Detecção de Objetos com Poucos Exemplos com YOLOv5 e Roboflow
Introdução
YOLO é um dos algoritmos de detecção de objetos mais famosos disponíveis. Ele precisa de poucas amostras para treinamento, oferecendo tempos de treinamento mais rápidos e alta precisão. Iremos demonstrar esses recursos um a um neste wiki, explicando todo o pipeline de aprendizado de máquina passo a passo, onde você coleta dados, os rotula, os treina e, por fim, detecta objetos usando os dados treinados executando o modelo treinado em um dispositivo de borda, como a plataforma NVIDIA Jetson. Além disso, iremos comparar a diferença entre usar conjuntos de dados personalizados e conjuntos de dados públicos.
O que é YOLOv5?
YOLO é uma abreviação do termo "You Only Look Once". É um algoritmo que detecta e reconhece vários objetos em uma imagem em tempo real. Ultralytics YOLOv5 é a versão mais recente do YOLO e agora é baseada no framework PyTorch.

O que é detecção de objetos com poucos exemplos?
Tradicionalmente, se você quiser treinar um modelo de aprendizado de máquina, usaria um conjunto de dados público, como o conjunto de dados Pascal VOC 2012, que consiste em cerca de 17112 imagens. No entanto, usaremos aprendizado por transferência para realizar detecção de objetos com poucos exemplos com YOLOv5, que precisa de apenas pouquíssimas amostras de treinamento. Iremos demonstrar isso neste wiki.
Hardware suportado
YOLOv5 é suportado pelo seguinte hardware:
-
Kits de Desenvolvimento Oficiais da NVIDIA:
- NVIDIA® Jetson Nano Developer Kit
- NVIDIA® Jetson Xavier NX Developer Kit
- NVIDIA® Jetson AGX Xavier Developer Kit
- NVIDIA® Jetson TX2 Developer Kit
-
SoMs Oficiais da NVIDIA:
- NVIDIA® Jetson Nano module
- NVIDIA® Jetson Xavier NX module
- NVIDIA® Jetson TX2 NX module
- NVIDIA® Jetson TX2 module
- NVIDIA® Jetson AGX Xavier module
-
Placas Carrier da Seeed:
- Jetson Mate
- Jetson SUB Mini PC
- Jetson Xavier AGX H01 Kit
- A203 Carrier Board
- A203 (Version 2) Carrier Board
- A205 Carrier Board
- A206 Carrier Board
Pré-requisitos
-
Qualquer um dos dispositivos Jetson acima executando o JetPack v4.6.1 mais recente com todos os componentes do SDK instalados (consulte este wiki como referência para instalação)
-
PC host
- O treinamento local precisa de um PC com Linux (de preferência Ubuntu)
- O treinamento em nuvem pode ser realizado a partir de um PC com qualquer sistema operacional
Primeiros passos
Executar seu primeiro projeto de detecção de objetos em um dispositivo de borda, como a plataforma Jetson, envolve simplesmente 4 etapas principais!
-
Coletar conjunto de dados ou usar conjunto de dados disponível publicamente
- Coletar conjunto de dados manualmente
- Usar conjunto de dados disponível publicamente
-
Anotar conjunto de dados usando o Roboflow
-
Treinar em PC local ou na nuvem
- Treinar em PC local (Linux)
- Treinar no Google Colab
-
Inferência em dispositivo Jetson
Coletar conjunto de dados ou usar conjunto de dados disponível publicamente
A primeira etapa de um projeto de detecção de objetos é obter dados para treinamento. Você pode baixar conjuntos de dados disponíveis publicamente ou criar seu próprio conjunto de dados! Normalmente, conjuntos de dados públicos são usados para fins educacionais e de pesquisa. No entanto, se você quiser criar projetos específicos de detecção de objetos em que os conjuntos de dados públicos não tenham os objetos que você deseja detectar, talvez queira criar seu próprio conjunto de dados.
Coletar conjunto de dados manualmente
Recomenda-se que você primeiro grave um vídeo do objeto que deseja reconhecer. Você precisa garantir que cubra todos os ângulos (360 graus) do objeto, coloque o objeto em diferentes ambientes, diferentes iluminações e diferentes condições climáticas. O vídeo total que gravamos tem 9 minutos de duração, dos quais 4,5 minutos são para flores e os 4,5 minutos restantes são para folhas. A gravação pode ser dividida da seguinte forma:

- manhã com clima normal
- manhã com clima ventoso
- manhã com clima chuvoso
- meio-dia com clima normal
- meio-dia com clima ventoso
- meio-dia com clima chuvoso
- noite com clima normal
- noite com clima ventoso
- noite com clima chuvoso
Nota: Mais tarde, converteremos esse vídeo em uma série de imagens para compor o conjunto de dados para treinamento.
Usar conjunto de dados disponível publicamente
Você pode baixar vários conjuntos de dados disponíveis publicamente, como o conjunto de dados COCO, conjunto de dados Pascal VOC e muitos outros. O Roboflow Universe é uma plataforma recomendada que fornece uma ampla gama de conjuntos de dados e possui 90.000+ conjuntos de dados com 66+ milhões de imagens disponíveis para construir modelos de visão computacional. Além disso, você pode simplesmente pesquisar conjuntos de dados de código aberto no Google e escolher entre uma variedade de conjuntos de dados disponíveis.
Anotar conjunto de dados usando o Roboflow
Em seguida, passaremos a anotar o conjunto de dados que temos. Anotar significa simplesmente desenhar caixas retangulares ao redor de cada objeto que queremos detectar e atribuir rótulos a eles. Iremos explicar como fazer isso usando o Roboflow.
Roboflow é uma ferramenta de anotação baseada online. Aqui podemos importar diretamente o vídeo que gravamos antes para o Roboflow e ele será exportado em uma série de imagens. Essa ferramenta é muito conveniente porque nos ajuda a distribuir o conjunto de dados em "treinamento, validação e teste". Além disso, essa ferramenta nos permitirá adicionar mais processamento a essas imagens após rotulá-las. Além disso, ela pode facilmente exportar o conjunto de dados rotulado para o formato YOLOV5 PyTorch, que é exatamente o que precisamos!
-
Passo 1. Clique aqui para se inscrever em uma conta Roboflow
-
Passo 2. Clique em Create New Project para iniciar nosso projeto
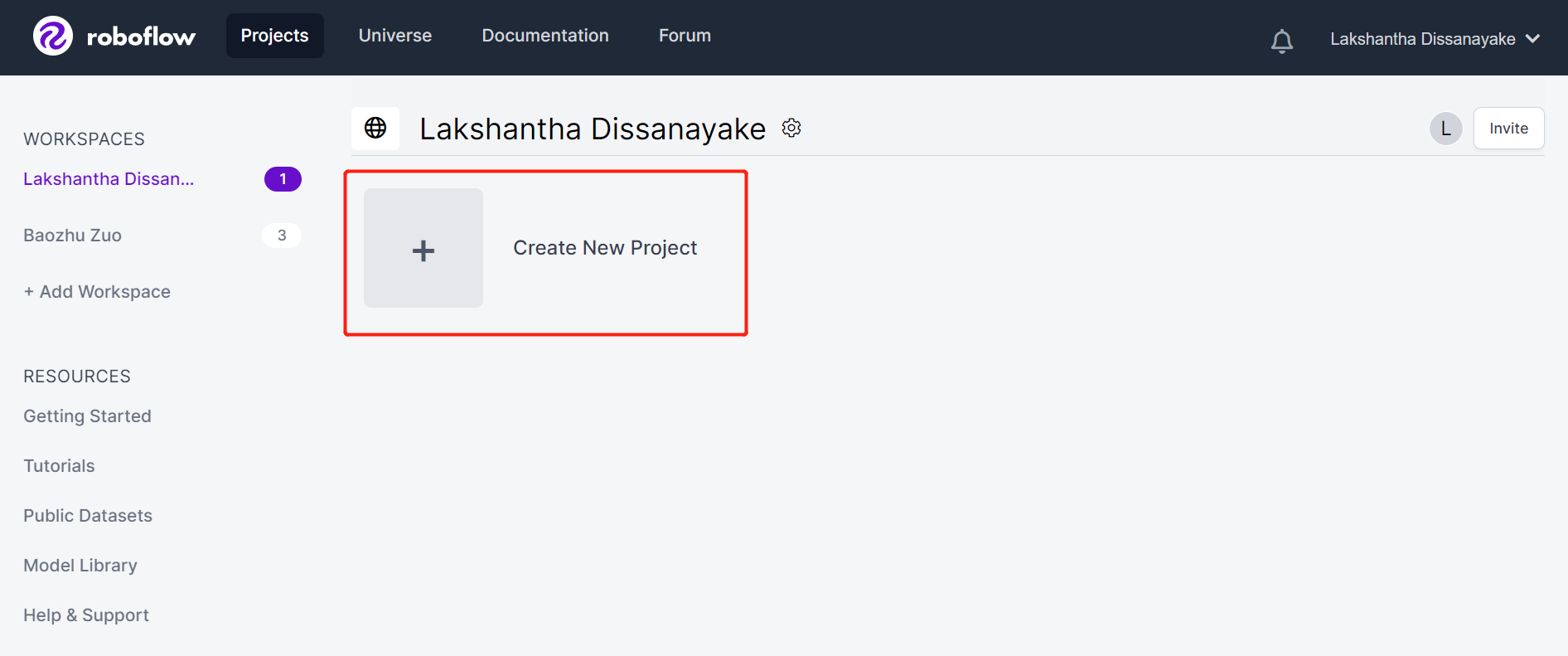
- Passo 3. Preencha o Project Name, mantenha o License (CC BY 4.0) e o Project type (Object Detection (Bounding Box)) como padrão. Na coluna What will your model predict?, preencha um nome de grupo de anotações. Por exemplo, no nosso caso escolhemos plants. Esse nome deve destacar todas as classes do seu conjunto de dados. Por fim, clique em Create Public Project.
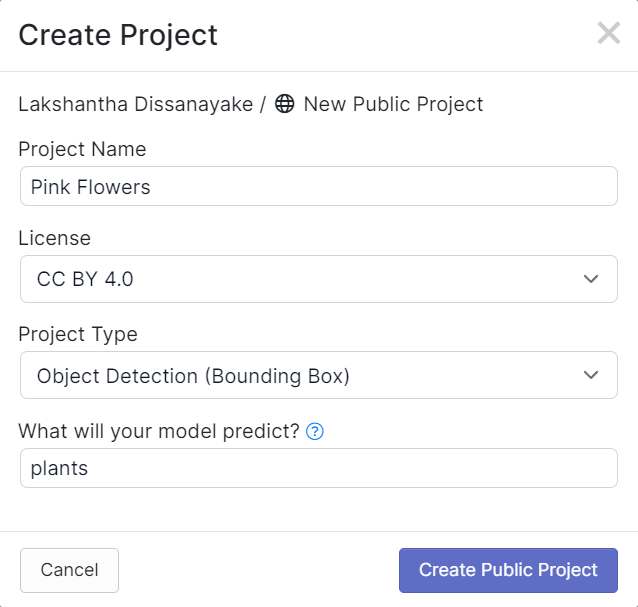
- Passo 4. Arraste e solte o vídeo que você gravou anteriormente
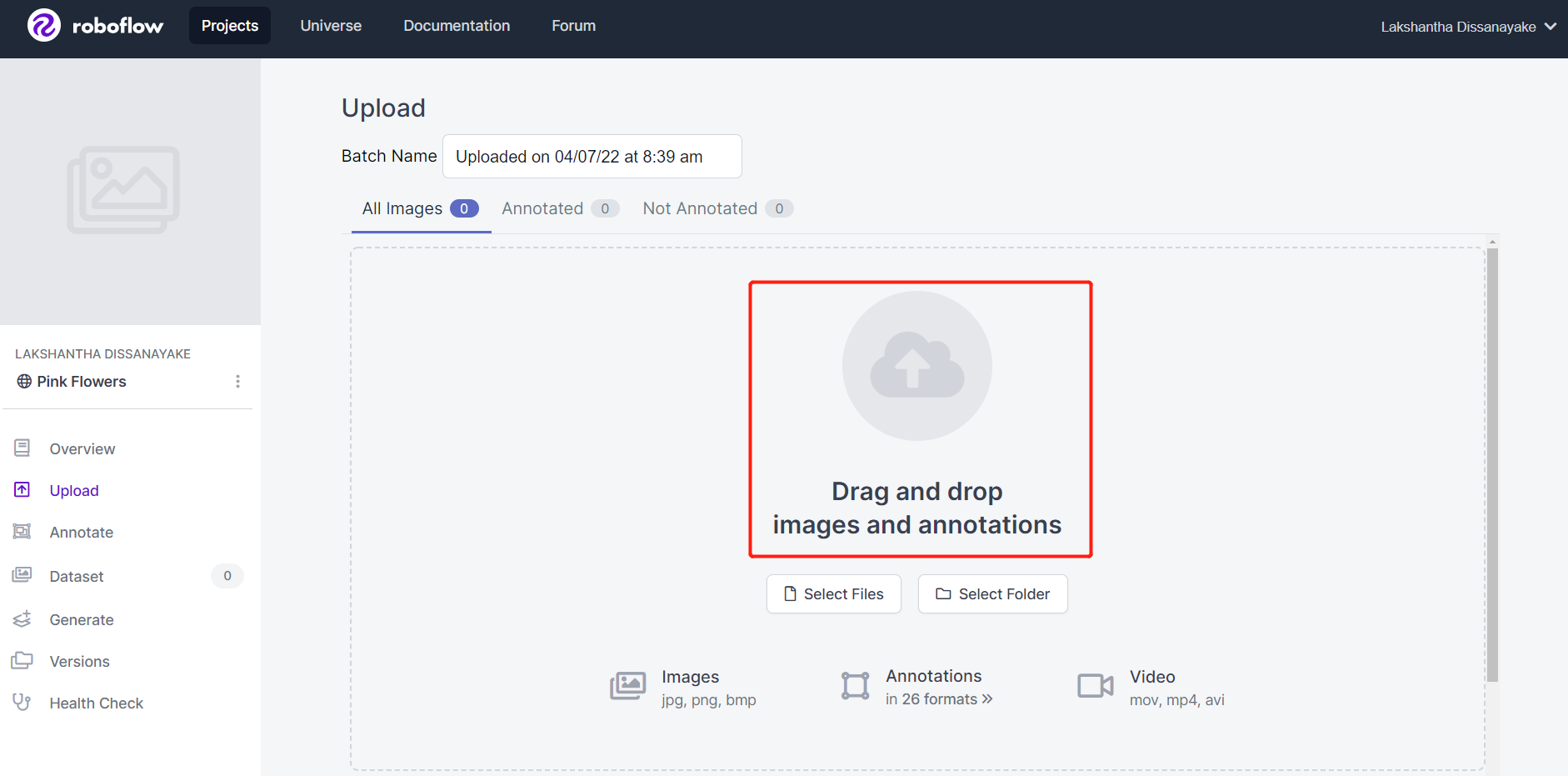
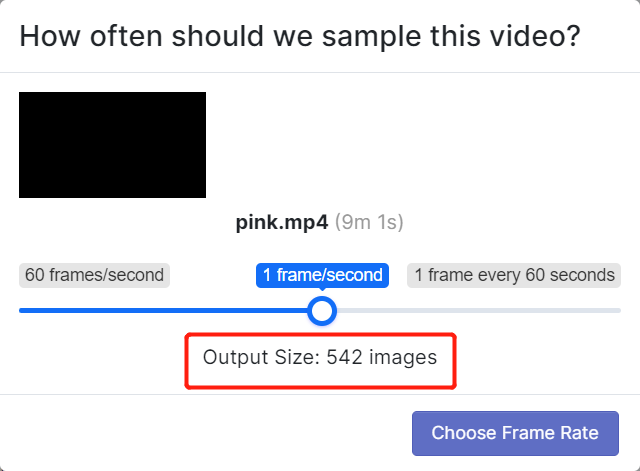
- Passo 5. Escolha uma taxa de quadros para que o vídeo seja dividido em uma série de imagens. Aqui usaremos a taxa de quadros padrão, que é 1 frame/second, e isso irá gerar um total de 542 imagens. Depois de selecionar uma taxa de quadros deslizando o controle deslizante, clique em Choose Frame Rate. Esse processo levará de alguns segundos a alguns minutos (dependendo do comprimento do vídeo).
- Passo 6. Depois que as imagens forem processadas, clique em Finish Uploading. Aguarde pacientemente até que as imagens sejam enviadas.
- Passo 7. Depois que as imagens forem enviadas, clique em Assign Images
- Passo 8. Selecione uma imagem, desenhe uma caixa retangular ao redor de uma flor, escolha o rótulo como pink flower e pressione ENTER
- Passo 9. Repita o mesmo para as flores restantes
- Passo 10. Desenhe uma caixa retangular ao redor de uma folha, escolha o rótulo como leaf e pressione ENTER
- Passo 11. Repita o mesmo para as folhas restantes
Nota: Tente rotular todos os objetos que você vê dentro da imagem. Se apenas uma parte do objeto estiver visível, tente rotular essa parte também.
