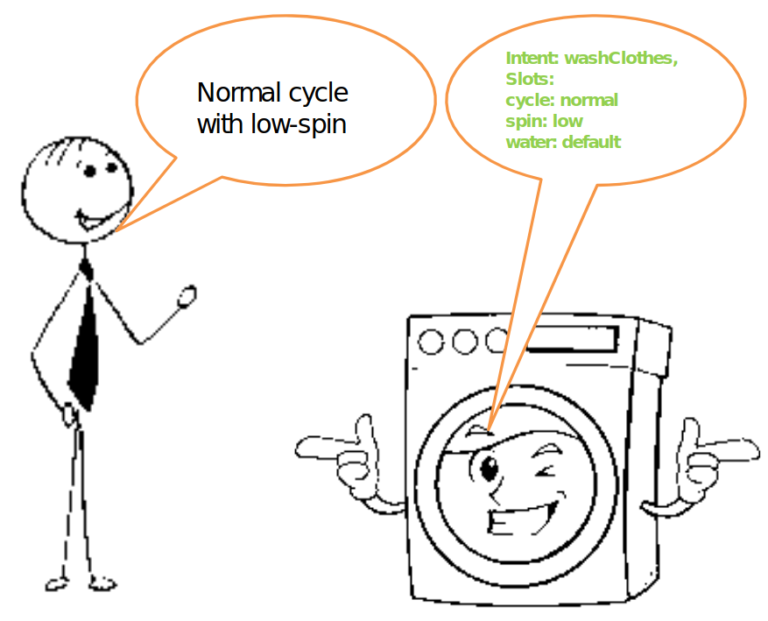
E isso é realmente tudo o que precisamos para conseguir controlar essa máquina de lavar inteligente com a voz.
A conversão de fala em intenção é bem representada em pesquisas, mas carece de implementações open‑source amplamente disponíveis que sejam adequadas para microcontroladores. Pronto para produção, não open‑source:
- Picovoice
- Fluent.ai
Pronto para produção, FOSS, não adequado para microcontroladores:
- Speechbrain.io
Para o treinamento do modelo você pode usar ou um Jupyter Notebook que preparamos ou scripts de treinamento do repositório do Github (encontre‑os na seção Referência ao final do artigo). O Jupyter Notebook contém uma implementação de modelo de referência bem básica e também traz explicações para cada célula.
Depois que o modelo estiver treinado, copie‑o para a pasta com o código do Wio Terminal e altere o nome do modelo na linha 106 para o nome do seu modelo. Vamos passar pelas partes mais importantes do código. Ele pode ser grosseiramente dividido em três partes:
- aquisição de áudio
- cálculo de MFCC
- inferência sobre as características MFCC
Aquisição de áudio

Para gravar som para processamento com o microfone embutido do Wio Terminal usamos a função DMA ADC do MCU Cortex M4F. DMA significa acesso direto à memória e é exatamente isso que o nome indica – uma parte específica do MCU chamada DMAC ou Direct Memory Access Control é configurada antecipadamente para “canalizar” os dados de um local (por exemplo, memória interna, SPI, I2C, ADC ou outra interface) para outro. Dessa forma, a transferência pode acontecer sem muita participação do MCU, além da configuração inicial. Definimos aqui a origem e o destino da transferência
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_0 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_1 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
Como especificamos com o parâmetro DMAC_BTCTRL_BLOCKACT_SUSPEND; no descritor de DMA, o canal de DMA deve ser suspenso após uma transferência completa de bloco. Em seguida, configuramos uma ISR (Interrupt Service Routine) disparada com o temporizador TC5:
// Configure Timer/Counter 5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // Enable perhipheral channel for TC5
GCLK_PCHCTRL_GEN_GCLK1; // Connect generic clock 0 at 48MHz
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // Set TC5 to Match Frequency(MFRQ) mode
TC5->COUNT16.CC[0].reg = 3000 - 1; // Set the trigger to 16 kHz: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // Wait for synchronization
// Start Timer/Counter 5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // Enable the TC5 timer
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // Wait for synchronization
A ISR chamará uma função específica em intervalos de tempo igualmente espaçados, controlados pelo temporizador TC5. Vamos dar uma olhada nessa função.
/**
* Interrupt Service Routine (ISR) for DMAC 1
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// Check if DMAC channel 1 has been suspended (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// Debug: make pin high before copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// Restart DMAC on channel 1 and clear SUSP interrupt flag
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// See which buffer has filled up, and dump results into large buffer
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// Flip to next buffer
count = (count + 1) % 2;
// Debug: make pin low after copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
A função ISR chamada DMAC1_Handler() verifica se o Canal 1 do DMAC foi suspenso – o que acontece quando um bloco de informações termina de ser gravado. Se foi, ela chama uma função definida pelo usuário, audio_rec_callback(), onde copiamos o conteúdo do buffer DMA ADC preenchido para um buffer (possivelmente) maior usado para calcular as características MFCC. Opcionalmente também aplicamos algum pós‑processamento de áudio nessa etapa.
Cálculo de MFCC
A extração de características MFCC para coincidir com o código da operação MFCC do TensorFlow é adaptada do repositório da ARM para Keyword Search em Microcontroladores ARM. Você pode encontrar o código original aqui.