- Passo 12. Continue a anotar todas as imagens do conjunto de dados
O Roboflow possui um recurso chamado Label Assist, em que ele pode prever os rótulos com antecedência para que sua rotulagem seja muito mais rápida. No entanto, ele não funcionará com todos os tipos de objetos, mas sim com um tipo selecionado de objetos. Para ativar esse recurso, você simplesmente precisa pressionar o botão Label Assist, selecionar um modelo, selecionar as classes e navegar pelas imagens para ver os rótulos previstos com caixas delimitadoras
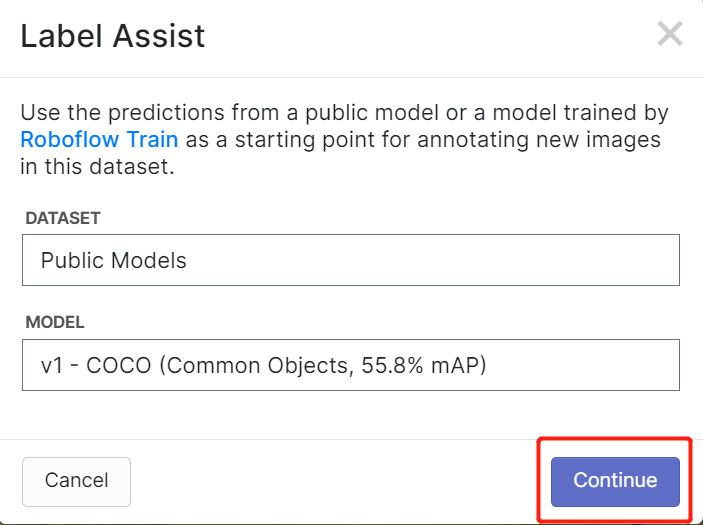
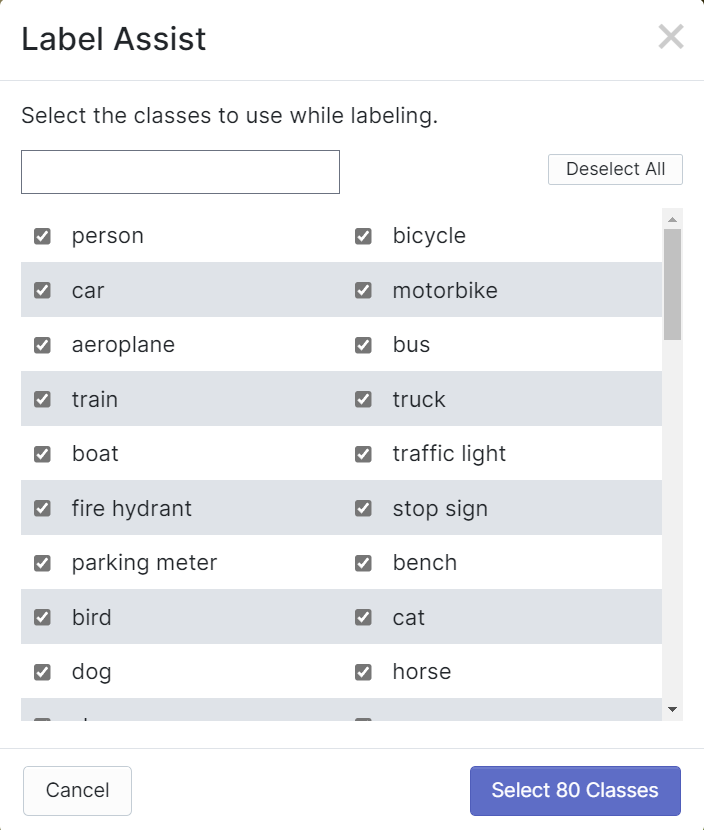
Como você pode ver acima, ele só pode ajudar a prever anotações para as 80 classes mencionadas. Se suas imagens não contiverem as classes de objetos acima, você não poderá usar o recurso de assistência de rótulos.
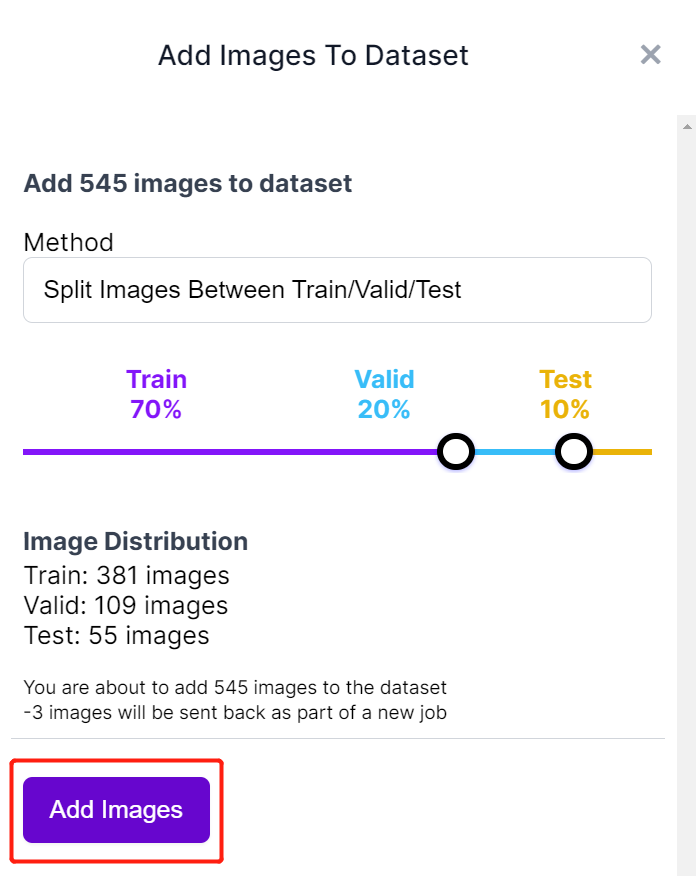
- Passo 13. Quando a rotulagem estiver concluída, clique em Add images to Dataset

- Passo 14. Em seguida, dividiremos as imagens entre "Train, Valid e Test". Mantenha as porcentagens padrão para a distribuição e clique em Add Images
- Passo 15. Clique em Generate New Version

- Passo 16. Agora você pode adicionar Preprocessing e Augmentation se preferir. Aqui nós vamos excluir a opção Resize e manter os tamanhos originais das imagens
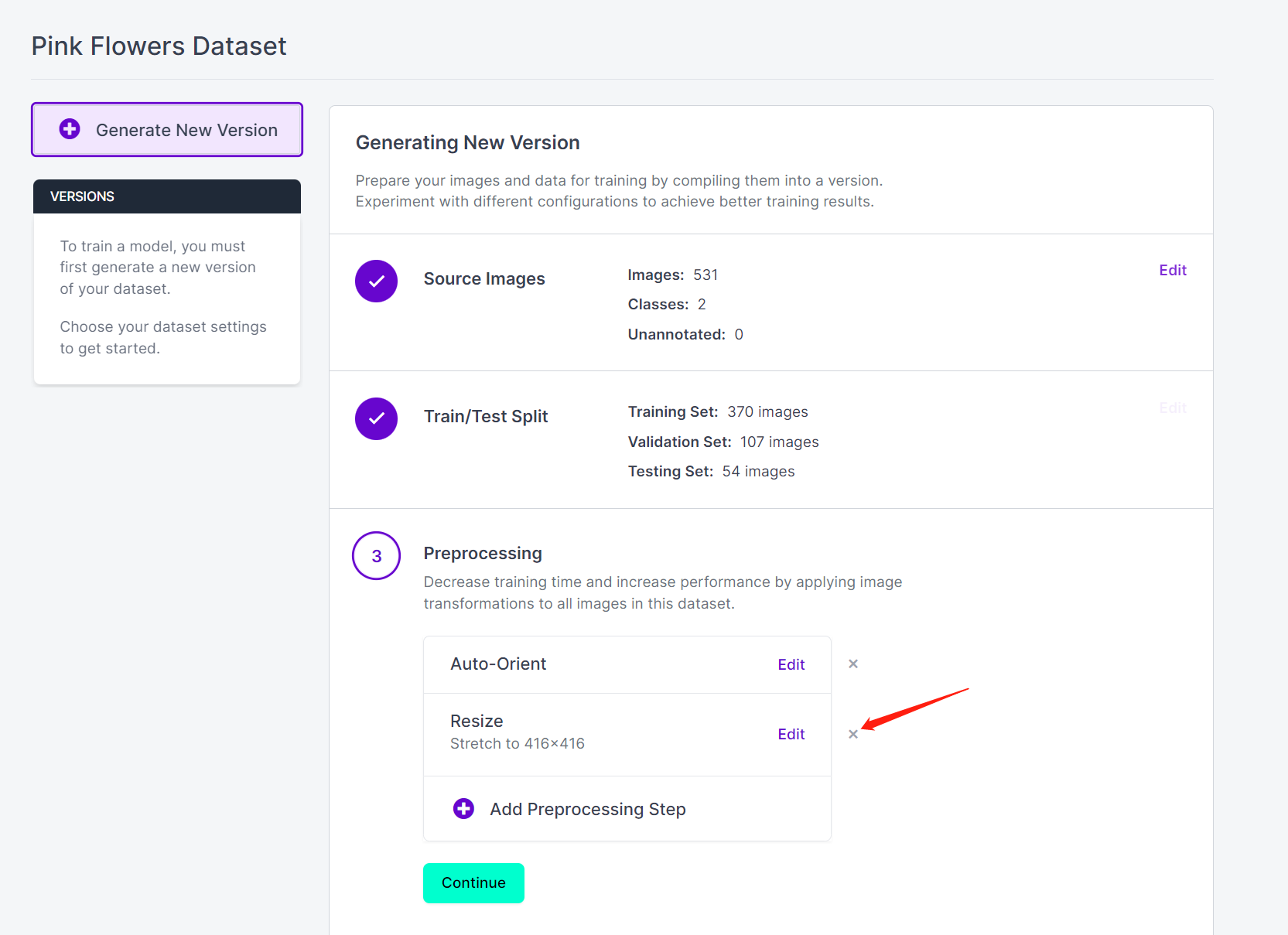
- Passo 17. Em seguida, prossiga com as demais configurações padrão e clique em Generate
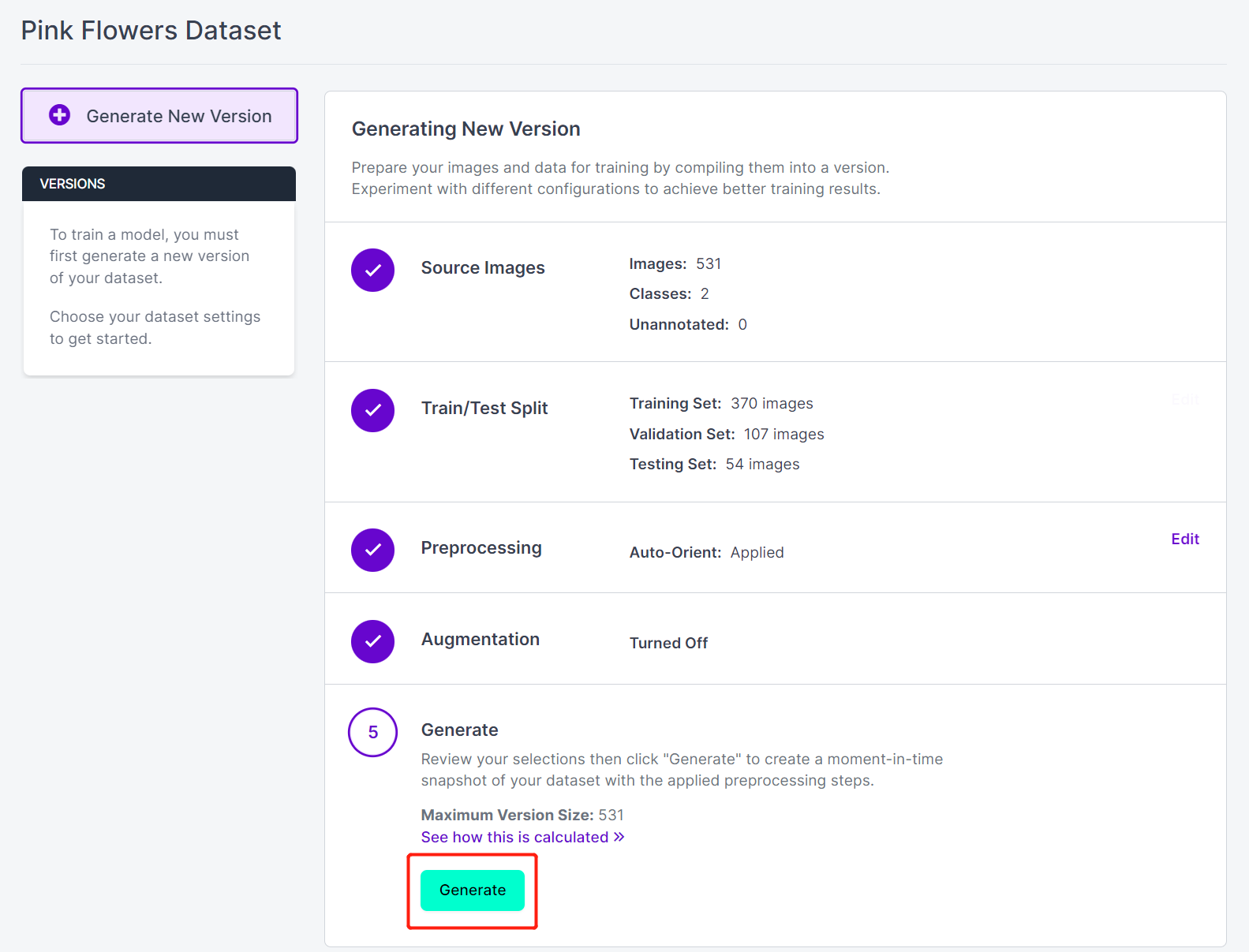
- Passo 18. Clique em Export
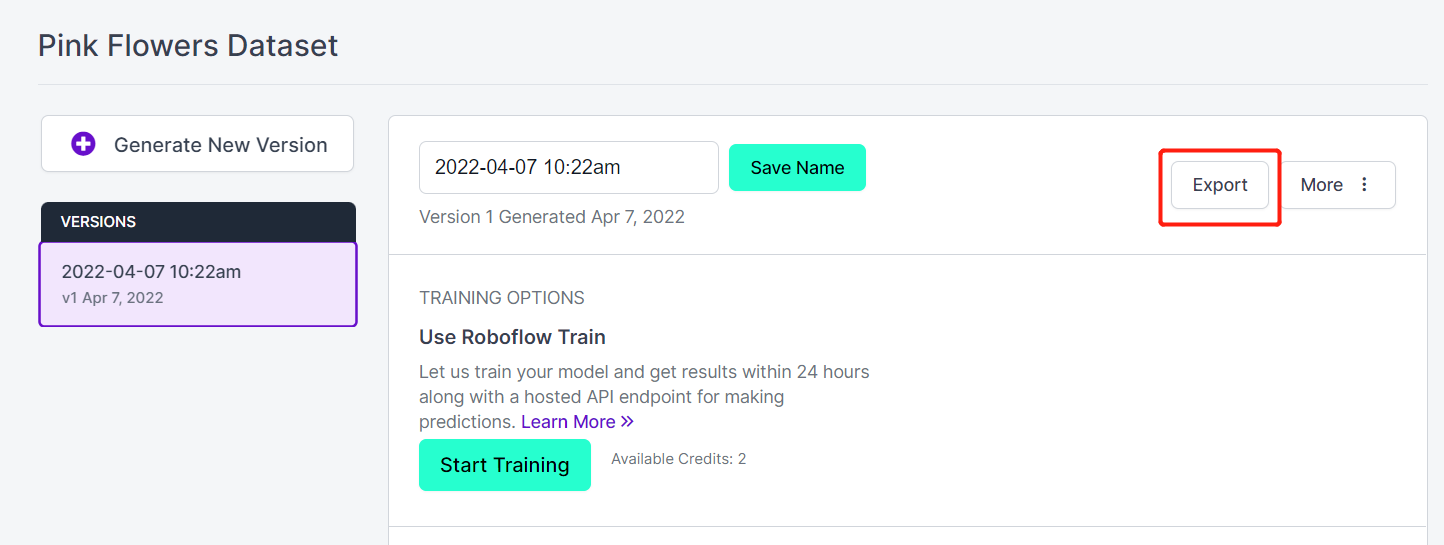
- Passo 19. Selecione download zip to computer, em "Select a Format" escolha YOLO v5 PyTorch e clique em Continue
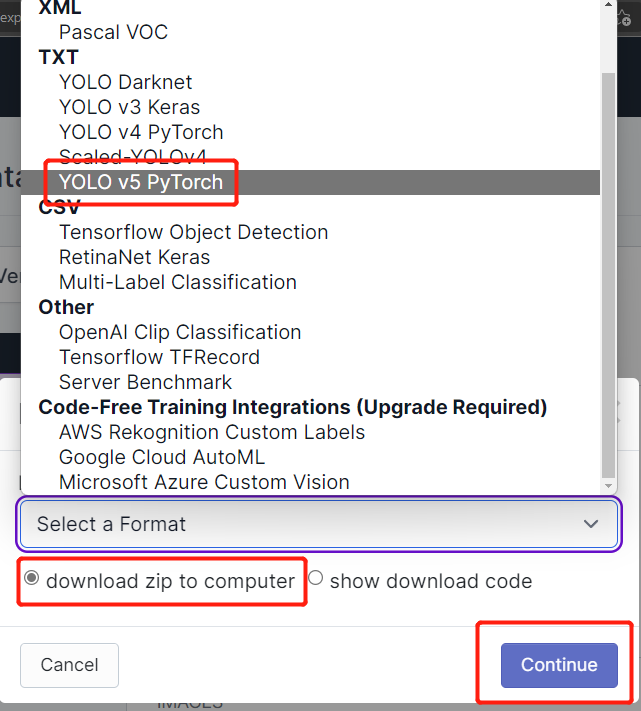
- Passo 20. Depois disso, um arquivo .zip será baixado para o seu computador. Vamos precisar desse arquivo .zip mais tarde para o nosso treinamento.