A maior parte do trabalho relacionado ao cálculo das características MFCC acontece dentro do método mfcc_compute(const int16_t audio_data, float mfcc_out) da classe MFCC. O método recebe um ponteiro para os dados de áudio, no nosso caso 320 pontos de dados de som, e um ponteiro para uma posição específica no array de valores de saída MFCC. Para um recorte de tempo fazemos as seguintes operações:
Normalizamos os dados para -1,1 e fazemos o padding (no nosso caso o padding não acontece, já que os dados de áudio têm sempre o tamanho exato necessário para calcular um recorte de características MFCC):
//TensorFlow way of normalizing .wav data to (-1,1)
for (i = 0; i < frame_len; i++) {
frame[i] = (float)audio_data[i]/(1<<15);
}
//Fill up remaining with zeros
memset(&frame[frame_len], 0, sizeof(float) * (frame_len_padded-frame_len));
Calculamos a RFTT ou Real Fast Fourier Transform com a função da biblioteca ARM Math:
//Compute FFT
arm_rfft_fast_f32(rfft, frame, buffer, 0);
Convertendo os valores para espectro de potência:
//frame is stored as [real0, realN/2-1, real1, im1, real2, im2, ...]
int32_t half_dim = frame_len_padded/2;
float first_energy = buffer[0] * buffer[0],
last_energy = buffer[1] * buffer[1]; // handle this special case
for (i = 1; i < half_dim; i++) {
float real = buffer[i*2], im = buffer[i*2 + 1];
buffer[i] = real*real + im*im;
}
buffer[0] = first_energy;
buffer[half_dim] = last_energy;
Em seguida, aplique bancos de filtros Mel às raízes quadradas dos dados salvos no buffer na última etapa. Os bancos de filtros Mel são criados quando a classe MFCC é instanciada, dentro do método create_mel_fbank(). O número de bancos de filtros, as frequências mínima e máxima são especificados pelo usuário antecipadamente – e é muito importante mantê-los consistentes entre o script de treinamento e o código de inferência, caso contrário haverá uma queda significativa na acurácia.
float sqrt_data;
//Apply mel filterbanks
for (bin = 0; bin < NUM_FBANK_BINS; bin++) {
j = 0;
float mel_energy = 0;
int32_t first_index = fbank_filter_first[bin];
int32_t last_index = fbank_filter_last[bin];
for (i = first_index; i <= last_index; i++) {
arm_sqrt_f32(buffer[i],&sqrt_data);
mel_energy += (sqrt_data) * mel_fbank[bin][j++];
}
mel_energies[bin] = mel_energy;
//avoid log of zero
if (mel_energy == 0.0)
mel_energies[bin] = FLT_MIN;
}
Por fim, fazemos a transformada cosseno discreta do array de energias Mel e a escrevemos no array de saída das características MFCC. No script original, uma quantização também é realizada nesta etapa, mas eu optei por usar o procedimento de quantização do exemplo do Tensorflow Lite para Microcontroladores.
Inferência em características MFCC
Quando todo o áudio de uma amostra (3 segundos) é processado e convertido em características MFCC, convertemos todo o array de características MFCC de valores FLOAT32 para INT8 e o alimentamos na rede neural. A inicialização e o processo de inferência do TensorFlow Lite para Microcontroladores já foram descritos em um dos meus artigos anteriores, então não vou repeti-los aqui.
Antes de compilar o sketch, certifique-se de que todas as bibliotecas necessárias estejam instaladas e que as definições das placas Seeed SAMD estejam na versão pelo menos 1.8.2 – isso é muito importante para que a biblioteca TensorFlow Lite seja compilada sem erros. Compile e faça o upload do sketch – se você tiver o parâmetro DEBUG definido como false, o código começará a rodar imediatamente e tudo o que você precisa fazer é pressionar o botão C na parte superior do Wio Terminal e dizer uma das frases do conjunto de dados. Os resultados serão exibidos tanto na tela quanto na saída do monitor Serial se o Wio Terminal estiver conectado ao computador.
Embora este curso seja baseado no Wio Terminal, já que ele é muito adequado para explorar Machine Learning Embarcada, é definitivamente possível implementá-lo em outros dispositivos. O mais fácil seria portar o código para outro MCU Cortex M4F, como o Nano33 BLE Sense – isso exigiria apenas o ajuste para um microfone diferente. Portar para outros MCUs ARM também deve ser relativamente trivial.

Portar para outras arquiteturas, por exemplo ESP32 ou K210 ou outras, exigiria reimplementar os cálculos de MFCC, já que eles usam funções específicas ARM do CMSIS-DSP.
Há várias melhorias que podem ser feitas nas arquiteturas básicas de redes neurais do projeto. Essas melhorias são:
- pré-treinamento de modelo
- seq2seq, LSTM, attention
- filtros treináveis
- AutoML, dados sintéticos
Dê uma olhada nesta palestra de TinyML sobre este tópico para saber mais sobre isso e encontrar links para os artigos!
Incentivamos você a fazer um fork do repositório de código, tentar treinar no seu próprio conjunto de dados e talvez tentar implementar arquiteturas mais avançadas ou técnicas de treinamento de modelos. Se fizer isso, não hesite em me chamar atenção aqui ou fazer um PR no Github!