Treinar em PC local ou na nuvem
Depois de terminarmos de anotar o conjunto de dados, precisamos treiná‑lo. Para o treinamento, vamos apresentar dois métodos. Um método será baseado online (Google Colab) e o outro será baseado em PC local (Linux).
Para o treinamento no Google Colab, usaremos dois métodos. No primeiro método, usaremos o Ultralytics HUB para enviar o conjunto de dados, configurar o treinamento no Colab, monitorar o treinamento e obter o modelo treinado. No segundo método, vamos obter o conjunto de dados do Roboflow via Roboflow api, treinar e baixar o modelo a partir do Colab.
Usar Google Colab com Ultralytics HUB
Ultralytics HUB é uma plataforma onde você pode treinar seus modelos sem precisar conhecer uma única linha de código. Simplesmente envie seus dados para o Ultralytics HUB, treine seu modelo e faça o deploy no mundo real! É rápido, simples e fácil de usar. Qualquer pessoa pode começar!
-
Passo 1. Acesse este link para se inscrever em uma conta gratuita do Ultralytics HUB
-
Passo 2. Insira suas credenciais e sign up with email ou inscreva‑se diretamente com uma conta Google, GitHub ou Apple
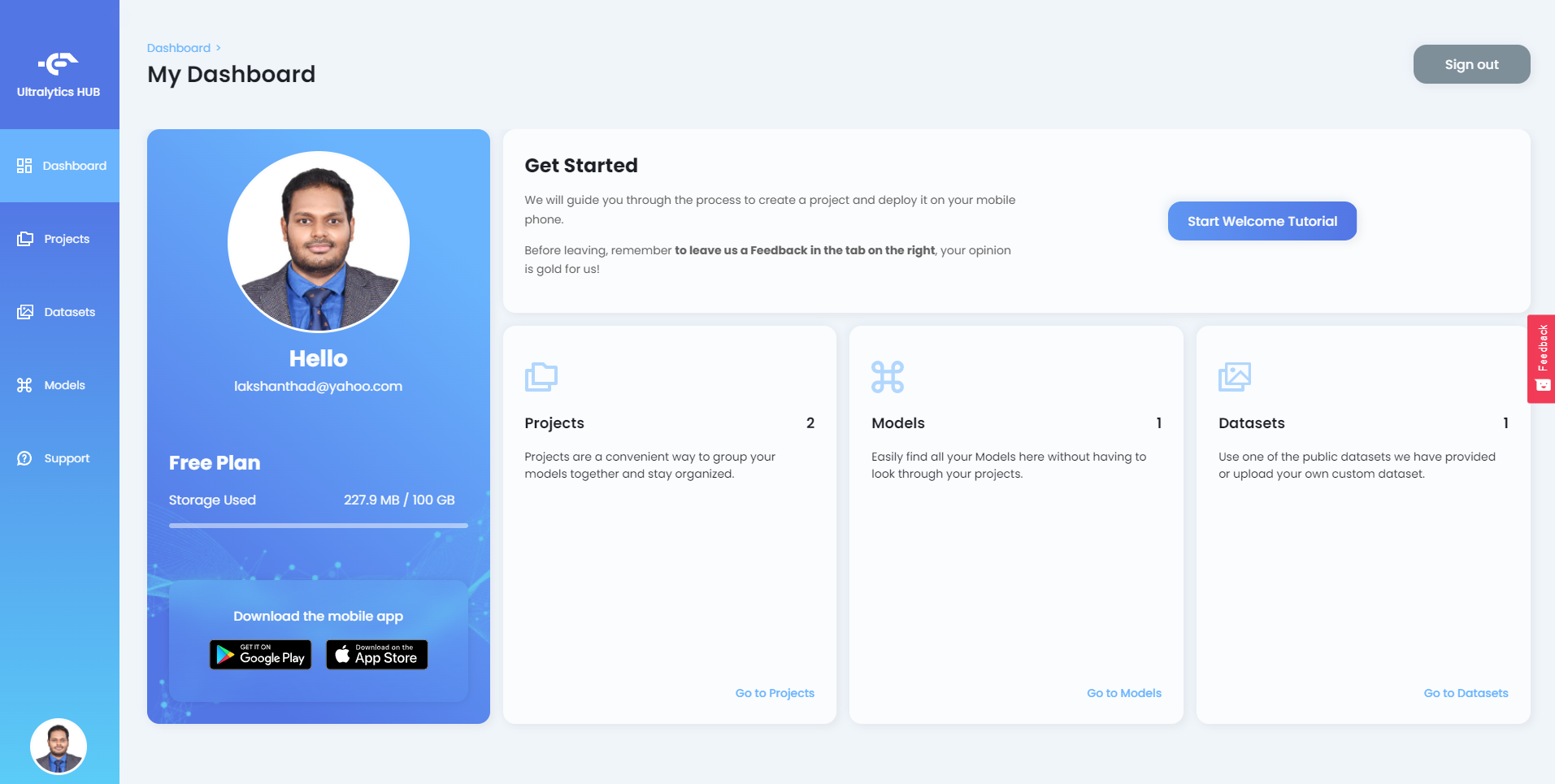
Depois que você fizer login no Ultralytics HUB, verá o painel conforme a seguir
-
Passo 3. Extraia o arquivo zip que baixamos anteriormente do Roboflow e coloque todos os arquivos incluídos dentro de uma nova pasta
-
Passo 4. Certifique‑se de que o seu dataset yaml e a pasta raiz (a pasta que criamos antes) tenham o mesmo nome. Por exemplo, se você nomear seu arquivo yaml como pinkflowers.yaml, a pasta raiz deve ser nomeada como pinkflowers.
-
Passo 5. Abra o arquivo pinkflowers.yaml e edite os diretórios train e val da seguinte forma
train: train/images
val: valid/images
- Passo 6. Compacte a pasta raiz como um .zip e dê a ela o mesmo nome da pasta raiz (pinkflowers.zip neste exemplo)
Agora preparamos o conjunto de dados que está pronto para ser enviado ao Ultalytics HUB.
- Passo 7. Clique na aba Datasets e clique em Upload Dataset
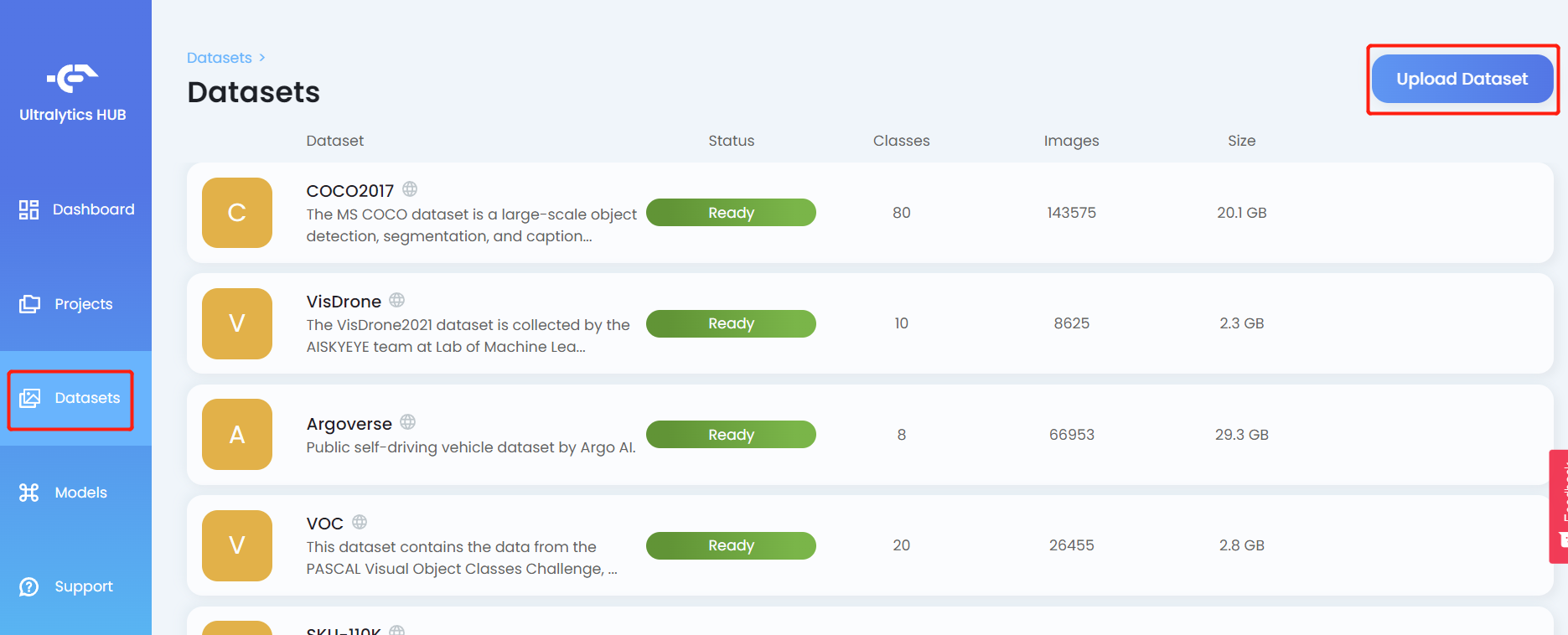
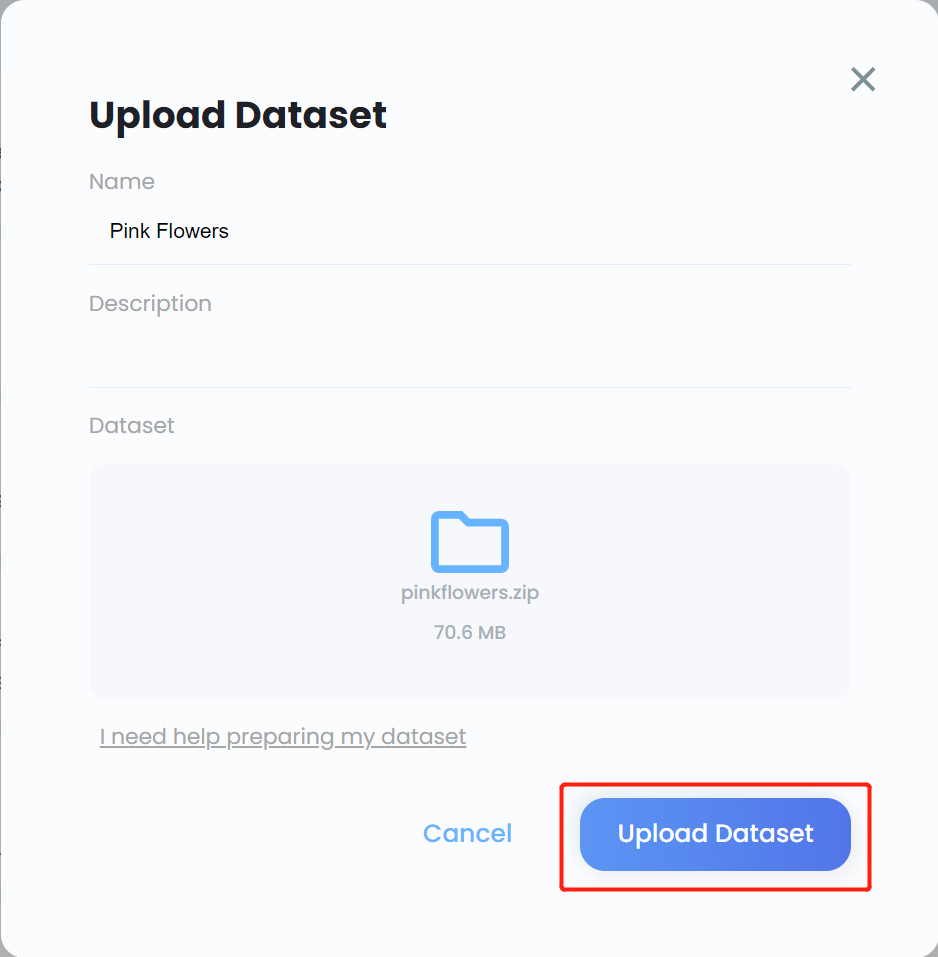
- Passo 8. Insira um Name para o conjunto de dados, insira uma Description se necessário, arraste e solte o arquivo .zip que criamos anteriormente no campo Dataset e clique em Upload Dataset
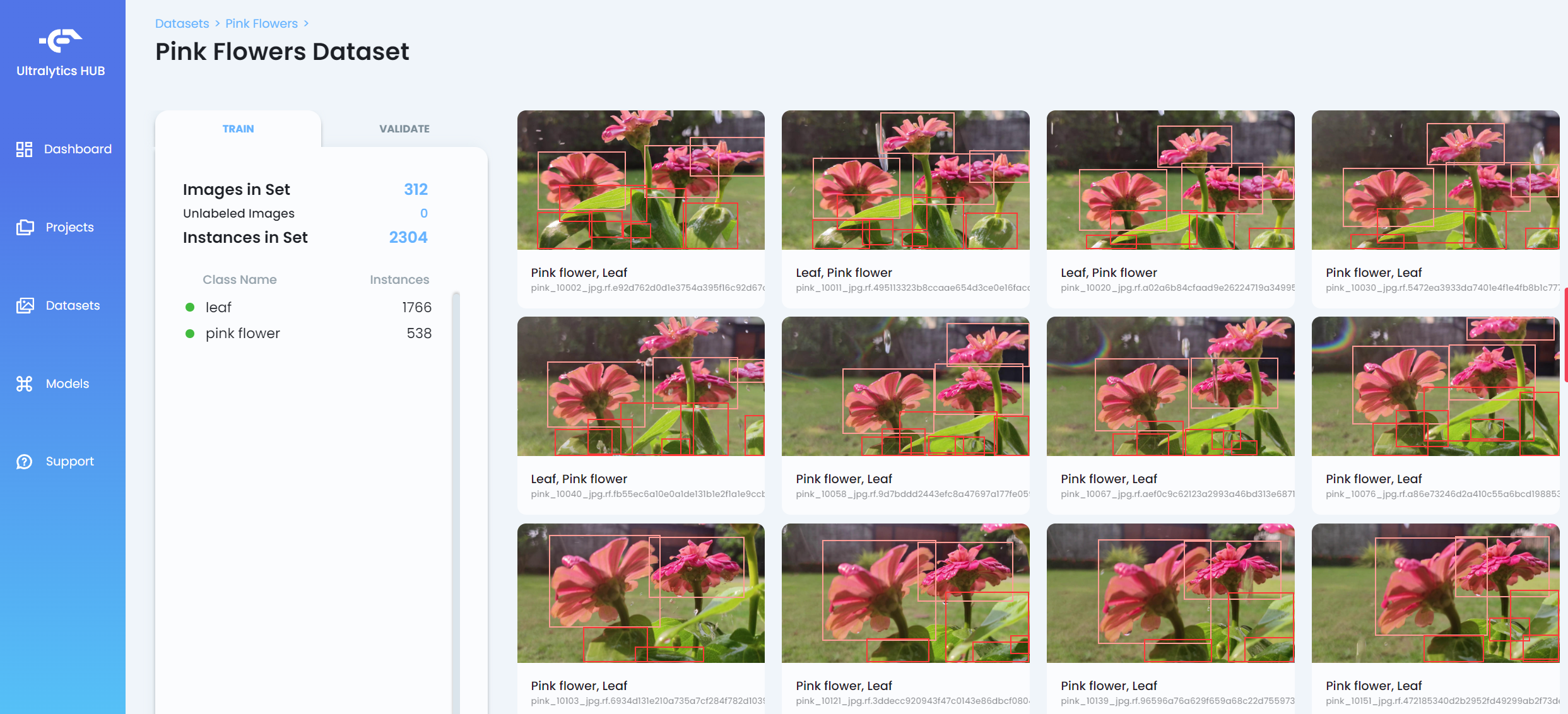
- Passo 9. Depois que o conjunto de dados for enviado, clique nele para ver mais detalhes sobre o conjunto de dados
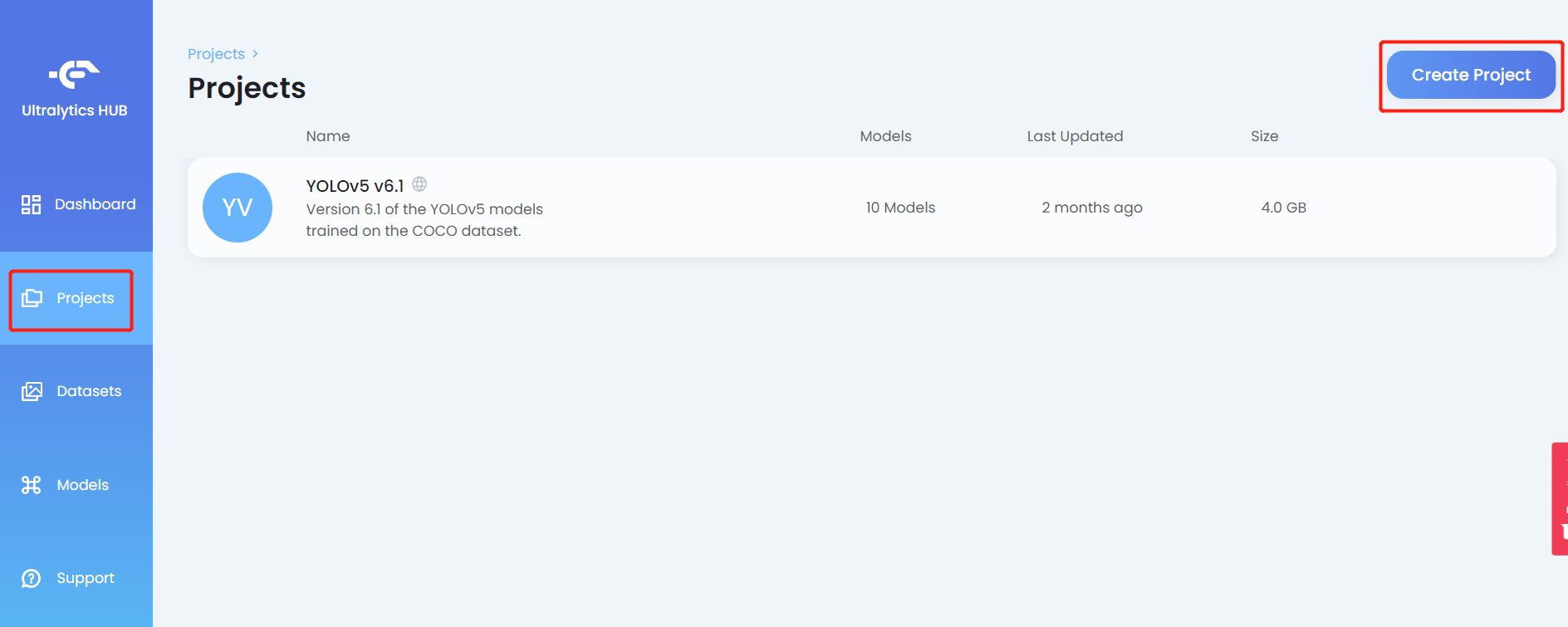
- Passo 10. Clique na aba Projects e clique em Create Project
- Passo 11. Insira um Name para o projeto, insira uma Description se necessário, adicione uma cover image se necessário e clique em Create Project
- Passo 12. Entre no projeto recém‑criado e clique em Create Model

- Passo 13. Insira um Model name, escolha YOLOv5n como o modelo pré‑treinado e clique em Next
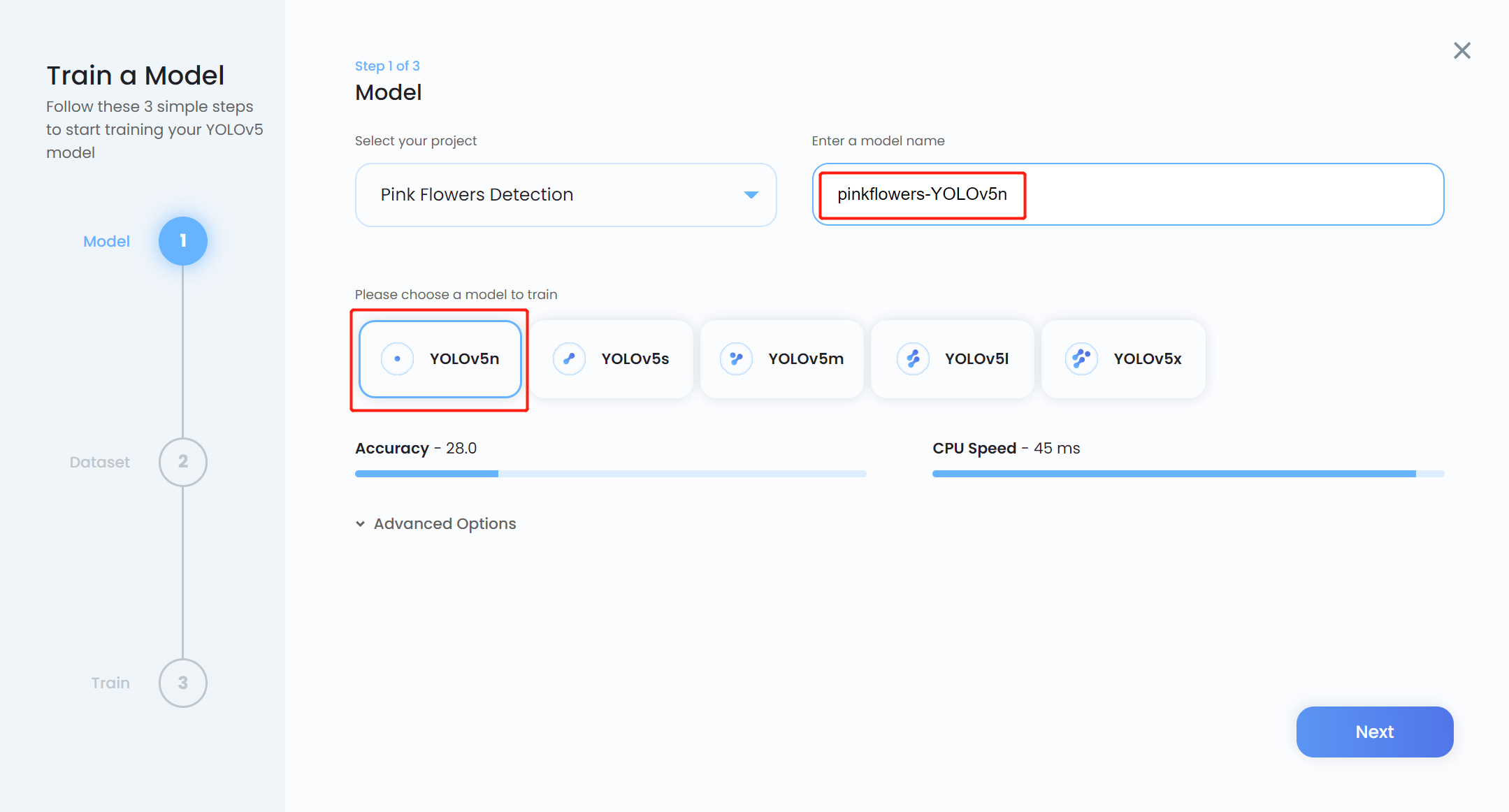
Nota: Normalmente YOLOv5n6 é preferido como o modelo pré‑treinado porque é adequado para ser usado em dispositivos de borda, como a plataforma Jetson. No entanto, o Ultralytics HUB ainda não tem suporte para ele. Então usamos YOLOv5n, que é um modelo ligeiramente semelhante.
- Passo 14. Escolha o conjunto de dados que enviamos anteriormente e clique em Next
- Passo 15. Escolha Google Colab como a plataforma de treinamento e clique no menu suspenso Advanced Options. Aqui podemos alterar algumas configurações para o treinamento. Por exemplo, vamos mudar o número de épocas de 300 para 100 e manter as outras configurações como estão. Clique em Save
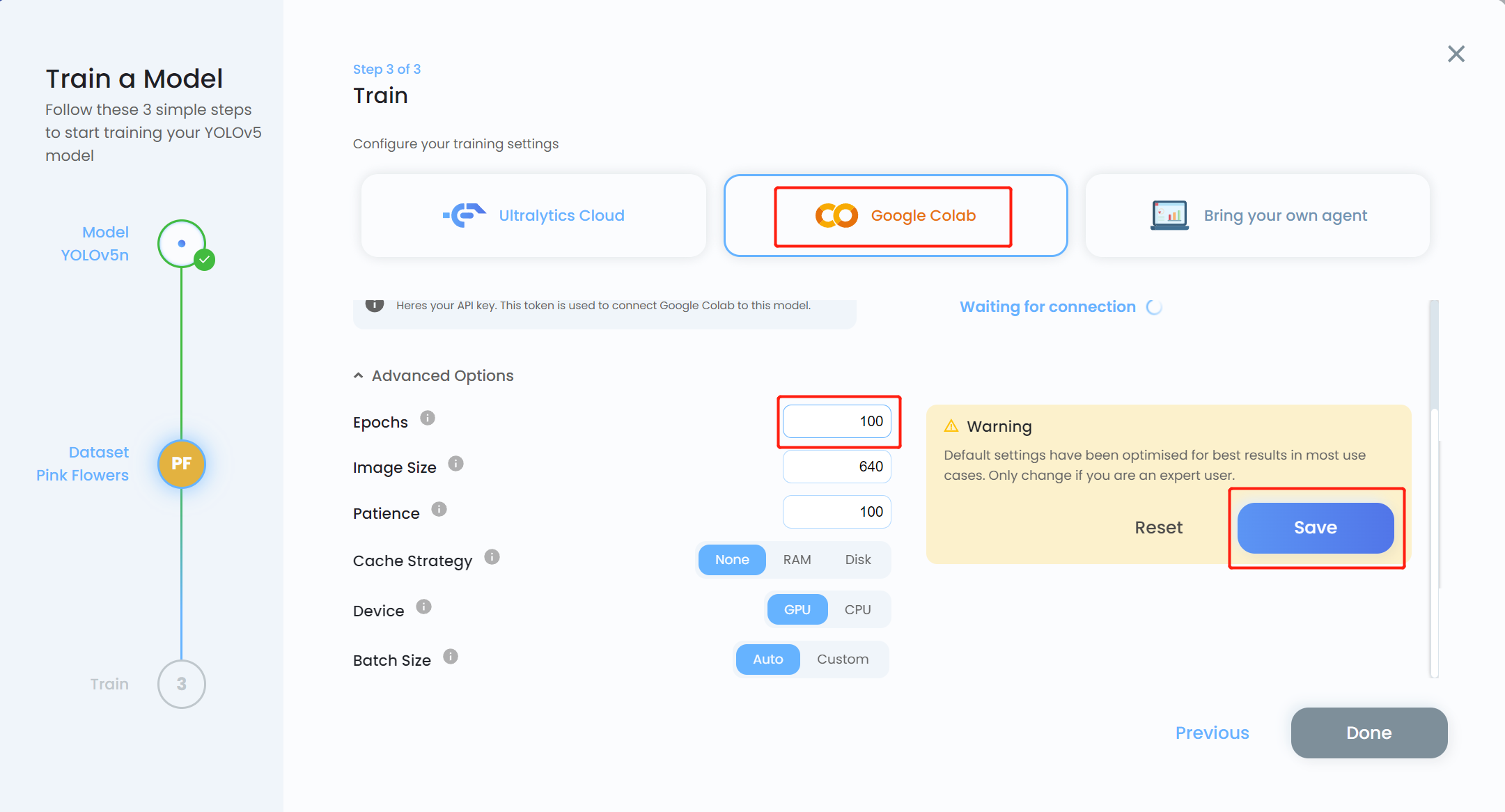
Nota: Você também pode escolher Bring your own agent se estiver planejando realizar o treinamento localmente
- Passo 16. Copie a API key e clique em Open Colab
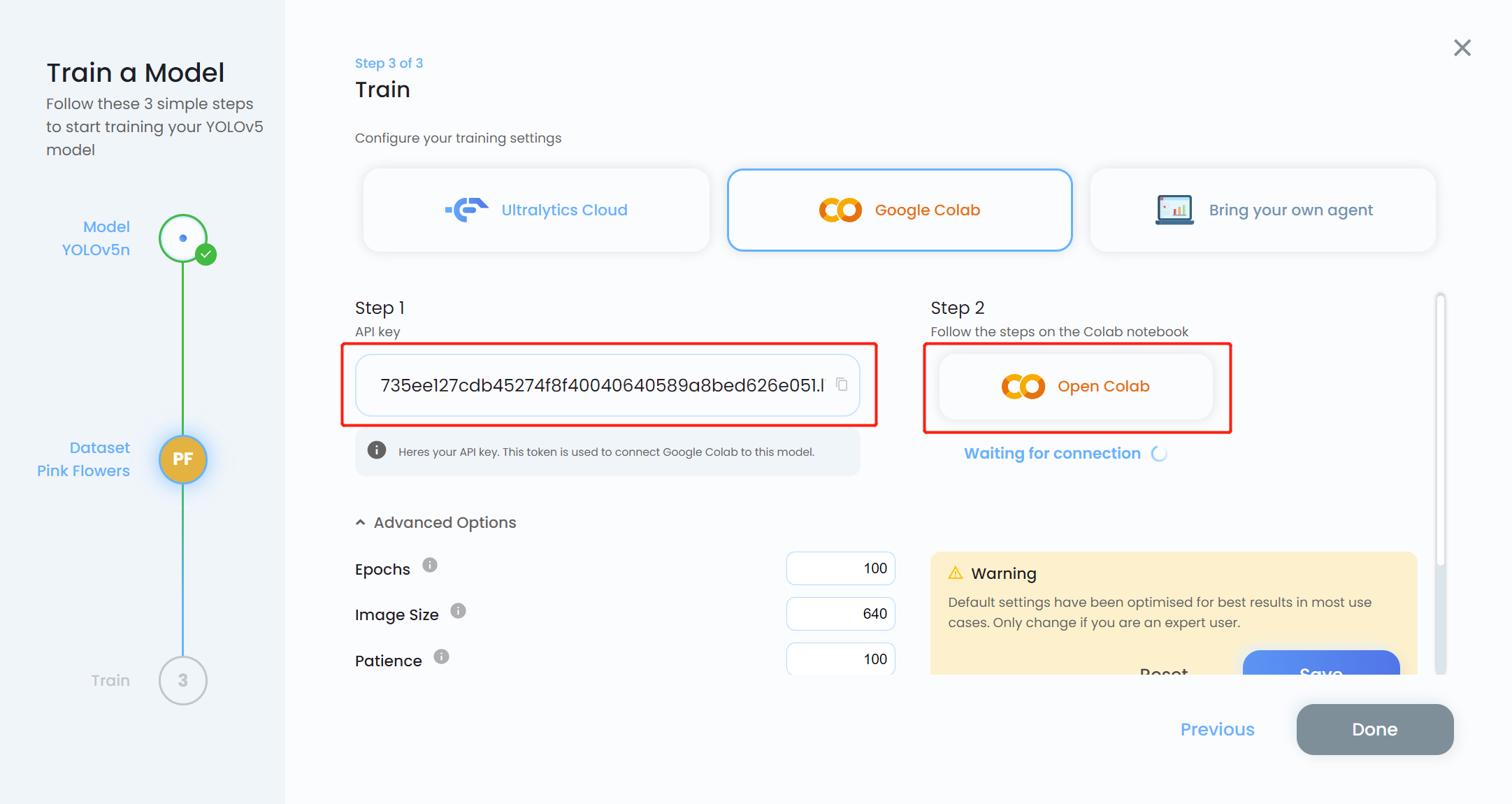
- Passo 17. Substitua MODEL_KEY pela API key que copiamos antes
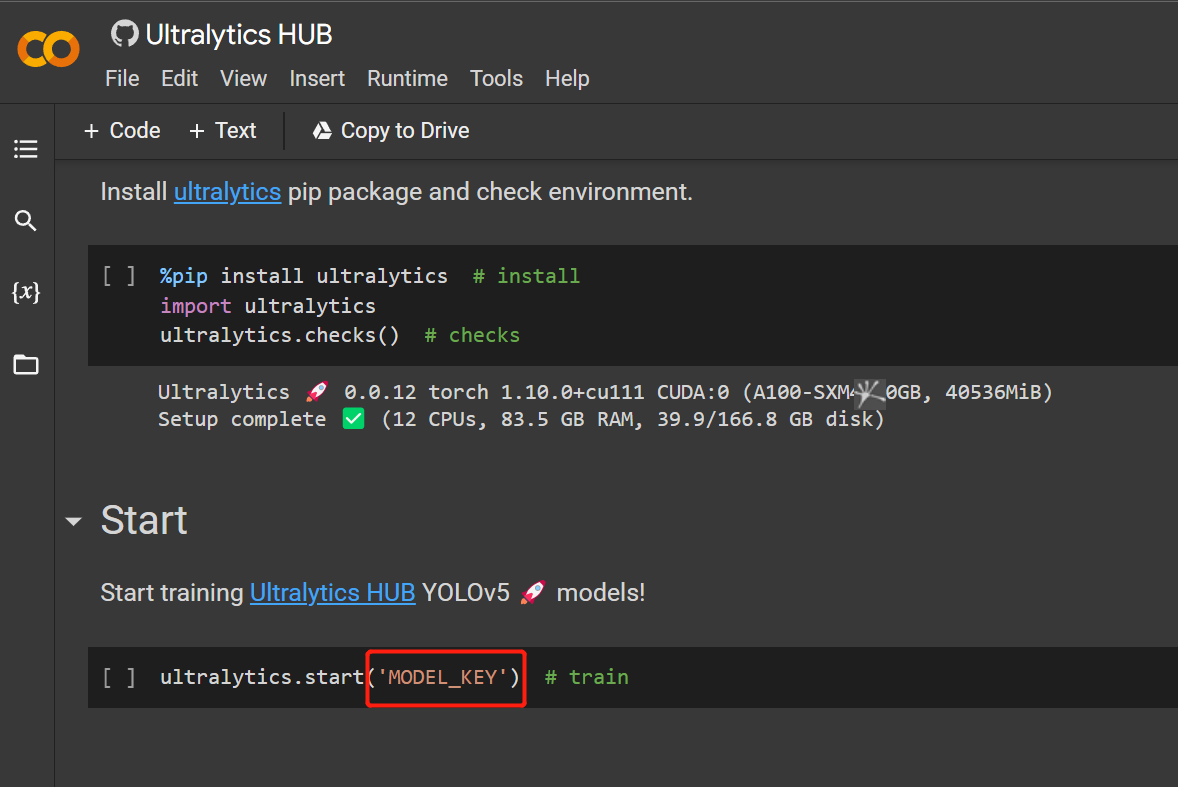
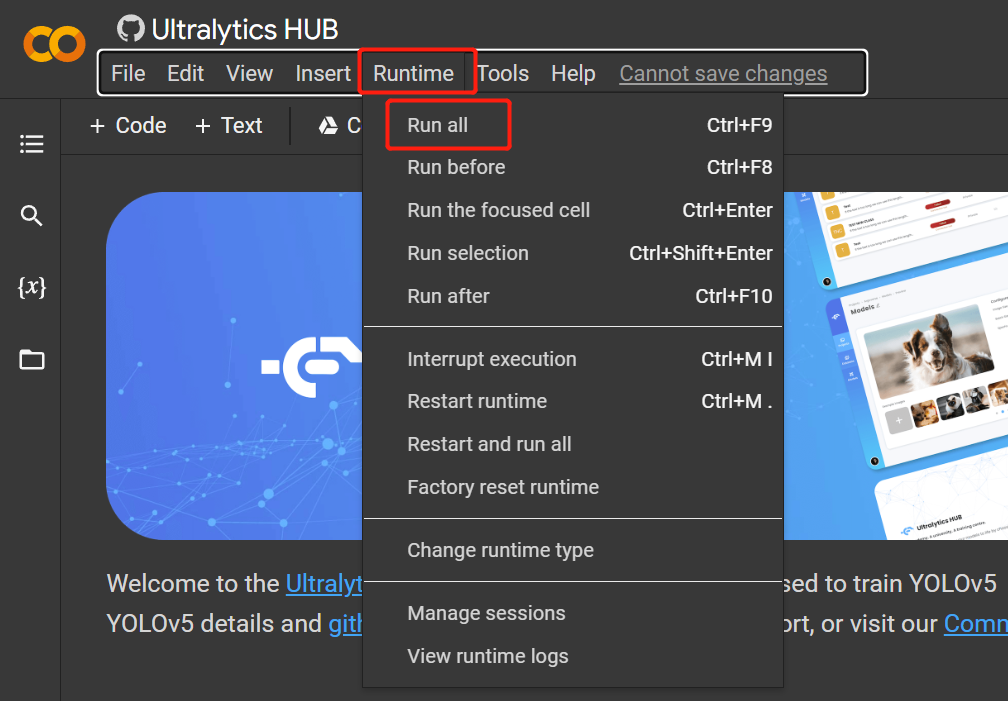
- Passo 18. Clique em
Runtime > Rull Allpara executar todas as células de código e iniciar o processo de treinamento
- Passo 19. Volte para o Ultralytics HUB e clique em Done quando ficar azul. Você também verá que o Colab aparece como Connected.
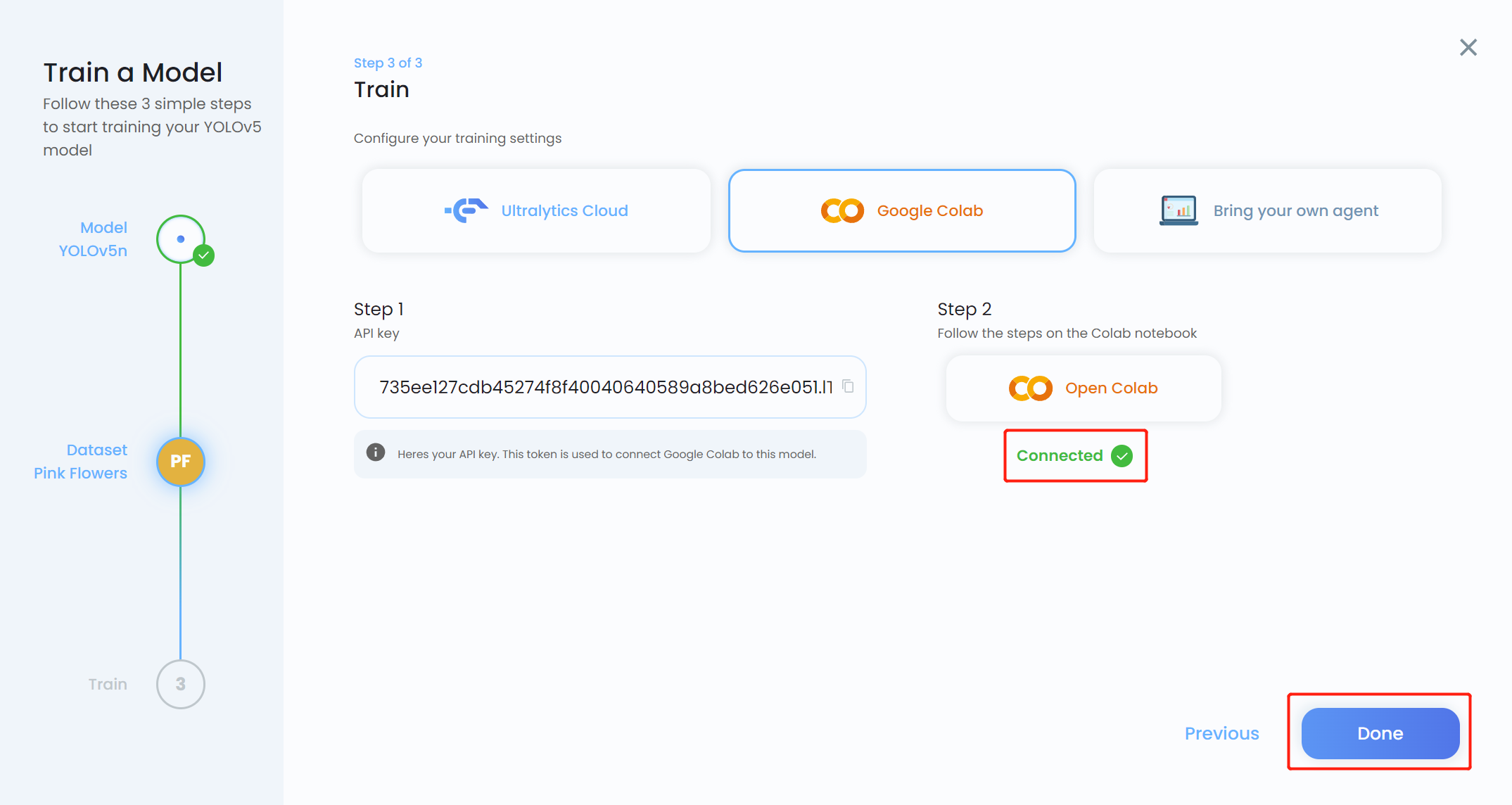
Agora você verá o progresso do treinamento no HUB
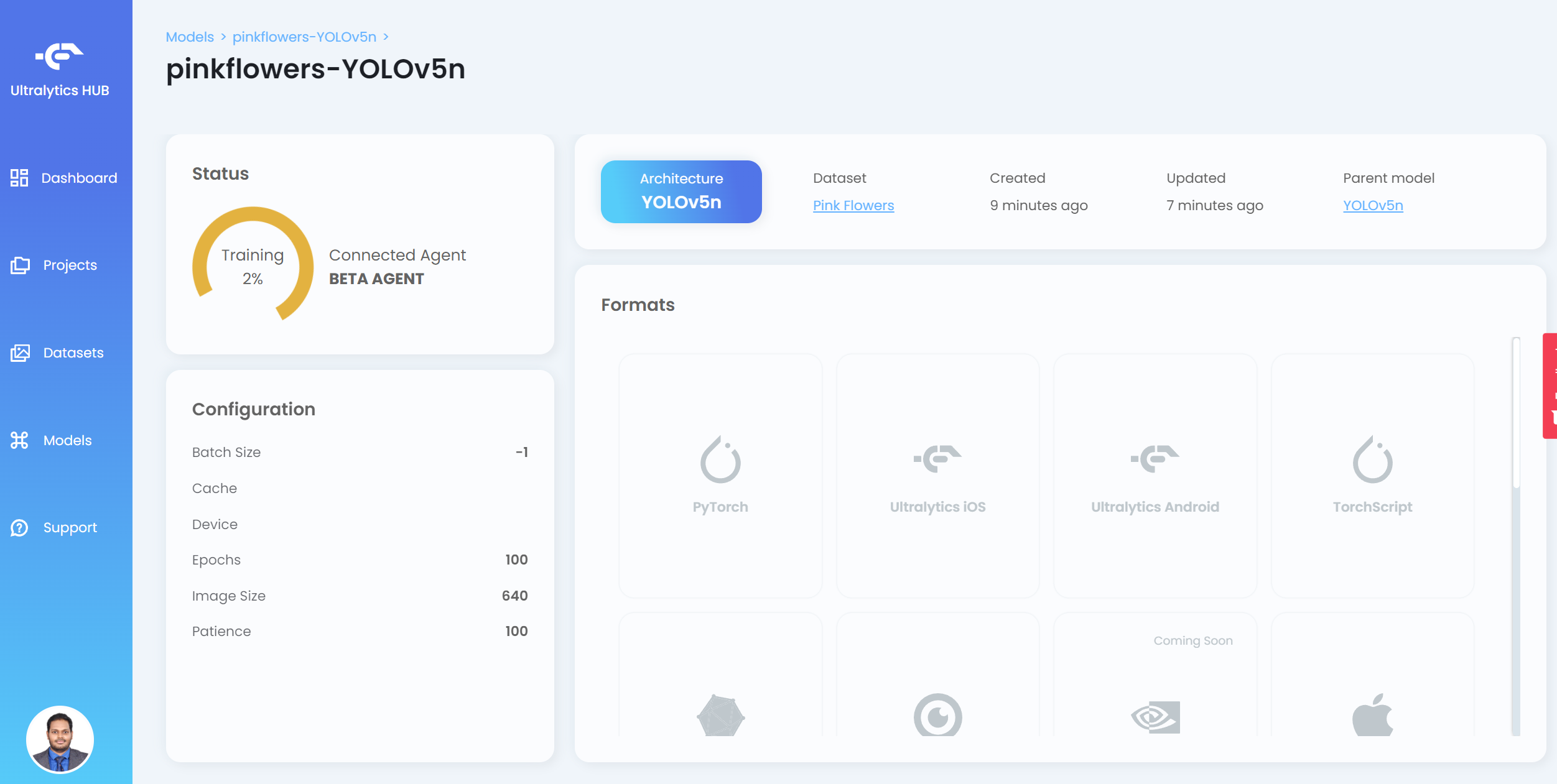
- Passo 20. Depois que o treinamento terminar, clique em PyTorch para baixar o modelo treinado em formato PyTorch. PyTorch é o formato de que precisamos para realizar inferência no dispositivo Jetson
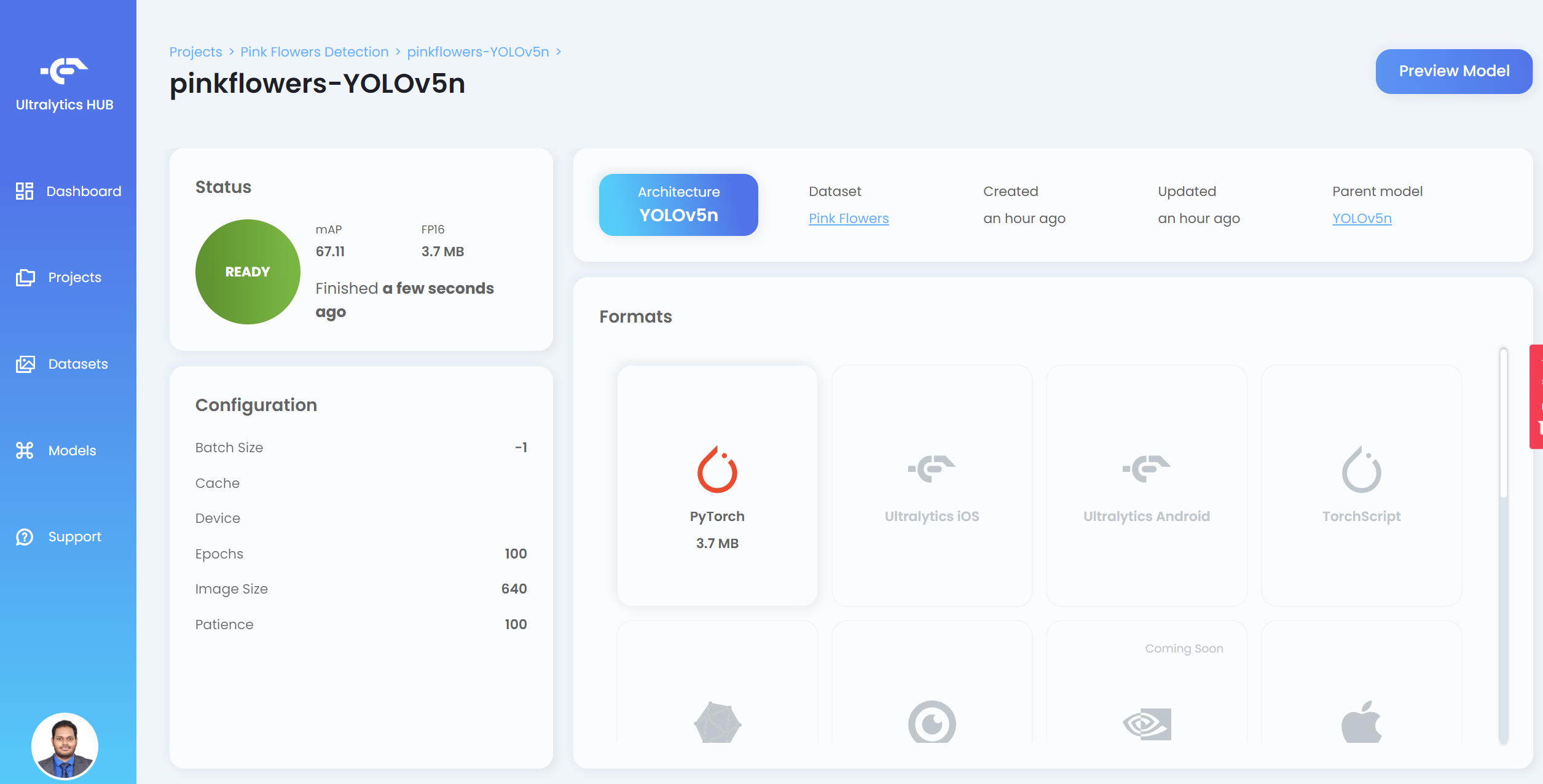
Nota: Você também pode exportar para outros formatos que são exibidos em Formats
Se você voltar ao Google Colab, poderá ver mais detalhes, conforme a seguir:
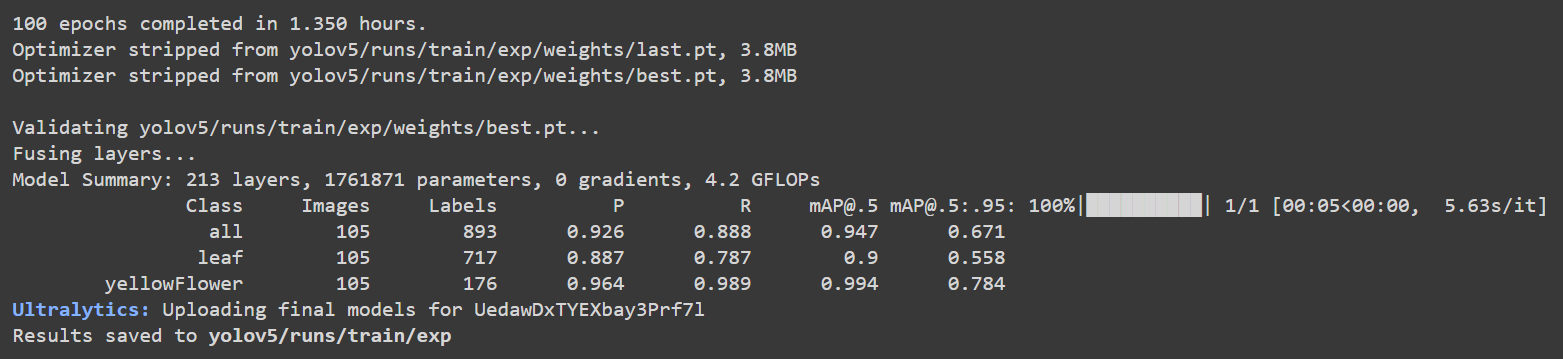
Aqui a acurácia [email protected] é de cerca de 90% e 99,4% para folha e flor, respectivamente, enquanto a acurácia total [email protected] é de cerca de 94,7%.
Usar Google Colab com Roboflow api
Aqui usamos um ambiente Google Colaboratory para realizar o treinamento na nuvem. Além disso, usamos Roboflow api dentro do Colab para baixar facilmente nosso conjunto de dados.
- Passo 1. Clique aqui para abrir um workspace do Google Colab já preparado e siga as etapas mencionadas no workspace
Depois que o treinamento for concluído, você verá uma saída como a seguir:
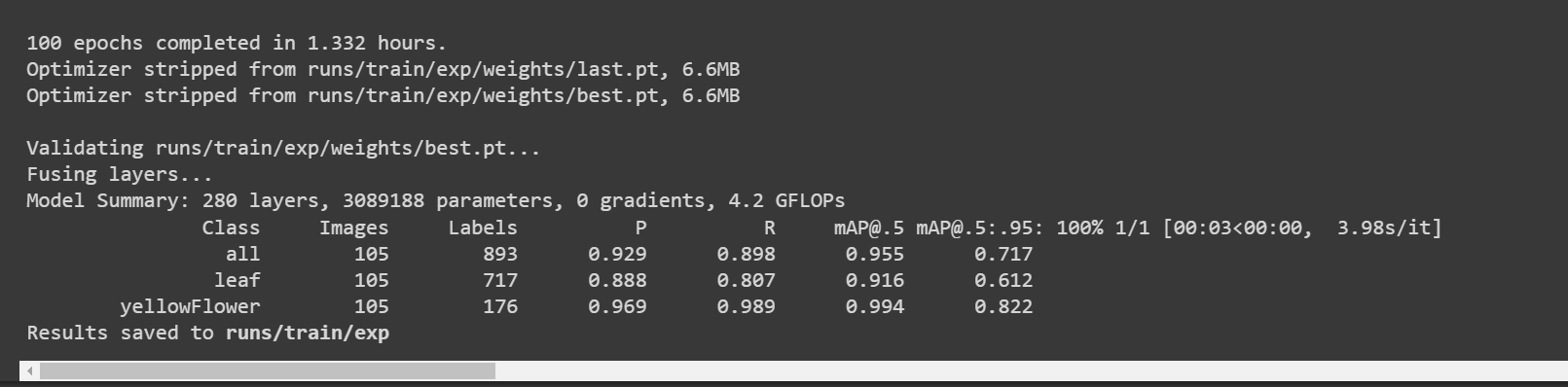
Aqui a acurácia [email protected] é de cerca de 91,6% e 99,4% para folha e flor, respectivamente, enquanto a acurácia total [email protected] é de cerca de 95,5%.
- Passo 2. Na aba Files, se você navegar até
runs/train/exp/weights, verá um arquivo chamado best.pt. Este é o modelo gerado a partir do treinamento. Baixe esse arquivo e copie‑o para o seu dispositivo Jetson, pois este é o modelo que vamos usar mais tarde para fazer inferência no dispositivo Jetson.
Usar PC local
Aqui você pode usar um PC com um sistema operacional Linux para treinamento. Usamos um PC com Ubuntu 20.04 para este wiki.
- Passo 1. Clone o repositório YOLOv5 e instale o requirements.txt em um ambiente Python>=3.7.0
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
- Passo 2. Copie e cole o arquivo .zip que baixamos anteriormente do Roboflow no diretório yolov5 e extraia‑o
# example
cp ~/Downloads/pink-flowers.v1i.yolov5pytorch.zip ~/yolov5
unzip pink-flowers.v1i.yolov5pytorch.zip
- Passo 3. Abra o arquivo data.yaml e edite os diretórios train e val da seguinte forma
train: train/images
val: valid/images
- Passo 4. Execute o seguinte para iniciar o treinamento
python3 train.py --data data.yaml --img-size 640 --batch-size -1 --epoch 100 --weights yolov5n6.pt
Como nosso conjunto de dados é relativamente pequeno (~500 imagens), espera‑se que o transfer learning produza melhores resultados do que o treinamento a partir do zero. Nosso modelo foi inicializado com pesos de um modelo COCO pré‑treinado, passando o nome do modelo (yolov5n6) para o argumento weights. Aqui usamos yolov5n6 porque ele é ideal para dispositivos de borda. Aqui o tamanho da imagem é definido como 640x640. Usamos batch-size como -1 porque isso determinará automaticamente o melhor tamanho de lote. Porém, se aparecer um erro dizendo "GPU memory not enough", escolha um tamanho de lote como 32, ou até 16. Você também pode alterar o epoch de acordo com sua preferência.
Depois que o treinamento terminar, você verá uma saída como a seguir:

Aqui a acurácia [email protected] é de cerca de 90,6% e 99,4% para folha e flor respectivamente, enquanto a acurácia total [email protected] é de cerca de 95%.
- Passo 5. Se você navegar até
runs/train/exp/weights, verá um arquivo chamado best.pt. Este é o modelo gerado a partir do treinamento. Copie e cole este arquivo no seu dispositivo Jetson porque este é o modelo que vamos usar depois para realizar a inferência no dispositivo Jetson.

Inferência no dispositivo Jetson
Usando TensorRT
Agora usaremos um dispositivo Jetson para executar inferência (detectar objetos) em imagens com a ajuda do modelo gerado a partir do nosso treinamento anterior. Aqui vamos usar o NVIDIA TensorRT para aumentar o desempenho de inferência na plataforma Jetson
- Passo 1. Acesse o terminal do dispositivo Jetson, instale o pip e atualize‑o
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Passo 2. Clone o repositório a seguir
git clone https://github.com/ultralytics/yolov5
- Passo 3. Abra o requirements.txt
cd yolov5
vi requirements.txt
- Passo 4. Edite as seguintes linhas. Aqui você precisa pressionar i primeiro para entrar no modo de edição. Pressione ESC, depois digite :wq para salvar e sair
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
Nota: Incluímos versões fixas para matplotlib e numpy para garantir que não haja erros ao executar o YOLOv5 depois. Além disso, torch e torchvision estão excluídos por enquanto porque serão instalados mais tarde.
- Passo 5. instale a dependência abaixo
sudo apt install -y libfreetype6-dev
- Passo 6. Instale os pacotes necessários
pip3 install -r requirements.txt
- Passo 7. Instale o torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Passo 8. Instale o torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- Passo 9. Clone o repositório a seguir
cd ~
git clone https://github.com/wang-xinyu/tensorrtx
-
Passo 10. Copie o arquivo best.pt do treinamento anterior para o diretório yolov5
-
Passo 11. Copie gen_wts.py de tensorrtx/yolov5 para o diretório yolov5
cp tensorrtx/yolov5/gen_wts.py yolov5
- Passo 12. Gere o arquivo .wts a partir do PyTorch com .pt
cd yolov5
python3 gen_wts.py -w best.pt -o best.wts
- Passo 13. Navegue até tensorrtx/yolov5
cd ~
cd tensorrtx/yolov5
- Passo 14. Abra yololayer.h com o editor de texto vi
vi yololayer.h
- Passo 15. Altere CLASS_NUM para o número de classes para o qual seu modelo foi treinado. No nosso exemplo, é 2
CLASS_NUM = 2
- Passo 16. Crie um novo diretório build e navegue para dentro dele
mkdir build
cd build
- Passo 17. Copie o arquivo best.wts gerado anteriormente para este diretório build
cp ~/yolov5/best.wts .
- Passo 18. Compile
cmake ..
make
- Passo 19. Serialize o modelo
sudo ./yolov5 -s [.wts] [.engine] [n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw]
#example
sudo ./yolov5 -s best.wts best.engine n6
Aqui usamos n6 porque isso é recomendado para dispositivos de borda, como a plataforma NVIDIA Jetson. No entanto, se você usar o Ultralytics HUB para configurar o treinamento, poderá usar apenas n porque n6 ainda não é suportado pelo HUB.
-
Passo 20. Copie as imagens que você deseja que o modelo detecte para uma nova pasta, como tensorrtx/yolov5/images
-
Passo 21. Desserialize e execute a inferência nas imagens da seguinte forma
sudo ./yolov5 -d best.engine images
Abaixo está uma comparação do tempo de inferência em execução no Jetson Nano versus Jetson Xavier NX.
Jetson Nano
Aqui a quantização é definida como FP16
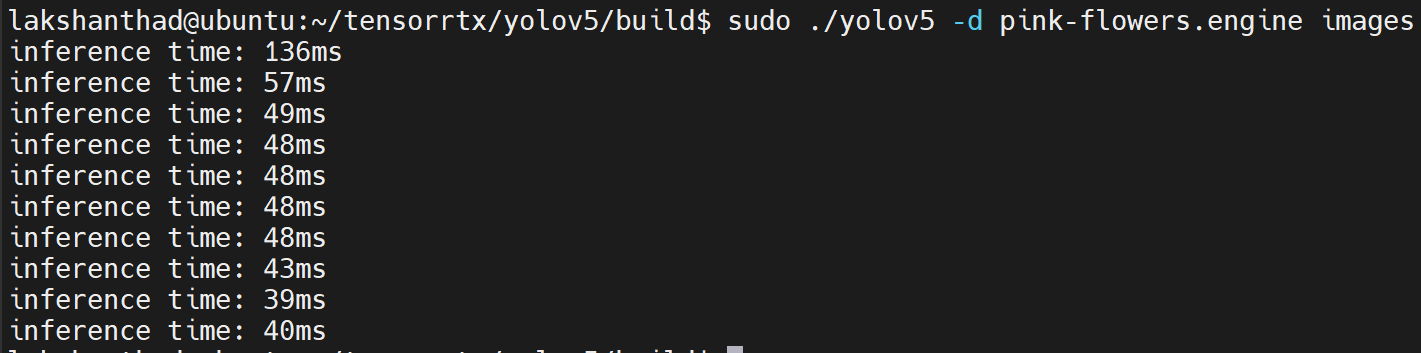
A partir dos resultados acima, podemos considerar a média como cerca de 47ms. Convertendo esse valor para quadros por segundo: 1000/47 = 21,2766 = 21fps.
Jetson Xavier NX
Aqui a quantização é definida como FP16
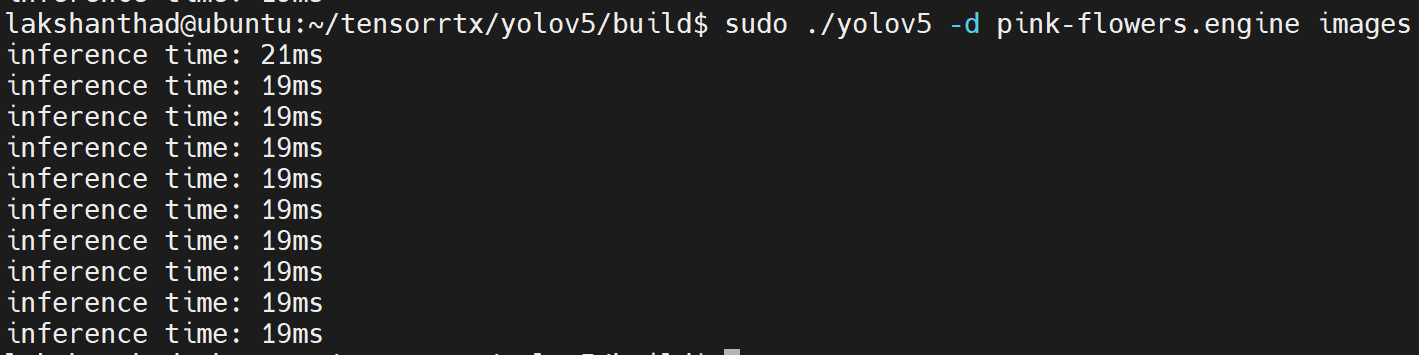
A partir dos resultados acima, podemos considerar a média como cerca de 20ms. Convertendo esse valor para quadros por segundo: 1000/20 = 50fps.
Além disso, as imagens de saída serão as seguintes com os objetos detectados:


Usando TensorRT e DeepStream SDK
Aqui usaremos o NVIDIA TensorRT junto com o NVIDIA DeepStream SDK para realizar inferência em uma filmagem de vídeo
- Passo 1. Certifique‑se de ter instalado corretamente todos os SDK Components e o DeepStream SDK no dispositivo Jetson. (consulte este wiki como referência para instalação)
Nota: Recomenda‑se usar o NVIDIA SDK Manager para instalar todos os componentes do SDK e o DeepStream SDK
- Passo 2. Acesse o terminal do dispositivo Jetson, instale o pip e atualize‑o
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Passo 3. Clone o repositório a seguir
git clone https://github.com/ultralytics/yolov5
- Passo 4. Abra o requirements.txt
cd yolov5
vi requirements.txt
- Passo 5. Edite as seguintes linhas. Aqui você precisa pressionar i primeiro para entrar no modo de edição. Pressione ESC, depois digite :wq para salvar e sair
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
Nota: Incluímos versões fixas para matplotlib e numpy para garantir que não haja erros ao executar o YOLOv5 depois. Além disso, torch e torchvision estão excluídos por enquanto porque serão instalados mais tarde.
- Passo 6. instale a dependência abaixo
sudo apt install -y libfreetype6-dev
- Passo 7. Instale os pacotes necessários
pip3 install -r requirements.txt
- Passo 8. Instale o torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Passo 9. Instale o torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- Passo 10. Clone o repositório a seguir
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Passo 11. Copie gen_wts_yoloV5.py de DeepStream-Yolo/utils para o diretório yolov5
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- Passo 12. Dentro do repositório yolov5, baixe o arquivo pt a partir dos releases do YOLOv5 (exemplo para YOLOv5s 6.1)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- Passo 13. Gere os arquivos cfg e wts
python3 gen_wts_yoloV5.py -w yolov5s.pt
Nota: Para alterar o tamanho de inferência (padrão: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- Passo 14. Copie os arquivos cfg e wts gerados para a pasta DeepStream-Yolo
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo
- Passo 15. Abra a pasta DeepStream-Yolo e compile a biblioteca
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
- Passo 16. Edite o arquivo config_infer_primary_yoloV5.txt de acordo com o seu modelo
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...
- Passo 17. Edite o arquivo deepstream_app_config
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt
- Passo 18. Execute a inferência
deepstream-app -c deepstream_app_config.txt
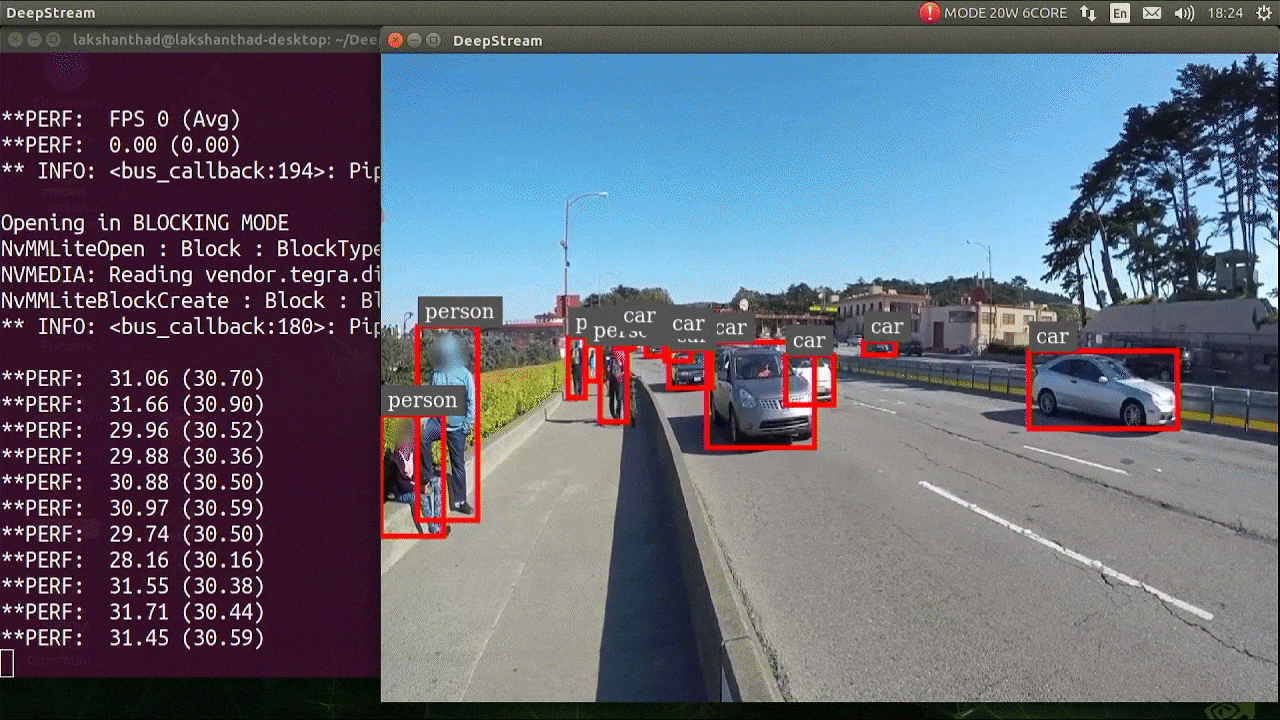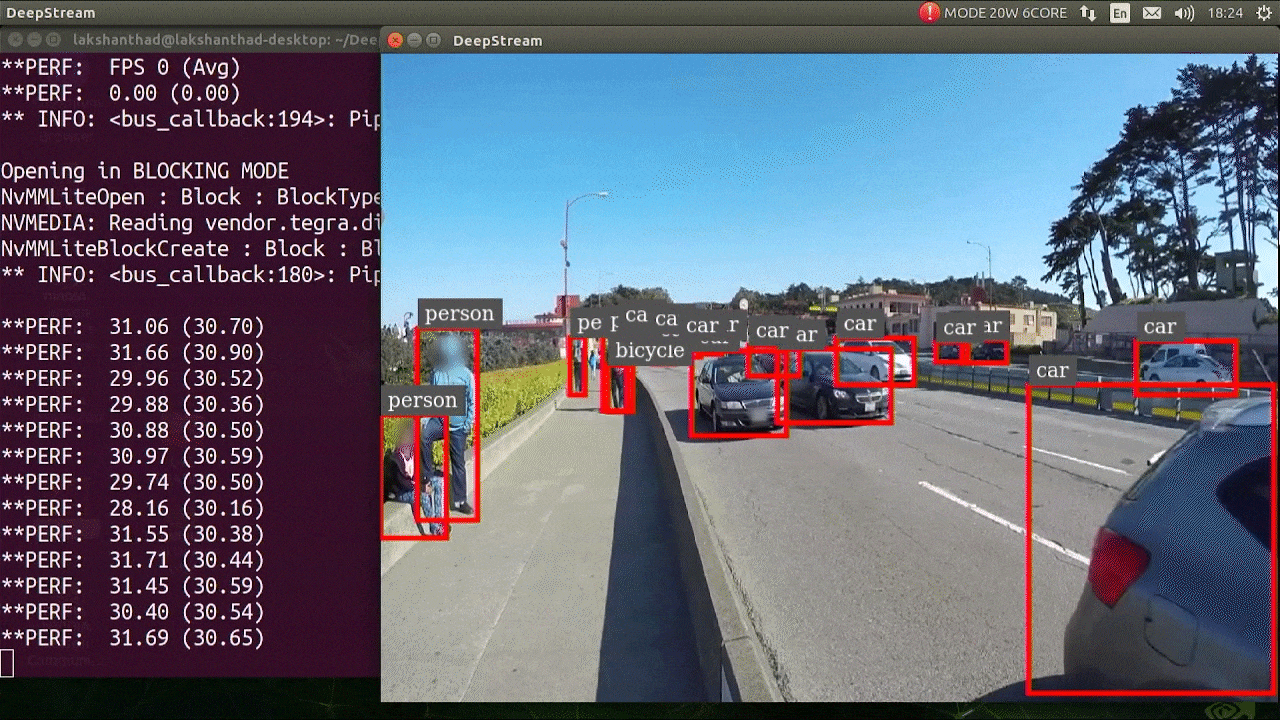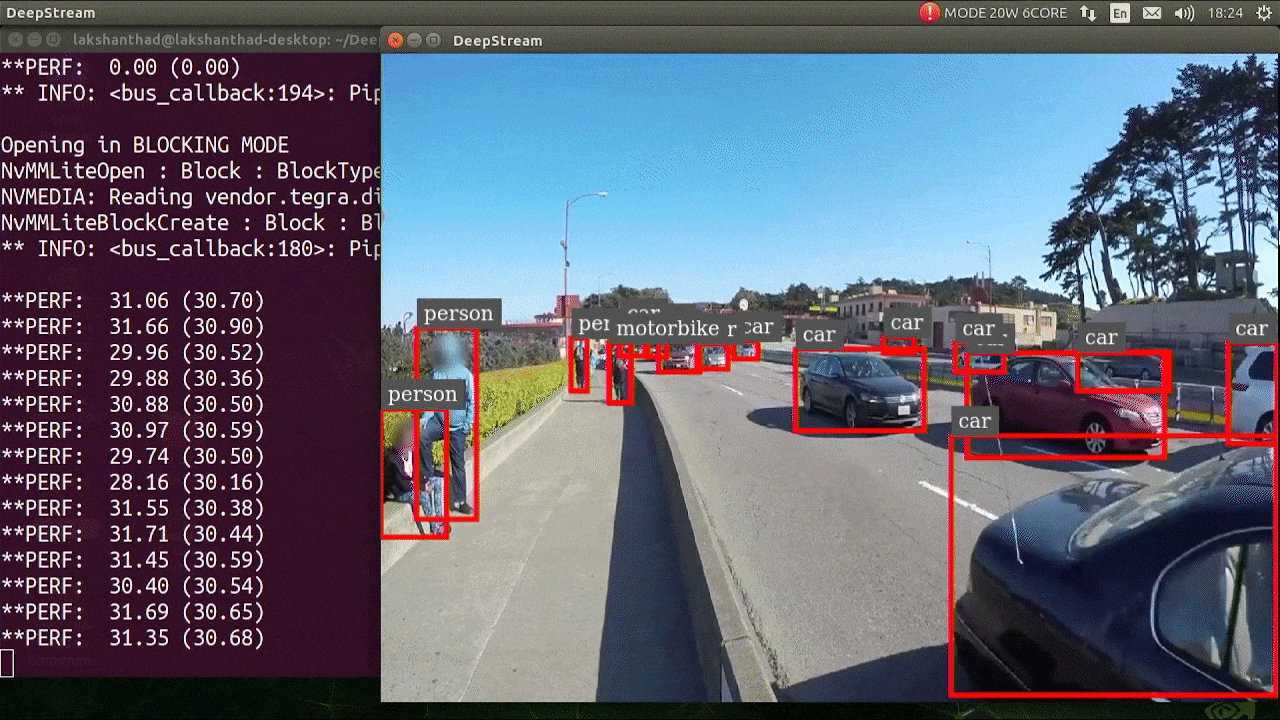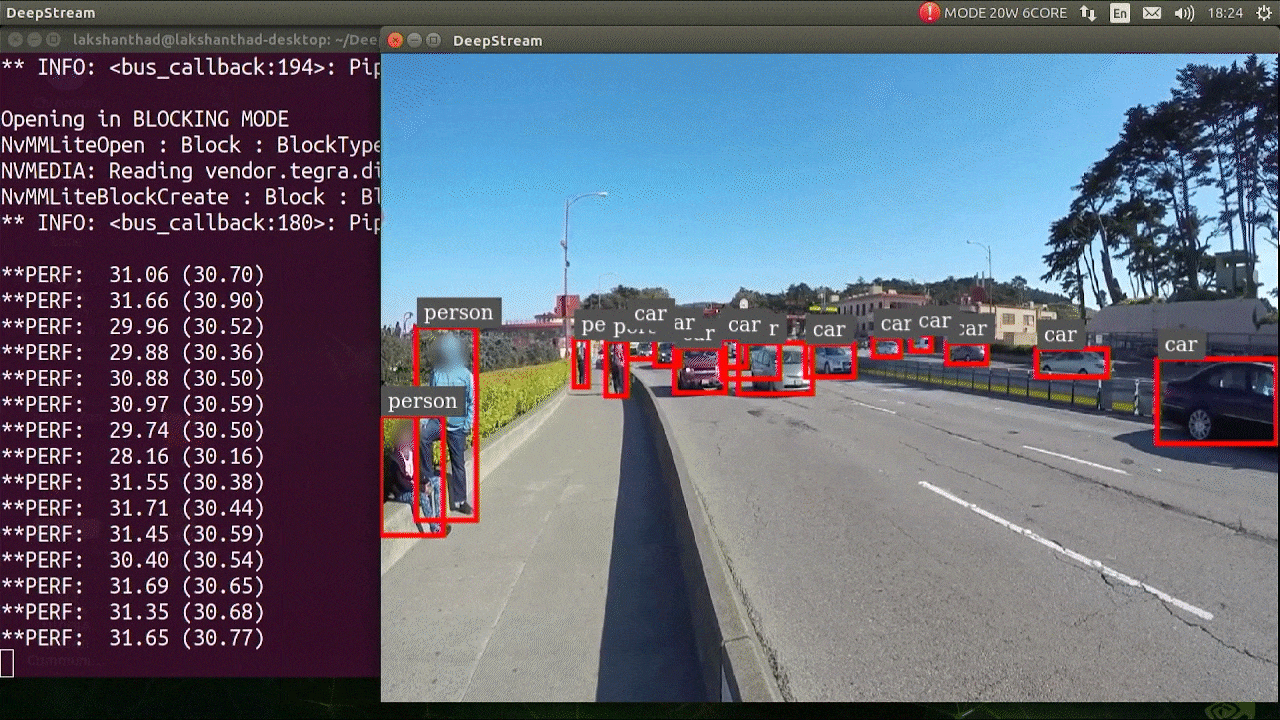
O resultado acima está sendo executado em um Jetson Xavier NX com FP32 e YOLOv5s 640x640. Podemos ver que o FPS está em torno de 30.
Calibração INT8
Se você quiser usar precisão INT8 para inferência, precisa seguir os passos abaixo
- Passo 1. Instale o OpenCV
sudo apt-get install libopencv-dev
- Passo 2. Compile/recompile a biblioteca nvdsinfer_custom_impl_Yolo com suporte ao OpenCV
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
-
Passo 3. Para o conjunto de dados COCO, baixe o val2017, extraia e mova para a pasta DeepStream-Yolo
-
Passo 4. Crie um novo diretório para as imagens de calibração
mkdir calibration
- Passo 5. Execute o seguinte para selecionar 1000 imagens aleatórias do conjunto de dados COCO para executar a calibração
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
Nota: A NVIDIA recomenda pelo menos 500 imagens para obter uma boa acurácia. Neste exemplo, 1000 imagens são escolhidas para obter uma acurácia melhor (mais imagens = mais acurácia). Valores mais altos de INT8_CALIB_BATCH_SIZE resultarão em mais acurácia e velocidade de calibração mais rápida. Defina-o de acordo com a memória da sua GPU. Você pode configurá-lo a partir de head -1000. Por exemplo, para 2000 imagens, head -2000. Este processo pode levar muito tempo.
- Passo 6. Crie o arquivo calibration.txt com todas as imagens selecionadas
realpath calibration/*jpg > calibration.txt
- Passo 7. Defina as variáveis de ambiente
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Passo 8. Atualize o arquivo config_infer_primary_yoloV5.txt
De
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
Para
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
- Passo 9. Execute a inferência
deepstream-app -c deepstream_app_config.txt
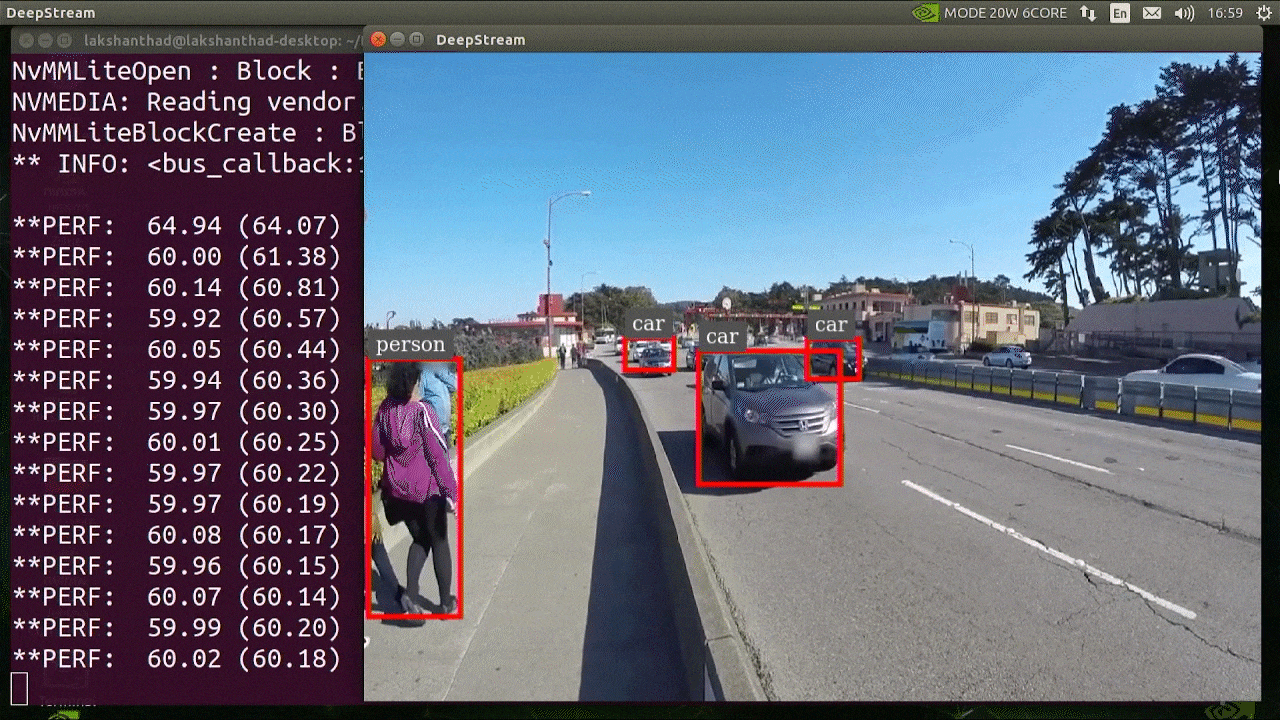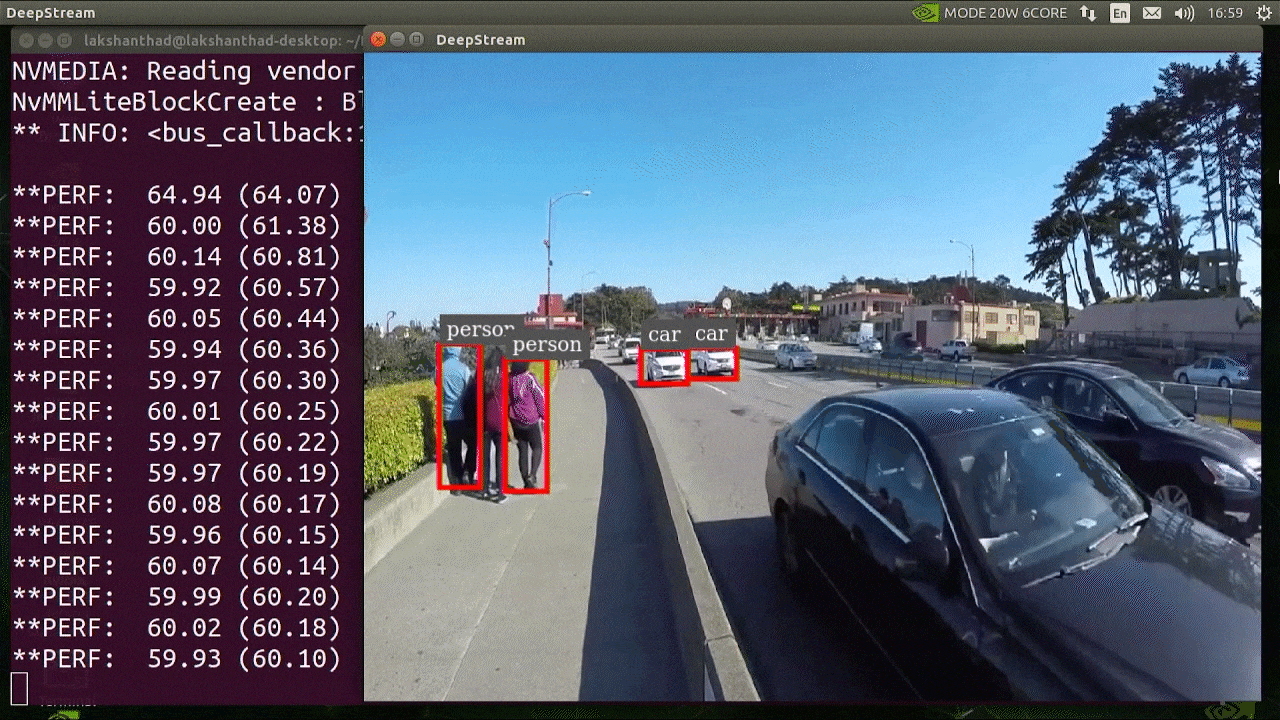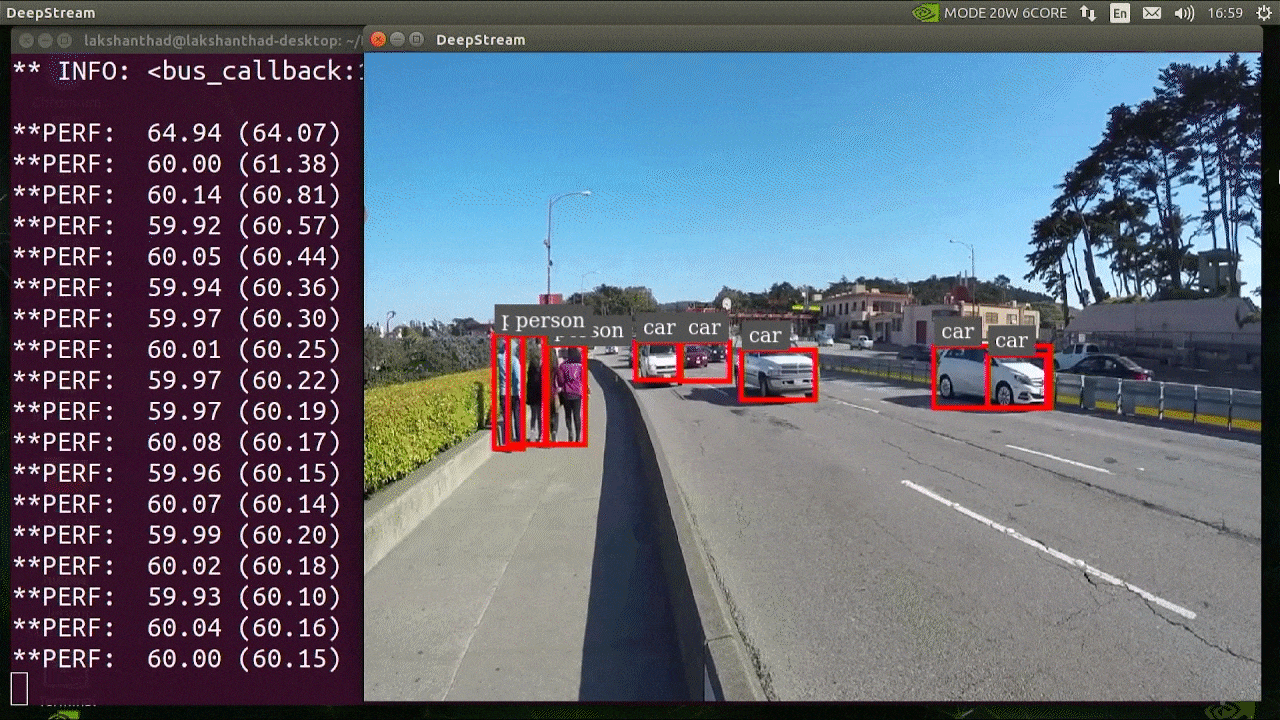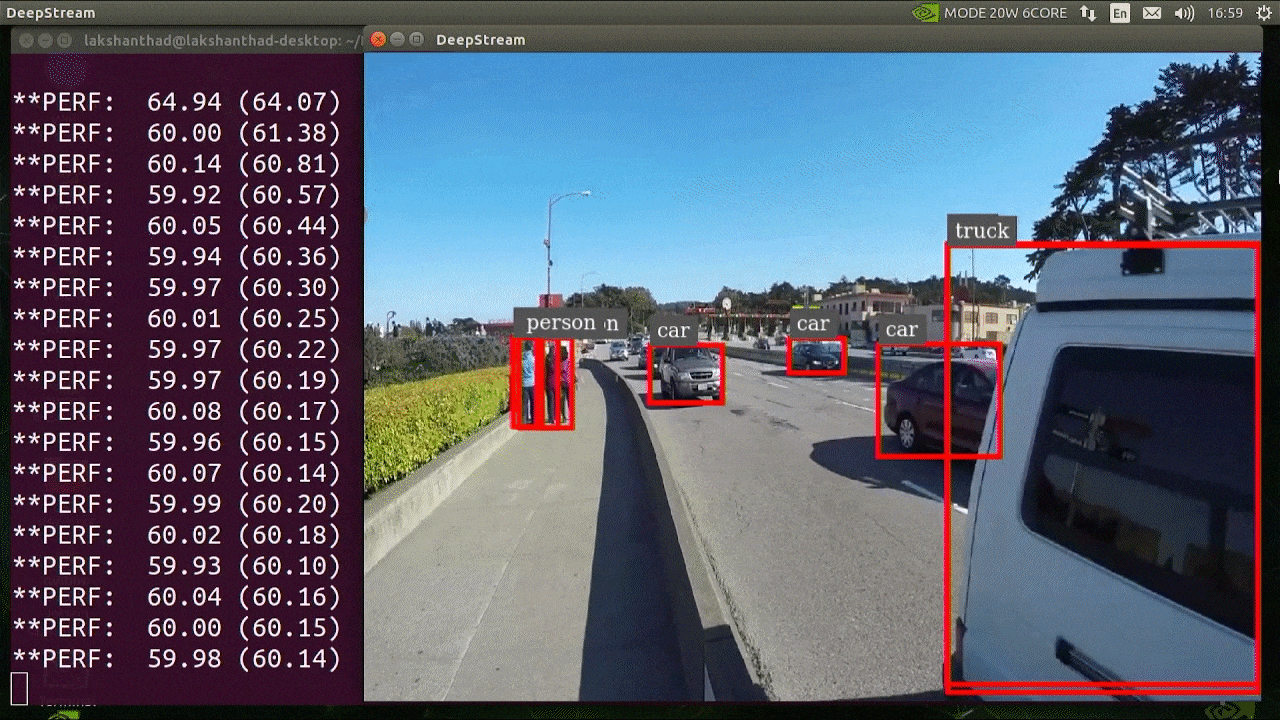
O resultado acima está sendo executado em um Jetson Xavier NX com INT8 e YOLOv5s 640x640. Podemos ver que o FPS está em torno de 60.
Resultados de benchmark
A tabela a seguir resume como diferentes modelos se comportam no Jetson Xavier NX.
| Nome do Modelo | Precisão | Tamanho da Inferência | Tempo de Inferência (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
Comparação entre o uso de conjuntos de dados públicos e conjuntos de dados personalizados
Agora vamos comparar a diferença entre o número de amostras de treinamento e o tempo de treinamento ao usar conjuntos de dados públicos e seus próprios conjuntos de dados personalizados
Número de amostras de treinamento
Conjunto de dados personalizado
Neste wiki, coletamos nosso conjunto de dados de plantas primeiro como um vídeo e depois convertemos o vídeo em uma série de imagens usando o Roboflow. Aqui obtivemos 542 imagens, o que é um conjunto de dados muito pequeno quando comparado com conjuntos de dados públicos.
Conjunto de dados público
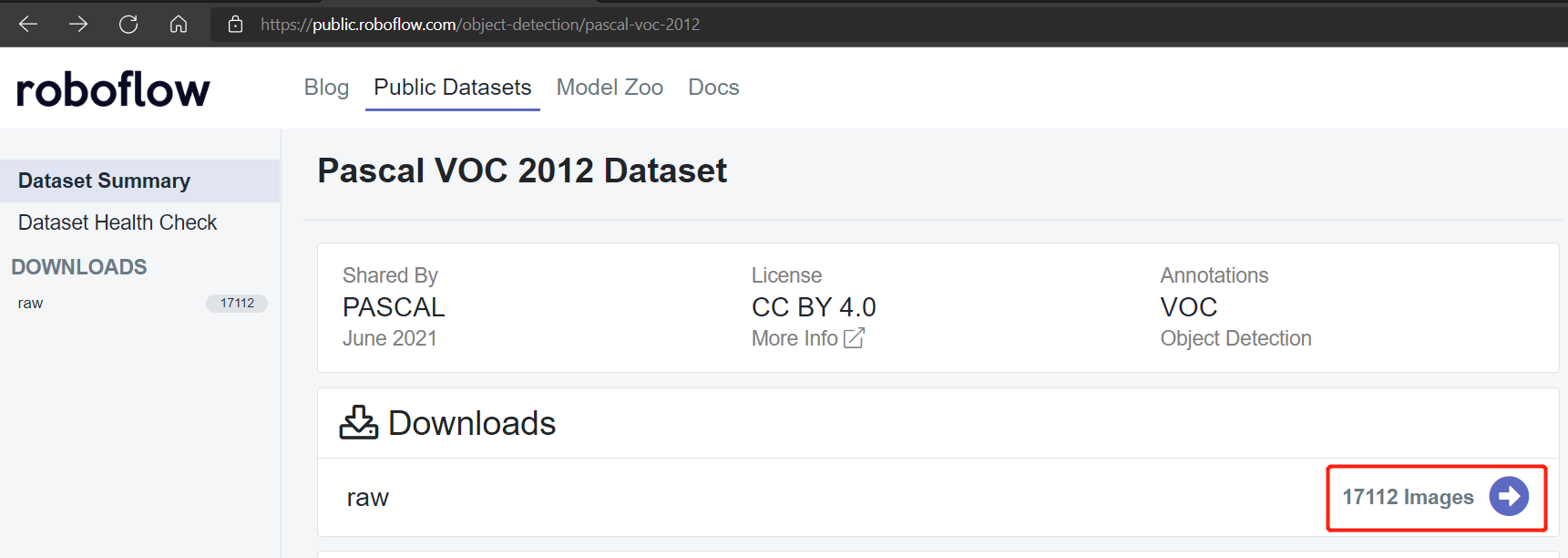
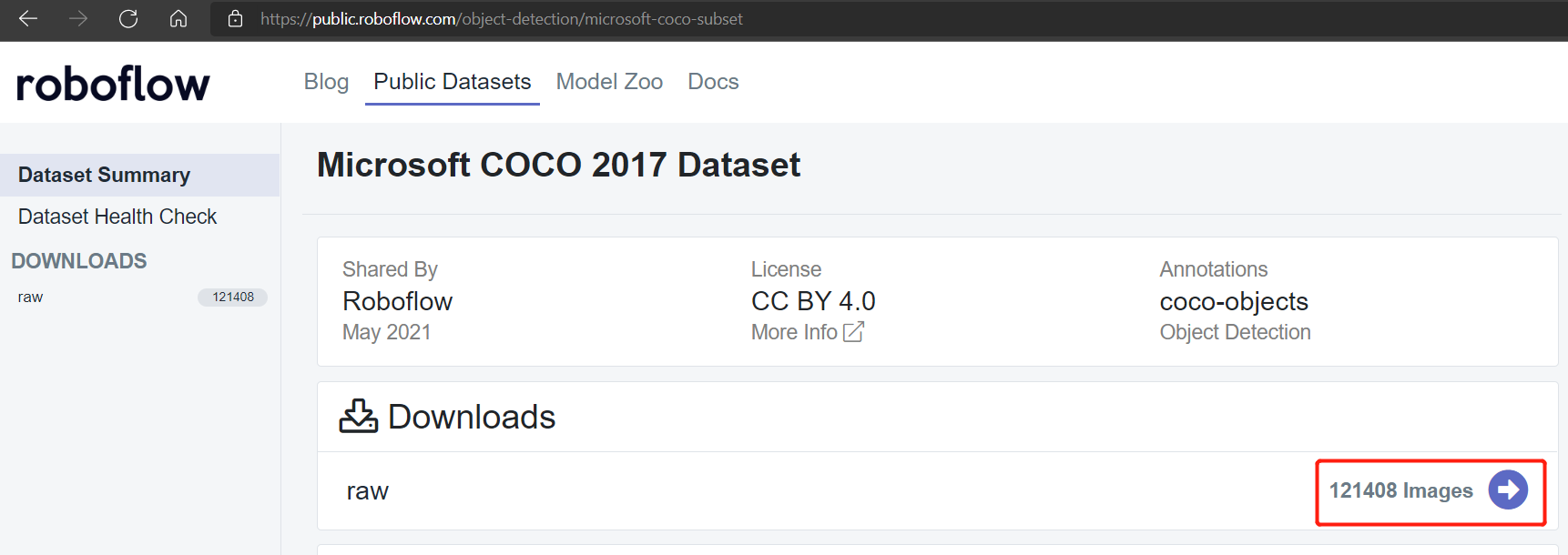
Conjuntos de dados públicos como o conjunto de dados Pascal VOC 2012 e Microsoft COCO 2017 possuem cerca de 17112 e 121408 imagens, respectivamente.
Conjunto de dados Pascal VOC 2012
Conjunto de dados Microsoft COCO 2017
Tempo de treinamento
Treinamento local
O treinamento foi feito em uma placa gráfica NVIDIA GeForce GTX 1660 Super com 6GB de memória
Conjunto de dados personalizado com treinamento local
Conjunto de dados com 540 imagens
De acordo com o treinamento local que realizamos antes para as plantas, obtivemos os seguintes resultados
Aqui levou apenas 2,2 horas para executar 100 épocas. Isso é relativamente mais rápido do que treinar usando conjuntos de dados públicos.
Conjunto de dados com 240 imagens
Reduzimos o conjunto de dados para 240 imagens e realizamos o treinamento novamente e obtivemos os seguintes resultados

Aqui levou apenas cerca de 1 hora para executar 100 épocas. Isso é relativamente mais rápido do que treinar usando conjuntos de dados públicos.
Conjunto de dados Pascal VOC 2012 com treinamento local
Usamos um conjunto de dados Pascal VOC 2012 para o treinamento neste cenário, mantendo os mesmos parâmetros de treinamento. Descobrimos que estava levando cerca de 50 minutos (0,846 horas * 60) para executar 1 época e, portanto, interrompemos o treinamento em 1 época.

Se calcularmos o tempo de treinamento para 100 épocas, levaria cerca de 50 * 100 minutos = 5000 minutos = 83 horas, o que é muito mais longo do que o tempo de treinamento para o conjunto de dados personalizado.
Conjunto de dados Microsoft COCO 2017 com treinamento local
Usamos um conjunto de dados Microsoft COCO 2017 para o treinamento neste cenário, mantendo os mesmos parâmetros de treinamento. Descobrimos que estava estimado levar cerca de 7,5 horas para executar 1 época e, portanto, interrompemos o treinamento antes que 1 época fosse concluída.

Se calcularmos o tempo de treinamento para 100 épocas, levaria cerca de 7,5 horas * 100 = 750 horas, o que é muito mais longo do que o tempo de treinamento para o conjunto de dados personalizado.
Treinamento no Google Colab
O treinamento foi feito em uma placa gráfica NVIDIA Tesla K80 com 12GB de memória
Conjunto de dados personalizado
Conjunto de dados com 540 imagens
De acordo com o treinamento no Google Colab que realizamos antes para as plantas com 540 imagens, obtivemos os seguintes resultados
Aqui levou apenas cerca de 1,3 horas para executar 100 épocas. Isso também é relativamente mais rápido do que treinar usando conjuntos de dados públicos.
Conjunto de dados com 240 imagens
Reduzimos o conjunto de dados para 240 imagens e realizamos o treinamento novamente e obtivemos os seguintes resultados
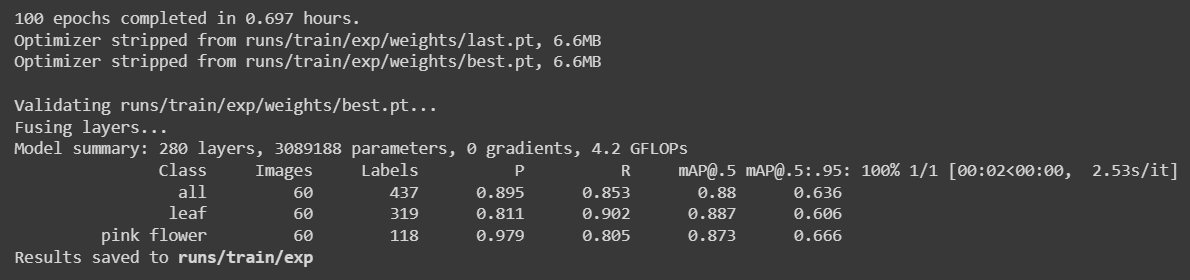
Aqui levou apenas cerca de 42 minutos (0,697 horas * 60) para executar 100 épocas. Isso é relativamente mais rápido do que treinar usando conjuntos de dados públicos.
Conjunto de dados Pascal VOC 2012 com treinamento no Google Colab
Usamos um conjunto de dados Pascal VOC 2012 para o treinamento neste cenário, mantendo os mesmos parâmetros de treinamento. Descobrimos que estava levando cerca de 9 minutos (0,148 horas * 60) para executar 1 época e, portanto, interrompemos o treinamento em 1 época.
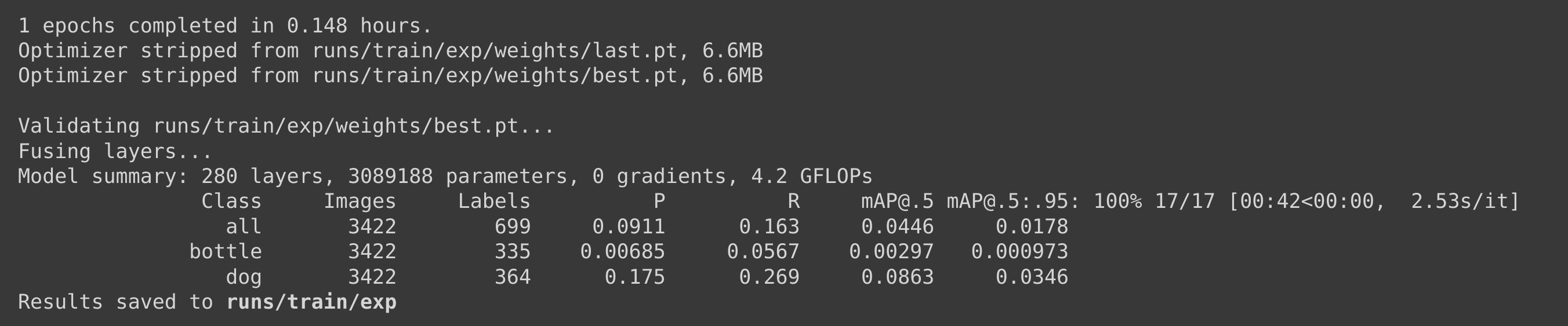
Se calcularmos o tempo de treinamento para 100 épocas, levaria cerca de 9 * 100 minutos = 900 minutos = 15 horas, o que é muito mais longo do que o tempo de treinamento para o conjunto de dados personalizado.
Conjunto de dados Microsoft COCO 2017 com treinamento no Google Colab
Usamos um conjunto de dados Microsoft COCO 2017 para o treinamento neste cenário, mantendo os mesmos parâmetros de treinamento. Descobrimos que estava estimado levar cerca de 1,25 horas para executar 1 época e, portanto, interrompemos o treinamento antes que 1 época fosse concluída.

Se calcularmos o tempo de treinamento para 100 épocas, levaria cerca de 1,25 horas * 100 = 125 horas, o que é muito mais longo do que o tempo de treinamento para o conjunto de dados personalizado.
Resumo do número de amostras de treinamento e tempo de treinamento
| Conjunto de dados | Número de amostras de treinamento | Tempo de treinamento no PC local (GTX 1660 Super) | Tempo de treinamento no Google Colab (NVIDIA Tesla K80) |
|---|---|---|---|
| Personalizado | 542 | 2,2 horas | 1,3 horas |
| 240 | 1 hora | 42 minutos | |
| Pascal VOC 2012 | 17112 | 83 horas | 15 horas |
| Microsoft COCO 2017 | 121408 | 750 horas | 125 horas |
Comparação de checkpoints pré-treinados
Você pode aprender mais sobre checkpoints pré-treinados na tabela abaixo. Aqui destacamos nosso cenário quando treinado com o Google Colab e inferência feita no Jetson Nano e Jetson Xavier NX com YOLOv5n6 como o checkpoint pré-treinado.
| Modelo | tamanho (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Velocidade CPU b1 (ms) | Velocidade V100 b1 (ms) | Velocidade V100 b32 (ms) | Velocidade Jetson Nano FP16 (ms) | Velocidade Jetson Xavier NX FP16 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | ||
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | ||
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | ||
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | ||
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | ||
| YOLOv5n6 | 640 | 71.7 | 95.5 | 153 | 8.1 | 2.1 | 47 | 20 | 3.1 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | ||
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | ||
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | ||
| YOLOv5x6 + [TTA] | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
Referência: YOLOv5 GitHub
Aplicações bônus
Como todas as etapas que explicamos acima são comuns para qualquer tipo de aplicação de detecção de objetos, você só precisa mudar o conjunto de dados para a sua própria aplicação de detecção de objetos!
Detecção de placas de trânsito
Aqui usamos o conjunto de dados de placas de trânsito do Roboflow e realizamos a inferência no NVIDIA Jetson!

Detecção de fumaça de incêndios florestais
Aqui usamos o wildfire smoke dataset do Roboflow e realizamos inferência no NVIDIA Jetson!

Recursos
-
[Web Page] Documentação do YOLOv5
-
[Web Page] Ultralytics HUB
-
[Web Page] Documentação do Roboflow
Suporte Técnico & Discussão de Produtos
Obrigado por escolher nossos produtos! Estamos aqui para oferecer diferentes tipos de suporte para garantir que sua experiência com nossos produtos seja a mais tranquila possível. Oferecemos vários canais de comunicação para atender a diferentes preferências e necessidades.